- 1、[CV] ReStyle: A Residual-Based StyleGAN Encoder via Iterative Refinement
- 2、[CV] gradSim: Differentiable simulation for system identification and visuomotor control
- 3、[LG] Benchmarks for Deep Off-Policy Evaluation
- 4、[CV] Deep Animation Video Interpolation in the Wild
- 5、[CV] Fourier Image Transformer
- [CV] SIMstack: A Generative Shape and Instance Model for Unordered Object Stacks
- [LG] GPU Domain Specialization via Composable On-Package Architecture
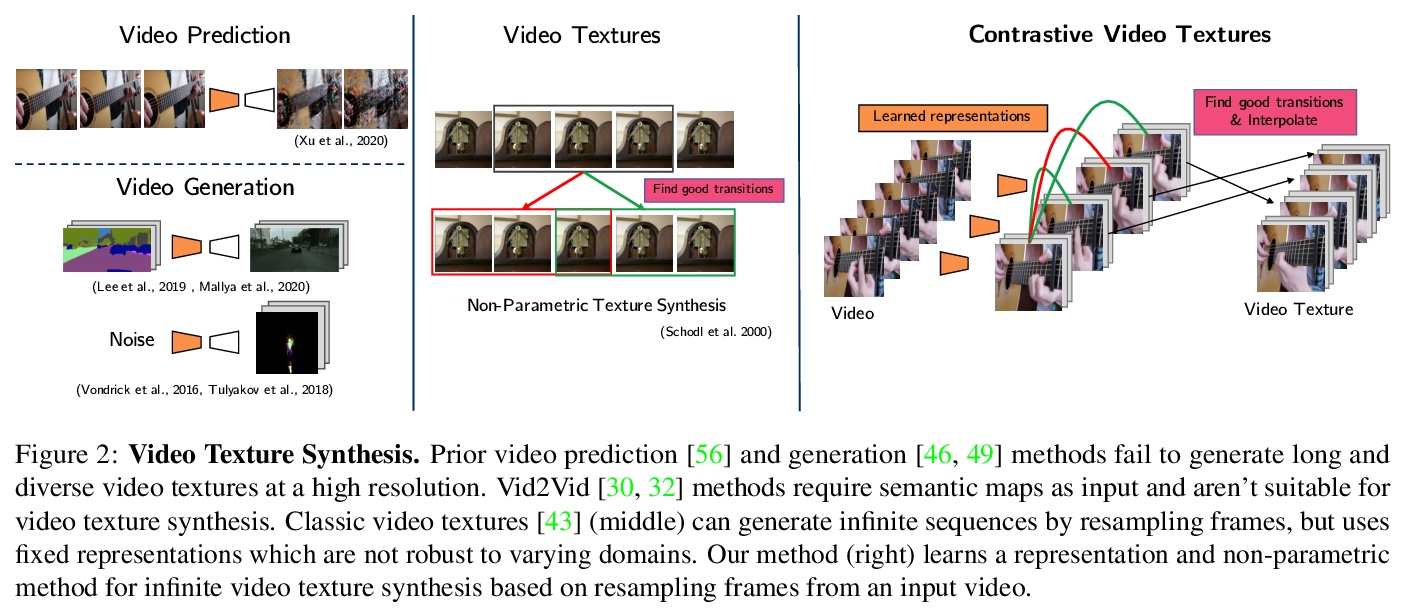
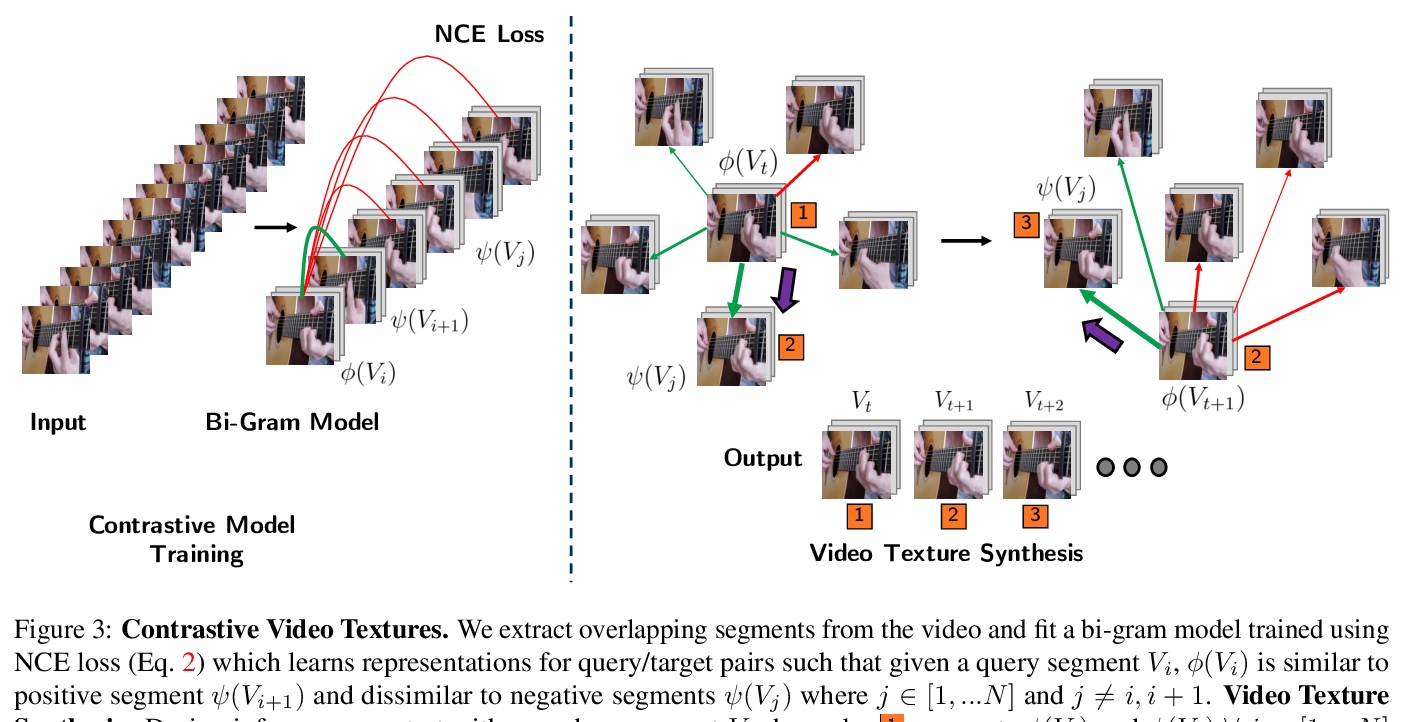
- [CV] Strumming to the Beat: Audio-Conditioned Contrastive Video Textures
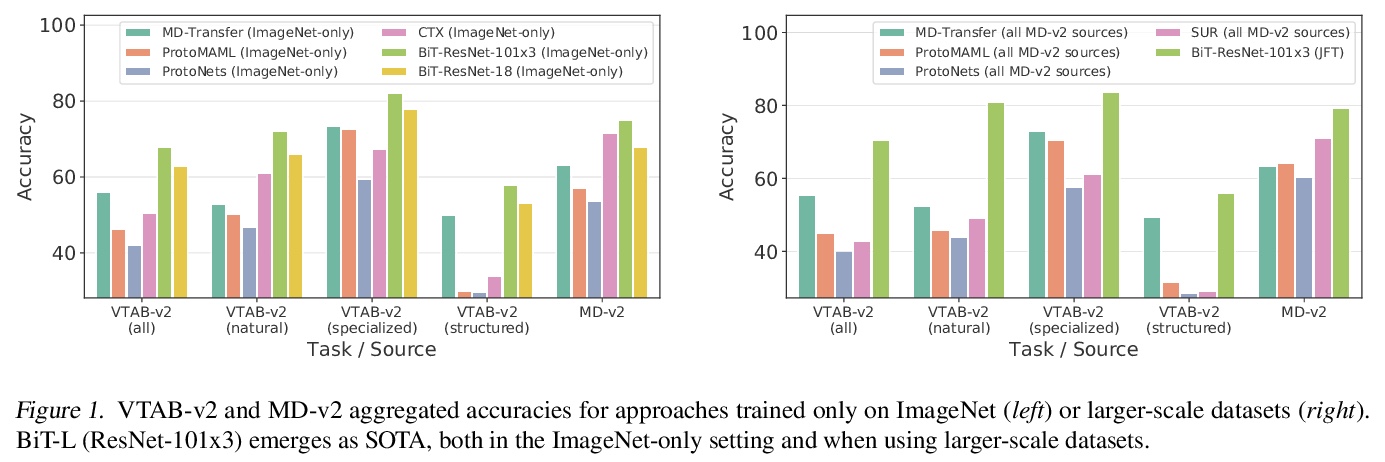
- [LG] Comparing Transfer and Meta Learning Approaches on a Unified Few-Shot Classification Benchmark
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] ReStyle: A Residual-Based StyleGAN Encoder via Iterative Refinement
Y Alaluf, O Patashnik, D Cohen-Or
[Tel-Aviv University]
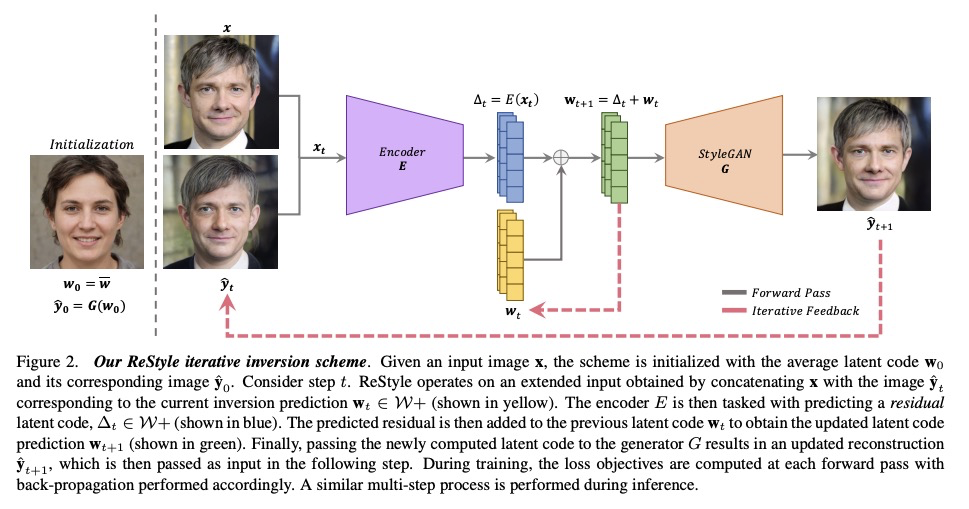
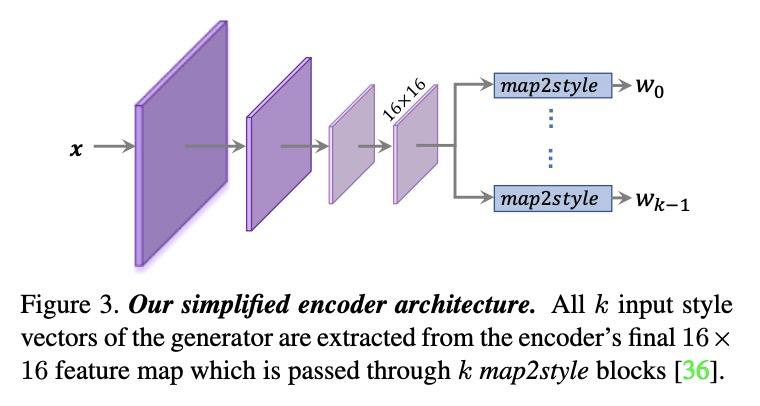
ReStyle: 基于迭代强化的残差StyleGAN编码器。提出一种用于训练和部署GAN逆映射编码器的新方案,引入迭代强化机制,扩展了目前基于编码器的逆映射方法。编码器的任务不是用单通道直接预测给定真实图像的潜码,而是以自校正方式预测相对于当前估计的逆映射潜码的残差,通过多次正向传递,更准确、更快速地收敛到目标逆映射。该方案让编码器学习如何有效地引导其收敛到所需的逆映射。基于残差的编码器,即ReStyle,与目前最先进的基于编码器的方法相比,精度更高,而推理时间的增加可以忽略不计。
Recently, the power of unconditional image synthesis has significantly advanced through the use of Generative Adversarial Networks (GANs). The task of inverting an image into its corresponding latent code of the trained GAN is of utmost importance as it allows for the manipulation of real images, leveraging the rich semantics learned by the network. Recognizing the limitations of current inversion approaches, in this work we present a novel inversion scheme that extends current encoder-based inversion methods by introducing an iterative refinement mechanism. Instead of directly predicting the latent code of a given real image using a single pass, the encoder is tasked with predicting a residual with respect to the current estimate of the inverted latent code in a self-correcting manner. Our residual-based encoder, named ReStyle, attains improved accuracy compared to current state-of-the-art encoder-based methods with a negligible increase in inference time. We analyze the behavior of ReStyle to gain valuable insights into its iterative nature. We then evaluate the performance of our residual encoder and analyze its robustness compared to optimization-based inversion and state-of-the-art encoders.
https://weibo.com/1402400261/K9TmzcnPo

2、[CV] gradSim: Differentiable simulation for system identification and visuomotor control
K M Jatavallabhula, M Macklin, F Golemo, V Voleti, L Petrini, M Weiss, B Considine, J Parent-Levesque, K Xie, K Erleben, L Paull, F Shkurti, D Nowrouzezahrai, S Fidler
[Montreal Robotics and Embodied AI Lab & NVIDIA & Mila]
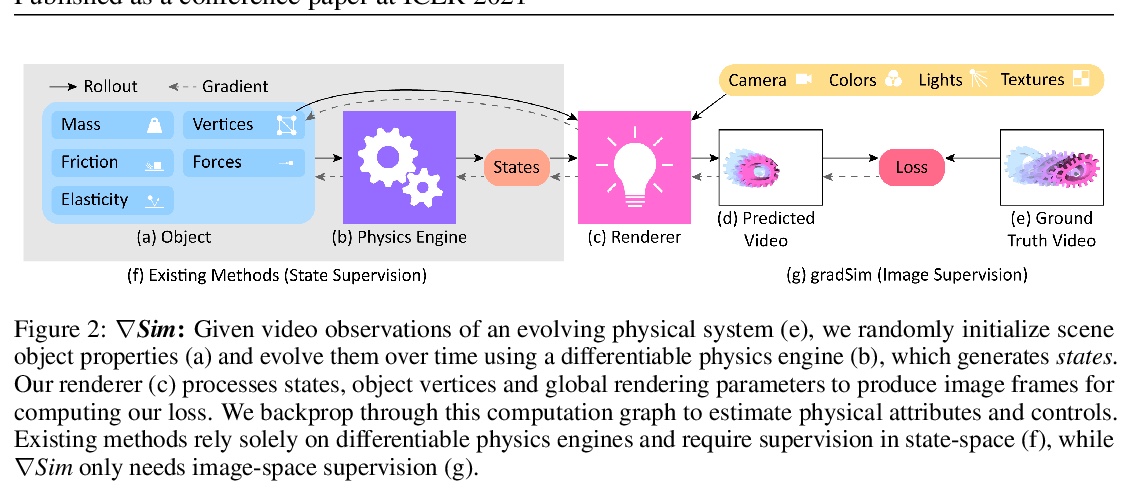
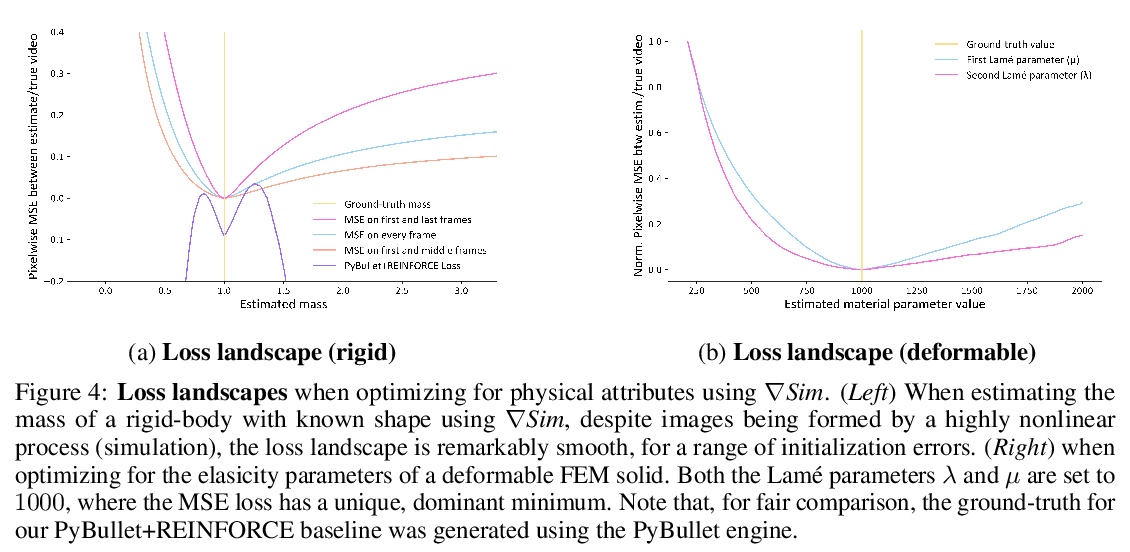
∇Sim:系统识别和视觉运动控制的可微仿真。提出了∇Sim,一种灵活的可微模拟器,通过在控制动力学和图像形成的物理过程中进行微分,实现视频的系统识别,利用可微的多物理仿真和可微渲染来联合仿真场景动力学和图像形成的演化,克服了对3D监督的依赖。这种新组合使得从视频序列中的像素到产生它们的底层物理属性的反向传播成为可能。其中的统一计算图—从动力学跨越到渲染过程—可在具有挑战性的视觉运动控制任务中进行学习,而不依赖于基于状态的(3D)监督,同时获得与依赖于精确3D标签的技术竞争或更好的性能。
We consider the problem of estimating an object’s physical properties such as mass, friction, and elasticity directly from video sequences. Such a system identification problem is fundamentally ill-posed due to the loss of information during image formation. Current solutions require precise 3D labels which are labor-intensive to gather, and infeasible to create for many systems such as deformable solids or cloth. We present gradSim, a framework that overcomes the dependence on 3D supervision by leveraging differentiable multiphysics simulation and differentiable rendering to jointly model the evolution of scene dynamics and image formation. This novel combination enables backpropagation from pixels in a video sequence through to the underlying physical attributes that generated them. Moreover, our unified computation graph — spanning from the dynamics and through the rendering process — enables learning in challenging visuomotor control tasks, without relying on state-based (3D) supervision, while obtaining performance competitive to or better than techniques that rely on precise 3D labels.
https://weibo.com/1402400261/K9TuFs1Eu

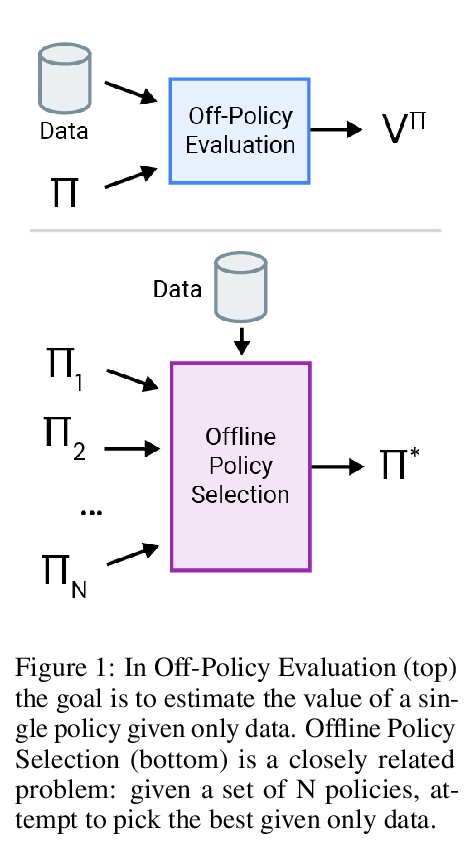
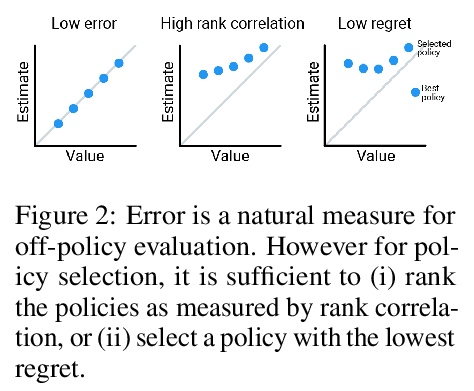
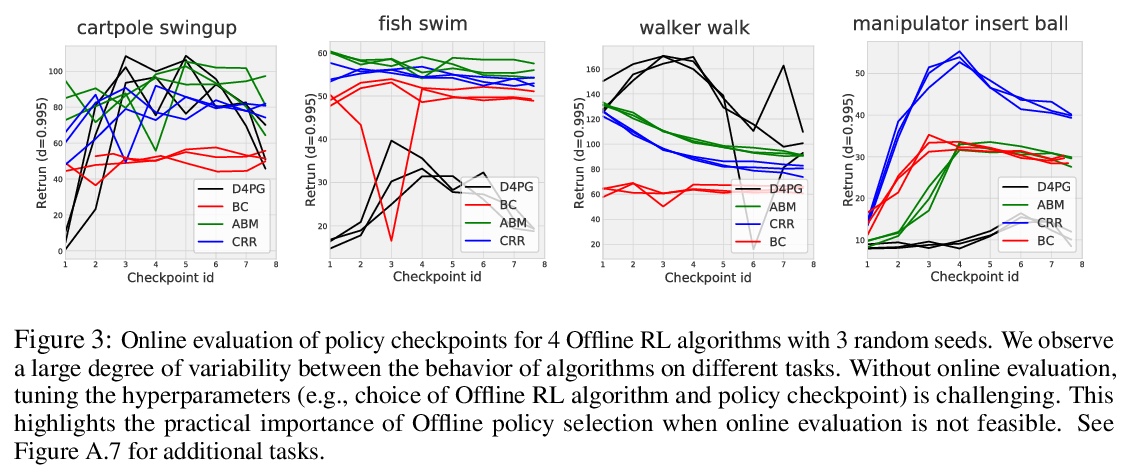
3、[LG] Benchmarks for Deep Off-Policy Evaluation
J Fu, M Norouzi, O Nachum, G Tucker, Z Wang, A Novikov, M Yang, M R. Zhang, Y Chen, A Kumar, C Paduraru, S Levine, T L Paine
[UC Berkeley & Google Brain & DeepMind]
深度Off-Policy评价基准。提出了”深度Off-Policy评价”(Deep Off-Policy Evaluation,DOPE)基准,旨在提供一个平台,用于研究广泛的挑战性任务和数据集的政策评估和选择。与之前基准相比,DOPE提供了多个数据集和策略,包括一系列具有挑战性的高维连续控制问题,广泛选择数据集和策略进行策略选择,允许研究人员研究数据分布如何影响性能,并评估各种指标,包括与离线政策选择相关的指标。
Off-policy evaluation (OPE) holds the promise of being able to leverage large, offline datasets for both evaluating and selecting complex policies for decision making. The ability to learn offline is particularly important in many real-world domains, such as in healthcare, recommender systems, or robotics, where online data collection is an expensive and potentially dangerous process. Being able to accurately evaluate and select high-performing policies without requiring online interaction could yield significant benefits in safety, time, and cost for these applications. While many OPE methods have been proposed in recent years, comparing results between papers is difficult because currently there is a lack of a comprehensive and unified benchmark, and measuring algorithmic progress has been challenging due to the lack of difficult evaluation tasks. In order to address this gap, we present a collection of policies that in conjunction with existing offline datasets can be used for benchmarking off-policy evaluation. Our tasks include a range of challenging high-dimensional continuous control problems, with wide selections of datasets and policies for performing policy selection. The goal of our benchmark is to provide a standardized measure of progress that is motivated from a set of principles designed to challenge and test the limits of existing OPE methods. We perform an evaluation of state-of-the-art algorithms and provide open-source access to our data and code to foster future research in this area.
https://weibo.com/1402400261/K9TBGbB8u
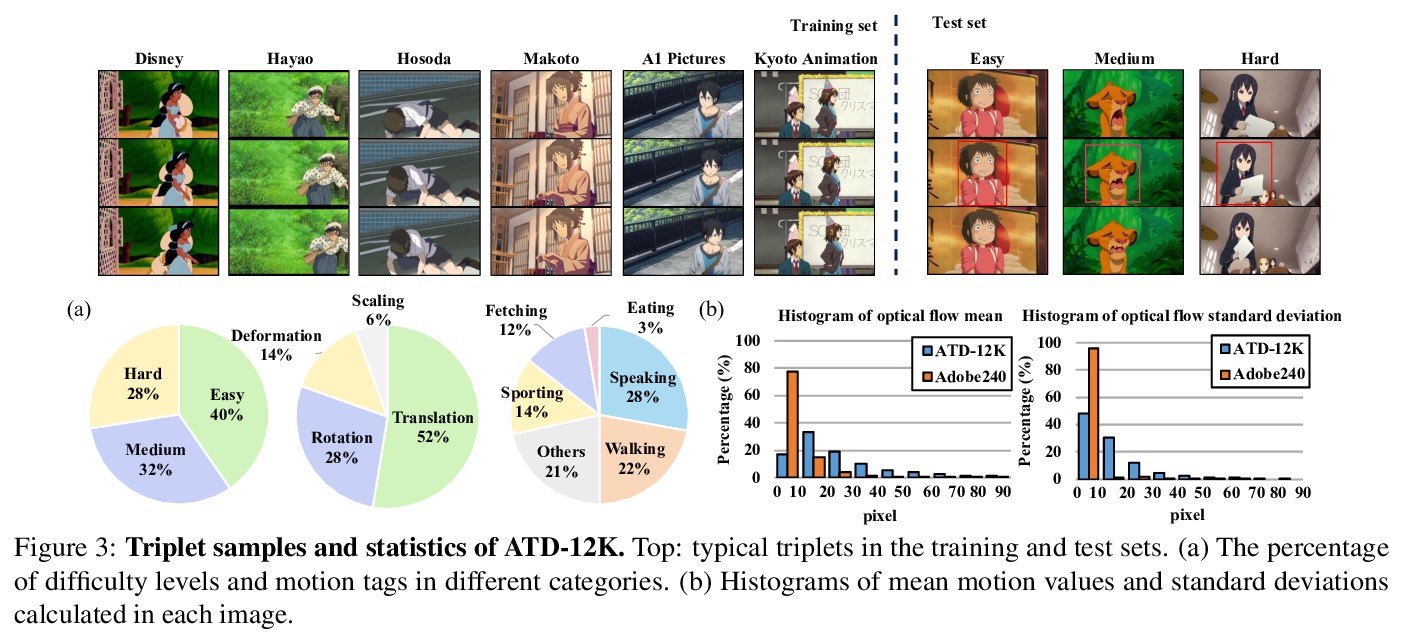
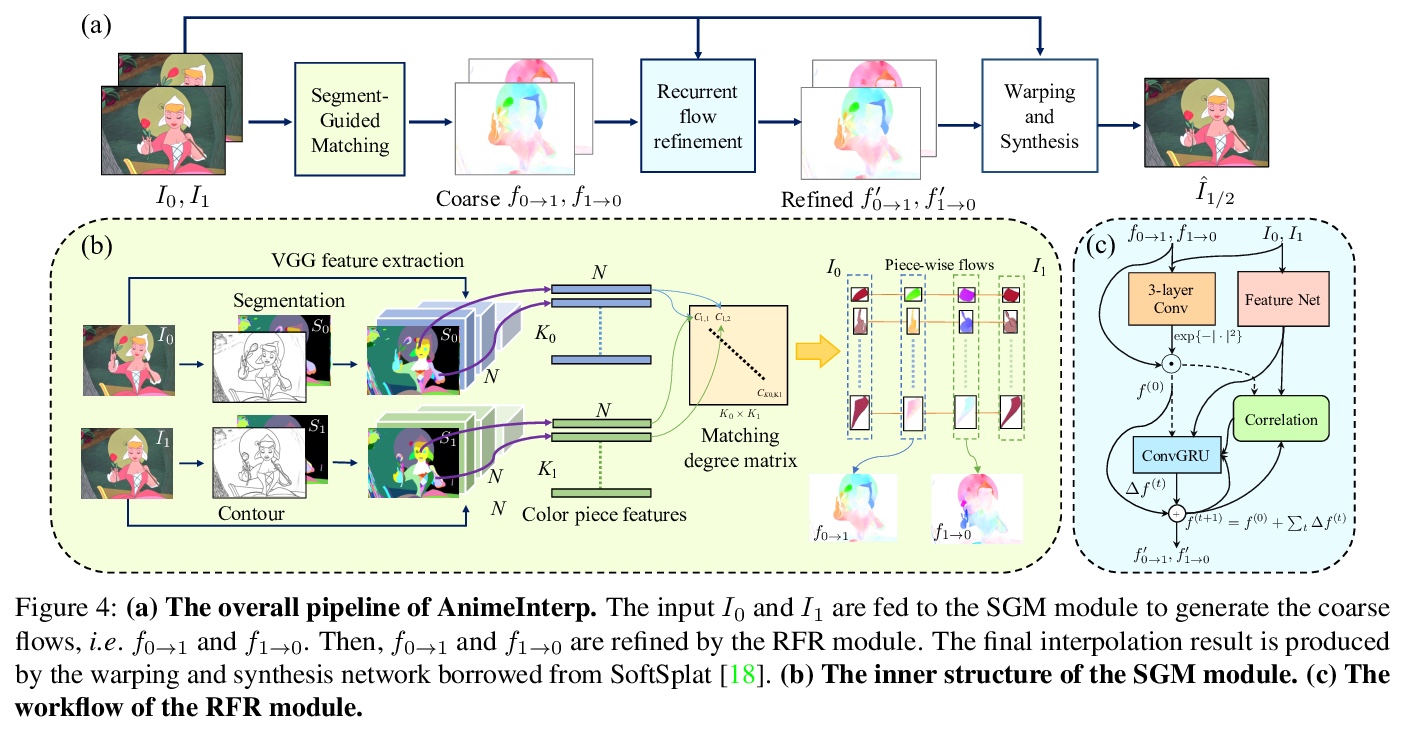
4、[CV] Deep Animation Video Interpolation in the Wild
L Siyao, S Zhao, W Yu, W Sun, D N. Metaxas, C C Loy, Z Liu
[SenseTime Research and Tetras.AI & Sun Yat-sen University & Nanyang Technological University]
真实场景深度动画视频插值。提出一种高效的动画插值框架AnimeInterp,用两个专门模块解决了”纹理匮乏”和”非线性与极大幅度运动”难题,在数量和质量上都优于现有的最先进方法。构建了名为ATD-12K的大规模卡通三元数据集,内容多样性很大,代表了多种类型的动画,用于测试动画视频插值方法。
In the animation industry, cartoon videos are usually produced at low frame rate since hand drawing of such frames is costly and time-consuming. Therefore, it is desirable to develop computational models that can automatically interpolate the in-between animation frames. However, existing video interpolation methods fail to produce satisfying results on animation data. Compared to natural videos, animation videos possess two unique characteristics that make frame interpolation difficult: 1) cartoons comprise lines and smooth color pieces. The smooth areas lack textures and make it difficult to estimate accurate motions on animation videos. 2) cartoons express stories via exaggeration. Some of the motions are non-linear and extremely large. In this work, we formally define and study the animation video interpolation problem for the first time. To address the aforementioned challenges, we propose an effective framework, AnimeInterp, with two dedicated modules in a coarse-to-fine manner. Specifically, 1) Segment-Guided Matching resolves the “lack of textures” challenge by exploiting global matching among color pieces that are piece-wise coherent. 2) Recurrent Flow Refinement resolves the “non-linear and extremely large motion” challenge by recurrent predictions using a transformer-like architecture. To facilitate comprehensive training and evaluations, we build a large-scale animation triplet dataset, ATD-12K, which comprises 12,000 triplets with rich annotations. Extensive experiments demonstrate that our approach outperforms existing state-of-the-art interpolation methods for animation videos. Notably, AnimeInterp shows favorable perceptual quality and robustness for animation scenarios in the wild. The proposed dataset and code are available at > this https URL.
https://weibo.com/1402400261/K9TEXbMp1

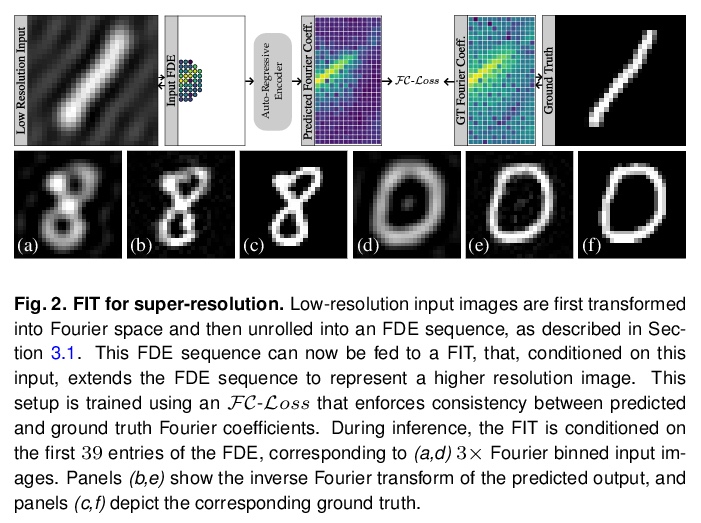
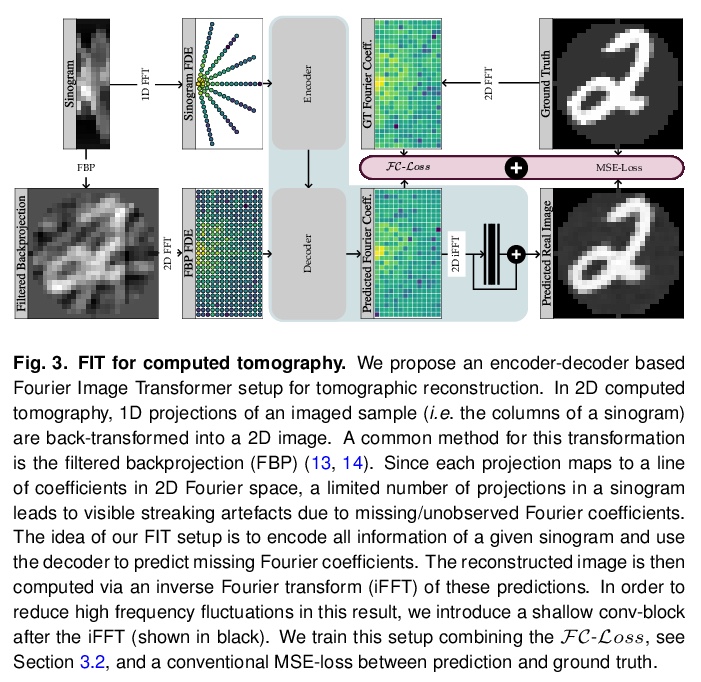
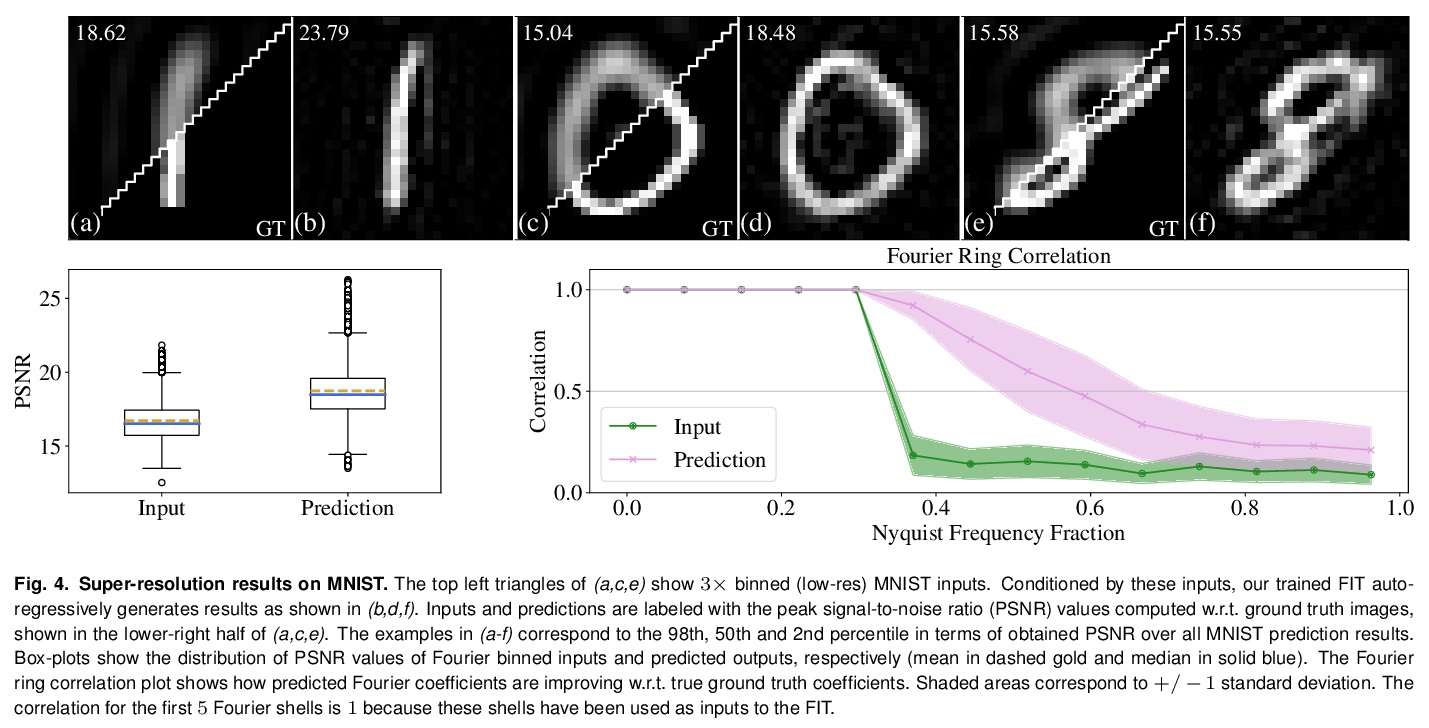
5、[CV] Fourier Image Transformer
T Buchholz, F Jug
[CSBD and MPI-C & Fondatione Human Technopo]
傅立叶图像Transformer。提出用序列图像表示,其中完整序列的每个前缀以降低的分辨率描述整个图像。用这样的傅里叶域编码(FDEs),一个自回归的图像补全任务就相当于给定一个低分辨率的输入,预测一个更高分辨率的输出。编码器-解码器设置可以用来查询给定一组傅里叶域观测值的任意傅里叶系数。展示了这种方法在计算机断层扫描(CT)图像重建背景下的实用性。傅里叶图像Transformer(FIT)可以用来解决傅里叶空间相关图像分析任务,而该领域本质上是卷积架构无法访问的。
Transformer architectures show spectacular performance on NLP tasks and have recently also been used for tasks such as image completion or image classification. Here we propose to use a sequential image representation, where each prefix of the complete sequence describes the whole image at reduced resolution. Using such Fourier Domain Encodings (FDEs), an auto-regressive image completion task is equivalent to predicting a higher resolution output given a low-resolution input. Additionally, we show that an encoder-decoder setup can be used to query arbitrary Fourier coefficients given a set of Fourier domain observations. We demonstrate the practicality of this approach in the context of computed tomography (CT) image reconstruction. In summary, we show that Fourier Image Transformer (FIT) can be used to solve relevant image analysis tasks in Fourier space, a domain inherently inaccessible to convolutional architectures.
https://weibo.com/1402400261/K9TIThqRw
另外几篇值得关注的论文:
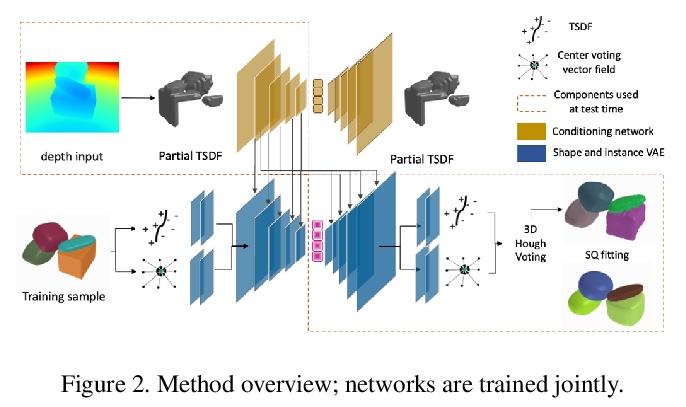
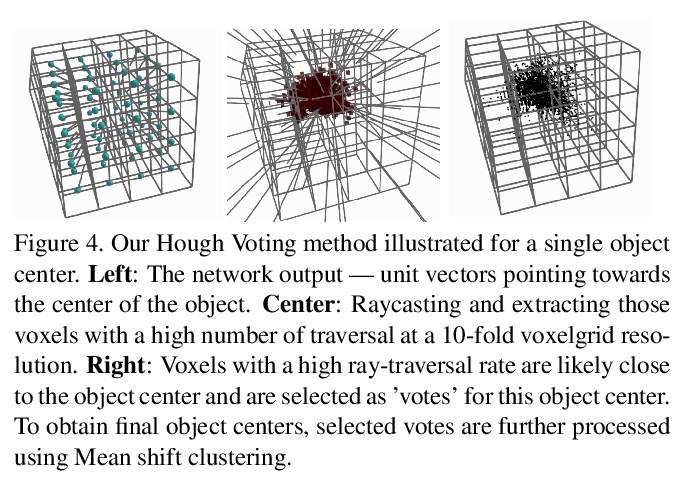
[CV] SIMstack: A Generative Shape and Instance Model for Unordered Object Stacks
SIMstack:无序对象栈的生成式形状和实例模型
Z Landgraf, R Scona, T Laidlow, S James, S Leutenegger, A J. Davison
[Imperial College London]
https://weibo.com/1402400261/K9TM93tvE

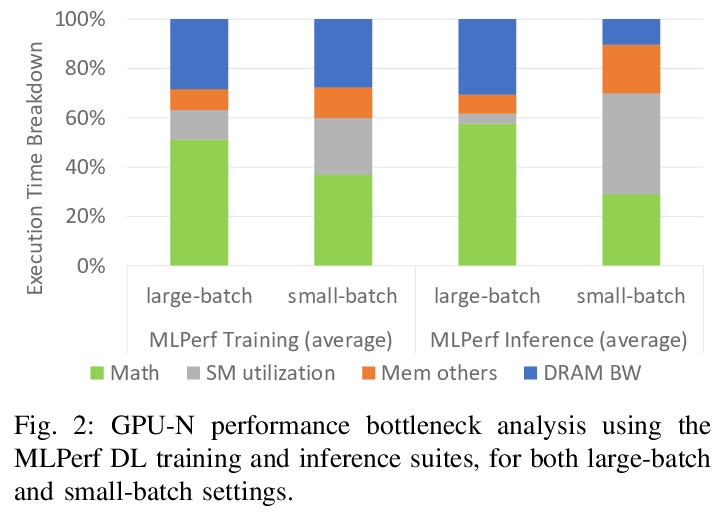
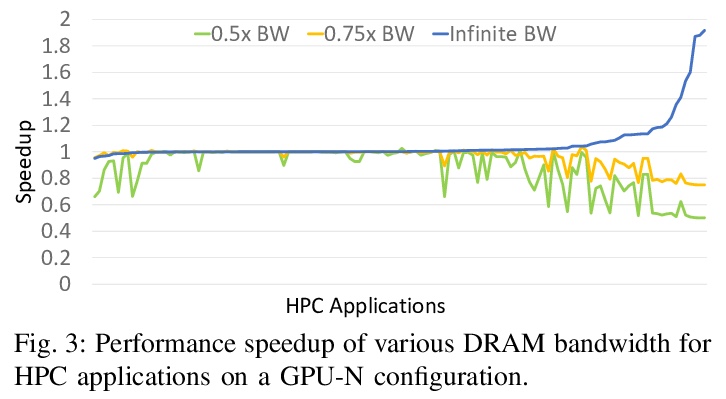
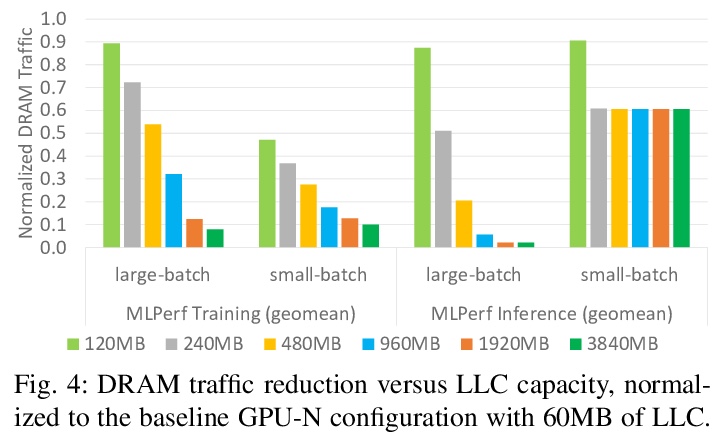
[LG] GPU Domain Specialization via Composable On-Package Architecture
基于可组合封装架构实现GPU的域专门化
Y Fu, E Bolotin, N Chatterjee, D Nellans, S W. Keckler
[NVIDIA]
https://weibo.com/1402400261/K9TNuEERz
[CV] Strumming to the Beat: Audio-Conditioned Contrastive Video Textures
随节拍弹奏:音频为条件的对比视频纹理
M Narasimhan, S Ginosar, A Owens, A A. Efros, T Darrell
[UC Berkeley & University of Michigan]
https://weibo.com/1402400261/K9TPIFrwQ

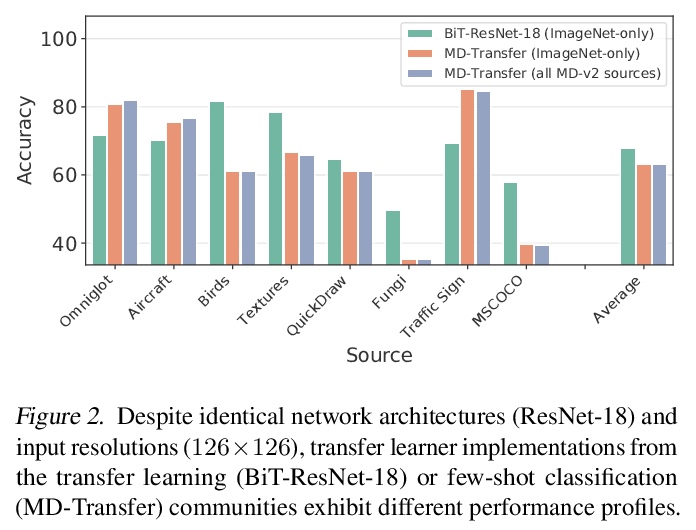
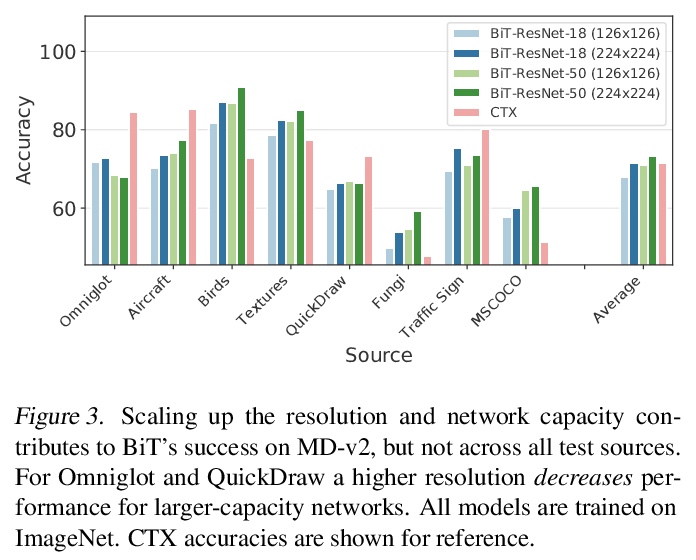
[LG] Comparing Transfer and Meta Learning Approaches on a Unified Few-Shot Classification Benchmark
统一少样本分类基准上的迁移学习和元学习方法比较
V Dumoulin, N Houlsby, U Evci, X Zhai, R Goroshin, S Gelly, H Larochelle
[Google Research]
https://weibo.com/1402400261/K9TRbpDmJ

若有收获,就点个赞吧
0 人点赞
