LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] *Neural Mechanics: Symmetry and Broken Conservation Laws in Deep Learning Dynamics
D Kunin, J Sagastuy-Brena, S Ganguli, D L.K. Yamins, H Tanaka
[Stanford University]
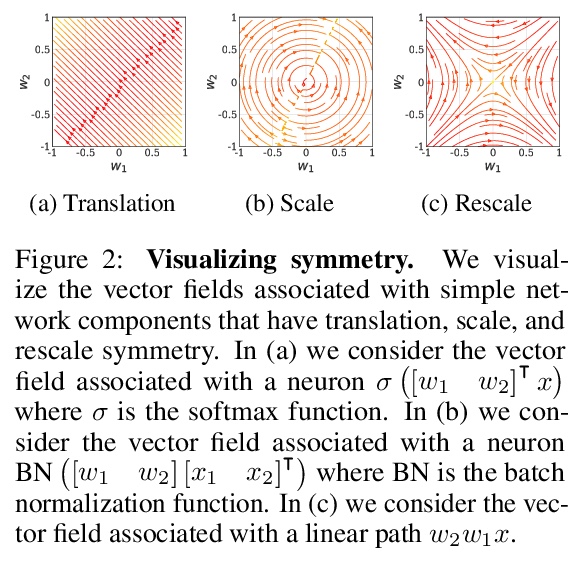
神经力学:深度学习动力学对称性和守恒律的打破。构建了统一的理论框架,基于所有数据集都存在的网络架构内在对称性,利用对称几何特性和更现实的学习动力学连续方程,来模拟权重衰减、动量、随机化和离散化。用这个框架推导出有意义的参数组合的精确动力学,并在大规模神经网络和数据集上进行了实验验证。对任何数据集上训练的技术架构状态,可以在有限的学习率和批处理规模下,分析描述各种参数组合的学习动力学。
Predicting the dynamics of neural network parameters during training is one of the key challenges in building a theoretical foundation for deep learning. A central obstacle is that the motion of a network in high-dimensional parameter space undergoes discrete finite steps along complex stochastic gradients derived from real-world datasets. We circumvent this obstacle through a unifying theoretical framework based on intrinsic symmetries embedded in a network’s architecture that are present for any dataset. We show that any such symmetry imposes stringent geometric constraints on gradients and Hessians, leading to an associated conservation law in the continuous-time limit of stochastic gradient descent (SGD), akin to Noether’s theorem in physics. We further show that finite learning rates used in practice can actually break these symmetry induced conservation laws. We apply tools from finite difference methods to derive modified gradient flow, a differential equation that better approximates the numerical trajectory taken by SGD at finite learning rates. We combine modified gradient flow with our framework of symmetries to derive exact integral expressions for the dynamics of certain parameter combinations. We empirically validate our analytic predictions for learning dynamics on VGG-16 trained on Tiny ImageNet. Overall, by exploiting symmetry, our work demonstrates that we can analytically describe the learning dynamics of various parameter combinations at finite learning rates and batch sizes for state of the art architectures trained on any dataset.
https://weibo.com/1402400261/JyFsjATR5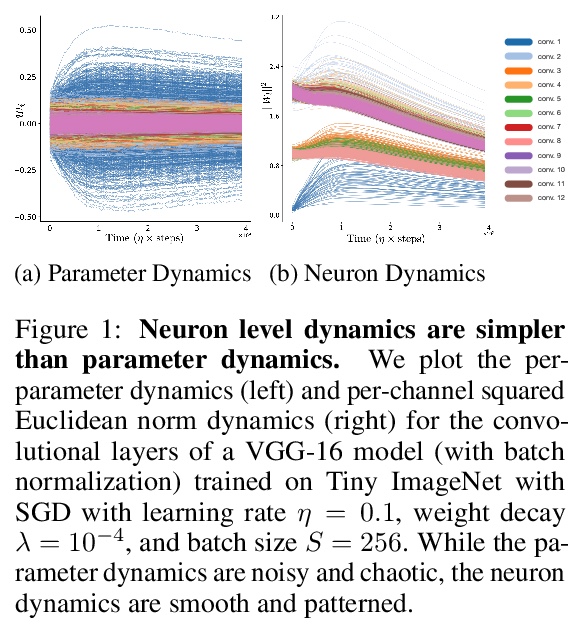

2、** **[LG] Variable-Shot Adaptation for Online Meta-Learning
T Yu, X Geng, C Finn, S Levine
[Stanford University & UC Berkeley]
在线元学习变化样本(数)自适应。在在线元学习的设置下,提出一种可变样本(数)元学习算法,用不同数量的数据进行自适应,优化整体性能。为学习率引入缩放规则,随学习样本数量而缩放。该方法明显优于为每种样本数量单独学习学习率的方法,验证了推导的正确性。
Few-shot meta-learning methods consider the problem of learning new tasks from a small, fixed number of examples, by meta-learning across static data from a set of previous tasks. However, in many real world settings, it is more natural to view the problem as one of minimizing the total amount of supervision —- both the number of examples needed to learn a new task and the amount of data needed for meta-learning. Such a formulation can be studied in a sequential learning setting, where tasks are presented in sequence. When studying meta-learning in this online setting, a critical question arises: can meta-learning improve over the sample complexity and regret of standard empirical risk minimization methods, when considering both meta-training and adaptation together? The answer is particularly non-obvious for meta-learning algorithms with complex bi-level optimizations that may demand large amounts of meta-training data. To answer this question, we extend previous meta-learning algorithms to handle the variable-shot settings that naturally arise in sequential learning: from many-shot learning at the start, to zero-shot learning towards the end. On sequential learning problems, we find that meta-learning solves the full task set with fewer overall labels and achieves greater cumulative performance, compared to standard supervised methods. These results suggest that meta-learning is an important ingredient for building learning systems that continuously learn and improve over a sequence of problems.
https://weibo.com/1402400261/JyFxGnIcd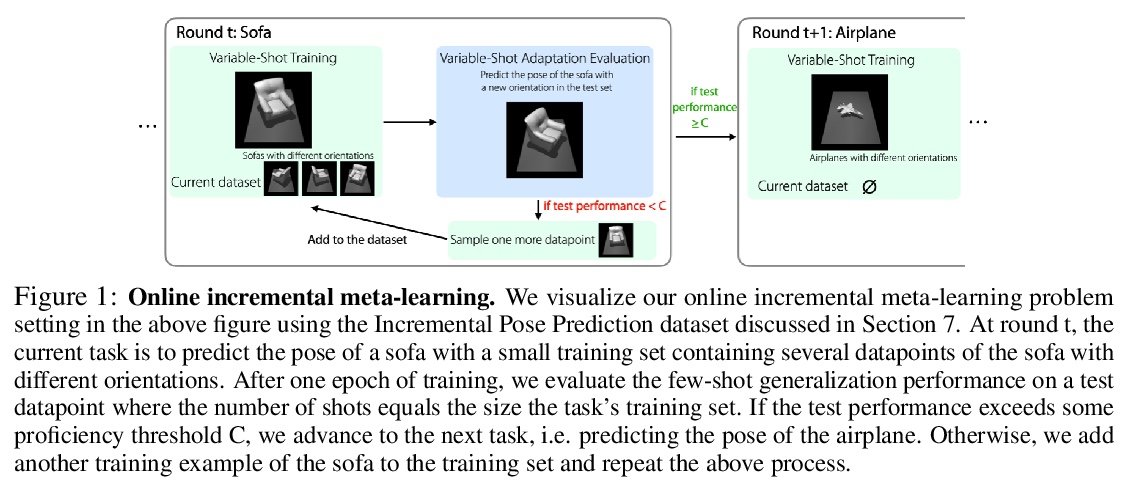

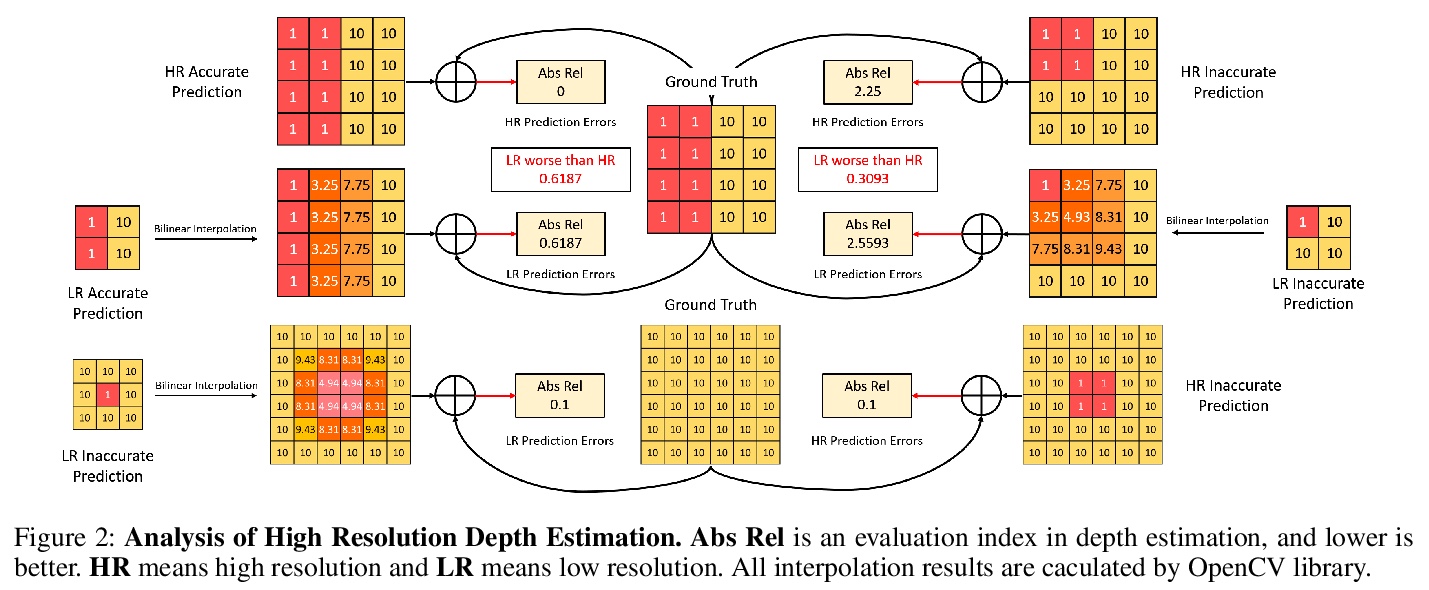
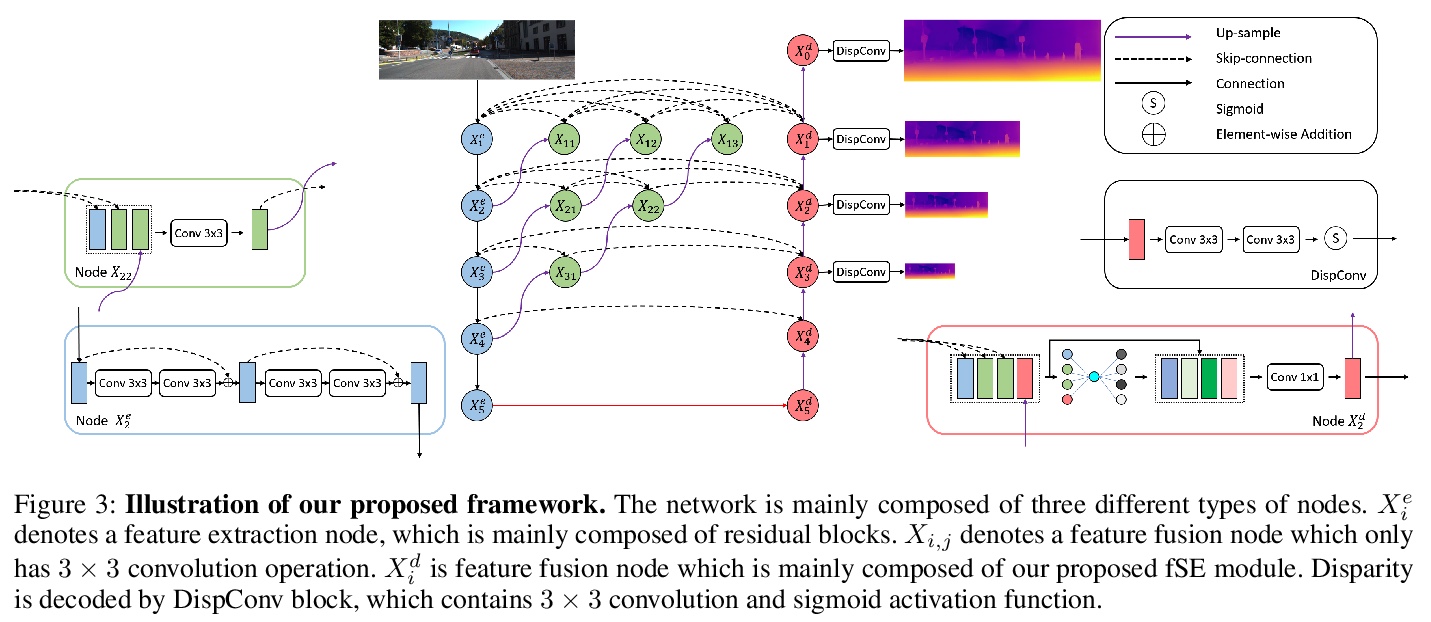
3、** **[CV] HR-Depth: High Resolution Self-Supervised Monocular Depth Estimation
X Lyu, L Liu, M Wang, X Kong, L Liu, Y Liu, X Chen, Y Yuan
[Zhejiang University & Fuxi AI Lab]
高分辨率自监督单目深度估计。提出一种改进的深度卷积网络HR-Depth,采用两种有效策略:(1)重新设计深度网络中的跳接,以获得更好的高分辨率特征;(2)提出特征融合压缩-激励(fSE)模块,以更有效地融合特征。该方法只对图像序列进行训练,但性能优于现有的自监督和半监督方法,甚至可与有监督方法相相比。此外,提出了简单而有效的轻量化网络设计策略。实验结果表明,Lite-HR-Depth模型在参数较少的情况下,可达到与大模型相当的效果。
Self-supervised learning shows great potential in monoculardepth estimation, using image sequences as the only source ofsupervision. Although people try to use the high-resolutionimage for depth estimation, the accuracy of prediction hasnot been significantly improved. In this work, we find thecore reason comes from the inaccurate depth estimation inlarge gradient regions, making the bilinear interpolation er-ror gradually disappear as the resolution increases. To obtainmore accurate depth estimation in large gradient regions, itis necessary to obtain high-resolution features with spatialand semantic information. Therefore, we present an improvedDepthNet, HR-Depth, with two effective strategies: (1) re-design the skip-connection in DepthNet to get better high-resolution features and (2) propose feature fusion Squeeze-and-Excitation(fSE) module to fuse feature more efficiently.Using Resnet-18 as the encoder, HR-Depth surpasses all pre-vious state-of-the-art(SoTA) methods with the least param-eters at both high and low resolution. Moreover, previousstate-of-the-art methods are based on fairly complex and deepnetworks with a mass of parameters which limits their realapplications. Thus we also construct a lightweight networkwhich uses MobileNetV3 as encoder. Experiments show thatthe lightweight network can perform on par with many largemodels like Monodepth2 at high-resolution with only20%parameters. All codes and models will be available at > this https URL.
https://weibo.com/1402400261/JyFCw3Ou9
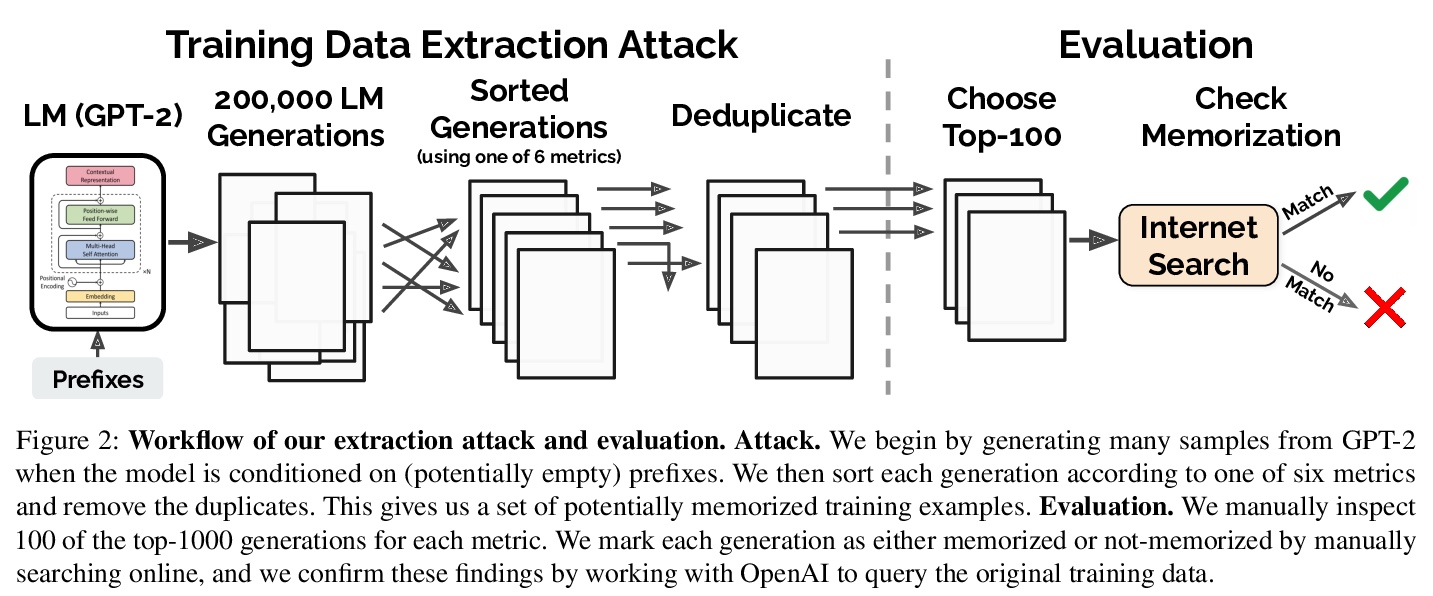
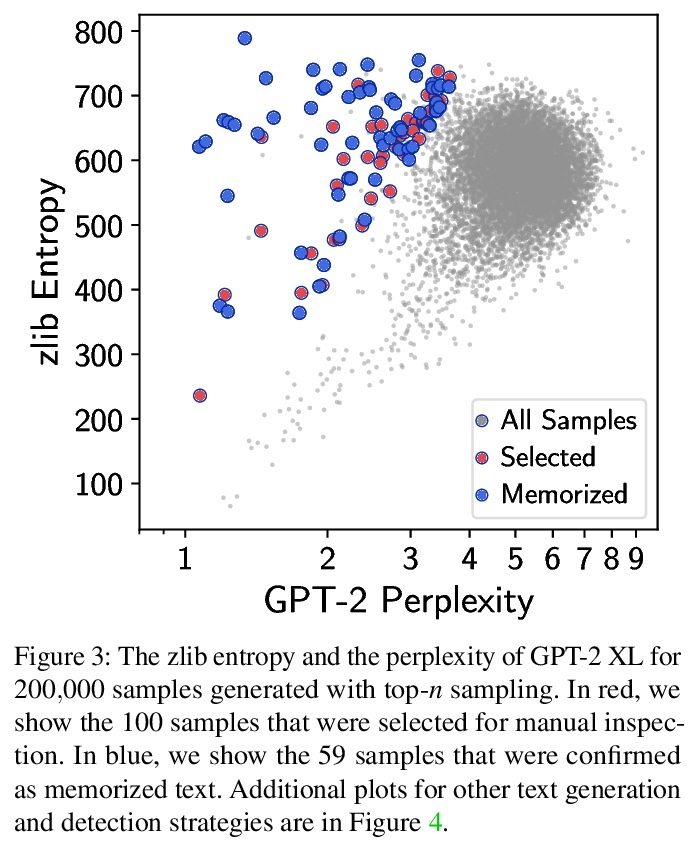
4、** **[CL] Extracting Training Data from Large Language Models
N Carlini, F Tramer, E Wallace, M Jagielski, A Herbert-Voss, K Lee, A Roberts, T Brown, D Song, U Erlingsson, A Oprea, C Raffel
[Google & Stanford & UC Berkeley & Northeastern University & OpenAI & Apple]
从大型语言模型中提取训练数据。发布基于私有数据集训练的大型(十亿级参数)语言模型已经非常普遍。本文证明,在这种情况下,攻击者可通过查询语言模型,进行训练数据提取攻击,恢复单个训练样本。演示了对GPT-2的攻击,GPT-2是基于公共互联网上的碎片训练的语言模型,通过攻击能提取出训练数据中数百个逐字文本序列。这些提取的样本中包括(公开的)个人身份信息、IRC对话、代码和128位UUID。文中对提取攻击进行全面评估,以了解导致其成功的因素。例如,较大的模型比较小的模型更容易受到攻击。该工作为大型语言模型的训练和发布敲响了警钟,说明在敏感数据上训练大型语言模型可能存在的隐患,同样的技术也适用于其他所有语言模型。由于随着语言变得更大,记忆的情况会变得更糟,预计这些漏洞将在未来变得更加重要。用差分隐私技术进行训练是一种缓解隐私泄露的方法,然而,有必要开发新的方法,可以在这种极端规模(例如,数十亿参数)下训练模型,而不牺牲模型精度或训练时间。更普遍的是,有许多开放性问题,有待将进一步研究,包括模型为什么记忆,记忆的危险,以及如何防止记忆等。
It has become common to publish large (billion parameter) language models that have been trained on private datasets. This paper demonstrates that in such settings, an adversary can perform a training data extraction attack to recover individual training examples by querying the language model.We demonstrate our attack on GPT-2, a language model trained on scrapes of the public Internet, and are able to extract hundreds of verbatim text sequences from the model’s training data. These extracted examples include (public) personally identifiable information (names, phone numbers, and email addresses), IRC conversations, code, and 128-bit UUIDs. Our attack is possible even though each of the above sequences are included in just one document in the training data.We comprehensively evaluate our extraction attack to understand the factors that contribute to its success. For example, we find that larger models are more vulnerable than smaller models. We conclude by drawing lessons and discussing possible safeguards for training large language models.
https://weibo.com/1402400261/JyFH85Yn9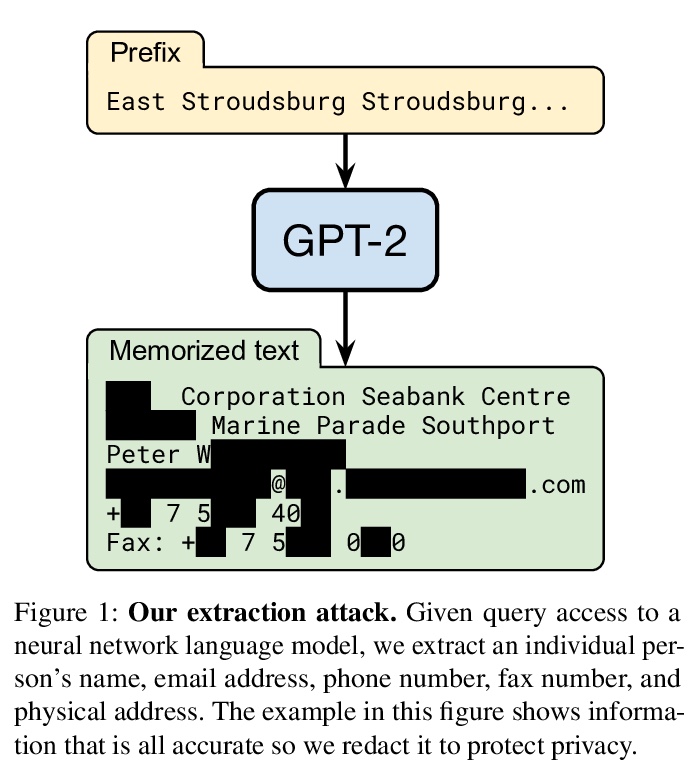
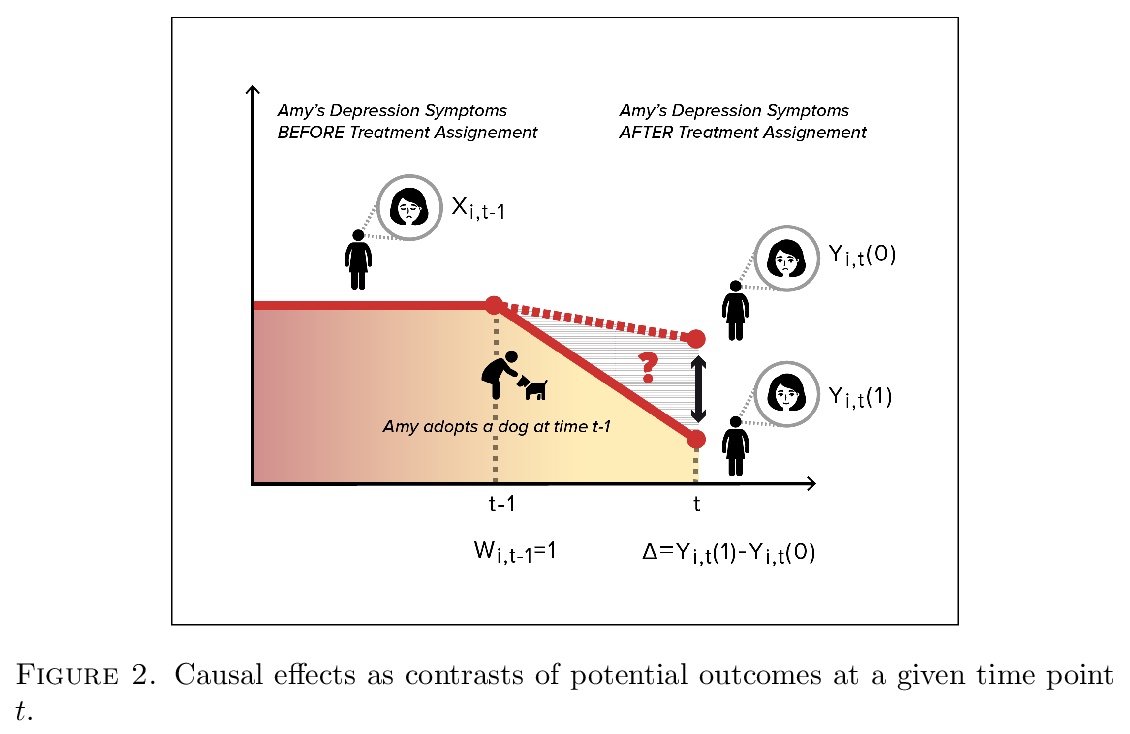
5、[ME] From controlled to undisciplined data: estimating causal effects in the era of data science using a potential outcome framework
F Dominici, F J. Bargagli-Stoffi, F Mealli
从受控数据到无序数据:用潜在结果框架估计因果效应。讨论了因果推理的基本原则,即从实验和观察数据中估计特定事件发生、处置、干预和呈现对特定结果影响的统计领域。解释了确定因果效应所需的关键假设,强调了与使用观测数据相关的挑战。强调实验思维在因果推理中至关重要。数据的质量(未必要求数量)、研究设计、假设满足的程度、以及统计分析的严密性,使我们能可靠地推断因果效应。虽然提倡利用大数据和机器学习(ML)算法应用来估计因果效应,但它们不能替代经过深思熟虑的研究设计。
This paper discusses the fundamental principles of causal inference - the area of statistics that estimates the effect of specific occurrences, treatments, interventions, and exposures on a given outcome from experimental and observational data. We explain the key assumptions required to identify causal effects, and highlight the challenges associated with the use of observational data. We emphasize that experimental thinking is crucial in causal inference. The quality of the data (not necessarily the quantity), the study design, the degree to which the assumptions are met, and the rigor of the statistical analysis allow us to credibly infer causal effects. Although we advocate leveraging the use of big data and the application of machine learning (ML) algorithms for estimating causal effects, they are not a substitute of thoughtful study design. Concepts are illustrated via examples.
https://weibo.com/1402400261/JyFMXoBYq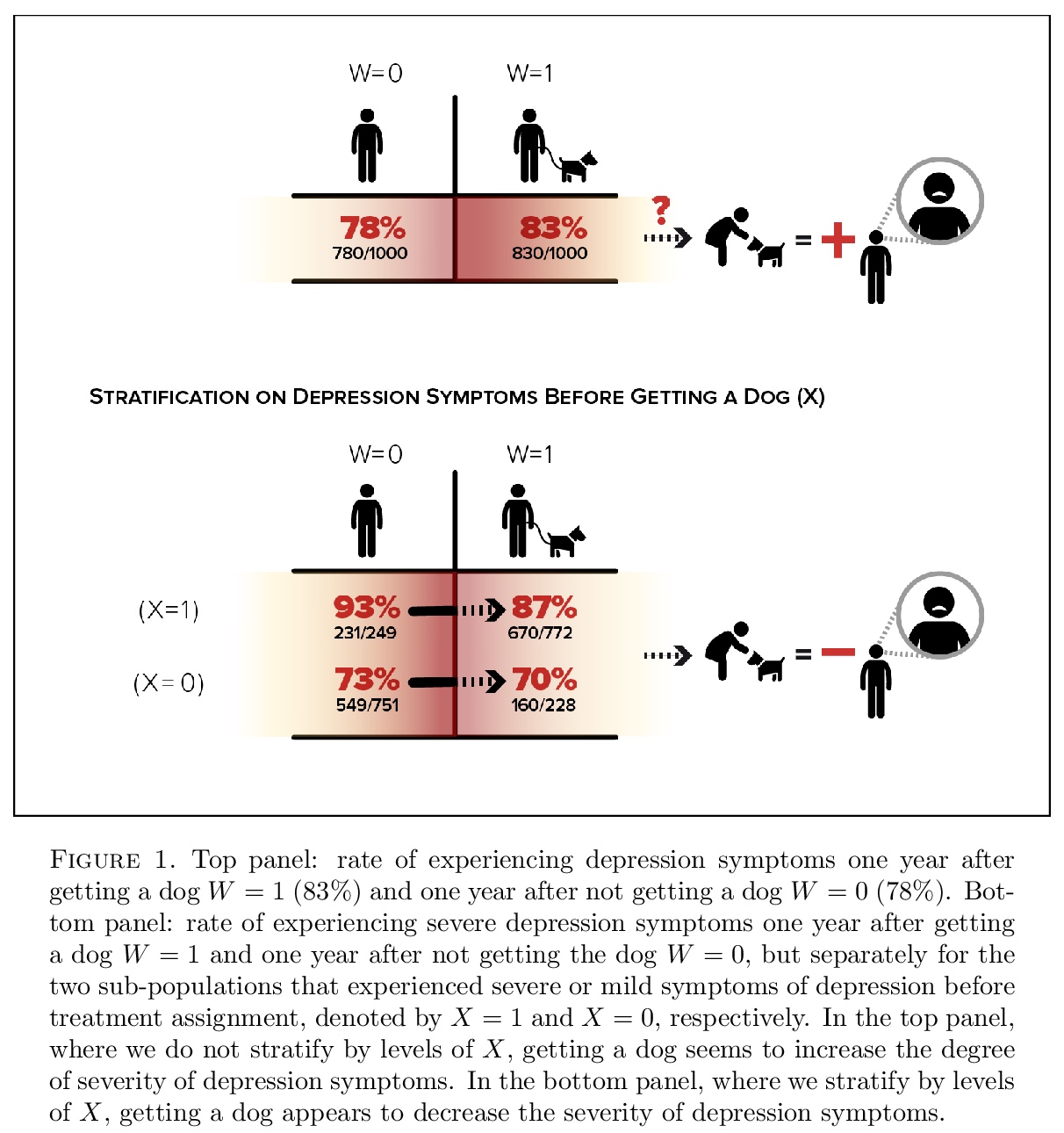
另外几篇值得关注的论文:
[LG] Relative Variational Intrinsic Control
相对变分内控(RVIC)技能学习目标
K Baumli, D Warde-Farley, S Hansen, V Mnih
[DeepMind]
https://weibo.com/1402400261/JyFRrcFEe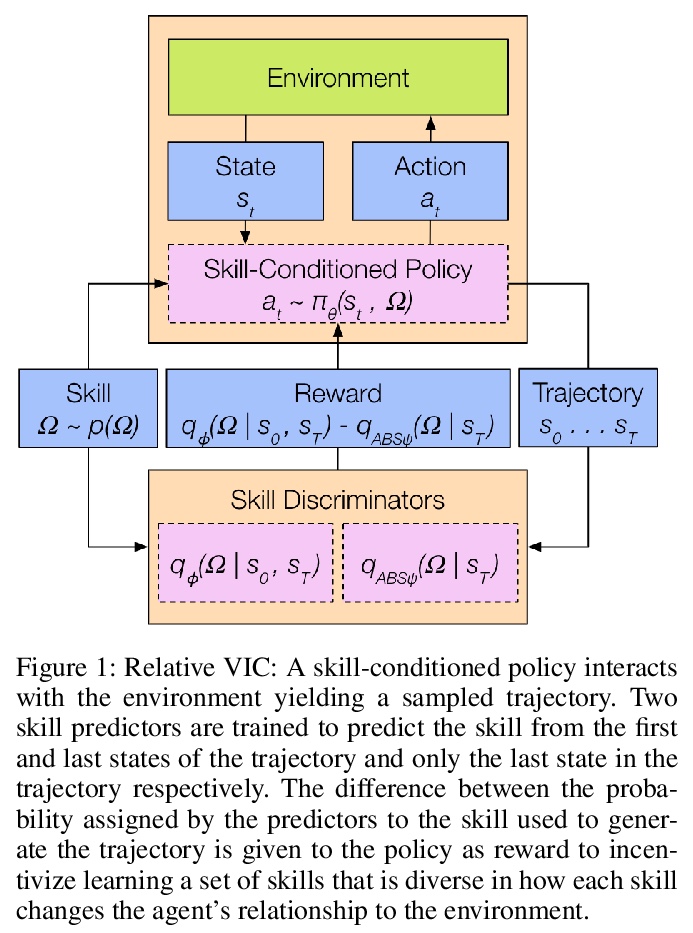

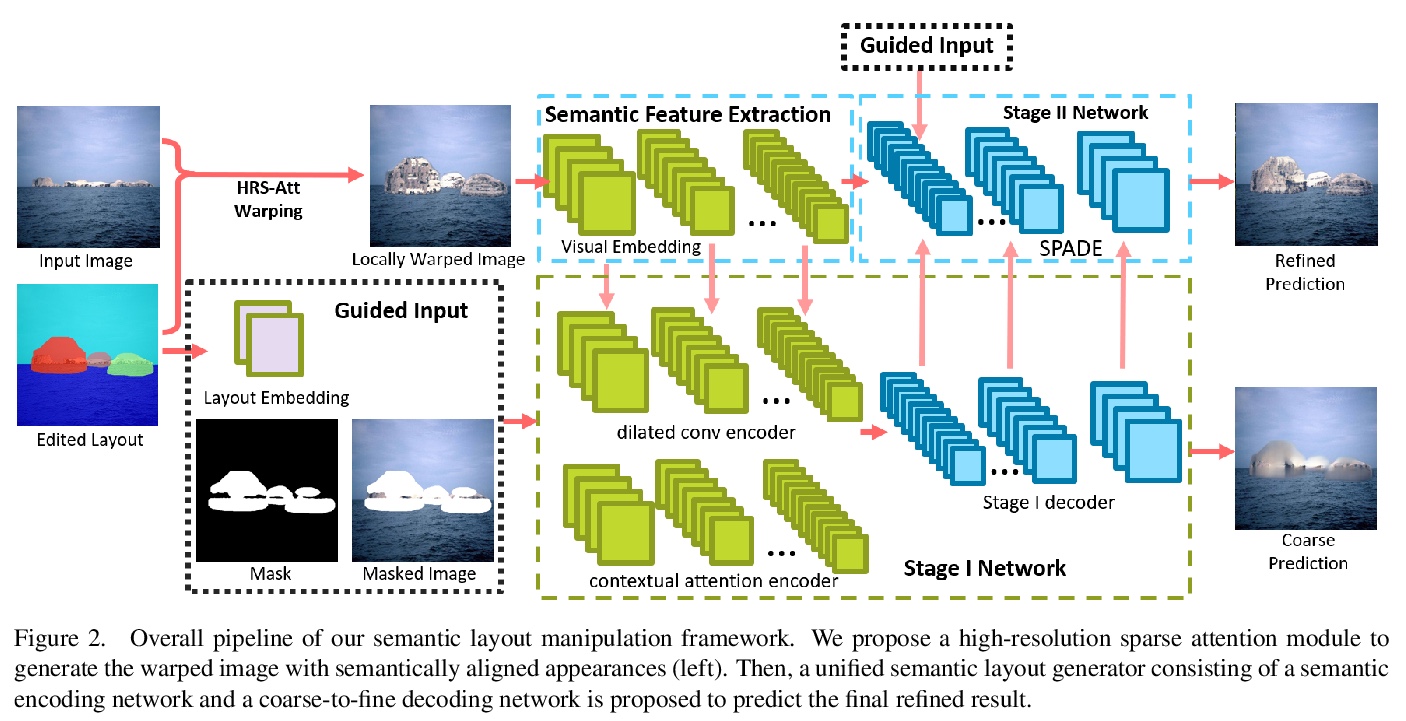
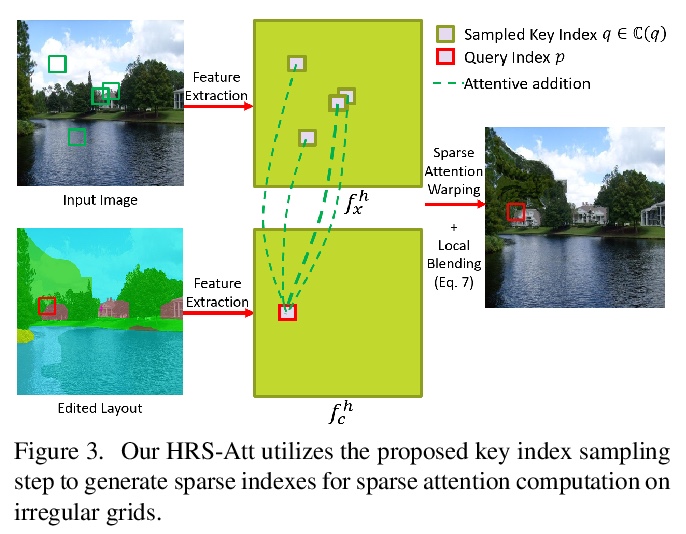
[CV] Semantic Layout Manipulation with High-Resolution Sparse Attention
高分辨率稀疏注意力语义布局操作
H Zheng, Z Lin, J Lu, S Cohen, J Zhang, N Xu, J Luo
[University of Rochester & Adobe Research]
https://weibo.com/1402400261/JyFUeFTzR
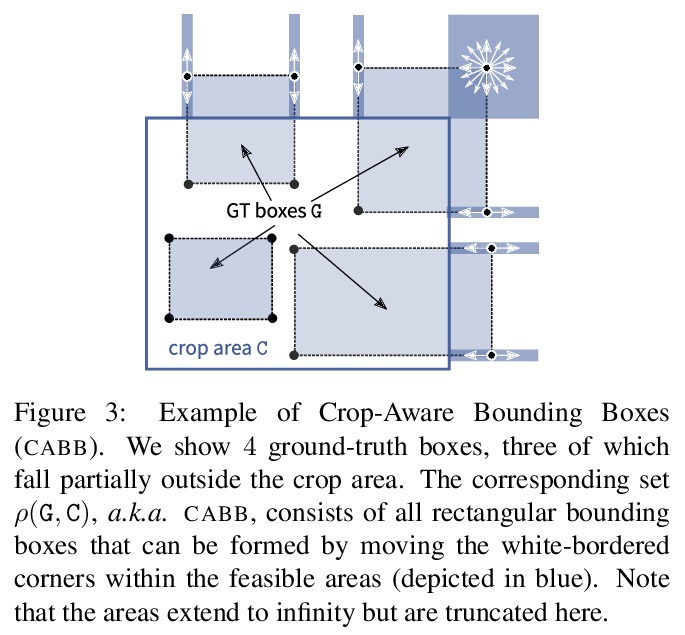
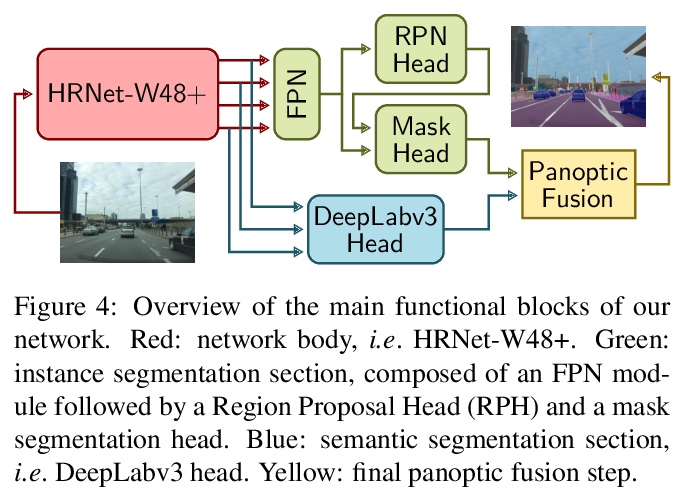
[CV] Improving Panoptic Segmentation at All Scales
在所有尺度上改进全景分割
L Porzi, S R Bulò, P Kontschieder
[Facebook]
https://weibo.com/1402400261/JyFVs110y
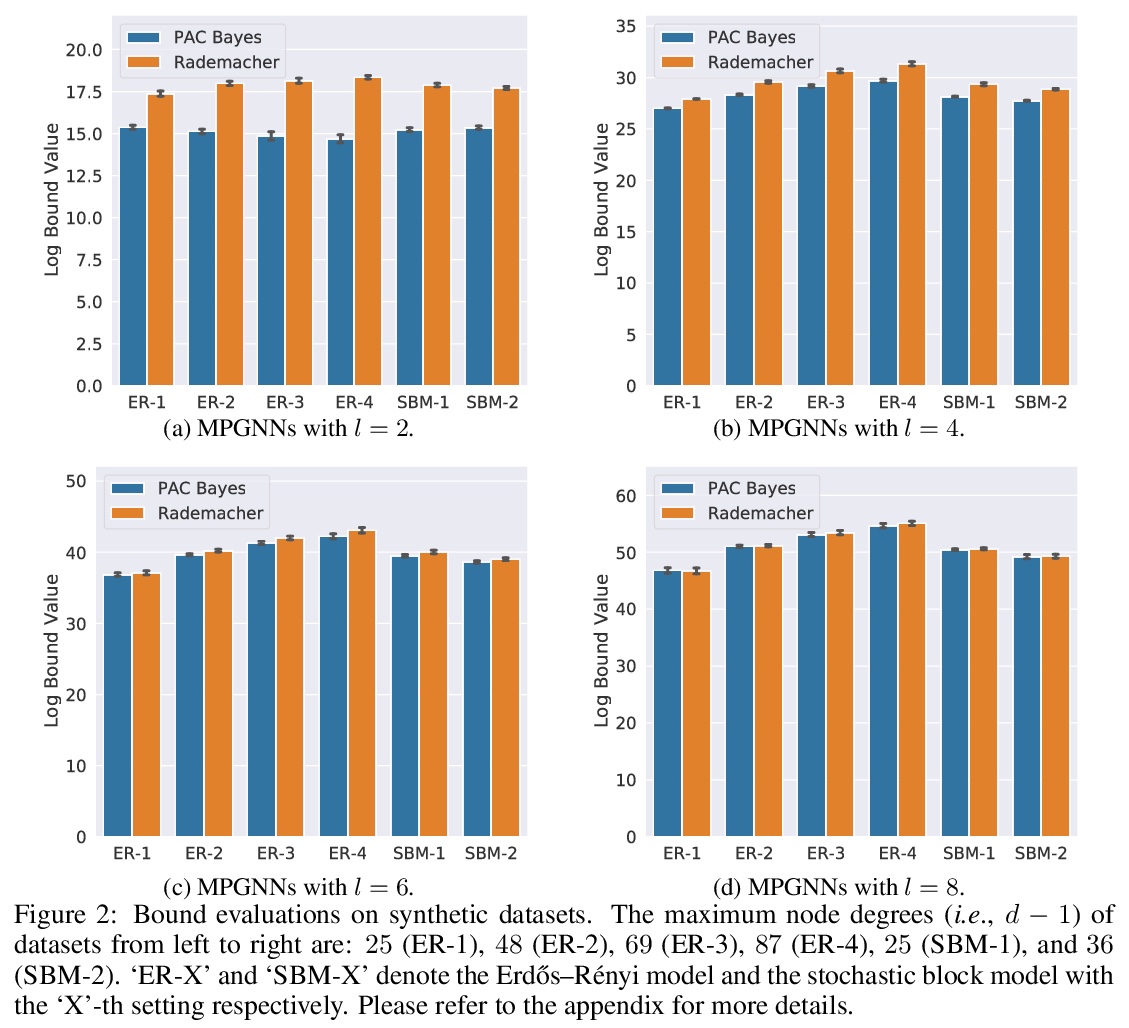
[LG] A PAC-Bayesian Approach to Generalization Bounds for Graph Neural Networks
图神经网络泛化界的PAC-Bayesian方法
R Liao, R Urtasun, R Zemel
[University of Toronto]
https://weibo.com/1402400261/JyFWslN3x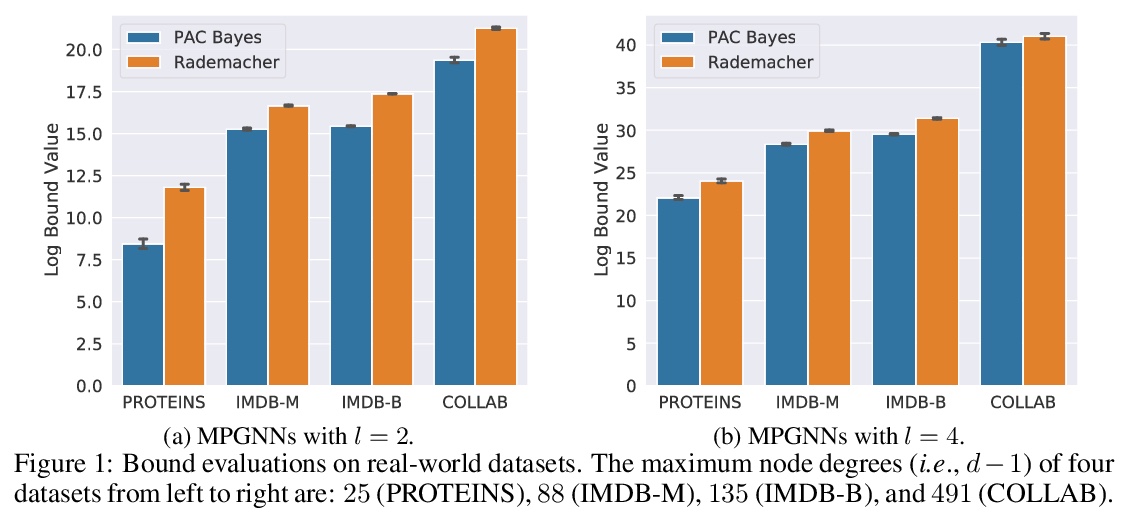
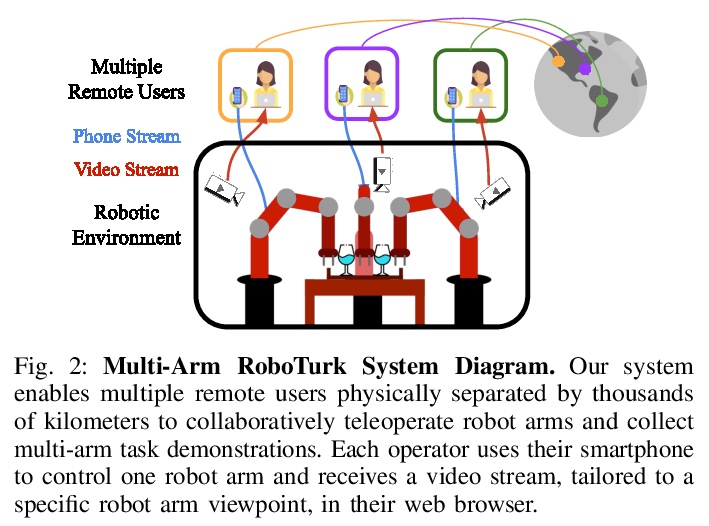
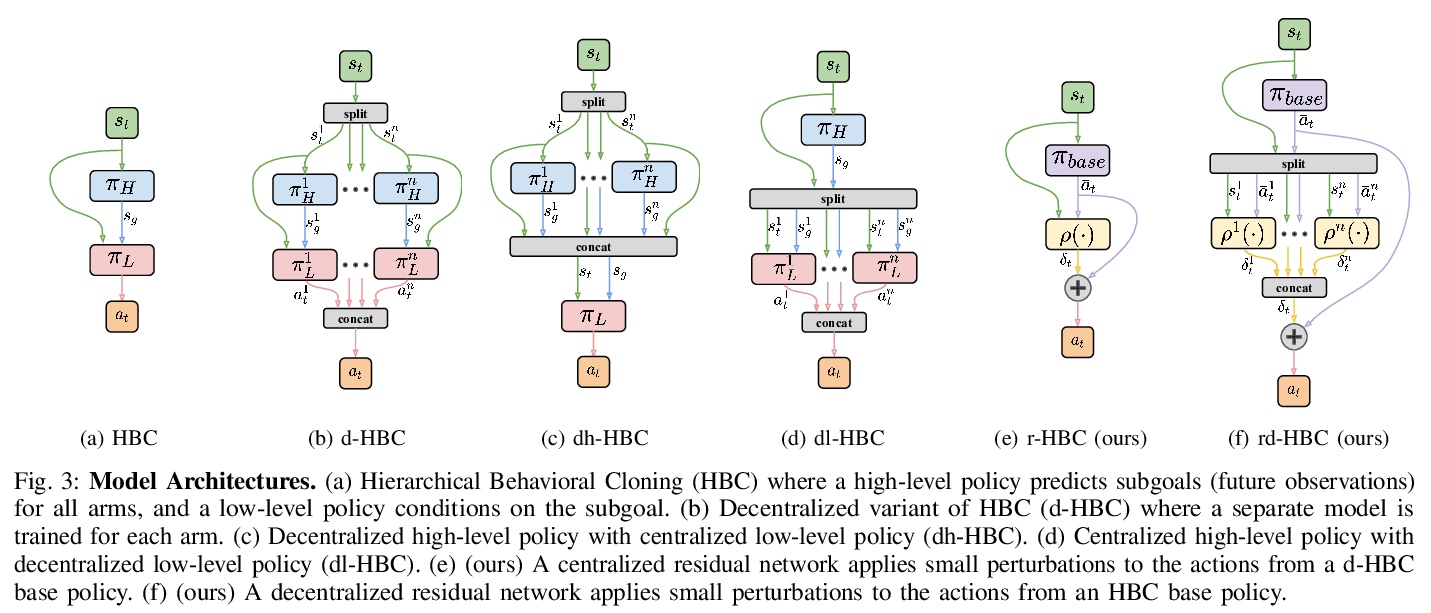
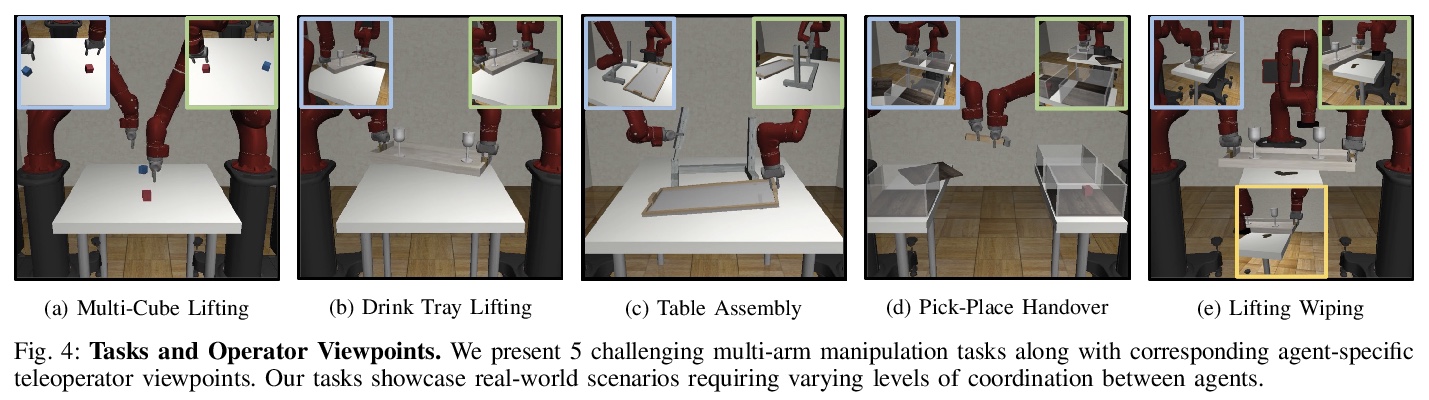
[RO] Learning Multi-Arm Manipulation Through Collaborative Teleoperation
通过协同遥操作学习多臂操作
A Tung, J Wong, A Mandlekar, R Martín-Martín, Y Zhu, L Fei-Fei, S Savarese
[Stanford & The University of Texas at Austin]
https://weibo.com/1402400261/JyFZZ0GKc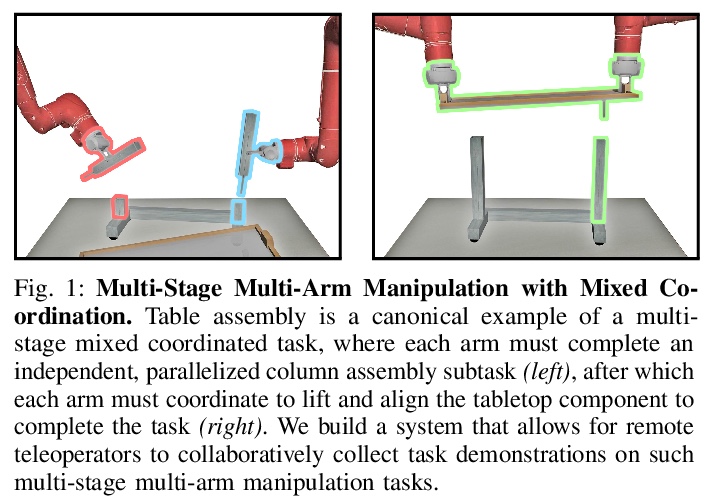

若有收获,就点个赞吧
0 人点赞
