- 1、[CV] Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans
- 2、[CV] OSTeC: One-Shot Texture Completion
- 3、[CV] Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
- 4、[CL] Fully Non-autoregressive Neural Machine Translation: Tricks of the Trade
- 5、[CL] CLEAR: Contrastive Learning for Sentence Representation
- [CV] TransTrack: Multiple-Object Tracking with Transformer
- [CL] BinaryBERT: Pushing the Limit of BERT Quantization
- [CV] Audio-Visual Floorplan Reconstruction
- [CL] BANG: Bridging Autoregressive and Non-autoregressive Generation with Large Scale Pretraining
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
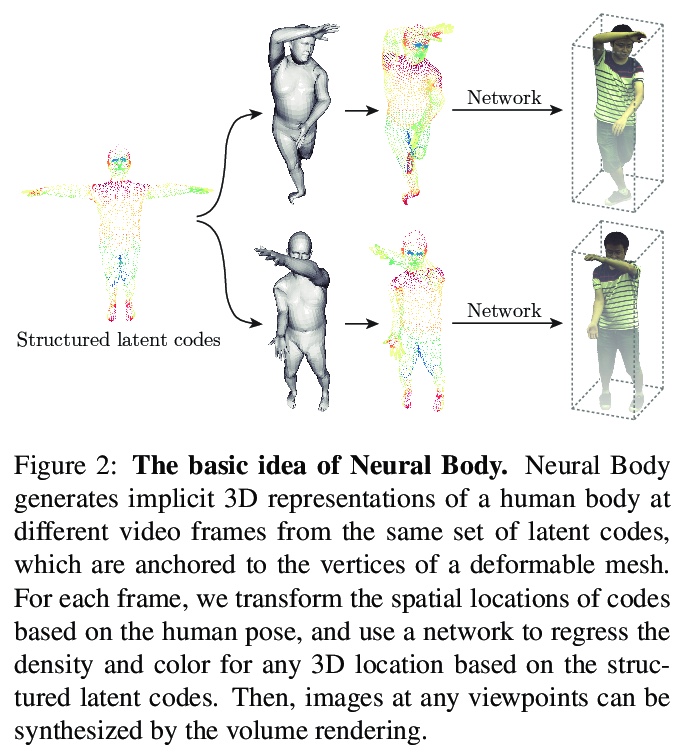
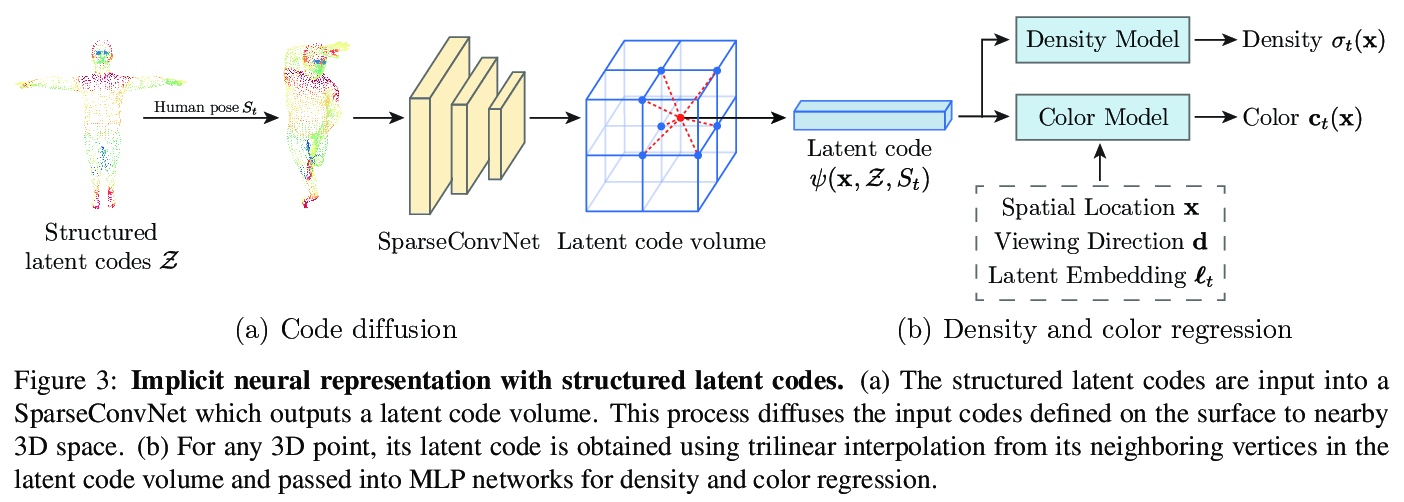
1、[CV] Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans
S Peng, Y Zhang, Y Xu, Q Wang, Q Shuai, H Bao, X Zhou
[Zhejiang University & The Chinese University of Hong Kong & Cornell University]
基于隐性神经表示与结构化潜码的动态人体新视图合成。提出一种新的人体表示Neural Body,用稀疏多视角视频进行动态人体新视图合成。各帧学到的神经表示共享同一组潜码,用神经网络编码局部几何和外观,锚定在一个可变形的网格上,跨帧的观测值可以自然整合。由此建立潜变量模型,在不同视频帧处从同一组潜码产生隐性场,有效结合跨视频帧对表演者的观察。可变形网格也为网络提供了几何指导,使网络更有效地学习3D表示。在视频上学习Neural Body,最终进行体渲染。创建了多视图数据集,以捕捉复杂运动中的动态人体。与之前在新收集的数据集和People-Snapshot数据集上的工作相比,Neural Body显示了更好的视图合成质量。
This paper addresses the challenge of novel view synthesis for a human performer from a very sparse set of camera views. Some recent works have shown that learning implicit neural representations of 3D scenes achieves remarkable view synthesis quality given dense input views. However, the representation learning will be ill-posed if the views are highly sparse. To solve this ill-posed problem, our key idea is to integrate observations over video frames. To this end, we propose Neural Body, a new human body representation which assumes that the learned neural representations at different frames share the same set of latent codes anchored to a deformable mesh, so that the observations across frames can be naturally integrated. The deformable mesh also provides geometric guidance for the network to learn 3D representations more efficiently. Experiments on a newly collected multi-view dataset show that our approach outperforms prior works by a large margin in terms of the view synthesis quality. We also demonstrate the capability of our approach to reconstruct a moving person from a monocular video on the People-Snapshot dataset. The code and dataset will be available at > this https URL.
https://weibo.com/1402400261/JBfW5DJPD

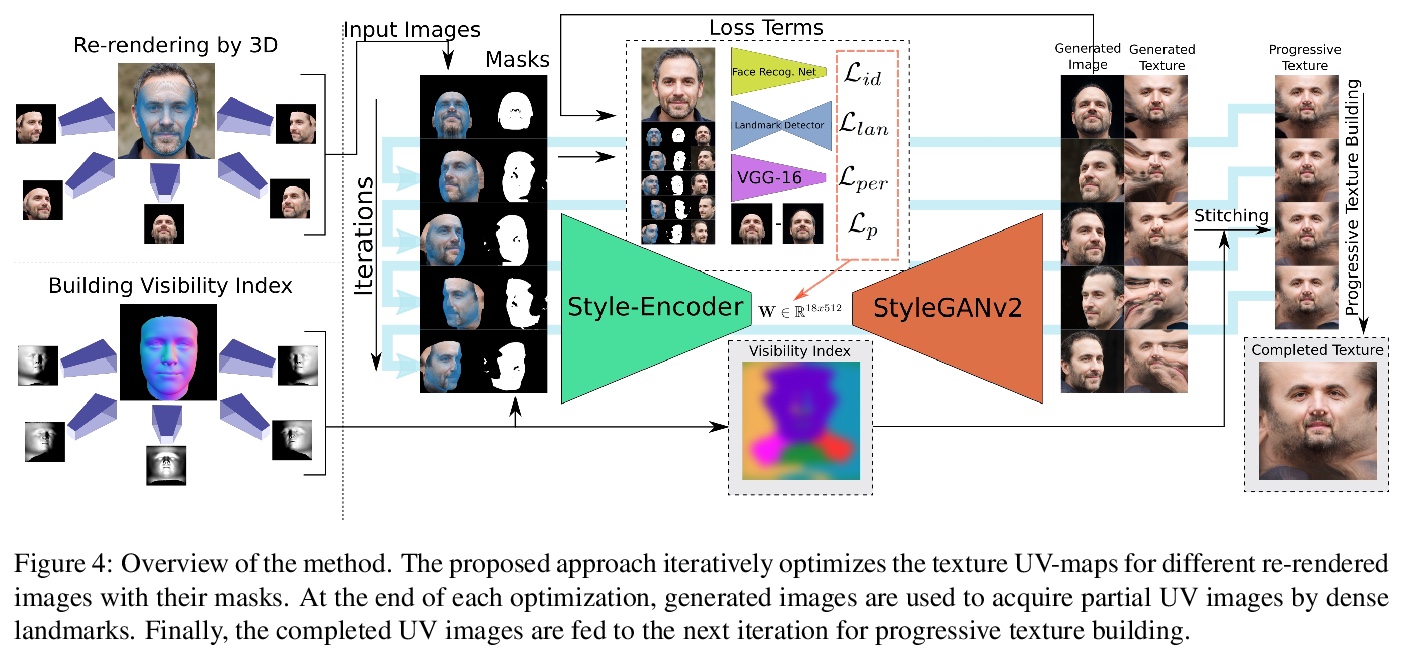
2、[CV] OSTeC: One-Shot Texture Completion
B Gecer, J Deng, S Zafeiriou
[Imperial College London]
OSTeC:单样本纹理补全。提出一种用于单样本3D人脸纹理补全的无监督方法,无需大规模纹理数据集,而是利用存储在2D人脸生成器中的知识。将输入图像进行三维旋转,根据可见部分在2D人脸生成器中重建旋转后的图像来填充不可见区域。在UV图像平面以不同角度缝合最可见的纹理。通过将完成的纹理投影到生成器,对目标图像进行正面化。可生成视觉效果显著、准确且与身份相似的完整纹理图和正面化人脸。实验表明,该方法在极端姿态下的精度和人脸匹配都优于其他方法。
The last few years have witnessed the great success of non-linear generative models in synthesizing high-quality photorealistic face images. Many recent 3D facial texture reconstruction and pose manipulation from a single image approaches still rely on large and clean face datasets to train image-to-image Generative Adversarial Networks (GANs). Yet the collection of such a large scale high-resolution 3D texture dataset is still very costly and difficult to maintain age/ethnicity balance. Moreover, regression-based approaches suffer from generalization to the in-the-wild conditions and are unable to fine-tune to a target-image. In this work, we propose an unsupervised approach for one-shot 3D facial texture completion that does not require large-scale texture datasets, but rather harnesses the knowledge stored in 2D face generators. The proposed approach rotates an input image in 3D and fill-in the unseen regions by reconstructing the rotated image in a 2D face generator, based on the visible parts. Finally, we stitch the most visible textures at different angles in the UV image-plane. Further, we frontalize the target image by projecting the completed texture into the generator. The qualitative and quantitative experiments demonstrate that the completed UV textures and frontalized images are of high quality, resembles the original identity, can be used to train a texture GAN model for 3DMM fitting and improve pose-invariant face recognition.
https://weibo.com/1402400261/JBg5pooqR


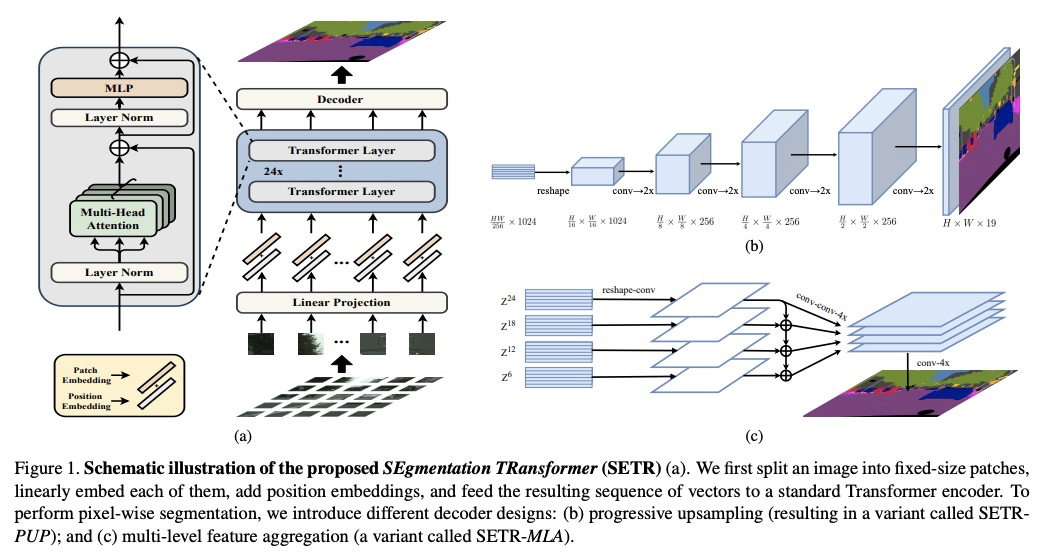
3、[CV] Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
S Zheng, J Lu, H Zhao, X Zhu, Z Luo, Y Wang, Y Fu, J Feng, T Xiang, P H.S. Torr, L Zhang
[Fudan University & University of Oxford & University of Surrey & Tencent Youtu Lab]
用Transformer从序列到序列角度反思语义分割问题。通过引入序列到序列预测框架,为图像语义分割提供另一种视角。现有基于FCN的方法通常通过扩张卷积和组件级注意力模块增大感受野,为彻底消除对FCN的依赖,解决有限感受野的挑战,提出一个纯Transformer(没有卷积和降分辨率),将图像编码为图块序列。随着全局上下文在Transformer的每一层中建模,编码器可与简单的解码器结合,提供强大的分割模型,称为SEgmentation TRansformer(SETR)。采用该方法,在竞争激烈的ADE20K测试服务器排行榜上取得了排名第一(44.42% mIoU)。
Most recent semantic segmentation methods adopt a fully-convolutional network (FCN) with an encoder-decoder architecture. The encoder progressively reduces the spatial resolution and learns more abstract/semantic visual concepts with larger receptive fields. Since context modeling is critical for segmentation, the latest efforts have been focused on increasing the receptive field, through either dilated/atrous convolutions or inserting attention modules. However, the encoder-decoder based FCN architecture remains unchanged. In this paper, we aim to provide an alternative perspective by treating semantic segmentation as a sequence-to-sequence prediction task. Specifically, we deploy a pure transformer (ie, without convolution and resolution reduction) to encode an image as a sequence of patches. With the global context modeled in every layer of the transformer, this encoder can be combined with a simple decoder to provide a powerful segmentation model, termed SEgmentation TRansformer (SETR). Extensive experiments show that SETR achieves new state of the art on ADE20K (50.28% mIoU), Pascal Context (55.83% mIoU) and competitive results on Cityscapes. Particularly, we achieve the first (44.42% mIoU) position in the highly competitive ADE20K test server leaderboard.
https://weibo.com/1402400261/JBg9Vx1Ck

4、[CL] Fully Non-autoregressive Neural Machine Translation: Tricks of the Trade
J Gu, X Kong
[Facebook AI Research & CMU]
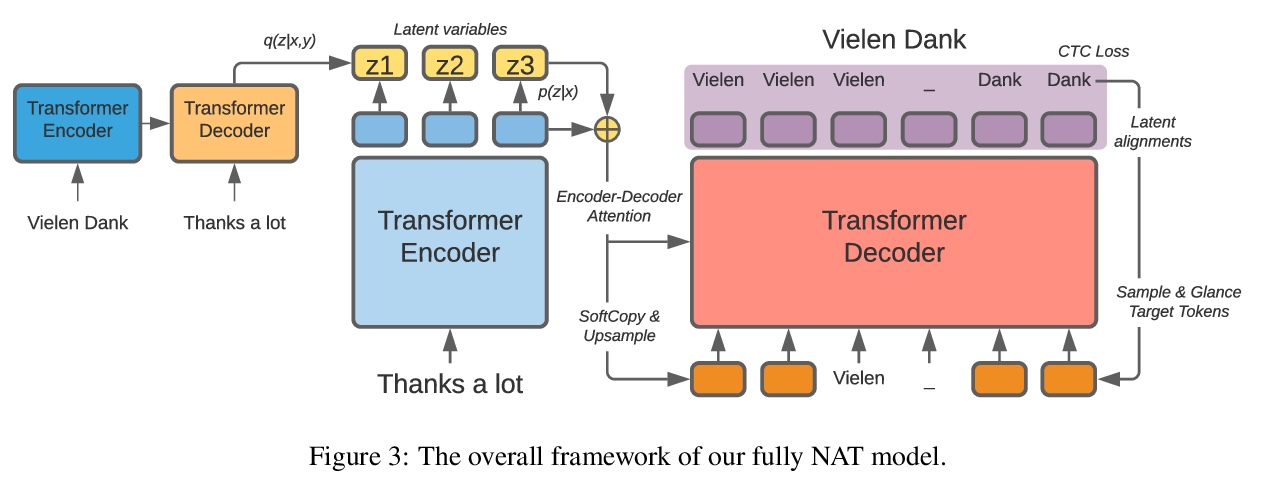
全非自回归神经网络机器翻译的性能改进。与Transformer基线相比,全非自回归神经网络机器翻译(NAT)用神经网络的单次前向同时预测词条,显著降低了推理延迟,但以质量下降为代价,这项工作的目标,就是在保持延迟优势的同时,缩小NAT和AT之间的性能差距。从四个不同方面回顾了已被证明有效的改进NAT模型的方法,并仔细结合这些技术进行必要的修改。在三个Transformer基准上的实验表明,所提出的系统在全NAT模型上取得了最先进的结果,并且获得了与自回归和迭代NAT系统相当的性能。
Fully non-autoregressive neural machine translation (NAT) is proposed to simultaneously predict tokens with single forward of neural networks, which significantly reduces the inference latency at the expense of quality drop compared to the Transformer baseline. In this work, we target on closing the performance gap while maintaining the latency advantage. We first inspect the fundamental issues of fully NAT models, and adopt dependency reduction in the learning space of output tokens as the basic guidance. Then, we revisit methods in four different aspects that have been proven effective for improving NAT models, and carefully combine these techniques with necessary modifications. Our extensive experiments on three translation benchmarks show that the proposed system achieves the new state-of-the-art results for fully NAT models, and obtains comparable performance with the autoregressive and iterative NAT systems. For instance, one of the proposed models achieves 27.49 BLEU points on WMT14 En-De with approximately 16.5X speed up at inference time.
https://weibo.com/1402400261/JBgg5kLAx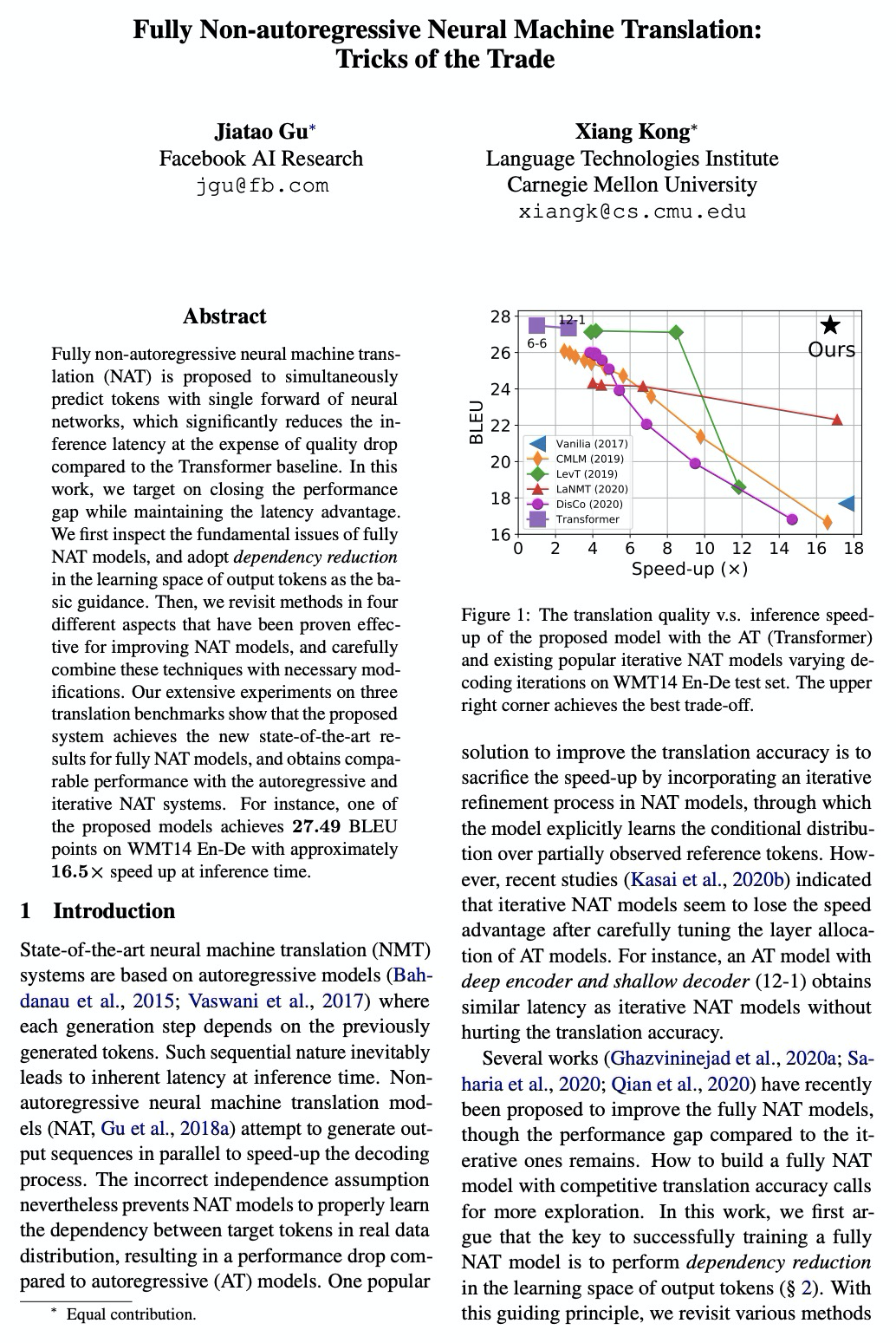

5、[CL] CLEAR: Contrastive Learning for Sentence Representation
Z Wu, S Wang, J Gu, M Khabsa, F Sun, H Ma
[University of Michigan & Facebook AI & Chinese Academy of Sciences]
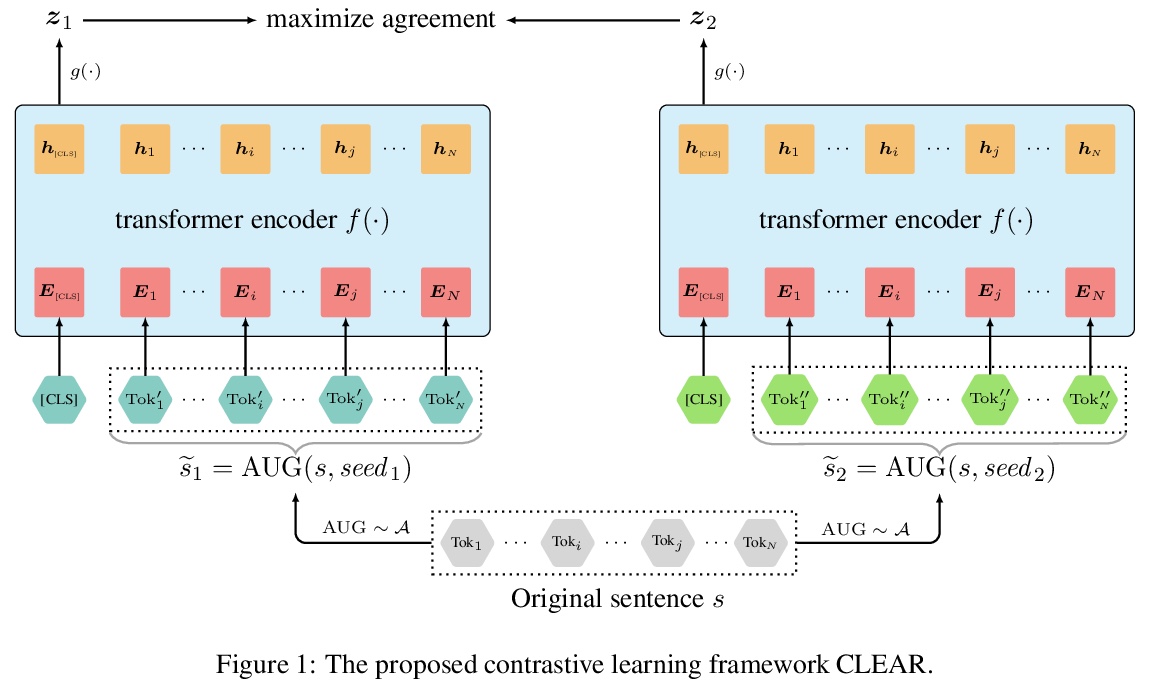
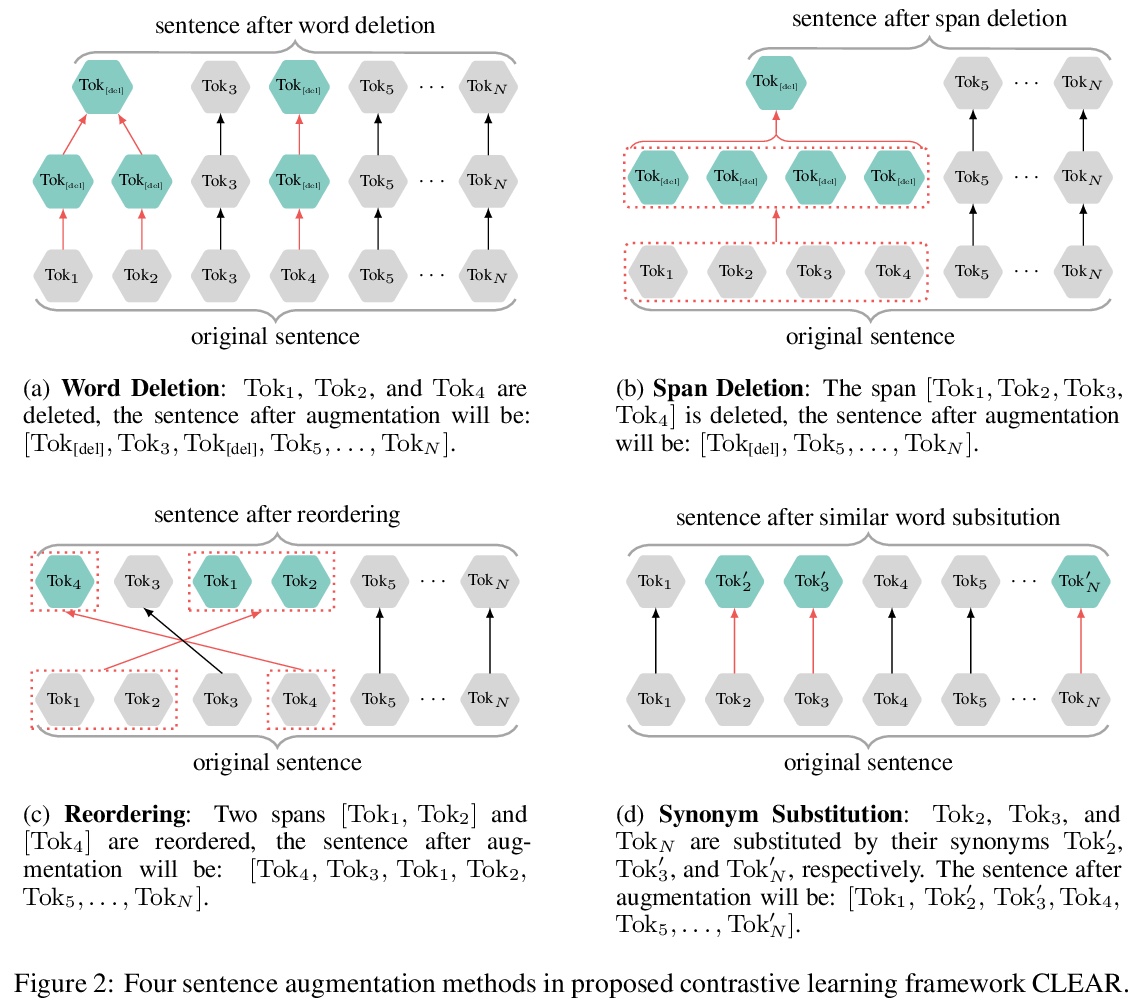
CLEAR:句子表示对比学习。针对句子级的训练目标,提出了句子表示的对比学习(CLEAR),用多个句子级增强策略来学习噪声不变的句子表示,包括对单词和span的删除、重排和替换。通过精心设计和测试不同的数据增强和组合,在不同的预训练语料库下验证了所提方法在GLUE和SentEval基准上的有效性。实验结果表明,在充分利用句子级监督的情况下,预训练模型具有更强的鲁棒性。揭示了不同的增强会让模型学到不同的特征。证明了性能的提高来自于更大的批处理规模和对比损失。
Pre-trained language models have proven their unique powers in capturing implicit language features. However, most pre-training approaches focus on the word-level training objective, while sentence-level objectives are rarely studied. In this paper, we propose Contrastive LEArning for sentence Representation (CLEAR), which employs multiple sentence-level augmentation strategies in order to learn a noise-invariant sentence representation. These augmentations include word and span deletion, reordering, and substitution. Furthermore, we investigate the key reasons that make contrastive learning effective through numerous experiments. We observe that different sentence augmentations during pre-training lead to different performance improvements on various downstream tasks. Our approach is shown to outperform multiple existing methods on both SentEval and GLUE benchmarks.
https://weibo.com/1402400261/JBgo2vgeF
另外几篇值得关注的论文:
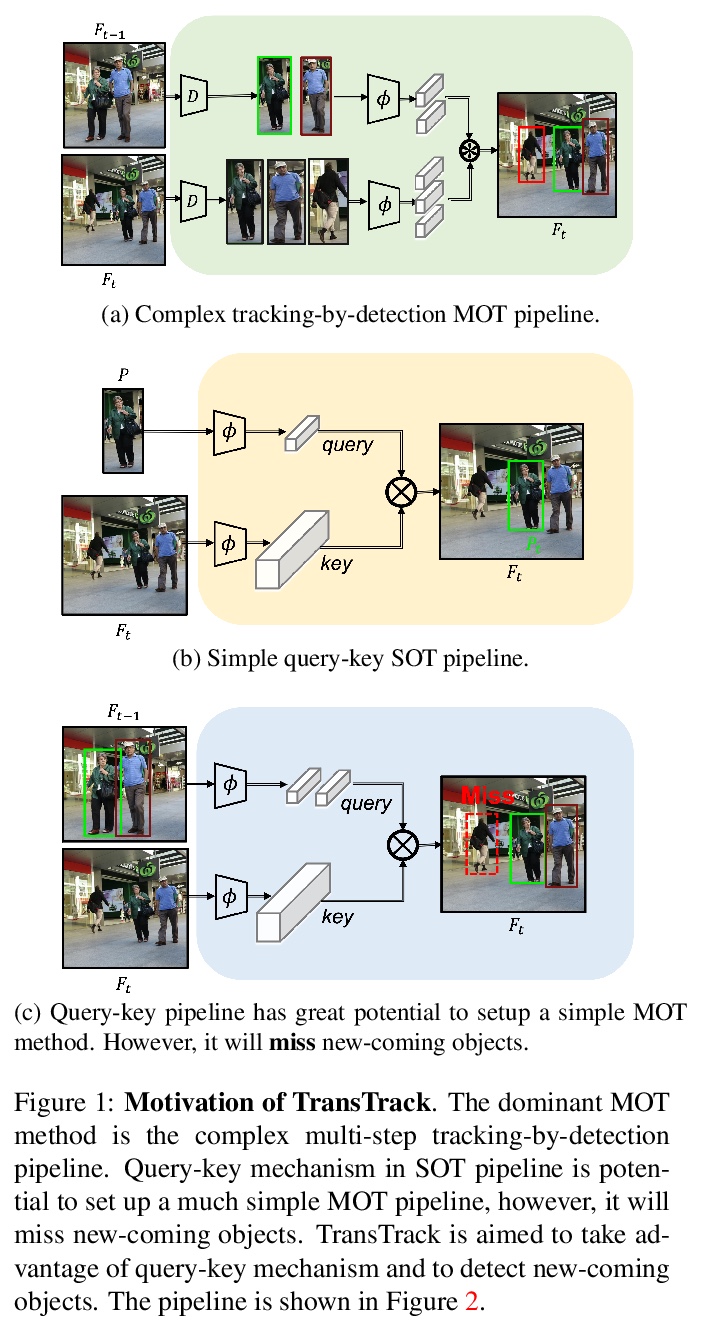
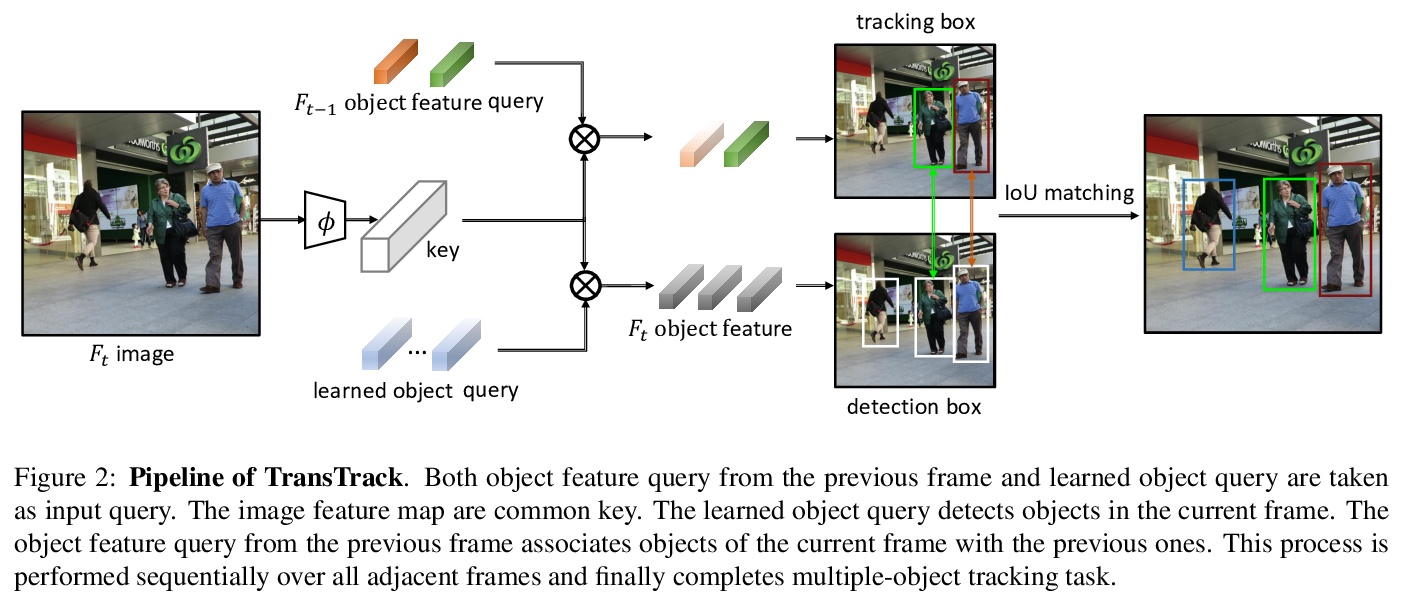
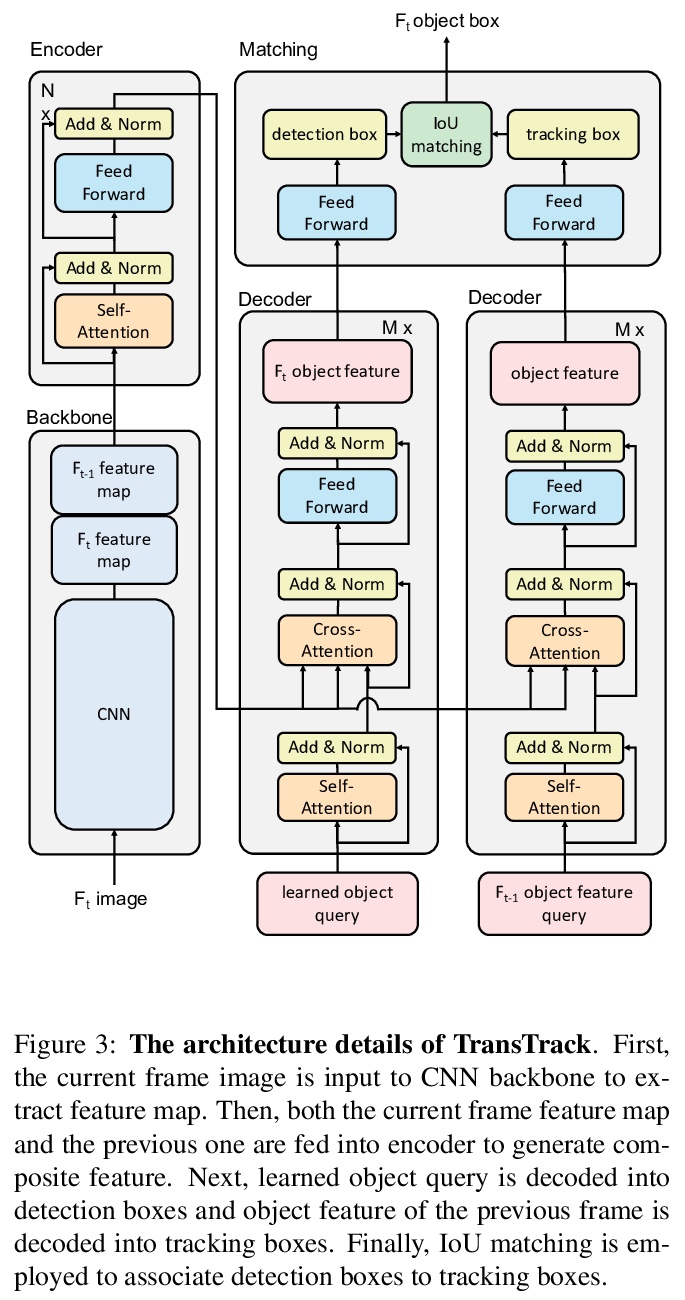
[CV] TransTrack: Multiple-Object Tracking with Transformer
TransTrack:基于Transformer的多目标跟踪
P Sun, Y Jiang, R Zhang, E Xie, J Cao, X Hu, T Kong, Z Yuan, C Wang, P Luo
[The University of Hong Kong & ByteDance AI Lab & Tongji University & CMU & Nanyang Technological University]
https://weibo.com/1402400261/JBgs8AoPz
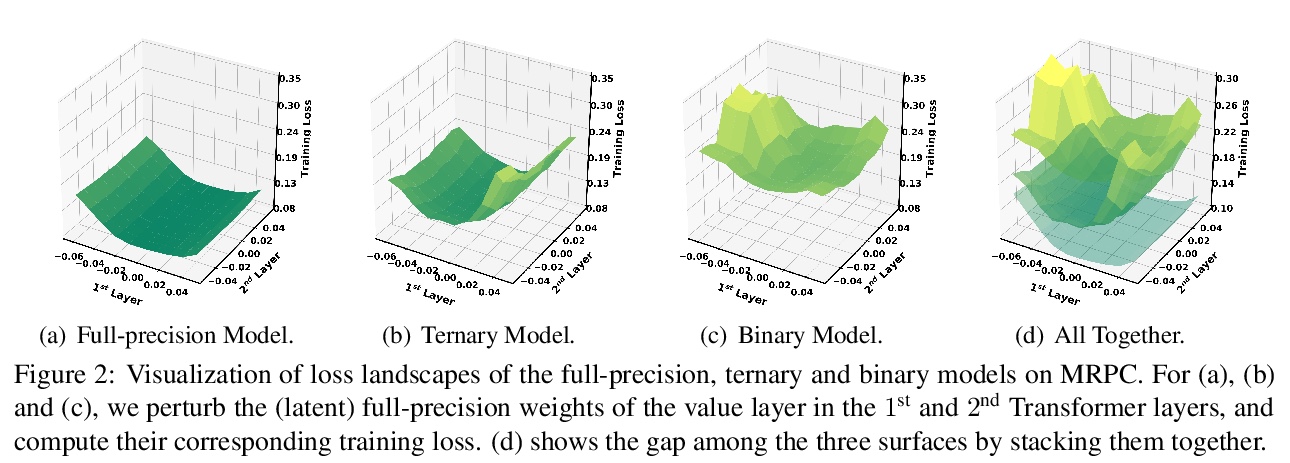
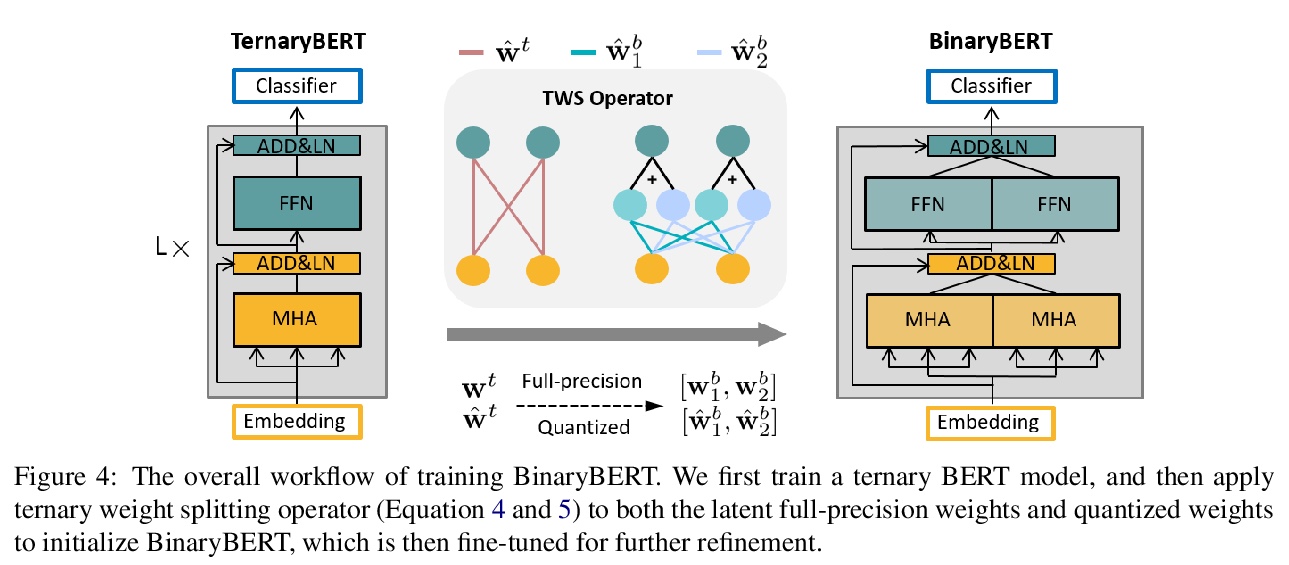
[CL] BinaryBERT: Pushing the Limit of BERT Quantization
BinaryBERT:基于加权二值化的BERT量化算法
H Bai, W Zhang, L Hou, L Shang, J Jin, X Jiang, Q Liu, M Lyu, I King
[The Chinese University of Hong Kong & Huawei Noah’s Ark Lab & Huawei Technologies Co]
https://weibo.com/1402400261/JBgttCnC8
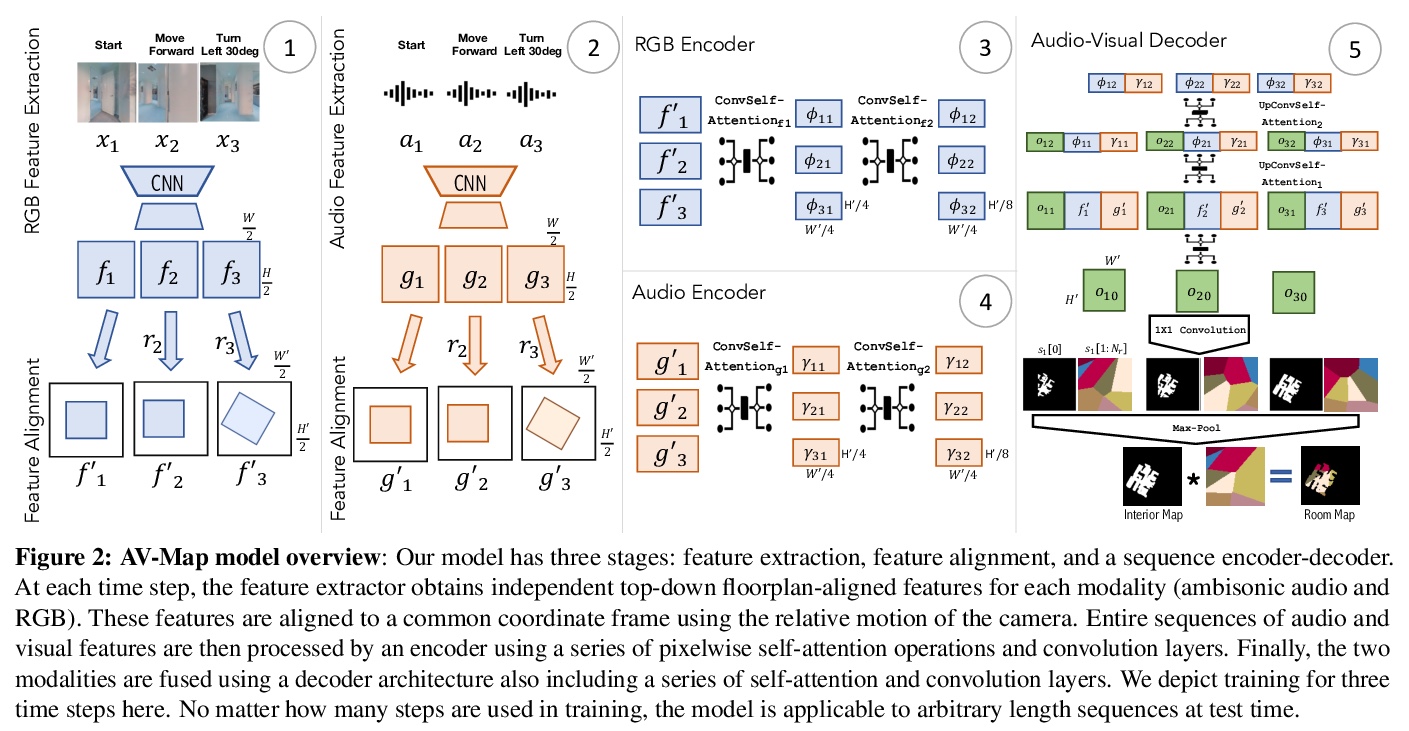
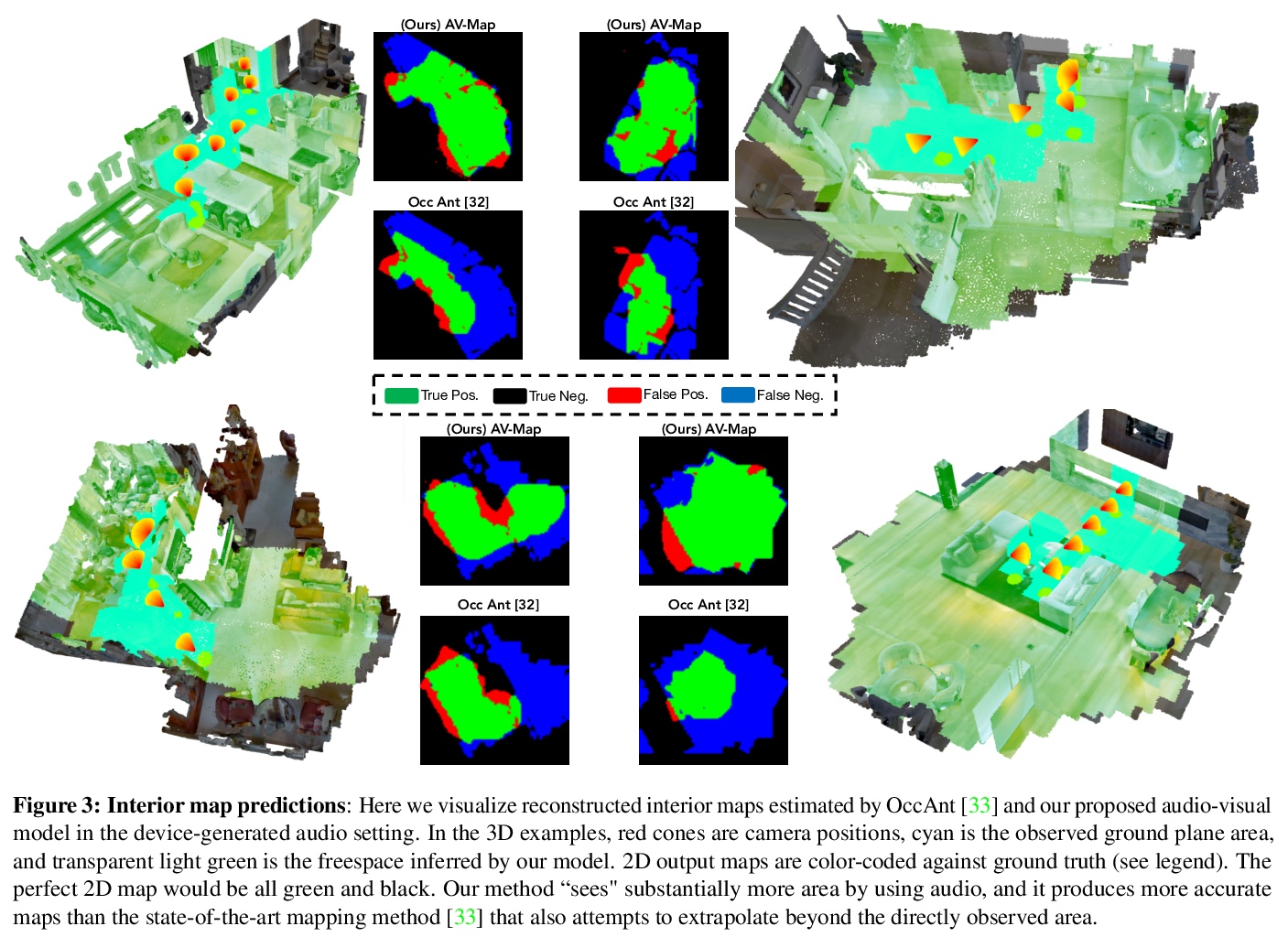
[CV] Audio-Visual Floorplan Reconstruction
面向平面图重建的音-视频多模态编解码框架AV-Map
S Purushwalkam, S V A Gari, V K Ithapu, C Schissler, P Robinson, A Gupta, K Grauman
[CMU & Facebook Reality Labs & Facebook AI Research]
https://weibo.com/1402400261/JBgxyinEw

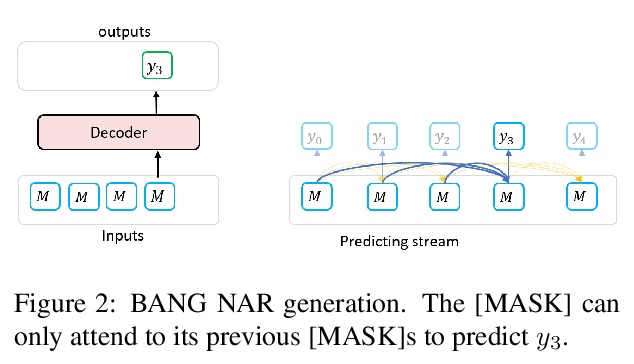
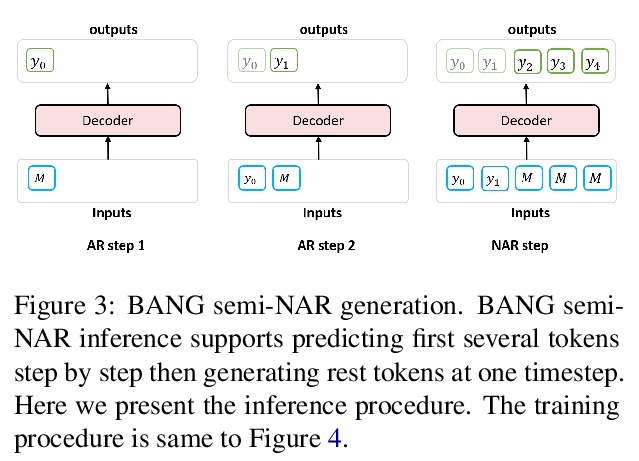
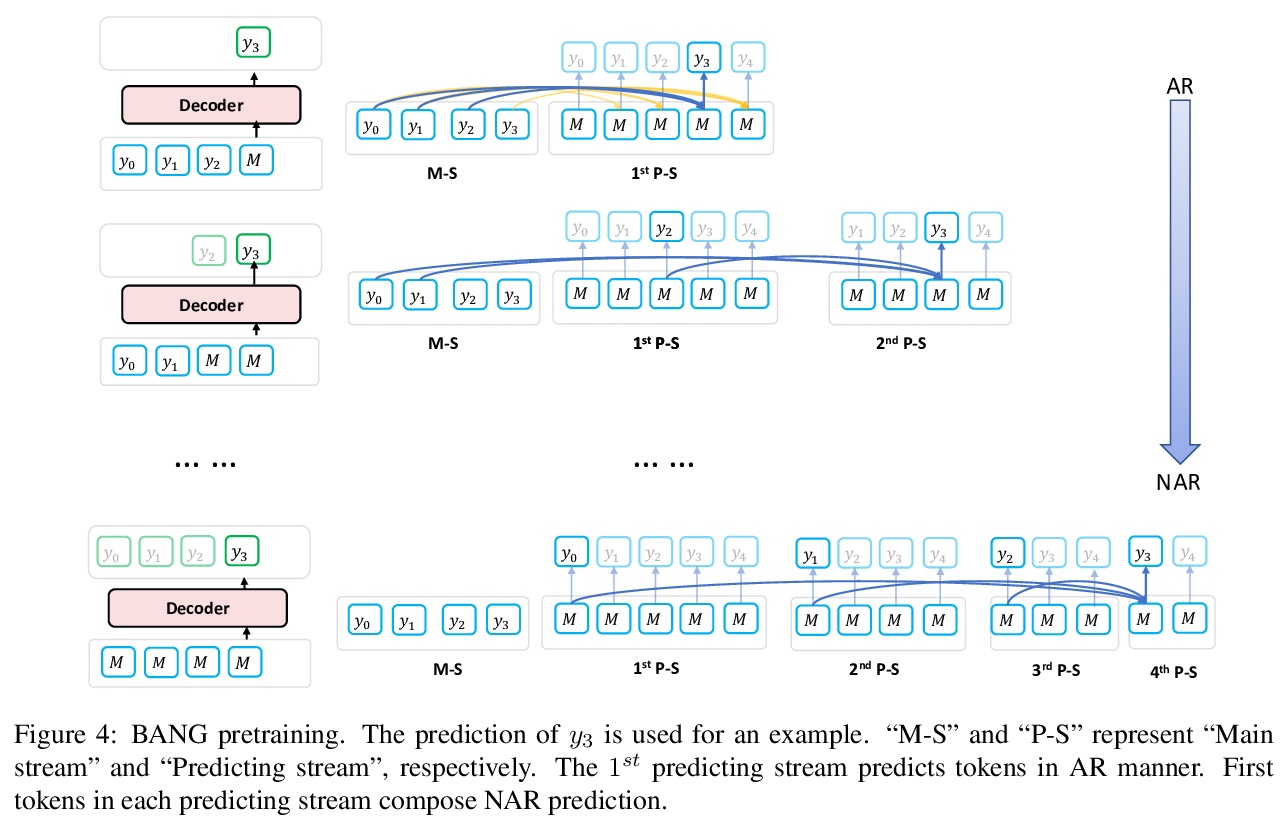
[CL] BANG: Bridging Autoregressive and Non-autoregressive Generation with Large Scale Pretraining
BANG:用大规模预处理缩小自回归和非自回归生成的差距
W Qi, Y Gong, J Jiao, Y Yan, D Liu, W Chen, K Tang, H Li, J Chen, R Zhang, M Zhou, N Duan
[University of Science and Technology of China & Microsoft & Microsoft Research Asia]
https://weibo.com/1402400261/JBgA0oCwJ

若有收获,就点个赞吧
0 人点赞
