- 1、[CV] COVID-19 Deterioration Prediction via Self-Supervised Representation Learning and Multi-Image Prediction
- 2、[LG] Counterfactual Generative Networks
- 3、[CV] ResizeMix: Mixing Data with Preserved Object Information and True Labels
- 4、[CV] Cross-Modal Contrastive Learning for Text-to-Image Generation
- 5、[LG] The Geometry of Deep Generative Image Models and its Applications
- [CV] Temporal-Relational CrossTransformers for Few-Shot Action Recognition
- [CV] Neural Volume Rendering: NeRF And Beyond
- [LG] Interpretable discovery of new semiconductors with machine learning
- [CV] OrigamiSet1.0: Two New Datasets for Origami Classification and Difficulty Estimation
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] COVID-19 Deterioration Prediction via Self-Supervised Representation Learning and Multi-Image Prediction
A Sriram, M Muckley, K Sinha, F Shamout, J Pineau, K J. Geras, L Azour, Y Aphinyanaphongs, N Yakubova, W Moore
[Facebook AI Research & NYU Abu Dhabi & NYU School of Medicine]
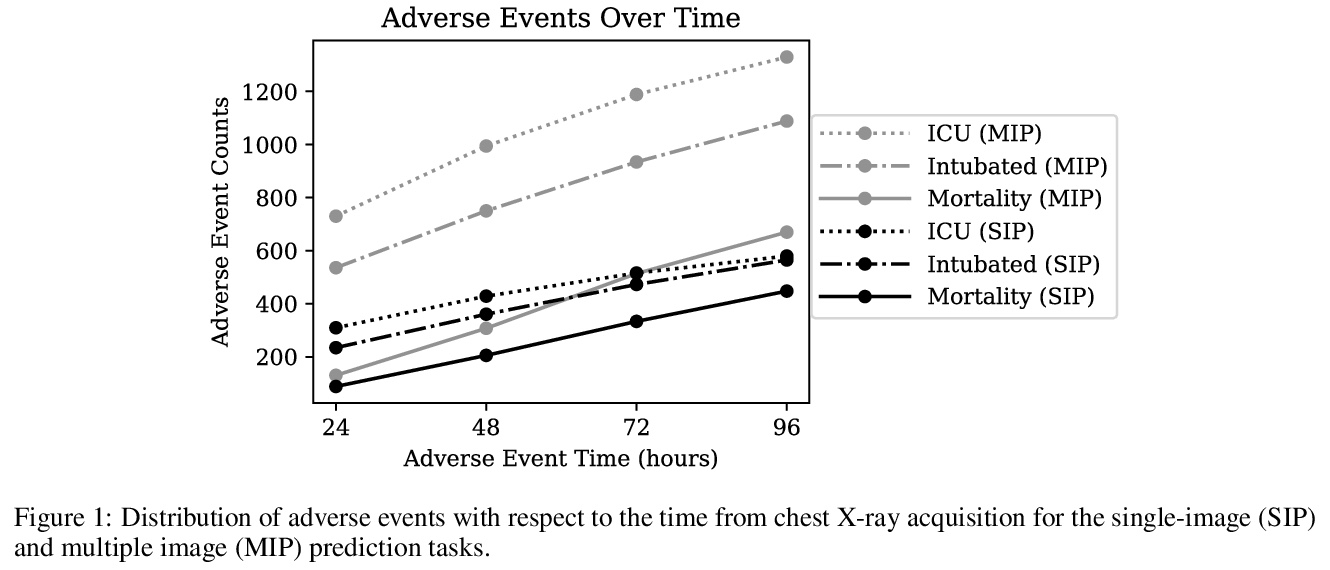
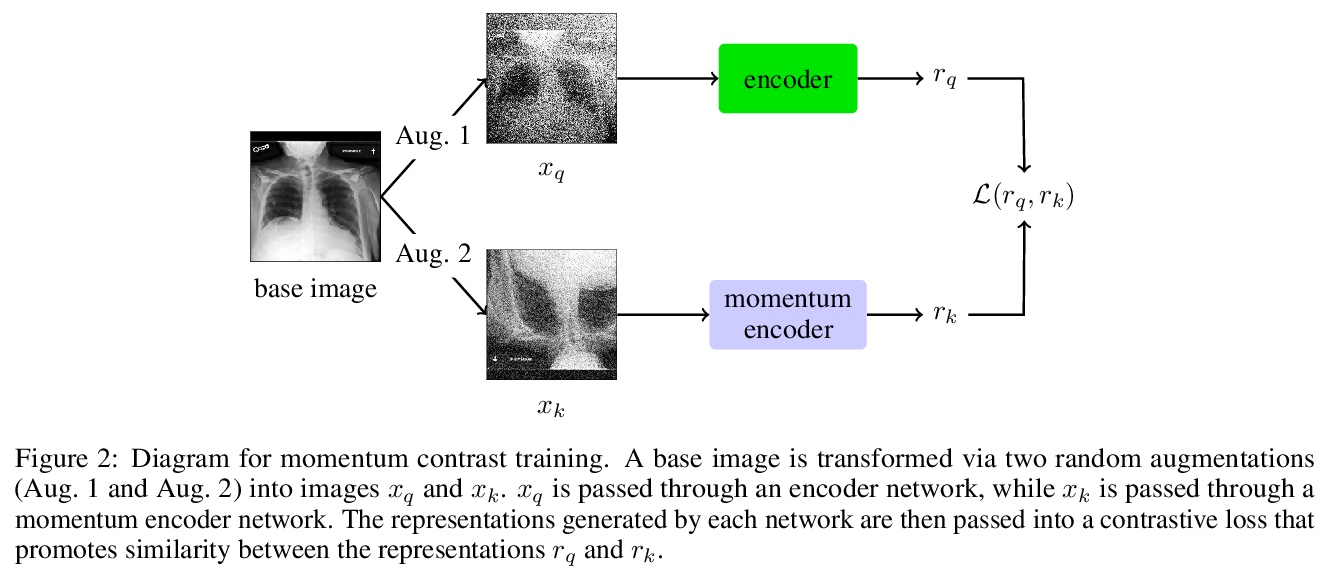
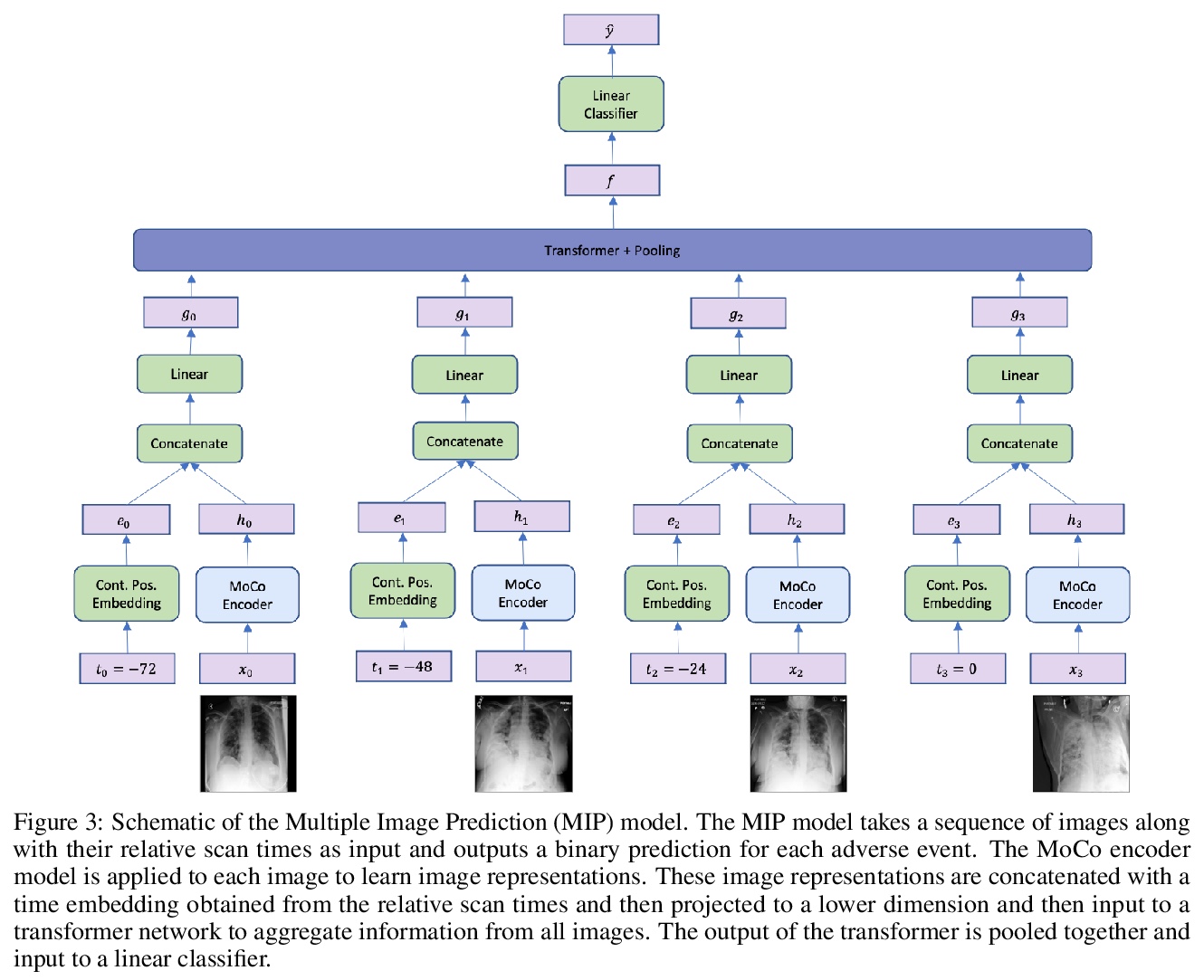
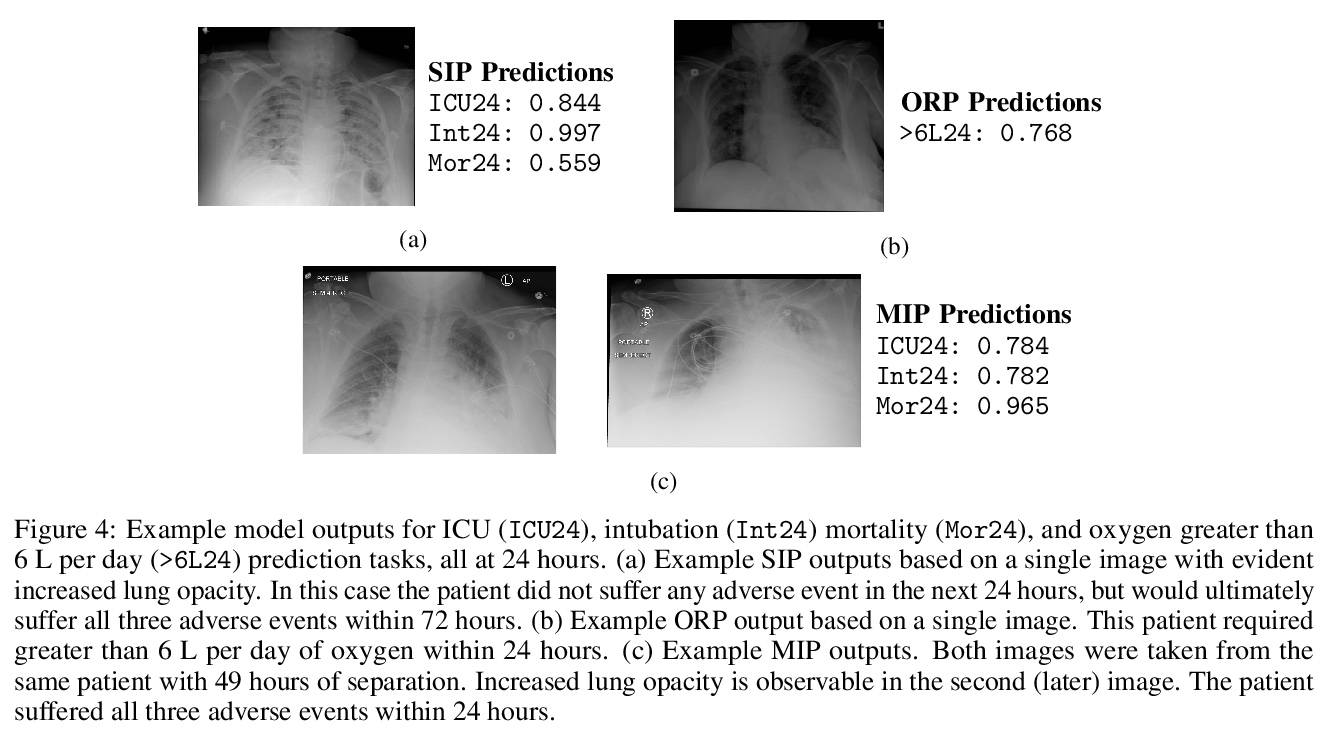
基于自监督表示学习和多图预测的新冠肺炎恶化预测。通过胸片预测新冠肺炎患者未来四天内是否需要重症监护。研究了自监督学习对COVID-19恶化预测任务的适用性,在预训练阶段用基于动量对比(MoCo)方法的自监督学习,来学习更通用的图像表示,用于下游任务。提出了一种新的基于transformer的架构,可处理多图像序列进行预测,该模型在预测96小时不良事件时可达到0.786的改进AUC,在预测96小时死亡率时可达到0.848的AUC。一项小型试点临床研究表明,所提出模型的预测准确性,与有经验的放射科医生分析相同信息的准确性相当。
The rapid spread of COVID-19 cases in recent months has strained hospital resources, making rapid and accurate triage of patients presenting to emergency departments a necessity. Machine learning techniques using clinical data such as chest X-rays have been used to predict which patients are most at risk of deterioration. We consider the task of predicting two types of patient deterioration based on chest X-rays: adverse event deterioration (i.e., transfer to the intensive care unit, intubation, or mortality) and increased oxygen requirements beyond 6 L per day. Due to the relative scarcity of COVID-19 patient data, existing solutions leverage supervised pretraining on related non-COVID images, but this is limited by the differences between the pretraining data and the target COVID-19 patient data. In this paper, we use self-supervised learning based on the momentum contrast (MoCo) method in the pretraining phase to learn more general image representations to use for downstream tasks. We present three results. The first is deterioration prediction from a single image, where our model achieves an area under receiver operating characteristic curve (AUC) of 0.742 for predicting an adverse event within 96 hours (compared to 0.703 with supervised pretraining) and an AUC of 0.765 for predicting oxygen requirements greater than 6 L a day at 24 hours (compared to 0.749 with supervised pretraining). We then propose a new transformer-based architecture that can process sequences of multiple images for prediction and show that this model can achieve an improved AUC of 0.786 for predicting an adverse event at 96 hours and an AUC of 0.848 for predicting mortalities at 96 hours. A small pilot clinical study suggested that the prediction accuracy of our model is comparable to that of experienced radiologists analyzing the same information.
https://weibo.com/1402400261/JDQ7P1aPA
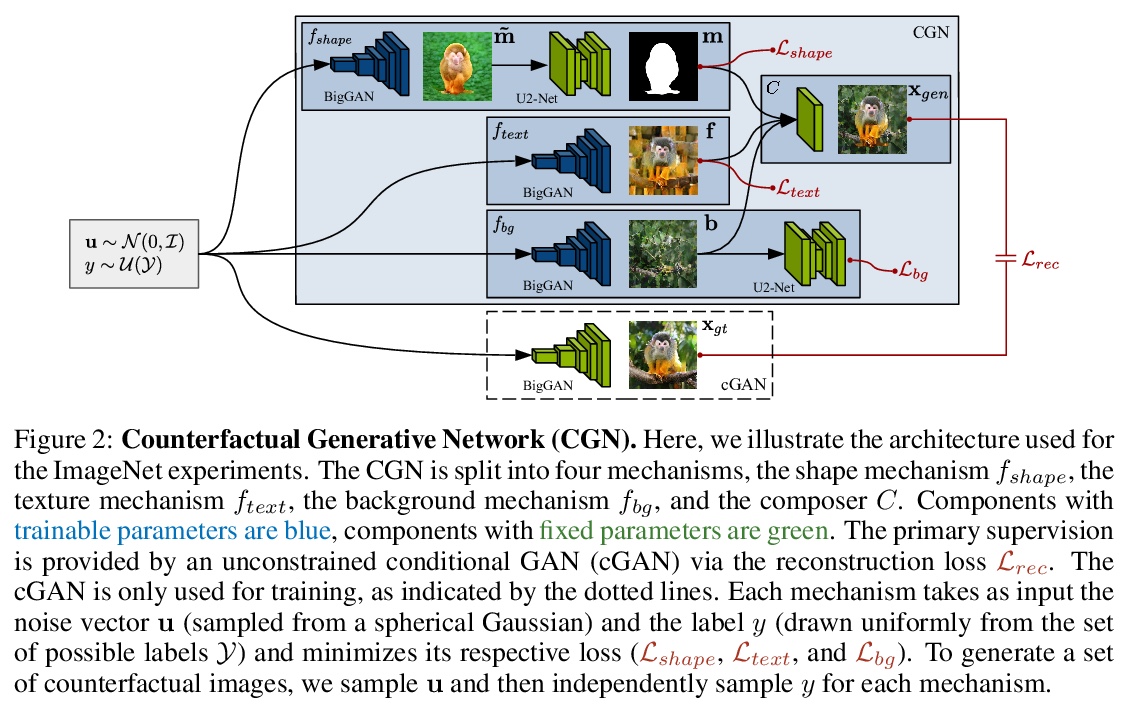
2、[LG] Counterfactual Generative Networks
A Sauer, A Geiger
[Max Planck Institute for Intelligent Systems]
反事实生成网络。将源自因果关系的思想应用到生成式建模和不变分类器的训练中,将生成式网络构架成用来生成对训练分类器有用的反事实图像的独立机制。将图像生成过程分解为独立的因果机制,在没有直接监督的情况下进行训练,通过适当利用归纳偏差,将物体形状、纹理和背景分离开来,用以生成反事实图像,在各种MNIST变体以及ImageNet上演示了该方法的有效性。
Neural networks are prone to learning shortcuts — they often model simple correlations, ignoring more complex ones that potentially generalize better. Prior works on image classification show that instead of learning a connection to object shape, deep classifiers tend to exploit spurious correlations with low-level texture or the background for solving the classification task. In this work, we take a step towards more robust and interpretable classifiers that explicitly expose the task’s causal structure. Building on current advances in deep generative modeling, we propose to decompose the image generation process into independent causal mechanisms that we train without direct supervision. By exploiting appropriate inductive biases, these mechanisms disentangle object shape, object texture, and background; hence, they allow for generating counterfactual images. We demonstrate the ability of our model to generate such images on MNIST and ImageNet. Further, we show that the counterfactual images can improve out-of-distribution robustness with a marginal drop in performance on the original classification task, despite being synthetic. Lastly, our generative model can be trained efficiently on a single GPU, exploiting common pre-trained models as inductive biases.
https://weibo.com/1402400261/JDQjtsy3y


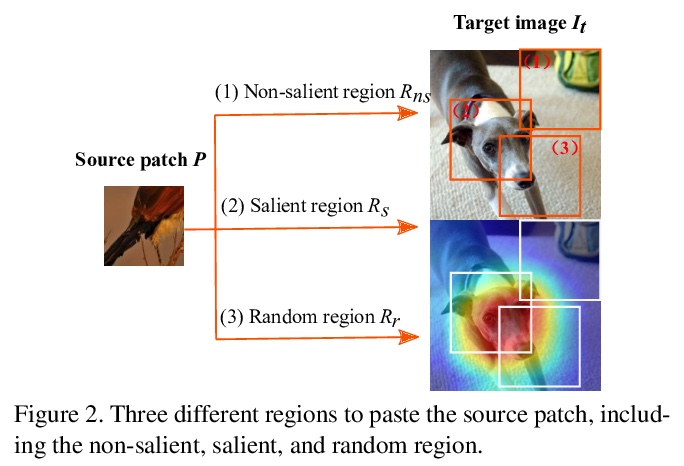
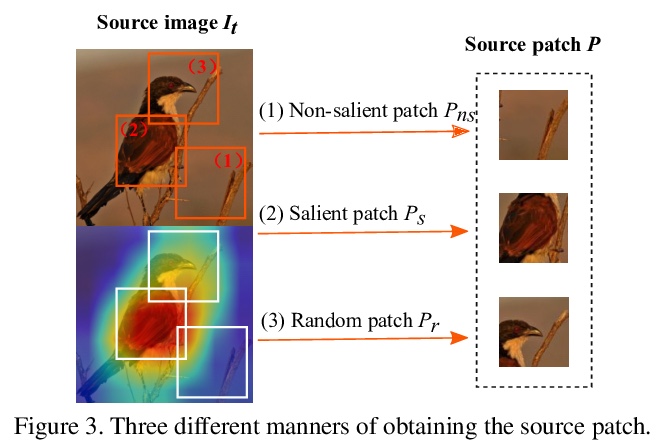
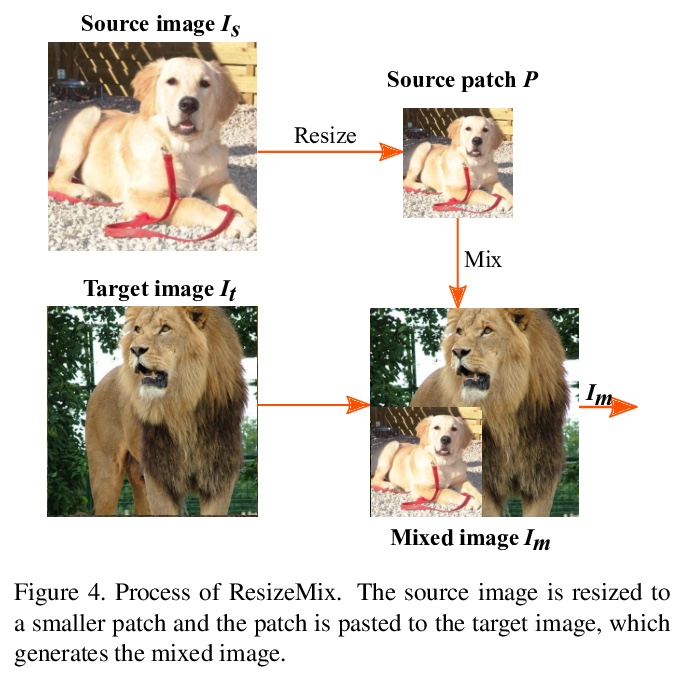
3、[CV] ResizeMix: Mixing Data with Preserved Object Information and True Labels
J Qin, J Fang, Q Zhang, W Liu, X Wang, X Wang
[University of Chinese Academy of Sciences & Huazhong University of Science and Technology & Horizon Robotics]
ResizeMix:保留目标信息和真实标签的数据混合数据增强。系统研究了基于CutMix的数据增强方法,发现数据混合中显著性信息并不是那么必要。验证了裁剪补丁进行混合,容易造成标签错配和目标信息缺失,提出一种新的混合方法ResizeMix,通过直接调整图像大小进行混合,解决了这两个问题。提出的ResizeMix与CutMix和显著性指导方法相比,在不增加计算成本的情况下,在图像分类和目标检测任务上都表现出明显优势,甚至优于大多数成本高昂的基于搜索的自动增强方法。
Data augmentation is a powerful technique to increase the diversity of data, which can effectively improve the generalization ability of neural networks in image recognition tasks. Recent data mixing based augmentation strategies have achieved great success. Especially, CutMix uses a simple but effective method to improve the classifiers by randomly cropping a patch from one image and pasting it on another image. To further promote the performance of CutMix, a series of works explore to use the saliency information of the image to guide the mixing. We systematically study the importance of the saliency information for mixing data, and find that the saliency information is not so necessary for promoting the augmentation performance. Furthermore, we find that the cutting based data mixing methods carry two problems of label misallocation and object information missing, which cannot be resolved simultaneously. We propose a more effective but very easily implemented method, namely ResizeMix. We mix the data by directly resizing the source image to a small patch and paste it on another image. The obtained patch preserves more substantial object information compared with conventional cut-based methods. ResizeMix shows evident advantages over CutMix and the saliency-guided methods on both image classification and object detection tasks without additional computation cost, which even outperforms most costly search-based automatic augmentation methods.
https://weibo.com/1402400261/JDQogpDOe
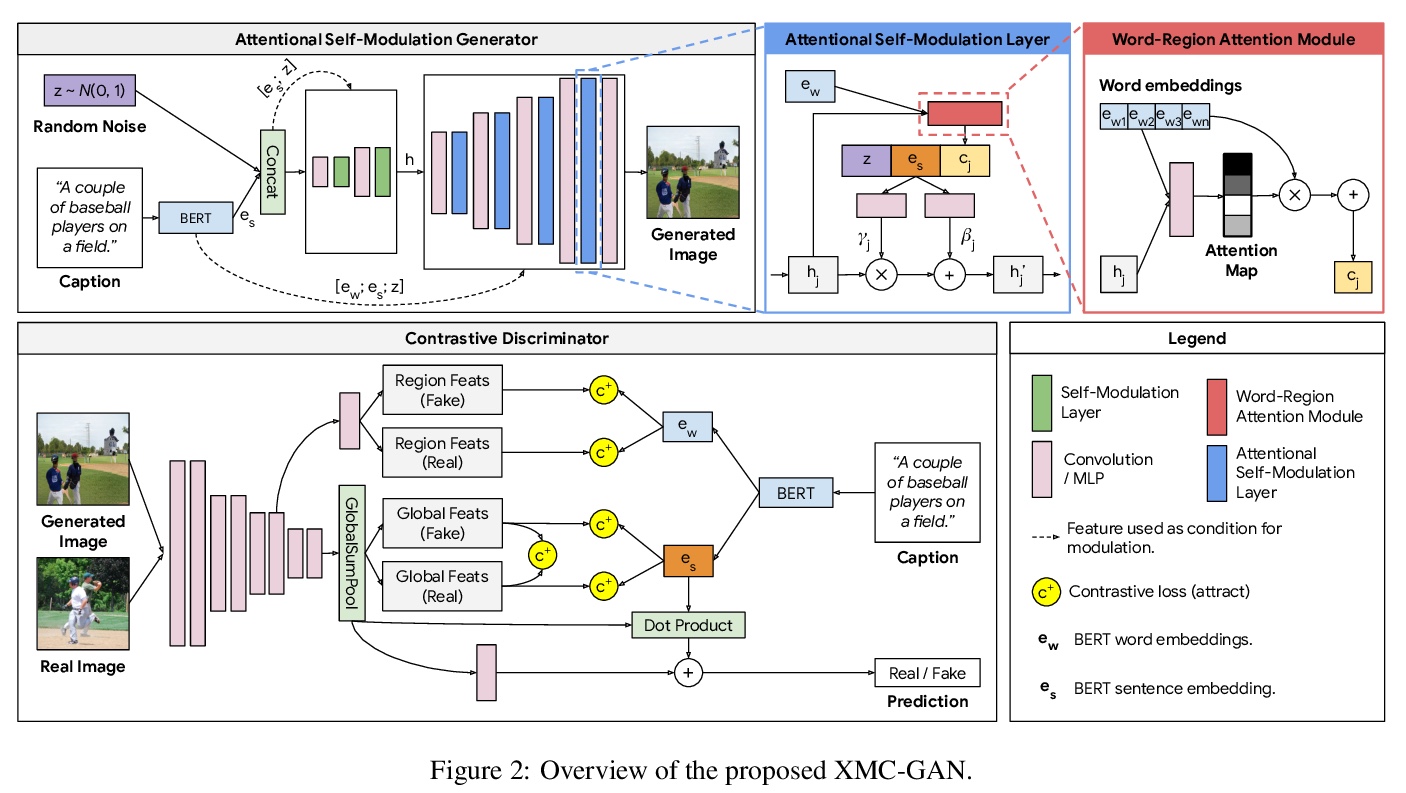
4、[CV] Cross-Modal Contrastive Learning for Text-to-Image Generation
H Zhang, J Y Koh, J Baldridge, H Lee, Y Yang
[Google Research & University of Michigan]
基于跨模态对比学习的文本到图像生成。提出跨模态对比生成对抗网络(XMC-GAN),通过最大化图像-文本互信息来生成连贯、清晰、逼真的场景图片,采用注意力自调制生成器,用来强制执行强文本-图像对应,以及对比鉴别器,作为批评者和对比学习的特征编码器,通过捕捉模态间和模态内对应关系的多重对比损失,来实现高质量的文本-图像生成。实验表明,XMC-GAN可产生更高质量的图像,更好地匹配输入文字描述,包括对于长而详细的叙述。
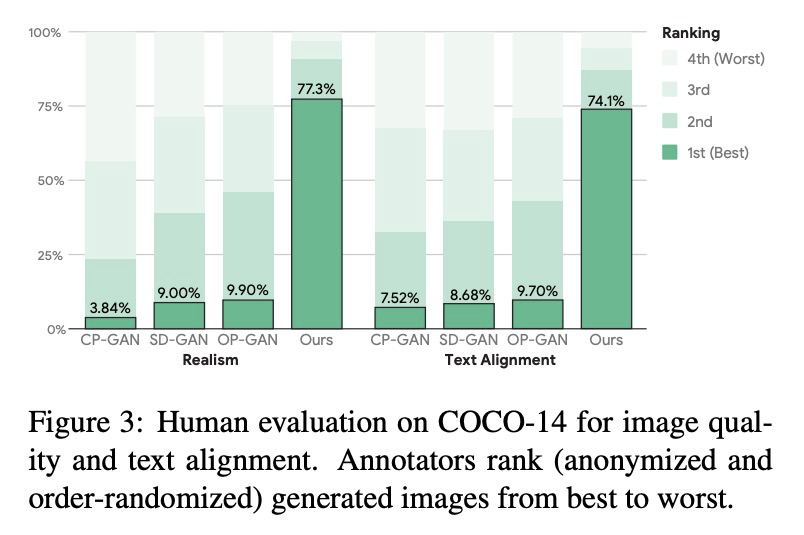
The output of text-to-image synthesis systems should be coherent, clear, photo-realistic scenes with high semantic fidelity to their conditioned text descriptions. Our Cross-Modal Contrastive Generative Adversarial Network (XMC-GAN) addresses this challenge by maximizing the mutual information between image and text. It does this via multiple contrastive losses which capture inter-modality and intra-modality correspondences. XMC-GAN uses an attentional self-modulation generator, which enforces strong text-image correspondence, and a contrastive discriminator, which acts as a critic as well as a feature encoder for contrastive learning. The quality of XMC-GAN’s output is a major step up from previous models, as we show on three challenging datasets. On MS-COCO, not only does XMC-GAN improve state-of-the-art FID from 24.70 to 9.33, but—more importantly—people prefer XMC-GAN by 77.3 for image quality and 74.1 for image-text alignment, compared to three other recent models. XMC-GAN also generalizes to the challenging Localized Narratives dataset (which has longer, more detailed descriptions), improving state-of-the-art FID from 48.70 to 14.12. Lastly, we train and evaluate XMC-GAN on the challenging Open Images data, establishing a strong benchmark FID score of 26.91.
https://weibo.com/1402400261/JDQwwvXuh
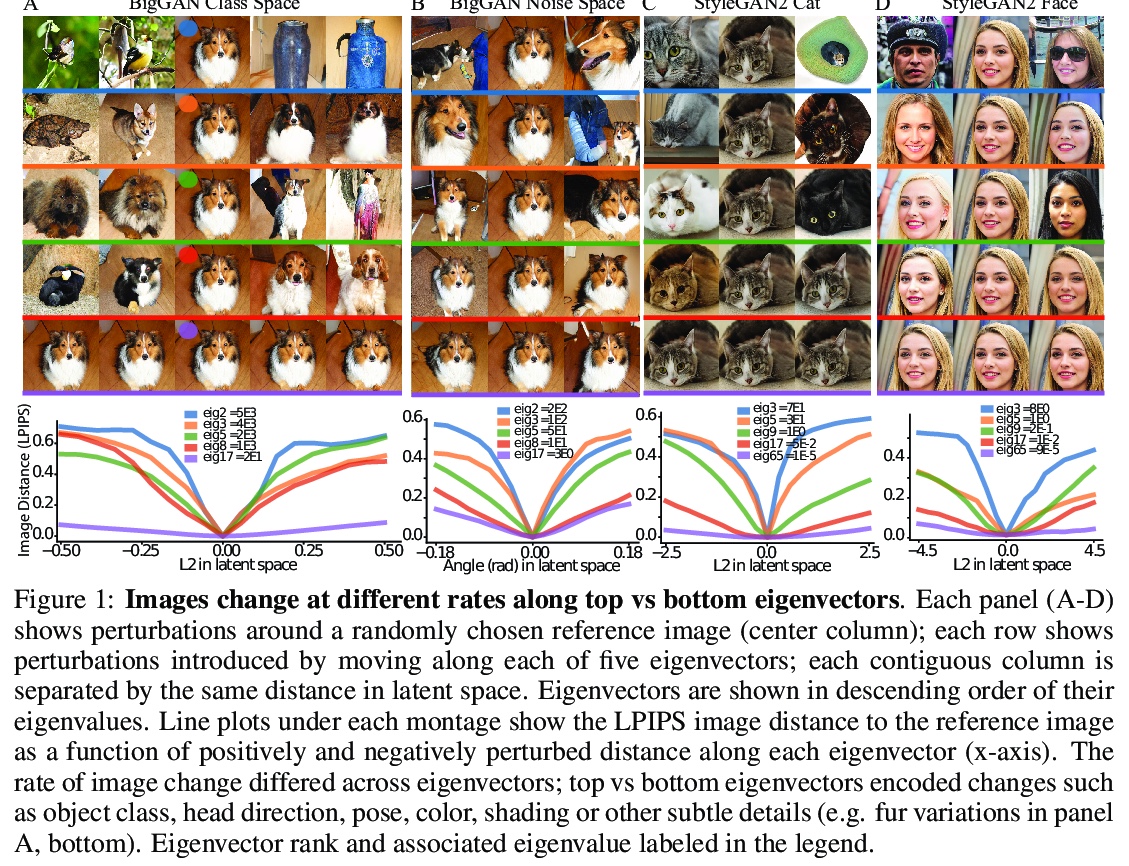
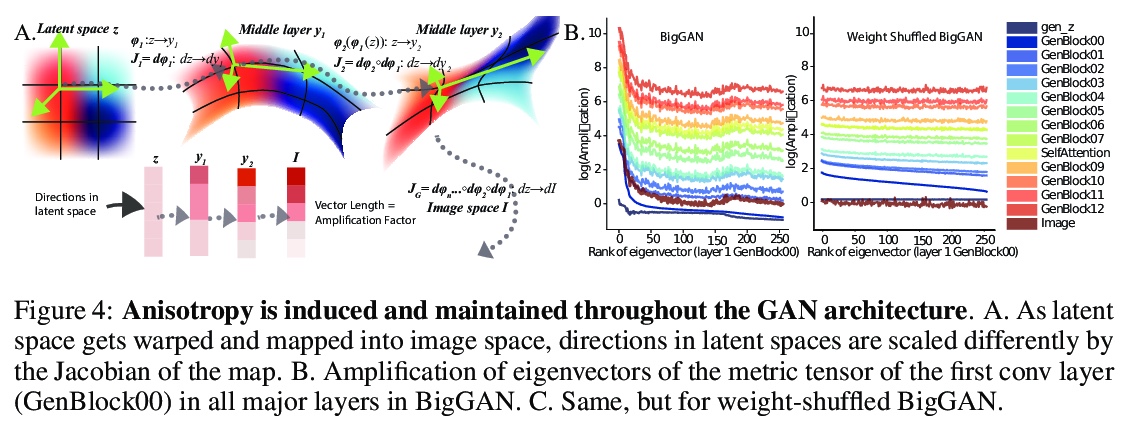
5、[LG] The Geometry of Deep Generative Image Models and its Applications
B Wang, C R. Ponce
[Washington University in St Louis]
深度生成图像模型几何学及其应用。GAN可在潜空间将随机输入映射到代表训练数据的新样本上,由于潜空间的高维度和生成器的非线性,潜空间结构很难直观,限制了其实用性,本文用一个几何框架,来解决以上问题,提出一种架构无关的方法,来计算GAN创建图像流形的黎曼度量。该度量的特征值分解,可隔离解释图像不同层次变化的轴。对几个预训练GAN的实验分析表明,每个位置周围的图像变化都集中在几个主要轴上(空间是高度各向异性的),而在空间不同位置上,产生这种大变化的方向是相似的(空间是均匀的)。许多头部特征向量对应于图像空间中可解释的变换,相当一部分特征空间对应于可压缩掉的次要变换。这种几何理解,统一了之前与GAN可解释性相关的关键结果。采用这种度量,可在潜空间中进行更有效的优化,并促进可解释轴的无监督发现。
Generative adversarial networks (GANs) have emerged as a powerful unsupervised method to model the statistical patterns of real-world data sets, such as natural images. These networks are trained to map random inputs in their latent space to new samples representative of the learned data. However, the structure of the latent space is hard to intuit due to its high dimensionality and the non-linearity of the generator, which limits the usefulness of the models. Understanding the latent space requires a way to identify input codes for existing real-world images (inversion), and a way to identify directions with known image transformations (interpretability). Here, we use a geometric framework to address both issues simultaneously. We develop an architecture-agnostic method to compute the Riemannian metric of the image manifold created by GANs. The eigen-decomposition of the metric isolates axes that account for different levels of image variability. An empirical analysis of several pretrained GANs shows that image variation around each position is concentrated along surprisingly few major axes (the space is highly anisotropic) and the directions that create this large variation are similar at different positions in the space (the space is homogeneous). We show that many of the top eigenvectors correspond to interpretable transforms in the image space, with a substantial part of eigenspace corresponding to minor transforms which could be compressed out. This geometric understanding unifies key previous results related to GAN interpretability. We show that the use of this metric allows for more efficient optimization in the latent space (e.g. GAN inversion) and facilitates unsupervised discovery of interpretable axes. Our results illustrate that defining the geometry of the GAN image manifold can serve as a general framework for understanding GANs.
https://weibo.com/1402400261/JDQEMjAZo

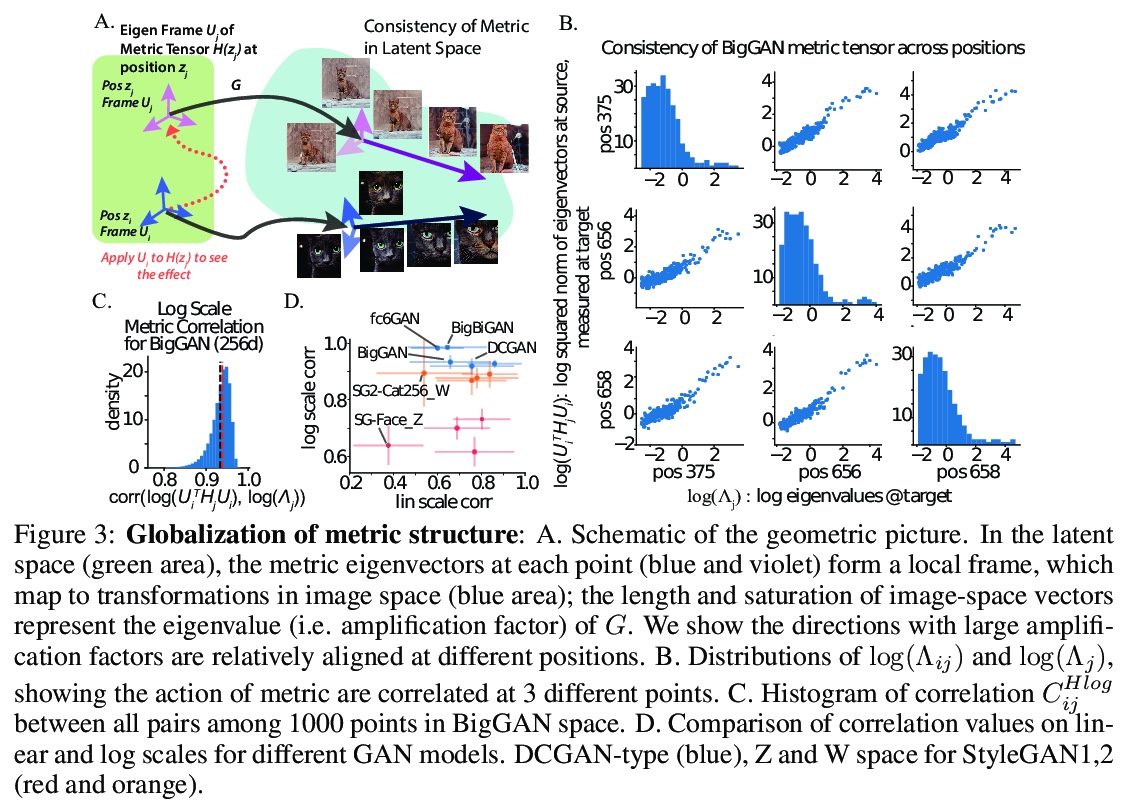
另外几篇值得关注的论文:
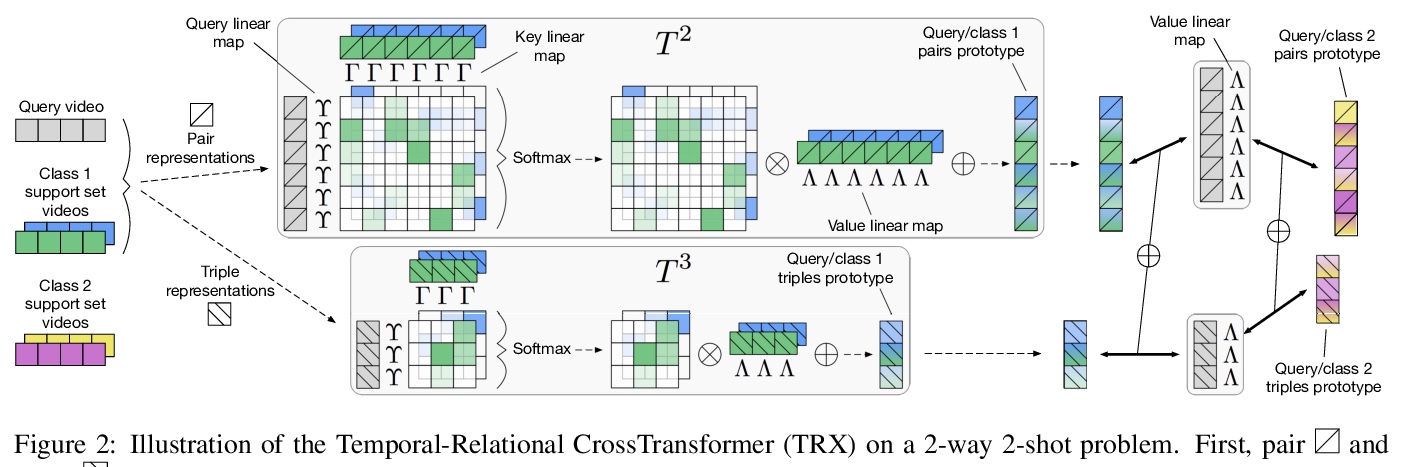
[CV] Temporal-Relational CrossTransformers for Few-Shot Action Recognition
基于时关系交叉变换器的少样本动作识别
T Perrett, A Masullo, T Burghardt, M Mirmehdi, D Damen
[University of Bristol]
https://weibo.com/1402400261/JDQMc5JiY
[CV] Neural Volume Rendering: NeRF And Beyond
神经网络体渲染综述
F Dellaert, L Yen-Chen
[Georgia Institute of Technology & MIT]
https://weibo.com/1402400261/JDQNFrjAz
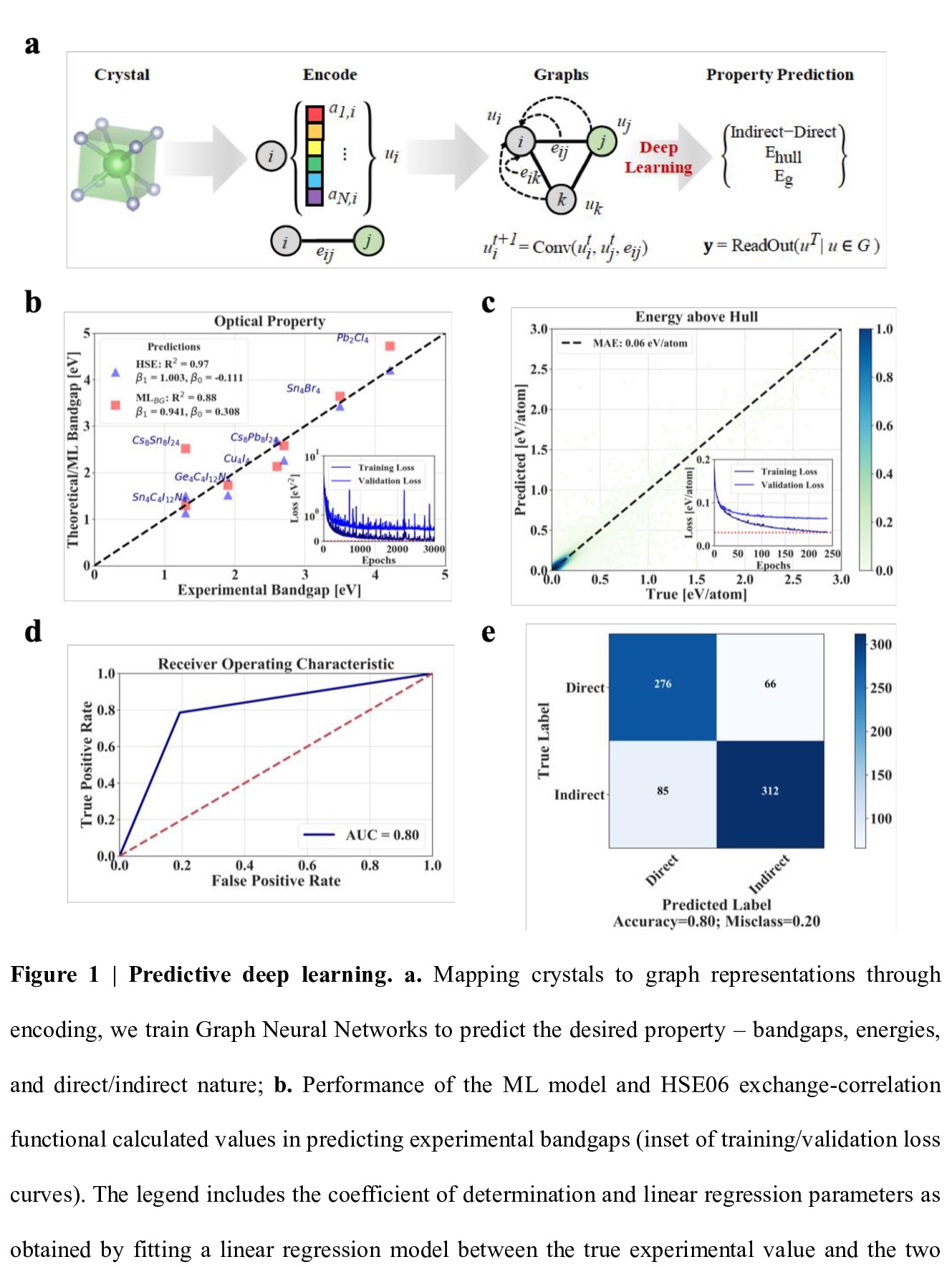
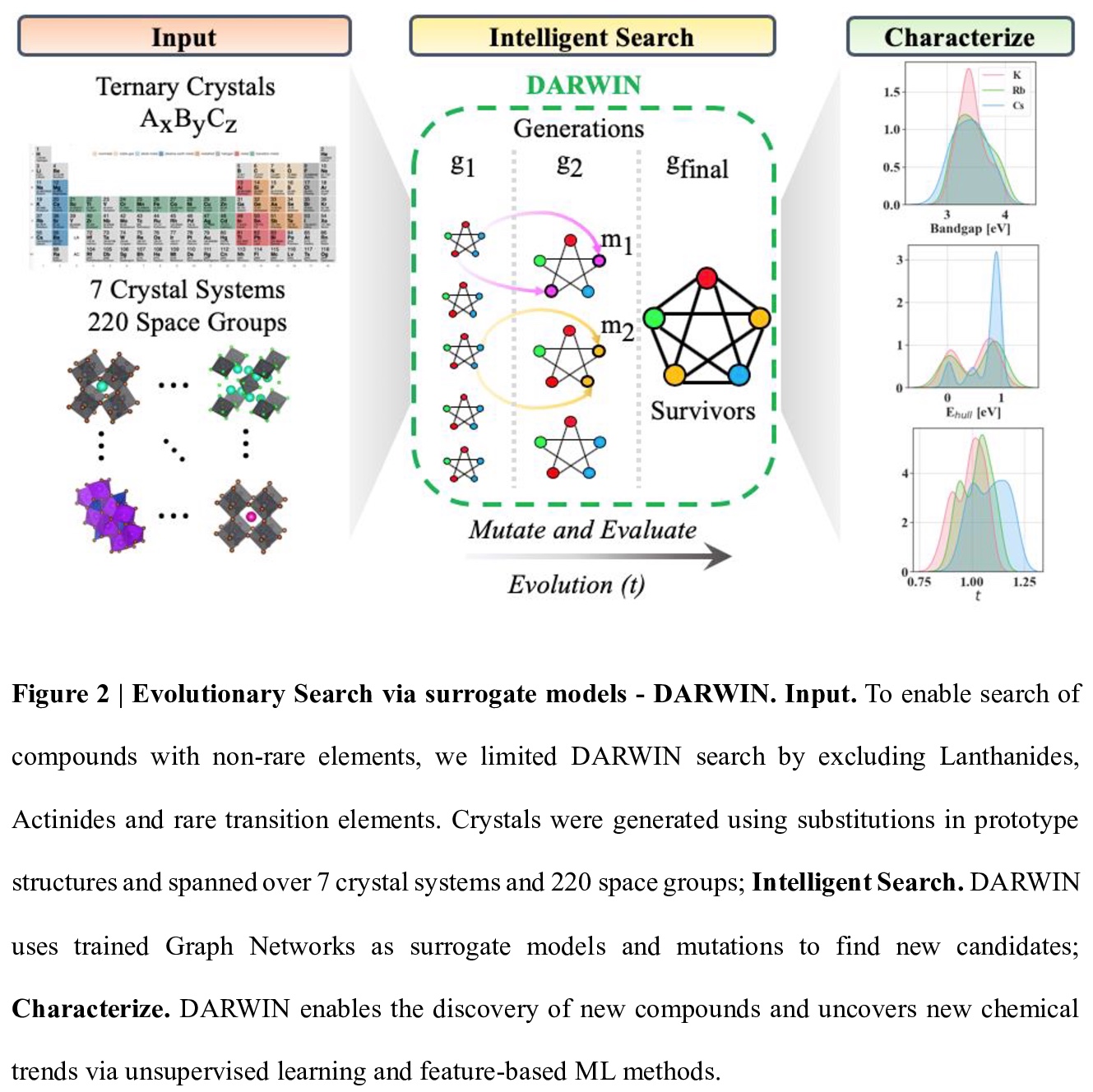
[LG] Interpretable discovery of new semiconductors with machine learning
机器学习新半导体可解释发现
H Choubisa, P Todorović…
[University of Toronto & National Research Council of Canada]
https://weibo.com/1402400261/JDQPGpN2n

[CV] OrigamiSet1.0: Two New Datasets for Origami Classification and Difficulty Estimation
OrigamiSet1.0:折纸分类/难度估计数据集
D Ma, G Friedland, M M Krell
[UC Berkeley]
https://weibo.com/1402400261/JDQR47uhZ



若有收获,就点个赞吧
0 人点赞
