- 1、[CV] Meticulous Object Segmentation
- 2、 [CV] OneNet: Towards End-to-End One-Stage Object Detection
- 3、 [CV] Semantic and Geometric Modeling with Neural Message Passing in 3D Scene Graphs for Hierarchical Mechanical Search
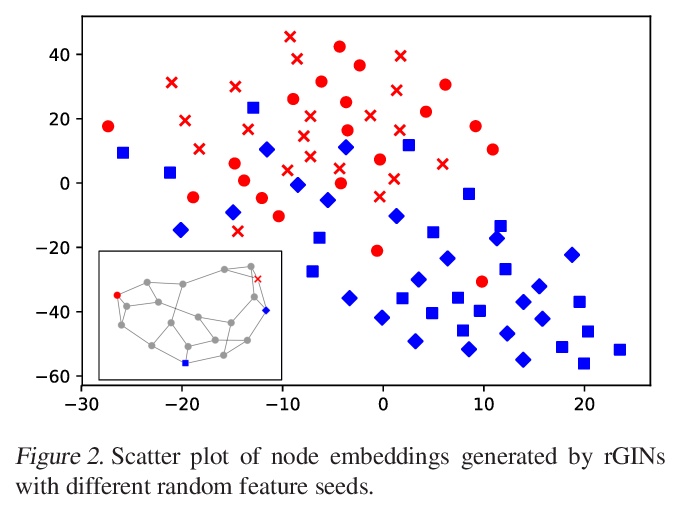
- 4、 [LG] Random Features Strengthen Graph Neural Networks
- 5、[CV] Learning to Recover 3D Scene Shape from a Single Image
- [CV] Human Mesh Recovery from Multiple Shots
- [CL] Domain specific BERT representation for Named Entity Recognition of lab protocol
- [LG] Solving Mixed Integer Programs Using Neural Networks
- [LG] Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Meticulous Object Segmentation
C Yang, Y Wang, J Zhang, H Zhang, Z Lin, A Yuille
[Johns Hopkins University & Adobe Inc]
精细目标分割。提出并研究了”精细目标分割”(Meticulous Object Segmentation,MOS)任务,针对高分辨率图像(如2k-4k)中具有精细形状的前景目标进行分割。提出MeticulousNet,利用专用解码器来捕捉目标边界细节,设计了层次点精炼(HierPR)块,以更好地划分目标边界,将解码过程重新定义为对象掩模的递归粗到细精炼过程。为评价目标边界附近分割质量,提出考虑掩模覆盖率和边界精度的Meticulosity Quality(MQ)分数。收集了MOS基准数据集,包括600张具有复杂目标的高质量图像。
Compared with common image segmentation tasks targeted at low-resolution images, higher resolution detailed image segmentation receives much less attention. In this paper, we propose and study a task named Meticulous Object Segmentation (MOS), which is focused on segmenting well-defined foreground objects with elaborate shapes in high resolution images (e.g. 2k - 4k). To this end, we propose the MeticulousNet which leverages a dedicated decoder to capture the object boundary details. Specifically, we design a Hierarchical Point-wise Refining (HierPR) block to better delineate object boundaries, and reformulate the decoding process as a recursive coarse to fine refinement of the object mask. To evaluate segmentation quality near object boundaries, we propose the Meticulosity Quality (MQ) score considering both the mask coverage and boundary precision. In addition, we collect a MOS benchmark dataset including 600 high quality images with complex objects. We provide comprehensive empirical evidence showing that MeticulousNet can reveal pixel-accurate segmentation boundaries and is superior to state-of-the-art methods for high resolution object segmentation tasks.
https://weibo.com/1402400261/JAuDBuAFc
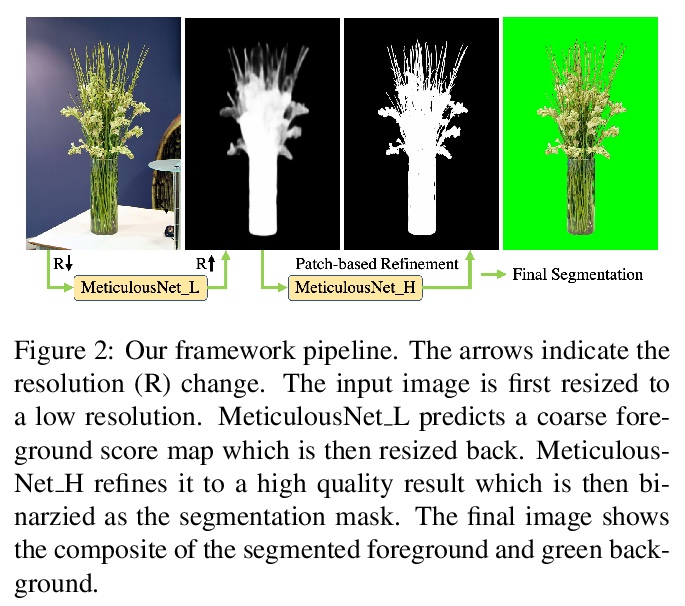
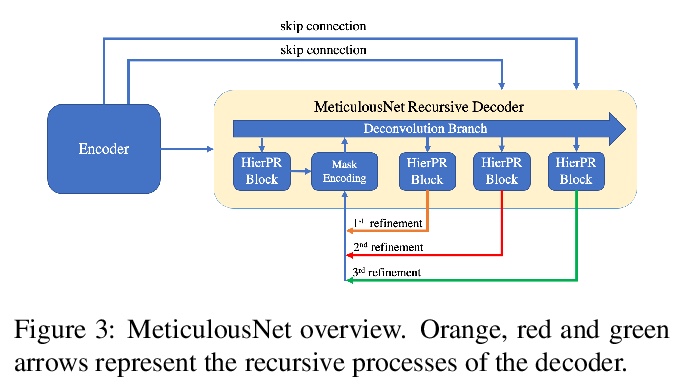
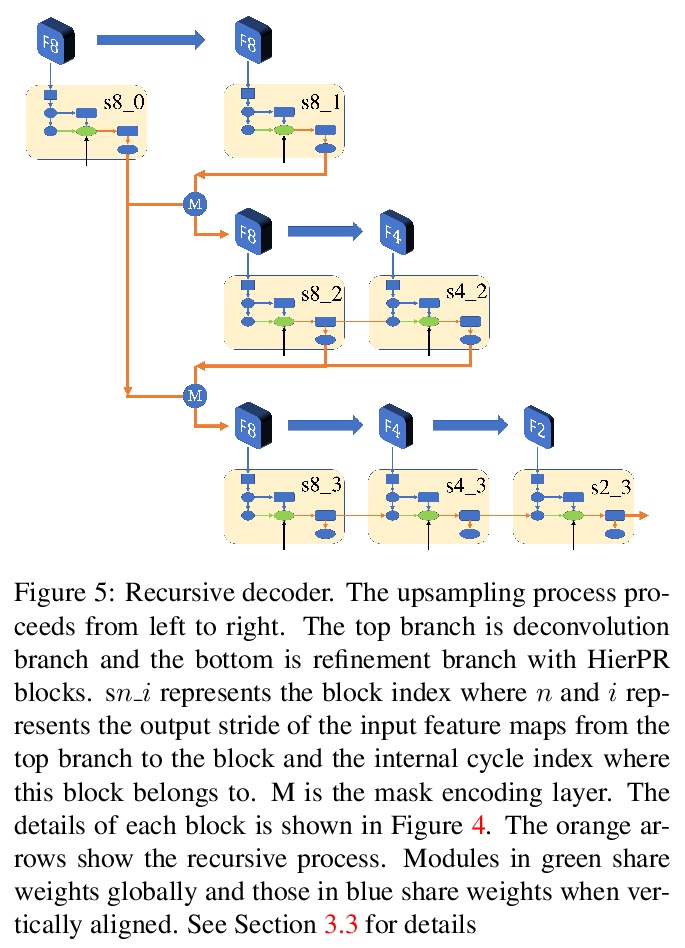
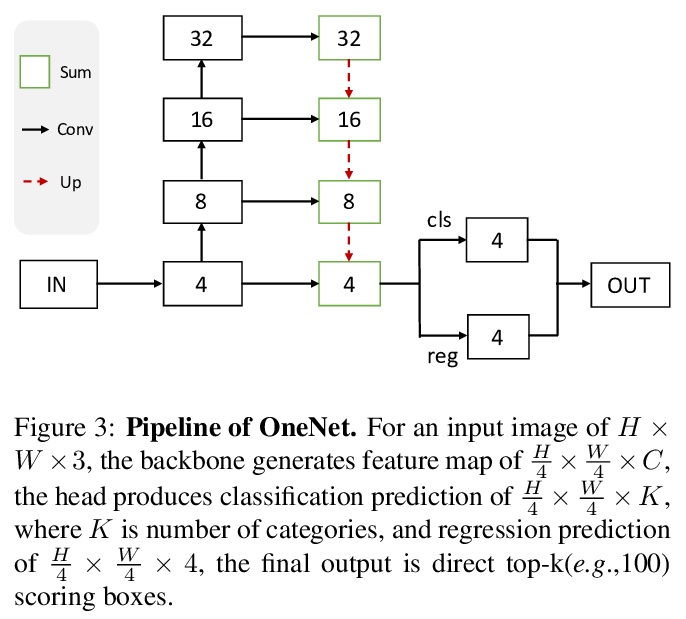
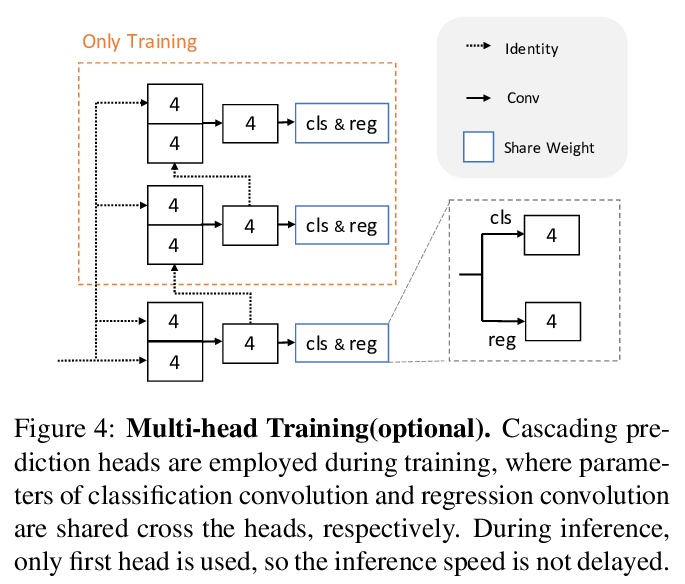
2、 [CV] OneNet: Towards End-to-End One-Stage Object Detection
P Sun, Y Jiang, E Xie, Z Yuan, C Wang, P Luo
[The University of Hong Kong & ByteDance AI Lab]
端到端单级目标检测探索。发现标签分配过程中,样本与真实值之间分类代价的缺失,是单级检测器消除非极大值抑制(Non-maximum Suppression,NMS)实现端到端的主要障碍,现有单级目标检测器只通过位置代价来分配标签,在没有分类代价的情况下,单纯的位置代价会导致推理中出现冗余的高置信度分数的框,必须对NMS进行后处理。为设计端到端单级目标检测器,提出了最小代价分配。代价是样本和真值之间的分类代价和位置代价之和。对于每个目标的真值,只有一个最小代价的样本被分配为正样本,其他都是负样本。设计了一个简单的单级检测器OneNet,避免产生重复框,实现了端到端检测。在COCO数据集上,OneNet实现了图像大小512像素上的35.0 AP/80 FPS和37.7 AP/50 FPS。
End-to-end one-stage object detection trailed thus far. This paper discovers that the lack of classification cost between sample and ground-truth in label assignment is the main obstacle for one-stage detectors to remove Non-maximum Suppression(NMS) and reach end-to-end. Existing one-stage object detectors assign labels by only location cost, e.g. box IoU or point distance. Without classification cost, sole location cost leads to redundant boxes of high confidence scores in inference, making NMS necessary post-processing. To design an end-to-end one-stage object detector, we propose Minimum Cost Assignment. The cost is the summation of classification cost and location cost between sample and ground-truth. For each object ground-truth, only one sample of minimum cost is assigned as the positive sample; others are all negative samples. To evaluate the effectiveness of our method, we design an extremely simple one-stage detector named OneNet. Our results show that when trained with Minimum Cost Assignment, OneNet avoids producing duplicated boxes and achieves to end-to-end detector. On COCO dataset, OneNet achieves 35.0 AP/80 FPS and 37.7 AP/50 FPS with image size of 512 pixels. We hope OneNet could serve as an effective baseline for end-to-end one-stage object detection. The code is available at: \url{> this https URL}.
https://weibo.com/1402400261/JAuI1s5Q3
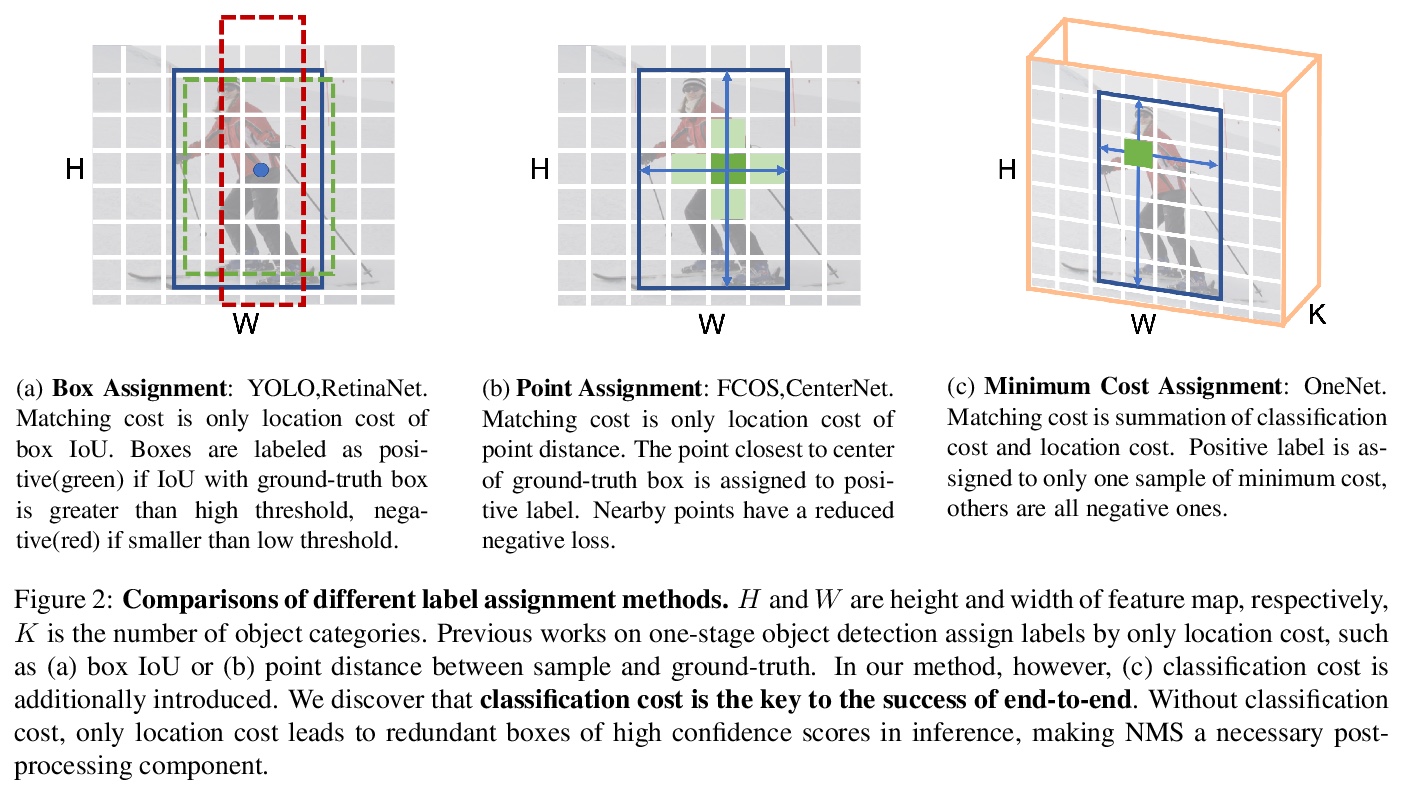
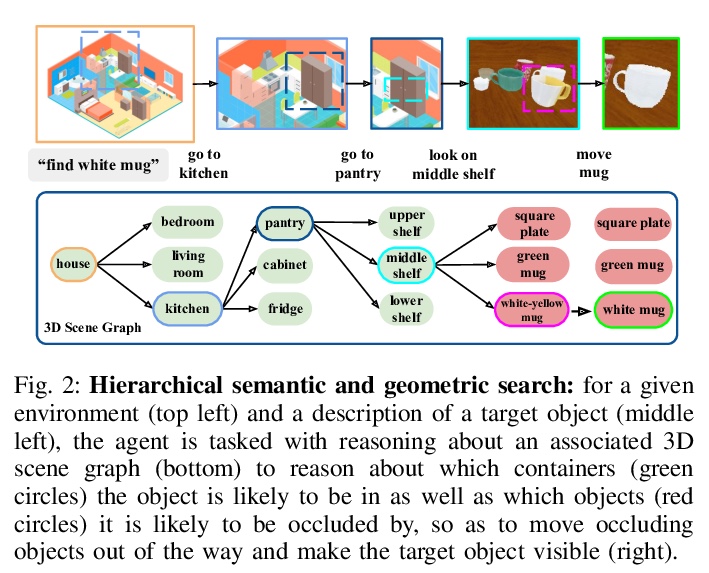
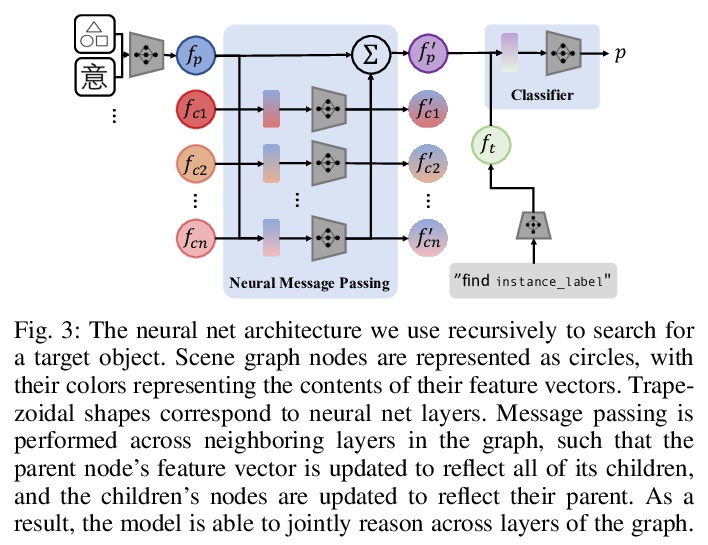
3、 [CV] Semantic and Geometric Modeling with Neural Message Passing in 3D Scene Graphs for Hierarchical Mechanical Search
A Kurenkov, R Martín-Martín, J Ichnowski, K Goldberg, S Savarese
[Stanford University & UC Berkeley]
面向层次机械搜索基于3D场景图神经信息传递的语义和几何建模。提出了层次机械搜索(HMS),一种利用3D场景图形式的环境布局先验信息,并联合推理语义和几何学,在有组织室内环境中搜索目标对象的方法。通过神经信息传递架构和搜索过程,HMS在图的各层间递归推理,帮助交互式智能体找到用自然语言描述指定的目标对象。在大量具有密集放置语义相关对象的3D场景图上进行的实验表明,HMS在高效查找对象方面明显优于现有基线。
Searching for objects in indoor organized environments such as homes or offices is part of our everyday activities. When looking for a target object, we jointly reason about the rooms and containers the object is likely to be in; the same type of container will have a different probability of having the target depending on the room it is in. We also combine geometric and semantic information to infer what container is best to search, or what other objects are best to move, if the target object is hidden from view. We propose to use a 3D scene graph representation to capture the hierarchical, semantic, and geometric aspects of this problem. To exploit this representation in a search process, we introduce Hierarchical Mechanical Search (HMS), a method that guides an agent’s actions towards finding a target object specified with a natural language description. HMS is based on a novel neural network architecture that uses neural message passing of vectors with visual, geometric, and linguistic information to allow HMS to reason across layers of the graph while combining semantic and geometric cues. HMS is evaluated on a novel dataset of 500 3D scene graphs with dense placements of semantically related objects in storage locations, and is shown to be significantly better than several baselines at finding objects and close to the oracle policy in terms of the median number of actions required. Additional qualitative results can be found at > this https URL.
https://weibo.com/1402400261/JAuOA2ZLU
4、 [LG] Random Features Strengthen Graph Neural Networks
R Sato, M Yamada, H Kashima
[Kyoto University]
随机特征增强图神经网络。证明了随机特征的加入从理论上加强了图同构网络(Graph Isomorphic Networks, GINs)的能力,特别是加入随机特征的GINs可以解决普通GNNs包括GCNs和GINs无法解决的各种问题。带有随机特征的GINs(rGINs)可以区分任意局部子结构,以最优近似比的方式解决最小支配集问题和最大匹配问题。rGINs可以与现有的GNN模型结合,只需稍加修改,即使在测试时,在任意大的测试图中也能保证其能力。
Graph neural networks (GNNs) are powerful machine learning models for various graph learning tasks. Recently, the limitations of the expressive power of various GNN models have been revealed. For example, GNNs cannot distinguish some non-isomorphic graphs and they cannot learn efficient graph algorithms, and several GNN models have been proposed to overcome these limitations. In this paper, we demonstrate that GNNs become powerful just by adding a random feature to each node. We prove that the random features enable GNNs to learn almost optimal polynomial-time approximation algorithms for the minimum dominating set problem and maximum matching problem in terms of the approximation ratio. The main advantage of our method is that it can be combined with off-the-shelf GNN models with slight modifications. Through experiments, we show that the addition of random features enables GNNs to solve various problems that normal GNNs, including GCNs and GINs, cannot solve.
https://weibo.com/1402400261/JAuSr8m5n

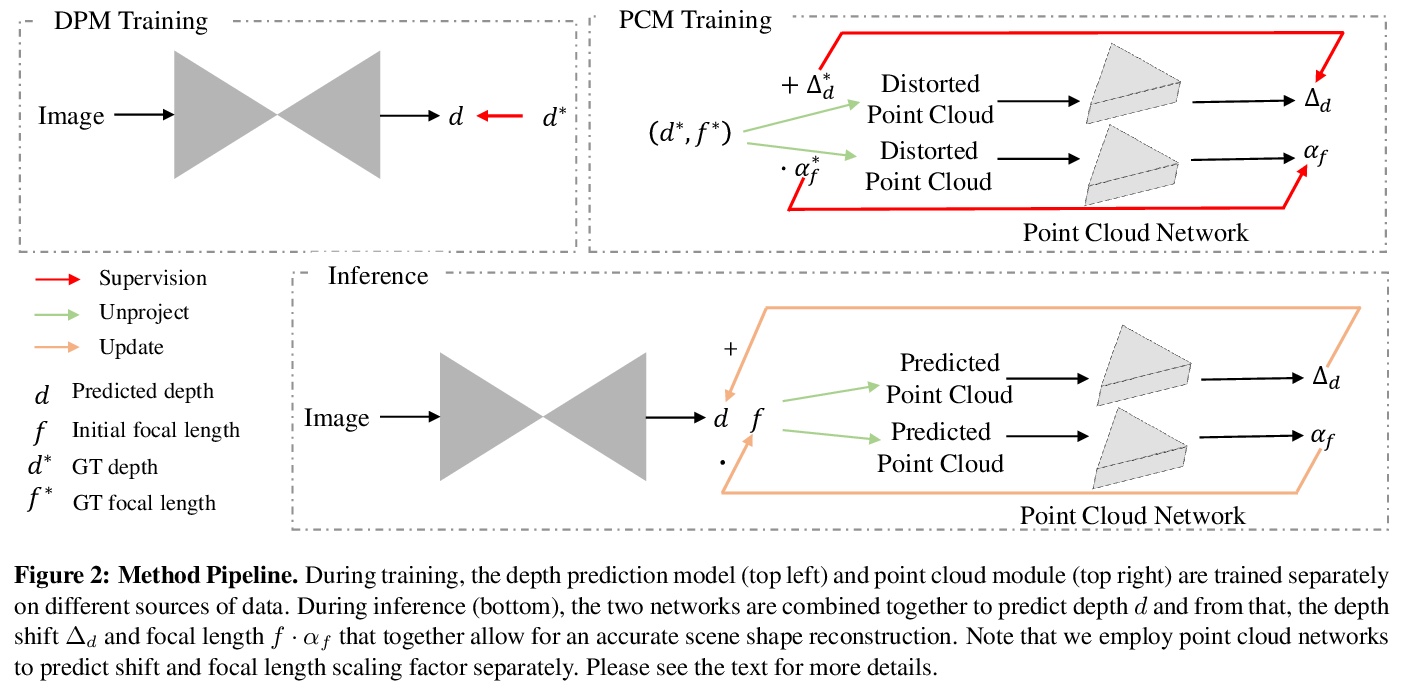
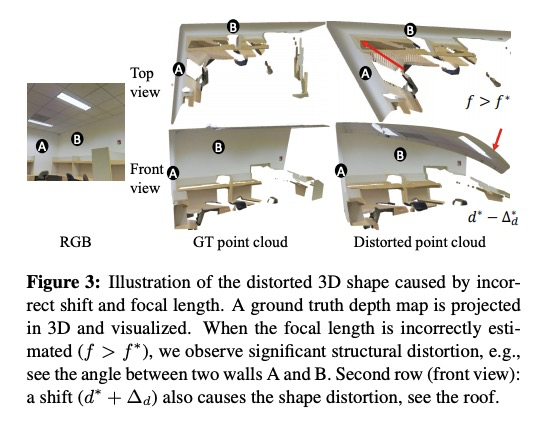
5、[CV] Learning to Recover 3D Scene Shape from a Single Image
W Yin, J Zhang, O Wang, S Niklaus, L Mai, S Chen, C Shen
[The University of Adelaide & Adobe Research]
学习从单一图像中恢复3D场景形状。提出完全由数据驱动的从单目图像重建3D场景形状的方法。为恢复用于三维重建的偏移和焦距,提出使用在具有已知全局深度移位和焦距的数据集上训练的点云网络。提出一种两级框架,先从单目图像预测深度到未知尺度和偏移,再用3D点云编码器来预测缺失的深度偏移和焦距,恢复真实3D场景形状。提出了图像级的归一化回归损失和一个基于法线的几何损失,以增强在混合数据集上训练的深度预测模型。该方法显示出强大的泛化能力,有助于相关的基于深度的任务。
Despite significant progress in monocular depth estimation in the wild, recent state-of-the-art methods cannot be used to recover accurate 3D scene shape due to an unknown depth shift induced by shift-invariant reconstruction losses used in mixed-data depth prediction training, and possible unknown camera focal length. We investigate this problem in detail, and propose a two-stage framework that first predicts depth up to an unknown scale and shift from a single monocular image, and then use 3D point cloud encoders to predict the missing depth shift and focal length that allow us to recover a realistic 3D scene shape. In addition, we propose an image-level normalized regression loss and a normal-based geometry loss to enhance depth prediction models trained on mixed datasets. We test our depth model on nine unseen datasets and achieve state-of-the-art performance on zero-shot dataset generalization. Code is available at: > this https URL
https://weibo.com/1402400261/JAuXRBDQR
另外几篇值得关注的论文:
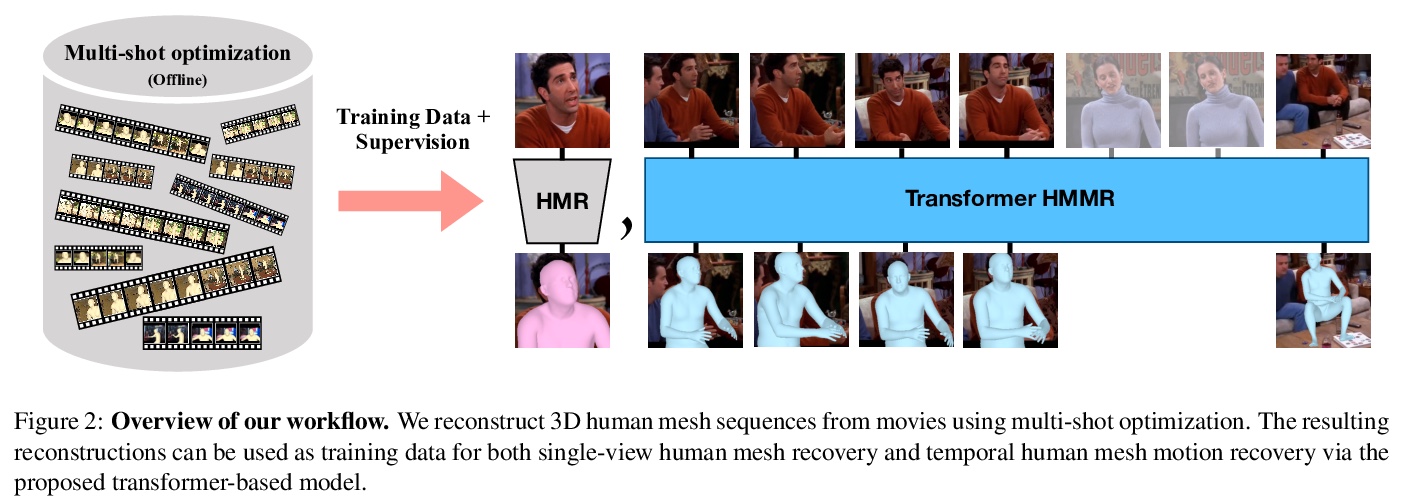
[CV] Human Mesh Recovery from Multiple Shots
多帧图像人体网格恢复
G Pavlakos, J Malik, A Kanazawa
[UC Berkeley]
https://weibo.com/1402400261/JAv1Pcafu

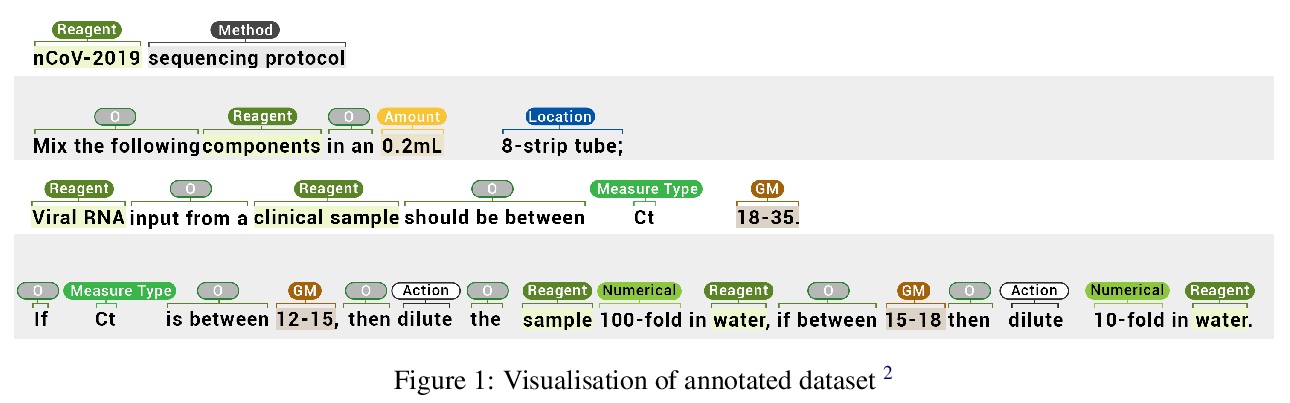
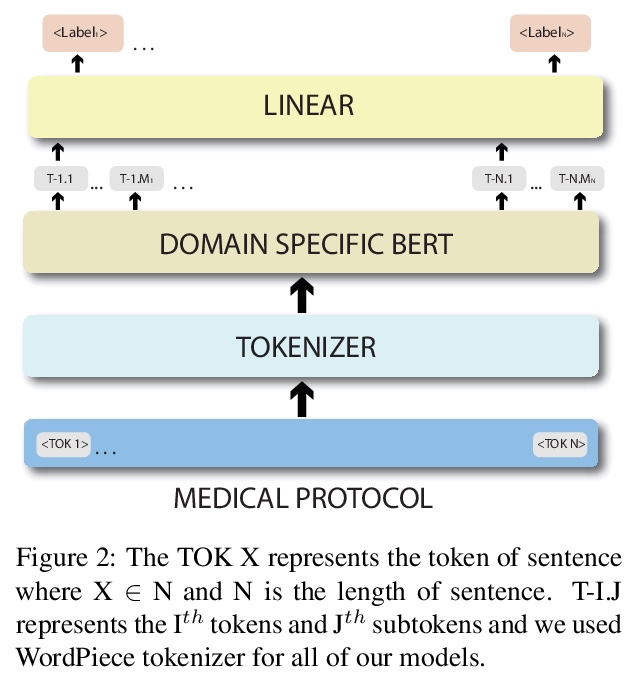
[CL] Domain specific BERT representation for Named Entity Recognition of lab protocol
面向医学领域名实体识别的领域特定BERT表示
T Vaidhya, A Kaushal
[Indian Institute of Technology, Kharagpur]
https://weibo.com/1402400261/JAv3c1IM5
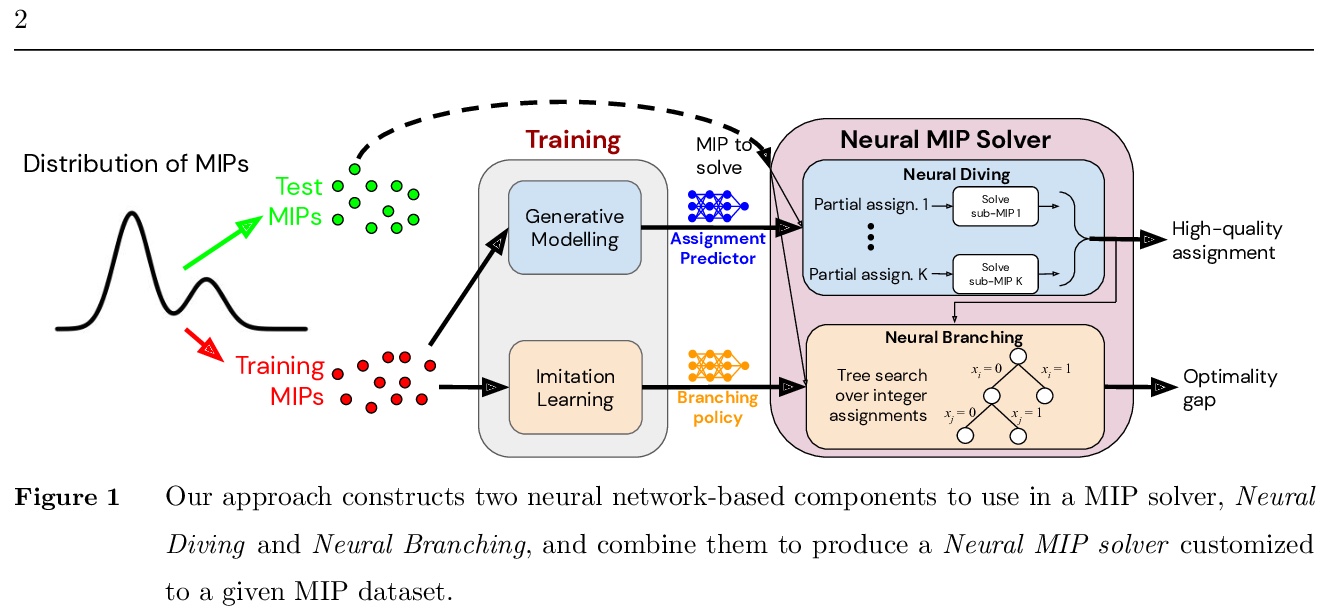
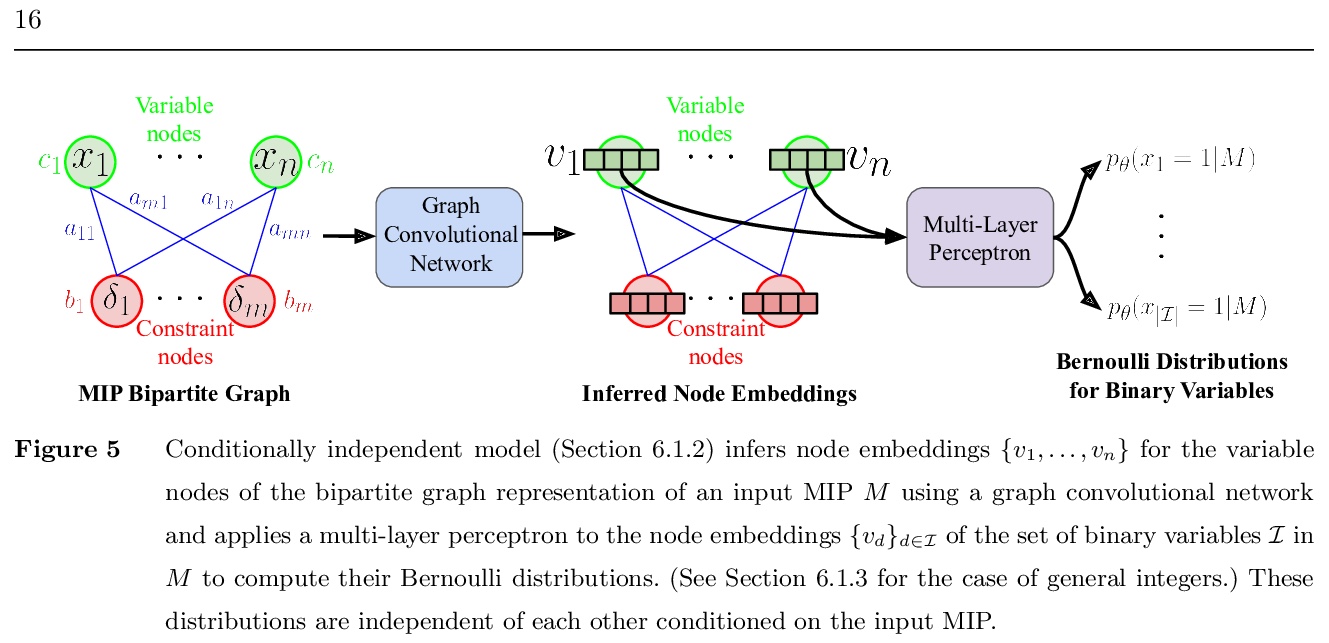
[LG] Solving Mixed Integer Programs Using Neural Networks
用神经网络解决混合整数规划问题
V Nair, S Bartunov, F Gimeno, I v Glehn, P Lichocki, I Lobov, B O’Donoghue, N Sonnerat, C Tjandraatmadja, P Wang, R Addanki, T Hapuarachchi, T Keck, J Keeling, P Kohli, I Ktena, Y Li, O Vinyals, Y Zwols
[DeepMind & Google Research]
https://weibo.com/1402400261/JAv8jEG18
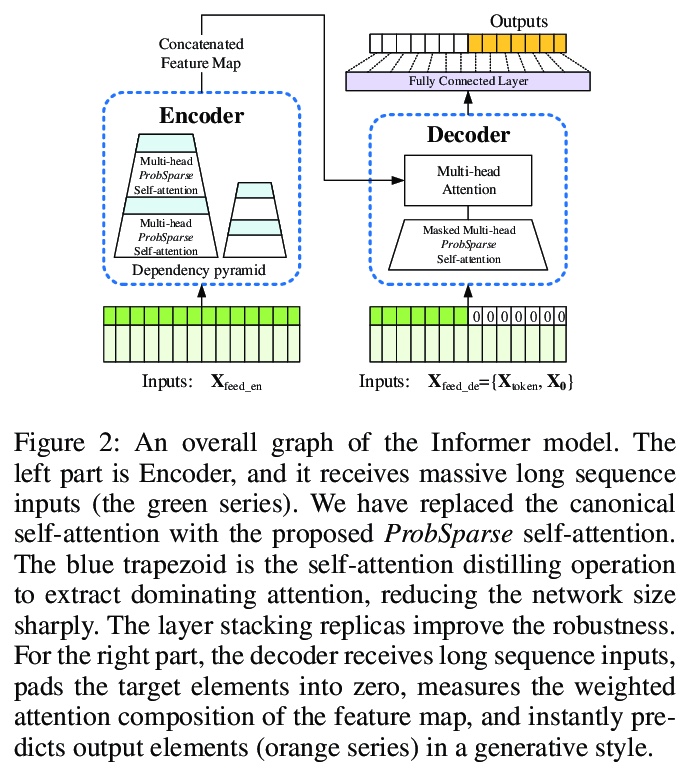
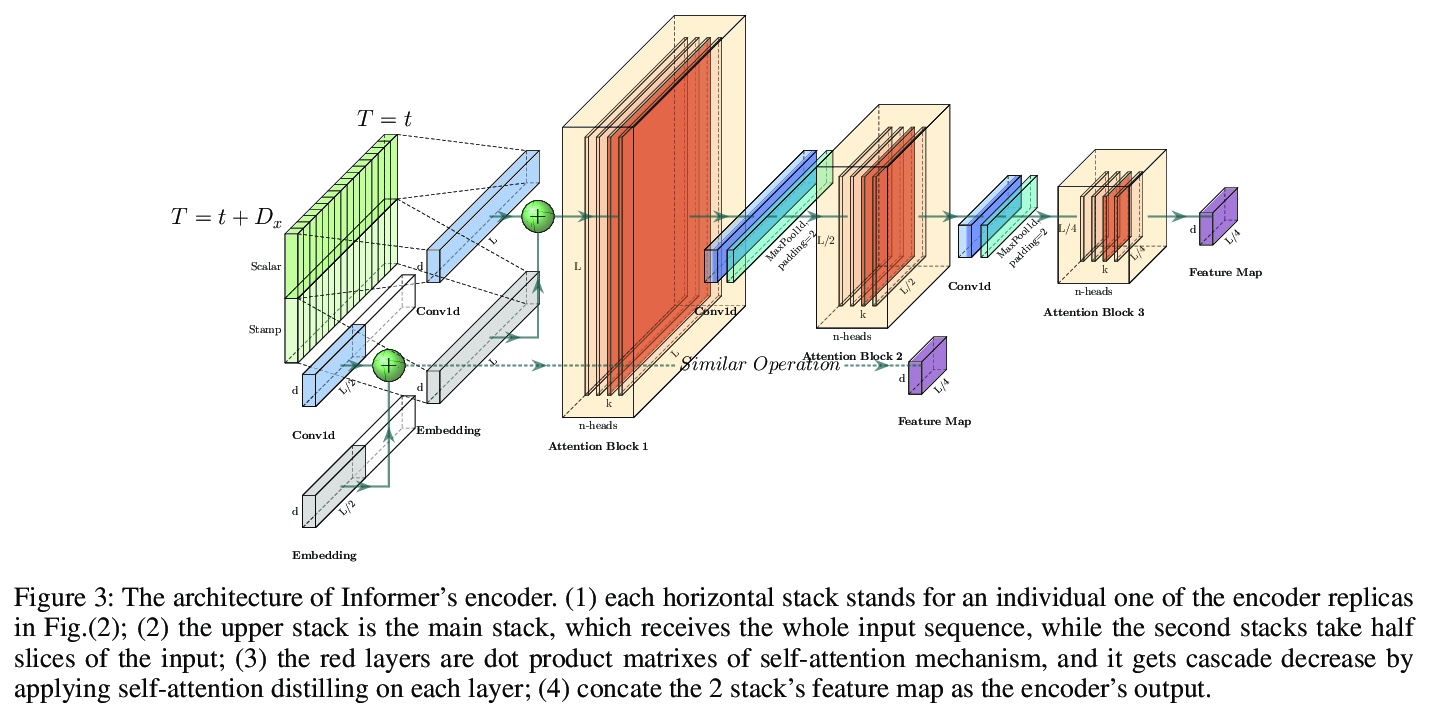
[LG] Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
Informer:面向长序列时序预测的高效Transformer
H Zhou, S Zhang, J Peng, S Zhang, J Li, H Xiong, W Zhang
[Beihang University & UC Berkeley & Rutgers University]
https://weibo.com/1402400261/JAva71GcT

若有收获,就点个赞吧
0 人点赞
