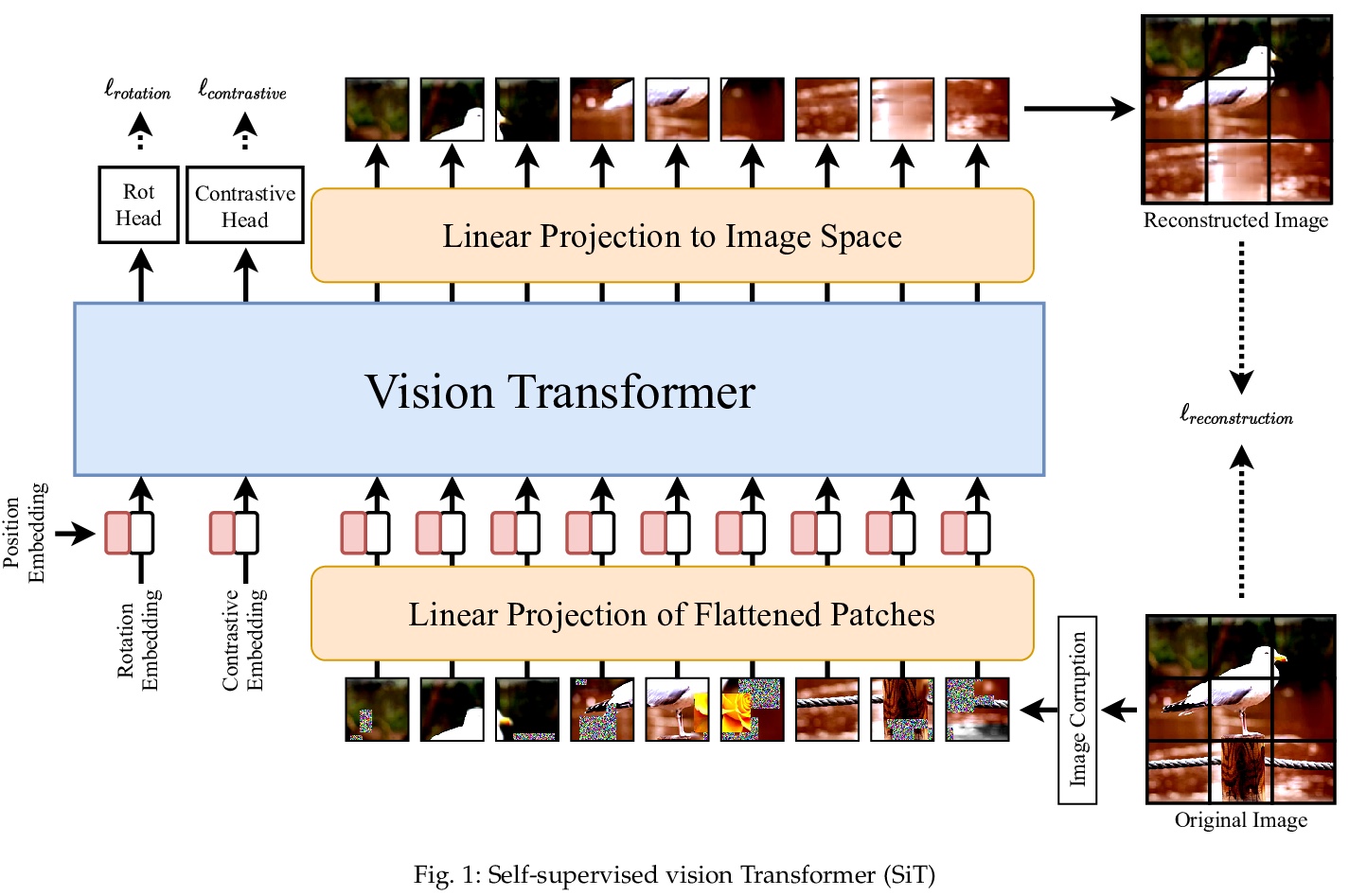
- 1、[CV] SiT: Self-supervised vIsion Transformer
- 2、[CL] Revisiting Simple Neural Probabilistic Language Models
- 3、[CV] InfinityGAN: Towards Infinite-Resolution Image Synthesis
- 4、[CV] De-rendering the World’s Revolutionary Artefacts
- 5、[CV] Does Your Dermatology Classifier Know What It Doesn’t Know? Detecting the Long-Tail of Unseen Conditions
- [CV] CoCoNets: Continuous Contrastive 3D Scene Representations
- [CV] SOLD2: Self-supervised Occlusion-aware Line Description and Detection
- [LG] A single gradient step finds adversarial examples on random two-layers neural networks
- [CV] Localizing Visual Sounds the Hard Way
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] SiT: Self-supervised vIsion Transformer
S Atito, M Awais, J Kittler
[University of Surrey]
SiT:自监督视觉Transformer。提出自监督的图像Transformer,用未标记数据训练来执行前文任务,并将预训练的模型作为初始化,用于下游分类任务的微调。提出用Transformer作为自编码器,通过在输出端使用单个线性层(得益于Transformer架构)来实现。利用Transformer架构的吸引力特性,特别适合将不同的损失函数与重构损失相结合。为每个损失增加了一个token,并将旋转和对比损失与重构损失结合在一起。所提出的SiT以较大优势优于最先进的自监督方法。
Self-supervised learning methods are gaining increasing traction in computer vision due to their recent success in reducing the gap with supervised learning. In natural language processing (NLP) self-supervised learning and transformers are already the methods of choice. The recent literature suggests that the transformers are becoming increasingly popular also in computer vision. So far, the vision transformers have been shown to work well when pretrained either using a large scale supervised data or with some kind of co-supervision, e.g. in terms of teacher network. These supervised pretrained vision transformers achieve very good results in downstream tasks with minimal changes. In this work we investigate the merits of self-supervised learning for pretraining image/vision transformers and then using them for downstream classification tasks. We propose Self-supervised vIsion Transformers (SiT) and discuss several self-supervised training mechanisms to obtain a pretext model. The architectural flexibility of SiT allows us to use it as an autoencoder and work with multiple self-supervised tasks seamlessly. We show that a pretrained SiT can be finetuned for a downstream classification task on small scale datasets, consisting of a few thousand images rather than several millions. The proposed approach is evaluated on standard datasets using common protocols. The results demonstrate the strength of the transformers and their suitability for self-supervised learning. We outperformed existing self-supervised learning methods by large margin. We also observed that SiT is good for few shot learning and also showed that it is learning useful representation by simply training a linear classifier on top of the learned features from SiT. Pretraining, finetuning, and evaluation codes will be available under: > this https URL.
https://weibo.com/1402400261/Kack5C3o0


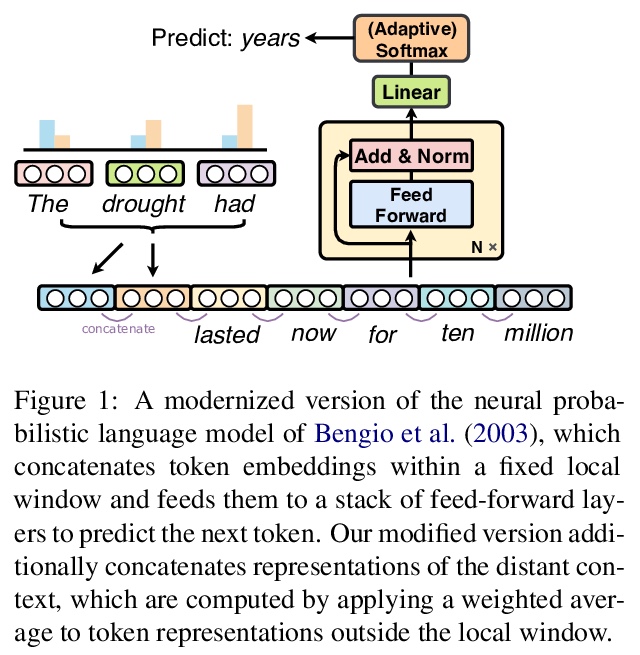
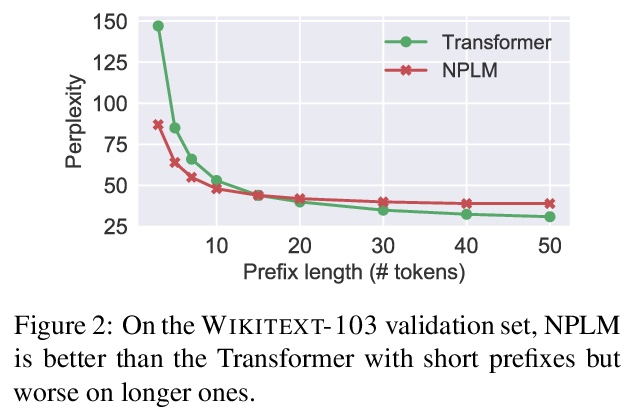
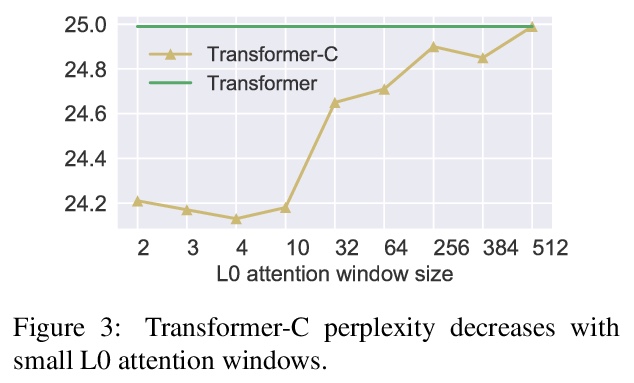
2、[CL] Revisiting Simple Neural Probabilistic Language Models
S Sun, M Iyyer
[University of Massachusetts Amherst]
重新审视简单神经概率语言模型。重新审视了神经概率语言模型(NPLM),简单地在固定窗口内连接词嵌入,并将结果通过前馈网络来预测下一词。扩展到现代硬件时,该模型(尽管有很多限制)在词级语言模型基准上的表现比预期的要好很多。分析显示,NPLM在短输入上下文的情况下,实现了比基线Transformer更低的困惑度,但在处理长程依赖性时却很吃力。受这一结果的启发,对Transformer进行修改,用NPLM的局部连接层替换其第一个自注意层,在三个词级语言建模数据集上实现了小而一致的困惑度降低。
Recent progress in language modeling has been driven not only by advances in neural architectures, but also through hardware and optimization improvements. In this paper, we revisit the neural probabilistic language model (NPLM) of Bengio2003ANP, which simply concatenates word embeddings within a fixed window and passes the result through a feed-forward network to predict the next word. When scaled up to modern hardware, this model (despite its many limitations) performs much better than expected on word-level language model benchmarks. Our analysis reveals that the NPLM achieves lower perplexity than a baseline Transformer with short input contexts but struggles to handle long-term dependencies. Inspired by this result, we modify the Transformer by replacing its first self-attention layer with the NPLM’s local concatenation layer, which results in small but consistent perplexity decreases across three word-level language modeling datasets.
https://weibo.com/1402400261/Kacq2704M
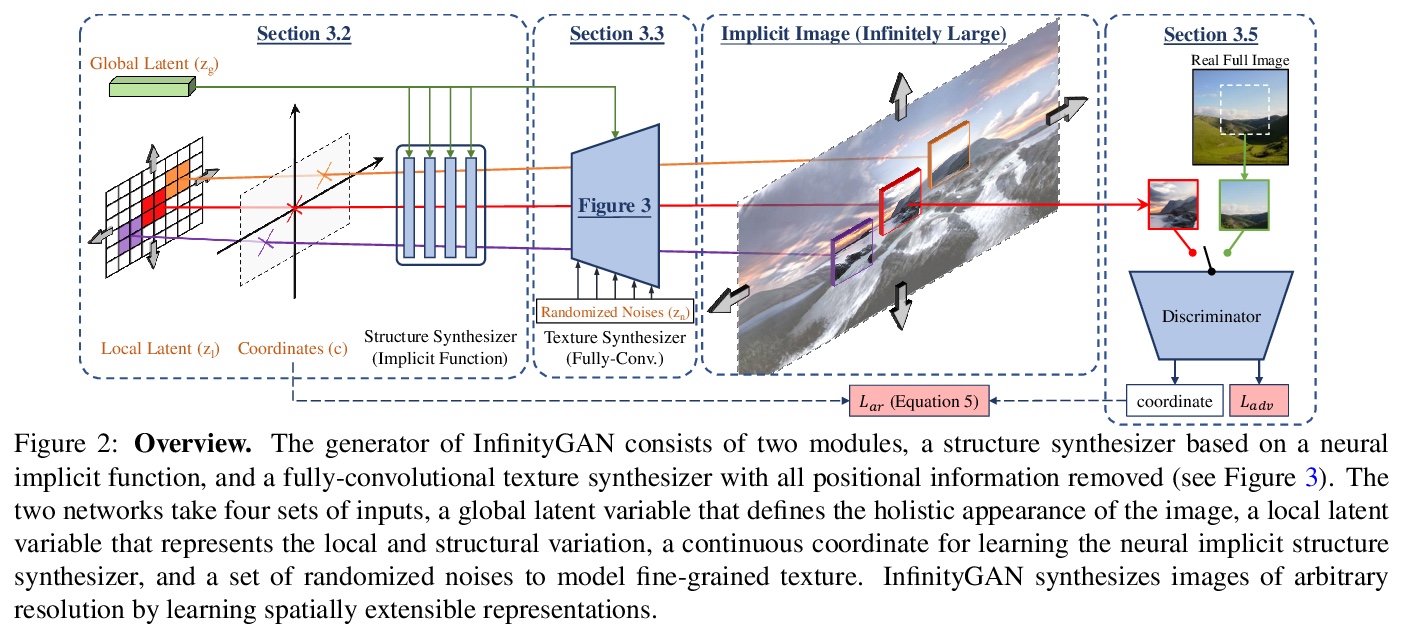
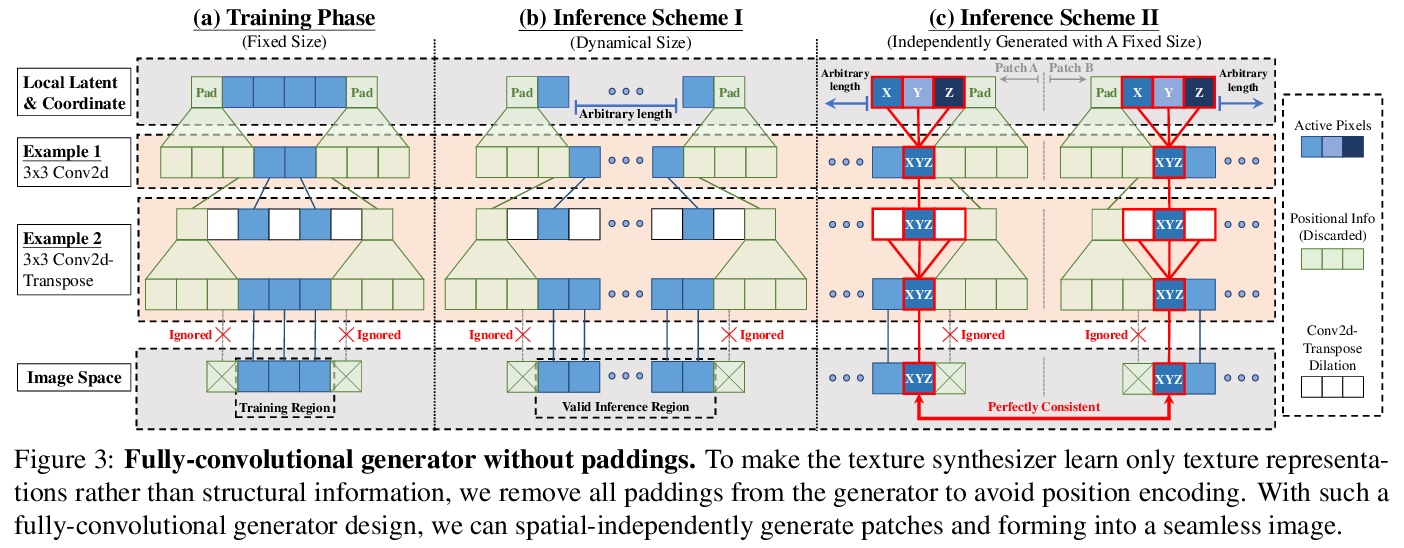
3、[CV] InfinityGAN: Towards Infinite-Resolution Image Synthesis
C H Lin, H Lee, Y Cheng, S Tulyakov, M Yang
[UC Merced & Snap Inc & CMU]
InfinityGAN:无限分辨率图像合成探索。提出InfinityGAN,一种在有限的低分辨率数据集上进行训练,同时在推理时生成无限分辨率图像的方法。为达到全局一致性,假设一个大图像中的所有图块具有相同的整体外观。局部纹理和结构被分别建模,使得该方法可合成不同的局部细节。InfinityGAN由一个神经隐函数(结构合成器)和一个全卷积StyleGAN2生成器(纹理合成器)组成。结构合成器以全局外观为条件,从一个可扩展到无限分辨率的隐式图像中抽取子区域样本,并产生局部结构表示。纹理合成器是为了避免CNN的通用位置编码,为结构合成器提供的结构生成纹理。InfinityGAN可推断出场景令人信服的全局构成,并真实呈现其局部细节。InfinityGAN在小图块上进行训练,实现了高质量、无缝和高分辨率的输出,所需计算资源很低—一台TITAN X就可以进行训练和测试。
We present InfinityGAN, a method to generate arbitrary-resolution images. The problem is associated with several key challenges. First, scaling existing models to a high resolution is resource-constrained, both in terms of computation and availability of high-resolution training data. Infinity-GAN trains and infers patch-by-patch seamlessly with low computational resources. Second, large images should be locally and globally consistent, avoid repetitive patterns, and look realistic. To address these, InfinityGAN takes global appearance, local structure and texture into account.With this formulation, we can generate images with resolution and level of detail not attainable before. Experimental evaluation supports that InfinityGAN generates imageswith superior global structure compared to baselines at the same time featuring parallelizable inference. Finally, we how several applications unlocked by our approach, such as fusing styles spatially, multi-modal outpainting and image inbetweening at arbitrary input and output resolutions
https://weibo.com/1402400261/Kacw6jUDo

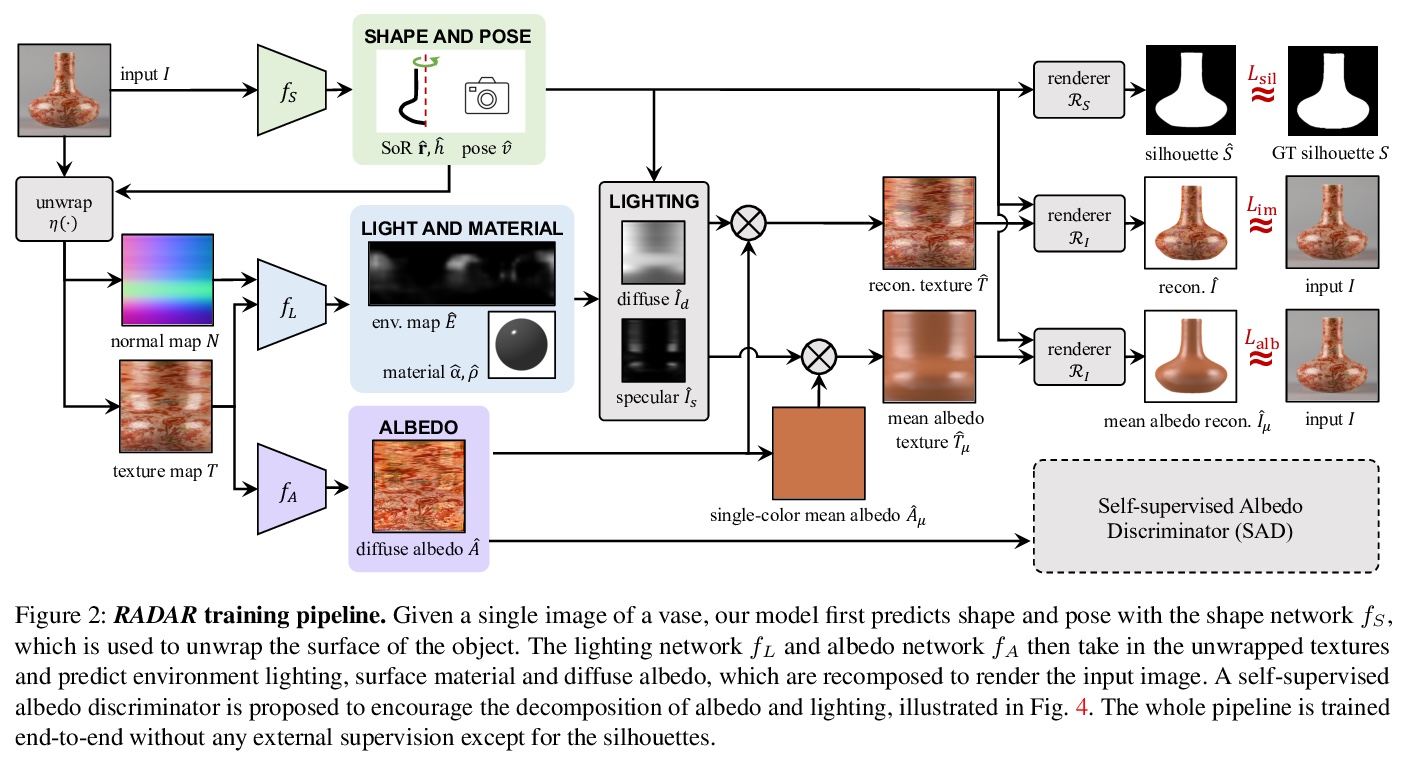
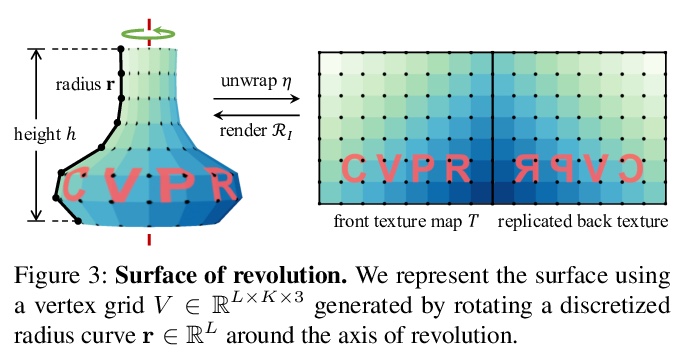
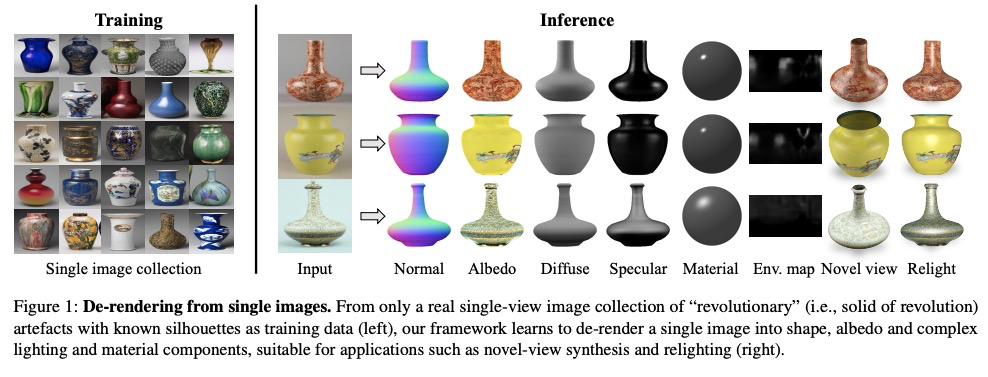
4、[CV] De-rendering the World’s Revolutionary Artefacts
S Wu, A Makadia, J Wu, N Snavely, R Tucker, A Kanazawa
[University of Oxford & Stanford University & UC Berkeley & Google Research]
旋转对称工艺品的反渲染。提出RADAR方法,可从实际的单幅图像集合中恢复环境照明和表面材料,既不依赖于显式的3D监督,也不依赖于多视角或多光线图像。RADAR专注于旋转对称的人工制品,其表现出具有挑战性的表面特性,包括镜面反射,如花瓶。引入了一种新的自监督反照率判别器,在训练过程中不需要任何真实值监督就能恢复可信的反照率。结合利用旋转对称性的形状重建模块,构建了一个端到端学习框架,能实现旋转对称工艺品的反渲染。在一个真实的花瓶数据集上进行实验,展示了令人信服的分解结果,可应用于包括自由视角渲染和再照明。
Recent works have shown exciting results in unsupervised image de-rendering — learning to decompose 3D shape, appearance, and lighting from single-image collections without explicit supervision. However, many of these assume simplistic material and lighting models. We propose a method, termed RADAR, that can recover environment illumination and surface materials from real single-image collections, relying neither on explicit 3D supervision, nor on multi-view or multi-light images. Specifically, we focus on rotationally symmetric artefacts that exhibit challenging surface properties including specular reflections, such as vases. We introduce a novel self-supervised albedo discriminator, which allows the model to recover plausible albedo without requiring any ground-truth during training. In conjunction with a shape reconstruction module exploiting rotational symmetry, we present an end-to-end learning framework that is able to de-render the world’s revolutionary artefacts. We conduct experiments on a real vase dataset and demonstrate compelling decomposition results, allowing for applications including free-viewpoint rendering and relighting.
https://weibo.com/1402400261/KacBedBgg
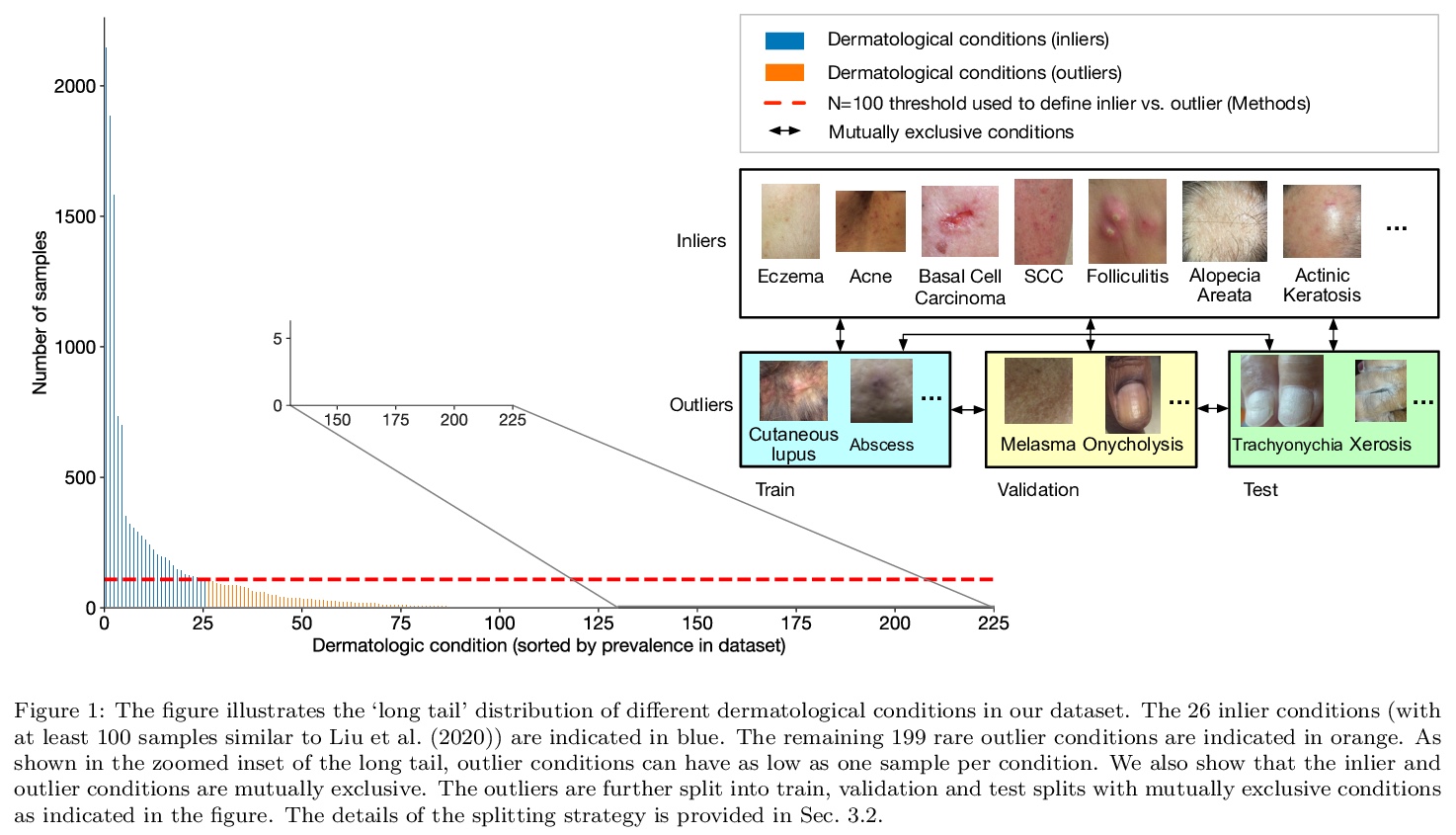
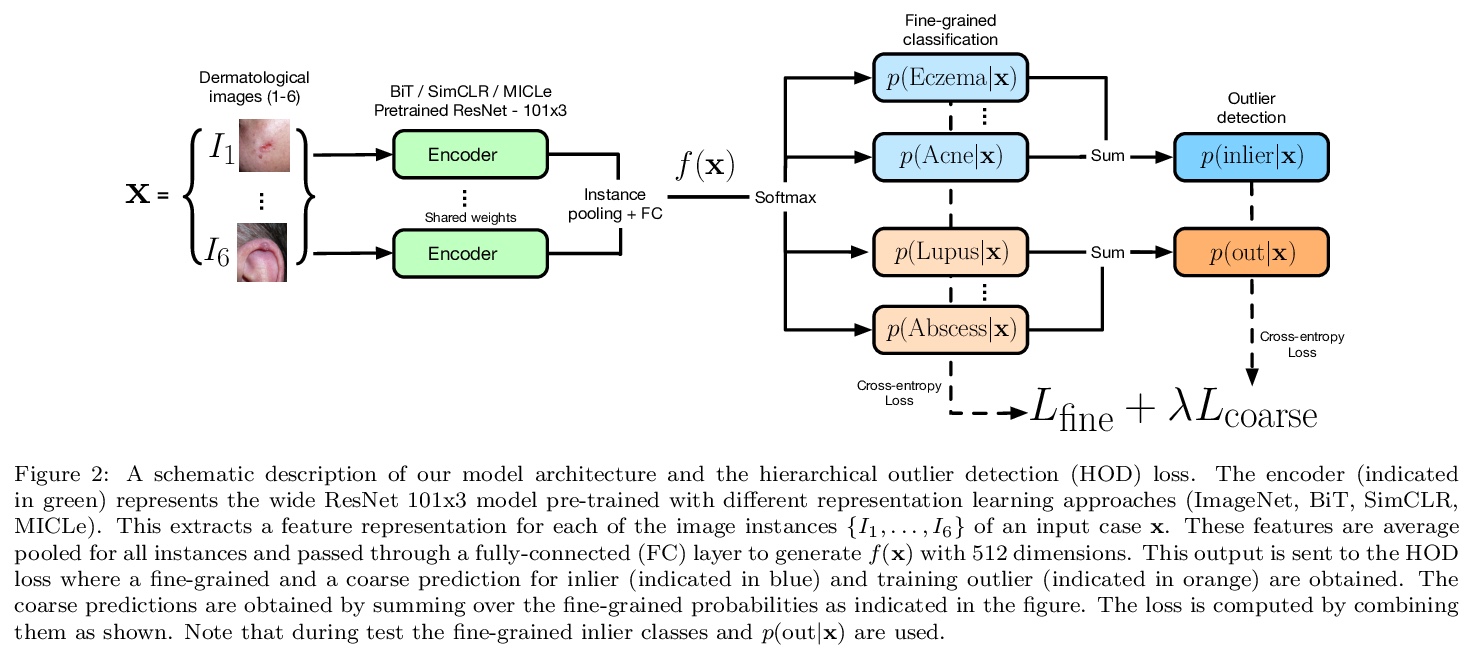
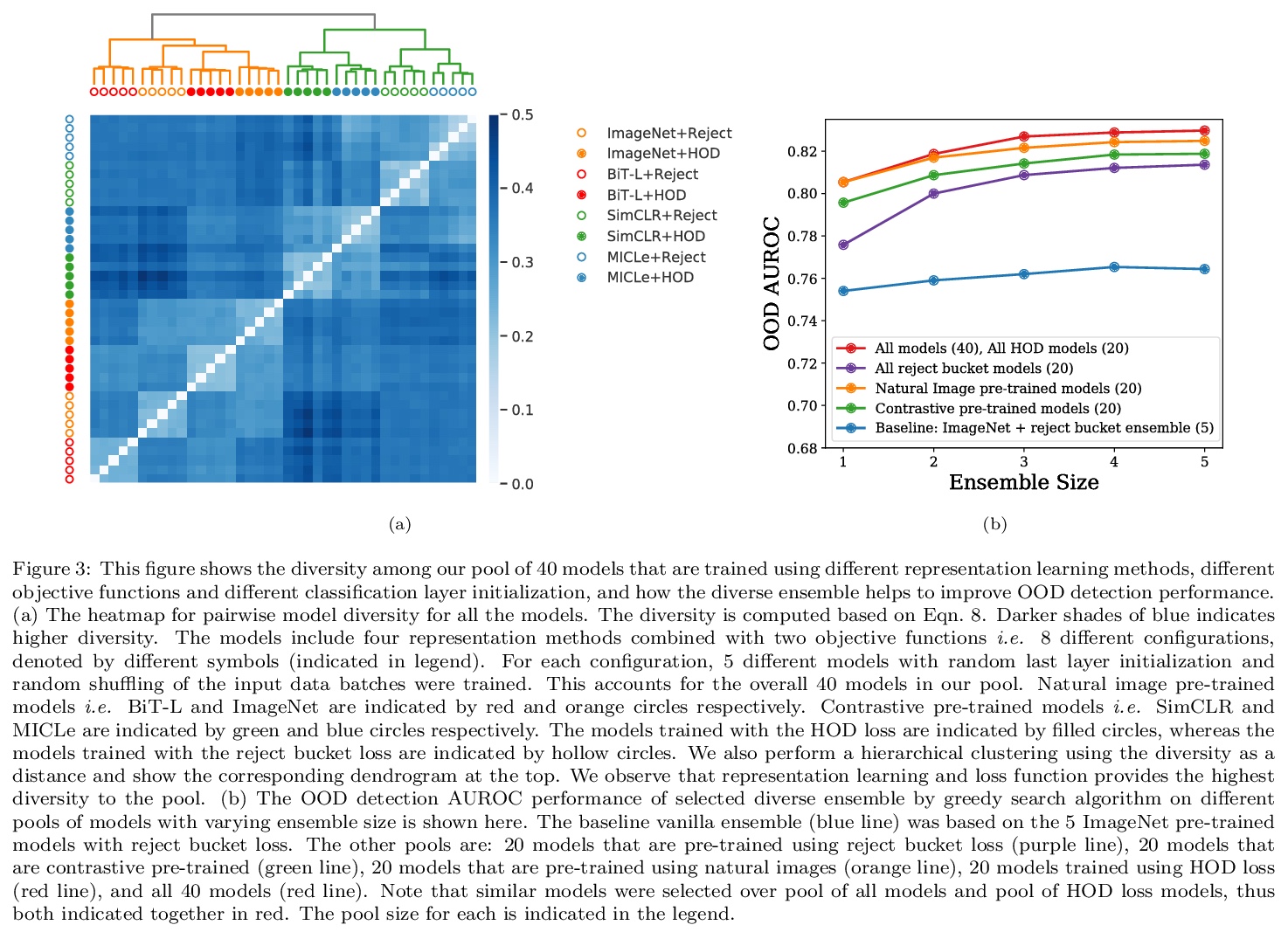
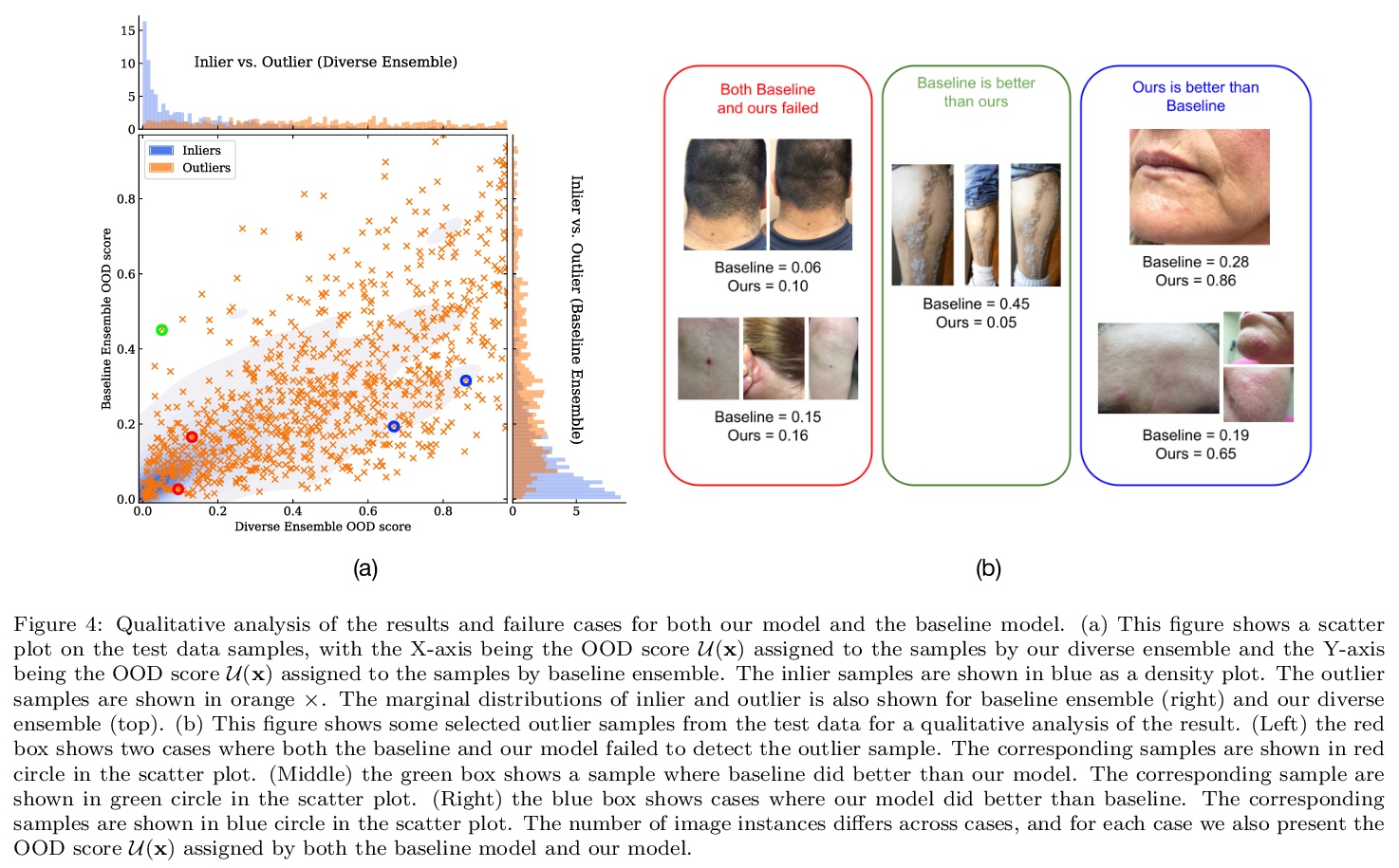
5、[CV] Does Your Dermatology Classifier Know What It Doesn’t Know? Detecting the Long-Tail of Unseen Conditions
A G Roy, J Ren, S Azizi, A Loh, V Natarajan, B Mustafa, N Pawlowski, J Freyberg, Y Liu, Z Beaver, N Vo, P Bui, S Winter, P MacWilliams, G S. Corrado, U Telang, Y Liu, T Cemgil, A Karthikesalingam, B Lakshminarayanan, J Winkens
[Google Health & Google Research & DeepMind]
不可见病症的长尾检测。现实世界中,许多皮肤病都是个别太不常见的,不适合用监督学习对每个病症进行分类,这些不常见的”异常值”条件在训练过程中很少看到(或根本没有),本文中,将这一任务框定为分布外检测(OOD)问题。建立了一个基准,确保离群值条件在模型训练、验证和测试集之间是不相干的。提出了一种新的层次离群检测(HOD)损失,优于现有的基于离群暴露的技术来检测OOD输入。展示了在多种不同的最先进的表示学习方法(基于SimCLR和MICLe的自监督对比式预训练)的背景下,新型HOD损失的附加效用,展示了大规模标准基准(ImageNet和BiT模型在大规模JFT数据集上预训练)上的OOD检测性能提升。建议用具有不同表征学习和目标的多样化合集来提高OOD检测性能。提出了一个用于模型信任分析的成本加权评估指标,该指标结合了下游的临床影响,以帮助评估现实世界的影响。
We develop and rigorously evaluate a deep learning based system that can accurately classify skin conditions while detecting rare conditions for which there is not enough data available for training a confident classifier. We frame this task as an out-of-distribution (OOD) detection problem. Our novel approach, hierarchical outlier detection (HOD) assigns multiple abstention classes for each training outlier class and jointly performs a coarse classification of inliers vs. outliers, along with fine-grained classification of the individual classes. We demonstrate the effectiveness of the HOD loss in conjunction with modern representation learning approaches (BiT, SimCLR, MICLe) and explore different ensembling strategies for further improving the results. We perform an extensive subgroup analysis over conditions of varying risk levels and different skin types to investigate how the OOD detection performance changes over each subgroup and demonstrate the gains of our framework in comparison to baselines. Finally, we introduce a cost metric to approximate downstream clinical impact. We use this cost metric to compare the proposed method against a baseline system, thereby making a stronger case for the overall system effectiveness in a real-world deployment scenario.
https://weibo.com/1402400261/KacGQEWqt
另外几篇值得关注的论文:
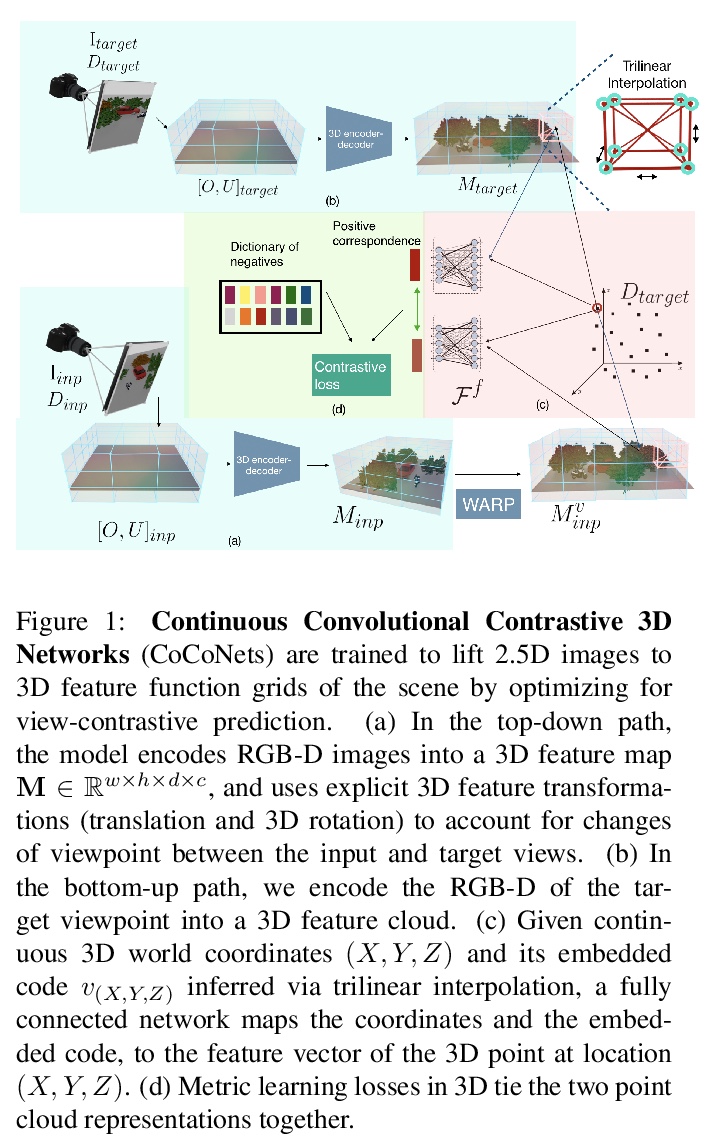
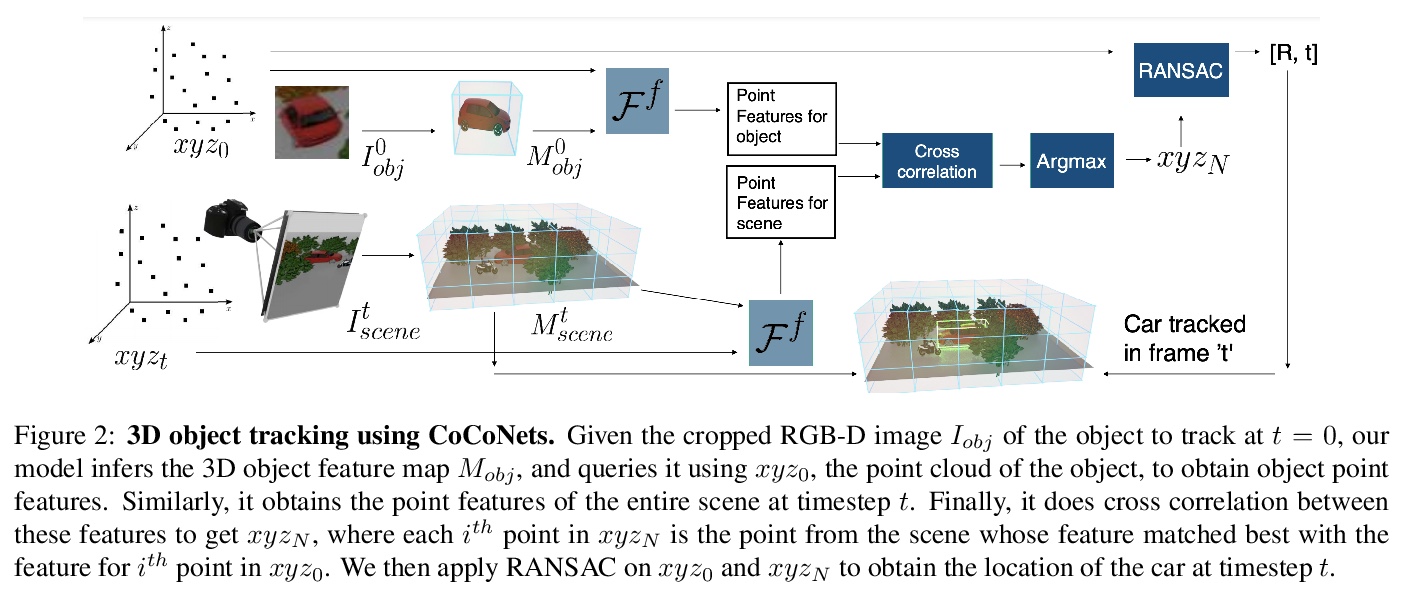
[CV] CoCoNets: Continuous Contrastive 3D Scene Representations
CoCoNets:连续对比3D场景表示
S Lal, M Prabhudesai, I Mediratta, A W. Harley, K Fragkiadaki
[CMU]
https://weibo.com/1402400261/KacLaFBSV

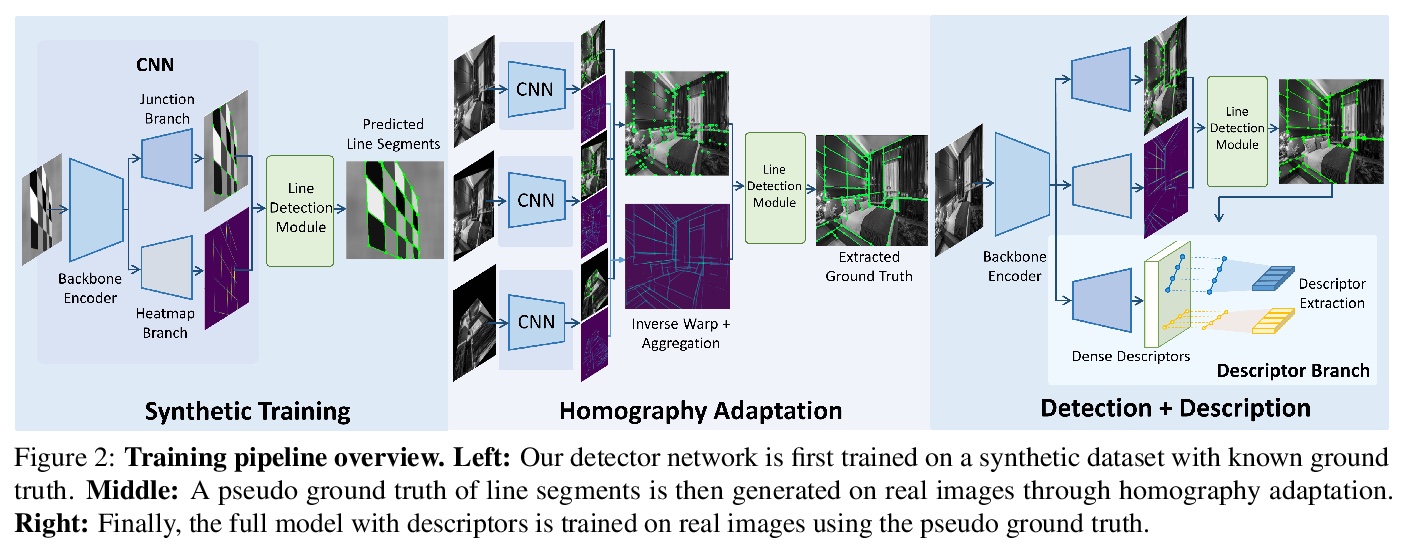
[CV] SOLD2: Self-supervised Occlusion-aware Line Description and Detection
SOLD2:自监督遮挡感知线描述与检测
R Pautrat, J Lin, V Larsson, M R. Oswald, M Pollefeys
[ETH Zurich]
https://weibo.com/1402400261/KacOc1k4u


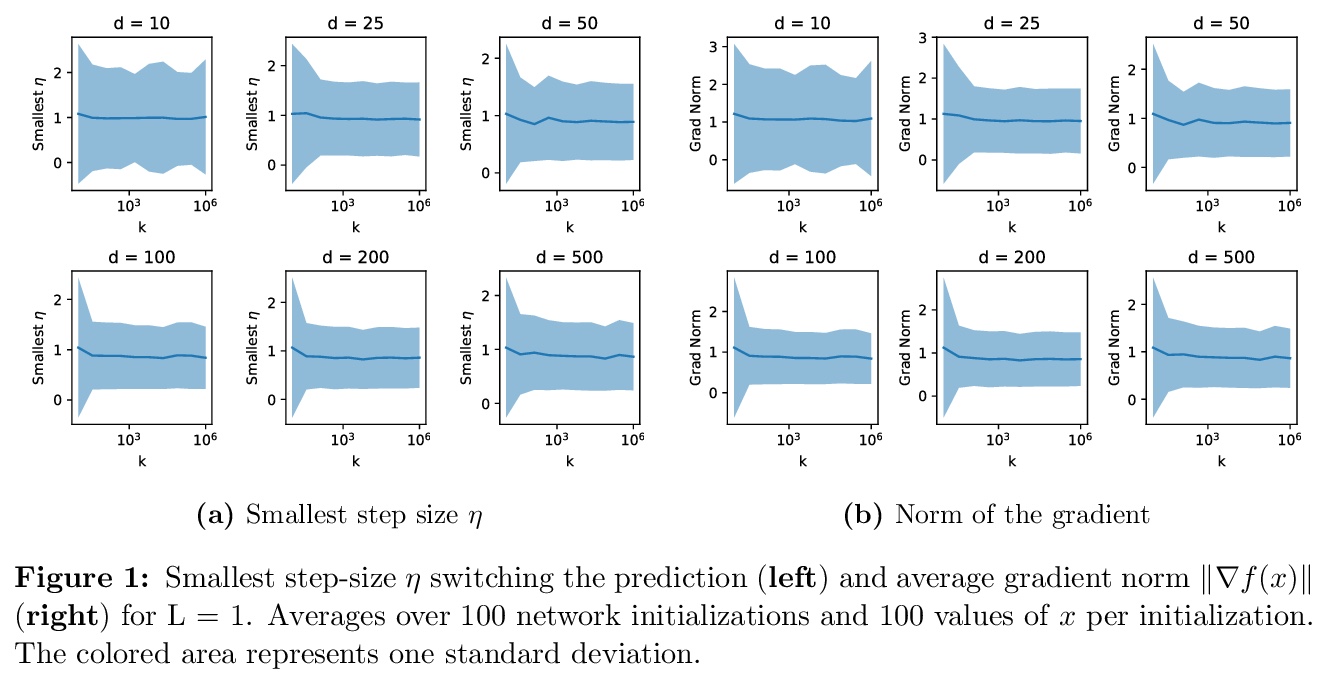
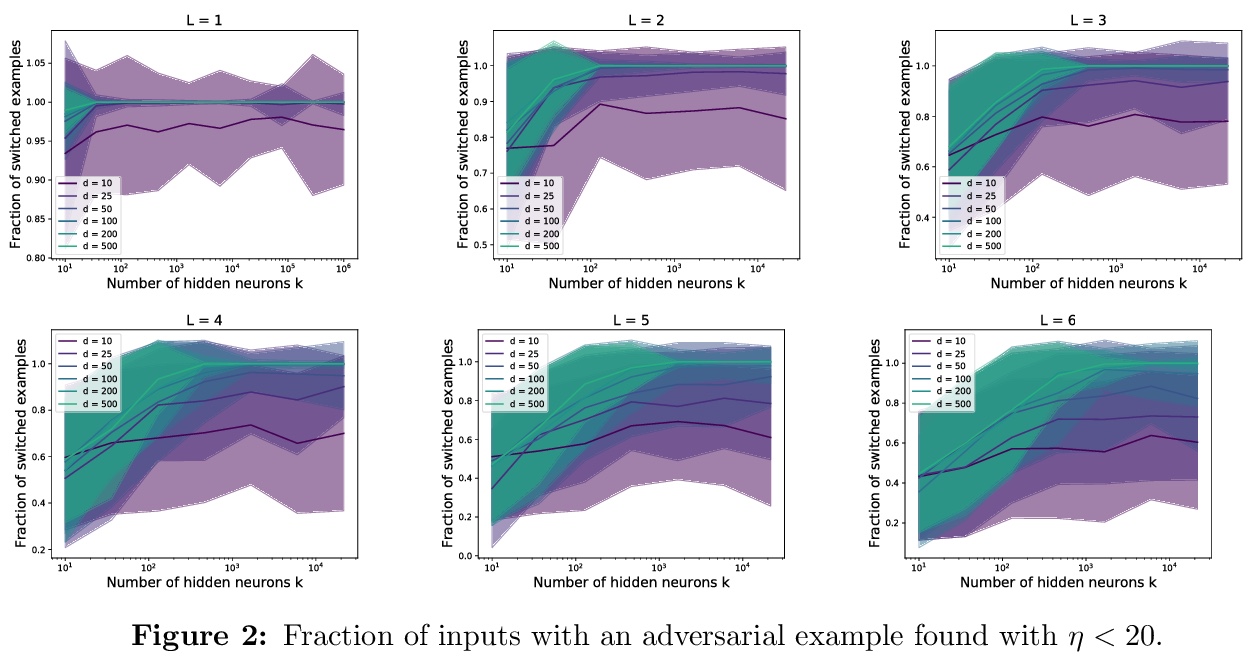
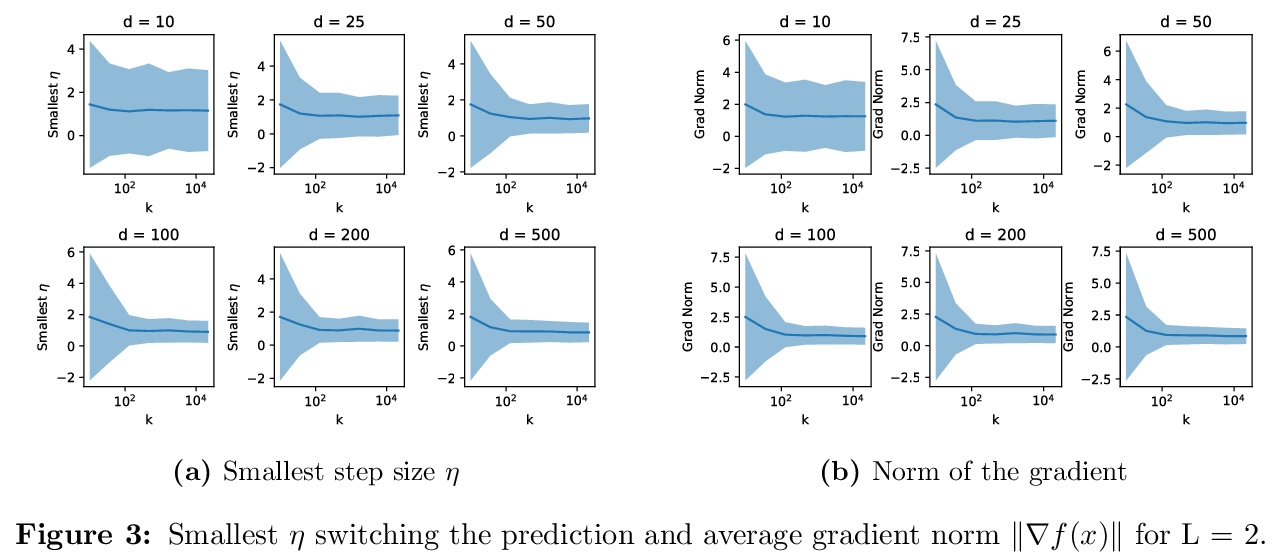
[LG] A single gradient step finds adversarial examples on random two-layers neural networks
随机两层神经网络单步梯度对抗样本发现
S Bubeck, Y Cherapanamjeri, G Gidel, R T d Combes
[Microsoft Research & UC Berkeley & Mila]
https://weibo.com/1402400261/KacR01N2J
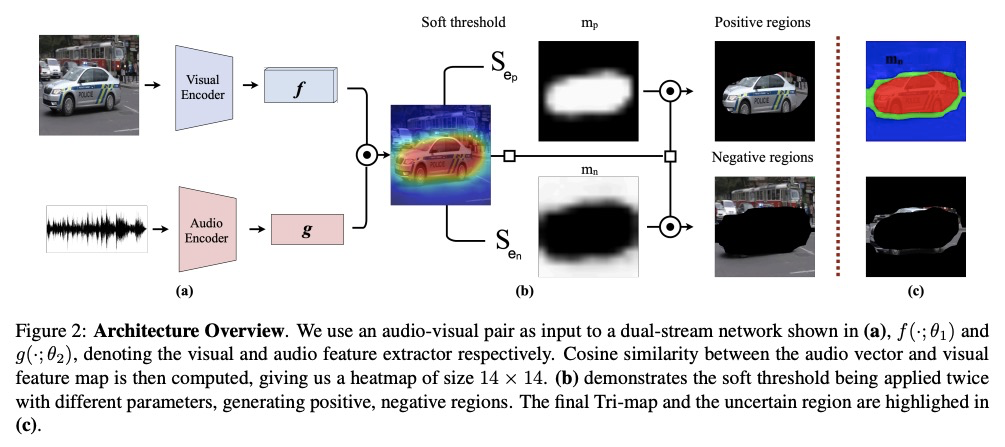
[CV] Localizing Visual Sounds the Hard Way
视觉音源定位
H Chen, W Xie, T Afouras, A Nagrani, A Vedaldi, A Zisserman
[University of Oxford]
https://weibo.com/1402400261/KacUmpmo3


若有收获,就点个赞吧
0 人点赞
