LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
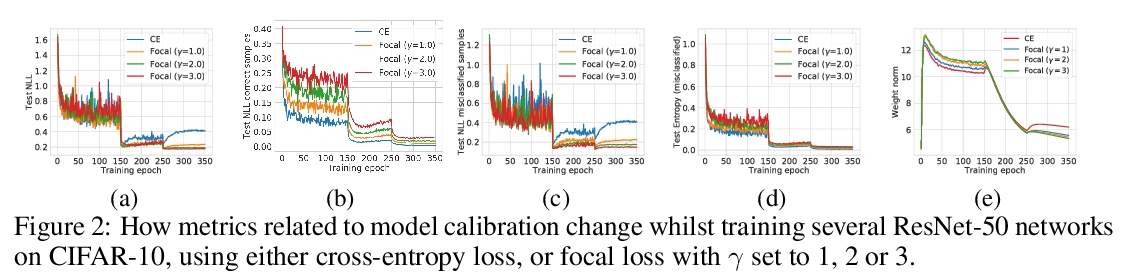
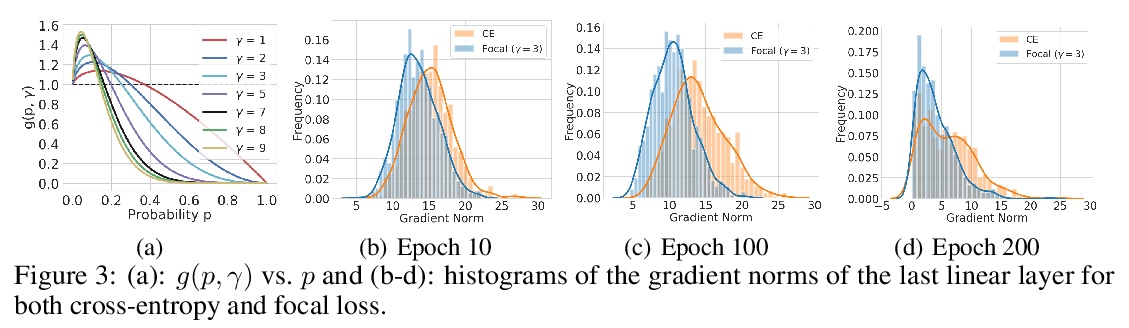
1、[LG] *Calibrating Deep Neural Networks using Focal Loss
J Mukhoti, V Kulharia, A Sanyal, S Golodetz, P H.S. Torr, P K. Dokania
[University of Oxford & FiveAI Ltd]
焦点损失深度网络校准。研究了焦点损失作为替代损失函数的特性,可在保持准确性的同时,产生比用传统交叉熵损失训练的分类网络更自然的校准。焦点损失隐式最大化熵,使预测分布和目标分布之间的KL散度最小化,在训练过程中自然正则化了网络权值,减少了NLL过拟合,从而改进了标定。**
Miscalibration - a mismatch between a model’s confidence and its correctness - of Deep Neural Networks (DNNs) makes their predictions hard to rely on. Ideally, we want networks to be accurate, calibrated and confident. We show that, as opposed to the standard cross-entropy loss, focal loss [Lin et. al., 2017] allows us to learn models that are already very well calibrated. When combined with temperature scaling, whilst preserving accuracy, it yields state-of-the-art calibrated models. We provide a thorough analysis of the factors causing miscalibration, and use the insights we glean from this to justify the empirically excellent performance of focal loss. To facilitate the use of focal loss in practice, we also provide a principled approach to automatically select the hyperparameter involved in the loss function. We perform extensive experiments on a variety of computer vision and NLP datasets, and with a wide variety of network architectures, and show that our approach achieves state-of-the-art calibration without compromising on accuracy in almost all cases. Code is available at > this https URL.
https://weibo.com/1402400261/Jw5hA5Pnl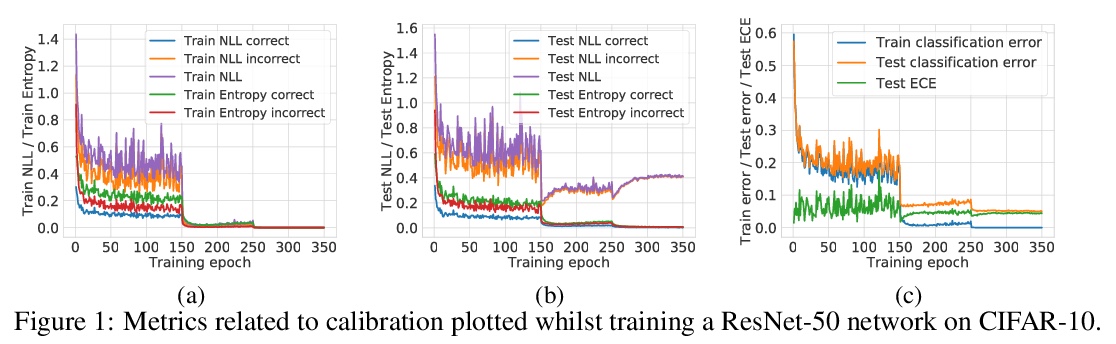
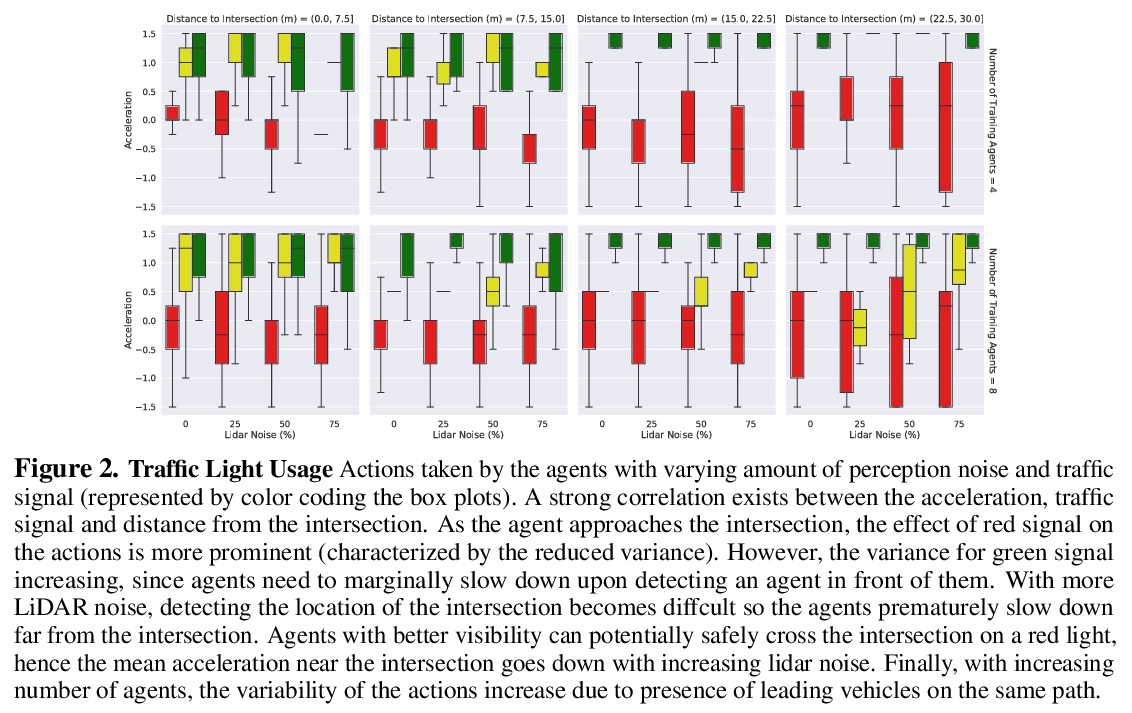
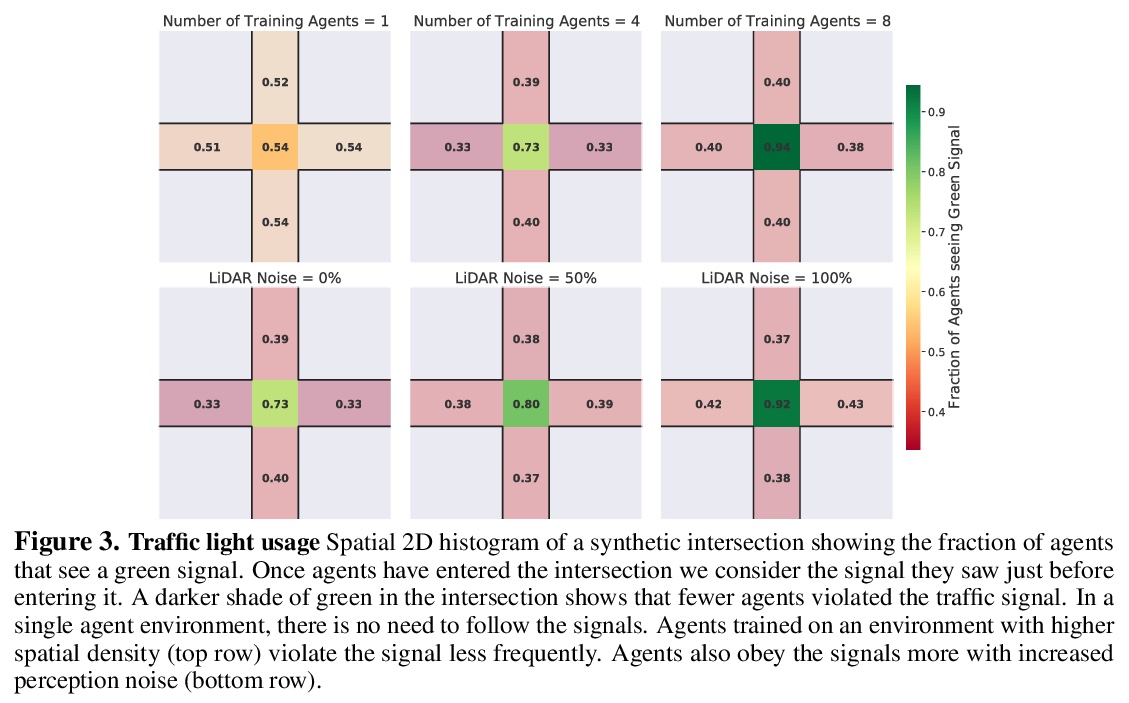
2、** **[LG] Emergent Road Rules In Multi-Agent Driving Environments
A Pal, J Philion, Y Liao, S Fidler
[IIT Kanpur & University of Toronto]
多智能体驾驶环境的自发道路规则。与其将道路规则硬编码到自动驾驶算法中,一种可扩展的替代方案是设计多智能体环境,使道路规则成为最大化交通流问题的最优解决方案。分析了驾驶环境中是什么因素导致了这些道路规则的产生,发现噪声感知和智能体的空间密度是两个关键因素,智能体依靠对车道和交通灯的共享概念来补偿他们的噪声感知。
For autonomous vehicles to safely share the road with human drivers, autonomous vehicles must abide by specific “road rules” that human drivers have agreed to follow. “Road rules” include rules that drivers are required to follow by law — such as the requirement that vehicles stop at red lights — as well as more subtle social rules — such as the implicit designation of fast lanes on the highway. In this paper, we provide empirical evidence that suggests that — instead of hard-coding road rules into self-driving algorithms — a scalable alternative may be to design multi-agent environments in which road rules emerge as optimal solutions to the problem of maximizing traffic flow. We analyze what ingredients in driving environments cause the emergence of these road rules and find that two crucial factors are noisy perception and agents’ spatial density. We provide qualitative and quantitative evidence of the emergence of seven social driving behaviors, ranging from obeying traffic signals to following lanes, all of which emerge from training agents to drive quickly to destinations without colliding. Our results add empirical support for the social road rules that countries worldwide have agreed on for safe, efficient driving.
https://weibo.com/1402400261/Jw5o1Ddzt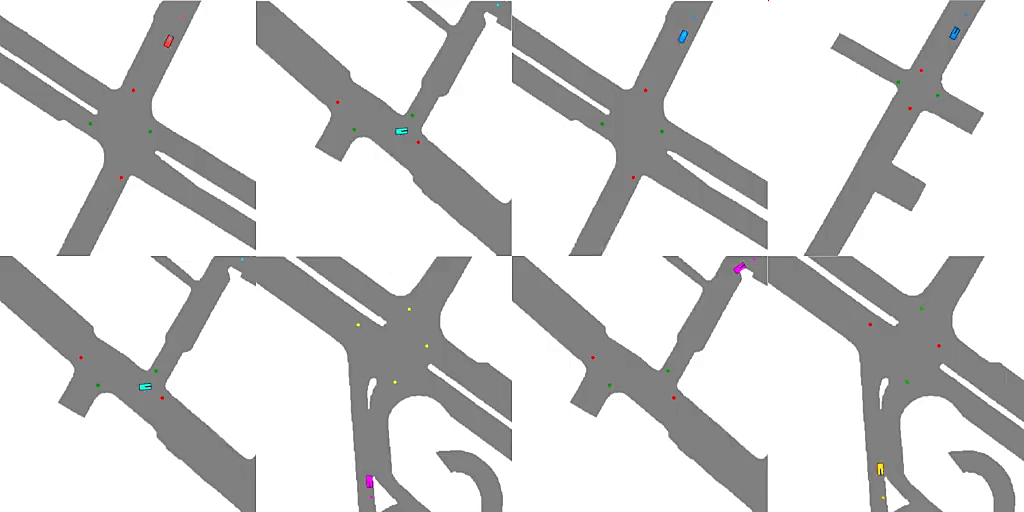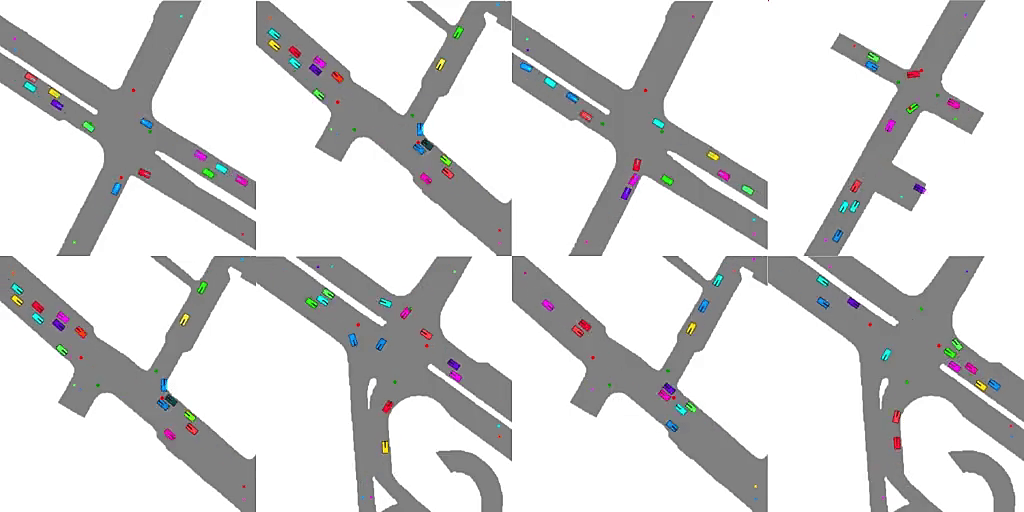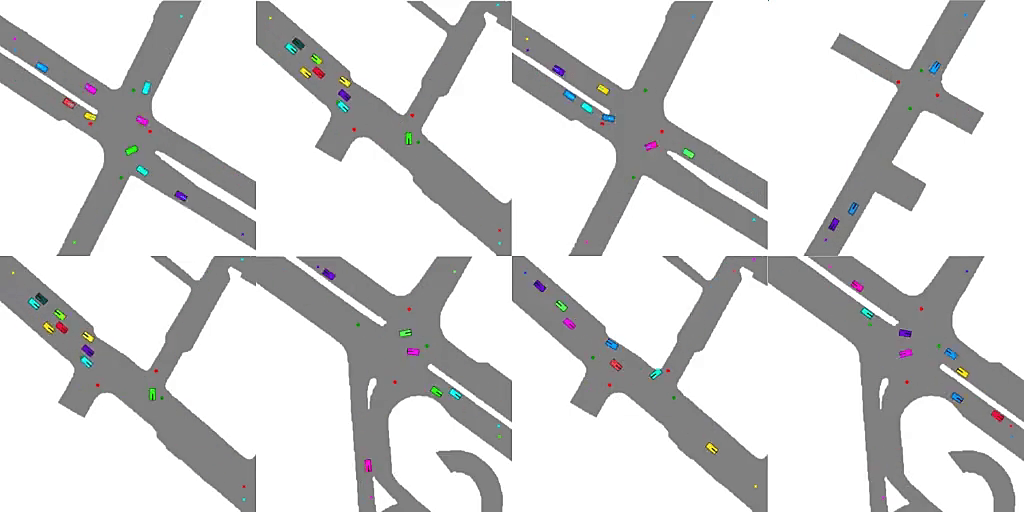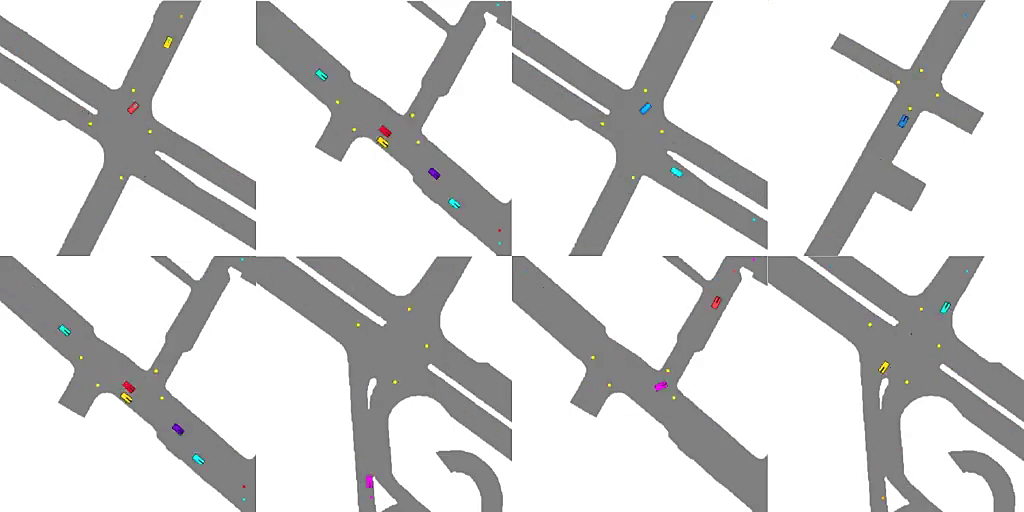
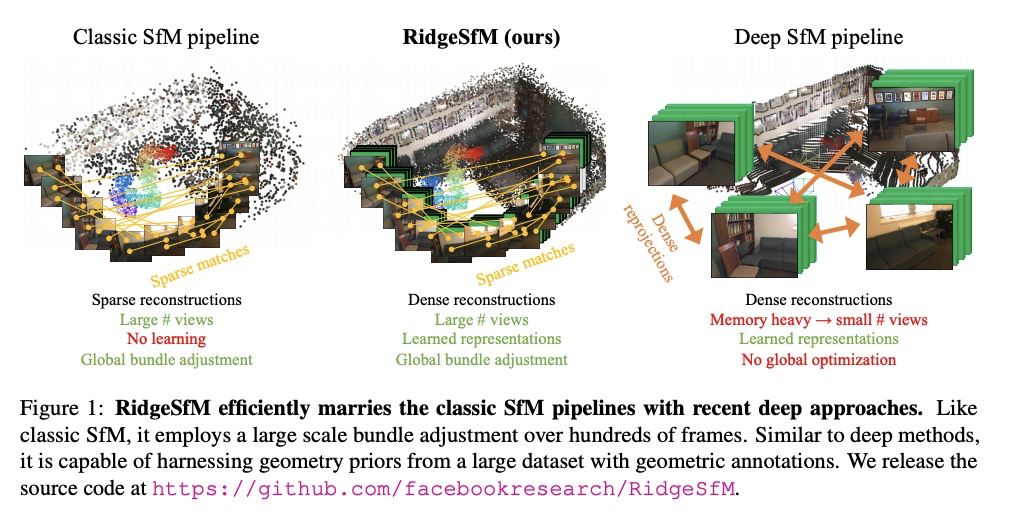
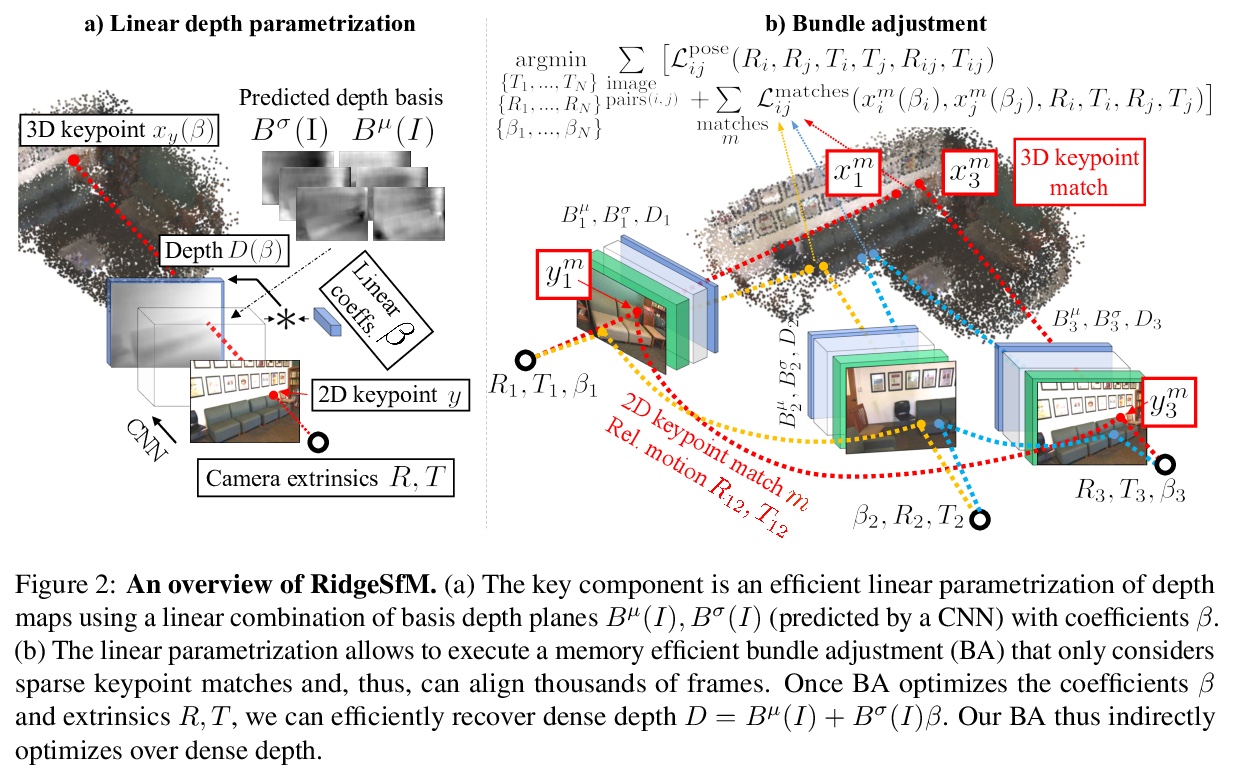
3、**[CV] RidgeSfM: Structure from Motion via Robust Pairwise Matching Under Depth Uncertainty
B Graham, D Novotny
[Facebook AI Research]
深度不确定性下鲁棒两两匹配运动结构估计。提出从运动中估计结构的新方法RidgeSfM,将经典SfM管道与深度重构器相结合,可对巨大图像集进行束调整。用单目深度网络预测的有限个基本“深度平面”的线性组合来参数化深度图,通过一组高质量的稀疏关键点匹配,对每帧深度平面和相机姿态的线性组合进行优化,以形成几何上一致的关键点云。RidgeSfM的有效深度线性参数化允许在一组稀疏匹配上执行成对和场景的几何优化,以间接方式恢复密集深度。**
We consider the problem of simultaneously estimating a dense depth map and camera pose for a large set of images of an indoor scene. While classical SfM pipelines rely on a two-step approach where cameras are first estimated using a bundle adjustment in order to ground the ensuing multi-view stereo stage, both our poses and dense reconstructions are a direct output of an altered bundle adjuster. To this end, we parametrize each depth map with a linear combination of a limited number of basis “depth-planes” predicted in a monocular fashion by a deep net. Using a set of high-quality sparse keypoint matches, we optimize over the per-frame linear combinations of depth planes and camera poses to form a geometrically consistent cloud of keypoints. Although our bundle adjustment only considers sparse keypoints, the inferred linear coefficients of the basis planes immediately give us dense depth maps. RidgeSfM is able to collectively align hundreds of frames, which is its main advantage over recent memory-heavy deep alternatives that can align at most 10 frames. Quantitative comparisons reveal performance superior to a state-of-the-art large-scale SfM pipeline.
https://weibo.com/1402400261/Jw5z84PHy

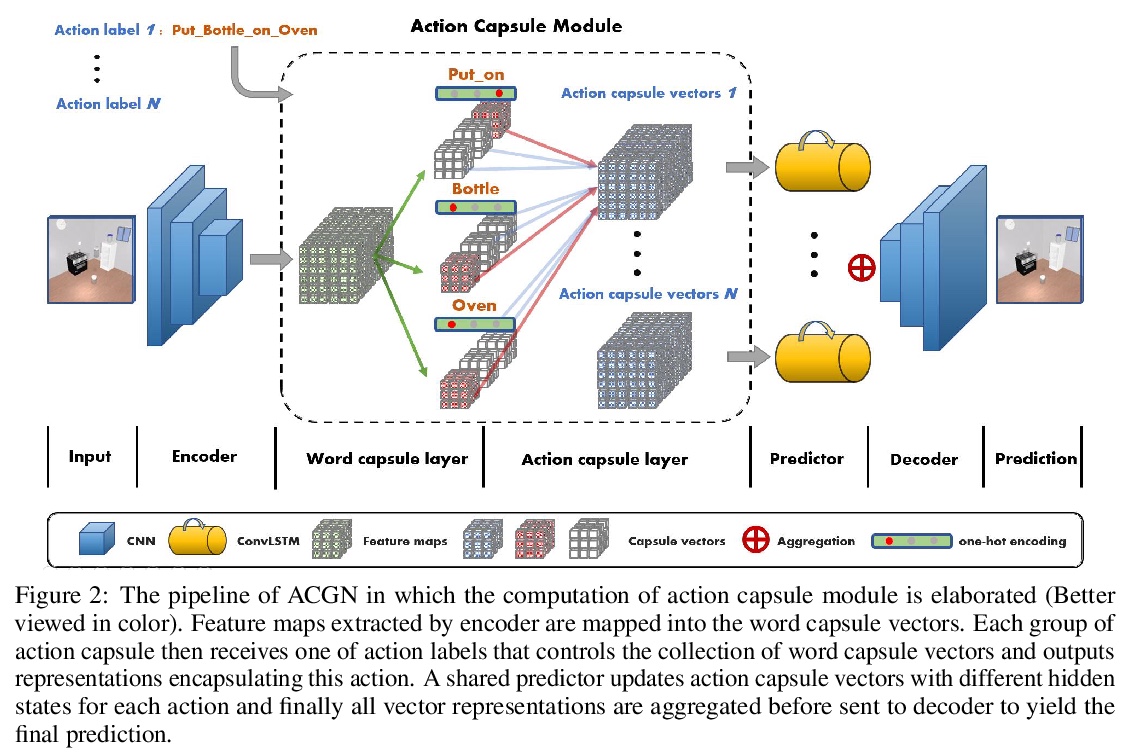
4、**[CV] Action Concept Grounding Network for Semantically-Consistent Video Generation
W Yu, W Chen, S Easterbrook, A Garg
[University of Toronto]
动作概念基础网络(ACGN)语义一致视频生成。提出语义动作条件视频预测的新任务,引入了两个新的数据集,旨在推动该任务在复杂交互场景中的鲁棒解决方案。利用胶囊网络与基础行动概念的思想,设计了一种新的视频预测模型ACGN,能正确根据指令进行条件设置并生成相应未来帧,不需要边界框等额外的辅助数据,可快速扩展和适应新的场景和实体。**
Recent works in self-supervised video prediction have mainly focused on passive forecasting and low-level action-conditional prediction, which sidesteps the problem of semantic learning. We introduce the task of semantic action-conditional video prediction, which can be regarded as an inverse problem of action recognition. The challenge of this new task primarily lies in how to effectively inform the model of semantic action information. To bridge vision and language, we utilize the idea of capsule and propose a novel video prediction model Action Concept Grounding Network (AGCN). Our method is evaluated on two newly designed synthetic datasets, CLEVR-Building-Blocks and Sapien-Kitchen, and experiments show that given different action labels, our ACGN can correctly condition on instructions and generate corresponding future frames without need of bounding boxes. We further demonstrate our trained model can make out-of-distribution predictions for concurrent actions, be quickly adapted to new object categories and exploit its learnt features for object detection. Additional visualizations can be found at > this https URL.
https://weibo.com/1402400261/Jw5GKgwYj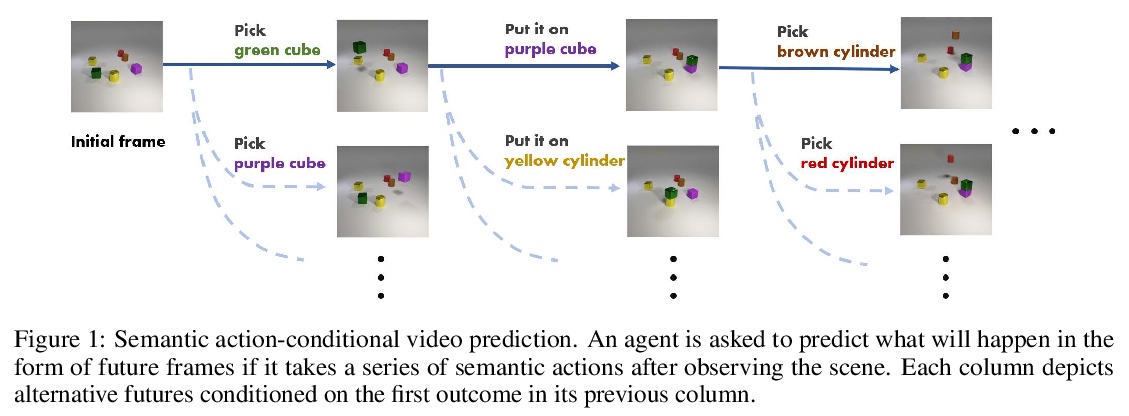

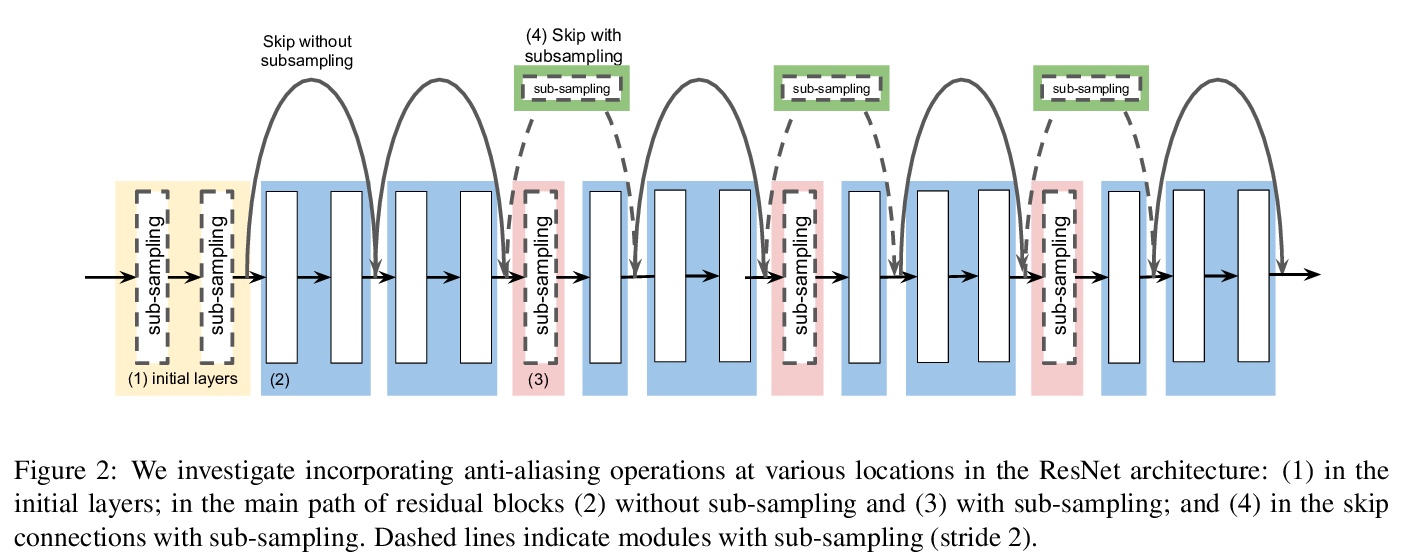
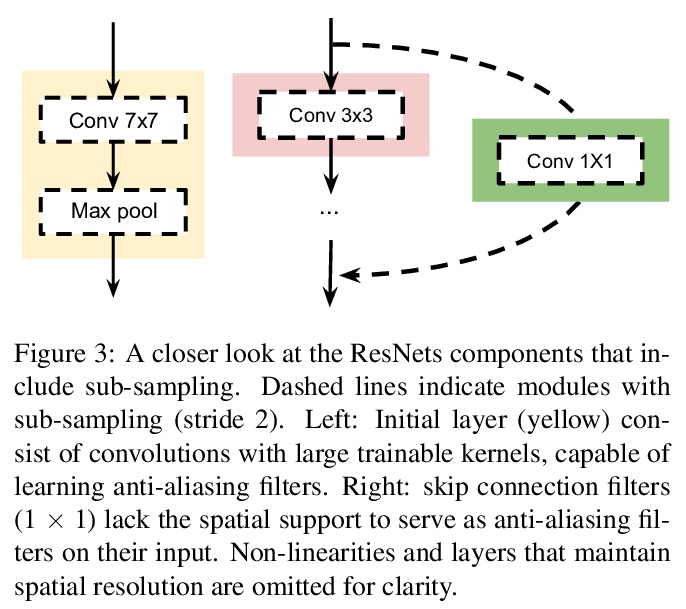
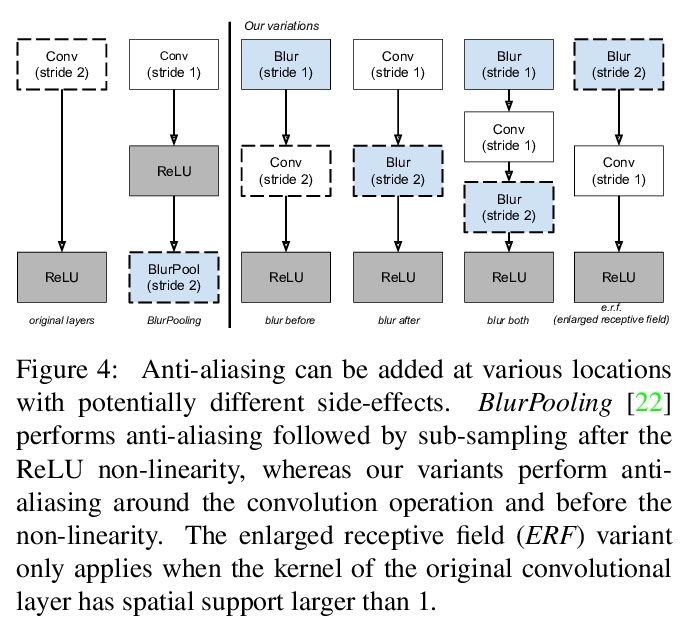
5、**[CV] An Effective Anti-Aliasing Approach for Residual Networks
C Vasconcelos, H Larochelle, V Dumoulin, N L Roux, R Goroshin
[Google Research]
残差网络高效抗混叠方法。频率混叠是在对任意信号(如图像或特征图)二次采样时可能发生的现象,会导致二次采样输出失真。可通过在关键位置放置不可训练的模糊滤波器、使用平滑的激活函数来减轻这种影响,特别是在网络缺乏学习能力的地方。与其他性能增强技术相比,抗混叠易于实现,计算成本低,且不需要额外的可训练参数。**
Image pre-processing in the frequency domain has traditionally played a vital role in computer vision and was even part of the standard pipeline in the early days of deep learning. However, with the advent of large datasets, many practitioners concluded that this was unnecessary due to the belief that these priors can be learned from the data itself. Frequency aliasing is a phenomenon that may occur when sub-sampling any signal, such as an image or feature map, causing distortion in the sub-sampled output. We show that we can mitigate this effect by placing non-trainable blur filters and using smooth activation functions at key locations, particularly where networks lack the capacity to learn them. These simple architectural changes lead to substantial improvements in out-of-distribution generalization on both image classification under natural corruptions on ImageNet-C [10] and few-shot learning on Meta-Dataset [17], without introducing additional trainable parameters and using the default hyper-parameters of open source codebases.
https://weibo.com/1402400261/Jw5MQdIc1

其他几篇值得关注的论文:
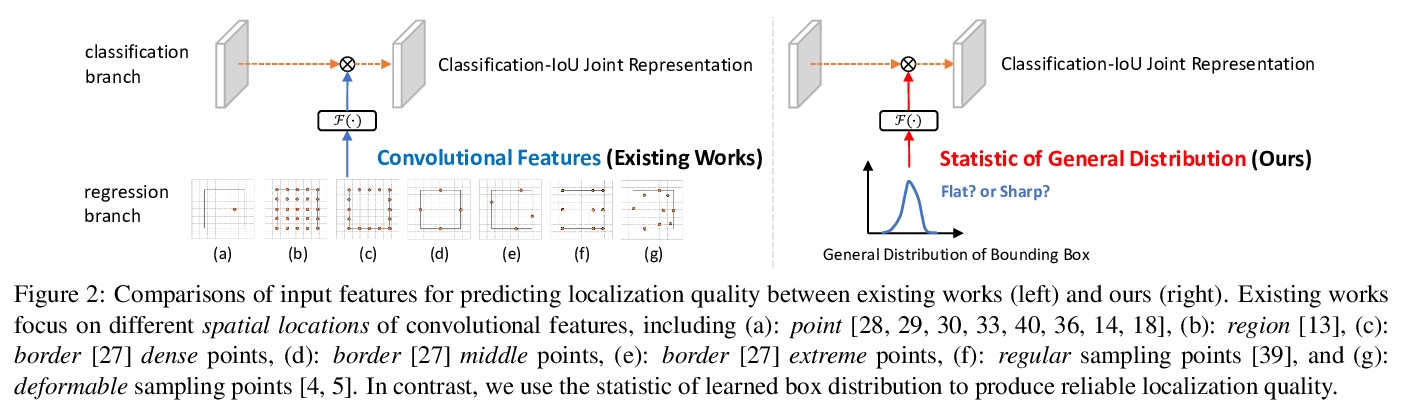
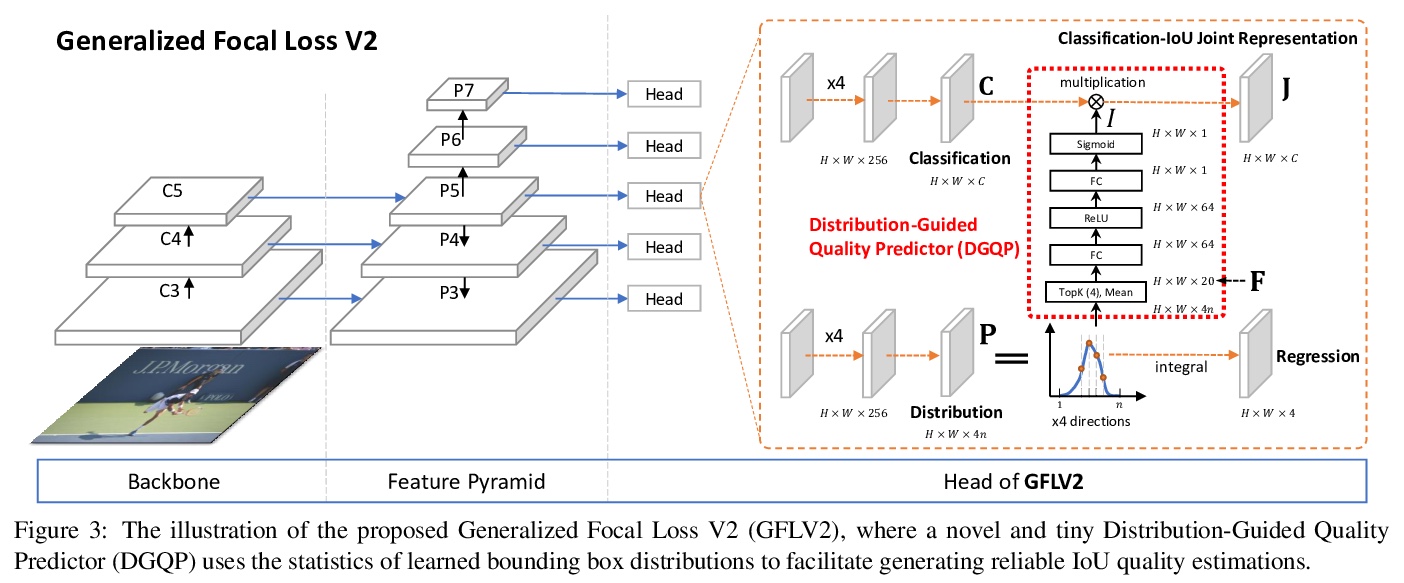
[CV] Generalized Focal Loss V2: Learning Reliable Localization Quality Estimation for Dense Object Detection
广义焦点损失V2:密集目标检测可靠定位质量估计学习
X Li, W Wang, X Hu, J Li, J Tang, J Yang
[Nanjing University of Science and Technology & Nanjing University & Tsinghua University]
https://weibo.com/1402400261/Jw5Qu2tub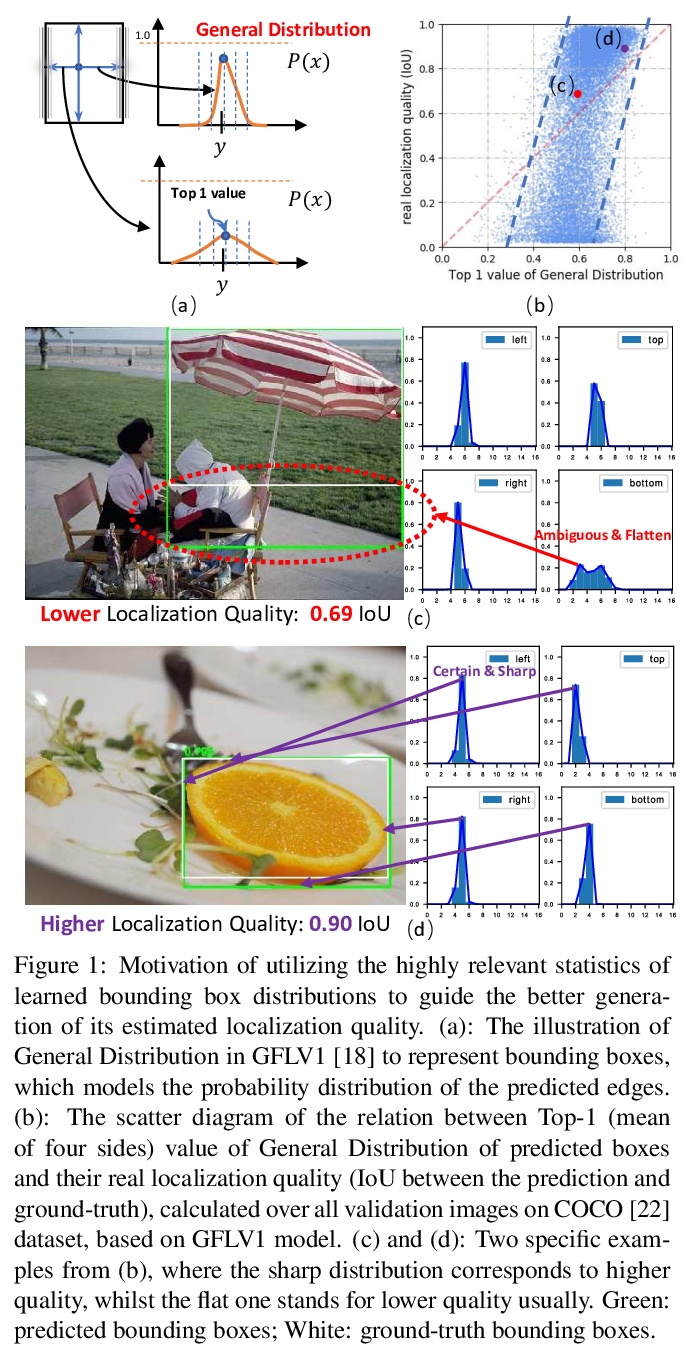

若有收获,就点个赞吧
0 人点赞
