- 1、[LG] DC3: A learning method for optimization with hard constraints
- 2、[CV] The Temporal Opportunist: Self-Supervised Multi-Frame Monocular Depth
- 3、[CV] Image-Level or Object-Level? A Tale of Two Resampling Strategies for Long-Tailed Detection
- 4、[LG] Model Learning with Personalized Interpretability Estimation (ML-PIE)
- 5、[LG] Probing artificial neural networks: insights from neuroscience
- [RO] RoboStack: Using the Robot Operating System alongside the Conda and Jupyter Data Science Ecosystems
- [CV] Twins: Revisiting Spatial Attention Design in Vision Transformers
- [CV] Multimodal Contrastive Training for Visual Representation Learning
- [CV] Learning optical flow from still images
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] DC3: A learning method for optimization with hard constraints
P L. Donti, D Rolnick, J. Z Kolter
[CMU & McGill University and Mila]
DC3:一种硬约束优化学习方法。许多情况下,会碰到带有硬约束的大型优化问题,然而经典的求解器往往会非常慢,促使深度网络成为廉价的”近似求解器”。但是,简单深度学习方法通常无法强制实现这类问题的硬约束,导致解决方案不可行。本文提出深度约束完成与修正(DC3),以解决该挑战,将(潜在的非凸的)等式和不等式约束纳入基于深度学习的优化算法。通过一个可微程序来实现可行性,隐式地完成部分解决方案以满足等式约束,并展开基于梯度的修正以满足不等式约束。实践证明了DC3的可行性,在凸和非凸优化环境中实施DC3算法。证明了该算法在产生近似解决方案方面的成功,其可行性明显优于其他深度学习方法,同时保持了解决方案的接近最优性。展示了用一般的DC3框架来优化电网上的电力流,这一困难的非凸优化任务必须得到大规模的解决,对于可再生能源的采用尤为关键。
Large optimization problems with hard constraints arise in many settings, yet classical solvers are often prohibitively slow, motivating the use of deep networks as cheap “approximate solvers.” Unfortunately, naive deep learning approaches typically cannot enforce the hard constraints of such problems, leading to infeasible solutions. In this work, we present Deep Constraint Completion and Correction (DC3), an algorithm to address this challenge. Specifically, this method enforces feasibility via a differentiable procedure, which implicitly completes partial solutions to satisfy equality constraints and unrolls gradient-based corrections to satisfy inequality constraints. We demonstrate the effectiveness of DC3 in both synthetic optimization tasks and the real-world setting of AC optimal power flow, where hard constraints encode the physics of the electrical grid. In both cases, DC3 achieves near-optimal objective values while preserving feasibility.
https://weibo.com/1402400261/KdH7Wdycu
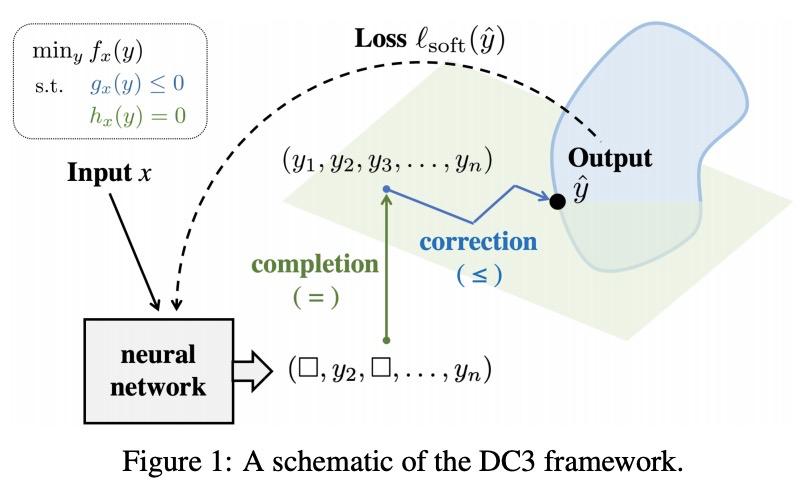
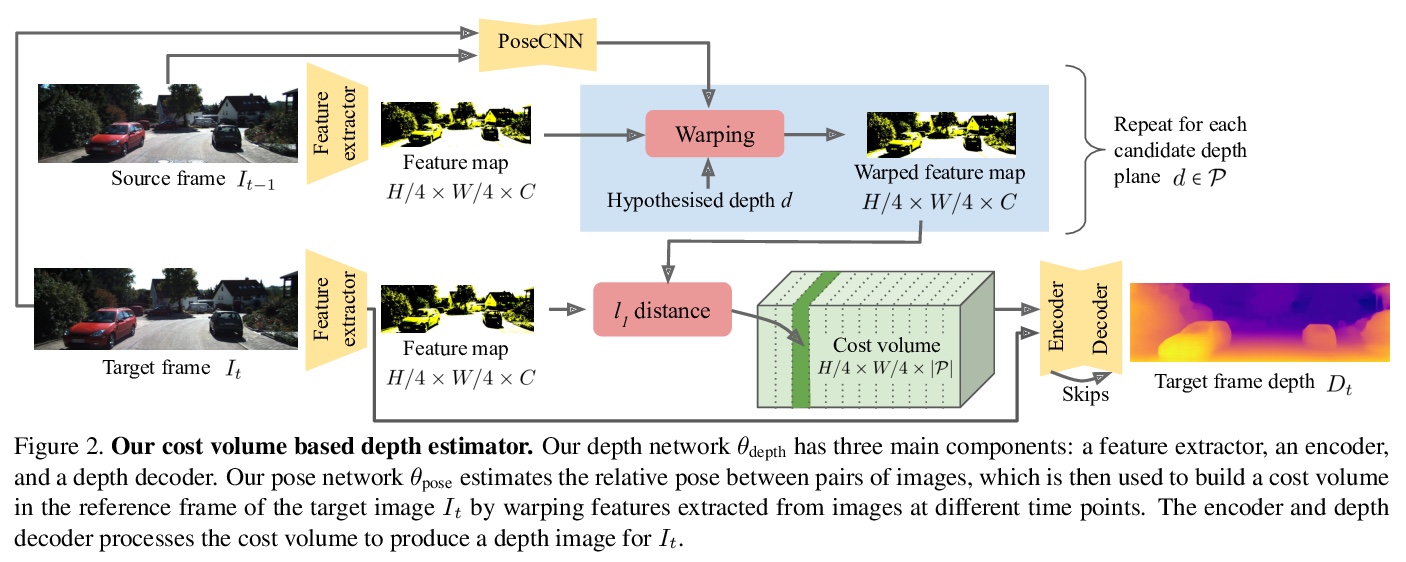
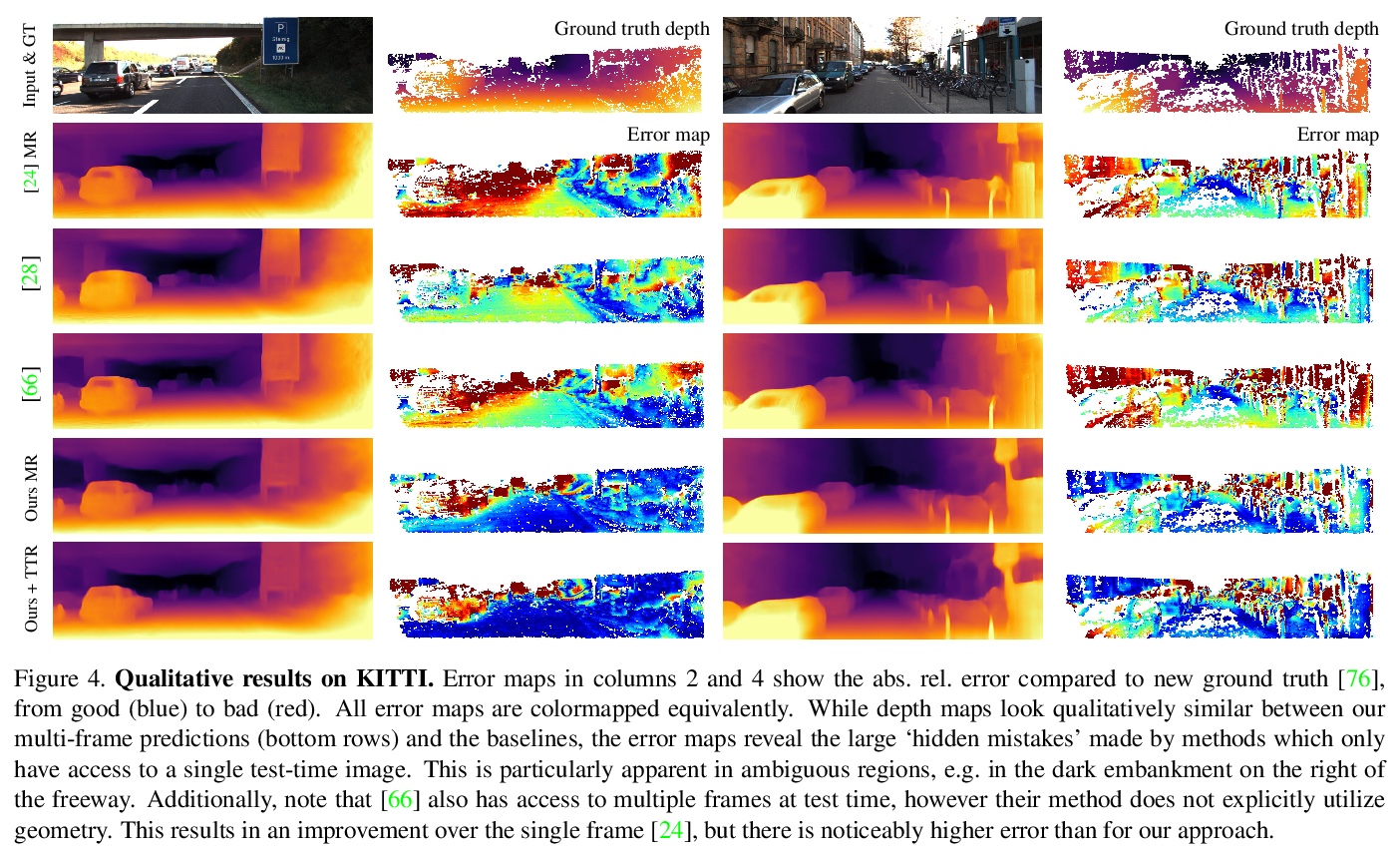
2、[CV] The Temporal Opportunist: Self-Supervised Multi-Frame Monocular Depth
J Watson, O M Aodha, V Prisacariu, G Brostow, M Firman
[Niantic & University of Edinburgh]
ManyDepth:自监督多帧单目深度估计。自监督单目深度估计网络在训练期间用邻近帧作为监督信号来预测场景深度。然而,对许多应用来说,视频帧形式的序列信息在测试时也是可用的。绝大多数的单目网络没有利用这个额外信号,忽略了可以用来改善深度预测的宝贵信息。而利用了这些信息的网络,要么用计算成本很高的测试时细化技术,要么用现成的递归网络,这些网络只是间接利用了固有的几何信息。本文提出ManyDepth,一种密集深度估计的自适应方法,结合了单目和多视角深度估计的优势,可在测试时利用可用序列信息,从单张图像或多张图像做出准确的深度预测。受多视角立体视觉启发,提出一种基于深度端到端代价体的方法,只用自监督进行训练。提出一种新的一致性损失,鼓励网络在代价体被认为不可靠的情况下,例如在移动物体的情况下,忽略代价体,并提出了一种增强方案来应对静态相机。在KITTI和Cityscapes上的实验表明,ManyDepth性能优于所有公布的自监督基线,包括那些在测试时使用单帧或多帧的基线。
Self-supervised monocular depth estimation networks are trained to predict scene depth using nearby frames as a supervision signal during training. However, for many applications, sequence information in the form of video frames is also available at test time. The vast majority of monocular networks do not make use of this extra signal, thus ignoring valuable information that could be used to improve the predicted depth. Those that do, either use computationally expensive test-time refinement techniques or off-theshelf recurrent networks, which only indirectly make use of the geometric information that is inherently available. We propose ManyDepth, an adaptive approach to dense depth estimation that can make use of sequence information at test time, when it is available. Taking inspiration from multi-view stereo, we propose a deep end-to-end cost volume based approach that is trained using self-supervision only. We present a novel consistency loss that encourages the network to ignore the cost volume when it is deemed unreliable, e.g. in the case of moving objects, and an augmentation scheme to cope with static cameras. Our detailed experiments on both KITTI and Cityscapes show that we outperform all published self-supervised baselines, including those that use single or multiple frames at test time.
https://weibo.com/1402400261/KdHfz0SV4

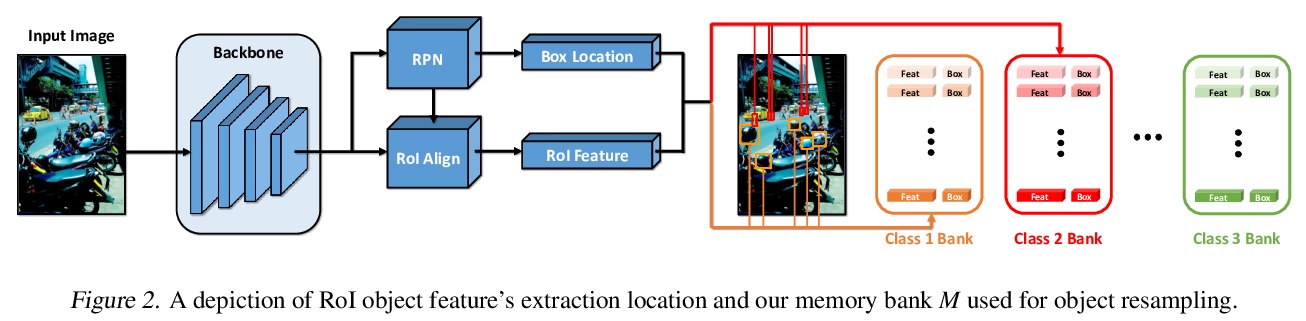
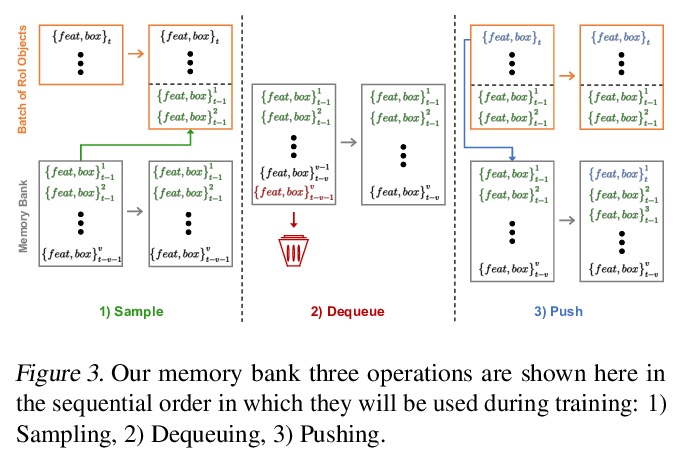
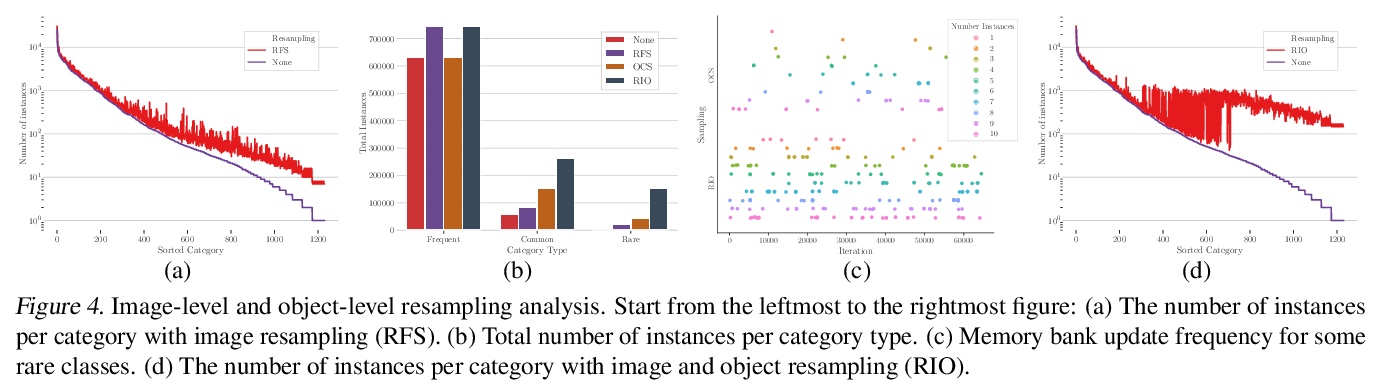
3、[CV] Image-Level or Object-Level? A Tale of Two Resampling Strategies for Long-Tailed Detection
N Chang, Z Yu, Y Wang, A Anandkumar, S Fidler, J M. Alvarez
[CMU & NVIDIA & Univ of Illinois at Urbana-Champaign]
图像级还是对象级?长尾检测的两种重采样策略。在具有长尾分布的数据集上进行训练,对分类和检测等主要识别任务来说是一个挑战。为应对这一挑战,图像重采样通常作为一种简单而有效的方法引入。然而,长尾检测与分类不同,因为一个图像中可能存在多个类别,仅靠图像重采样不足以在物体层面产生足够的平衡分布。通过引入以对象为中心的记忆重放策略,来解决对象层面的重采样问题,该策略基于动态的、偶发性的记忆库。所提出的策略有两方面优点:1)方便的对象级重采样,不需要大量的额外计算,2)来自模型更新的隐性特征级增强。图像级和对象级重采样都很重要,用联合重采样策略(RIO)将它们统一起来。所提方法在LVIS v0.5上的长尾检测和分割方法在各种骨架上的表现都超过了最先进的方法。
Training on datasets with long-tailed distributions has been challenging for major recognition tasks such as classification and detection. To deal with this challenge, image resampling is typically introduced as a simple but effective approach. However, we observe that long-tailed detection differs from classification since multiple classes may be present in one image. As a result, image resampling alone is not enough to yield a sufficiently balanced distribution at the object level. We address object-level resampling by introducing an object-centric memory replay strategy based on dynamic, episodic memory banks. Our proposed strategy has two benefits: 1) convenient object-level resampling without significant extra computation, and 2) implicit feature-level augmentation from model updates. We show that image-level and object-level resamplings are both important, and thus unify them with a joint resampling strategy (RIO). Our method outperforms state-of-the-art long-tailed detection and segmentation methods on LVIS v0.5 across various backbones.
https://weibo.com/1402400261/KdHqMik3X

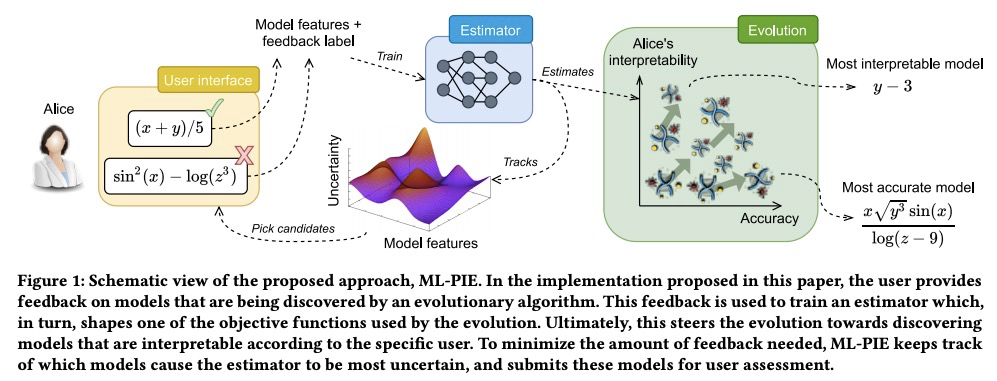
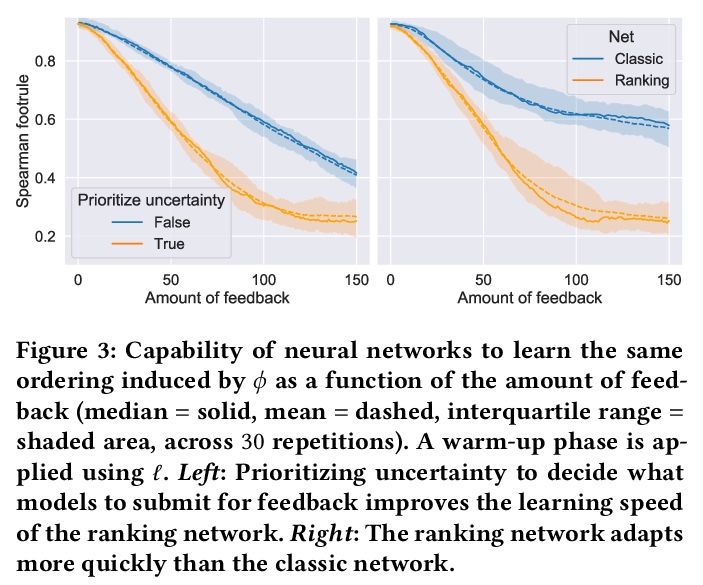
4、[LG] Model Learning with Personalized Interpretability Estimation (ML-PIE)
M Virgolin, A D Lorenzo, F Randone, E Medvet, M Wahde
[Chalmers University of Technology & University of Trieste & IMT Lucca]
基于个性化可解释性估计的模型学习。高风险应用要求人工智能生成的模型是可解释的。目前用于合成潜在可解释性模型的算法依赖于目标或正则化条件,这些条件仅粗略地表示可解释性(如模型大小),且不是为特定用户设计的。然而,可解释性在本质上是主观的。本文提出一种为用户量身定做的模型合成方法,使用户能根据其偏好来引导模型合成过程。用一种双目标进化算法来合成模型,在准确性和用户特定可解释性概念间进行权衡。后者由一个神经网络来进行估计,该网络使用用户反馈来训练进化,这些反馈是通过基于不确定性的主动学习收集的。该方法能学习对可解释性的估计,这些估计对不同的用户来说可能是非常不同的。
High-stakes applications require AI-generated models to be interpretable. Current algorithms for the synthesis of potentially interpretable models rely on objectives or regularization terms that represent interpretability only coarsely (e.g., model size) and are not designed for a specific user. Yet, interpretability is intrinsically subjective. In this paper, we propose an approach for the synthesis of models that are tailored to the user by enabling the user to steer the model synthesis process according to her or his preferences. We use a bi-objective evolutionary algorithm to synthesize models with trade-offs between accuracy and a user-specific notion of interpretability. The latter is estimated by a neural network that is trained concurrently to the evolution using the feedback of the user, which is collected using uncertainty-based active learning. To maximize usability, the user is only asked to tell, given two models at the time, which one is less complex. With experiments on two real-world datasets involving 61 participants, we find that our approach is capable of learning estimations of interpretability that can be very different for different users. Moreover, the users tend to prefer models found using the proposed approach over models found using non-personalized interpretability indices.
https://weibo.com/1402400261/KdHvUd6Ta

5、[LG] Probing artificial neural networks: insights from neuroscience
A A. Ivanova, J Hewitt, N Zaslavsky
[MIT & Stanford University]
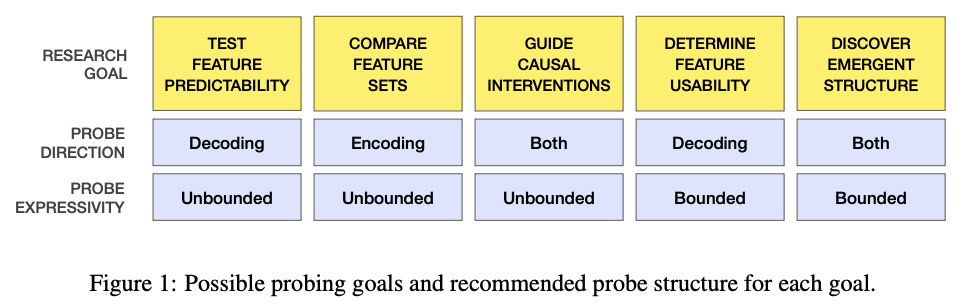
探索人工神经网络:受神经科学启发的见解。神经科学和机器学习的一个主要挑战,是开发有用的工具来理解复杂的信息处理系统。其中一个工具是探针,即把感兴趣的特征与生物或人工神经网络中产生的激活模式联系起来的监督模型。神经科学通过几十年来的大量研究,为使用这种模型铺平了道路。本文从神经科学得到启示,帮助指导机器学习的探测研究。强调探针的两个重要设计选择——方向和表现力——并将这些选择与研究目标联系起来。其目的是通过从神经科学中汲取见解,为ANN的探针设计提供参考。
A major challenge in both neuroscience and machine learning is the development of useful tools for understanding complex information processing systems. One such tool is probes, i.e., supervised models that relate features of interest to activation patterns arising in biological or artificial neural networks. Neuroscience has paved the way in using such models through numerous studies conducted in recent decades. In this work, we draw insights from neuroscience to help guide probing research in machine learning. We highlight two important design choices for probes — direction and expressivity — and relate these choices to research goals. We argue that specific research goals play a paramount role when designing a probe and encourage future probing studies to be explicit in stating these goals.
https://weibo.com/1402400261/KdHAfqP3n
另外几篇值得关注的论文:
[RO] RoboStack: Using the Robot Operating System alongside the Conda and Jupyter Data Science Ecosystems
RoboStack:在Conda和Jupyter数据科学生态环境中使用机器人操作系统(ROS)
T Fischer, W Vollprecht, S Traversaro, S Yen, C Herrero, M Milford
[Queensland University of Technology & QuantStack & Fondazione Istituto Italiano Di Tecnologia (Italian Institute of Technology) & Microsoft]
https://weibo.com/1402400261/KdHnvD2wt

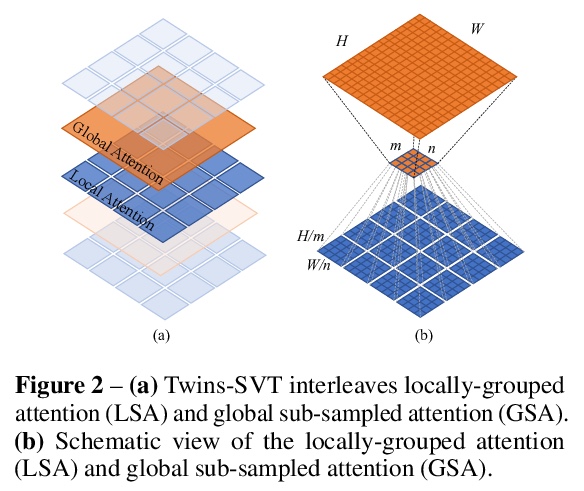
[CV] Twins: Revisiting Spatial Attention Design in Vision Transformers
Twins:视觉Transformer空间注意力设计的反思
X Chu, Z Tian, Y Wang, B Zhang, H Ren, X Wei, H Xia, C Shen
[Meituan Inc & The University of Adelaide]
https://weibo.com/1402400261/KdHu9fkFi

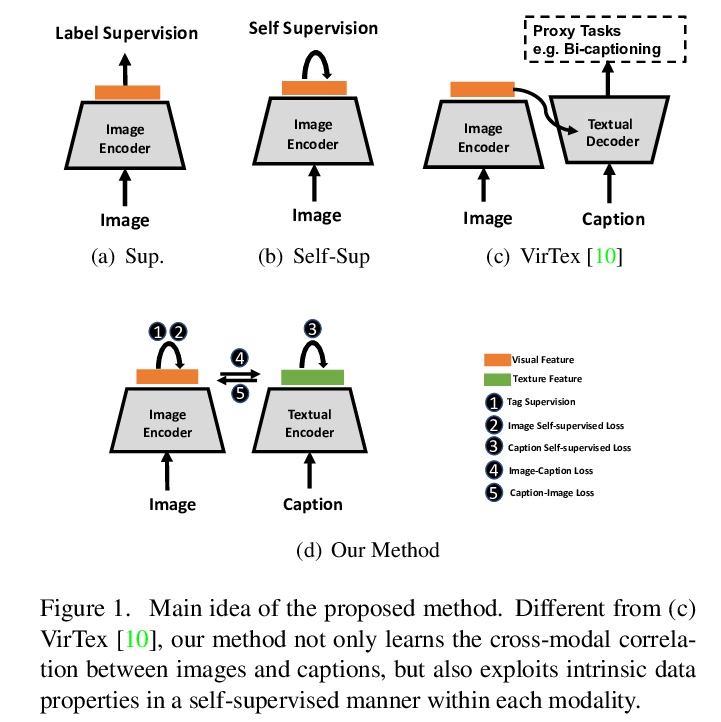
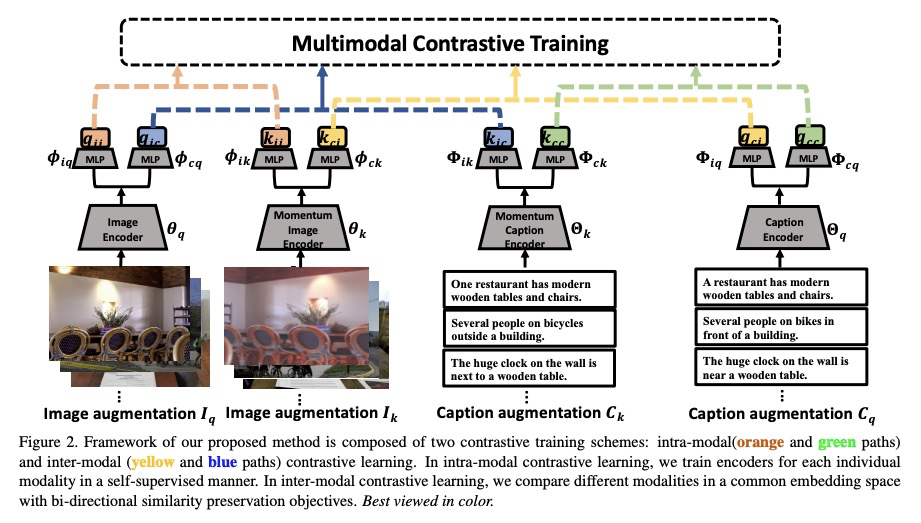
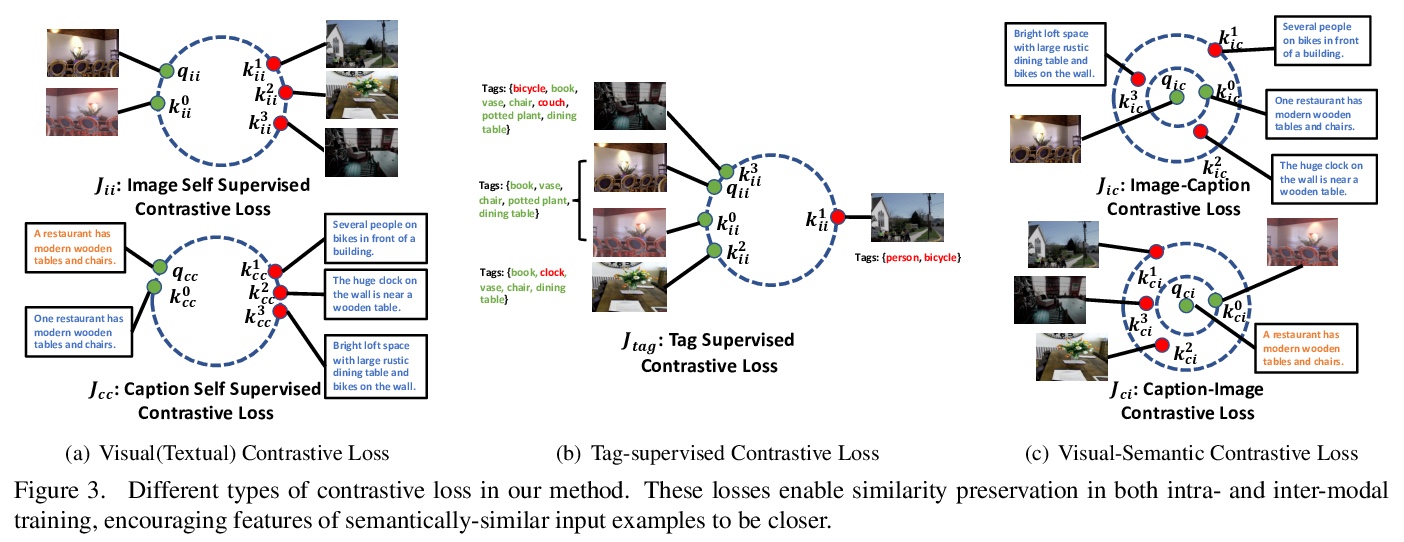
[CV] Multimodal Contrastive Training for Visual Representation Learning
多模态对比训练视觉表征学习
X Yuan, Z Lin, J Kuen, J Zhang, Y Wang, M Maire, A Kale, B Faieta
[University of Chicago & Adobe Research]
https://weibo.com/1402400261/KdHHaxmCl
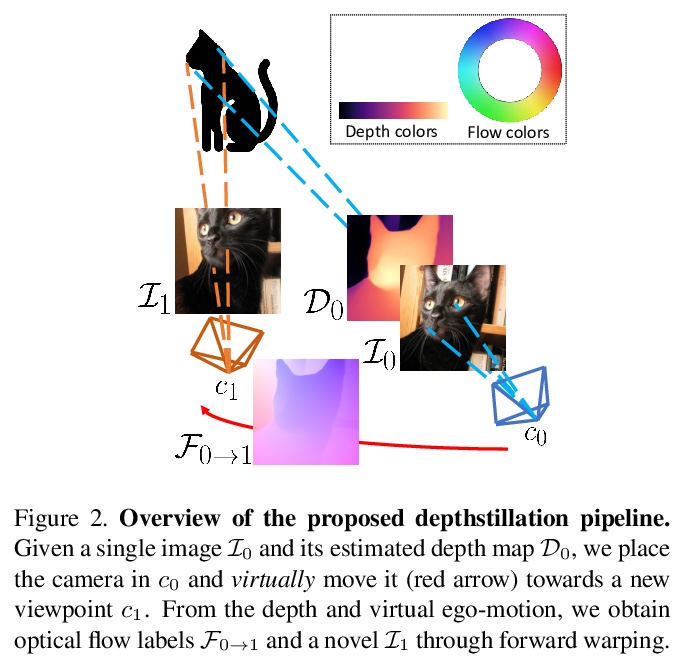
[CV] Learning optical flow from still images
静止图像光流学习
F Aleotti, M Poggi, S Mattoccia
[University of Bologna]
https://weibo.com/1402400261/KdHKFlnHh




若有收获,就点个赞吧
0 人点赞
