- 1、[CV] Convolution-Free Medical Image Segmentation using Transformers
- 2、[LG] First return, then explore
- 3、[LG] Random Feature Attention
- 4、[LG] Iterative SE(3)-Transformers
- 5、[LG] Named Tensor Notation
- [LG] Randomized Exploration is Near-Optimal for Tabular MDP
- [LG] On the Importance of Hyperparameter Optimization for Model-based Reinforcement Learning
- [CV] Where to look at the movies : Analyzing visual attention to understand movie editing
- [LG] Learning with invariances in random features and kernel models
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Convolution-Free Medical Image Segmentation using Transformers
D Karimi, S Vasylechko, A Gholipour
[Harvard Medical School]
基于Transformer的非卷积医学图像分割。提出一种基于相邻3D图块间自注意力的3D医学图像分割模型,无需任何卷积操作,即可实现有竞争力或更好的结果。给定一个3D图像块,该网络将其划分为n个3D块,其中n=3或5,为每个块计算1D嵌入,根据这些块嵌入间的自注意力,来预测该3D图像块中心块的分割图。该网络可在三个不同的医学图像分割数据集上实现优于或至少与最先进的CNN相当的分割精度。当有大量未标注的训练图像集时,可提高网络的分割精度。当标注训练图像数量较少时,该网络比最先进的CNN的预训练性能更好。
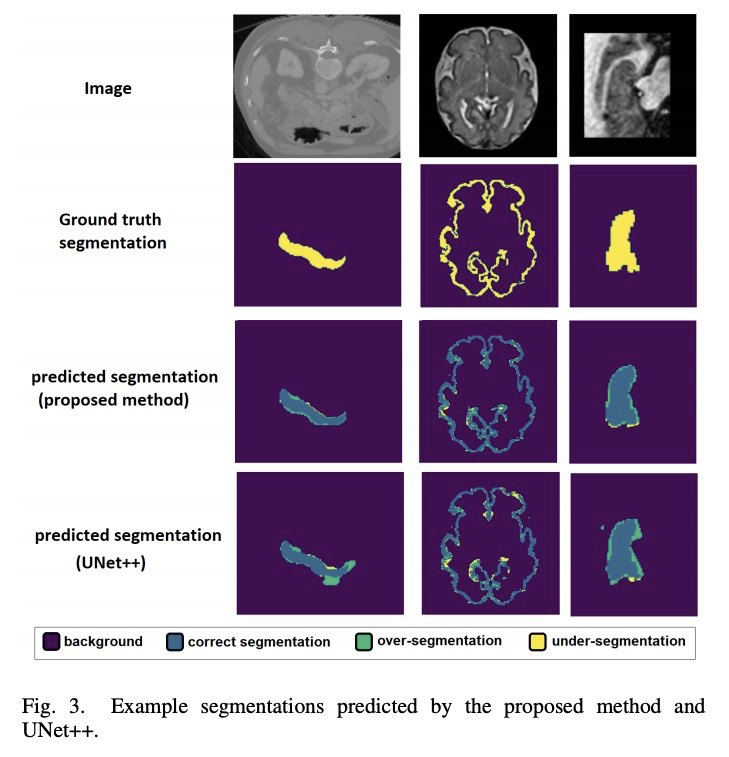
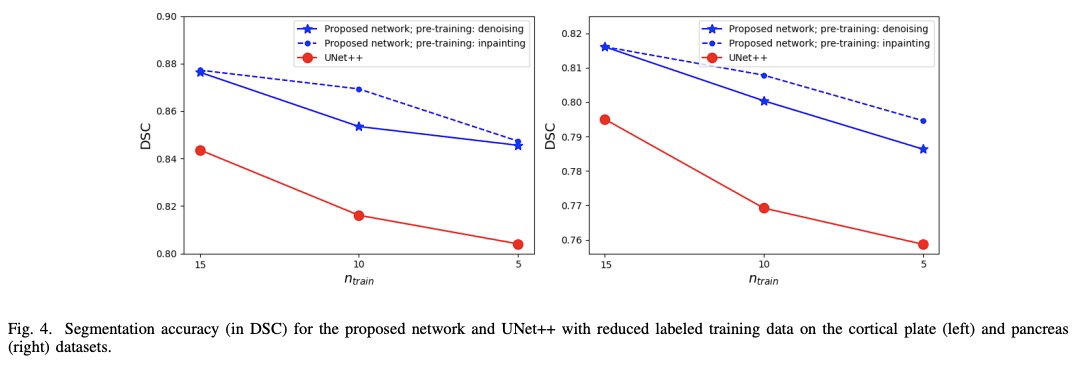
Like other applications in computer vision, medical image segmentation has been most successfully addressed using deep learning models that rely on the convolution operation as their main building block. Convolutions enjoy important properties such as sparse interactions, weight sharing, and translation equivariance. These properties give convolutional neural networks (CNNs) a strong and useful inductive bias for vision tasks. In this work we show that a different method, based entirely on self-attention between neighboring image patches and without any convolution operations, can achieve competitive or better results. Given a 3D image block, our network divides it into > n3 3D patches, where > n=3 or 5 and computes a 1D embedding for each patch. The network predicts the segmentation map for the center patch of the block based on the self-attention between these patch embeddings. We show that the proposed model can achieve segmentation accuracies that are better than the state of the art CNNs on three datasets. We also propose methods for pre-training this model on large corpora of unlabeled images. Our experiments show that with pre-training the advantage of our proposed network over CNNs can be significant when labeled training data is small.
https://weibo.com/1402400261/K4gBCgHok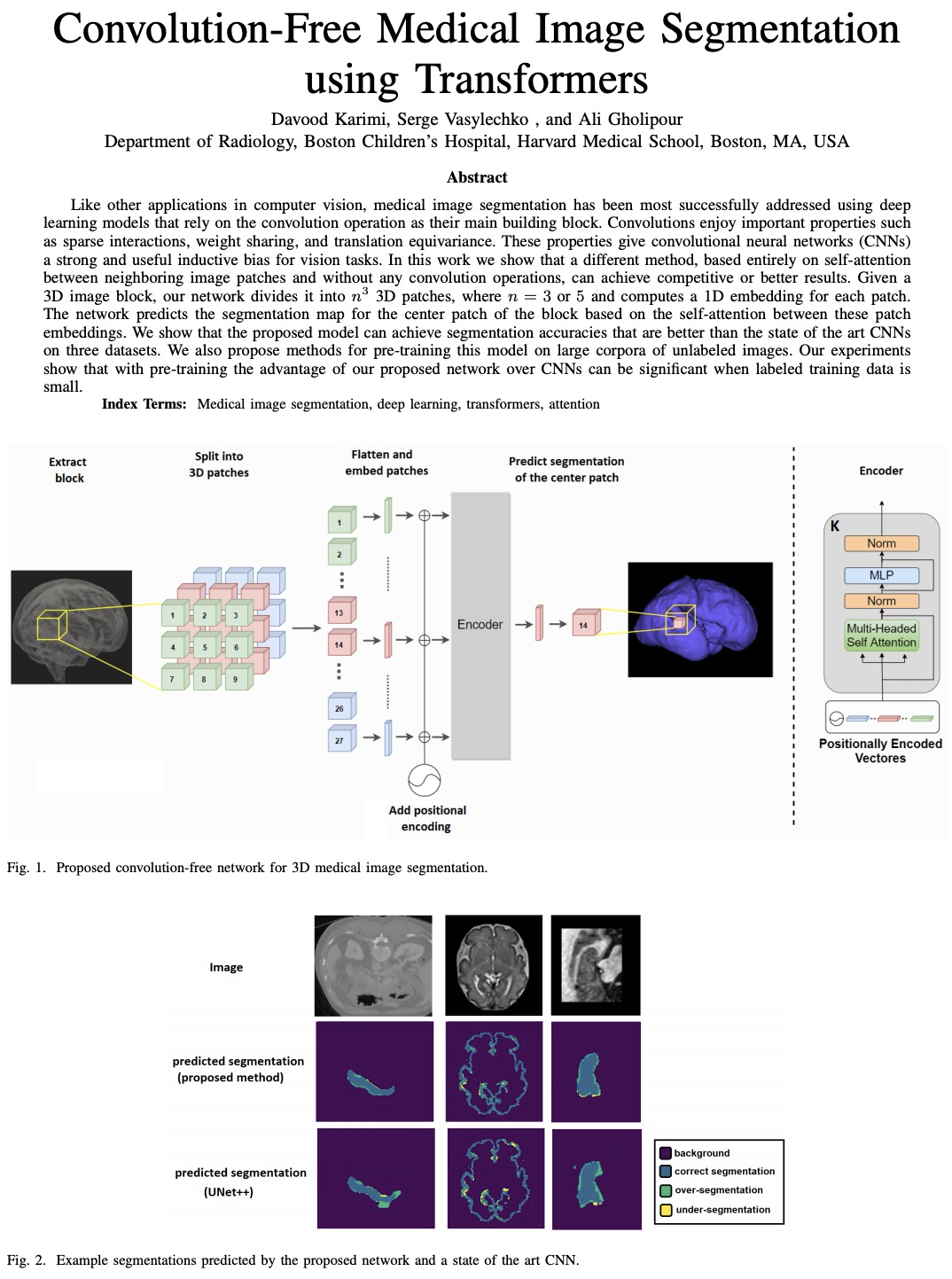
2、[LG] First return, then explore
A Ecoffet, J Huizinga, J Lehman, KO Stanley, J Clune
[Uber AI Labs]
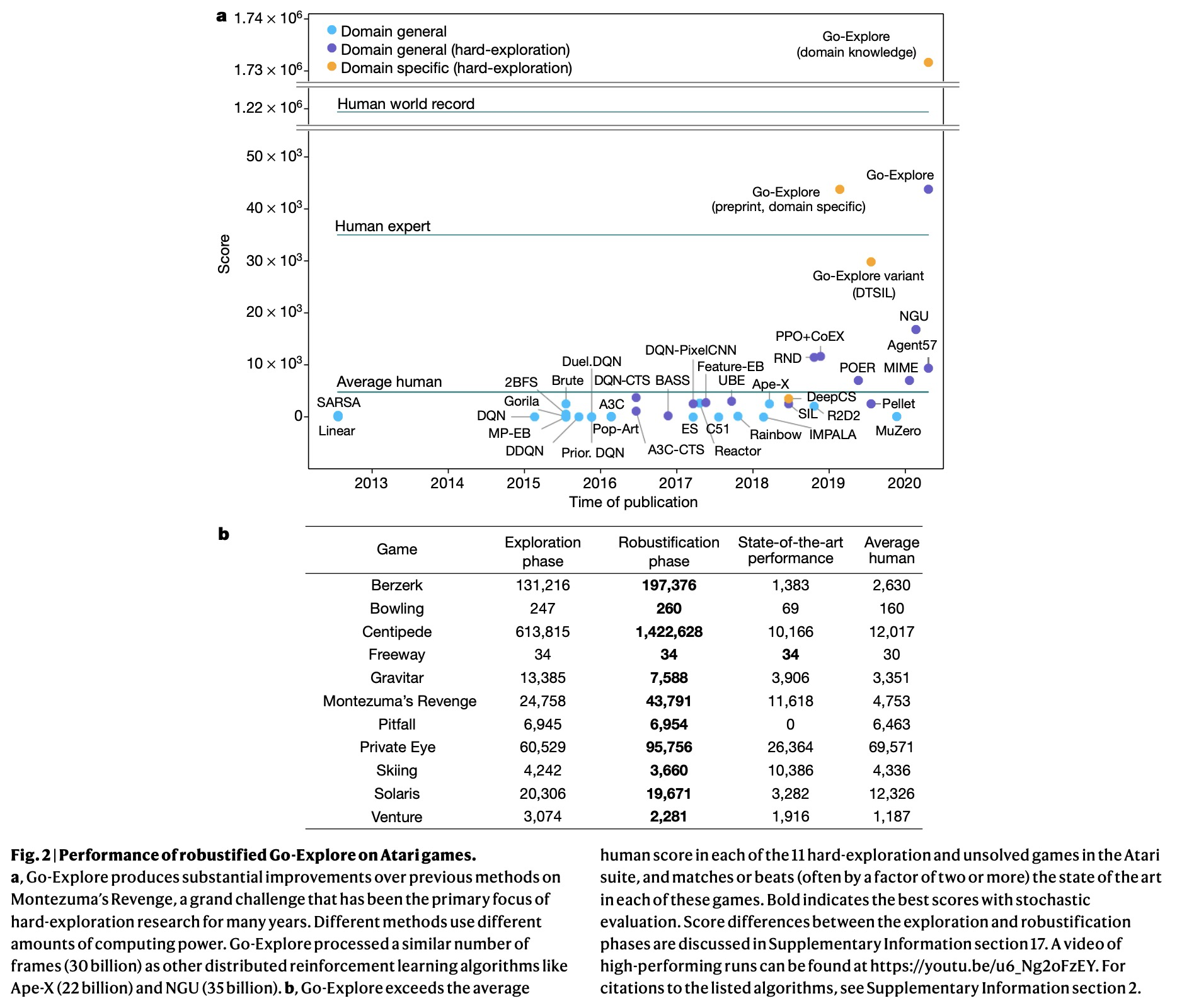
先返回,再探索。强化学习有望只通过指定一个高级奖励函数来自主解决复杂的顺序决策问题。然而,当(通常情况下)简单直观的奖励提供稀疏和欺骗性反馈时,强化学习算法会陷入困境。要避免这些陷阱,需要对环境进行彻底探索,但创造能够做到这一点的算法仍然是该领域的核心挑战之一。本文假设有效探索的主要障碍,源于算法忘记如何到达之前访问过的状态(脱离),以及在从状态中探索之前未能首先返回到一个状态(脱轨)。提出Go-Explore算法族,通过明确”记忆”有希望的状态,以及在有意探索前返回这些状态的简单原则,解决这两个挑战。Go-Explore解决了所有之前未解决的Atari游戏,超越了所有难探索游戏的技术水平,对Montezuma’s Revenge和Pitfall的巨大挑战实现了数量级的改进。展示了Go-Explore在稀疏奖励的拾取/放置机器人任务上的实际潜力,添加目标条件策略可进一步提高Go-Explore的探索效率,并使其能够在整个训练过程中处理随机性。Go-Explore的大幅性能提升表明,记住状态、返回状态、并从中探索的简单原则,是一种强大而通用的探索方法——这一见解可能对创建真正的智能学习智能体至关重要。
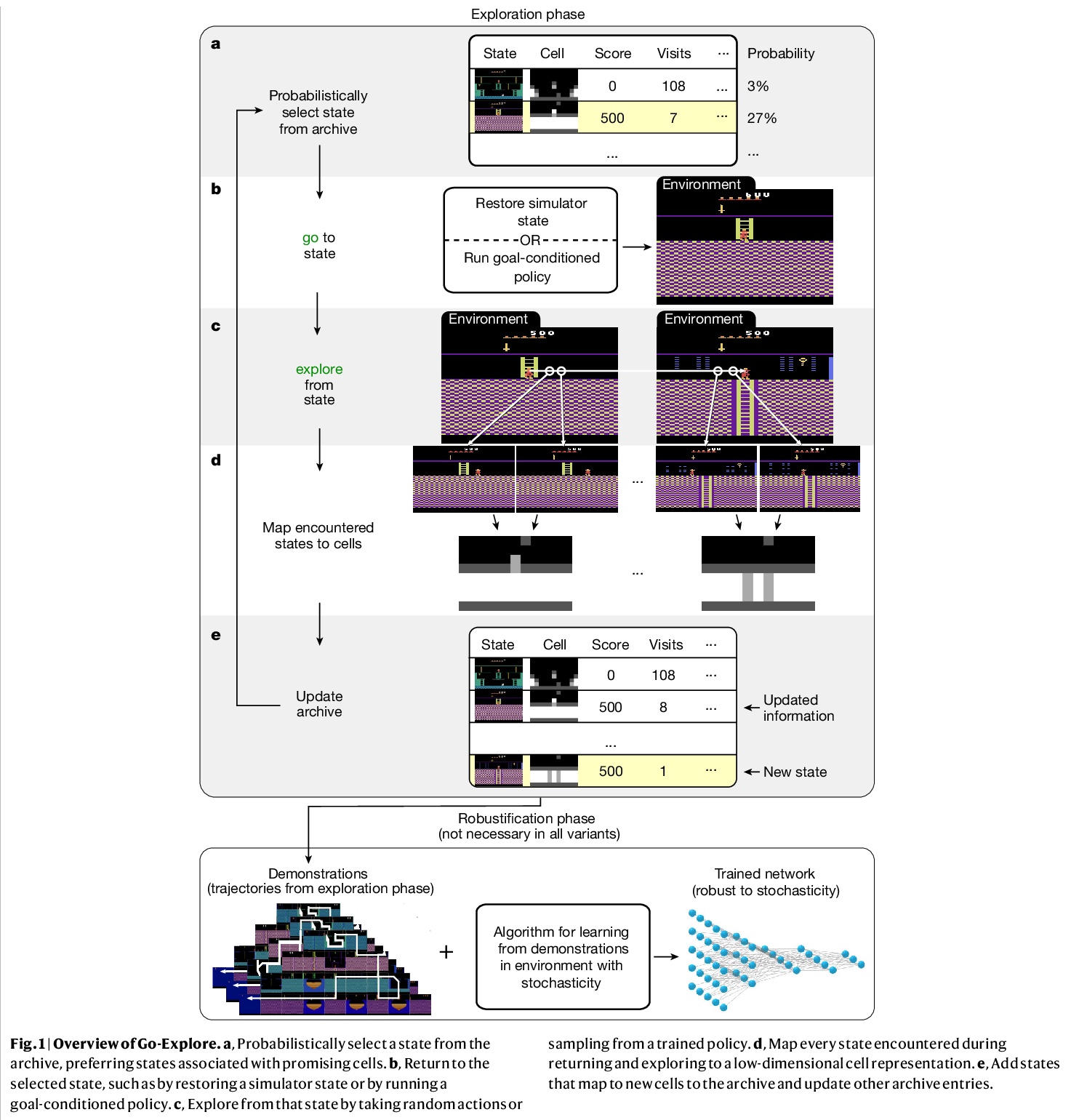
Reinforcement learning promises to solve complex sequential-decision problems autonomously by specifying a high-level reward function only. However, reinforcement learning algorithms struggle when, as is often the case, simple and intuitive rewards provide sparse1 and deceptive2 feedback. Avoiding these pitfalls requires a thorough exploration of the environment, but creating algorithms that can do so remains one of the central challenges of the field. Here we hypothesize that the main impediment to effective exploration originates from algorithms forgetting how to reach previously visited states (detachment) and failing to first return to a state before exploring from it (derailment). We introduce Go-Explore, a family of algorithms that addresses these two challenges directly through the simple principles of explicitly ‘remembering’ promising states and returning to such states before intentionally exploring. Go-Explore solves all previously unsolved Atari games and surpasses the state of the art on all hard-exploration games1, with orders-of-magnitude improvements on the grand challenges of Montezuma’s Revenge and Pitfall. We also demonstrate the practical potential of Go-Explore on a sparse-reward pick-and-place robotics task. Additionally, we show that adding a goal-conditioned policy can further improve Go-Explore’s exploration efficiency and enable it to handle stochasticity throughout training. The substantial performance gains from Go-Explore suggest that the simple principles of remembering states, returning to them, and exploring from them are a powerful and general approach to exploration—an insight that may prove critical to the creation of truly intelligent learning agents.
https://weibo.com/1402400261/K4gOycrjA
3、[LG] Random Feature Attention
H Peng, N Pappas, D Yogatama, R Schwartz, N Smith, L Kong
[Peking University & University of Washington & DeepMind & CMU & Hebrew University]
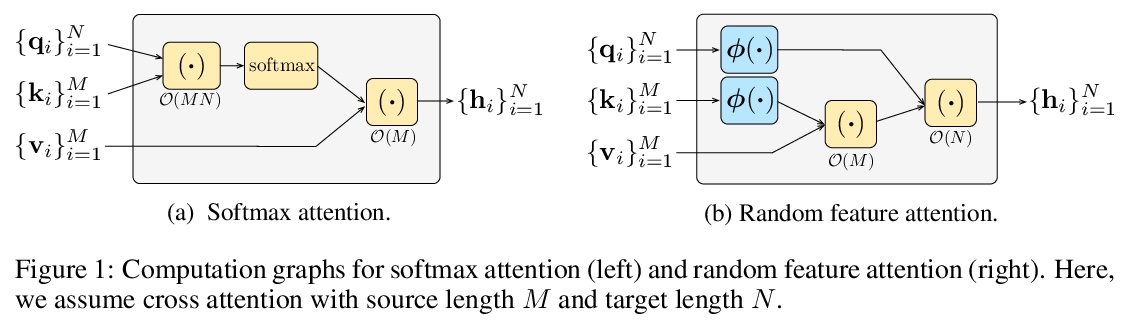
随机特征注意力。提出一种线性时空注意力RFA,使用随机特征方法来逼近softmax函数,并探索其在Transformer中的应用。RFA通过一个可选的门控机制,提供了一种直接的带有recency偏差的学习方式,可作为传统softmax注意力的有效替代。语言建模和机器翻译的实验表明,与强Transformer基线相比,RFA实现了类似或更好的性能。在机器翻译实验中,RFA的解码速度是vanilla transformer的两倍。与现有的高效transformer变体相比,RFA在三个长文本分类数据集上的准确率和效率都具有竞争力。RFA在长序列上的效率提升尤为显著,这表明RFA在需要处理大输入、快速解码或低内存占用的任务中会特别有用。
Transformers are state-of-the-art models for a variety of sequence modeling tasks. At their core is an attention function which models pairwise interactions between the inputs at every timestep. While attention is powerful, it does not scale efficiently to long sequences due to its quadratic time and space complexity in the sequence length. We propose RFA, a linear time and space attention that uses random feature methods to approximate the softmax function, and explore its applications in transformers. RFA offers a straightforward way of learning with recency bias through an optional gating mechanism and can be used as a drop-in replacement for conventional softmax attention. Experiments on language modeling and machine translation demonstrate that RFA achieves similar or better performance compared to strong transformer baselines. In the machine translation experiment, RFA decodes twice as fast as a vanilla transformer. Compared to existing efficient transformer variants, RFA is competitive in terms of both accuracy and efficiency on three long text classification datasets. Our analysis shows that RFA’s efficiency gains are especially notable on long sequences, suggesting that RFA will be particularly useful in tasks that require working with large inputs, fast decoding speed, or low memory footprints.
https://weibo.com/1402400261/K4gUEbPyI
4、[LG] Iterative SE(3)-Transformers
F B. Fuchs, E Wagstaff, J Dauparas, I Posner
[University of Oxford & University of Washington]
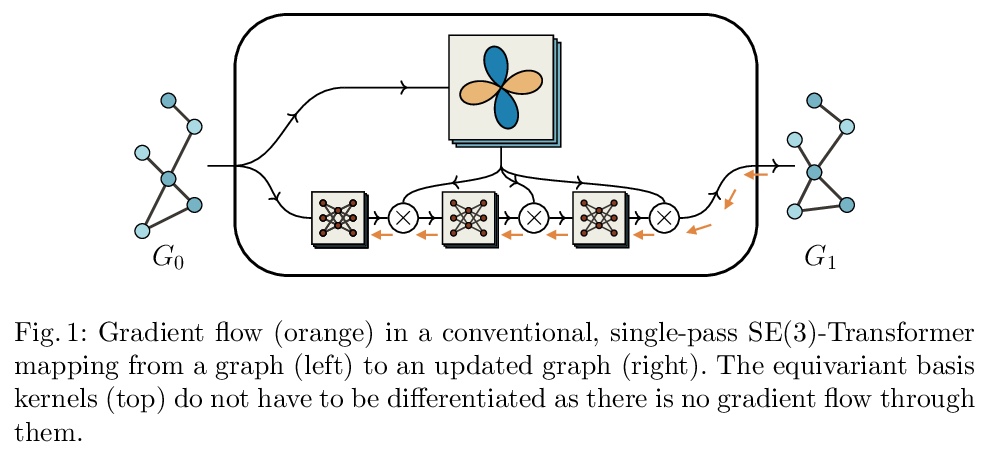
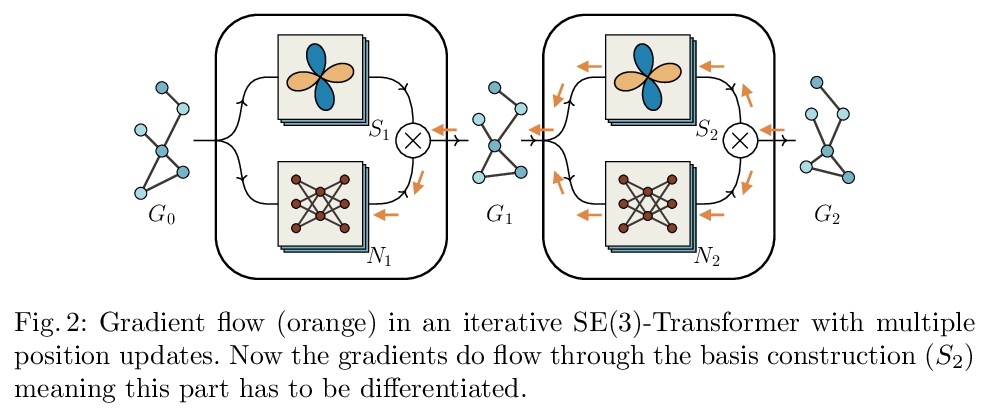
迭代SE(3)-Transformers。处理3D数据时,可通过应用SE(3)-等变模型,来确保旋转和平移对称性。蛋白质结构预测是显示这些对称性的任务的一个突出例子。本文实现了SE(3)-Transformer的迭代版本,一个基于SE(3)-等变注意力的图数据模型,解决了以迭代方式应用SE(3)-Transformer时出现的额外复杂问题,并考虑了为什么迭代模型在某些问题设置中可能是有益的。
When manipulating three-dimensional data, it is possible to ensure that rotational and translational symmetries are respected by applying so-called SE(3)-equivariant models. Protein structure prediction is a prominent example of a task which displays these symmetries. Recent work in this area has successfully made use of an SE(3)-equivariant model, applying an iterative SE(3)-equivariant attention mechanism. Motivated by this application, we implement an iterative version of the SE(3)-Transformer, an SE(3)-equivariant attention-based model for graph data. We address the additional complications which arise when applying the SE(3)-Transformer in an iterative fashion, compare the iterative and single-pass versions on a toy problem, and consider why an iterative model may be beneficial in some problem settings. We make the code for our implementation available to the community.
https://weibo.com/1402400261/K4gXL87Y4
5、[LG] Named Tensor Notation
D Chiang, A M. Rush, B Barak
[University of Notre Dame & Cornell University & Harvard University]
命名张量符。为带有命名轴的张量提出了一个符号,以减轻作者、读者和未来的实现者跟踪轴的顺序和每个轴的目的的负担,也使得对低阶张量的操作很容易扩展到高阶张量的操作(例如,将对图像的操作扩展到图像的小批次,或者将注意力机制扩展到多注意力头)。在简要概述该符号之后,通过几个现代机器学习的例子来说明它,从像注意力和卷积这样的构建块,到像Transformer和LeNet这样的完整模型。最后,给出形式化的定义,并描述了一些扩展。
We propose a notation for tensors with named axes, which relieves the author, reader, and future implementers from the burden of keeping track of the order of axes and the purpose of each. It also makes it easy to extend operations on low-order tensors to higher order ones (e.g., to extend an operation on images to minibatches of images, or extend the attention mechanism to multiple attention heads). After a brief overview of our notation, we illustrate it through several examples from modern machine learning, from building blocks like attention and convolution to full models like Transformers and LeNet. Finally, we give formal definitions and describe some extensions. Our proposals build on ideas from many previous papers and software libraries. We hope that this document will encourage more authors to use named tensors, resulting in clearer papers and less bug-prone implementations.The source code for this document can be found at > this https URL. We invite anyone to make comments on this proposal by submitting issues or pull requests on this repository.
https://weibo.com/1402400261/K4gI6rBFT
另外几篇值得关注的论文:
[LG] Randomized Exploration is Near-Optimal for Tabular MDP
随机探索是表格MDP的近似最优
Z Xiong, R Shen, S S. Du
[University of Washington]
https://weibo.com/1402400261/K4h1slHR3
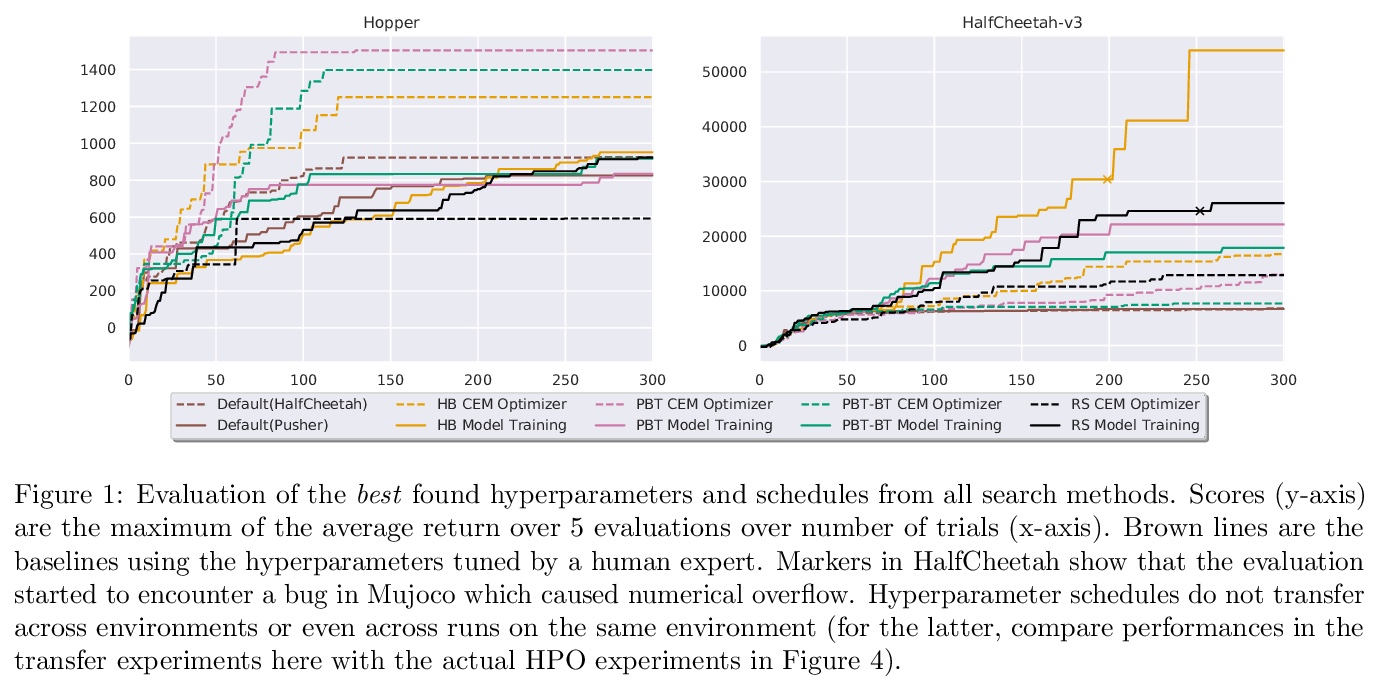
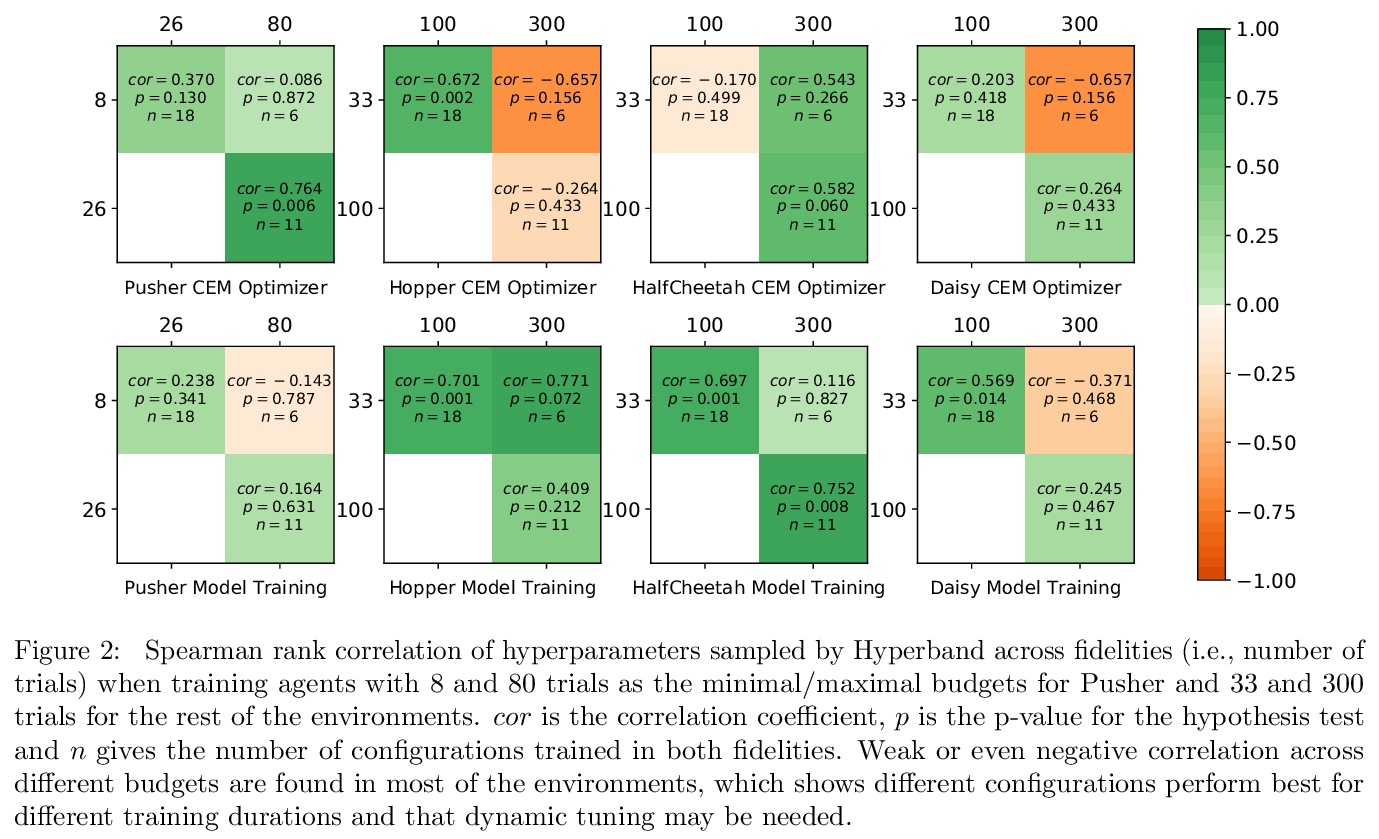
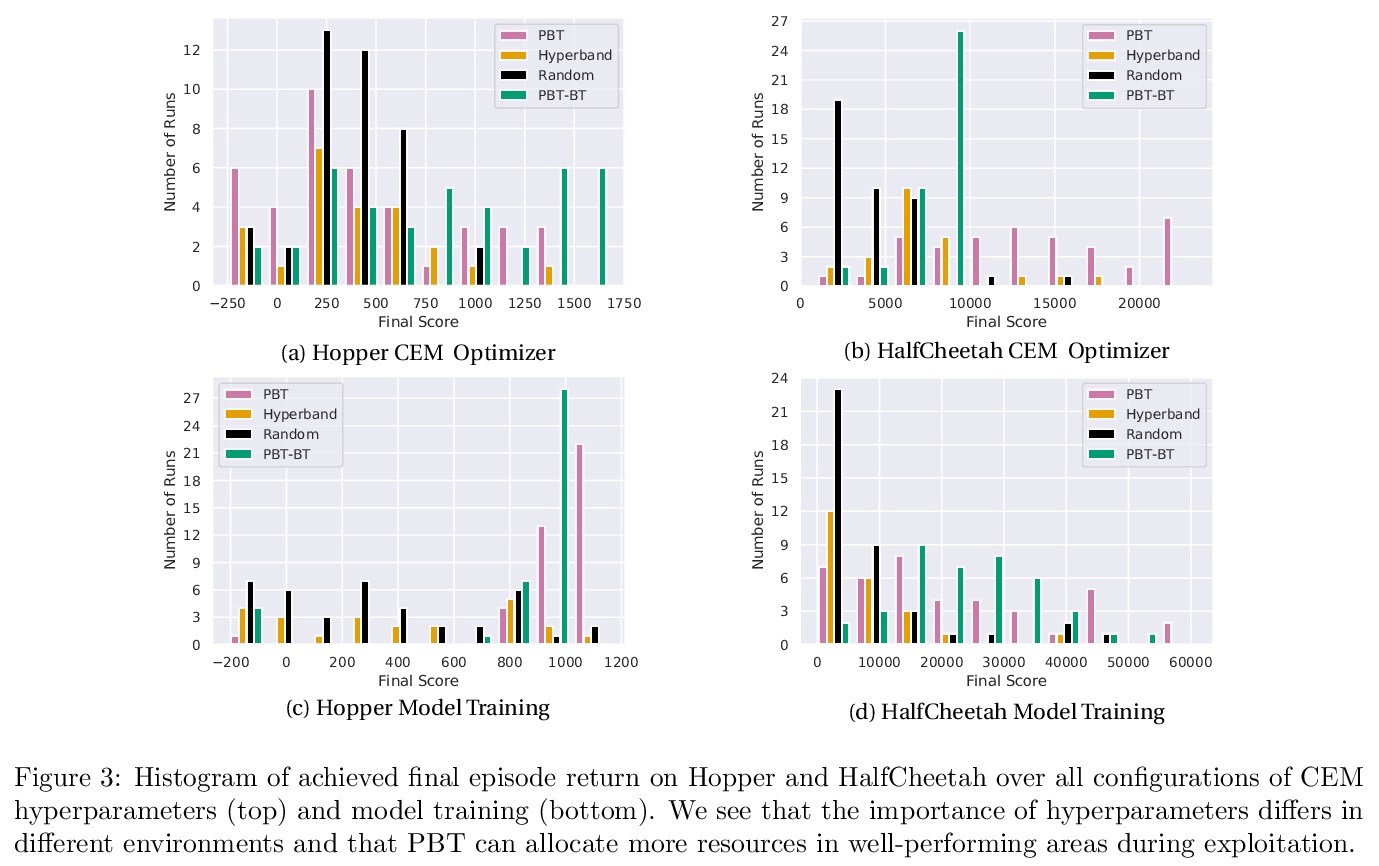
[LG] On the Importance of Hyperparameter Optimization for Model-based Reinforcement Learning
超参数优化对基于模型强化学习的重要性
B Zhang, R Rajan, L Pineda, N Lambert, A Biedenkapp, K Chua, F Hutter, R Calandra
[University of Freiburg & Facebook AI Research & UC Berkeley & Princeton University]
https://weibo.com/1402400261/K4h5cmHcy
[CV] Where to look at the movies : Analyzing visual attention to understand movie editing
通过视觉注意力分析理解电影剪辑
A Bruckert, M Christie, O L Meur
[Univ. Rennes]
https://weibo.com/1402400261/K4h6JdWn4



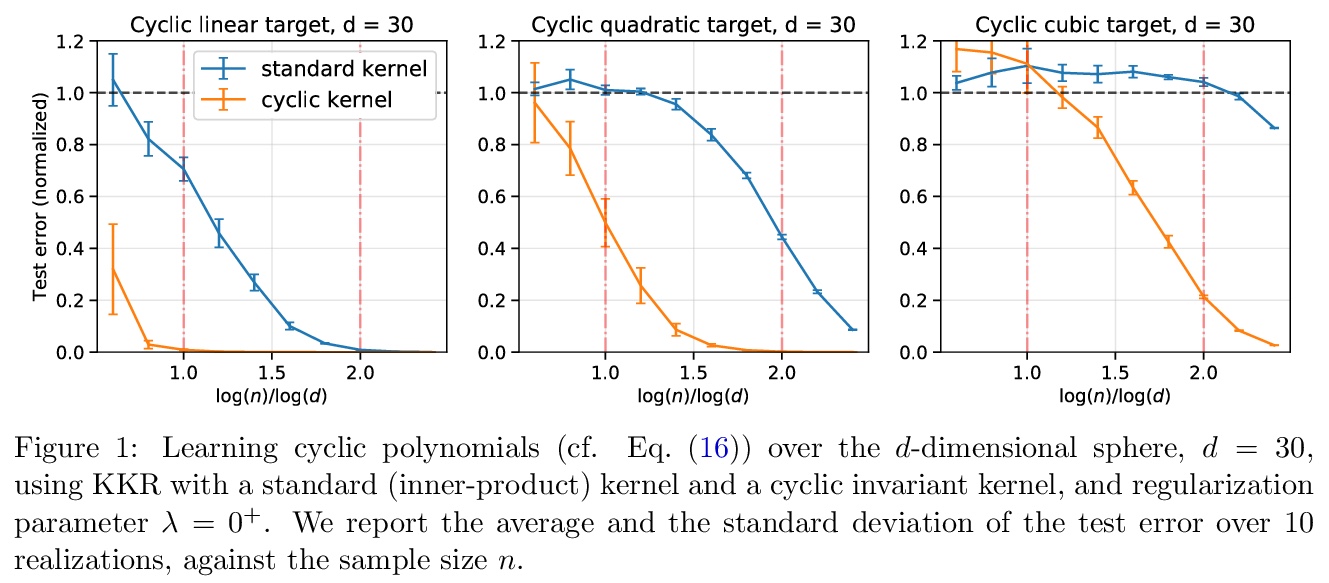
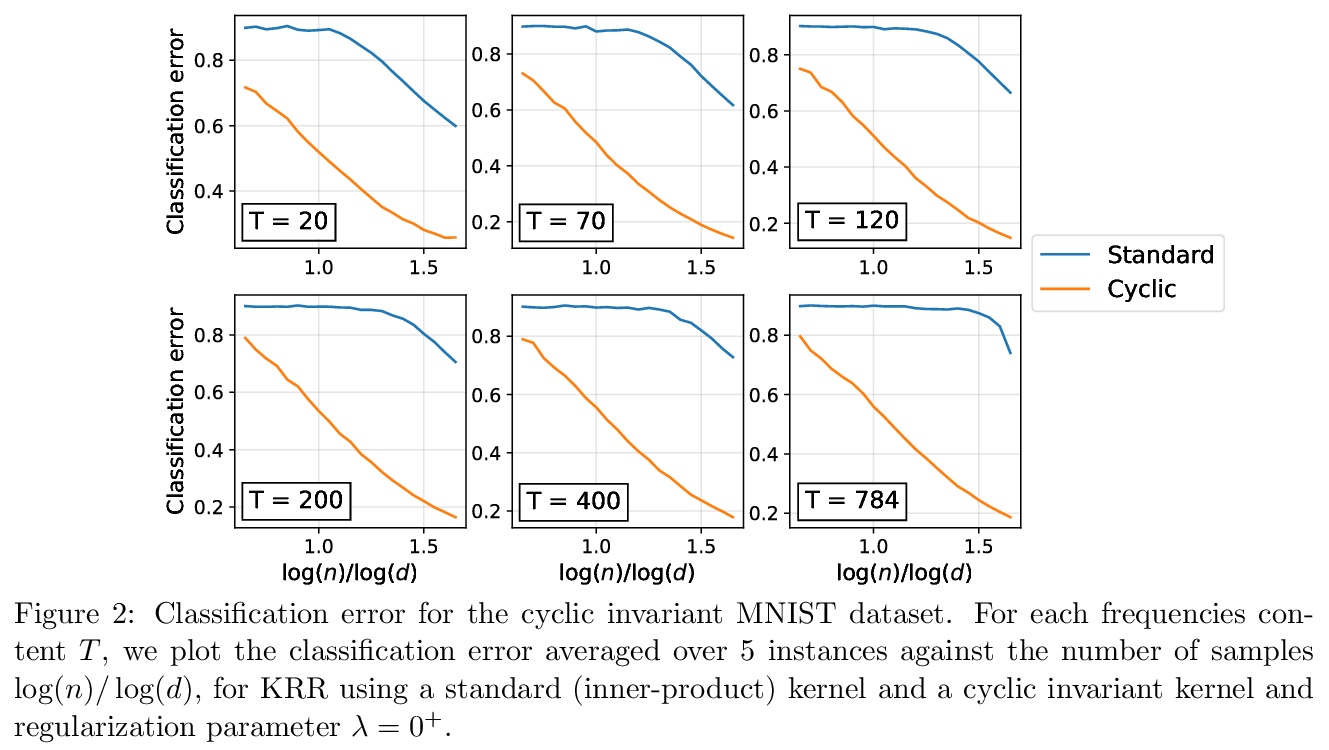
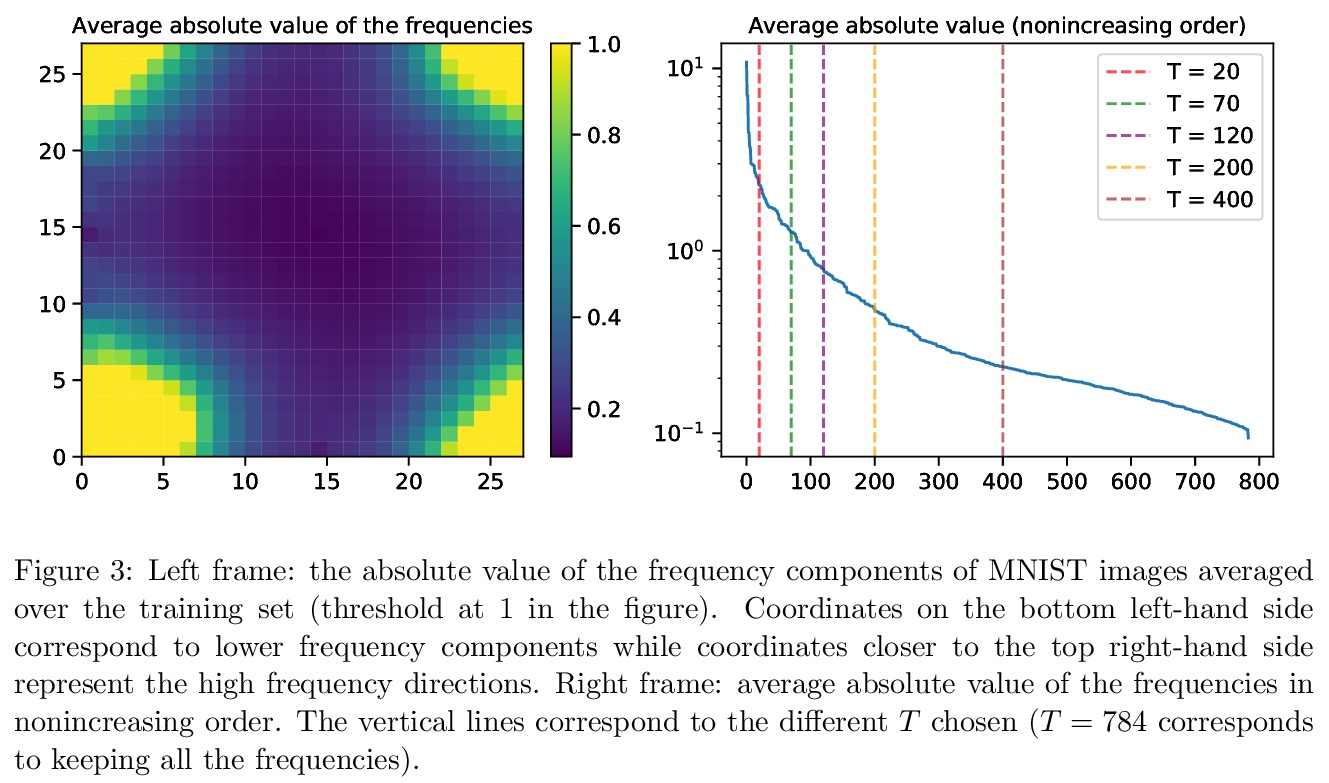
[LG] Learning with invariances in random features and kernel models
随机特征和核模型的不变性学习
S Mei, T Misiakiewicz, A Montanari
[UC Berkeley & Stanford University]
https://weibo.com/1402400261/K4h8BktZb

若有收获,就点个赞吧
0 人点赞
