LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[AS] **Universal MelGAN: A Robust Neural Vocoder for High-Fidelity Waveform Generation in Multiple Domains
W Jang, D Lim, J Yoon
[Kakao Enterprise Corp & Kakao Corp]
可产生多域高保真语音的鲁棒神经网络声码器。提出Universal MelGAN,通过在模型上附加多分辨率谱图鉴别器,解决了导致金属声的过平滑问题。实验表明,该模型在可见域和不可见域大多数情况下都获得了最高的MOS值,特别是在说话人、情绪和语言等不可见域表现优异,证明了该模型的通用性。**
We propose Universal MelGAN, a vocoder that synthesizes high-fidelity speech in multiple domains. To preserve sound quality when the MelGAN-based structure is trained with a dataset of hundreds of speakers, we added multi-resolution spectrogram discriminators to sharpen the spectral resolution of the generated waveforms. This enables the model to generate realistic waveforms of multi-speakers, by alleviating the over-smoothing problem in the high frequency band of the large footprint model. Our structure generates signals close to ground-truth data without reducing the inference speed, by discriminating the waveform and spectrogram during training. The model achieved the best mean opinion score (MOS) in most scenarios using ground-truth mel-spectrogram as an input. Especially, it showed superior performance in unseen domains with regard of speaker, emotion, and language. Moreover, in a multi-speaker text-to-speech scenario using mel-spectrogram generated by a transformer model, it synthesized high-fidelity speech of 4.22 MOS. These results, achieved without external domain information, highlight the potential of the proposed model as a universal vocoder.
https://weibo.com/1402400261/JuRKi39tp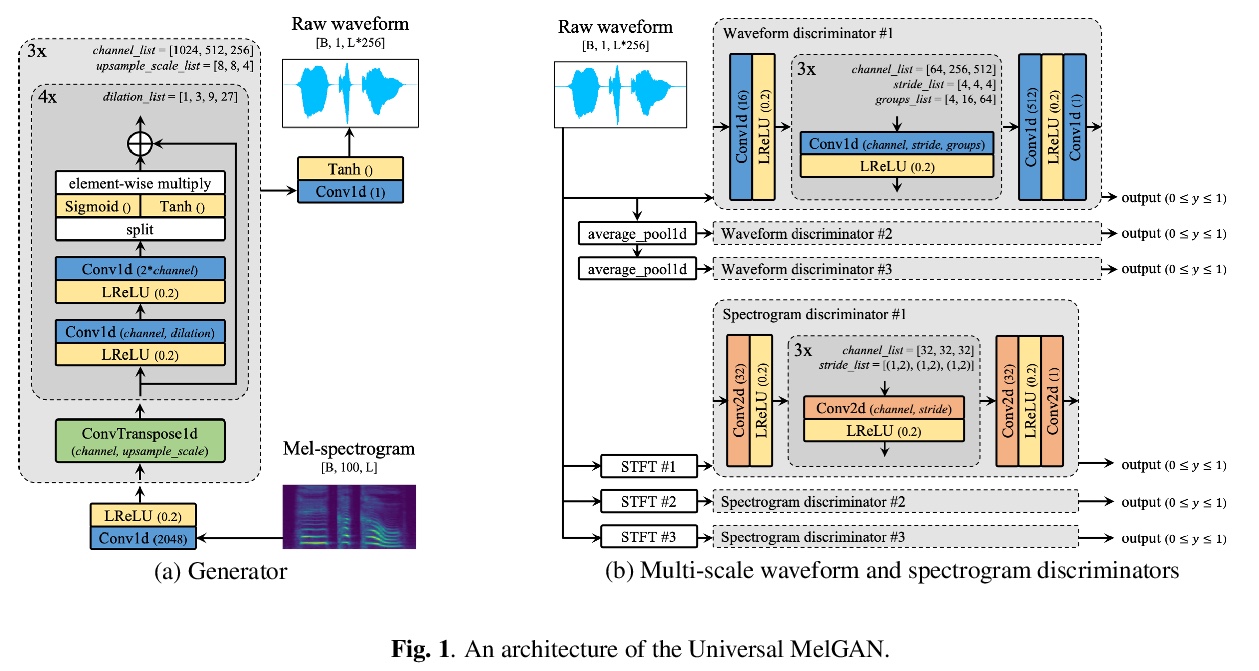
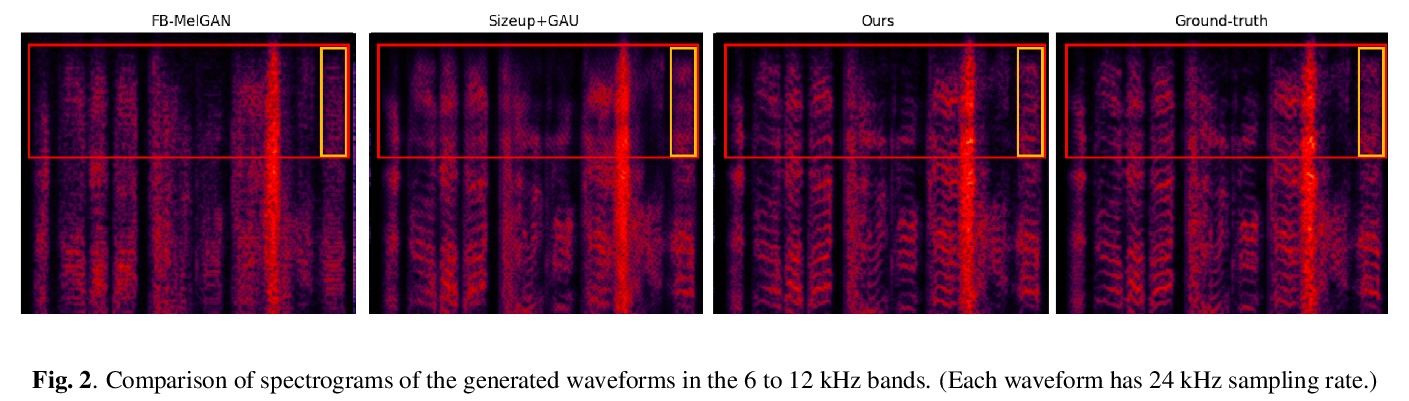
2、[LG] **Parrot: Data-Driven Behavioral Priors for Reinforcement Learning
A Singh, H Liu, G Zhou, A Yu, N Rhinehart, S Levine
[UC Berkeley]
数据驱动的强化学习行为先验。提出一种从系列任务成功试验中学习行为先验的方法PARROT,从对成功试验的观察中捕获复杂的输入-输出关系,可用于新任务的快速学习,同时不影响其尝试新行为的能力。从先验中学习加快了强化学习对新任务的适应——包括从高维图像观察中操作以前不可见的对象——这是从零开始强化学习往往无法学到的。**
Reinforcement learning provides a general framework for flexible decision making and control, but requires extensive data collection for each new task that an agent needs to learn. In other machine learning fields, such as natural language processing or computer vision, pre-training on large, previously collected datasets to bootstrap learning for new tasks has emerged as a powerful paradigm to reduce data requirements when learning a new task. In this paper, we ask the following question: how can we enable similarly useful pre-training for RL agents? We propose a method for pre-training behavioral priors that can capture complex input-output relationships observed in successful trials from a wide range of previously seen tasks, and we show how this learned prior can be used for rapidly learning new tasks without impeding the RL agent’s ability to try out novel behaviors. We demonstrate the effectiveness of our approach in challenging robotic manipulation domains involving image observations and sparse reward functions, where our method outperforms prior works by a substantial margin.
https://weibo.com/1402400261/JuRRF7n5p
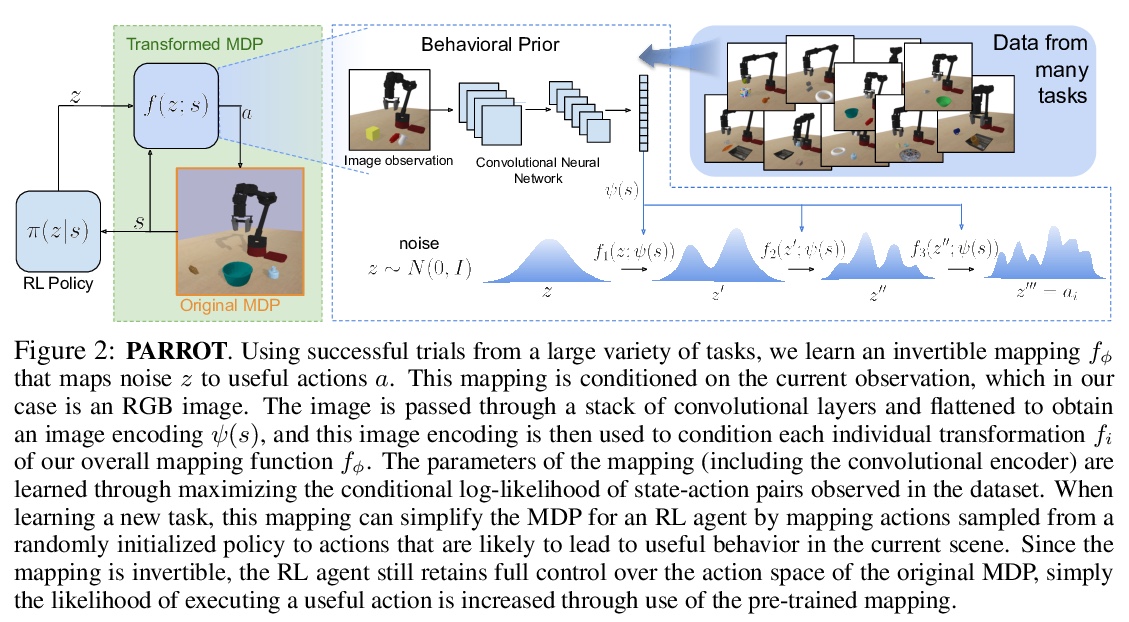
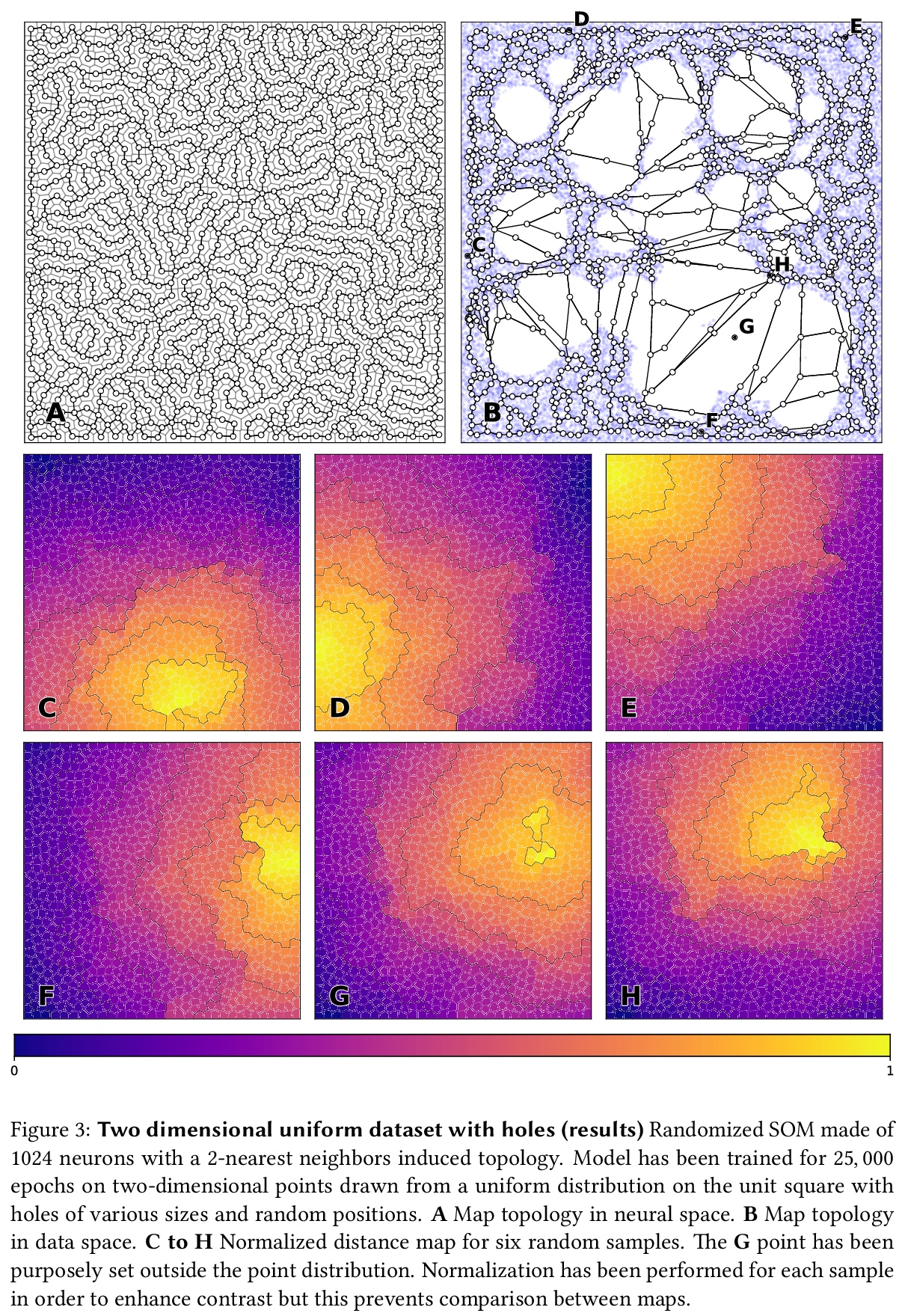
3、[LG] **Randomized Self Organizing Map
N P. Rougier, G Is. Detorakis
[Inria Bordeaux Sud-Ouestad & Nomus Inc]
随机化自组织映射。提出自组织映射算法的一种变体,通过考虑在二维流形上随机放置神经元,遵循可推导出各种拓扑的蓝噪声分布,这些拓扑具有随机的(但可控制的)不连续性,允许更灵活的自组织,特别是对于高维数据。**
We propose a variation of the self organizing map algorithm by considering the random placement of neurons on a two-dimensional manifold, following a blue noise distribution from which various topologies can be derived. These topologies possess random (but controllable) discontinuities that allow for a more flexible self-organization, especially with high-dimensional data. The proposed algorithm is tested on one-, two- and three-dimensions tasks as well as on the MNIST handwritten digits dataset and validated using spectral analysis and topological data analysis tools. We also demonstrate the ability of the randomized self-organizing map to gracefully reorganize itself in case of neural lesion and/or neurogenesis.
https://weibo.com/1402400261/JuS05gtFe

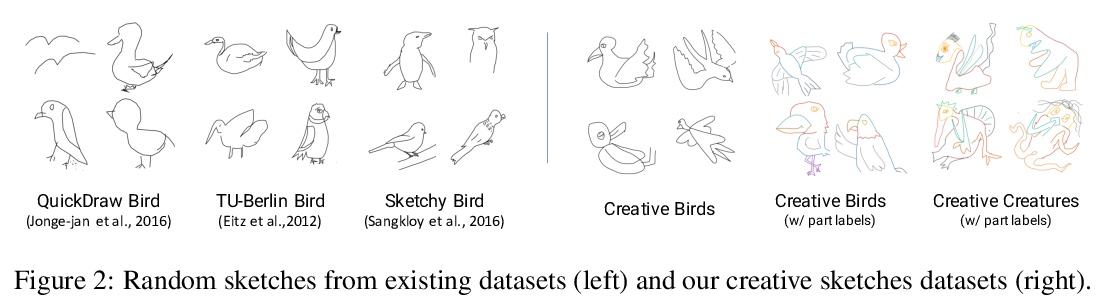
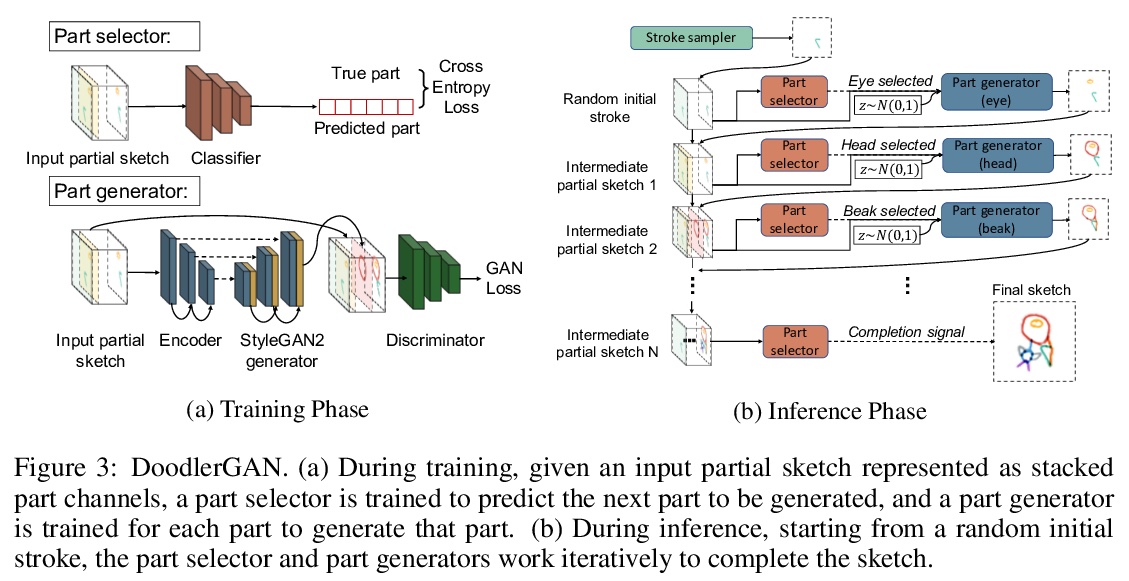
4、[CV] **Creative Sketch Generation
S Ge, V Goswami, C. L Zitnick, D Parikh
[University of Maryland & Facebook AI Research]
创造性涂鸦生成。收集了两个创造性涂鸦数据集——创造性的鸟和创造性生物,分别包含10k草图及部分标记。提出了DoodlerGAN图形生成模型,可生成未见的新奇部分外观组成。定量评估和人类研究表明,该方法生成的涂鸦比现有方法更具创造性,质量更高。**
Sketching or doodling is a popular creative activity that people engage in. However, most existing work in automatic sketch understanding or generation has focused on sketches that are quite mundane. In this work, we introduce two datasets of creative sketches — Creative Birds and Creative Creatures — containing 10k sketches each along with part annotations. We propose DoodlerGAN — a part-based Generative Adversarial Network (GAN) — to generate unseen compositions of novel part appearances. Quantitative evaluations as well as human studies demonstrate that sketches generated by our approach are more creative and of higher quality than existing approaches. In fact, in Creative Birds, subjects prefer sketches generated by DoodlerGAN over those drawn by humans! Our code can be found at > this https URL and a demo can be found at > this http URL.
https://weibo.com/1402400261/JuS6D1rie
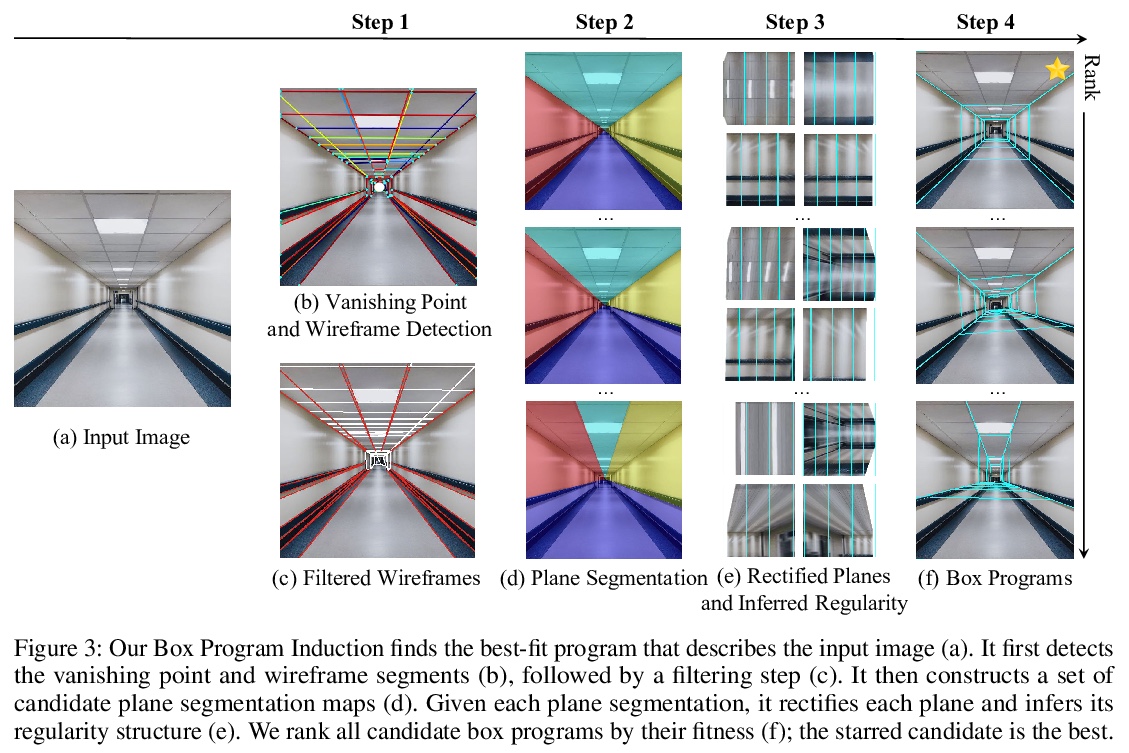
5、[CV] Multi-Plane Program Induction with 3D Box Priors
Y Li, J Mao, X Zhang, B Freeman, J Tenenbaum, N Snavely, J Wu
[MIT CSAIL & Google Research & Stanford University]
3D框先验多平面程序归纳。提出了框程序归纳(BPI),基于2D平面和3D平面规则纹理与模式的程序推理框架,可从单幅图像推断出类似程序的场景表示,同时对多个二维平面重复结构、三维位置和平面方向进行建模,推断程序可用于指导透视和规则感知的图像操作任务,实现3D感知交互式图像编辑,如补全、外推和视图合成等。
We consider two important aspects in understanding and editing images: modeling regular, program-like texture or patterns in 2D planes, and 3D posing of these planes in the scene. Unlike prior work on image-based program synthesis, which assumes the image contains a single visible 2D plane, we present Box Program Induction (BPI), which infers a program-like scene representation that simultaneously models repeated structure on multiple 2D planes, the 3D position and orientation of the planes, and camera parameters, all from a single image. Our model assumes a box prior, i.e., that the image captures either an inner view or an outer view of a box in 3D. It uses neural networks to infer visual cues such as vanishing points, wireframe lines to guide a search-based algorithm to find the program that best explains the image. Such a holistic, structured scene representation enables 3D-aware interactive image editing operations such as inpainting missing pixels, changing camera parameters, and extrapolate the image contents.
https://weibo.com/1402400261/JuSdhvD7a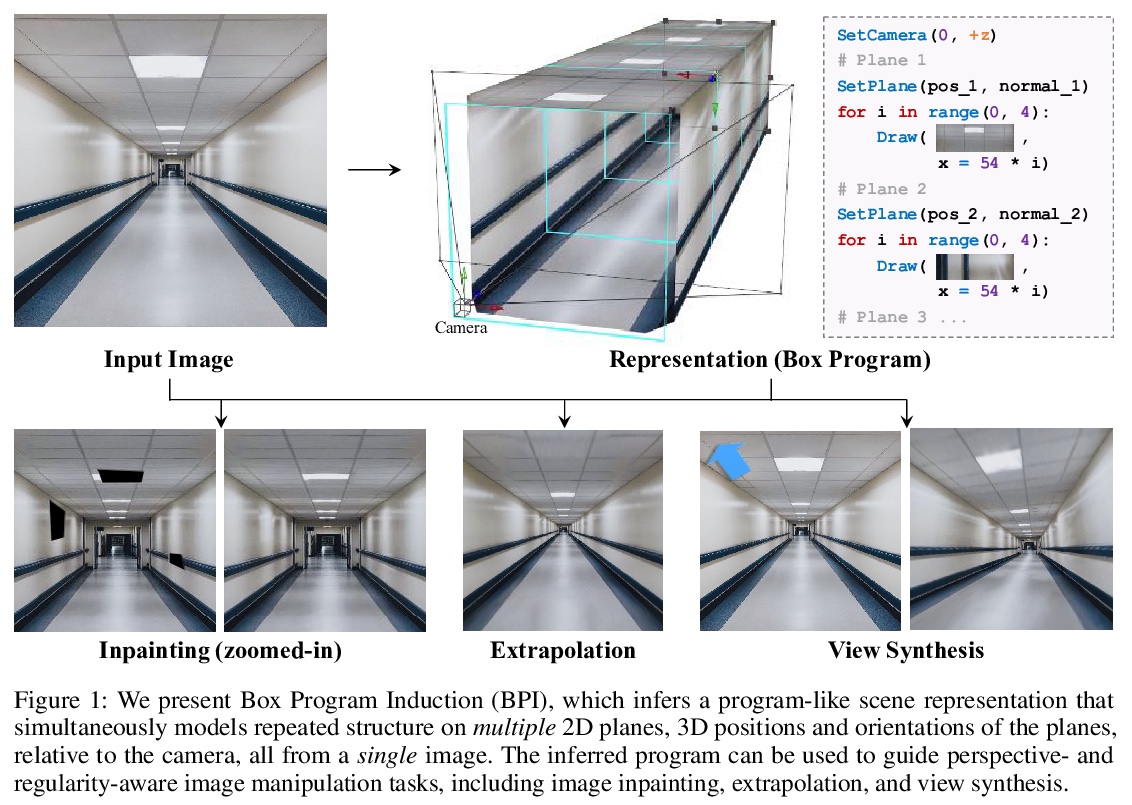

其他几篇值得关注的论文:
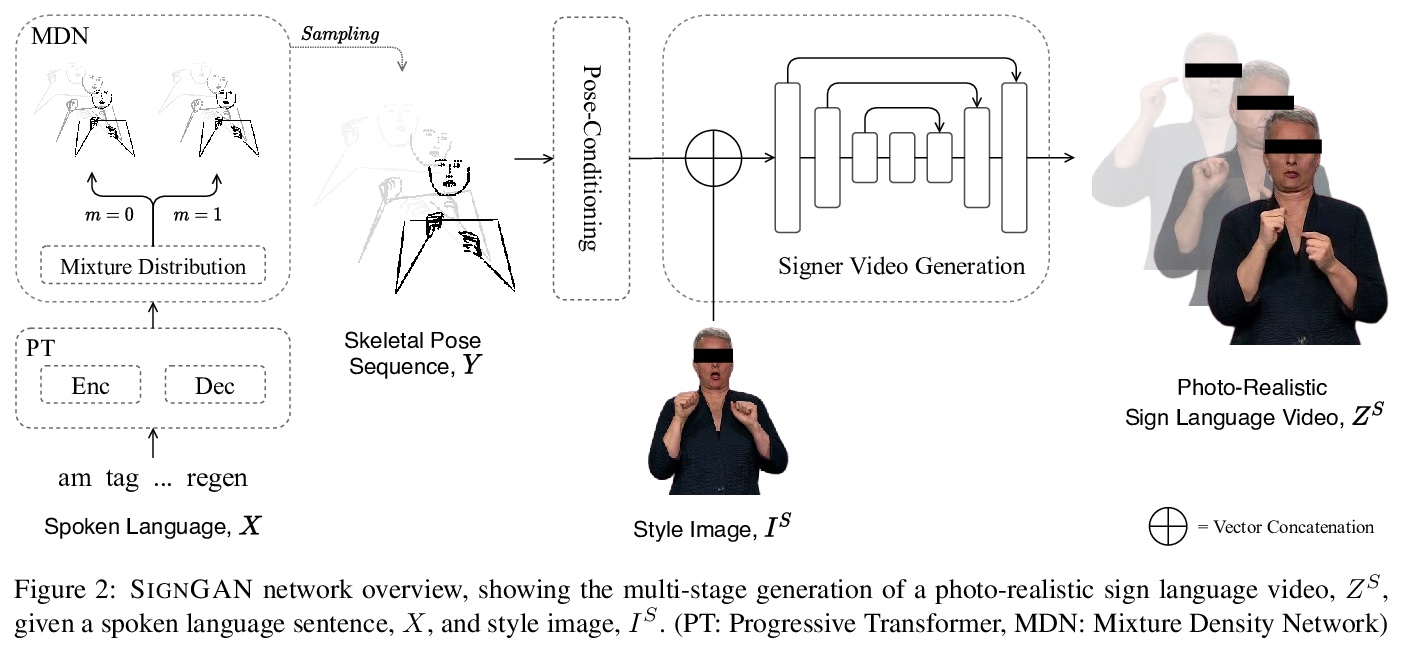
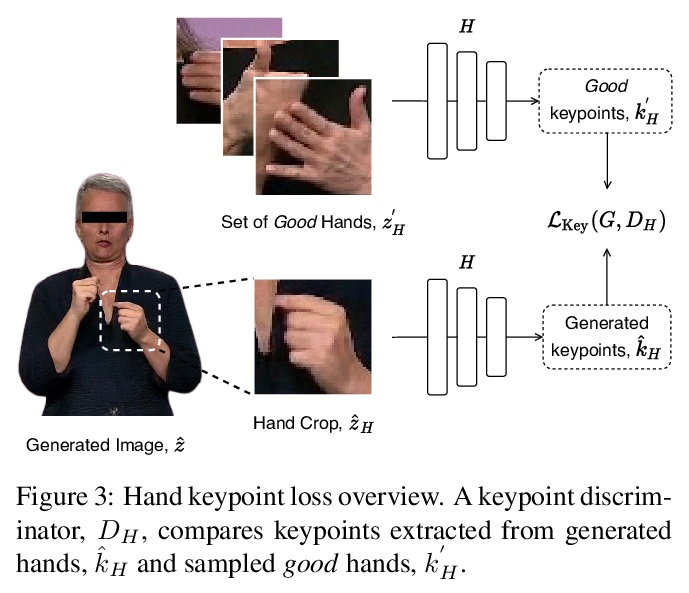
[CV] Everybody Sign Now: Translating Spoken Language to Photo Realistic Sign Language Video
真人手语合成:将口语翻译成照片级手语视频
B Saunders, N C Camgoz, R Bowden
[University of Surrey]
https://weibo.com/1402400261/JuSkfduFq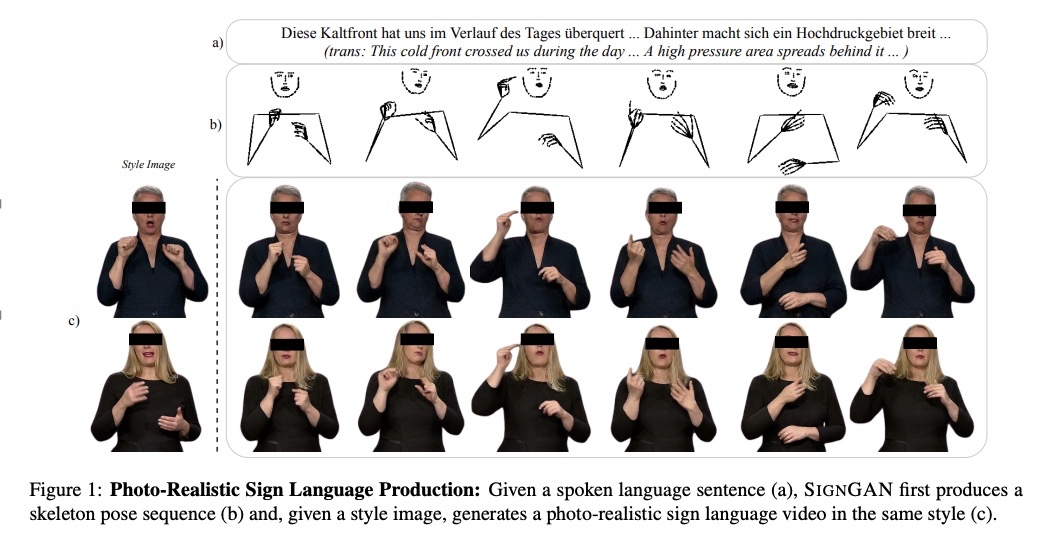

若有收获,就点个赞吧
0 人点赞
