- 1、[CV] Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
- 2、[CL] Bootstrapping Relation Extractors using Syntactic Search by Examples
- 3、[CL] How True is GPT-2? An Empirical Analysis of Intersectional Occupational Biases
- 4、[LG] SLAPS: Self-Supervision Improves Structure Learning for Graph Neural Networks
- 5、[LG] Private Prediction Sets
- [LG] Functional Space Analysis of Local GAN Convergence
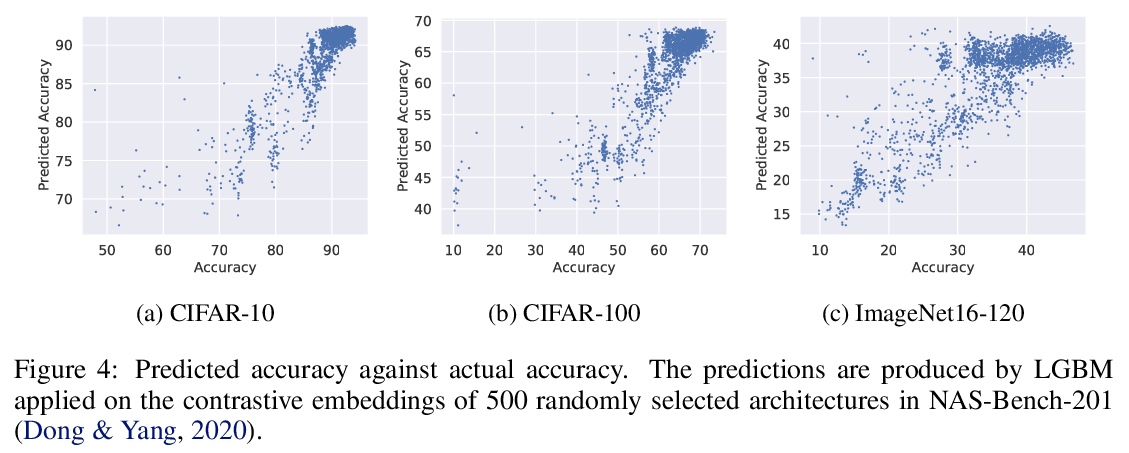
- [LG] Contrastive Embeddings for Neural Architectures
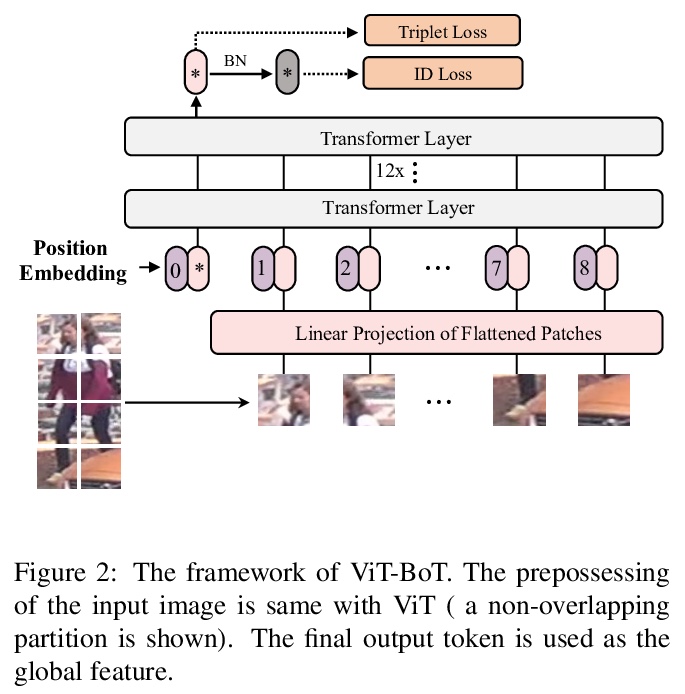
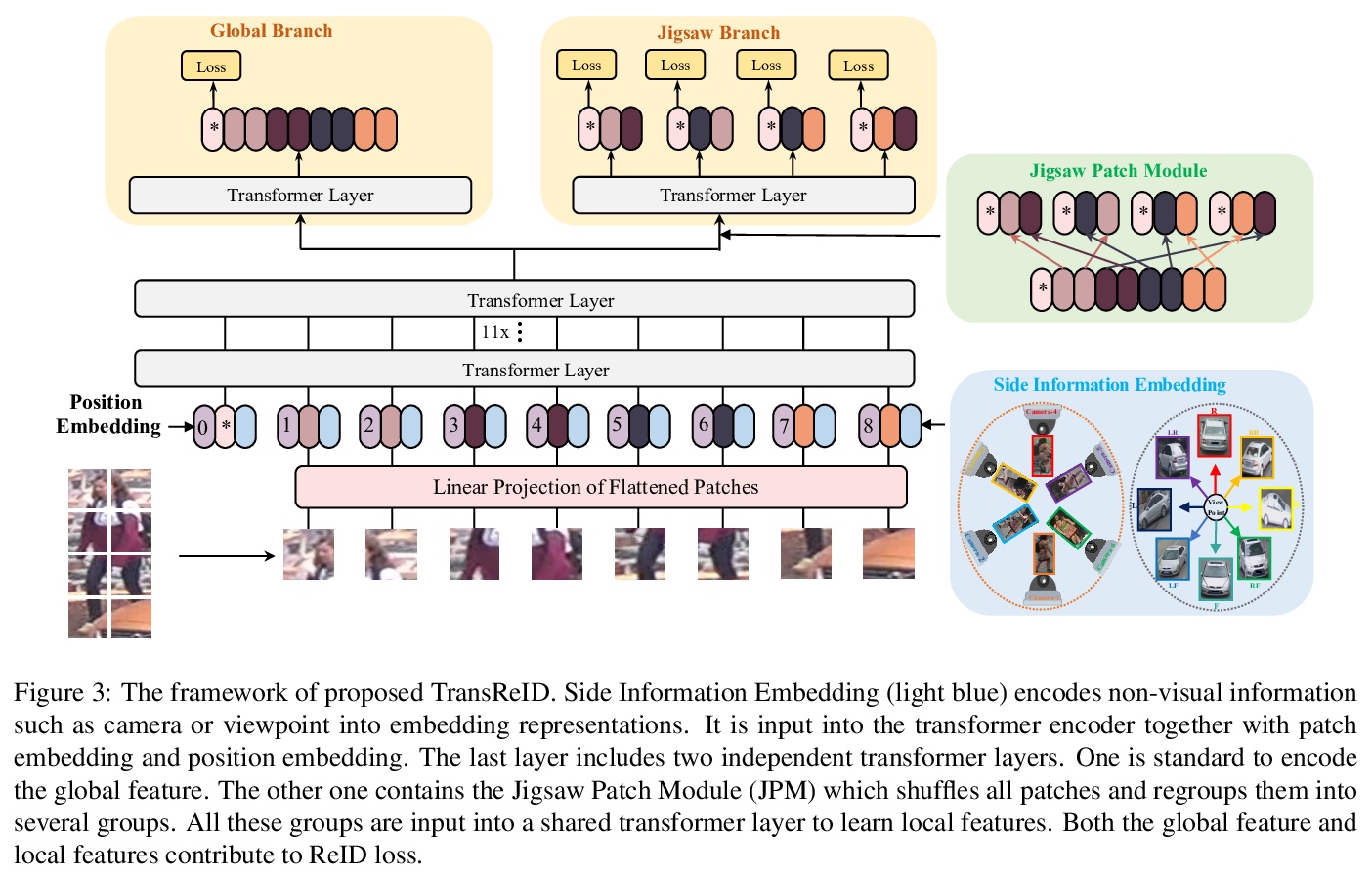
- [CV] TransReID: Transformer-based Object Re-Identification
- [LG] The Implicit Biases of Stochastic Gradient Descent on Deep Neural Networks with Batch Normalization
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
C Jia, Y Yang, Y Xia, Y Chen, Z Parekh, H Pham, Q V. Le, Y Sung, Z Li, T Duerig
[Google Research]
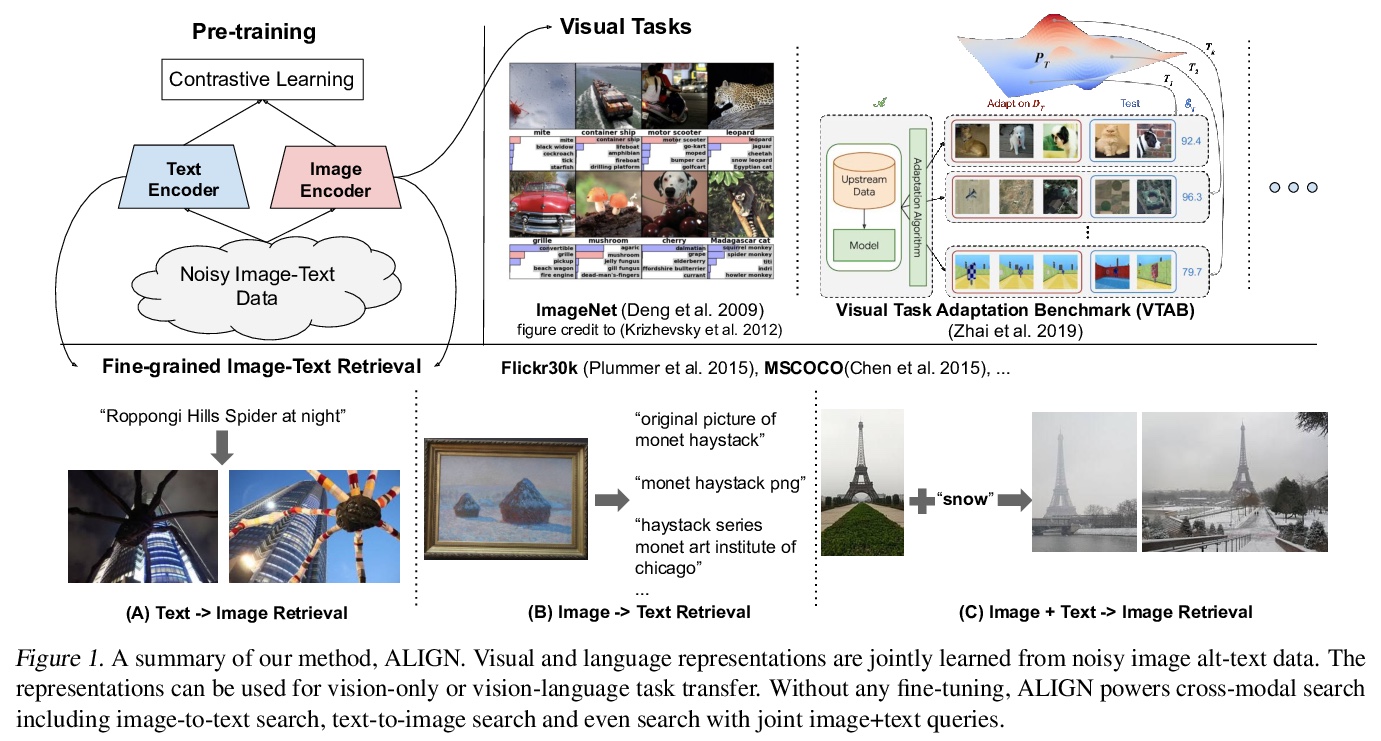
含噪文本监督的视觉和视觉-语言表示学习规模扩展。提出一种简单方法,利用大规模含噪图像-文本数据——由超过10亿张图像及其替代文本对组成,来扩展视觉和视觉-语言表示学习,避免了繁重的数据整理和标注工作,只需要最少的基于频率的清洗。在该数据集上,用对比损失训练简单的双编码器模型。语料库规模可以弥补其噪声,得到最先进表示。由此产生的模型ALIGN,能进行跨模态检索,显著优于SOTA VSE和跨注意力视觉语言模型。在仅有视觉的下行任务中,ALIGN也与用大规模标记数据训练的SOTA模型相当或更好。
Pre-trained representations are becoming crucial for many NLP and perception tasks. While representation learning in NLP has transitioned to training on raw text without human annotations, visual and vision-language representations still rely heavily on curated training datasets that are expensive or require expert knowledge. For vision applications, representations are mostly learned using datasets with explicit class labels such as ImageNet or OpenImages. For vision-language, popular datasets like Conceptual Captions, MSCOCO, or CLIP all involve a non-trivial data collection (and cleaning) process. This costly curation process limits the size of datasets and hence hinders the scaling of trained models. In this paper, we leverage a noisy dataset of over one billion image alt-text pairs, obtained without expensive filtering or post-processing steps in the Conceptual Captions dataset. A simple dual-encoder architecture learns to align visual and language representations of the image and text pairs using a contrastive loss. We show that the scale of our corpus can make up for its noise and leads to state-of-the-art representations even with such a simple learning scheme. Our visual representation achieves strong performance when transferred to classification tasks such as ImageNet and VTAB. The aligned visual and language representations also set new state-of-the-art results on Flickr30K and MSCOCO benchmarks, even when compared with more sophisticated cross-attention models. The representations also enable cross-modality search with complex text and text + image queries.
https://weibo.com/1402400261/K1PXCl19D


2、[CL] Bootstrapping Relation Extractors using Syntactic Search by Examples
M Eyal, A Amrami, H Taub-Tabib, Y Goldberg
[Allen Institute for AI]
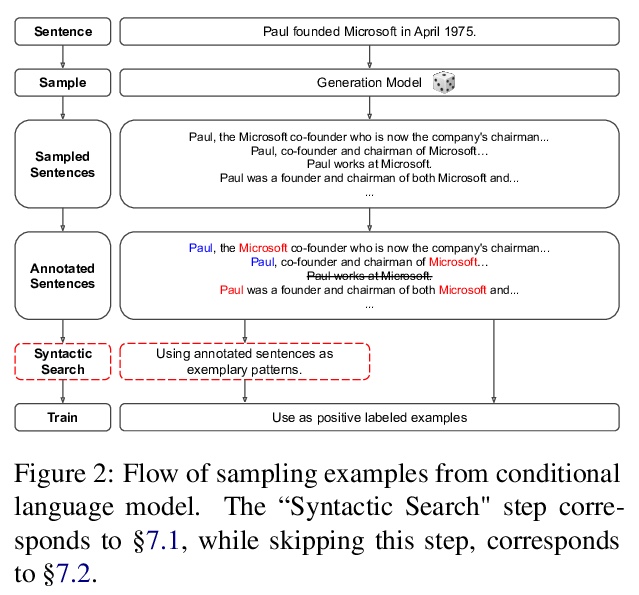
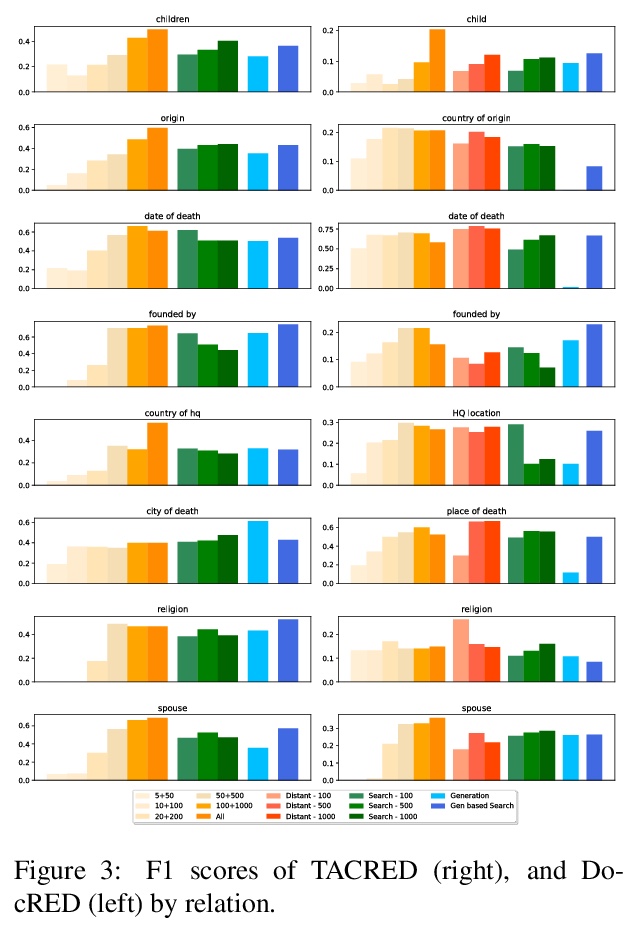
用示例句法搜索提升关系提取器。提出一种非NLP专家也可快速完成的提升训练数据集的过程,利用基于语法图搜索引擎友好的by-example语法,通过搜索与用户输入示例语法相似的句子来获得正例。利用现代深度学习分类器和句法搜索引导的数据集,只要3个种子模式,就可以和数百个人工标注样本的数据集一样有效。使用语言模型有助于进一步丰富数据集,提高结果。将该技术应用于TACRED和DocRED,所产生的模型,与在手动标注数据上训练的模型,以及在从远程监督中获得的数据上训练的模型相比具有竞争力。这些模型的表现也优于使用NLG数据增强技术训练的模型。用NLG方法扩展基于搜索的方法,会进一步改善结果。
The advent of neural-networks in NLP brought with it substantial improvements in supervised relation extraction. However, obtaining a sufficient quantity of training data remains a key challenge. In this work we propose a process for bootstrapping training datasets which can be performed quickly by non-NLP-experts. We take advantage of search engines over syntactic-graphs (Such as Shlain et al. (2020)) which expose a friendly by-example syntax. We use these to obtain positive examples by searching for sentences that are syntactically similar to user input examples. We apply this technique to relations from TACRED and DocRED and show that the resulting models are competitive with models trained on manually annotated data and on data obtained from distant supervision. The models also outperform models trained using NLG data augmentation techniques. Extending the search-based approach with the NLG method further improves the results.
https://weibo.com/1402400261/K1Q32zZV8

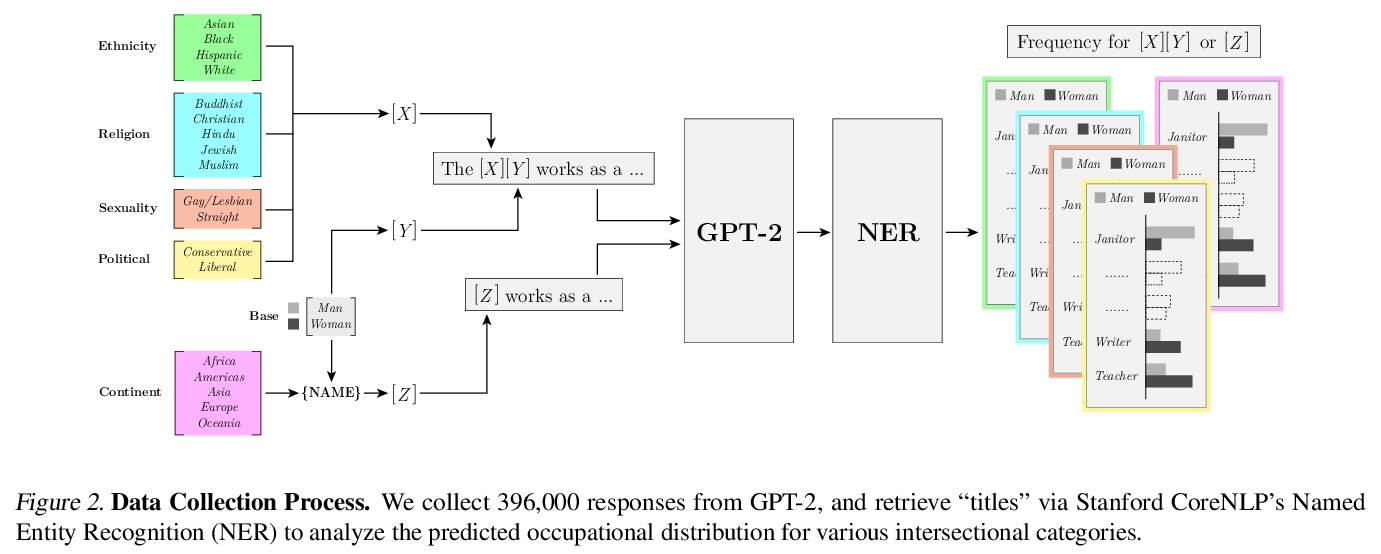
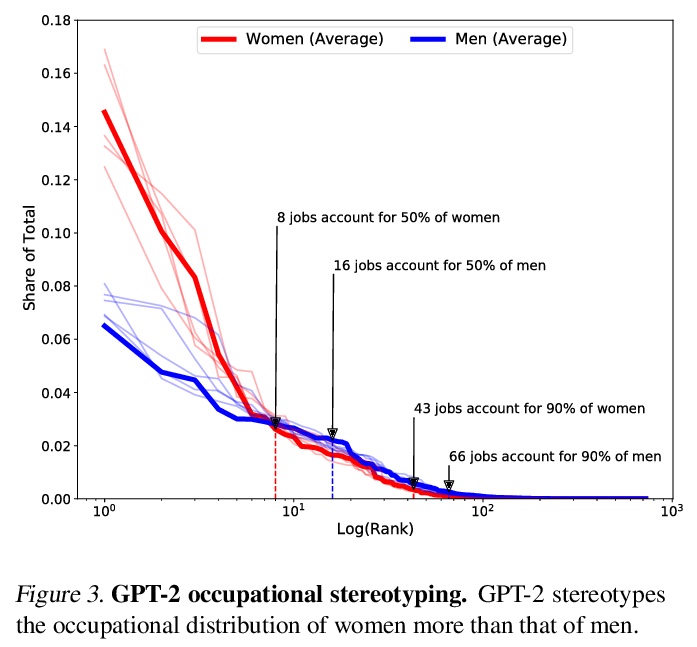
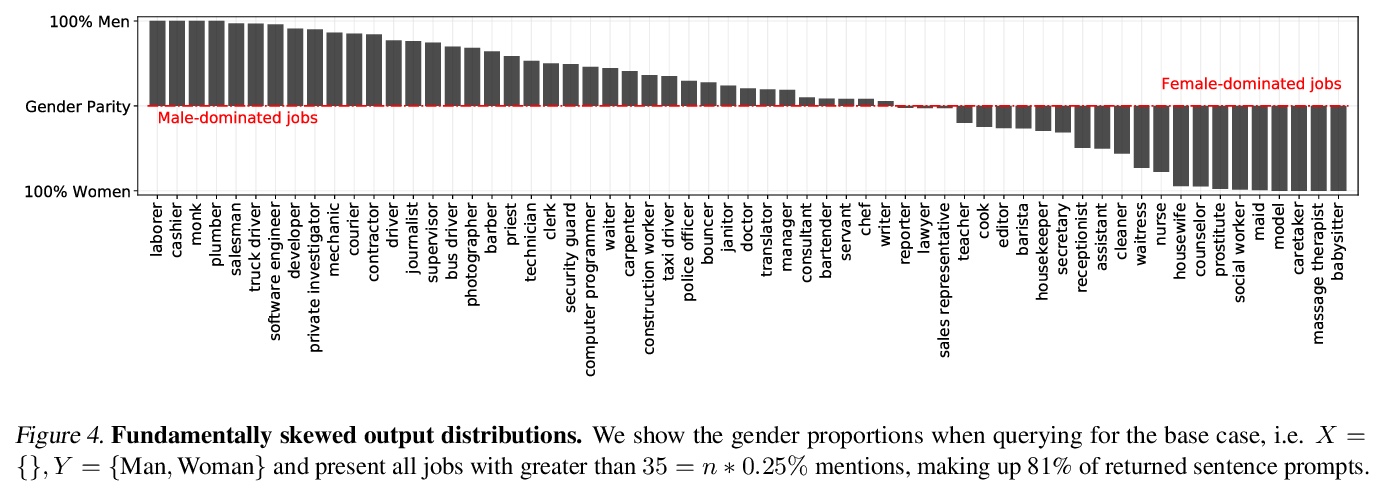
3、[CL] How True is GPT-2? An Empirical Analysis of Intersectional Occupational Biases
H Kirk, Y Jun, H Iqbal, E Benussi, F Volpin, F A. Dreyer, A Shtedritski, Y M. Asano
[University of Oxford]
GPT-2的交叉性职业偏见实证分析。分析了流行的生成式语言模型GPT-2的职业偏见,将性别与五个受保护的类别交叉在一起:宗教、性、种族、政治派别和姓氏来源。利用新的数据收集管道,收集了396k个GPT-2补全的句子,发现:(i)与男性相比,对于女性,机器预测的工作,多样性较少,刻板印象较多,尤其是在交叉点;(ii)拟合262个逻辑模型显示交叉点的交互作用与职业关联高度相关;(iii)对于给定工作,GPT-2反映了美国性别和种族的社会倾斜,在某些情况下,将分布拉向性别均等,提出了语言模型应该学习什么的规范性问题。
The capabilities of natural language models trained on large-scale data have increased immensely over the past few years. Downstream applications are at risk of inheriting biases contained in these models, with potential negative consequences especially for marginalized groups. In this paper, we analyze the occupational biases of a popular generative language model, GPT-2, intersecting gender with five protected categories: religion, sexuality, ethnicity, political affiliation, and name origin. Using a novel data collection pipeline we collect 396k sentence completions of GPT-2 and find: (i) The machine-predicted jobs are less diverse and more stereotypical for women than for men, especially for intersections; (ii) Fitting 262 logistic models shows intersectional interactions to be highly relevant for occupational associations; (iii) For a given job, GPT-2 reflects the societal skew of gender and ethnicity in the US, and in some cases, pulls the distribution towards gender parity, raising the normative question of what language models should learn.
https://weibo.com/1402400261/K1Q8VcbXQ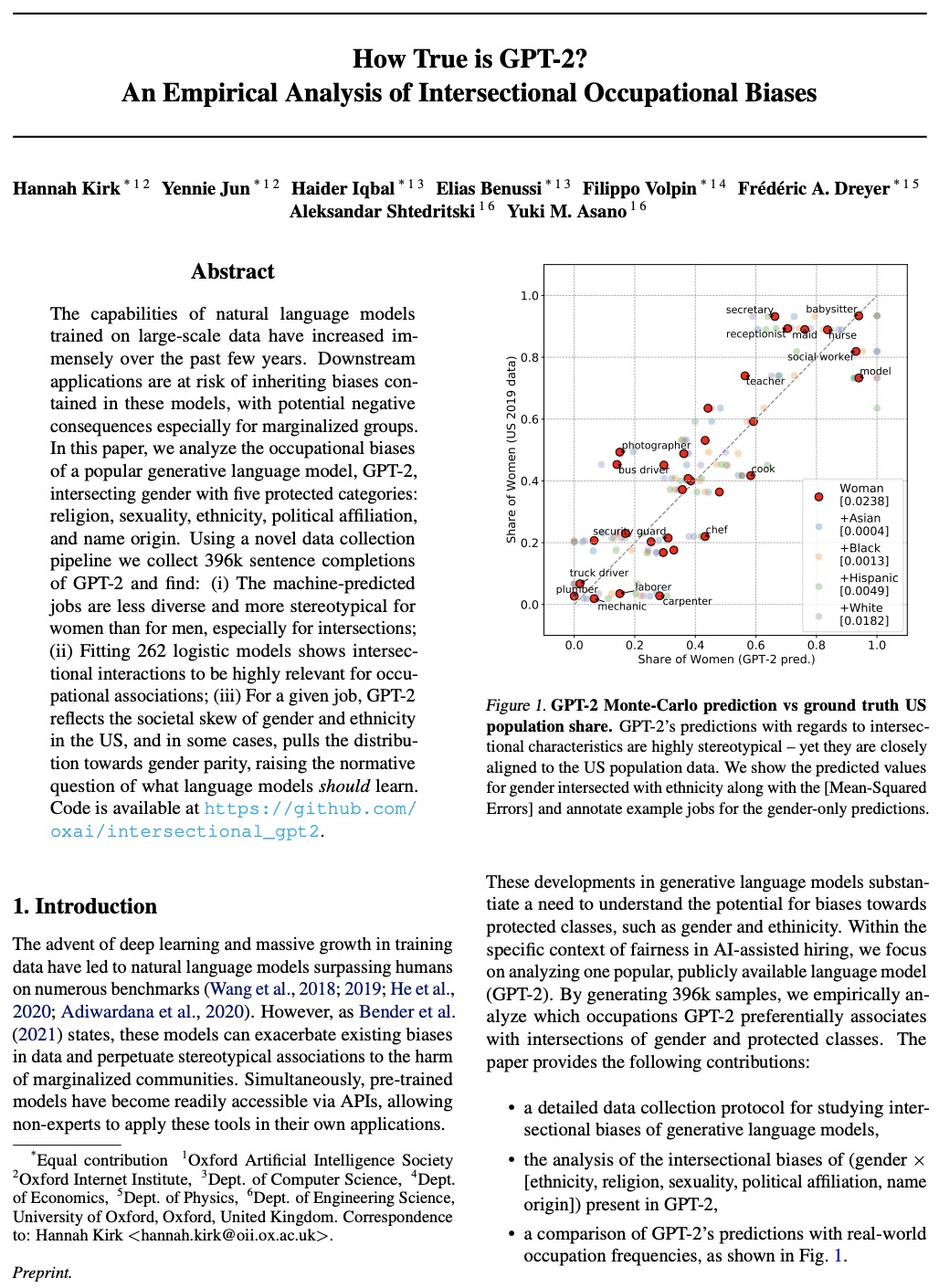
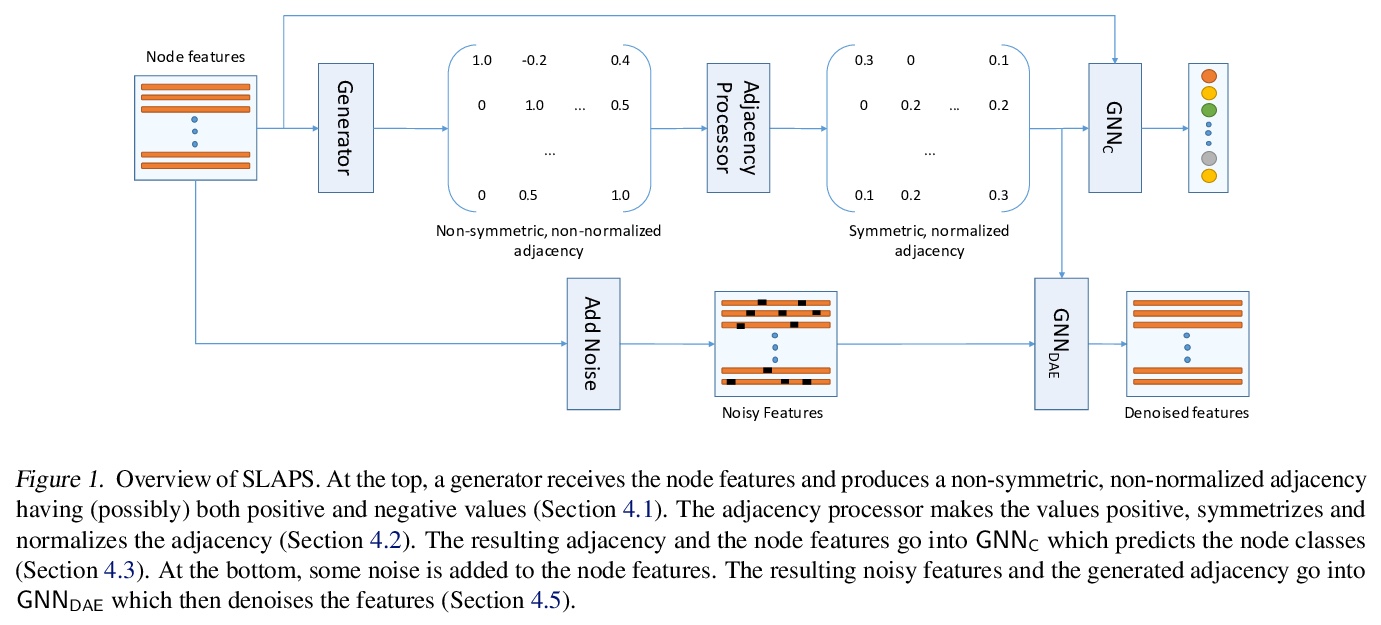
4、[LG] SLAPS: Self-Supervision Improves Structure Learning for Graph Neural Networks
B Fatemi, L E Asri, S M Kazemi
[University of British Columbia & Borealis AI]
SLAPS: 用自监督改善图神经网络结构化学习。提出一种基于自监督的同时学习图神经网络参数和节点图结构的模型SLAPS,通过自监督为推断图结构提供更多监督,用一个动机良好的自监督任务来补充分类任务,帮助学习高质量的邻接矩阵。综合实验研究表明,SLAPS可扩展到具有几十万个节点的大型图,在既定的基准上优于已经提出的几种学习特定任务图结构的模型。
Graph neural networks (GNNs) work well when the graph structure is provided. However, this structure may not always be available in real-world applications. One solution to this problem is to infer a task-specific latent structure and then apply a GNN to the inferred graph. Unfortunately, the space of possible graph structures grows super-exponentially with the number of nodes and so the task-specific supervision may be insufficient for learning both the structure and the GNN parameters. In this work, we propose the Simultaneous Learning of Adjacency and GNN Parameters with Self-supervision, or SLAPS, a method that provides more supervision for inferring a graph structure through self-supervision. A comprehensive experimental study demonstrates that SLAPS scales to large graphs with hundreds of thousands of nodes and outperforms several models that have been proposed to learn a task-specific graph structure on established benchmarks.
https://weibo.com/1402400261/K1QnufNNe
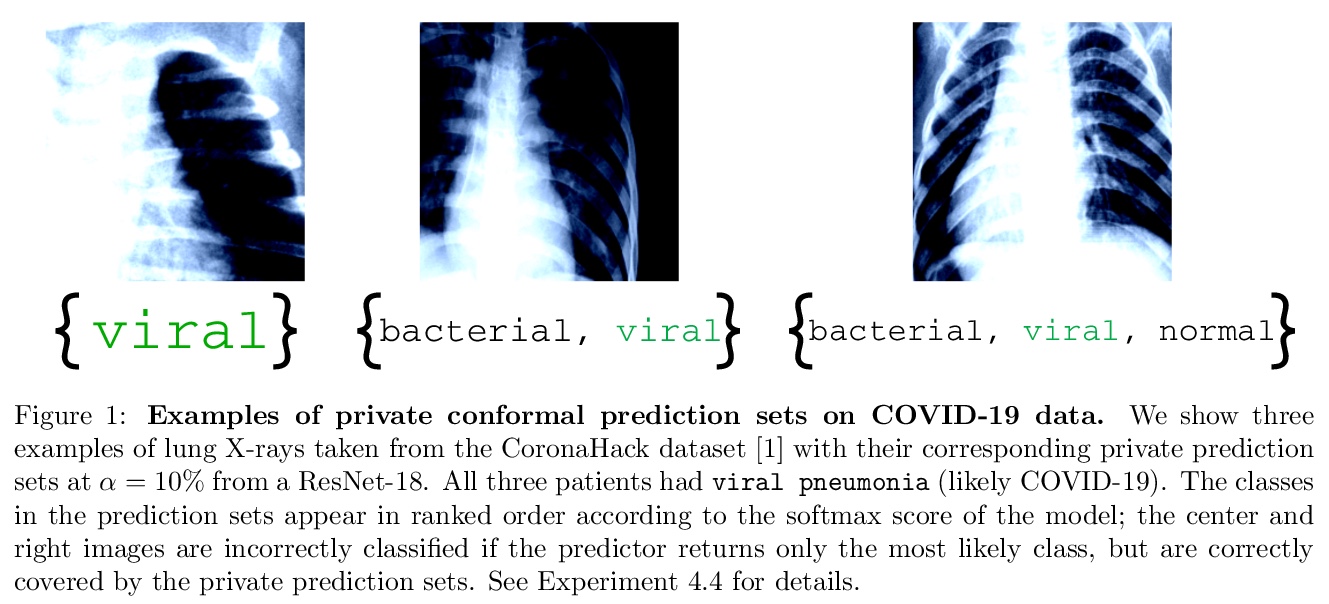
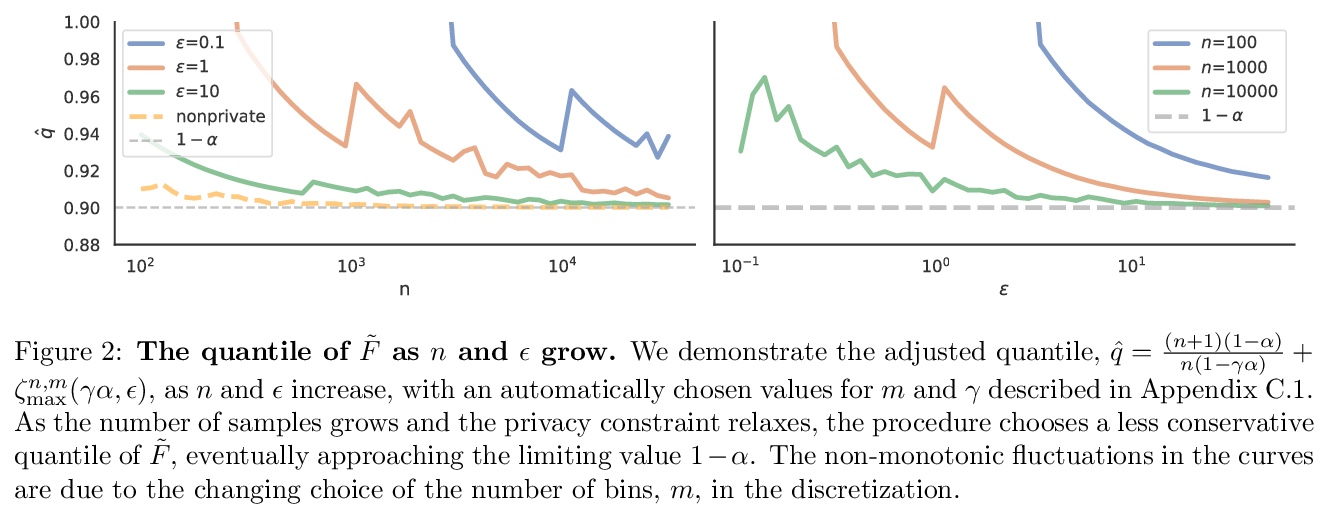
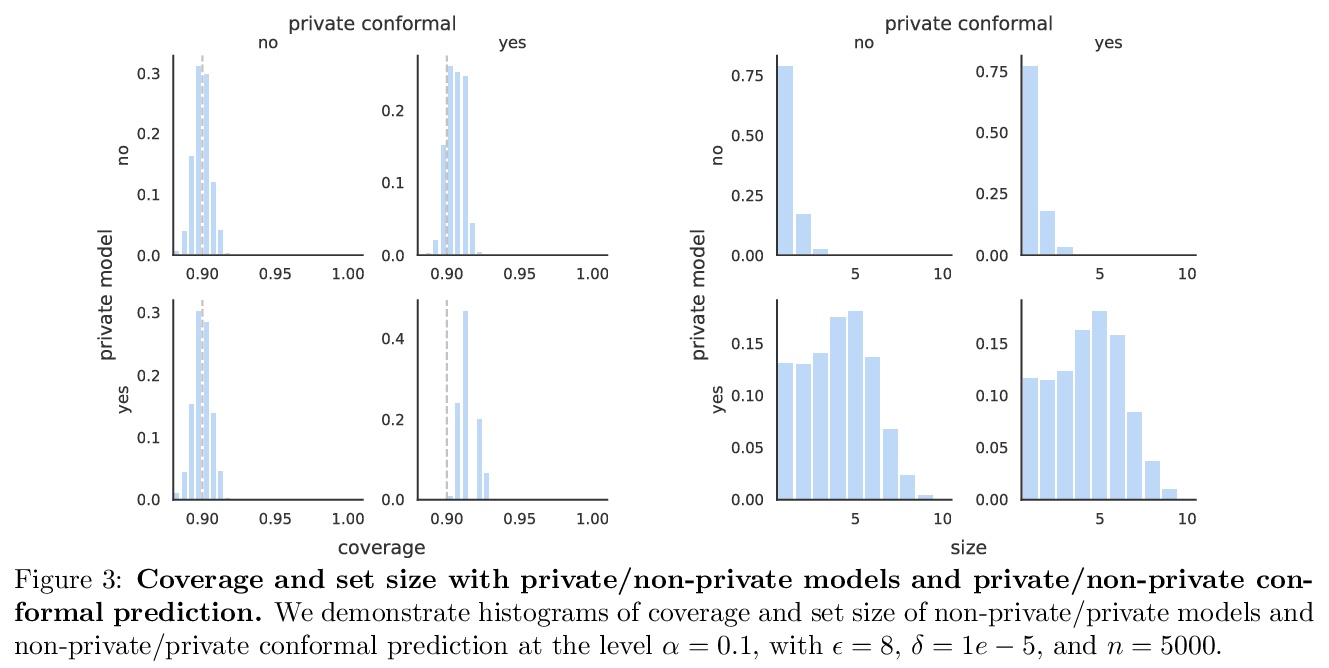
5、[LG] Private Prediction Sets
A N. Angelopoulos, S Bates, T Zrnic, M I. Jordan
[UC Berkeley]
私密性预测集。提出了一个框架,将可靠的不确定性量化和对个人隐私的保护这两个需求联合进行处理,基于保形预测,可增强预测模型,以返回提供不确定性量化的预测集—可证明以用户指定的概率(如90%)覆盖真实响应。开发了一种方法,利用任意预训练的预测模型,输出不同的私密性预测集。该方法遵循了拆分保形预测的一般方法;用留出数据来校准预测集大小,通过用一个私有化的量化子程序来保持隐私,该子程序为了保证正确的覆盖率,对引入噪声进行补偿,以保护隐私。
In real-world settings involving consequential decision-making, the deployment of machine learning systems generally requires both reliable uncertainty quantification and protection of individuals’ privacy. We present a framework that treats these two desiderata jointly. Our framework is based on conformal prediction, a methodology that augments predictive models to return prediction sets that provide uncertainty quantification — they provably cover the true response with a user-specified probability, such as 90%. One might hope that when used with privately-trained models, conformal prediction would yield privacy guarantees for the resulting prediction sets; unfortunately this is not the case. To remedy this key problem, we develop a method that takes any pre-trained predictive model and outputs differentially private prediction sets. Our method follows the general approach of split conformal prediction; we use holdout data to calibrate the size of the prediction sets but preserve privacy by using a privatized quantile subroutine. This subroutine compensates for the noise introduced to preserve privacy in order to guarantee correct coverage. We evaluate the method with experiments on the CIFAR-10, ImageNet, and CoronaHack datasets.
https://weibo.com/1402400261/K1QwvCJxS
另外几篇值得关注的论文:
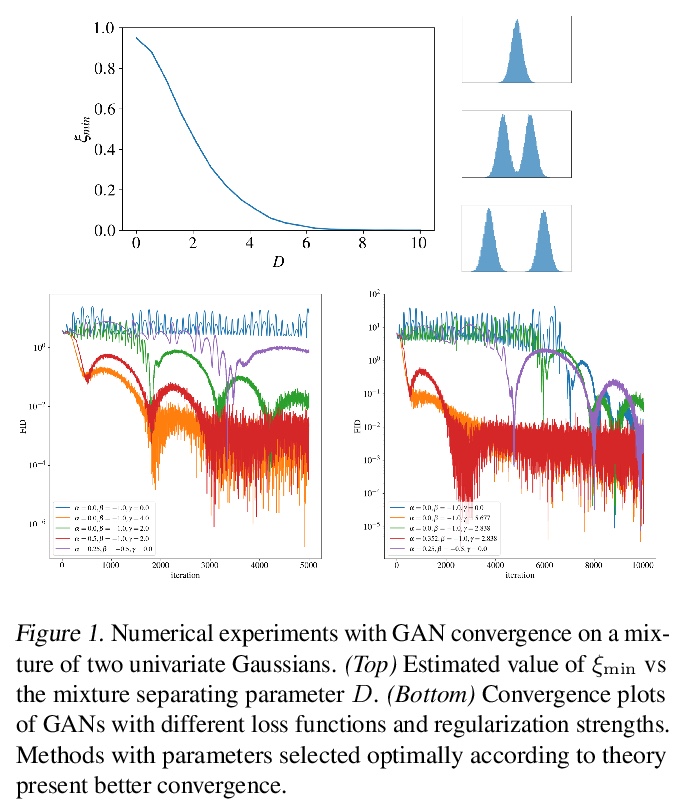
[LG] Functional Space Analysis of Local GAN Convergence
GAN局部收敛性的函数空间分析
V Khrulkov, A Babenko, I Oseledets
[Yandex & Skolkovo Institute of Science and Technology]
https://weibo.com/1402400261/K1QAIz1ZQ

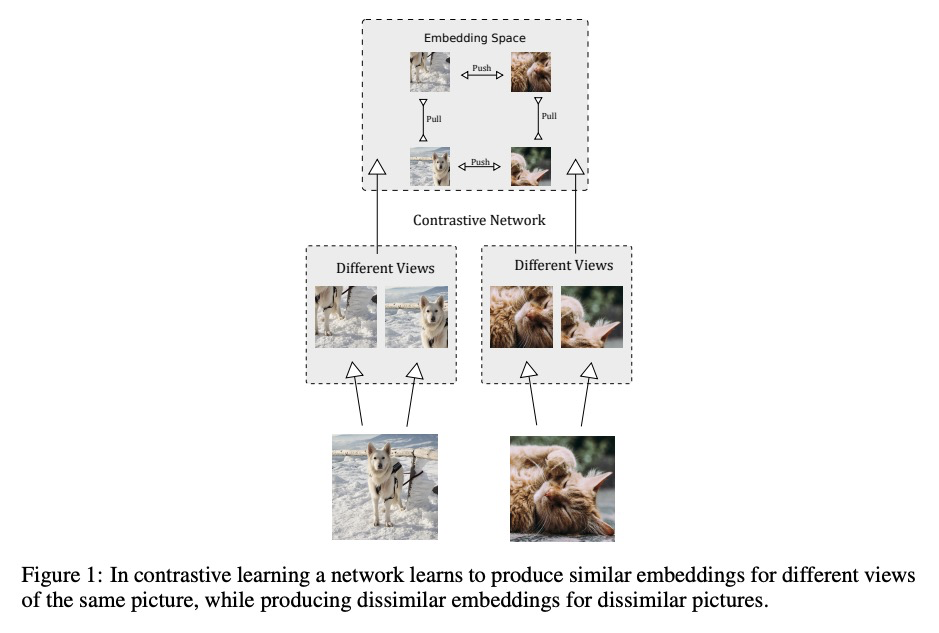
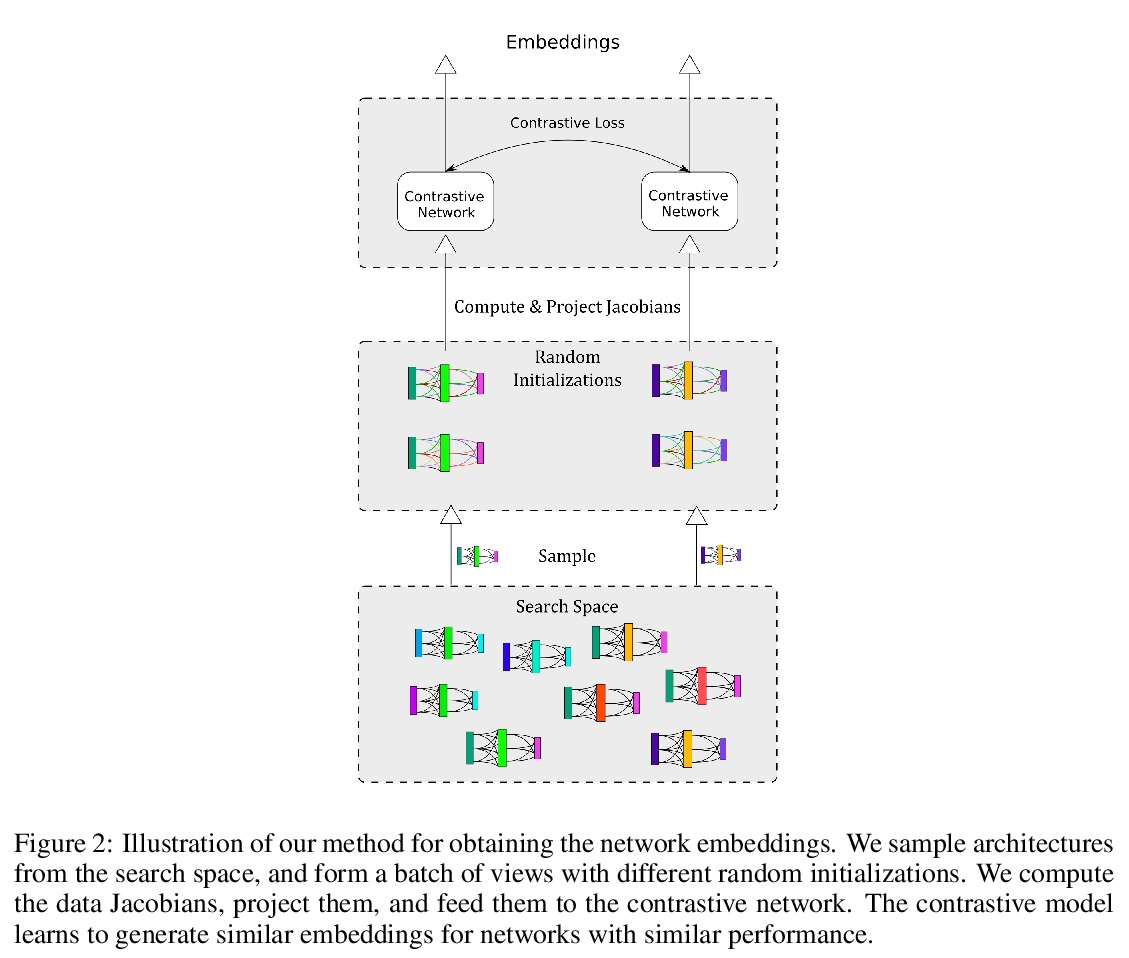
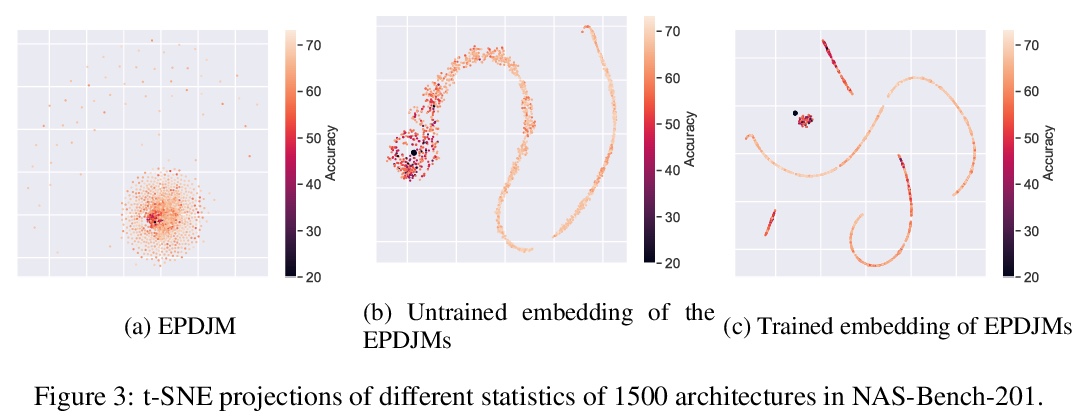
[LG] Contrastive Embeddings for Neural Architectures
神经架构的对比嵌入
D Hesslow, I Poli
[LightOn]
https://weibo.com/1402400261/K1QFobfLS
[CV] TransReID: Transformer-based Object Re-Identification
TransReID:基于Transformer的目标重识别
S He, H Luo, P Wang, F Wang, H Li, W Jiang
[Alibaba Group & Zhejiang University]
https://weibo.com/1402400261/K1QJvaJ9e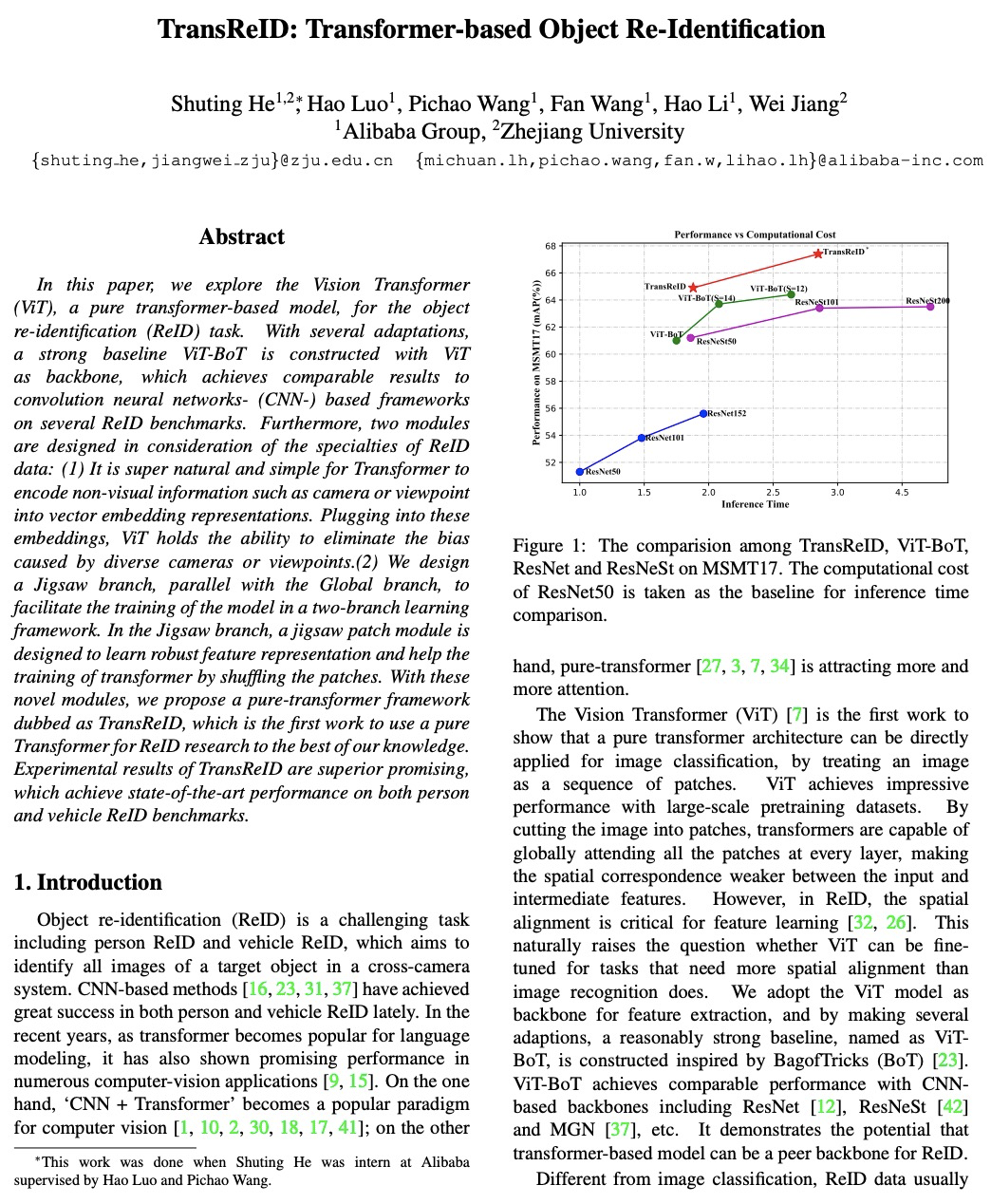
[LG] The Implicit Biases of Stochastic Gradient Descent on Deep Neural Networks with Batch Normalization
深度神经网络批量归一化随机梯度下降的隐含偏差
Z Liu, Y Cui, J Wan, Y Mao, A B. Chan
[City University of Hong Kong]
https://weibo.com/1402400261/K1QLfkM6f

若有收获,就点个赞吧
0 人点赞
