- 1、[CL] Calibrate Before Use: Improving Few-Shot Performance of Language Models
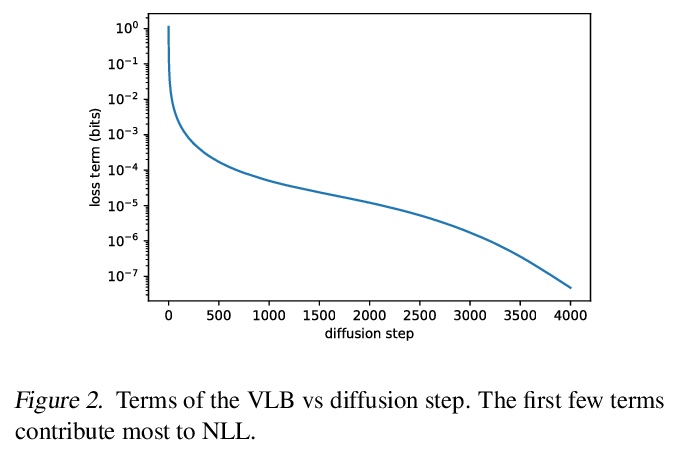
- 2、[LG] Improved Denoising Diffusion Probabilistic Models
- 3、[LG] Therapeutics Data Commons: Machine Learning Datasets and Tasks for Therapeutics
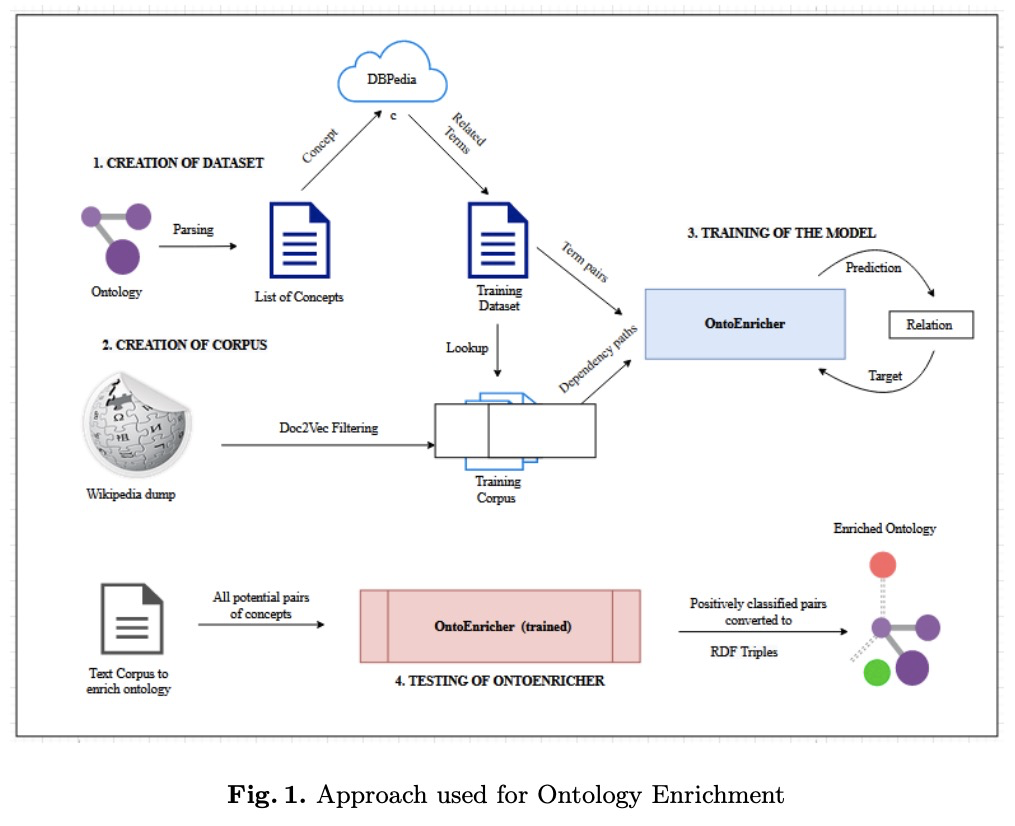
- 4、[CL] OntoEnricher: A Deep Learning Approach for Ontology Enrichment from Unstructured Text
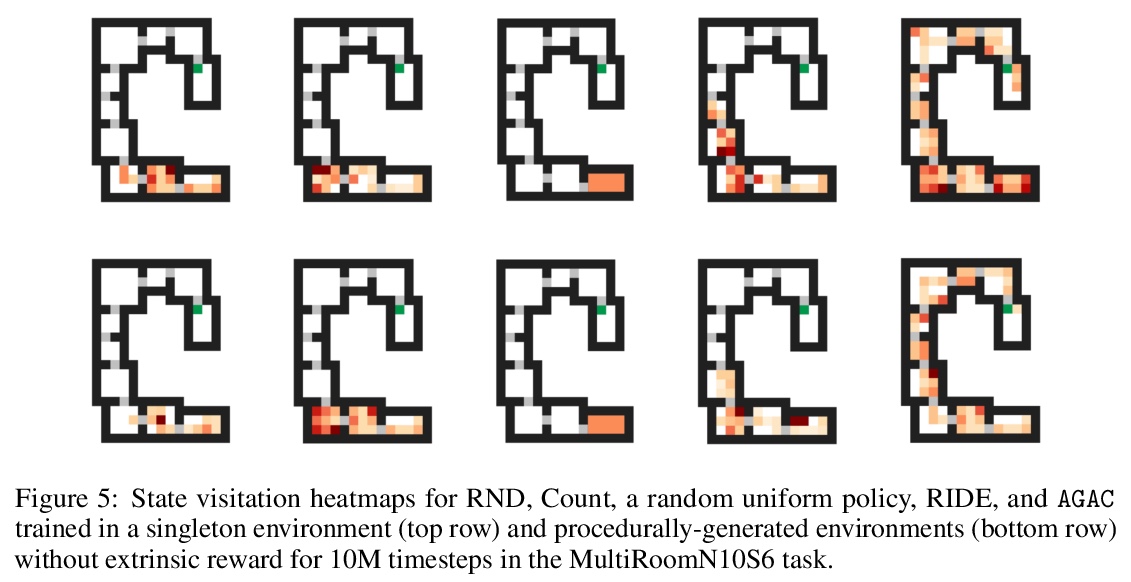
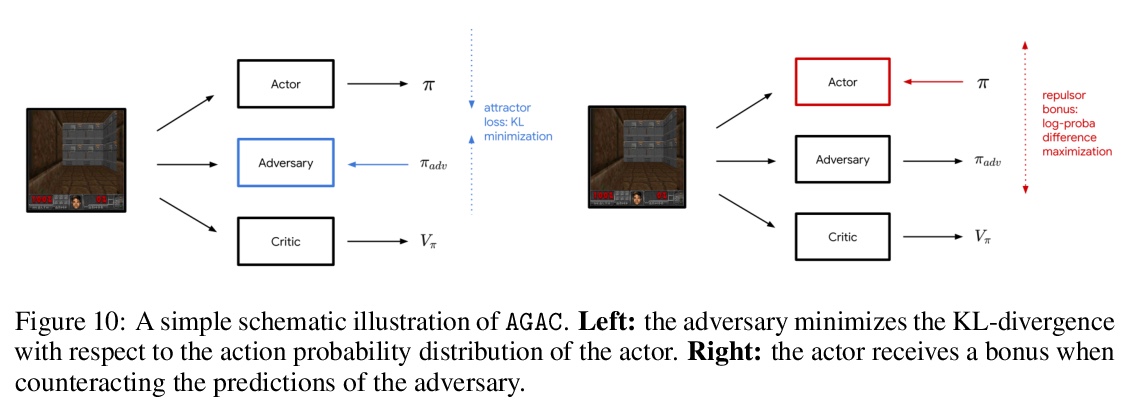
- 5、[LG] Adversarially Guided Actor-Critic
- [CV] NuCLS: A scalable crowdsourcing, deep learning approach and dataset for nucleus classification, localization and segmentation
- [CL] Characterizing English Variation across Social Media Communities with BERT
- [AI] Inferring spatial relations from textual descriptions of images
- [LG] Hierarchical VAEs Know What They Don’t Know
- [CV] End-to-end Audio-visual Speech Recognition with Conformers
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CL] Calibrate Before Use: Improving Few-Shot Performance of Language Models
T Z. Zhao, E Wallace, S Feng, D Klein, S Singh
[UC Berkeley & University of Maryland & UC Irvine]
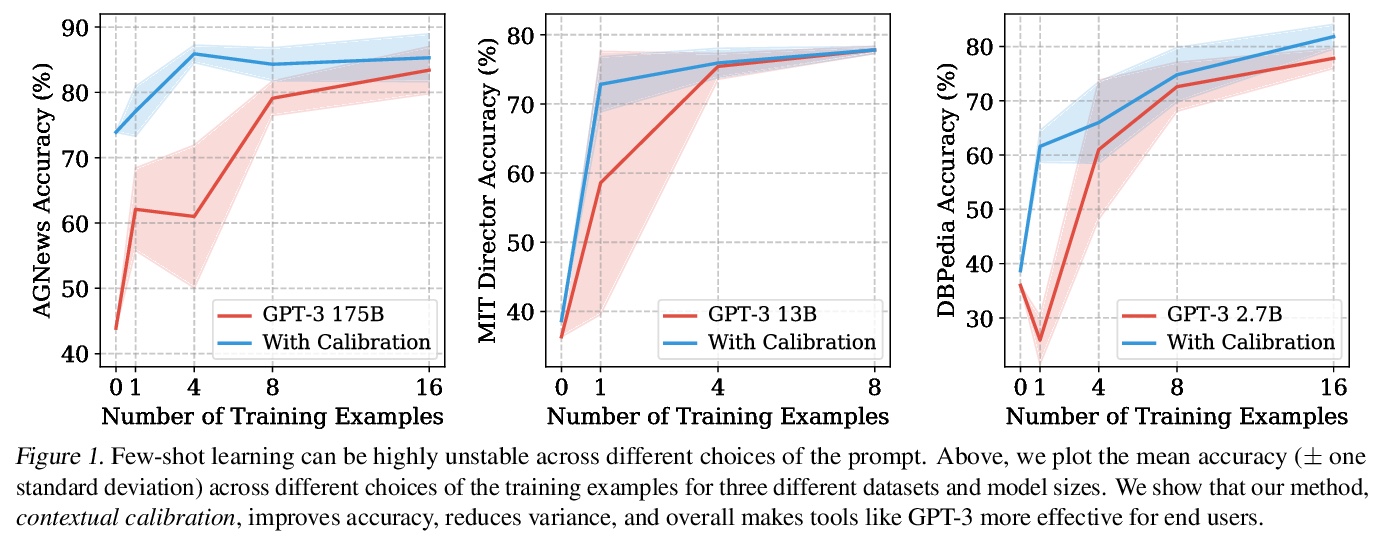
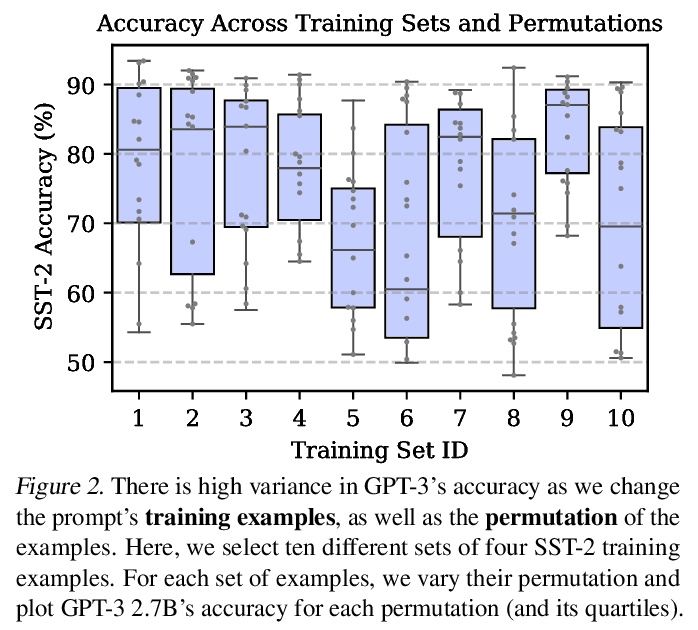
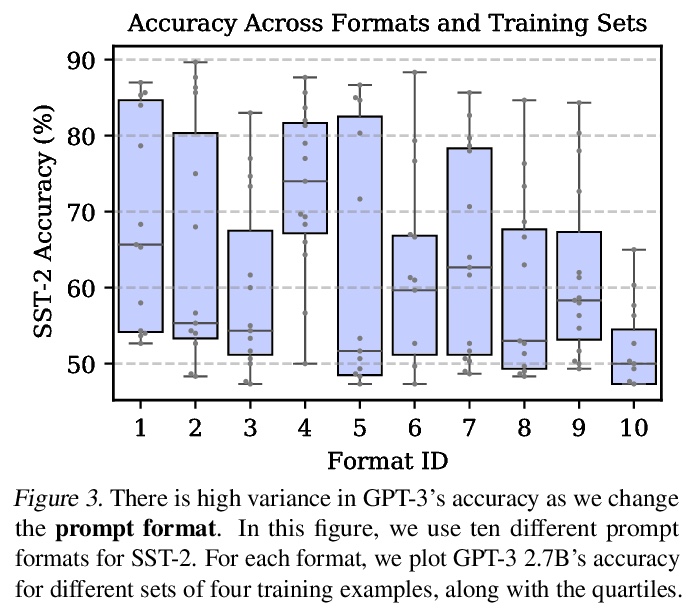
使用前校准:提高语言模型少样本性能。只要提供包含少数训练样本的自然语言提示,GPT-3就能执行许多任务,但这种类型的少样本学习可能是不稳定的:提示格式的选择、训练样本、甚至训练样本顺序都可能导致准确性在接近偶然到接近最先进水平之间漂移,这种不稳定性源于语言模型对预测某些答案的偏差,例如,那些被放在提示语末尾附近的答案,或在预训练数据中常见的答案,这些偏差往往会导致模型的输出分布发生变化。为缓解这种情况,通过询问模型在给定训练提示和无内容测试输入(如 “N/A”)时对每个答案的预测,来估计模型对每个答案的偏差,对校准参数进行拟合,使无内容输入的每个答案具有统一的分数。这种上下文校准程序提供了一个良好的校准参数设置,无需额外的训练数据。在不同任务集上,这种上下文校准程序大幅提高了GPT-3和GPT-2的平均准确率(绝对值高达30.0%),并降低了提示不同选择的差异。
GPT-3 can perform numerous tasks when provided a natural language prompt that contains a few training examples. We show that this type of few-shot learning can be unstable: the choice of prompt format, training examples, and even the order of the training examples can cause accuracy to vary from near chance to near state-of-the-art. We demonstrate that this instability arises from the bias of language models towards predicting certain answers, e.g., those that are placed near the end of the prompt or are common in the pre-training data. To mitigate this, we first estimate the model’s bias towards each answer by asking for its prediction when given the training prompt and a content-free test input such as “N/A”. We then fit calibration parameters that cause the prediction for this input to be uniform across answers. On a diverse set of tasks, this contextual calibration procedure substantially improves GPT-3 and GPT-2’s average accuracy (up to 30.0% absolute) and reduces variance across different choices of the prompt.
https://weibo.com/1402400261/K3cyy41Dp
2、[LG] Improved Denoising Diffusion Probabilistic Models
A Nichol, P Dhariwal
[OpenAI]
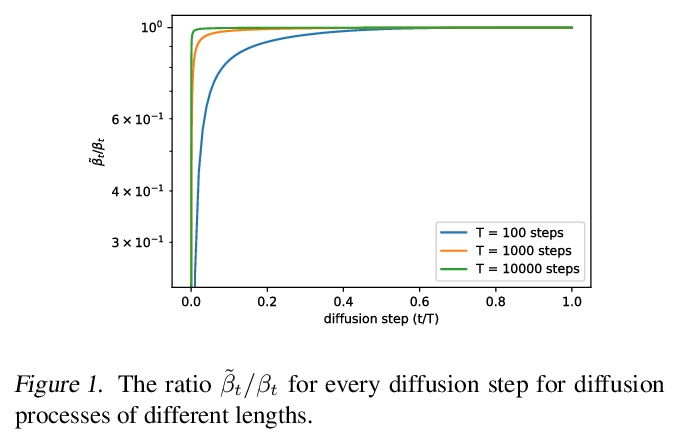
改进的去噪扩散概率模型。去噪扩散概率模型(Denoising diffusion probabilistic models,DDPM)是一类生成式模型,最近被证明可用来产生优秀的样本。通过一些简单的修改,DDPM可以更快地采样,并在保持高样本质量的同时实现更好的对数似然,使得这些模型的似然更接近于其他基于似然的模型。DDPM可以与GAN的样本质量相匹敌,同时实现召回率指标下更好的模式覆盖率。研究了DDPM如何随着可用的训练计算量而扩展,并发现更多的训练计算量琐碎地导致更好的样本质量和对数似然。
Denoising diffusion probabilistic models (DDPM) are a class of generative models which have recently been shown to produce excellent samples. We show that with a few simple modifications, DDPMs can also achieve competitive log-likelihoods while maintaining high sample quality. Additionally, we find that learning variances of the reverse diffusion process allows sampling with an order of magnitude fewer forward passes with a negligible difference in sample quality, which is important for the practical deployment of these models. We additionally use precision and recall to compare how well DDPMs and GANs cover the target distribution. Finally, we show that the sample quality and likelihood of these models scale smoothly with model capacity and training compute, making them easily scalable. We release our code at > this https URL
https://weibo.com/1402400261/K3cLBq8a8


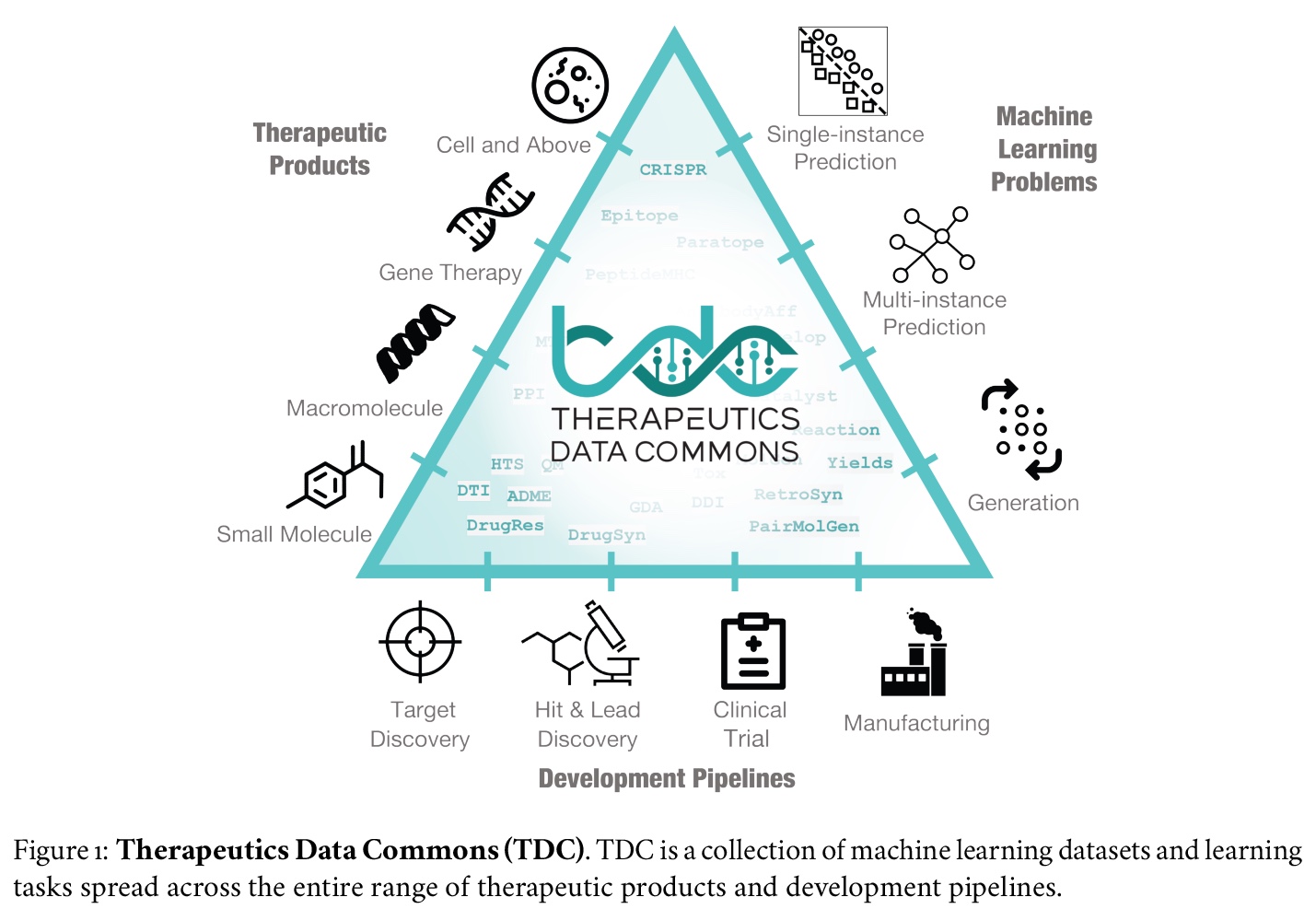
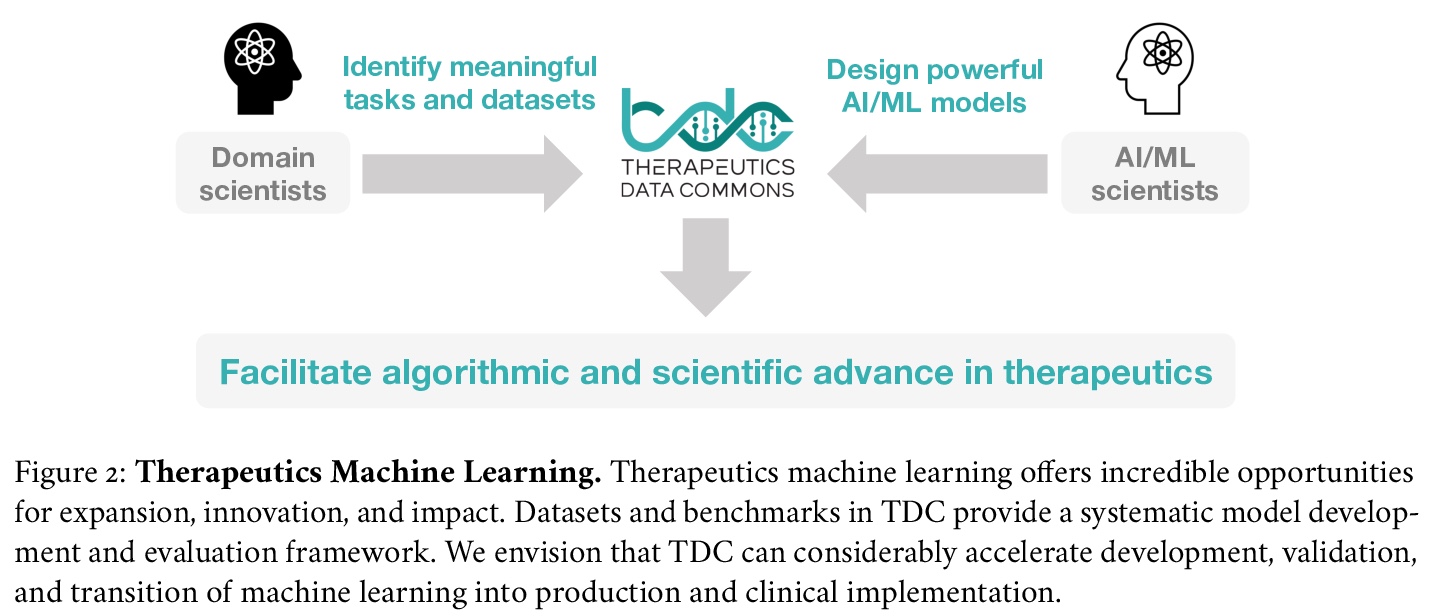
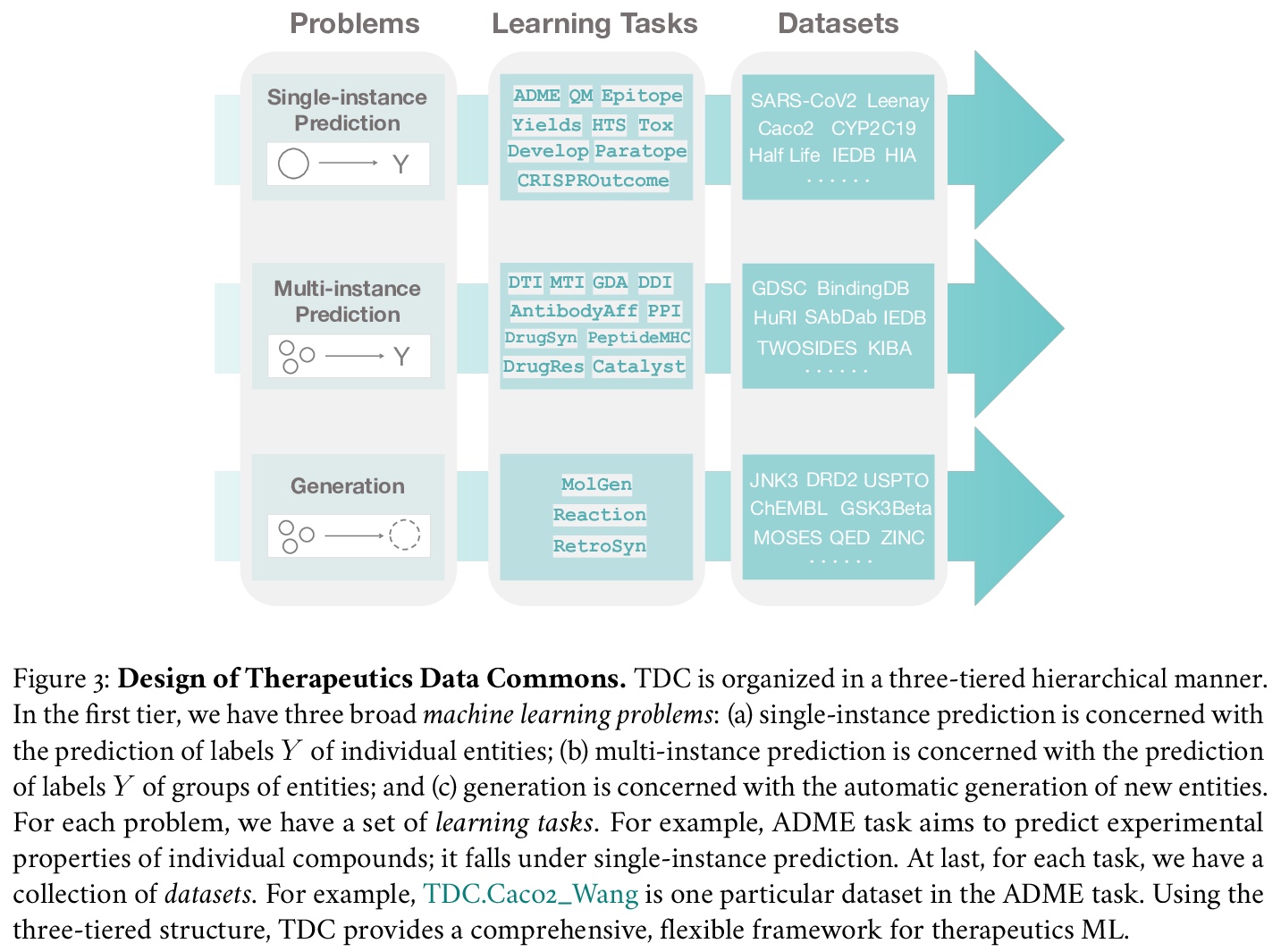
3、[LG] Therapeutics Data Commons: Machine Learning Datasets and Tasks for Therapeutics
K Huang, T Fu, W Gao, Y Zhao, Y Roohani, J Leskovec, C W. Coley, C Xiao, J Sun, M Zitnik
[Harvard University & Georgia Institute of Technology & MIT & CMU & Stanford University & IQVIA & University of Illinois at Urbana-Champaign]
治疗数据共享:面向治疗学的机器学习数据集和任务。介绍治疗学数据共享(TDC)——第一个系统性访问和评价整个治疗学范围机器学习的统一框架。TDC核心是一个策划的数据集和学习任务的集合,将算法创新转化为生物医学和临床实施。迄今为止,TDC包括来自22个学习任务的66个机器学习数据集,涵盖了安全有效药物的发现和开发。TDC还提供了一个由工具、库、排行榜和社区资源组成的生态系统,包括数据功能、系统化模型评价策略、有意义的数据分割、数据处理器等。所有数据集和学习任务都是集成的,可通过开源库访问。
Machine learning for therapeutics is an emerging field with incredible opportunities for innovation and expansion. Despite the initial success, many key challenges remain open. Here, we introduce Therapeutics Data Commons (TDC), the first unifying framework to systematically access and evaluate machine learning across the entire range of therapeutics. At its core, TDC is a collection of curated datasets and learning tasks that can translate algorithmic innovation into biomedical and clinical implementation. To date, TDC includes 66 machine learning-ready datasets from 22 learning tasks, spanning the discovery and development of safe and effective medicines. TDC also provides an ecosystem of tools, libraries, leaderboards, and community resources, including data functions, strategies for systematic model evaluation, meaningful data splits, data processors, and molecule generation oracles. All datasets and learning tasks are integrated and accessible via an open-source library. We envision that TDC can facilitate algorithmic and scientific advances and accelerate development, validation, and transition into production and clinical implementation. TDC is a continuous, open-source initiative, and we invite contributions from the research community. TDC is publicly available at > this https URL.
https://weibo.com/1402400261/K3cQirur6
4、[CL] OntoEnricher: A Deep Learning Approach for Ontology Enrichment from Unstructured Text
L M Sanagavarapu, V Iyer, Y R Reddy
[IIIT Hyderabad]
OntoEnricher: 用非结构化文本丰富本体的深度学习方法。现有的基于自然语言处理和机器学习模型的本体丰富化算法,在词、短语和句子概念上下文提取方面存在问题,需要序列深度学习架构来遍历文本中的依存路径,并从学习路径表示中提取嵌入的漏洞、威胁、控制、产品和其他安全相关概念和实例。在所提出方法中,部署了在大型DBpedia数据集和2.8 GB的Wikipedia语料库上训练的双向LSTMs以及通用句子编码器,以丰富基于ISO 27001的信息安全本体。当使用本体和网页实例中的淘汰概念进行测试以验证其鲁棒性时,产生了超过80%的测试准确率。
Information Security in the cyber world is a major cause for concern, with significant increase in the number of attack surfaces. Existing information on vulnerabilities, attacks, controls, and advisories available on the web provides an opportunity to represent knowledge and perform security analytics to mitigate some of the concerns. Representing security knowledge in the form of ontology facilitates anomaly detection, threat intelligence, reasoning and relevance attribution of attacks, and many more. This necessitates dynamic and automated enrichment of information security ontologies. However, existing ontology enrichment algorithms based on natural language processing and ML models have issues with the contextual extraction of concepts in words, phrases and sentences. This motivates the need for sequential Deep Learning architectures that traverse through dependency paths in text and extract embedded vulnerabilities, threats, controls, products and other security related concepts and instances from learned path representations. In the proposed approach, Bidirectional LSTMs trained on a large DBpedia dataset and Wikipedia corpus of 2.8 GB along with Universal Sentence Encoder was deployed to enrich ISO 27001 based information security ontology. The approach yielded a test accuracy of over 80\% when tested with knocked out concepts from ontology and web page instances to validate the robustness.
https://weibo.com/1402400261/K3cUg37lS

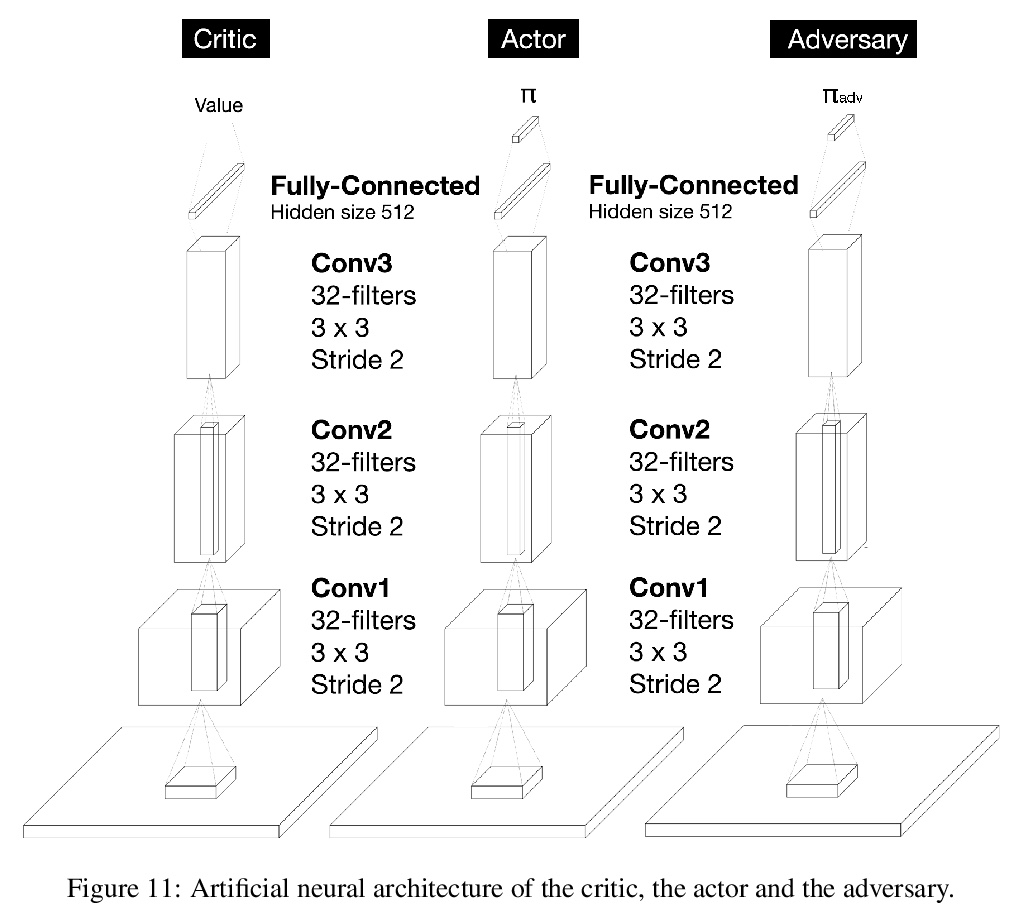
5、[LG] Adversarially Guided Actor-Critic
Y Flet-Berliac, J Ferret, O Pietquin, P Preux, M Geist
[Inria & Google Research]
对抗式引导行动者-批判者(Actor-Critic)模型。提出对抗式引导行动者-批判者(Actor-Critic)算法,是对传统的Actor-Critic框架的改进:增加了对手网络,作为第三个主角。对手通过最小化各自行动分布间的KL-散度来模仿行动者,而行动者除了学习解决任务外,还试图将自己与对手的预测区分开来。这个新的目标刺激行动者遵循从以前的轨迹中无法正确预测的策略,使其在奖励极其罕见的任务中的行为具有创新性。从策略迭代的角度讨论了AGAC机制,对所提出的算法内部运作提供了理论上的见解:对手迫使智能体保持接近当前策略,同时远离之前的策略——对手的影响,使得行动者实现了保守地多样化。实验分析表明,由此产生的对抗式引导行动者-批判者(AGAC)算法会导致更详尽的探索。
Despite definite success in deep reinforcement learning problems, actor-critic algorithms are still confronted with sample inefficiency in complex environments, particularly in tasks where efficient exploration is a bottleneck. These methods consider a policy (the actor) and a value function (the critic) whose respective losses are built using different motivations and approaches. This paper introduces a third protagonist: the adversary. While the adversary mimics the actor by minimizing the KL-divergence between their respective action distributions, the actor, in addition to learning to solve the task, tries to differentiate itself from the adversary predictions. This novel objective stimulates the actor to follow strategies that could not have been correctly predicted from previous trajectories, making its behavior innovative in tasks where the reward is extremely rare. Our experimental analysis shows that the resulting Adversarially Guided Actor-Critic (AGAC) algorithm leads to more exhaustive exploration. Notably, AGAC outperforms current state-of-the-art methods on a set of various hard-exploration and procedurally-generated tasks.
https://weibo.com/1402400261/K3d0ejcr8
另外几篇值得关注的论文:
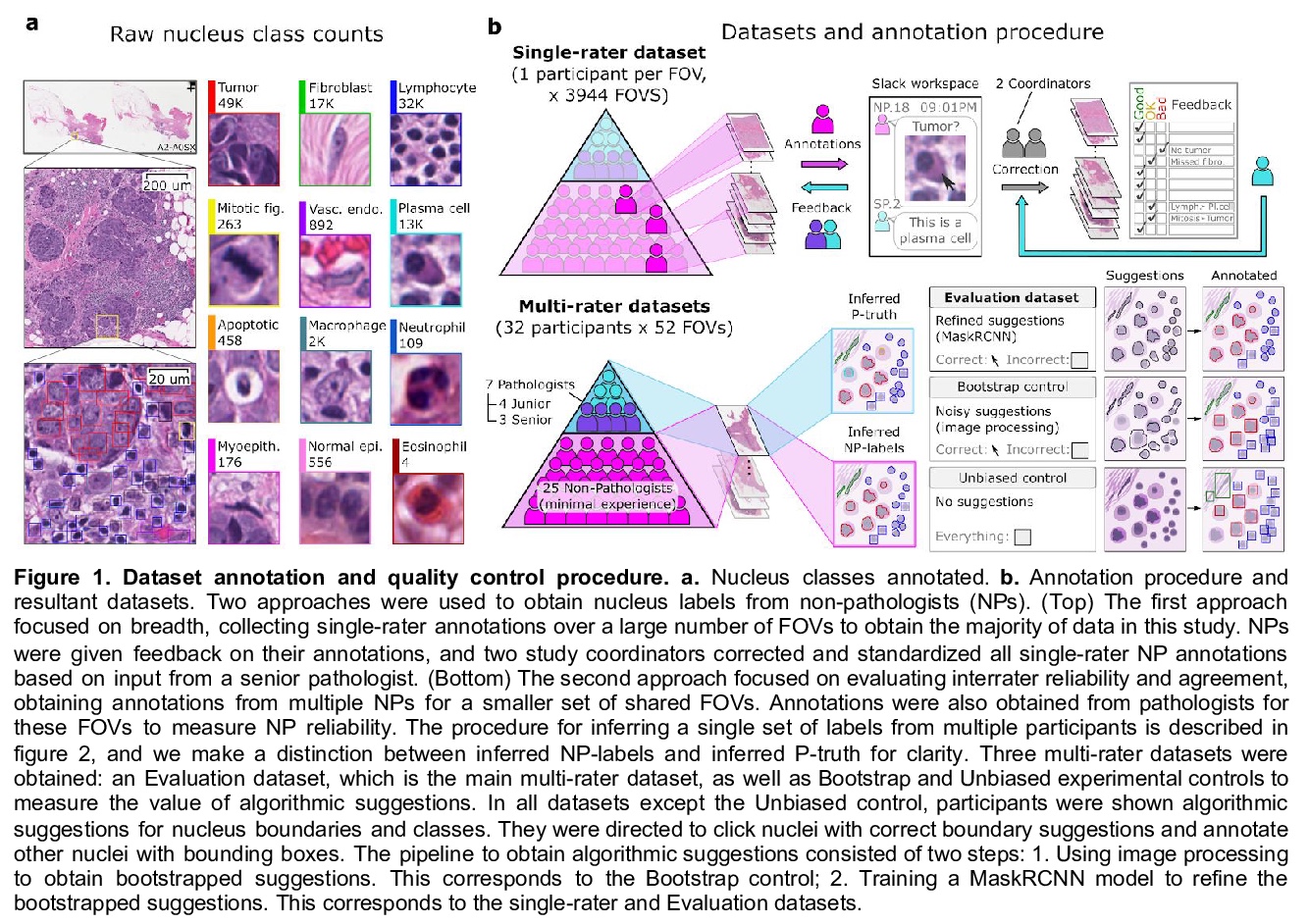
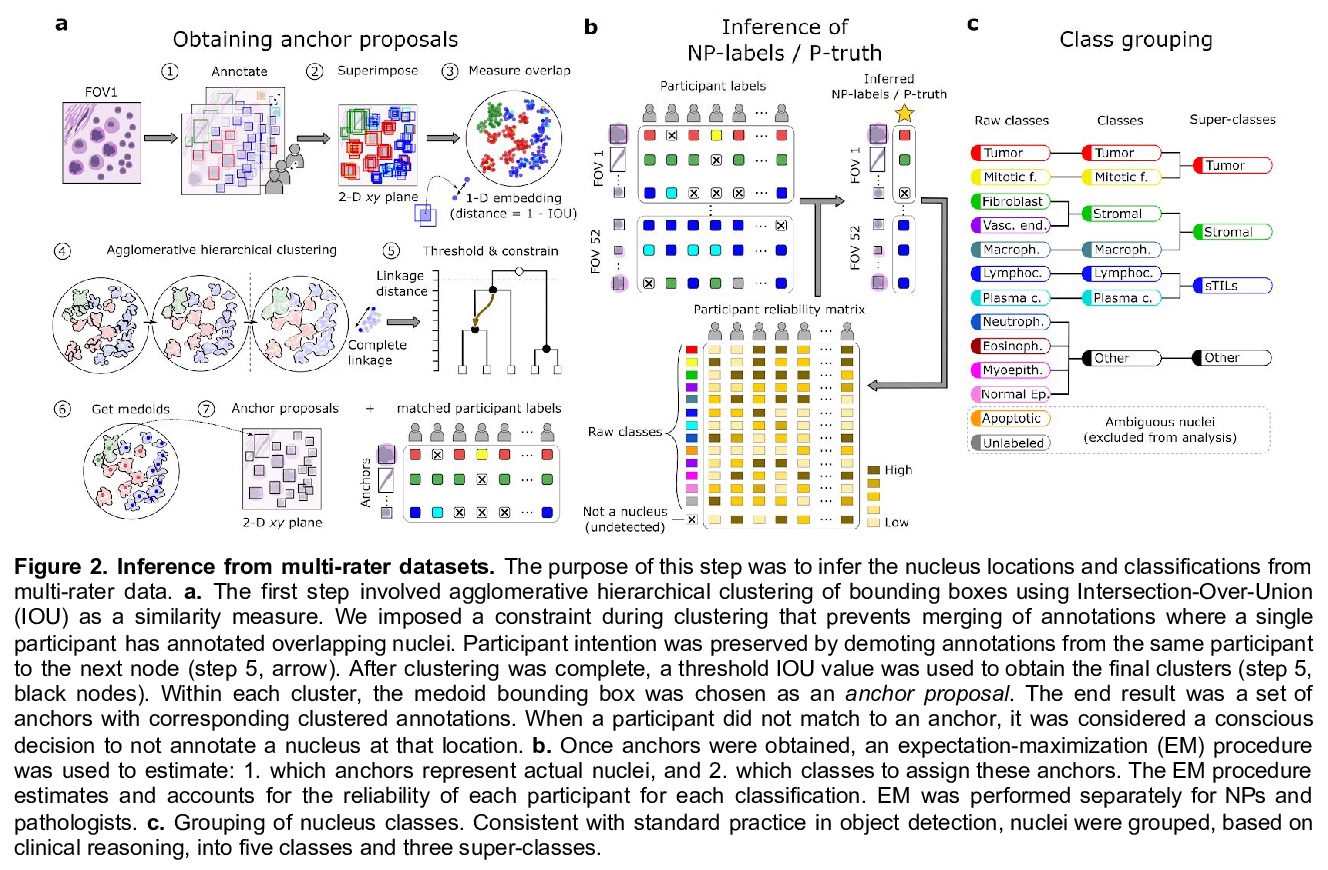
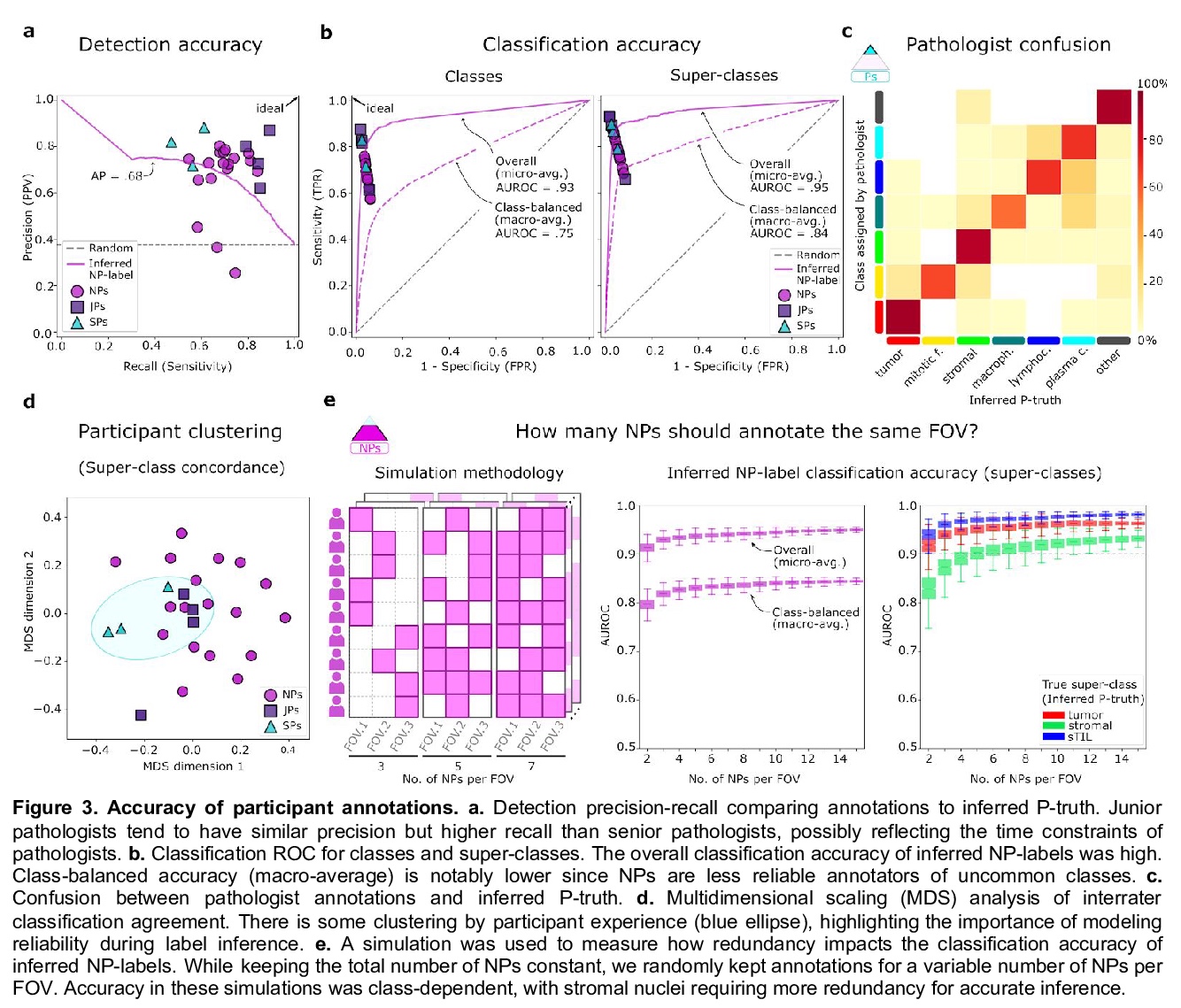
[CV] NuCLS: A scalable crowdsourcing, deep learning approach and dataset for nucleus classification, localization and segmentation
NuCLS:面向核分类、定位和分割的可扩展众包、深度学习方法和数据集
Mohamed A, Lamees A. A…
[Northwestern University, Egyptian Ministry of Health…]
https://weibo.com/1402400261/K3d80cMek
[CL] Characterizing English Variation across Social Media Communities with BERT
用BERT描述社交媒体社区中的英语变体
L Lucy, D Bamman
[UC Berkeley]
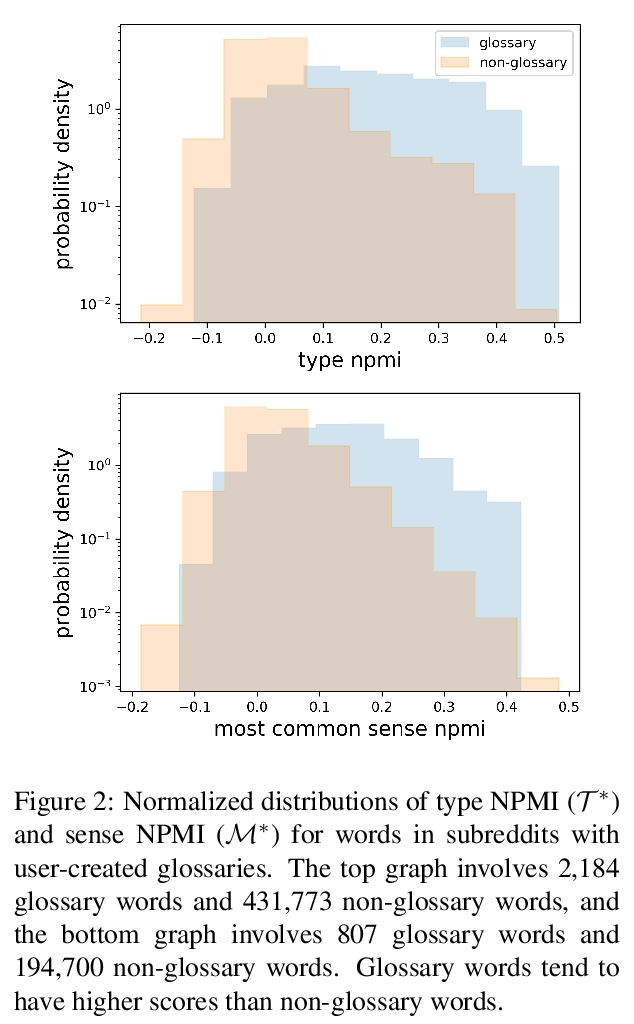
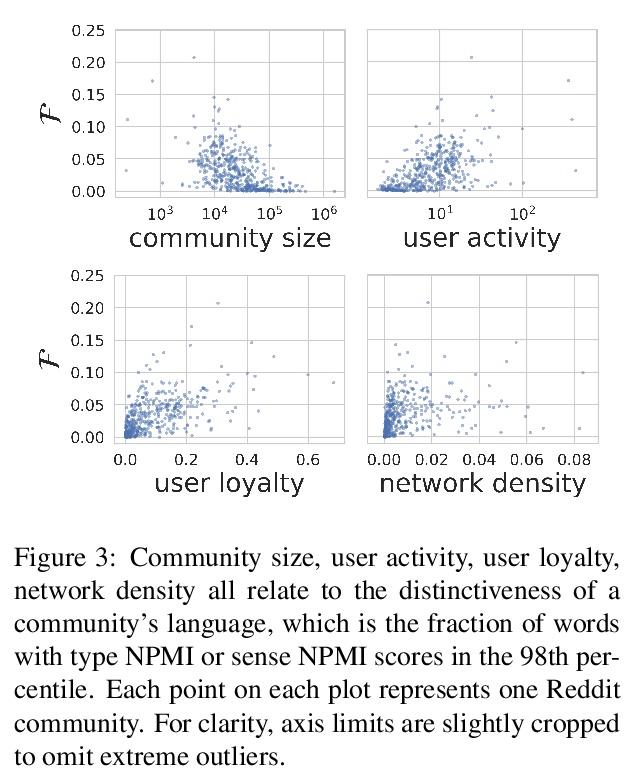
https://weibo.com/1402400261/K3d9LzQX9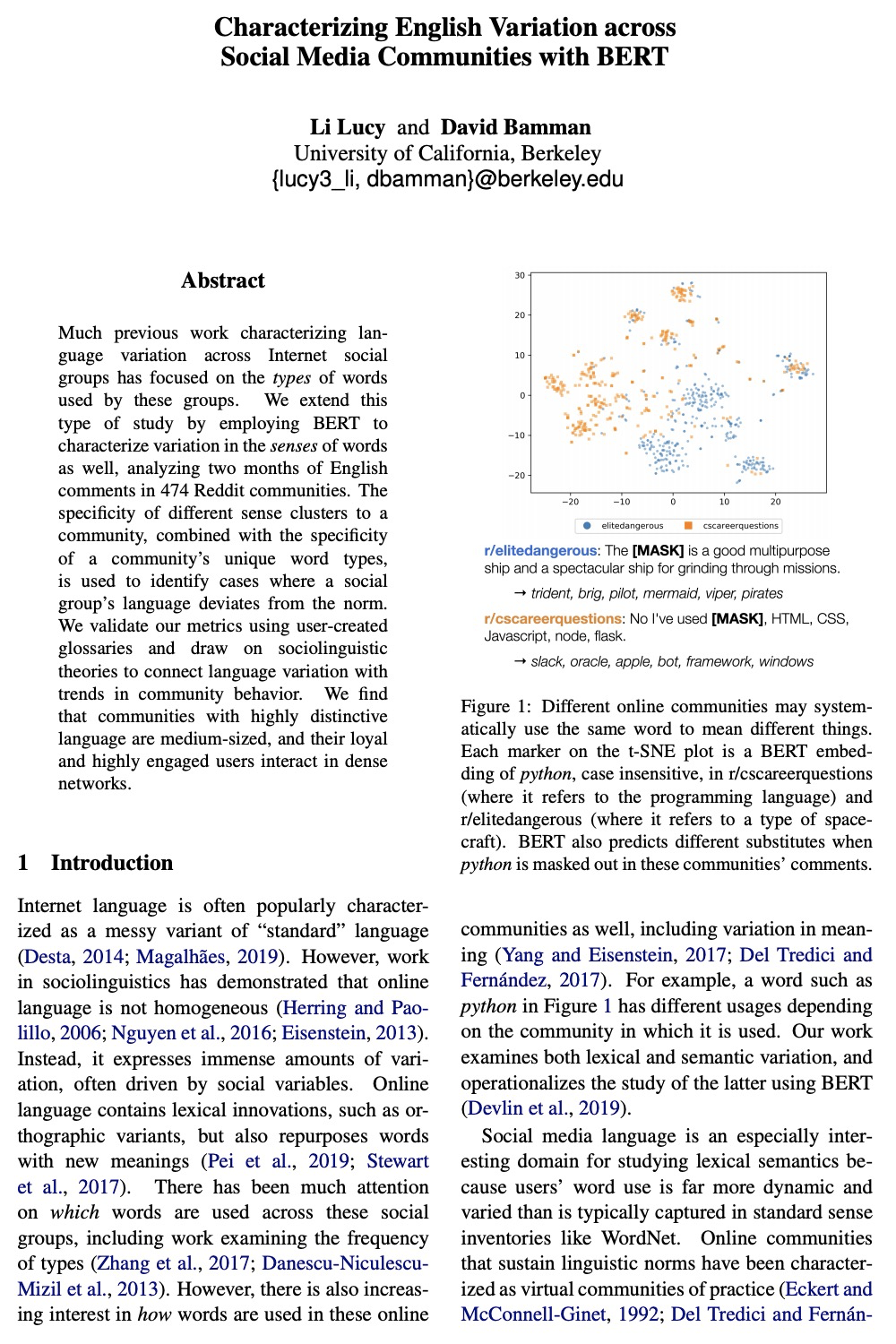
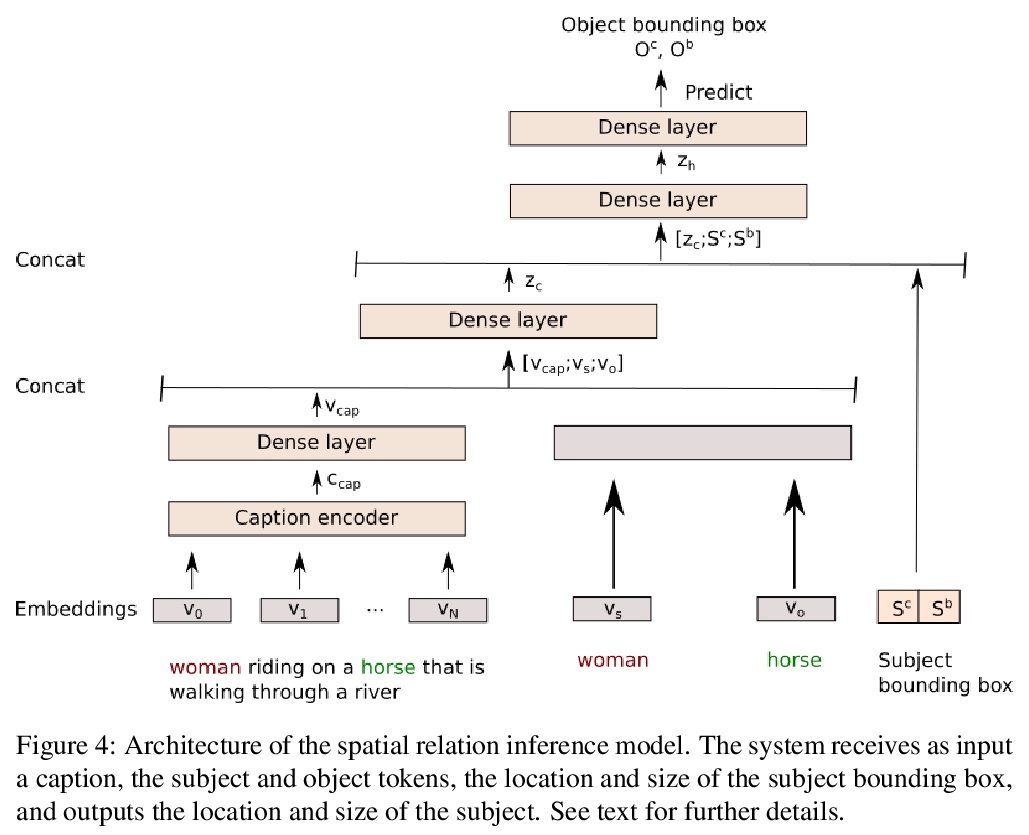
[AI] Inferring spatial relations from textual descriptions of images
从图像文本描述推断空间关系
A Elu, G Azkune, O L d Lacalle, I Arganda-Carreras, A Soroa, E Agirre
[University of the Basque Country UPV/EHU]
https://weibo.com/1402400261/K3dcuxPMy




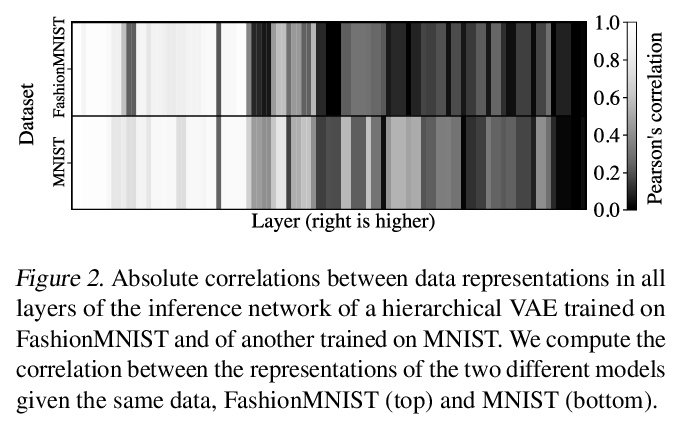
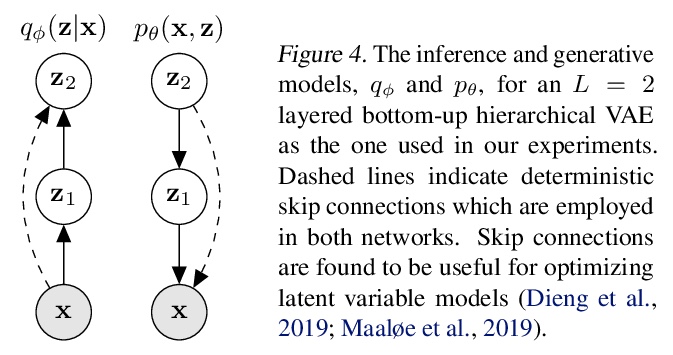
[LG] Hierarchical VAEs Know What They Don’t Know
层次VAE知道它们不知道什么
J D. Havtorn, J Frellsen, S Hauberg, L Maaløe
[Technical University of Denmark]
https://weibo.com/1402400261/K3de1aLSy

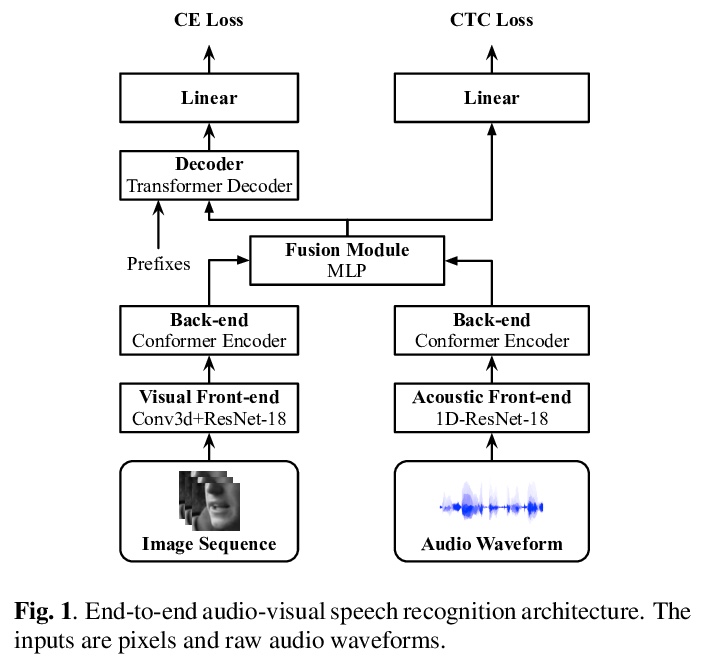
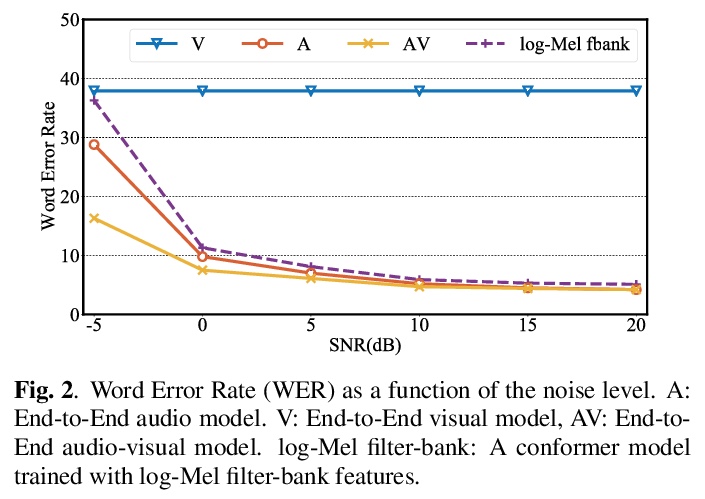
[CV] End-to-end Audio-visual Speech Recognition with Conformers
基于卷积增强Transformer的端到端视听语音识别
P Ma, S Petridis, M Pantic
[Imperial College London]
https://weibo.com/1402400261/K3dg08uvE

若有收获,就点个赞吧
0 人点赞
