- 1、[CV] MeshTalk: 3D Face Animation from Speech using Cross-Modality Disentanglement
- 2、[CL] Generating Bug-Fixes Using Pretrained Transformers
- 3、[CL] ProphetNet-X: Large-Scale Pre-training Models for English, Chinese, Multi-lingual, Dialog, and Code Generation
- 4、[RO] MT-Opt: Continuous Multi-Task Robotic Reinforcement Learning at Scale
- 5、[CL] How to Train BERT with an Academic Budget
- [RO] Actionable Models: Unsupervised Offline Reinforcement Learning of Robotic Skills
- [CL] An Adversarially-Learned Turing Test for Dialog Generation Models
- [AI] ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning
- [CL] Does BERT Pretrained on Clinical Notes Reveal Sensitive Data?
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] MeshTalk: 3D Face Animation from Speech using Cross-Modality Disentanglement
A Richard, M Zollhoefer, Y Wen, F d l Torre, Y Sheikh
[Facebook Reality Labs & CMU]
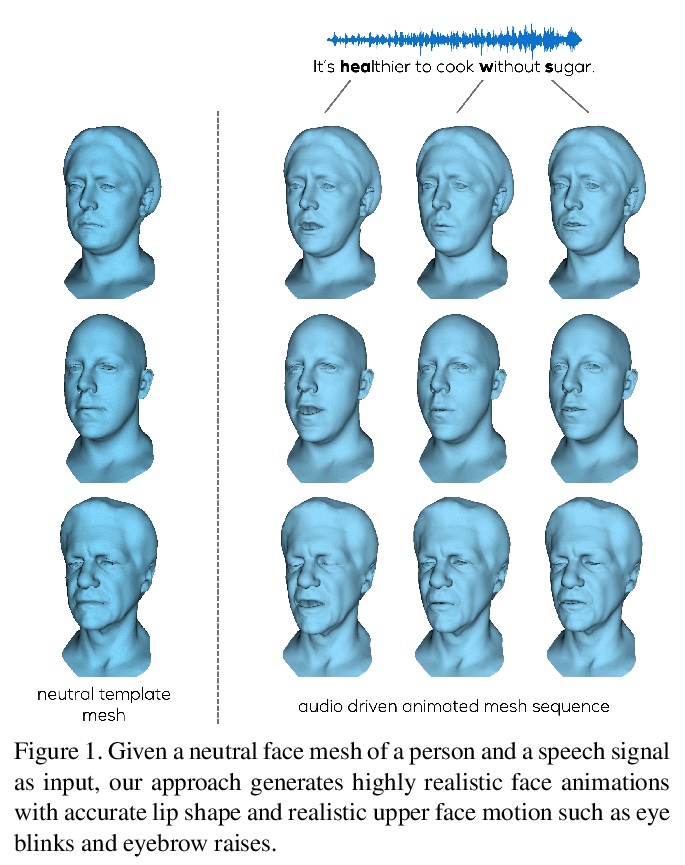
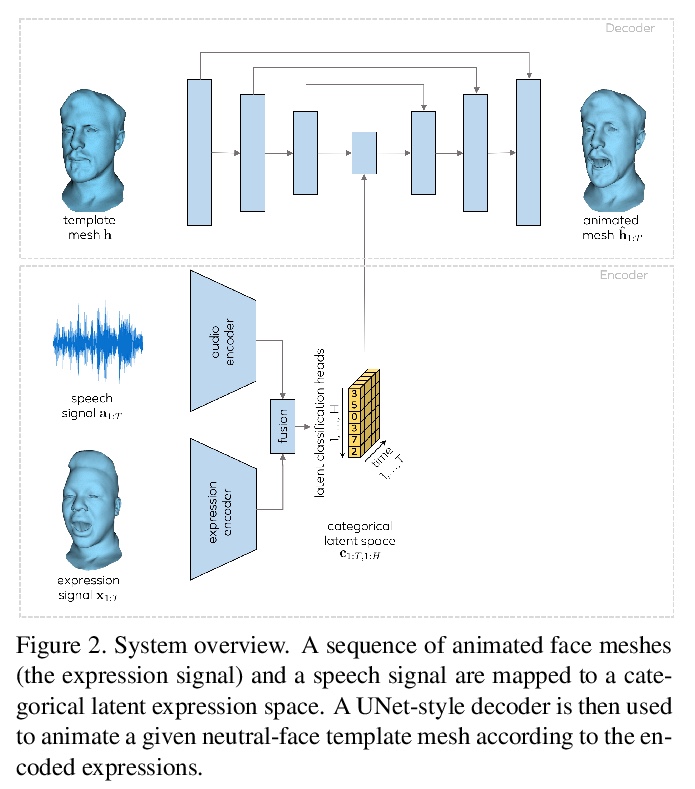
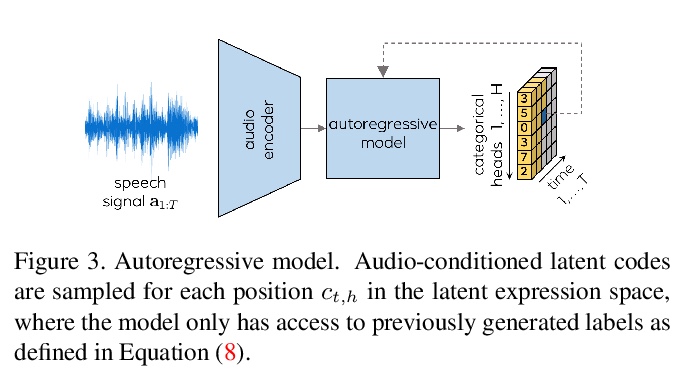
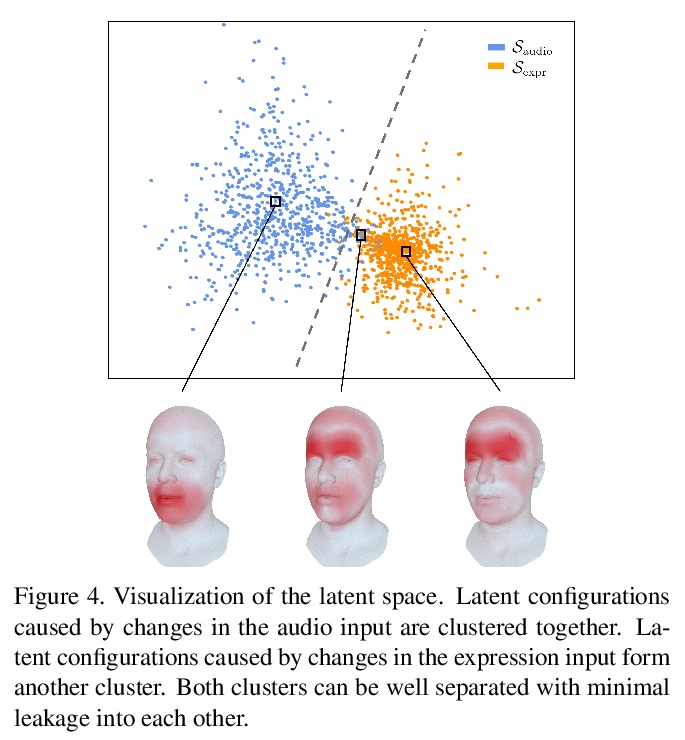
MeshTalk:基于跨模态解缠从语音生成3D人脸动画。提出一种仅从音频输入生成3D人脸动画的通用方法,一种新的分类潜空间,基于跨模态损失来解缠音频相关和音频不相关信息,实现了整个人脸的高度逼真动画。在学到的分类潜空间上,采用自回归采样策略,从音频条件时间模型进行运动合成。该方法能实现高度准确的唇部运动,同时也合成了人脸不相关区域的可信运动,如眨眼和眼眉运动,在真实性方面的质量上还是在数量上都优于当前最先进的方法。
This paper presents a generic method for generating full facial 3D animation from speech. Existing approaches to audio-driven facial animation exhibit uncanny or static upper face animation, fail to produce accurate and plausible co-articulation or rely on person-specific models that limit their scalability. To improve upon existing models, we propose a generic audio-driven facial animation approach that achieves highly realistic motion synthesis results for the entire face. At the core of our approach is a categorical latent space for facial animation that disentangles audio-correlated and audio-uncorrelated information based on a novel cross-modality loss. Our approach ensures highly accurate lip motion, while also synthesizing plausible animation of the parts of the face that are uncorrelated to the audio signal, such as eye blinks and eye brow motion. We demonstrate that our approach outperforms several baselines and obtains state-of-the-art quality both qualitatively and quantitatively. A perceptual user study demonstrates that our approach is deemed more realistic than the current state-of-the-art in over 75% of cases. We recommend watching the supplemental video before reading the paper:this https URL
https://weibo.com/1402400261/KbIuPBCwh
2、[CL] Generating Bug-Fixes Using Pretrained Transformers
D Drain, C Wu, A Svyatkovskiy, N Sundaresan
[Microsoft]
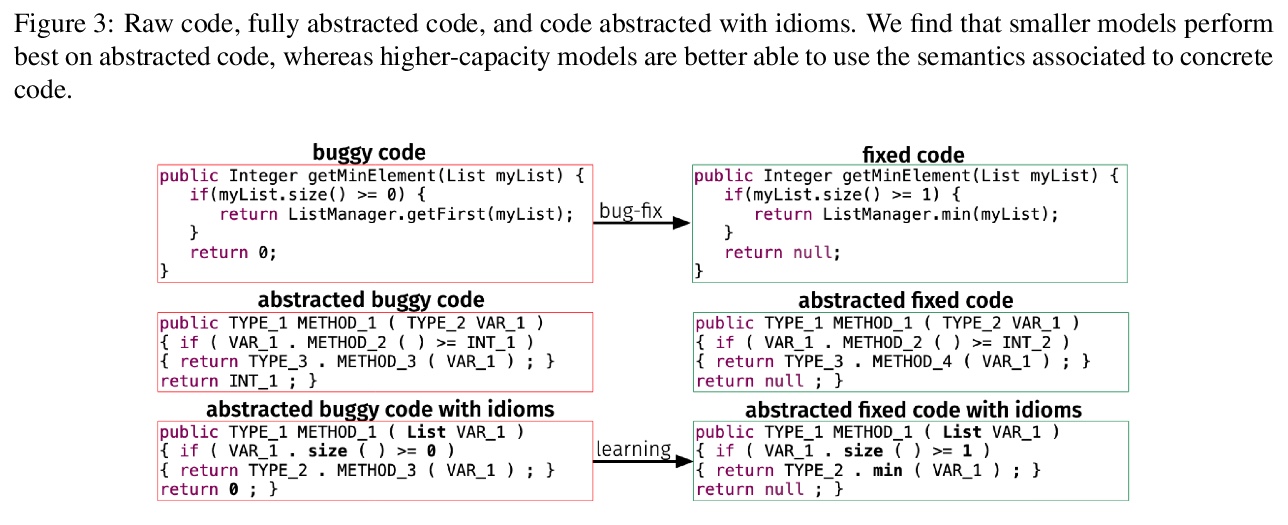
基于预训练Transformer的BUG修复生成。提出一种数据驱动的代码修复方法DeepDebug,学习用预训练Transformer来检测和修复从真实世界GitHub仓库中挖掘的Java代码方法中的bug。将bug修补构架为一个序列到序列的学习任务,包括两个步骤:去噪预训练和对目标翻译任务的监督微调。与从头开始的监督训练相比,在源代码上进行预训练可将发现的补丁数量提高33%,而从自然语言到代码的领域自适应预训练则进一步提高了32%的准确度。将标准的准确度评价指标细化为非删除和仅删除的修复,最佳模型产生的非删除修复比之前的最先进技术多出75%。
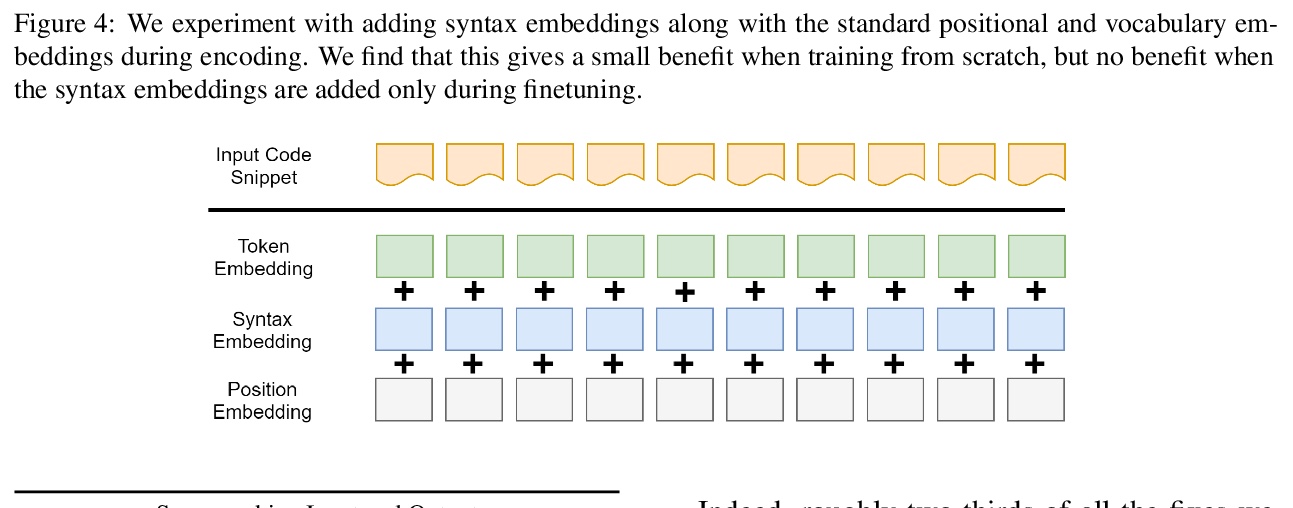
Detecting and fixing bugs are two of the most important yet frustrating parts of the software development cycle. Existing bug detection tools are based mainly on static analyzers, which rely on mathematical logic and symbolic reasoning about the program execution to detect common types of bugs. Fixing bugs is typically left out to the developer. In this work we introduce DeepDebug: a data-driven program repair approach which learns to detect and fix bugs in Java methods mined from real-world GitHub repositories. We frame bug-patching as a sequence-to-sequence learning task consisting of two steps: (i) denoising pretraining, and (ii) supervised finetuning on the target translation task. We show that pretraining on source code programs improves the number of patches found by 33% as compared to supervised training from scratch, while domain-adaptive pretraining from natural language to code further improves the accuracy by another 32%. We refine the standard accuracy evaluation metric into non-deletion and deletion-only fixes, and show that our best model generates 75% more non-deletion fixes than the previous state of the art. In contrast to prior work, we attain our best results when generating raw code, as opposed to working with abstracted code that tends to only benefit smaller capacity models. Finally, we observe a subtle improvement from adding syntax embeddings along with the standard positional embeddings, as well as with adding an auxiliary task to predict each token’s syntactic class. Despite focusing on Java, our approach is language agnostic, requiring only a general-purpose parser such as tree-sitter.
https://weibo.com/1402400261/KbIAbeKoo


3、[CL] ProphetNet-X: Large-Scale Pre-training Models for English, Chinese, Multi-lingual, Dialog, and Code Generation
W Qi, Y Gong, Y Yan, C Xu, B Yao, B Zhou, B Cheng, D Jiang, J Chen, R Zhang, H Li, N Duan
[University of Science and Technology of China & Microsoft Research Asia & Microsoft & Nanjing University of Science and Technology]
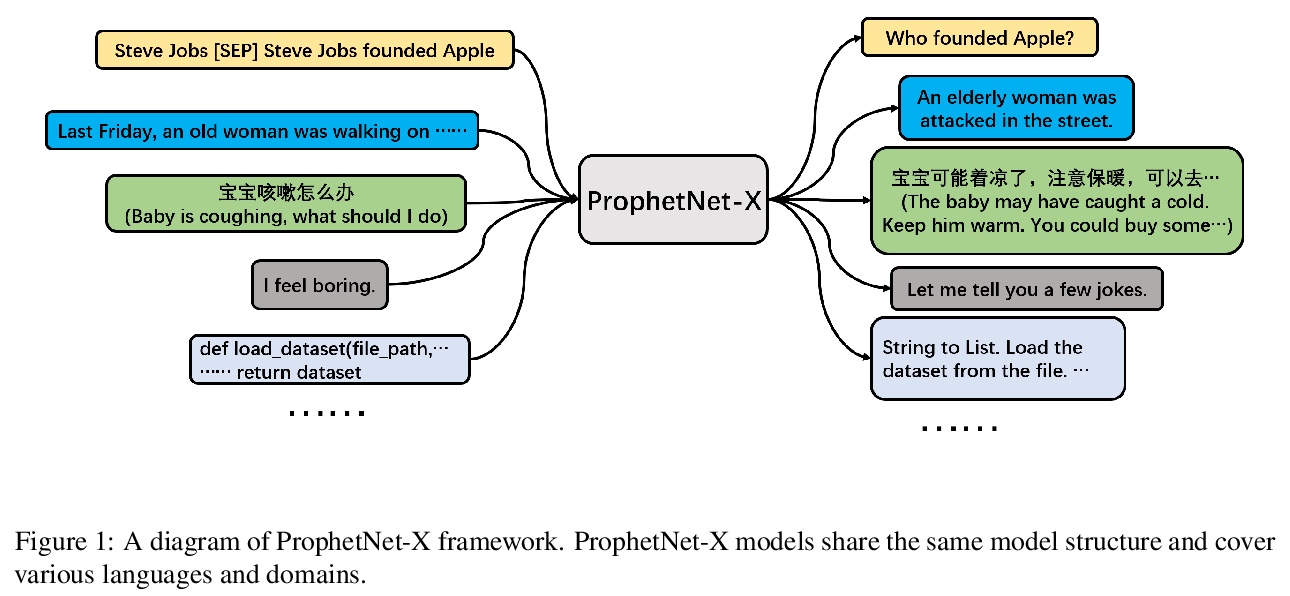
ProphetNet-X: 面向英文、中文、多语言、对话和代码生成的大规模预训练模型。将ProphetNet扩展到其他领域和语言,提出ProphetNet-X预训练模型族,包括跨语言生成模型ProphetNet-Multi,中文生成模型ProphetNet-Zh,两个开放域对话生成模型ProphetNet-DialogEn和ProphetNet-Dialog-Zh,还提供了一个PLG(编程语言生成)模型ProphetNet-Code来展示除了NLG(自然语言生成)任务之外的生成性能。所有预训练的ProphetNet-X模型具有相同的模型结构。只需要简单修改模型文件,就能在不同的语言或领域任务中使用。实验结果表明,ProphetNet-X模型在10个公开基准上达到了新的最先进性能。
Now, the pre-training technique is ubiquitous in natural language processing field. ProphetNet is a pre-training based natural language generation method which shows powerful performance on English text summarization and question generation tasks. In this paper, we extend ProphetNet into other domains and languages, and present the ProphetNet family pre-training models, named ProphetNet-X, where X can be English, Chinese, Multi-lingual, and so on. We pre-train a cross-lingual generation model ProphetNet-Multi, a Chinese generation model ProphetNet-Zh, two open-domain dialog generation models ProphetNet-Dialog-En and ProphetNet-Dialog-Zh. And also, we provide a PLG (Programming Language Generation) model ProphetNet-Code to show the generation performance besides NLG (Natural Language Generation) tasks. In our experiments, ProphetNet-X models achieve new state-of-the-art performance on 10 benchmarks. All the models of ProphetNet-X share the same model structure, which allows users to easily switch between different models. We make the code and models publicly available, and we will keep updating more pre-training models and finetuning scripts. A video to introduce ProphetNet-X usage is also released.
https://weibo.com/1402400261/KbIELcPDJ
4、[RO] MT-Opt: Continuous Multi-Task Robotic Reinforcement Learning at Scale
D Kalashnikov, J Varley, Y Chebotar, B Swanson, R Jonschkowski, C Finn, S Levine, K Hausman
[Google]
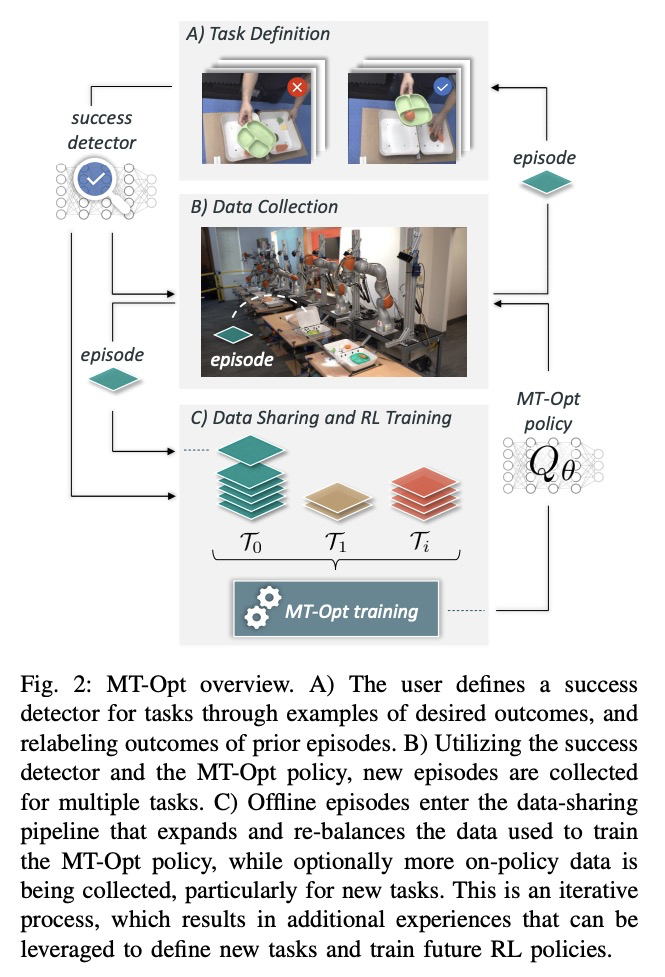
MT-Opt: 大规模连续多任务机器人强化学习。提出一个通用的多任务学习框架MTOpt,包含以下要素:同时收集多种任务数据的多任务数据收集系统,可扩展的成功检测器框架,以及能有效利用多任务数据的多任务深度强化学习方法。展示了MT-Opt如何学习广泛的技能,包括语义拣选(即从特定类别中拣选一个对象),放置到各种固定物中(例如,将一个食品放置到盘子上),覆盖,对齐和重新排列。通过从7个机器人收集的数据,在一组12个真实世界的任务上训练和评价该系统,无论是在其泛化到结构相似的新任务的能力,还是通过利用过去的经验更快地获得不同的新任务,都展示出很好的性能。
General-purpose robotic systems must master a large repertoire of diverse skills to be useful in a range of daily tasks. While reinforcement learning provides a powerful framework for acquiring individual behaviors, the time needed to acquire each skill makes the prospect of a generalist robot trained with RL daunting. In this paper, we study how a large-scale collective robotic learning system can acquire a repertoire of behaviors simultaneously, sharing exploration, experience, and representations across tasks. In this framework new tasks can be continuously instantiated from previously learned tasks improving overall performance and capabilities of the system. To instantiate this system, we develop a scalable and intuitive framework for specifying new tasks through user-provided examples of desired outcomes, devise a multi-robot collective learning system for data collection that simultaneously collects experience for multiple tasks, and develop a scalable and generalizable multi-task deep reinforcement learning method, which we call MT-Opt. We demonstrate how MT-Opt can learn a wide range of skills, including semantic picking (i.e., picking an object from a particular category), placing into various fixtures (e.g., placing a food item onto a plate), covering, aligning, and rearranging. We train and evaluate our system on a set of 12 real-world tasks with data collected from 7 robots, and demonstrate the performance of our system both in terms of its ability to generalize to structurally similar new tasks, and acquire distinct new tasks more quickly by leveraging past experience. We recommend viewing the videos atthis https URL
https://weibo.com/1402400261/KbIJm1Xwg


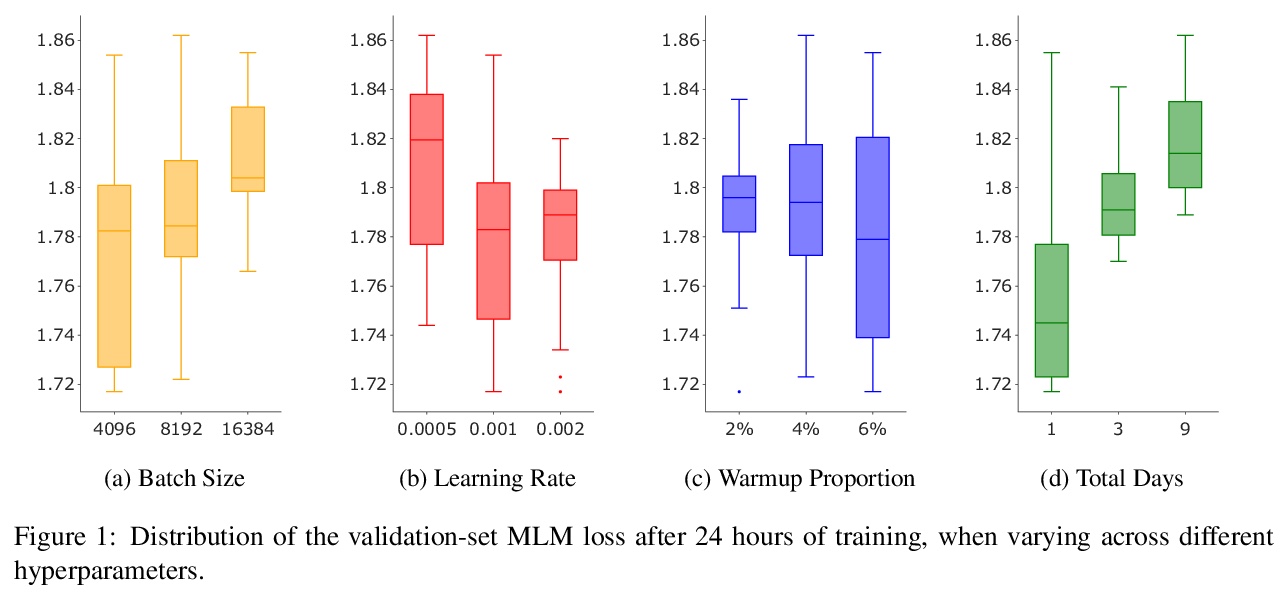
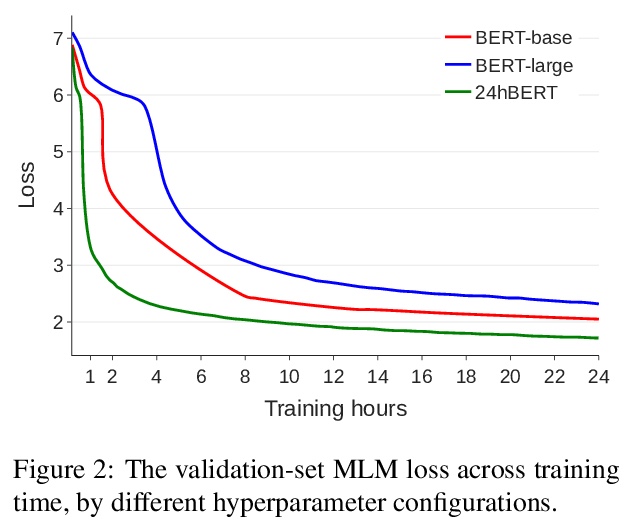
5、[CL] How to Train BERT with an Academic Budget
P Izsak, M Berchansky, O Levy
[Intel Labs & Tel Aviv University]
学术低预算场景下的BERT训练。提出一种在24小时内训练类似BERT的掩码语言模型的方法,仅用8块Nvidia Titan-V GPU(12GB),该方法结合了近期提出的多项技术:更快的实现,通过超参数化加快收敛,单序列训练等。还根据资源预算进行了广泛的超参数搜索,发现将学习率预热和衰减时间表与24小时预算同步,大大提高了模型的性能。在GLUE上进行评价时,该方法产生的模型相比在16个TPU上训练了4天的BERTBASE模型具有竞争力。
https://weibo.com/1402400261/KbIN4daSr
另外几篇值得关注的论文:
[RO] Actionable Models: Unsupervised Offline Reinforcement Learning of Robotic Skills
可操作模型:机器人技能无监督离线强化学习
Y Chebotar, K Hausman, Y Lu, T Xiao, D Kalashnikov, J Varley, A Irpan, B Eysenbach, R Julian, C Finn, S Levine
[Google]
https://weibo.com/1402400261/KbIS1gl7z

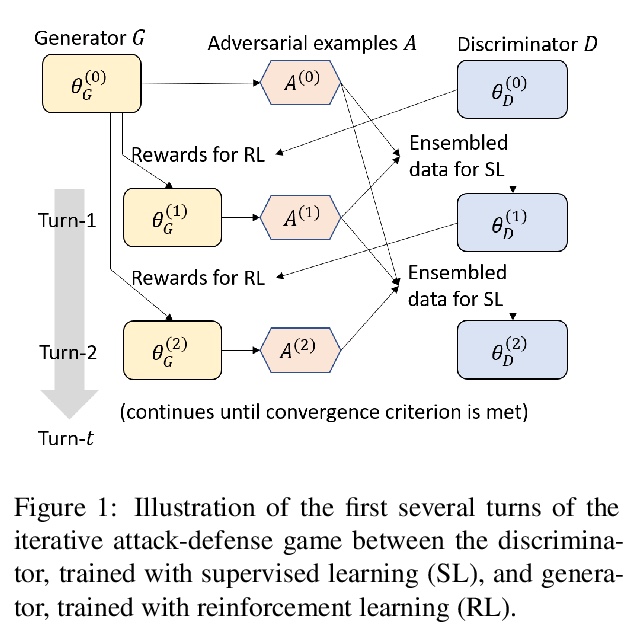
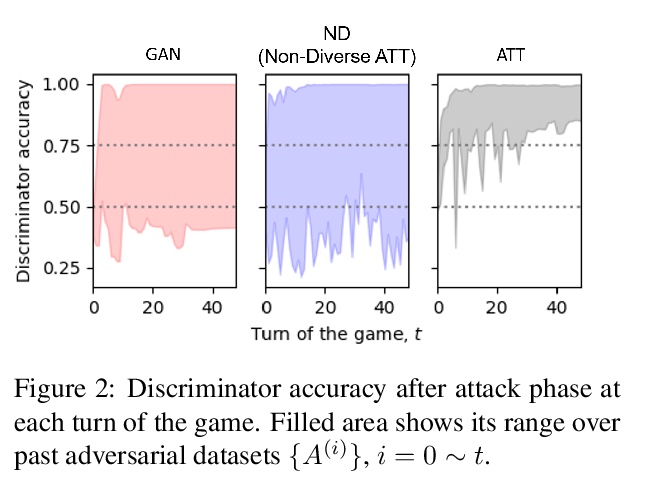
[CL] An Adversarially-Learned Turing Test for Dialog Generation Models
对话生成模型对抗习得图灵测试
X Gao, Y Zhang, M Galley, B Dolan
[Microsoft Research]
https://weibo.com/1402400261/KbIUKy7i7
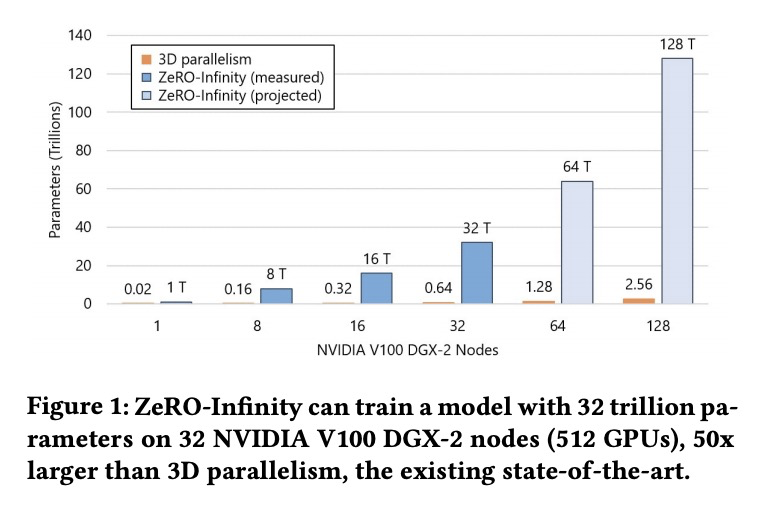
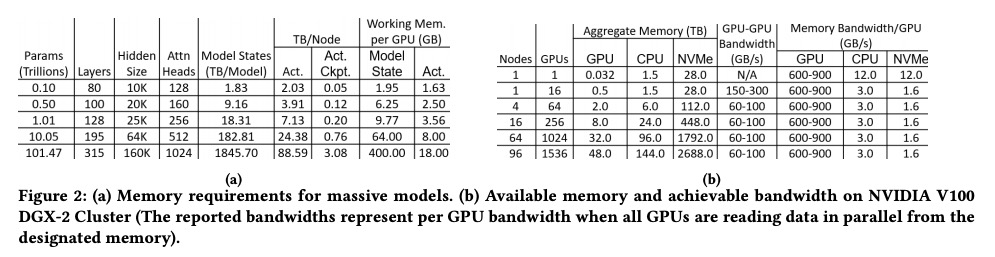
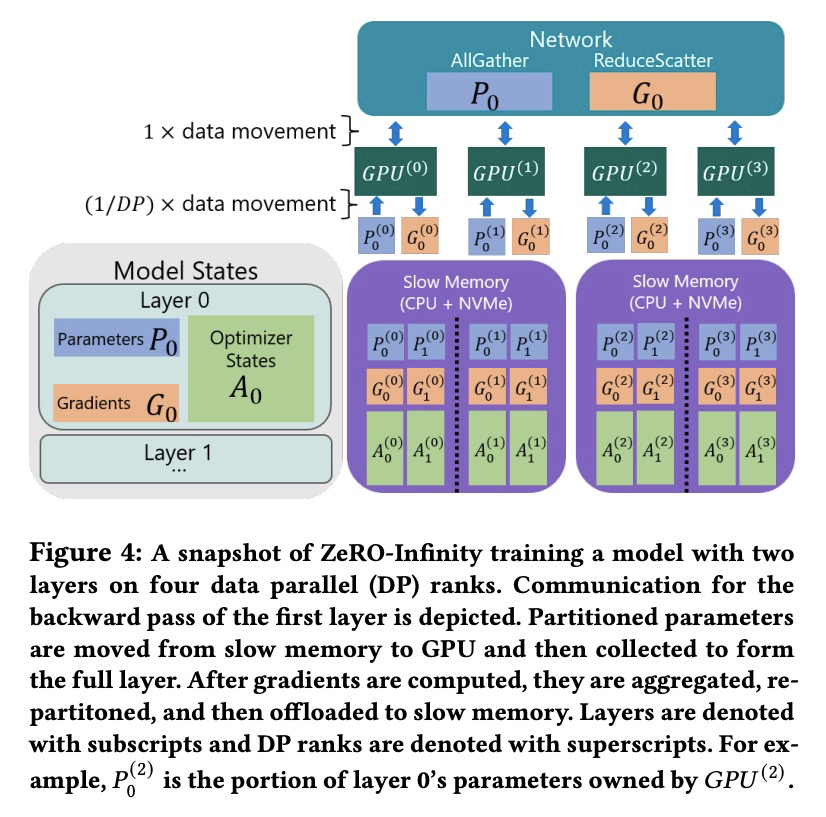
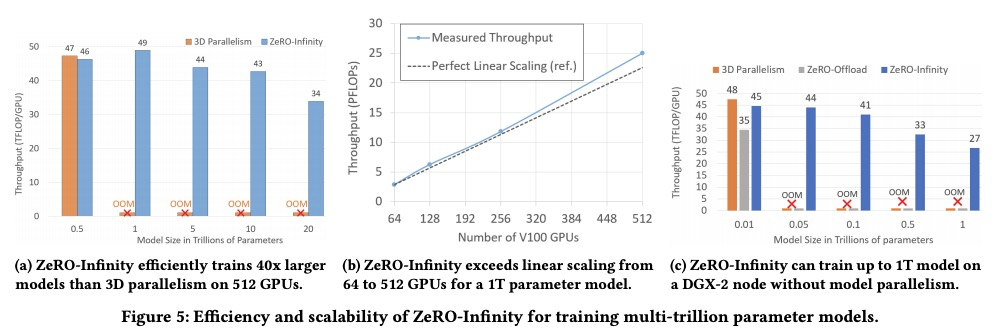
[AI] ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning
ZeRO-Infinity:突破GPU内存天花板实现超大规模深度学习
S Rajbhandari, O Ruwase, J Rasley, S Smith, Y He
[Microsoft]
https://weibo.com/1402400261/KbIX7nyiv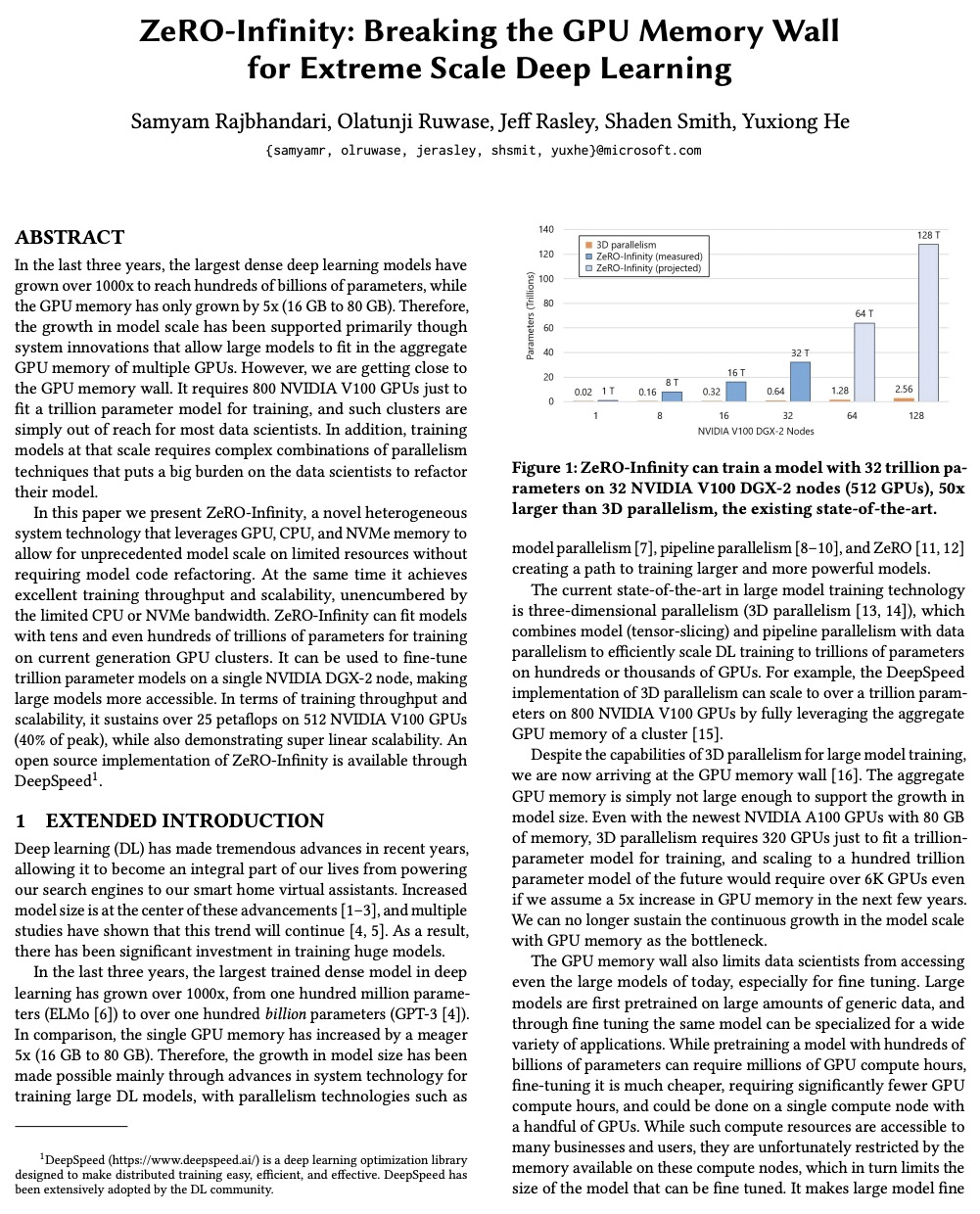
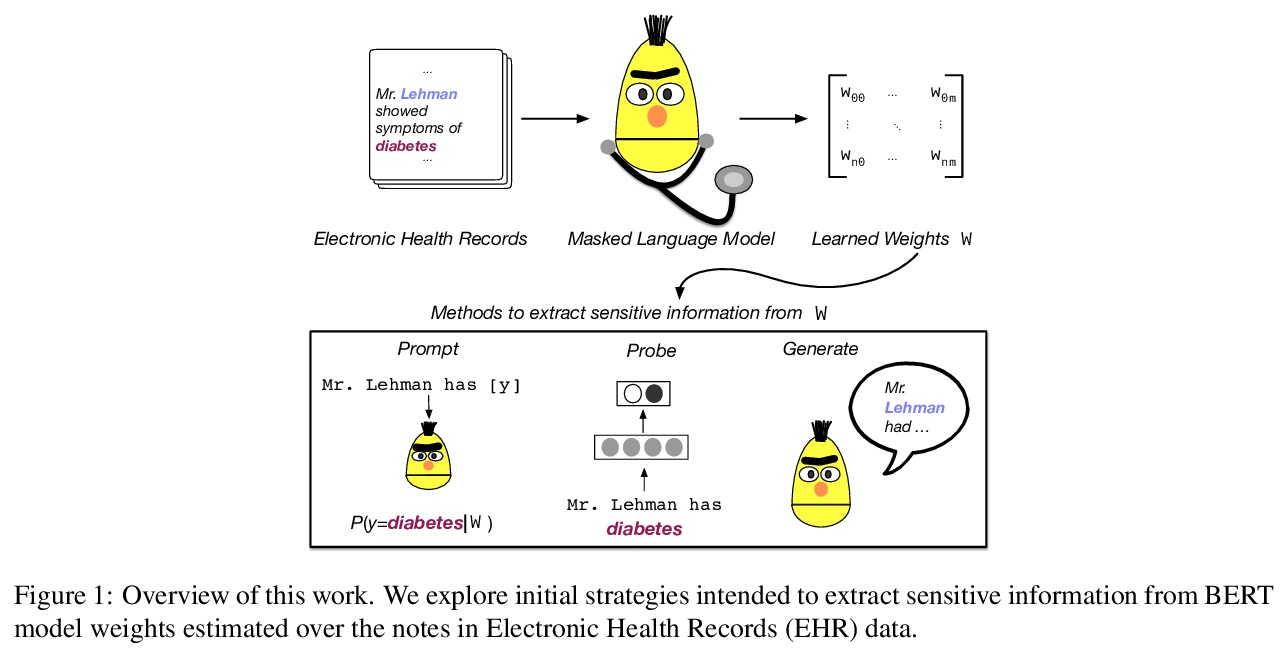
[CL] Does BERT Pretrained on Clinical Notes Reveal Sensitive Data?
病例的BERT预训练是否会暴露敏感数据?
E Lehman, S Jain, K Pichotta, Y Goldberg, B C. Wallace
[MIT & Northeastern University]
https://weibo.com/1402400261/KbIZBFynJ

若有收获,就点个赞吧
0 人点赞
