- 1、[CV] GANcraft: Unsupervised 3D Neural Rendering of Minecraft Worlds
- 2、[IR] Deep Learning-based Online Alternative Product Recommendations at Scale
- 3、[CV] Geometry-Free View Synthesis: Transformers and no 3D Priors
- 4、[CL] Retrieval Augmentation Reduces Hallucination in Conversation
- 5、[CL] Generating Datasets with Pretrained Language Models
- [CV] Self-supervised Video Object Segmentation by Motion Grouping
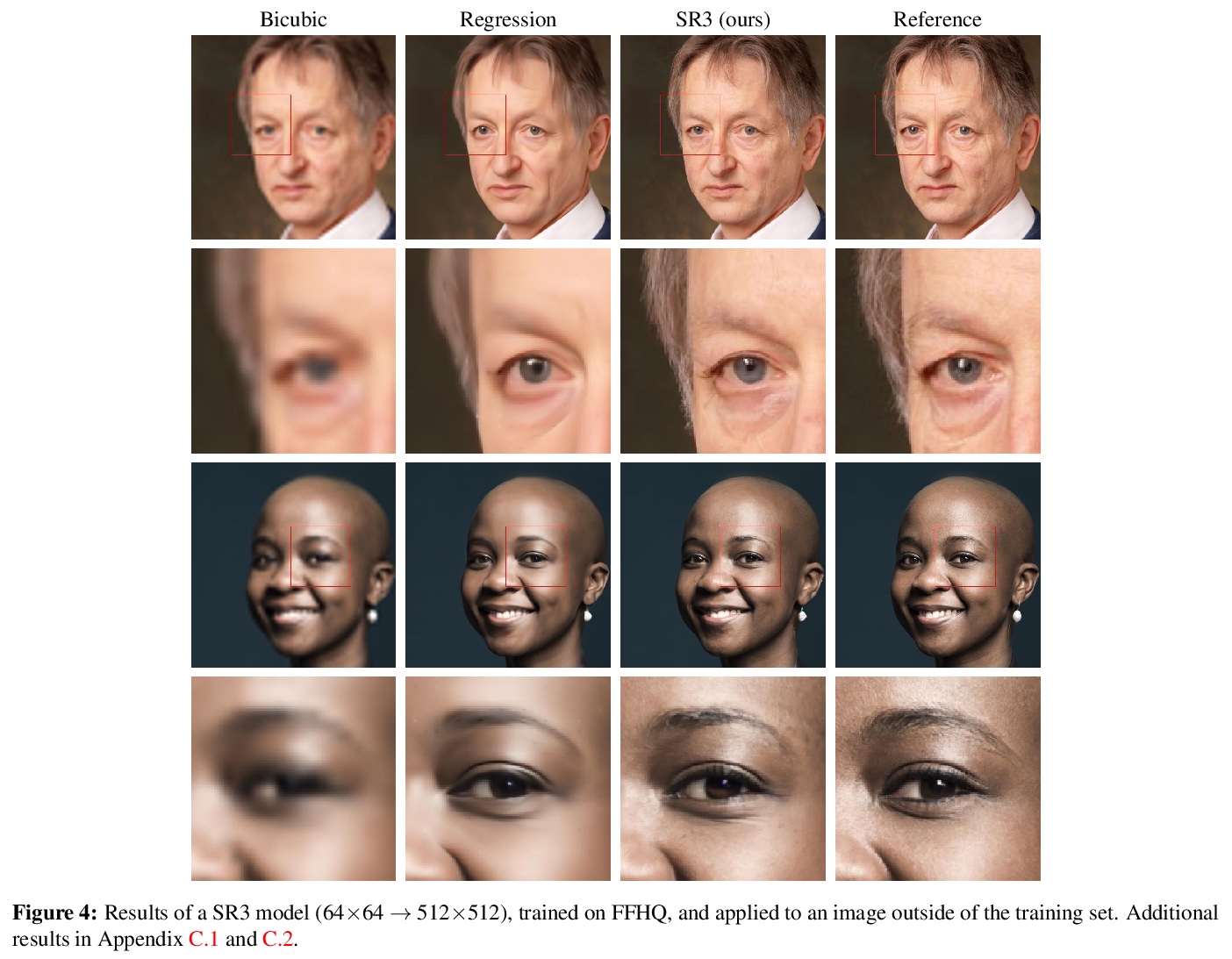
- [CV] Image Super-Resolution via Iterative Refinement
- [RO] Auto-Tuned Sim-to-Real Transfer
- [LG] Self-Supervised Exploration via Latent Bayesian Surprise
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] GANcraft: Unsupervised 3D Neural Rendering of Minecraft Worlds
Z Hao, A Mallya, S Belongie, M Liu
[NVIDIA & Cornell University]
GANcraft: “我的世界”无监督3D神经渲染。想想一下,让每个“我的世界”玩家都变成3D画家,用代表各种材料的积木搭建简单的3D世界,通过算法的转换,就能得到一个看起来相当逼真的3D世界,其中有高大的绿树、冰雪覆盖的山峰和蓝色的大海,世界该多么美好。本文提出一种无监督的神经渲染框架,用于生成大型3D块状世界(如“我的世界”中创建的方块世界)的照片级逼真图像,实现世界到世界的变换,本质上是图像到图像变换的3D扩展。该方法将语义方块世界作为输入,每个方块配有一个语义标签,如泥土、草地或水,将世界表示为一个连续的体函数,训练模型为用户控制的相机渲染与视图一致的逼真图像。针对方块世界缺乏成对真实参照图像的情况,设计了一种基于伪真实参照图像和对抗性损失的训练技术,由2D的图像到图像变换网络生成的伪真实参照图像,提供了有效的监督手段,与之前用于视图合成的神经渲染工作有很大区别,不需要真实参照图像来估计场景几何和视图相关外观。除了相机轨迹,GANcraft还允许用户控制场景语义和输出风格。与强基线比较的实验结果,显示了GANcraft在这个新颖的逼真画面3D方块世界合成任务上的有效性。
We present GANcraft, an unsupervised neural rendering framework for generating photorealistic images of large 3D block worlds such as those created in Minecraft. Our method takes a semantic block world as input, where each block is assigned a semantic label such as dirt, grass, or water. We represent the world as a continuous volumetric function and train our model to render view-consistent photorealistic images for a user-controlled camera. In the absence of paired ground truth real images for the block world, we devise a training technique based on pseudo-ground truth and adversarial training. This stands in contrast to prior work on neural rendering for view synthesis, which requires ground truth images to estimate scene geometry and view-dependent appearance. In addition to camera trajectory, GANcraft allows user control over both scene semantics and output style. Experimental results with comparison to strong baselines show the effectiveness of GANcraft on this novel task of photorealistic 3D block world synthesis. The project website is available atthis https URL.
https://weibo.com/1402400261/KbgdxvAoL


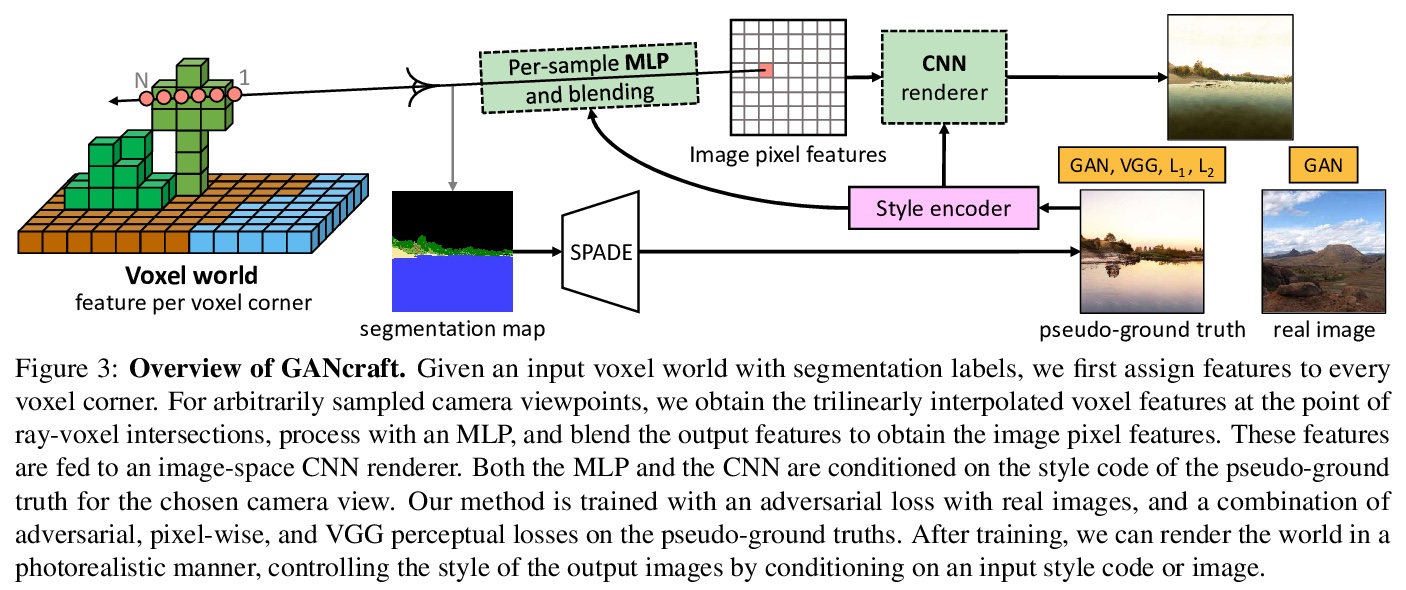

2、[IR] Deep Learning-based Online Alternative Product Recommendations at Scale
M Guo, N Yan, X Cui, S H Wu, U Ahsan, R West, K A Jadda
[The Home Depot]
基于深度学习的大规模在线替代产品推荐。替代品推荐系统对电子商务公司来说至关重要,能引导客户探索庞大的产品目录,协助客户在大量选项中找到合适的产品。然而,推荐符合客户需求的替代产品是一项非平凡任务。本文用文本产品信息(如产品标题和描述)和客户行为数据来推荐替代产品,以更好地处理冷启动和相关性问题。为更好地捕捉产品信息语义,构建了一个具有双向LSTM的孪生网络,来学习产品嵌入。为了学习更符合真实客户偏好的相似度空间,用历史客户行为的共同对比数据作为标签来训练网络,指导监督学习过程。用NMSLIB来加速数百万产品的计算昂贵的kNN计算,使替代产品推荐能够扩展到大型电子商务网站的整个目录。结果表明,在离线评价中,替代产品的覆盖率及召回率和精度,都有显著提高。A/B测试显示,该算法在统计上显著提高了12%的转化率。
Alternative recommender systems are critical for ecommerce companies. They guide customers to explore a massive product catalog and assist customers to find the right products among an overwhelming number of options. However, it is a non-trivial task to recommend alternative products that fit customer needs. In this paper, we use both textual product information (e.g. product titles and descriptions) and customer behavior data to recommend alternative products. Our results show that the coverage of alternative products is significantly improved in offline evaluations as well as recall and precision. The final A/B test shows that our algorithm increases the conversion rate by 12 percent in a statistically significant way. In order to better capture the semantic meaning of product information, we build a Siamese Network with Bidirectional LSTM to learn product embeddings. In order to learn a similarity space that better matches the preference of real customers, we use co-compared data from historical customer behavior as labels to train the network. In addition, we use NMSLIB to accelerate the computationally expensive kNN computation for millions of products so that the alternative recommendation is able to scale across the entire catalog of a major ecommerce site.
https://weibo.com/1402400261/KbgmCpgHl

3、[CV] Geometry-Free View Synthesis: Transformers and no 3D Priors
R Rombach, P Esser, B Ommer
[Heidelberg University]
免几何视图合成:无3D先验的Transformer。提出一种基于Transformer的概率模型,适当考虑了任务中固有的不确定性,学习可能的目标图像分布,并以高保真度合成它们,可从具有强烈视角变化的单一源图像进行新视图合成,解决基于单一初始图像和所需视角变化的新视图合成的问题。对Transformer的各种显式和隐式3D感应偏置的比较表明,在架构中显式使用3D变换对其性能没有帮助。即使没有深度信息作为输入,模型也能学会在其内部表示中推断深度。用全局注意力机制隐式学习源视图和目标视图间的长程3D对应关系,通过概率方式捕捉从单一图像预测新视图所固有的模糊性,克服之前方法仅限于相对较小视角变化的局限性。提出的两种隐式Transformer方法在视觉质量和保真度上都比目前的技术状态有显著的改进。
Is a geometric model required to synthesize novel views from a single image? Being bound to local convolutions, CNNs need explicit 3D biases to model geometric transformations. In contrast, we demonstrate that a transformer-based model can synthesize entirely novel views without any hand-engineered 3D biases. This is achieved by (i) a global attention mechanism for implicitly learning long-range 3D correspondences between source and target views, and (ii) a probabilistic formulation necessary to capture the ambiguity inherent in predicting novel views from a single image, thereby overcoming the limitations of previous approaches that are restricted to relatively small viewpoint changes. We evaluate various ways to integrate 3D priors into a transformer architecture. However, our experiments show that no such geometric priors are required and that the transformer is capable of implicitly learning 3D relationships between images. Furthermore, this approach outperforms the state of the art in terms of visual quality while covering the full distribution of possible realizations. Code is available atthis https URL
https://weibo.com/1402400261/KbgsYCzl9
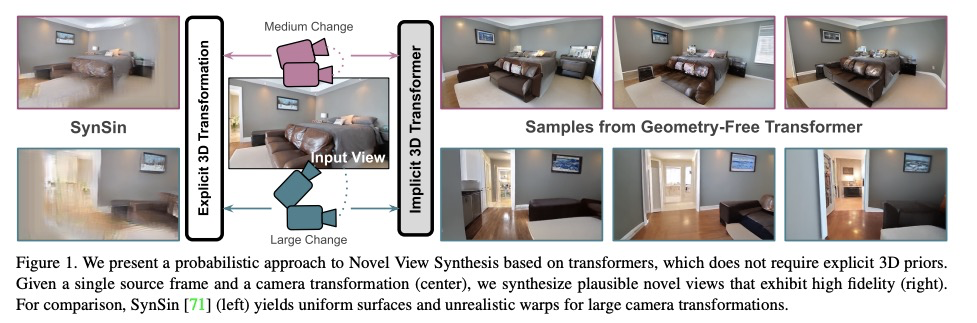
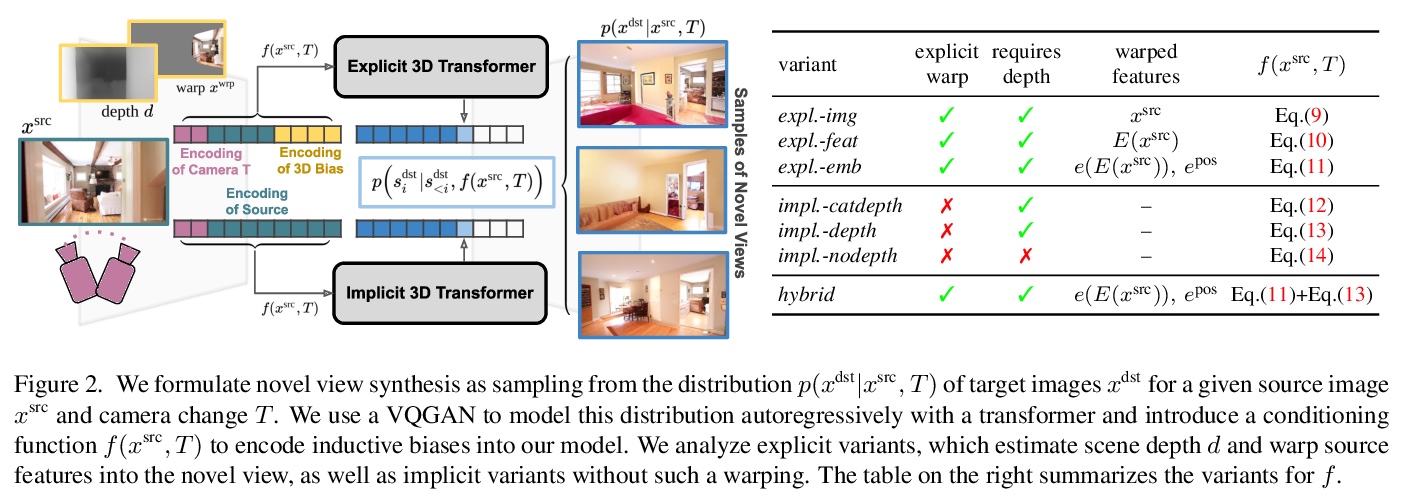
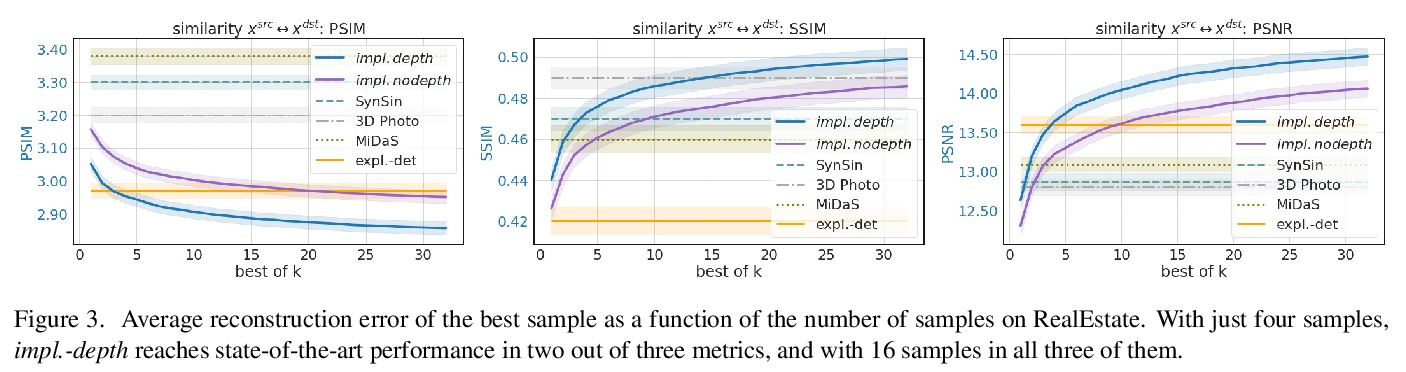

4、[CL] Retrieval Augmentation Reduces Hallucination in Conversation
K Shuster, S Poff, M Chen, D Kiela, J Weston
[Facebook AI Research]
通过检索增强减轻对话错觉。大型语料库上训练的大型语言模型,在对话智能体的流畅性和对话能力方面取得了很大进步,知识被隐式存储在模型权重中,使其有可能在开放域的主题上给出一些知识,但即使是最大的模型,也会受到所谓”错觉”问题的困扰,产生看似可信、但事实上不正确的陈述。本文研究了对话智能体的知识错觉问题,探索了最近在开放域QA中证明有效的“神经检索在环路”架构的使用,研究了具有多个组件——检索器、排序器和编-解码器——的各类架构,目标是在保留对话能力的同时最大化知识性,证明该问题的发生与语言模型大小或训练数据无关,检索增强生成是直观上很有希望解决这个问题的方法,最佳模型在两个基于知识的对话任务上提供了最先进的结果,在详细的实验中,证明了此类方法可显著减少对话中的错觉问题,可帮助在训练数据之外对以前未见过的分布进行泛化。
Despite showing increasingly human-like conversational abilities, state-of-the-art dialogue models often suffer from factual incorrectness and hallucination of knowledge (Roller et al., 2020). In this work we explore the use of neural-retrieval-in-the-loop architectures - recently shown to be effective in open-domain QA (Lewis et al., 2020b; Izacard and Grave, 2020) - for knowledge-grounded dialogue, a task that is arguably more challenging as it requires querying based on complex multi-turn dialogue context and generating conversationally coherent responses. We study various types of architectures with multiple components - retrievers, rankers, and encoder-decoders - with the goal of maximizing knowledgeability while retaining conversational ability. We demonstrate that our best models obtain state-of-the-art performance on two knowledge-grounded conversational tasks. The models exhibit open-domain conversational capabilities, generalize effectively to scenarios not within the training data, and, as verified by human evaluations, substantially reduce the well-known problem of knowledge hallucination in state-of-the-art chatbots.
https://weibo.com/1402400261/KbgzJD1RN

5、[CL] Generating Datasets with Pretrained Language Models
T Schick, H Schütze
[LMU Munich]
基于预训练语言模型的数据集生成。为了从预训练语言模型获得高质量的句子嵌入,必须用额外的预训练目标来增强,或者在大量标注文本对上进行微调。虽然后一种方法通常优于前者,但需要极大的人力来生成足够规模的数据集。本文探索了用大型预训练语言模型来获得高质量嵌入,无需任何标注数据、微调或修改其预训练目标。提出DINO,一种用大型预训练语言模型从头开始生成具有相似性标记句子对的完整数据集的方法。生成的标注文本对数据集,可用来对更小的模型进行常规微调。该完全无监督方法在几个英语语义文本相似性数据集上的表现优于强基线。
To obtain high-quality sentence embeddings from pretrained language models, they must either be augmented with additional pretraining objectives or finetuned on large amounts of labeled text pairs. While the latter approach typically outperforms the former, it requires great human effort to generate suitable datasets of sufficient size. In this paper, we show how large pretrained language models can be leveraged to obtain high-quality embeddings without requiring any labeled data, finetuning or modifications to their pretraining objective: We utilize their generative abilities to generate entire datasets of labeled text pairs from scratch, which can then be used for regular finetuning of much smaller models. Our fully unsupervised approach outperforms strong baselines on several English semantic textual similarity datasets.
https://weibo.com/1402400261/KbgFtqzRS


另外几篇值得关注的论文:
[CV] Self-supervised Video Object Segmentation by Motion Grouping
基于运动分组的自监督视频目标分割
C Yang, H Lamdouar, E Lu, A Zisserman, W Xie
[University of Oxford]
https://weibo.com/1402400261/KbgKwCFHT

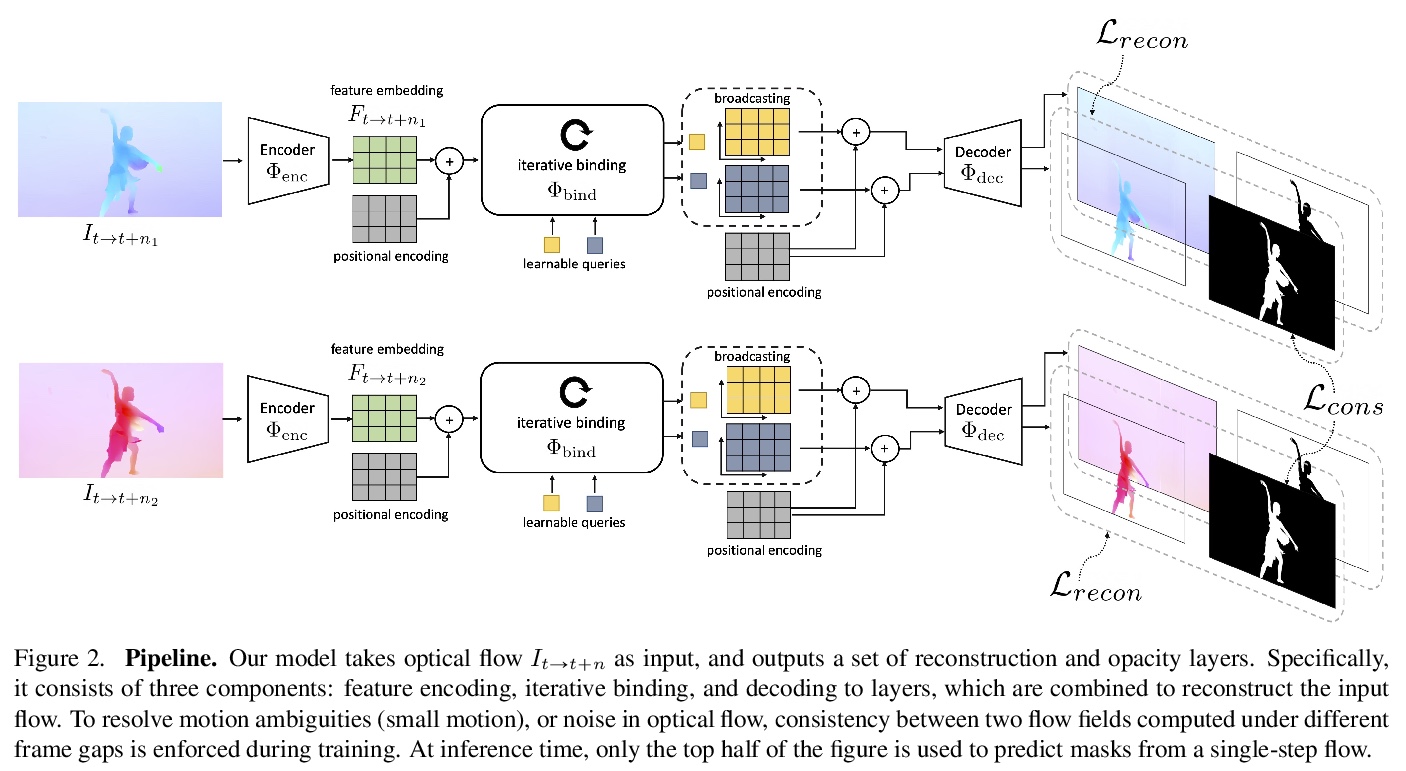

[CV] Image Super-Resolution via Iterative Refinement
基于迭代细化的图像超分辨率
C Saharia, J Ho, W Chan, T Salimans, D J. Fleet, M Norouzi
[Google Research]
https://weibo.com/1402400261/KbgNI4sR1



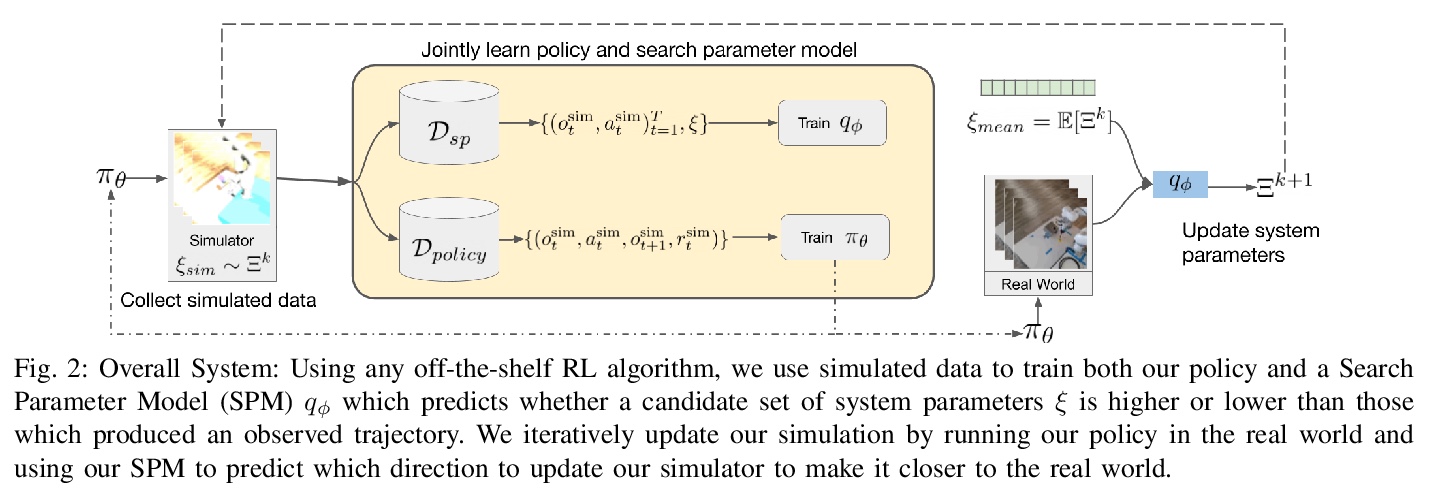
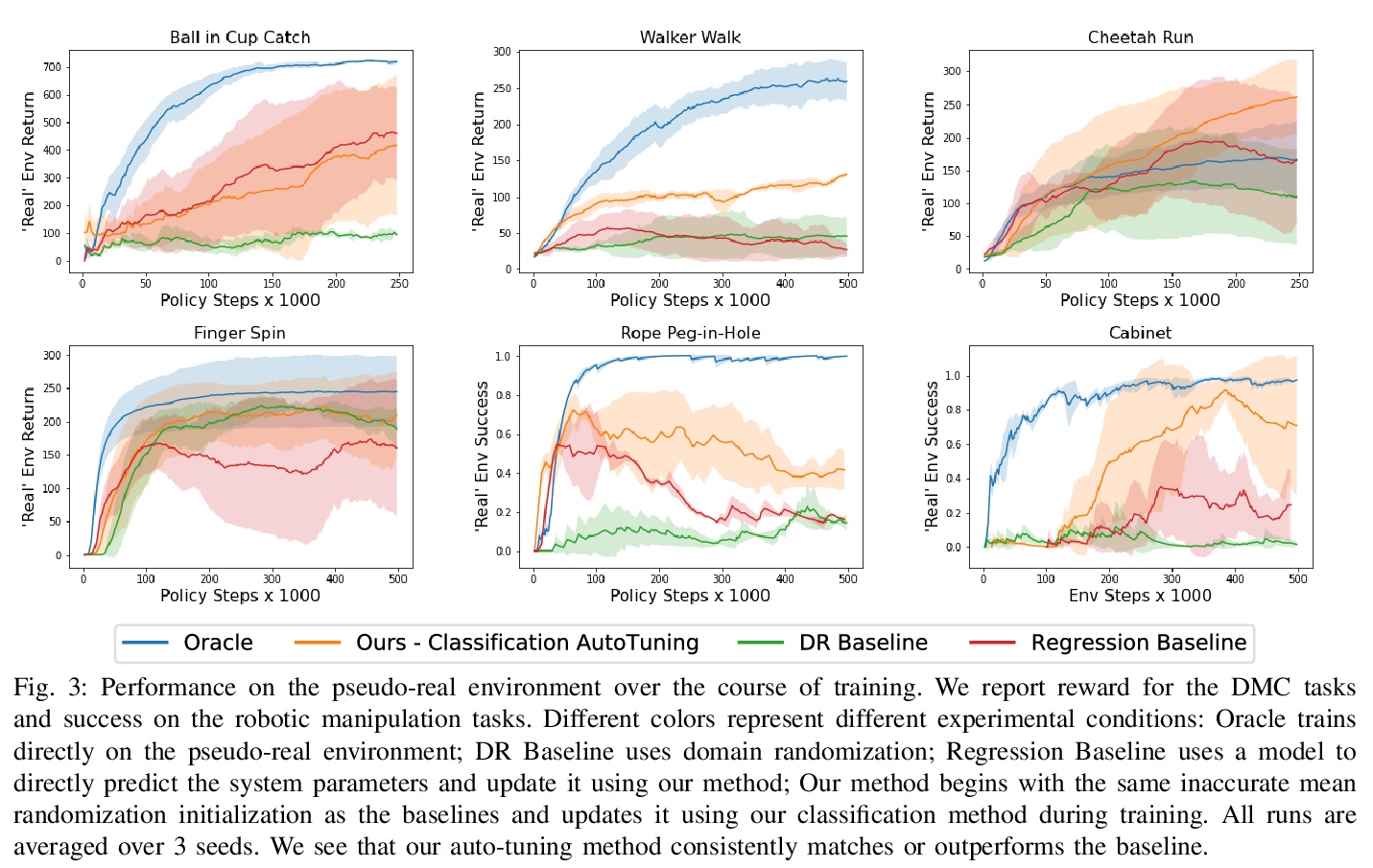
[RO] Auto-Tuned Sim-to-Real Transfer
Y Du, O Watkins, T Darrell, P Abbeel, D Pathak
[UC Berkeley & CMU]
自调模拟-真实迁移
https://weibo.com/1402400261/KbgPt5xFH

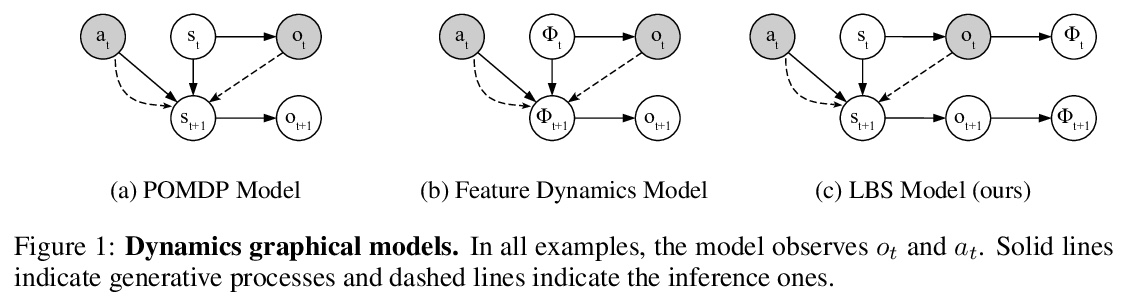
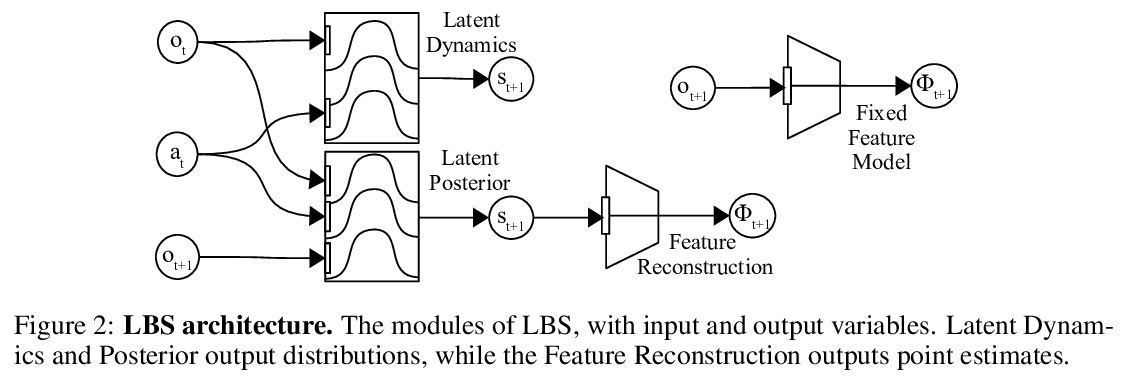
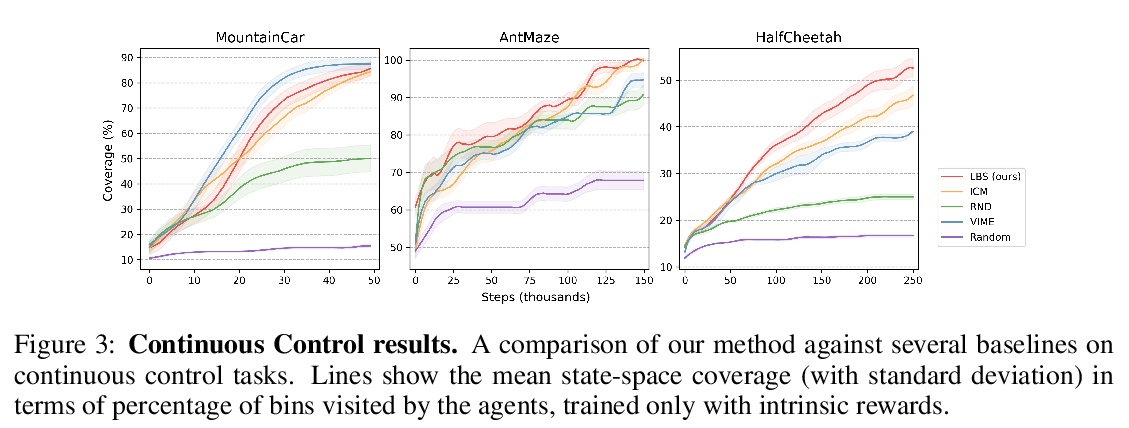
[LG] Self-Supervised Exploration via Latent Bayesian Surprise
基于潜贝叶斯惊奇的自监督探索
P Mazzaglia, O Catal, T Verbelen, B Dhoedt
[Ghent University]
https://weibo.com/1402400261/KbgUmdL7T

若有收获,就点个赞吧
0 人点赞
