- 1、[LG] A learning agent that acquires social norms from public sanctions in decentralized multi-agent settings
- 2、[CL] Paraphrastic Representations at Scale
- 3、[CV] Fine-Tuning StyleGAN2 For Cartoon Face Generation
- 4、[LG] Real-time Neural Radiance Caching for Path Tracing
- 5、[LG] Weisfeiler and Lehman Go Cellular: CW Networks
- [CV] Co-advise: Cross Inductive Bias Distillation
[LG] Deep Gaussian Processes: A Survey- [LG] Stable, Fast and Accurate: Kernelized Attention with Relative Positional Encoding
- [LG] Approximate Bayesian Computation with Path Signatures
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[LG] A learning agent that acquires social norms from public sanctions in decentralized multi-agent settings
E Vinitsky, R Köster, J P. Agapiou, E Duéñez-Guzmán, A S Vezhnevets, J Z. Leibo
[DeepMind]
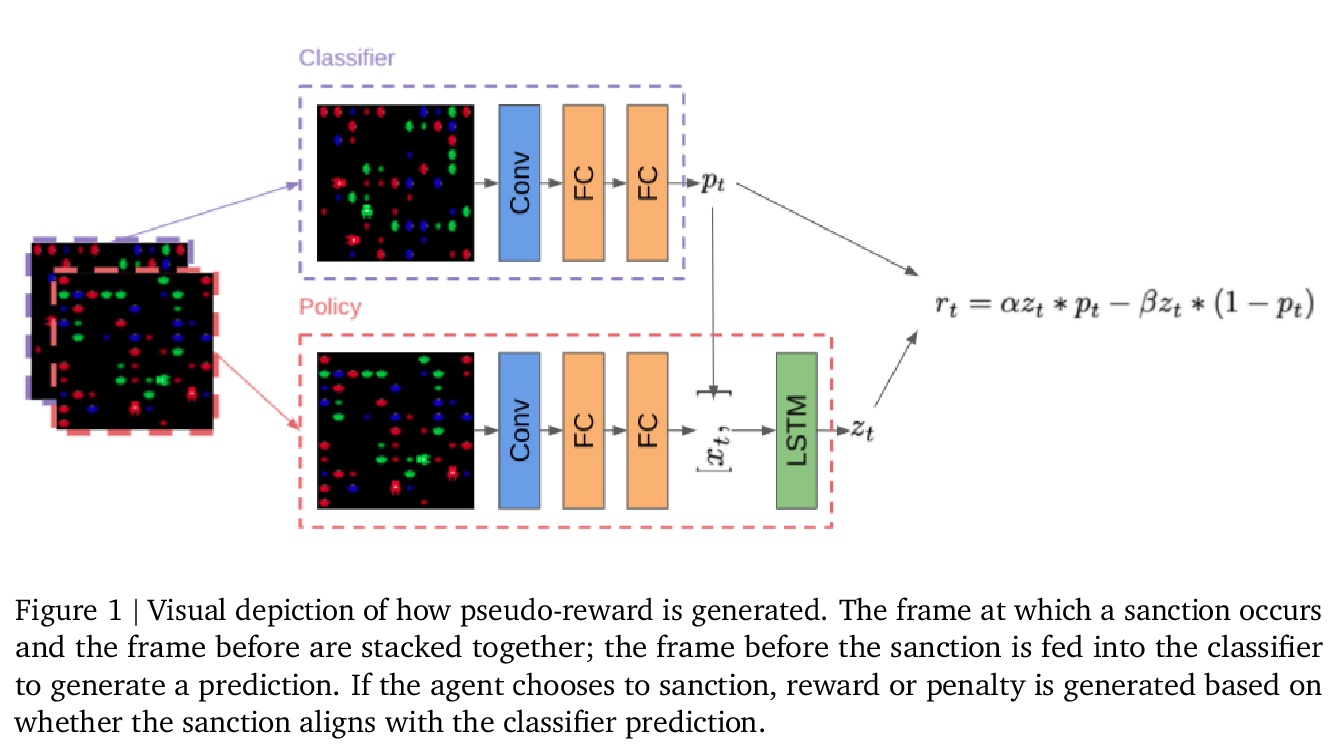
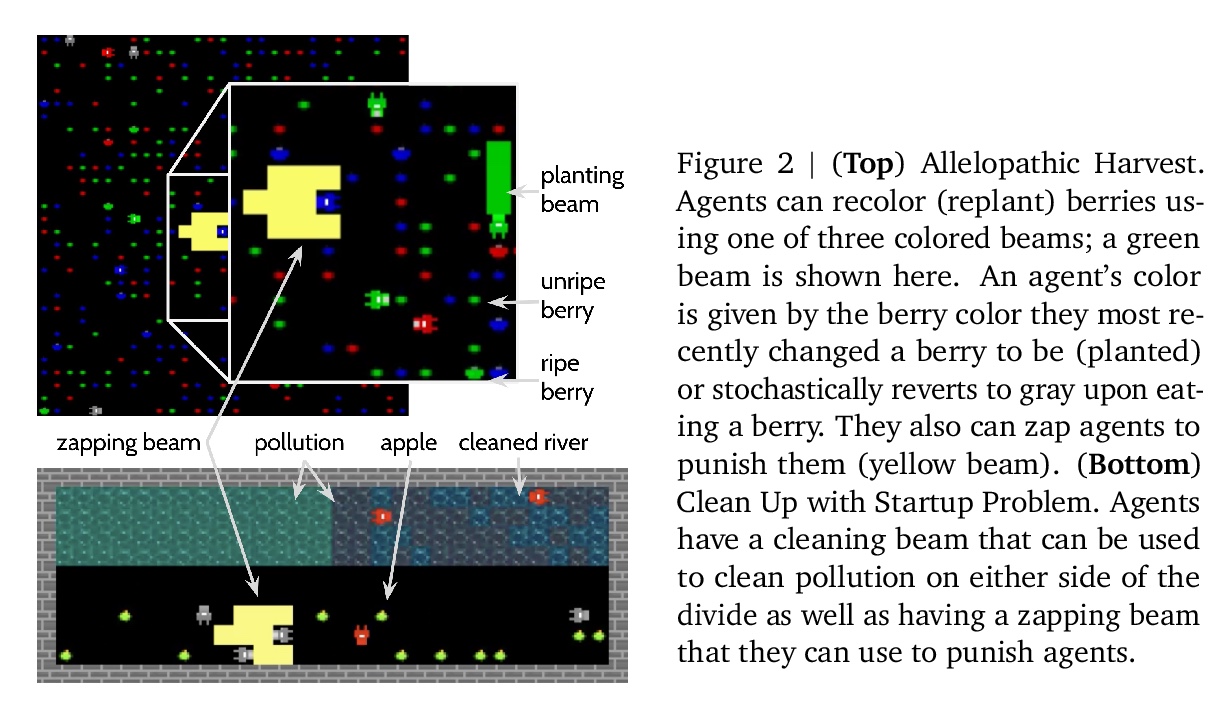
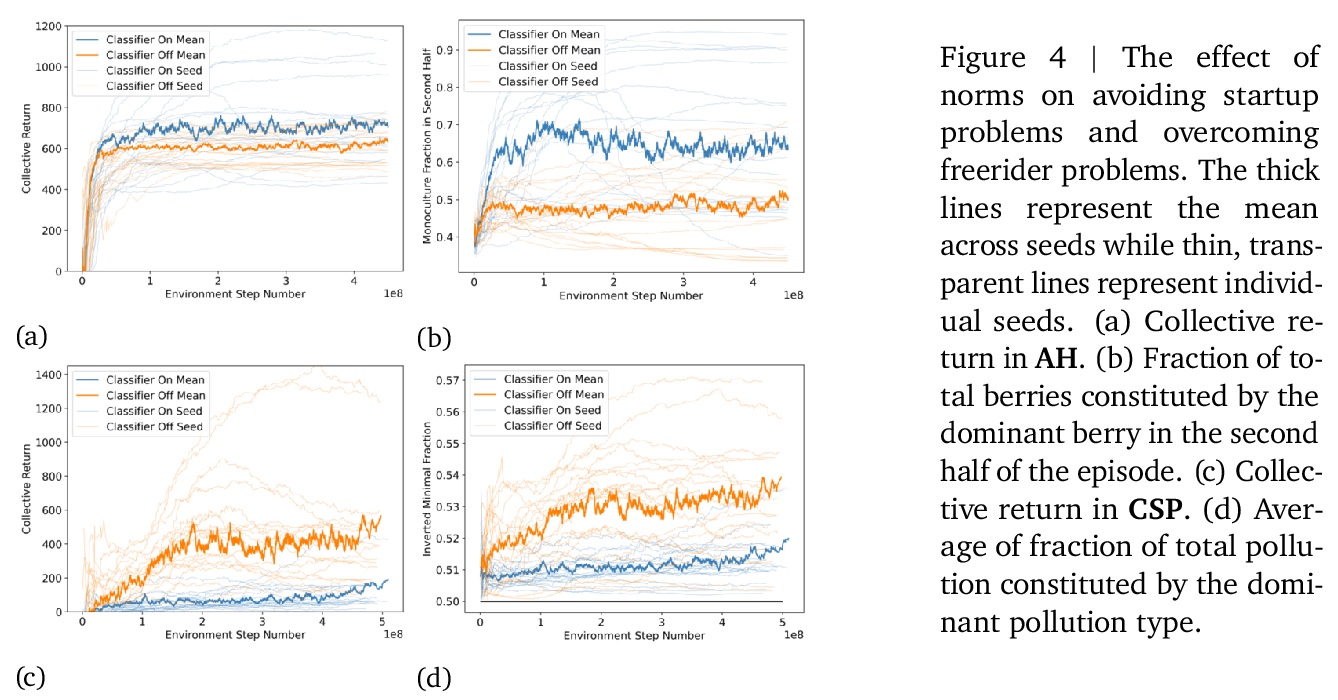
去中心化多智能体设置下从公共制裁中获得社会规范的学习型智能体。社会的特点是存在各种社会规范:用于防止不当协作和自由投机的协同制裁模式。受此启发,本文的目标是构建学习动力学,在其中可能出现潜在有益的社会规范。由于社会规范以制裁为基础,引入了一种训练制度,智能体可以访问所有制裁事件,但学习是分散的。这种设置在技术上很有趣,因为在奖励或策略共享不可行或不可取的去中心化多智能体系统中,制裁事件可能是唯一可用的公共信号。为了在这种情况下实现协同行动,构建了一个智能体架构,包含一个分类器模块,该模块将观察到的行为分类为允许或不允许,以及根据群体进行惩罚的动机。实验表明,社会规范出现在了包含该智能体的多智能体系统中。
Society is characterized by the presence of a variety of social norms: collective patterns of sanctioning that can prevent miscoordination and free-riding. Inspired by this, we aim to construct learning dynamics where potentially beneficial social norms can emerge. Since social norms are underpinned by sanctioning, we introduce a training regime where agents can access all sanctioning events but learning is otherwise decentralized. This setting is technologically interesting because sanctioning events may be the only available public signal in decentralized multi-agent systems where reward or policy-sharing is infeasible or undesirable. To achieve collective action in this setting we construct an agent architecture containing a classifier module that categorizes observed behaviors as approved or disapproved, and a motivation to punish in accord with the group. We show that social norms emerge in multi-agent systems containing this agent and investigate the conditions under which this helps them achieve socially beneficial outcomes.
https://weibo.com/1402400261/KlKCOD5bH

2、[CL] Paraphrastic Representations at Scale
J Wieting, K Gimpel, G Neubig, T Berg-Kirkpatrick
[CMU & Toyota Technological Institute at Chicago & University of California San Diego]
大规模意译表示。本文提出一个系统,允许用户训练各语言自己的最先进意译句子表示。发布了针对英语、阿拉伯语、德语、法语、西班牙语、俄语、土耳其语和中文的训练模型。在大量数据上训练这些模型,与提出一套单语言语义相似性、跨语言语义相似性和双文本挖掘任务的方法的之前论文相比,性能显著提高。此外,由此产生的模型超越了所有之前关于无监督语义文本相似性的工作,甚至显著优于SentenceBERT等基于BERT的模型。此外,所提出模型比之前的工作快几个数量级,可以在 CPU 上使用,推理速度几乎没有差异(甚至在使用更多CPU内核时提高了GPU的速度),使这些模型成为无GPU用户的有吸引力的选择,或用于嵌入式设备。
We present a system that allows users to train their own state-of-the-art paraphrastic sentence representations in a variety of languages. We also release trained models for English, Arabic, German, French, Spanish, Russian, Turkish, and Chinese. We train these models on large amounts of data, achieving significantly improved performance from the original papers proposing the methods on a suite of monolingual semantic similarity, cross-lingual semantic similarity, and bitext mining tasks. Moreover, the resulting models surpass all prior work on unsupervised semantic textual similarity, significantly outperforming even BERT-based models like SentenceBERT (Reimers and Gurevych, 2019). Additionally, our models are orders of magnitude faster than prior work and can be used on CPU with little difference in inference speed (even improved speed over GPU when using more CPU cores), making these models an attractive choice for users without access to GPUs or for use on embedded devices. Finally, we add significantly increased functionality to the code bases for training paraphrastic sentence models, easing their use for both inference and for training them for any desired language with parallel data. We also include code to automatically download and preprocess training data.
https://weibo.com/1402400261/KlKIAsvo4



3、[CV] Fine-Tuning StyleGAN2 For Cartoon Face Generation
J Back
[Seoul National University]
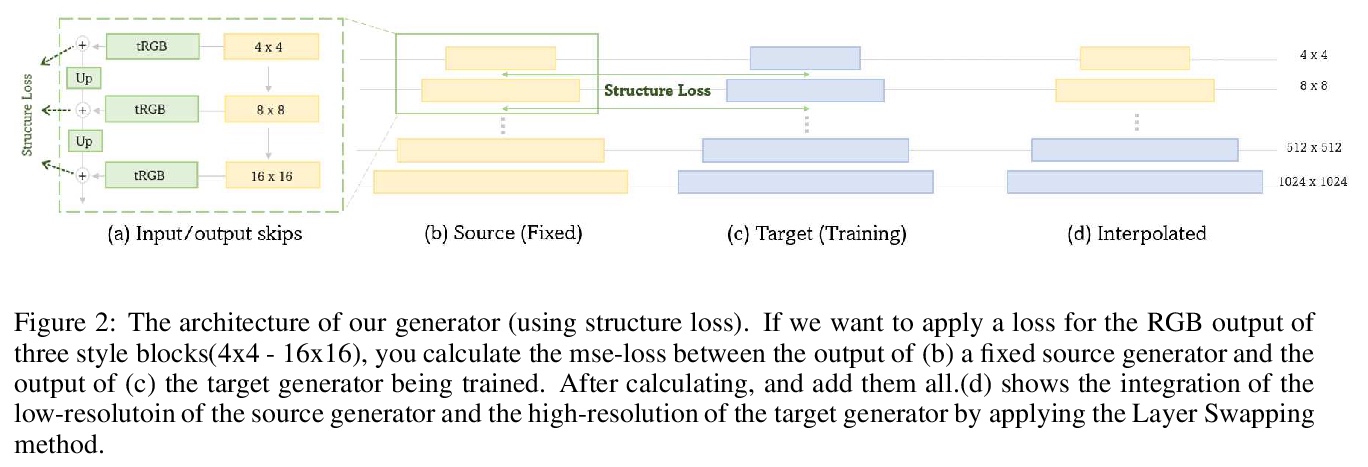
微调StyleGAN2卡通脸生成。最新研究表明,在无监督图像到图像(I2I)变换方面取得了显著的成功。然而,由于数据不平衡,学习不同域的联合分布仍然非常具有挑战性。虽然现有模型可以生成逼真的目标图像,但很难保持源图像结构。此外,在多域的大数据上训练生成模型需要大量时间和计算资源。为解决这些限制,本文提出一种新的图像到图像变换方法,通过微调StyleGAN2预训练模型生成目标域图像。StyleGAN2模型适用于非平衡数据集上的无监督I2I变换,非常稳定,可以生成逼真的图像,甚至可以在应用简单的微调技术时从有限数据中正确学习。本文提出了保留源图像结构并在目标域中生成逼真图像的新方法。
Recent studies have shown remarkable success in the unsupervised image to image (I2I) translation. However, due to the imbalance in the data, learning joint distribution for various domains is still very challenging. Although existing models can generate realistic target images, it’s difficult to maintain the structure of the source image. In addition, training a generative model on large data in multiple domains requires a lot of time and computer resources. To address these limitations, we propose a novel image-to-image translation method that generates images of the target domain by finetuning a stylegan2 pretrained model. The stylegan2 model is suitable for unsupervised I2I translation on unbalanced datasets; it is highly stable, produces realistic images, and even learns properly from limited data when applied with simple fine-tuning techniques. Thus, in this paper, we propose new methods to preserve the structure of the source images and generate realistic images in the target domain.
https://weibo.com/1402400261/KlKMfs6J4



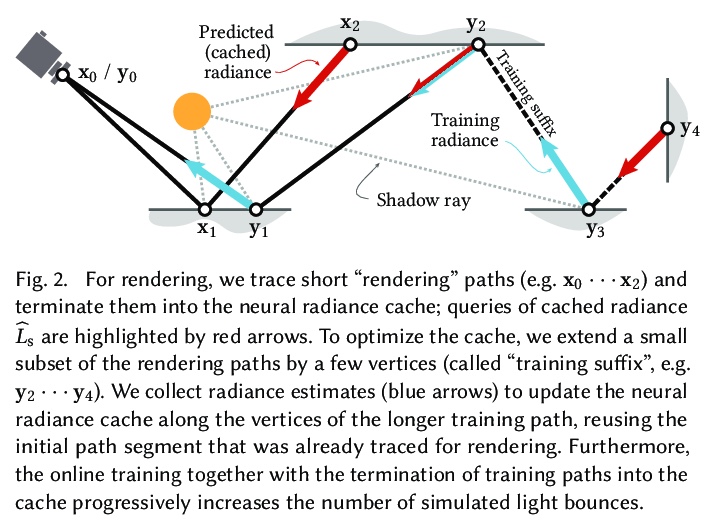
4、[LG] Real-time Neural Radiance Caching for Path Tracing
T Müller, F Rousselle, J Novák, A Keller
[NVIDIA]
实时神经辐射缓存路径追踪。本文提出一种用于路径跟踪全局照明的实时神经辐射缓存方法。系统旨在处理全动态场景,不对照明、几何形状和材料做任何假设。其数据驱动特性回避了缓存算法的许多困难,例如定位、插值和更新缓存点。由于预训练神经网络来处理新动态场景是一项艰巨的泛化挑战,所提出方法取消了预训练,而是通过自适应实现泛化,选择在渲染时训练辐射缓存。采用自训练来提供低噪声训练目标,并通过仅迭代少弹跳训练更新来模拟无限弹跳传输。由于神经网络的流实现充分利用了现代硬件,更新和缓存查询会产生轻微开销——在全高清分辨率下大约为2.6毫秒。以极少的归纳偏差为代价实现了显著的降噪,并在许多具有挑战性的场景中得到了最先进的实时性能。
We present a real-time neural radiance caching method for path-traced global illumination. Our system is designed to handle fully dynamic scenes, and makes no assumptions about the lighting, geometry, and materials. The data-driven nature of our approach sidesteps many difficulties of caching algorithms, such as locating, interpolating, and updating cache points. Since pretraining neural networks to handle novel, dynamic scenes is a formidable generalization challenge, we do away with pretraining and instead achieve generalization via adaptation, i.e. we opt for training the radiance cache while rendering. We employ self-training to provide low-noise training targets and simulate infinite-bounce transport by merely iterating few-bounce training updates. The updates and cache queries incur a mild overhead — about 2.6ms on full HD resolution — thanks to a streaming implementation of the neural network that fully exploits modern hardware. We demonstrate significant noise reduction at the cost of little induced bias, and report state-of-the-art, real-time performance on a number of challenging scenarios.
https://weibo.com/1402400261/KlKPvz37p



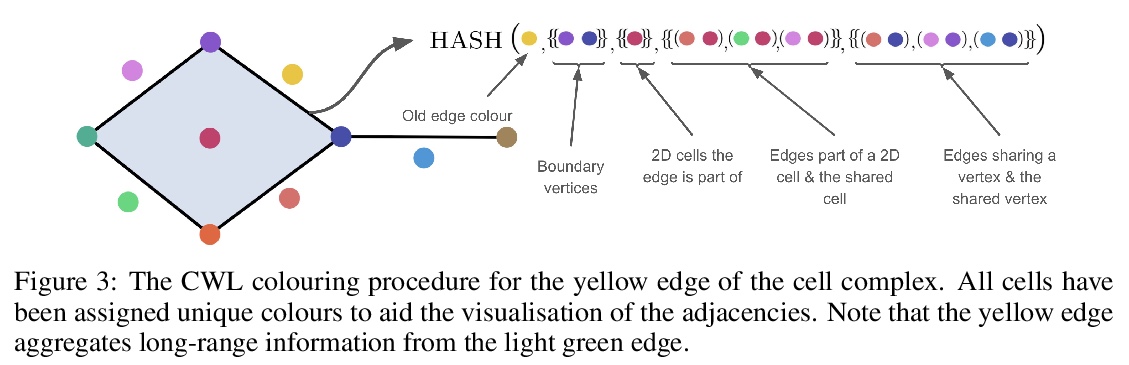
5、[LG] Weisfeiler and Lehman Go Cellular: CW Networks
C Bodnar, F Frasca, N Otter, Y G Wang, P Liò, G Montúfar, M Bronstein
[University of Cambridge & Imperial College London & UCLA & UNSW & University of Cambridge]
比GNN表达能力更强的CWN。图神经网络(GNN)的表达能力有限,在处理长程相互作用时很吃力,而且缺乏对高阶结构建模的原则性方法。这些问题可归因于计算图和输入图结构间的强耦合。最近提出的消息传递单纯网络,通过对图的团簇进行消息传递,自然地将这些元素解耦。然而,这些模型受到单纯簇(SC)僵化的组合结构的严重制约。本文将最近关于单纯簇的理论结果扩展到常规细胞簇——灵活纳入单纯簇和图的拓扑对象。这种概括提供了一套强大的图”提升”变换,每个变换都导致一个独特的分层信息传递过程。由此产生的方法,称为CW网络(CWN),严格来说比WL测试更强大,而且在某些情况下,不比3-WL测试更差。证明了一种基于环的此类方案在应用于分子图问题时的有效性。所提出的架构得益于比常用的GNN更大的表达能力,对高阶信号的原则性建模以及对节点之间距离的压缩。
Graph Neural Networks (GNNs) are limited in their expressive power, struggle with long-range interactions and lack a principled way to model higher-order structures. These problems can be attributed to the strong coupling between the computational graph and the input graph structure. The recently proposed Message Passing Simplicial Networks naturally decouple these elements by performing message passing on the clique complex of the graph. Nevertheless, these models are severely constrained by the rigid combinatorial structure of Simplicial Complexes (SCs). In this work, we extend recent theoretical results on SCs to regular Cell Complexes, topological objects that flexibly subsume SCs and graphs. We show that this generalisation provides a powerful set of graph “lifting” transformations, each leading to a unique hierarchical message passing procedure. The resulting methods, which we collectively call CW Networks (CWNs), are strictly more powerful than the WL test and, in certain cases, not less powerful than the 3-WL test. In particular, we demonstrate the effectiveness of one such scheme, based on rings, when applied to molecular graph problems. The proposed architecture benefits from provably larger expressivity than commonly used GNNs, principled modelling of higherorder signals and from compressing the distances between nodes. We demonstrate that our model achieves state-of-the-art results on a variety of molecular datasets.
https://weibo.com/1402400261/KlKUc06Ky
另外几篇值得关注的论文:
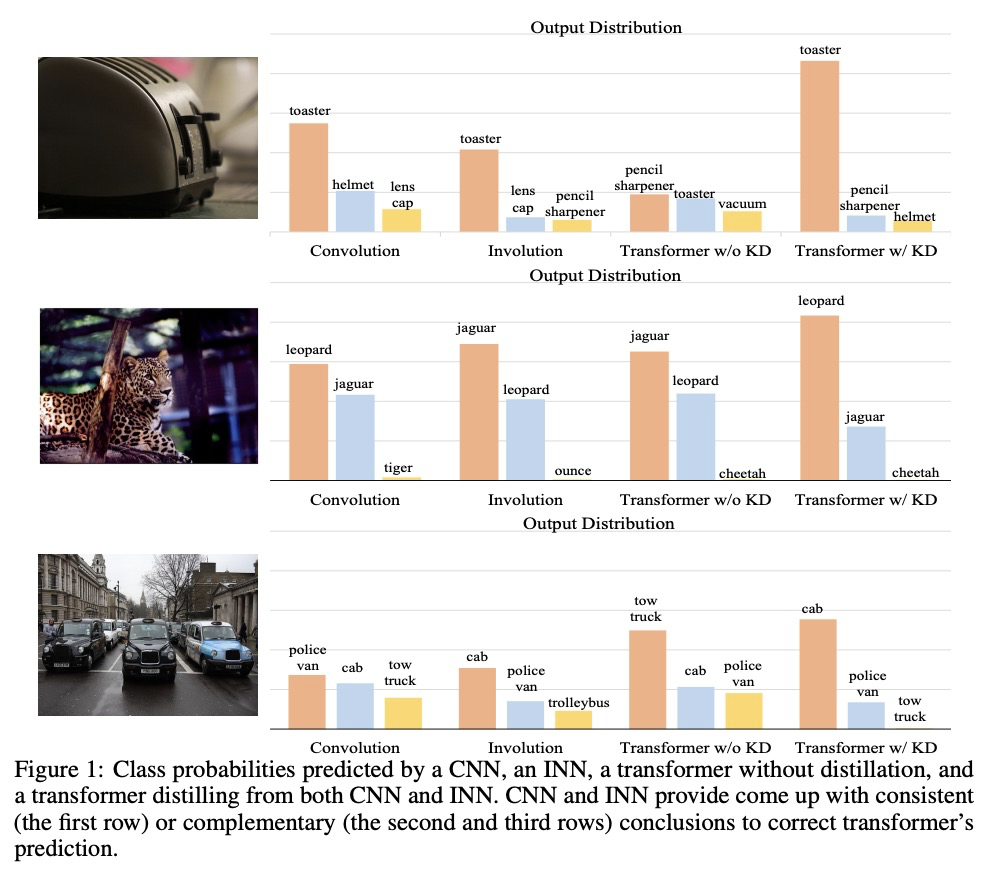
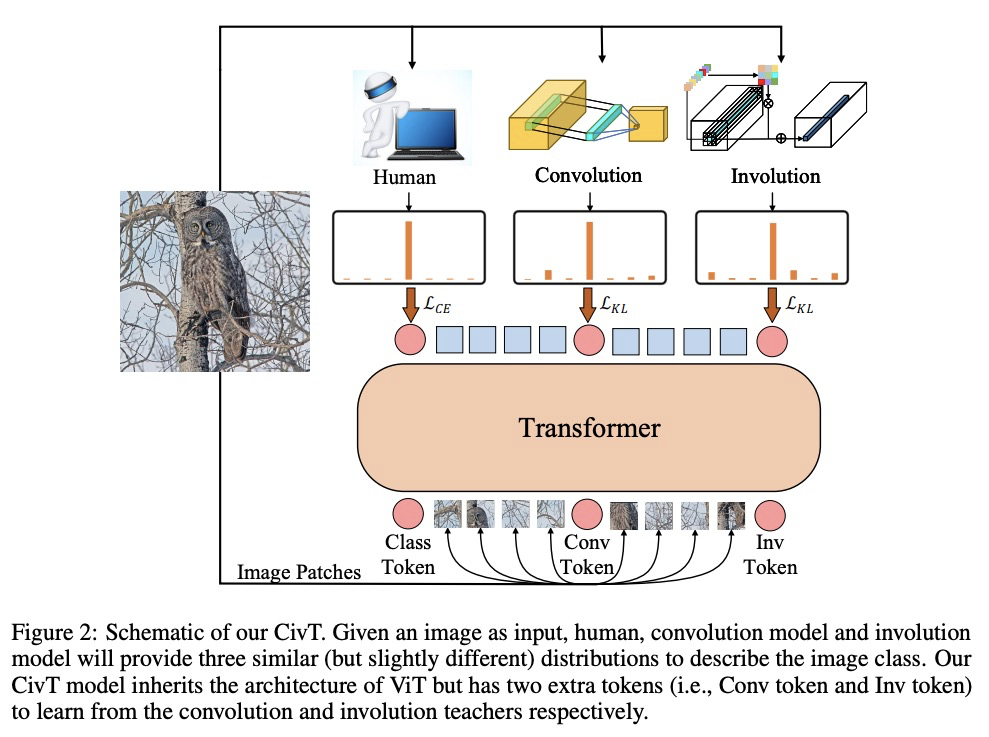
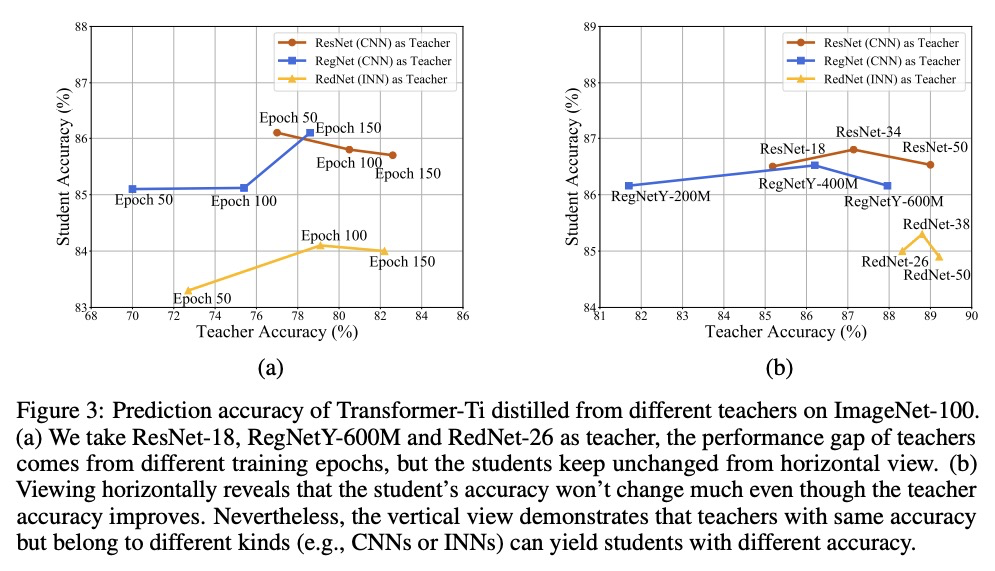
[CV] Co-advise: Cross Inductive Bias Distillation
Co-advise:交叉归纳偏差蒸馏
S Ren, Z Gao, T Hua, Z Xue, Y Tian, S He, H Zhao
[South China University of Technology & MIT & University of Texas at Austin & Tsinghua University]
https://weibo.com/1402400261/KlKZq9k85
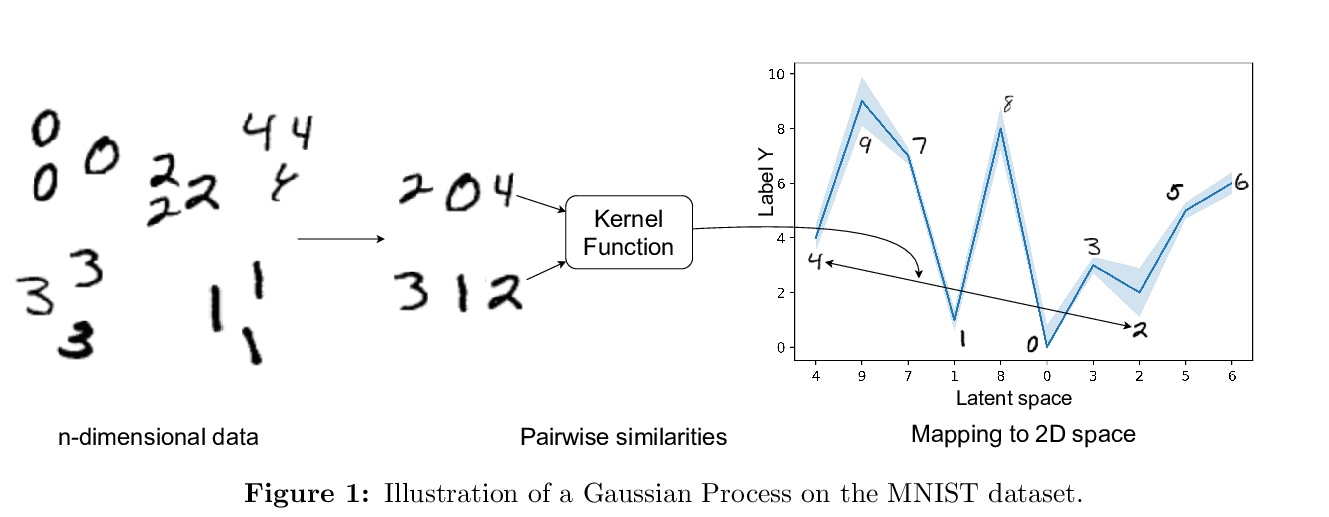
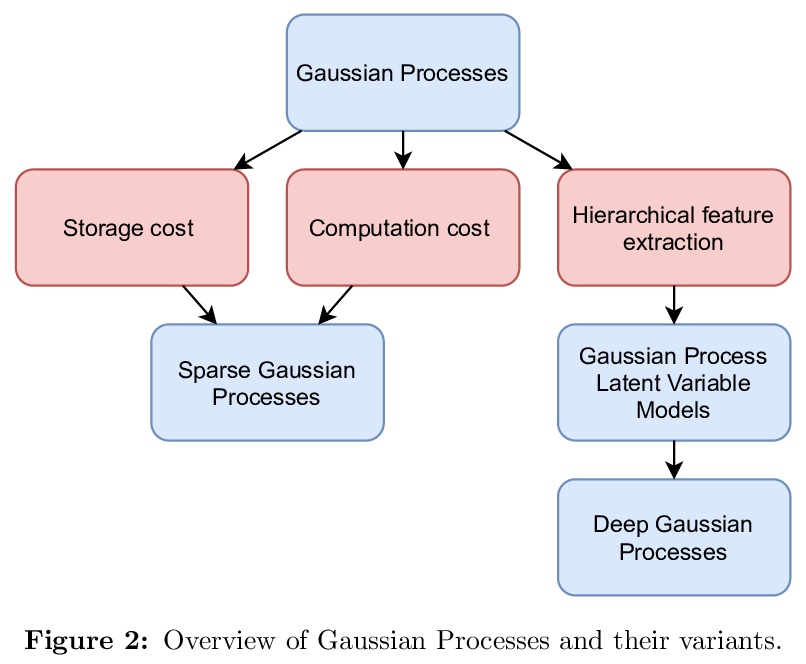
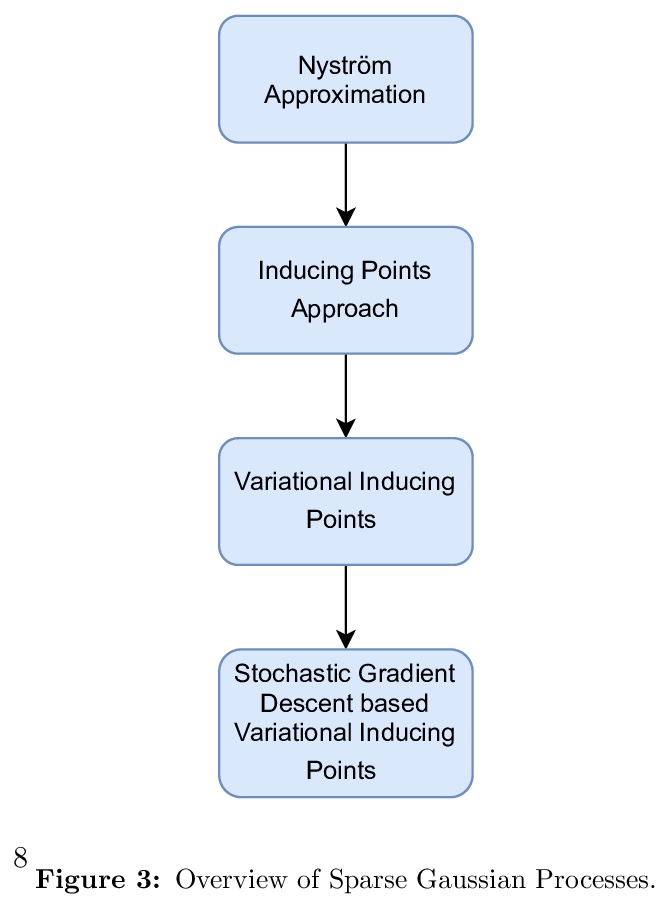
[LG] Deep Gaussian Processes: A Survey
深度高斯过程综述
K Jakkala
[University of North Carolina at Charlotte]
https://weibo.com/1402400261/KlL0IxN3y
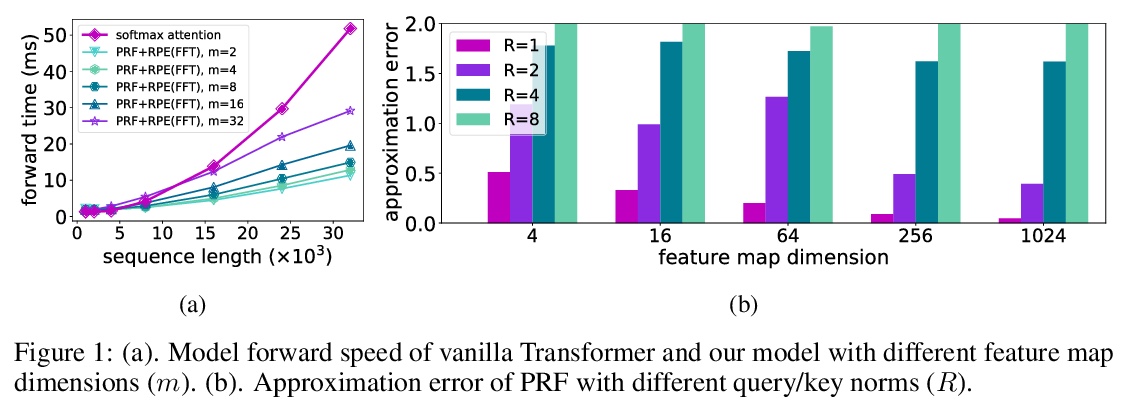
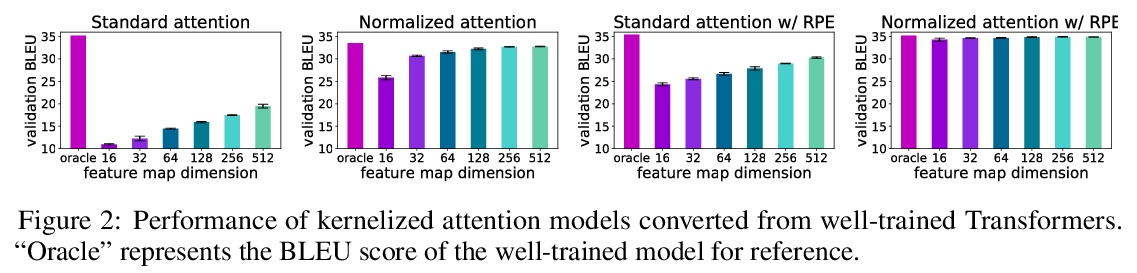
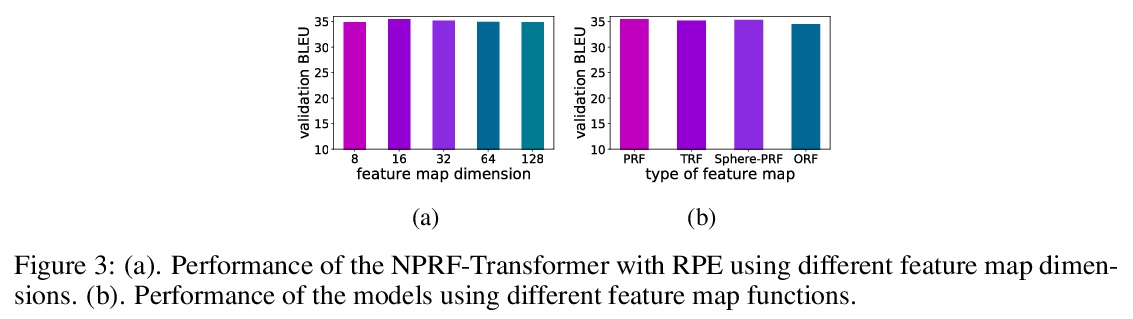
[LG] Stable, Fast and Accurate: Kernelized Attention with Relative Positional Encoding
稳定、快速、准确:相对位置编码核化注意力
S Luo, S Li, T Cai, D He, D Peng, S Zheng, G Ke, L Wang, T Liu
[Peking University & Princeton University & University of Science and Technology of China & Microsoft Research]
https://weibo.com/1402400261/KlL1WuiT7
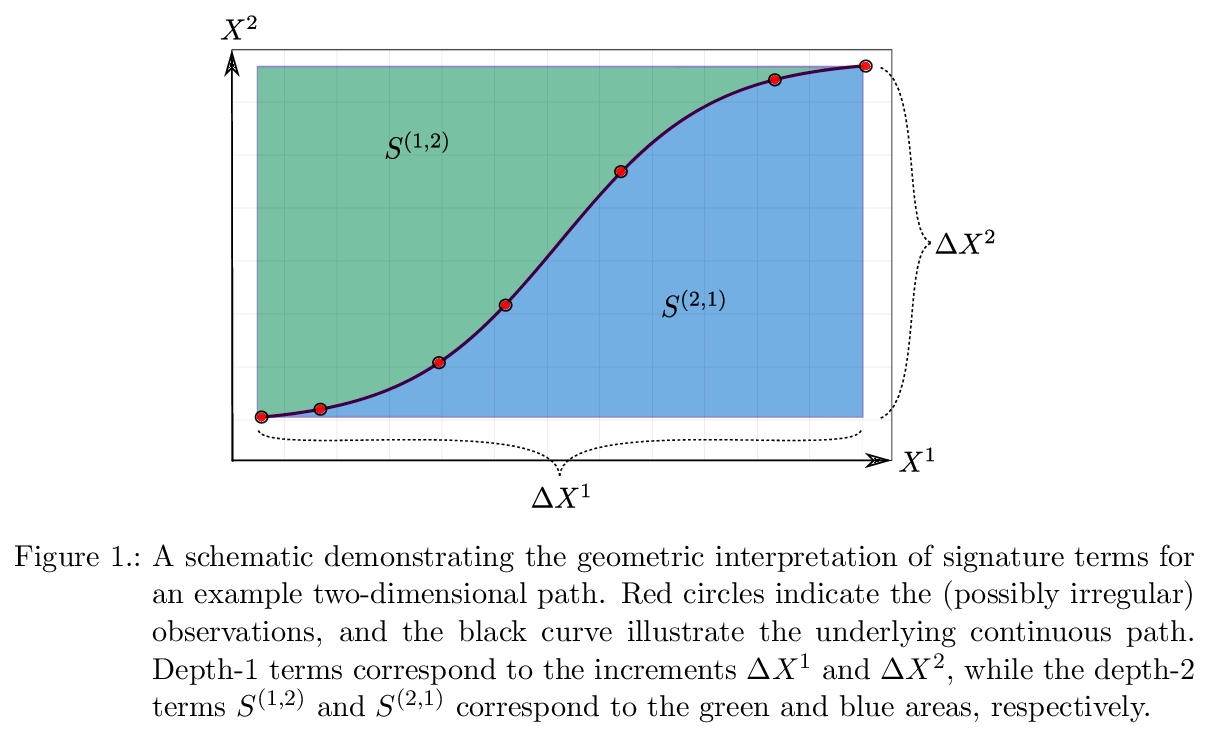
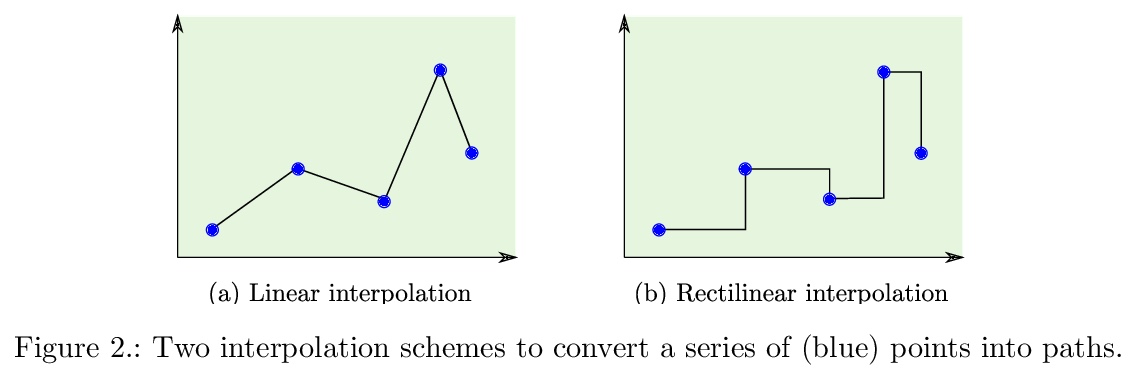
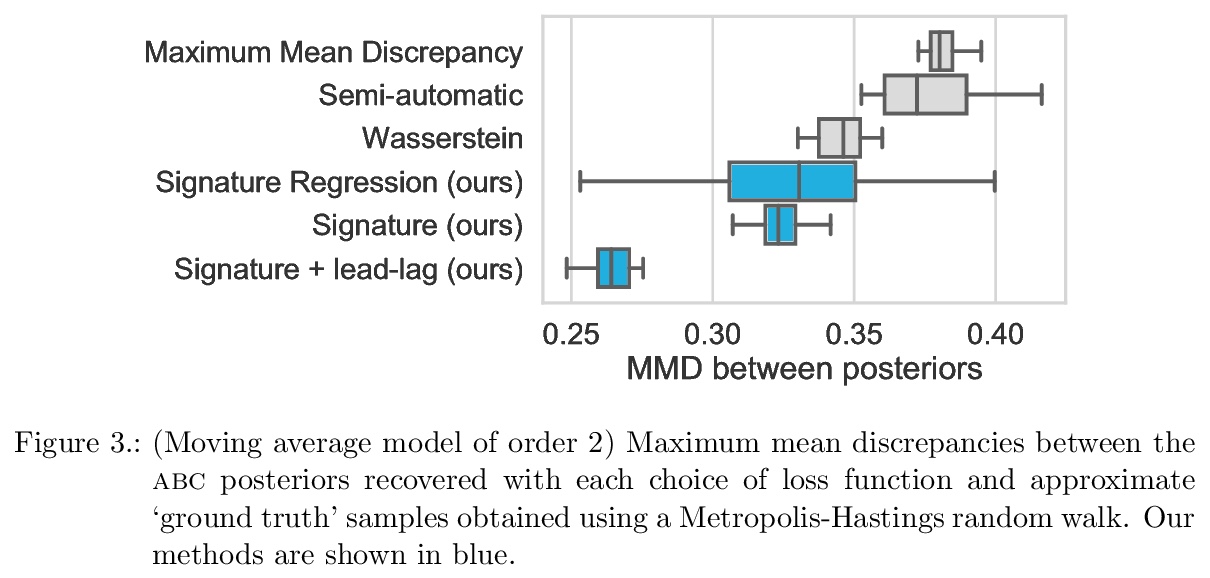
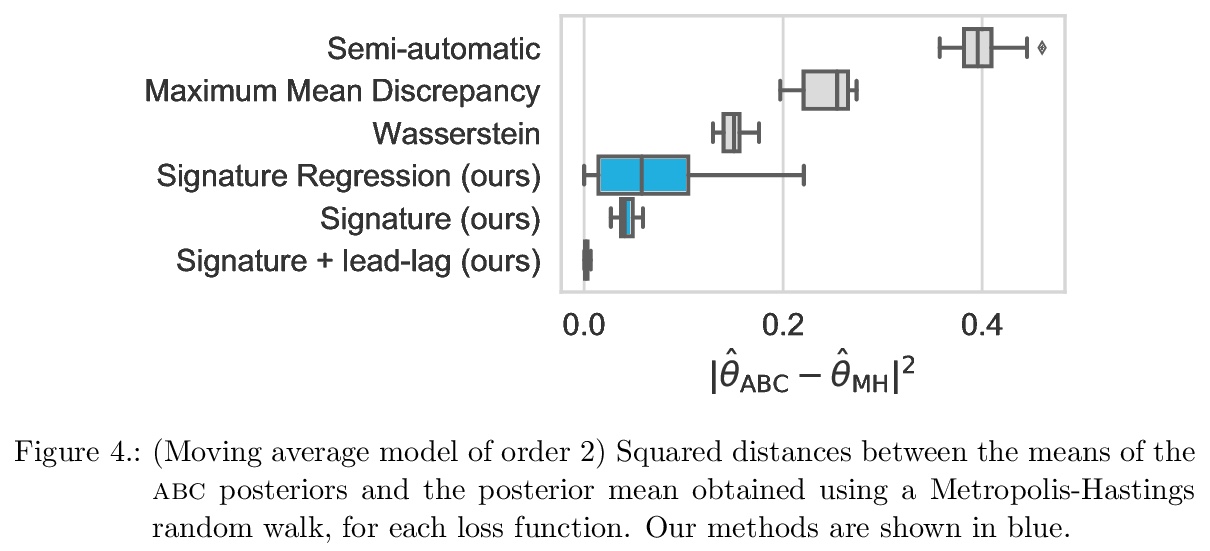
[LG] Approximate Bayesian Computation with Path Signatures
基于路径签名的近似贝叶斯计算
J Dyer, P Cannon, S M Schmon
[University of Oxford & Improbable]
https://weibo.com/1402400261/KlL3mcMl4

若有收获,就点个赞吧
0 人点赞
