- 1、[CV] SSTVOS: Sparse Spatiotemporal Transformers for Video Object Segmentation
- 2、[LG] On Maximum Likelihood Training of Score-Based Generative Models
- 3、[CV] Progressive Image Super-Resolution via Neural Differential Equation
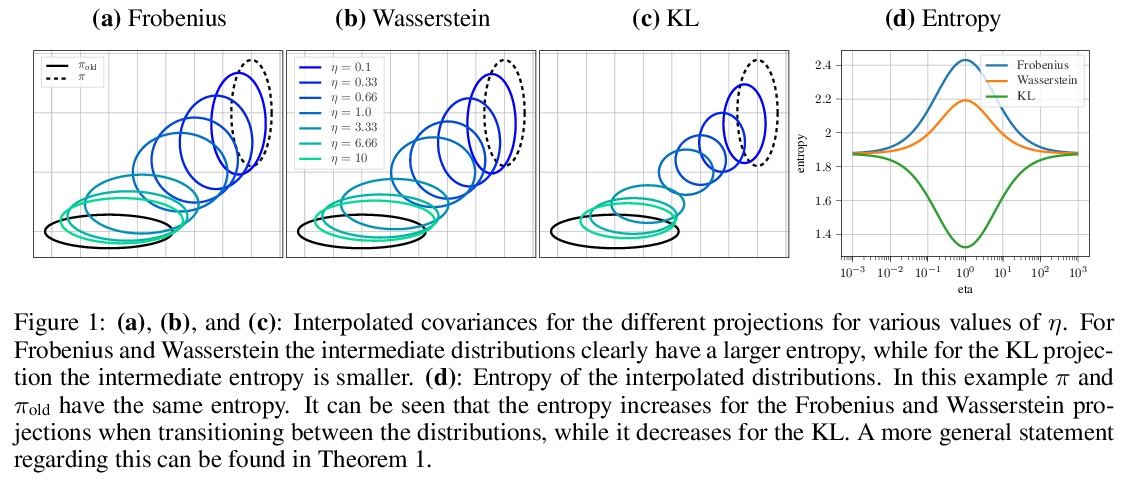
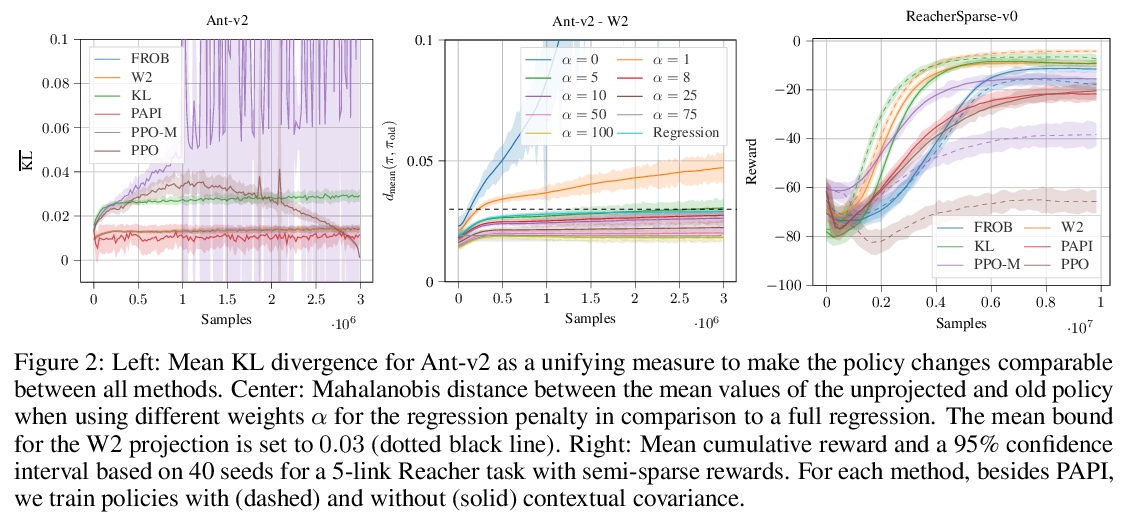
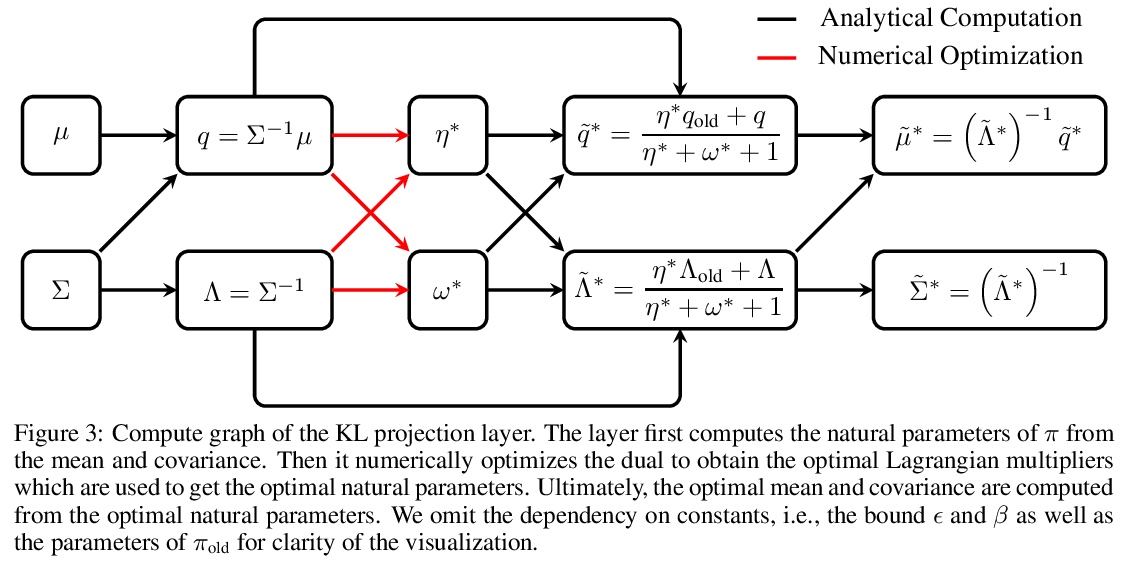
- 4、[LG] Differentiable Trust Region Layers for Deep Reinforcement Learning
- 5、[CV] Towards Enhancing Fine-grained Details for Image Matting
- [CL] Extracting Lifestyle Factors for Alzheimer’s Disease from Clinical Notes Using Deep Learning with Weak Supervision
- [CV] Hybrid Rotation Averaging: A Globally Guaranteed Fast and Robust Rotation Averaging Approach
- [LG] Stable Recovery of Entangled Weights: Towards Robust Identification of Deep Neural Networks from Minimal Samples
- [LG] PyGlove: Symbolic Programming for Automated Machine Learning
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] SSTVOS: Sparse Spatiotemporal Transformers for Video Object Segmentation
B Duke, A Ahmed, C Wolf, P Aarabi, G W. Taylor
[University of Toronto & University of Guelph & Universite Lyon & Modiface, Inc]
SSTVOS:基于稀疏时空Transformer的视频目标分割。为解决复合误差和可扩展性问题,提出一种可扩展的、端到端视频目标分割(VOS)方法——稀疏时空Transformer(SST)。SST用时空特征上的稀疏注意力提取视频中各目标每像素表示。基于注意力的视频目标分割范式,允许模型在多帧历史上学习进行关注,为执行解决运动分割的类似计算提供合适的归纳偏差。SST的时空结构化表示比递归模型的平面隐式表示更有优势。SST在基准VOS数据集YouTube-VOS上获得了最先进结果,达到G=81.8的总分,同时与之前最先进方法(包括基于递归的方法)相比,具有更好的运行时扩展性。
In this paper we introduce a Transformer-based approach to video object segmentation (VOS). To address compounding error and scalability issues of prior work, we propose a scalable, end-to-end method for VOS called Sparse Spatiotemporal Transformers (SST). SST extracts per-pixel representations for each object in a video using sparse attention over spatiotemporal features. Our attention-based formulation for VOS allows a model to learn to attend over a history of multiple frames and provides suitable inductive bias for performing correspondence-like computations necessary for solving motion segmentation. We demonstrate the effectiveness of attention-based over recurrent networks in the spatiotemporal domain. Our method achieves competitive results on YouTube-VOS and DAVIS 2017 with improved scalability and robustness to occlusions compared with the state of the art.
https://weibo.com/1402400261/JETYOr8Xv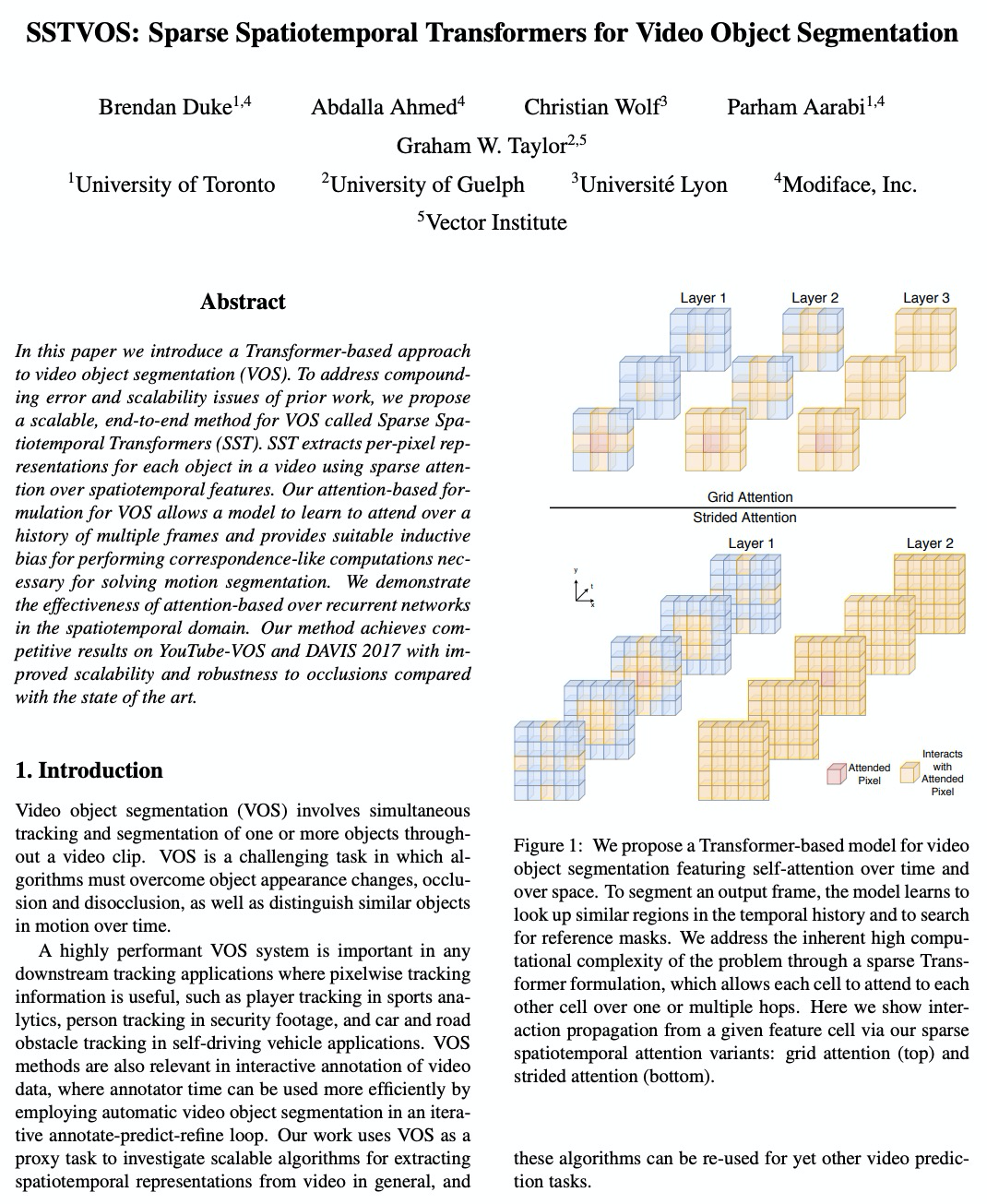
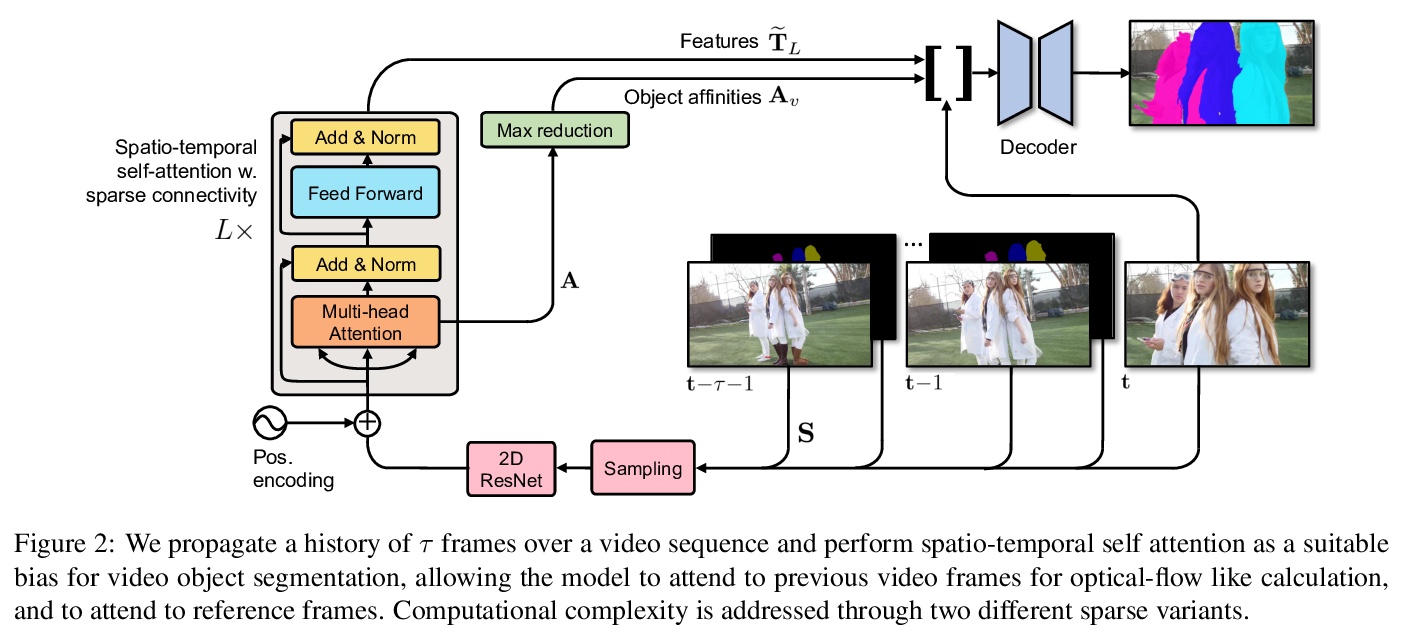
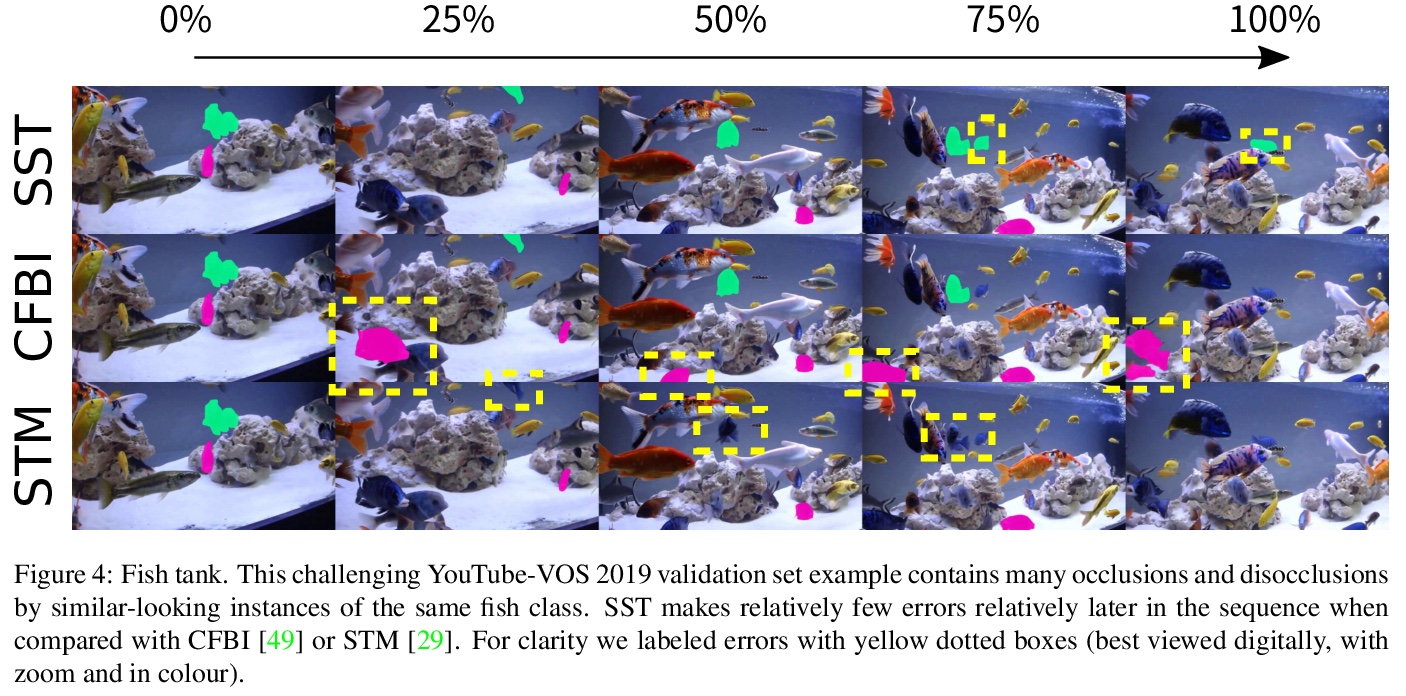
2、[LG] On Maximum Likelihood Training of Score-Based Generative Models
C Durkan, Y Song
[University of Edinburgh & Stanford University]
基于得分的生成模型的最大似然训练。建立了最大似然估计和得分匹配损失加权混合之间的等价关系。特别是,当选择一个合适的加权函数时,优化得分匹配损失的加权混合就等同于最大似然。这种等价具有多重意义:可以明确地选择一个加权函数,使目标等同于最大似然。这就产生了一种原则性方法,来对得分匹配目标进行跨时间加权,而之前工作中的加权主要是以启发式方式来选择的;当使用这些特殊权重时,可通过直接评价其损失函数,来比较不同的基于得分的生成模型;从熟悉的基于似然方法的角度出发,对基于得分的生成模型有了新的理解。通过基于得分的技术,可以单独通过得分函数的参数化,来进行最大似然训练和精确似然评估。
Score-based generative modeling has recently emerged as a promising alternative to traditional likelihood-based or implicit approaches. Learning in score-based models involves first perturbing data with a continuous-time stochastic process, and then matching the time-dependent gradient of the logarithm of the noisy data density - or score function - using a continuous mixture of score matching losses. In this note, we show that such an objective is equivalent to maximum likelihood for certain choices of mixture weighting. This connection provides a principled way to weight the objective function, and justifies its use for comparing different score-based generative models. Taken together with previous work, our result reveals that both maximum likelihood training and test-time log-likelihood evaluation can be achieved through parameterization of the score function alone, without the need to explicitly parameterize a density function.
https://weibo.com/1402400261/JEU5tfn2i
3、[CV] Progressive Image Super-Resolution via Neural Differential Equation
S Park, T H Kim
[Hanyang University]
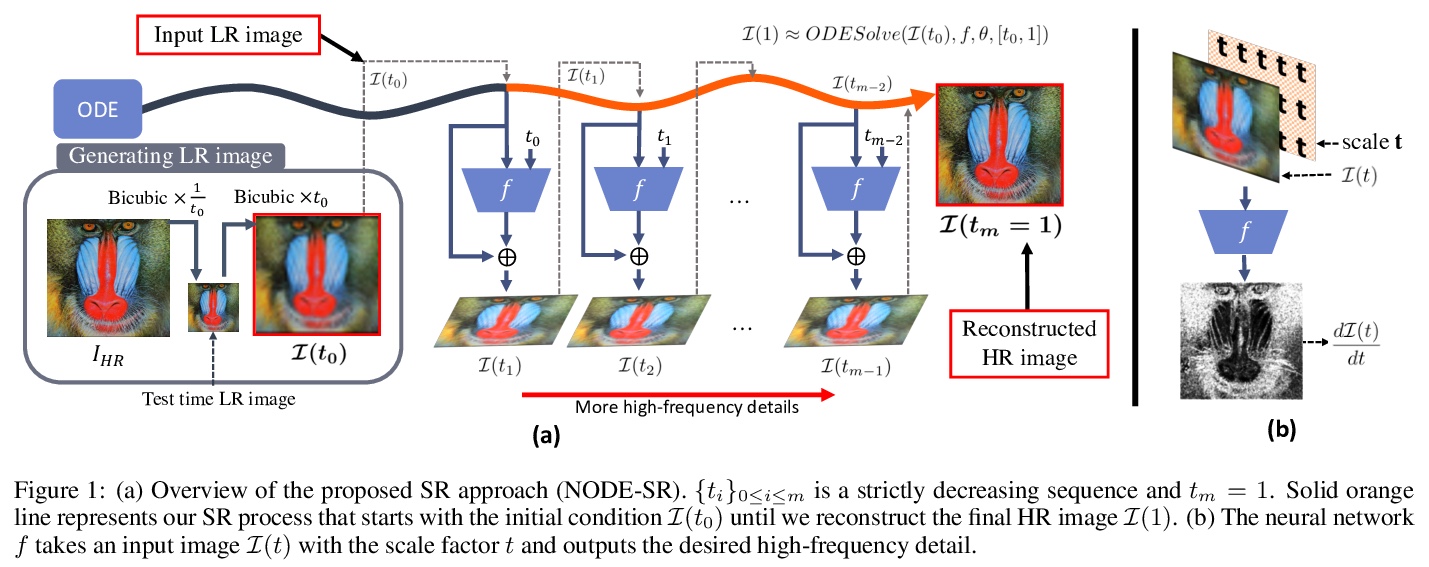
基于神经微分方程的渐进式图像超分辨率。提出一种新的基于神经常微分方程的图像超分辨率(SR)方法,从输入低分辨率(LR)图像渐进式恢复出高分辨率(HR)图像。将SR问题表述为初始值问题,其中初始值为输入的LR图像。与传统渐进式SR方法直接利用迭代机制渐进式更新不同,该SR过程是在显式建模基础上以具体方式进行,具有更清晰的理解。该方法可以很容易地使用传统的神经网络来实现图像修复,可以在连续域上对任意尺度因子的图像进行超分辨率处理,比现有SR方法具有更优越的SR性能。
We propose a new approach for the image super-resolution (SR) task that progressively restores a high-resolution (HR) image from an input low-resolution (LR) image on the basis of a neural ordinary differential equation. In particular, we newly formulate the SR problem as an initial value problem, where the initial value is the input LR image. Unlike conventional progressive SR methods that perform gradual updates using straightforward iterative mechanisms, our SR process is formulated in a concrete manner based on explicit modeling with a much clearer understanding. Our method can be easily implemented using conventional neural networks for image restoration. Moreover, the proposed method can super-resolve an image with arbitrary scale factors on continuous domain, and achieves superior SR performance over state-of-the-art SR methods.
https://weibo.com/1402400261/JEUbiz6FR


4、[LG] Differentiable Trust Region Layers for Deep Reinforcement Learning
F Otto, P Becker, N A Vien, H C Ziesche, G Neumann
[Universitat Tubingen & Karlsruhe Insitute of Technology & Bosch Center for Artificial Intelligence]
深度强化学习的可微置信域层。提出了可微的神经网络层,通过闭型投影实现深度高斯策略置信域。与现有方法不同,这些层将每个状态的置信域单独形式化,可完善现有的强化学习算法。基于高斯分布的KL散度、Wasserstein L2距离和Frobenius范数推导了置信域投影,这些投影层实现了与现有方法相似或更好的结果,同时对具体的实现选择几乎不可知。
Trust region methods are a popular tool in reinforcement learning as they yield robust policy updates in continuous and discrete action spaces. However, enforcing such trust regions in deep reinforcement learning is difficult. Hence, many approaches, such as Trust Region Policy Optimization (TRPO) and Proximal Policy Optimization (PPO), are based on approximations. Due to those approximations, they violate the constraints or fail to find the optimal solution within the trust region. Moreover, they are difficult to implement, lack sufficient exploration, and have been shown to depend on seemingly unrelated implementation choices. In this work, we propose differentiable neural network layers to enforce trust regions for deep Gaussian policies via closed-form projections. Unlike existing methods, those layers formalize trust regions for each state individually and can complement existing reinforcement learning algorithms. We derive trust region projections based on the Kullback-Leibler divergence, the Wasserstein L2 distance, and the Frobenius norm for Gaussian distributions. We empirically demonstrate that those projection layers achieve similar or better results than existing methods while being almost agnostic to specific implementation choices.
https://weibo.com/1402400261/JEUfplnOa
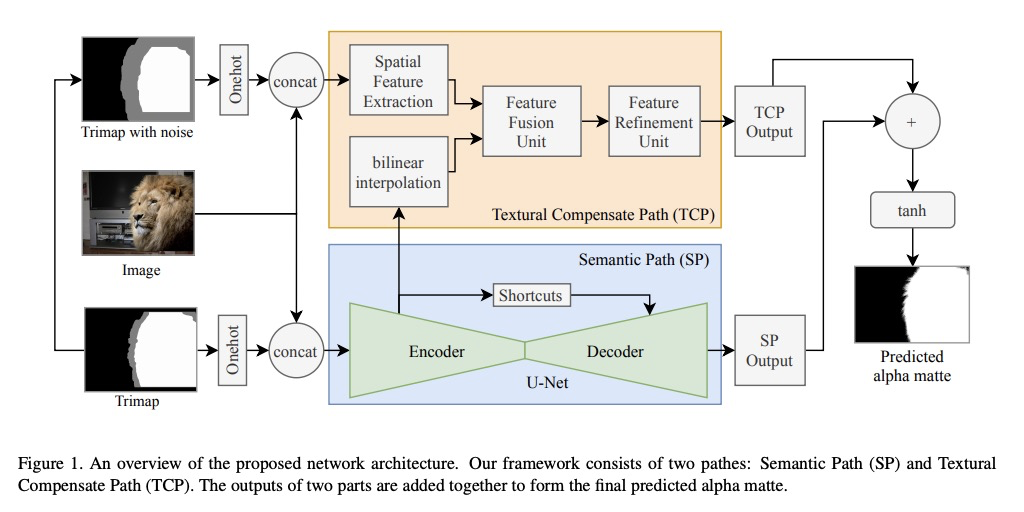
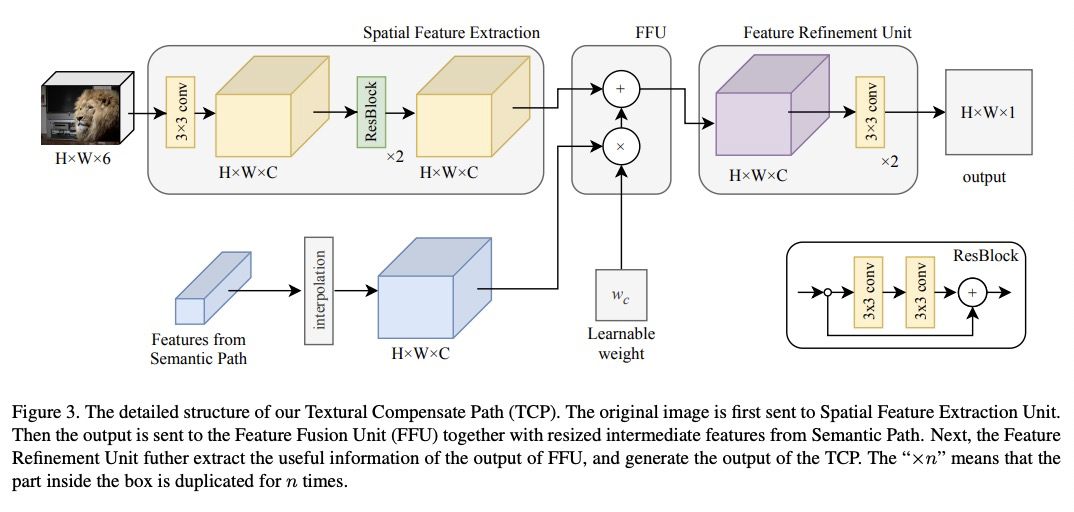
5、[CV] Towards Enhancing Fine-grained Details for Image Matting
C Liu, H Ding, X Jiang
[Nanyang Technological University]
深度抠图细粒度细节的改善。目前基于编-解码器的深度抠图模型中,毛发、毛皮等微观细节所依赖的低级但高清晰度的纹理特征,在很早阶段就被降采样,导致这些细粒度细节的丢失。为解决该问题,增强微观细节,设计了深度图像抠图模型,由两条平行路径组成:一条是传统的编-解码器语义路径,另一条是独立的无降采样纹理补偿路径(TCP)。TCP的提出是为了提取原始图像尺寸中的线条和边缘等细粒度细节,从而大大提高预测精细度。为了充分利用高层上下文的优势,提出了特征融合单元(FFU),将语义路径中的多尺度特征融合并注入到TCP中。提出了新的损失函数项和trimap生成方法,以提高模型对trimap的鲁棒性。
In recent years, deep natural image matting has been rapidly evolved by extracting high-level contextual features into the model. However, most current methods still have difficulties with handling tiny details, like hairs or furs. In this paper, we argue that recovering these microscopic details relies on low-level but high-definition texture features. However, {these features are downsampled in a very early stage in current encoder-decoder-based models, resulting in the loss of microscopic details}. To address this issue, we design a deep image matting model {to enhance fine-grained details. Our model consists of} two parallel paths: a conventional encoder-decoder Semantic Path and an independent downsampling-free Textural Compensate Path (TCP). The TCP is proposed to extract fine-grained details such as lines and edges in the original image size, which greatly enhances the fineness of prediction. Meanwhile, to leverage the benefits of high-level context, we propose a feature fusion unit(FFU) to fuse multi-scale features from the semantic path and inject them into the TCP. In addition, we have observed that poorly annotated trimaps severely affect the performance of the model. Thus we further propose a novel term in loss function and a trimap generation method to improve our model’s robustness to the trimaps. The experiments show that our method outperforms previous start-of-the-art methods on the Composition-1k dataset.
https://weibo.com/1402400261/JEUlXkDRF

另外几篇值得关注的论文:
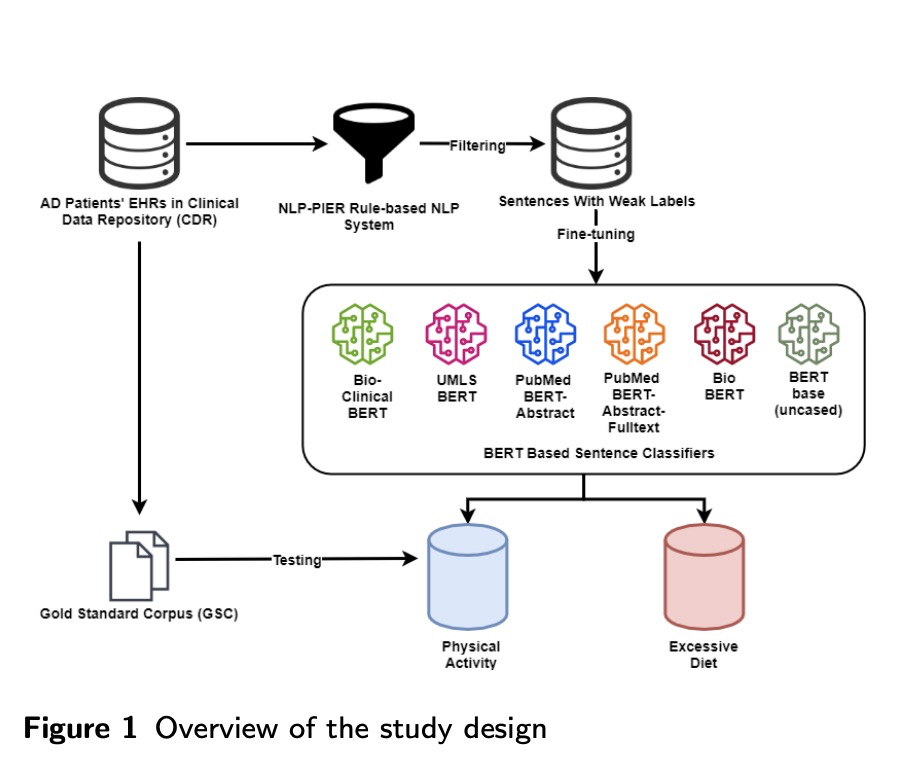
[CL] Extracting Lifestyle Factors for Alzheimer’s Disease from Clinical Notes Using Deep Learning with Weak Supervision
用弱监督深度学习从电子病历中提取阿尔茨海默症生活因子
Z Shen, Y Yi, A Bompelli, F Yu, Y Wang, R Zhang
[University of Minnesota & Arizona State University]
https://weibo.com/1402400261/JEUwRmsnC
[CV] Hybrid Rotation Averaging: A Globally Guaranteed Fast and Robust Rotation Averaging Approach
混合旋转平均法:具有全局保证的快速鲁棒旋转平均方法
Y Chen, J Zhao, L Kneip
[Peking University & TuSimple & ShanghaiTech University]
https://weibo.com/1402400261/JEUBXy4mf


[LG] Stable Recovery of Entangled Weights: Towards Robust Identification of Deep Neural Networks from Minimal Samples
纠缠权值的稳定恢复:最少样本的深度神经网络鲁棒辨识
C Fiedler, M Fornasier, T Klock, M Rauchensteiner
[Max Planck Institute for Intelligent Systems]
https://weibo.com/1402400261/JEUFn8B4D
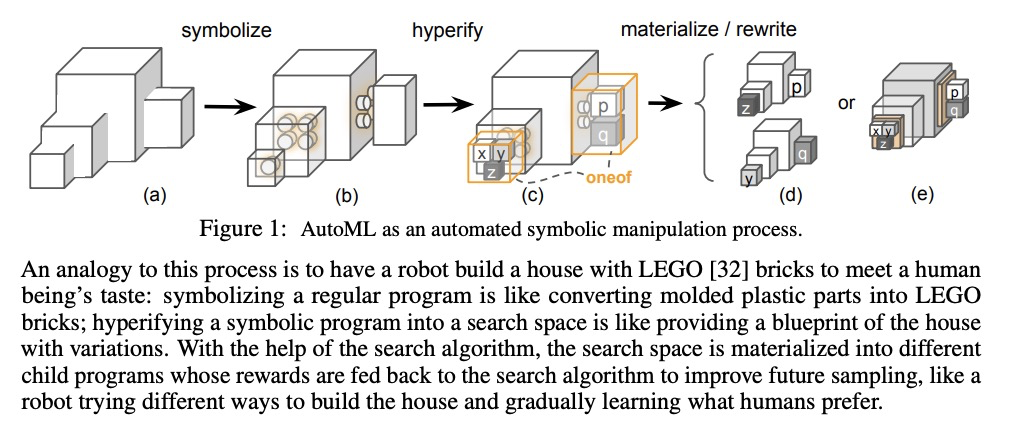
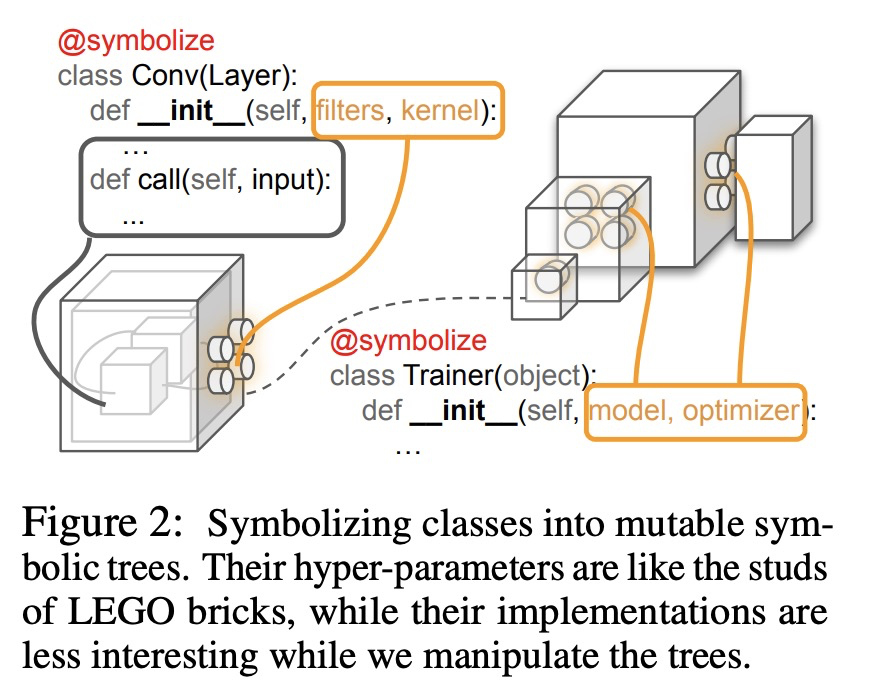
[LG] PyGlove: Symbolic Programming for Automated Machine Learning
PyGlove:面向自动化机器学习的符号编程
D Peng, X Dong, E Real, M Tan, Y Lu, H Liu, G Bender, A Kraft, C Liang, Q V. Le
[Google Research]
https://weibo.com/1402400261/JEUJhqGbF

若有收获,就点个赞吧
0 人点赞
