LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
(*表示值得重点关注)
1、[AI] Neurosymbolic AI: The 3rd Wave
A d Garcez, L C. Lamb
[University of London & Federal University of Rio Grande do Sul]
神经符号AI:第三波浪潮。多年来,神经符号计算一直是活跃的研究领域,试图通过网络模型的符号表示,将神经网络中的鲁棒学习,与推理和解释能力结合起来。本文将神经符号人工智能的研究结果,与探索下一波人工智能系统关键成分的目标联系起来,将基于神经网络的学习与符号知识表示和逻辑推理结合起来。20年来神经符号计算所提供的洞见,为人工智能日益突出的信任、安全、可解释性和问责性提供了新的视角。文章还从神经符号系统的角度确定了未来十年人工智能研究的前景方向和挑战。
Current advances in Artificial Intelligence (AI) and Machine Learning (ML) have achieved unprecedented impact across research communities and industry. Nevertheless, concerns about trust, safety, interpretability and accountability of AI were raised by influential thinkers. Many have identified the need for well-founded knowledge representation and reasoning to be integrated with deep learning and for sound explainability. Neural-symbolic computing has been an active area of research for many years seeking to bring together robust learning in neural networks with reasoning and explainability via symbolic representations for network models. In this paper, we relate recent and early research results in neurosymbolic AI with the objective of identifying the key ingredients of the next wave of AI systems. We focus on research that integrates in a principled way neural network-based learning with symbolic knowledge representation and logical reasoning. The insights provided by 20 years of neural-symbolic computing are shown to shed new light onto the increasingly prominent role of trust, safety, interpretability and accountability of AI. We also identify promising directions and challenges for the next decade of AI research from the perspective of neural-symbolic systems.
https://weibo.com/1402400261/Jy3RBscty
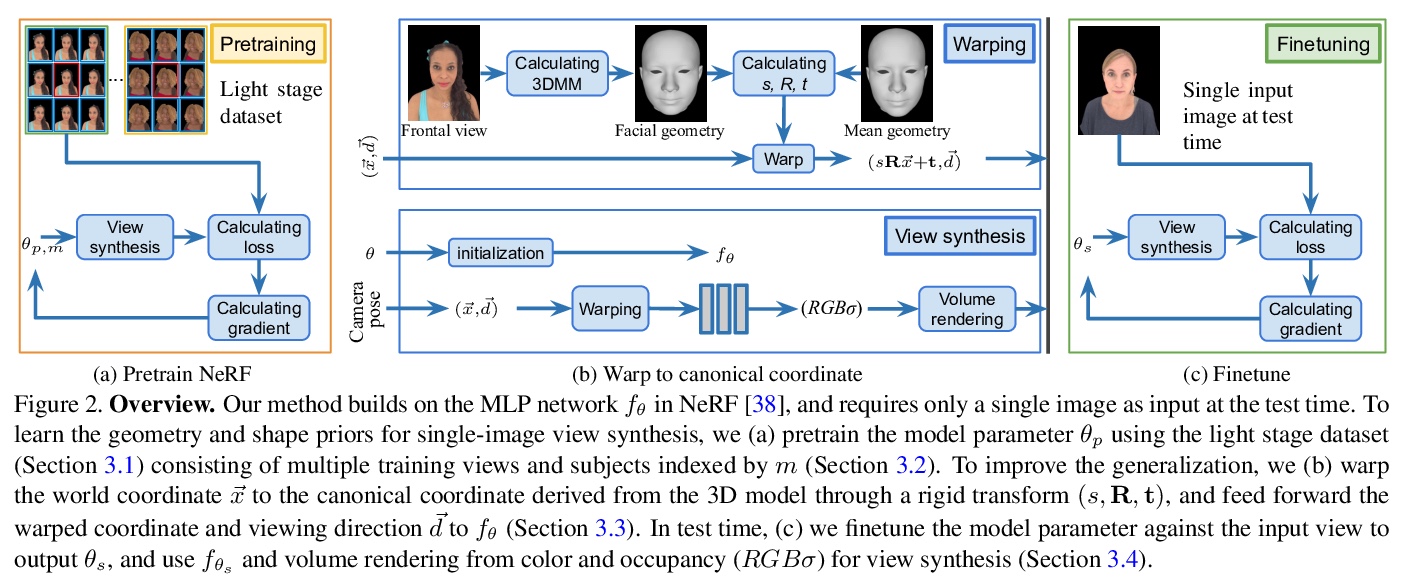
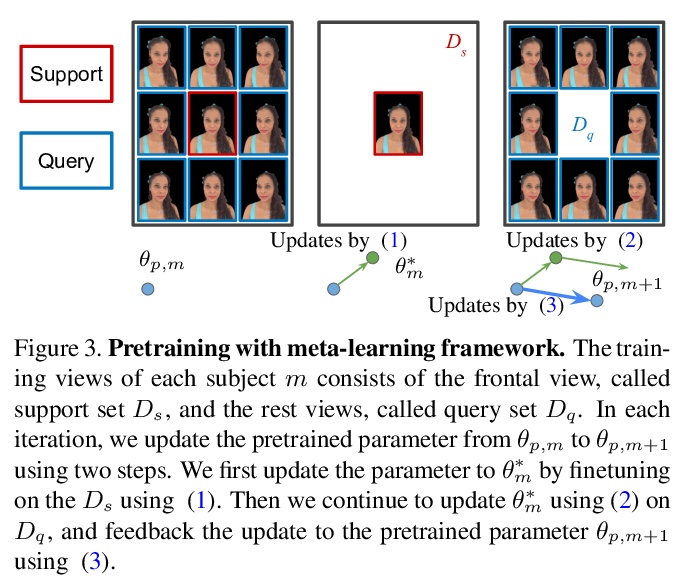
2、** **[CV] Portrait Neural Radiance Fields from a Single Image
C Gao, Y Shih, W Lai, C Liang, J Huang
[Virginia Tech & Google]
基于单图像的肖像神经辐射场。提出一种用单张头像照片估计神经辐射场、合成人像视图的方法,提出预训练多层感知器(MLP)权值,隐式模拟体密度和颜色,用梯度元学习预训练NeRF模型,能快速适应灯光舞台捕获元训练数据集,解决了在标准化人脸空间学习NeRF模型造成的主题形状变化。
We present a method for estimating Neural Radiance Fields (NeRF) from a single headshot portrait. While NeRF has demonstrated high-quality view synthesis, it requires multiple images of static scenes and thus impractical for casual captures and moving subjects. In this work, we propose to pretrain the weights of a multilayer perceptron (MLP), which implicitly models the volumetric density and colors, with a meta-learning framework using a light stage portrait dataset. To improve the generalization to unseen faces, we train the MLP in the canonical coordinate space approximated by 3D face morphable models. We quantitatively evaluate the method using controlled captures and demonstrate the generalization to real portrait images, showing favorable results against state-of-the-arts.
https://weibo.com/1402400261/Jy3ZymciD

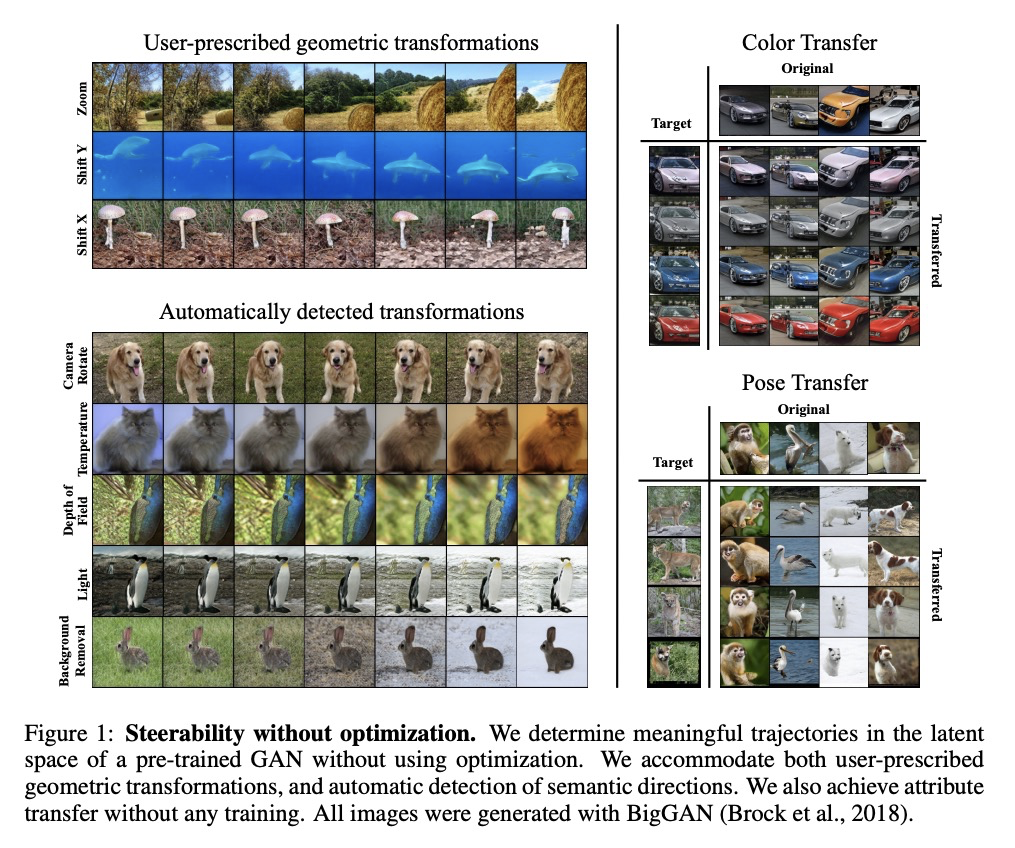
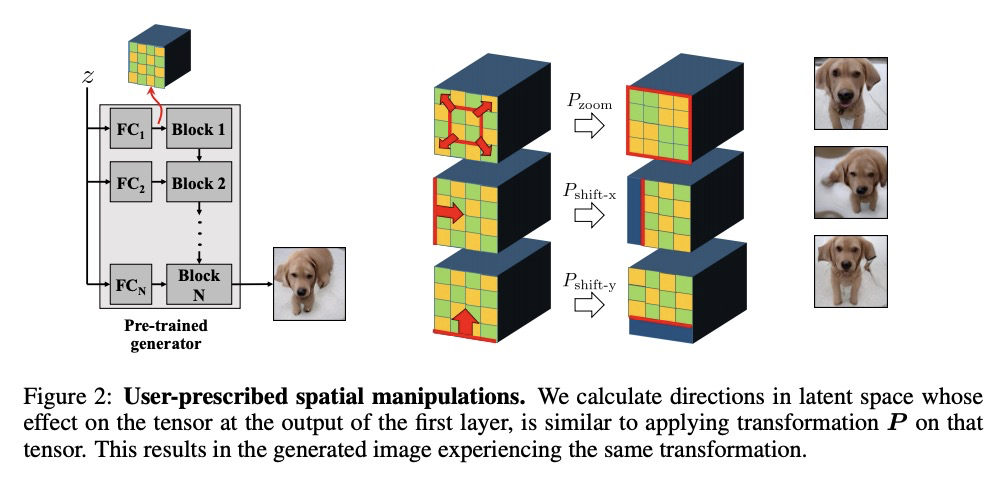
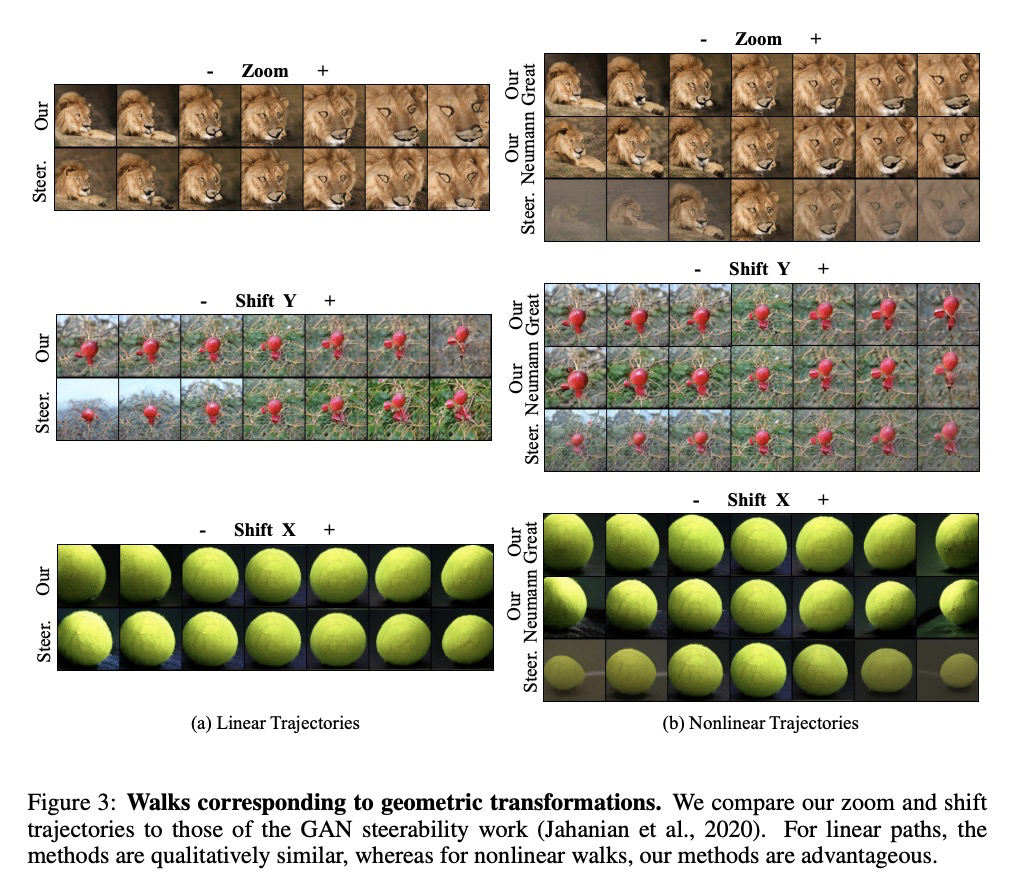
3、[CV] GAN Steerability without optimization
N Spingarn-Eliezer, R Banner, T Michaeli
[Habana Labs & Technion]
无需优化实现GANs可操纵性。提出了在预训练GANs潜在空间中确定操纵路径的方法,对应于语义意义的变换,直接从生成器权重中提取轨迹,无需任何形式的优化或训练,比现有技术高效很多。确定了一组更大的独特语义方向,首次明确地考虑了数据集自身偏差,适用于用户指定的几何变换,以及更复杂效果的无监督发现。
Recent research has shown remarkable success in revealing “steering” directions in the latent spaces of pre-trained GANs. These directions correspond to semantically meaningful image transformations e.g., shift, zoom, color manipulations), and have similar interpretable effects across all categories that the GAN can generate. Some methods focus on user-specified transformations, while others discover transformations in an unsupervised manner. However, all existing techniques rely on an optimization procedure to expose those directions, and offer no control over the degree of allowed interaction between different transformations. In this paper, we show that “steering” trajectories can be computed in closed form directly from the generator’s weights without any form of training or optimization. This applies to user-prescribed geometric transformations, as well as to unsupervised discovery of more complex effects. Our approach allows determining both linear and nonlinear trajectories, and has many advantages over previous methods. In particular, we can control whether one transformation is allowed to come on the expense of another (e.g. zoom-in with or without allowing translation to keep the object centered). Moreover, we can determine the natural end-point of the trajectory, which corresponds to the largest extent to which a transformation can be applied without incurring degradation. Finally, we show how transferring attributes between images can be achieved without optimization, even across different categories.
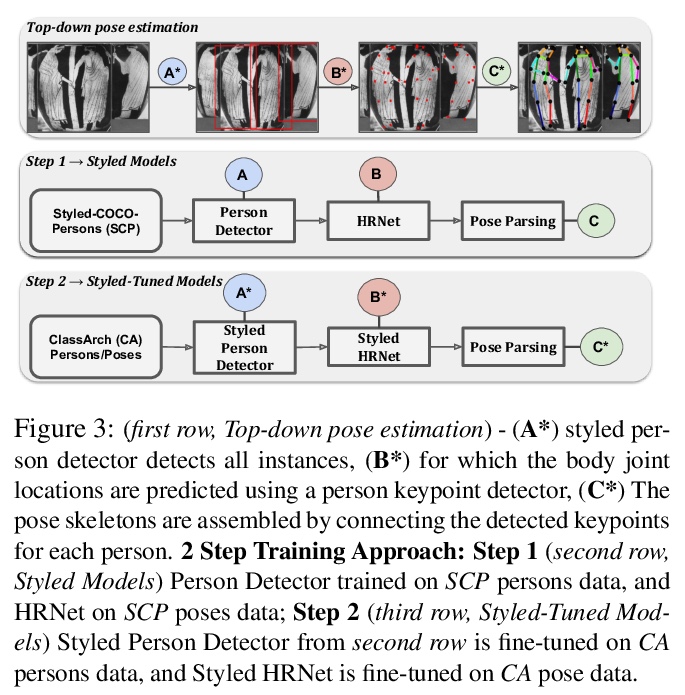
4、**[CV] Enhancing Human Pose Estimation in Ancient Vase Paintings via Perceptually-grounded Style Transfer Learning
P Madhu, A Villar-Corrales, R Kosti, T Bendschus, C Reinhardt, P Bell, A Maier, V Christlein
[Friedrich-Alexander-Universitat Erlangen-Nurnberg]
用感知画风迁移学习改善古代花瓶绘画人体姿态估计。人体姿态估计(Human pose estimate, HPE)是理解艺术品收藏(如希腊花瓶画)中人物的视觉叙事和身体动作的中心部分。本文提出一种用画风迁移和迁移学习、结合感知一致性的两步训练方法,改善古希腊花瓶绘画中的姿态估计。用画风转移学习作为这类数据的领域自适应技术,可显著提高最先进的姿态估计模型在未标记数据上的性能。**
Human pose estimation (HPE) is a central part of understanding the visual narration and body movements of characters depicted in artwork collections, such as Greek vase paintings. Unfortunately, existing HPE methods do not generalise well across domains resulting in poorly recognized poses. Therefore, we propose a two step approach: (1) adapting a dataset of natural images of known person and pose annotations to the style of Greek vase paintings by means of image style-transfer. We introduce a perceptually-grounded style transfer training to enforce perceptual consistency. Then, we fine-tune the base model with this newly created dataset. We show that using style-transfer learning significantly improves the SOTA performance on unlabelled data by more than 6% mean average precision (mAP) as well as mean average recall (mAR). (2) To improve the already strong results further, we created a small dataset (ClassArch) consisting of ancient Greek vase paintings from the 6-5th century BCE with person and pose annotations. We show that fine-tuning on this data with a style-transferred model improves the performance further. In a thorough ablation study, we give a targeted analysis of the influence of style intensities, revealing that the model learns generic domain styles. Additionally, we provide a pose-based image retrieval to demonstrate the effectiveness of our method.
https://weibo.com/1402400261/Jy4b58TYD

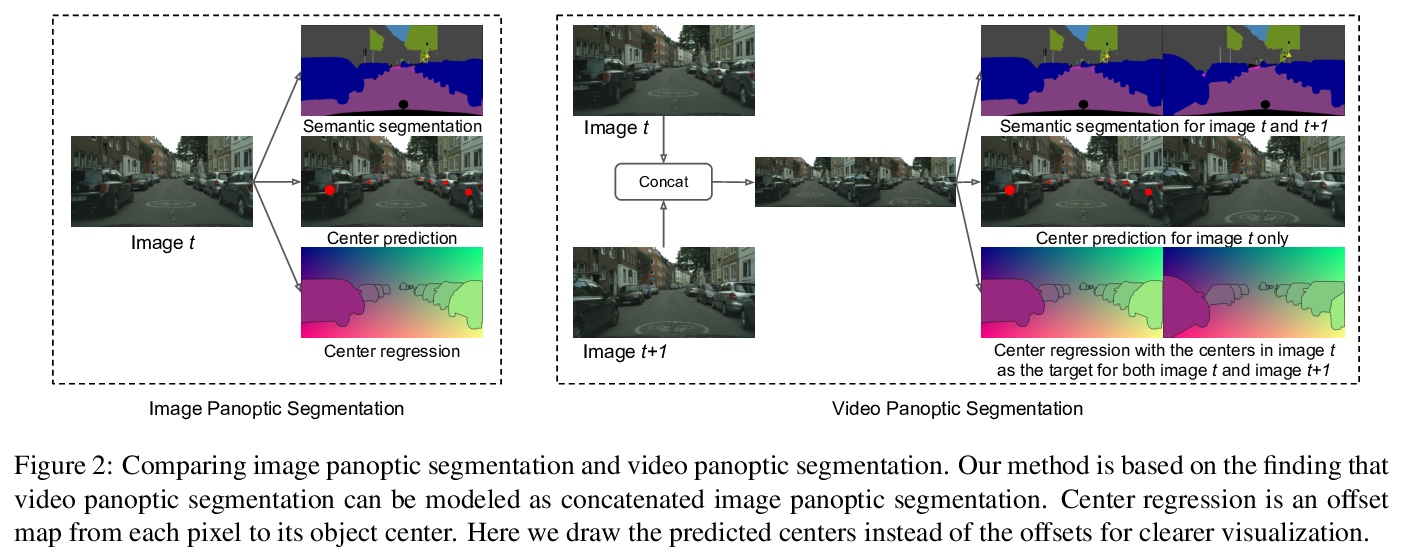
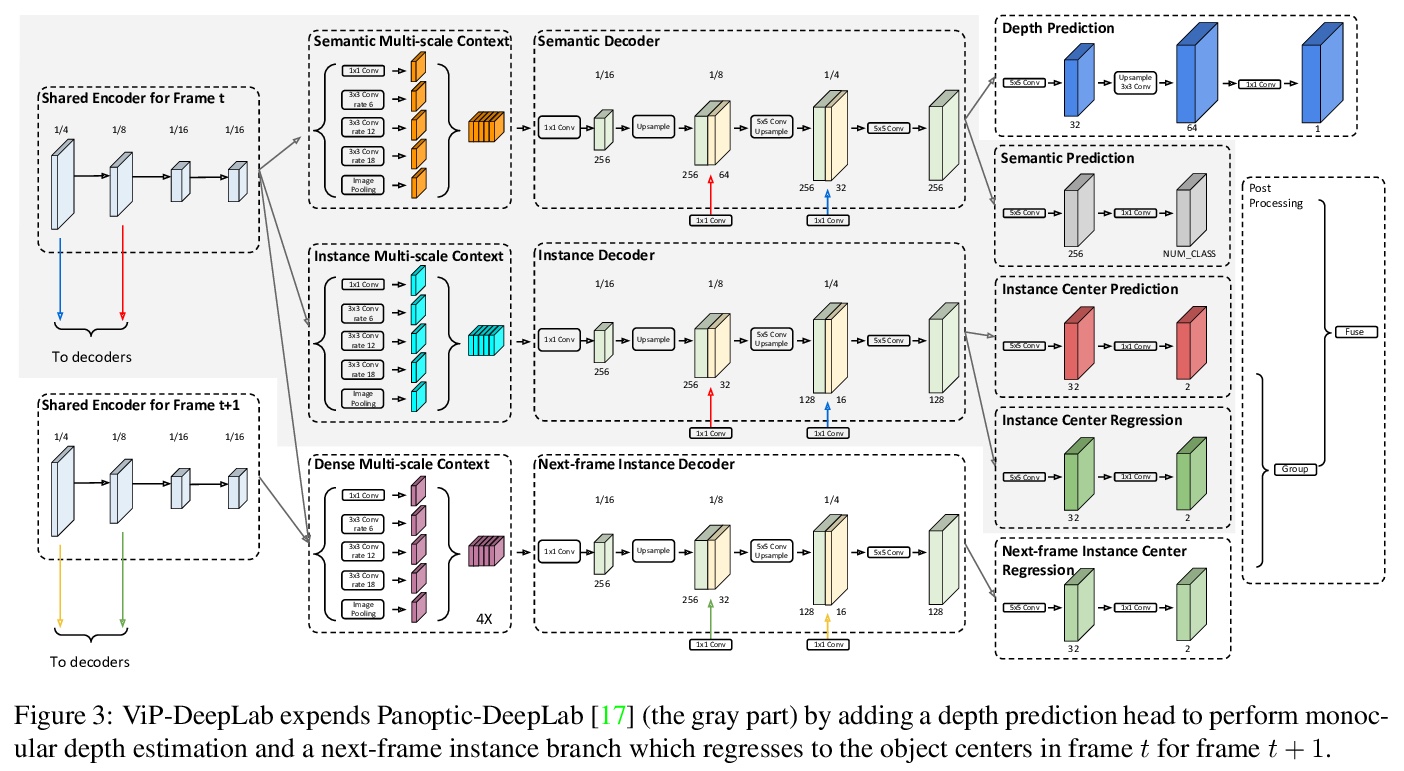
5、**[CV] ViP-DeepLab: Learning Visual Perception with Depth-aware Video Panoptic Segmentation
S Qiao, Y Zhu, H Adam, A Yuille, L Chen
[Johns Hopkins University & Google Research]
基于深度感知视频全景分割的视觉感知学习。提出一种新的具有挑战性的任务——深度感知视频全景分割,结合单目深度估计和视频全景分割,以解决视觉中的逆投影问题。针对此任务,结合两个衍生数据集,提出了深度感知视频全景质量作为评估指标。提出统一模型ViP-DeepLab,从透视图像序列恢复点云,同时为每个点提供实例级语义解释。**
In this paper, we present ViP-DeepLab, a unified model attempting to tackle the long-standing and challenging inverse projection problem in vision, which we model as restoring the point clouds from perspective image sequences while providing each point with instance-level semantic interpretations. Solving this problem requires the vision models to predict the spatial location, semantic class, and temporally consistent instance label for each 3D point. ViP-DeepLab approaches it by jointly performing monocular depth estimation and video panoptic segmentation. We name this joint task as Depth-aware Video Panoptic Segmentation, and propose a new evaluation metric along with two derived datasets for it, which will be made available to the public. On the individual sub-tasks, ViP-DeepLab also achieves state-of-the-art results, outperforming previous methods by 5.1% VPQ on Cityscapes-VPS, ranking 1st on the KITTI monocular depth estimation benchmark, and 1st on KITTI MOTS pedestrian. The datasets and the evaluation codes are made publicly available.
https://weibo.com/1402400261/Jy4fJyWft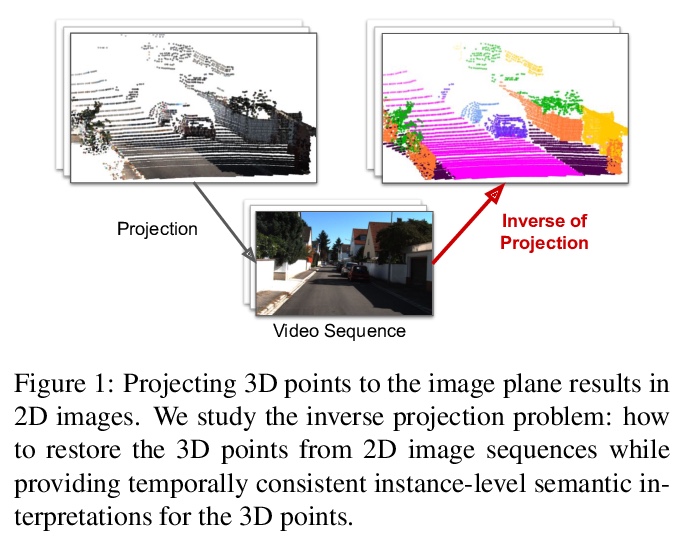
另外几篇值得关注的论文:
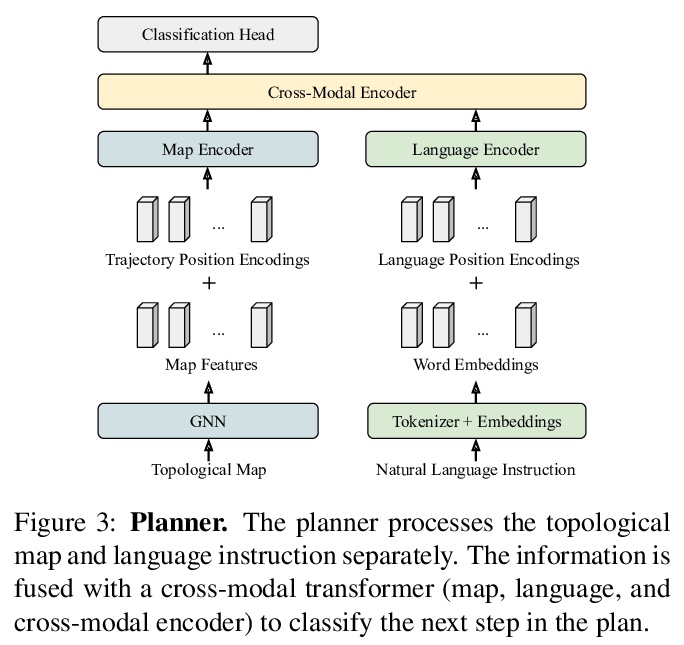
[RO] Topological Planning with Transformers for Vision-and-Language Navigation
面向视觉-语言导航的Transformer拓扑规划
K Chen, J K. Chen, J Chuang, M Vázquez, S Savarese
[Stanford University & Yale University]
https://weibo.com/1402400261/Jy4ofBzSL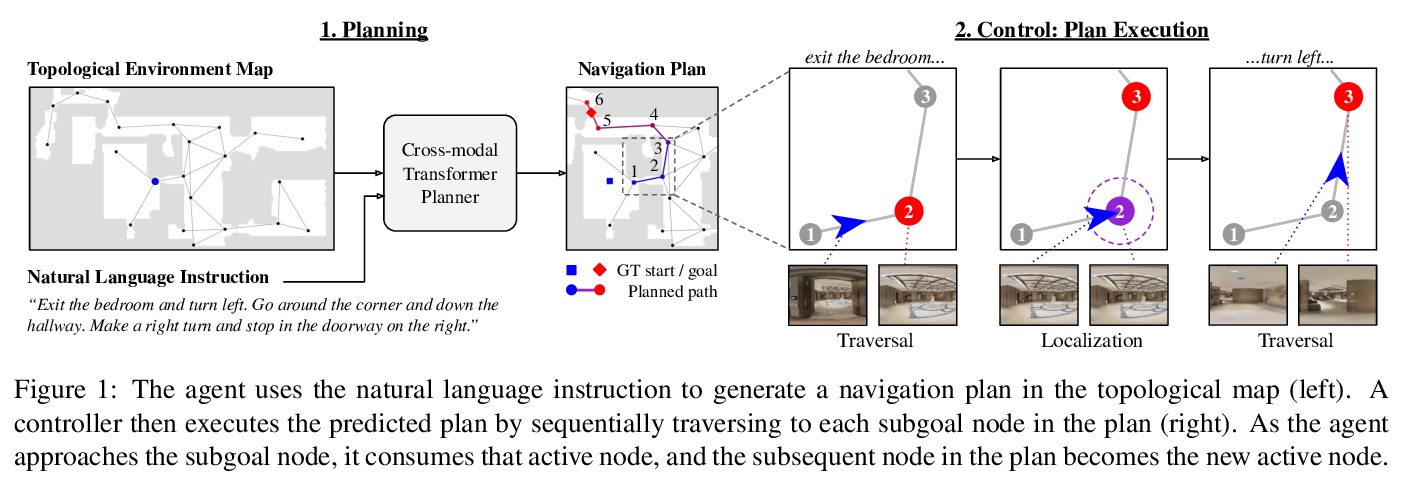

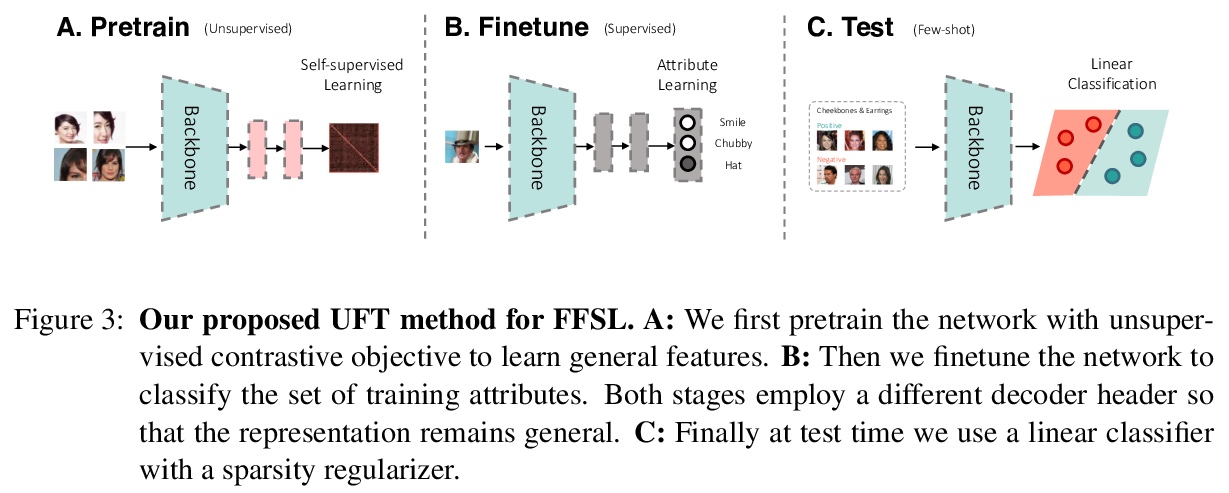
[LG] Flexible Few-Shot Learning with Contextual Similarity
基于上下文相似性的灵活少样本学习
M Ren, E Triantafillou, K Wang, J Lucas, J Snell, X Pitkow, A S. Tolias, R Zemel
[University of Toronto & Rice University & Baylor College of Medicine]
https://weibo.com/1402400261/Jy4q8CsBv

[LG] Scalable and interpretable rule-based link prediction for large heterogeneous knowledge graphs
大型异构知识图谱基于规则可扩展、可解释的链接预测
S Ott, L Graf, A Agibetov, C Meilicke, M Samwald
[Medical University of Vienna & University Mannheim]
https://weibo.com/1402400261/Jy4qThFJi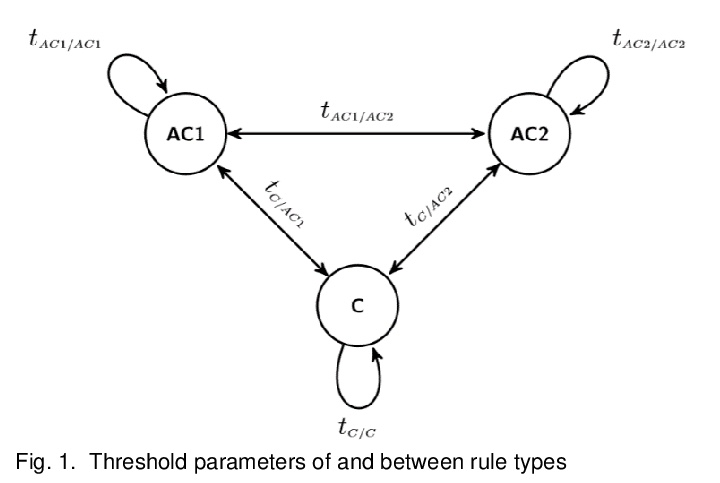
[CL] As good as new. How to successfully recycle English GPT-2 to make models for other languages
回收英语GPT-2为其他语言训练模型
W d Vries, M Nissim
[University of Groningen]
https://weibo.com/1402400261/Jy4sBoJ5a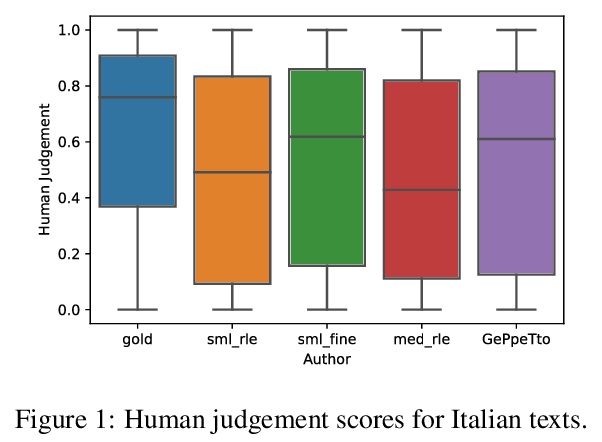

若有收获,就点个赞吧
0 人点赞
