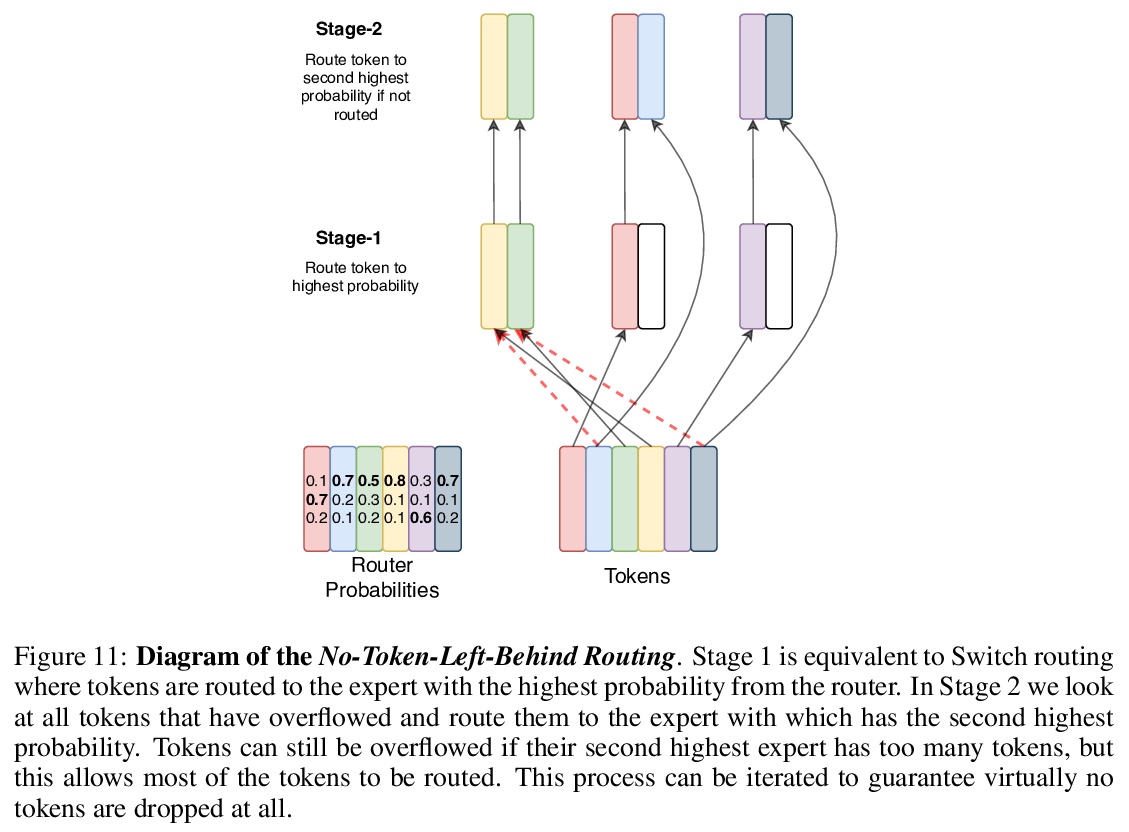
- 1、[LG] Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
- 2、[CV] Investigating the Vision Transformer Model for Image Retrieval Tasks
- 3、[LG] How to Train Your Energy-Based Models
- 4、[CV] Learning to Segment Rigid Motions from Two Frames
- 5、[CV] Towards Real-World Blind Face Restoration with Generative Facial Prior
- [CV] ArrowGAN : Learning to Generate Videos by Learning Arrow of Time
- [CV] RepVGG: Making VGG-style ConvNets Great Again
- [LG] Technology Readiness Levels for Machine Learning Systems
- [CV] Learning from Weakly-labeled Web Videos via Exploring Sub-Concepts
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
W Fedus, B Zoph, N Shazeer
[Google Brain]
Switch Transformers:用简单有效的稀疏性扩展到万亿参数模型。提出Switch Transformers,可扩展且高效的自然语言学习器,简化了Mixture of Experts(MoE)的路由算法,设计了直观的易于理解、稳定的训练架构,降低了通信和计算成本,比同等大小的密集模型大大提高了样本效率。所提出的训练技术有助于解决不稳定性问题,在不同的自然语言任务集和不同的训练体系中表现出色,包括预训练、微调和多任务训练,使得训练具有数千亿到数万亿参数的模型成为可能。大型稀疏模型可以用较低精度(bfloat16)格式进行训练,设计了基于T5-Base和T5-Large的模型,以相同的计算资源获得高达7倍的预训练速度的提高。
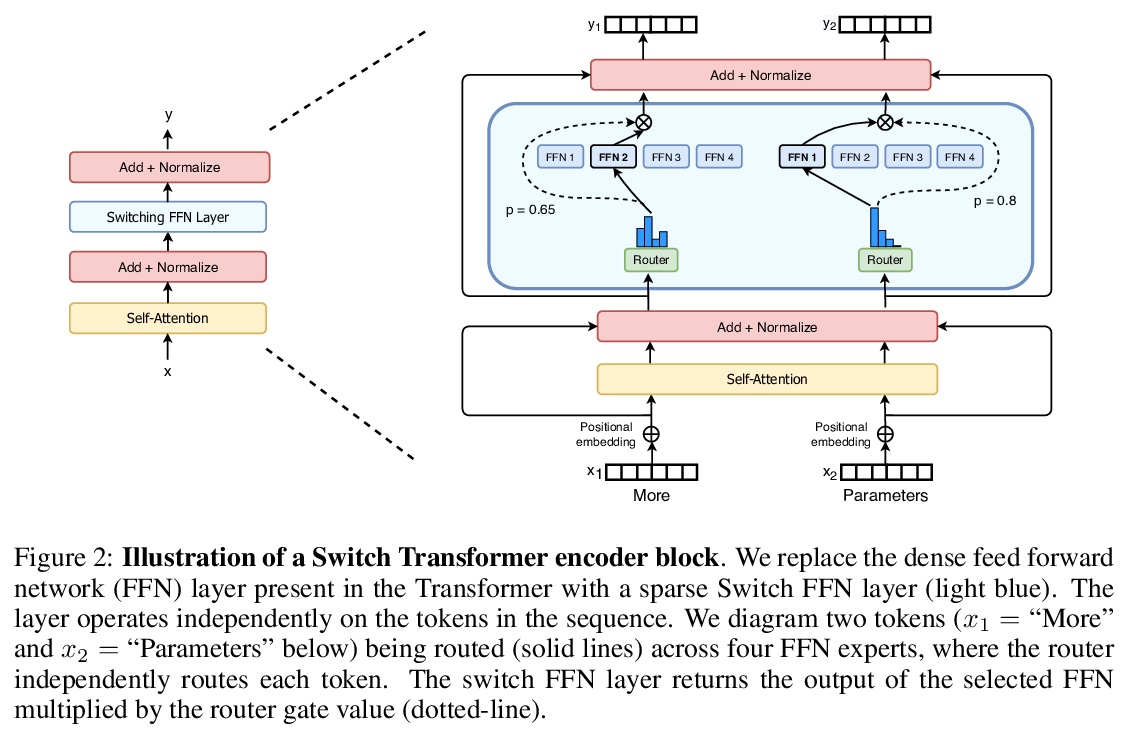
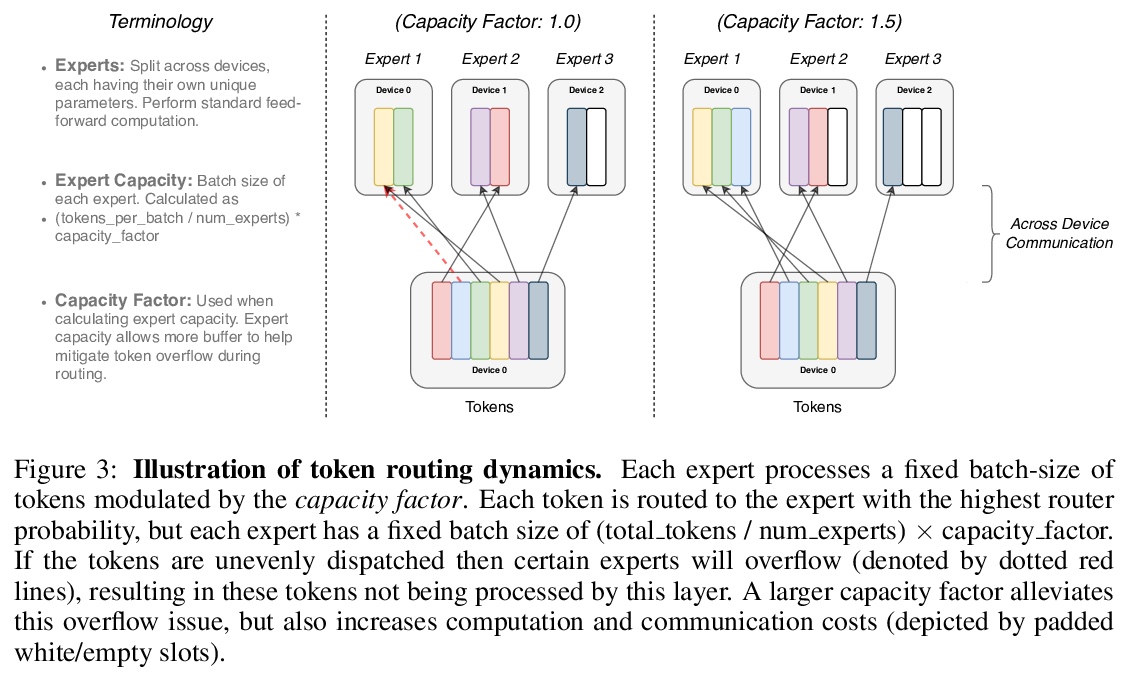
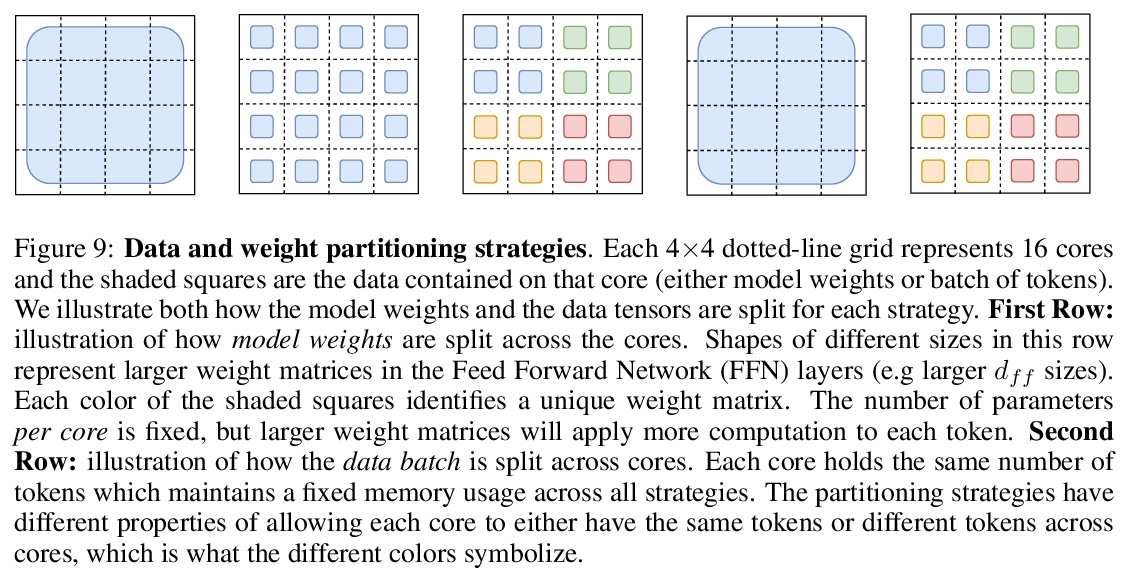
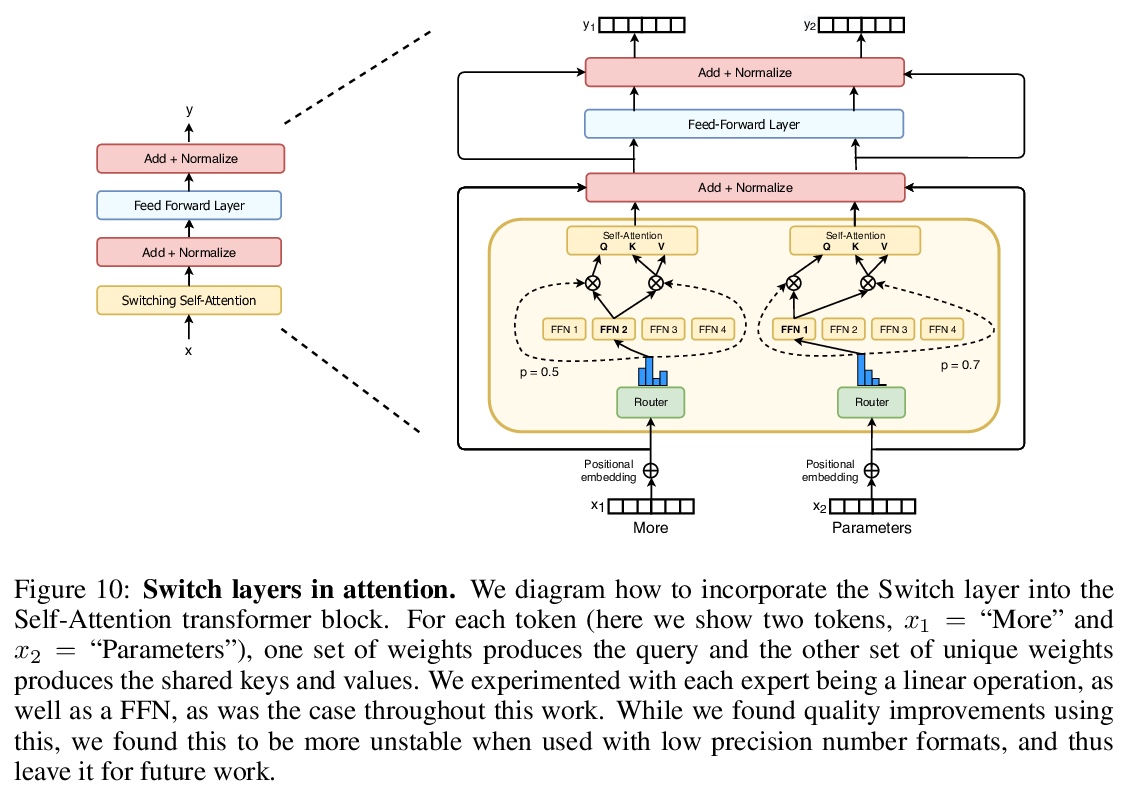
In deep learning, models typically reuse the same parameters for all inputs. Mixture of Experts (MoE) defies this and instead selects different parameters for each incoming example. The result is a sparsely-activated model — with outrageous numbers of parameters — but a constant computational cost. However, despite several notable successes of MoE, widespread adoption has been hindered by complexity, communication costs and training instability — we address these with the Switch Transformer. We simplify the MoE routing algorithm and design intuitive improved models with reduced communication and computational costs. Our proposed training techniques help wrangle the instabilities and we show large sparse models may be trained, for the first time, with lower precision (bfloat16) formats. We design models based off T5-Base and T5-Large to obtain up to 7x increases in pre-training speed with the same computational resources. These improvements extend into multilingual settings where we measure gains over the mT5-Base version across all 101 languages. Finally, we advance the current scale of language models by pre-training up to trillion parameter models on the “Colossal Clean Crawled Corpus” and achieve a 4x speedup over the T5-XXL model.
https://weibo.com/1402400261/JCVv5m1c3
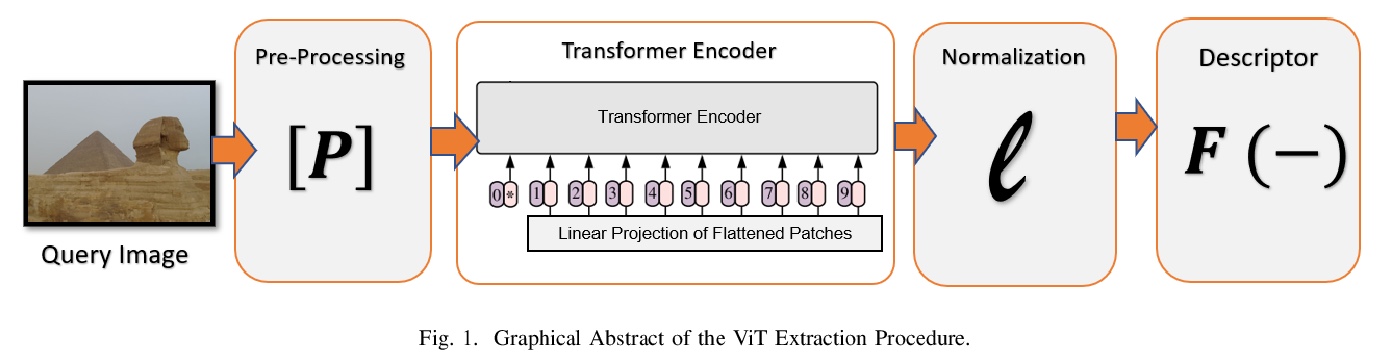
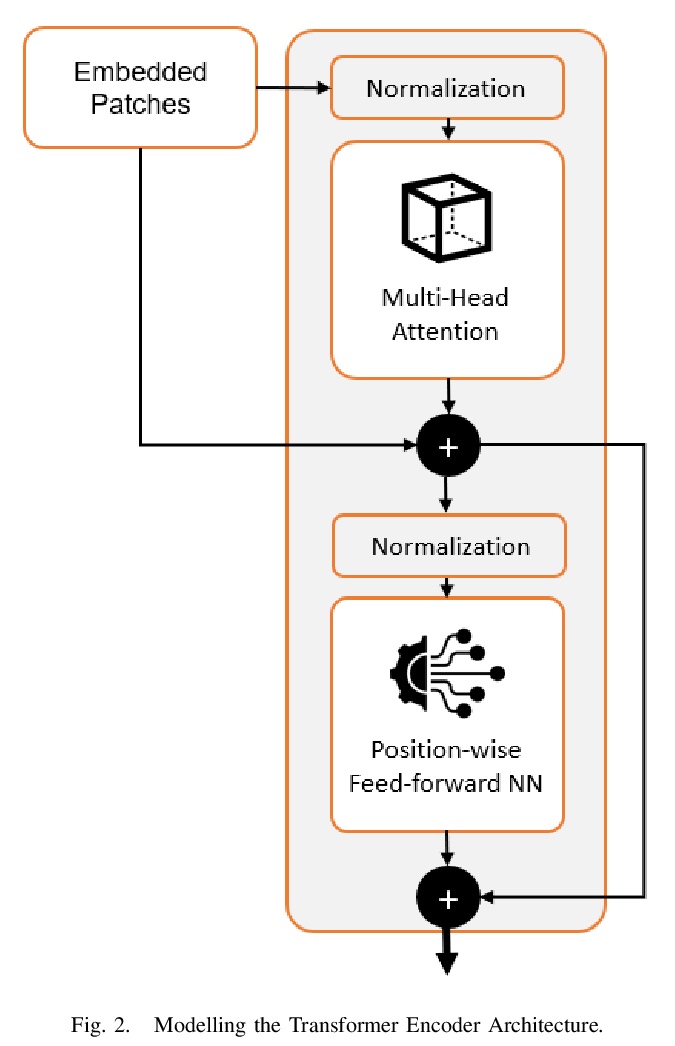
2、[CV] Investigating the Vision Transformer Model for Image Retrieval Tasks
S Gkelios, Y Boutalis, S A. Chatzichristofis
[Democritus University of Thrace & Neapolis University Pafos]
面向图像检索任务的视觉Transformer模型研究。提出一种基于Vision Transformer网络的完全无监督、非参数图像检索描述子,用于基于内容的图像检索任务。由于无需微调和低复杂度,所提出方法可替代传统的、被广泛采用的基于CNN的方法,用作图像检索的基线模型。
This paper introduces a plug-and-play descriptor that can be effectively adopted for image retrieval tasks without prior initialization or preparation. The description method utilizes the recently proposed Vision Transformer network while it does not require any training data to adjust parameters. In image retrieval tasks, the use of Handcrafted global and local descriptors has been very successfully replaced, over the last years, by the Convolutional Neural Networks (CNN)-based methods. However, the experimental evaluation conducted in this paper on several benchmarking datasets against 36 state-of-the-art descriptors from the literature demonstrates that a neural network that contains no convolutional layer, such as Vision Transformer, can shape a global descriptor and achieve competitive results. As fine-tuning is not required, the presented methodology’s low complexity encourages adoption of the architecture as an image retrieval baseline model, replacing the traditional and well adopted CNN-based approaches and inaugurating a new era in image retrieval approaches.
https://weibo.com/1402400261/JCVATjUPD
3、[LG] How to Train Your Energy-Based Models
Y Song, D P. Kingma
[Stanford University & Google Research]
基于能量模型(EBM)的训练方法介绍。从解释马尔科夫链蒙特卡洛(MCMC)最大似然训练开始,到非MCMC方法,包括得分匹配(SM)和噪声抑制估计(NCE),强调了这三种方法之间的理论联系,并对还在积极研究中的替代训练方法进行了简要综述。本教程针对的是对生成模型有基本了解,想应用EBM或开始这个方向研究的读者。
Energy-Based Models (EBMs), also known as non-normalized probabilistic models, specify probability density or mass functions up to an unknown normalizing constant. Unlike most other probabilistic models, EBMs do not place a restriction on the tractability of the normalizing constant, thus are more flexible to parameterize and can model a more expressive family of probability distributions. However, the unknown normalizing constant of EBMs makes training particularly difficult. Our goal is to provide a friendly introduction to modern approaches for EBM training. We start by explaining maximum likelihood training with Markov chain Monte Carlo (MCMC), and proceed to elaborate on MCMC-free approaches, including Score Matching (SM) and Noise Constrastive Estimation (NCE). We highlight theoretical connections among these three approaches, and end with a brief survey on alternative training methods, which are still under active research. Our tutorial is targeted at an audience with basic understanding of generative models who want to apply EBMs or start a research project in this direction.
https://weibo.com/1402400261/JCVL1cZtE

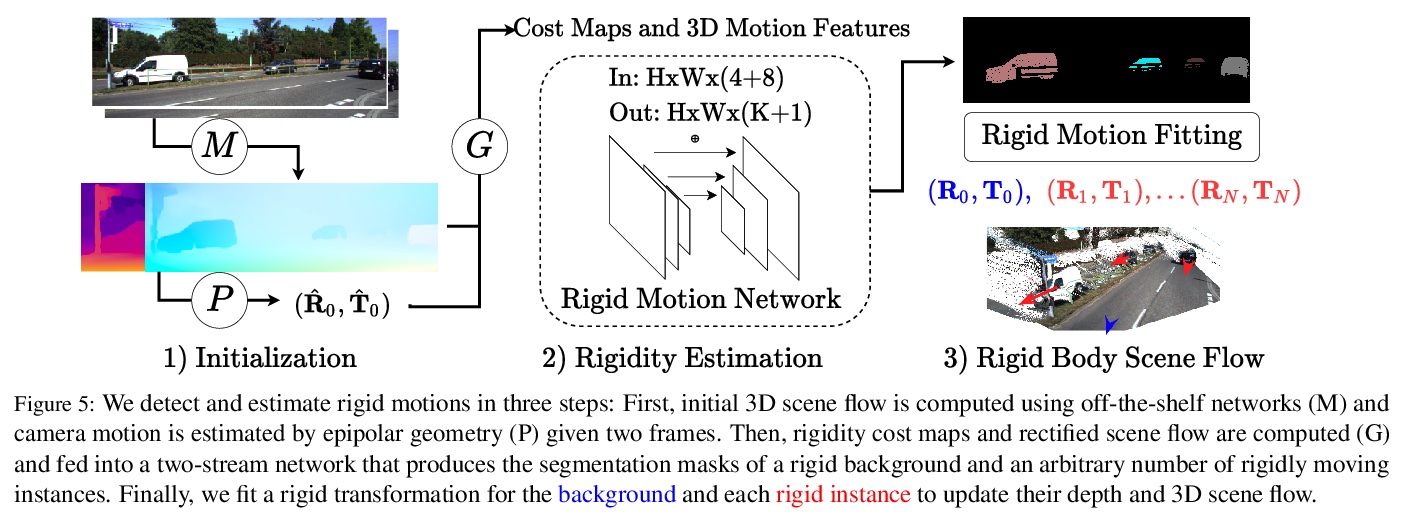
4、[CV] Learning to Segment Rigid Motions from Two Frames
G Yang, D Ramanan
[CMU]
学习从双帧分割刚性运动。研究了开放环境双帧刚体运动分割问题,分析了几何运动分割中的退化情况,引入新的标准和输入来解决这种模糊性。提出一个模块化网络,将两个连续帧作为输入,预测背景和多个刚性运动物体的分割掩膜,通过3D刚性变换进行参数化。该架构对噪声观测和不同运动类型具有鲁棒性,在刚性运动分割、深度和场景流估计任务中展示了最先进的性能,在KITTI场景流排行榜上排名第一。
Appearance-based detectors achieve remarkable performance on common scenes, but tend to fail for scenarios lack of training data. Geometric motion segmentation algorithms, however, generalize to novel scenes, but have yet to achieve comparable performance to appearance-based ones, due to noisy motion estimations and degenerate motion configurations. To combine the best of both worlds, we propose a modular network, whose architecture is motivated by a geometric analysis of what independent object motions can be recovered from an egomotion field. It takes two consecutive frames as input and predicts segmentation masks for the background and multiple rigidly moving objects, which are then parameterized by 3D rigid transformations. Our method achieves state-of-the-art performance for rigid motion segmentation on KITTI and Sintel. The inferred rigid motions lead to a significant improvement for depth and scene flow estimation. At the time of submission, our method ranked 1st on KITTI scene flow leaderboard, out-performing the best published method (scene flow error: 4.89% vs 6.31%).
https://weibo.com/1402400261/JCVPgbaHx




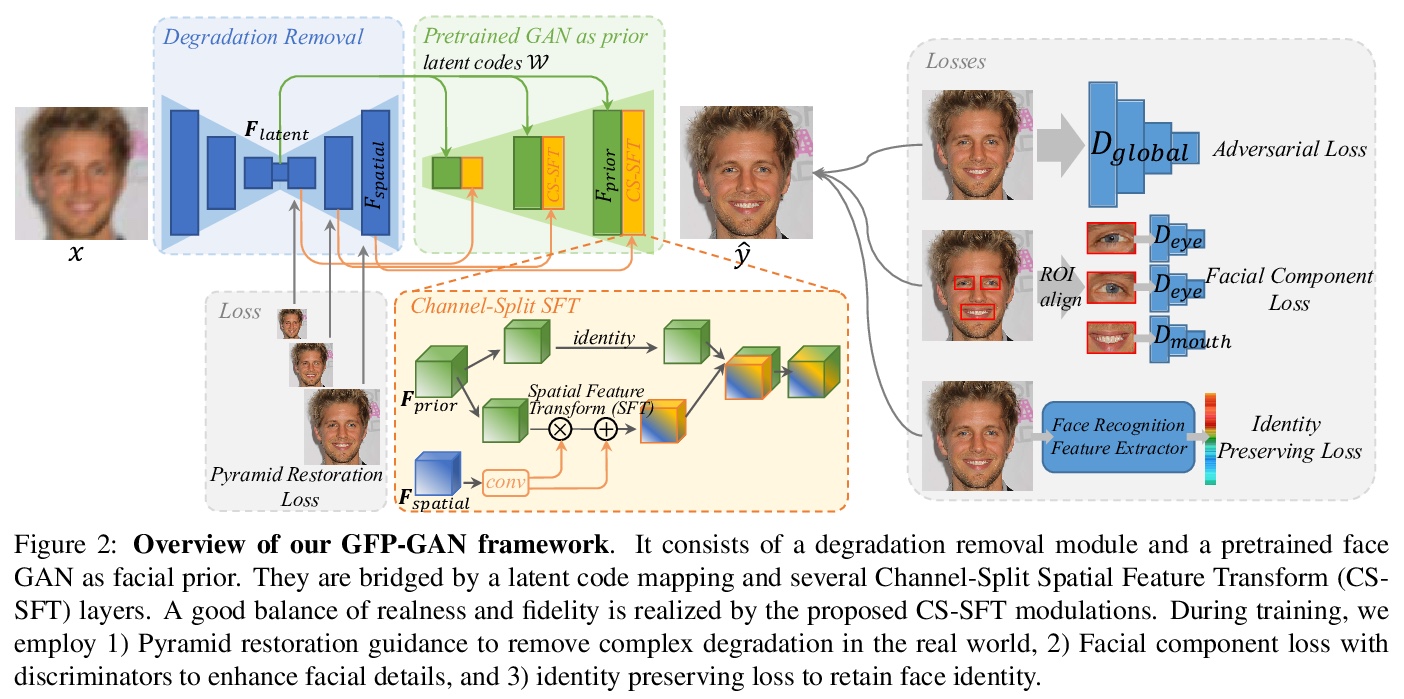
5、[CV] Towards Real-World Blind Face Restoration with Generative Facial Prior
X Wang, Y Li, H Zhang, Y Shan
[Tencent PCG]
基于生成式人脸先验实现真实世界的人脸盲修复。提出GFP-GAN框架,利用丰富的生成式人脸先验,完成人脸盲修复任务。该先验通过新的通道分割空间特征变换层融入到修复过程中,可实现逼真性和还原性的良好平衡。引入了人脸成分损失、身份保存损失和金字塔修复引导等细节设计。
Blind face restoration usually relies on facial priors, such as facial geometry prior or reference prior, to restore realistic and faithful details. However, very low-quality inputs cannot offer accurate geometric prior while high-quality references are inaccessible, limiting the applicability in real-world scenarios. In this work, we propose GFP-GAN that leverages rich and diverse priors encapsulated in a pretrained face GAN for blind face restoration. This Generative Facial Prior (GFP) is incorporated into the face restoration process via novel channel-split spatial feature transform layers, which allow our method to achieve a good balance of realness and fidelity. Thanks to the powerful generative facial prior and delicate designs, our GFP-GAN could jointly restore facial details and enhance colors with just a single forward pass, while GAN inversion methods require expensive image-specific optimization at inference. Extensive experiments show that our method achieves superior performance to prior art on both synthetic and real-world datasets.
https://weibo.com/1402400261/JCVWteO5K

另外几篇值得关注的论文:
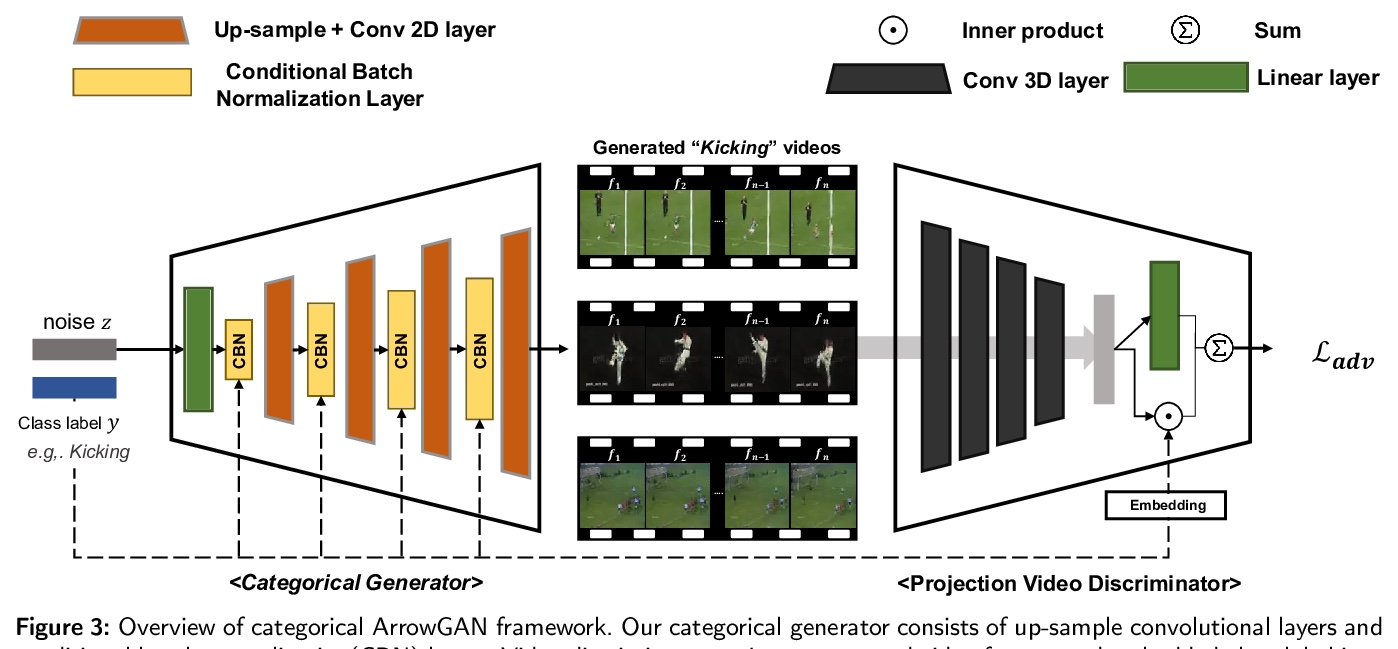
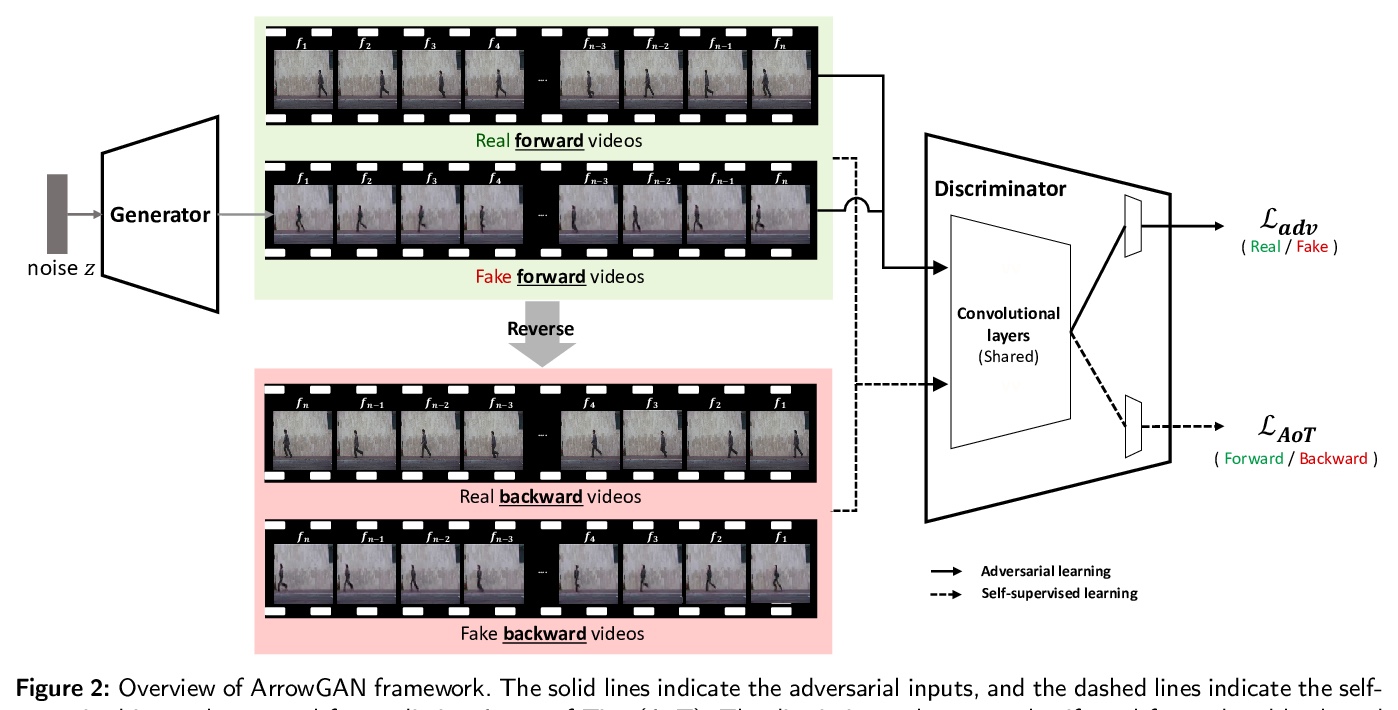
[CV] ArrowGAN : Learning to Generate Videos by Learning Arrow of Time
ArrowGAN:通过学习时间之箭(Arrow of Time)来学习生成视频
K Hong, Y Uh, H Byun
[Yonsei University & Clova AI Research]
https://weibo.com/1402400261/JCWeLlLBm

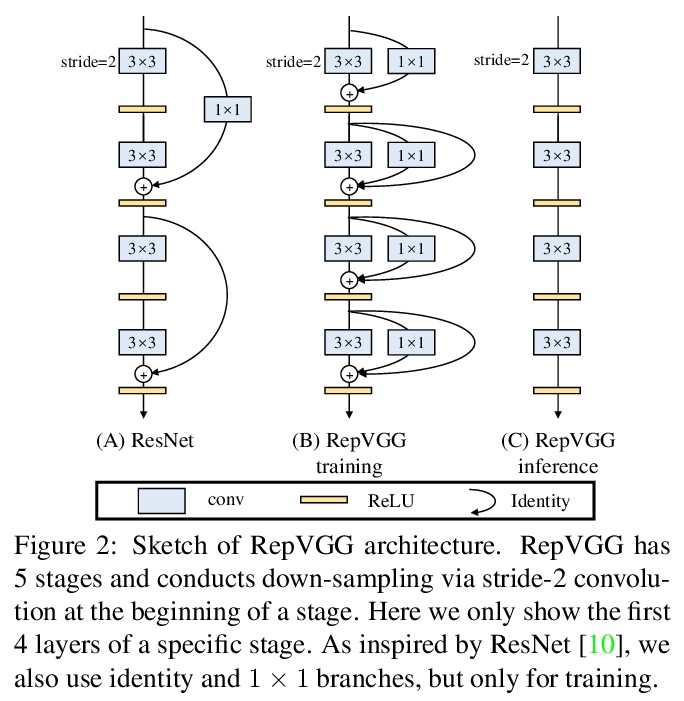
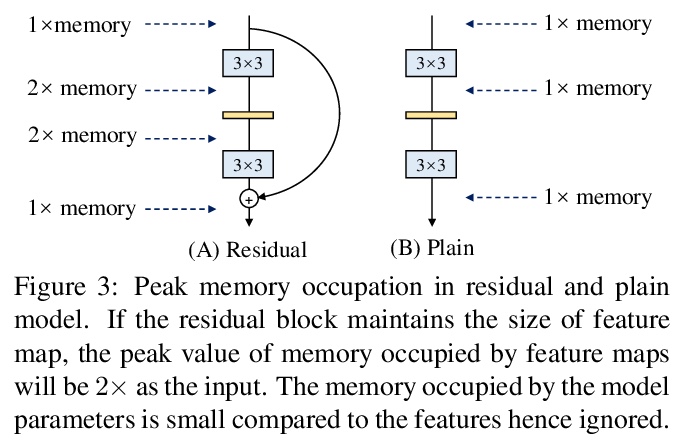
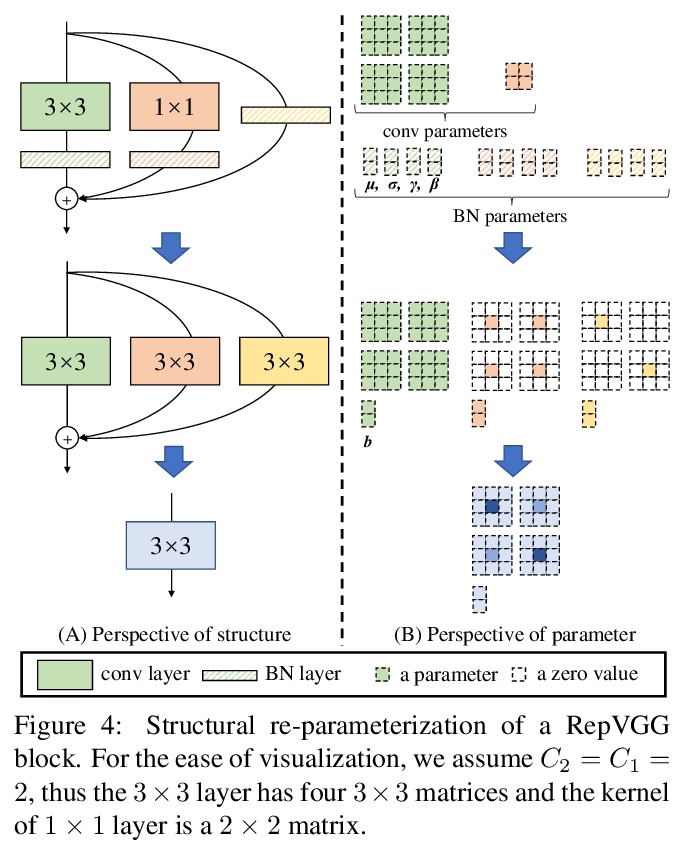
[CV] RepVGG: Making VGG-style ConvNets Great Again
RepVGG:让VGG卷积网络再次强大
X Ding, X Zhang, N Ma, J Han, G Ding, J Sun
[Tsinghua University & MEGVII Technology & Hong Kong University of Science and Technology]
https://weibo.com/1402400261/JCWklCrsE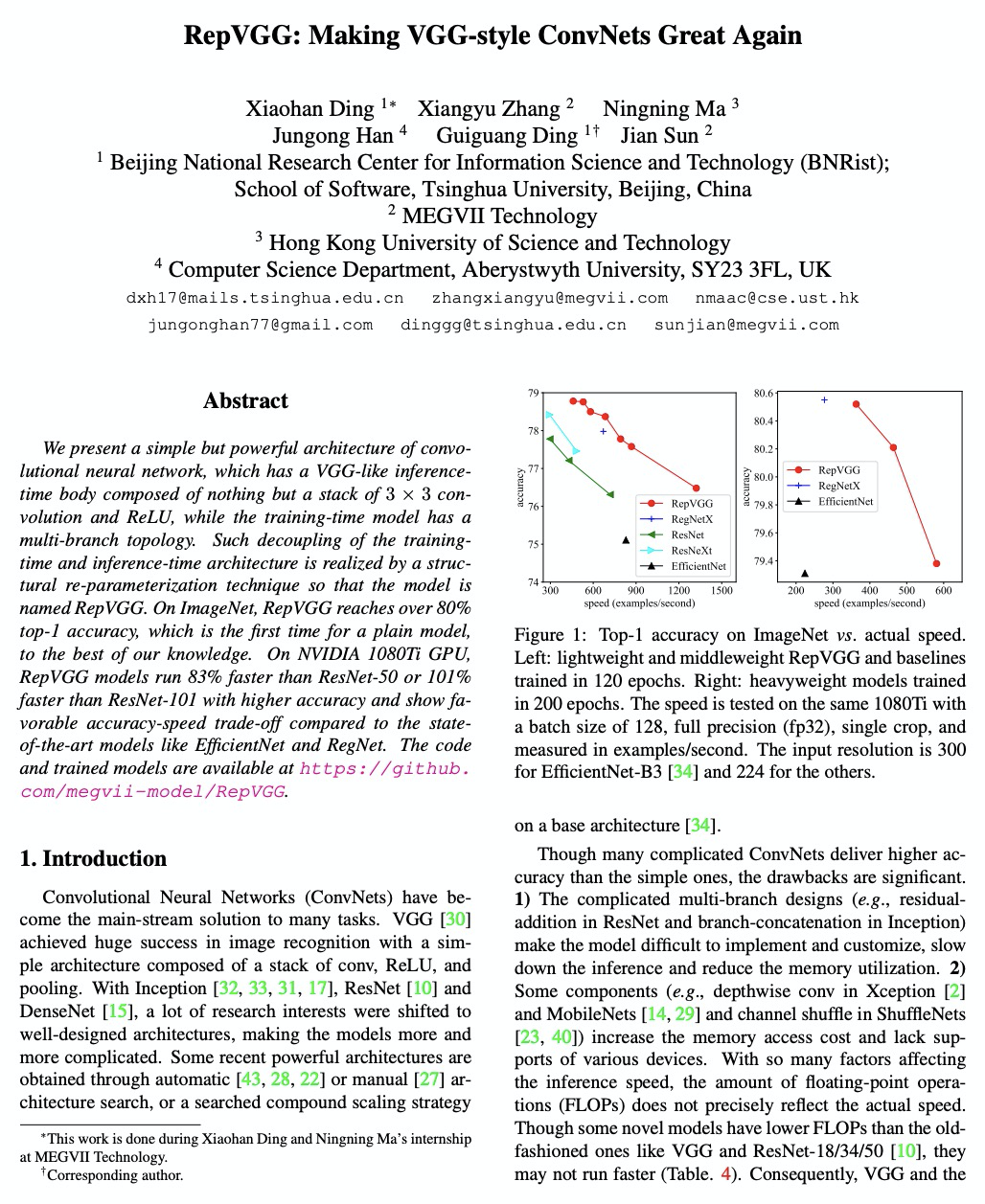
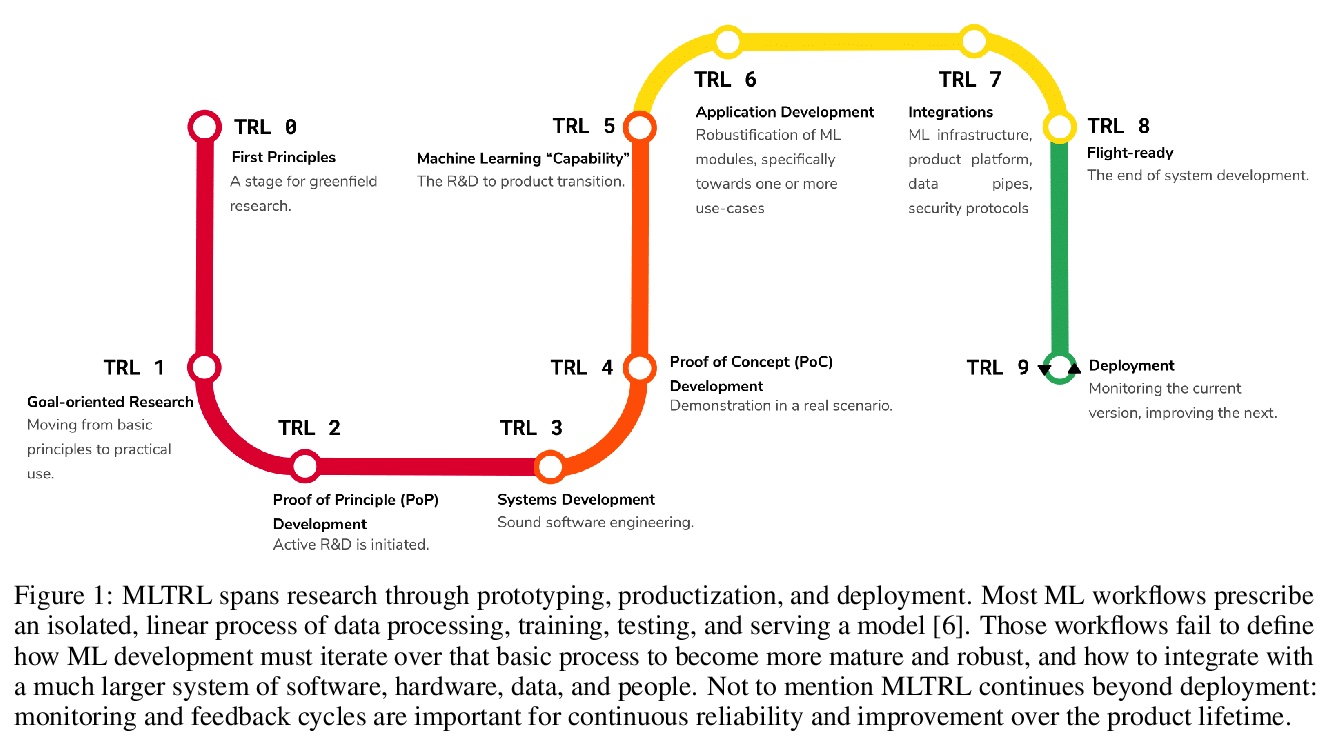
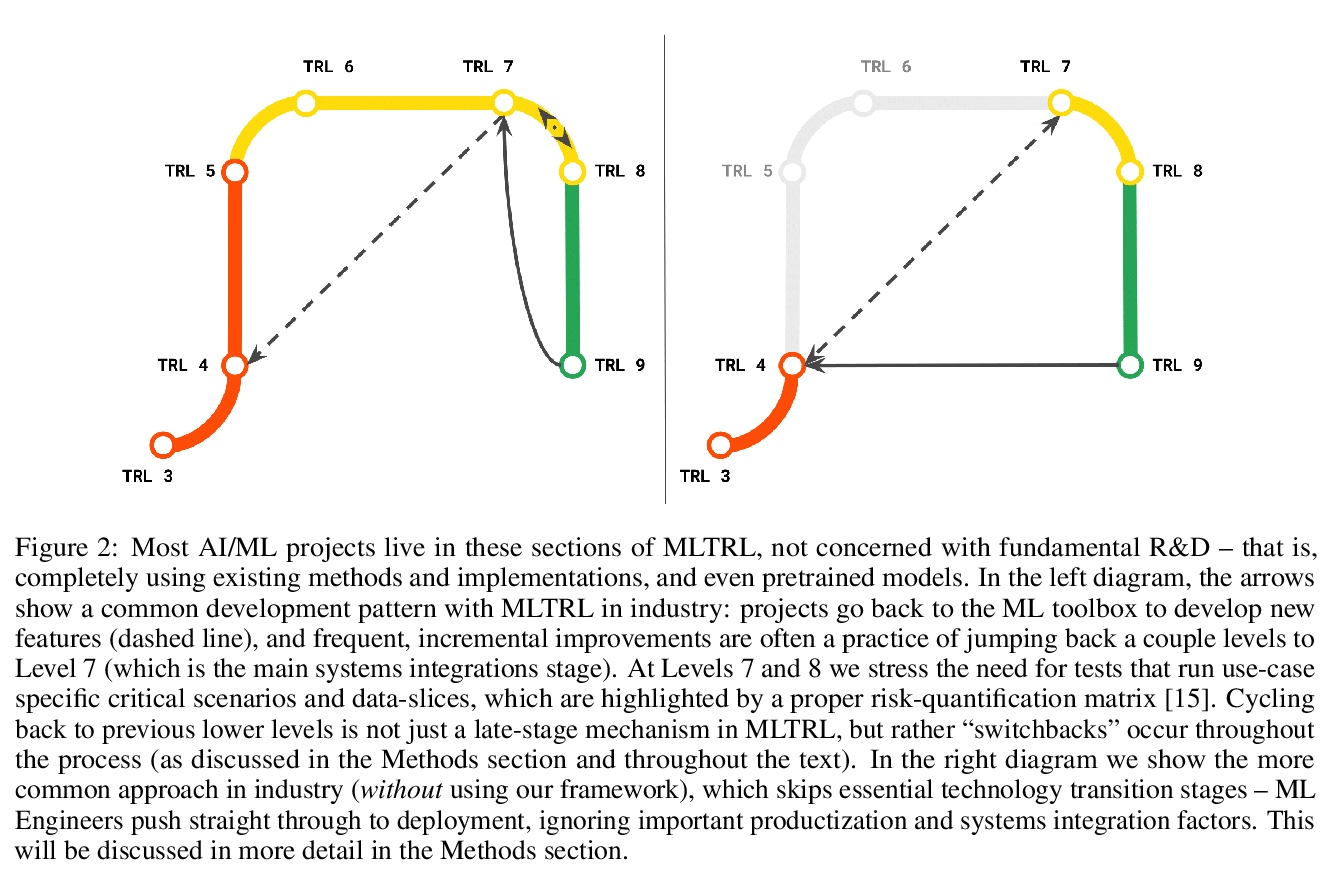
[LG] Technology Readiness Levels for Machine Learning Systems
机器学习系统技术成熟度
A Lavin, C M. Gilligan-Lee, A Visnjic, S Ganju, D Newman, S Ganguly, D Lange, A G Baydin, A Sharma, A Gibson, Y Gal, E P. Xing, C Mattmann, J Parr
[Latent Sciences & Spotify & WhyLabs & Nvidia & MIT…]
https://weibo.com/1402400261/JCWm96216

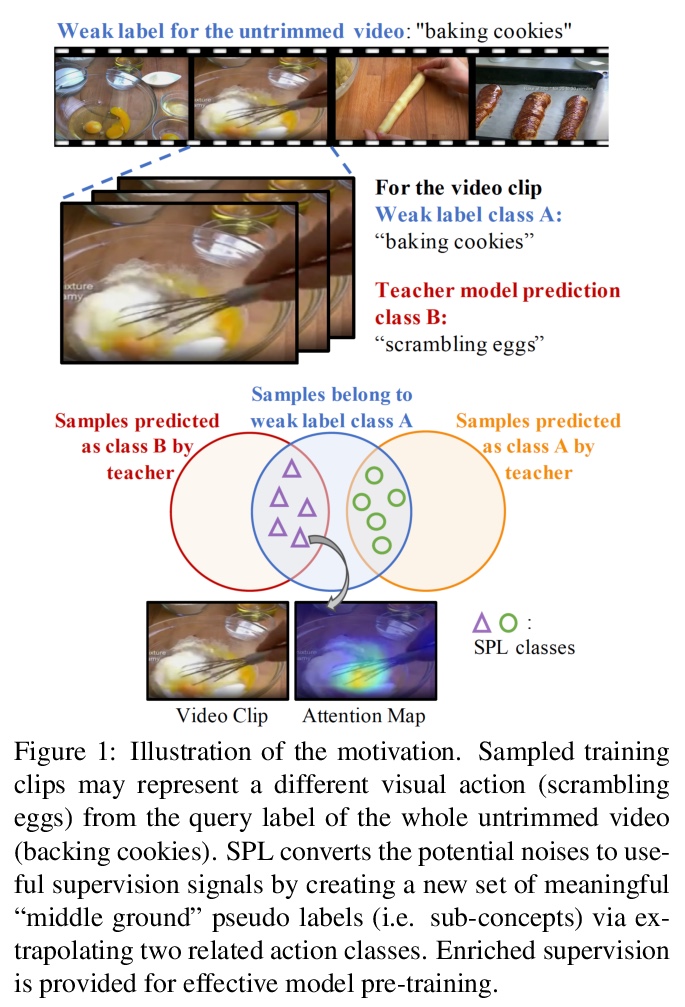
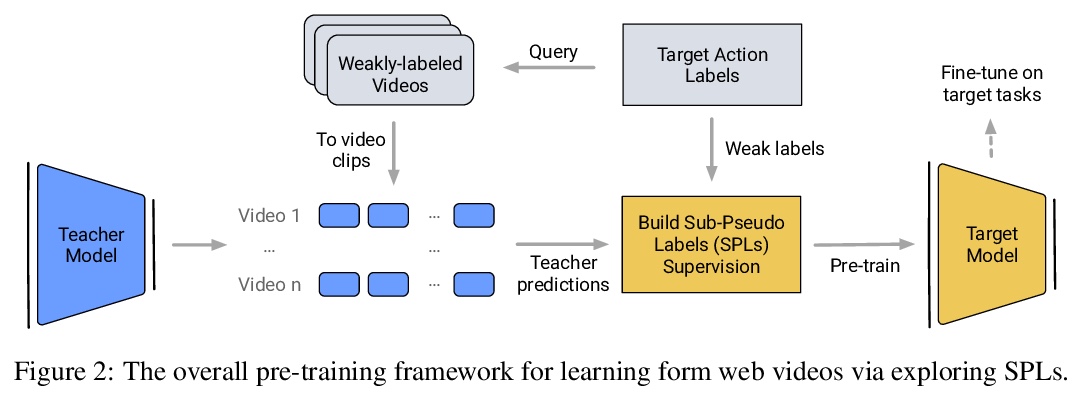
[CV] Learning from Weakly-labeled Web Videos via Exploring Sub-Concepts
通过子概念探索学习弱标记网络视频
K Li, Z Zhang, G Wu, X Xiong, C Lee, Z Lu, Y Fu, T Pfister
[Northeastern University & Google Cloud AI]
https://weibo.com/1402400261/JCWqU09Cc

若有收获,就点个赞吧
0 人点赞
