- 1、[CV] 3D Human Pose and Shape Regression with Pyramidal Mesh Alignment Feedback Loop
- 2、[LG] Self-supervised Representation Learning with Relative Predictive Coding
- 3、[CV] USB: Universal-Scale Object Detection Benchmark
- 4、[RO] A Portable, Self-Contained Neuroprosthetic Hand with Deep Learning-Based Finger Control
- 5、[CV] Unsupervised Learning of 3D Object Categories from Videos in the Wild
- [CV] Foveated Neural Radiance Fields for Real-Time and Egocentric Virtual Reality
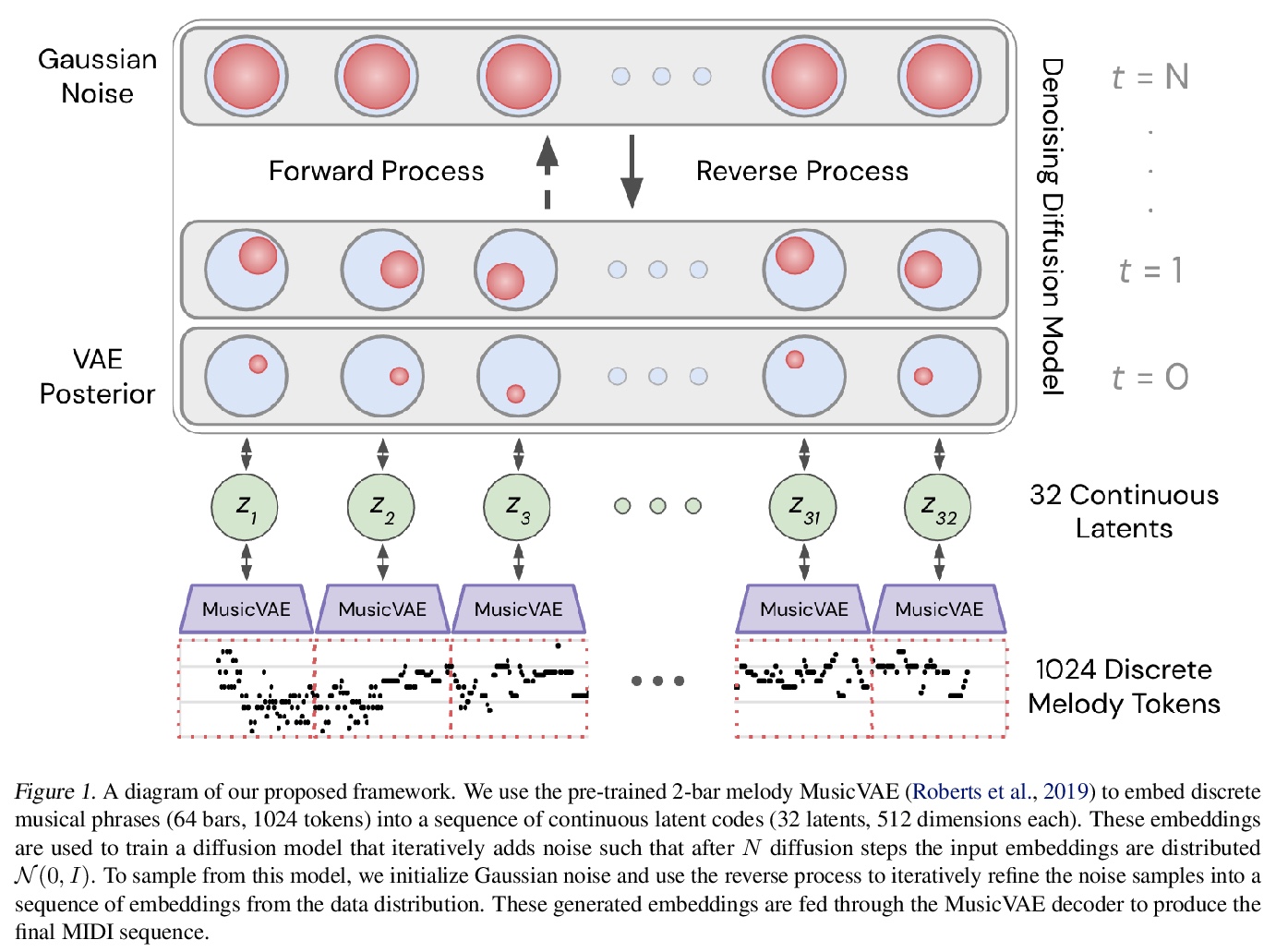
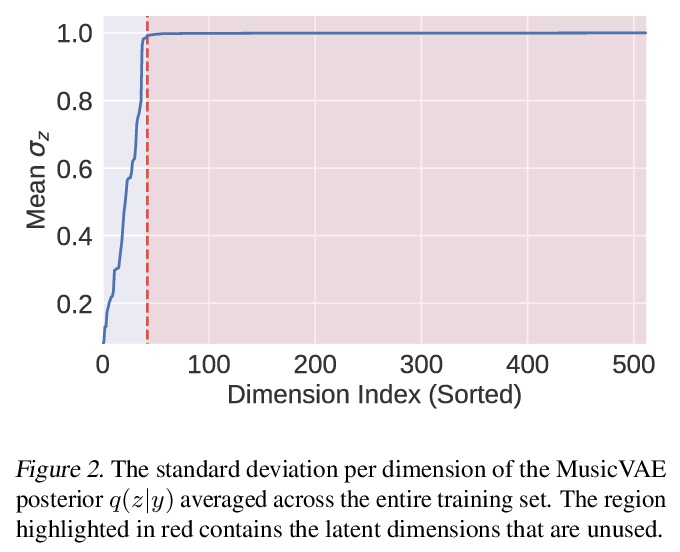
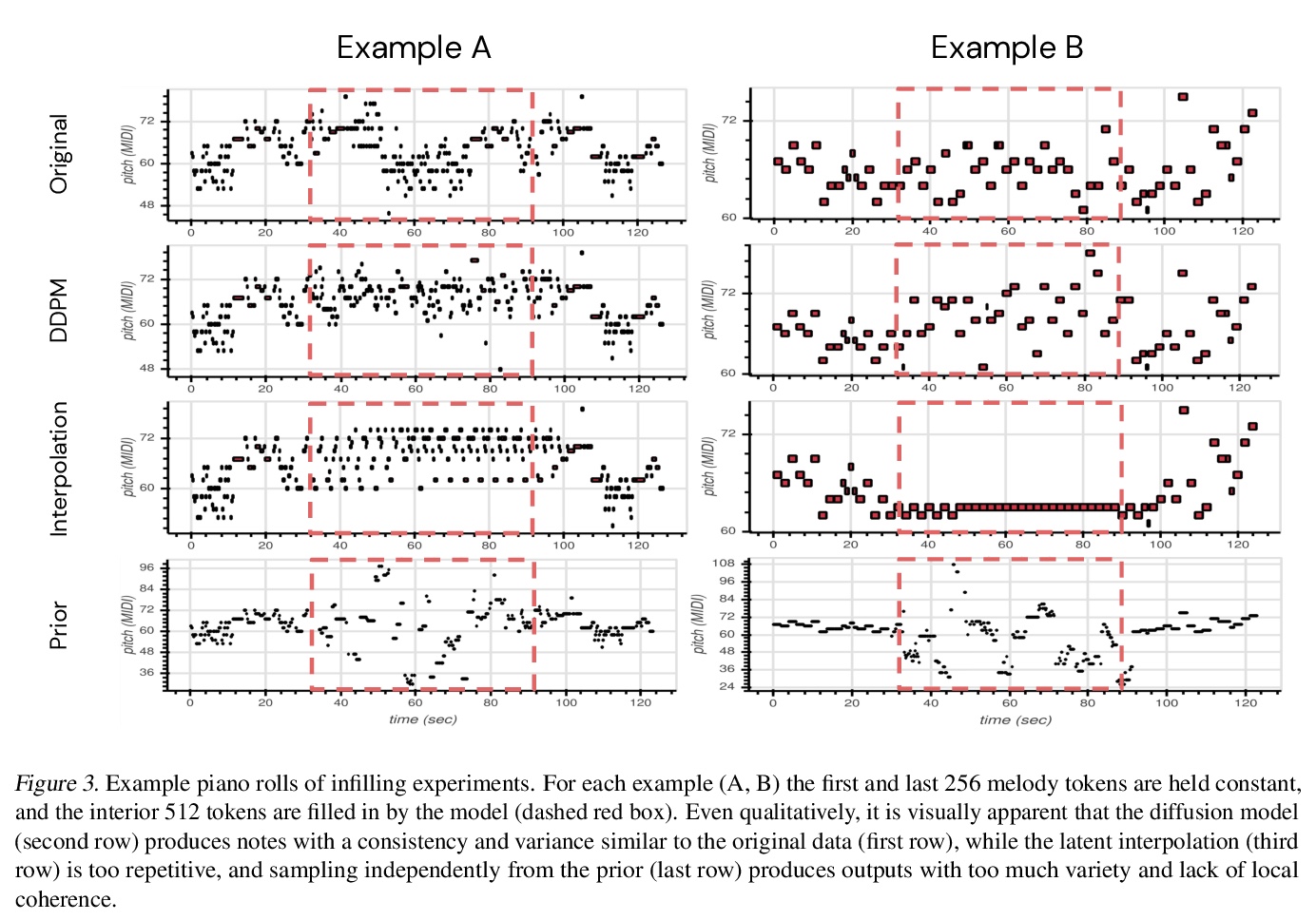
- [AS] Symbolic Music Generation with Diffusion Models
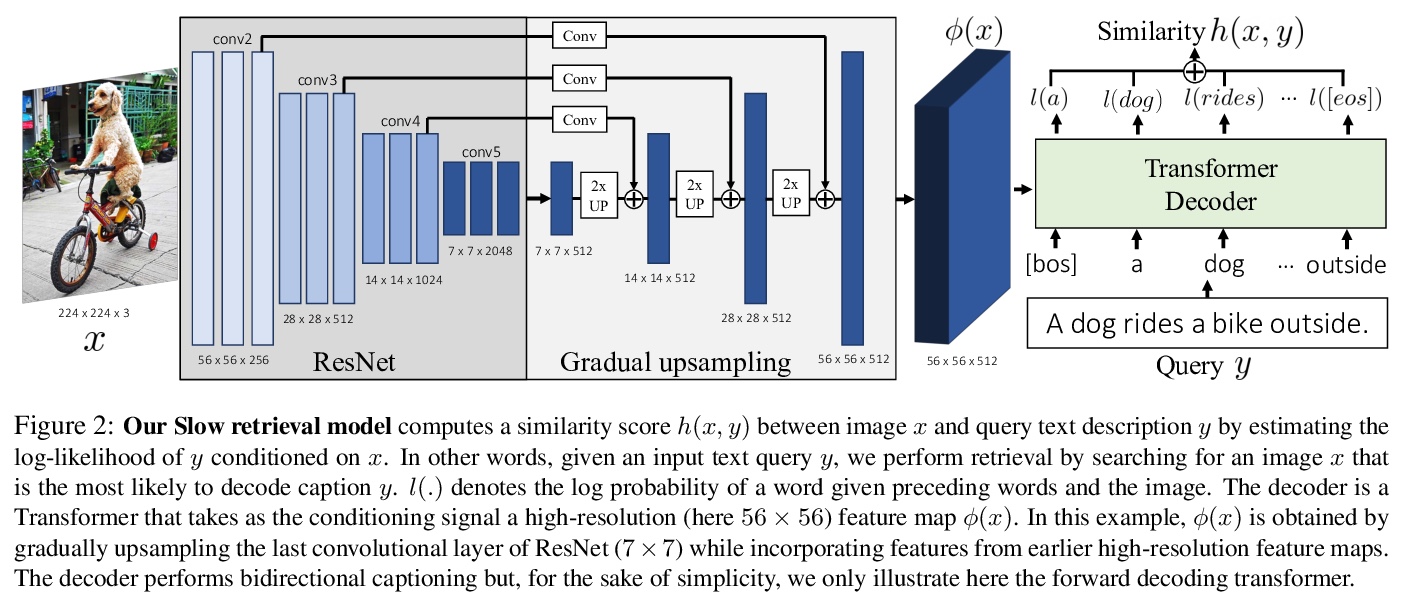
- [CV] Thinking Fast and Slow: Efficient Text-to-Visual Retrieval with Transformers
- [CV] Benchmarking Representation Learning for Natural World Image Collections
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] 3D Human Pose and Shape Regression with Pyramidal Mesh Alignment Feedback Loop
H Zhang, Y Tian, X Zhou, W Ouyang, Y Liu, L Wang, Z Sun
[Chinese Academy of Sciences & Nanjing University & The University of Sydney & Tsinghua University]
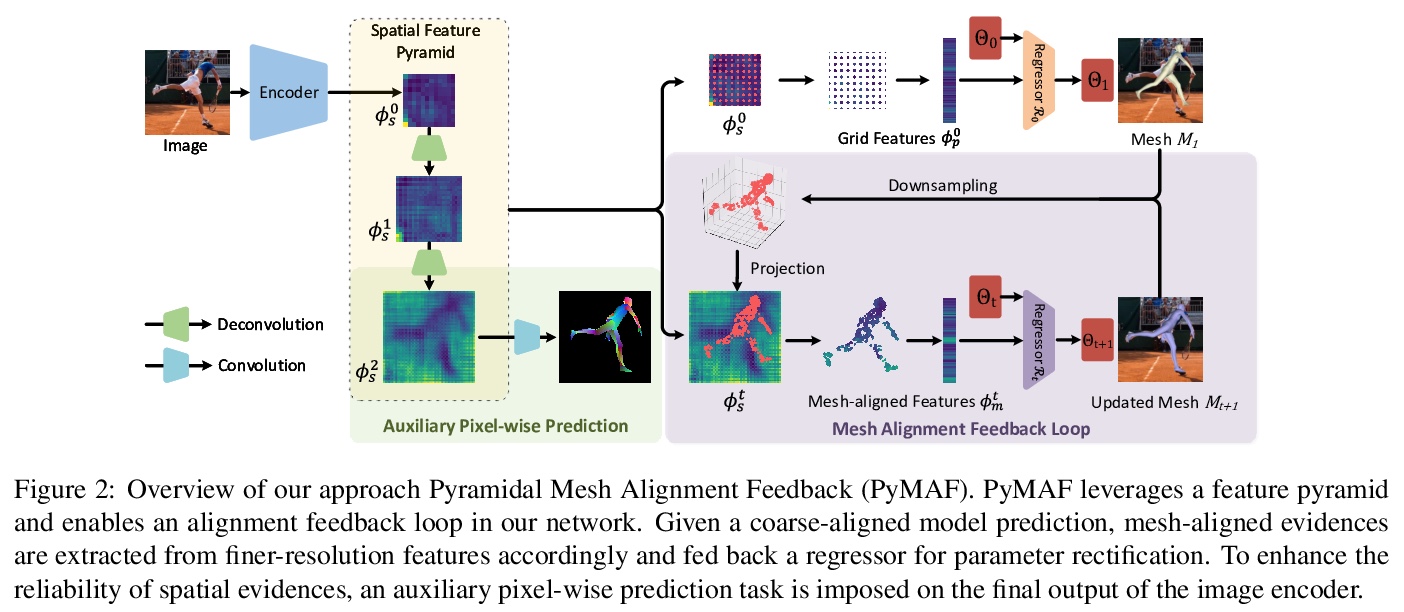
基于金字塔网格对齐反馈环路的3D人体姿态和形态回归。提出了面向基于回归的人体网格恢复的金字塔网格对齐反馈(PyMAF)。参数回归器利用来自特征金字塔的空间信息,可根据当前估计网格的对齐状态,在反馈循环中显式修正参数偏差。给定粗对齐网格预测,从空间特征图中提取网格对齐特征,反馈到回归器中进行参数修正。在深度回归器训练过程中,对空间特征图施加辅助的密集对应任务。通过这种方式,像素方面的监督信号提供了指导,以提高网格对准特征的相关性和可靠性。PyMAF在3D姿态基准上取得了有竞争力的结果,比之前基于优化和回归的方法改善了重建模型的网格-图像对齐。
Regression-based methods have recently shown promising results in reconstructing human meshes from monocular images. By directly mapping from raw pixels to model parameters, these methods can produce parametric models in a feed-forward manner via neural networks. However, minor deviation in parameters may lead to noticeable misalignment between the estimated meshes and image evidences. To address this issue, we propose a Pyramidal Mesh Alignment Feedback (PyMAF) loop to leverage a feature pyramid and rectify the predicted parameters explicitly based on the mesh-image alignment status in our deep regressor. In PyMAF, given the currently predicted parameters, mesh-aligned evidences will be extracted from finer-resolution features accordingly and fed back for parameter rectification. To reduce noise and enhance the reliability of these evidences, an auxiliary pixel-wise supervision is imposed on the feature encoder, which provides mesh-image correspondence guidance for our network to preserve the most related information in spatial features. The efficacy of our approach is validated on several benchmarks, including Human3.6M, 3DPW, LSP, and COCO, where experimental results show that our approach consistently improves the mesh-image alignment of the reconstruction. Our code is publicly available at > this https URL .
https://weibo.com/1402400261/K8Pk0BAOl


2、[LG] Self-supervised Representation Learning with Relative Predictive Coding
Y H Tsai, M Q. Ma, M Yang, H Zhao, L Morency, R Salakhutdinov
[CMU & D.E. Shaw & Co.]
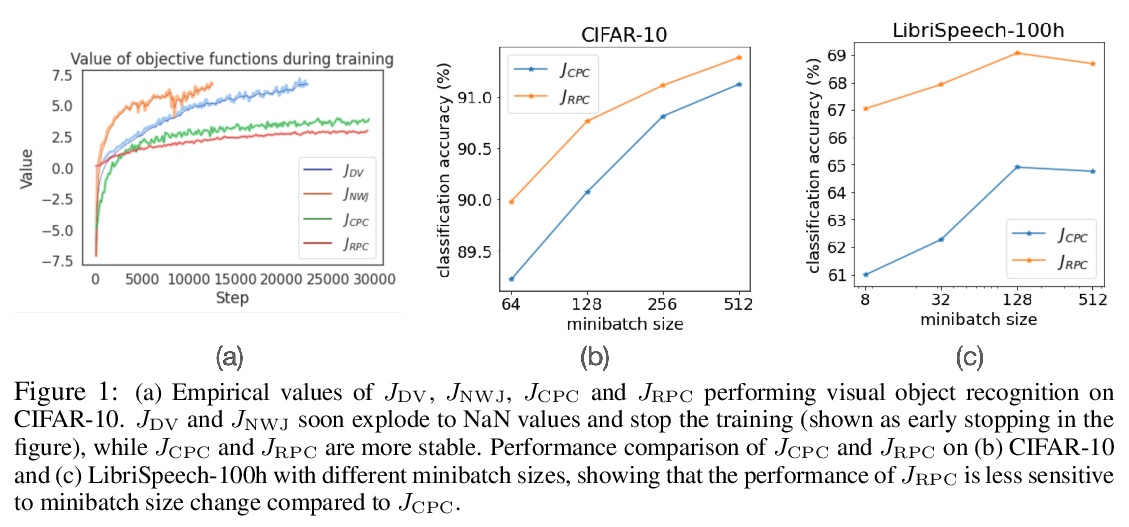
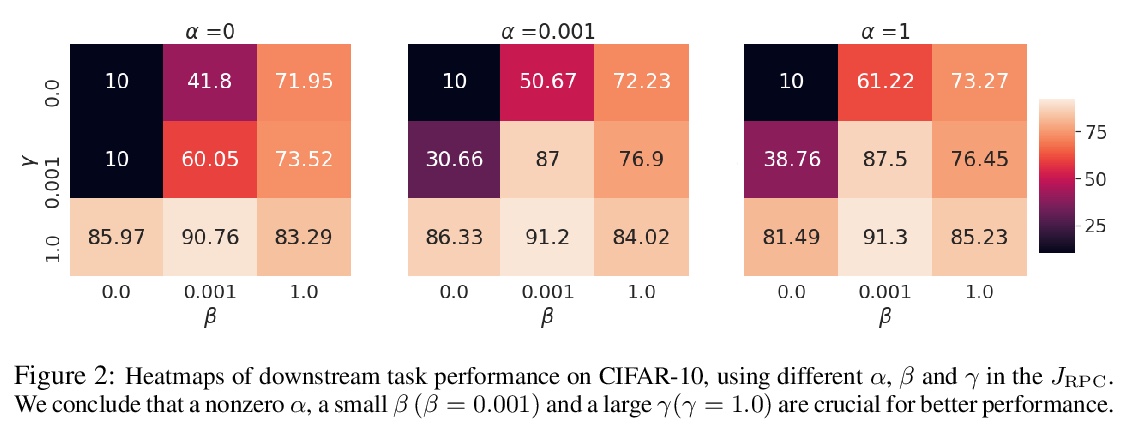
基于相对预测编码的自监督表示学习。提出了相对预测编码(RPC),一种新的对比式表示学习目标,能在训练稳定性、minibatch大小敏感性和下游任务性能之间保持良好的平衡。RPC引入了相对参数来规范化目标的边界性和低方差,且不包含对数和指数得分函数,而这些函数是导致之前对比性目标训练不稳定的主要原因。在基准视觉和语音自监督学习任务上实证了RPC的有效性。
This paper introduces Relative Predictive Coding (RPC), a new contrastive representation learning objective that maintains a good balance among training stability, minibatch size sensitivity, and downstream task performance. The key to the success of RPC is two-fold. First, RPC introduces the relative parameters to regularize the objective for boundedness and low variance. Second, RPC contains no logarithm and exponential score functions, which are the main cause of training instability in prior contrastive objectives. We empirically verify the effectiveness of RPC on benchmark vision and speech self-supervised learning tasks. Lastly, we relate RPC with mutual information (MI) estimation, showing RPC can be used to estimate MI with low variance.
https://weibo.com/1402400261/K8PpaEReo

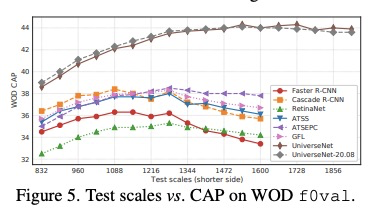
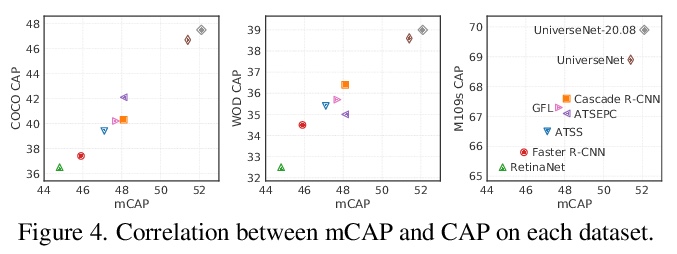
3、[CV] USB: Universal-Scale Object Detection Benchmark
Y Shinya
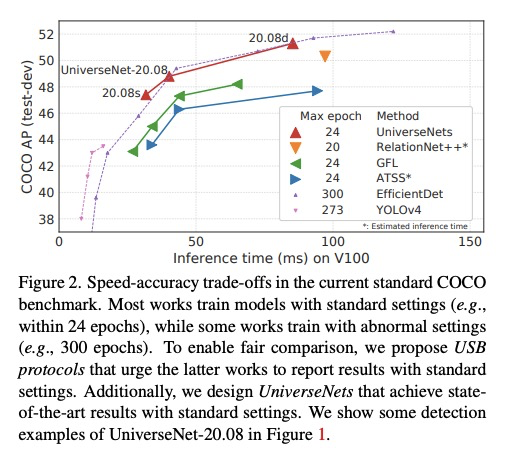
USB:通用尺度目标检测基准。介绍了通用尺度目标检测基准(USB),将COCO与最近提出的Waymo Open Dataset和Manga109-s数据集相结合,在目标尺度和图像域上有足够丰富的变化。建立了USB协议,用于公平的训练和评估,以实现更具包容性的目标检测研究。USB协议通过定义训练轮数和评价图像分辨率的多阈值,实现了公平、简单、可扩展的比较。通过分析为多尺度目标检测而开发的方法,设计了快速、准确的目标检测器UniverseNets,在USB上表现优于所有基线,并在现有基准上取得了最先进的结果。
Benchmarks, such as COCO, play a crucial role in object detection. However, existing benchmarks are insufficient in scale variation, and their protocols are inadequate for fair comparison. In this paper, we introduce the Universal-Scale object detection Benchmark (USB). USB has variations in object scales and image domains by incorporating COCO with the recently proposed Waymo Open Dataset and Manga109-s dataset. To enable fair comparison, we propose USB protocols by defining multiple thresholds for training epochs and evaluation image resolutions. By analyzing methods on the proposed benchmark, we designed fast and accurate object detectors called UniverseNets, which surpassed all baselines on USB and achieved state-of-the-art results on existing benchmarks. Specifically, UniverseNets achieved 54.1% AP on COCO test-dev with 20 epochs training, the top result among single-stage detectors on the Waymo Open Dataset Challenge 2020 2D detection, and the first place in the NightOwls Detection Challenge 2020 all objects track. The code is available at > this https URL .
https://weibo.com/1402400261/K8Ptnuz4O
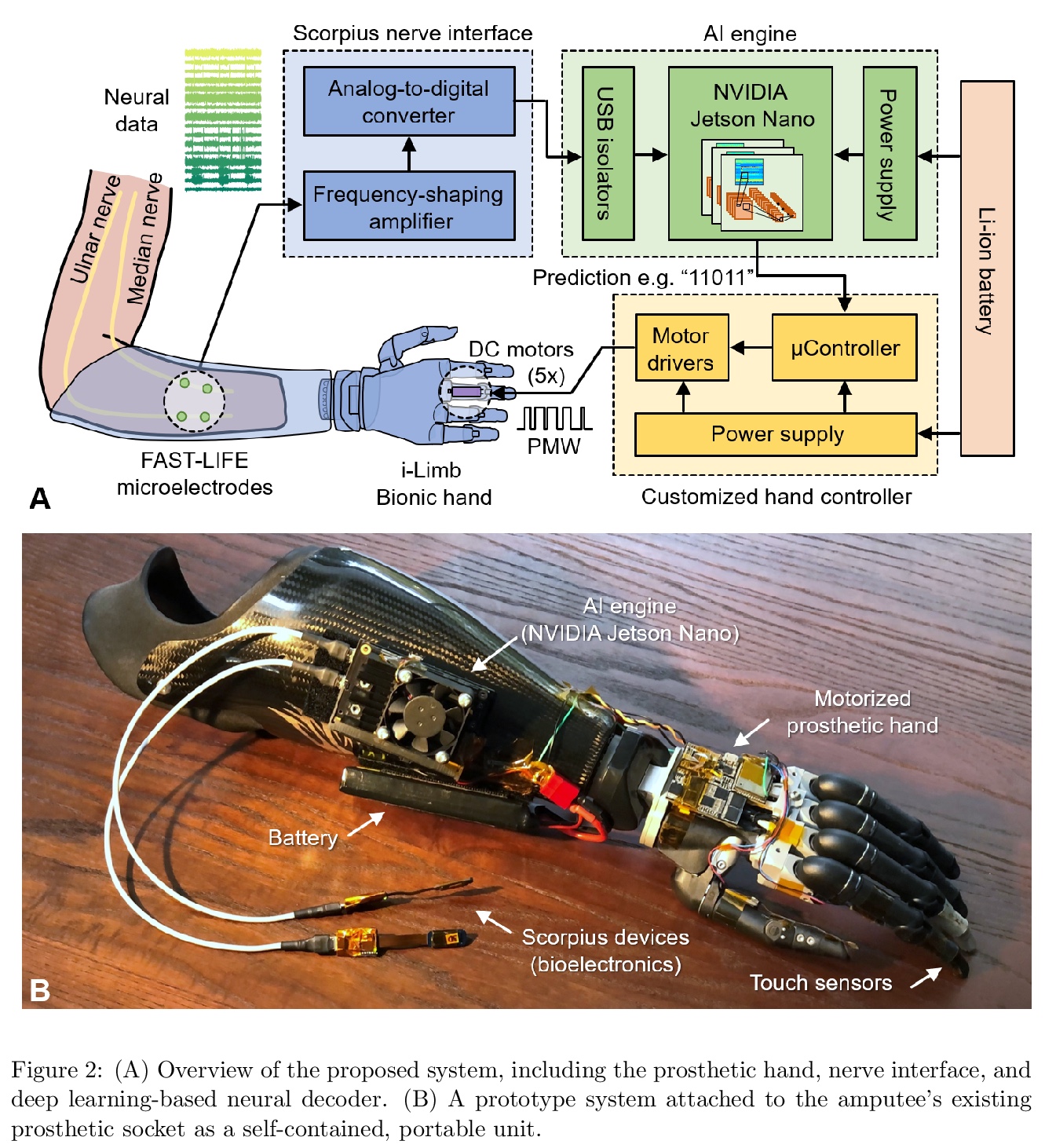
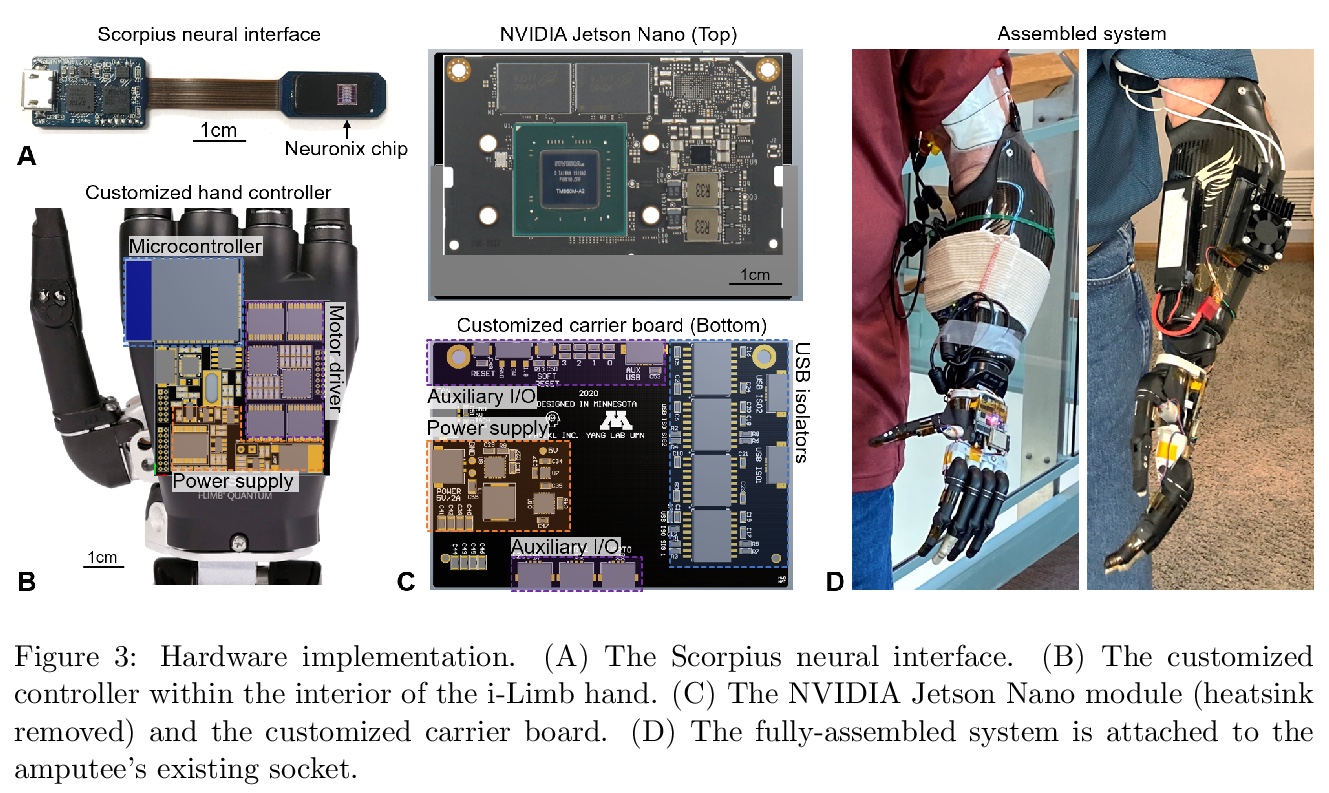
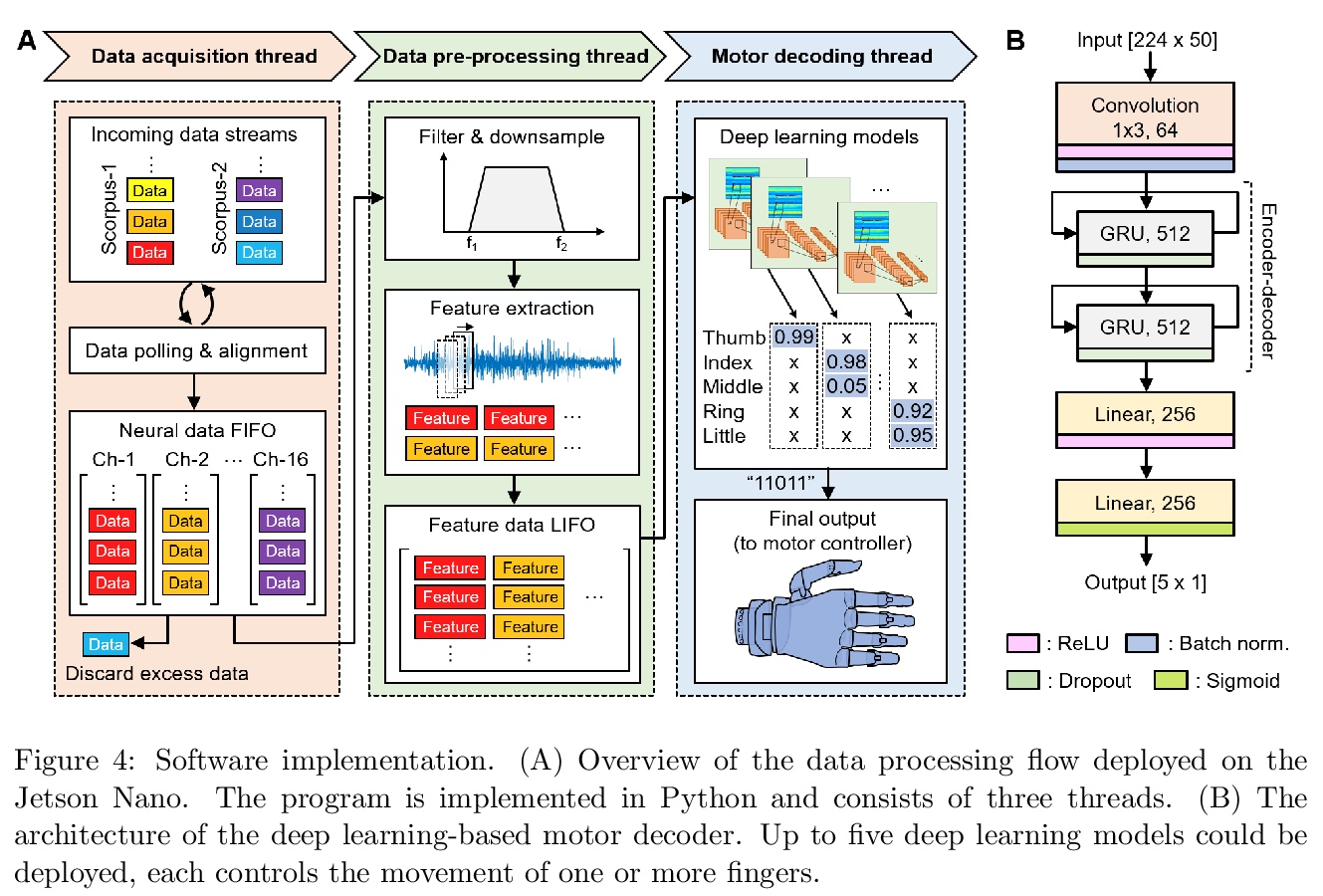
4、[RO] A Portable, Self-Contained Neuroprosthetic Hand with Deep Learning-Based Finger Control
A T Nguyen, M W. Drealan, D K Luu, M Jiang, J Xu, J Cheng, Q Zhao, E W. Keefer, Z Yang
[University of Minnesota & University of Texas Southwestern Medical Center & Nerves Incorporated]
深度学习手指控制的便携式独立神经义肢手。提出一种嵌入式基于深度学习控制的神经义肢手实现。神经解码器基于循环神经网络(RNN)架构设计,并部署在NVIDIA Jetson Nano上,神经义肢手作为一个便携、独立的单元,可实时控制单个手指运动。所提出系统在一个经桡骨截肢者身上进行评估,使用植入的筋膜内微电极周边神经信号(ENG),结果证明该系统在各种实验室和现实世界环境中可提供鲁棒、高精度(95-99%)和低延迟(50-120毫秒)控制单个手指运动的能力。
Objective: Deep learning-based neural decoders have emerged as the prominent approach to enable dexterous and intuitive control of neuroprosthetic hands. Yet few studies have materialized the use of deep learning in clinical settings due to its high computational requirements. Methods: Recent advancements of edge computing devices bring the potential to alleviate this problem. Here we present the implementation of a neuroprosthetic hand with embedded deep learning-based control. The neural decoder is designed based on the recurrent neural network (RNN) architecture and deployed on the NVIDIA Jetson Nano - a compacted yet powerful edge computing platform for deep learning inference. This enables the implementation of the neuroprosthetic hand as a portable and self-contained unit with real-time control of individual finger movements. Results: The proposed system is evaluated on a transradial amputee using peripheral nerve signals (ENG) with implanted intrafascicular microelectrodes. The experiment results demonstrate the system’s capabilities of providing robust, high-accuracy (95-99%) and low-latency (50-120 msec) control of individual finger movements in various laboratory and real-world environments. Conclusion: Modern edge computing platforms enable the effective use of deep learning-based neural decoders for neuroprosthesis control as an autonomous system. Significance: This work helps pioneer the deployment of deep neural networks in clinical applications underlying a new class of wearable biomedical devices with embedded artificial intelligence.
https://weibo.com/1402400261/K8PAw9xQc

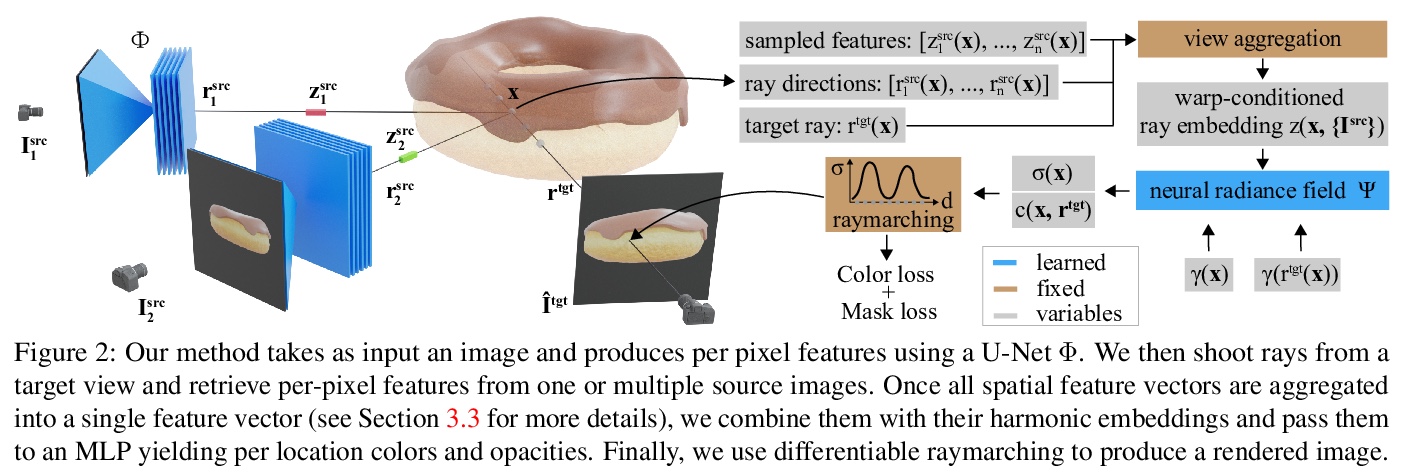
5、[CV] Unsupervised Learning of 3D Object Categories from Videos in the Wild
P Henzler, J Reizenstein, P Labatut, R Shapovalov, T Ritschel, A Vedaldi, D Novotny
[University College London & Facebook AI Research]
从现实视频中无监督学习3D目标分类。介绍了一个新的目标中心视频大型数据集,适合训练和基准测试大规模目标实例集合多视图学习模型。现有的利用网格、体素或隐式曲面的技术,孤立目标重建效果很好,但在这种具有挑战性的数据上却失败了。提出了一种新的神经网络设计翘曲条件射线嵌入(WCR),显著改善了重建,获得了物体表面和纹理的详细隐式表示,还补偿了初始SfM重建中的噪声,引导了学习过程。实验表明,在现有基准和新数据集上,WCR的性能比之前的深度单目重建基线有所提高。
Our goal is to learn a deep network that, given a small number of images of an object of a given category, reconstructs it in 3D. While several recent works have obtained analogous results using synthetic data or assuming the availability of 2D primitives such as keypoints, we are interested in working with challenging real data and with no manual annotations. We thus focus on learning a model from multiple views of a large collection of object instances. We contribute with a new large dataset of object centric videos suitable for training and benchmarking this class of models. We show that existing techniques leveraging meshes, voxels, or implicit surfaces, which work well for reconstructing isolated objects, fail on this challenging data. Finally, we propose a new neural network design, called warp-conditioned ray embedding (WCR), which significantly improves reconstruction while obtaining a detailed implicit representation of the object surface and texture, also compensating for the noise in the initial SfM reconstruction that bootstrapped the learning process. Our evaluation demonstrates performance improvements over several deep monocular reconstruction baselines on existing benchmarks and on our novel dataset.
https://weibo.com/1402400261/K8PFieuAk


另外几篇值得关注的论文:
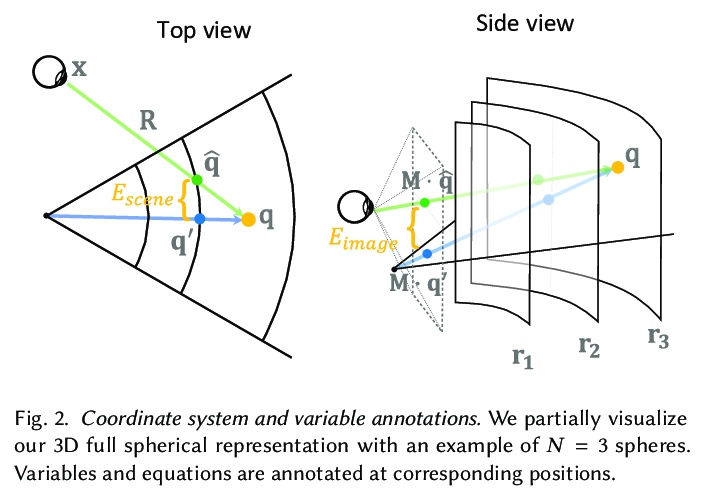
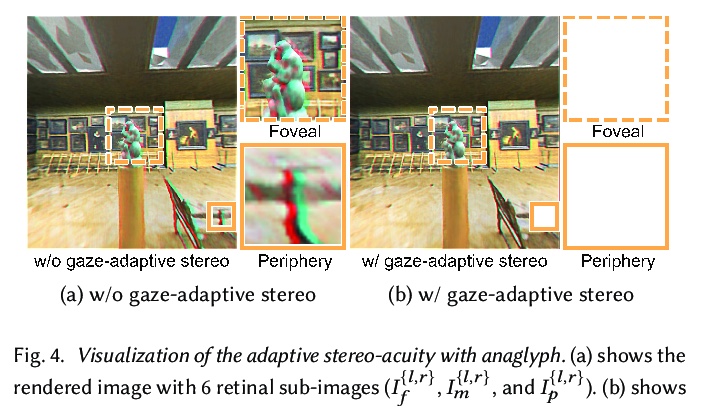
[CV] Foveated Neural Radiance Fields for Real-Time and Egocentric Virtual Reality
面向实时和自我中心虚拟现实的视点神经辐射场
N Deng, Z He, J Ye, P Chakravarthula, X Yang, Q Sun
[Shanghai Jiao Tong University & New York University & University of North Carolina at Chapel Hill]
https://weibo.com/1402400261/K8PJbq82D

[AS] Symbolic Music Generation with Diffusion Models
基于扩散模型的符号化音乐生成
G Mittal, J Engel, C Hawthorne, I Simon
[UC Berkeley & Google Brain]
https://weibo.com/1402400261/K8PKN1aay
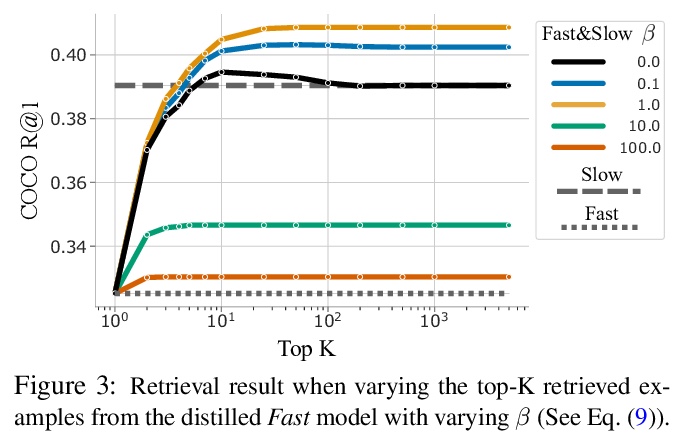
[CV] Thinking Fast and Slow: Efficient Text-to-Visual Retrieval with Transformers
基于Transformer实现高效的文本-视觉检索
A Miech, J Alayrac, I Laptev, J Sivic, A Zisserman
[DeepMind & ENS/Inria & CIIRC CTU]
https://weibo.com/1402400261/K8PMRwajb
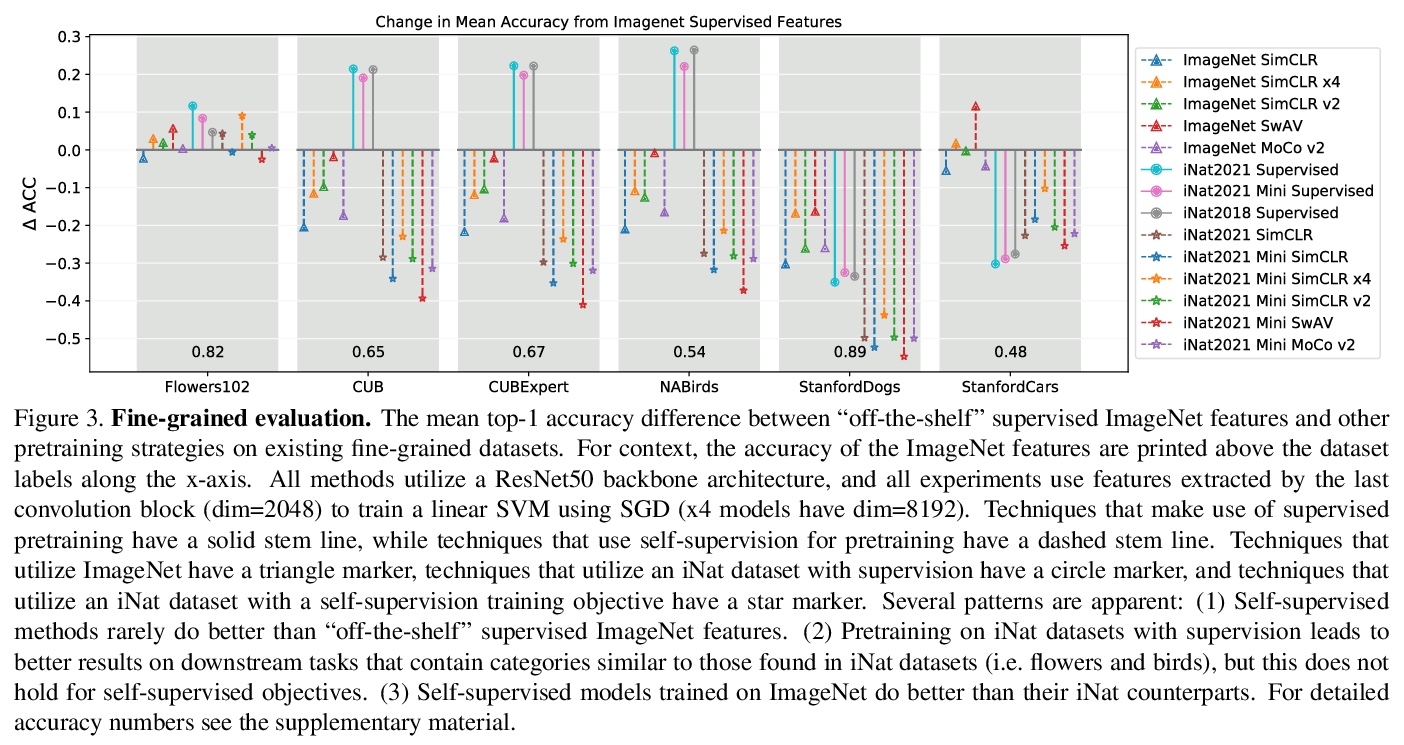
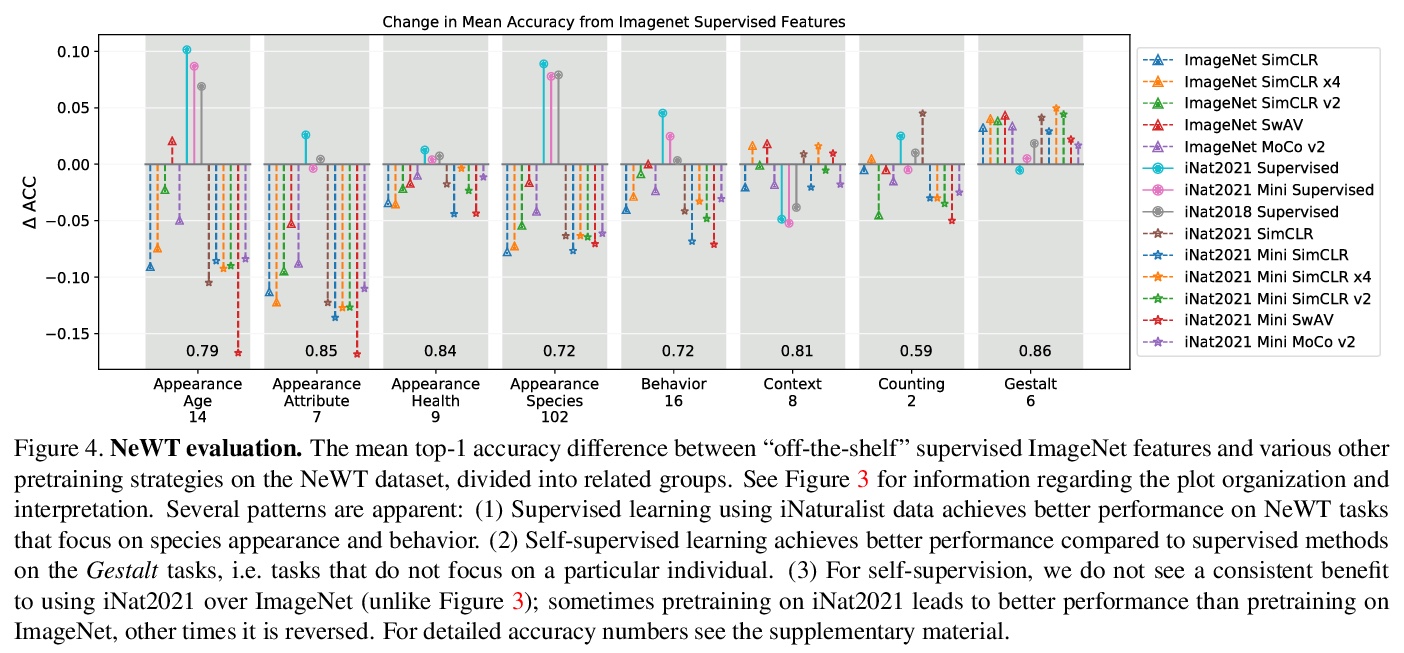
[CV] Benchmarking Representation Learning for Natural World Image Collections
自然世界图像集合表示学习基准
G V Horn, E Cole, S Beery, K Wilber, S Belongie, O M Aodha
[Cornell University & Caltech & Google & University of Edinburgh]
https://weibo.com/1402400261/K8PPosMNl


若有收获,就点个赞吧
0 人点赞
