- 1、[CL] Multitask Learning for Emotion and Personality Detection
- 2、[CV] STaR: Self-supervised Tracking and Reconstruction of Rigid Objects in Motion with Neural Rendering
- 3、[CV] Learning the Predictability of the Future
- 4、[CV] Consensus-Guided Correspondence Denoising
- 5、[CL] VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation
- [CV] Novel View Synthesis via Depth-guided Skip Connections
- [CV] Support Vector Machine and YOLO for a Mobile Food Grading System
- [CV] VisualSparta: Sparse Transformer Fragment-level Matching for Large-scale Text-to-Image Search
- [CL] Intrinsic Bias Metrics Do Not Correlate with Application Bias
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CL] Multitask Learning for Emotion and Personality Detection
Y Li, A Kazameini, Y Mehta, E Cambria
[Northwestern Polytechnical University & Western University & University College London & Nanyang Technological University]
面向情感和个性检测的多任务学习。提出了个性特征检测和情感检测的多任务学习框架SoGMTL,采用类似MAML的框架进行模型优化,实证评价并讨论了两个任务之间不同的信息共享机制,基于CNN的多任务模型计算效率更高,在多个人格和情感数据集上达到了最先进性能,甚至超过了基于语言模型的方法。
In recent years, deep learning-based automated personality trait detection has received a lot of attention, especially now, due to the massive digital footprints of an individual. Moreover, many researchers have demonstrated that there is a strong link between personality traits and emotions. In this paper, we build on the known correlation between personality traits and emotional behaviors, and propose a novel multitask learning framework, SoGMTL that simultaneously predicts both of them. We also empirically evaluate and discuss different information-sharing mechanisms between the two tasks. To ensure the high quality of the learning process, we adopt a MAML-like framework for model optimization. Our more computationally efficient CNN-based multitask model achieves the state-of-the-art performance across multiple famous personality and emotion datasets, even outperforming Language Model based models.
https://weibo.com/1402400261/JCCF1wKH4
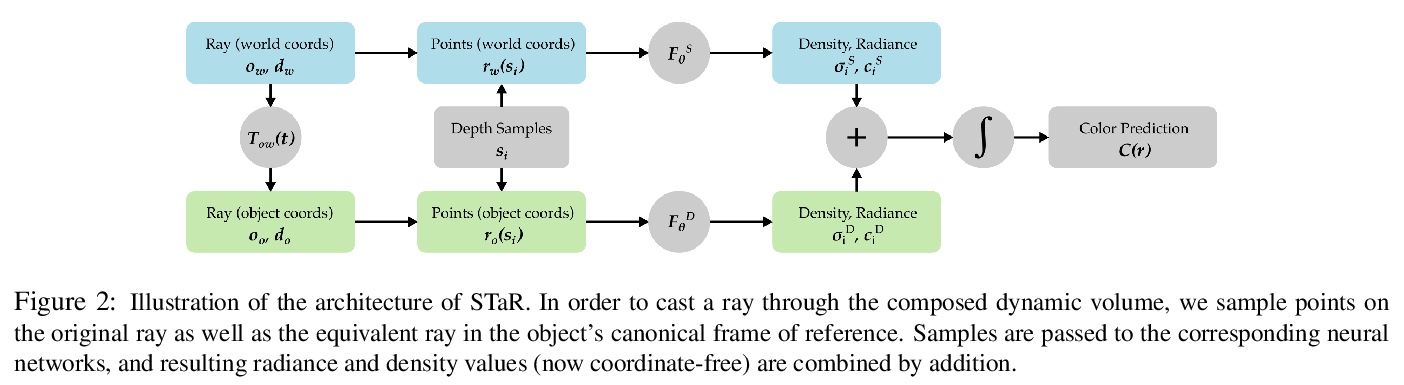
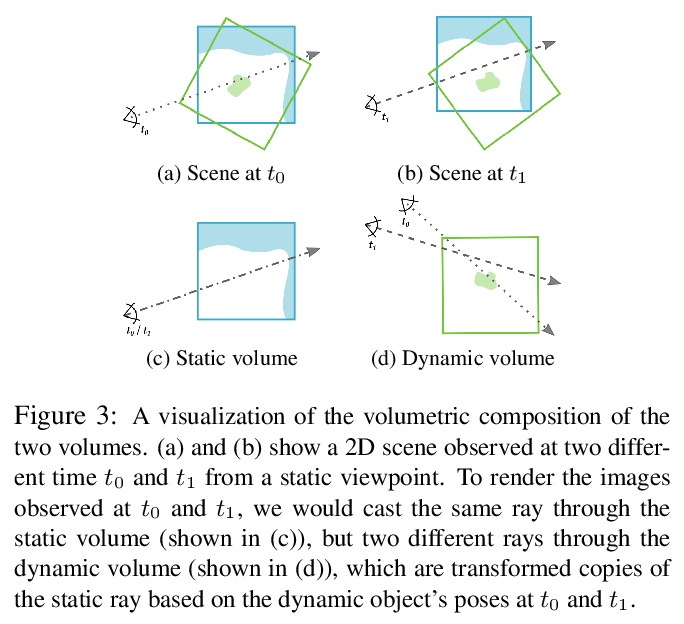
2、[CV] STaR: Self-supervised Tracking and Reconstruction of Rigid Objects in Motion with Neural Rendering
W Yuan, Z Lv, T Schmidt, S Lovegrove
[University of Washington & Facebook Reality Labs Research]
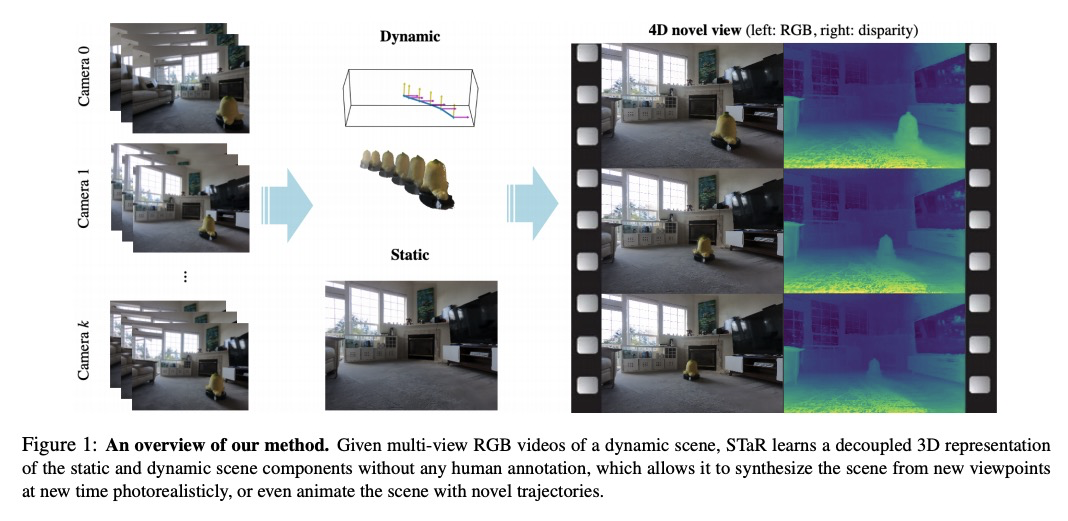
STaR:基于神经网络渲染的运动刚性物体自监督跟踪和重建。提出STaR,从多视角RGB视频中执行具有刚性运动的动态场景的自我监督跟踪和重建,无需人工标注。在辐射场神经表示的上下文显式模拟了物体的刚性运动,通过同时将运动中单个刚性物体分解为其两个组成部分,并将每部分用其自己的神经表示进行编码,来重建动态场景。通过联合优化两个神经辐射场和在各帧与这两个场对齐的刚性姿态参数来实现该目标。
We present STaR, a novel method that performs Self-supervised Tracking and Reconstruction of dynamic scenes with rigid motion from multi-view RGB videos without any manual annotation. Recent work has shown that neural networks are surprisingly effective at the task of compressing many views of a scene into a learned function which maps from a viewing ray to an observed radiance value via volume rendering. Unfortunately, these methods lose all their predictive power once any object in the scene has moved. In this work, we explicitly model rigid motion of objects in the context of neural representations of radiance fields. We show that without any additional human specified supervision, we can reconstruct a dynamic scene with a single rigid object in motion by simultaneously decomposing it into its two constituent parts and encoding each with its own neural representation. We achieve this by jointly optimizing the parameters of two neural radiance fields and a set of rigid poses which align the two fields at each frame. On both synthetic and real world datasets, we demonstrate that our method can render photorealistic novel views, where novelty is measured on both spatial and temporal axes. Our factored representation furthermore enables animation of unseen object motion.
https://weibo.com/1402400261/JCCLOCof8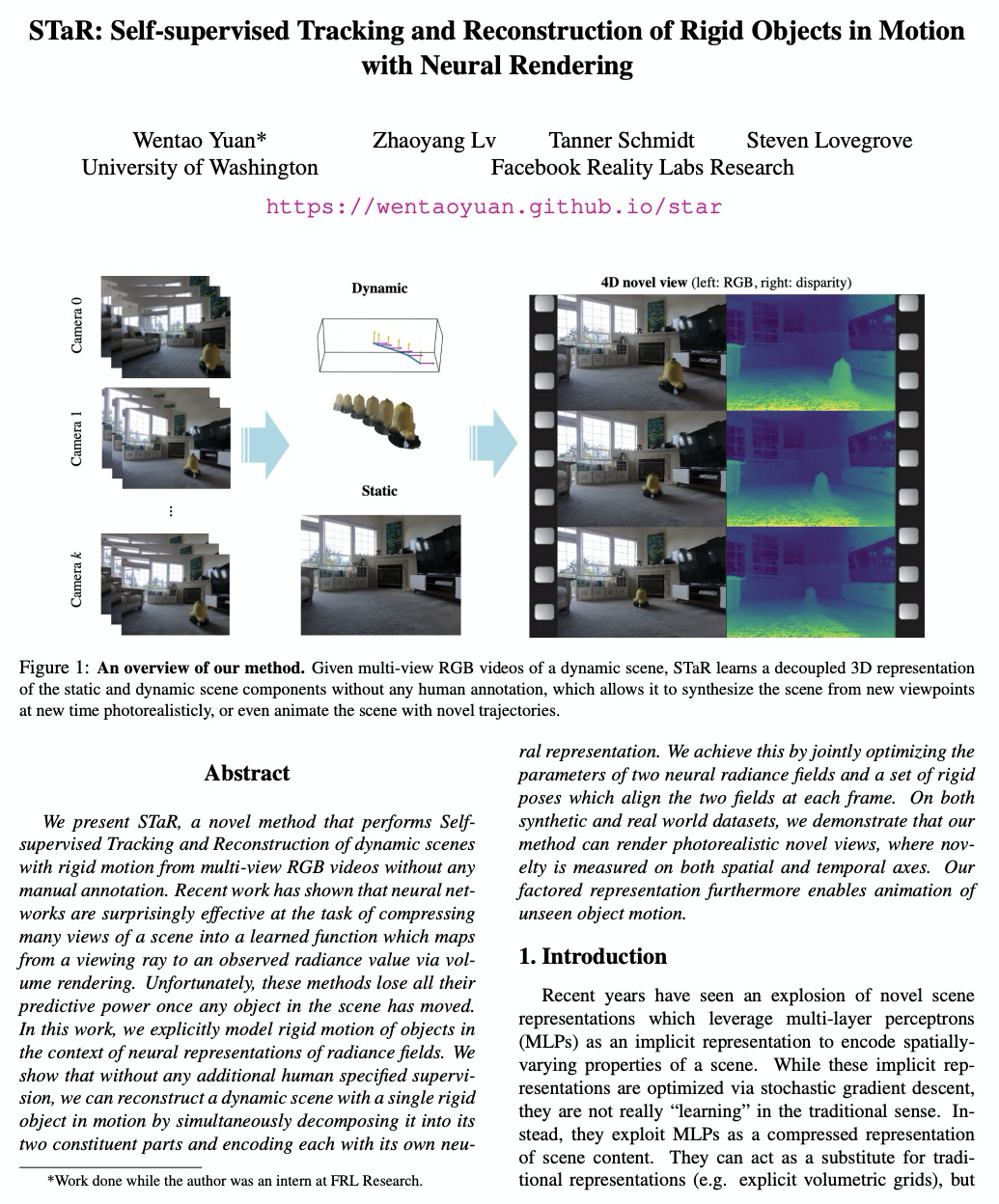
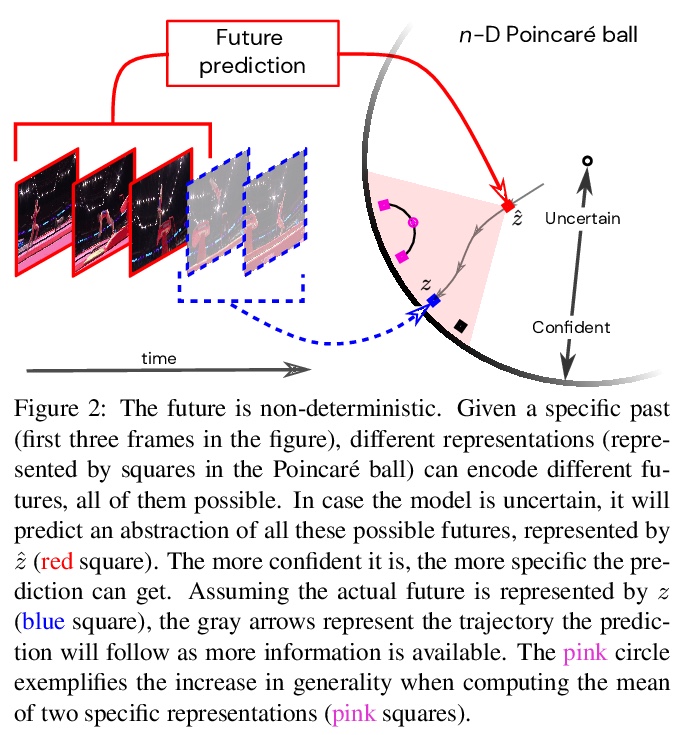
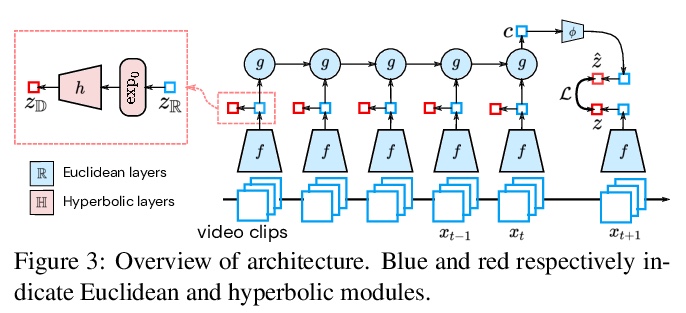
3、[CV] Learning the Predictability of the Future
D Surís, R Liu, C Vondrick
[Columbia University]
未来可预测性学习。为视频预测引入双曲空间预测模型,对不确定性进行分层表示,从未标记视频中学习未来可预测内容。当模型最自信的时候,会在具体层次结构中进行预测,当模型不自信的时候,会学习自动选择更高抽象层次。在两个已有数据集上的实验显示了层次化表示对于动作预测的关键作用。
We introduce a framework for learning from unlabeled video what is predictable in the future. Instead of committing up front to features to predict, our approach learns from data which features are predictable. Based on the observation that hyperbolic geometry naturally and compactly encodes hierarchical structure, we propose a predictive model in hyperbolic space. When the model is most confident, it will predict at a concrete level of the hierarchy, but when the model is not confident, it learns to automatically select a higher level of abstraction. Experiments on two established datasets show the key role of hierarchical representations for action prediction. Although our representation is trained with unlabeled video, visualizations show that action hierarchies emerge in the representation.
https://weibo.com/1402400261/JCCRkiiB7
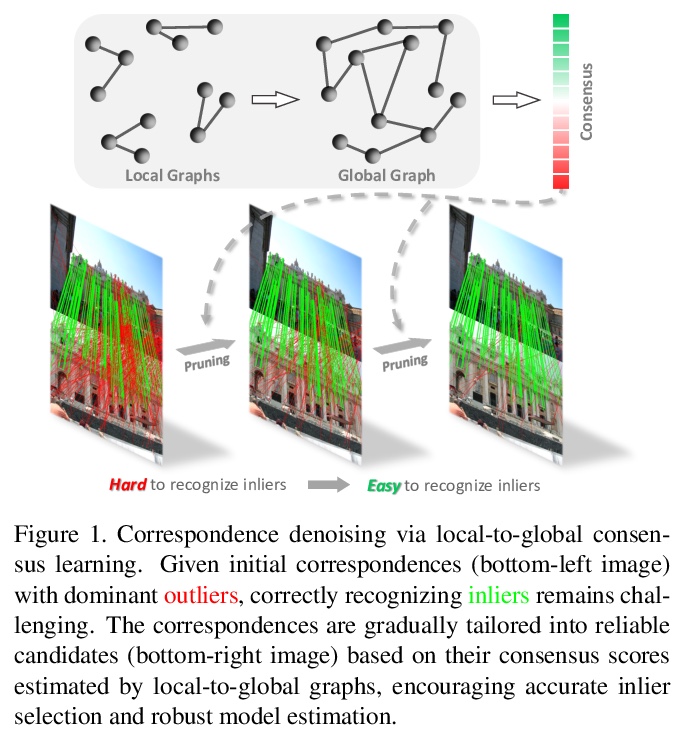
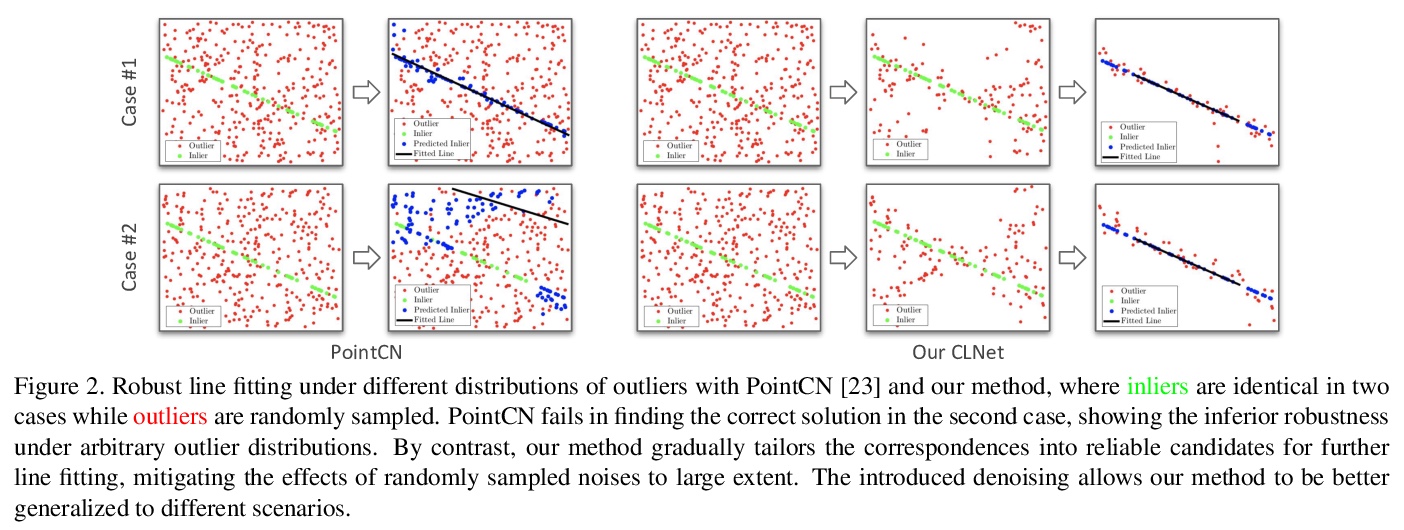
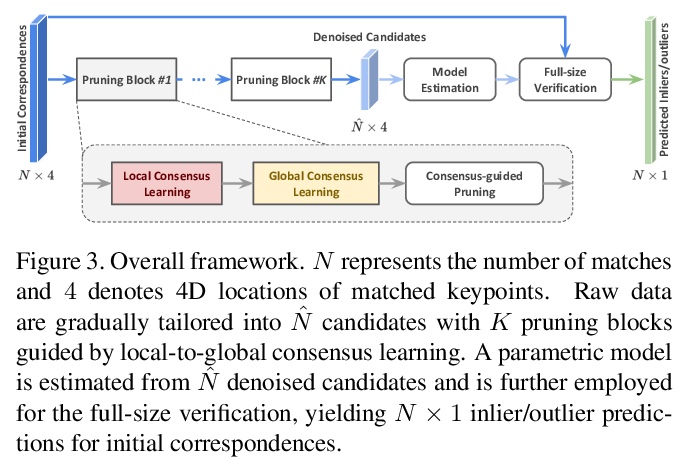
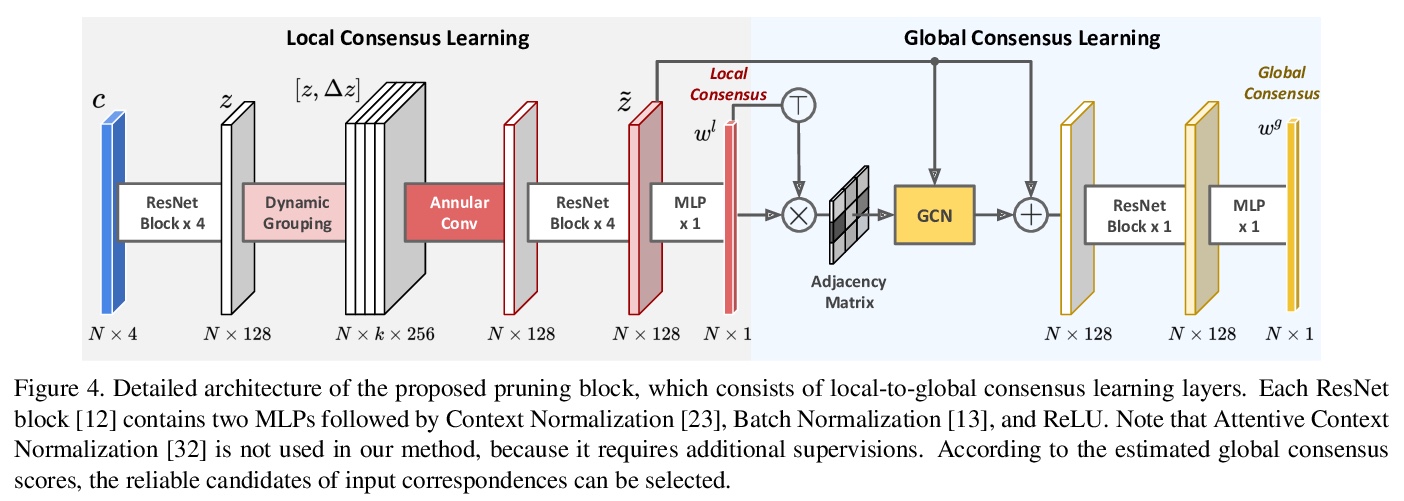
4、[CV] Consensus-Guided Correspondence Denoising
C Zhao, Y Ge, J Yang, F Zhu, R Zhao, H Li
[EPFL & SenseTime Research & The Chinese University of Hong Kong & Northwestern Polytechnical University]
共识(Consensus)指导的对应去噪。针对两组特征点间的对应选择,即从初始噪声匹配中正确识别出一致匹配,提出用局部到全局的共识学习框架对对应关系去噪,引入新的”修剪”块,根据从局部到全局区域的动态图中估计的共识得分,从初始匹配中筛选出可靠的候选对应关系。所提出的对应关系去噪是通过依次堆叠多个修剪块逐步实现的。该方法在鲁棒线拟合、宽基线图像匹配和图像定位等基准上,表现明显优于现有技术,在初始匹配的不同分布上表现出了良好的泛化能力。
Correspondence selection between two groups of feature points aims to correctly recognize the consistent matches (inliers) from the initial noisy matches. The selection is generally challenging since the initial matches are generally extremely unbalanced, where outliers can easily dominate. Moreover, random distributions of outliers lead to the limited robustness of previous works when applied to different scenarios. To address this issue, we propose to denoise correspondences with a local-to-global consensus learning framework to robustly identify correspondence. A novel “pruning” block is introduced to distill reliable candidates from initial matches according to their consensus scores estimated by dynamic graphs from local to global regions. The proposed correspondence denoising is progressively achieved by stacking multiple pruning blocks sequentially. Our method outperforms state-of-the-arts on robust line fitting, wide-baseline image matching and image localization benchmarks by noticeable margins and shows promising generalization capability on different distributions of initial matches.
https://weibo.com/1402400261/JCCX87p4C
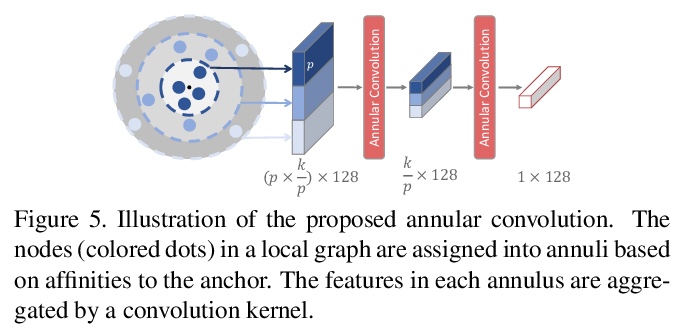
5、[CL] VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation
C Wang, M Rivière, A Lee, A Wu, C Talnikar, D Haziza, M Williamson, J Pino, E Dupoux
[Facebook AI]
VoxPopuli:面向表示学习、半监督学习和解释的大规模多语言语音语料库。介绍了大规模多语言语音语料库VoxPopuli,提供了23种语言的10万小时的未标注语音数据,是迄今为止最大的用于无监督表示学习及半监督学习的开放数据。VoxPopuli还包含了16种语言的1.8万小时的转录语音,以及它们在另外五种语言中的对齐口头解释,共计5.1万小时。提供了语音识别基线,验证了VoxPopuli无标签数据在具有挑战性的域外环境下半监督学习的通用性。
We introduce VoxPopuli, a large-scale multilingual corpus providing 100K hours of unlabelled speech data in 23 languages. It is the largest open data to date for unsupervised representation learning as well as semi-supervised learning. VoxPopuli also contains 1.8K hours of transcribed speeches in 16 languages and their aligned oral interpretations into 5 other languages totaling 5.1K hours. We provide speech recognition baselines and validate the versatility of VoxPopuli unlabelled data in semi-supervised learning under challenging out-of-domain settings. We will release the corpus at > this https URL under an open license.
https://weibo.com/1402400261/JCD51txAZ
另外几篇值得关注的论文:
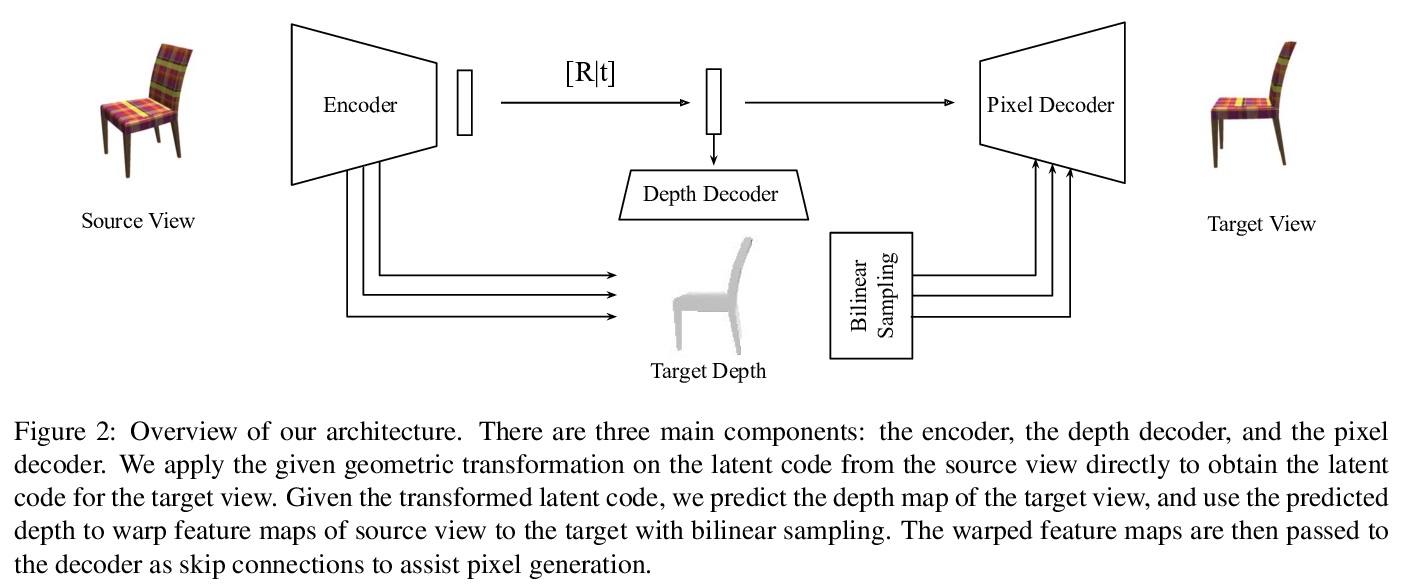
[CV] Novel View Synthesis via Depth-guided Skip Connections
基于深度引导跳接的新视图合成
Y Hou, A Solin, J Kannala
[Aalto University]
https://weibo.com/1402400261/JCDaofiTI

[CV] Support Vector Machine and YOLO for a Mobile Food Grading System
基于SVM和YOLO的手机端食品分级系统
L Zhu, P Spachos
[University of Guelph]
https://weibo.com/1402400261/JCDdHyXFc
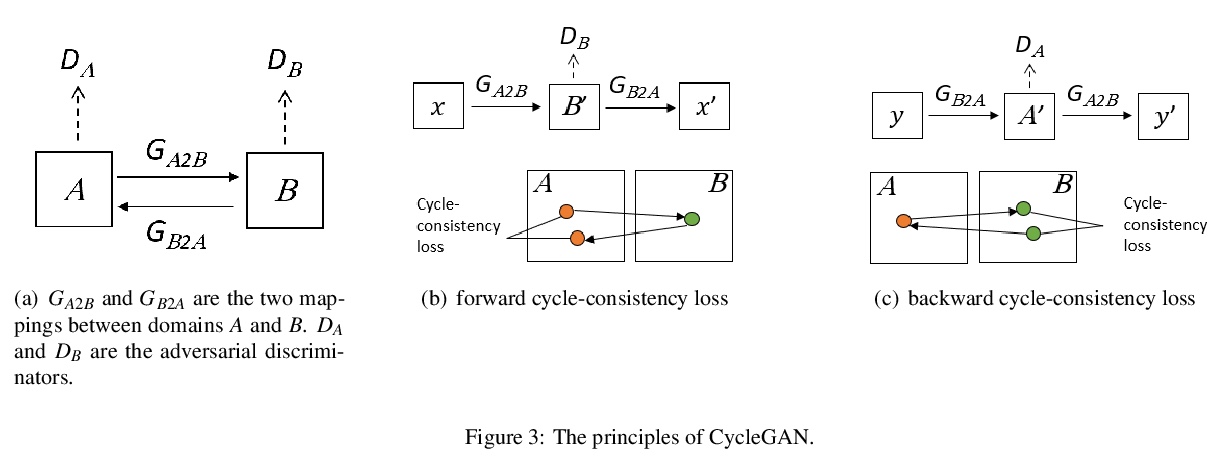
[CV] VisualSparta: Sparse Transformer Fragment-level Matching for Large-scale Text-to-Image Search
VisualSparta:基于稀疏Transformer片段级匹配的大规模文本-图像搜索
X Lu, T Zhao, K Lee
[CMU & SOCO Inc]
https://weibo.com/1402400261/JCDjB7GYp
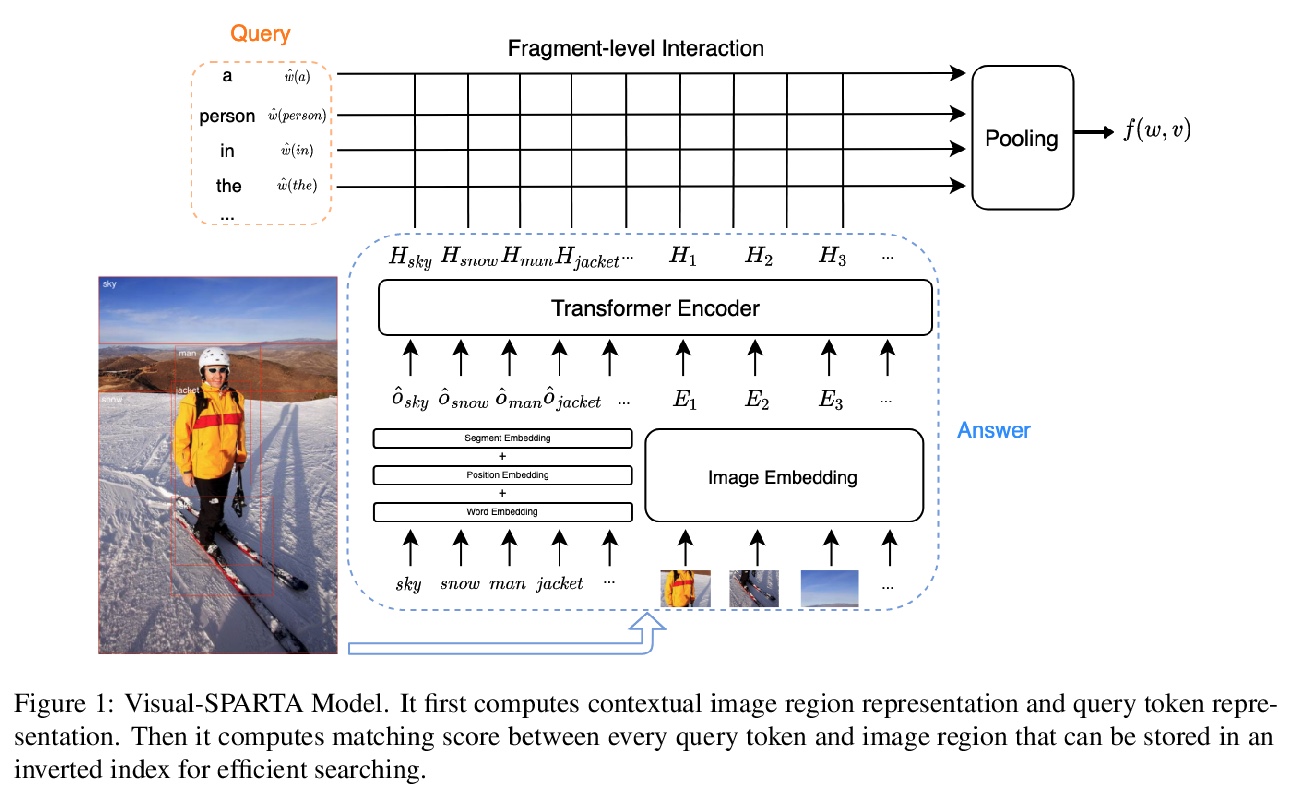

[CL] Intrinsic Bias Metrics Do Not Correlate with Application Bias
内在偏差指标与应用偏差不相关
S Goldfarb-Tarrant, R Marchant, R M Sanchez, M Pandya, A Lopez
[University of Edinburgh]
https://weibo.com/1402400261/JCDltefq7

若有收获,就点个赞吧
0 人点赞
