- 1、[CV] Bottleneck Transformers for Visual Recognition
- 2、[LG] Identification of brain states, transitions, and communities using functional MRI
- 3、[CV] Automatic Comic Generation with Stylistic Multi-page Layouts and Emotion-driven Text Balloon Generation
- 4、[CL] VisualMRC: Machine Reading Comprehension on Document Images
- 5、[CL] Muppet: Massive Multi-task Representations with Pre-Finetuning
- [CL] Mining Large-Scale Low-Resource Pronunciation Data From Wikipedia
- [RO] Autonomous Off-road Navigation over Extreme Terrains with Perceptually-challenging Conditions
- [LG] LDLE: Low Distortion Local Eigenmaps
- [LG] Text2Gestures: A Transformer-Based Network for Generating Emotive Body Gestures for Virtual Agents
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Bottleneck Transformers for Visual Recognition
A Srinivas, T Lin, N Parmar, J Shlens, P Abbeel, A Vaswani
[UC Berkeley & Google Research]
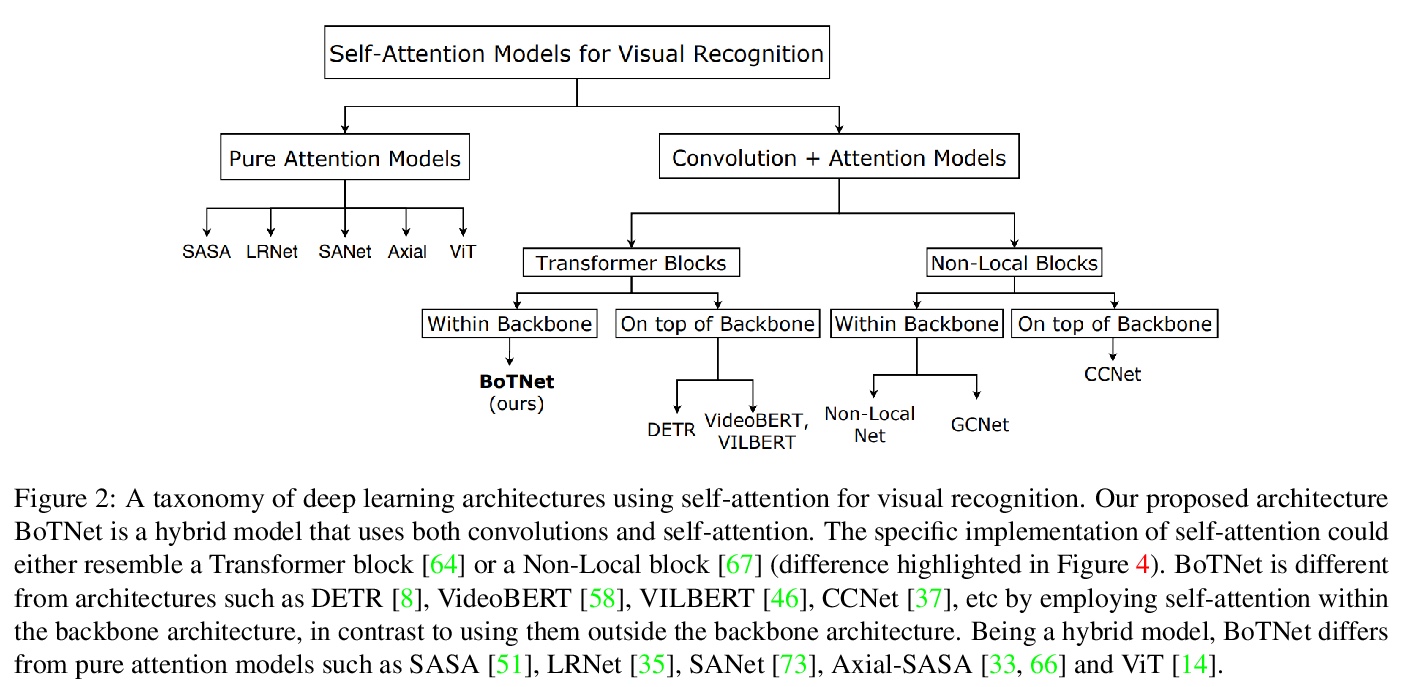
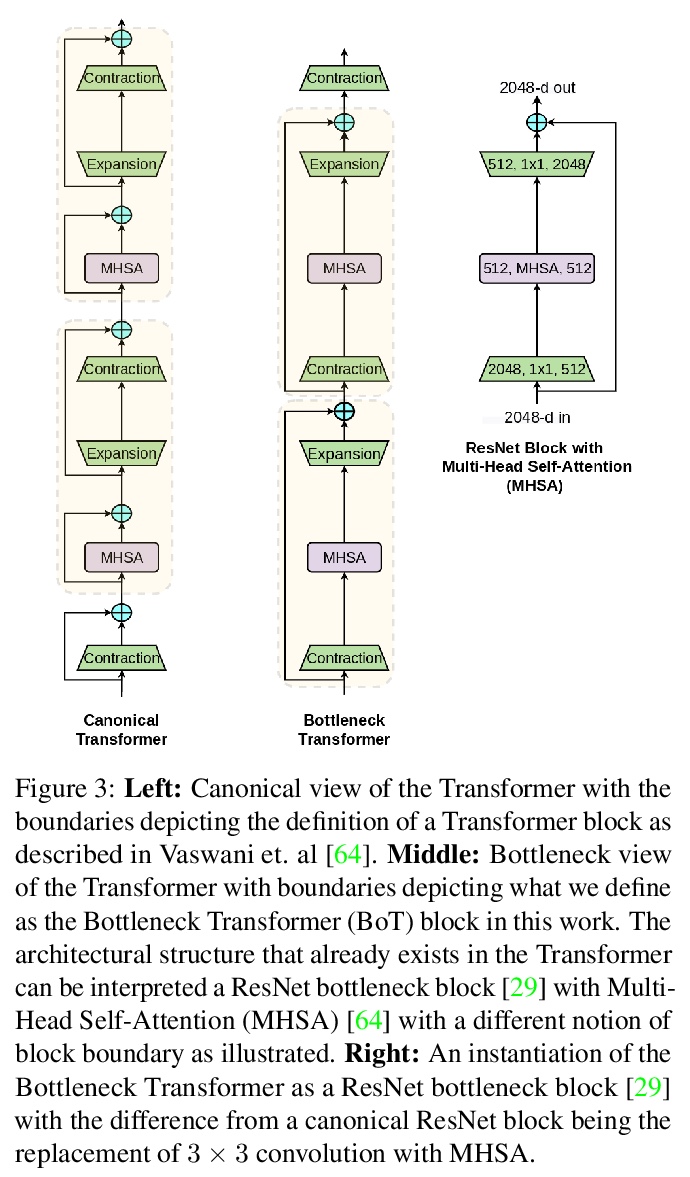
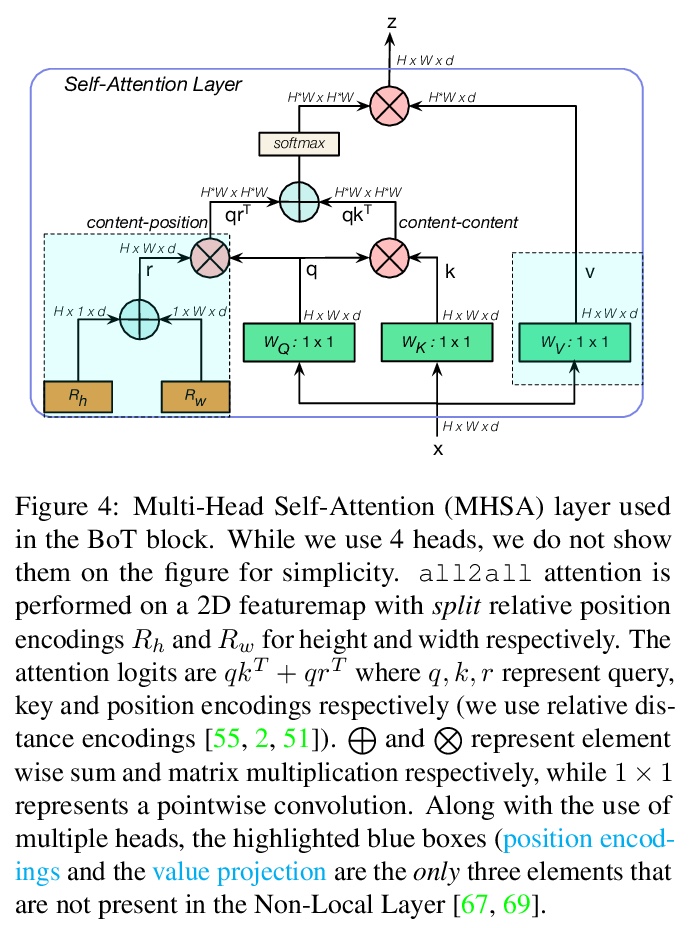
瓶颈Transformers视觉识别。提出BoTNet,结合自注意力的概念简单但功能强大的骨干架构,可用于多种计算机视觉任务,包括图像分类、目标检测和实例分割。虽然卷积运算可有效捕捉局部信息,但目标检测、实例分割、关键点检测等视觉任务,需要对长程依赖进行建模。通过只在ResNet最后三个瓶颈块中用全局自注意力替换空间卷积,不做其他改变,在实例分割和目标检测上显著改善了基线,同时降低了参数,并且延迟开销最小。通过BoTNet的设计,指出了如何将自带注意力的ResNet瓶颈块看成Transformer块。BoTNet在使用Mask R-CNN框架的COCO实例分割基准上实现了44.4%的Mask AP和49.7%的Box AP;超过了之前公布的ResNeSt在COCO验证集上评价的最佳单模型和单规模结果。提出了一个简单的面向图像分类的BoTNet修改版设计,使模型在ImageNet基准上达到了84.7%的top-1精度,同时在计算时间上比TPU-v3硬件上流行的EfficientNet模型快2.33倍。
We present BoTNet, a conceptually simple yet powerful backbone architecture that incorporates self-attention for multiple computer vision tasks including image classification, object detection and instance segmentation. By just replacing the spatial convolutions with global self-attention in the final three bottleneck blocks of a ResNet and no other changes, our approach improves upon the baselines significantly on instance segmentation and object detection while also reducing the parameters, with minimal overhead in latency. Through the design of BoTNet, we also point out how ResNet bottleneck blocks with self-attention can be viewed as Transformer blocks. Without any bells and whistles, BoTNet achieves 44.4% Mask AP and 49.7% Box AP on the COCO Instance Segmentation benchmark using the Mask R-CNN framework; surpassing the previous best published single model and single scale results of ResNeSt evaluated on the COCO validation set. Finally, we present a simple adaptation of the BoTNet design for image classification, resulting in models that achieve a strong performance of 84.7% top-1 accuracy on the ImageNet benchmark while being up to 2.33x faster in compute time than the popular EfficientNet models on TPU-v3 hardware. We hope our simple and effective approach will serve as a strong baseline for future research in self-attention models for vision.
https://weibo.com/1402400261/JFmmy0pm2

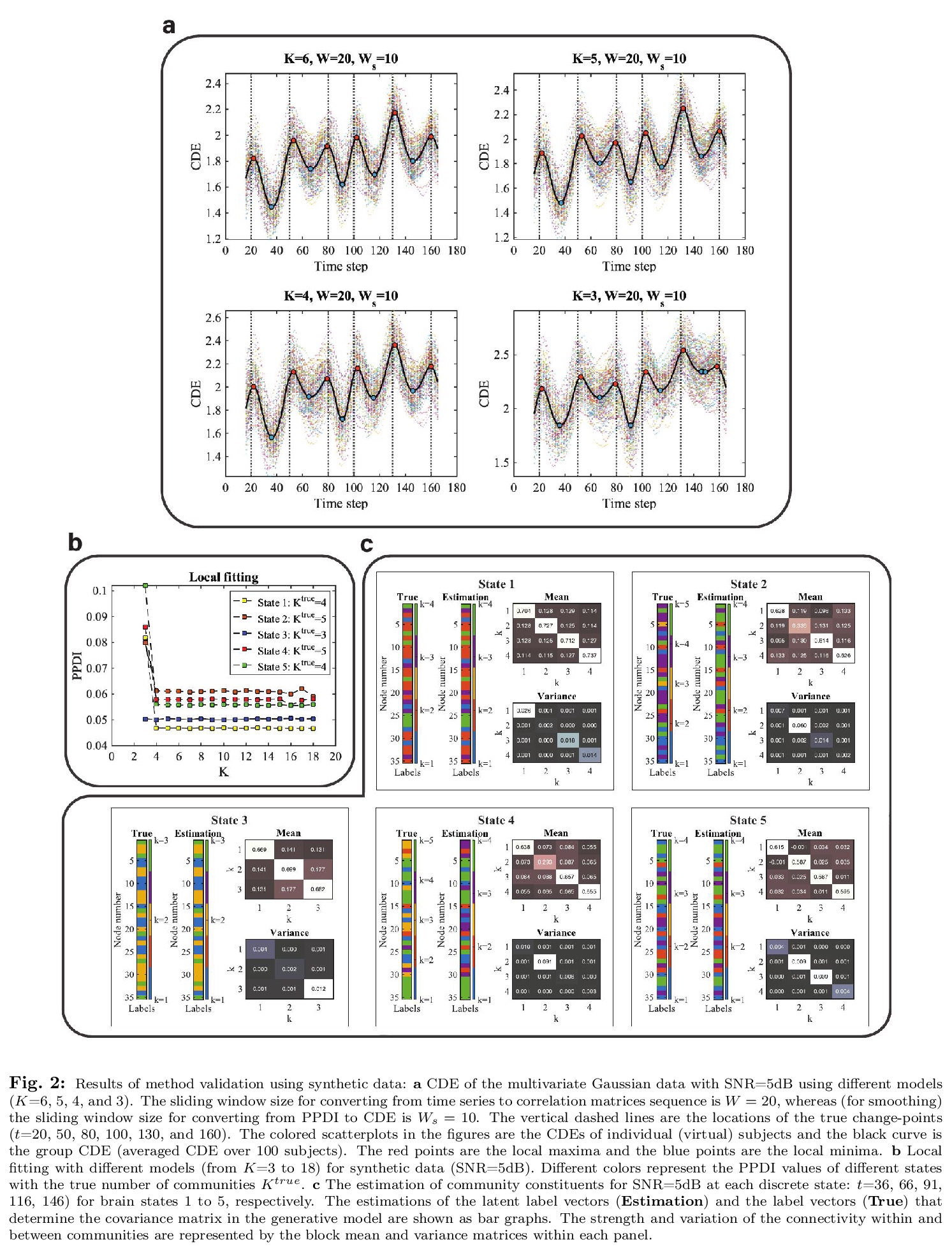
2、[LG] Identification of brain states, transitions, and communities using functional MRI
L Bian, T Cui, B.T. T Yeo, A Fornito, A Razi, J Keith
[Monash University & National University of Singapore]
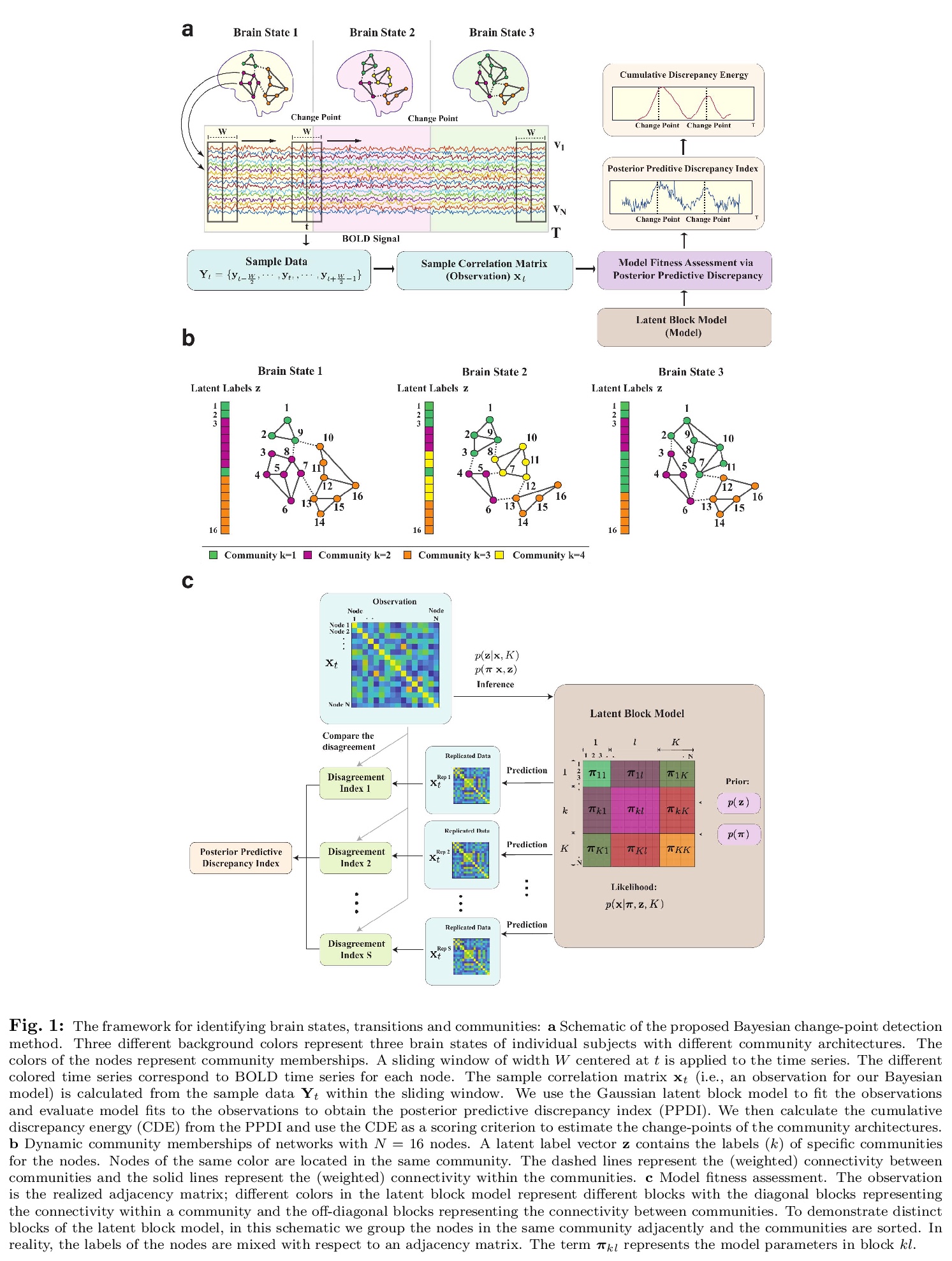
用功能磁共振成像(fMRI)识别大脑状态、转换和群。提出一种基于贝叶斯模型的脑潜状态表征方法,展示了基于后验预测差异的新方法,利用潜块模型来检测血氧水平依赖时间序列(BOLD)中脑潜状态的转换。模型中的估计参数集包括将网络节点分配到群的潜标签向量,也包括反映群内和群间加权连接的块模型参数。除了广泛的in-silico模型评价,还提供了用100个健康成年人的人连接组项目(HCP)数据集的经验验证(和复制)。通过分析工作记忆表现期间的任务-fMRI数据获得的结果显示,外部任务需求和大脑状态之间的变化点之间存在适当的滞后,具有区分固定、低需求和高需求任务条件的独特群模式。
Brain function relies on a precisely coordinated and dynamic balance between the functional integration and segregation of distinct neural systems. Characterizing the way in which neural systems reconfigure their interactions to give rise to distinct but hidden brain states remains an open challenge. In this paper, we propose a Bayesian model-based characterization of latent brain states and showcase a novel method based on posterior predictive discrepancy using the latent block model to detect transitions between latent brain states in blood oxygen level-dependent (BOLD) time series. The set of estimated parameters in the model includes a latent label vector that assigns network nodes to communities, and also block model parameters that reflect the weighted connectivity within and between communities. Besides extensive in-silico model evaluation, we also provide empirical validation (and replication) using the Human Connectome Project (HCP) dataset of 100 healthy adults. Our results obtained through an analysis of task-fMRI data during working memory performance show appropriate lags between external task demands and change-points between brain states, with distinctive community patterns distinguishing fixation, low-demand and high-demand task conditions.
https://weibo.com/1402400261/JFmvmqxhg
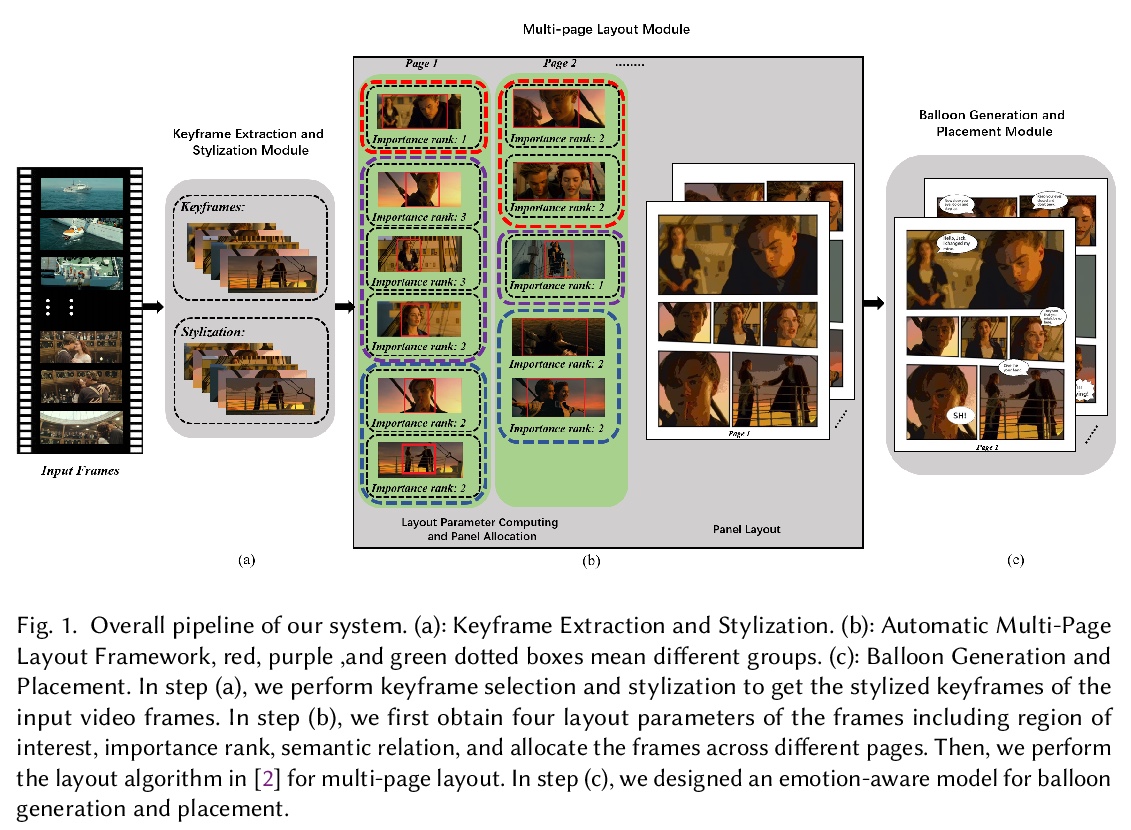
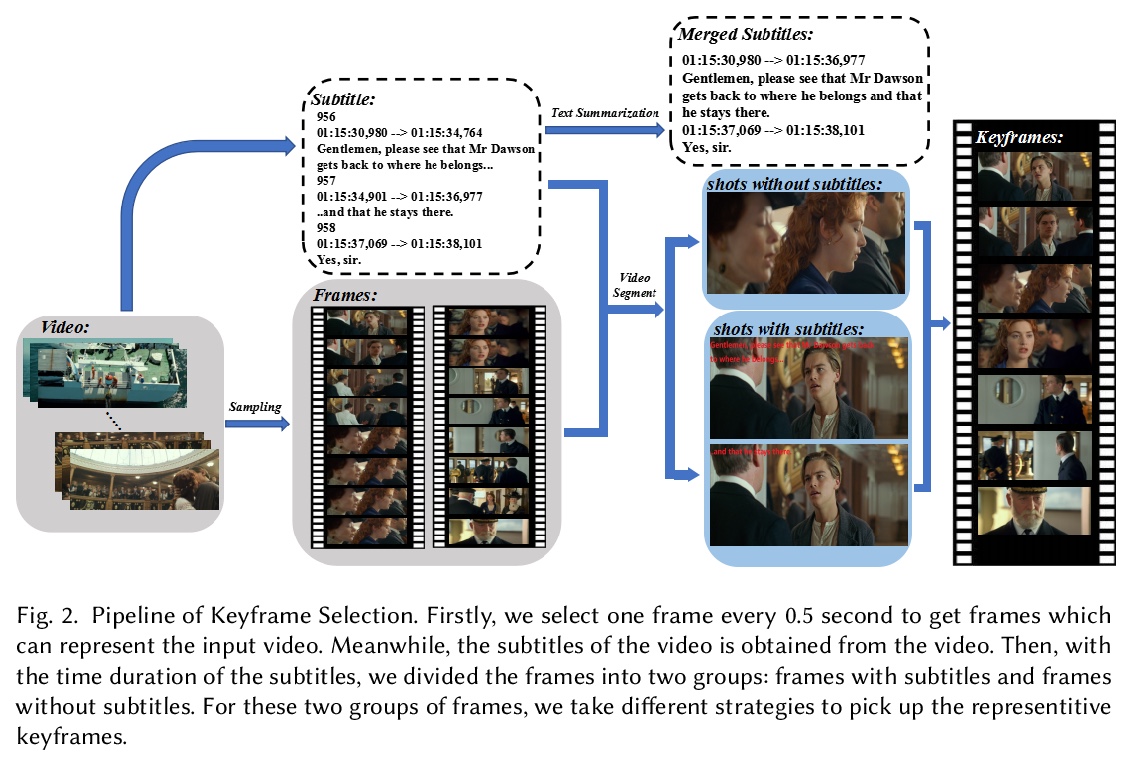
3、[CV] Automatic Comic Generation with Stylistic Multi-page Layouts and Emotion-driven Text Balloon Generation
X Yang, Z Ma, L Yu, Y Cao, B Yin, X Wei, Q Zhang, R W.H. Lau
[City University of Hong Kong & Dalian University of Technology]
带有风格化多页布局和情感驱动对话泡泡的视频-漫画自动生成。提出一个用于从视频中生成漫画书的全自动系统,给定输入视频及其字幕,先通过分析字幕提取信息关键帧,将关键帧风格化为漫画风格图像。采用新的自动多页布局框架,将图像分配到多个页面,并根据图像的丰富语义(如重要性和图像间关系)来合成视觉上有趣的布局。提出一种情感感知对话泡生成方法,通过分析字幕和音频情感来创建不同类型的文字泡泡,可根据不同情绪改变气球形状和文字大小,带来更丰富的阅读体验,生成的泡泡会通过说话人检测将其放置在对应的说话人附近。
In this paper, we propose a fully automatic system for generating comic books from videos without any human intervention. Given an input video along with its subtitles, our approach first extracts informative keyframes by analyzing the subtitles, and stylizes keyframes into comic-style images. Then, we propose a novel automatic multi-page layout framework, which can allocate the images across multiple pages and synthesize visually interesting layouts based on the rich semantics of the images (e.g., importance and inter-image relation). Finally, as opposed to using the same type of balloon as in previous works, we propose an emotion-aware balloon generation method to create different types of word balloons by analyzing the emotion of subtitles and audios. Our method is able to vary balloon shapes and word sizes in balloons in response to different emotions, leading to more enriched reading experience. Once the balloons are generated, they are placed adjacent to their corresponding speakers via speaker detection. Our results show that our method, without requiring any user inputs, can generate high-quality comic pages with visually rich layouts and balloons. Our user studies also demonstrate that users prefer our generated results over those by state-of-the-art comic generation systems.
https://weibo.com/1402400261/JFmKRjG2W


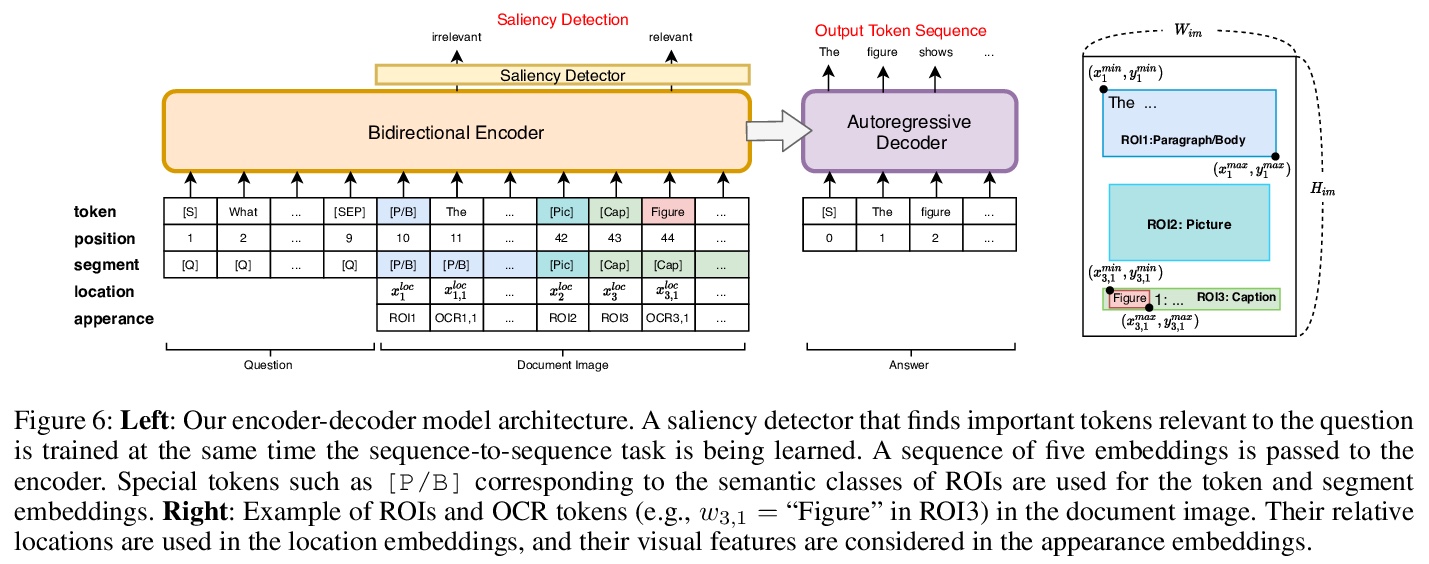
4、[CL] VisualMRC: Machine Reading Comprehension on Document Images
R Tanaka, K Nishida, S Yoshida
[NTT Corporation]
VisualMRC:文档图像的机器阅读理解。引入了一个新的视觉机器阅读理解数据集VisualMRC,给定一个问题和文档图像,机器阅读并理解图像中的文本,用自然语言回答问题,与现有的包含图像中文本的视觉问答(VQA)数据集相比,更注重培养自然语言理解和生成能力。VisualMRC包含了针对来源于多领域网页的10000+文档图片的30000+个问题-抽象答案对。提出一个新模型,考虑到文档的视觉布局和内容,扩展了现有序列到序列模型,预训练了大规模文本语料库。VisualMRC上的实验表明,该模型表现优于基本的序列到序列模型和最先进的VQA模型。
Recent studies on machine reading comprehension have focused on text-level understanding but have not yet reached the level of human understanding of the visual layout and content of real-world documents. In this study, we introduce a new visual machine reading comprehension dataset, named VisualMRC, wherein given a question and a document image, a machine reads and comprehends texts in the image to answer the question in natural language. Compared with existing visual question answering (VQA) datasets that contain texts in images, VisualMRC focuses more on developing natural language understanding and generation abilities. It contains 30,000+ pairs of a question and an abstractive answer for 10,000+ document images sourced from multiple domains of webpages. We also introduce a new model that extends existing sequence-to-sequence models, pre-trained with large-scale text corpora, to take into account the visual layout and content of documents. Experiments with VisualMRC show that this model outperformed the base sequence-to-sequence models and a state-of-the-art VQA model. However, its performance is still below that of humans on most automatic evaluation metrics. The dataset will facilitate research aimed at connecting vision and language understanding.
https://weibo.com/1402400261/JFmQ16qY1


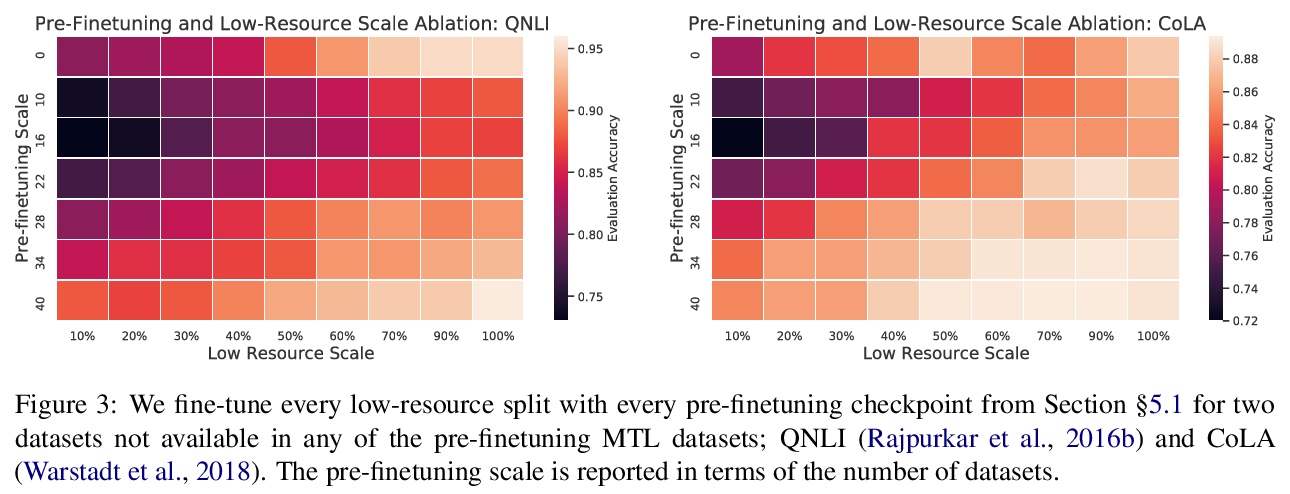
5、[CL] Muppet: Massive Multi-task Representations with Pre-Finetuning
A Aghajanyan, A Gupta, A Shrivastava, X Chen, L Zettlemoyer, S Gupta
[Facebook]
Muppet:预微调大规模多任务表示。提出预微调(Pre-Finetuning),介于语言模型预训练和微调之间的额外的大规模学习阶段。预微调是一种大规模多任务学习(约50个数据集、超过480万个标记样本),旨在鼓励学习能更好概括多种不同任务的表示。实验表明,在广泛的任务(句子预测、常识推理、MRC等)上,预微调持续提高了预训练的鉴别器(如RoBERTa)和生成模型(如BART)的性能,同时也显著提高了微调期间的样本效率。大规模多任务处理是至关重要的;当任务很少的时,预调优可能会损害性能,直到一个临界点(通常超过15),之后性能会随着任务数量线性提高。
We propose pre-finetuning, an additional large-scale learning stage between language model pre-training and fine-tuning. Pre-finetuning is massively multi-task learning (around 50 datasets, over 4.8 million total labeled examples), and is designed to encourage learning of representations that generalize better to many different tasks. We show that pre-finetuning consistently improves performance for pretrained discriminators (e.g.~RoBERTa) and generation models (e.g.~BART) on a wide range of tasks (sentence prediction, commonsense reasoning, MRC, etc.), while also significantly improving sample efficiency during fine-tuning. We also show that large-scale multi-tasking is crucial; pre-finetuning can hurt performance when few tasks are used up until a critical point (usually above 15) after which performance improves linearly in the number of tasks.
https://weibo.com/1402400261/JFmUEzWf0
另外几篇值得关注的论文:
[CL] Mining Large-Scale Low-Resource Pronunciation Data From Wikipedia
用维基百科挖掘大规模低资源语音数据
T Chakraborty, M Prasad, T Breiner, S Ritchie, D v Esch
[Google Research]
https://weibo.com/1402400261/JFn3Cn33Z


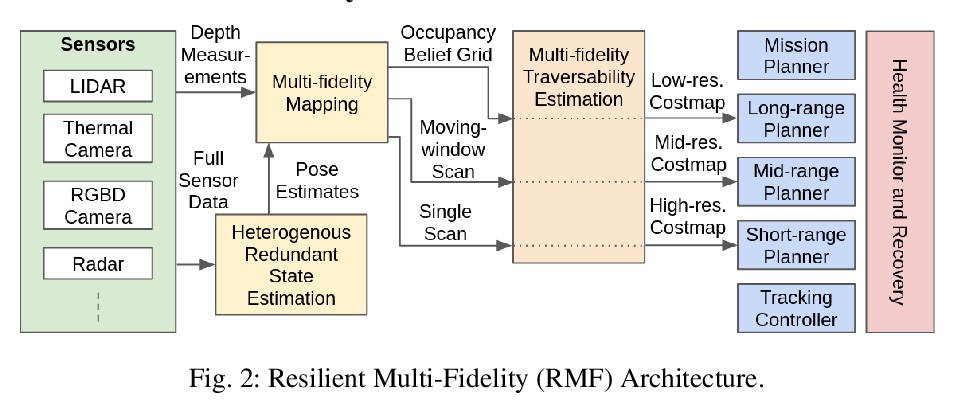
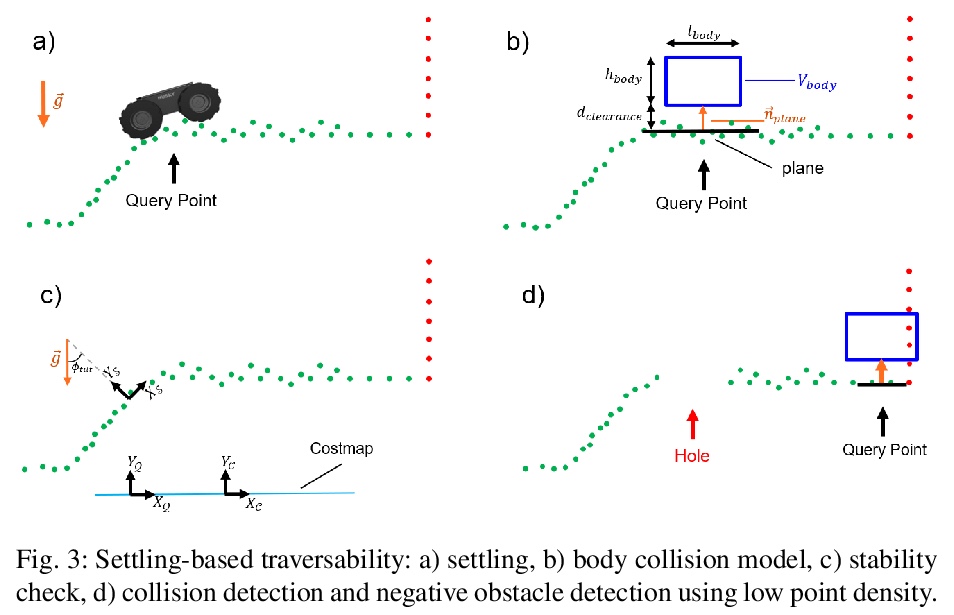
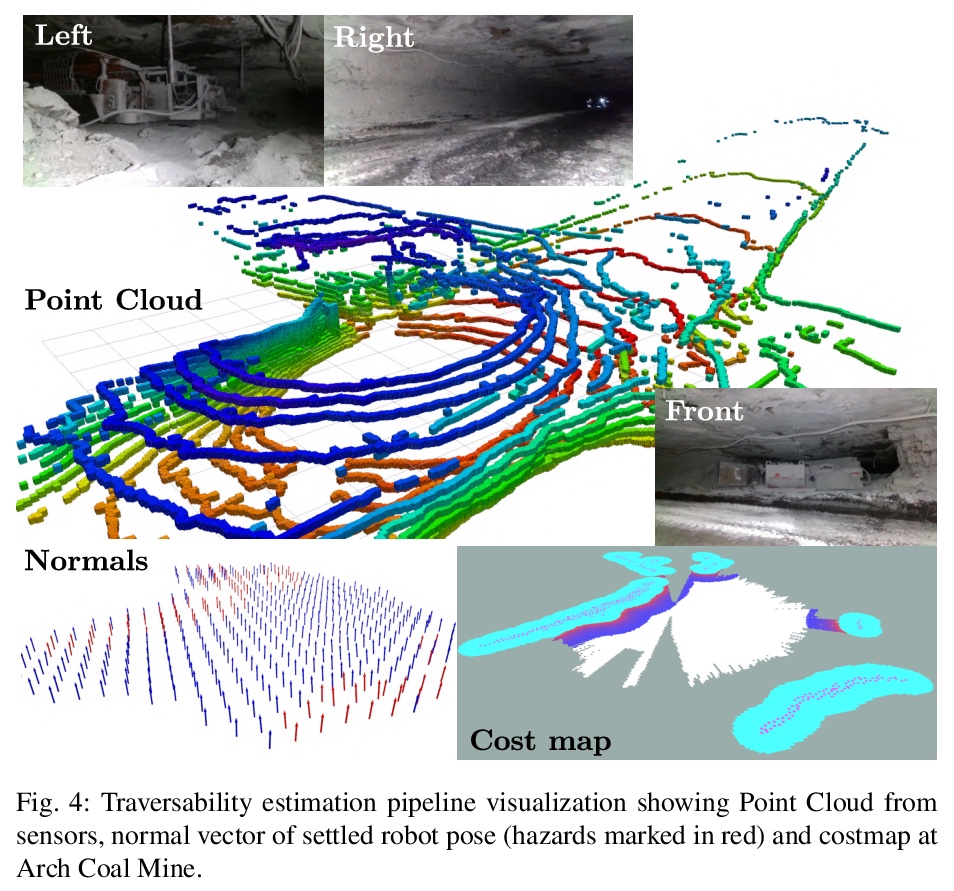
[RO] Autonomous Off-road Navigation over Extreme Terrains with Perceptually-challenging Conditions
感知挑战性条件极端地形自主越野导航
R Thakker, N Alatur, D D. Fan, J Tordesillas, M Paton, K Otsu, O Toupet, A Agha-mohammadi
[California Institute of Technology (Caltech)]
https://weibo.com/1402400261/JFn7xBFeu

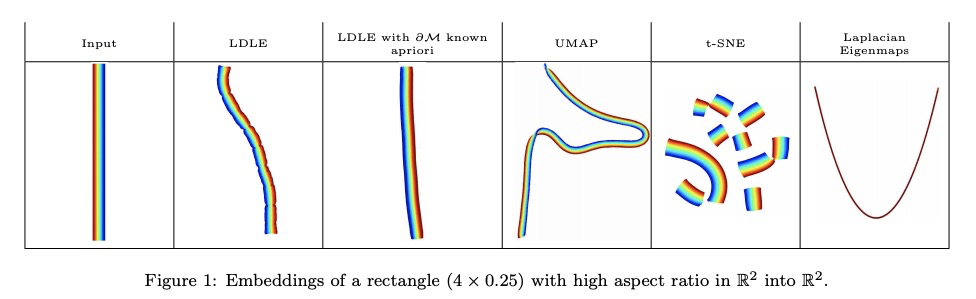
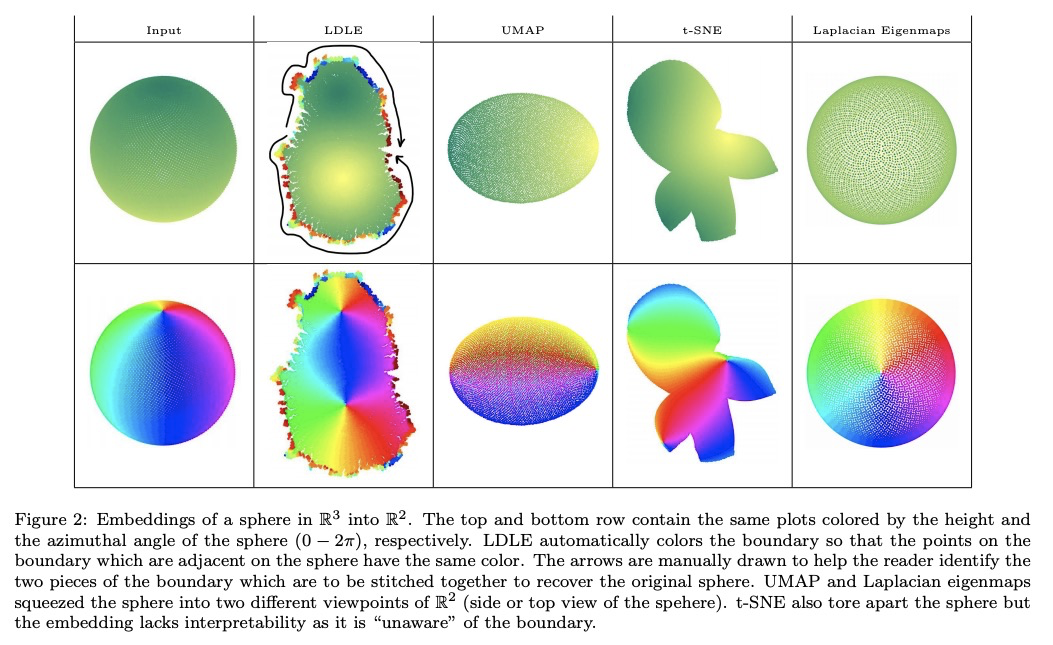
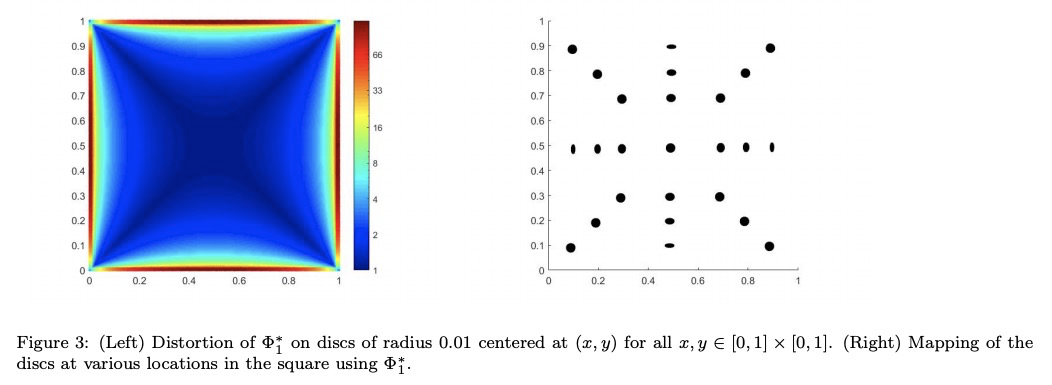
[LG] LDLE: Low Distortion Local Eigenmaps
LDLE:低失真局部特征映射流形学习
D Kohli, A Cloninger, G Mishne
[University of California, San Diego]
https://weibo.com/1402400261/JFnbUgXq1
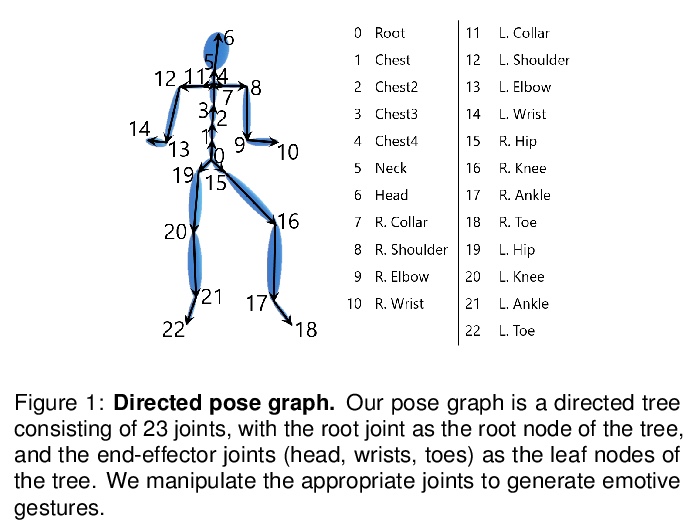
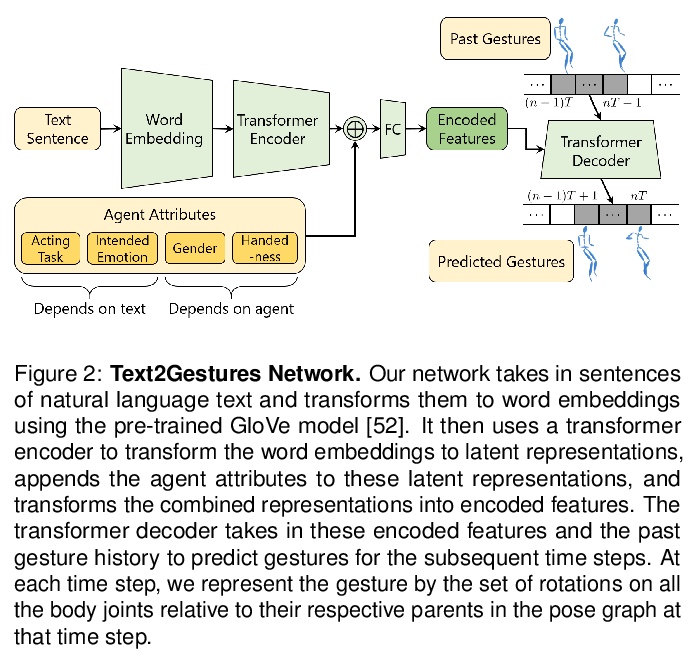
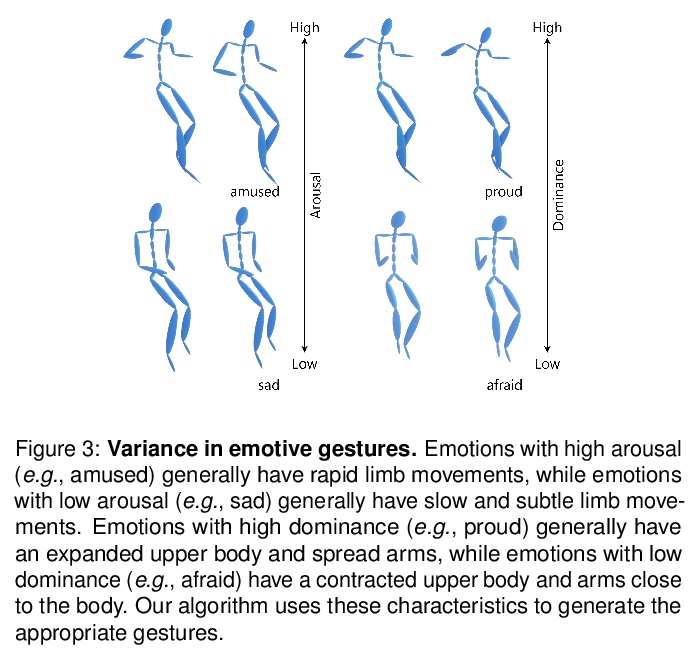
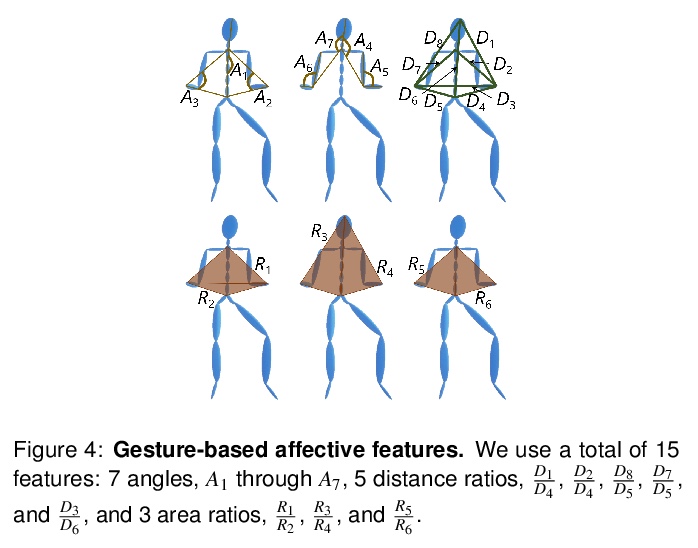
[LG] Text2Gestures: A Transformer-Based Network for Generating Emotive Body Gestures for Virtual Agents
Text2Gestures:面向虚拟人物情绪化体态生成的Transformer网络
U Bhattacharya, N Rewkowski, A Banerjee, P Guhan, A Bera, D Manocha
[University of Maryland]
https://weibo.com/1402400261/JFnejdMr4

若有收获,就点个赞吧
0 人点赞
