LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
(*表示值得重点关注)
1、** **[LG] Navigating the GAN Parameter Space for Semantic Image Editing
A Cherepkov, A Voynov, A Babenko
[Moscow Institute of Physics and Technology & Yandex]
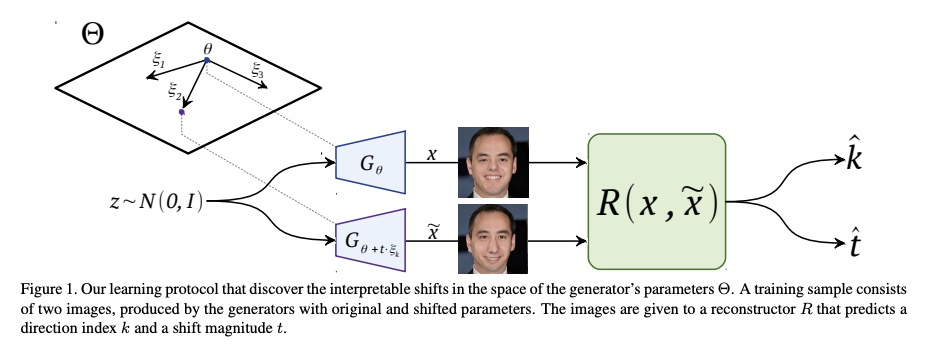
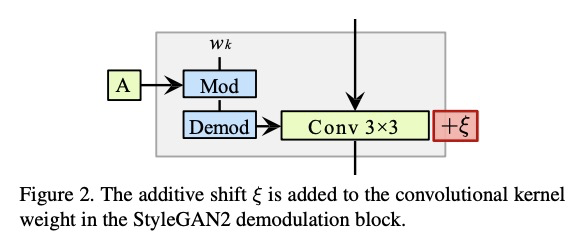
基于GAN参数空间漫游的图像语义编辑。通过在生成器参数空间平滑漫游,实现基于GAN的语义编辑,扩展用最先进模型(如StyleGAN2)实现的视觉效果范围。在生成器参数空间发现了可解释的方向,这些方向是重要语义操作的极佳来源,所发现的操作不能通过潜代码转换来实现,可用于编辑合成图像或真实图像。
Generative Adversarial Networks (GANs) are currently an indispensable tool for visual editing, being a standard component of image-to-image translation and image restoration pipelines. Furthermore, GANs are especially useful for controllable generation since their latent spaces contain a wide range of interpretable directions, well suited for semantic editing operations. By gradually changing latent codes along these directions, one can produce impressive visual effects, unattainable without GANs.In this paper, we significantly expand the range of visual effects achievable with the state-of-the-art models, like StyleGAN2. In contrast to existing works, which mostly operate by latent codes, we discover interpretable directions in the space of the generator parameters. By several simple methods, we explore this space and demonstrate that it also contains a plethora of interpretable directions, which are an excellent source of non-trivial semantic manipulations. The discovered manipulations cannot be achieved by transforming the latent codes and can be used to edit both synthetic and real images. We release our code and models and hope they will serve as a handy tool for further efforts on GAN-based image editing.
https://weibo.com/1402400261/Jwo6si3wW
2、**[CV] Neural Scene Flow Fields for Space-Time View Synthesis of Dynamic Scenes
Z Li, S Niklaus, N Snavely, O Wang
[Cornell Tech & Adobe Research]
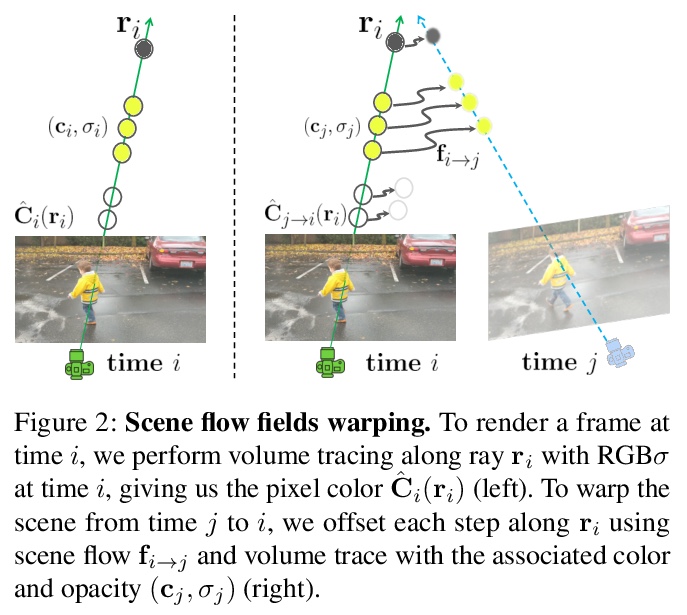
基于神经场景流场的空-时动态场景合成。提出一种利用神经场景流场(Neural Scene Flow Fields)进行单目动态场景新视图和时间合成的方法,神经场景流场是一种新的表示,将动态场景建模为外观、几何形状和3D场景运动的时变连续函数。该方法可产生引人注目的时空合成视图,以及自然的场景运动结果。**
We present a method to perform novel view and time synthesis of dynamic scenes, requiring only a monocular video with known camera poses as input. To do this, we introduce Neural Scene Flow Fields, a new representation that models the dynamic scene as a time-variant continuous function of appearance, geometry, and 3D scene motion. Our representation is optimized through a neural network to fit the observed input views. We show that our representation can be used for complex dynamic scenes, including thin structures, view-dependent effects, and natural degrees of motion. We conduct a number of experiments that demonstrate our approach significantly outperforms recent monocular view synthesis methods, and show qualitative results of space-time view synthesis on a variety of real-world videos.
https://weibo.com/1402400261/Jwocdy2nv

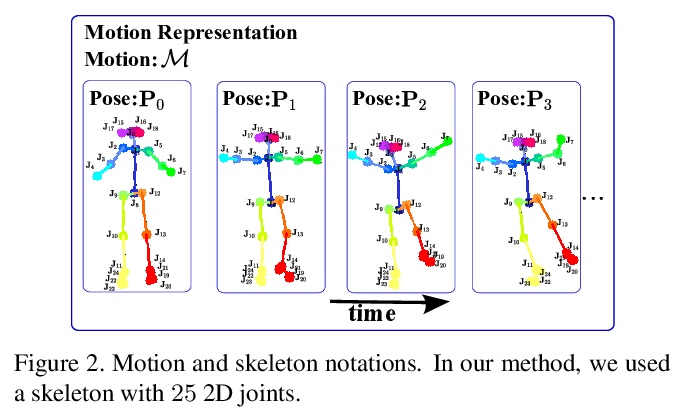
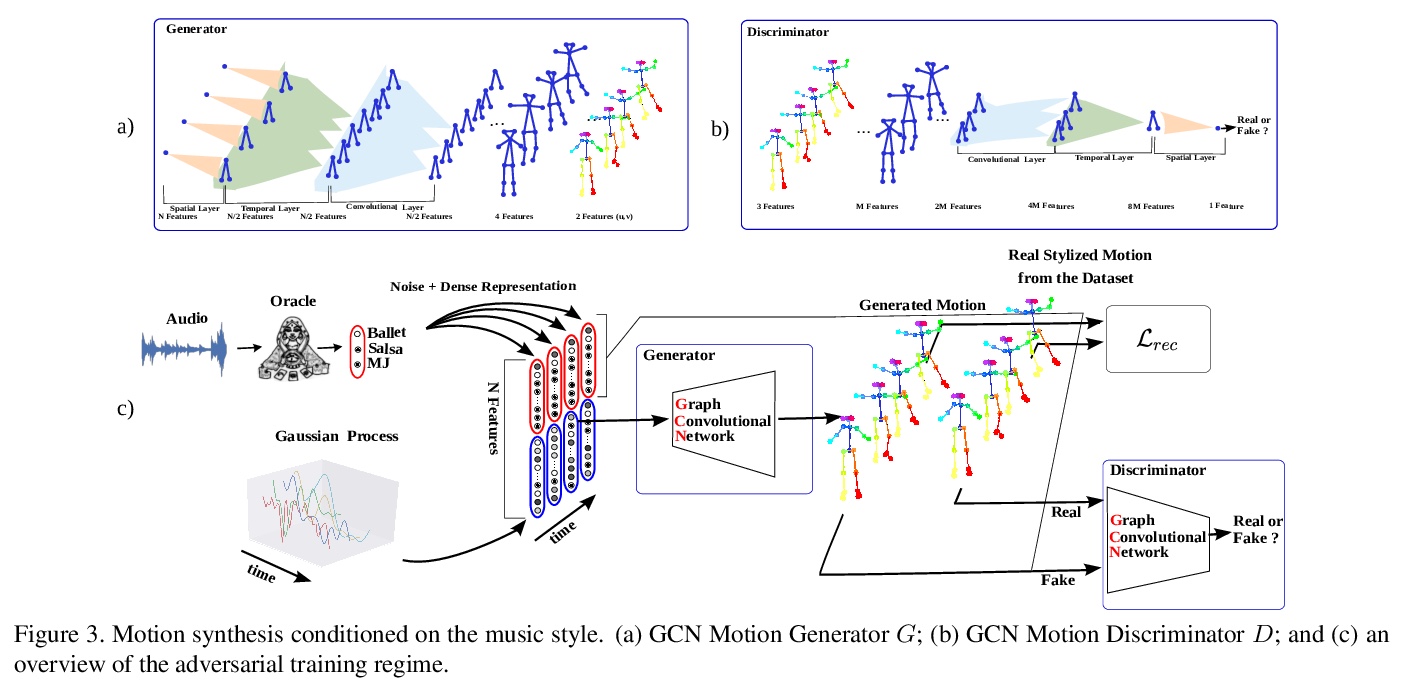
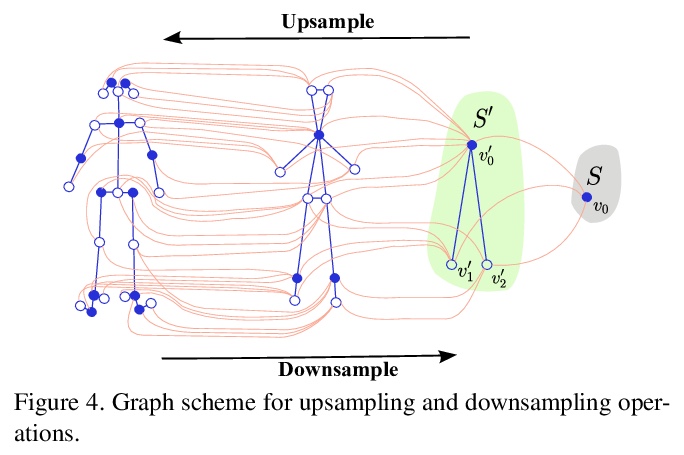
3、** **[CV] Learning to dance: A graph convolutional adversarial network to generate realistic dance motions from audio
J P. Ferreira, T M. Coutinho, T L. Gomes, J F. Neto, R Azevedo, R Martins, E R. Nascimento
[UFMG & UFOP & INRIA]
从音频生成逼真舞蹈动作的图卷积对抗网络。使用以输入音乐音频为条件的对抗学习方案来创建自然动作,同时保留不同音乐风格的关键动作。提出新的音频/视频数据集,用于评价舞蹈场景中人体动作合成算法。
Synthesizing human motion through learning techniques is becoming an increasingly popular approach to alleviating the requirement of new data capture to produce animations. Learning to move naturally from music, i.e., to dance, is one of the more complex motions humans often perform effortlessly. Each dance movement is unique, yet such movements maintain the core characteristics of the dance style. Most approaches addressing this problem with classical convolutional and recursive neural models undergo training and variability issues due to the non-Euclidean geometry of the motion manifold > this http URL this paper, we design a novel method based on graph convolutional networks to tackle the problem of automatic dance generation from audio information. Our method uses an adversarial learning scheme conditioned on the input music audios to create natural motions preserving the key movements of different music styles. We evaluate our method with three quantitative metrics of generative methods and a user study. The results suggest that the proposed GCN model outperforms the state-of-the-art dance generation method conditioned on music in different experiments. Moreover, our graph-convolutional approach is simpler, easier to be trained, and capable of generating more realistic motion styles regarding qualitative and different quantitative metrics. It also presented a visual movement perceptual quality comparable to real motion data.
https://weibo.com/1402400261/JwohWq9b2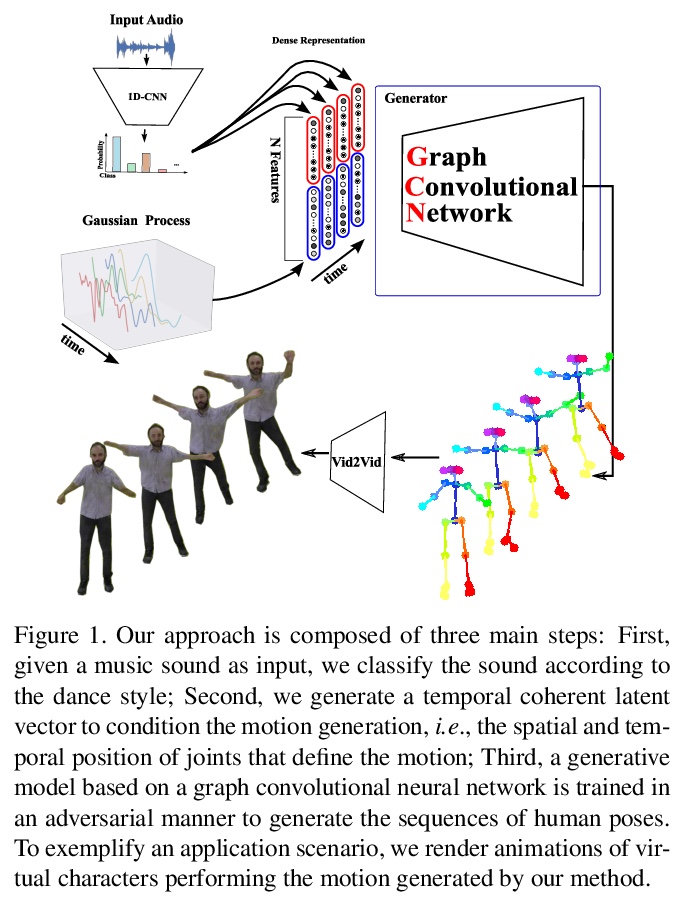
4、[CV] 4D Human Body Capture from Egocentric Video via 3D Scene Grounding
M Liu, D Yang, Y Zhang, Z Cui, J M. Rehg, S Tang
[Georgia Institute of Technology & ETH Zurich & Zhejiang University]
自我中心视频4D人体捕捉。引入一个新任务,从单目自我中心视频中,重构第二人称3D人体网格时间序列。提出新的基于优化的方法,利用整个视频序列的2D观察和人-场景交互约束,来估计自我中心视角捕捉的3D环境下第二人称姿态、形状和全局运动,实现第二人称3D人体捕捉。引入了新的自我中心视频数据集EgoMocap,并提供广泛的定量和定性分析。
To understand human daily social interaction from egocentric perspective, we introduce a novel task of reconstructing a time series of second-person 3D human body meshes from monocular egocentric videos. The unique viewpoint and rapid embodied camera motion of egocentric videos raise additional technical barriers for human body capture. To address those challenges, we propose a novel optimization-based approach that leverages 2D observations of the entire video sequence and human-scene interaction constraint to estimate second-person human poses, shapes and global motion that are grounded on the 3D environment captured from the egocentric view. We conduct detailed ablation studies to validate our design choice. Moreover, we compare our method with previous state-of-the-art method on human motion capture from monocular video, and show that our method estimates more accurate human-body poses and shapes under the challenging egocentric setting. In addition, we demonstrate that our approach produces more realistic human-scene interaction. Our project page is available at: > this https URL
https://weibo.com/1402400261/JwomxCn2v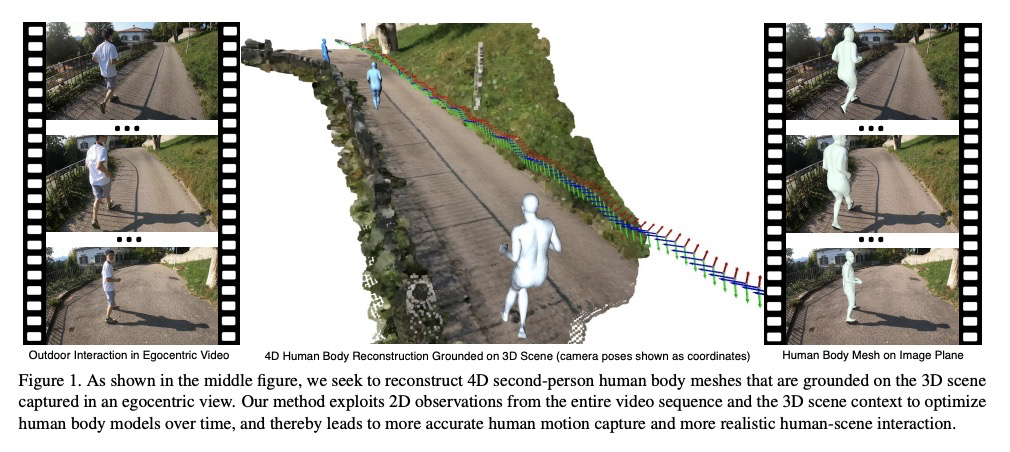


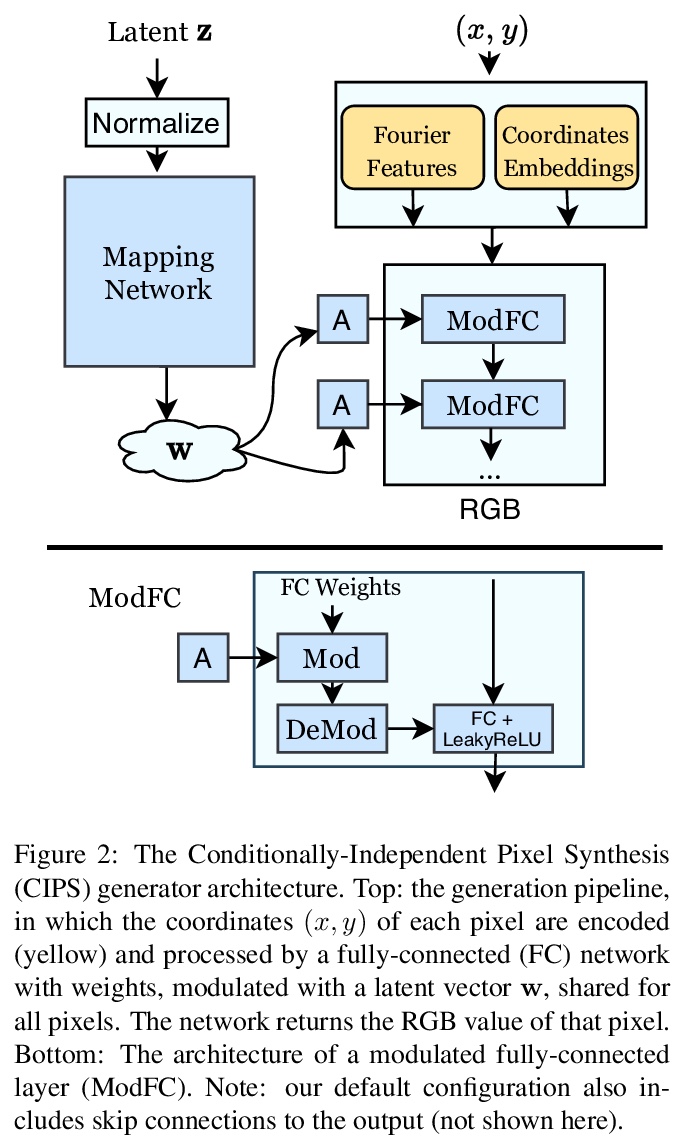
5、** **[CV] Image Generators with Conditionally-Independent Pixel Synthesis
I Anokhin, K Demochkin, T Khakhulin, G Sterkin, V Lempitsky, D Korzhenkov
[Samsung AI Center]
基于条件独立像素合成的图像生成器。提出新生成器模型CIPS,一种具有条件独立像素合成的高质量架构,只用随机噪声和坐标位置计算颜色值,合成过程中不涉及空间卷积或类似的跨像素传播信息的操作,无需注意力、上采样等操作,其生成质量可媲美最先进的StyleGANv2。
Existing image generator networks rely heavily on spatial convolutions and, optionally, self-attention blocks in order to gradually synthesize images in a coarse-to-fine manner. Here, we present a new architecture for image generators, where the color value at each pixel is computed independently given the value of a random latent vector and the coordinate of that pixel. No spatial convolutions or similar operations that propagate information across pixels are involved during the synthesis. We analyze the modeling capabilities of such generators when trained in an adversarial fashion, and observe the new generators to achieve similar generation quality to state-of-the-art convolutional generators. We also investigate several interesting properties unique to the new architecture.
https://weibo.com/1402400261/Jworz5x3Z

另外几篇值得关注的论文:
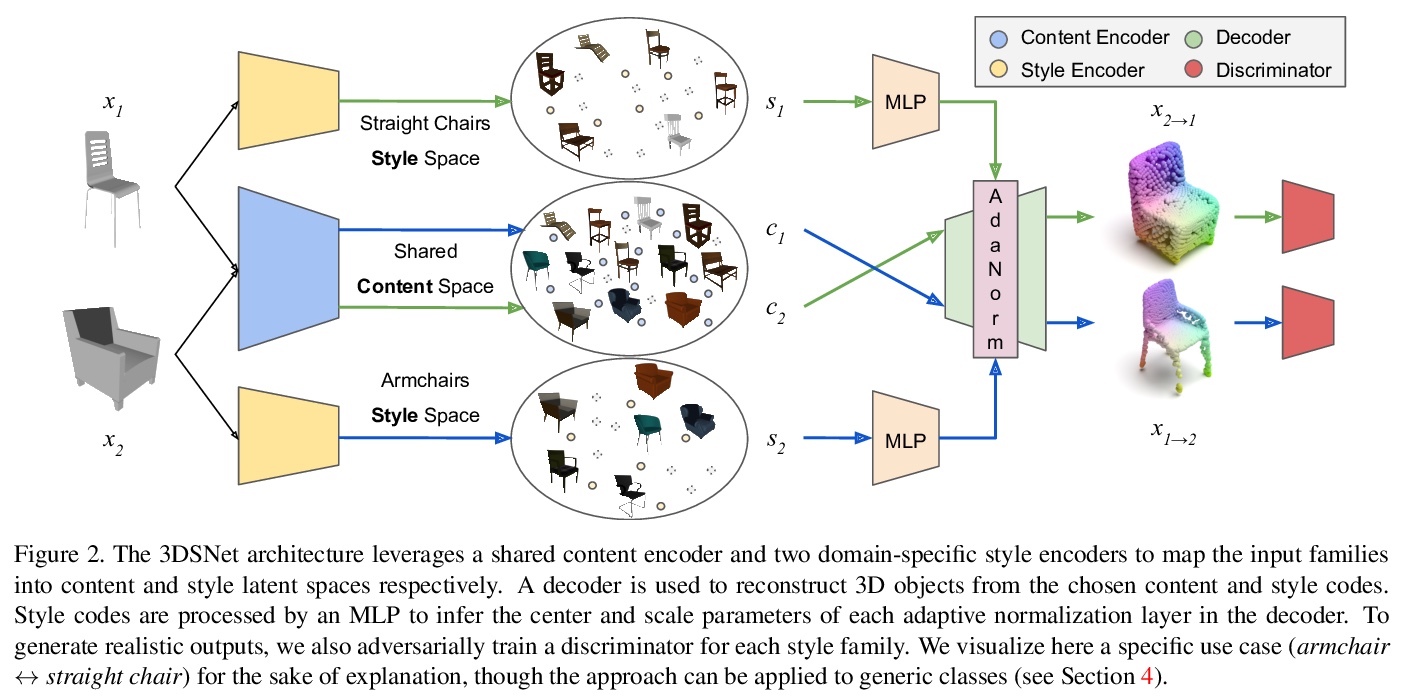
[CV] 3DSNet: Unsupervised Shape-to-Shape 3D Style Transfer
3DSNet:无监督形状到形状3D风格转换
M Segu, M Grinvald, R Siegwart, F Tombari
[ETH Zurich & CAMP - TU Munich]
https://weibo.com/1402400261/Jwow2wfdd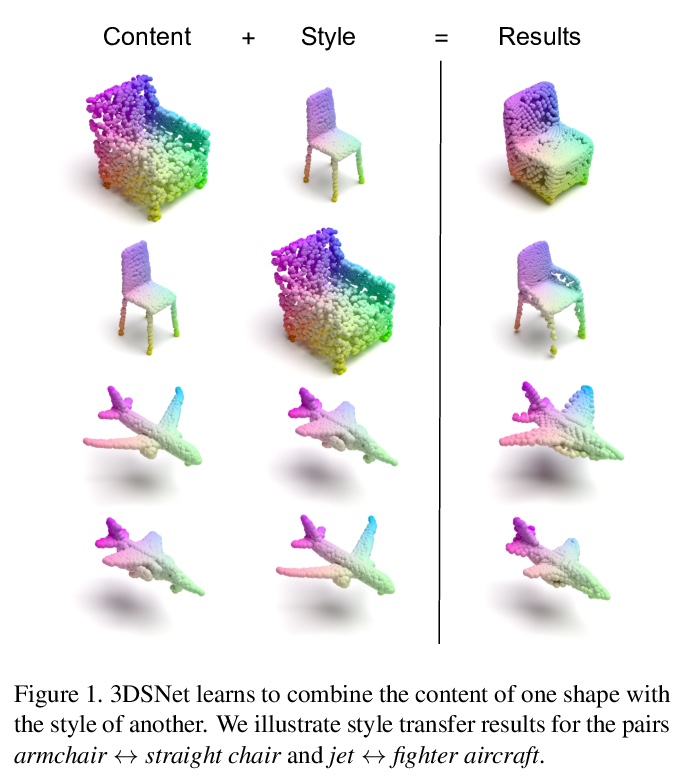
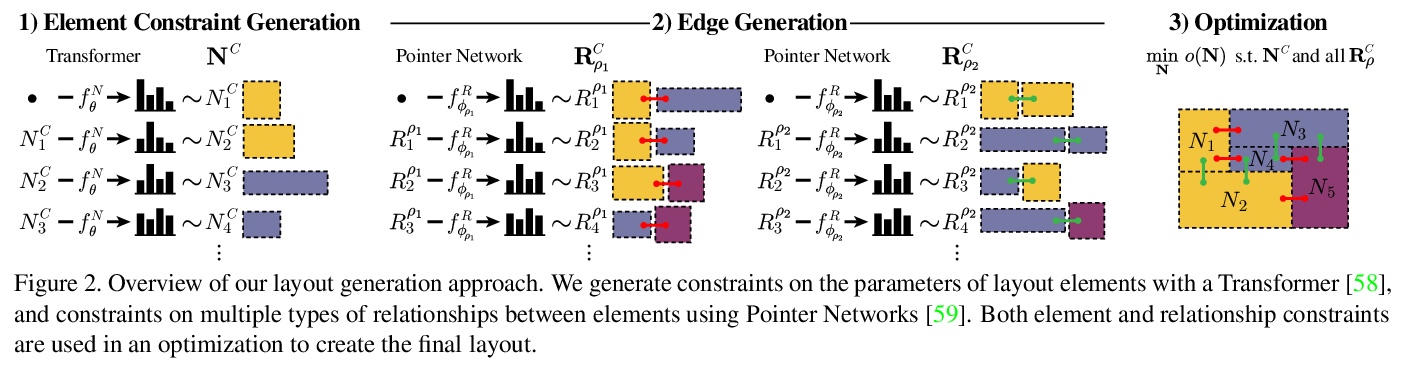
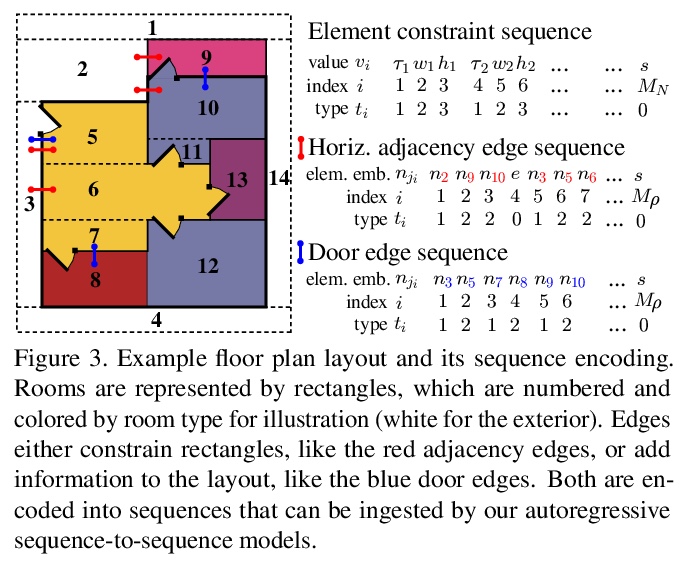
[CV] Generative Layout Modeling using Constraint Graphs
基于约束图的生成式布局建模
W Para, P Guerrero, T Kelly, L Guibas, P Wonka
[KAUST & Adobe Research & University of Leeds & Stanford University]
https://weibo.com/1402400261/Jwoxazem6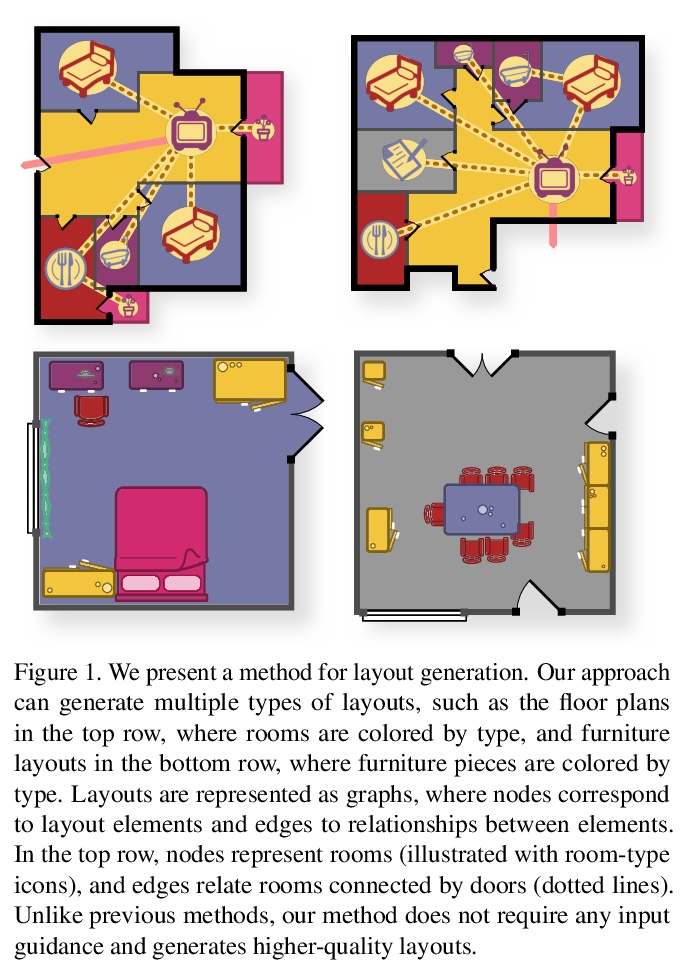
[LG] Skill Transfer via Partially Amortized Hierarchical Planning
基于部分摊余分级规划的技能迁移
K Xie, H Bharadhwaj, D Hafner, A Garg, F Shkurti
[University of Toronto and Vector Institute]
https://weibo.com/1402400261/JwoylbkHu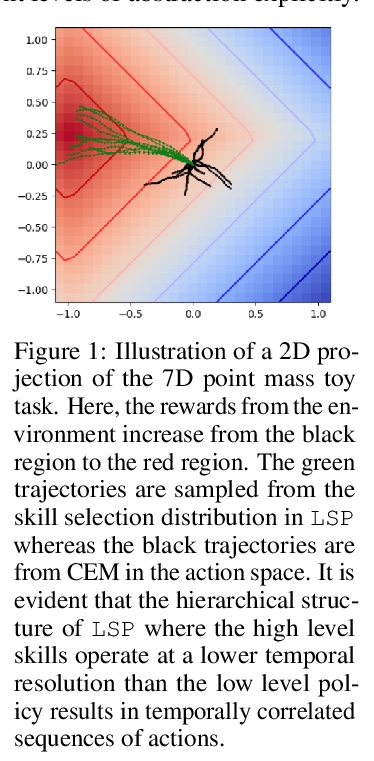
[CV] Omni-GAN: On the Secrets of cGANs and Beyond
Omni-GAN:条件生成式对抗网络(cGANs)优化
P Zhou, L Xie, B Ni, Q Tian
[Shanghai Jiao Tong University & Huawei Inc]
https://weibo.com/1402400261/JwoBdm9lo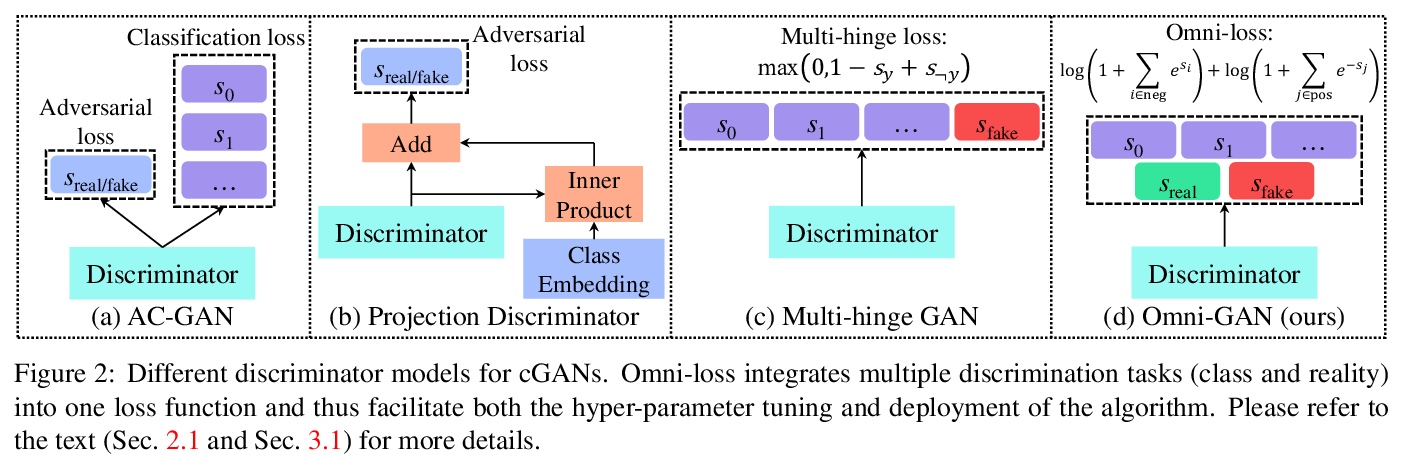

若有收获,就点个赞吧
0 人点赞
