- 1、[CV] Zero-Shot Text-to-Image Generation
- 2、[CV] Image Completion via Inference in Deep Generative Models
- 3、[CV] Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
- 4、[LG] Do Transformer Modifications Transfer Across Implementations and Applications?
- 5、[LG] A Framework for Integrating Gesture Generation Models into Interactive Conversational Agents
- [ME] Semiparametric counterfactual density estimation
- [CV] A Straightforward Framework For Video Retrieval Using CLIP
- [CV] Deep Video Prediction for Time Series Forecasting
- [CV] GDR-Net: Geometry-Guided Direct Regression Network for Monocular 6D Object Pose Estimation
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Zero-Shot Text-to-Image Generation
A Ramesh, M Pavlov, G Goh, S Gray, C Voss, A Radford, M Chen, I Sutskever
[OpenAI]
零样本文本-图像生成。描述了一种基于transformer的简单方法,用于实现文本到图像生成,将文本和图像token作为单一数据流进行自回归建模。在有足够数据和规模的情况下,以零样本方式进行评价时,该方法与之前的特定领域模型相比具有竞争力。无论在相对于之前特定领域方法的零样本性能方面,还是在单一生成模型的能力范围方面,规模化都可以提高泛化能力。在从互联网上收集的2.5亿个图像-文本对上训练一个120亿参数的自回归transformer,得到一个灵活的、高保真的、可通过自然语言控制的图像生成模型。
Text-to-image generation has traditionally focused on finding better modeling assumptions for training on a fixed dataset. These assumptions might involve complex architectures, auxiliary losses, or side information such as object part labels or segmentation masks supplied during training. We describe a simple approach for this task based on a transformer that autoregressively models the text and image tokens as a single stream of data. With sufficient data and scale, our approach is competitive with previous domain-specific models when evaluated in a zero-shot fashion.
https://weibo.com/1402400261/K3EKfgEAG


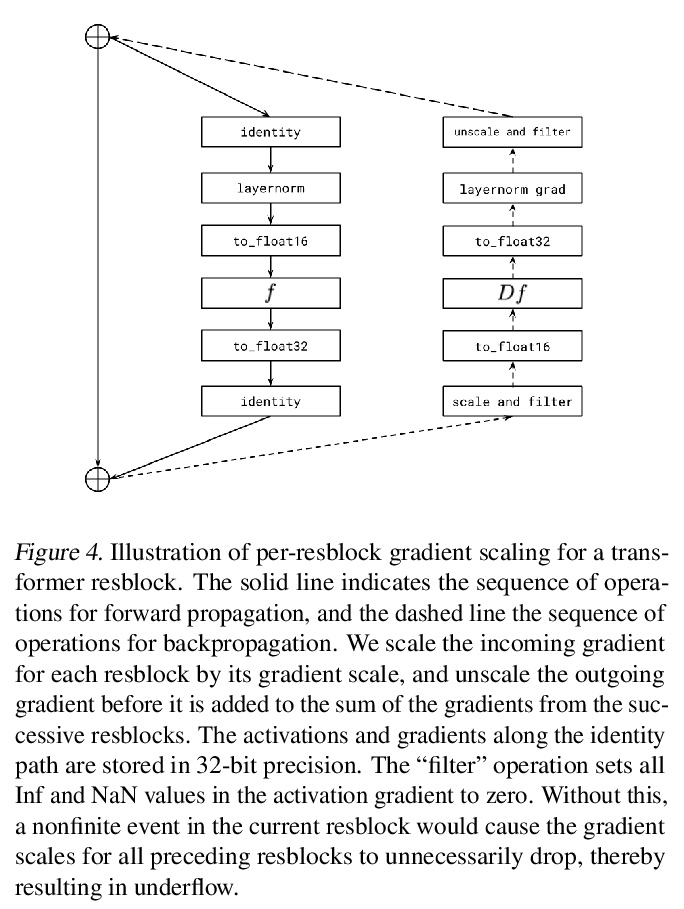
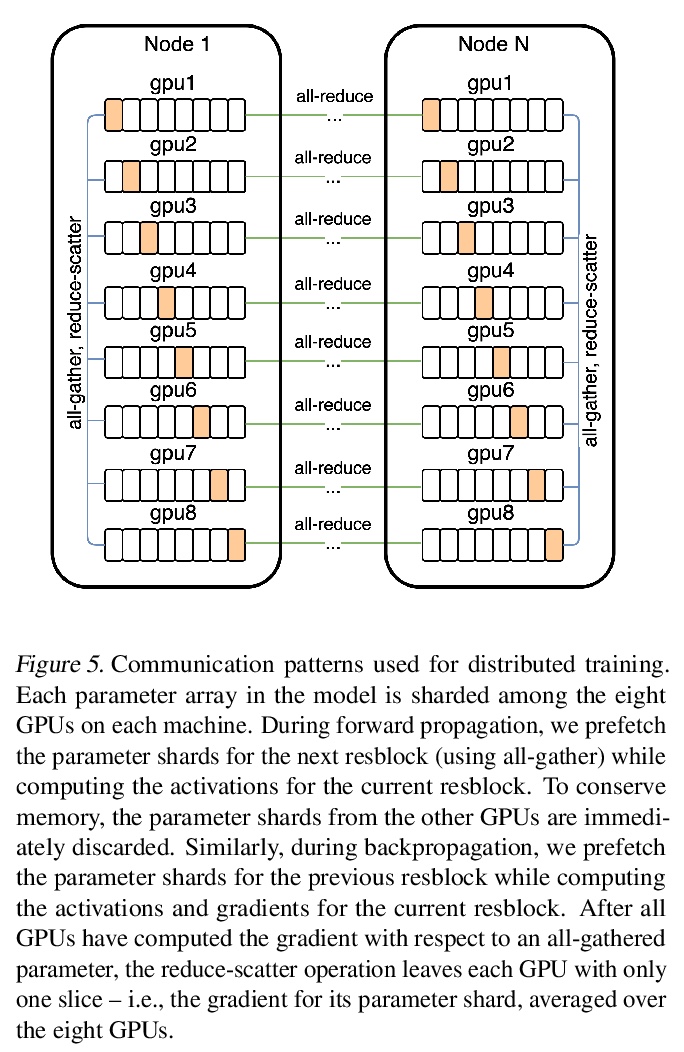

2、[CV] Image Completion via Inference in Deep Generative Models
W Harvey, S Naderiparizi, F Wood
[University of British Columbia]
基于深度生成模型推理的图像补全。提出了一种通过VAE潜空间摊销推理生成多样化和高质量图像补全的方法,利用最先进的变分自编码器架构,在模型中进行摊销推理,即使在图像绝大部分缺失的情况下,也能产生多样化、逼真的图像补全。推导并比较了两个训练目标,并表明其中一个目标始终优于所有基线。
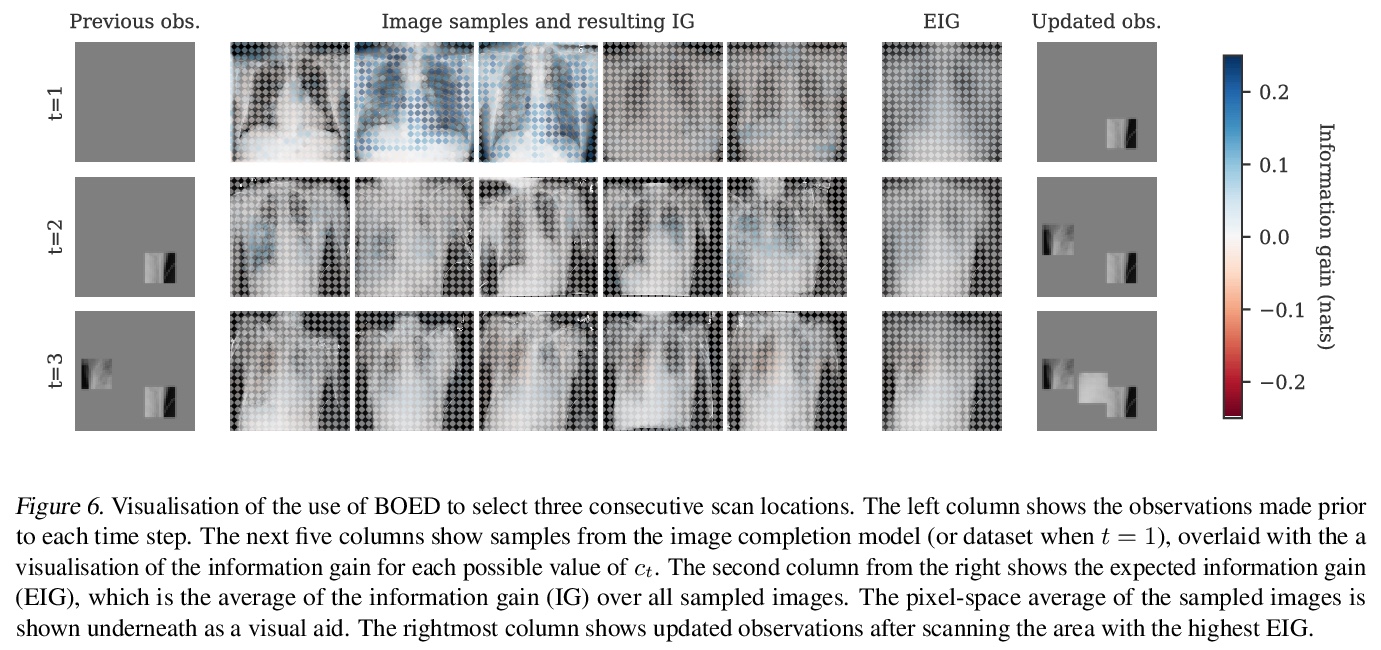
We consider image completion from the perspective of amortized inference in an image generative model. We leverage recent state of the art variational auto-encoder architectures that have been shown to produce photo-realistic natural images at non-trivial resolutions. Through amortized inference in such a model we can train neural artifacts that produce diverse, realistic image completions even when the vast majority of an image is missing. We demonstrate superior sample quality and diversity compared to prior art on the CIFAR-10 and FFHQ-256 datasets. We conclude by describing and demonstrating an application that requires an in-painting model with the capabilities ours exhibits: the use of Bayesian optimal experimental design to select the most informative sequence of small field of view x-rays for chest pathology detection.
https://weibo.com/1402400261/K3EU7AvIx

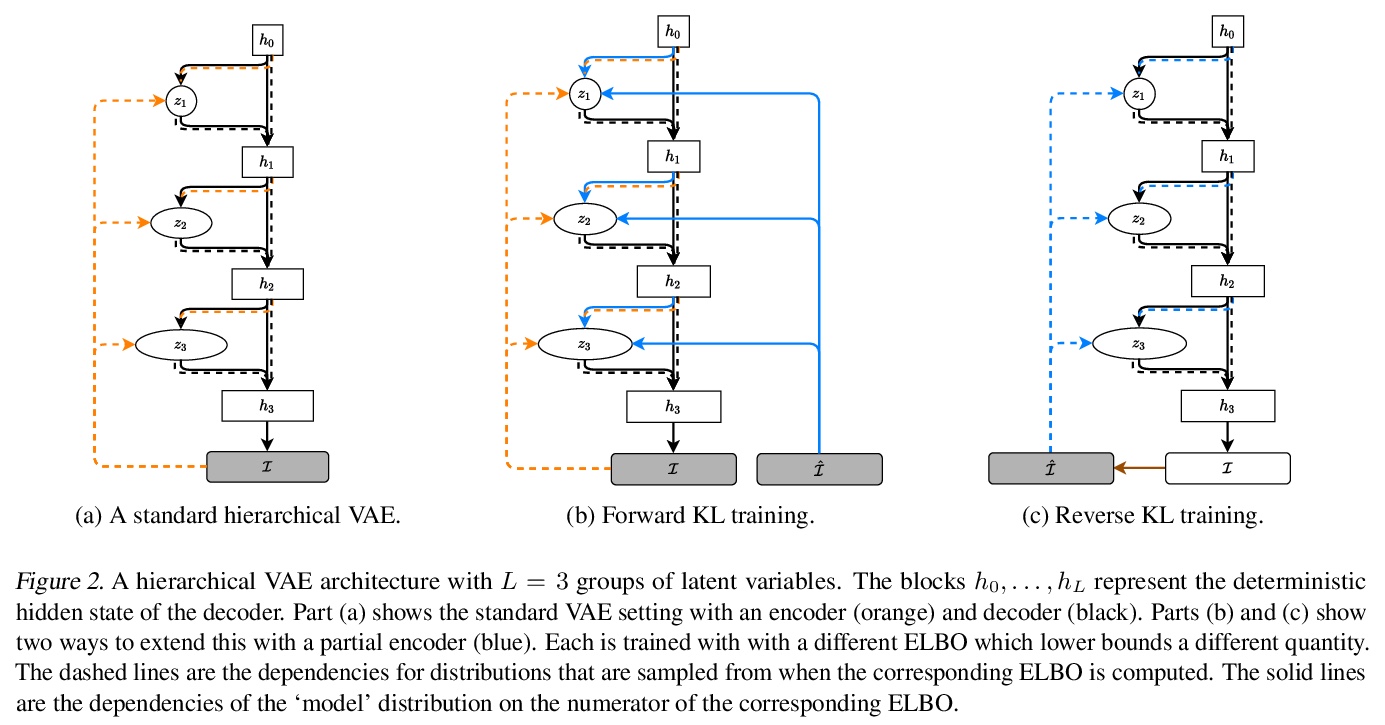

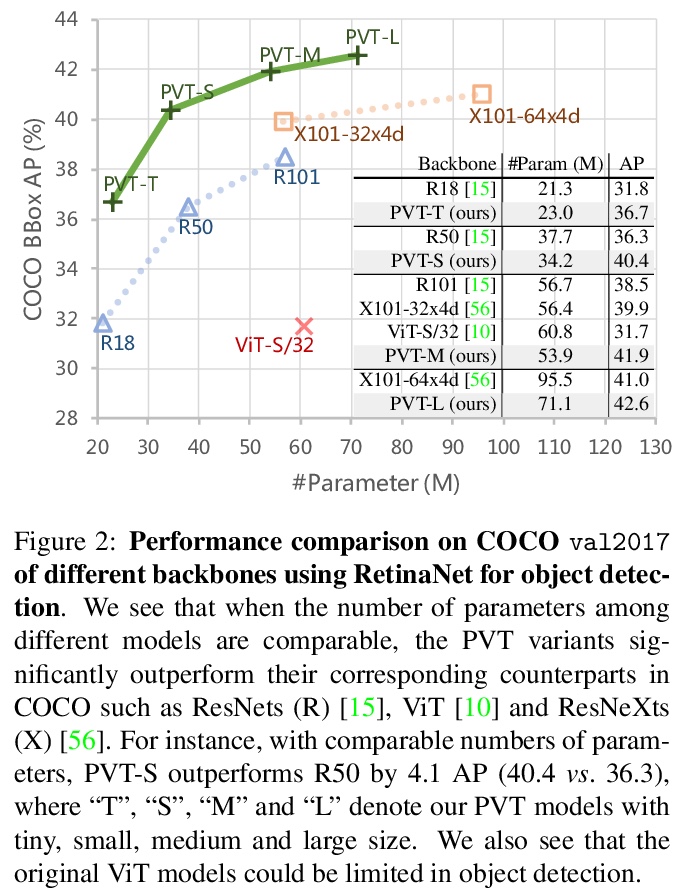
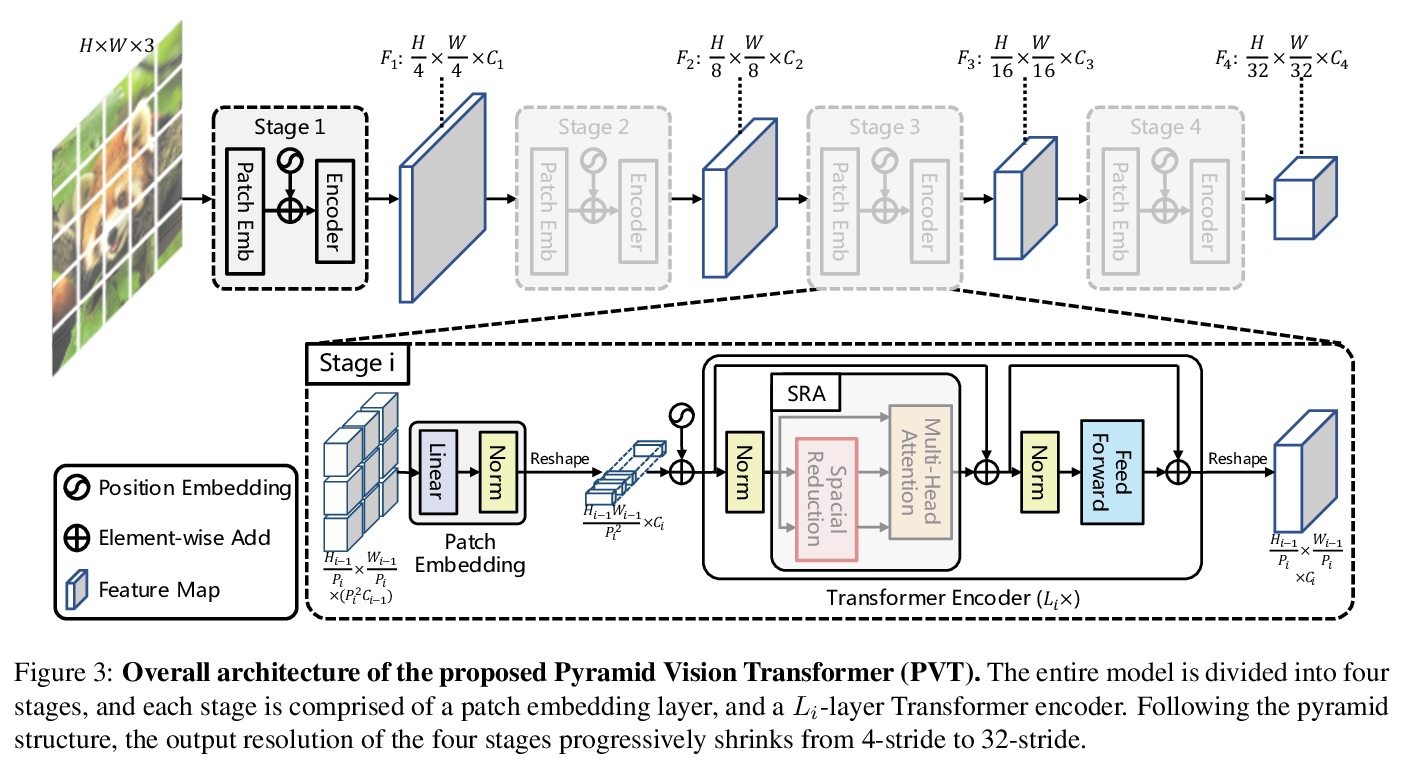
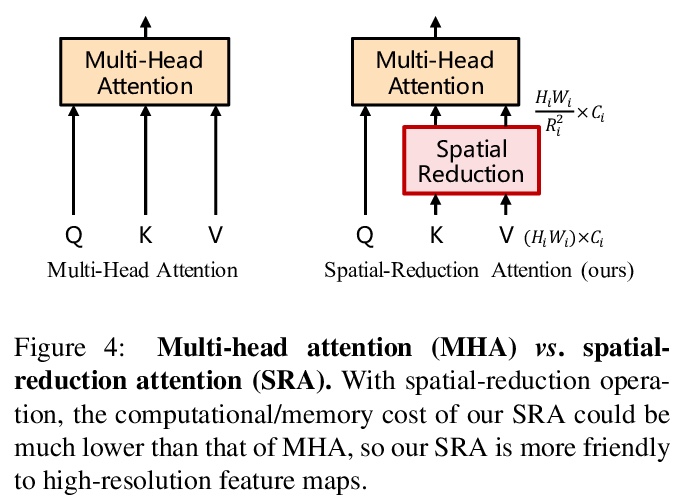
3、[CV] Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
W Wang, E Xie, X Li, D Fan, K Song, D Liang, T Lu, P Luo, L Shao
[Nanjing University & The University of Hong Kong & Nanjing University of Science and Technology & IIAI & SenseTime Research]
金字塔视觉Transformer:无需卷积的密集预测多功能骨干系统。提出了金字塔视觉Transformer(PVT),引入了渐进式收缩金字塔,可像传统的CNN骨干一样生成多尺度特征图,将Transformer移植到各种密集预测任务中。提出了渐进式收缩金字塔和空间还原注意力层,可在有限的计算/内存资源下获得多尺度特征图。与之前技术相比,PVT具有以下优点:1)更灵活-可在不同阶段生成不同尺度、不同通道的特征图;2)更通用-可在大多数下游任务模型中方便地套用;3)对计算/内存更友好-可处理更高分辨率的特征图。
Although using convolutional neural networks (CNNs) as backbones achieves great successes in computer vision, this work investigates a simple backbone network useful for many dense prediction tasks without convolutions. Unlike the recently-proposed Transformer model (e.g., ViT) that is specially designed for image classification, we propose Pyramid Vision Transformer~(PVT), which overcomes the difficulties of porting Transformer to various dense prediction tasks. PVT has several merits compared to prior arts. (1) Different from ViT that typically has low-resolution outputs and high computational and memory cost, PVT can be not only trained on dense partitions of the image to achieve high output resolution, which is important for dense predictions but also using a progressive shrinking pyramid to reduce computations of large feature maps. (2) PVT inherits the advantages from both CNN and Transformer, making it a unified backbone in various vision tasks without convolutions by simply replacing CNN backbones. (3) We validate PVT by conducting extensive experiments, showing that it boosts the performance of many downstream tasks, e.g., object detection, semantic, and instance segmentation. For example, with a comparable number of parameters, RetinaNet+PVT achieves 40.4 AP on the COCO dataset, surpassing RetinNet+ResNet50 (36.3 AP) by 4.1 absolute AP. We hope PVT could serve as an alternative and useful backbone for pixel-level predictions and facilitate future researches. Code is available at > this https URL.
https://weibo.com/1402400261/K3EZwkQVh
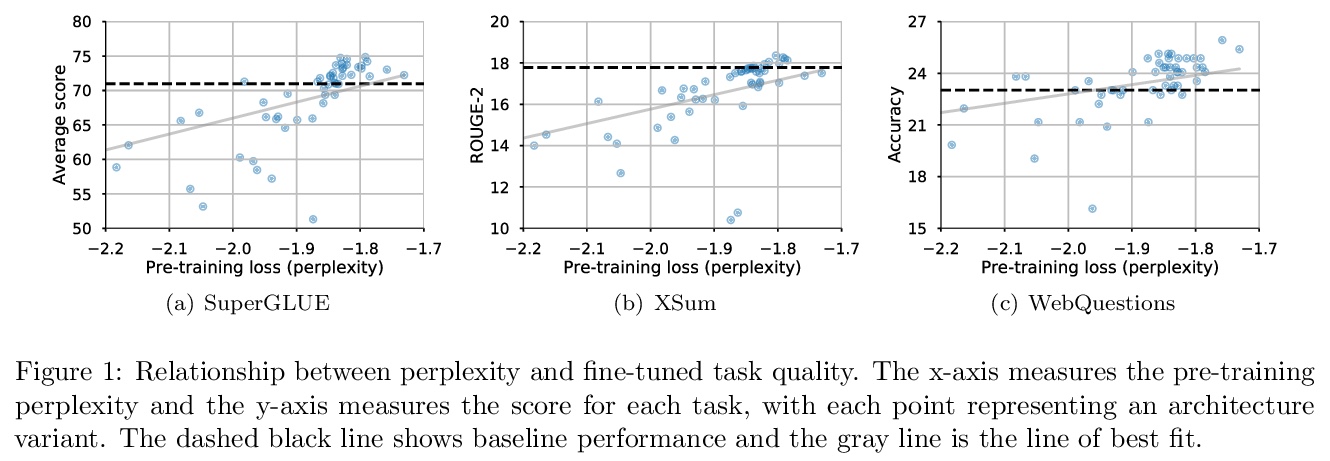
4、[LG] Do Transformer Modifications Transfer Across Implementations and Applications?
S Narang, H W Chung, Y Tay, W Fedus, T Fevry, M Matena, K Malkan, N Fiedel, N Shazeer, Z Lan, Y Zhou, W Li, N Ding, J Marcus, A Roberts, C Raffel
[Google]
Transformer的改进能在不同实现和应用间迁移吗?试图发现为什么大多数对Transformer提出的修改没有被广泛采用。为回答这个问题,在Transformer通常应用的一套任务上重新实施和评价了各种Transformer变体。主要发现是,在实验环境中,许多Transformer修改并没有带来性能的提高。确实产生更好性能的变体,往往是那些相当小的变化和/或在进行评价的代码库中开发的。性能的提高可能强烈依赖于实现细节,相应提出了一些建议,以提高实验的通用性。
The research community has proposed copious modifications to the Transformer architecture since it was introduced over three years ago, relatively few of which have seen widespread adoption. In this paper, we comprehensively evaluate many of these modifications in a shared experimental setting that covers most of the common uses of the Transformer in natural language processing. Surprisingly, we find that most modifications do not meaningfully improve performance. Furthermore, most of the Transformer variants we found beneficial were either developed in the same codebase that we used or are relatively minor changes. We conjecture that performance improvements may strongly depend on implementation details and correspondingly make some recommendations for improving the generality of experimental results.
https://weibo.com/1402400261/K3F3Udb9P
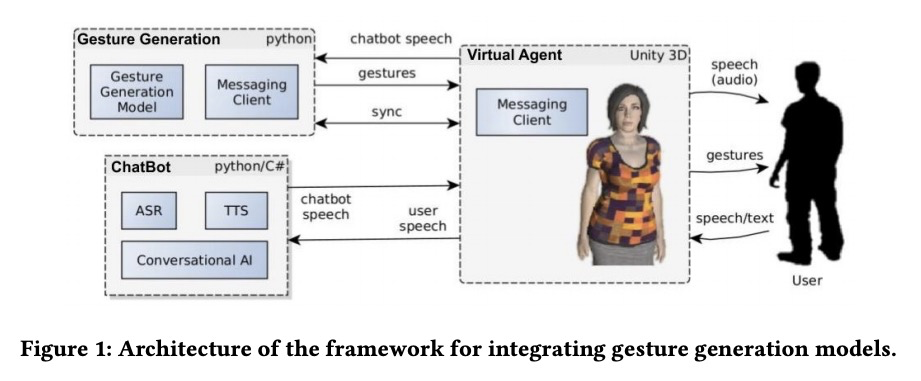
5、[LG] A Framework for Integrating Gesture Generation Models into Interactive Conversational Agents
R Nagy, T Kucherenko, B Moell, A Pereira, H Kjellström, U Bernardet
[KTH]
将手势生成模型集成到交互式对话智能体的框架。提出一个概念验证框架,将最先进的数据驱动手势生成模型与具身对话智能体整合在一起,旨在促进现代手势生成模型在交互中的评价。展示了一个可扩展的开源框架,包含三个组件:1)3D交互智能体;2)聊天机器人后台;3)手势系统。每个组件都可以被替换,使得所提出的框架适用于研究不同手势模型在实时交互中与不同的通信方式、聊天机器人后端或不同的智能体外观的效果。
Embodied conversational agents (ECAs) benefit from non-verbal behavior for natural and efficient interaction with users. Gesticulation - hand and arm movements accompanying speech - is an essential part of non-verbal behavior. Gesture generation models have been developed for several decades: starting with rule-based and ending with mainly data-driven methods. To date, recent end-to-end gesture generation methods have not been evaluated in a real-time interaction with users. We present a proof-of-concept framework, which is intended to facilitate evaluation of modern gesture generation models in interaction.We demonstrate an extensible open-source framework that contains three components: 1) a 3D interactive agent; 2) a chatbot backend; 3) a gesticulating system. Each component can be replaced, making the proposed framework applicable for investigating the effect of different gesturing models in real-time interactions with different communication modalities, chatbot backends, or different agent appearances. The code and video are available at the project page > this https URL.
https://weibo.com/1402400261/K3F7S36Rw
另外几篇值得关注的论文:
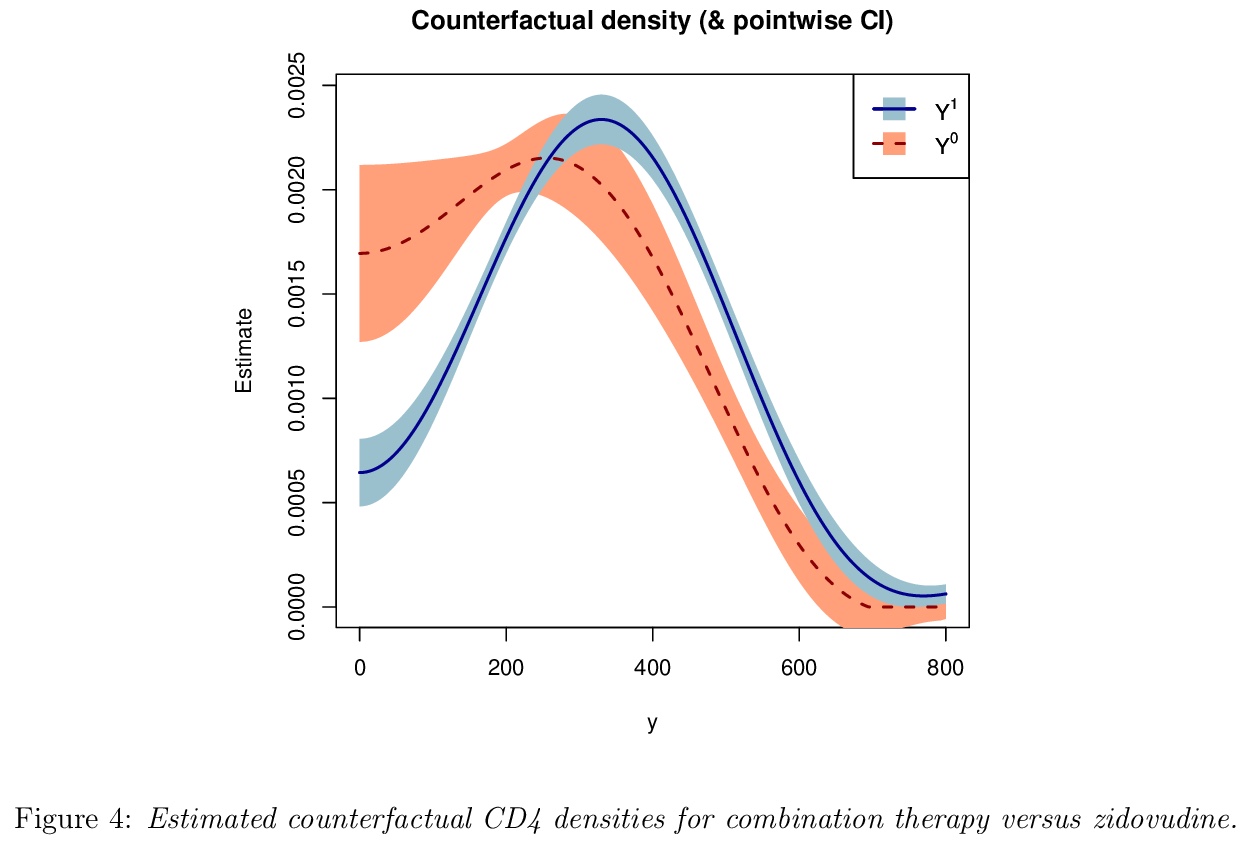
[ME] Semiparametric counterfactual density estimation
半参数化反事实密度估计
E H. Kennedy, S Balakrishnan, L Wasserman
[CMU]
https://weibo.com/1402400261/K3ESd2N5K
[CV] A Straightforward Framework For Video Retrieval Using CLIP
基于CLIP的简单视频检索框架
J A Portillo-Quintero, J C Ortiz-Bayliss, H Terashima-Marín
[Tecnologico de Monterrey]
https://weibo.com/1402400261/K3FaKhejQ

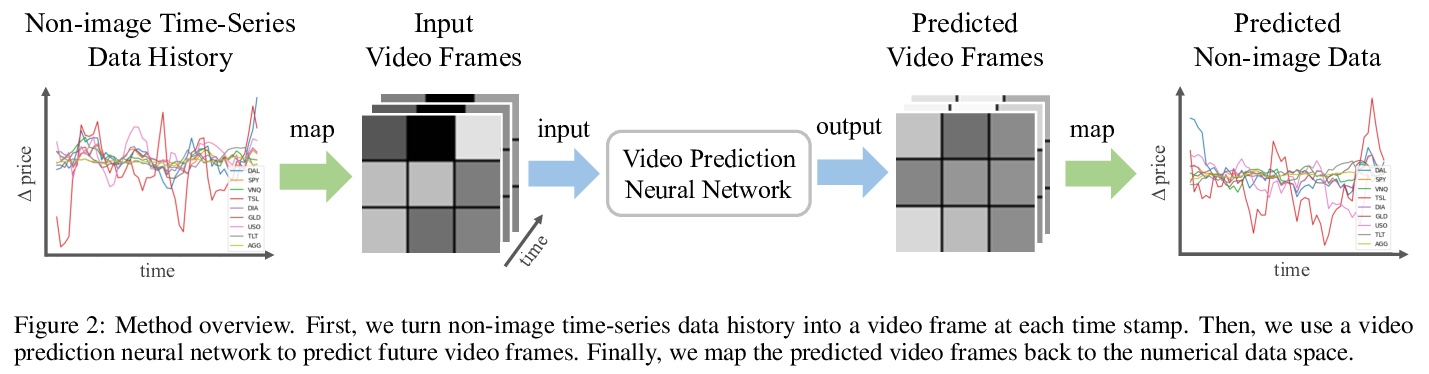
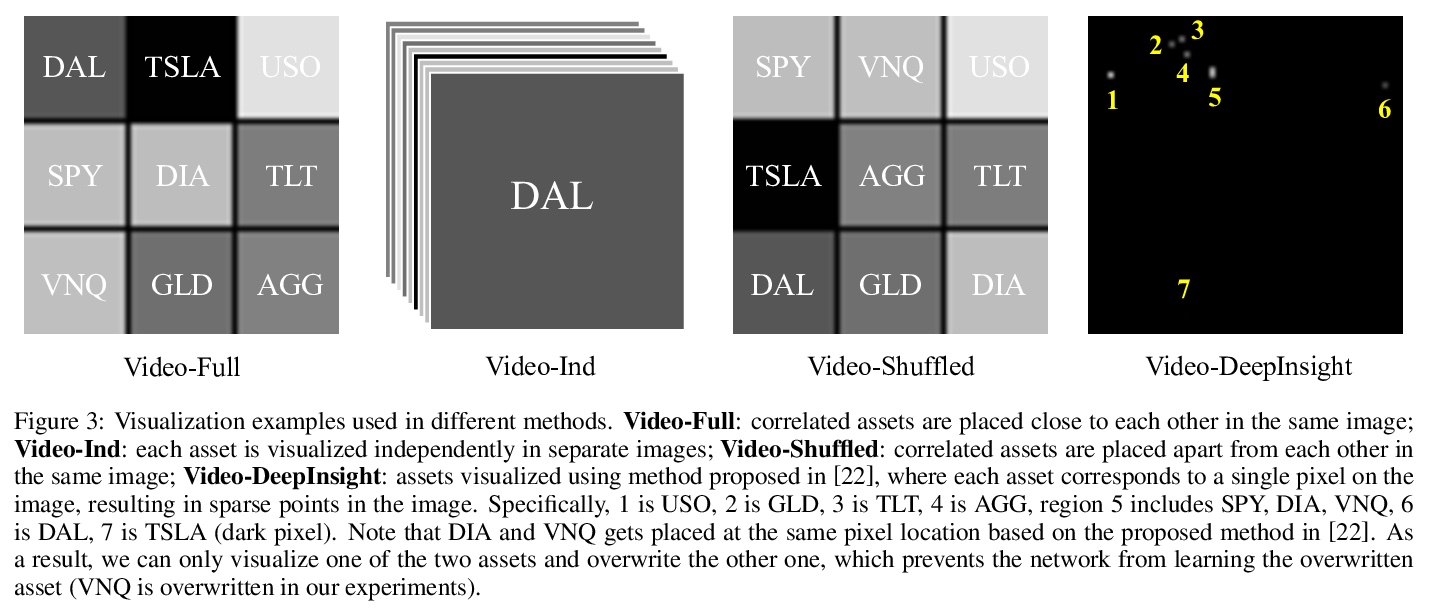
[CV] Deep Video Prediction for Time Series Forecasting
面向时间序列预测的深度视频预测
Z Zeng, T Balch, M Veloso
[J.P.Morgan AI Research]
https://weibo.com/1402400261/K3FbSyvSd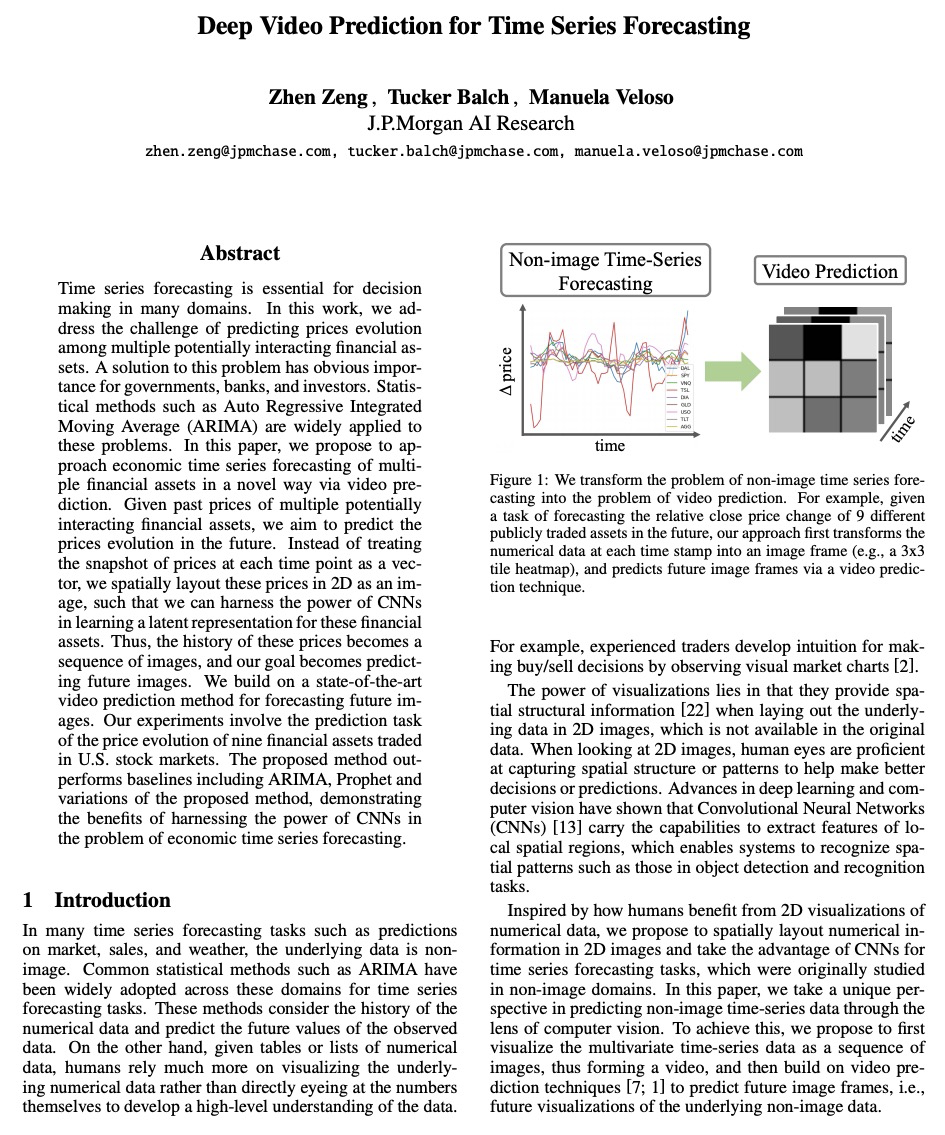
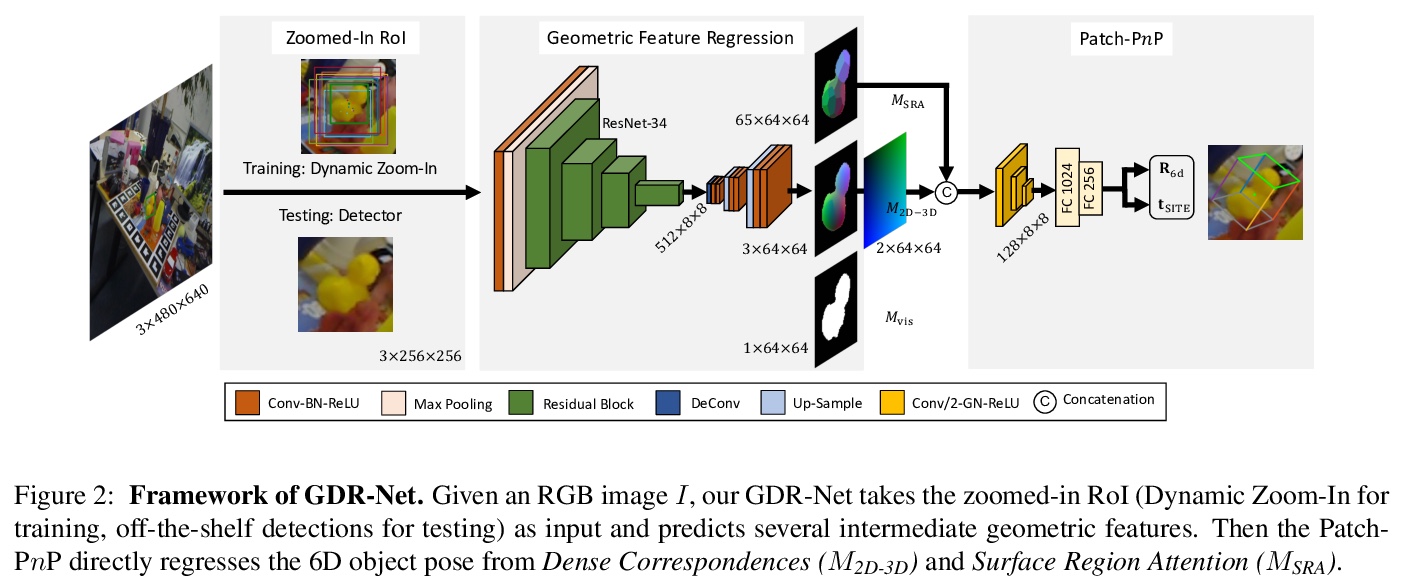
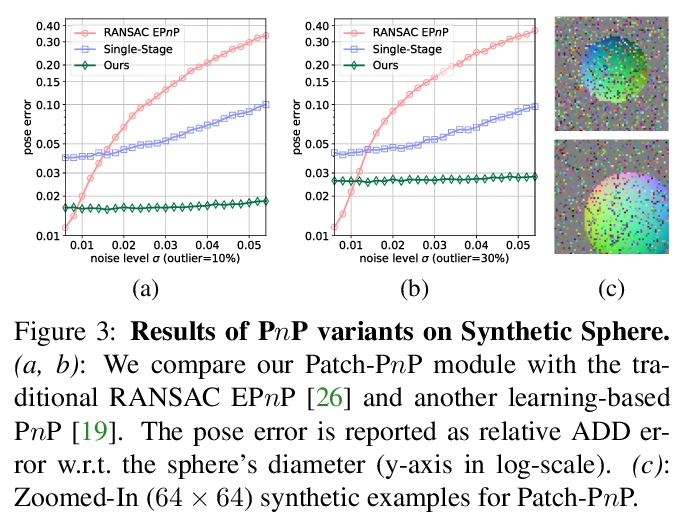
[CV] GDR-Net: Geometry-Guided Direct Regression Network for Monocular 6D Object Pose Estimation
GDR-Net:用于单目6D目标姿态估计的几何引导直接回归网络
G Wang, F Manhardt, F Tombari, X Ji
[Tsinghua University & Technical University of Munich]
https://weibo.com/1402400261/K3FfQ7Wxr

若有收获,就点个赞吧
0 人点赞
