- 1、[CV] TransGAN: Two Transformers Can Make One Strong GAN
- 2、[CL] DOBF: A Deobfuscation Pre-Training Objective for Programming Languages
- 3、[CV] NeRF−−: Neural Radiance Fields Without Known Camera Parameters
- 4、[RO] End-to-End Egospheric Spatial Memory
- 5、[LG] Understanding Negative Samples in Instance Discriminative Self-supervised Representation Learning
- [LG] Does Standard Backpropagation Forget Less Catastrophically Than Adam?
- [CV] Learning Speech-driven 3D Conversational Gestures from Video
- [CL] Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm
- [CV] Learning Intra-Batch Connections for Deep Metric Learning
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] TransGAN: Two Transformers Can Make One Strong GAN
Y Jiang, S Chang, Z Wang
[University of Texas at Austin & IBM Research]
TransGAN:用两个Transformer实现一个强大的的GAN。提出TransGAN,只用纯Transformer架构,构建完全不需要卷积的GAN,TransGAN包括一个内存友好的基于Transformer的生成器,在降低嵌入维度的同时逐步增加特征分辨率,以及一个同样基于Transformer的图块级鉴别器。证明了TransGAN显著受益于数据增强(比标准GANs更多),生成器的多任务协同训练策略,以及强调自然图像邻域平滑性的局部初始化自注意力,使得TransGAN可以有效地扩展更大的模型和高分辨率图像数据集。与当前基于卷积骨架的最先进的GAN相比,TransGAN最佳架构实现了极具竞争力的性能。
The recent explosive interest on transformers has suggested their potential to become powerful “universal” models for computer vision tasks, such as classification, detection, and segmentation. However, how further transformers can go - are they ready to take some more notoriously difficult vision tasks, e.g., generative adversarial networks (GANs)? Driven by that curiosity, we conduct the first pilot study in building a GAN \textbf{completely free of convolutions}, using only pure transformer-based architectures. Our vanilla GAN architecture, dubbed \textbf{TransGAN}, consists of a memory-friendly transformer-based generator that progressively increases feature resolution while decreasing embedding dimension, and a patch-level discriminator that is also transformer-based. We then demonstrate TransGAN to notably benefit from data augmentations (more than standard GANs), a multi-task co-training strategy for the generator, and a locally initialized self-attention that emphasizes the neighborhood smoothness of natural images. Equipped with those findings, TransGAN can effectively scale up with bigger models and high-resolution image datasets. Specifically, our best architecture achieves highly competitive performance compared to current state-of-the-art GANs based on convolutional backbones. Specifically, TransGAN sets \textbf{new state-of-the-art} IS score of 10.10 and FID score of 25.32 on STL-10. It also reaches competitive 8.64 IS score and 11.89 FID score on Cifar-10, and 12.23 FID score on CelebA > 64×64, respectively. We also conclude with a discussion of the current limitations and future potential of TransGAN. The code is available at > this https URL.
https://weibo.com/1402400261/K2ibpwqX6
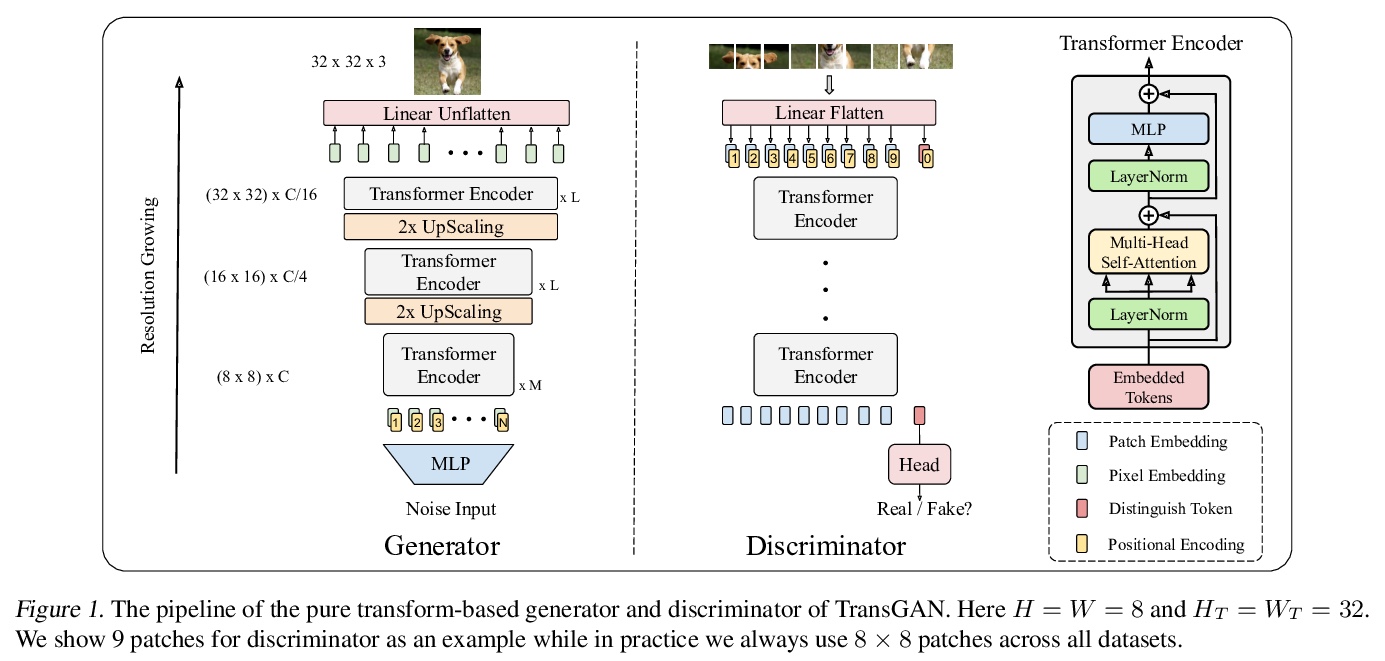
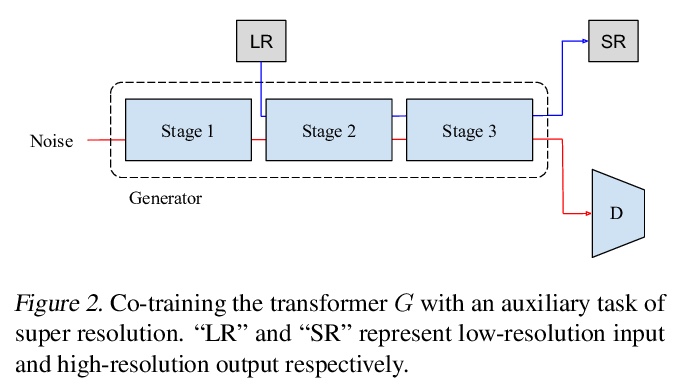


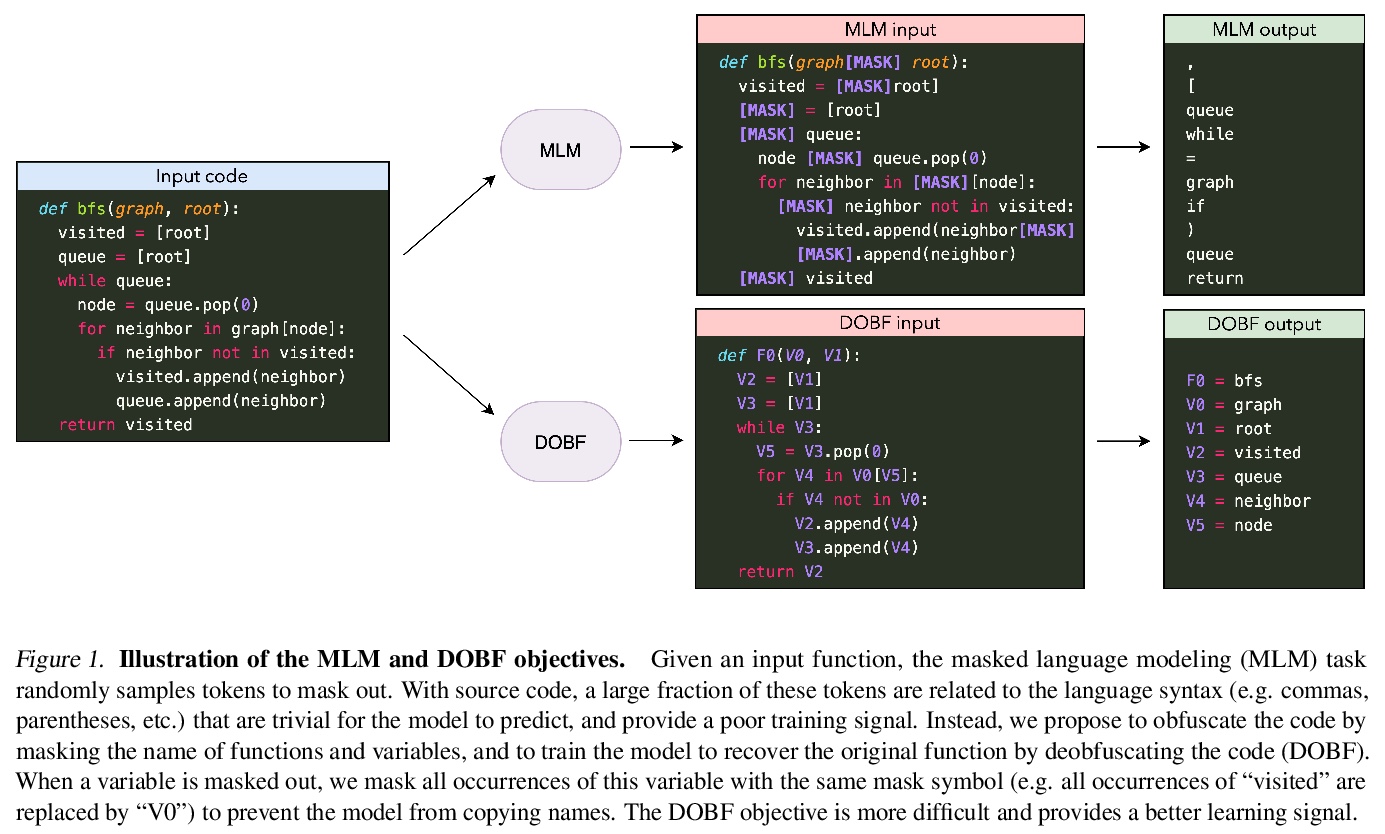
2、[CL] DOBF: A Deobfuscation Pre-Training Objective for Programming Languages
B Roziere, M Lachaux, M Szafraniec, G Lample
[Facebook AI Research]
DOBF:编程语言的去混淆预训练目标。提出DOBF,一种新的基于去混淆的预训练目标,利用编程语言的结构方面预训练模型以恢复混淆源代码原始版本。实验表明DOBF可以用于三个目的:恢复完全混淆的代码,建议相关的标识符名称,以及为编程语言相关任务预训练转化模型。DOBF在多个任务上的表现明显优于MLM(如BERT),如代码搜索、代码摘要或无监督代码翻译。通过设计,用DOBF预训练的模型,可用来理解具有非信息标识符名称的函数,还能成功地对完全混淆的源文件进行去混淆。这些结果表明,DOBF利用源代码的特殊结构,以一种特别有效的方式向输入序列添加噪声。其他适应源代码的噪声函数或代用目标可能会进一步提高性能。
Recent advances in self-supervised learning have dramatically improved the state of the art on a wide variety of tasks. However, research in language model pre-training has mostly focused on natural languages, and it is unclear whether models like BERT and its variants provide the best pre-training when applied to other modalities, such as source code. In this paper, we introduce a new pre-training objective, DOBF, that leverages the structural aspect of programming languages and pre-trains a model to recover the original version of obfuscated source code. We show that models pre-trained with DOBF significantly outperform existing approaches on multiple downstream tasks, providing relative improvements of up to 13% in unsupervised code translation, and 24% in natural language code search. Incidentally, we found that our pre-trained model is able to de-obfuscate fully obfuscated source files, and to suggest descriptive variable names.
https://weibo.com/1402400261/K2imm43Ju


3、[CV] NeRF−−: Neural Radiance Fields Without Known Camera Parameters
Z Wang, S Wu, W Xie, M Chen, V A Prisacariu
[University of Oxford]
NeRF—:相机参数未知的神经辐射场。提出NeRF—,一种基于NeRF的无姿态监督的新视图合成框架,只给定一组稀疏的未校准场景图像作为输入,相机参数未知,NeRF—管线估计输入图像的相机外延和内延,同时通过联合优化训练神经辐射场(NeRF),消除用潜在错误的SfM方法(如COLMAP)预先计算相机参数的需要,仍然实现了与基于COLMAP的NeRF基线相当的视图合成结果,能从新奇的、看不见的视角呈现新图像。
This paper tackles the problem of novel view synthesis (NVS) from 2D images without known camera poses and intrinsics. Among various NVS techniques, Neural Radiance Field (NeRF) has recently gained popularity due to its remarkable synthesis quality. Existing NeRF-based approaches assume that the camera parameters associated with each input image are either directly accessible at training, or can be accurately estimated with conventional techniques based on correspondences, such as Structure-from-Motion. In this work, we propose an end-to-end framework, termed NeRF—, for training NeRF models given only RGB images, without pre-computed camera parameters. Specifically, we show that the camera parameters, including both intrinsics and extrinsics, can be automatically discovered via joint optimisation during the training of the NeRF model. On the standard LLFF benchmark, our model achieves comparable novel view synthesis results compared to the baseline trained with COLMAP pre-computed camera parameters. We also conduct extensive analyses to understand the model behaviour under different camera trajectories, and show that in scenarios where COLMAP fails, our model still produces robust results.
https://weibo.com/1402400261/K2iqXaMDT
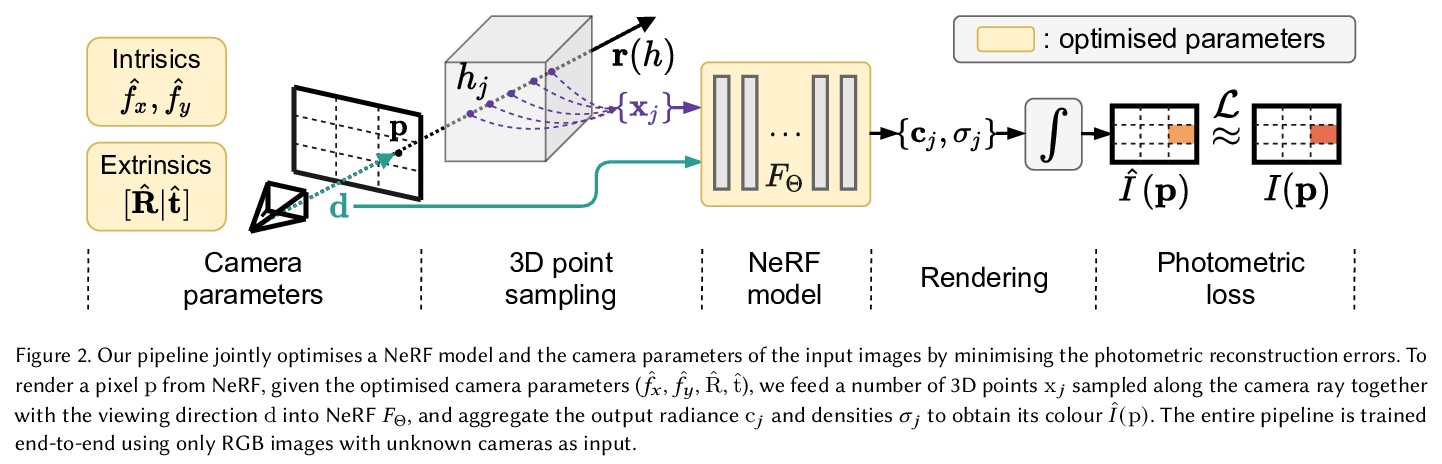


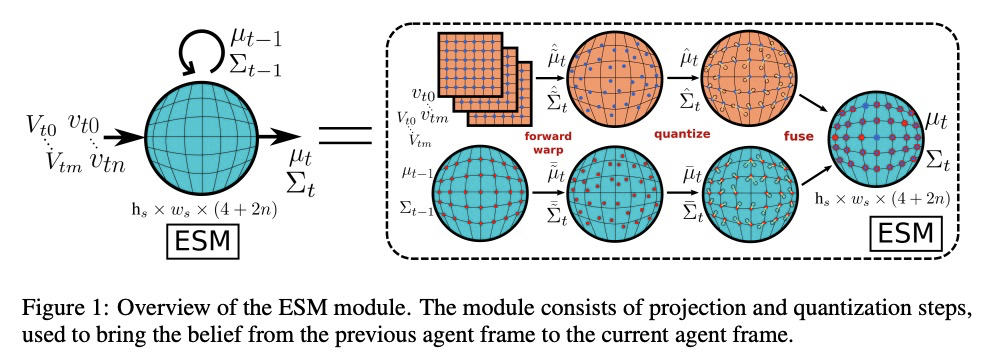
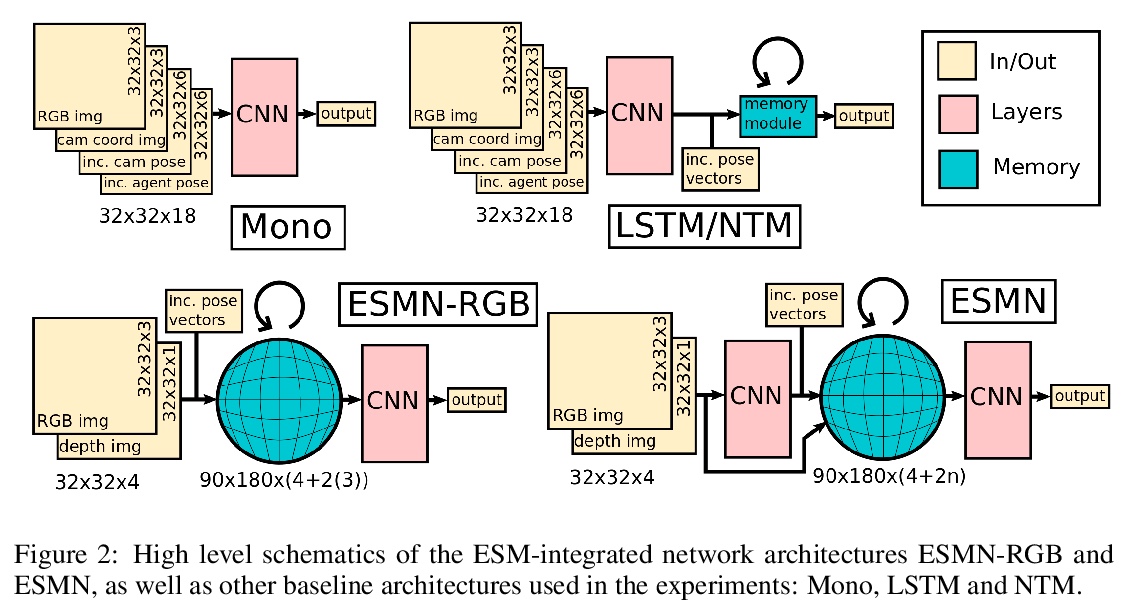
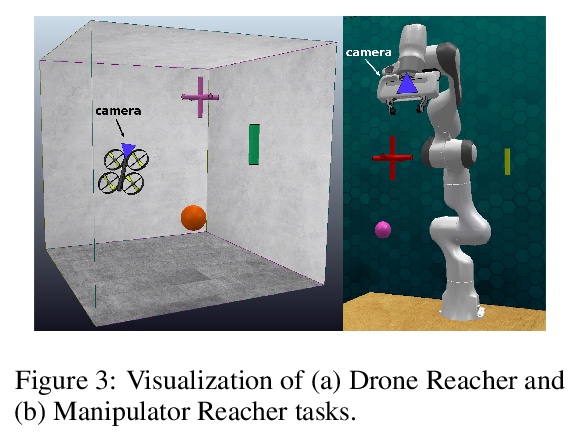
4、[RO] End-to-End Egospheric Spatial Memory
D Lenton, S James, R Clark, A J. Davison
[Dyson Robotics Lab & Imperial College London]
端到端自球体空间记忆。提出一个无参数模块—自我球空间记忆(ESM),将记忆编码在智能体周围的自球体中,实现了富有表现力的3D表征。ESM可通过模仿学习或强化学习进行端到端训练,并在无人机和操纵器视觉运动控制任务上提高训练效率和最终性能。明确的自中心几何也使其能将学习到的控制器与其他非学习模式无缝结合,例如局部障碍物回避。展示了在ScanNet数据集上的语义分割应用,其中ESM自然结合了图像级和地图级的推理模式。实验表明ESM为体现空间推理提供了一个通用的计算图,形成了实时映射系统和可微存储器架构之间的桥梁。
Spatial memory, or the ability to remember and recall specific locations and objects, is central to autonomous agents’ ability to carry out tasks in real environments. However, most existing artificial memory modules have difficulty recalling information over long time periods and are not very adept at storing spatial information. We propose a parameter-free module, Egospheric Spatial Memory (ESM), which encodes the memory in an ego-sphere around the agent, enabling expressive 3D representations. ESM can be trained end-to-end via either imitation or reinforcement learning, and improves both training efficiency and final performance against other memory baselines on both drone and manipulator visuomotor control tasks. The explicit egocentric geometry also enables us to seamlessly combine the learned controller with other non-learned modalities, such as local obstacle avoidance. We further show applications to semantic segmentation on the ScanNet dataset, where ESM naturally combines image-level and map-level inference modalities. Through our broad set of experiments, we show that ESM provides a general computation graph for embodied spatial reasoning, and the module forms a bridge between real-time mapping systems and differentiable memory architectures.
https://weibo.com/1402400261/K2iuXnune
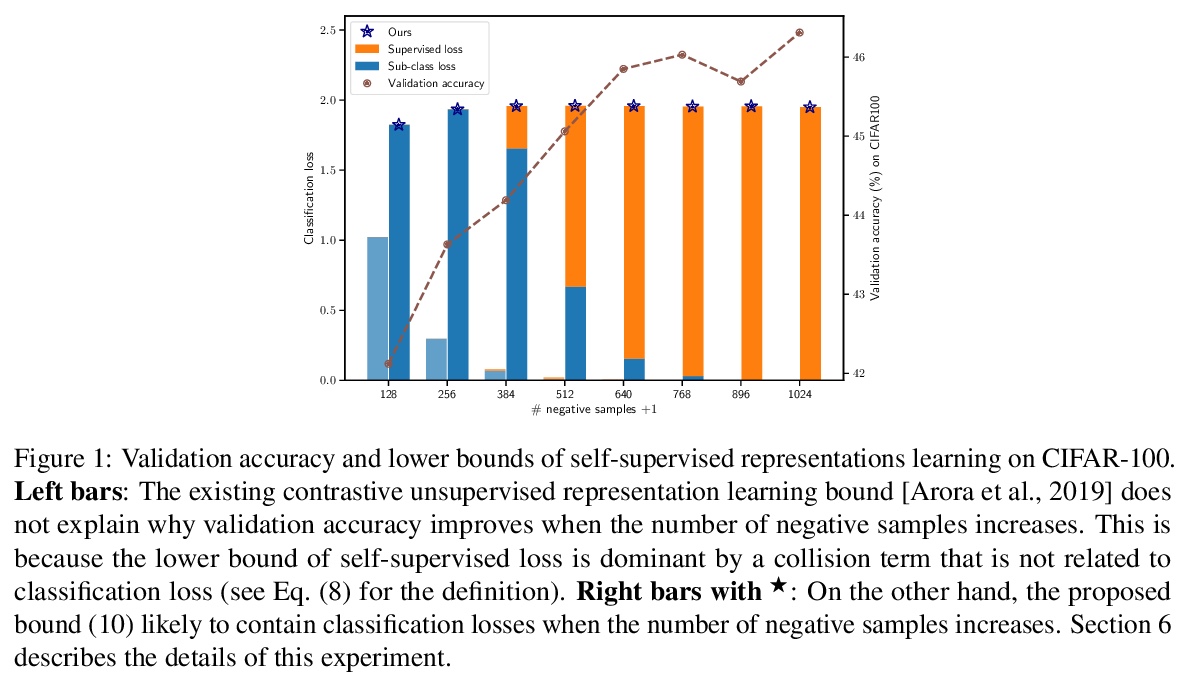
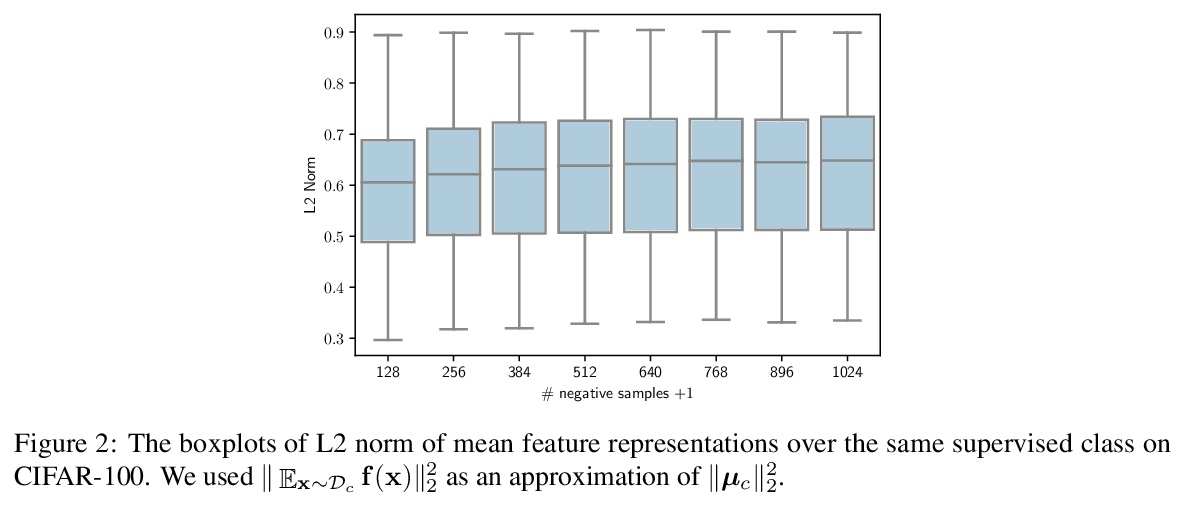
5、[LG] Understanding Negative Samples in Instance Discriminative Self-supervised Representation Learning
K Nozawa, I Sato
[The University of Tokyo & RIKEN]
理解实例判别式自监督表示学习中的负样本。自监督表示学习在实践中负样本数量普遍多于监督类数量,理论上,大量负样本会降低监督性能,而经验上,负样本反而会提高性能。从理论上指出了现有框架不能解释为什么大量负样本在实践中没有降低性能,提出了一个广泛使用的自监督损失的新下界来解释这个现象。
Instance discriminative self-supervised representation learning has been attracted attention thanks to its unsupervised nature and informative feature representation for downstream tasks. Self-supervised representation learning commonly uses more negative samples than the number of supervised classes in practice. However, there is an inconsistency in the existing analysis; theoretically, a large number of negative samples degrade supervised performance, while empirically, they improve the performance. We theoretically explain this empirical result regarding negative samples. We empirically confirm our analysis by conducting numerical experiments on CIFAR-10/100 datasets.
https://weibo.com/1402400261/K2iBhcUSl
另外几篇值得关注的论文:
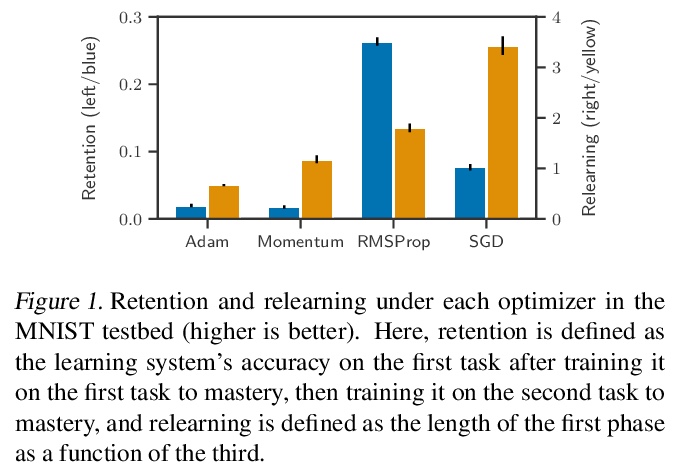
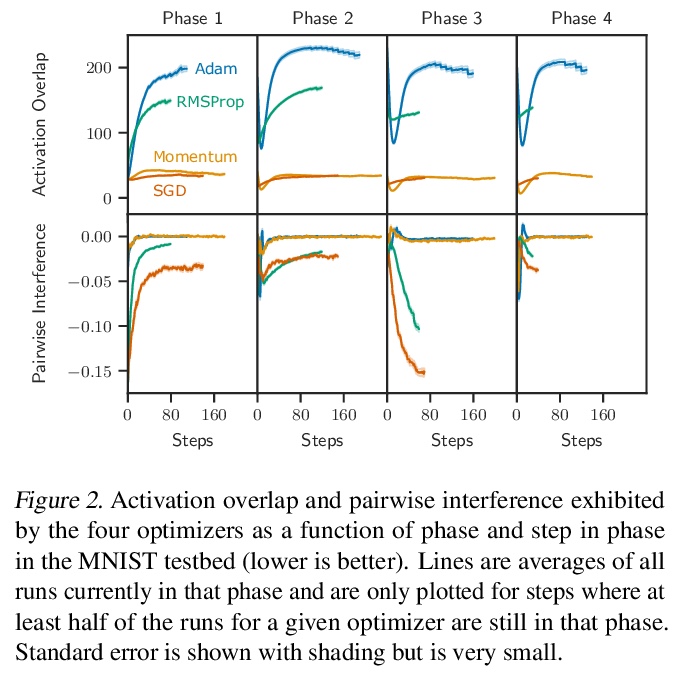
[LG] Does Standard Backpropagation Forget Less Catastrophically Than Adam?
标准反向传播比Adam灾难性遗忘更少吗?
D R. Ashley, S Ghiassian, R S. Sutton
[The Swiss AI Lab IDSIA/USI/SUPSI & University of Alberta]
https://weibo.com/1402400261/K2iKumUGZ
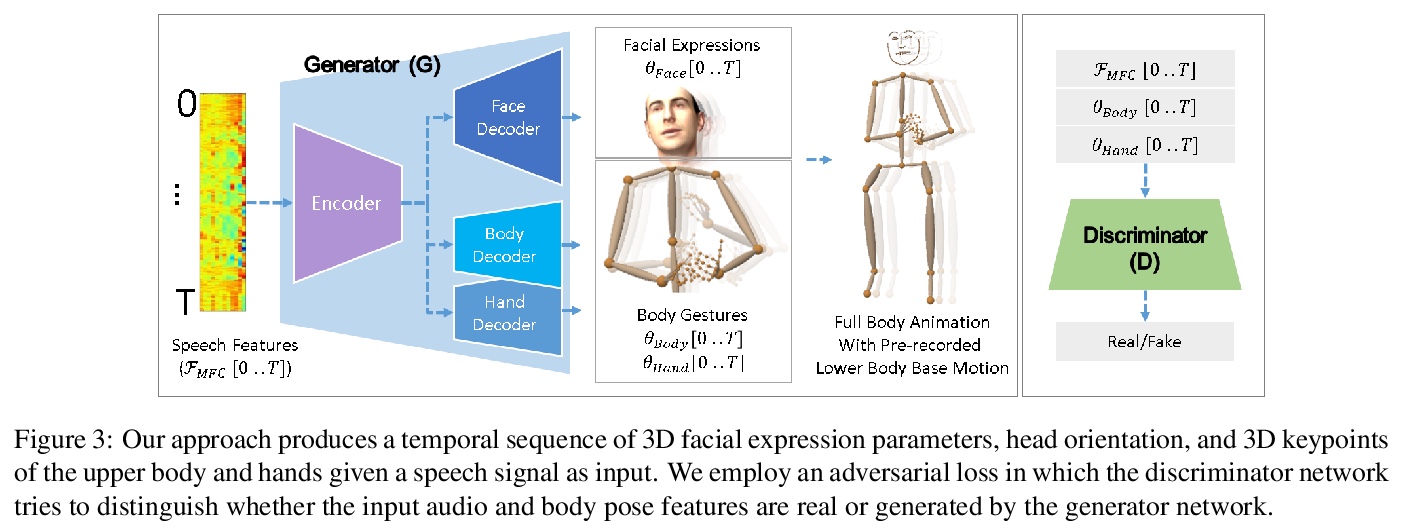
[CV] Learning Speech-driven 3D Conversational Gestures from Video
视频语音驱动3D会话手势学习
I Habibie, W Xu, D Mehta, L Liu, H Seidel, G Pons-Moll, M Elgharib, C Theobalt
[Max Planck Institute for Informatics & Facebook Reality Labs]
https://weibo.com/1402400261/K2iU2BbO8


[CL] Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm
大型语言模型的提示编程:超越少样本范式
L Reynolds, K McDonell
[Computational Neuroscience & ML research group]
https://weibo.com/1402400261/K2iVmp2tF



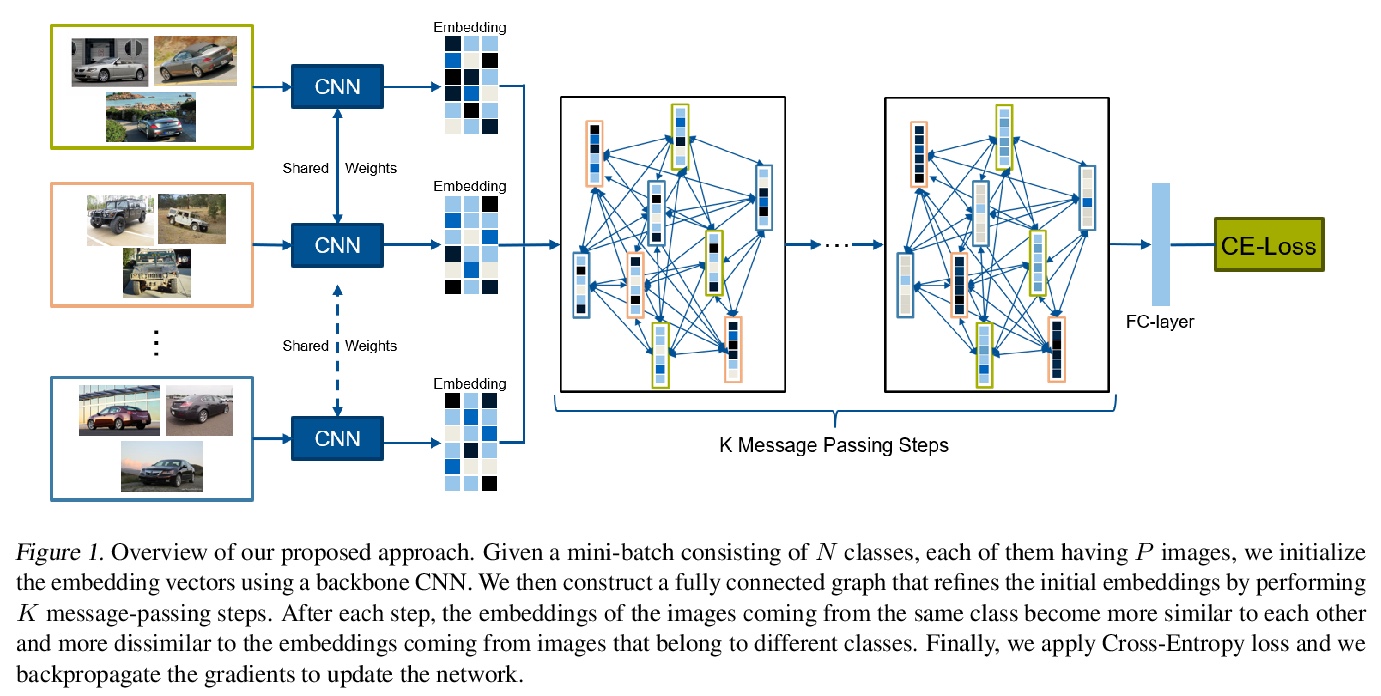
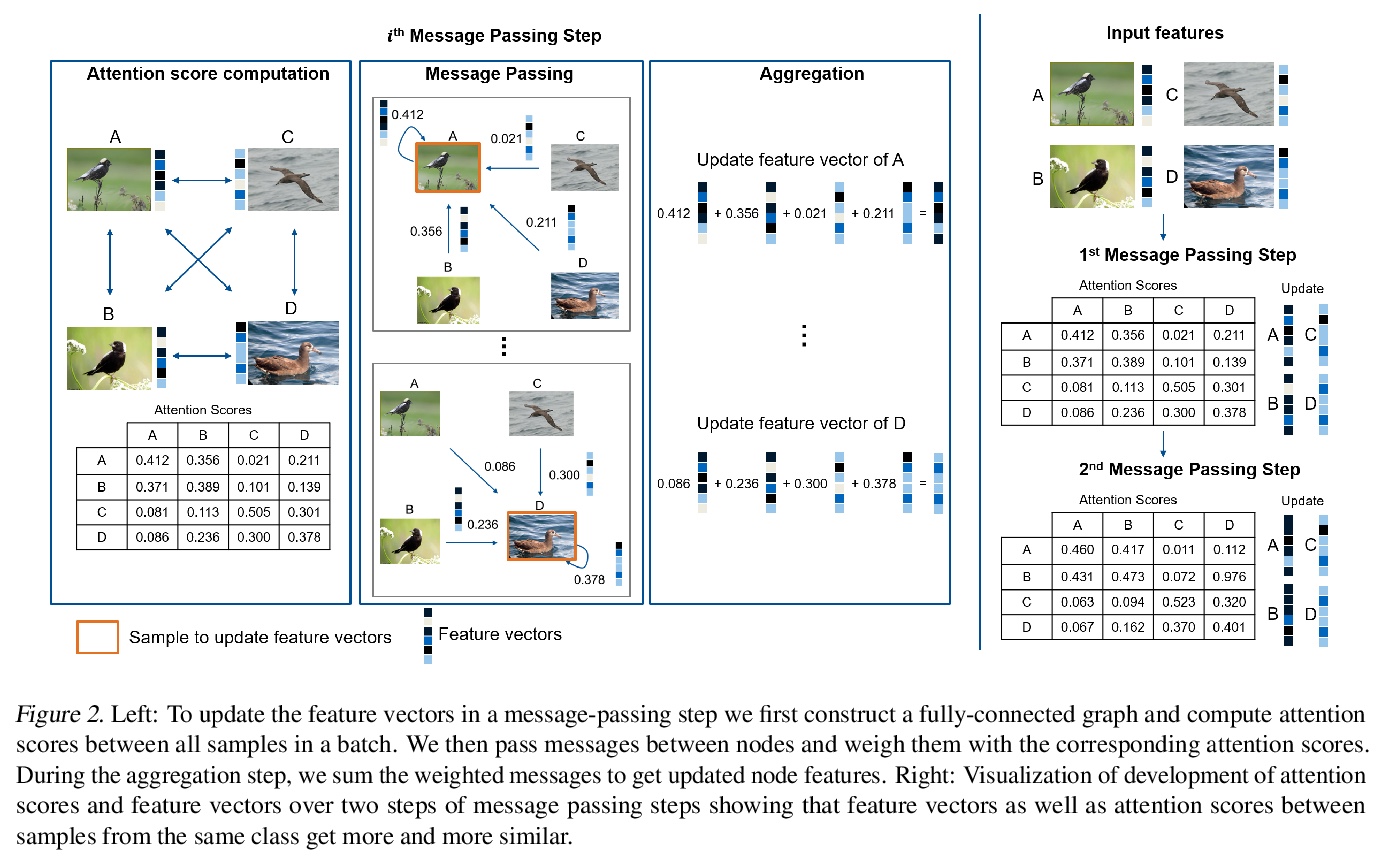
[CV] Learning Intra-Batch Connections for Deep Metric Learning
批内连接学习深度度量学习
J Seidenschwarz, I Elezi, L Leal-Taixé
[Technical University of Munich]
https://weibo.com/1402400261/K2j1U7Ool


若有收获,就点个赞吧
0 人点赞
