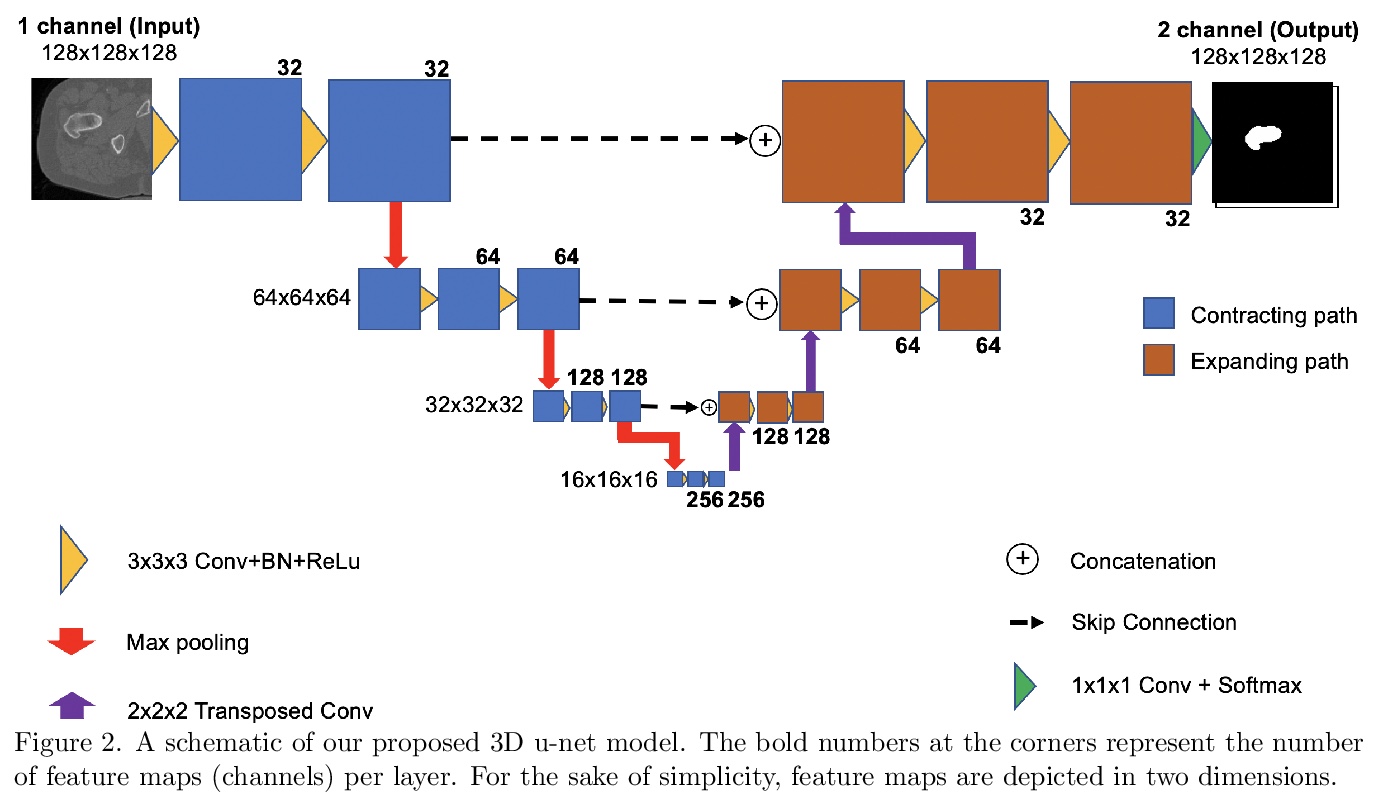
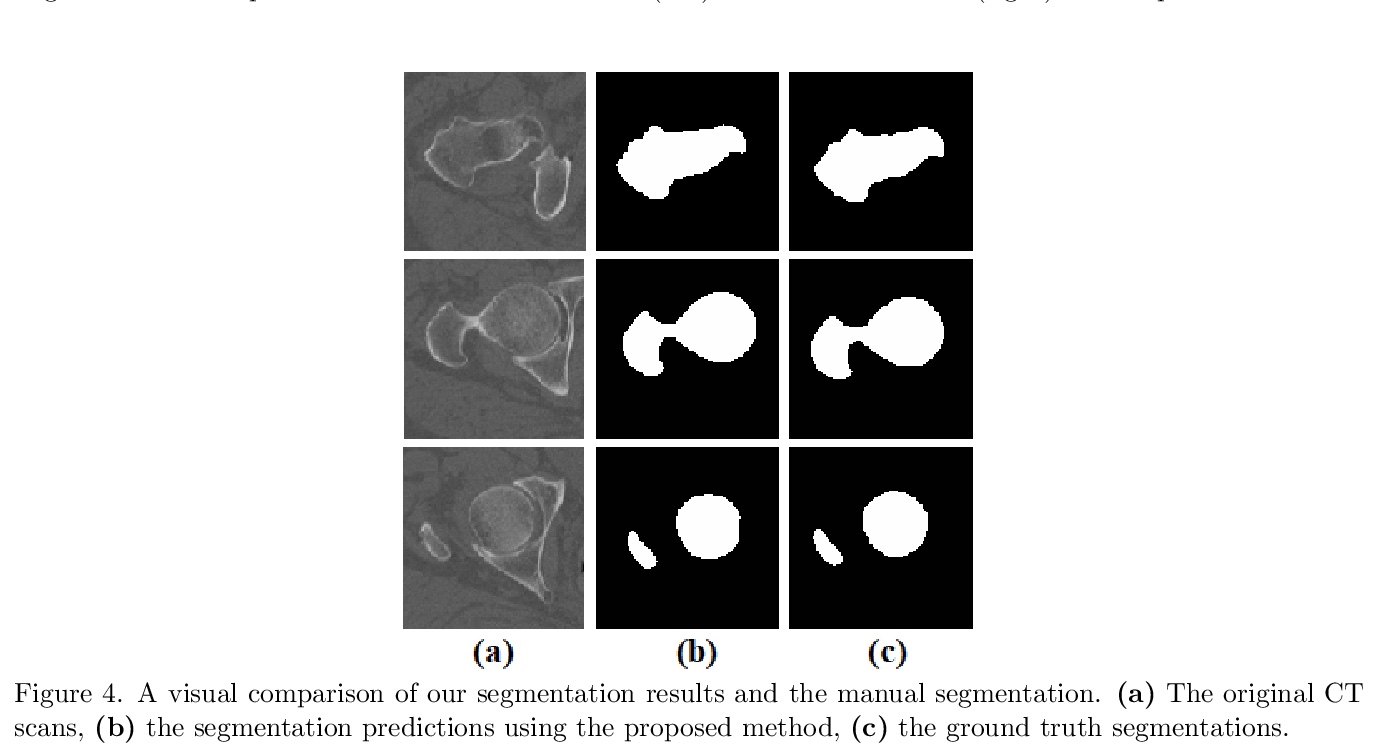
- 1、[CV] Automated femur segmentation from computed tomography images using a deep neural network
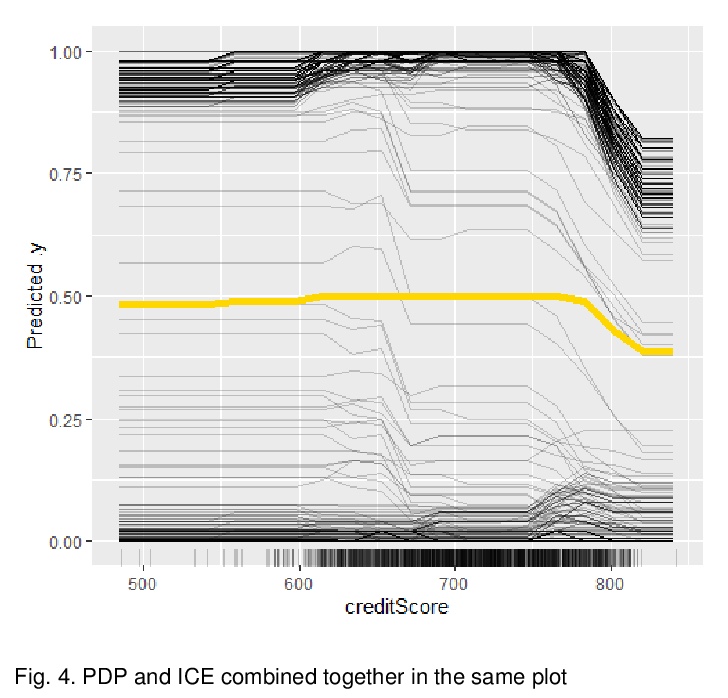
- 2、[AI] Explainable Artificial Intelligence Approaches: A Survey
- 3、[CL] Distilling Large Language Models into Tiny and Effective Students using pQRNN
- 4、[LG] The MineRL 2020 Competition on Sample Efficient Reinforcement Learning using Human Priors
- 5、[LG] SyReNN: A Tool for Analyzing Deep Neural Networks
- [AI] Logic Tensor Networks
- [CV] Revisiting Contrastive Learning for Few-Shot Classification
- [CV] Generative Multi-Label Zero-Shot Learning
- [CL] Transformer Based Deliberation for Two-Pass Speech Recognition
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Automated femur segmentation from computed tomography images using a deep neural network
P.A. Bjornsson, B. Helgason, H. Palsson, S. Sigurdsson, V. Gudnason, L.M. Ellingsen
[The University of Iceland & The Icelandic Heart Association]
基于深度网络的CT扫描图像股骨分割。为识别易发生髋关节骨折的个体,提出一种新型股骨近端分割方法,用深度卷积神经网络从CT扫描中产生准确、自动、鲁棒和快速的股骨分割,可产生亚毫米级精度的分割结果。网络架构基于u-net,包括一个下采样路径,以提取输入图块的越来越复杂的特征,以及一个上采样路径,以将获得的低分辨率图像转换为高分辨率图像。使用跳接以恢复下采样过程中丢失的关键空间信息。模型在30个人工分割的CT图像上进行训练,在200个人工分割图像上进行评价,平均Dice相似度系数(DSC)和95百分位豪斯多夫距离(HD95)分别为0.990和0.981毫米。
Osteoporosis is a common bone disease that occurs when the creation of new bone does not keep up with the loss of old bone, resulting in increased fracture risk. Adults over the age of 50 are especially at risk and see their quality of life diminished because of limited mobility, which can lead to isolation and depression. We are developing a robust screening method capable of identifying individuals predisposed to hip fracture to address this clinical challenge. The method uses finite element analysis and relies on segmented computed tomography (CT) images of the hip. Presently, the segmentation of the proximal femur requires manual input, which is a tedious task, prone to human error, and severely limits the practicality of the method in a clinical context. Here we present a novel approach for segmenting the proximal femur that uses a deep convolutional neural network to produce accurate, automated, robust, and fast segmentations of the femur from CT scans. The network architecture is based on the renowned u-net, which consists of a downsampling path to extract increasingly complex features of the input patch and an upsampling path to convert the acquired low resolution image into a high resolution one. Skipped connections allow us to recover critical spatial information lost during downsampling. The model was trained on 30 manually segmented CT images and was evaluated on 200 ground truth manual segmentations. Our method delivers a mean Dice similarity coefficient (DSC) and 95th percentile Hausdorff distance (HD95) of 0.990 and 0.981 mm, respectively.
https://weibo.com/1402400261/JFOBKrsbT
2、[AI] Explainable Artificial Intelligence Approaches: A Survey
S R Islam, W Eberle, S K Ghafoor, M Ahmed
[University of Hartford & Tennessee Tech University & Edith Cowan University]
可解释的人工智能方法综述。以信用违约预测的研究/任务案例来展示流行的可解释人工智能方法,并解释其工作机制,从多角度(全局与局部、事后与事前、固有与模拟/近似可解释性)比较每种方法的优点、缺点、竞争优势及相关挑战,提供量化可解释性的有意义的见解,以可解释的人工智能为媒介,推荐一条通往负责任或以人为本的人工智能的道路。
The lack of explainability of a decision from an Artificial Intelligence (AI) based “black box” system/model, despite its superiority in many real-world applications, is a key stumbling block for adopting AI in many high stakes applications of different domain or industry. While many popular Explainable Artificial Intelligence (XAI) methods or approaches are available to facilitate a human-friendly explanation of the decision, each has its own merits and demerits, with a plethora of open challenges. We demonstrate popular XAI methods with a mutual case study/task (i.e., credit default prediction), analyze for competitive advantages from multiple perspectives (e.g., local, global), provide meaningful insight on quantifying explainability, and recommend paths towards responsible or human-centered AI using XAI as a medium. Practitioners can use this work as a catalog to understand, compare, and correlate competitive advantages of popular XAI methods. In addition, this survey elicits future research directions towards responsible or human-centric AI systems, which is crucial to adopt AI in high stakes applications.
https://weibo.com/1402400261/JFOI4whrV

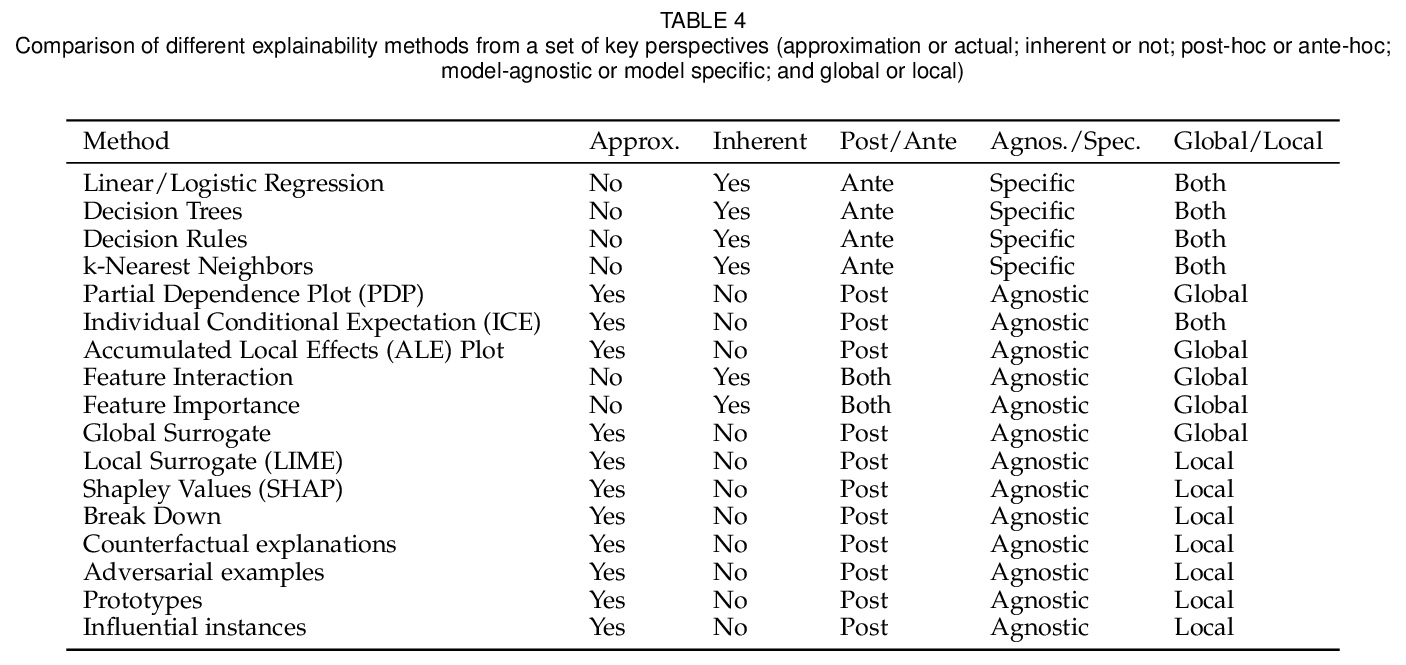
3、[CL] Distilling Large Language Models into Tiny and Effective Students using pQRNN
P Kaliamoorthi, A Siddhant, E Li, M Johnson
[Google]
用pQRNN将大型语言模型蒸馏成微小有效的学生模型。提出了pQRNN,一种基于投影的无嵌入神经网络编码器,对于自然语言处理任务来说,它是微小而有效的。在不进行预训练的情况下,pQRNNs体积小了140倍,但表现明显优于具有预训练嵌入的LSTM模型。在参数数量相同的情况下,表现优于transformer基线,展示了其参数效率。pQRNNs是有效的学生架构,可用于提炼大型预训练语言模型。提出了一种简单有效的数据增强策略,进一步提高了质量,在两个语义分析数据集的实验表明,pQRNN学生模型能够达到教师模型性能的95%以上,同时比教师模型小350倍。
Large pre-trained multilingual models like mBERT, XLM-R achieve state of the art results on language understanding tasks. However, they are not well suited for latency critical applications on both servers and edge devices. It’s important to reduce the memory and compute resources required by these models. To this end, we propose pQRNN, a projection-based embedding-free neural encoder that is tiny and effective for natural language processing tasks. Without pre-training, pQRNNs significantly outperform LSTM models with pre-trained embeddings despite being 140x smaller. With the same number of parameters, they outperform transformer baselines thereby showcasing their parameter efficiency. Additionally, we show that pQRNNs are effective student architectures for distilling large pre-trained language models. We perform careful ablations which study the effect of pQRNN parameters, data augmentation, and distillation settings. On MTOP, a challenging multilingual semantic parsing dataset, pQRNN students achieve 95.9\% of the performance of an mBERT teacher while being 350x smaller. On mATIS, a popular parsing task, pQRNN students on average are able to get to 97.1\% of the teacher while again being 350x smaller. Our strong results suggest that our approach is great for latency-sensitive applications while being able to leverage large mBERT-like models.
https://weibo.com/1402400261/JFOLZ9uD5
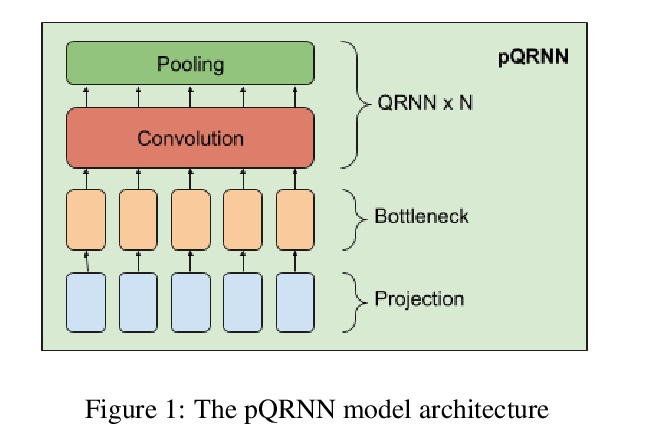

4、[LG] The MineRL 2020 Competition on Sample Efficient Reinforcement Learning using Human Priors
W H. Guss, M Y Castro, S Devlin, B Houghton, N S Kuno, C Loomis, S Milani, S Mohanty, K Nakata, R Salakhutdinov, J Schulman, S Shiroshita, N Topin, A Ummadisingu, O Vinyals
[CMU & Preferred Networks & Microsoft Research]
NeurIPS 2020 MineRL竞赛:基于人类先验的样本高效强化学习竞赛。提出第二届MineRL竞赛,主要目标是促进算法发展,以有效利用人工演示来大幅减少解决复杂、分层和稀疏环境问题所需的样本数量。参赛者在有限的环境样本复杂度预算下,开发能够解决Minecraft中MineRL ObtainDiamond任务的系统,这是一个需要长程规划、分层控制和高效探索方法的序列决策环境。比赛分两轮,参赛者将获得不同游戏纹理和着色器的数据集和环境的多个配对版本。在每一轮比赛结束时,参赛者将其学习算法的容器化版本提交到AIcrowd平台,在该平台上,他们将在一个预先指定的硬件平台上,从头开始对一个不变的数据集和环境对进行总共4天的训练。
Although deep reinforcement learning has led to breakthroughs in many difficult domains, these successes have required an ever-increasing number of samples, affording only a shrinking segment of the AI community access to their development. Resolution of these limitations requires new, sample-efficient methods. To facilitate research in this direction, we propose this second iteration of the MineRL Competition. The primary goal of the competition is to foster the development of algorithms which can efficiently leverage human demonstrations to drastically reduce the number of samples needed to solve complex, hierarchical, and sparse environments. To that end, participants compete under a limited environment sample-complexity budget to develop systems which solve the MineRL ObtainDiamond task in Minecraft, a sequential decision making environment requiring long-term planning, hierarchical control, and efficient exploration methods. The competition is structured into two rounds in which competitors are provided several paired versions of the dataset and environment with different game textures and shaders. At the end of each round, competitors submit containerized versions of their learning algorithms to the AIcrowd platform where they are trained from scratch on a hold-out dataset-environment pair for a total of 4-days on a pre-specified hardware platform. In this follow-up iteration to the NeurIPS 2019 MineRL Competition, we implement new features to expand the scale and reach of the competition. In response to the feedback of the previous participants, we introduce a second minor track focusing on solutions without access to environment interactions of any kind except during test-time. Further we aim to prompt domain agnostic submissions by implementing several novel competition mechanics including action-space randomization and desemantization of observations and actions.
https://weibo.com/1402400261/JFOPMDHqe



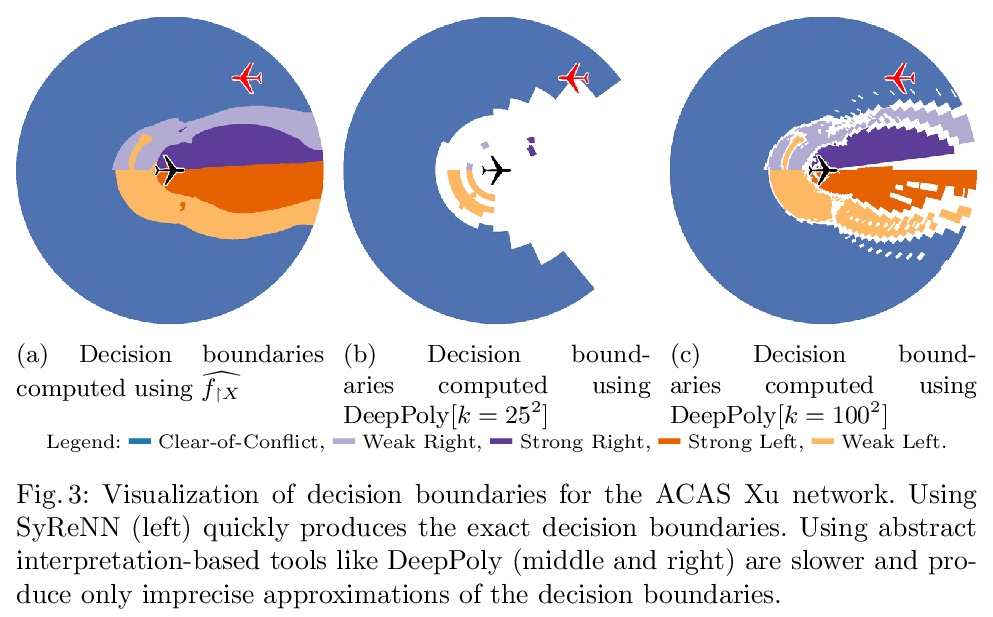
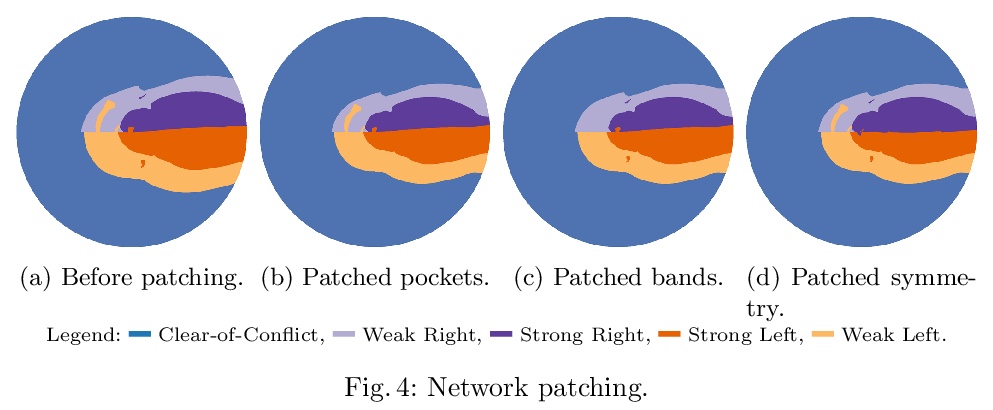
5、[LG] SyReNN: A Tool for Analyzing Deep Neural Networks
M Sotoudeh, A V. Thakur
[University of California, Davis]
SyReNN: 深度神经网络分析工具。介绍了用于理解和分析DNN的工具SyReNN。给定一个分段线性网络和输入子空间的低维多面子空间,SyReNN计算一个符号表示法,将DNN行为分解成有限多个线性函数。展示了如何高效计算这种表示,并介绍了相应工具设计。SyReNN可具体应用于三个方面:计算精确IG,可视化DNN行为,以及修补(修复)DNN。SyReNN探索了DNN分析工具设计空间中的一个独特点。特别是,SyReNN没有用分析的精度来换取效率,而是专注于分析DNN在领域的低维子空间上的行为,可同时提供效率和精度。
https://weibo.com/1402400261/JFOWkoFrM
另外几篇值得关注的论文:
[AI] Logic Tensor Networks
逻辑张量网络
S Badreddine, A d Garcez, L Serafini, M Spranger
[Sony CSL & City University of London & Fondazione Bruno Kessler]
https://weibo.com/1402400261/JFP2ThaoW
[CV] Revisiting Contrastive Learning for Few-Shot Classification
CIDS:有监督对比实例判别少样本分类
O Majumder, A Ravichandran, S Maji, M Polito, R Bhotika, S Soatto
[AWS & UMass Amherst]
https://weibo.com/1402400261/JFP4HiRqY

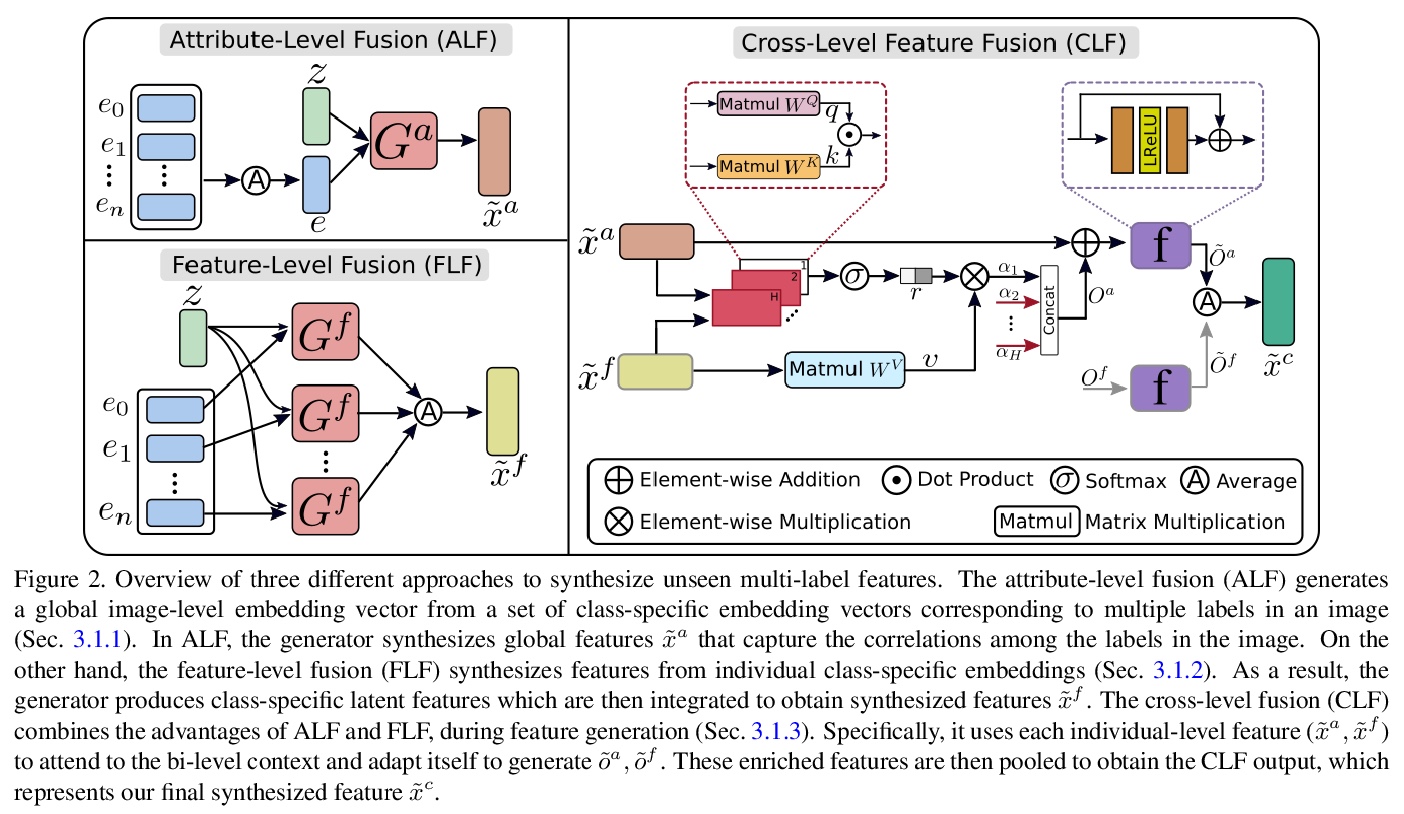
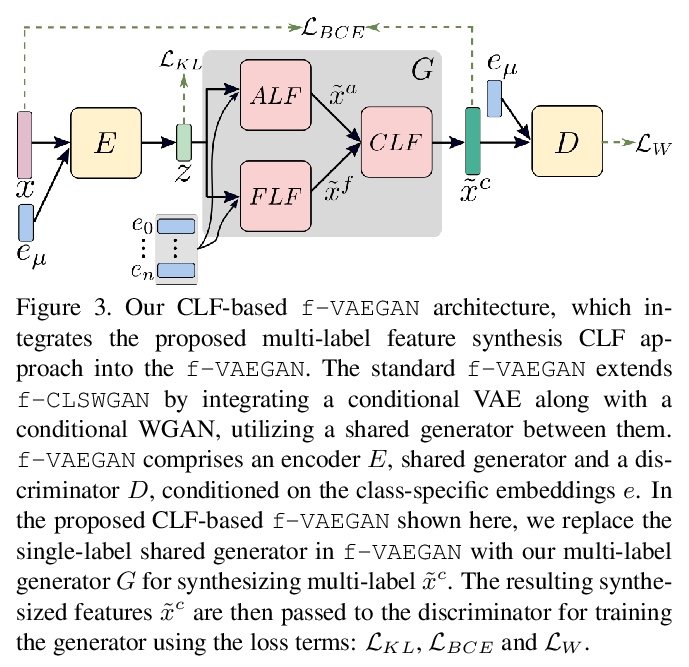
[CV] Generative Multi-Label Zero-Shot Learning
生成式多标签零样本学习
A Gupta, S Narayan, S Khan, F S Khan, L Shao, J v d Weijer
[Inception Institute of Artificial Intelligence & Mohamed Bin Zayed University of AI & Universitat Autonoma de Barcelona]
https://weibo.com/1402400261/JFP6xkeae
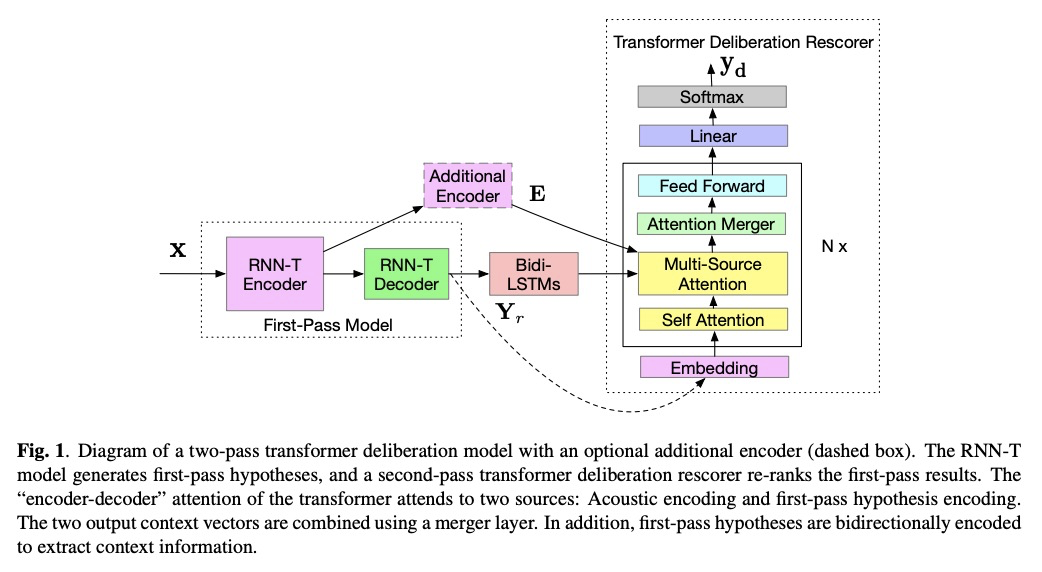
[CL] Transformer Based Deliberation for Two-Pass Speech Recognition
基于Transformer的双通语音识别
K Hu, R Pang, T N. Sainath, T Strohman
[Google]
https://weibo.com/1402400261/JFP7C8iDH

若有收获,就点个赞吧
0 人点赞
