LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CL] *Scaling Hidden Markov Language Models
J T. Chiu, A M. Rush
[Cornell Tech]
隐马尔可夫语言模型的扩展。提出将HMM在并行硬件上有效扩展到大状态空间的方法,同时保持有效的精确推理、紧凑的参数化和高效的正则化,引入了三种技术:阻塞发射约束、神经参数化和状态dropout,使得HMM优于n-gram模型和先前的HMM。一旦扩展并利用现代硬件,非常大的HMM相比小的HMM更有意义。HMM是一类有用的概率模型,与神经网络相比,具有不同的归纳偏差、性能特征和条件独立结构。实验表明,该方法得到的模型比之前的HMM和基于n-gram的方法更精确,在性能上有很大进步,达到了先进的神经网络模型的水平。
The hidden Markov model (HMM) is a fundamental tool for sequence modeling that cleanly separates the hidden state from the emission structure. However, this separation makes it difficult to fit HMMs to large datasets in modern NLP, and they have fallen out of use due to very poor performance compared to fully observed models. This work revisits the challenge of scaling HMMs to language modeling datasets, taking ideas from recent approaches to neural modeling. We propose methods for scaling HMMs to massive state spaces while maintaining efficient exact inference, a compact parameterization, and effective regularization. Experiments show that this approach leads to models that are more accurate than previous HMM and n-gram-based methods, making progress towards the performance of state-of-the-art neural models.
https://weibo.com/1402400261/JtEmO3nVW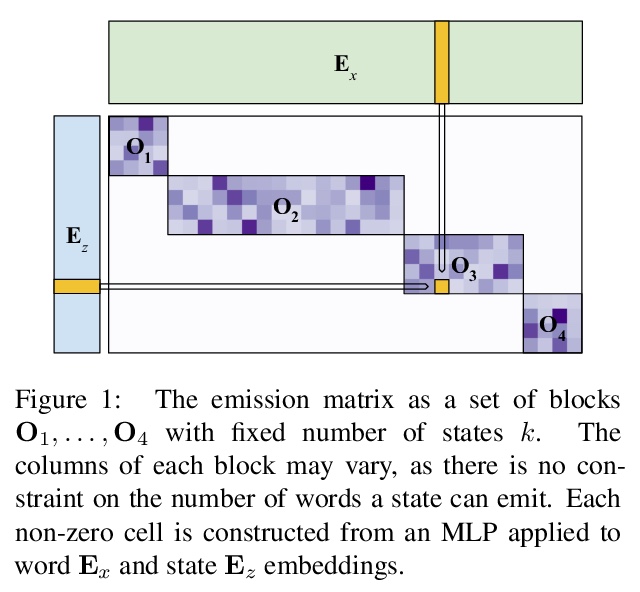

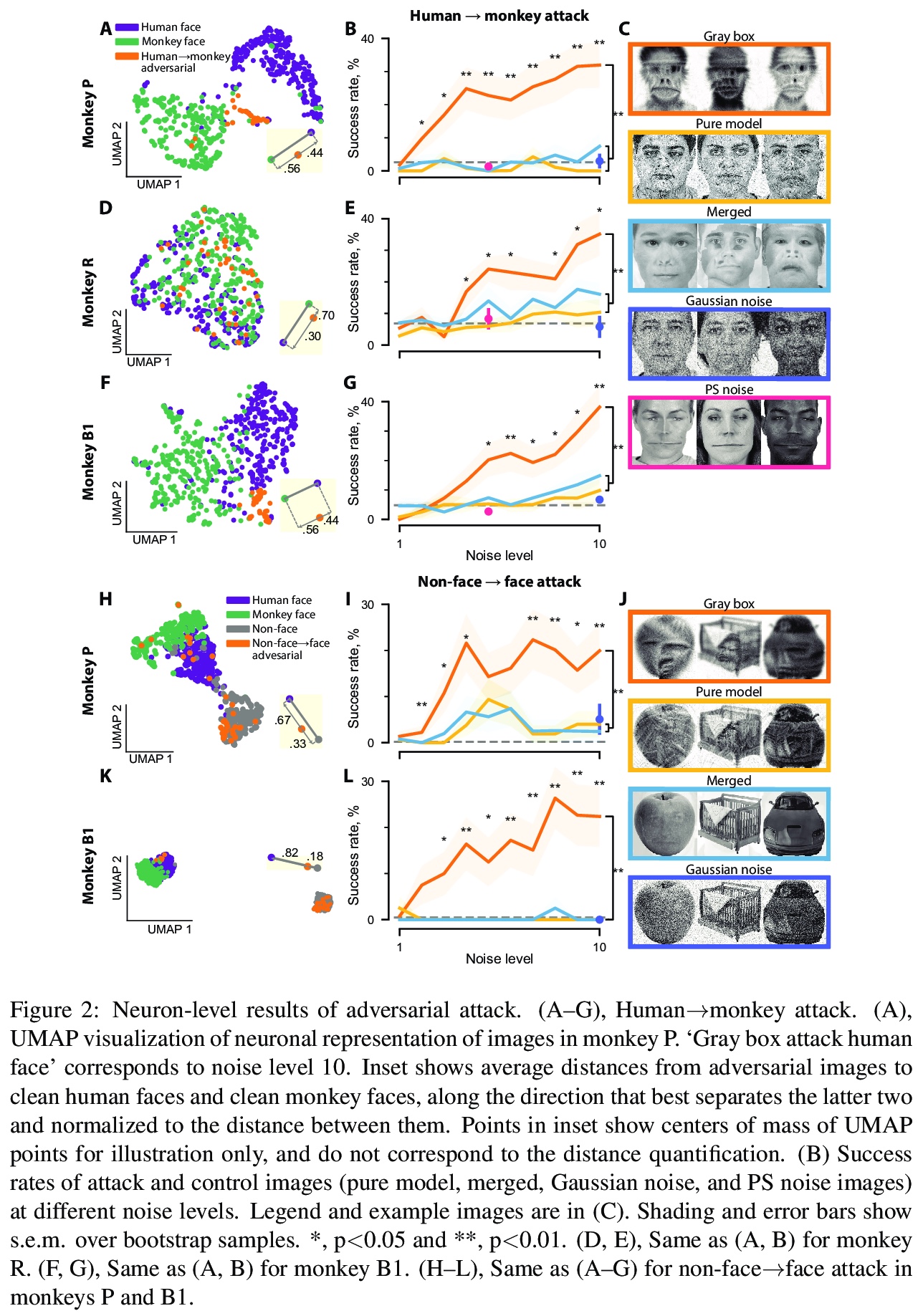
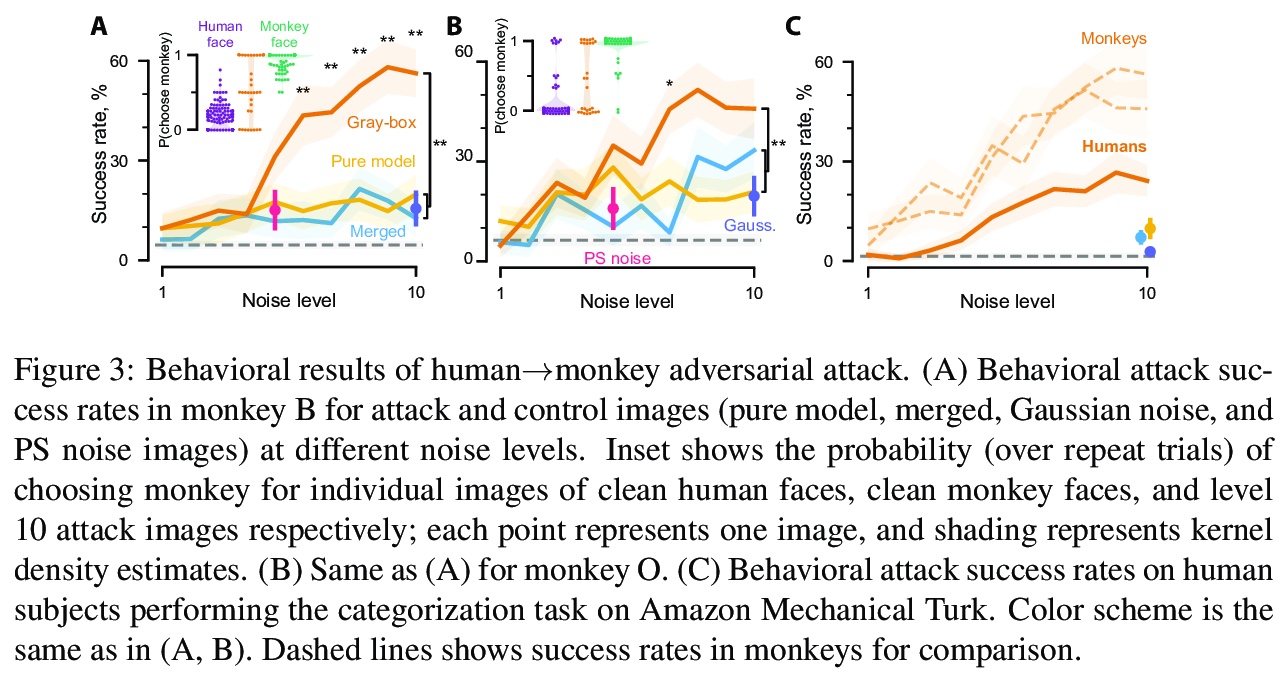
2、[CV] Adversarial images for the primate brain
L Yuan, W Xiao, G Kreiman, F E.H. Tay, J Feng, M S. Livingstone
[Harvard Medical School & Boston Children’s Hospital & National University of Singapore]
灵长类动物大脑对对抗性图像对鲁棒性。灵长类动物的视觉被认为对对抗性图像有很强的抵抗力,本文通过设计对抗图像来欺骗灵长类动物的视觉来评估这一假设。首先训练了一个模型来预测猕猴颞下皮质中面部选择性神经元的反应。接下来,修改图像,如人脸,以匹配模型预测神经元对目标类别的反应,如猴子的脸。这些对抗性图像引起的神经反应与目标类别相似。值得注意的是,同样的图片在行为层面上愚弄了猴子和人类。这些结果挑战了关于计算机和灵长类动物视觉相似性的基本假设,并表明神经元活动模型可以选择性地指导灵长类动物的视觉行为。
Deep artificial neural networks have been proposed as a model of primate vision. However, these networks are vulnerable to adversarial attacks, whereby introducing minimal noise can fool networks into misclassifying images. Primate vision is thought to be robust to such adversarial images. We evaluated this assumption by designing adversarial images to fool primate vision. To do so, we first trained a model to predict responses of face-selective neurons in macaque inferior temporal cortex. Next, we modified images, such as human faces, to match their model-predicted neuronal responses to a target category, such as monkey faces. These adversarial images elicited neuronal responses similar to the target category. Remarkably, the same images fooled monkeys and humans at the behavioral level. These results challenge fundamental assumptions about the similarity between computer and primate vision and show that a model of neuronal activity can selectively direct primate visual behavior.
https://weibo.com/1402400261/JtEsJjWZt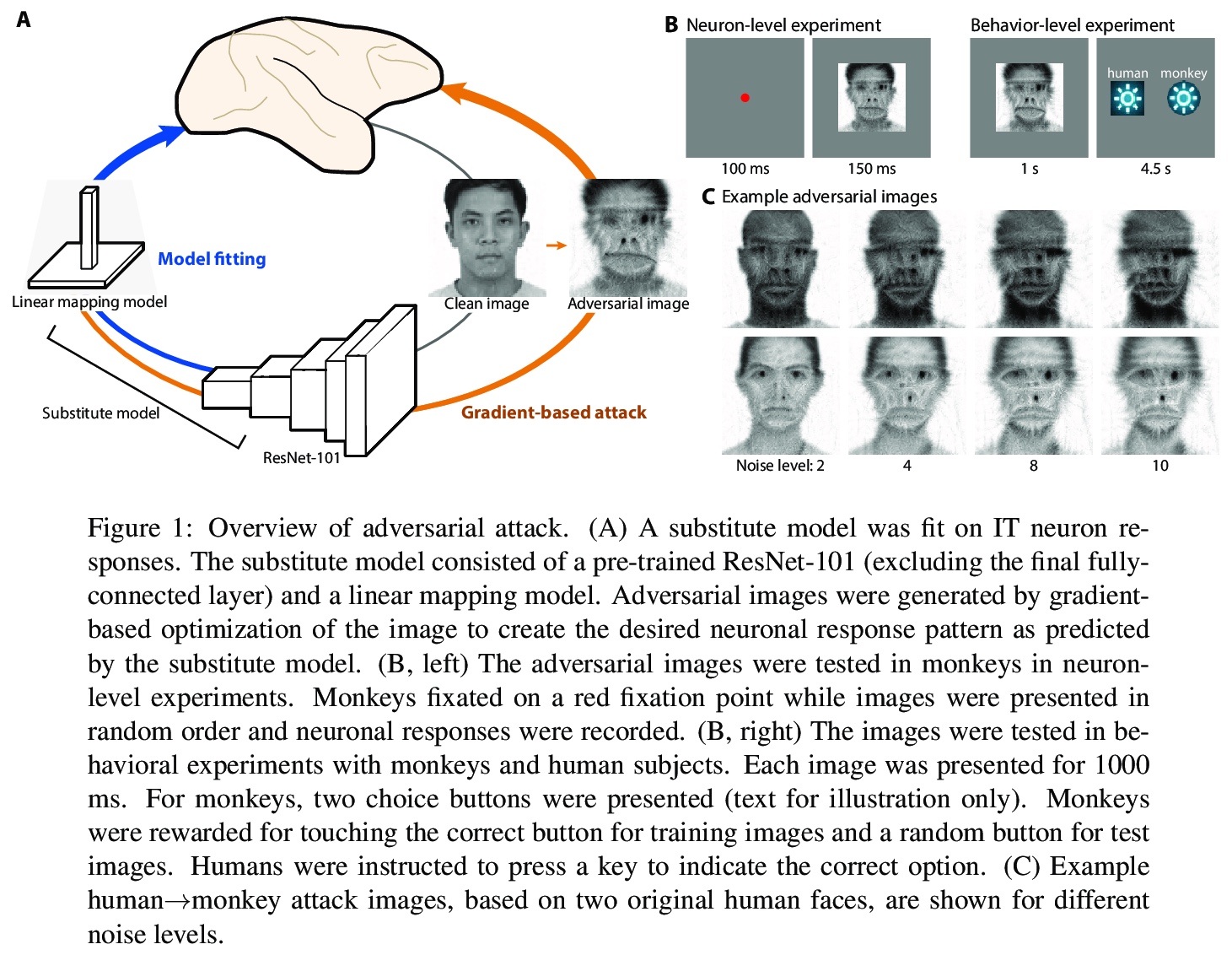
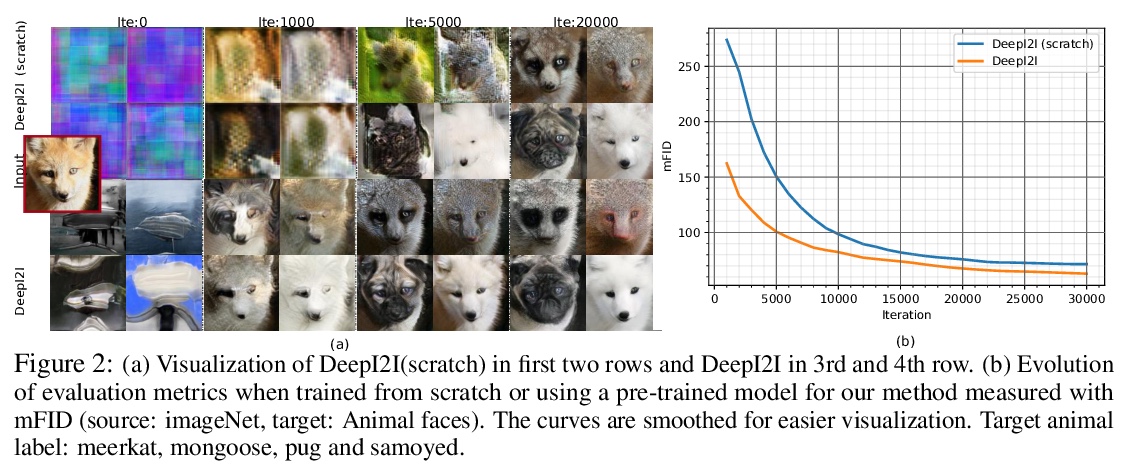
3、[CV] **DeepI2I: Enabling Deep Hierarchical Image-to-Image Translation by Transferring from GANs
Y Wang, L Yu, J v d Weijer
[Universitat Autònoma de Barcelona]
DeepI2I:通过GAN迁移实现深度分层图-图变换。利用层次特征:(a)包含在浅层的结构信息 和 (b)从深层提取的语义信息 来学习模型。为了在小数据集上训练深度图-图变换模型,提出了新的迁移学习方法,从预训练GAN中迁移知识,引入适配器网络来解决知识转移带来的编码器和生成器间对齐的问题。定性和定量地证明了迁移学习显著提高了图-图变换系统的性能。**
Image-to-image translation has recently achieved remarkable results. But despite current success, it suffers from inferior performance when translations between classes require large shape changes. We attribute this to the high-resolution bottlenecks which are used by current state-of-the-art image-to-image methods. Therefore, in this work, we propose a novel deep hierarchical Image-to-Image Translation method, called DeepI2I. We learn a model by leveraging hierarchical features: (a) structural information contained in the shallow layers and (b) semantic information extracted from the deep layers. To enable the training of deep I2I models on small datasets, we propose a novel transfer learning method, that transfers knowledge from pre-trained GANs. Specifically, we leverage the discriminator of a pre-trained GANs (i.e. BigGAN or StyleGAN) to initialize both the encoder and the discriminator and the pre-trained generator to initialize the generator of our model. Applying knowledge transfer leads to an alignment problem between the encoder and generator. We introduce an adaptor network to address this. On many-class image-to-image translation on three datasets (Animal faces, Birds, and Foods) we decrease mFID by at least 35% when compared to the state-of-the-art. Furthermore, we qualitatively and quantitatively demonstrate that transfer learning significantly improves the performance of I2I systems, especially for small datasets. Finally, we are the first to perform I2I translations for domains with over 100 classes.
https://weibo.com/1402400261/JtEwb2Xpb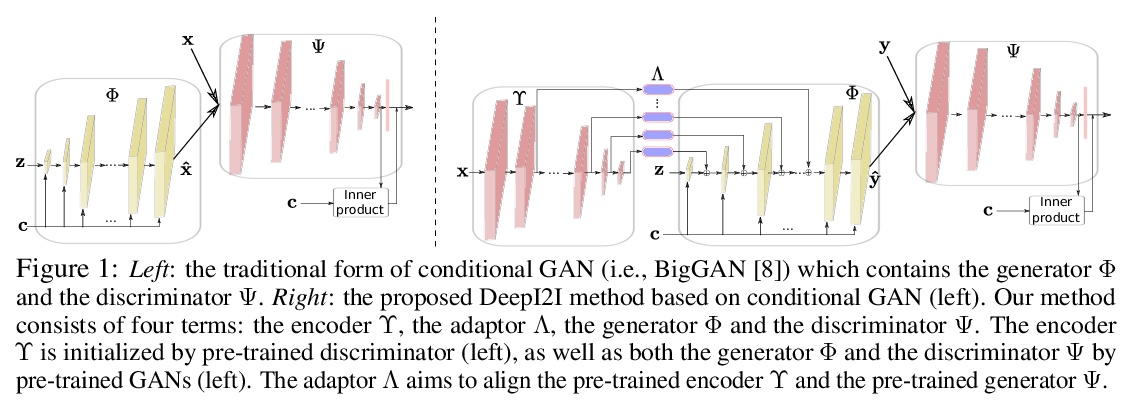
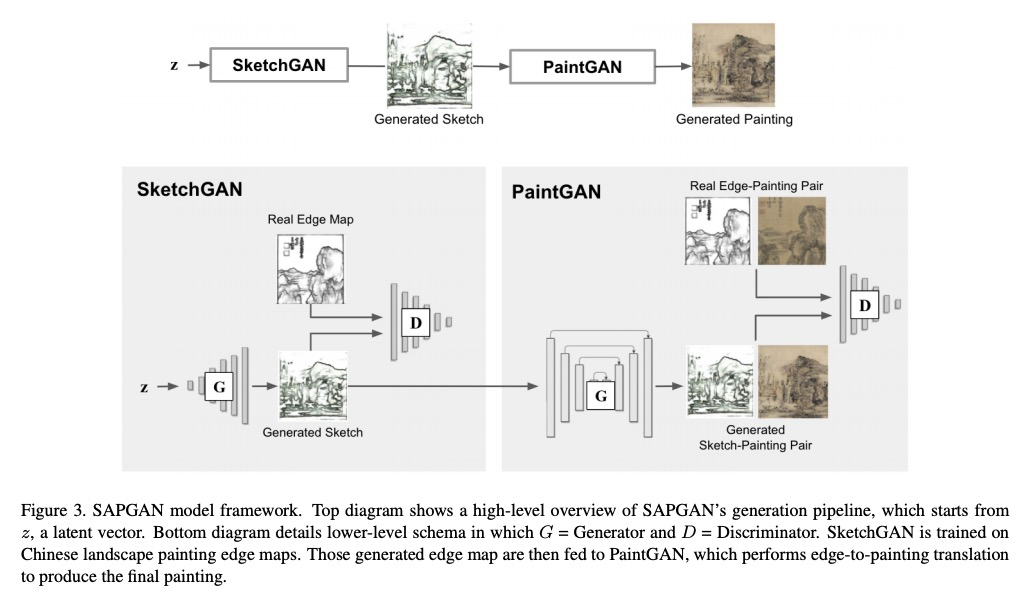
4、[CV] **End-to-End Chinese Landscape Painting Creation Using Generative Adversarial Networks
A Xue
[Princeton University]
基于GAN的端到端中国山水画创作。提出了Sketch-And-Paint GAN (SAPGAN),不依赖条件性输入的中国山水画端到端生成模型,由两个GAN组成:SketchGAN用于生成边缘地图,PaintGAN用于随后的边缘到绘画的转换。SAPGAN将生成过程分解为草图生成以创建高层次的结构,并通过图像到图像变换生成绘画。在实验中,242名人类评价者有超过一半的时间(55%的频率)将生成画作误认为是人类作品,显著高于基线模型中的绘画。**
Current GAN-based art generation methods produce unoriginal artwork due to their dependence on conditional input. Here, we propose Sketch-And-Paint GAN (SAPGAN), the first model which generates Chinese landscape paintings from end to end, without conditional input. SAPGAN is composed of two GANs: SketchGAN for generation of edge maps, and PaintGAN for subsequent edge-to-painting translation. Our model is trained on a new dataset of traditional Chinese landscape paintings never before used for generative research. A 242-person Visual Turing Test study reveals that SAPGAN paintings are mistaken as human artwork with 55% frequency, significantly outperforming paintings from baseline GANs. Our work lays a groundwork for truly machine-original art generation.
https://weibo.com/1402400261/JtEAy0WqF

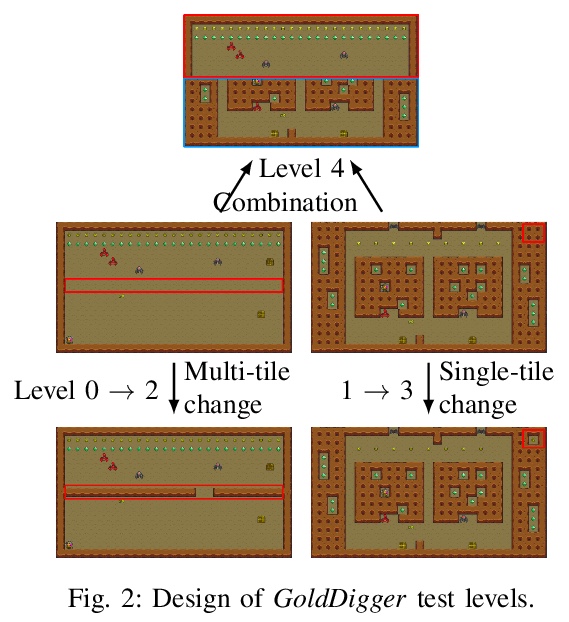
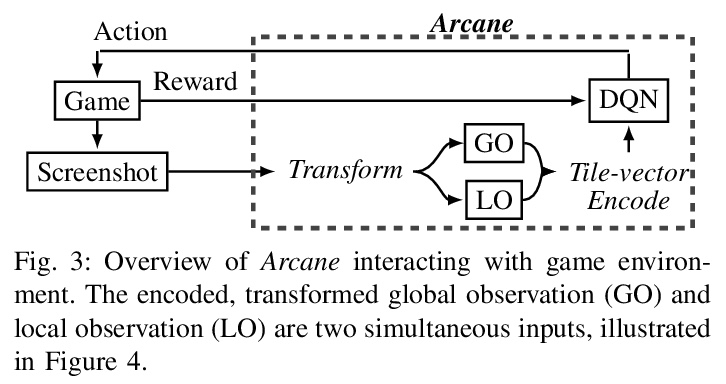
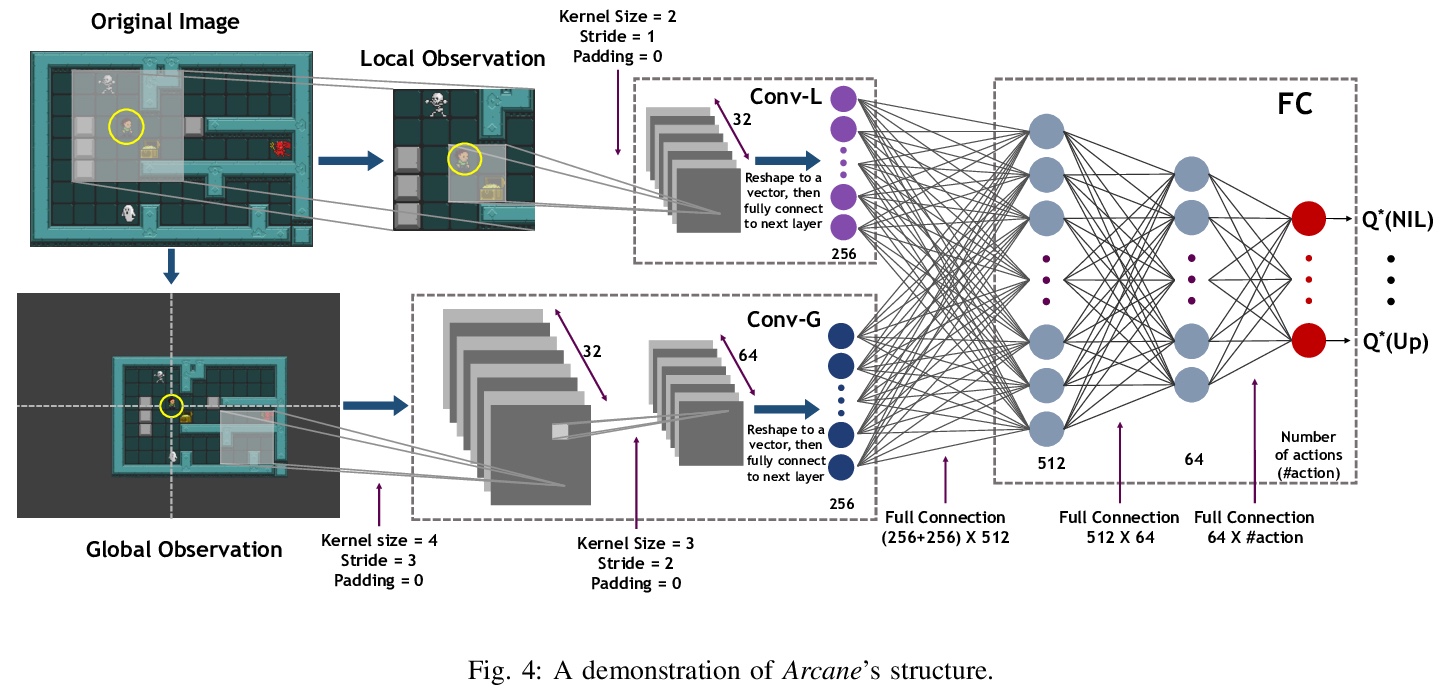
5、[AI] **Robust Reinforcement Learning for General Video Game Playing
C Hu, Z Wang, T Shu, Y Tao, H Tong, J Togelius, X Yao, J Liu
[Southern University of Science and Technology & University of Birmingham & New York University]
用来玩一般的电子游戏的鲁棒强化学习。介绍了在第十六届“来自自然的并行问题解决国际会议”和2020年IEEE游戏会议上举办的2020通用电子游戏AI学习比赛、参赛作品和结果,设计了三种奖励分别为稀疏、周期和密集的新游戏。设计了一个强化学习智能体Arcane,用于一般的电子游戏。假设它更有可能观察到不同层次的相似的局部信息,而不是全局信息,不是直接输入当前游戏屏幕的原始像素截图,而是将游戏屏幕的编码、转换后的全局和局部观察结果作为两个同时输入,旨在学习局部信息,以便玩新关卡。Arcane的两个版本在测试过程中使用了随机或确定性的决策策略,在2020通用电子游戏AI学习竞赛的游戏集上表现出了良好的性能。**
Reinforcement learning has successfully learned to play challenging board and video games. However, its generalization ability remains under-explored. The General Video Game AI Learning Competition aims at designing agents that are capable of learning to play different games levels that were unseen during training. This paper presents the games, entries and results of the 2020 General Video Game AI Learning Competition, held at the Sixteenth International Conference on Parallel Problem Solving from Nature and the 2020 IEEE Conference on Games. Three new games with sparse, periodic and dense rewards, respectively, were designed for this competition and the test levels were generated by adding minor perturbations to training levels or combining training levels. In this paper, we also design a reinforcement learning agent, called Arcane, for general video game playing. We assume that it is more likely to observe similar local information in different levels rather than global information. Therefore, instead of directly inputting a single, raw pixel-based screenshot of current game screen, Arcane takes the encoded, transformed global and local observations of the game screen as two simultaneous inputs, aiming at learning local information for playing new levels. Two versions of Arcane, using a stochastic or deterministic policy for decision-making during test, both show robust performance on the game set of the 2020 General Video Game AI Learning Competition.
https://weibo.com/1402400261/JtEFCB4SZ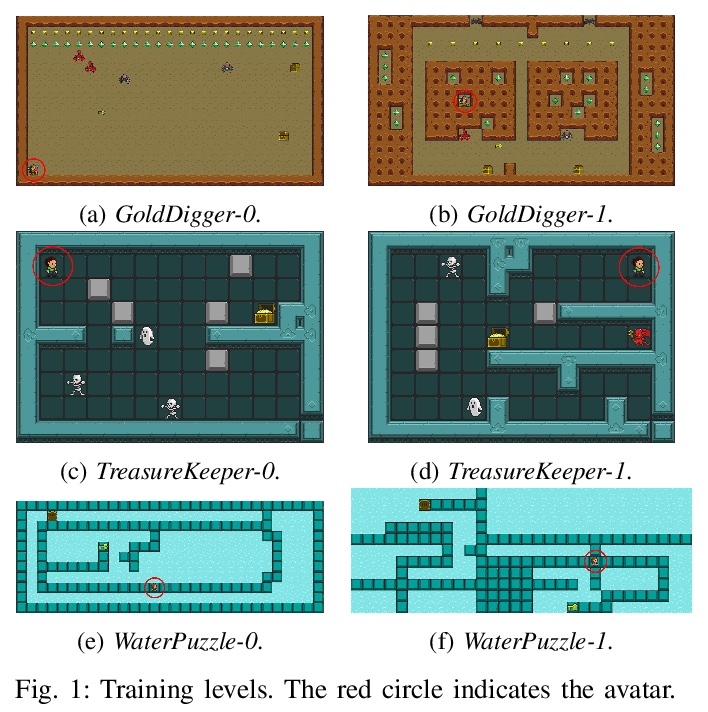
另外几篇值得关注的论文:
[LG] Transformers for One-Shot Visual Imitation
单样本视觉模仿Transformers
S Dasari, A Gupta
[CMU]
https://weibo.com/1402400261/JtEK6sqJC
[CL] The Impact of Text Presentation on Translator Performance
文本呈现方式对翻译者工作效率的影响
S Läubli, P Simianer, J Wuebker, G Kovacs, R Sennrich, S Green
[University of Zurich & Lilt, Inc]
https://weibo.com/1402400261/JtEMDDlPX
[CL] Don’t Read Too Much into It: Adaptive Computation for Open-Domain Question Answering
开放域问答的自适应计算
Y Wu, S Riedel, P Minervini, P Stenetorp
[University College London]
https://weibo.com/1402400261/JtENPuGxR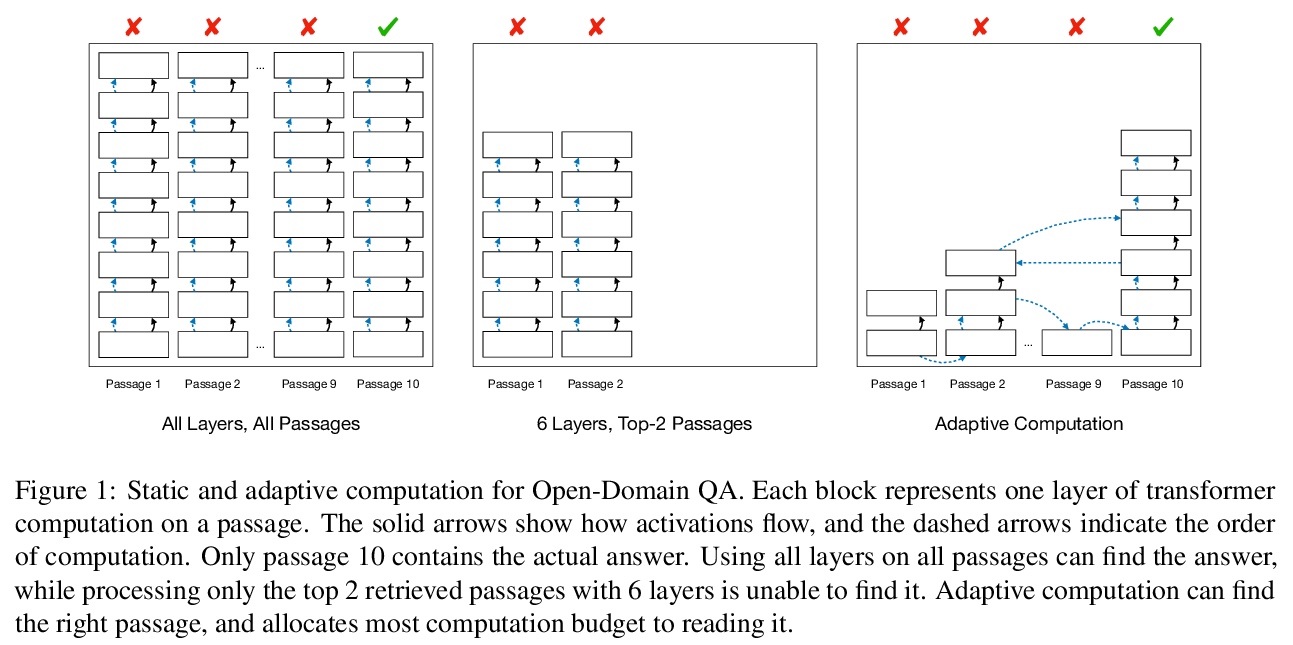
[CL] On the Sentence Embeddings from Pre-trained Language Models
(BERT)预训练语言模型句嵌入
B Li, H Zhou, J He, M Wang, Y Yang, L Li
[ByteDance AI Lab & CMU]
https://weibo.com/1402400261/JtEPB5dcS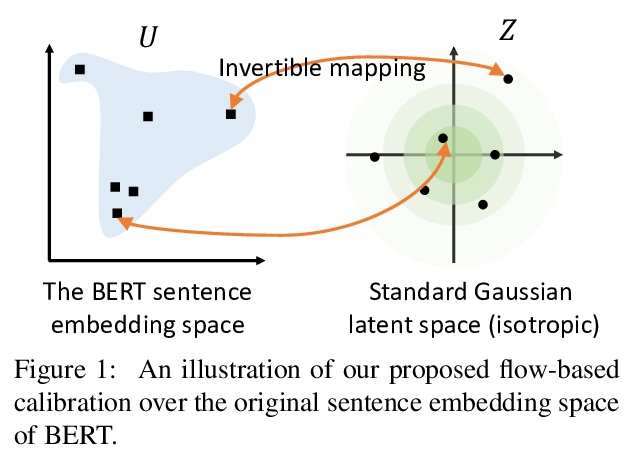
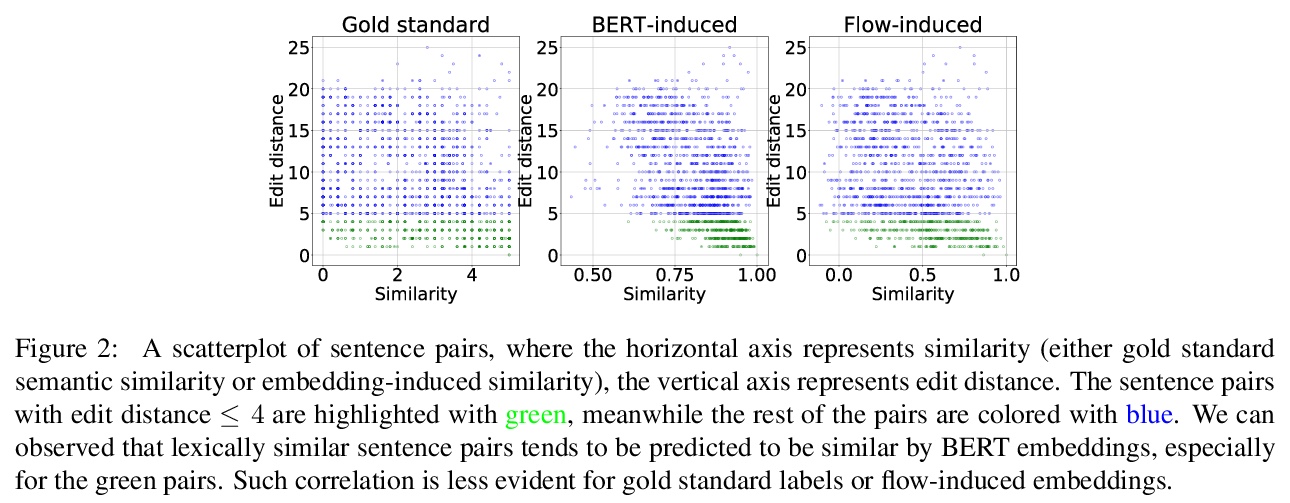
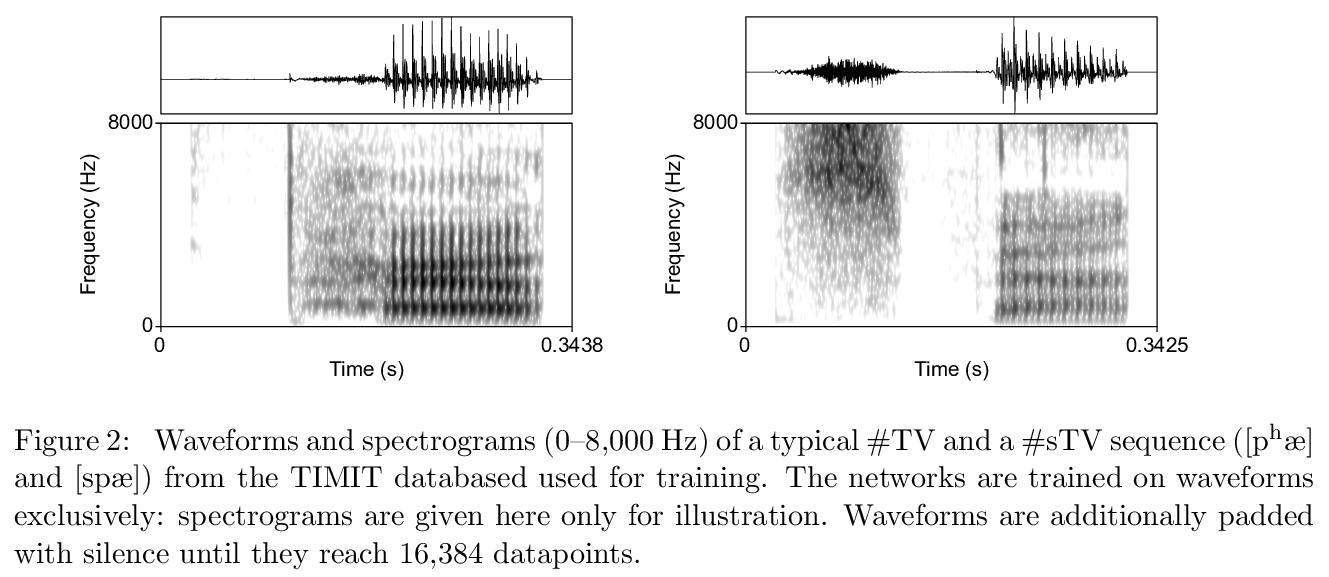
[CL] Artificial sound change: Language change and deep convolutional neural networks in iterative learning
结合深度卷积神经网络和迭代学习的声音变化建模框架
G Beguš
[UC Berkeley] 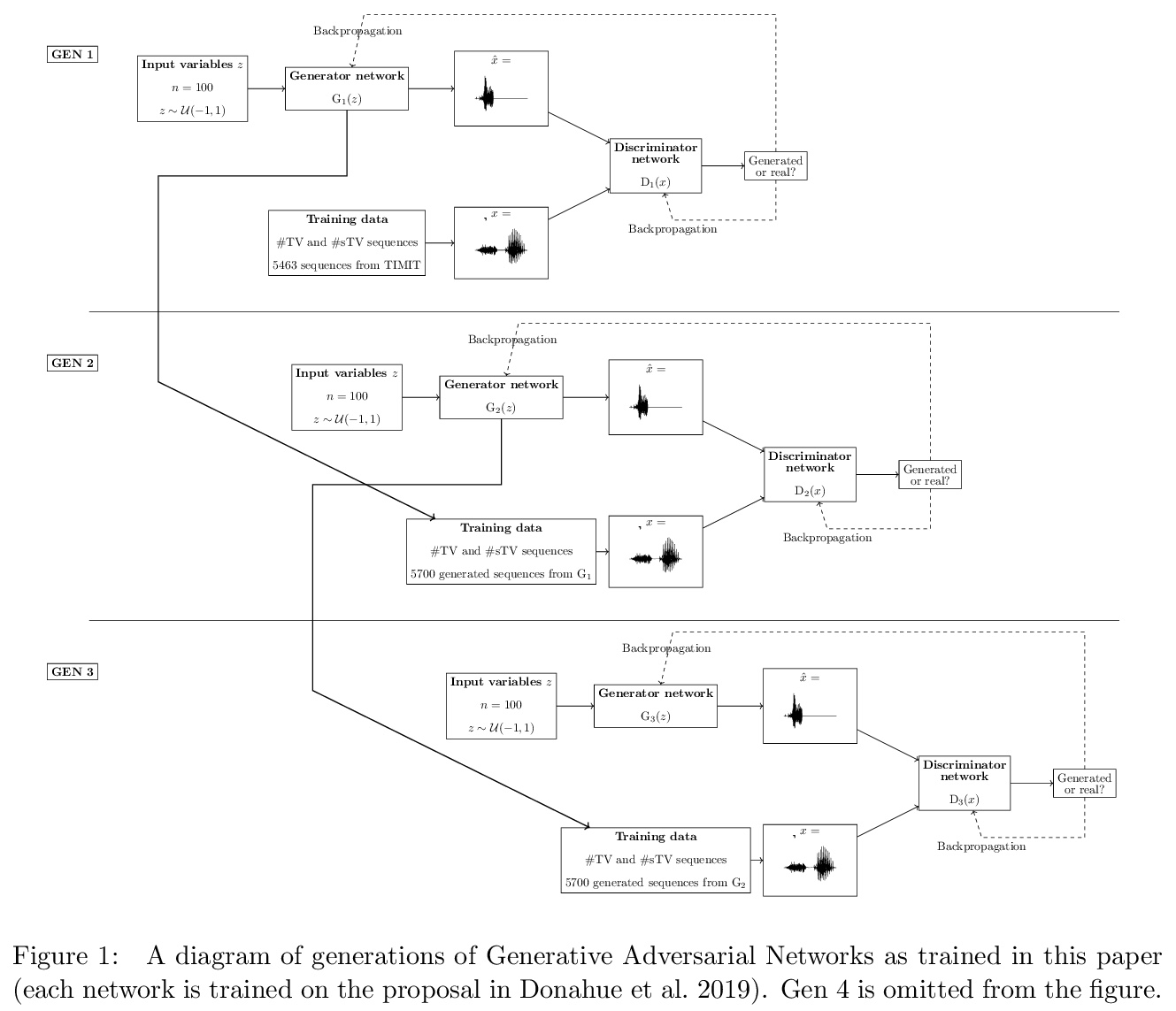

若有收获,就点个赞吧
0 人点赞
