- 1、[CV] ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases
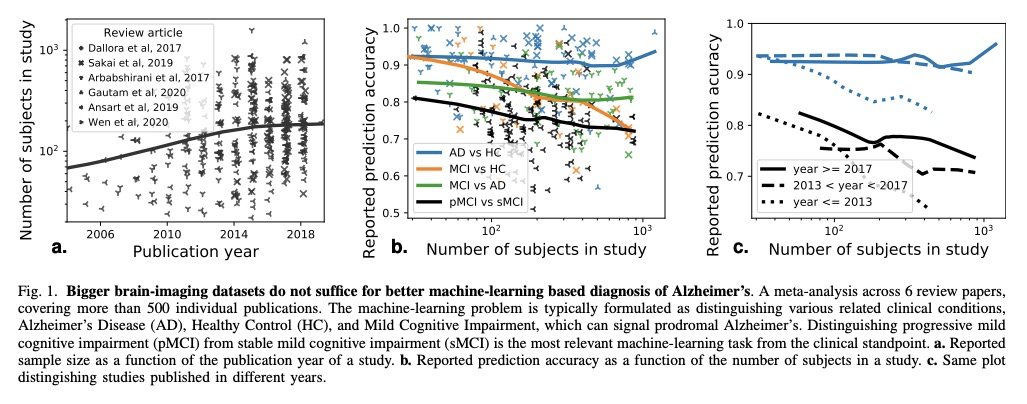
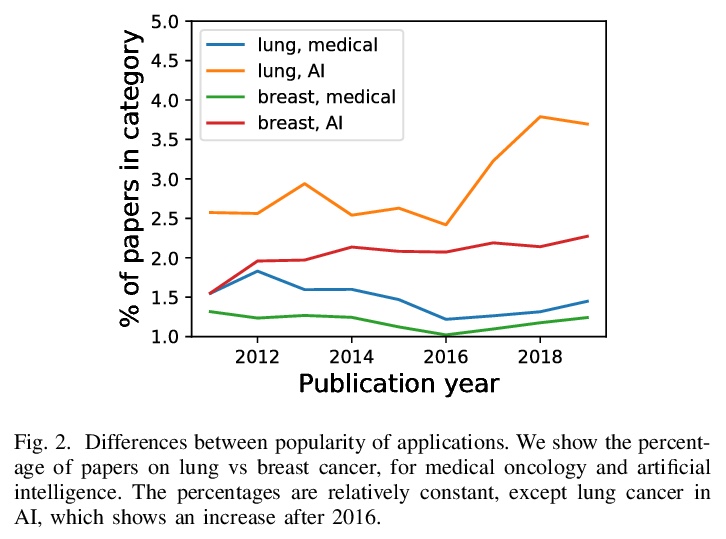
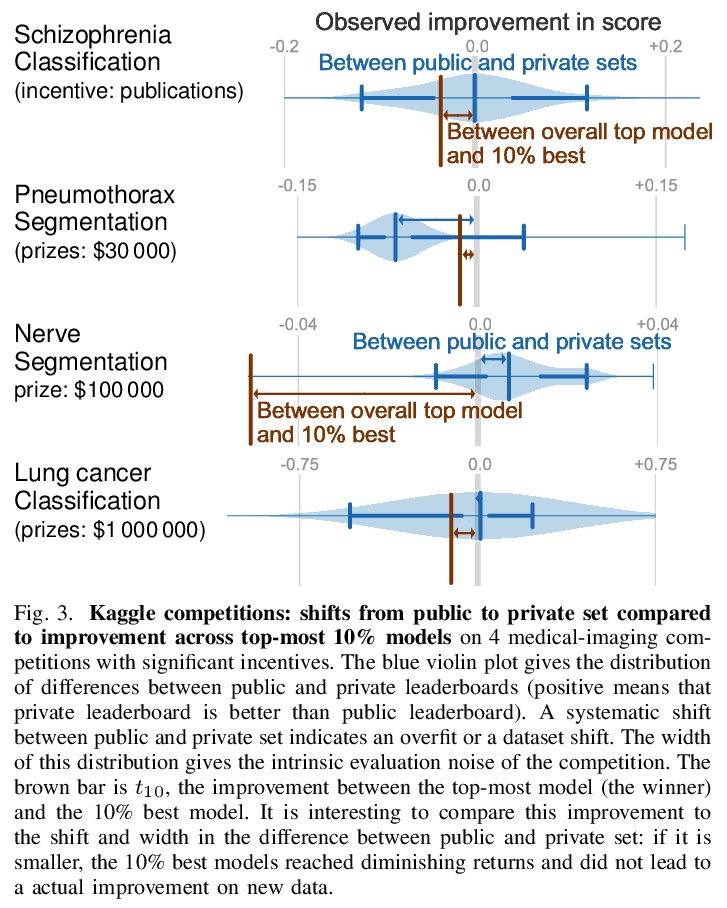
- 2、[CV] How I failed machine learning in medical imaging — shortcomings and recommendations
- 3、[CV] Paint by Word
- 4、[CV] Rotation Coordinate Descent for Fast Globally Optimal Rotation Averaging
- 5、[LG] Reading Isn’t Believing: Adversarial Attacks On Multi-Modal Neurons
- [CV] CheXbreak: Misclassification Identification for Deep Learning Models Interpreting Chest X-rays
- [IR] TripClick: The Log Files of a Large Health Web Search Engine
- [CL] Bilingual Dictionary-based Language Model Pretraining for Neural Machine Translation
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases
S d’Ascoli, H Touvron, M Leavitt, A Morcos, G Biroli, L Sagun
[acebook AI Research & Université PSL]
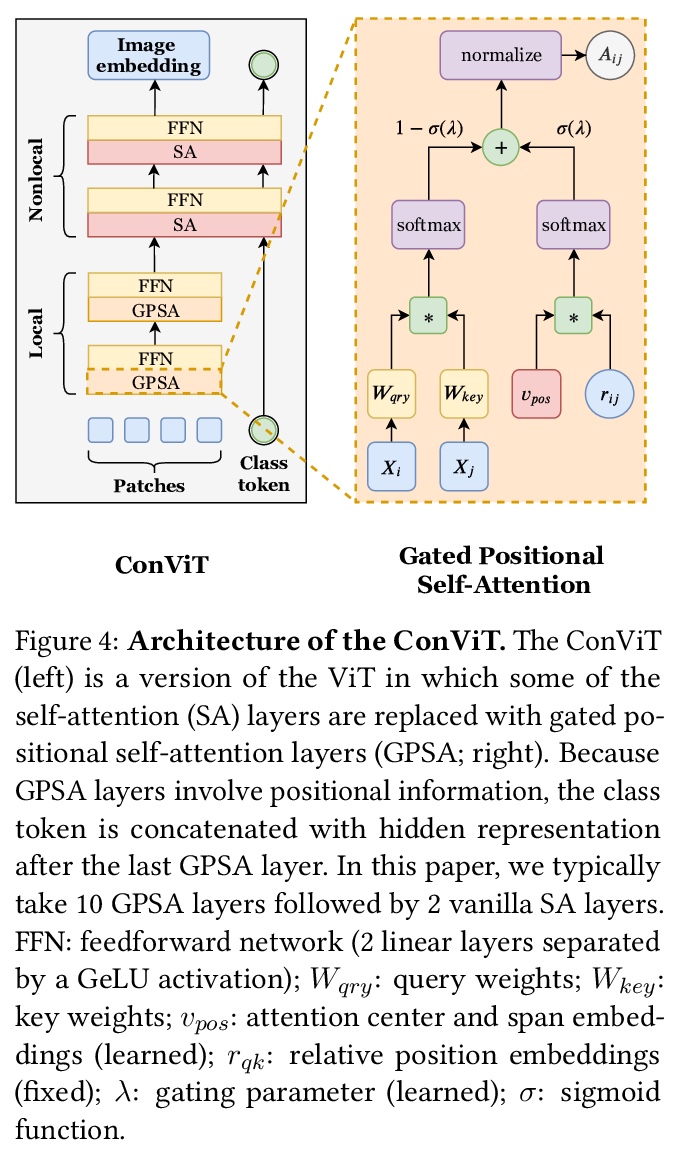
ConViT:用柔性卷积归纳偏差改进视觉Transformer。研究了初始化和归纳偏差在视觉Transformer学习中的重要性。展示了以柔性方式利用卷积约束,融合了架构先验和表达能力的优点。结果是在不增加模型大小、不需要任何调优的情况下,提高训练性和样本有效性的简单方法。引入了门控位置自注意力(GPSA),一种位置自注意力的形式,可以配备一个”软”卷积归纳偏差。初始化GPSA层以模仿卷积层的位置性,通过调整门控参数来调节对位置信息与内容信息的关注度,给每个关注头以摆脱位置性的自由。由此产生的类似卷积的视觉Transformer架构ConViT在ImageNet上的表现优于DeiT。
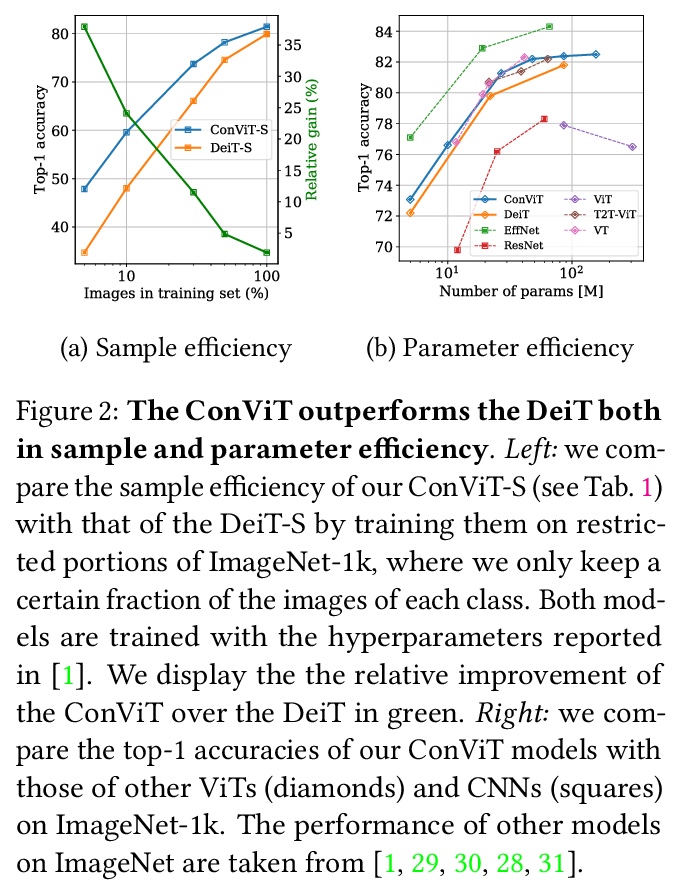
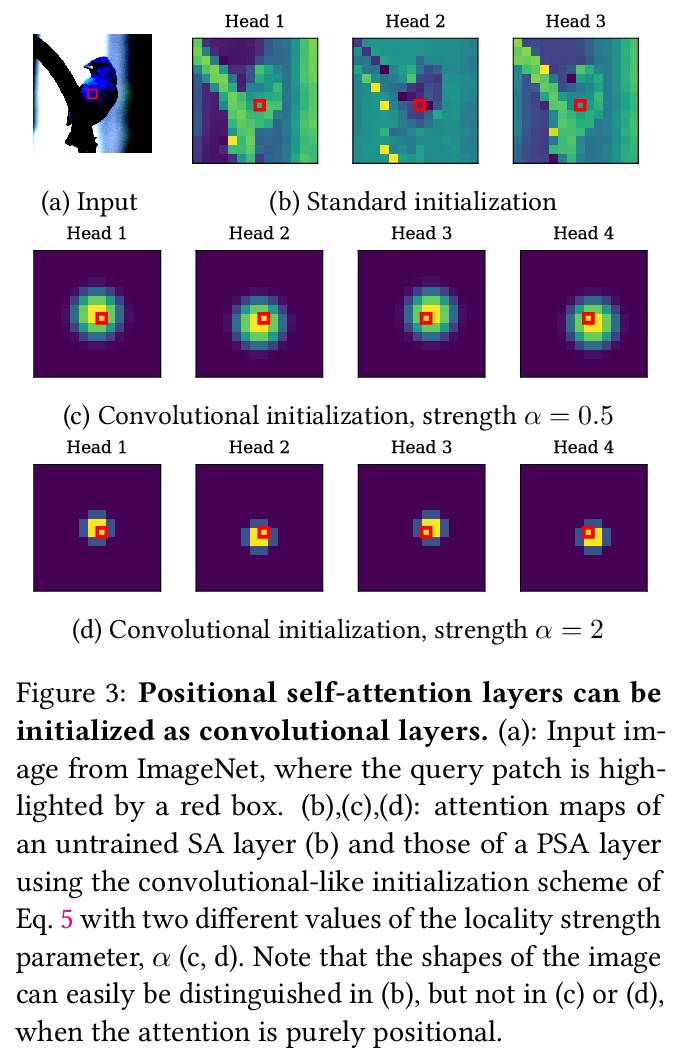
Convolutional architectures have proven extremely successful for vision tasks. Their hard inductive biases enable sample-efficient learning, but come at the cost of a potentially lower performance ceiling. Vision Transformers (ViTs) rely on more flexible self-attention layers, and have recently outperformed CNNs for image classification. However, they require costly pre-training on large external datasets or distillation from pre-trained convolutional networks. In this paper, we ask the following question: is it possible to combine the strengths of these two architectures while avoiding their respective limitations? To this end, we introduce gated positional self-attention (GPSA), a form of positional self-attention which can be equipped with a “soft” convolutional inductive bias. We initialize the GPSA layers to mimic the locality of convolutional layers, then give each attention head the freedom to escape locality by adjusting a gating parameter regulating the attention paid to position versus content information. The resulting convolutional-like ViT architecture, ConViT, outperforms the DeiT on ImageNet, while offering a much improved sample efficiency. We further investigate the role of locality in learning by first quantifying how it is encouraged in vanilla self-attention layers, then analyzing how it is escaped in GPSA layers. We conclude by presenting various ablations to better understand the success of the ConViT. Our code and models are released publicly.
https://weibo.com/1402400261/K7sy8acA5
2、[CV] How I failed machine learning in medical imaging — shortcomings and recommendations
G Varoquaux, V Cheplygina
[INRIA & IT University of Copenhagen]
我的医学影像机器学习是如何失败的——不足与建议。回顾了与选择数据集、方法、评价指标和发表策略有关的几个问题。通过对文献的回顾和自己的分析,对可能会减缓医学影像及相关计算领域的问题进行了广泛的综述,表明在每一步潜在的偏差都会悄然而至。第一项分析表明,数据集的大小并不是万能的,虽然数据集在慢慢变大,但预测性能却没有变大;第二项分析表明,数据集的可用性可能会影响医学影像选择工作的内容,可能会将注意力从其他未解决的问题上转移开;第三项分析表明,超越一个先进的方法可能并不总是有意义的,因此可能会造成一种进步的错觉。另外,还提供了一系列广泛的策略来解决这种情况,其中一些策略已经被引入。
Medical imaging is an important research field with many opportunities for improving patients’ health. However, there are a number of challenges that are slowing down the progress of the field as a whole, such optimizing for publication. In this paper we reviewed several problems related to choosing datasets, methods, evaluation metrics, and publication strategies. With a review of literature and our own analysis, we show that at every step, potential biases can creep in. On a positive note, we also see that initiatives to counteract these problems are already being started. Finally we provide a broad range of recommendations on how to further these address problems in the future. For reproducibility, data and code for our analyses are available on \url{> this https URL}
https://weibo.com/1402400261/K7sCG4d80
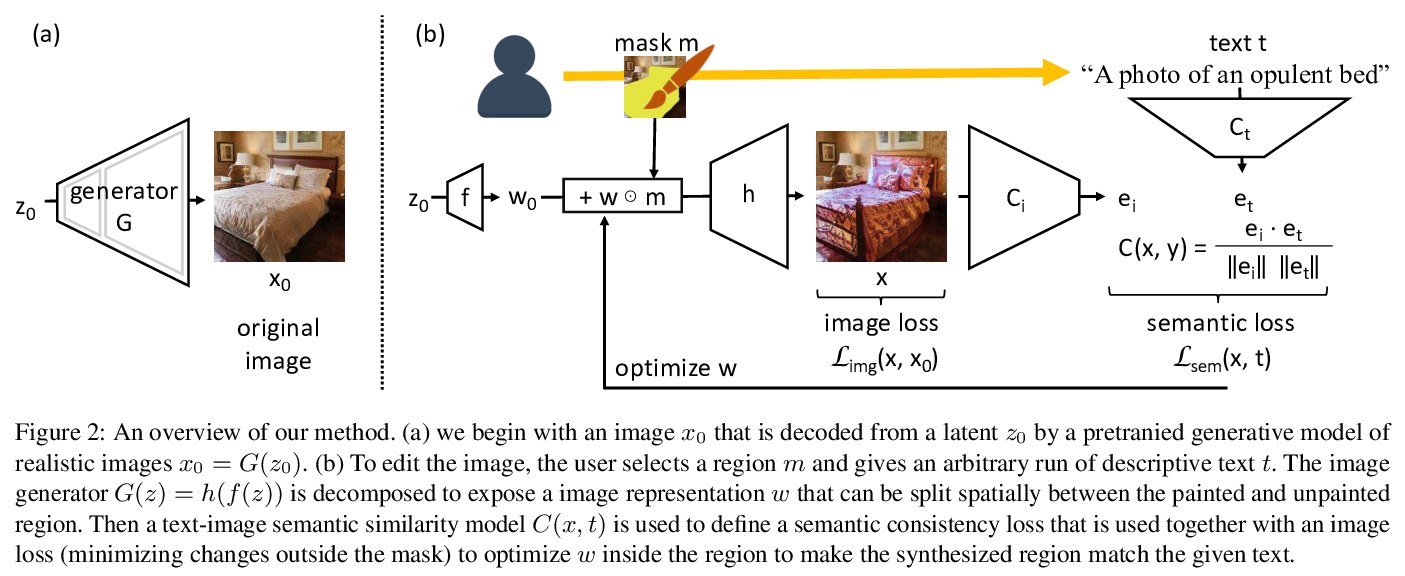
3、[CV] Paint by Word
D Bau, A Andonian, A Cui, Y Park, A Jahanian, A Oliva, A Torralba
[MIT]
以图配词。研究零样本语义图像绘制的问题。不只使用具体的颜色或有限的语义概念集将修改画到图像上,而是追问如何基于开放的全文描述创建语义图像:目标是能够指向合成图像中的具体位置,并应用任意的新概念,如 “乡村”或 “富丽堂皇”或 “快乐的狗”。为做到这一点,将现实图像的最先进生成模型与最先进的文本-图像语义相似网络相结合。发现为了进行大的改变,使用非梯度方法探索潜空间是很重要的,而放松GAN的计算,将改变锁定在特定区域是很重要的。
We investigate the problem of zero-shot semantic image painting. Instead of painting modifications into an image using only concrete colors or a finite set of semantic concepts, we ask how to create semantic paint based on open full-text descriptions: our goal is to be able to point to a location in a synthesized image and apply an arbitrary new concept such as “rustic” or “opulent” or “happy dog.” To do this, our method combines a state-of-the art generative model of realistic images with a state-of-the-art text-image semantic similarity network. We find that, to make large changes, it is important to use non-gradient methods to explore latent space, and it is important to relax the computations of the GAN to target changes to a specific region. We conduct user studies to compare our methods to several baselines.
https://weibo.com/1402400261/K7sFxjB3o

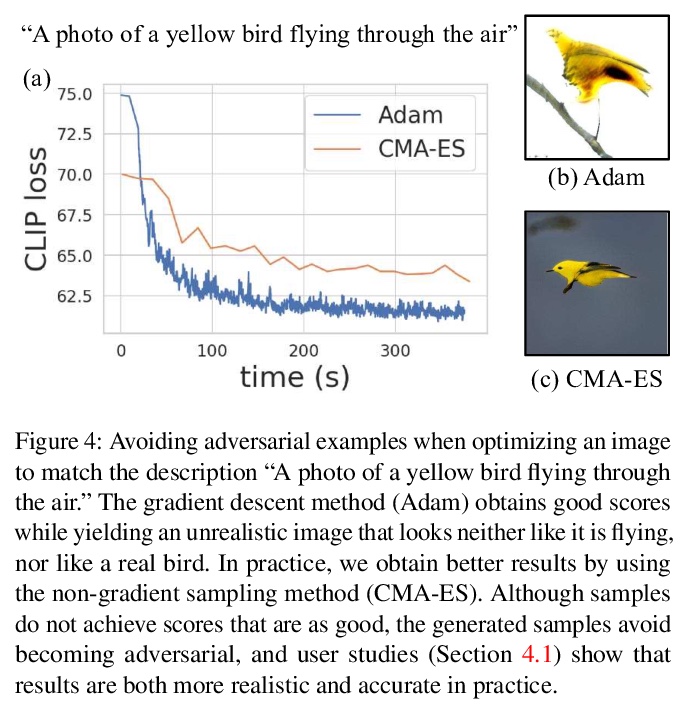
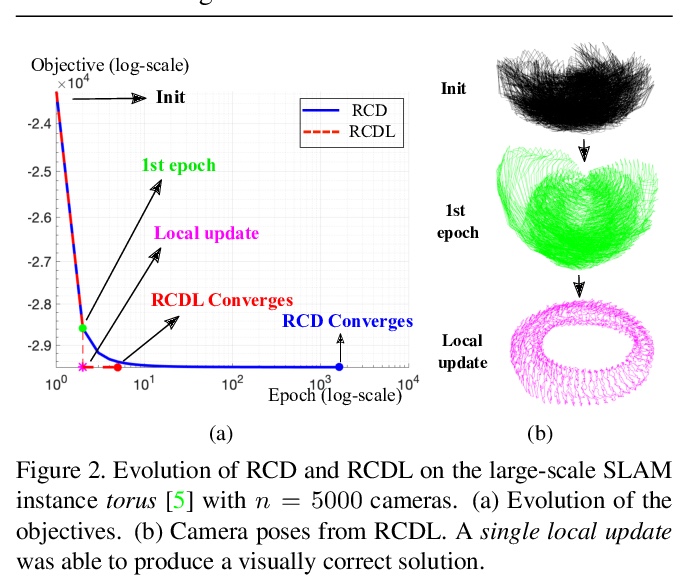
4、[CV] Rotation Coordinate Descent for Fast Globally Optimal Rotation Averaging
Á Parra, S Chng, T Chin, A Eriksson, I Reid
[The University of Adelaide & University of Queensland]
用于快速全局最优旋转平均的旋转坐标下降法。提出一种实现全局最优化的快速算法,称为旋转坐标下降(RCD)。与块坐标下降(BCD)通过逐行更新半定矩阵的方式解决SDP不同,RCD在整个迭代过程中直接维护和更新所有有效的旋转。这就避免了存储大量密集的半定义矩阵的需要。用数学方法证明了算法的收敛性,并通过实验证明了在各种问题配置上比最先进的全局方法更高的效率。保持有效的旋转也有利于纳入局部优化例程,以进一步提高速度。
Under mild conditions on the noise level of the measurements, rotation averaging satisfies strong duality, which enables global solutions to be obtained via semidefinite programming (SDP) relaxation. However, generic solvers for SDP are rather slow in practice, even on rotation averaging instances of moderate size, thus developing specialised algorithms is vital. In this paper, we present a fast algorithm that achieves global optimality called rotation coordinate descent (RCD). Unlike block coordinate descent (BCD) which solves SDP by updating the semidefinite matrix in a row-by-row fashion, RCD directly maintains and updates all valid rotations throughout the iterations. This obviates the need to store a large dense semidefinite matrix. We mathematically prove the convergence of our algorithm and empirically show its superior efficiency over state-of-the-art global methods on a variety of problem configurations. Maintaining valid rotations also facilitates incorporating local optimisation routines for further speed-ups. Moreover, our algorithm is simple to implement; see supplementary material for a demonstration program.
https://weibo.com/1402400261/K7sJWB3Lh
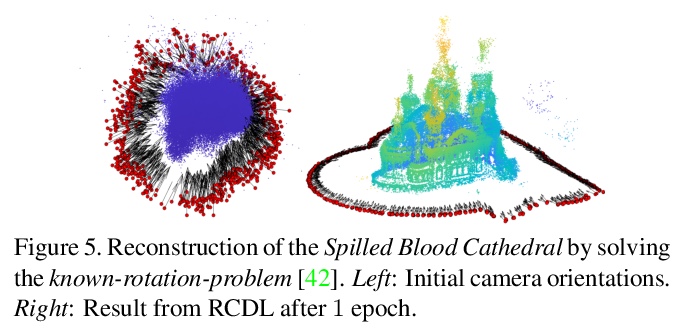
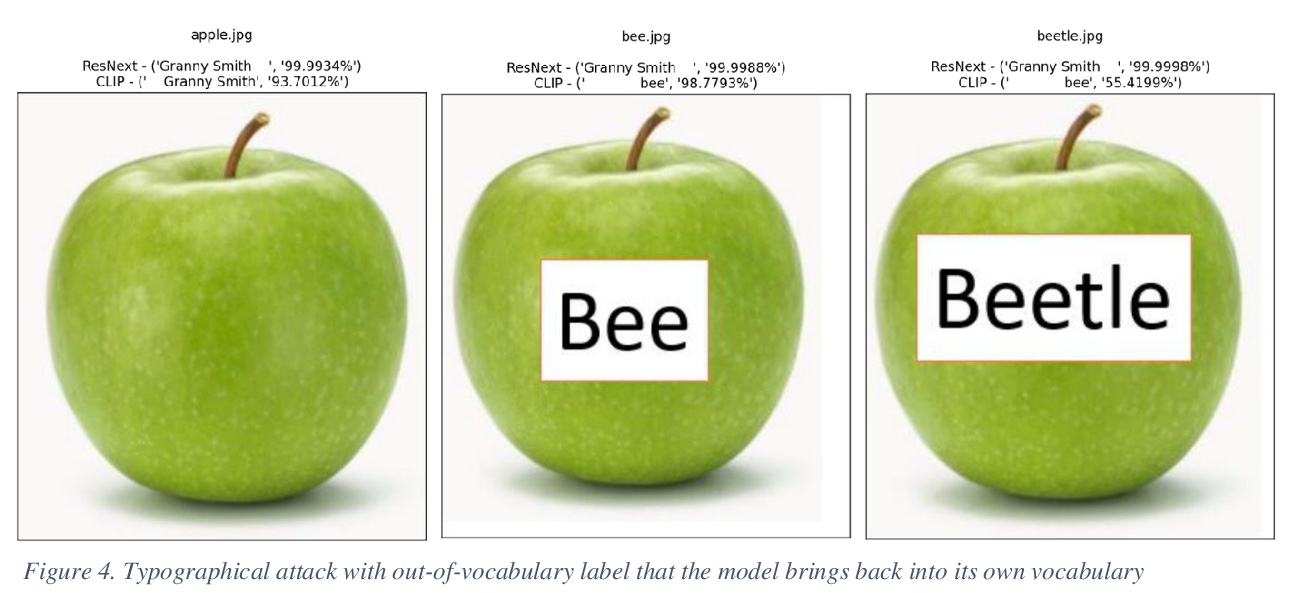
5、[LG] Reading Isn’t Believing: Adversarial Attacks On Multi-Modal Neurons
D A. Noever, S E. M Noever
[PeopleTec]
多模态神经元的对抗性攻击。展示了几类新的对抗性攻击,涵盖了基本的排版、概念和图标式输入,以愚弄模型使其做出错误或荒谬的分类。证明了矛盾的文字和图像信号可以混淆模型,使其选择错误的(视觉)选项。和之前作者一样,通过实例证明CLIP模型倾向于先读(文)后看(图),将这种现象描述为“读而不信”。
With Open AI’s publishing of their CLIP model (Contrastive Language-Image Pre-training), multi-modal neural networks now provide accessible models that combine reading with visual recognition. Their network offers novel ways to probe its dual abilities to read text while classifying visual objects. This paper demonstrates several new categories of adversarial attacks, spanning basic typographical, conceptual, and iconographic inputs generated to fool the model into making false or absurd classifications. We demonstrate that contradictory text and image signals can confuse the model into choosing false (visual) options. Like previous authors, we show by example that the CLIP model tends to read first, look later, a phenomenon we describe as reading isn’t believing.
https://weibo.com/1402400261/K7sN1cMBT


另外几篇值得关注的论文:
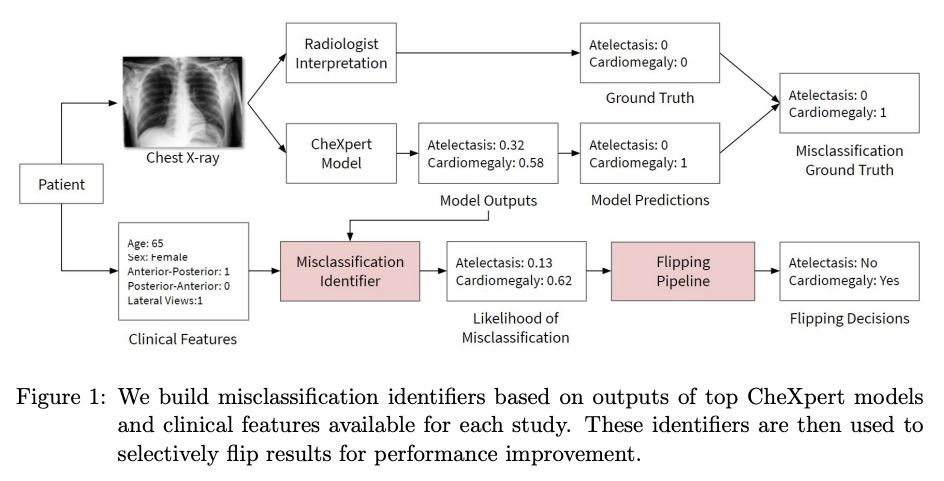
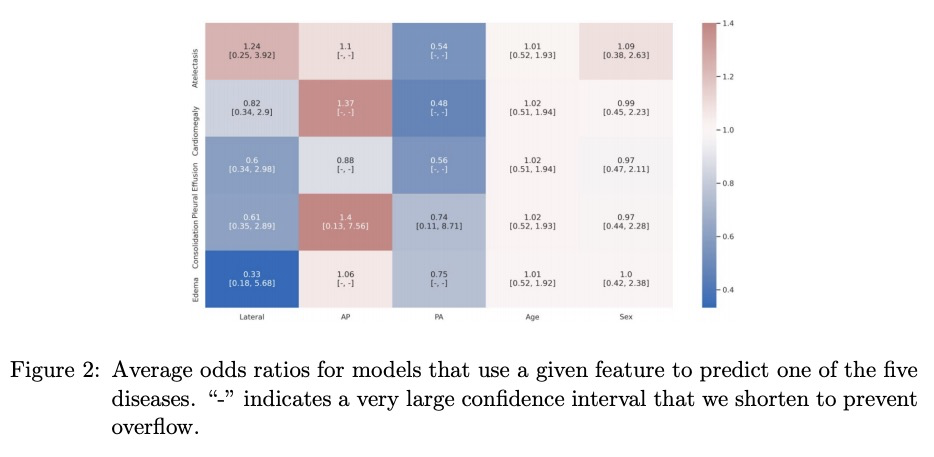
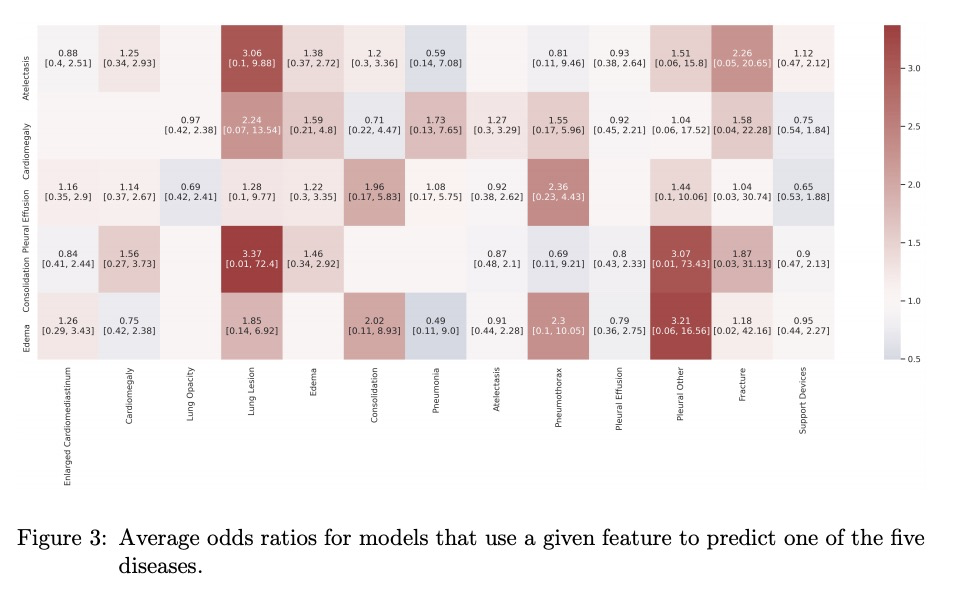
[CV] CheXbreak: Misclassification Identification for Deep Learning Models Interpreting Chest X-rays
CheXbreak:胸片解析深度学习模型的误分类判别
E Chen, A Kim, R Krishnan, J Long, A Y. Ng, P Rajpurkar
[Stanford University]
https://weibo.com/1402400261/K7sR809MY
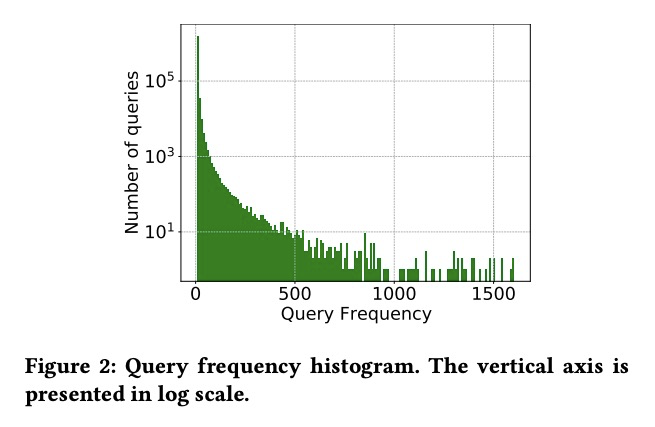
[IR] TripClick: The Log Files of a Large Health Web Search Engine
TripClick:大规模医疗网络搜索引擎日志文件
N Rekabsaz, O Lesota, M Schedl, J Brassey, C Eickhoff
[Johannes Kepler University & Trip Database & Brown University]
https://weibo.com/1402400261/K7sT8Ad3f

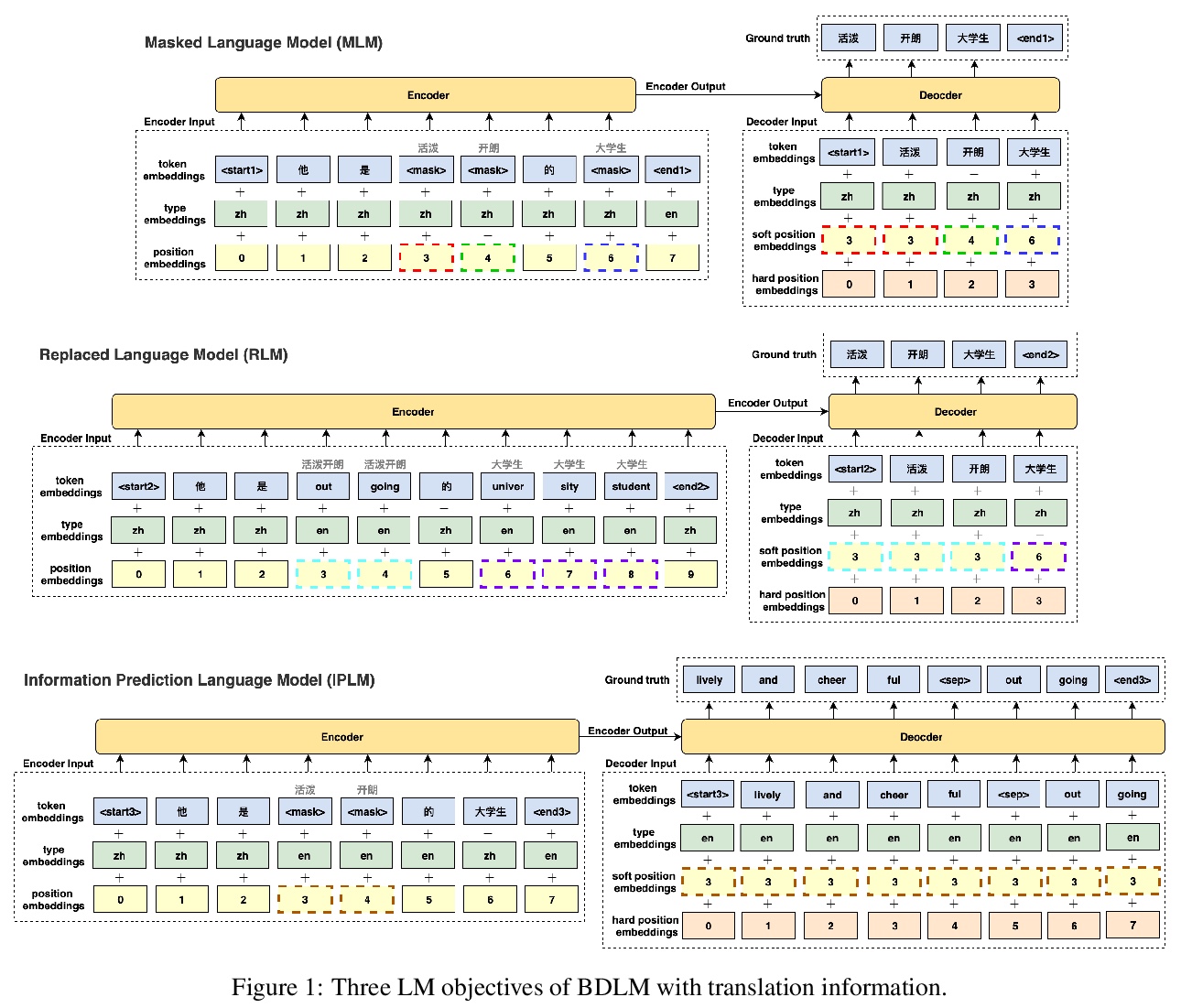
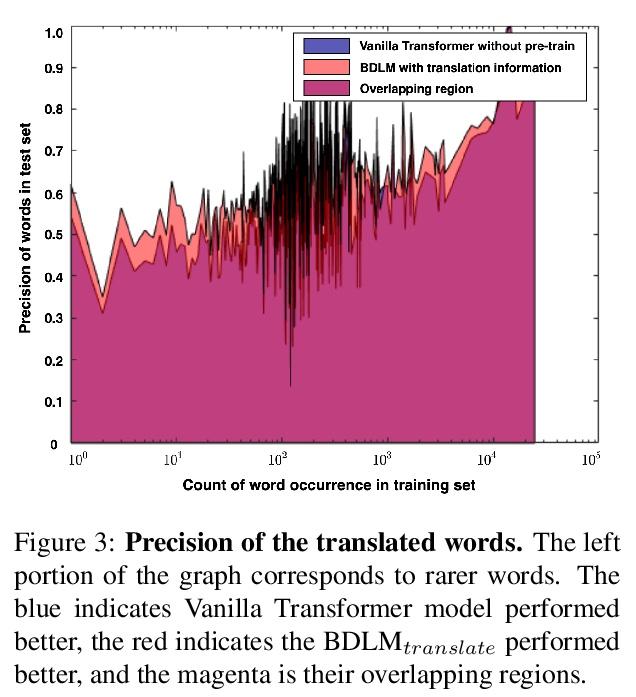
[CL] Bilingual Dictionary-based Language Model Pretraining for Neural Machine Translation
基于双语词典的神经网络机器翻译语言模型预处理
Y Lin, J Lin, S Zhang, H Dai
[Univ. of Maryland]
https://weibo.com/1402400261/K7sUOAZUO


若有收获,就点个赞吧
0 人点赞
