- 1、[LG] Unsupervised Learning of Visual 3D Keypoints for Control
- 2、[CV] Styleformer: Transformer based Generative Adversarial Networks with Style Vector
- 3、[LG] Break-It-Fix-It: Unsupervised Learning for Program Repair
- 4、[LG] Thinking Like Transformers
- 5、[CV] Improved Transformer for High-Resolution GANs
- [CL] Graph Neural Networks for Natural Language Processing: A Survey
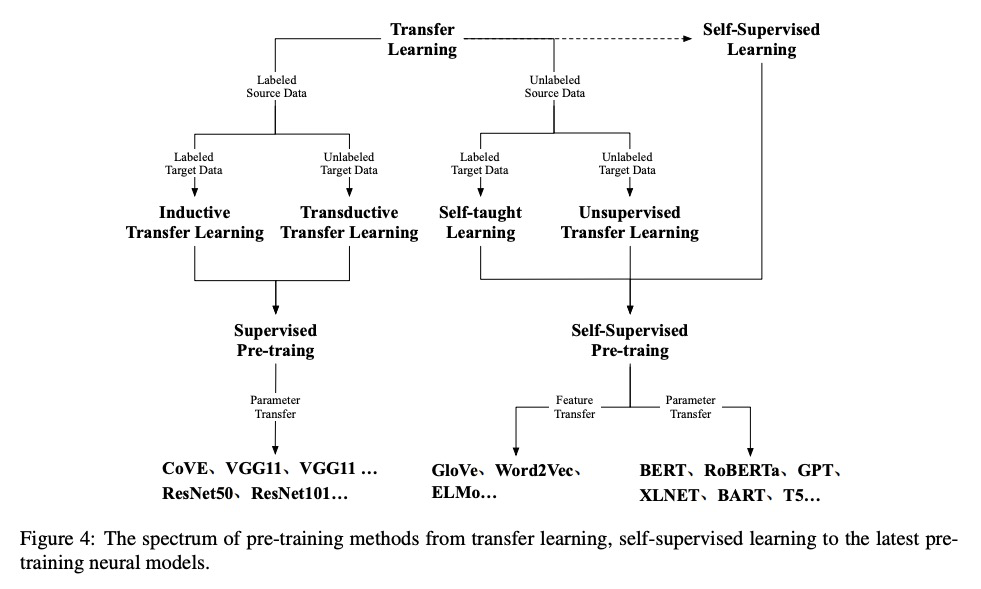
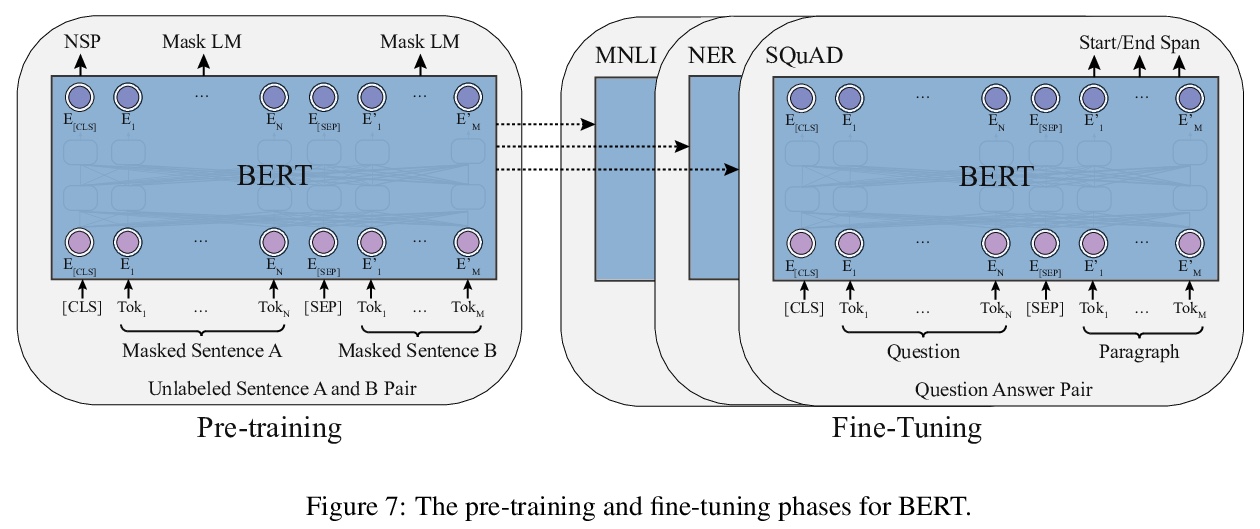
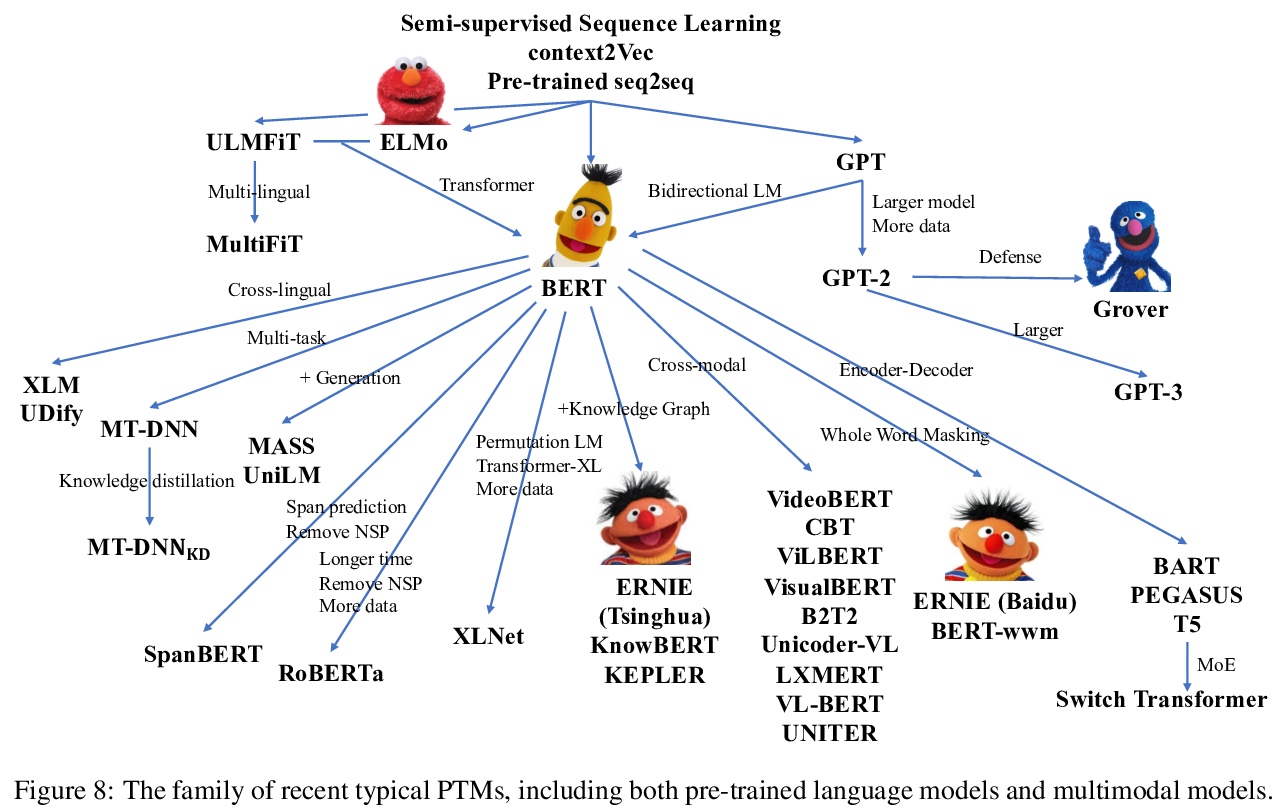
- [LG] Pre-Trained Models: Past, Present and Future
- [LG] Scalars are universal: Gauge-equivariant machine learning, structured like classical physics
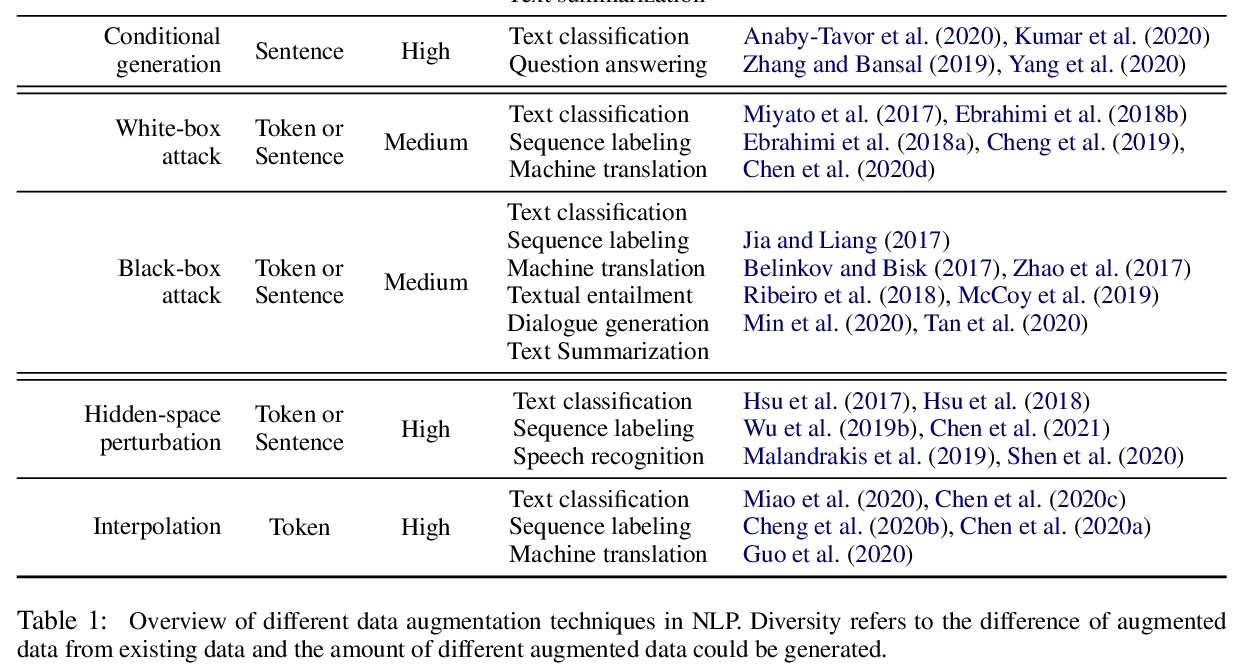
- [CL] An Empirical Survey of Data Augmentation for Limited Data Learning in NLP
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[LG] Unsupervised Learning of Visual 3D Keypoints for Control
B Chen, P Abbeel, D Pathak
[UC Berkelely & CMU]
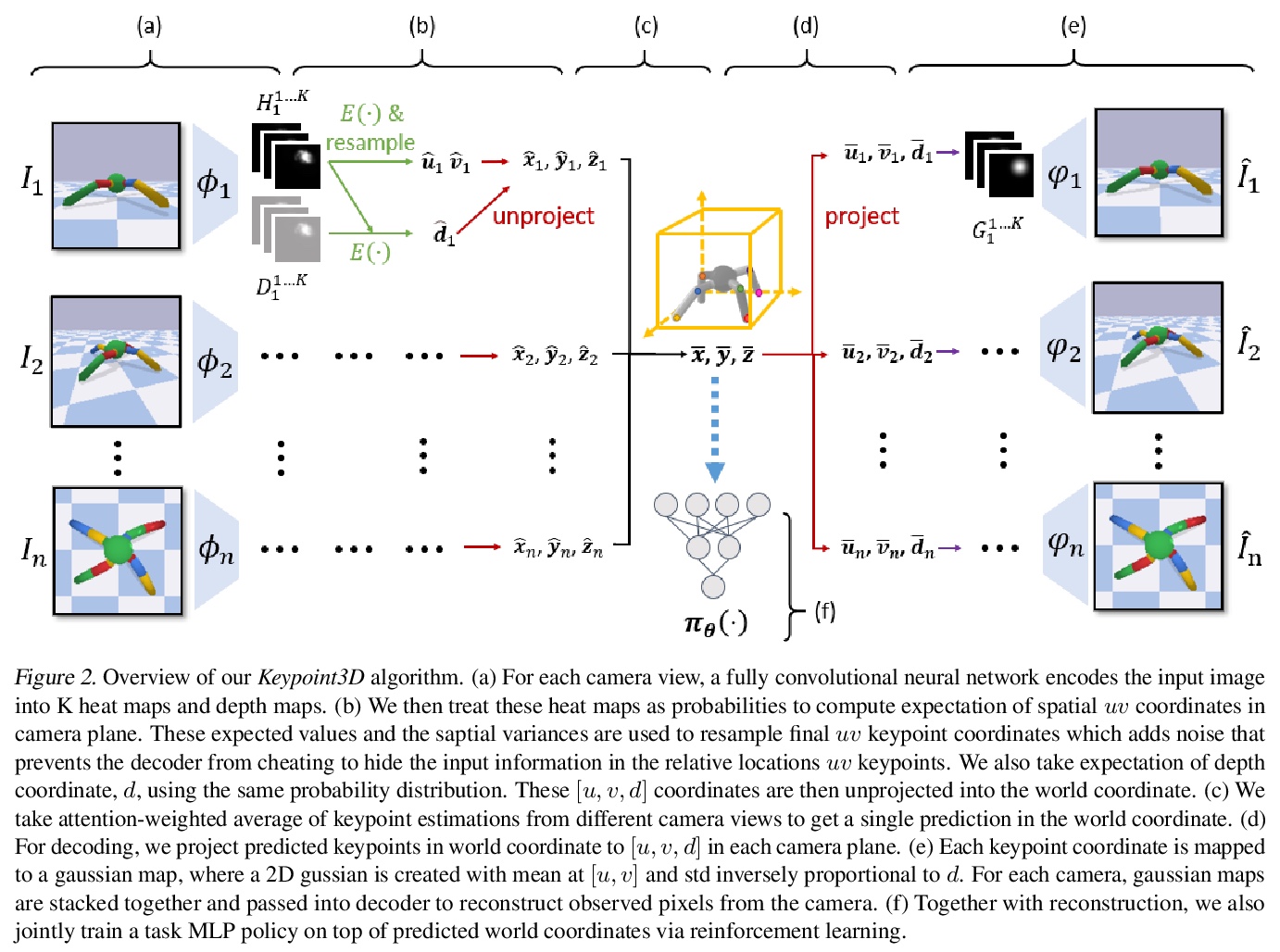
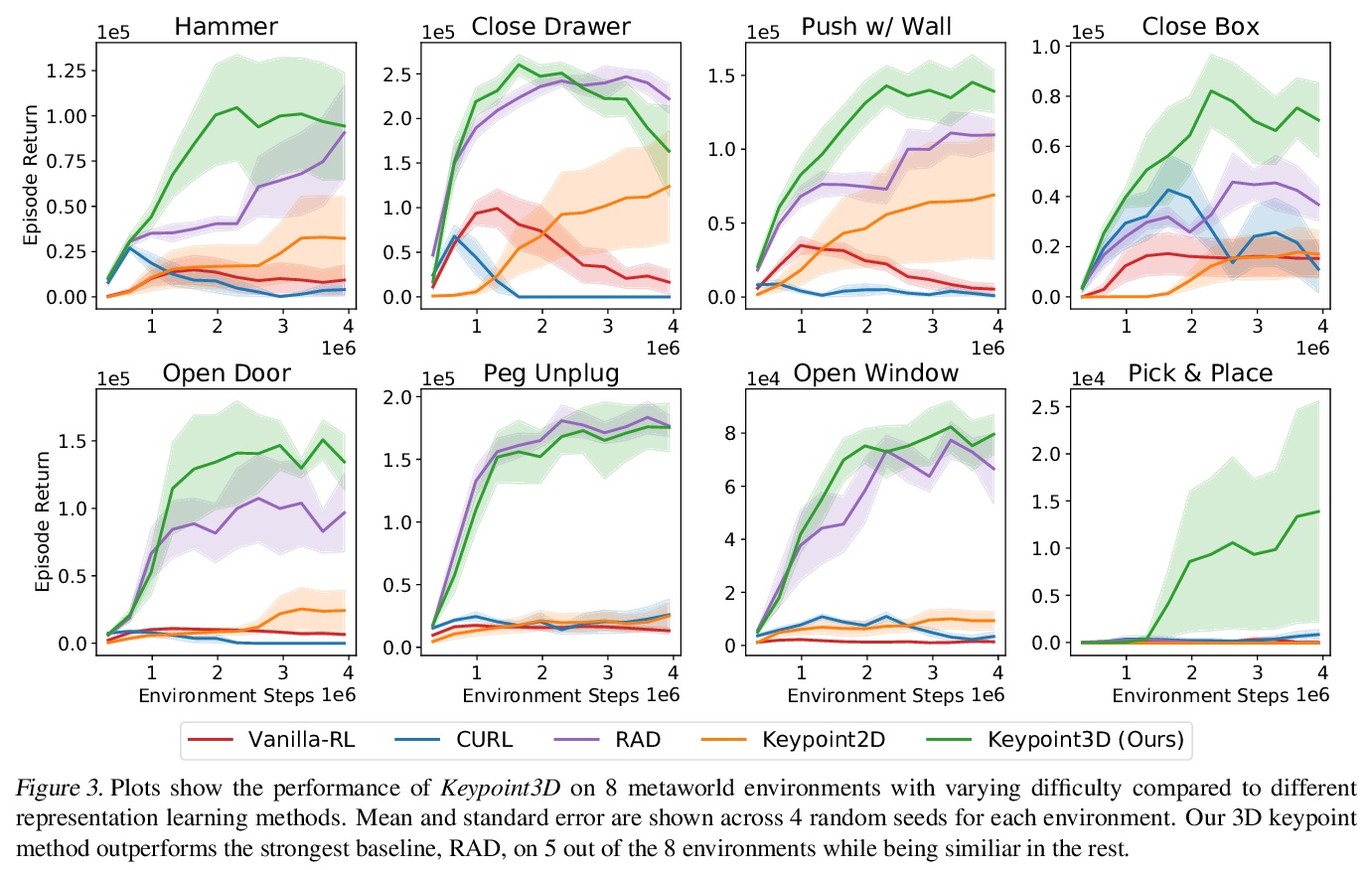
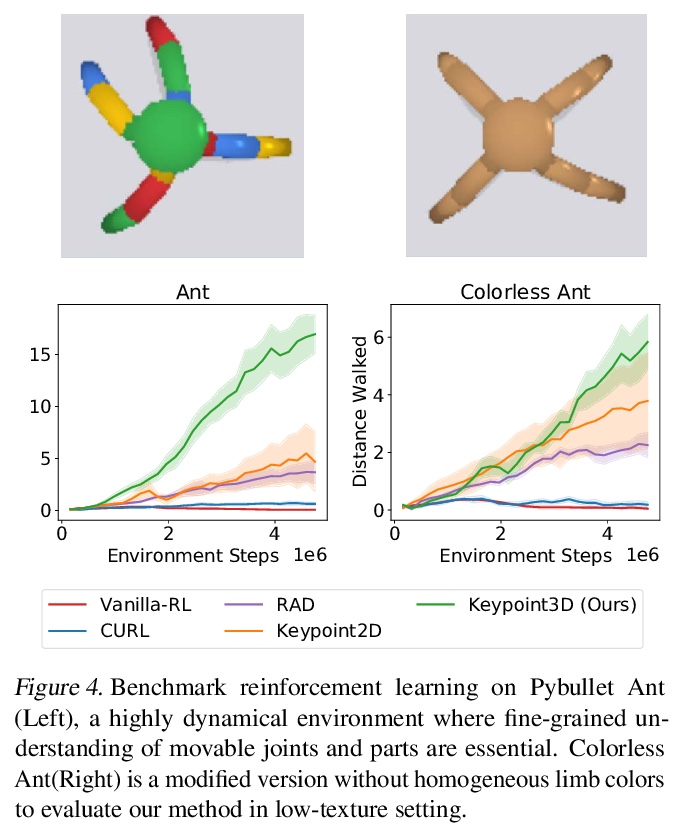
面向控制的视觉3D关键点无监督学习。从高维图像中学习传感运动控制策略,关键在于基础视觉表示的质量。之前的工作表明,结构化的潜空间,如视觉关键点,往往优于非结构化的机器人控制表示。然而,大多数这些表示,无论是结构化的还是非结构化的,都是在2D空间中学习的,尽管控制任务通常是在3D环境中进行的。本文提出一种框架,以端到端无监督方式直接从图像中学习3D几何结构。将无监督3D关键点学习与强化学习联合训练,在各种3D控制环境中实现了显著的样本效率改进。输入图像通过可微编码器嵌入为潜3D关键点,编码器被训练来优化多视图一致性损失和下游任务目标。这些发现的3D关键点倾向于以一致方式在时间和3D空间内有意义地捕捉机器人的关节和物体运动。所提出的方法在各种强化学习基准中的表现优于之前的先进方法。
Learning sensorimotor control policies from highdimensional images crucially relies on the quality of the underlying visual representations. Prior works show that structured latent space such as visual keypoints often outperforms unstructured representations for robotic control. However, most of these representations, whether structured or unstructured are learned in a 2D space even though the control tasks are usually performed in a 3D environment. In this work, we propose a framework to learn such a 3D geometric structure directly from images in an end-toend unsupervised manner. The input images are embedded into latent 3D keypoints via a differentiable encoder which is trained to optimize both a multi-view consistency loss and downstream task objective. These discovered 3D keypoints tend to meaningfully capture robot joints as well as object movements in a consistent manner across both time and 3D space. The proposed approach outperforms prior state-of-art methods across a variety of reinforcement learning benchmarks.
https://weibo.com/1402400261/KknPWp0Za

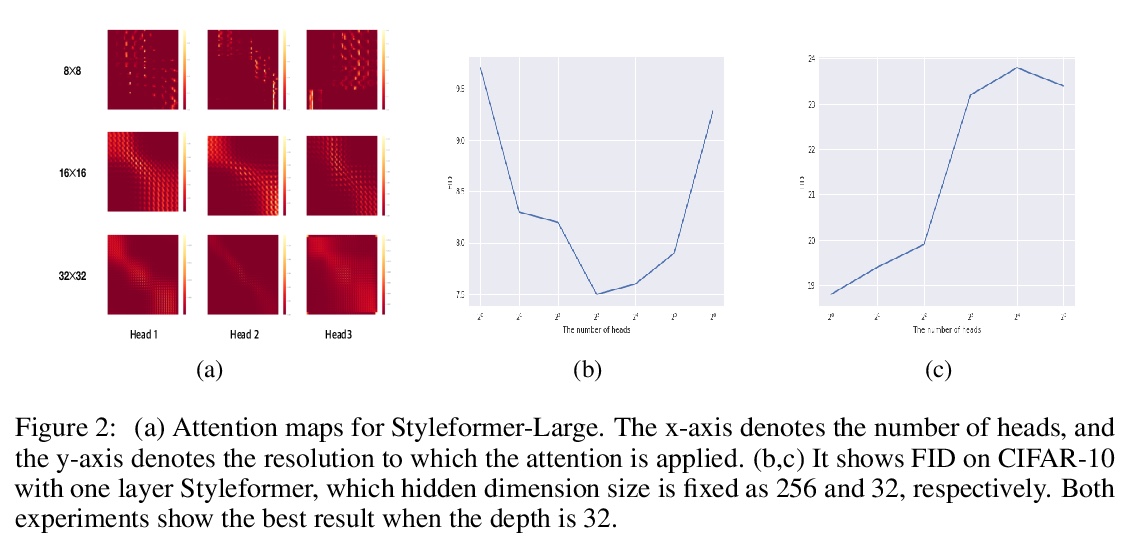
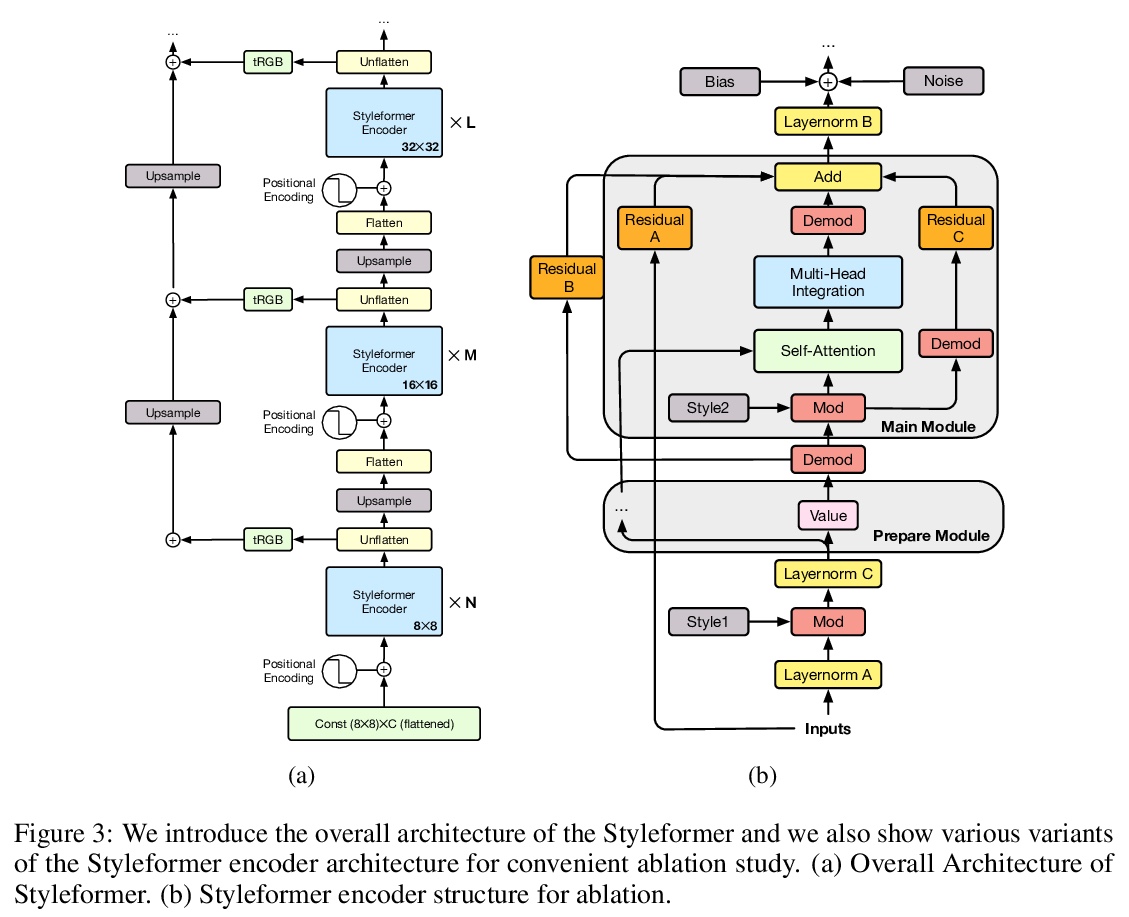
2、[CV] Styleformer: Transformer based Generative Adversarial Networks with Style Vector
J Park, Y Kim
[Seoul National University]
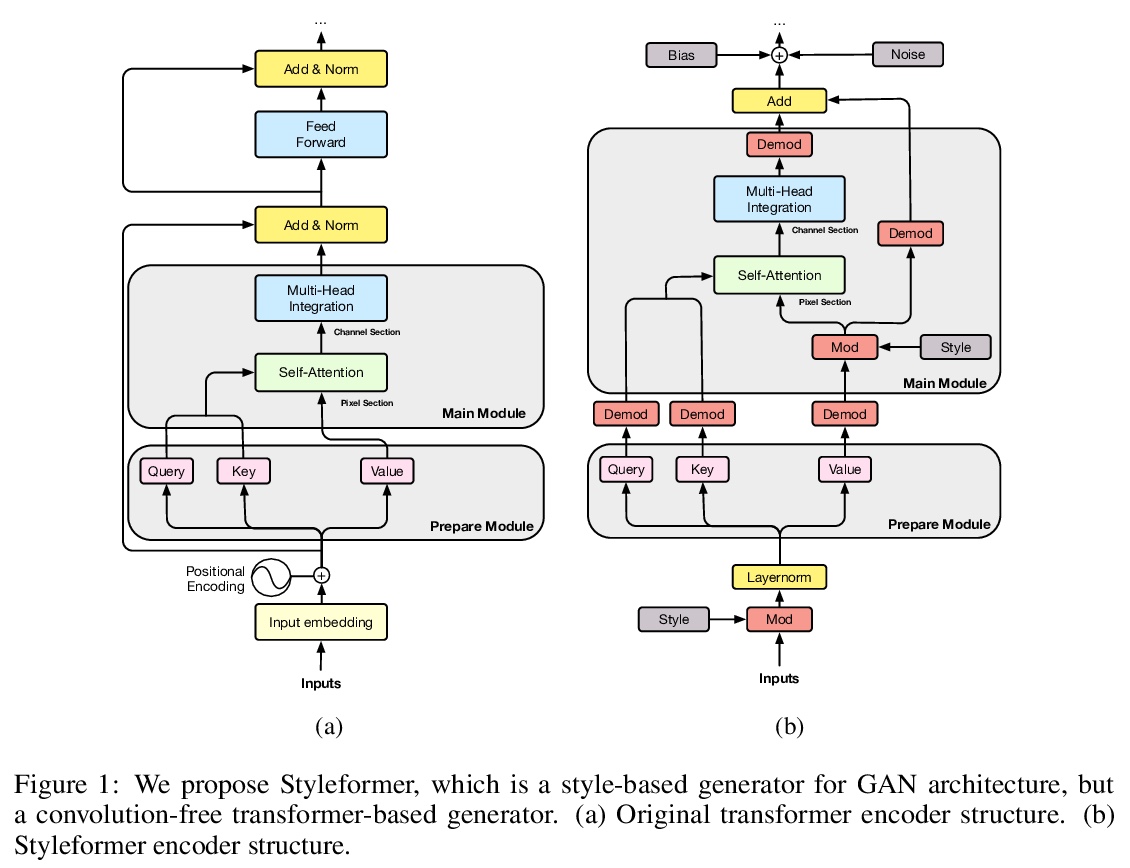
Styleformer: 基于Transformer的风格向量生成式对抗网络。提出Styleformer,一种基于风格的GAN架构非卷积Transformer生成器。解释了Transformer如何生成高质量图像,克服卷积操作难以捕捉图像全局特征的缺点。改变了StyleGAN2的解调方式,修改了现有的Transformer结构(如残差连接、层归一化),以创建一个具有非卷积结构的强大的基于风格的生成器。通过应用Linformer使Styleformer变得更轻,使Styleformer能够生成更高分辨率图像,并在速度和内存方面带来改进。用CIFAR-10这样的低分辨率图像数据集以及LSUN-church这样的高分辨率图像数据集进行实验。Styleformer在CIFAR-10这个基准数据集上达到了FID 2.82和IS 9.94,与目前最先进性能相当,超过了所有基于GAN的生成模型,包括在无条件设置下参数较少的StyleGAN2-ADA,在STL-10和CelebA上分别以FID 20.11、IS 10.16和FID 3.66达到了新的最先进水平。
We propose Styleformer, which is a style-based generator for GAN architecture, but a convolution-free transformer-based generator. In our paper, we explain how a transformer can generate high-quality images, overcoming the disadvantage that convolution operations are difficult to capture global features in an image. Furthermore, we change the demodulation of StyleGAN2 and modify the existing transformer structure (e.g., residual connection, layer normalization) to create a strong style-based generator with a convolution-free structure. We also make Styleformer lighter by applying Linformer, enabling Styleformer to generate higher resolution images and result in improvements in terms of speed and memory. We experiment with the low-resolution image dataset such as CIFAR-10, as well as the high-resolution image dataset like LSUN-church. Styleformer records FID 2.82 and IS 9.94 on CIFAR-10, a benchmark dataset, which is comparable performance to the current state-of-the-art and outperforms all GAN-based generative models, including StyleGAN2-ADA with fewer parameters on the unconditional setting. We also both achieve new state-of-the-art with FID 20.11, IS 10.16, and FID 3.66, respectively on STL-10 and CelebA.
https://weibo.com/1402400261/KknYT1hX9

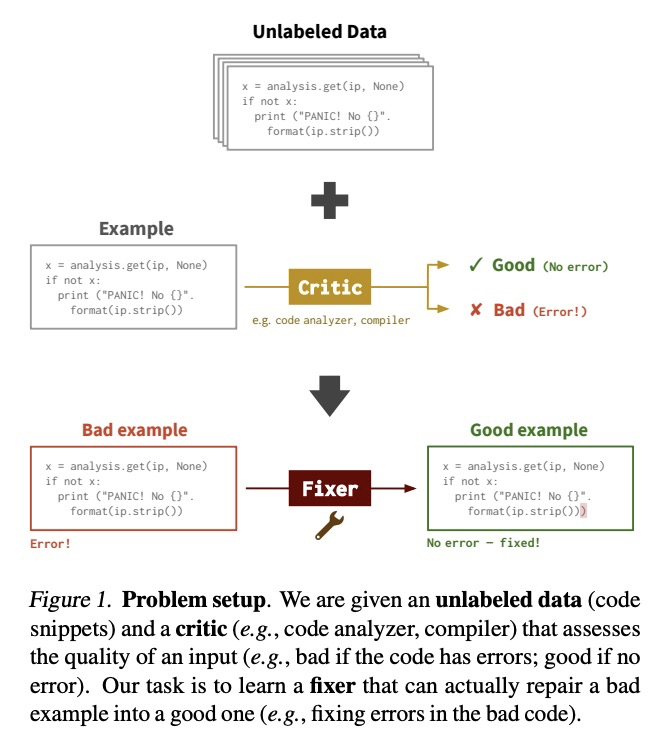
3、[LG] Break-It-Fix-It: Unsupervised Learning for Program Repair
M Yasunaga, P Liang
[Stanford University]
Break-It-Fix-It:无监督学习代码修复。考虑代码修复任务:给定一个评估输入质量的批评者(例如,编译器),目标是训练一个修复器,将坏样本(例如,有语法错误的代码)转换成好样本(例如,没有语法错误的代码)。现有工作是采用启发式方法(例如,删词)破坏好样本来创建(坏,好)样本对组成的训练数据。然而,在这种合成数据上训练的修复器,并不能很好地推断出坏样本的真实分布。为弥补这一差距,本文提出一种新的训练方法,即Break-It-Fix-It(BIFI),有两个关键思想:(i) 用批评者来检查修复器在真实的坏输入上的输出,并将好的(修复的)输出添加到训练数据中,(ii) 训练一个破坏器从好代码中生成现实的坏代码。基于这些想法,迭代更新破坏器和修复器,同时将它们结合起来使用,以产生更多的配对数据。在两个代码修复数据集上评估BIFI。GitHub-Python是本文提出的一个新数据集,目标是修复有AST解析错误的Python代码;DeepFix的目标是修复有编译器错误的C代码。BIFI超越了最先进的方法,在GitHubPython上获得了90.5%的修复精度(+28.5%),在DeepFix上获得了71.7%的修复精度(+5.6%)。值得注意的是,BIFI不需要任何标记的数据;我们希望它能成为各种修复任务的无监督学习的有力起点。
We consider repair tasks: given a critic (e.g., compiler) that assesses the quality of an input, the goal is to train a fixer that converts a bad example (e.g., code with syntax errors) into a good one (e.g., code with no syntax errors). Existing works create training data consisting of (bad, good) pairs by corrupting good examples using heuristics (e.g., dropping tokens). However, fixers trained on this synthetically-generated data do not extrapolate well to the real distribution of bad inputs. To bridge this gap, we propose a new training approach, Break-It-Fix-It (BIFI), which has two key ideas: (i) we use the critic to check a fixer’s output on real bad inputs and add good (fixed) outputs to the training data, and (ii) we train a breaker to generate realistic bad code from good code. Based on these ideas, we iteratively update the breaker and the fixer while using them in conjunction to generate more paired data. We evaluate BIFI on two code repair datasets: GitHub-Python, a new dataset we introduce where the goal is to repair Python code with AST parse errors; and DeepFix, where the goal is to repair C code with compiler errors. BIFI outperforms state-of-the-art methods, obtaining 90.5% repair accuracy on GitHubPython (+28.5%) and 71.7% on DeepFix (+5.6%). Notably, BIFI does not require any labeled data; we hope it will be a strong starting point for unsupervised learning of various repair tasks.
https://weibo.com/1402400261/Kko2h98Gb


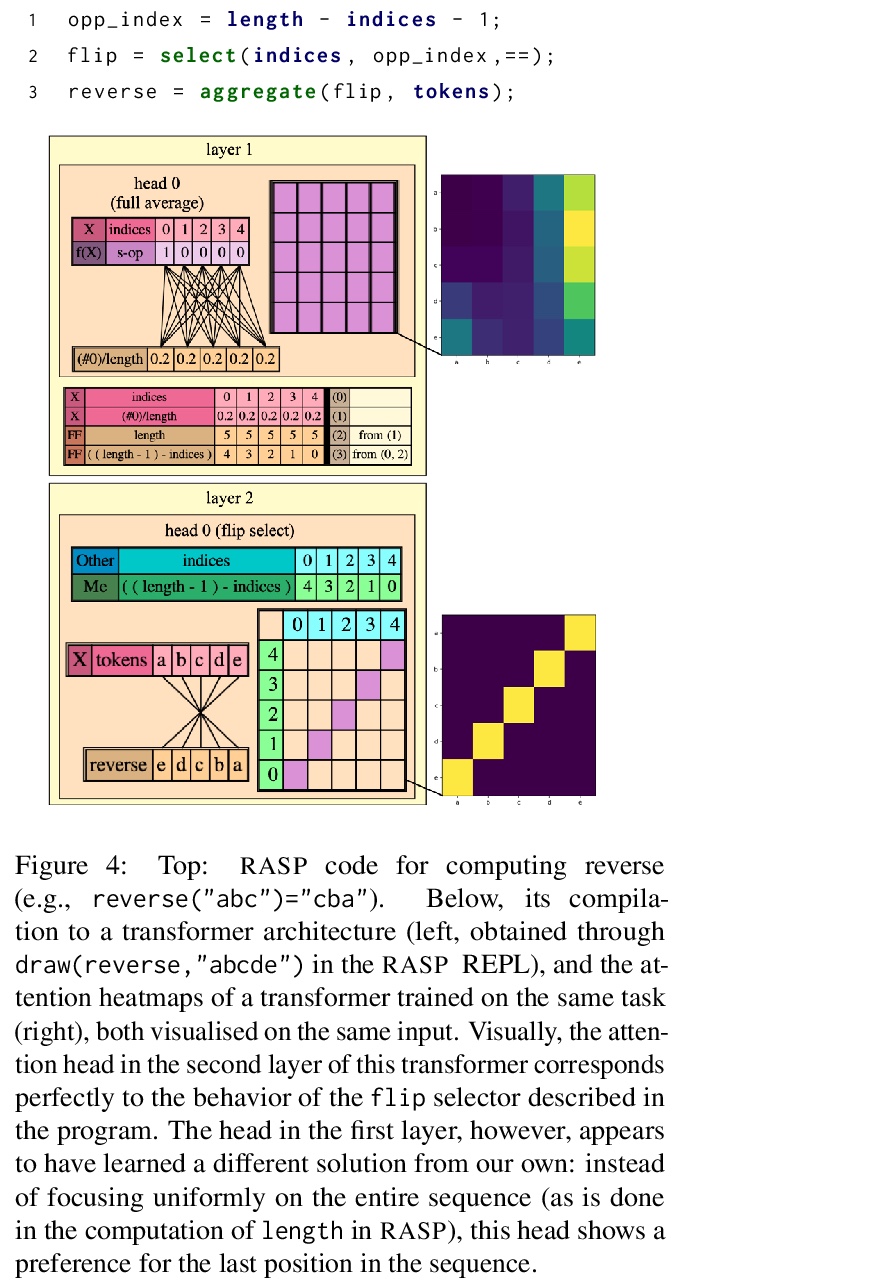
4、[LG] Thinking Like Transformers
G Weiss, Y Goldberg, E Yahav
[Technion & Bar Ilan University]
像Transformer一样思考。Transformer背后的计算模型是什么?递归神经网络与有限状态机有直接的相似之处,允许围绕架构变体或训练模型进行清晰的讨论和思考,而Transformer却没有这种熟悉的相似之处。本文旨在改变这种情况,以编程语言的形式提出一个Transformer编码器的计算模型。将Transformer编码器的基本组成部分——注意力和前馈计算——映射成简单基元,围绕这些基元形成了一种编程语言:受限访问序列处理语言(RASP)。RASP捕捉到了Transformer中存在的对信息流的独特约束。考虑到计算问题和它们在RASP中的实现,我们可以 “像Transformer一样思考”,同时抽象出神经网络的技术细节,以利于符号程序。展示了RASP如何用于编程解决可以想象由Transformer学习的任务,以及Transformer如何训练以模仿RASP的解决方案。为直方图、排序和Dyck语言提供了RASP程序。进一步用该模型将难度与所需的层数和注意力头数联系起来:分析一个RASP程序意味着在一个Transformer中编码一个任务所需的最大头数和层数。
What is the computational model behind a Transformer? Where recurrent neural networks have direct parallels in finite state machines, allowing clear discussion and thought around architecture variants or trained models, Transformers have no such familiar parallel. In this paper we aim to change that, proposing a computational model for the transformer-encoder in the form of a programming language. We map the basic components of a transformer-encoder—attention and feed-forward computation—into simple primitives, around which we form a programming language: the Restricted Access Sequence Processing Language (RASP). We show how RASP can be used to program solutions to tasks that could conceivably be learned by a Transformer, and how a Transformer can be trained to mimic a RASP solution. In particular, we provide RASP programs for histograms, sorting, and Dyck-languages. We further use our model to relate their difficulty in terms of the number of required layers and attention heads: analyzing a RASP program implies a maximum number of heads and layers necessary to encode a task in a transformer. Finally, we see how insights gained from our abstraction might be used to explain phenomena seen in recent works.
https://weibo.com/1402400261/Kko8hscb2



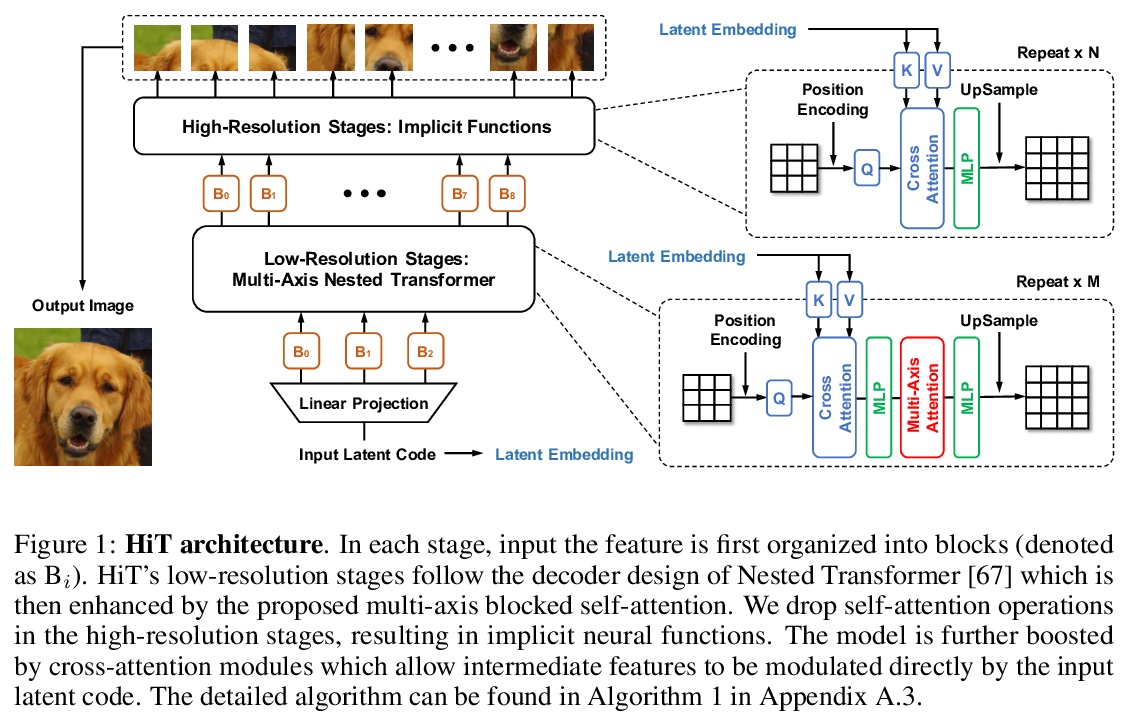
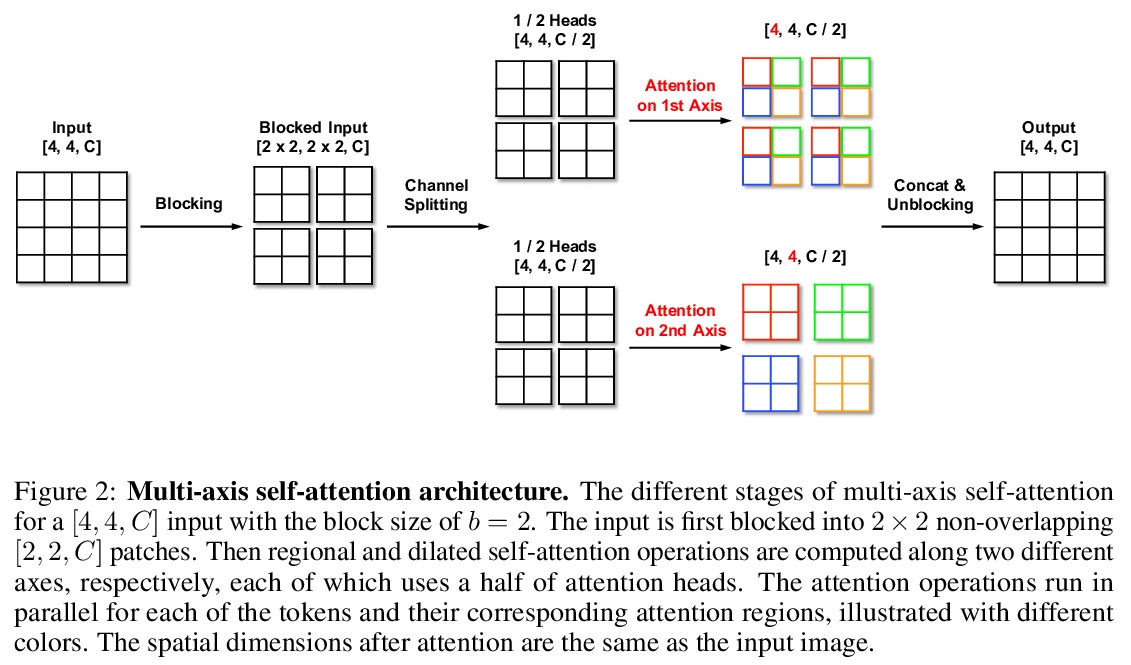
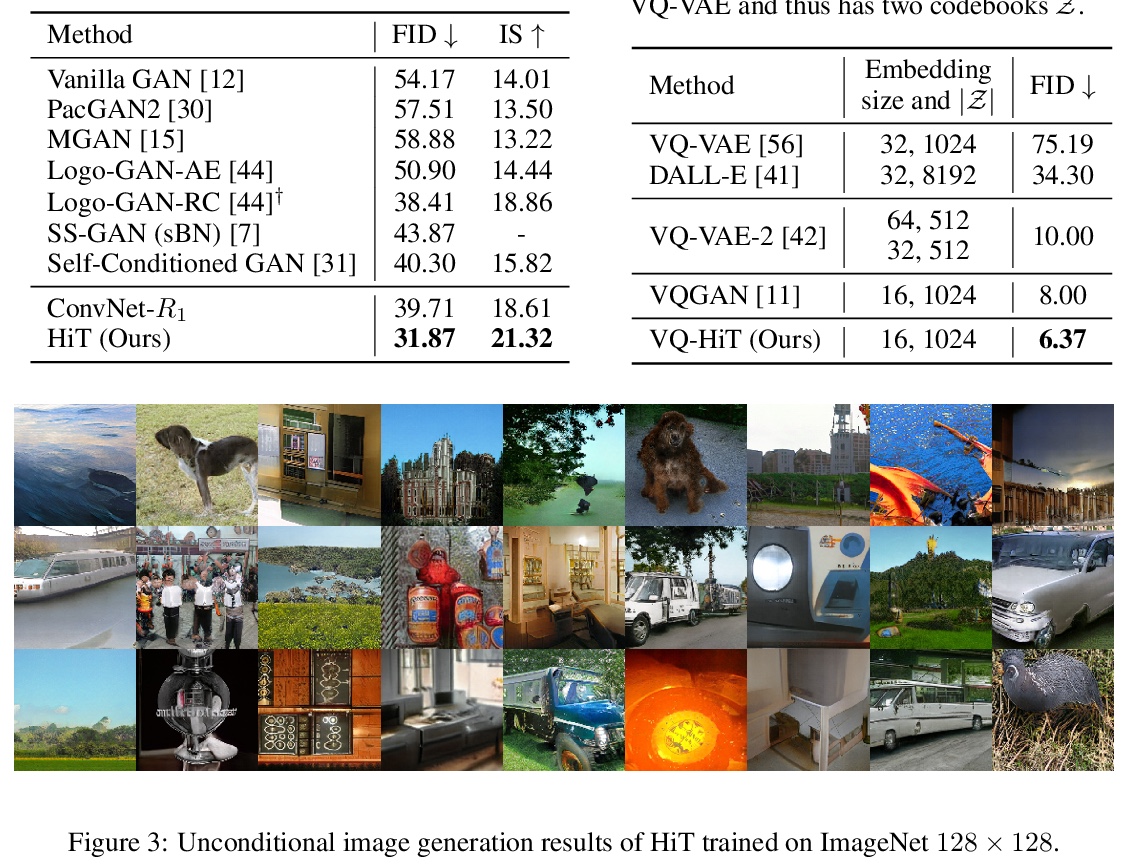
5、[CV] Improved Transformer for High-Resolution GANs
L Zhao, Z Zhang, T Chen, D N. Metaxas, H Zhang
[Rutgers University & Google Cloud AI & Google Research]
面向高分辨率GAN的改进型Transformer。以Transformer为代表的基于注意力的模型,可有效地模拟长程依赖,但受到自我注意力操作的二次复杂性的影响,使得它们很难用于基于生成对抗网络(GAN)的高分辨率图像生成。本文为Transformer引入了两个关键成分来解决这一挑战。首先,在生成过程的低分辨率阶段,标准的全局自我注意力被提出的多轴阻断自我注意力所取代,允许有效地混合局部和全局注意力。第二,在高分辨率阶段,放弃了自我注意力,只保留多层感知器,让人联想到隐性神经功能。为进一步提高性能,引入一个额外的基于交叉注意力的自调节成分。由此产生的模型HiT,其计算复杂度与图像大小呈线性关系,可直接扩展到合成高清图像。实验表明,所提出的HiT在无条件的ImageNet 128 × 128和FFHQ 256 × 256上分别达到了最先进的FID分数31.87和2.95,并具有合理的吞吐量。
Attention-based models, exemplified by the Transformer, can effectively model long range dependency, but suffer from the quadratic complexity of self-attention operation, making them difficult to be adopted for high-resolution image generation based on Generative Adversarial Networks (GANs). In this paper, we introduce two key ingredients to Transformer to address this challenge. First, in low-resolution stages of the generative process, standard global self-attention is replaced with the proposed multi-axis blocked self-attention which allows efficient mixing of local and global attention. Second, in high-resolution stages, we drop self-attention while only keeping multi-layer perceptrons reminiscent of the implicit neural function. To further improve the performance, we introduce an additional selfmodulation component based on cross-attention. The resulting model, denoted as HiT, has a linear computational complexity with respect to the image size and thus directly scales to synthesizing high definition images. We show in the experiments that the proposed HiT achieves state-of-the-art FID scores of 31.87 and 2.95 on unconditional ImageNet 128 × 128 and FFHQ 256 × 256, respectively, with a reasonable throughput. We believe the proposed HiT is an important milestone for generators in GANs which are completely free of convolutions.
https://weibo.com/1402400261/KkobEn0Bc

另外几篇值得关注的论文:
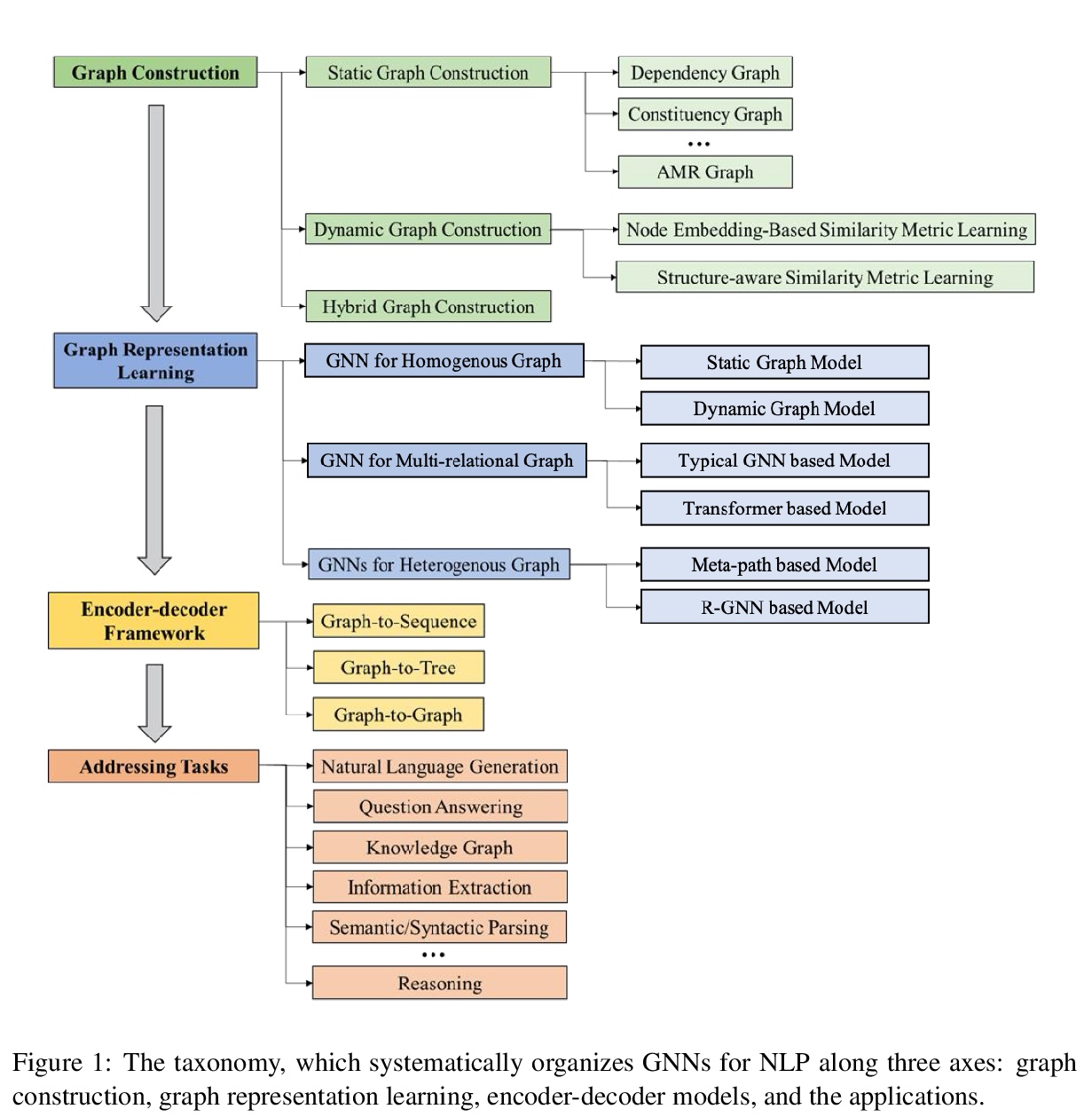
[CL] Graph Neural Networks for Natural Language Processing: A Survey
图神经网络自然语言处理综述
L Wu, Y Chen, K Shen, X Guo, H Gao, S Li, J Pei, B Long
[JD.COM Silicon Valley Research Center & Rensselaer Polytechnic Institute & Zhejiang University]
https://weibo.com/1402400261/KknKO77UV
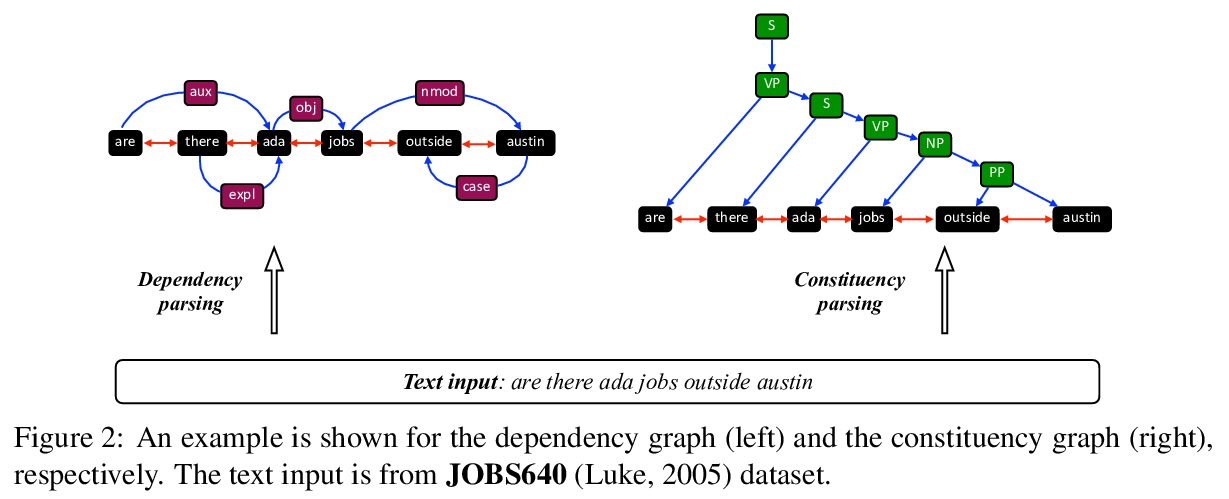
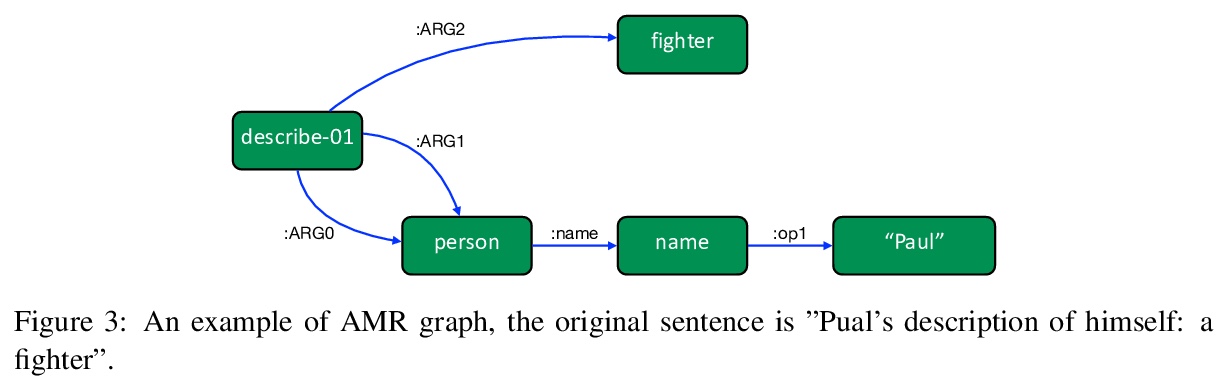
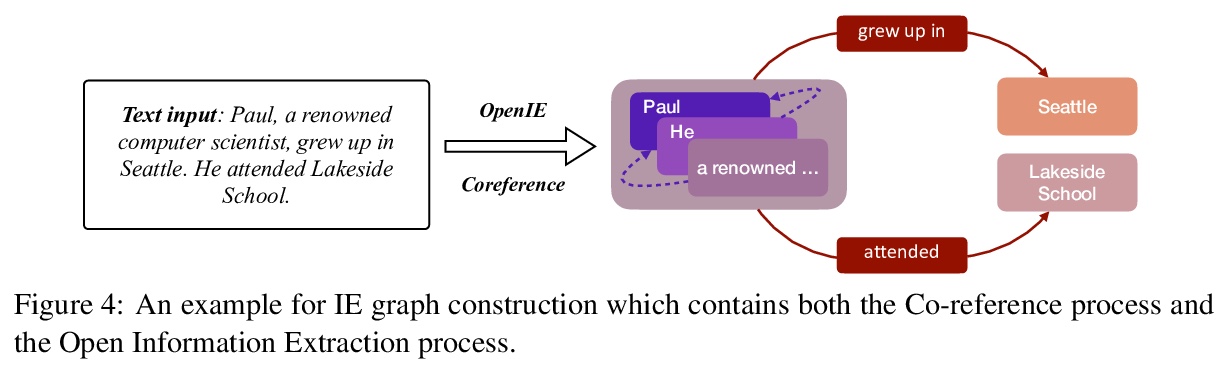
[LG] Pre-Trained Models: Past, Present and Future
预训练模型综述:过去、现在和未来
H Xu, Z Zhengyan, D Ning, G Yuxian, L Xiao, H Yuqi, Q Jiezhong, Z Liang, H Wentao, H Minlie, J Qin, L Yanyan, L Yang, L Zhiyuan, L Zhiwu, Q Xipeng, S Ruihua, T Jie, W Ji-Rong, Y Jinhui, Z W Xin, Z Jun
[Tsinghua University & Renmin University of China & Fudan University & OneFlow Inc]
https://weibo.com/1402400261/KknNe0tE9
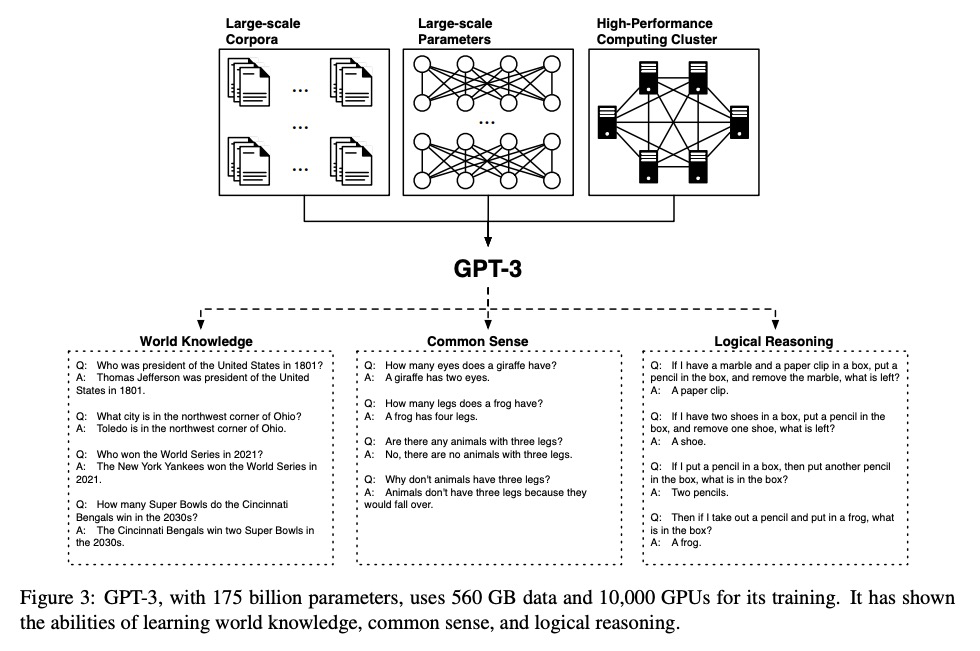
[LG] Scalars are universal: Gauge-equivariant machine learning, structured like classical physics
经典物理学与规范等变机器学习
S Villar, D W Hogg, K Storey-Fisher, W Yao, B Blum-Smith
[Johns Hopkins University & Flatiron Institute & New York University]
https://weibo.com/1402400261/KknTHyE7b
[CL] An Empirical Survey of Data Augmentation for Limited Data Learning in NLP
自然语言处理面向有限数据学习的数据增扩的实证性综述
J Chen, D Tam, C Raffel, M Bansal, D Yang
[Georgia Institute of Technology & UNC Chapel Hill]
https://weibo.com/1402400261/Kko6b9C89

若有收获,就点个赞吧
0 人点赞
