- 1、[CV] SiamMOT: Siamese Multi-Object Tracking
- 2、[CV] High-Frequency aware Perceptual Image Enhancement
- 3、[CV] PixMatch: Unsupervised Domain Adaptation via Pixelwise Consistency Training
- 4、[CL] Focus Attention: Promoting Faithfulness and Diversity in Summarization
- 5、[CL] Understanding the Properties of Minimum Bayes Risk Decoding in Neural Machine Translation
- [CL] A practical introduction to the Rational Speech Act modeling framework
- [CV] VISITRON: Visual Semantics-Aligned Interactively Trained Object-Navigator
- [CL] Pretraining the Noisy Channel Model for Task-Oriented Dialogue
- [CL] Robustly Optimized and Distilled Training for Natural Language Understanding
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[CV] SiamMOT: Siamese Multi-Object Tracking
B Shuai, A Berneshawi, X Li, D Modolo, J Tighe
[Amazon Web Services (AWS)]
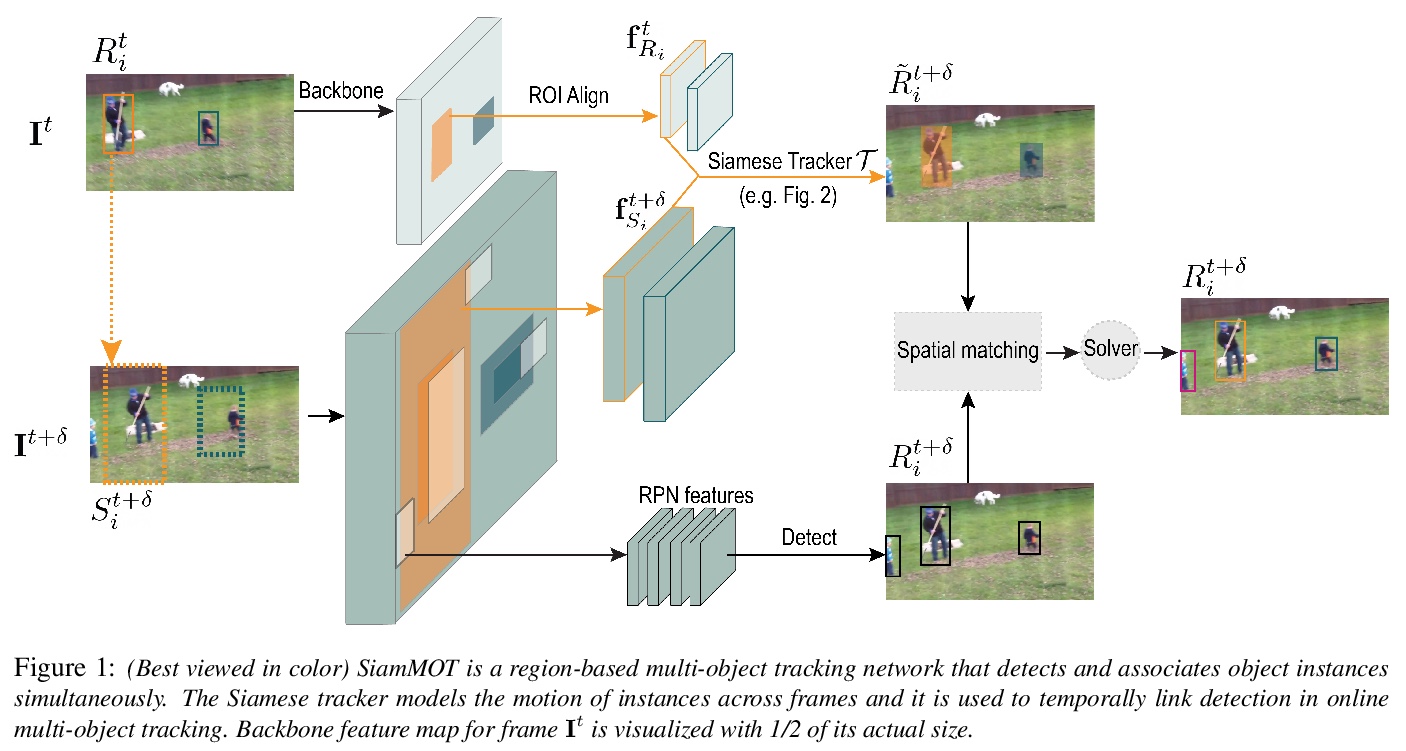
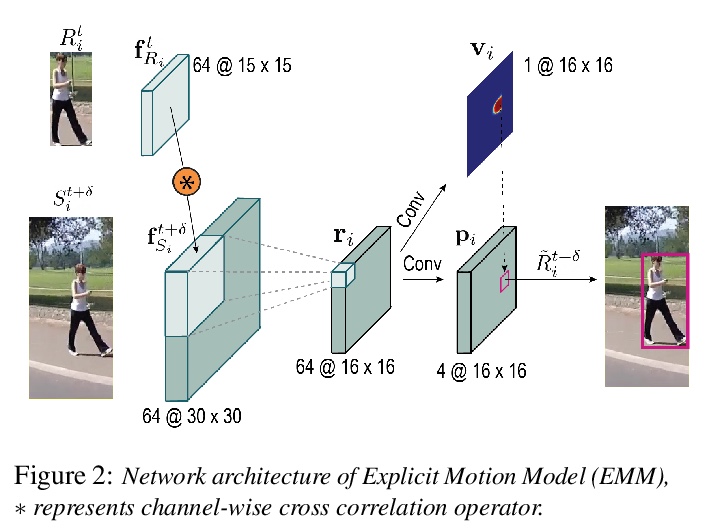
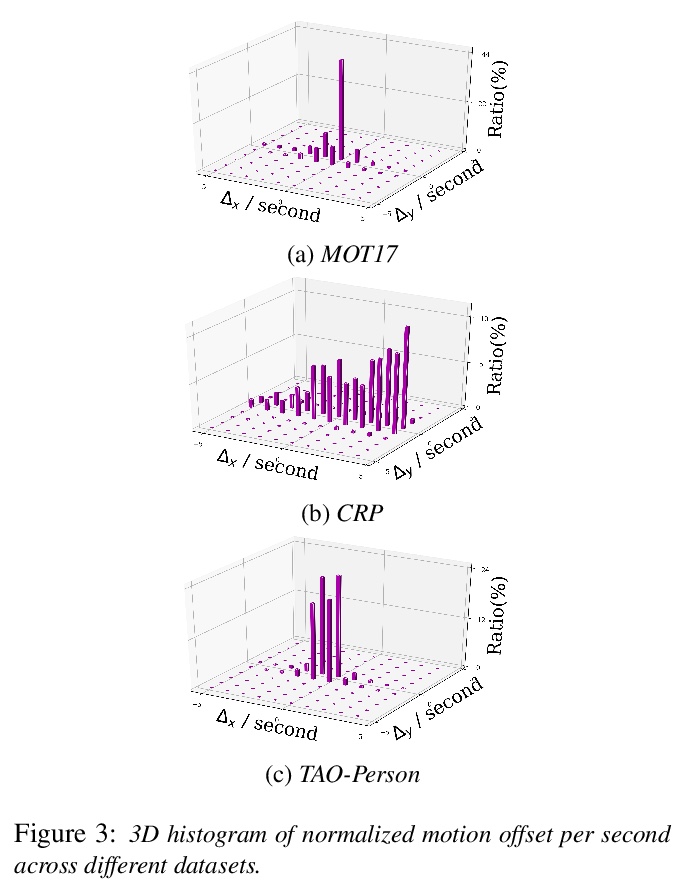
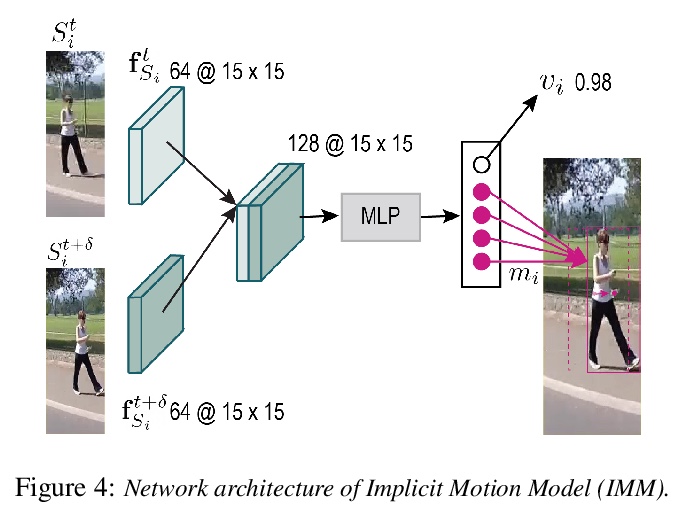
SiamMOT:Siamese多目标追踪。本文专注于改进在线多目标追踪(MOT),提出一种基于区域的Siamese多目标追踪网络SiamMOT,同时检测和关联目标实例。SiamMOT包括一个运动模型,用于估计实例在两帧间的运动,从而使检测到的实例具有关联性。为探索运动模型如何影响其追踪能力,提出两种Siamese追踪器的变体,隐式运动模型和显式运动模型。在三个不同的MOT数据集上进行了广泛的定量实验,分别是MOT17、TAO-person和Caltech Roadside Pedestrians,显示了运动建模对MOT的重要性,以及SiamMOT大幅超越最先进水平的能力。SiamMOT在HiEve数据集上的表现也超过了ACM MM’20 HiEve Grand Challenge的优胜者。SiamMOT是高效的,在单个现代GPU上以17 FPS运行720P视频。
In this paper, we focus on improving online multi-object tracking (MOT). In particular, we introduce a region-based Siamese Multi-Object Tracking network, which we name SiamMOT. SiamMOT includes a motion model that estimates the instance’s movement between two frames such that detected instances are associated. To explore how the motion modelling affects its tracking capability, we present two variants of Siamese tracker, one that implicitly models motion and one that models it explicitly. We carry out extensive quantitative experiments on three different MOT datasets: MOT17, TAO-person and Caltech Roadside Pedestrians, showing the importance of motion modelling for MOT and the ability of SiamMOT to substantially outperform the state-of-the-art. Finally, SiamMOT also outperforms the winners of ACM MM’20 HiEve Grand Challenge on HiEve dataset. Moreover, SiamMOT is efficient, and it runs at 17 FPS for 720P videos on a single modern GPU.
https://weibo.com/1402400261/KhlfyDY0I
2、[CV] High-Frequency aware Perceptual Image Enhancement
H Roh, M Kang
[Seoul National University]
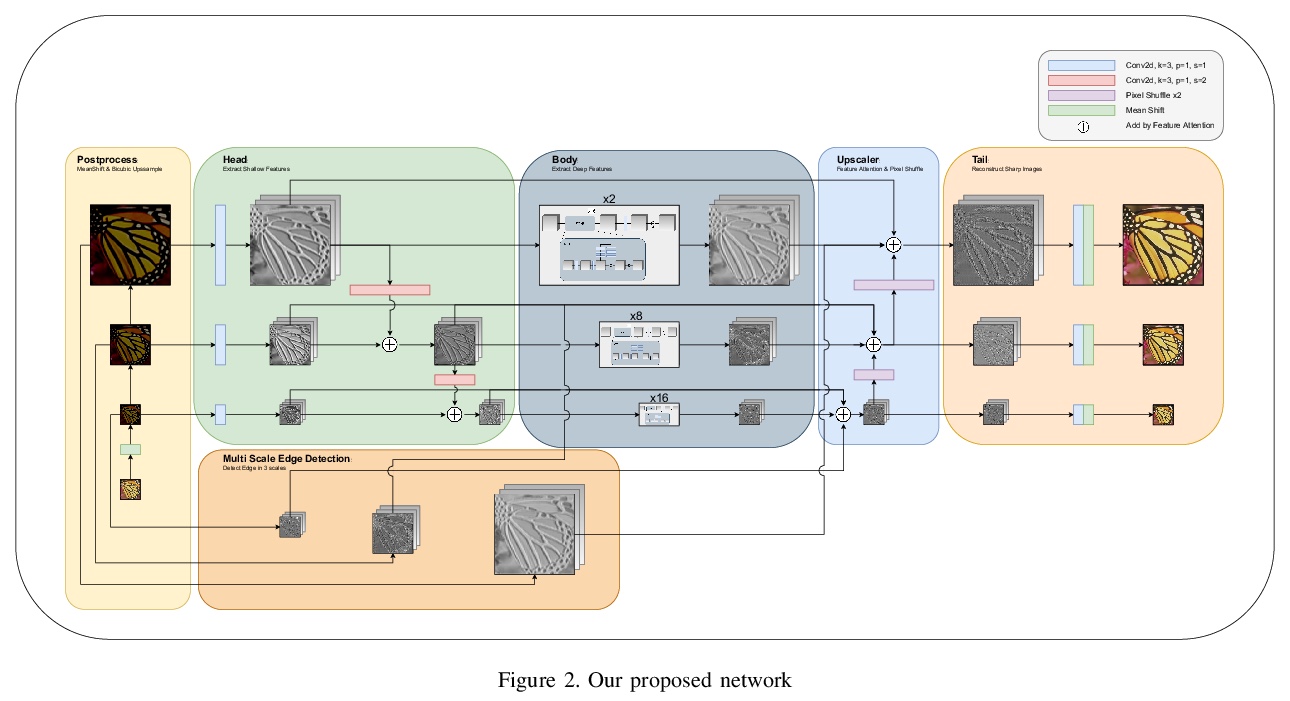
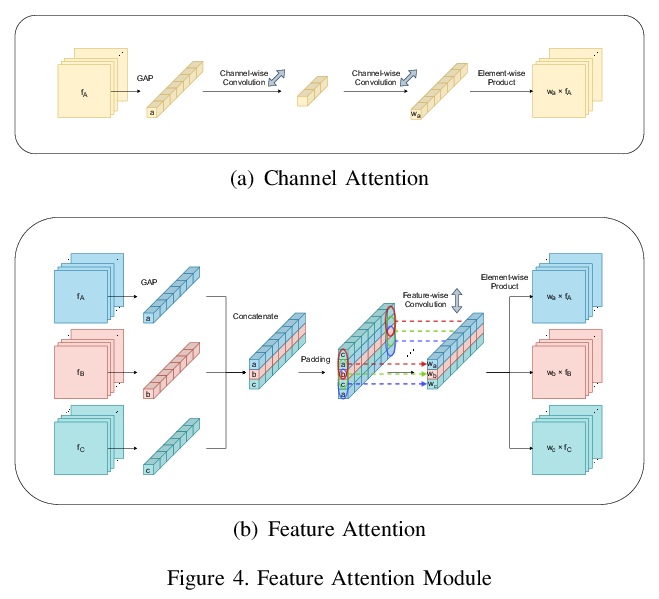
高频感知的感知图像增强。提出一种适合多尺度分析的新型深度神经网络,引入多尺度边缘过滤,从噪声图像中提取高频信息,有助于模型进行适合于图像各区域的统计分析和重建。提出了有效的模型诊断方法,帮助网络从高频域提取信息以重建更清晰图像。模型可应用于多尺度图像增强,包括去噪、去模糊和单图像超分辨率。在SIDD、Flickr2K、DIV2K和REDS数据集上的实验表明,该方法在每个任务上都取得了最先进的性能,能克服现有的以PSNR为导向的方法中常见的过度平滑问题,通过应用对抗性训练生成更自然的高分辨率图像。
In this paper, we introduce a novel deep neural network suitable for multi-scale analysis and propose efficient model-agnostic methods that help the network extract information from high-frequency domains to reconstruct clearer images. Our model can be applied to multi-scale image enhancement problems including denoising, deblurring and single image super-resolution. Experiments on SIDD, Flickr2K, DIV2K, and REDS datasets show that our method achieves state-of-the-art performance on each task. Furthermore, we show that our model can overcome the over-smoothing problem commonly observed in existing PSNR-oriented methods and generate more natural high-resolution images by applying adversarial training.
https://weibo.com/1402400261/KhlnNAyoR


3、[CV] PixMatch: Unsupervised Domain Adaptation via Pixelwise Consistency Training
L Melas-Kyriazi, A K. Manrai
[Harvard University]
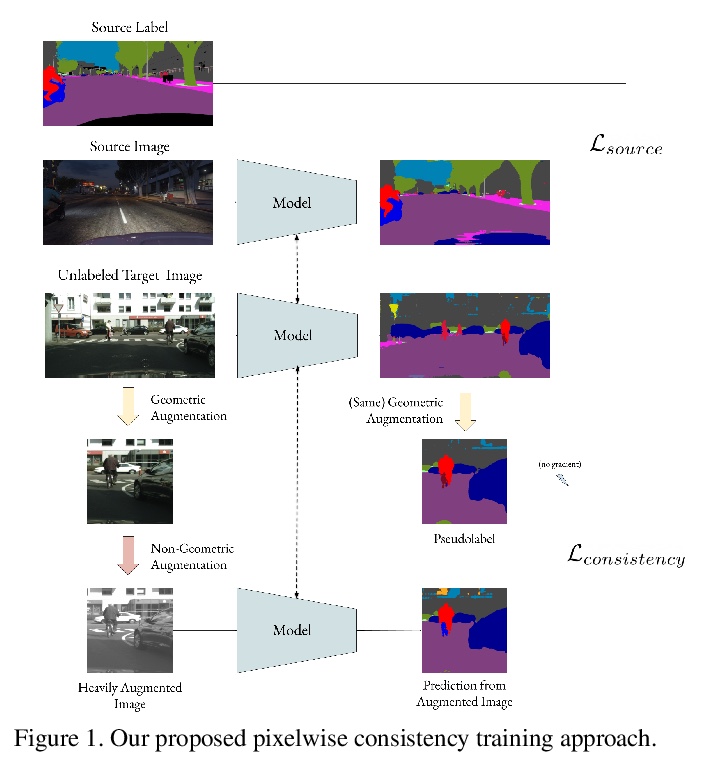
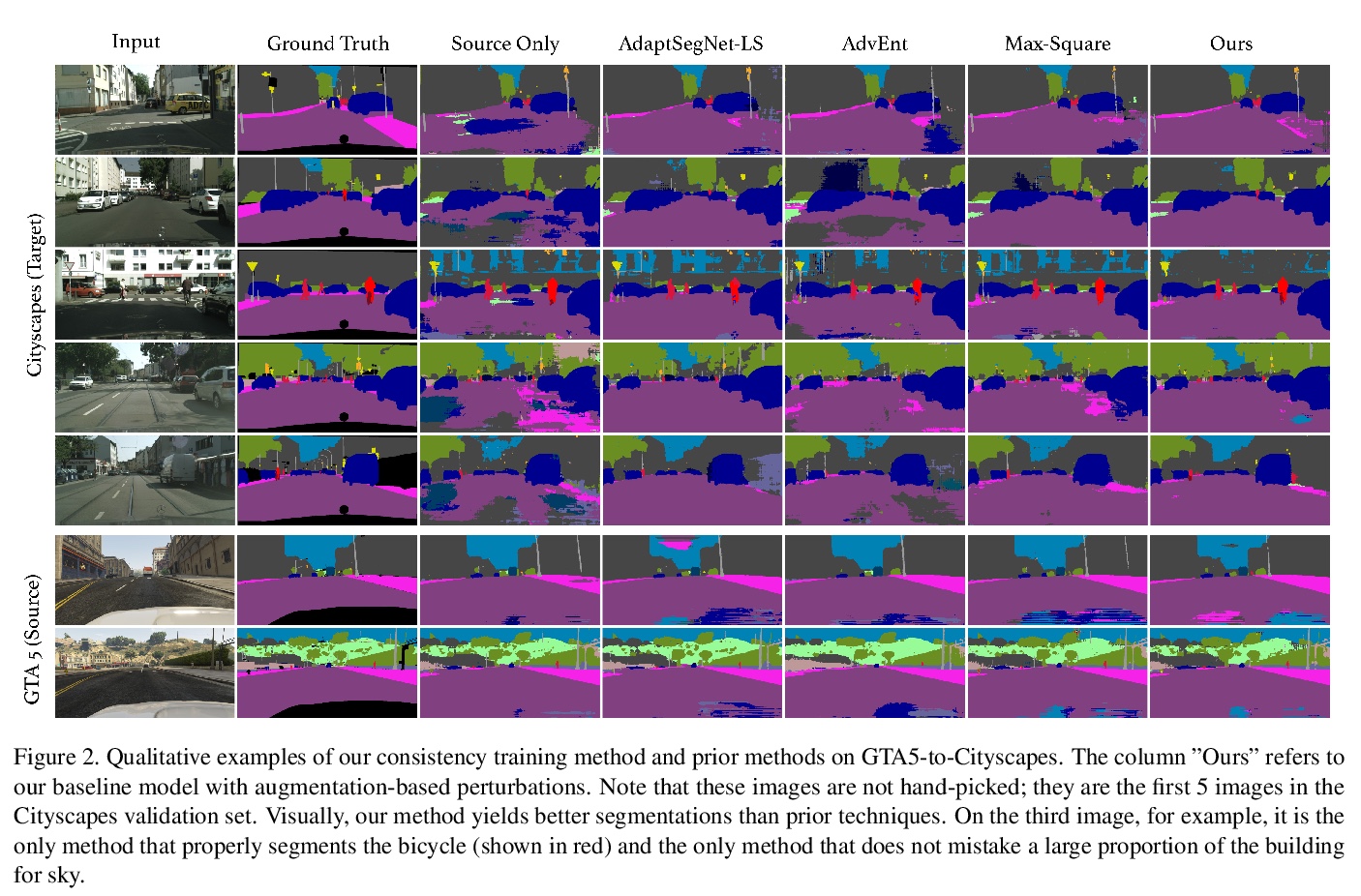
PixMatch: 基于像素一致性训练的无监督域自适应。对于语义分割和其他计算机视觉任务来说,无监督域自适应是一种很有前途的技术,对这些任务来说,大规模数据标注是昂贵且耗时的。语义分割中,在模拟(源)域的标注图像上训练模型,并将其部署在真实(目标)域上是很有吸引力的。本文提出一种基于目标域一致性训练概念的无监督域自适应的新框架。为了在目标域表现良好,模型的输出应该与目标域中输入的小扰动相一致。引入一种新的损失项,用于强制执行模型对目标图像预测和同一图像扰动版本之间的像素一致性。与流行的对抗性自适应方法相比,该方法更简单,更容易实现,在训练中更节省内存。实验表明,该简单方法在GTA5-Cityscapes和SYNTHIA-Cityscapes两个具有挑战性的合成到真实的基准上取得了非常好的结果。
Unsupervised domain adaptation is a promising technique for semantic segmentation and other computer vision tasks for which large-scale data annotation is costly and time-consuming. In semantic segmentation, it is attractive to train models on annotated images from a simulated (source) domain and deploy them on real (target) domains. In this work, we present a novel framework for unsupervised domain adaptation based on the notion of target-domain consistency training. Intuitively, our work is based on the idea that in order to perform well on the target domain, a model’s output should be consistent with respect to small perturbations of inputs in the target domain. Specifically, we introduce a new loss term to enforce pixelwise consistency between the model’s predictions on a target image and a perturbed version of the same image. In comparison to popular adversarial adaptation methods, our approach is simpler, easier to implement, and more memory-efficient during training. Experiments and extensive ablation studies demonstrate that our simple approach achieves remarkably strong results on two challenging synthetic-to-real benchmarks, GTA5-to-Cityscapes and SYNTHIA-to-Cityscapes.
https://weibo.com/1402400261/KhlqHyX90


4、[CL] Focus Attention: Promoting Faithfulness and Diversity in Summarization
R Aralikatte, S Narayan, J Maynez, S Rothe, R McDonald
[University of Copenhagen & Google Research & ASAPP]
焦点注意力:促进摘要的忠实性和多样性。专业摘要基于文档级信息进行总结,比如文件主题。这与大多数seq2seq解码器形成鲜明对比,后者在每个解码步骤同时学习关注突出内容并决定生成什么。为缩小这一差距,本文提出焦点注意力机制,鼓励解码器主动生成与输入文档相似或带有主题性的标记。提出一种焦点采样的方法,以生成多样化的摘要。在对BBC的极端总结任务进行评估时,两个最先进模型在”焦点注意力”增强下,生成的摘要更接近目标,更忠实于输入文档,在ROUGE和多种忠实度指标上都优于普通模型。与基于top-k或核采样的解码方法相比,焦点采样在生成多样化和忠实的摘要方面更加有效。
Professional summaries are written with document-level information, such as the theme of the document, in mind. This is in contrast with most seq2seq decoders which simultaneously learn to focus on salient content, while deciding what to generate, at each decoding step. With the motivation to narrow this gap, we introduce Focus Attention Mechanism, a simple yet effective method to encourage decoders to proactively generate tokens that are similar or topical to the input document. Further, we propose a Focus Sampling method to enable generation of diverse summaries, an area currently understudied in summarization. When evaluated on the BBC extreme summarization task, two state-of-the-art models augmented with Focus Attention generate summaries that are closer to the target and more faithful to their input documents, outperforming their vanilla counterparts on \rouge and multiple faithfulness measures. We also empirically demonstrate that Focus Sampling is more effective in generating diverse and faithful summaries than top-k or nucleus sampling-based decoding methods.
https://weibo.com/1402400261/KhltObsb7

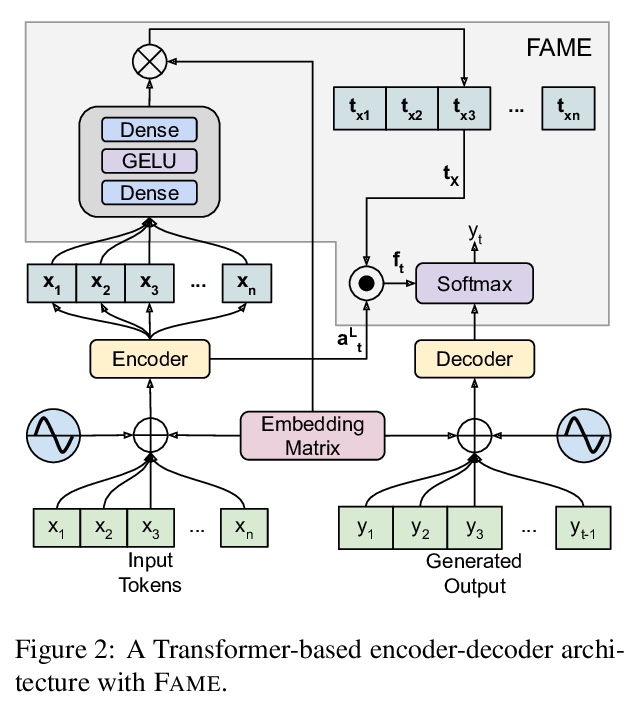
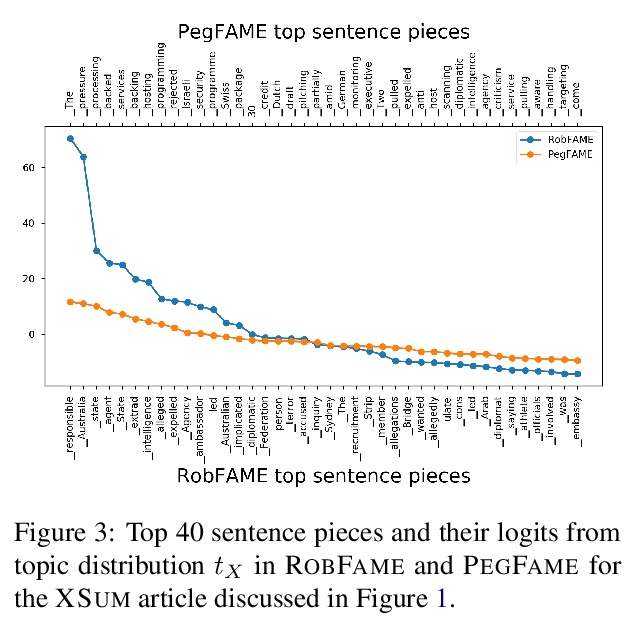
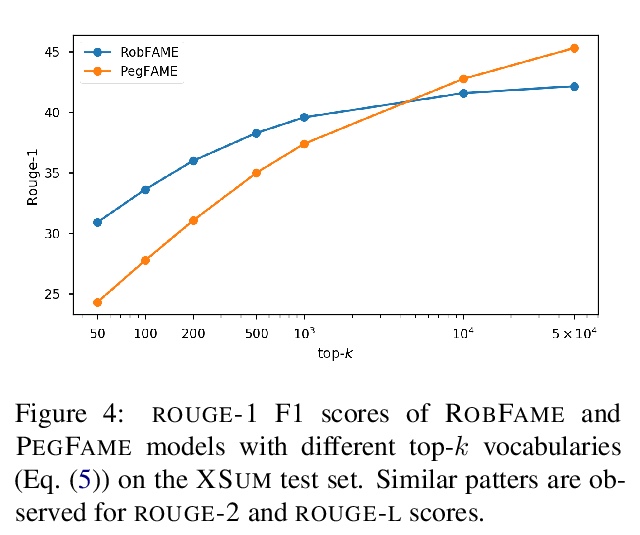
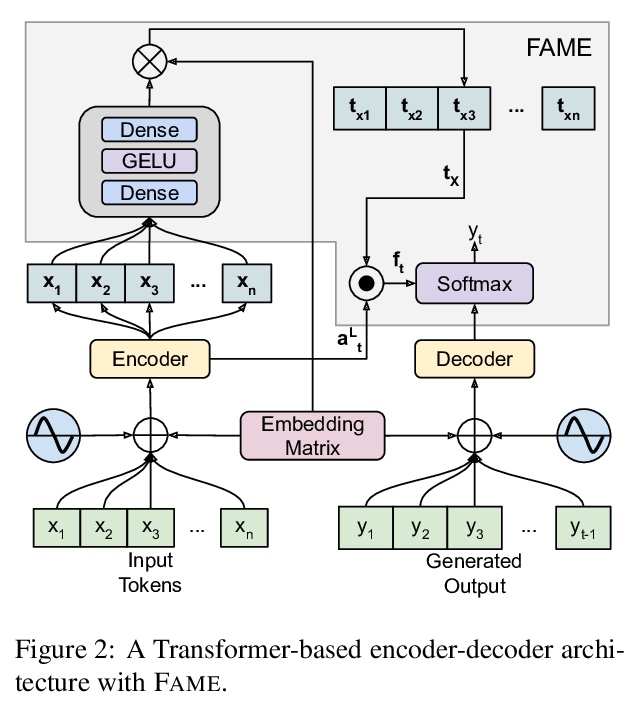
5、[CL] Understanding the Properties of Minimum Bayes Risk Decoding in Neural Machine Translation
M Müller, R Sennrich
[University of Zurich]
理解神经机器翻译最小贝叶斯风险解码的特性。神经网络机器翻译(NMT)目前表现出一些偏差,如产生太短的翻译和过度生成频繁单词,并对训练数据或域迁移中的复制噪声表现出较差的鲁棒性。最近的工作将这些缺点与集束搜索——NMT中事实上的标准推理算法——联系起来,在无偏的样本上用最小贝叶斯风险(MBR)解码来代替。本文实证研究了MBR解码在一些之前存在偏差和集束搜索失败案例上的特性,发现由于作为效用函数的MT指标,MBR仍然表现出长度和标记频率的偏差,但也增加了对训练数据中复制噪声和域迁移的鲁棒性。
Neural Machine Translation (NMT) currently exhibits biases such as producing translations that are too short and overgenerating frequent words, and shows poor robustness to copy noise in training data or domain shift. Recent work has tied these shortcomings to beam search — the de facto standard inference algorithm in NMT — and Eikema & Aziz (2020) propose to use Minimum Bayes Risk (MBR) decoding on unbiased samples instead.
In this paper, we empirically investigate the properties of MBR decoding on a number of previously reported biases and failure cases of beam search. We find that MBR still exhibits a length and token frequency bias, owing to the MT metrics used as utility functions, but that MBR also increases robustness against copy noise in the training data and domain shift.
https://weibo.com/1402400261/Khly2Big0

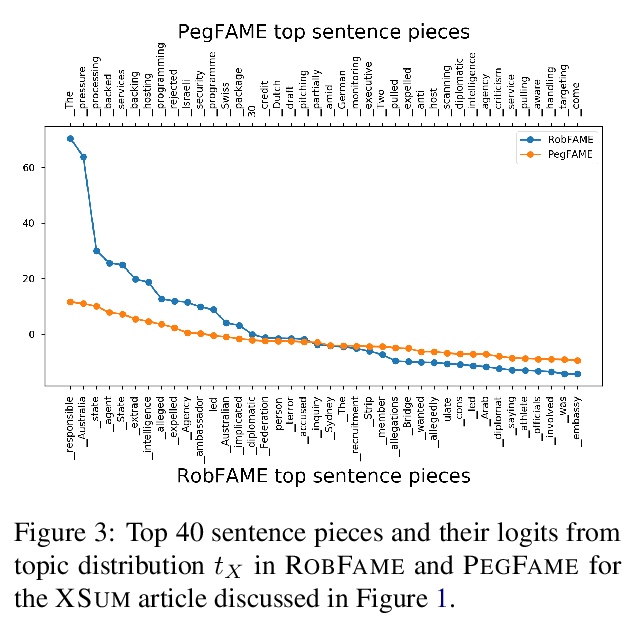
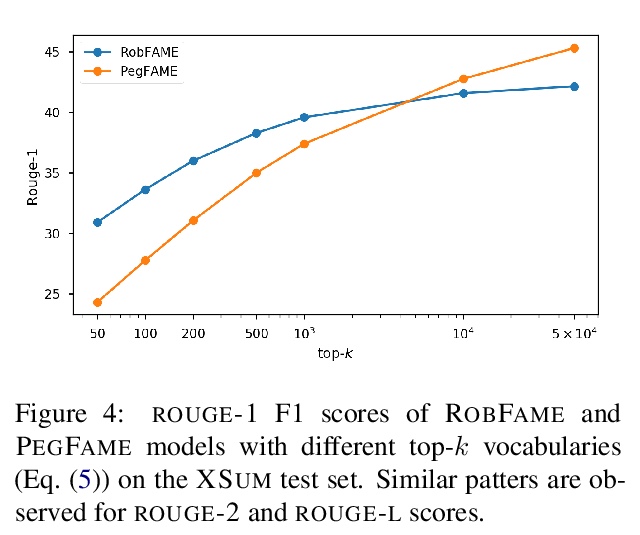
另外几篇值得关注的论文:
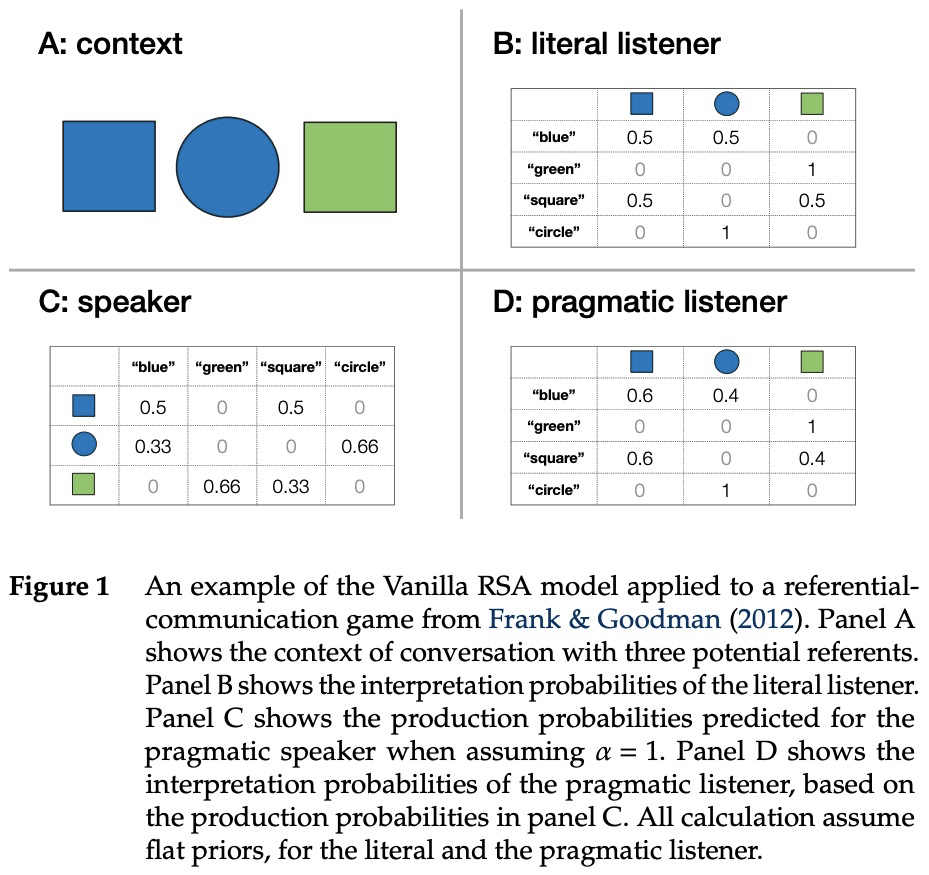
[CL] A practical introduction to the Rational Speech Act modeling framework
理性言语行为建模框架实用介绍
G Scontras, M H Tessler, M Franke
[University of California, Irvine & MIT & University of Osnabrück]
https://weibo.com/1402400261/Khlk2s1ts
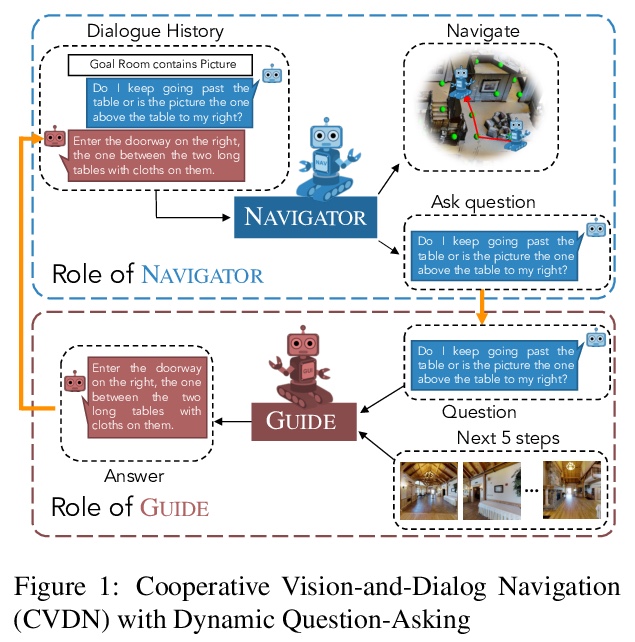
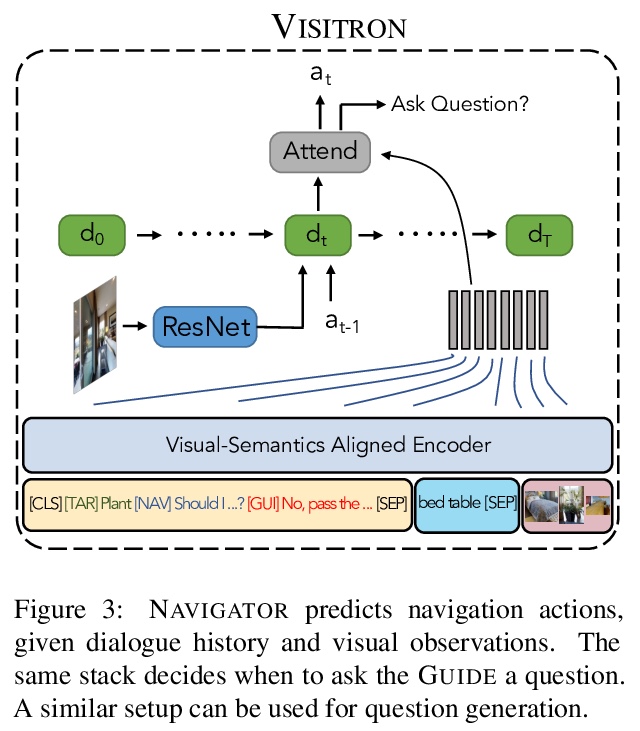
[CV] VISITRON: Visual Semantics-Aligned Interactively Trained Object-Navigator
VISITRON:视觉语义对齐交互式训练对象导航器
A Shrivastava, K Gopalakrishnan, Y Liu, R Piramuthu, G Tür, D Parikh, D Hakkani-Tür
[Georgia Tech & Amazon Alexa AI]
https://weibo.com/1402400261/KhlBdDxW2
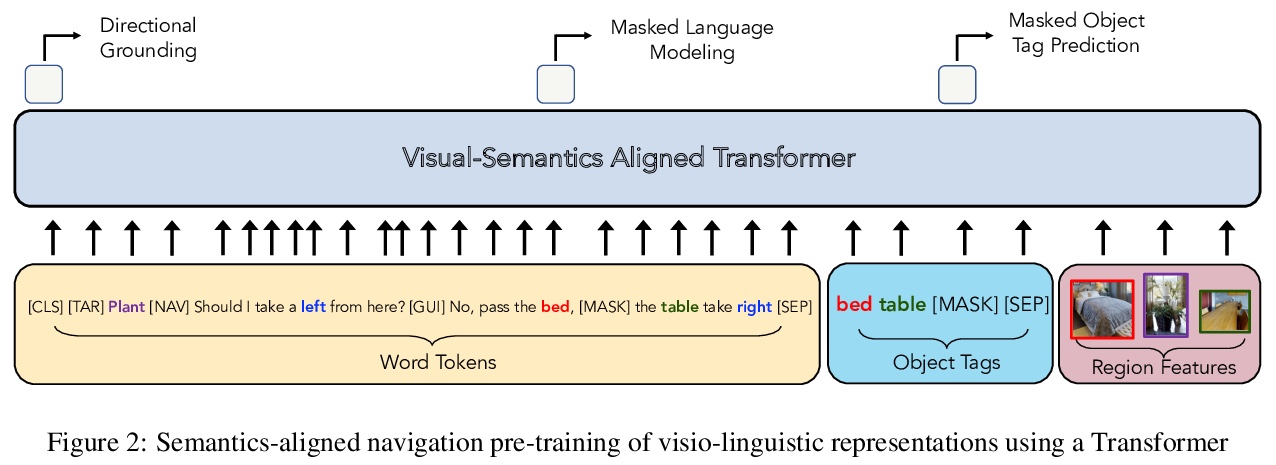
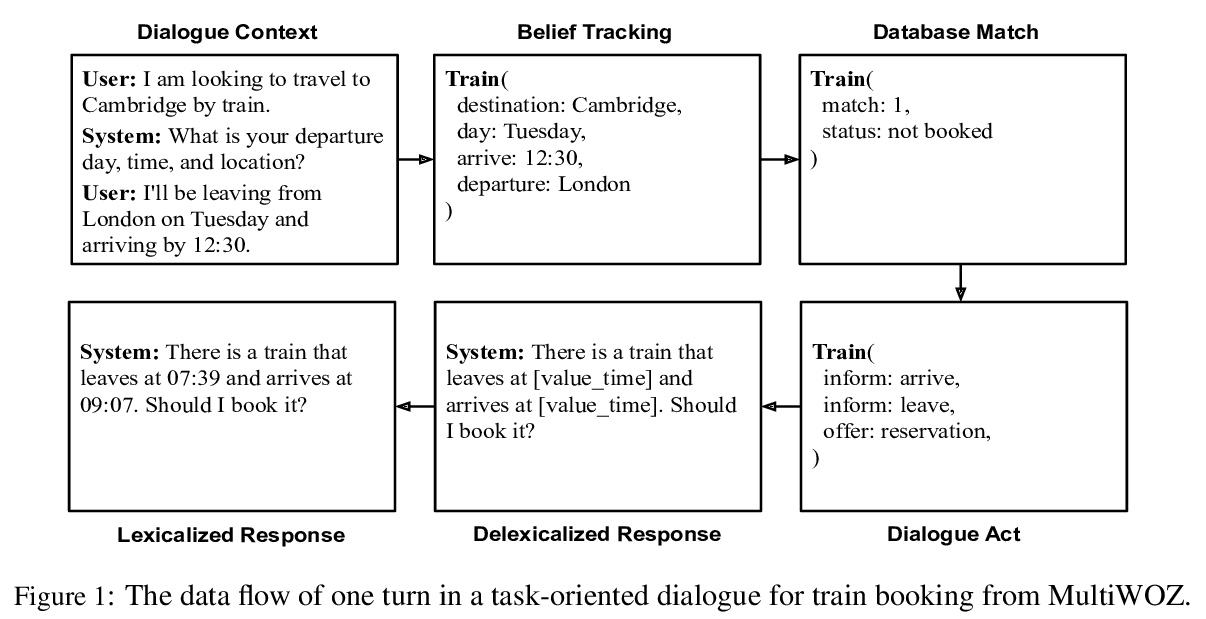
[CL] Pretraining the Noisy Channel Model for Task-Oriented Dialogue
面向任务对话的含噪通道模型预处理
Q Liu, L Yu, L Rimell, P Blunsom
[DeepMind & University of Oxford]
https://weibo.com/1402400261/KhlCzmFnI
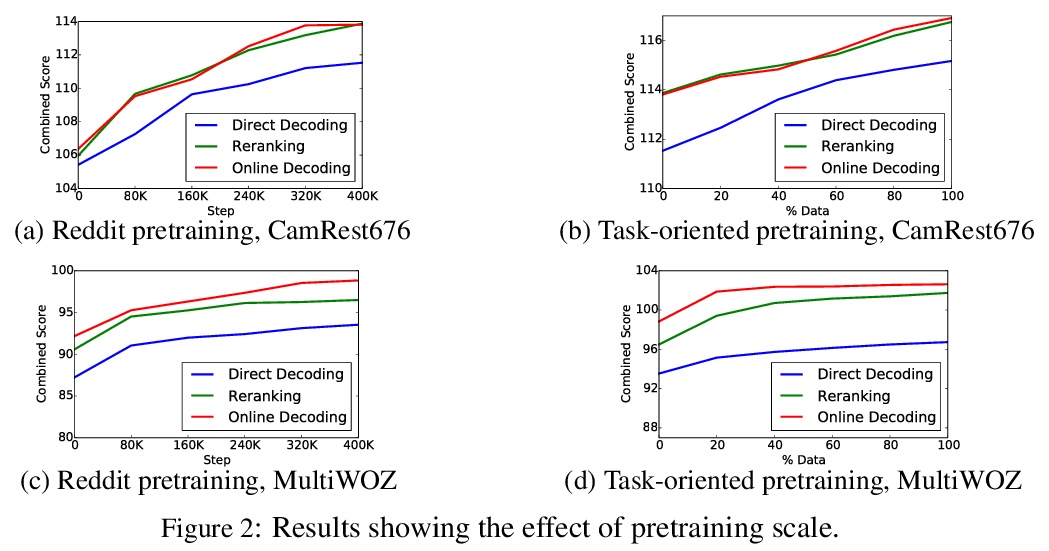
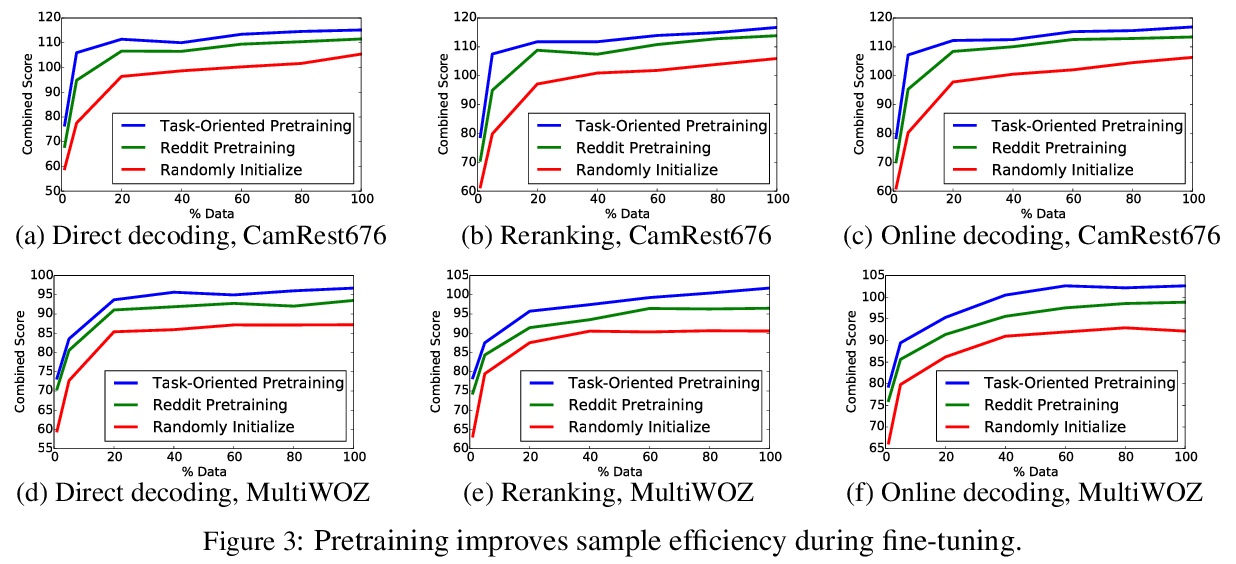
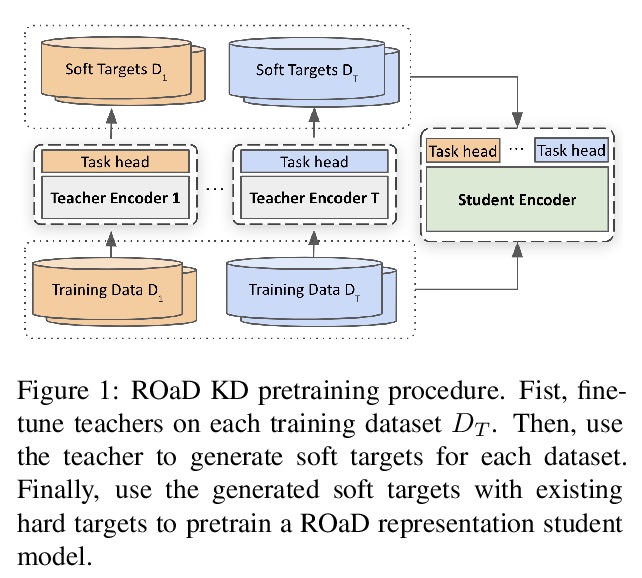
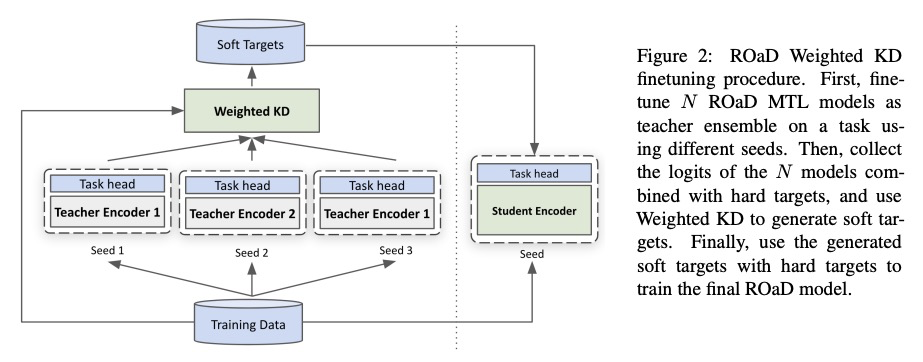
[CL] Robustly Optimized and Distilled Training for Natural Language Understanding
自然语言理解的鲁棒性优化和蒸馏训练
H ElFadeel, S Peshterliev
[Facebook]
https://weibo.com/1402400261/KhlE7jfk7

若有收获,就点个赞吧
0 人点赞
