LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[AS] *Self-training and Pre-training are Complementary for Speech Recognition
Q Xu, A Baevski, T Likhomanenko, P Tomasello, A Conneau, R Collobert, G Synnaeve, M Auli
[Facebook AI Research]
对语音识别来说无监督预训练和自训练是互补的。证明了伪标记和wav2vec 2.0预训练在各种标记数据设置中是互补的,只需要10分钟的转录(标记)语音就可建立语音识别系统,词错误率和一年前用960小时标记数据训练得到的最好系统相当,是语音识别技术的巨大进步。
Self-training and unsupervised pre-training have emerged as effective approaches to improve speech recognition systems using unlabeled data. However, it is not clear whether they learn similar patterns or if they can be effectively combined. In this paper, we show that pseudo-labeling and pre-training with wav2vec 2.0 are complementary in a variety of labeled data setups. Using just 10 minutes of labeled data from Libri-light as well as 53k hours of unlabeled data from LibriVox achieves WERs of 3.0%/5.2% on the clean and other test sets of Librispeech - rivaling the best published systems trained on 960 hours of labeled data only a year ago. Training on all labeled data of Librispeech achieves WERs of 1.5%/3.1%.
https://weibo.com/1402400261/Jrn0ahOio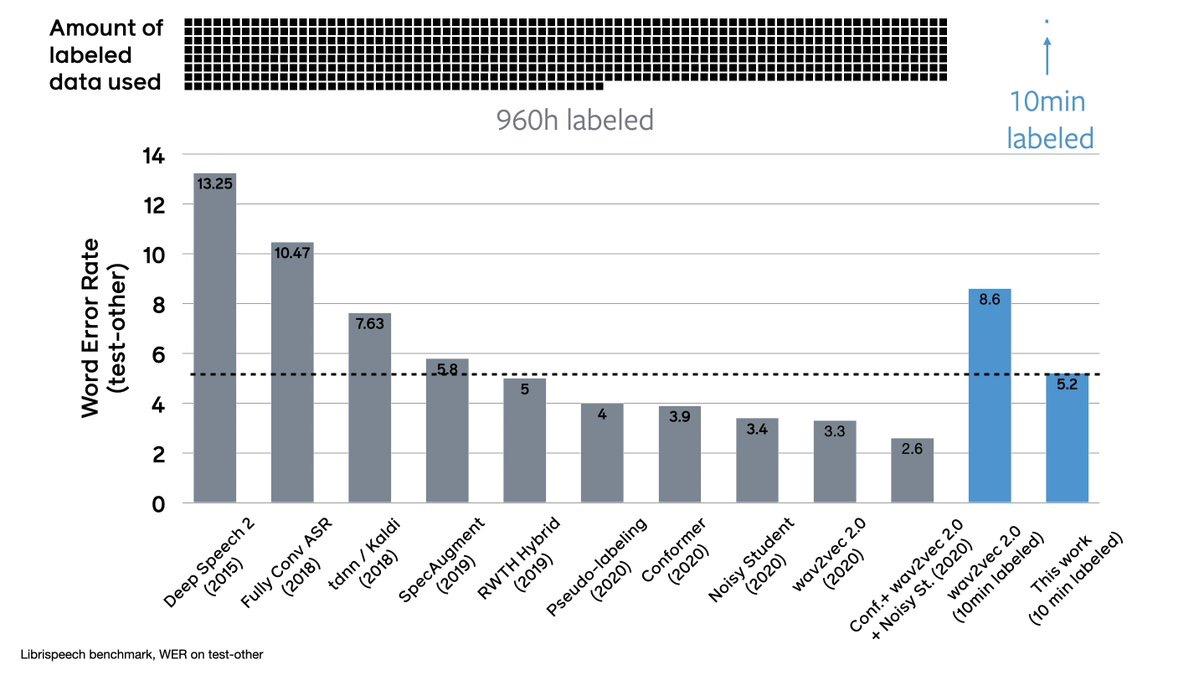
2、[RO] **COG: Connecting New Skills to Past Experience with Offline Reinforcement Learning
A Singh, A Yu, J Yang, J Zhang, A Kumar, S Levine
[UC Berkeley]
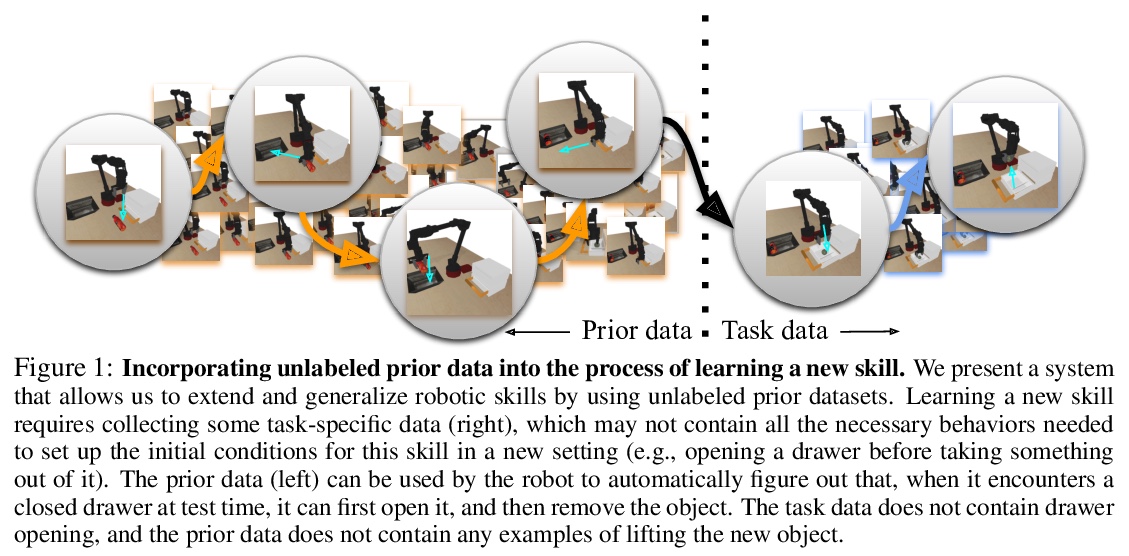
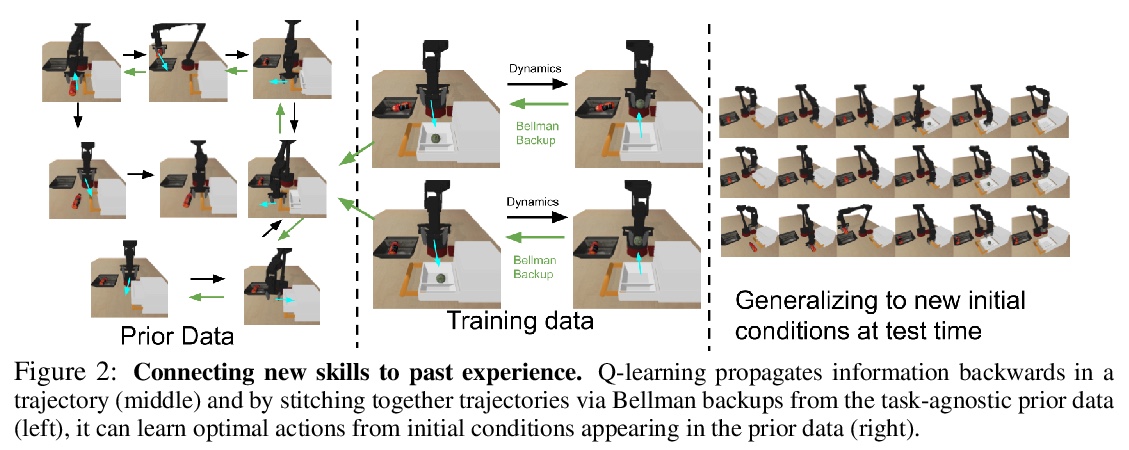
COG用离线强化学习结合过往数据泛化新技能,用离线强化学习让机器人能通过将新数据与过往经验相结合获得某种“常识”,通过动态规划重用之前数据来扩展新技能,即使过往数据不能真正成功地解决新任务,仍可用于学习更好的策略。**
Reinforcement learning has been applied to a wide variety of robotics problems, but most of such applications involve collecting data from scratch for each new task. Since the amount of robot data we can collect for any single task is limited by time and cost considerations, the learned behavior is typically narrow: the policy can only execute the task in a handful of scenarios that it was trained on. What if there was a way to incorporate a large amount of prior data, either from previously solved tasks or from unsupervised or undirected environment interaction, to extend and generalize learned behaviors? While most prior work on extending robotic skills using pre-collected data focuses on building explicit hierarchies or skill decompositions, we show in this paper that we can reuse prior data to extend new skills simply through dynamic programming. We show that even when the prior data does not actually succeed at solving the new task, it can still be utilized for learning a better policy, by providing the agent with a broader understanding of the mechanics of its environment. We demonstrate the effectiveness of our approach by chaining together several behaviors seen in prior datasets for solving a new task, with our hardest experimental setting involving composing four robotic skills in a row: picking, placing, drawer opening, and grasping, where a +1/0 sparse reward is provided only on task completion. We train our policies in an end-to-end fashion, mapping high-dimensional image observations to low-level robot control commands, and present results in both simulated and real world domains. Additional materials and source code can be found on our project website: > this https URL
https://weibo.com/1402400261/Jrn7Wbo80
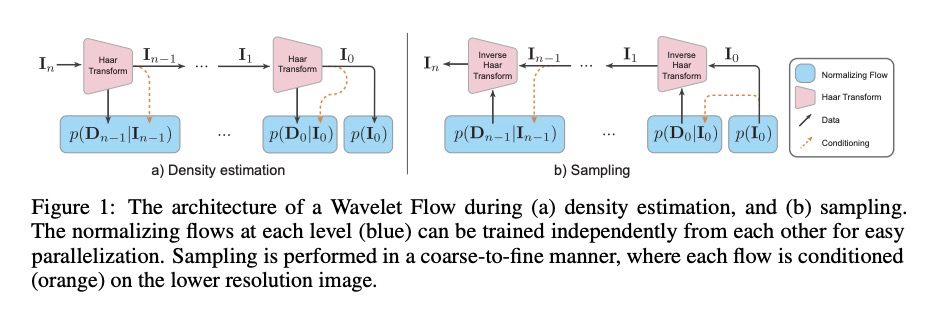
3、[CV] Wavelet Flow: Fast Training of High Resolution Normalizing Flows
J J. Yu, K G. Derpanis, M A. Brubaker
[York University & Ryerson University]
用小波流实现高分辨率规范化流的快速训练。提出了一种基于小波的多尺度规范化流结构——小波流(Wavelet Flow)。小波流具有信号尺度的明确表示,本身就包含低分辨率信号模型和高分辨率信号条件生成(即超分辨率)。小波流一个主要优点是能为高分辨率数据构建生成模型,在标准(低分辨率)基准上,相比之前的规范化训练速度可提高15倍。
Normalizing flows are a class of probabilistic generative models which allow for both fast density computation and efficient sampling and are effective at modelling complex distributions like images. A drawback among current methods is their significant training cost, sometimes requiring months of GPU training time to achieve state-of-the-art results. This paper introduces Wavelet Flow, a multi-scale, normalizing flow architecture based on wavelets. A Wavelet Flow has an explicit representation of signal scale that inherently includes models of lower resolution signals and conditional generation of higher resolution signals, i.e., super resolution. A major advantage of Wavelet Flow is the ability to construct generative models for high resolution data (e.g., 1024 x 1024 images) that are impractical with previous models. Furthermore, Wavelet Flow is competitive with previous normalizing flows in terms of bits per dimension on standard (low resolution) benchmarks while being up to 15x faster to train.
https://weibo.com/1402400261/Jrnivzibc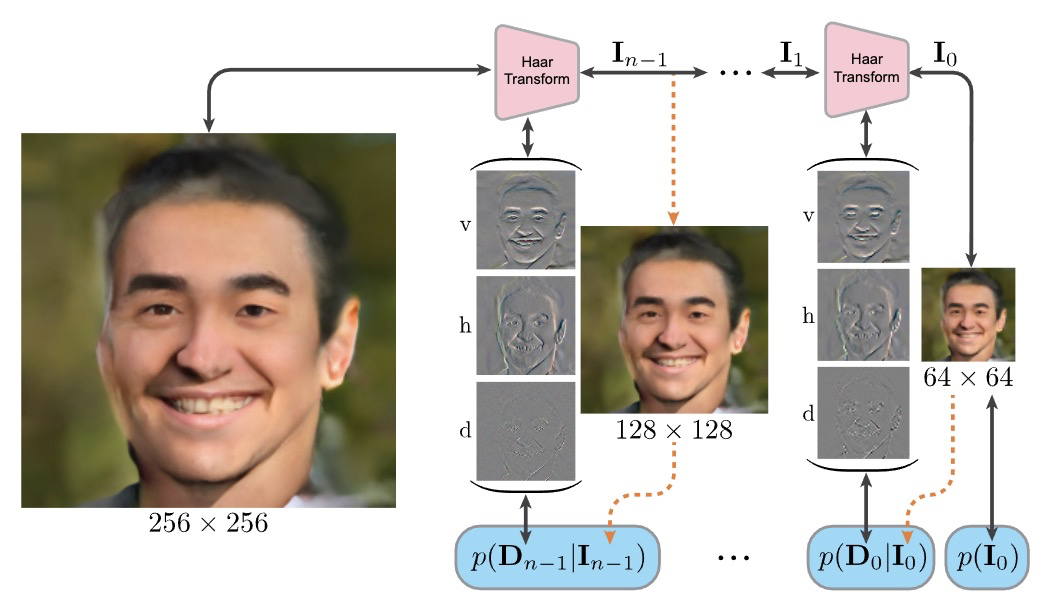

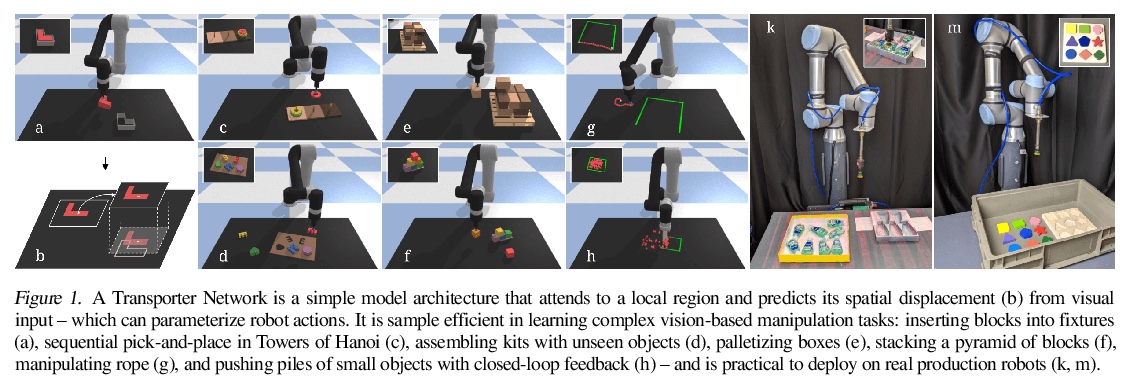
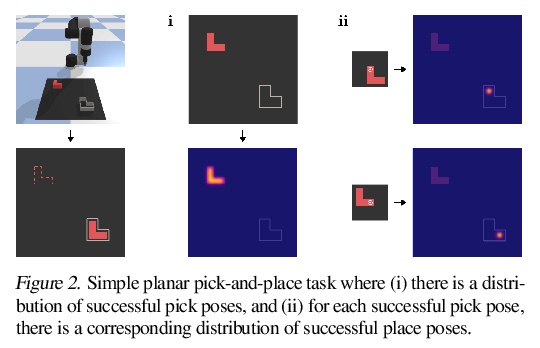
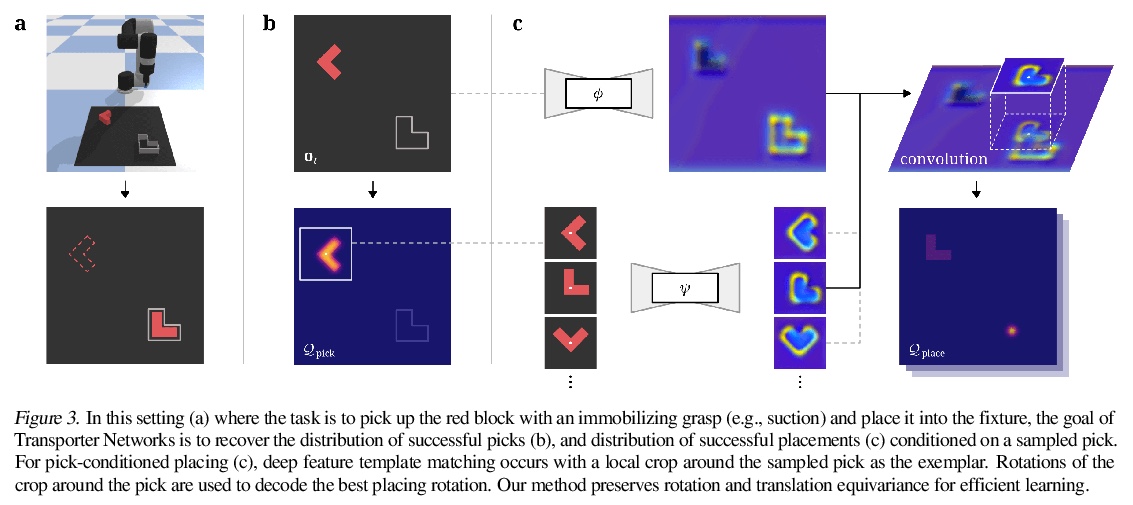
4、[RO] **Transporter Networks: Rearranging the Visual World for Robotic Manipulation
A Zeng, P Florence, J Tompson, S Welker, J Chien, M Attarian, T Armstrong, I Krasin, D Duong, V Sindhwani, J Lee
[Robotics at Google]
用传输器网络从视觉输入推断空间位移。提出了传输器网络(Transporter Network),重排深度特征,可推断空间位移,从视觉输入参数化机器人行动。在10个模拟任务上的实验表明,与各种端到端基线相比,传输器网络学习速度更快,泛化效果更好。**
Robotic manipulation can be formulated as inducing a sequence of spatial displacements: where the space being moved can encompass an object, part of an object, or end effector. In this work, we propose the Transporter Network, a simple model architecture that rearranges deep features to infer spatial displacements from visual input - which can parameterize robot actions. It makes no assumptions of objectness (e.g. canonical poses, models, or keypoints), it exploits spatial symmetries, and is orders of magnitude more sample efficient than our benchmarked alternatives in learning vision-based manipulation tasks: from stacking a pyramid of blocks, to assembling kits with unseen objects; from manipulating deformable ropes, to pushing piles of small objects with closed-loop feedback. Our method can represent complex multi-modal policy distributions and generalizes to multi-step sequential tasks, as well as 6DoF pick-and-place. Experiments on 10 simulated tasks show that it learns faster and generalizes better than a variety of end-to-end baselines, including policies that use ground-truth object poses. We validate our methods with hardware in the real world. Experiment videos and code will be made available at > this https URL
https://weibo.com/1402400261/JrnmQ9pbP
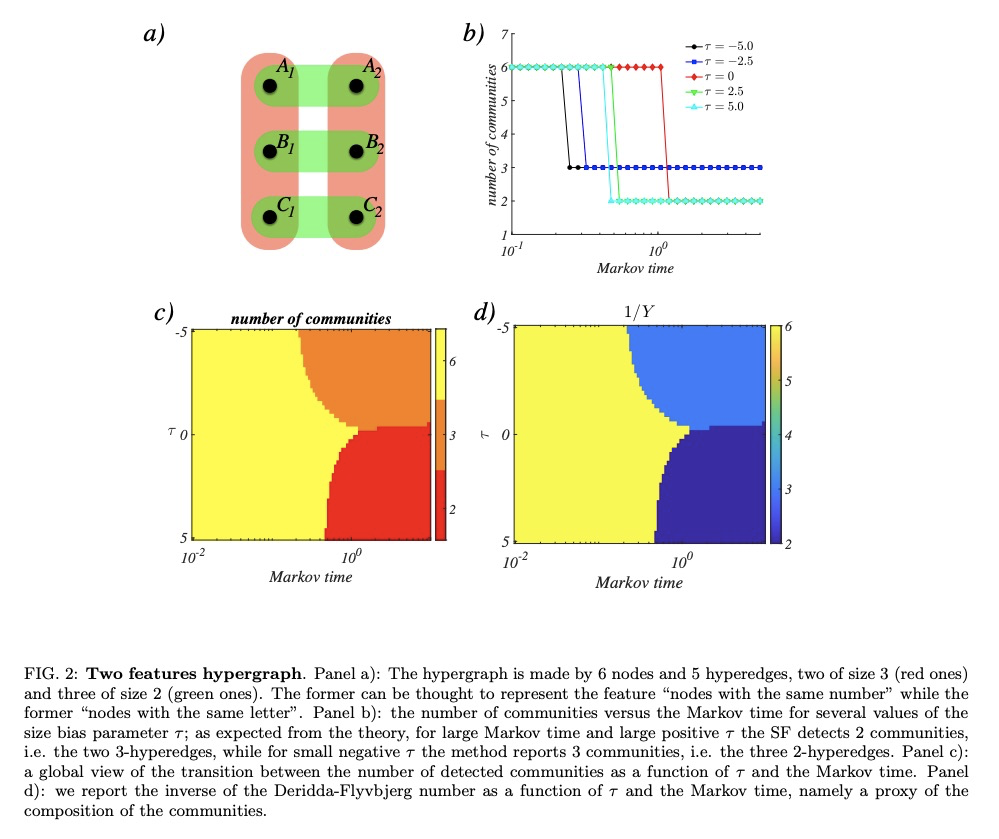
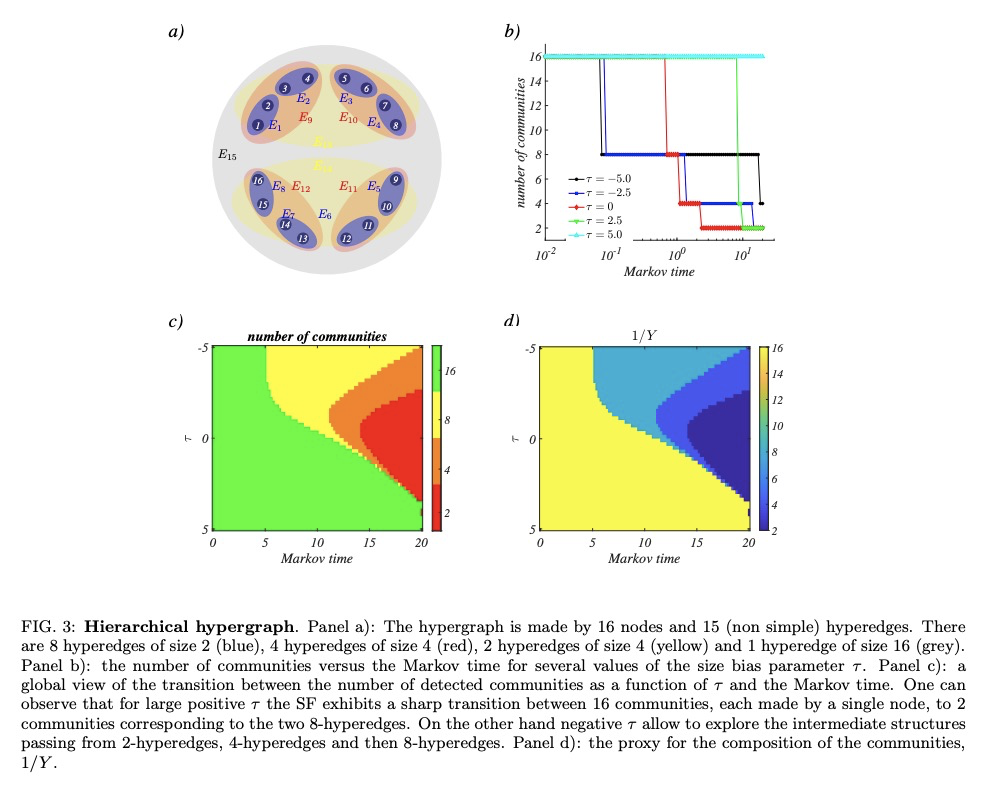
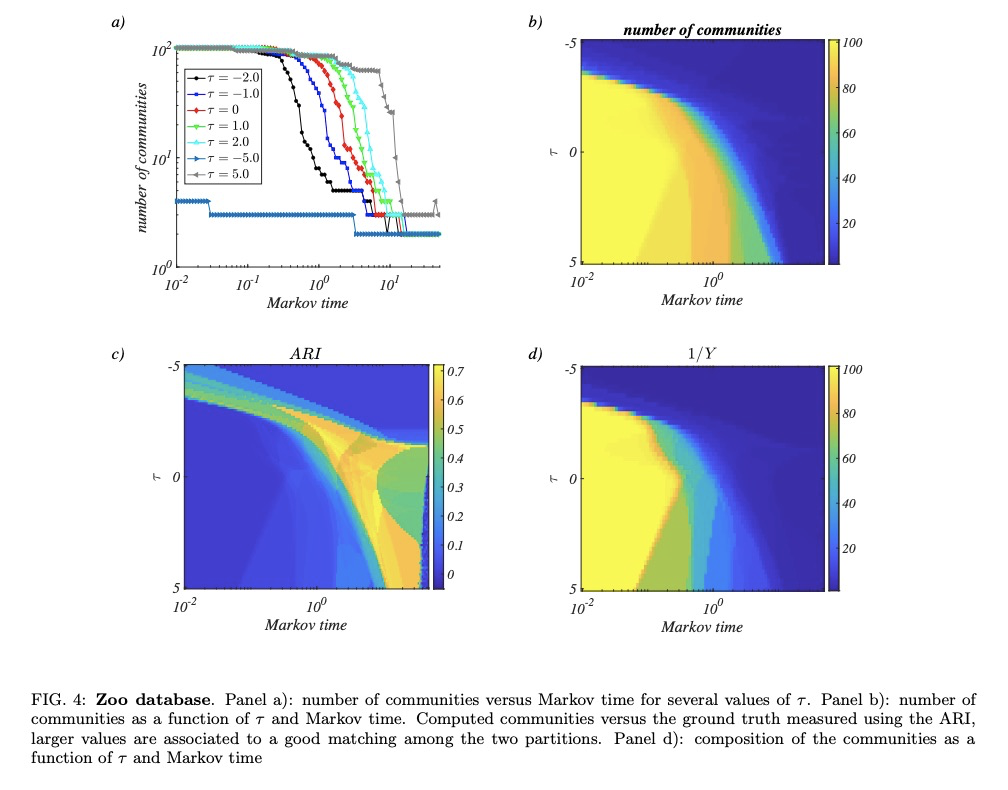
5、[SI] **Random walks and community detection in hypergraphs
T Carletti, D Fanelli, R Lambiotte
[University of Namur & Universita degli Studi di Firenze & University of Oxford]
超图上的随机游走与社区检测。在超图上提出了一个单参数的随机游走过程,其中参数控制游走器的动力学偏向于低基数或高基数的超边,根据偏差参数不同,最终的预测结果也会有根本不同。通过考虑与每个随机游走过程相关的社区结构来探讨它们之间的差异。**
We propose a one parameter family of random walk processes on hypergraphs, where a parameter biases the dynamics of the walker towards hyperedges of low or high cardinality. We show that for each value of the parameter the resulting process defines its own hypergraph projection on a weighted network. We then explore the differences between them by considering the community structure associated to each random walk process. To do so, we generalise the Markov stability framework to hypergraphs and test it on artificial and real-world hypergraphs.
https://weibo.com/1402400261/Jrns68oYf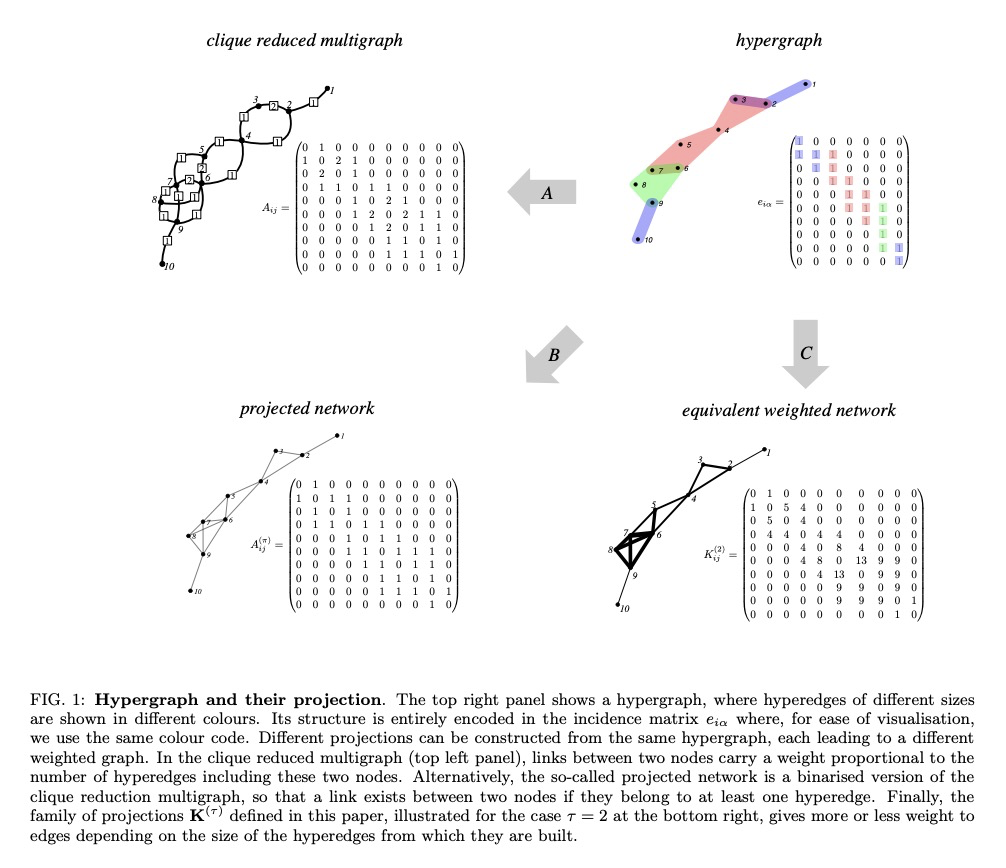
另外几篇值得关注的论文:
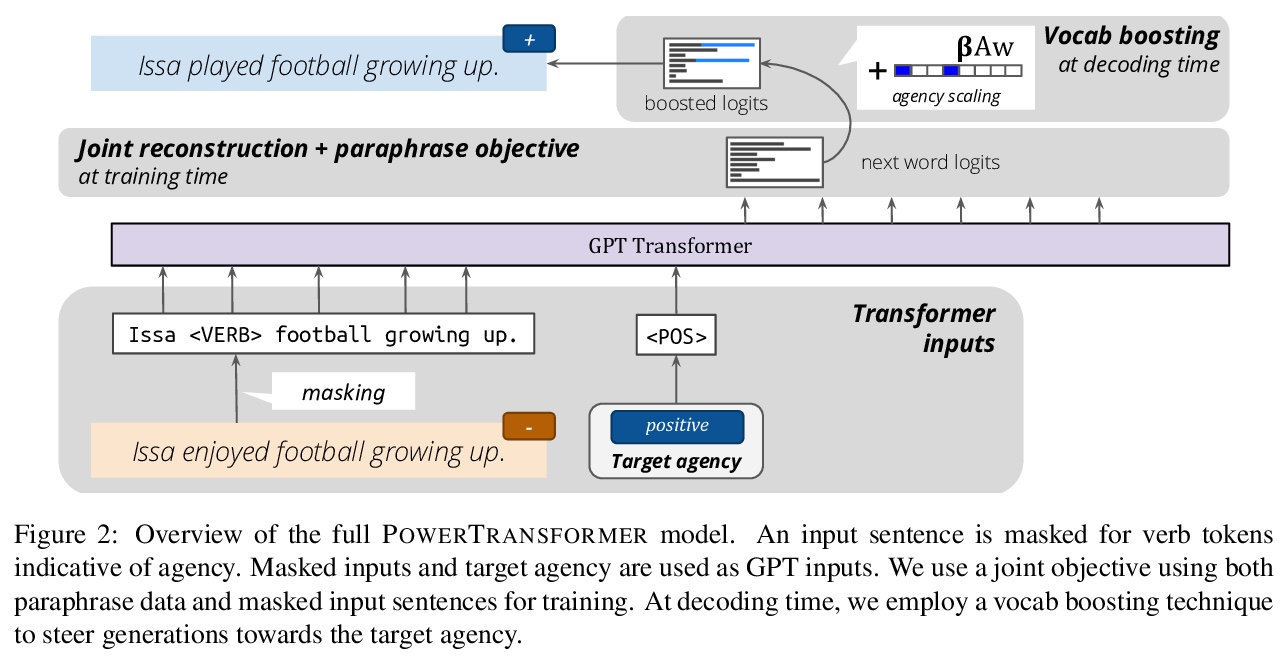
[CL] PowerTransformer: Unsupervised Controllable Revision for Biased Language Correction
PowerTransformer:无监督可控偏见语言校正
X Ma, M Sap, H Rashkin, Y Choi
[University of Washington]
https://weibo.com/1402400261/JrnvucWXz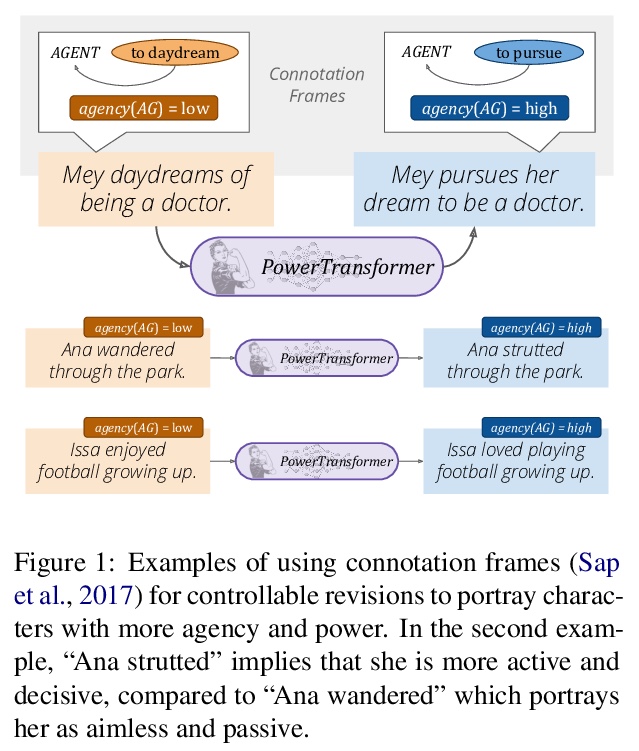
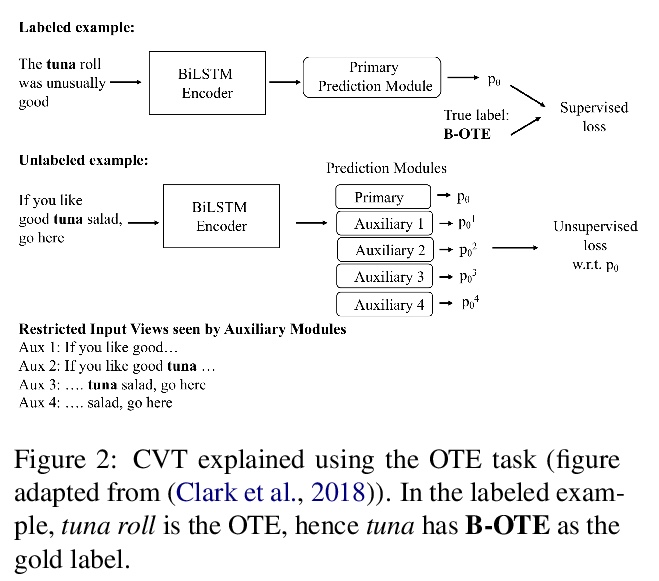
[CL] To BERT or Not to BERT: Comparing Task-specific and Task-agnostic Semi-Supervised Approaches for Sequence Tagging
To BERT or Not to BERT:序列标记的特定任务和任务不可知半监督方法比较
K Bhattacharjee, M Ballesteros, R Anubhai, S Muresan, J Ma, F Ladhak, Y Al-Onaizan
[Amazon AI]
https://weibo.com/1402400261/JrnxgoRCz
[LG] On the Transfer of Disentangled Representations in Realistic Settings
现实环境解缠表示的迁移
A Dittadi, F Träuble, F Locatello, M Wüthrich, V Agrawal, O Winther, S Bauer, B Schölkopf
[Technical University of Denmark & Max Planck Institute for Intelligent Systems]
https://weibo.com/1402400261/JrnA32oxW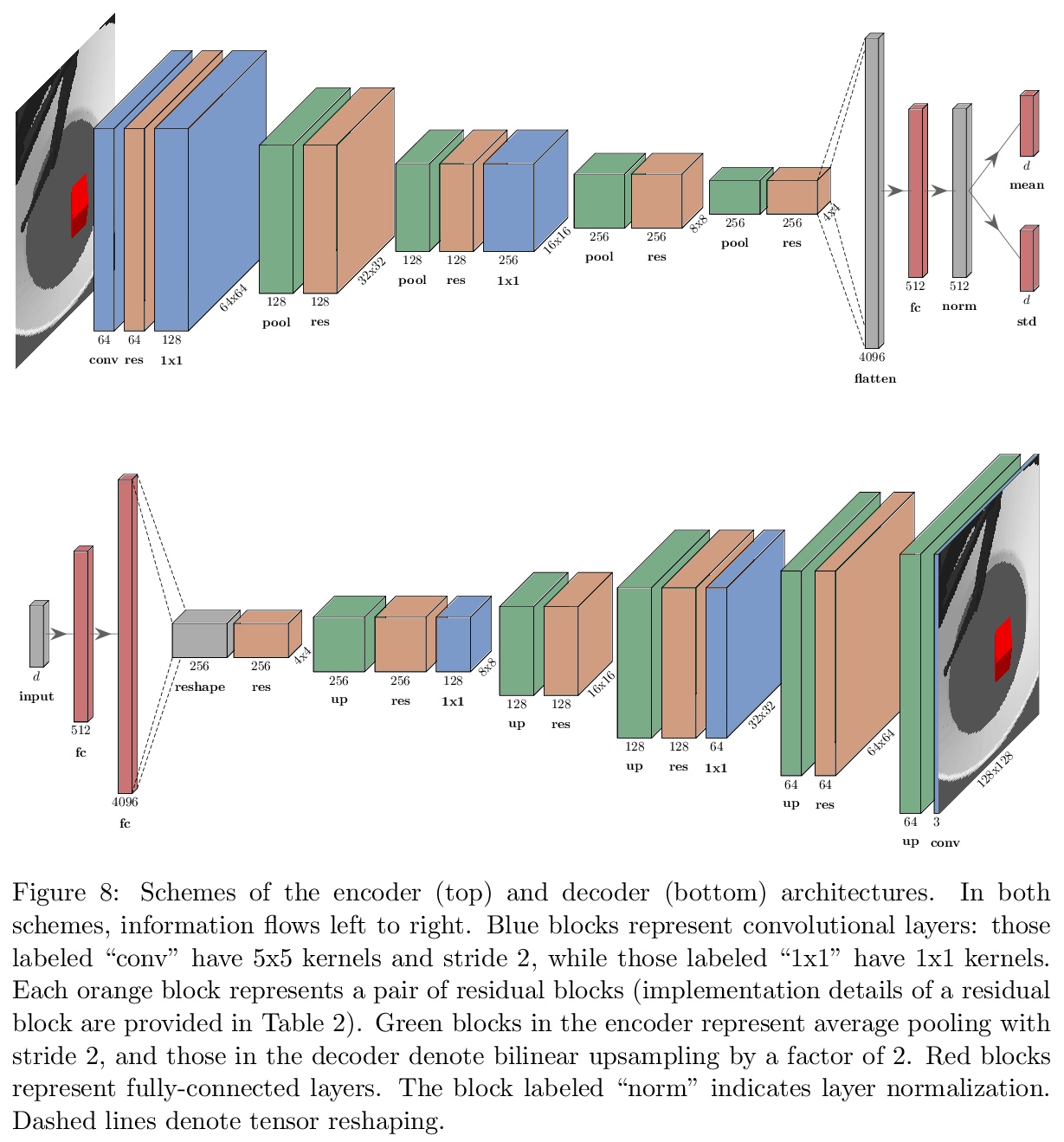
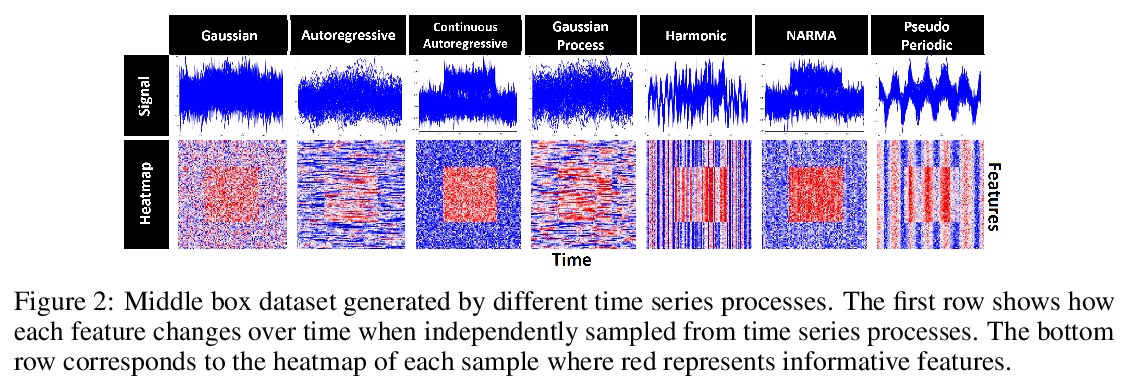
[LG] Benchmarking Deep Learning Interpretability in Time Series Predictions
深度学习时序预测可解释性评测
A A Ismail, M Gunady, H C Bravo, S Feizi
[University of Maryland]
https://weibo.com/1402400261/JrnDuFF0x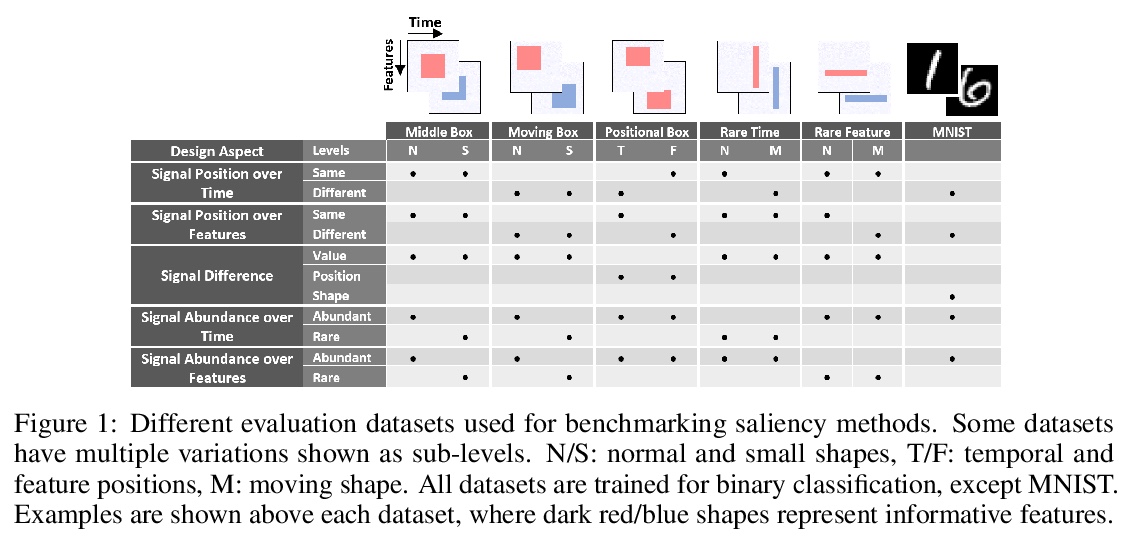


若有收获,就点个赞吧
0 人点赞
