LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 GR - 图形学 ME - 统计方法 (*表示值得重点关注)
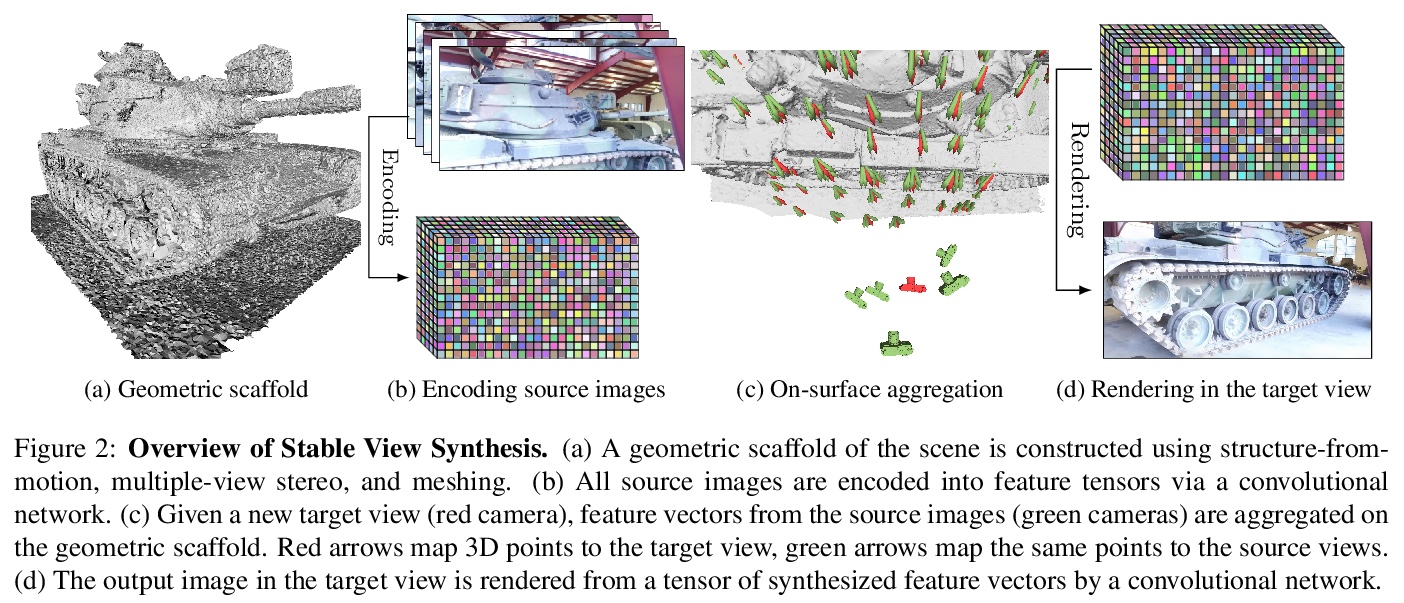
1、[CV] **Stable View Synthesis
G Riegler, V Koltun
[Intel Labs]
稳定视图合成(SVS)。提出一种基于表面特征可微处理的视图合成方法,利用可微集网络(differentiable set network)在场景几何支架上自适应聚合源图像的深度特征,其核心是依赖于视图的表面特征聚合,即处理每个3D点上的方向性特征向量,为将该点映射到新目标视图的射线生成新的特征向量。用端到端训练学习从所有图像中聚合特征,避免了对“相关”源图像进行启发式选择,可实现在大规模真实世界场景最先进水平的照片级真实感视图合成。**
We present Stable View Synthesis (SVS). Given a set of source images depicting a scene from freely distributed viewpoints, SVS synthesizes new views of the scene. The method operates on a geometric scaffold computed via structure-from-motion and multi-view stereo. Each point on this 3D scaffold is associated with view rays and corresponding feature vectors that encode the appearance of this point in the input images. The core of SVS is view-dependent on-surface feature aggregation, in which directional feature vectors at each 3D point are processed to produce a new feature vector for a ray that maps this point into the new target view. The target view is then rendered by a convolutional network from a tensor of features synthesized in this way for all pixels. The method is composed of differentiable modules and is trained end-to-end. It supports spatially-varying view-dependent importance weighting and feature transformation of source images at each point; spatial and temporal stability due to the smooth dependence of on-surface feature aggregation on the target view; and synthesis of view-dependent effects such as specular reflection. Experimental results demonstrate that SVS outperforms state-of-the-art view synthesis methods both quantitatively and qualitatively on three diverse real-world datasets, achieving unprecedented levels of realism in free-viewpoint video of challenging large-scale scenes.
https://weibo.com/1402400261/JvaNMrj6Z
2、[CV] **Deep Active Surface Models
U Wickramasinghe, G Knott, P Fua
[EPFL]
深度有效表面模型。提出一种方法,将有效形状模型整合到层中,可无缝集成到图卷积网络中,用可接受的计算成本执行复杂的平滑先验。通过将平滑直接嵌入到更新方程,可提供比单纯依赖正则化损失项的方法更平滑和更准确的网格。所得模型用于从2D图像进行3D表面重建和3D体分割时,优于使用传统正则化损失项来施加光滑先验的等效结构。**
Active Surface Models have a long history of being useful to model complex 3D surfaces but only Active Contours have been used in conjunction with deep networks, and then only to produce the data term as well as meta-parameter maps controlling them. In this paper, we advocate a much tighter integration. We introduce layers that implement them that can be integrated seamlessly into Graph Convolutional Networks to enforce sophisticated smoothness priors at an acceptable computational cost. We will show that the resulting Deep Active Surface Models outperform equivalent architectures that use traditional regularization loss terms to impose smoothness priors for 3D surface reconstruction from 2D images and for 3D volume segmentation.
https://weibo.com/1402400261/JvaVeFIpY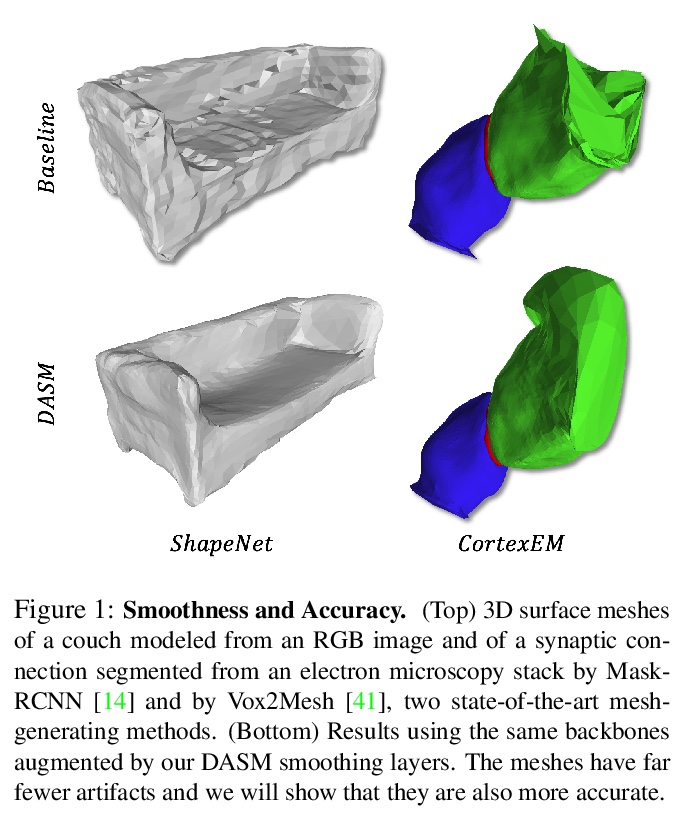
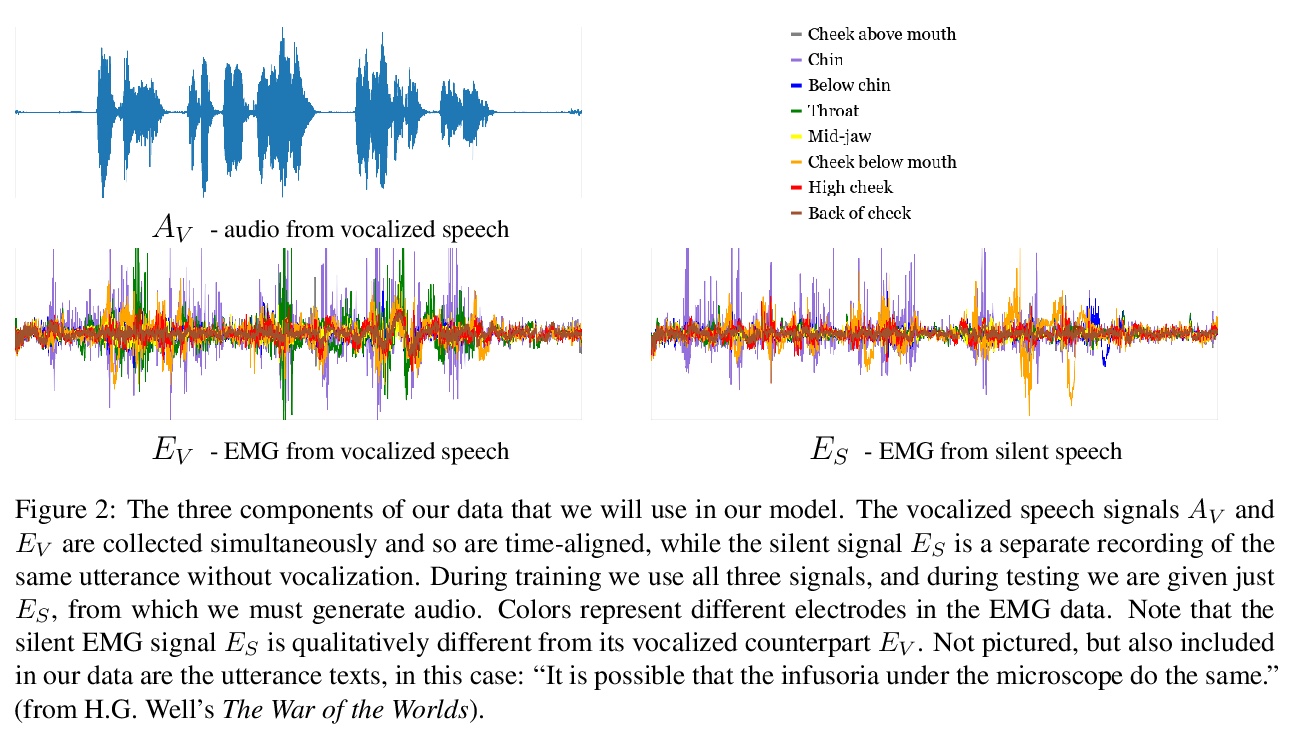
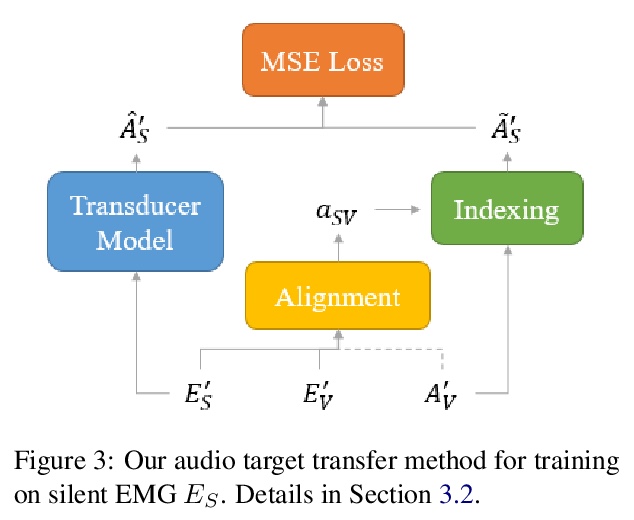
3、[AS] **Digital Voicing of Silent Speech
D Gaddy, D Klein
[UC Berkeley]
“无声语音“的数字发声。基于肌电图(EMG)传感器测量捕获肌肉脉冲,实现无声讲话的数字发声。提出一种无声肌电信号训练方法,通过将发声信号转换为无声信号来训练无声肌电信号。与只训练发声数据的基线相比,该方法大大提高了从无声肌电信号生成的音频的可理解性。**
In this paper, we consider the task of digitally voicing silent speech, where silently mouthed words are converted to audible speech based on electromyography (EMG) sensor measurements that capture muscle impulses. While prior work has focused on training speech synthesis models from EMG collected during vocalized speech, we are the first to train from EMG collected during silently articulated speech. We introduce a method of training on silent EMG by transferring audio targets from vocalized to silent signals. Our method greatly improves intelligibility of audio generated from silent EMG compared to a baseline that only trains with vocalized data, decreasing transcription word error rate from 64% to 4% in one data condition and 88% to 68% in another. To spur further development on this task, we share our new dataset of silent and vocalized facial EMG measurements.
https://weibo.com/1402400261/Jvb0l84ig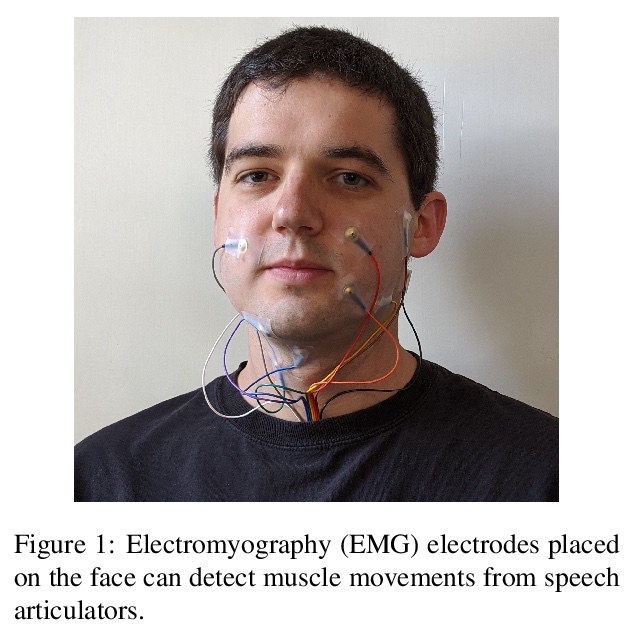
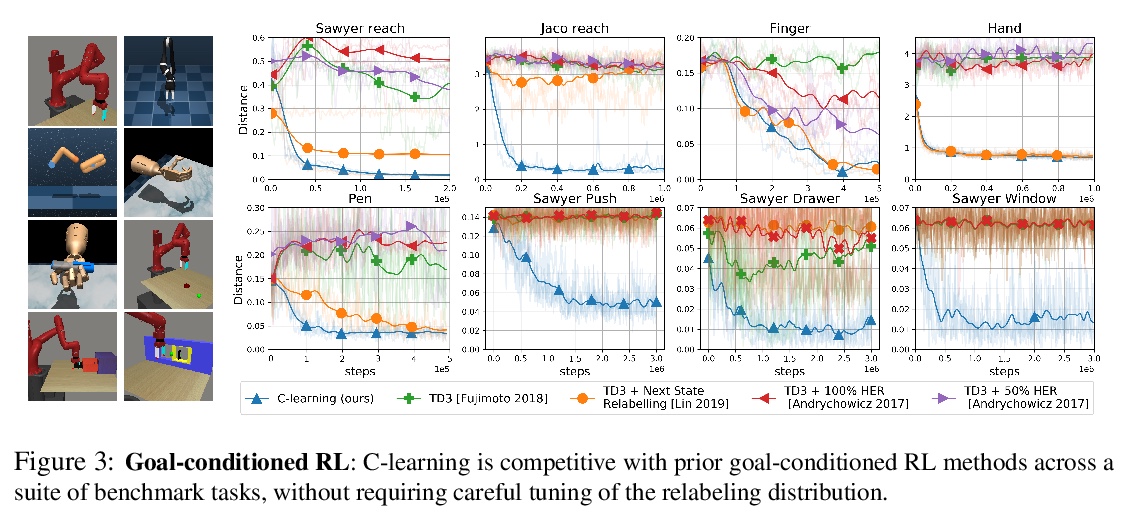
4、[LG] **C-Learning: Learning to Achieve Goals via Recursive Classification
B Eysenbach, R Salakhutdinov, S Levine
[CMU & UC Berkeley]
C-Learning:学习通过递归分类来实现目标。研究了自治智能体未来状态分布的预测和控制问题,将标准目标条件下的强化学习问题,重新表述为一个估计和优化未来状态密度函数的问题,证明了Q-learning在具有连续状态的(随机)环境中不能直接解决这个问题,采用C-learning可以得到更精确的解决方案,可扩展到高维连续控制任务,**
We study the problem of predicting and controlling the future state distribution of an autonomous agent. This problem, which can be viewed as a reframing of goal-conditioned reinforcement learning (RL), is centered around learning a conditional probability density function over future states. Instead of directly estimating this density function, we indirectly estimate this density function by training a classifier to predict whether an observation comes from the future. Via Bayes’ rule, predictions from our classifier can be transformed into predictions over future states. Importantly, an off-policy variant of our algorithm allows us to predict the future state distribution of a new policy, without collecting new experience. This variant allows us to optimize functionals of a policy’s future state distribution, such as the density of reaching a particular goal state. While conceptually similar to Q-learning, our work lays a principled foundation for goal-conditioned RL as density estimation, providing justification for goal-conditioned methods used in prior work. This foundation makes hypotheses about Q-learning, including the optimal goal-sampling ratio, which we confirm experimentally. Moreover, our proposed method is competitive with prior goal-conditioned RL methods.
https://weibo.com/1402400261/Jvb3Gy08i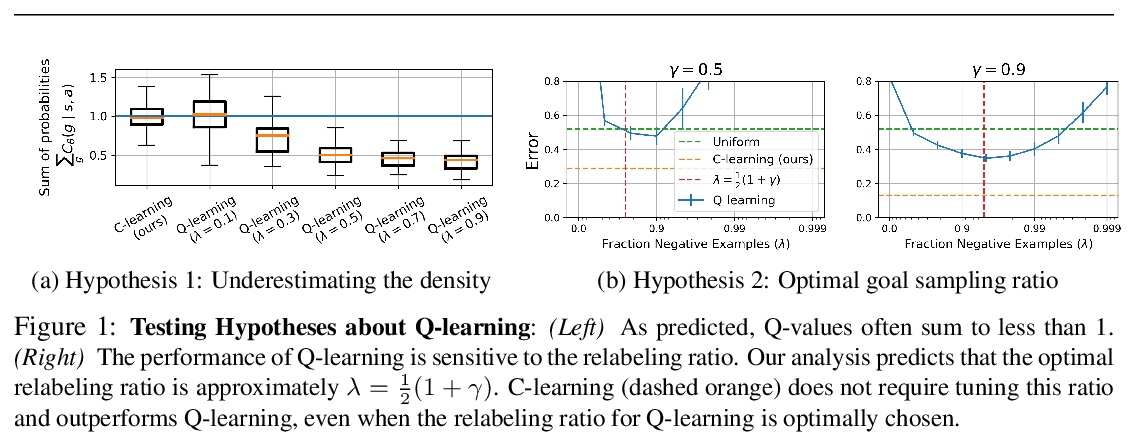

5、[CV] Style Intervention: How to Achieve Spatial Disentanglement with Style-based Generators?
Y Liu, Q Li, Z Sun, T Tan
[CASIA]
风格干预:用基于风格的生成器实现空间解缠。提出了“风格干预”,一种基于优化的轻量级算法,通过提高特征空间维数,实现对对空间对解缠和平移。可实现对单特征图的精确操作,适应任意输入图像,在灵活的目标下呈现自然的变换效果。
Generative Adversarial Networks (GANs) with style-based generators (e.g. StyleGAN) successfully enable semantic control over image synthesis, and recent studies have also revealed that interpretable image translations could be obtained by modifying the latent code. However, in terms of the low-level image content, traveling in the latent space would lead to `spatially entangled changes’ in corresponding images, which is undesirable in many real-world applications where local editing is required. To solve this problem, we analyze properties of the ‘style space’ and explore the possibility of controlling the local translation with pre-trained style-based generators. Concretely, we propose ‘Style Intervention’, a lightweight optimization-based algorithm which could adapt to arbitrary input images and render natural translation effects under flexible objectives. We verify the performance of the proposed framework in facial attribute editing on high-resolution images, where both photo-realism and consistency are required. Extensive qualitative results demonstrate the effectiveness of our method, and quantitative measurements also show that the proposed algorithm outperforms state-of-the-art benchmarks in various aspects.



其他几篇值得关注的论文:
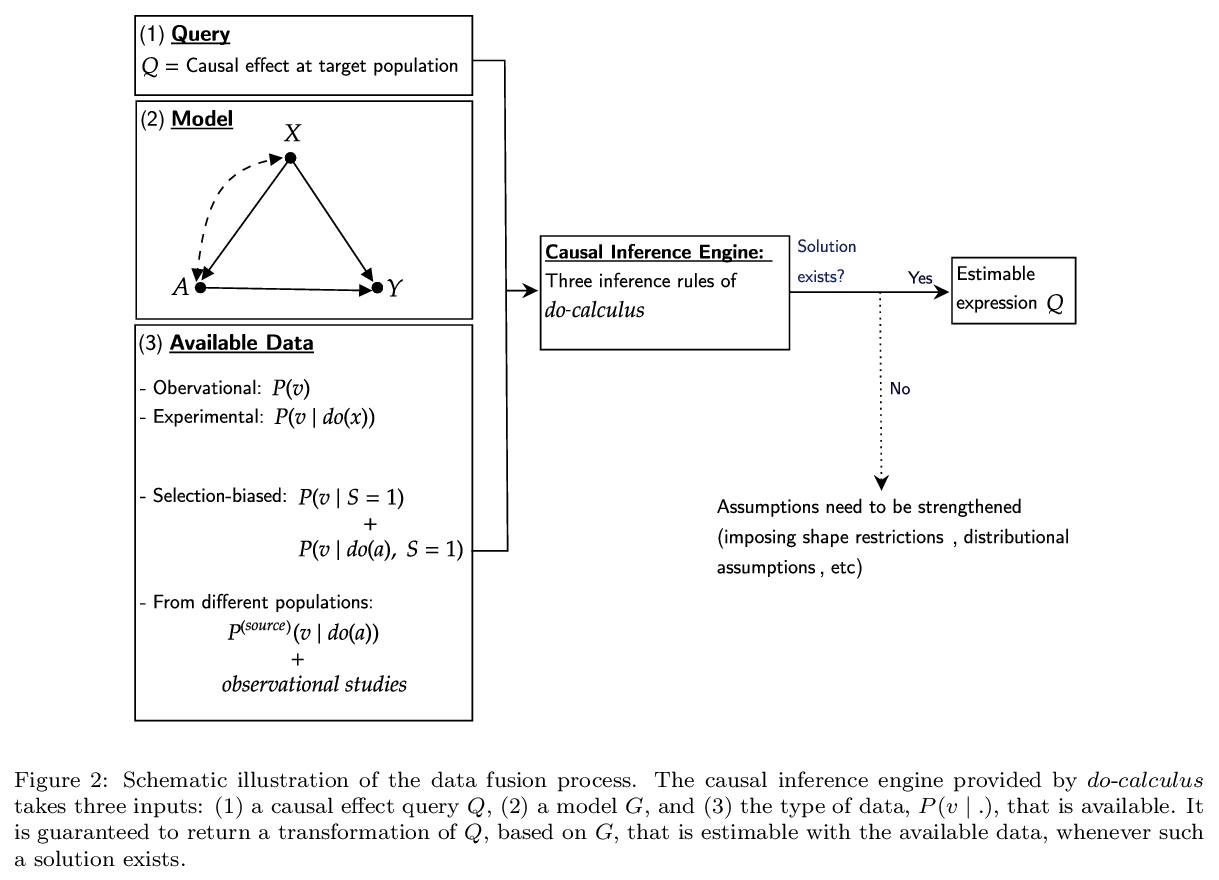
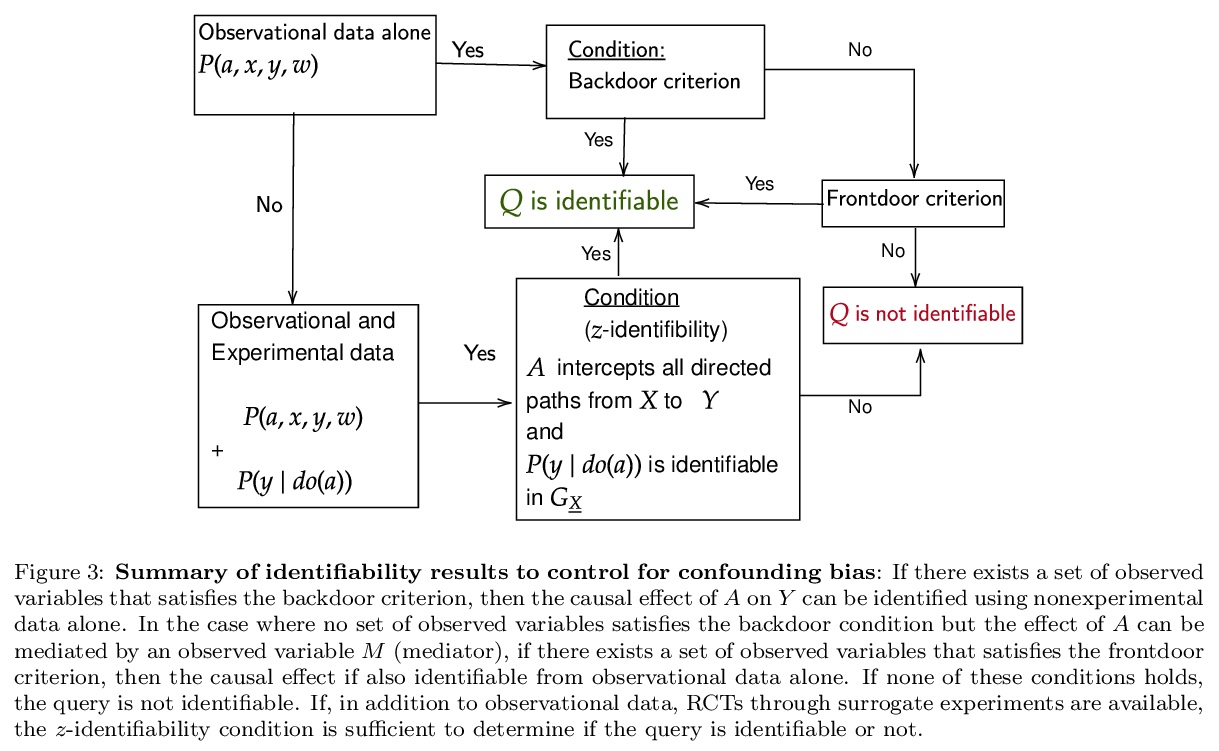
[ME] Causal inference methods for combining randomized trials and observational studies: a review
随机试验和观察性研究相结合的因果推断方法:综述
B Colnet, I Mayer, G Chen, A Dieng, R Li, G Varoquaux, J Vert, J Josse, S Yang
[Université Paris-Saclay & PSL University & University of Wisconsin-Madison & Google Research]
https://weibo.com/1402400261/JvaJXcP0S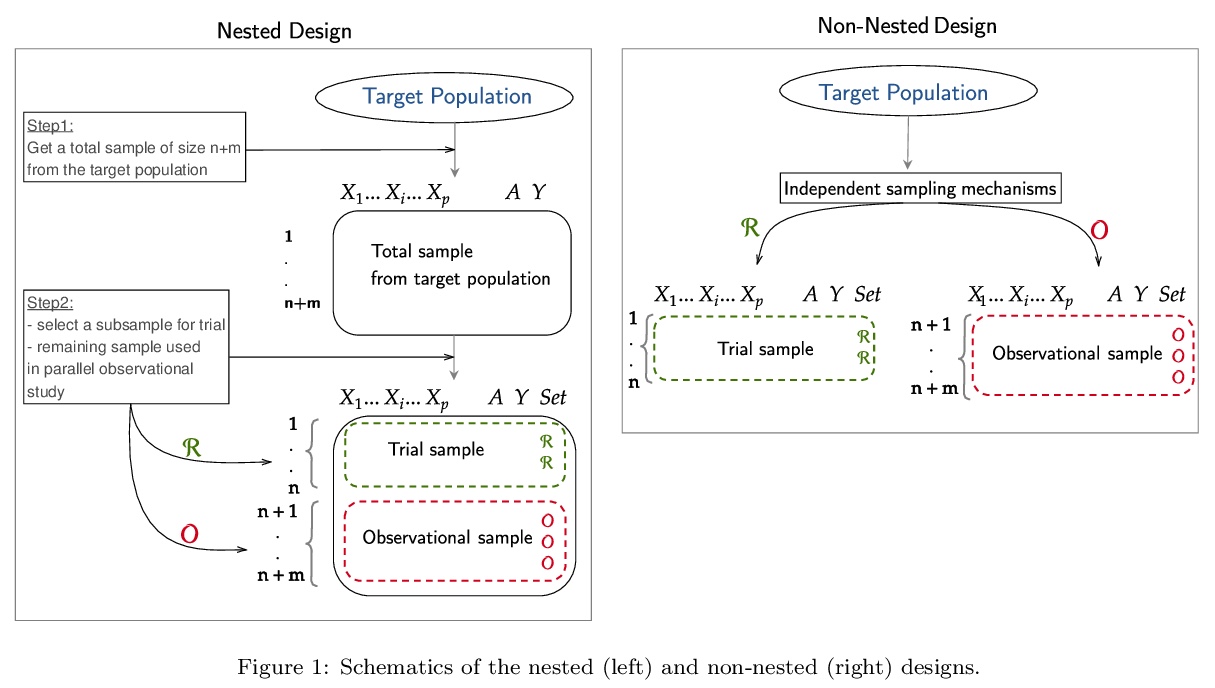
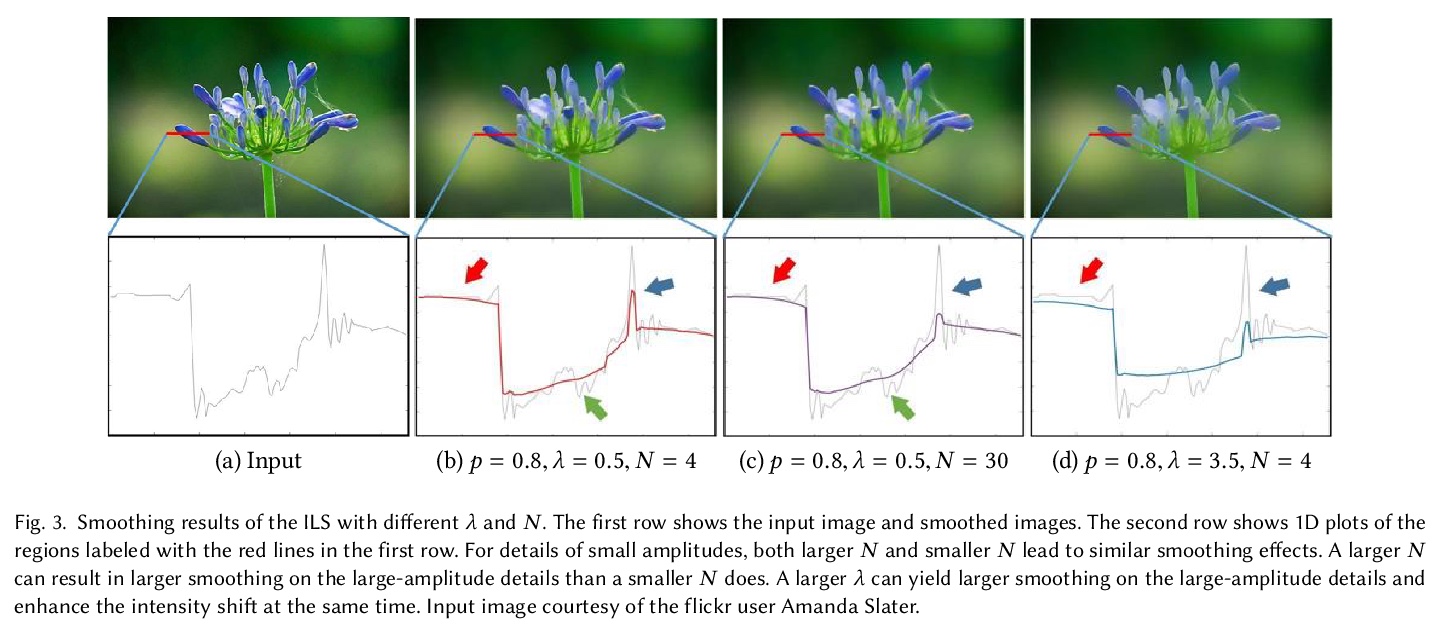
[GR] Real-time Image Smoothing via Iterative Least Squares
基于迭代最小二乘法实现的实时图像平滑
W Liu, P Zhang, X Huang, J Yang, C Shen, I Reid
[The University of Adelaide, Australia & Dalian University of Technology & Shanghai Jiao Tong University]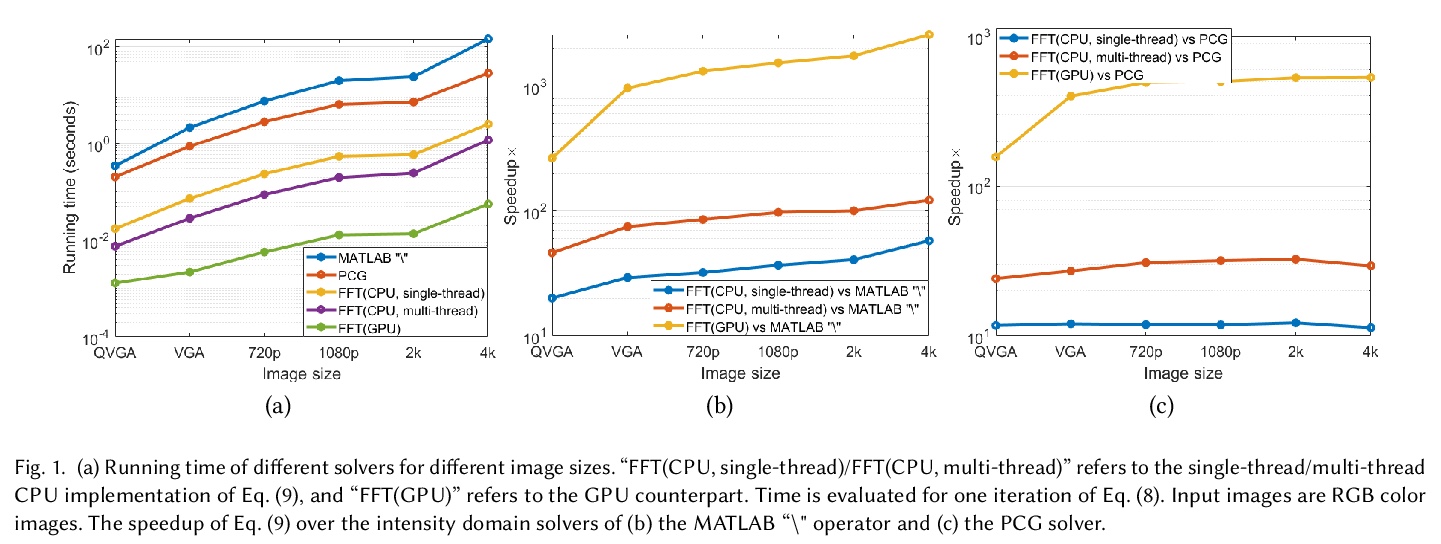

[CV] High-level Prior-based Loss Functions for Medical Image Segmentation: A Survey
医学图像分割高级先验损失函数:综述
R E Jurdia, C Petitjean, P Honeine, V Cheplygina, F Abdallah
[Normandie Univ & University of Technology, Eindhoven]
https://weibo.com/1402400261/JvbdsA8t1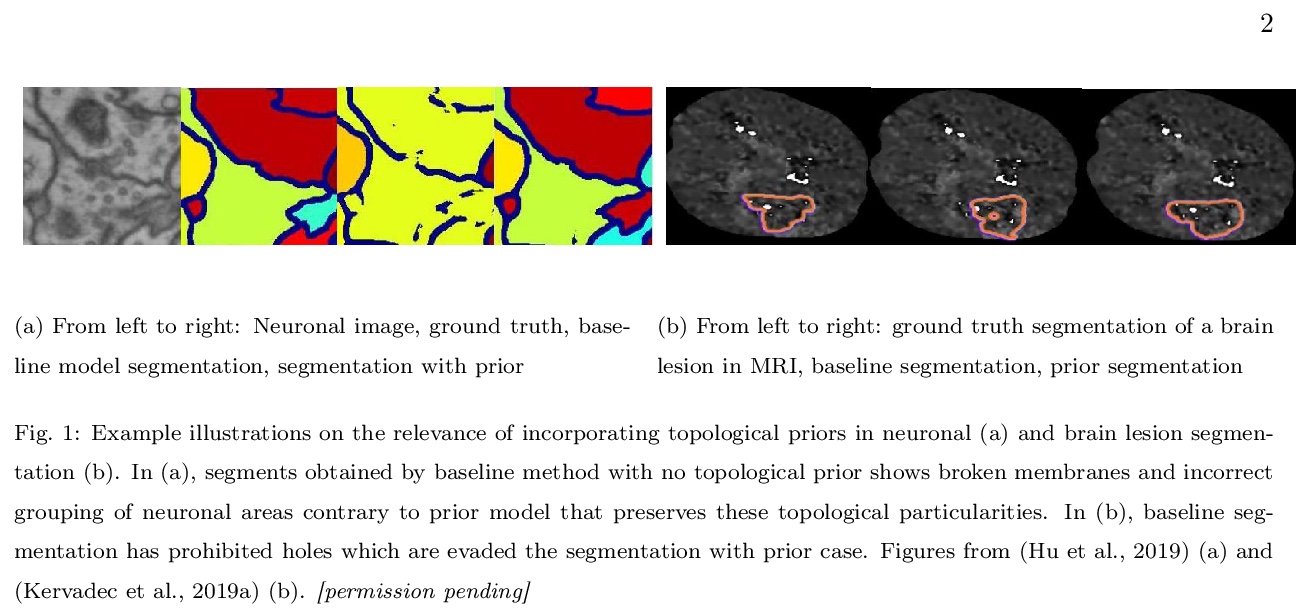
[CL] WikiAsp: A Dataset for Multi-domain Aspect-based Summarization
WikiAsp:多域方面摘要数据集
H Hayashi, P Budania, P Wang, C Ackerson, R Neervannan, G Neubig
[CMU]
https://weibo.com/1402400261/JvbfQl0MF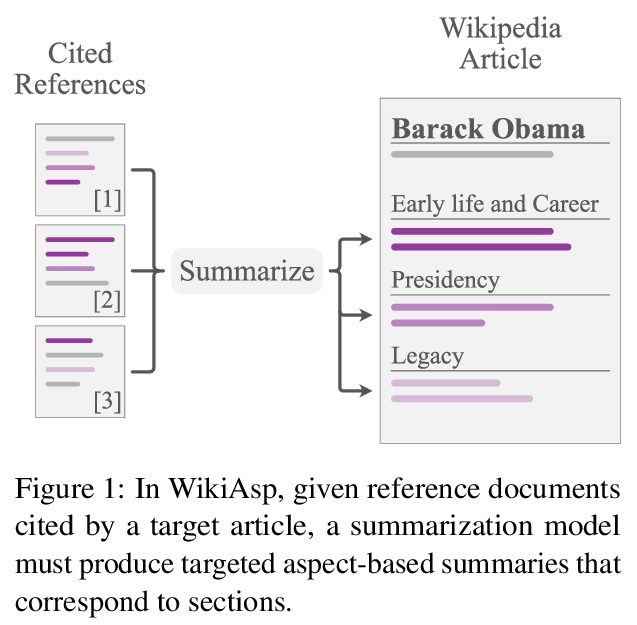

若有收获,就点个赞吧
0 人点赞
