- 1、[CL] WikiGraphs: A Wikipedia Text - Knowledge Graph Paired Dataset
- 2、[LG] Large-scale graph representation learning with very deep GNNs and self-supervision
- 3、[CL] Conversational Question Answering: A Survey
- 4、[LG] Optimal Complexity in Decentralized Training
- 5、[CL] Neural Abstructions: Abstractions that Support Construction for Grounded Language Learning
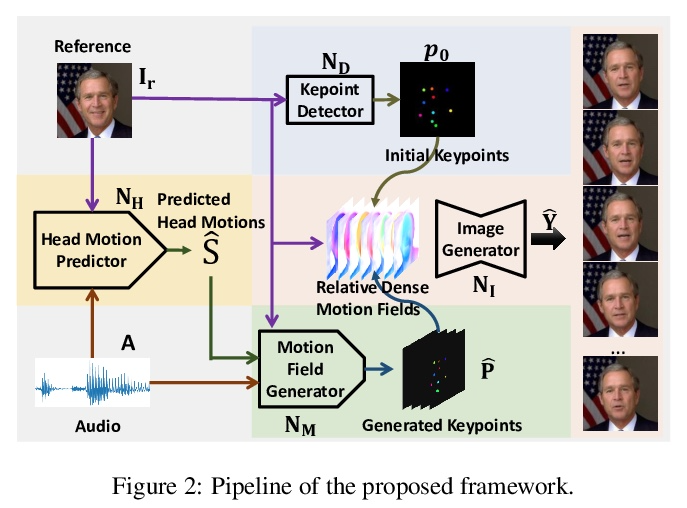
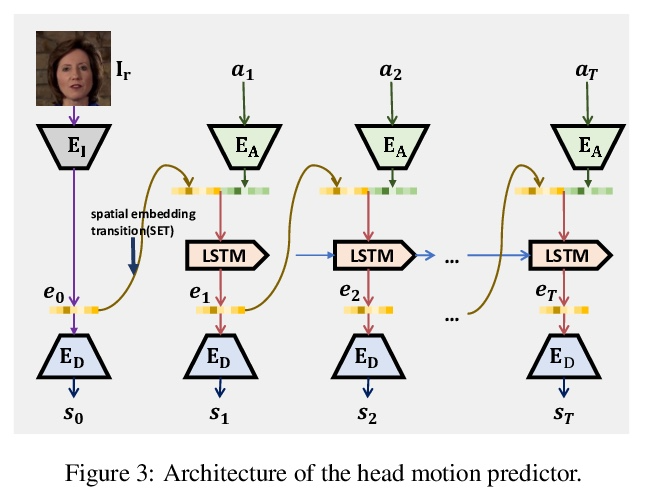
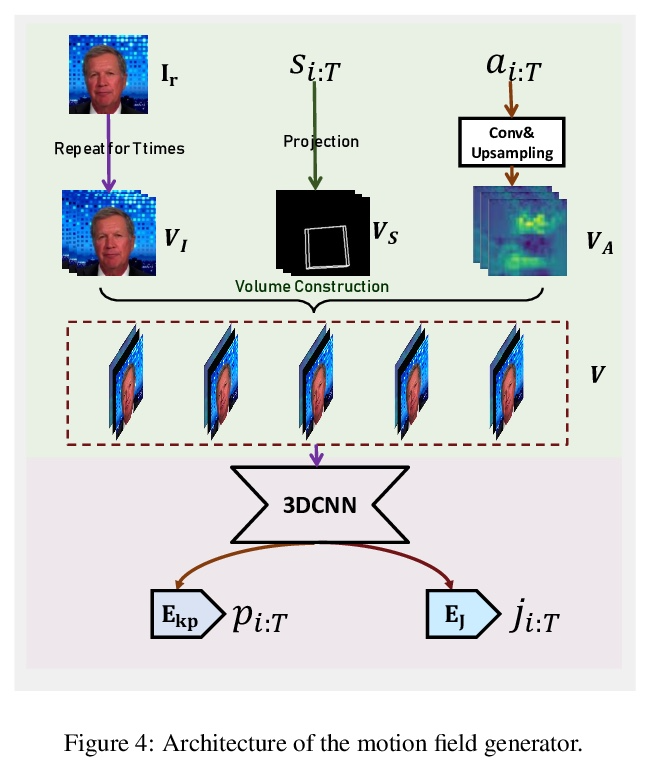
- [CV] Audio2Head: Audio-driven One-shot Talking-head Generation with Natural Head Motion
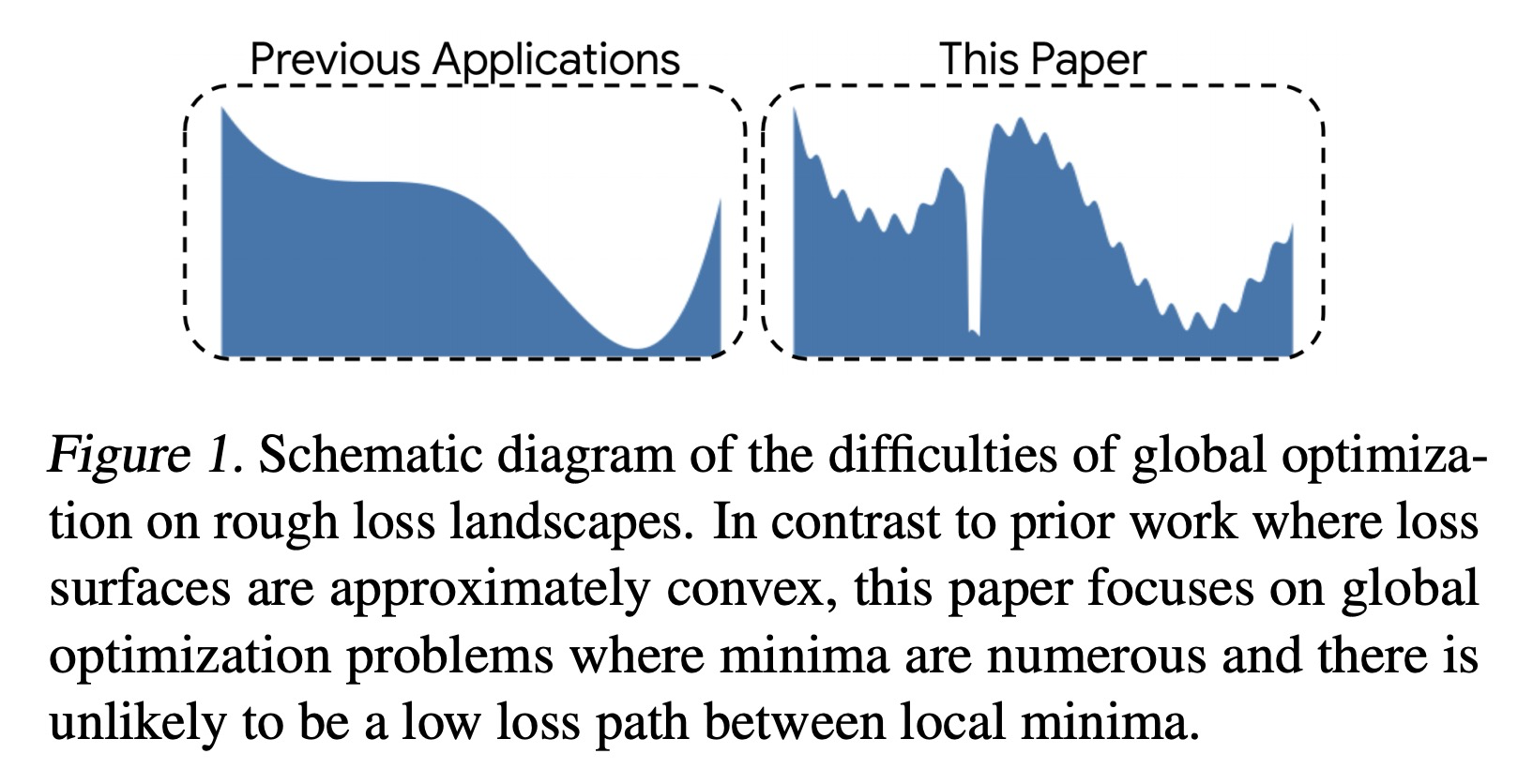
- [LG] Learn2Hop: Learned Optimization on Rough Landscapes
- [LG] Open Problem: Is There an Online Learning Algorithm That Learns Whenever Online Learning Is Possible?
- [CV] ReSSL: Relational Self-Supervised Learning with Weak Augmentation
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[CL] WikiGraphs: A Wikipedia Text - Knowledge Graph Paired Dataset
L Wang, Y Li, O Aslan, O Vinyals
[DeepMind]
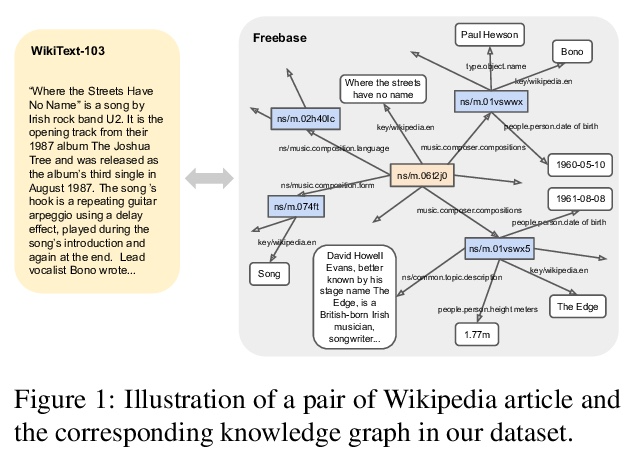
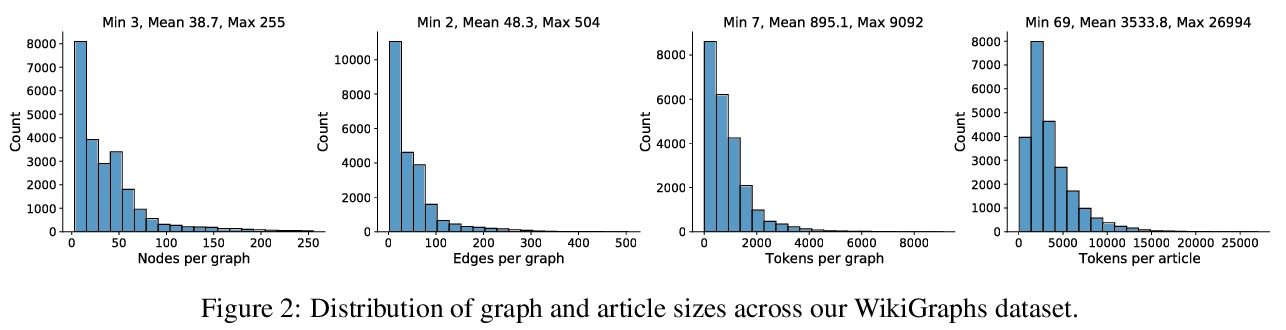
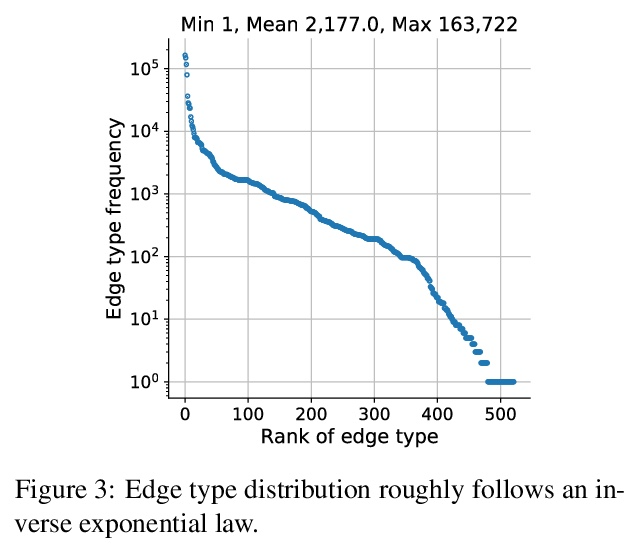
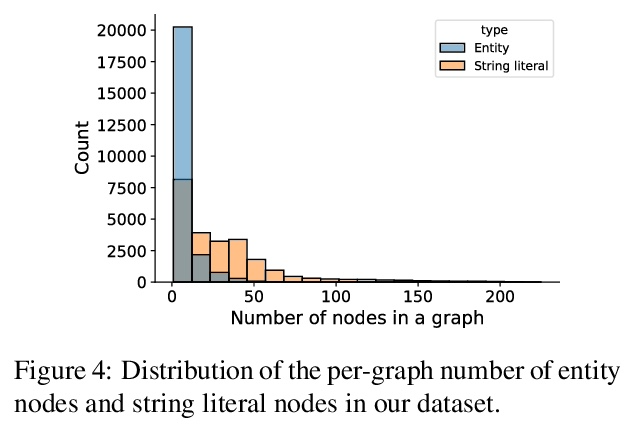
WikiGraphs:维基百科文本-知识图谱配对数据集。本文提出一个新的维基百科文章数据集,每篇文章都与一个知识图谱配对,以促进条件文本生成、图谱生成和图谱表示学习方面的研究。现有的图-文本配对数据集通常包含小的图和短小的文本(1句或几句),限制了可以在数据上学习的模型的能力。WikiGraphs通过将已建立的WikiText-103基准中的每篇维基百科文章与Freebase知识图谱中的一个子图配对收集,很容易相对其他能够生生成段连贯文本的最先进的文本生成模型进行评测。与之前的图-文本配对数据集相比,图和文本数据的规模都要大得多。在该数据集上展示了基线图神经网络和transformer模型在3个任务上的结果:图→文本生成、图→文本检索和文本→图检索。结果表明,对图进行更好的调节可以提高生成和检索的质量,但仍有很大的改进空间。
We present a new dataset of Wikipedia articles each paired with a knowledge graph, to facilitate the research in conditional text generation, graph generation and graph representation learning. Existing graph-text paired datasets typically contain small graphs and short text (1 or few sentences), thus limiting the capabilities of the models that can be learned on the data. Our new dataset WikiGraphs is collected by pairing each Wikipedia article from the established WikiText-103 benchmark (Merity et al., 2016) with a subgraph from the Freebase knowledge graph (Bollacker et al., 2008). This makes it easy to benchmark against other state-of-the-art text generative models that are capable of generating long paragraphs of coherent text. Both the graphs and the text data are of significantly larger scale compared to prior graph-text paired datasets. We present baseline graph neural network and transformer model results on our dataset for 3 tasks: graph → text generation, graph→ text retrieval and text → graph retrieval. We show that better conditioning on the graph provides gains in generation and retrieval quality but there is still large room for improvement.
https://weibo.com/1402400261/KpQOW9hha 
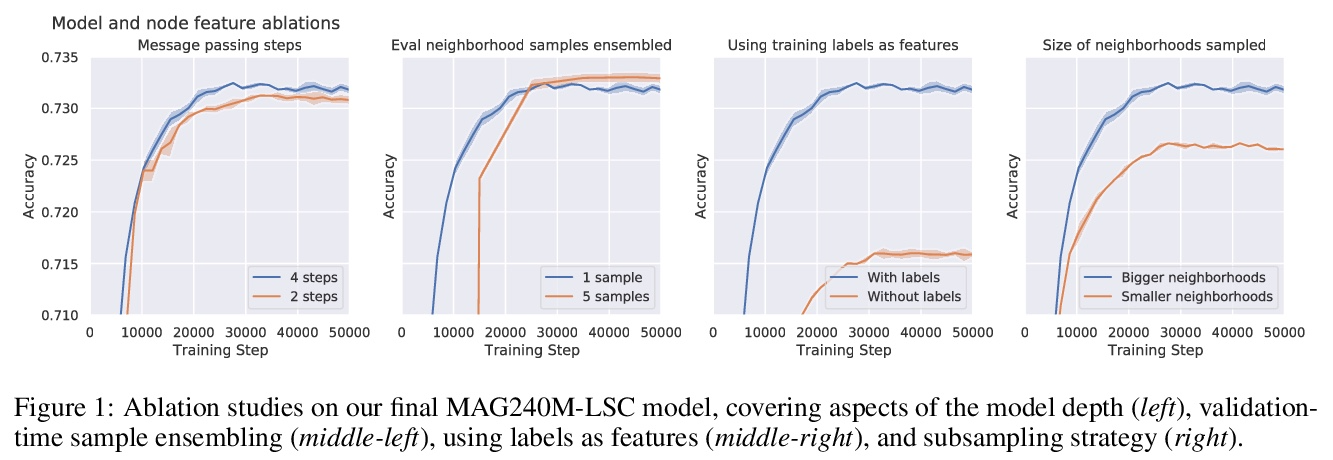
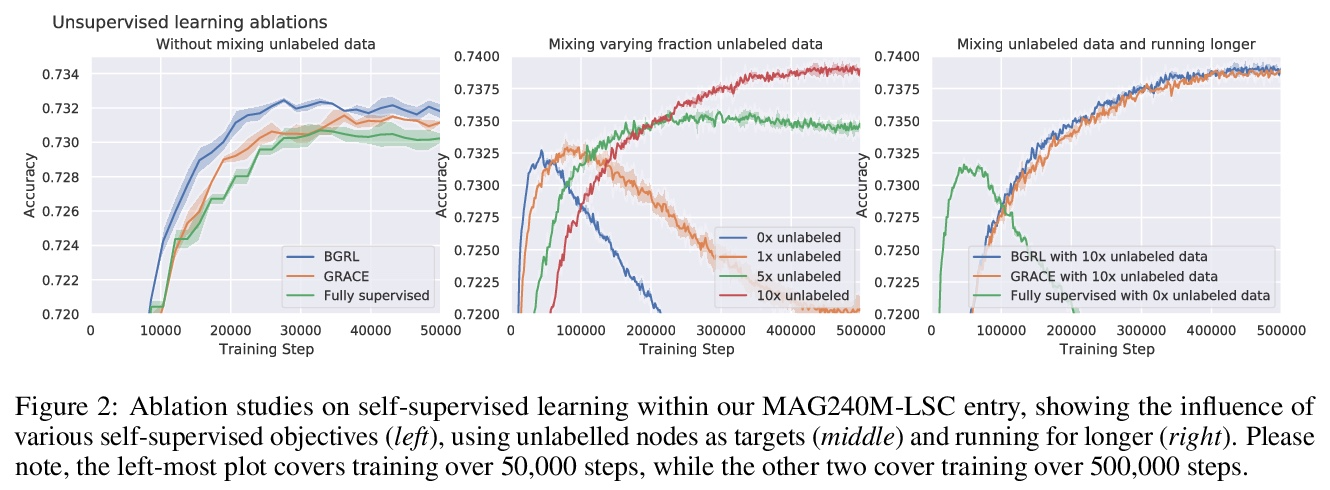
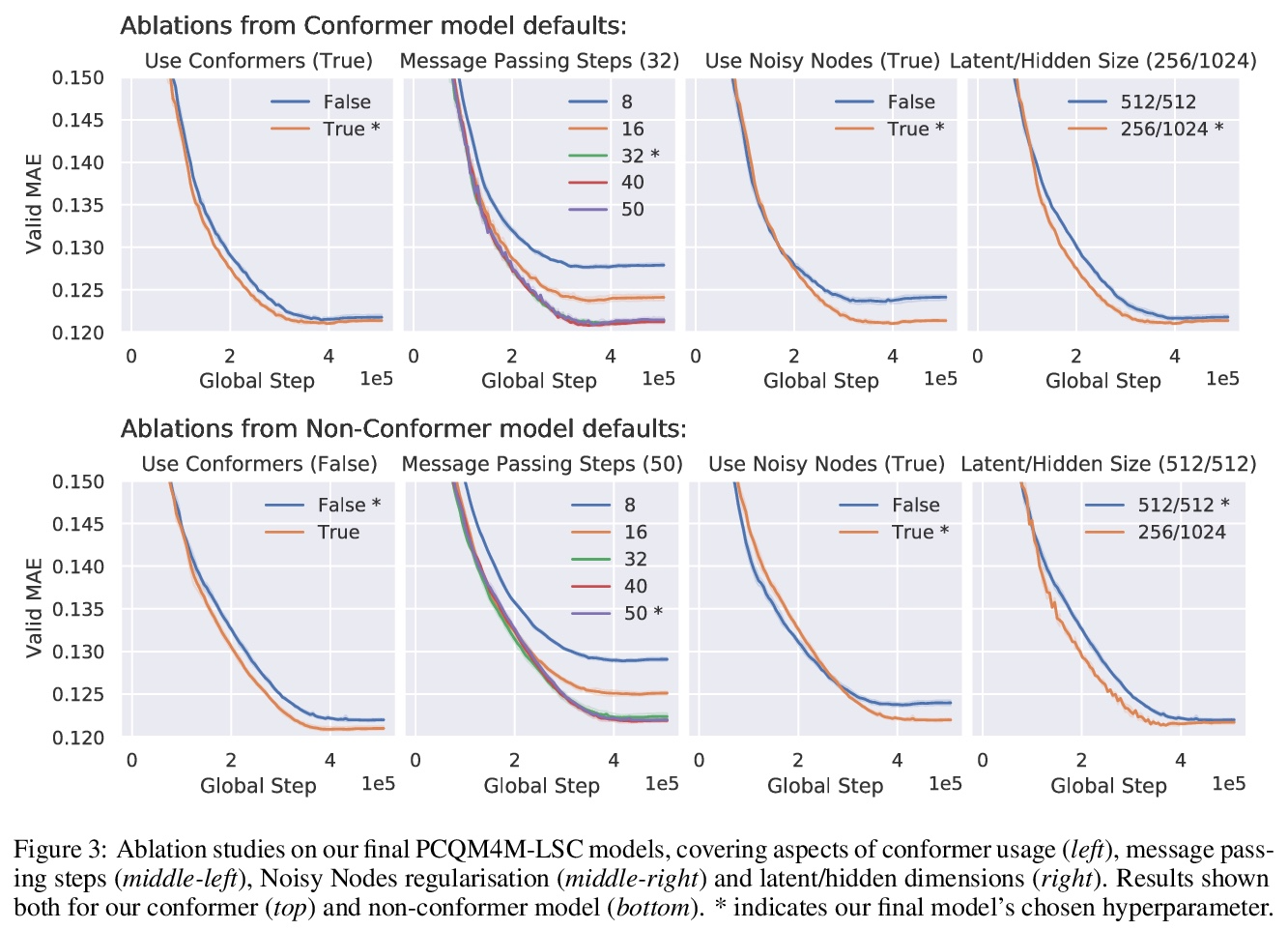
2、[LG] Large-scale graph representation learning with very deep GNNs and self-supervision
R Addanki, P W. Battaglia, D Budden, A Deac, J Godwin, T Keck, W L S Li, A Sanchez-Gonzalez, J Stott, S Thakoor, P Veličković
[DeepMind]
用极深的GNN和自监督进行大规模的图表示学习。有效且高效地大规模部署图神经网络(GNN)仍然是图表示学习最大挑战之一。许多强大的解决方案只在相对较小的数据集上得到了验证,往往会出现反直觉的结果——这一障碍已经被开放图谱基准大规模挑战赛(OGB-LSC)所打破。本文携两个大规模GNN参加了OGB-LSC:一个由bootstrapping驱动的深度归纳节点分类器,以及一个由去噪目标规范化的非常深(多达50层)的归纳图回归器。两模型在MAG240M和PCQM4M基准测试中都取得了获奖级别(前三名)的表现。在此过程中,展示了可扩展的自监督图表示学习的证据,以及非常深的GNN的效用。
Effectively and efficiently deploying graph neural networks (GNNs) at scale remains one of the most challenging aspects of graph representation learning. Many powerful solutions have only ever been validated on comparatively small datasets, often with counter-intuitive outcomes—a barrier which has been broken by the Open Graph Benchmark Large-Scale Challenge (OGB-LSC). We entered the OGB-LSC with two large-scale GNNs: a deep transductive node classifier powered by bootstrapping, and a very deep (up to 50-layer) inductive graph regressor regularised by denoising objectives. Our models achieved an award-level (top-3) performance on both the MAG240M and PCQM4M benchmarks. In doing so, we demonstrate evidence of scalable self-supervised graph representation learning, and utility of very deep GNNs—both very important open issues.
https://weibo.com/1402400261/KpQTuhAum 
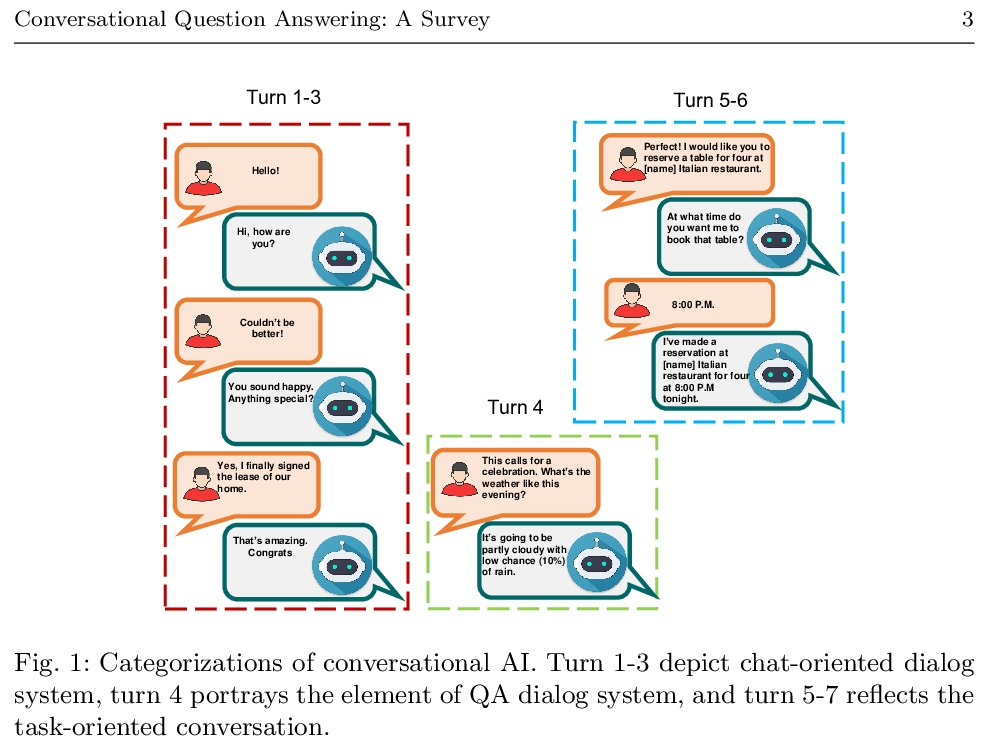
3、[CL] Conversational Question Answering: A Survey
M Zaib, W E Zhang, Q Z. Sheng, A Mahmood, Y Zhang
[Macquarie Universie & University of Adelai]
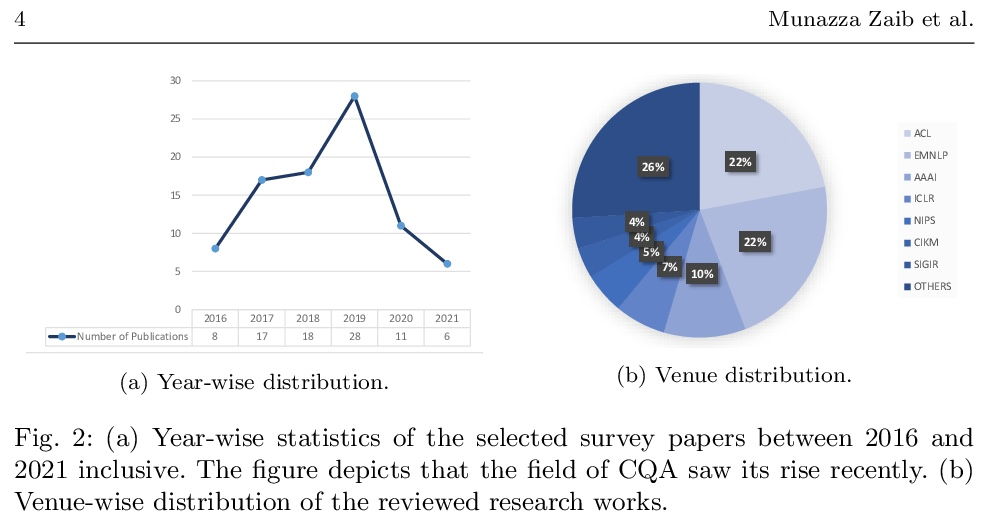
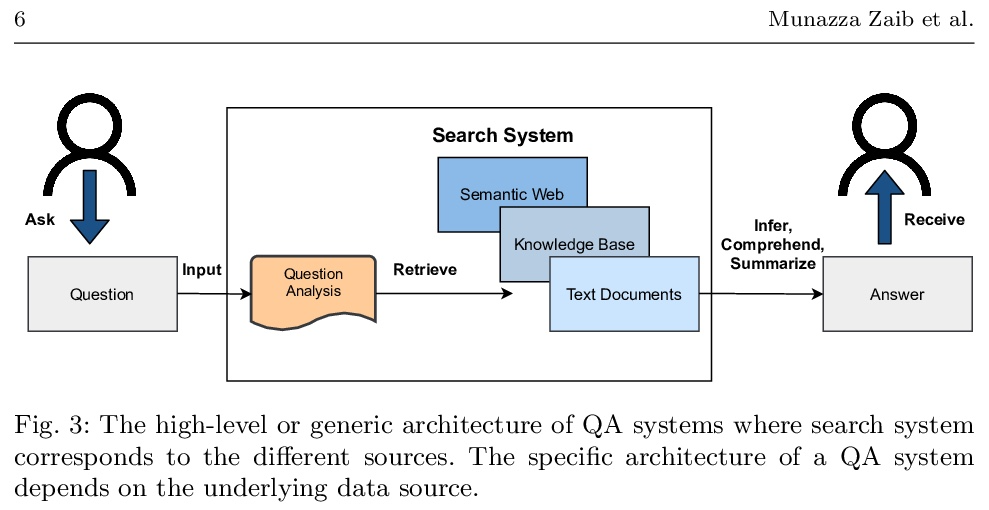
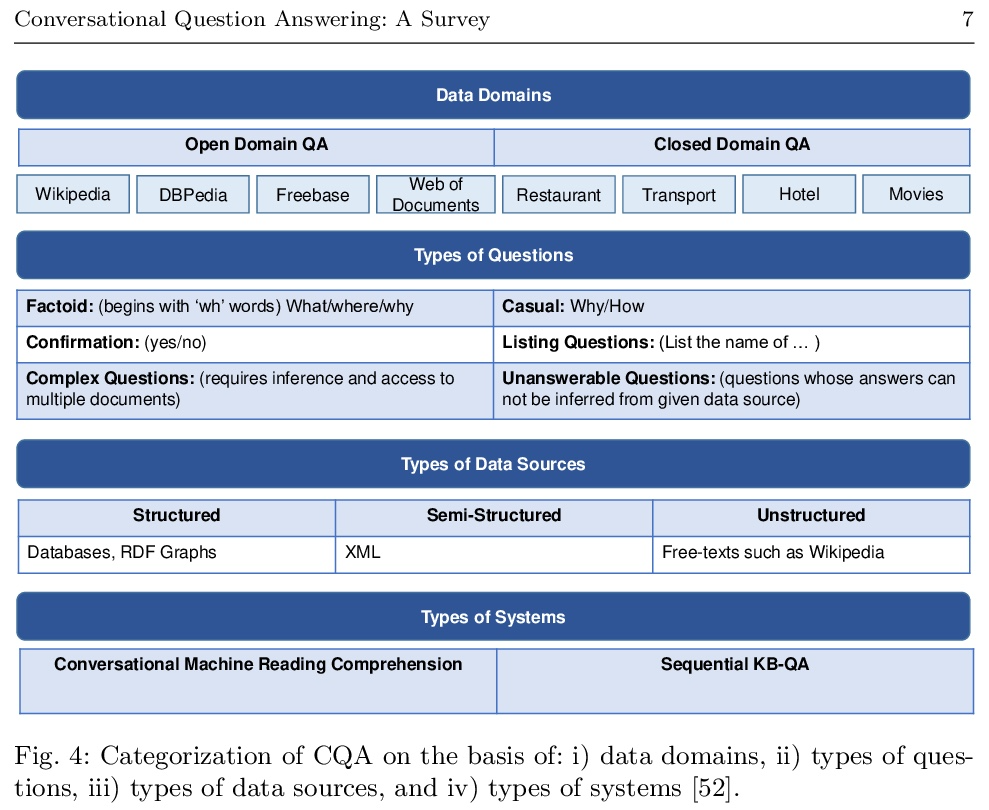
对话式问答综述。问答(QA)系统提供了查询各种格式信息的一种方式,包括但不限于自然语言的非结构化和结构化数据。它构成了对话式人工智能(AI)的一个重要部分,这导致了对话式问答(CQA)这一特殊研究课题的引入,其中系统需要理解给定环境,然后参与多轮QA以满足用户的信息需求。虽然大多数现有的研究工作的重点是在单轮QA上,但由于大规模的多轮QA数据集的出现和预训练语言模型的发展,多轮QA领域最近得到了更多关注。最近,每年都有大量的模型和研究论文加入到文献中,迫切需要以统一的方式规划和介绍相关工作,以简化未来的研究。因此,本综述主要是根据2016-2021年的评审论文,努力对CQA的最先进研究趋势进行全面回顾。本文发现表明,已经出现了从单轮到多轮QA的趋势转变,这从不同的角度增强了对话式人工智能领域的能力。
Question answering (QA) systems provide a way of querying the information available in various formats including, but not limited to, unstructured and structured data in natural languages. It constitutes a considerable part of conversational artificial intelligence (AI) which has led to the introduction of a special research topic on Conversational Question Answering (CQA), wherein a system is required to understand the given context and then engages in multi-turn QA to satisfy a user’s information needs. Whilst the focus of most of the existing research work is subjected to single-turn QA, the field of multi-turn QA has recently grasped attention and prominence owing to the availability of large-scale, multiturn QA datasets and the development of pre-trained language models. With a good amount of models and research papers adding to the literature every year recently, there is a dire need of arranging and presenting the related work in a unified manner to streamline future research. This survey, therefore, is an effort to present a comprehensive review of the state-of-the-art research trends of CQA primarily based on reviewed papers from 2016-2021. Our findings show that there has been a trend shift from single-turn to multi-turn QA which empowers the field of Conversational AI from different perspectives. This survey is intended to provide an epitome for the research community with the hope of laying a strong foundation for the field of CQA.
https://weibo.com/1402400261/KpQWq2sJ7 
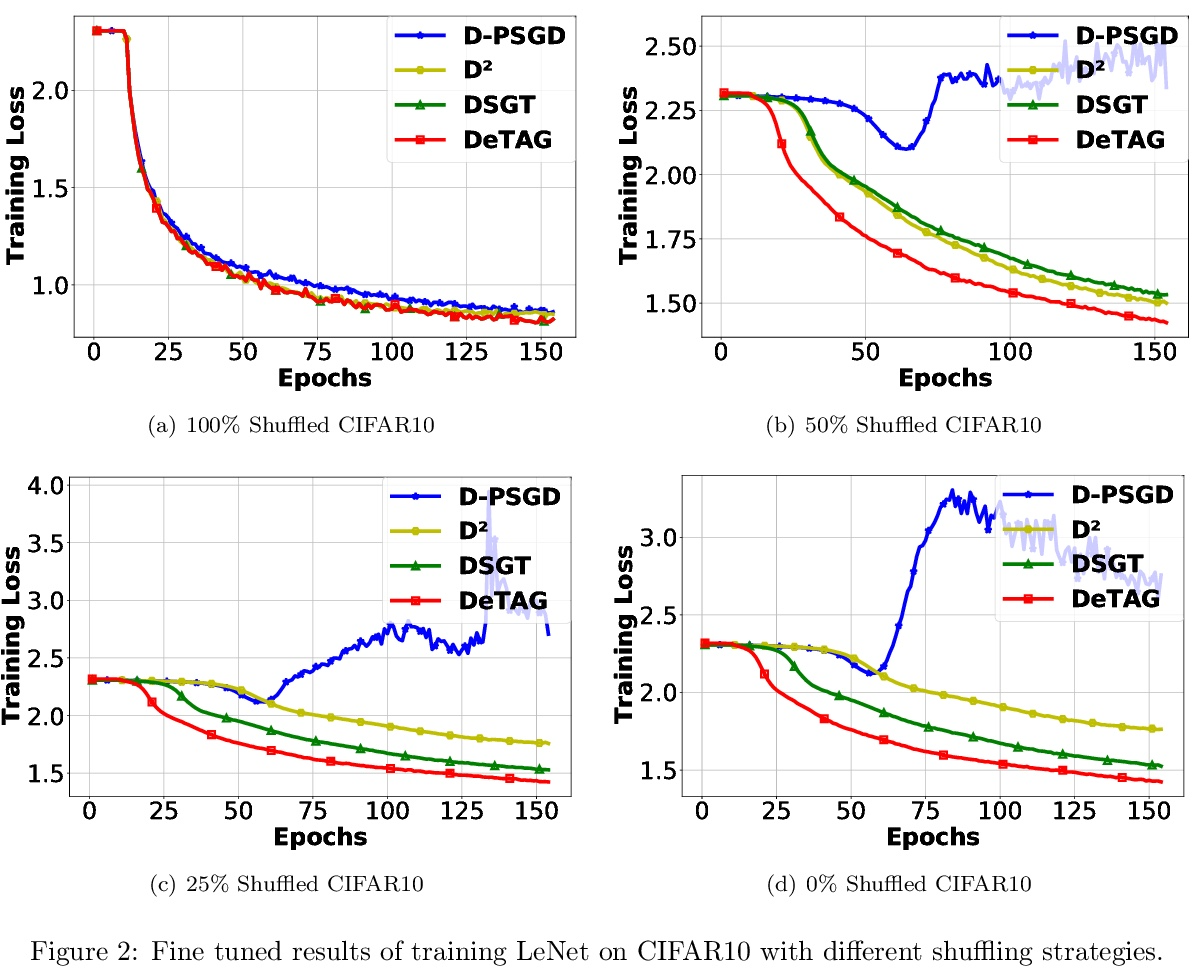
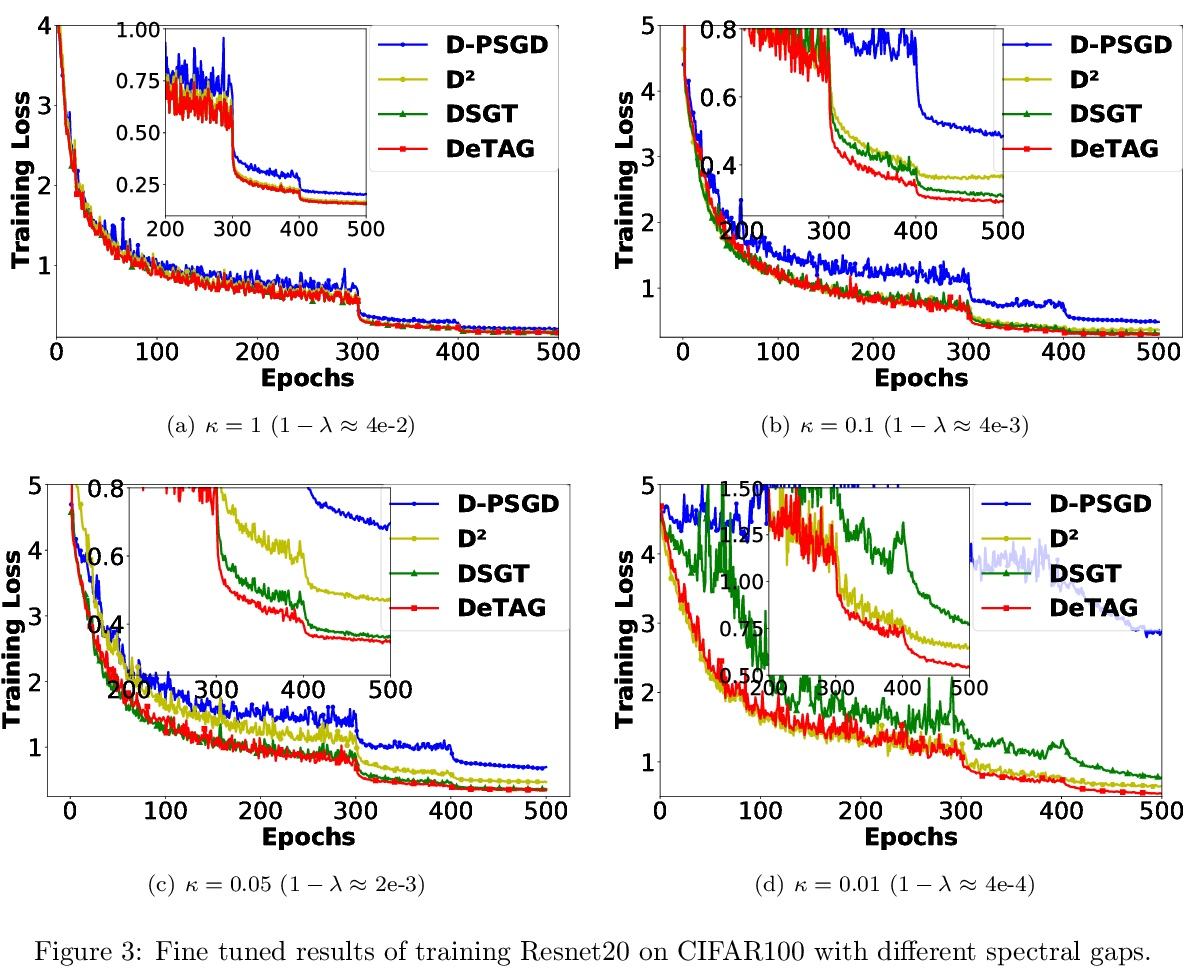
4、[LG] Optimal Complexity in Decentralized Training
Y Lu, C D Sa
[Cornell University]
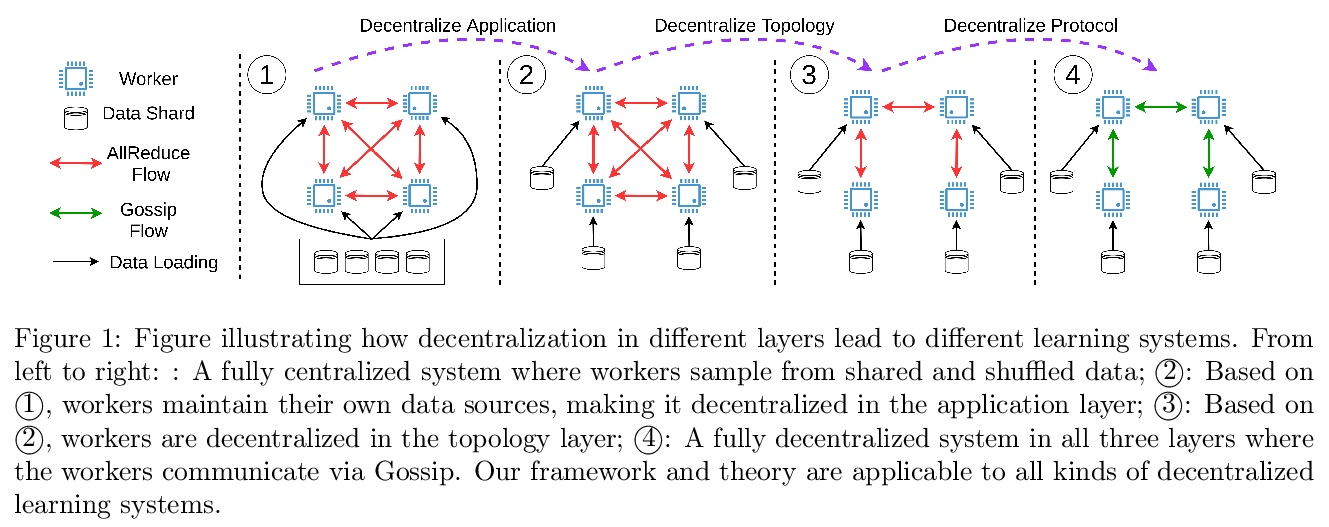
分散训练中的最优复杂度。分散化是扩大并行机器学习系统规模的一种有前途的方法。本文为这种方法在随机非凸环境下的迭代复杂性提供了一个严格的下界,该下界揭示了许多现有分散训练算法(如D-PSGD)的已知收敛率的理论差距。通过构造证明了这个下界是严格的和可实现的。进一步提出了DeTAG,一种实用的Gossip协议分散算法,只用对数差距就能达到下界。在经验上,将DeTAG与其他分散式算法在图像分类任务上进行了比较,表明DeTAG与基线相比具有更快的收敛性,特别是在非洗练数据和稀疏网络中。
Decentralization is a promising method of scaling up parallel machine learning systems. In this paper, we provide a tight lower bound on the iteration complexity for such methods in a stochastic non-convex setting. Our lower bound reveals a theoretical gap in known convergence rates of many existing decentralized training algorithms, such as D-PSGD. We prove by construction this lower bound is tight and achievable. Motivated by our insights, we further propose DeTAG, a practical gossip-style decentralized algorithm that achieves the lower bound with only a logarithm gap. Empirically, we compare DeTAG with other decentralized algorithms on image classification tasks, and we show DeTAG enjoys faster convergence compared to baselines, especially on unshuffled data and in sparse networks.
https://weibo.com/1402400261/KpQZaxhf1 
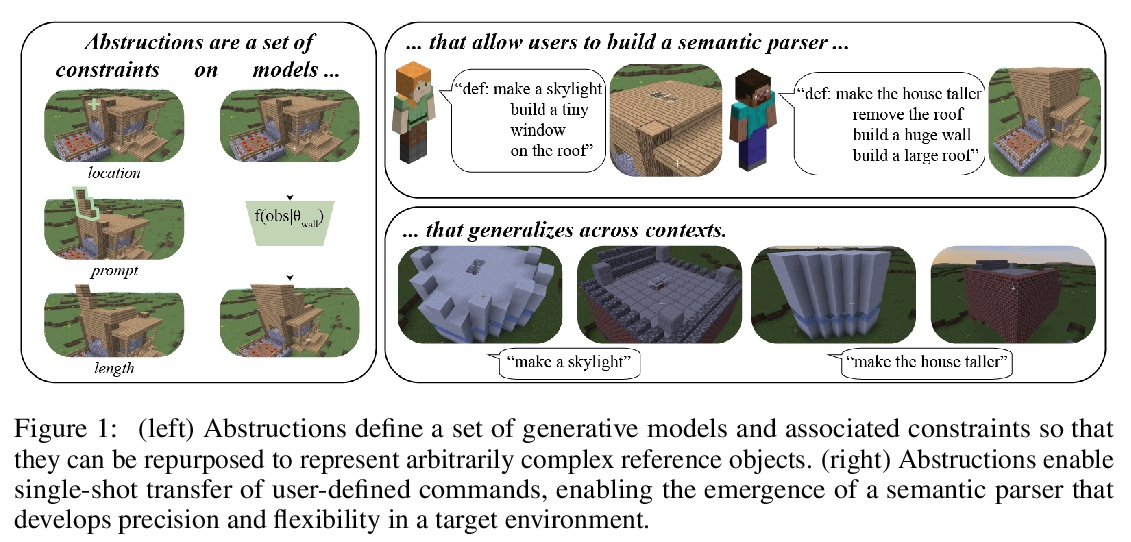
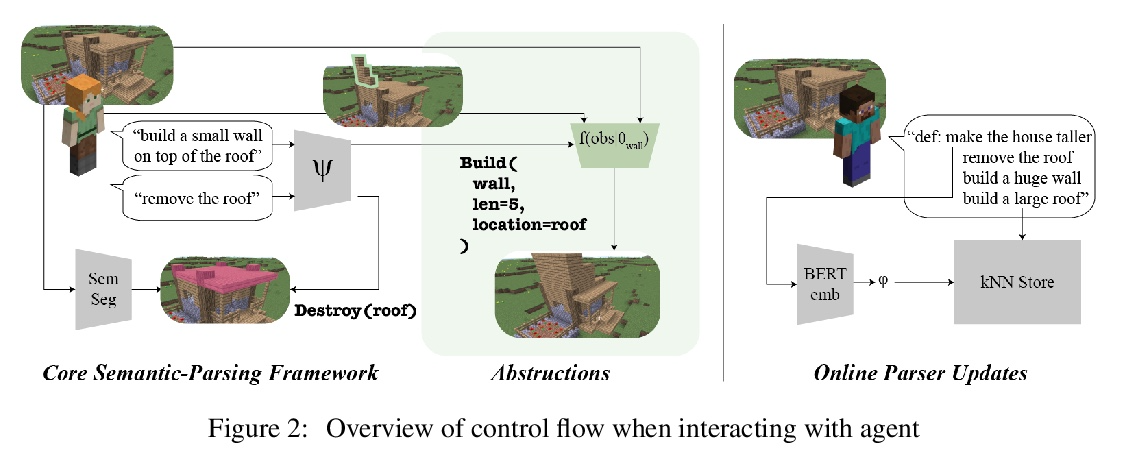
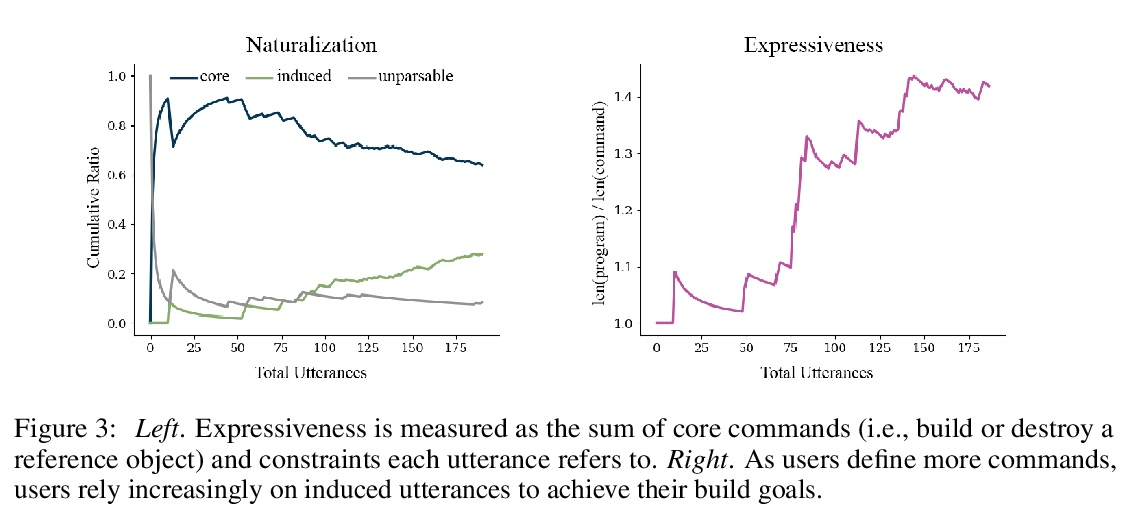
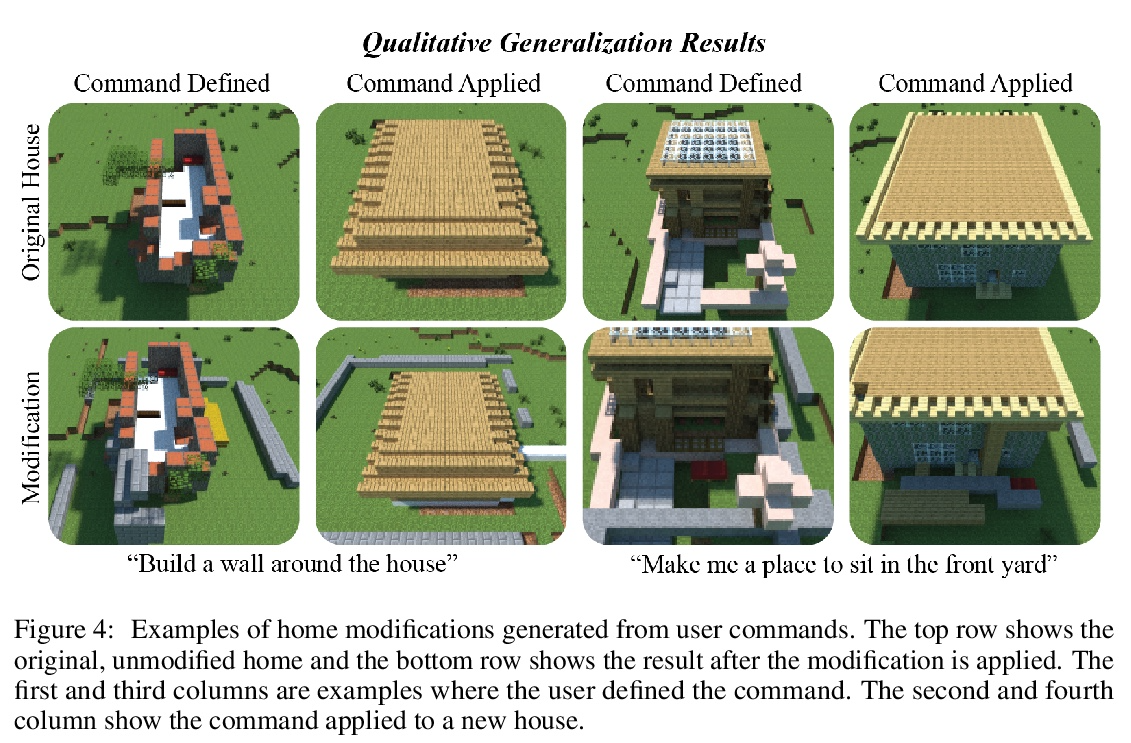
5、[CL] Neural Abstructions: Abstractions that Support Construction for Grounded Language Learning
K Burns, C D. Manning, L Fei-Fei
[Stanford University]
Neural Abstructions:支持基础语言学习构建的抽象。尽管虚拟智能体越来越多地处于自然语言作为与人类互动最有效模式的环境中,但这些交流很少被用作学习的机会。有效利用语言互动需要解决两种最常见的语言基础方法的局限性:建立在固定对象类别之上的语义解析器是精确的,但不灵活;端到端模型具有强大的表现力,但易变且不透明。本文的目标是开发一个系统,平衡每种方法的优势,以便用户可以教给智能体新指令,从单一实例实现泛化。本文引入了Neural Abstructions的概念:一组对标签条件生成模型的推理过程的约束,可影响标签在上下文中的意义。从一个在abstruction上操作的核心编程语言开始,用户可以定义越来越复杂的从自然语言到行动的映射。通过这种方法,一个用户群体能够为Minecraft中的开放式房屋改造任务建立一个语义分析器。由此产生的语义解析器既灵活又富有表现力:在191次总的交流过程中,来自于重新定义的语料的百分比稳步增加,最终达到28%的数值。
Although virtual agents are increasingly situated in environments where natural language is the most effective mode of interaction with humans, these exchanges are rarely used as an opportunity for learning. Leveraging language interactions effectively requires addressing limitations in the two most common approaches to language grounding: semantic parsers built on top of fixed object categories are precise but inflexible and end-to-end models are maximally expressive, but fickle and opaque. Our goal is to develop a system that balances the strengths of each approach so that users can teach agents new instructions that generalize broadly from a single example. We introduce the idea of neural abstructions: a set of constraints on the inference procedure of a label-conditioned generative model that can affect the meaning of the label in context. Starting from a core programming language that operates over abstructions, users can define increasingly complex mappings from natural language to actions. We show that with this method a user population is able to build a semantic parser for an open-ended house modification task in Minecraft. The semantic parser that results is both flexible and expressive: the percentage of utterances sourced from redefinitions increases steadily over the course of 191 total exchanges, achieving a final value of 28%.
https://weibo.com/1402400261/KpR2LkkeV 
另外几篇值得关注的论文:
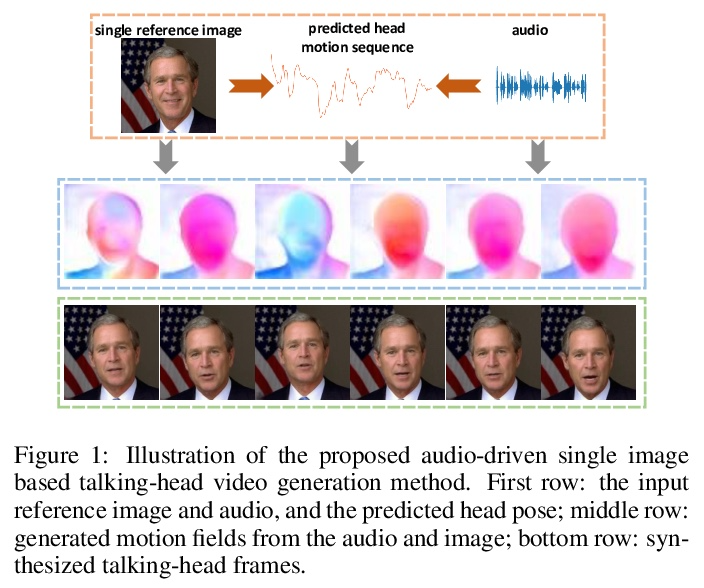
[CV] Audio2Head: Audio-driven One-shot Talking-head Generation with Natural Head Motion
Audio2Head:音频驱动的具有自然头部运动的单样本说话头部生成
S Wang, L Li, Y Ding, C Fan, X Yu
[Netease Fuxi AI Lab & University of Technology Sydney]
https://weibo.com/1402400261/KpRfUEmzw 
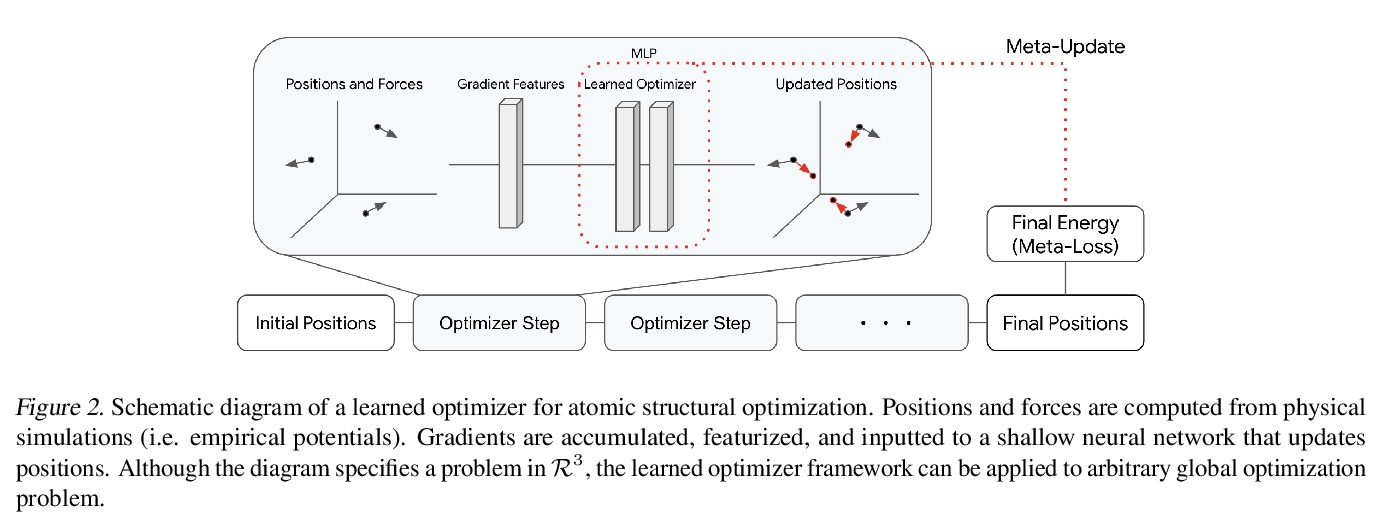
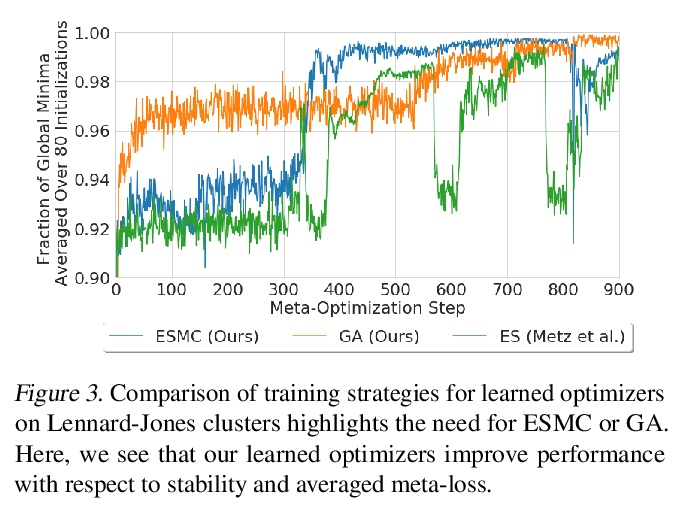
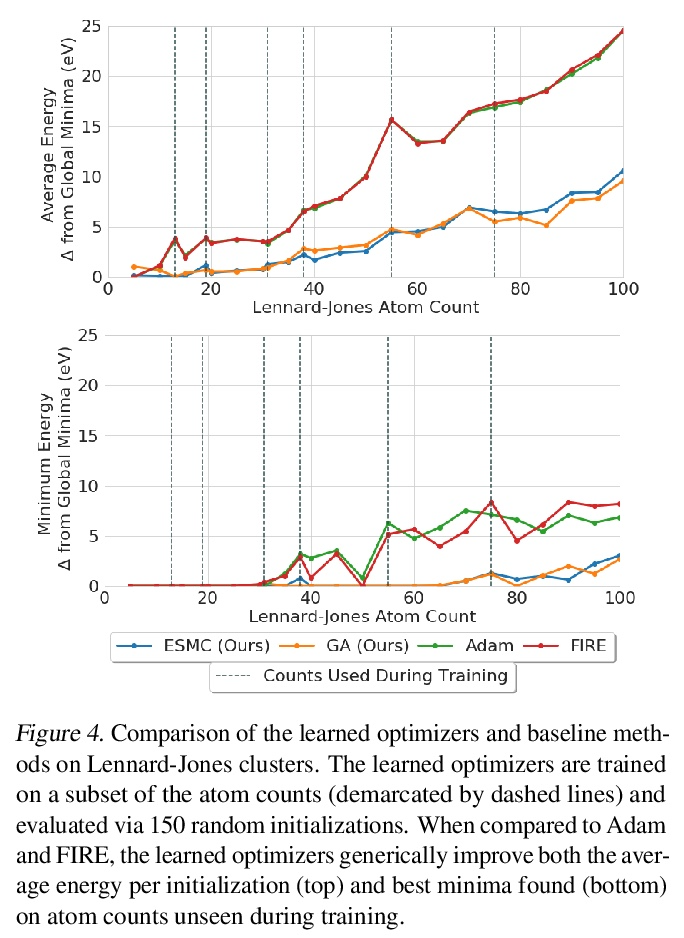
[LG] Learn2Hop: Learned Optimization on Rough Landscapes
Learn2Hop:粗糙景观习得优化
A Merchant, L Metz, S Schoenholz, E D Cubuk
[Google Research]
https://weibo.com/1402400261/KpRv85rYQ 
[LG] Open Problem: Is There an Online Learning Algorithm That Learns Whenever Online Learning Is Possible?
开放问题:有没有一种在线学习算法只要在线学习有可能就会学习?
S Hanneke
[Toyota Technological Institute at Chicago]
https://weibo.com/1402400261/KpRwCCYt5 
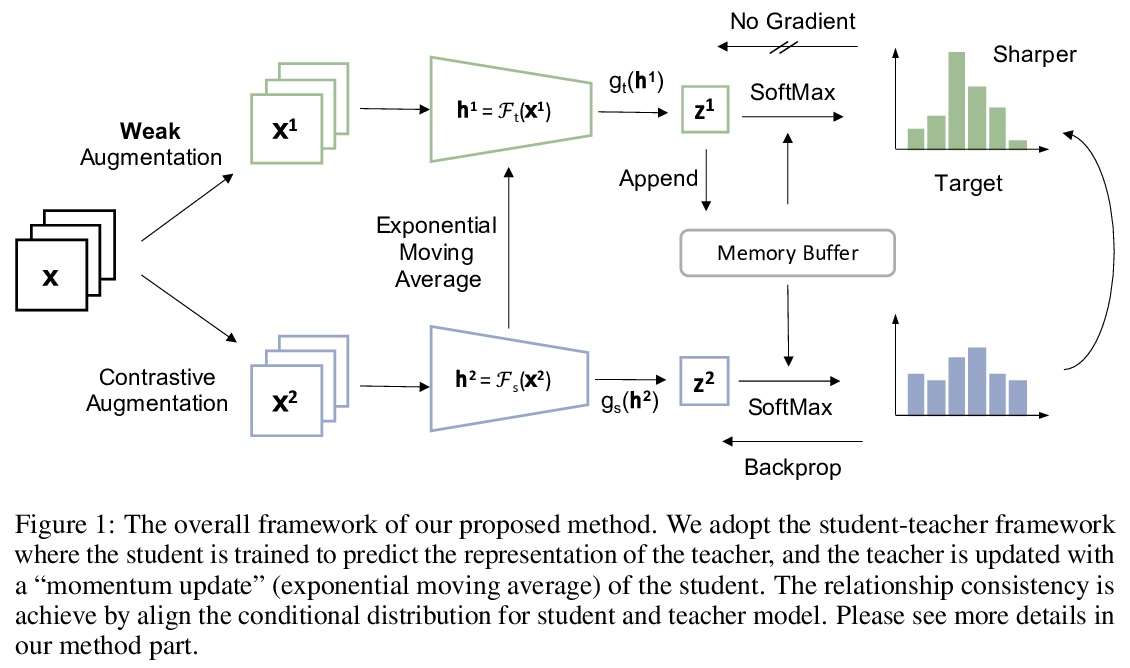
[CV] ReSSL: Relational Self-Supervised Learning with Weak Augmentation
ReSSL:弱增强的关系自监督学习
M Zheng, S You, F Wang, C Qian, C Zhang, X Wang, C Xu
[SenseTime Research & Tsinghua University & The University of Sydney]
https://weibo.com/1402400261/KpRyThhr5 



若有收获,就点个赞吧
0 人点赞
