- 1、[CV] iMAP: Implicit Mapping and Positioning in Real-Time
- 2、[LG] Generative Minimization Networks: Training GANs Without Competition
- 3、[CV] Scaling Local Self-Attention For Parameter Efficient Visual Backbones
- 4、[CV] Self-Supervised Pretraining Improves Self-Supervised Pretraining
- 5、[CV] Transformers Solve the Limited Receptive Field for Monocular Depth Prediction
- [RO] Spatial Intention Maps for Multi-Agent Mobile Manipulation
- [CV] End-to-End Trainable Multi-Instance Pose Estimation with Transformers
- [CL] Multilingual Autoregressive Entity Linking
- [CV] Leveraging background augmentations to encourage semantic focus in self-supervised contrastive learning
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] iMAP: Implicit Mapping and Positioning in Real-Time
E Sucar, S Liu, J Ortiz, A J. Davison
[Imperial College London]
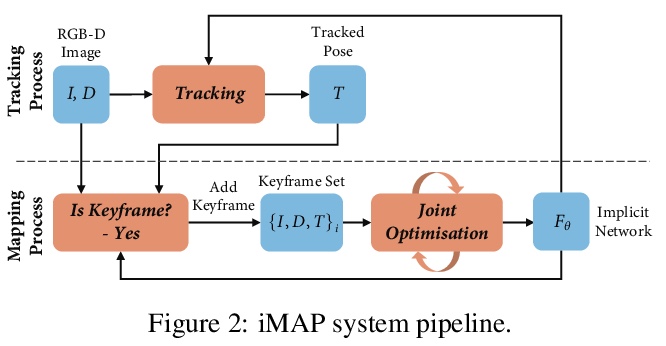
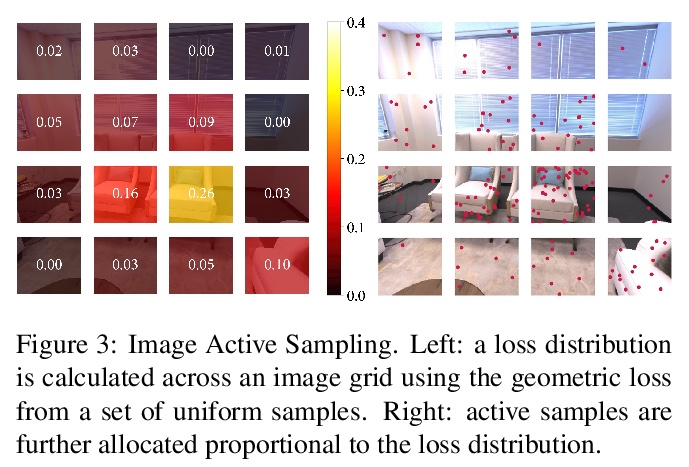
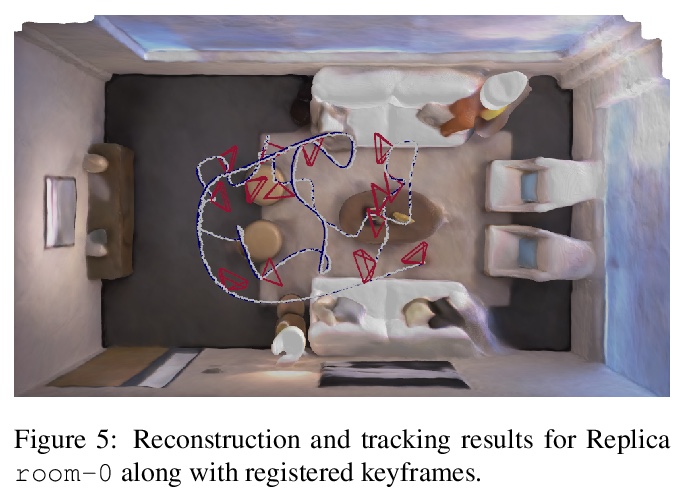
iMAP:实时隐式测绘与定位。提出一个基于隐式神经网络场景表示的密集实时SLAM系统,能联合优化完整3D地图和相机姿态。将密集SLAM视为实时持续学习,并表明MLP可以从头开始训练,作为实时系统中唯一的场景表示,从而使RGB-D摄像机能够针对房间规模场景的完整和准确的体模型进行构建和跟踪。所提出方法的关键是并行跟踪和映射,通过损失引导的像素采样实现快速优化,以及智能关键帧选择作为重放以避免网络遗忘,实时增量训练隐式场景网络。提出的SLAM方法的并行实现可作为手持RGB-D摄像机实时SLAM系统。所提出iMAP算法采用关键帧结构和多处理计算流,以动态信息引导像素采样来提高速度,跟踪速度为10Hz,全局地图更新速度为2Hz。与标准的密集SLAM技术相比,隐式MLP的优势包括:高效的几何表示与自动细节控制,以及平滑、可信填充未观察区域,如物体背面。
We show for the first time that a multilayer perceptron (MLP) can serve as the only scene representation in a real-time SLAM system for a handheld RGB-D camera. Our network is trained in live operation without prior data, building a dense, scene-specific implicit 3D model of occupancy and colour which is also immediately used for tracking.Achieving real-time SLAM via continual training of a neural network against a live image stream requires significant innovation. Our iMAP algorithm uses a keyframe structure and multi-processing computation flow, with dynamic information-guided pixel sampling for speed, with tracking at 10 Hz and global map updating at 2 Hz. The advantages of an implicit MLP over standard dense SLAM techniques include efficient geometry representation with automatic detail control and smooth, plausible filling-in of unobserved regions such as the back surfaces of objects.
https://weibo.com/1402400261/K7Lg4oQyj

2、[LG] Generative Minimization Networks: Training GANs Without Competition
P Grnarova, Y Kilcher, K Y. Levy, A Lucchi, T Hofmann
[ETH Zurich & Technion-Israel Institute of Technology]
生成式最小化网络:无竞争训练GAN。提出利用博弈论中的二元性差距概念,通过新的目标函数训练GAN,而不依赖于复杂的最小化结构,并推导出收敛率。证明了自适应优化方法适合于训练该目标,利用目标的某些特性,使收敛更快。提出一种简单实用的算法,将GAN(以及WGAN、BEGAN等)的博弈论公式变成优化问题。在几个玩具数据集和真实数据集上验证了该方法,并表明它表现出理想的收敛性和稳定性,同时获得了改进的样本保真度。
Many applications in machine learning can be framed as minimization problems and solved efficiently using gradient-based techniques. However, recent applications of generative models, particularly GANs, have triggered interest in solving min-max games for which standard optimization techniques are often not suitable. Among known problems experienced by practitioners is the lack of convergence guarantees or convergence to a non-optimum cycle. At the heart of these problems is the min-max structure of the GAN objective which creates non-trivial dependencies between the players. We propose to address this problem by optimizing a different objective that circumvents the min-max structure using the notion of duality gap from game theory. We provide novel convergence guarantees on this objective and demonstrate why the obtained limit point solves the problem better than known techniques.
https://weibo.com/1402400261/K7LkynU1b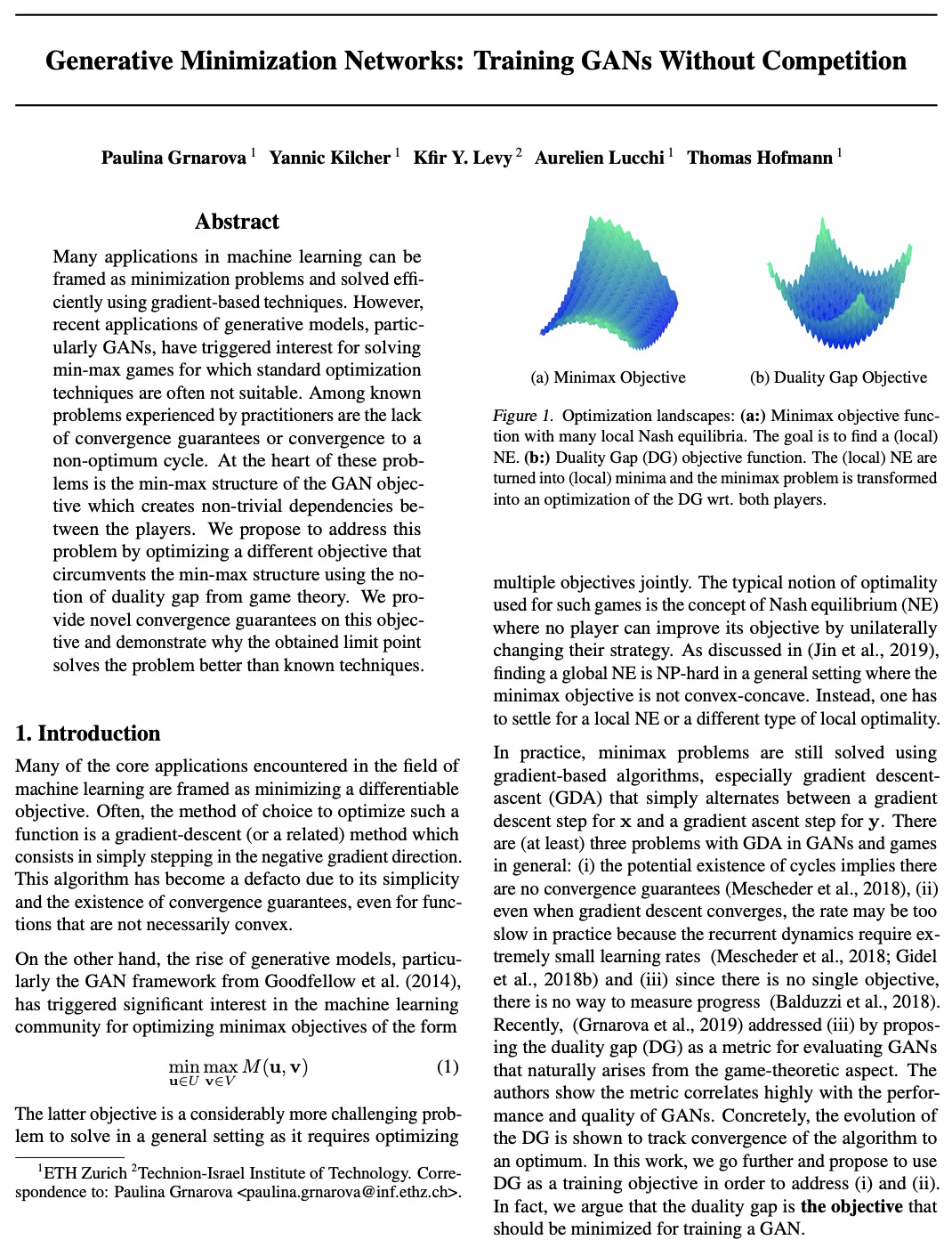
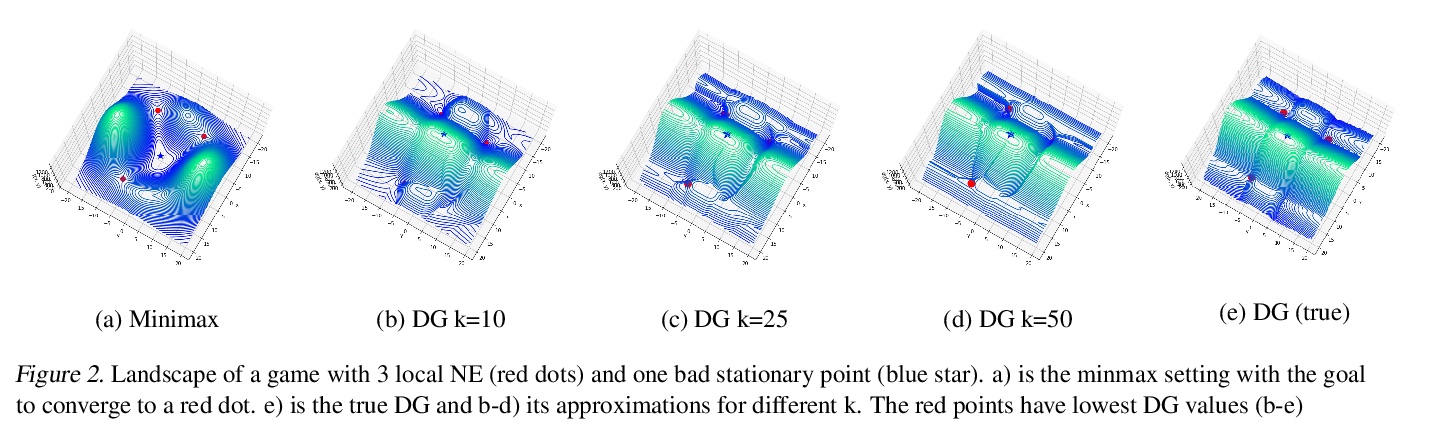

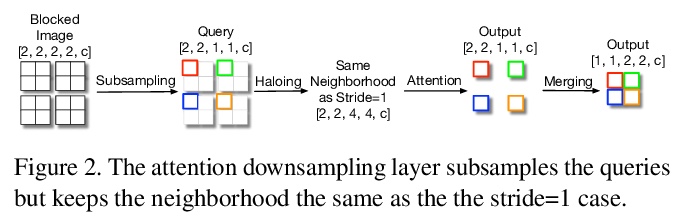
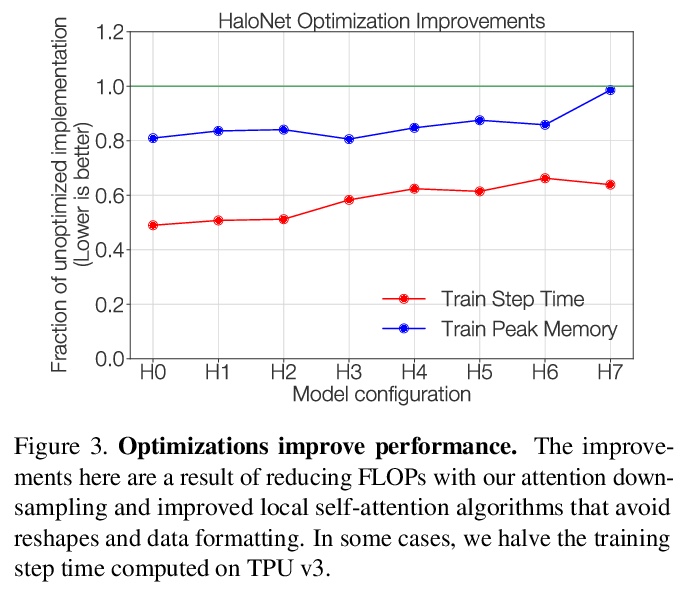
3、[CV] Scaling Local Self-Attention For Parameter Efficient Visual Backbones
A Vaswani, P Ramachandran, A Srinivas, N Parmar, B Hechtman, J Shlens
[Google Research]
为参数高效视觉骨架扩展局部自注意力。提出了两种注意力改进方法:阻断局部注意力和注意力降采样,结合更高效的自注意力实现,提高了模型速度、内存使用和准确性,利用这些改进开发了一个新的自注意力模型族HaloNets,在ImageNet分类基准的参数限制设置上达到了最先进精度。在初步的迁移学习实验中,发现HaloNet模型的表现优于更大的模型,并且具有更好的推理性能。在更难的任务上,如目标检测和实例分割,简单的局部自注意力和卷积混合模型显示出相对强大基线的改进。
Self-attention has the promise of improving computer vision systems due to parameter-independent scaling of receptive fields and content-dependent interactions, in contrast to parameter-dependent scaling and content-independent interactions of convolutions. Self-attention models have recently been shown to have encouraging improvements on accuracy-parameter trade-offs compared to baseline convolutional models such as ResNet-50. In this work, we aim to develop self-attention models that can outperform not just the canonical baseline models, but even the high-performing convolutional models. We propose two extensions to self-attention that, in conjunction with a more efficient implementation of self-attention, improve the speed, memory usage, and accuracy of these models. We leverage these improvements to develop a new self-attention model family, \emph{HaloNets}, which reach state-of-the-art accuracies on the parameter-limited setting of the ImageNet classification benchmark. In preliminary transfer learning experiments, we find that HaloNet models outperform much larger models and have better inference performance. On harder tasks such as object detection and instance segmentation, our simple local self-attention and convolutional hybrids show improvements over very strong baselines. These results mark another step in demonstrating the efficacy of self-attention models on settings traditionally dominated by convolutional models.
https://weibo.com/1402400261/K7LnQ1VhM

4、[CV] Self-Supervised Pretraining Improves Self-Supervised Pretraining
C J. Reed, X Yue, A Nrusimha, S Ebrahimi, V Vijaykumar, R Mao, B Li, S Zhang, D Guillory, S Metzger, K Keutzer, T Darrell
[UC Berkeley & Georgia Tech]
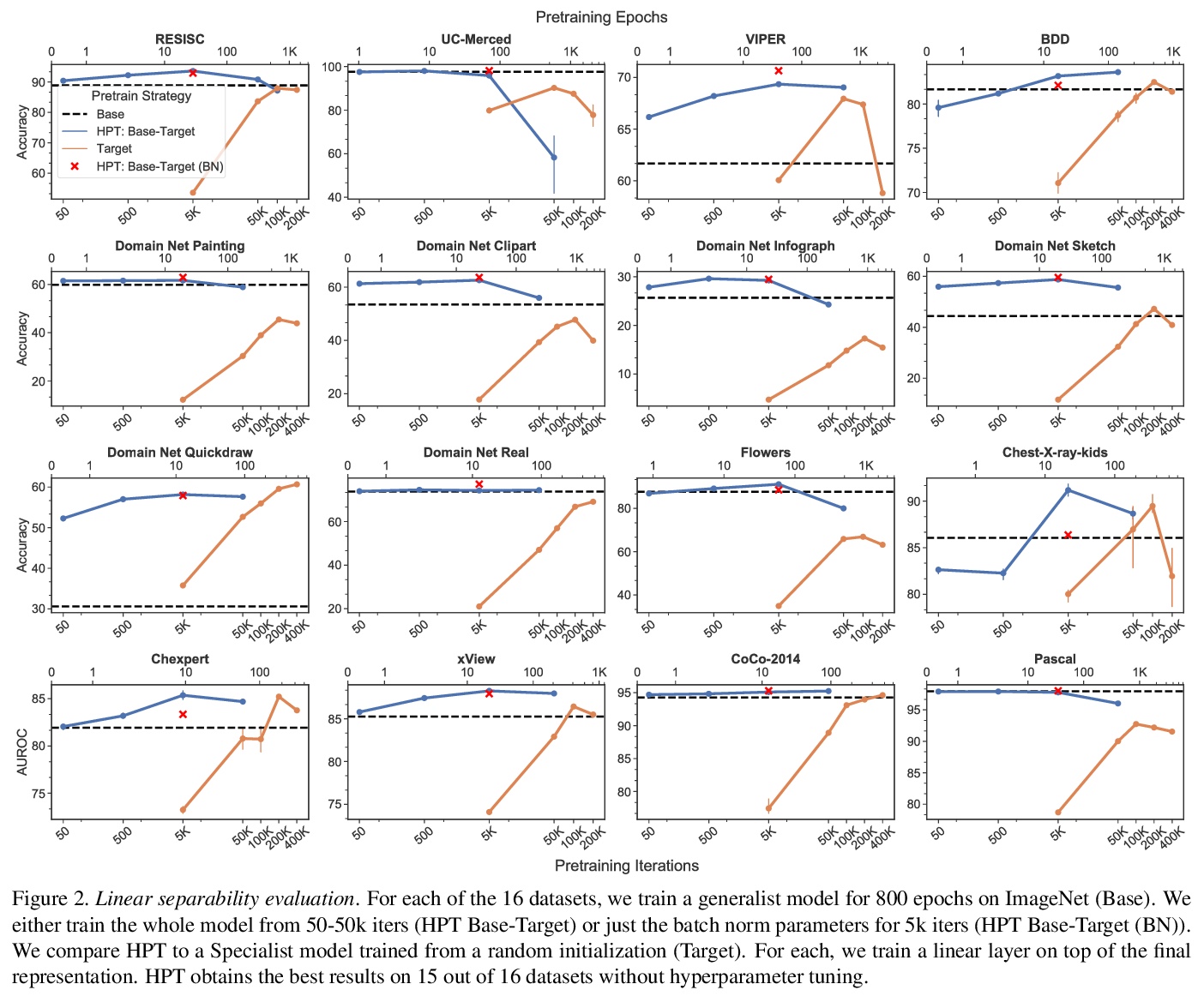
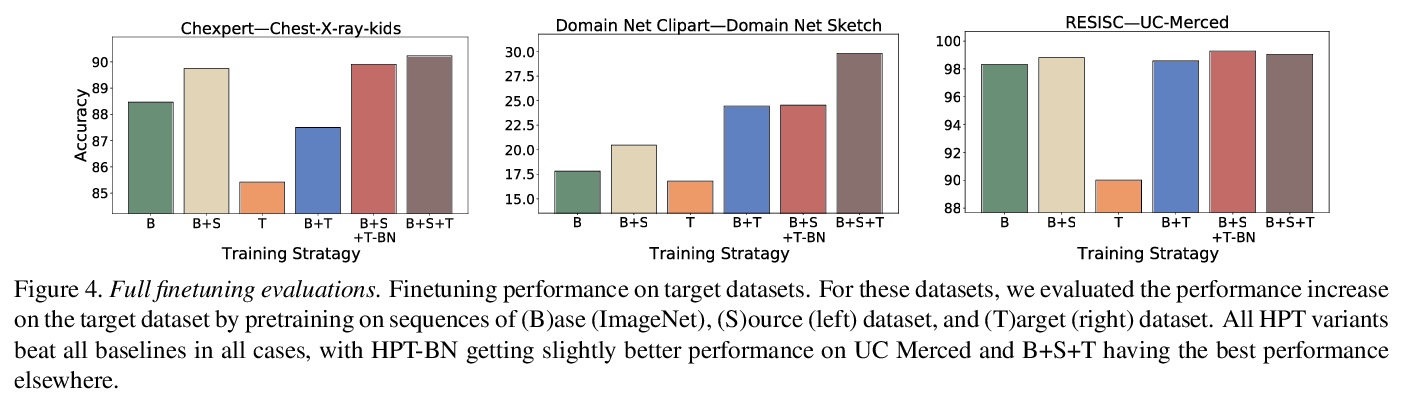
用自监督预训练提高自监督预训练。提出了分层预训练(Hierarchical PreTraining,HPT),通过用现有的预训练模型来初始化预训练过程,减少收敛时间,提高准确性。通过在16个不同的视觉数据集上的实验,表明HPT收敛速度快达80倍,提高了跨任务的准确性,且提高了自监督预训练过程对图像增强策略或预训练数据量变化的鲁棒性。HPT提供了一个简单的框架,可用较少的计算资源获得更好的预训练表征。
While self-supervised pretraining has proven beneficial for many computer vision tasks, it requires expensive and lengthy computation, large amounts of data, and is sensitive to data augmentation. Prior work demonstrates that models pretrained on datasets dissimilar to their target data, such as chest X-ray models trained on ImageNet, underperform models trained from scratch. Users that lack the resources to pretrain must use existing models with lower performance. This paper explores Hierarchical PreTraining (HPT), which decreases convergence time and improves accuracy by initializing the pretraining process with an existing pretrained model. Through experimentation on 16 diverse vision datasets, we show HPT converges up to 80x faster, improves accuracy across tasks, and improves the robustness of the self-supervised pretraining process to changes in the image augmentation policy or amount of pretraining data. Taken together, HPT provides a simple framework for obtaining better pretrained representations with less computational resources.
https://weibo.com/1402400261/K7LrflI4S

5、[CV] Transformers Solve the Limited Receptive Field for Monocular Depth Prediction
G Yang, H Tang, M Ding, N Sebe, E Ricci
[Haerbin Institute of Technology & University of Trento]
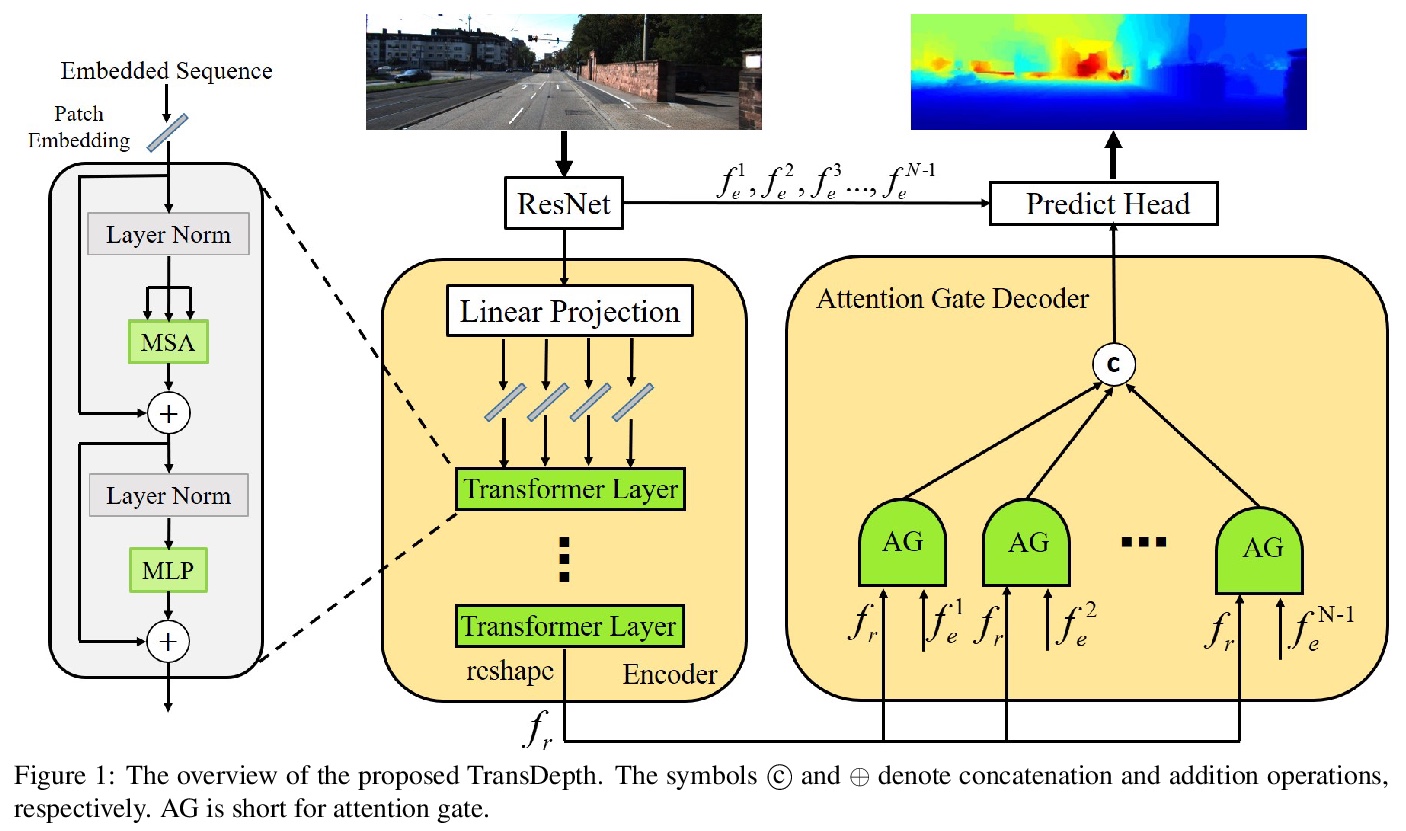
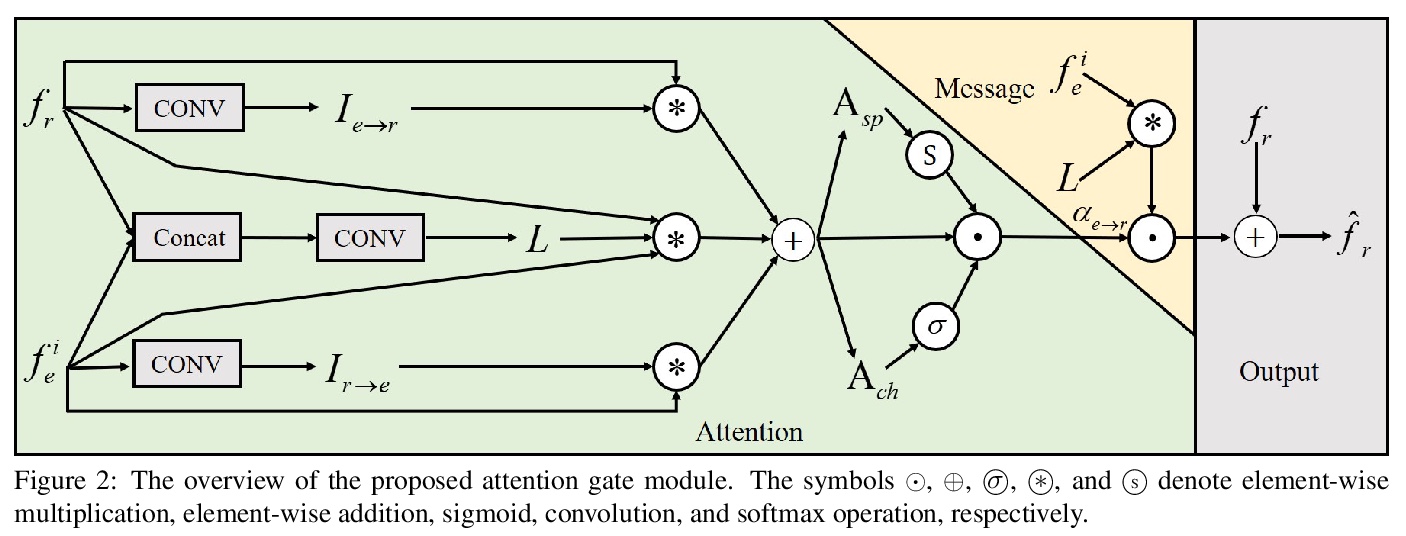
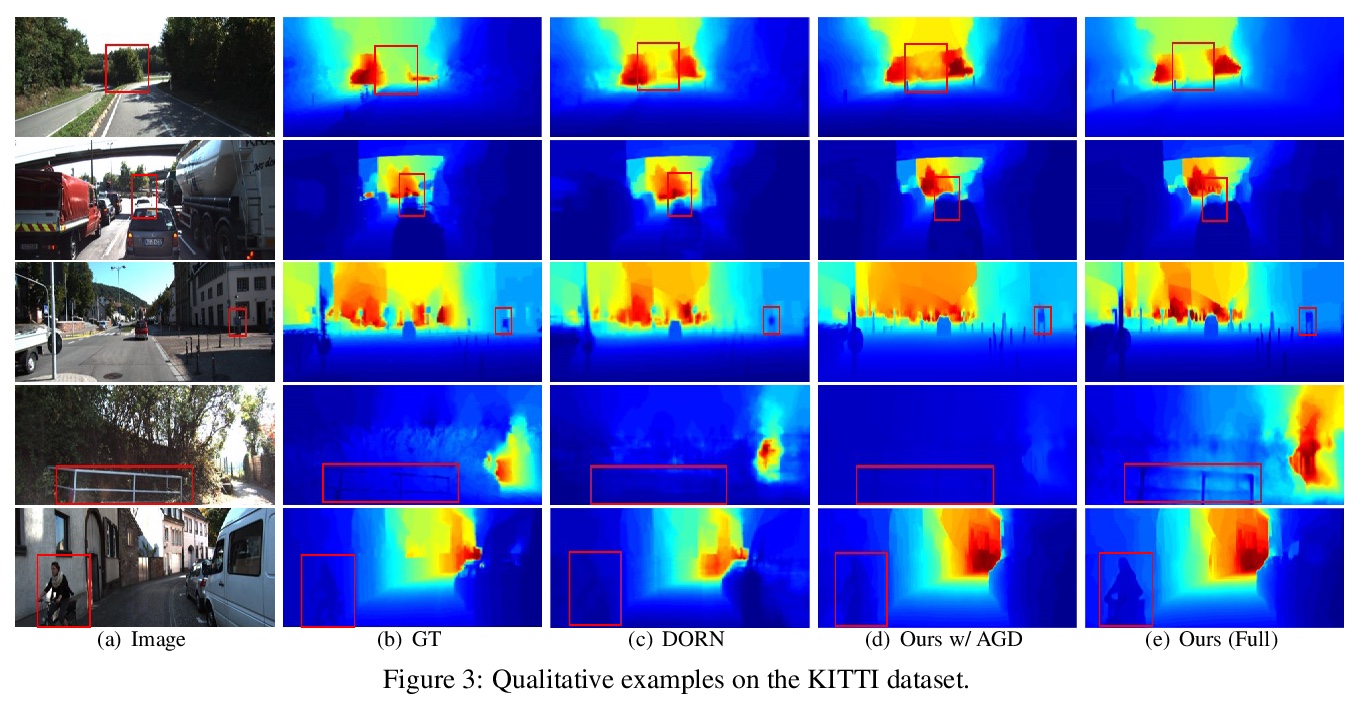
用Transformer解决单目深度预测有限感受野问题。提出TransDepth,一个同时受益于卷积神经网络和Transformer的架构。为避免网络因采用Transformer而丧失捕捉局部级细节的能力,提出了一种采用基于门的注意力机制的新解码器,将Transformer应用于涉及连续标签的像素级预测问题(即单目深度预测和表面法线估计)。实验表明,所提出的TransDepth在三个具有挑战性的数据集上实现了最先进的性能。
While convolutional neural networks have shown a tremendous impact on various computer vision tasks, they generally demonstrate limitations in explicitly modeling long-range dependencies due to the intrinsic locality of the convolution operation. Transformers, initially designed for natural language processing tasks, have emerged as alternative architectures with innate global self-attention mechanisms to capture long-range dependencies. In this paper, we propose TransDepth, an architecture which benefits from both convolutional neural networks and transformers. To avoid the network to loose its ability to capture local-level details due to the adoption of transformers, we propose a novel decoder which employs on attention mechanisms based on gates. Notably, this is the first paper which applies transformers into pixel-wise prediction problems involving continuous labels (i.e., monocular depth prediction and surface normal estimation). Extensive experiments demonstrate that the proposed TransDepth achieves state-of-the-art performance on three challenging datasets. The source code and trained models are available at > this https URL.
https://weibo.com/1402400261/K7LtTyNqt
另外几篇值得关注的论文:
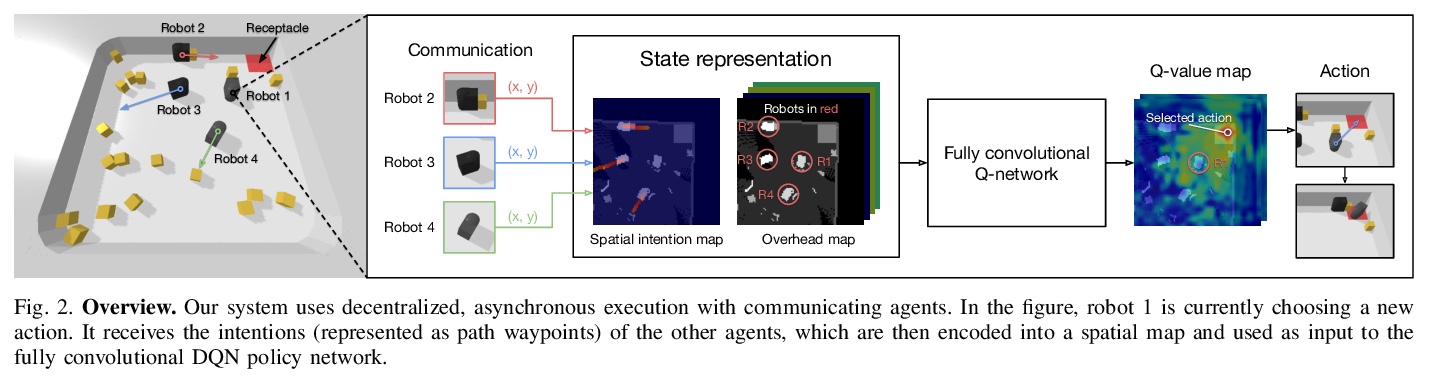
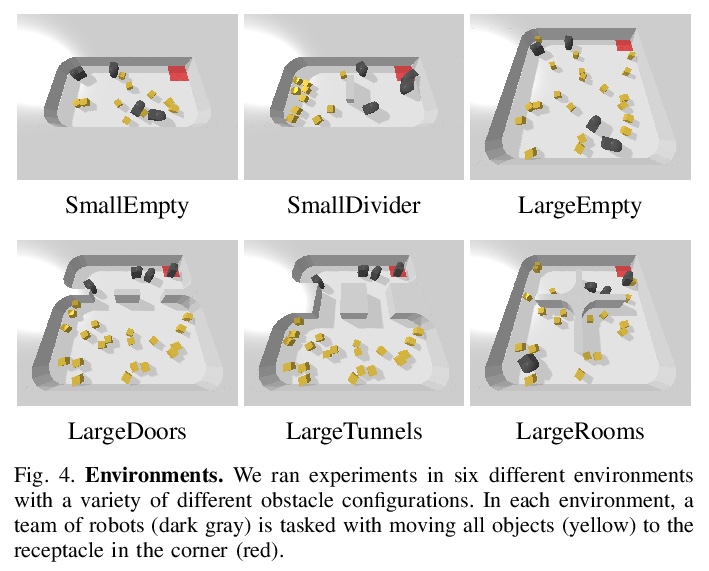
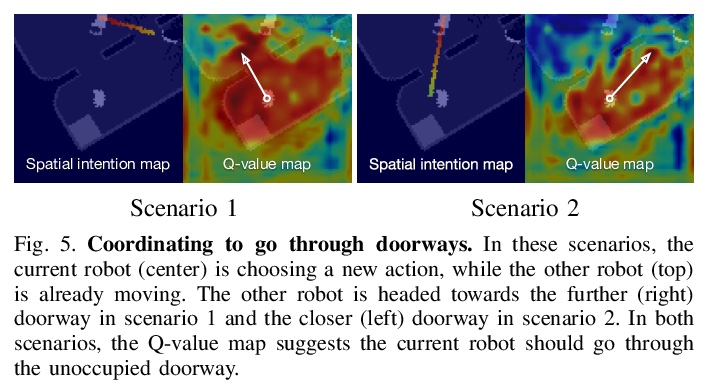
[RO] Spatial Intention Maps for Multi-Agent Mobile Manipulation
面向多智能体移动操作的空间意图地图
J Wu, X Sun, A Zeng, S Song, S Rusinkiewicz, T Funkhouser
[Princeton University & Google & Columbia University]
https://weibo.com/1402400261/K7LAiqIhL

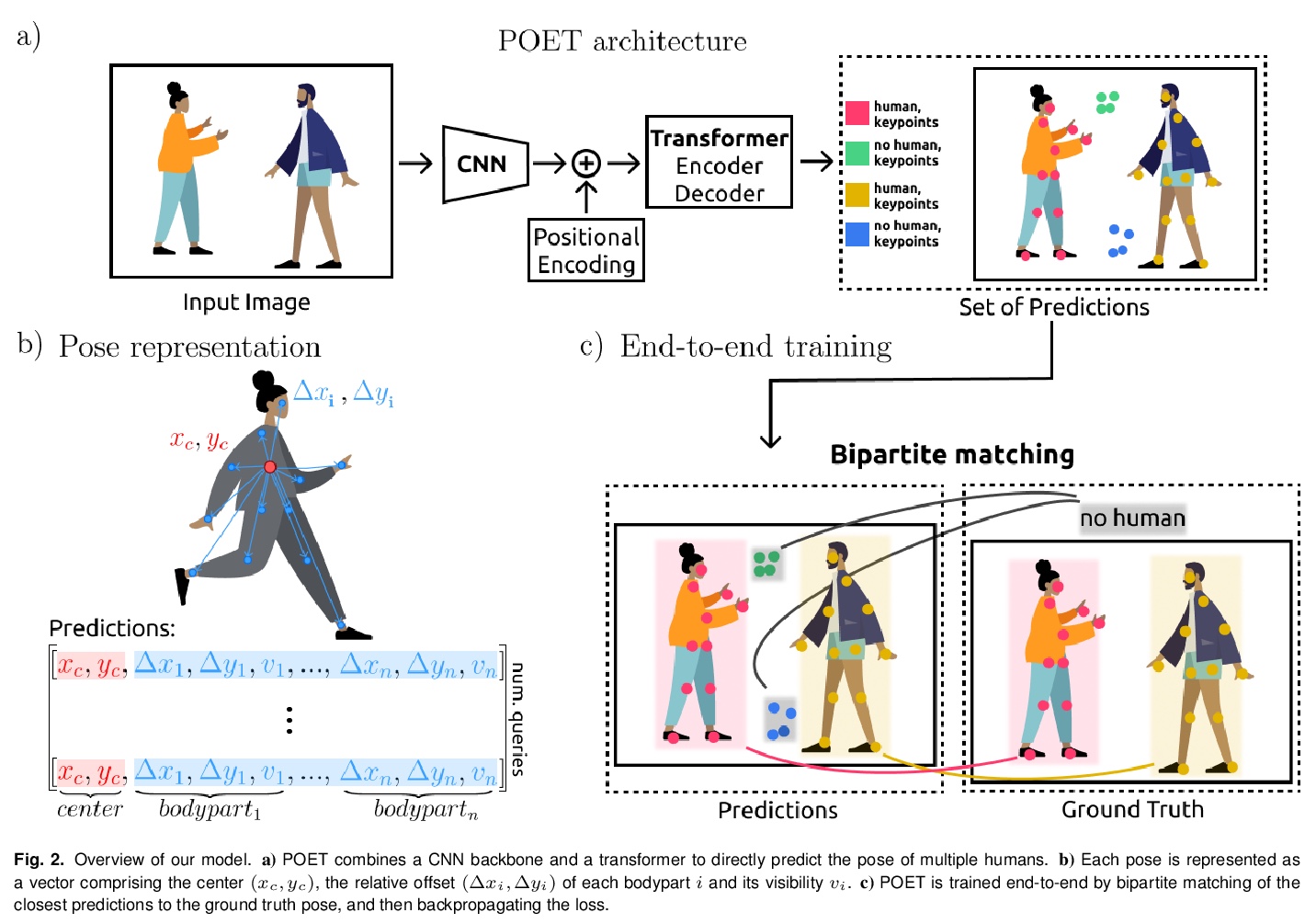
[CV] End-to-End Trainable Multi-Instance Pose Estimation with Transformers
基于Transformer的端到端可训练多实例姿态估计
L Stoffl, M Vidal, A Mathis
[Swiss Federal Institute of Technology (EPFL)]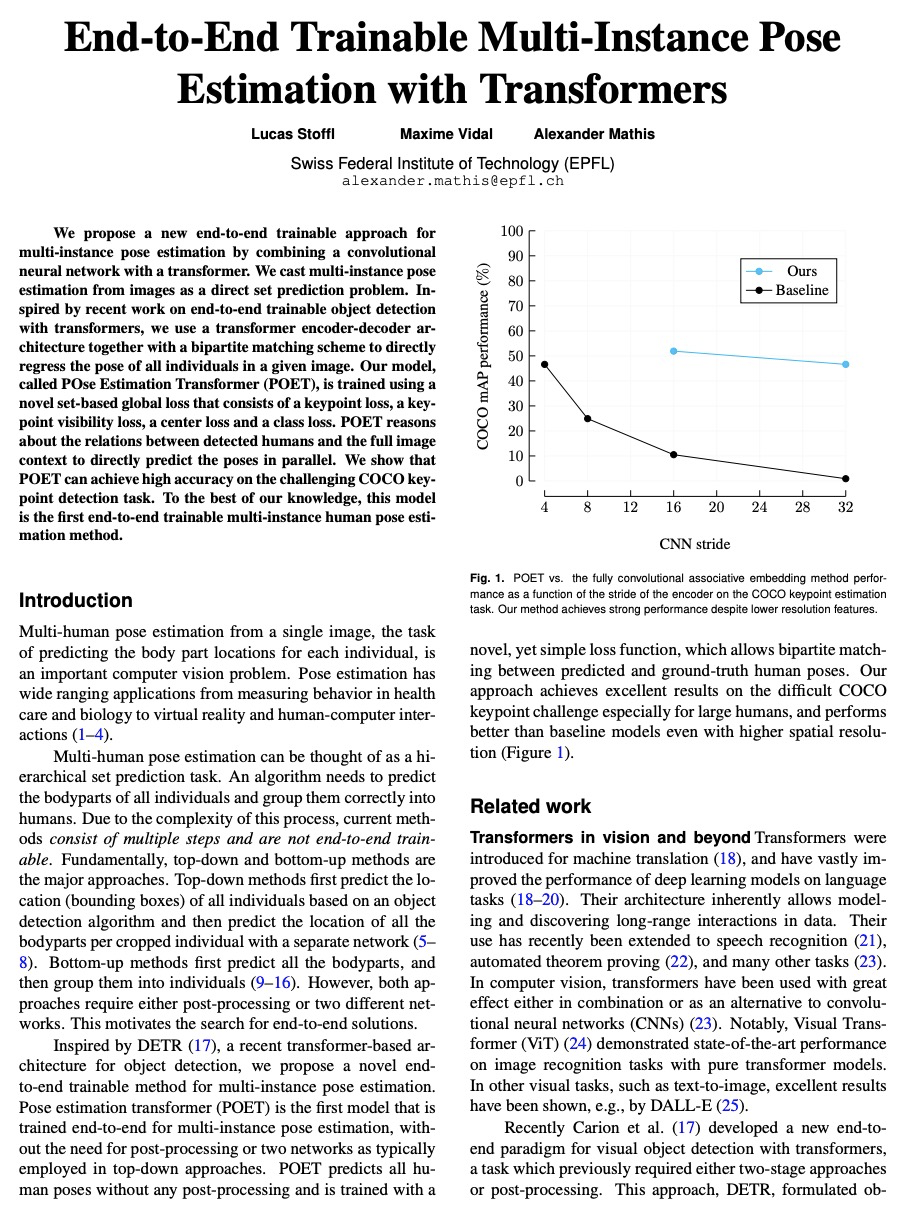

[CL] Multilingual Autoregressive Entity Linking
多语言自回归实体链接
N D Cao, L Wu, K Popat, M Artetxe, N Goyal, M Plekhanov, L Zettlemoyer, N Cancedda, S Riedel, F Petroni
[Facebook AI]
https://weibo.com/1402400261/K7LDTwsyf


[CV] Leveraging background augmentations to encourage semantic focus in self-supervised contrastive learning
自监督对比学习用背景增强鼓励语义聚焦
C K. Ryali, D J. Schwab, A S. Morcos
[UC San Diego & Facebook AI Research]
https://weibo.com/1402400261/K7LHN12w5


若有收获,就点个赞吧
0 人点赞
