- 1、[CL] Understanding the Capabilities, Limitations, and Societal Impact of Large Language Models
- 2、[LG] Machine learning accelerated computational fluid dynamics
- 3、[CV] About Face: A Survey of Facial Recognition Evaluation
- 4、[LG] Keep the Gradients Flowing: Using Gradient Flow to Study Sparse Network Optimization
- 5、[LG] On the mapping between Hopfield networks and Restricted Boltzmann Machines
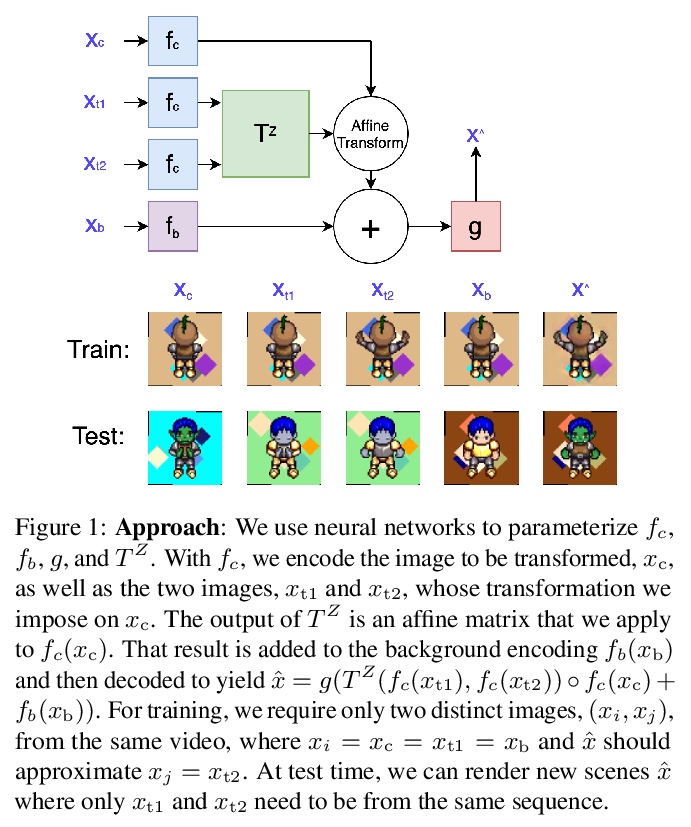
- [CV] Self-Supervised Equivariant Scene Synthesis from Video
- [CV] Resolution enhancement in the recovery of underdrawings via style transfer by generative adversarial deep neural networks
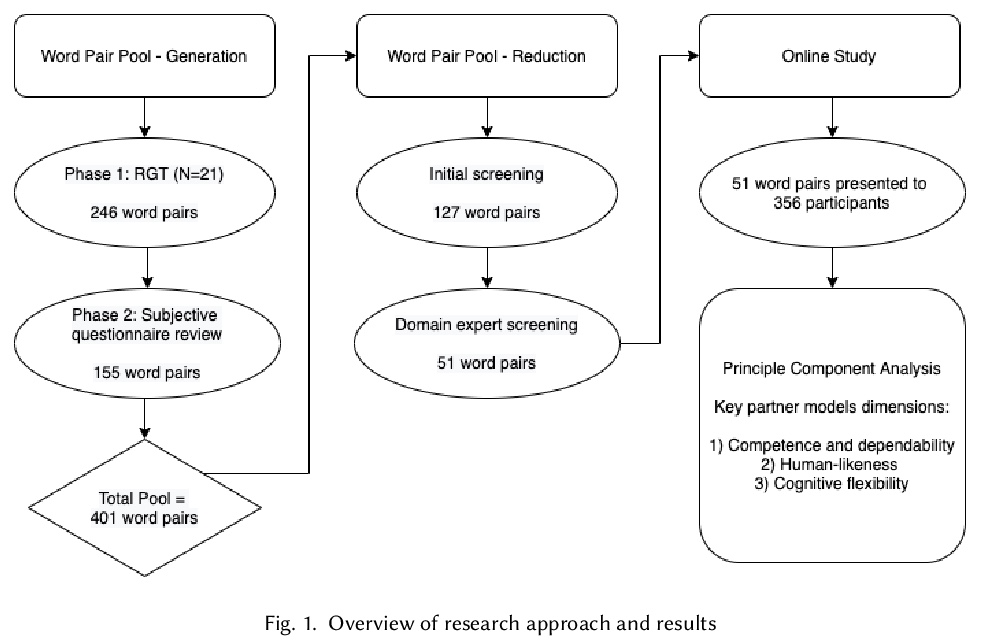
- [AI] What Do We See in Them? Identifying Dimensions of Partner Models for Speech Interfaces Using a Psycholexical Approach
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CL] Understanding the Capabilities, Limitations, and Societal Impact of Large Language Models
A Tamkin, M Brundage, J Clark, D Ganguli
[Stanford University & OpenAI & AI Index]
理解大型语言模型的能力、局限性和社会影响。2020年10月14日,来自OpenAI、斯坦福大学以人为本人工智能研究所等大学的研究人员召开会议,围绕当时最大的公开披露的密集语言模型GPT-3进行公开研究问题的讨论。讨论者来自不同研究背景,包括计算机科学、语言学、哲学、政治学、通信、网络政策等。讨论大致围绕两个问题展开:1)大型语言模型的技术能力和局限性是什么?讨论涉及几个关键领域,包括:规模对模型能力的惊人影响,评价大型语言模型是否真正理解语言的难度,在多种数据模式上训练模型的重要性,以及模型目标与人类价值一致性挑战。2)大型语言模型的广泛应用会带来哪些社会影响?讨论涉及到几个关键领域,包括:难以界定通用语言模型所有可能的用途(或误用),组织在模型部署中可能面临的挑战,这些模型在算法上传播虚假信息的可能性,减轻模型偏见的困难(如种族、性别、宗教等),以及基于语言模型的自动化对劳动力市场的影响。
On October 14th, 2020, researchers from OpenAI, the Stanford Institute for Human-Centered Artificial Intelligence, and other universities convened to discuss open research questions surrounding GPT-3, the largest publicly-disclosed dense language model at the time. The meeting took place under Chatham House Rules. Discussants came from a variety of research backgrounds including computer science, linguistics, philosophy, political science, communications, cyber policy, and more. Broadly, the discussion centered around two main questions: 1) What are the technical capabilities and limitations of large language models? 2) What are the societal effects of widespread use of large language models? Here, we provide a detailed summary of the discussion organized by the two themes above.
https://weibo.com/1402400261/K0M36imo6
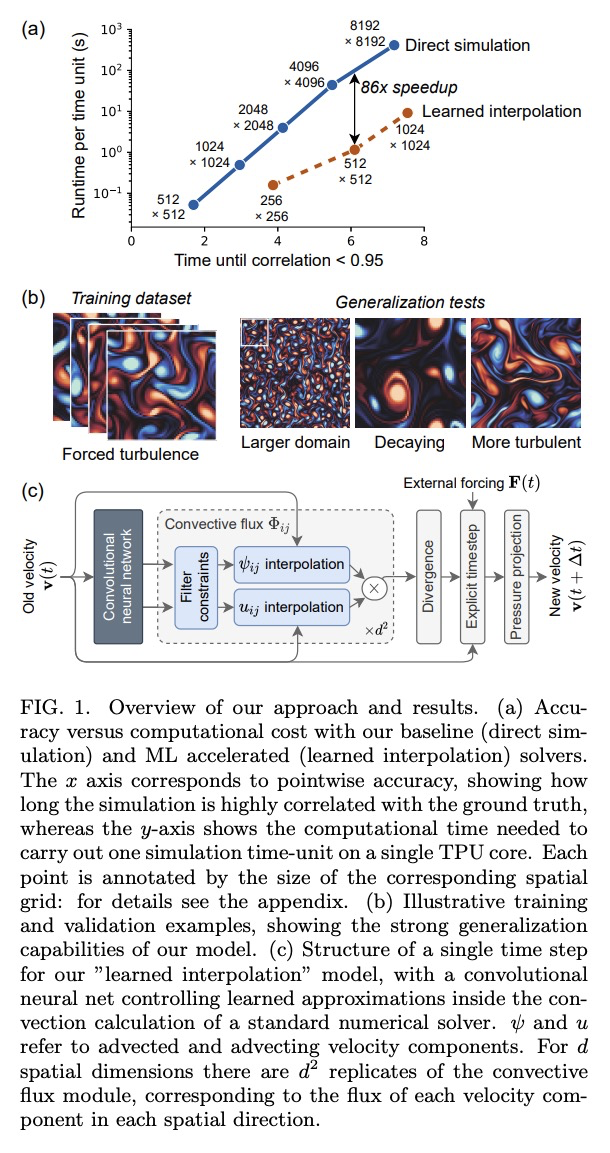
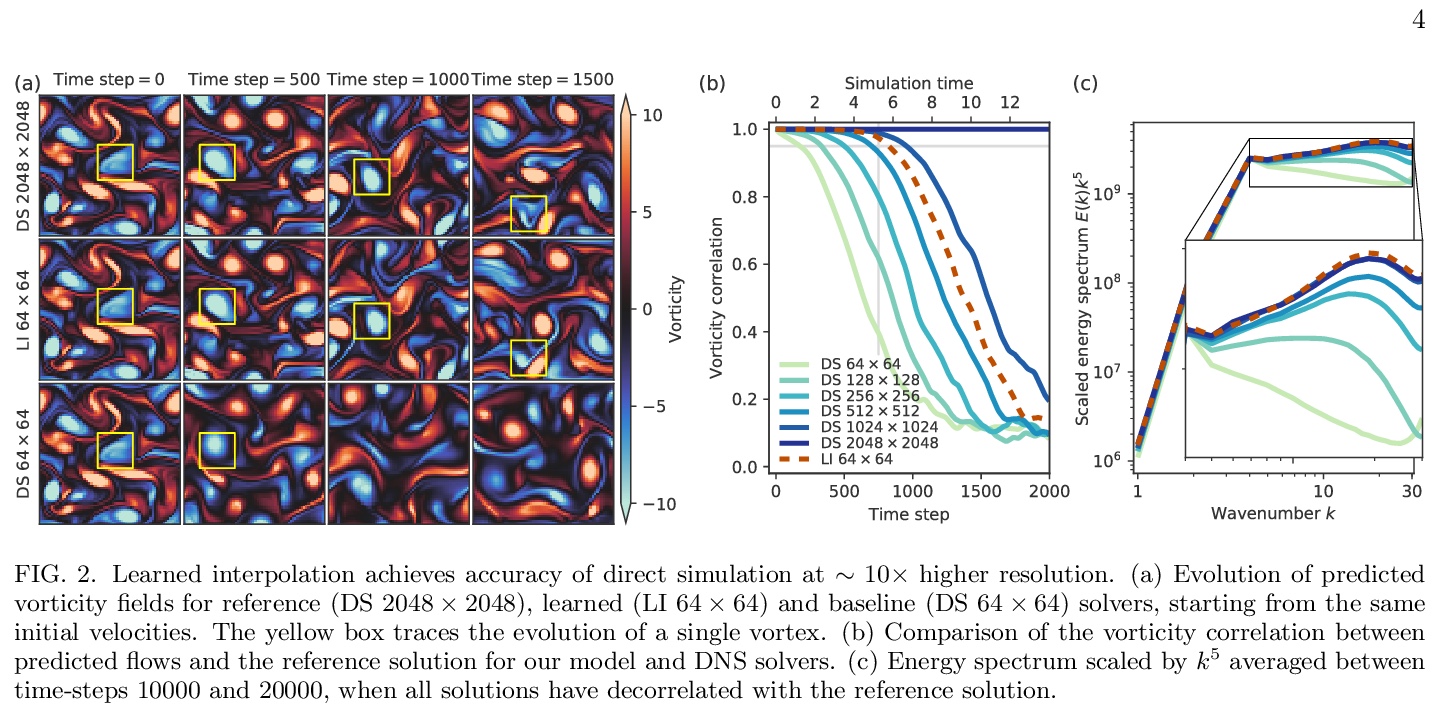
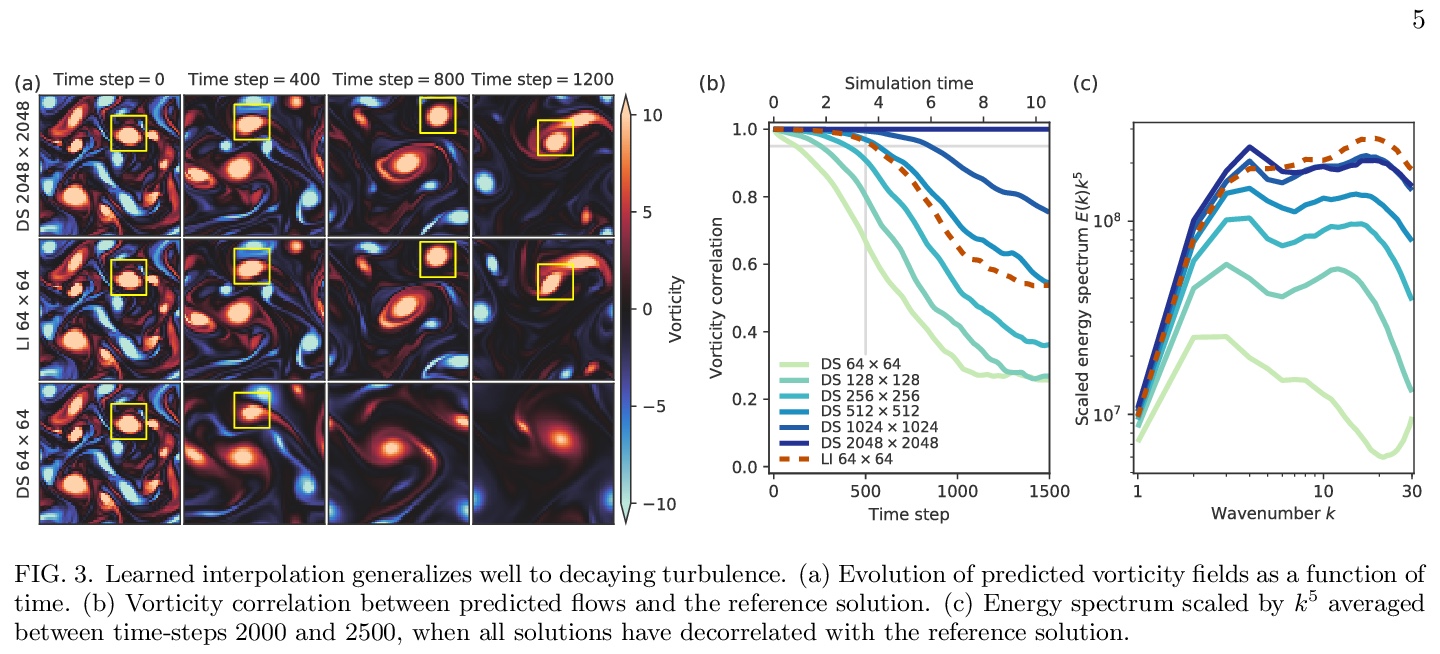
2、[LG] Machine learning accelerated computational fluid dynamics
D Kochkov, J A. Smith, A Alieva, Q Wang, M P. Brenner, S Hoyer
[Google Research]
用机器学习加速计算流体力学。提出一种数据驱动的数值方法,用端到端的深度学习改进计算流体动力学内部近似,以模拟二维湍流,可实现与传统的有限差分/有限体积方法相同的精度,但具有更粗的分辨率。对于湍流进行直接数值模拟和大涡流模拟,得到的结果和基线求解器一样精确,在每个空间维度上有8-10倍精细的分辨率,计算速度提高40-80倍。在传统的数值离散化框架下,利用机器学习在粗尺度上进行更好的插值,能在长期模拟过程中保持稳定,并可泛化到训练它的流动之外的强迫函数和雷诺数,比纯黑盒机器学习方法的泛化性要好得多,体现了科学计算如何利用机器学习和硬件加速器来改善模拟,而不牺牲精度或泛化。
Numerical simulation of fluids plays an essential role in modeling many physical phenomena, such as weather, climate, aerodynamics and plasma physics. Fluids are well described by the Navier-Stokes equations, but solving these equations at scale remains daunting, limited by the computational cost of resolving the smallest spatiotemporal features. This leads to unfavorable trade-offs between accuracy and tractability. Here we use end-to-end deep learning to improve approximations inside computational fluid dynamics for modeling two-dimensional turbulent flows. For both direct numerical simulation of turbulence and large eddy simulation, our results are as accurate as baseline solvers with 8-10x finer resolution in each spatial dimension, resulting in 40-80x fold computational speedups. Our method remains stable during long simulations, and generalizes to forcing functions and Reynolds numbers outside of the flows where it is trained, in contrast to black box machine learning approaches. Our approach exemplifies how scientific computing can leverage machine learning and hardware accelerators to improve simulations without sacrificing accuracy or generalization.
https://weibo.com/1402400261/K0M7Q1CWB
3、[CV] About Face: A Survey of Facial Recognition Evaluation
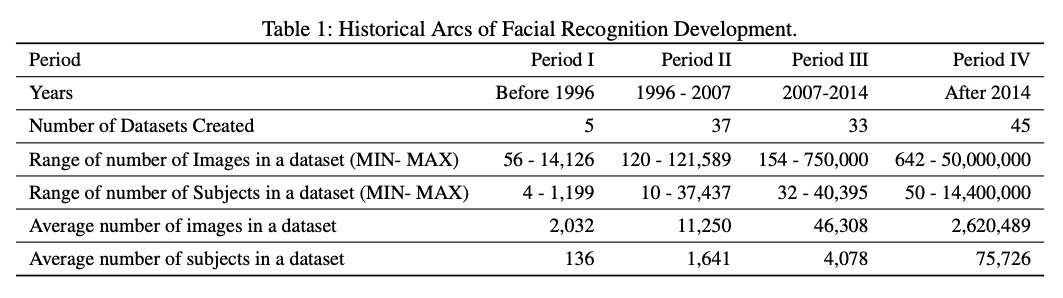
I D Raji, G Fried
人脸识别评价综述。调研了1976年到2019年间构建的100多个人脸数据集,这些数据集包含了1700多万个体的1.45亿张图像,来自不同的来源、人员分布和条件。调研显示,这些数据集受政治动机、技术能力和当前规范的变化这些背景信息所约束。讨论了这些影响如何掩盖了一些具体手段,其中一些可能实际上是有害的或有问题的,提出了明确沟通这些细节的理由,以便对技术在现实世界中的功能有更扎实的了解。
We survey over 100 face datasets constructed between 1976 to 2019 of 145 million images of over 17 million subjects from a range of sources, demographics and conditions. Our historical survey reveals that these datasets are contextually informed, shaped by changes in political motivations, technological capability and current norms. We discuss how such influences mask specific practices (some of which may actually be harmful or otherwise problematic) and make a case for the explicit communication of such details in order to establish a more grounded understanding of the technology’s function in the real world.
https://weibo.com/1402400261/K0MfPvBN6
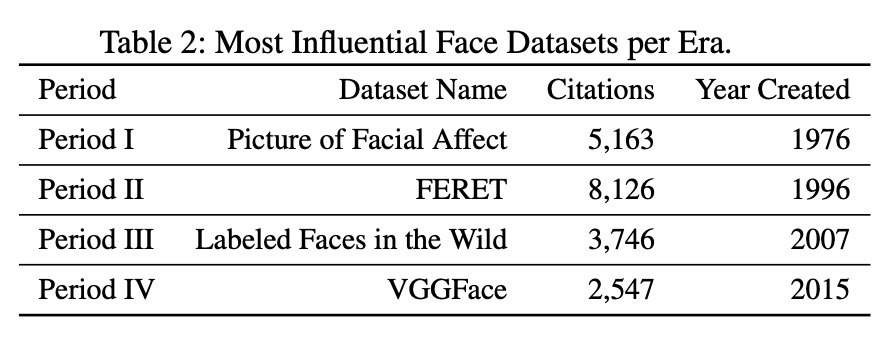
4、[LG] Keep the Gradients Flowing: Using Gradient Flow to Study Sparse Network Optimization
K Tessera, S Hooker, B Rosman
[University of the Witwatersrand & Google Brain]
用梯度流研究稀疏网络优化。以更广泛的视角来训练稀疏网络,并考虑正则化、优化和架构选择对稀疏模型的作用。提出一个简单的实验框架,即同容量稀疏与密集比较(SC-SDC),可对稀疏网络和密集网络进行公平的比较。提出一种新的梯度流度量,即有效梯度流(EGF),能更好体现稀疏网络性能。通过使用top-line指标、SC-SDC和EGF,表明用于密集网络的优化器、激活函数和正则化器的默认选择会使稀疏网络处于不利地位,稀疏网络中的梯度流可通过重新考虑架构设计和训练制度的各方面来改善,初始化只是问题的一部分,从更广泛的角度出发,对稀疏网络进行定制化优化,会产生有希望的结果。
Training sparse networks to converge to the same performance as dense neural architectures has proven to be elusive. Recent work suggests that initialization is the key. However, while this direction of research has had some success, focusing on initialization alone appears to be inadequate. In this paper, we take a broader view of training sparse networks and consider the role of regularization, optimization and architecture choices on sparse models. We propose a simple experimental framework, Same Capacity Sparse vs Dense Comparison (SC-SDC), that allows for fair comparison of sparse and dense networks. Furthermore, we propose a new measure of gradient flow, Effective Gradient Flow (EGF), that better correlates to performance in sparse networks. Using top-line metrics, SC-SDC and EGF, we show that default choices of optimizers, activation functions and regularizers used for dense networks can disadvantage sparse networks. Based upon these findings, we show that gradient flow in sparse networks can be improved by reconsidering aspects of the architecture design and the training regime. Our work suggests that initialization is only one piece of the puzzle and taking a wider view of tailoring optimization to sparse networks yields promising results.
https://weibo.com/1402400261/K0MnlgLiK
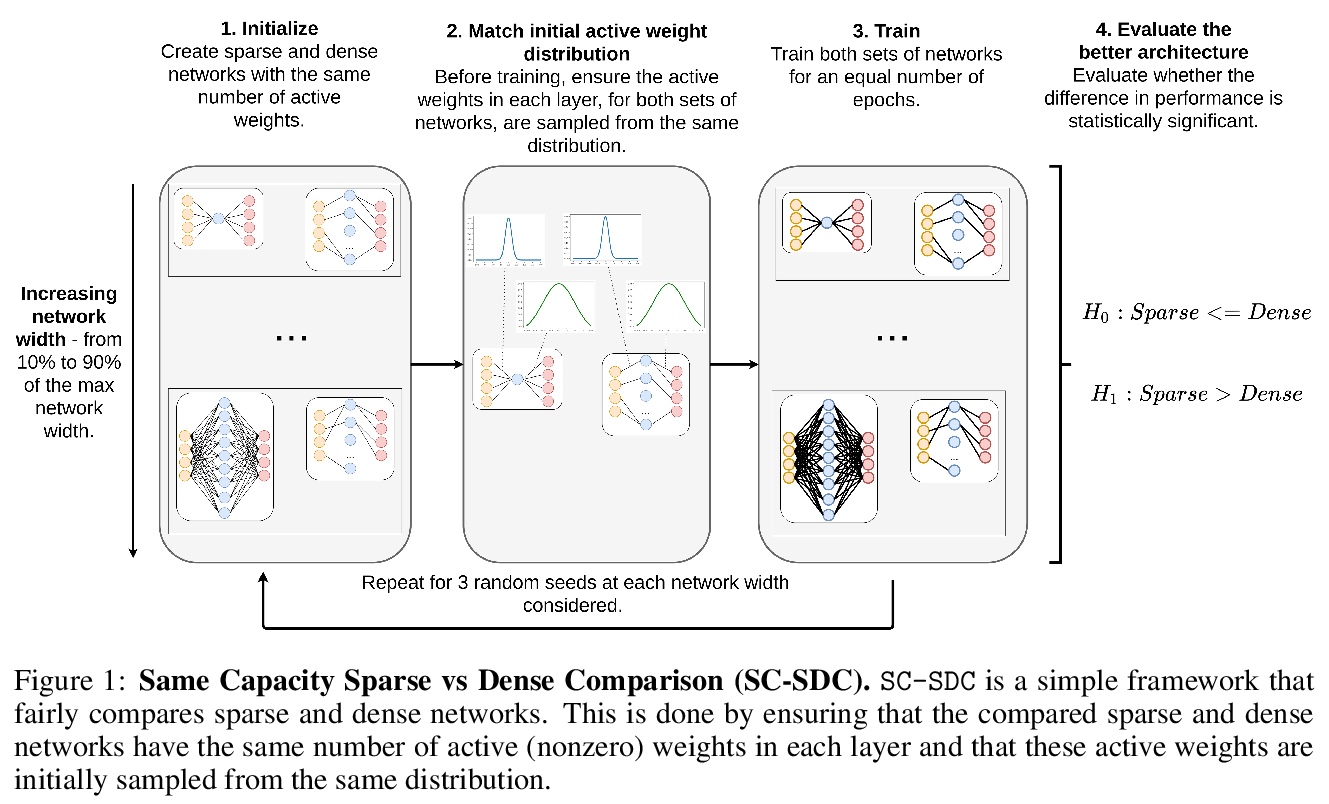

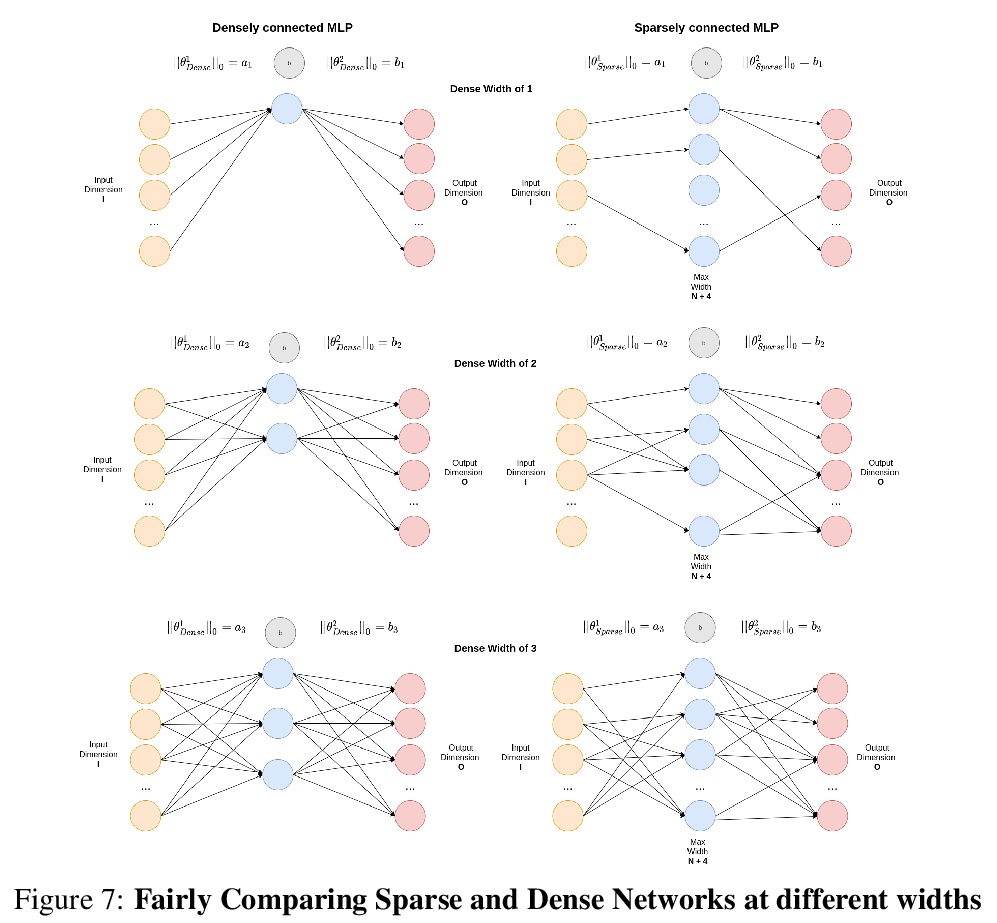
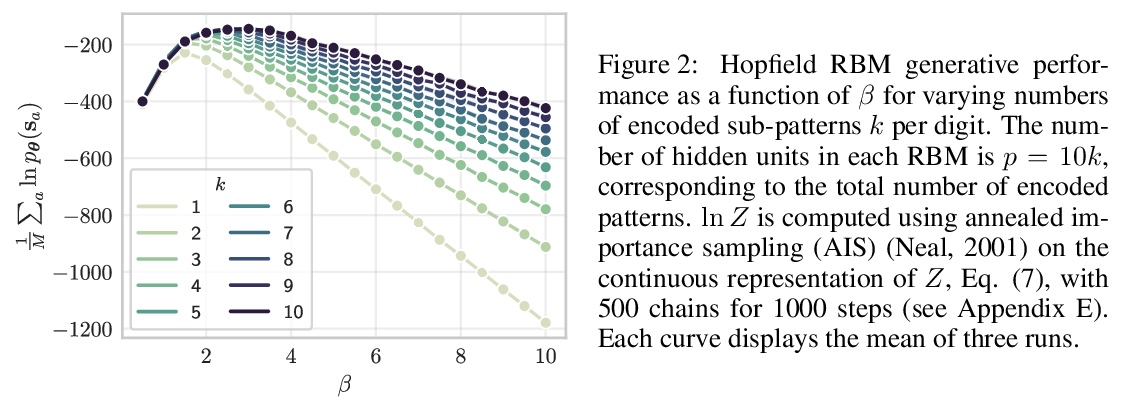
5、[LG] On the mapping between Hopfield networks and Restricted Boltzmann Machines
M Smart, A Zilman
[University of Toronto]
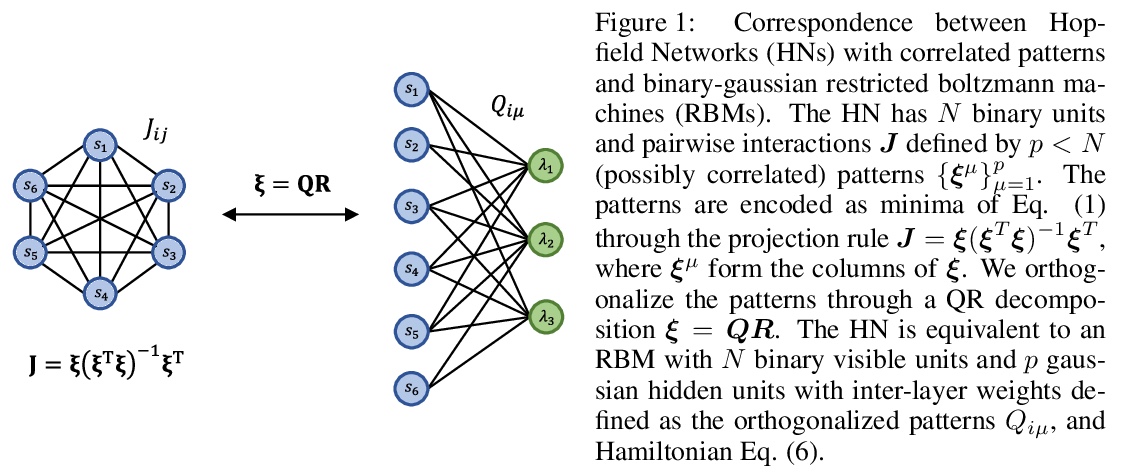
Hopfield网络与受限玻尔兹曼机之间的映射关系。提出了相关模式Hopfield网络一般情况下的精确映射,更广泛地适用于现有数据集。具体来说,任何具有N个二进制变量和p<N个任意二进制模式的Hopfield网络都可以转化为具有N个二进制可见变量和p个高斯隐藏变量的受限玻尔兹曼机。将Hopfield网络转换为等价的受限玻尔兹曼机具有实际的效用:以简单的形式换取更快的处理速度。概述了反向映射存在的条件,在MNIST数据集上进行了实验,表明映射为受限玻尔兹曼机权重提供了有用的初始化。讨论了这种对应关系对于受限玻尔兹曼机训练的潜在重要性,以及对于理解利用受限玻尔兹曼机的深度架构的性能。
Hopfield networks (HNs) and Restricted Boltzmann Machines (RBMs) are two important models at the interface of statistical physics, machine learning, and neuroscience. Recently, there has been interest in the relationship between HNs and RBMs, due to their similarity under the statistical mechanics formalism. An exact mapping between HNs and RBMs has been previously noted for the special case of orthogonal (uncorrelated) encoded patterns. We present here an exact mapping in the general case of correlated pattern HNs, which are more broadly applicable to existing datasets. Specifically, we show that any HN with > N binary variables and > p

另外几篇值得关注的论文:
[CV] Self-Supervised Equivariant Scene Synthesis from Video
视频自监督等变场景合成
C Resnick, O Litany, C Heiß, H Larochelle, J Bruna, K Cho
[NYU & NVidia & Technical University of Berlin & Google]
https://weibo.com/1402400261/K0MucaKwp
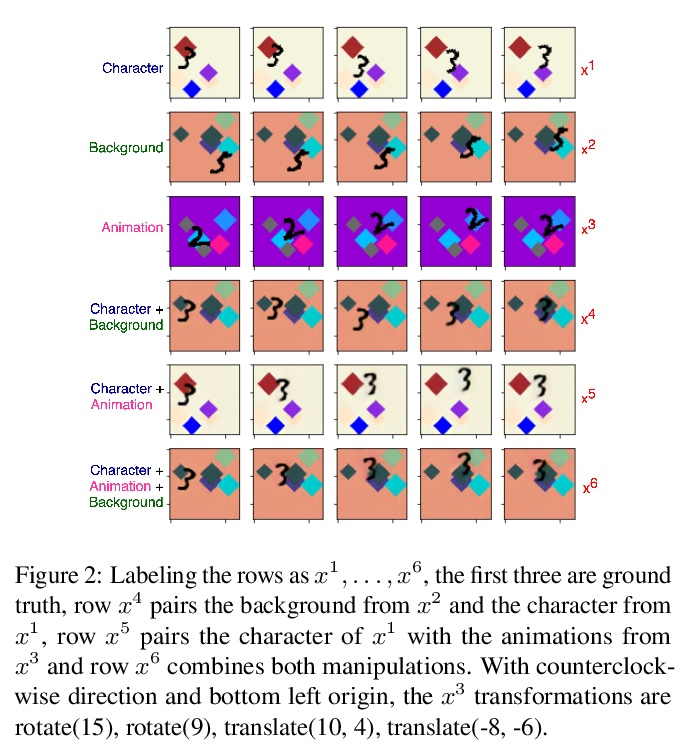

[CV] Resolution enhancement in the recovery of underdrawings via style transfer by generative adversarial deep neural networks
基于生成对抗网络画风迁移的底稿恢复分辨率增强
G Cann, A Bourached, R Griffiths, D Stork
[University College London & Oxia Palus & University of Cambridge & Portola Valley]
https://weibo.com/1402400261/K0MyHFy28



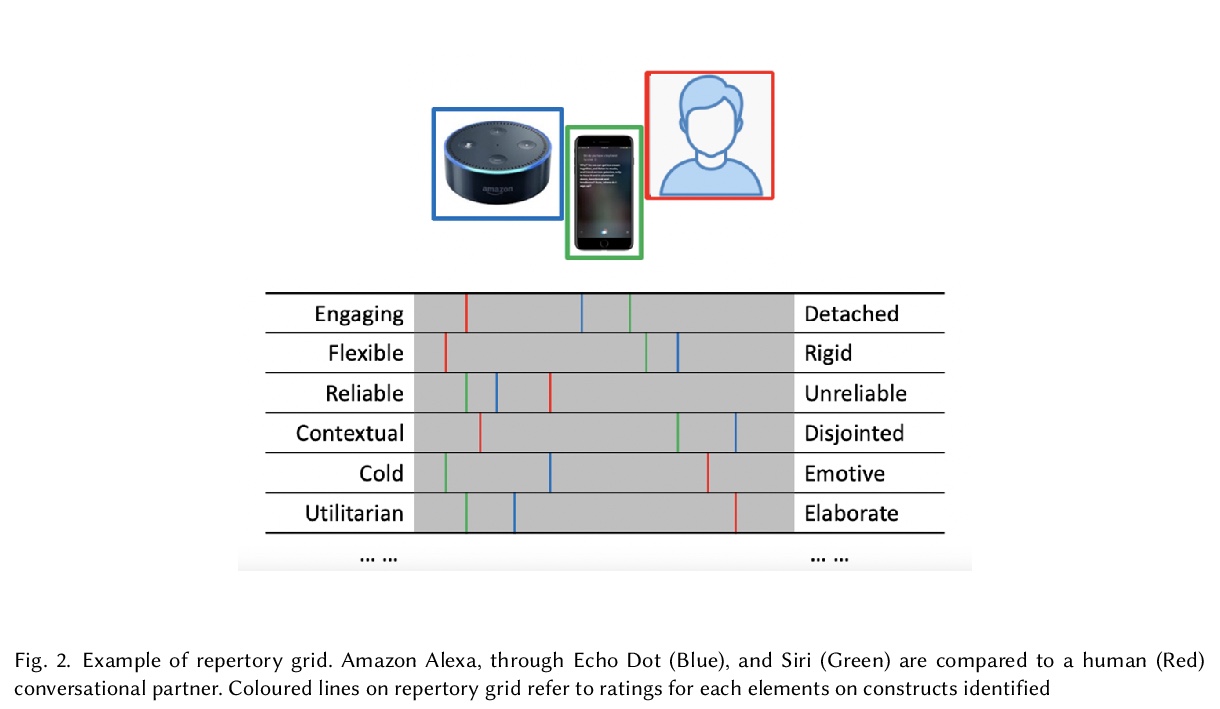
[AI] What Do We See in Them? Identifying Dimensions of Partner Models for Speech Interfaces Using a Psycholexical Approach
用心理学方法识别语音接口伙伴模型维度
P R Doyle, L Clark, B R Cowan
[College Dublin & Swansea University & University College Dublin]
https://weibo.com/1402400261/K0MvyoFEz

若有收获,就点个赞吧
0 人点赞
