- 1、[LG] SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training
- 2、[CL] ByT5: Towards a token-free future with pre-trained byte-to-byte models
- 3、[LG] Towards Deeper Deep Reinforcement Learning
- 4、[CL] Implicit Representations of Meaning in Neural Language Models
- 5、[LG] A Generalizable Approach to Learning Optimizers
- [CL] Efficient Passage Retrieval with Hashing for Open-domain Question Answering
- [CL] On the Efficacy of Adversarial Data Collection for Question Answering: Results from a Large-Scale Randomized Study
- [CL] What Ingredients Make for an Effective Crowdsourcing Protocol for Difficult NLU Data Collection Tasks?
- [LG] Diffusion Schrödinger Bridge with Applications to Score-Based Generative Modeling
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[LG] SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training
G Somepalli, M Goldblum, A Schwarzschild, C. B Bruss, T Goldstein
[University of Maryland & Capital One]
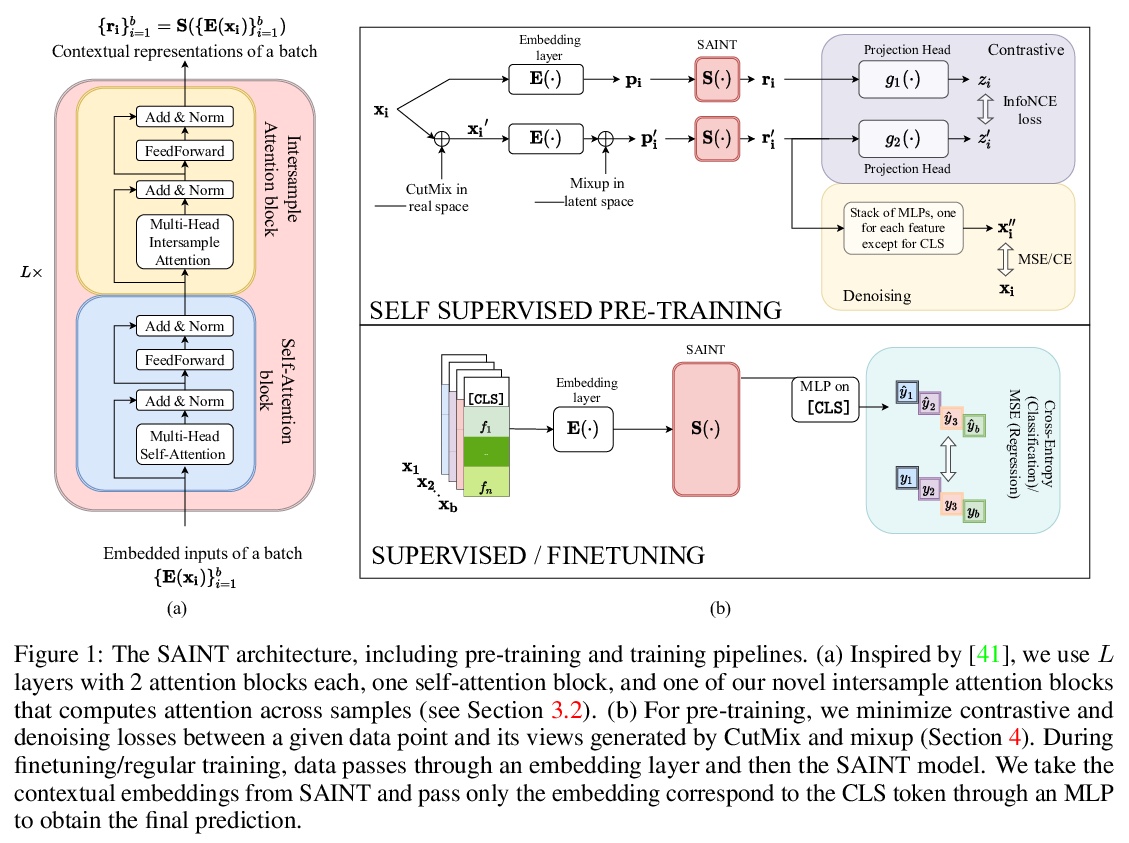
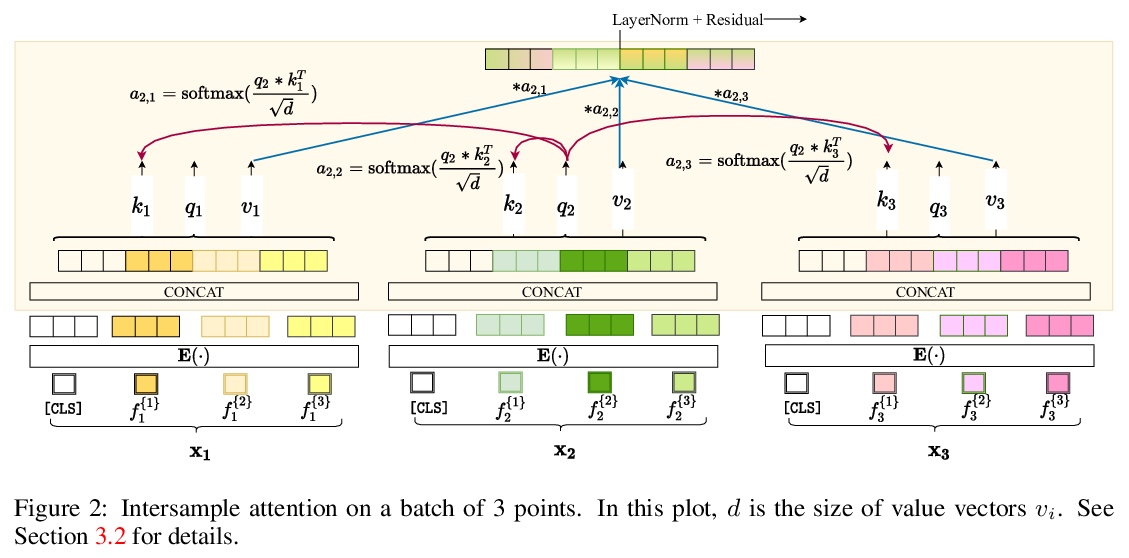
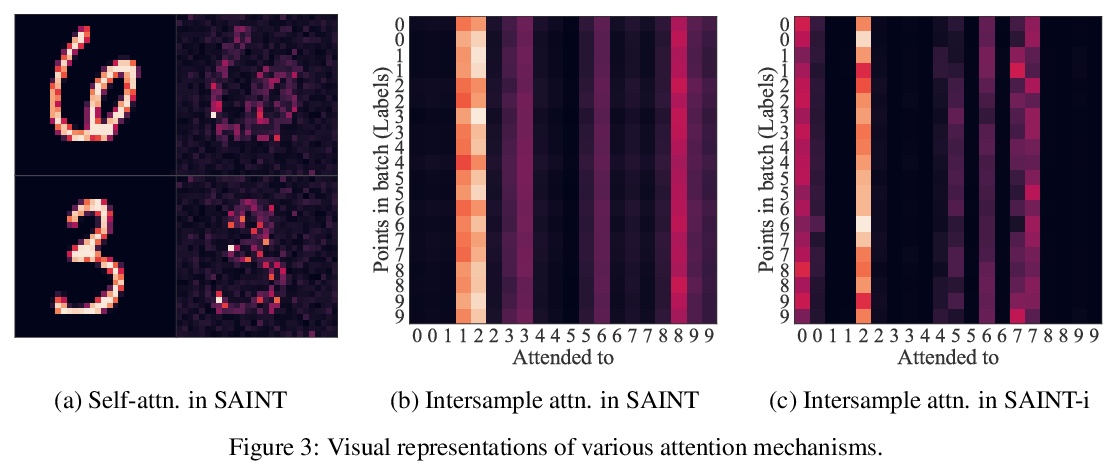
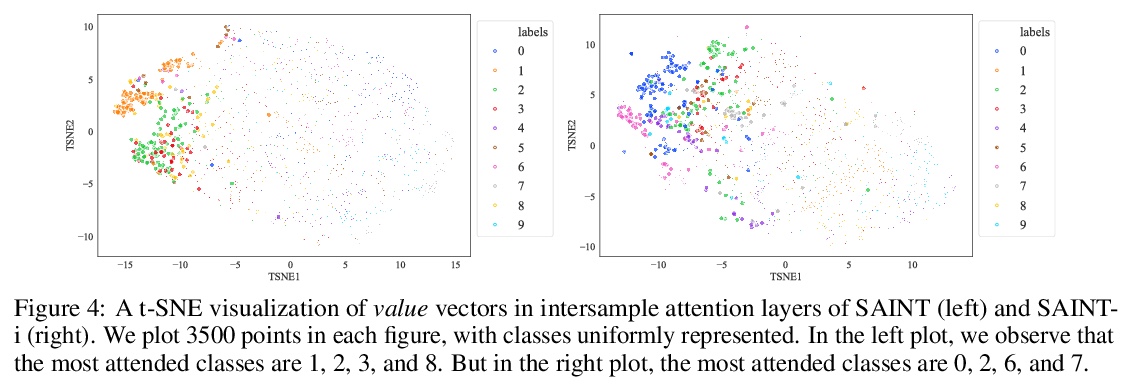
SAINT:基于行注意力和对比预训练改善表格数据神经网络。表格数据是机器学习的众多高影响力应用的基础,从欺诈检测到基因组学及医疗等。解决表格问题的经典方法,如梯度提升和随机森林,被广泛使用,而最近的深度学习方法已经可以达到与流行技术相竞争的性能。本文设计了一种混合深度学习方法,用来解决表格数据问题。所提出的SAINT方法,包括行和列的注意力,一种增强的嵌入方法,以及一种新的对比自监督预训练方法,可在标记稀缺的情况下使用。SAINT的性能比之前的深度学习方法好,甚至比梯度提升方法,包括XGBoost、CatBoost和LightGBM,在各种基准任务中的平均性能都更好。
Tabular data underpins numerous high-impact applications of machine learning from fraud detection to genomics and healthcare. Classical approaches to solving tabular problems, such as gradient boosting and random forests, are widely used by practitioners. However, recent deep learning methods have achieved a degree of performance competitive with popular techniques. We devise a hybrid deep learning approach to solving tabular data problems. Our method, SAINT, performs attention over both rows and columns, and it includes an enhanced embedding method. We also study a new contrastive self-supervised pre-training method for use when labels are scarce. SAINT consistently improves performance over previous deep learning methods, and it even outperforms gradient boosting methods, including XGBoost, CatBoost, and LightGBM, on average over a variety of benchmark tasks.
https://weibo.com/1402400261/KiyFdDUEy
2、[CL] ByT5: Towards a token-free future with pre-trained byte-to-byte models
L Xue, A Barua, N Constant, R Al-Rfou, S Narang, M Kale, A Roberts, C Raffel
[Google Research]
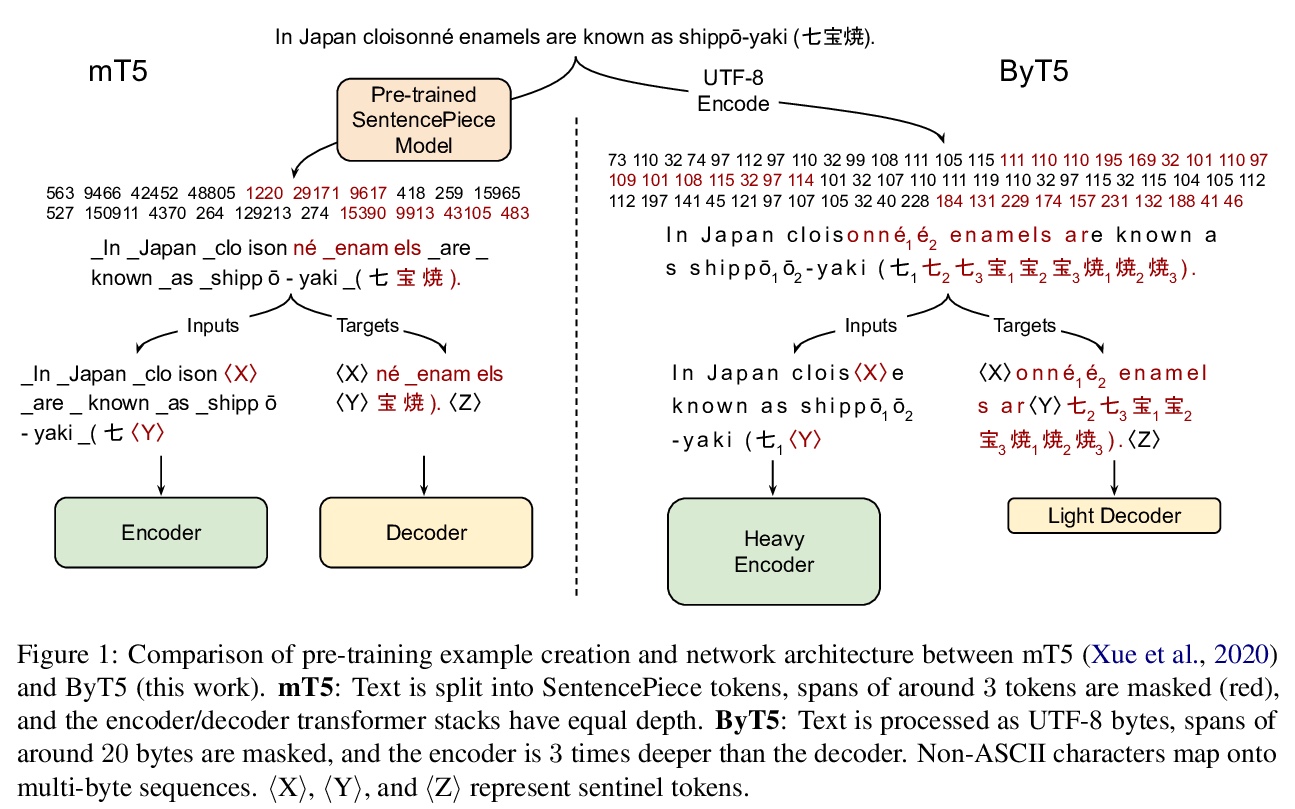
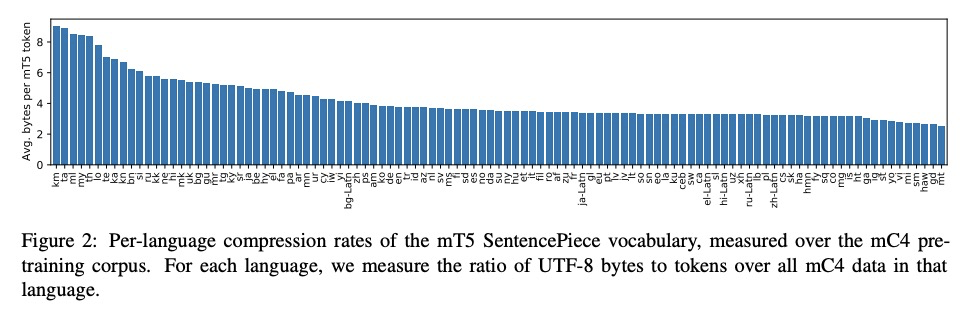
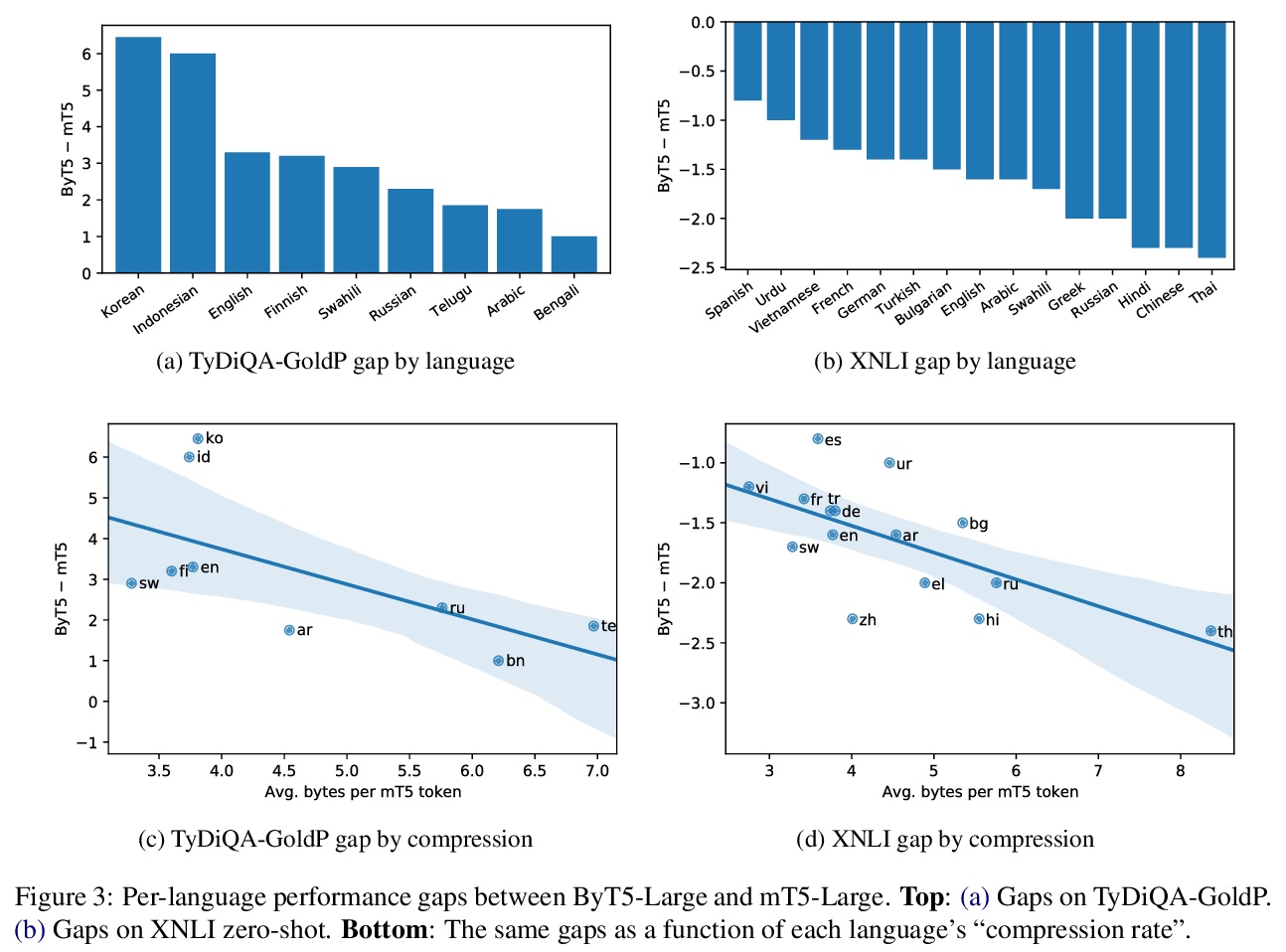
ByT5:基于预训练字节到字节模型的免分词NLP。大多数广泛使用的预训练语言模型,都是在词或子词单元的标记序列上进行处理的。将文本编码为标记序列,需要一个标记器(分词器),通常作为模型的一个独立组件创建。直接对原始文本(字节或字符)进行操作的无标记模型有很多好处:可以开箱即用处理任何语言的文本,对噪声更鲁棒,通过消除复杂和容易出错的文本预处理管线,将技术债务降到最低。由于字节或字符序列比标记序列更长,之前无标记模型的工作常引入新的模型架构,以摊销直接在原始文本上操作的成本。本文提出一种标准Transformer架构,可用最小的修改来处理字节序列。描述了在参数规模、训练计算量和推理速度方面的权衡,表明字节级模型与其他标记级模型相比有竞争性,字节级模型对噪声的鲁棒性明显更强,在对拼写和发音敏感的任务中表现更好。
Most widely-used pre-trained language models operate on sequences of tokens corresponding to word or subword units. Encoding text as a sequence of tokens requires a tokenizer, which is typically created as an independent artifact from the model. Token-free models that instead operate directly on raw text (bytes or characters) have many benefits: they can process text in any language out of the box, they are more robust to noise, and they minimize technical debt by removing complex and errorprone text preprocessing pipelines. Since byte or character sequences are longer than token sequences, past work on token-free models has often introduced new model architectures designed to amortize the cost of operating directly on raw text. In this paper, we show that a standard Transformer architecture can be used with minimal modifications to process byte sequences. We carefully characterize the trade-offs in terms of parameter count, training FLOPs, and inference speed, and show that byte-level models are competitive with their token-level counterparts. We also demonstrate that byte-level models are significantly more robust to noise and perform better on tasks that are sensitive to spelling and pronunciation. As part of our contribution, we release a new set of pre-trained byte-level Transformer models based on the T5 architecture, as well as all code and data used in our experiments.
https://weibo.com/1402400261/KiyIIwksJ
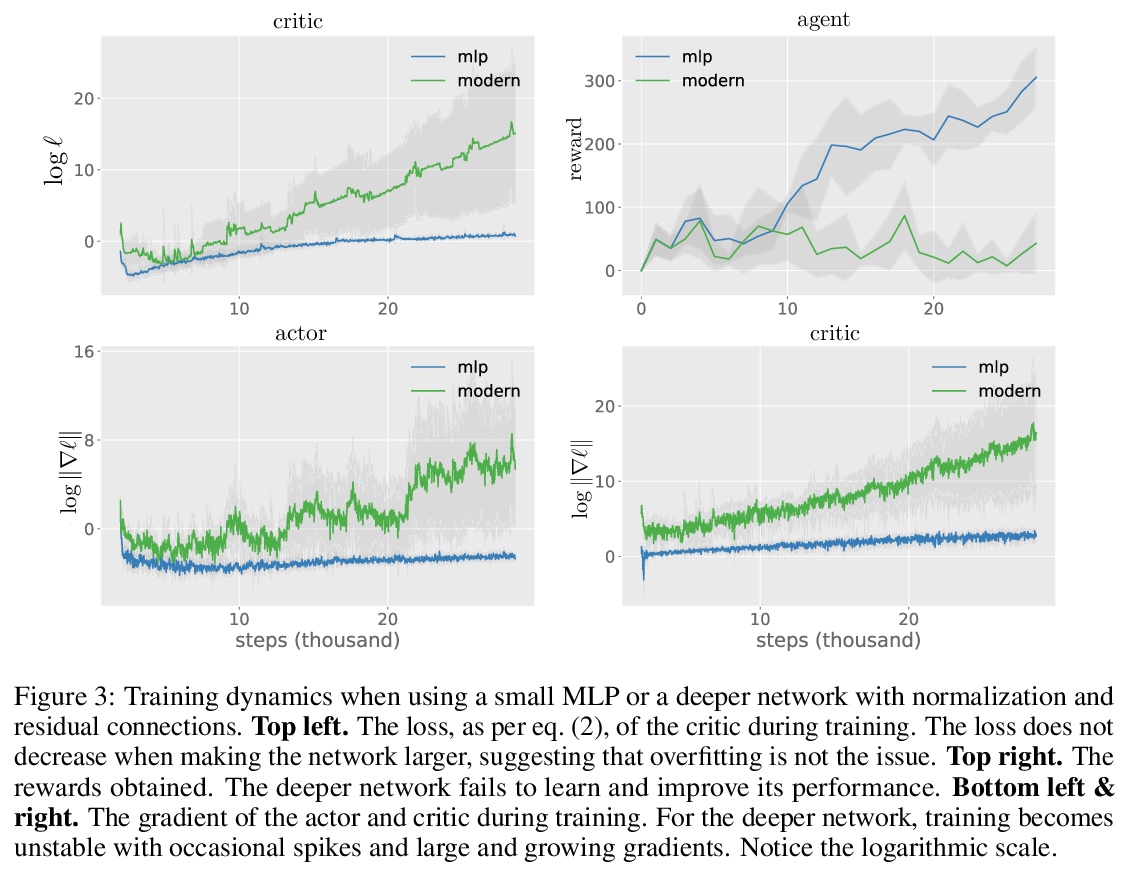
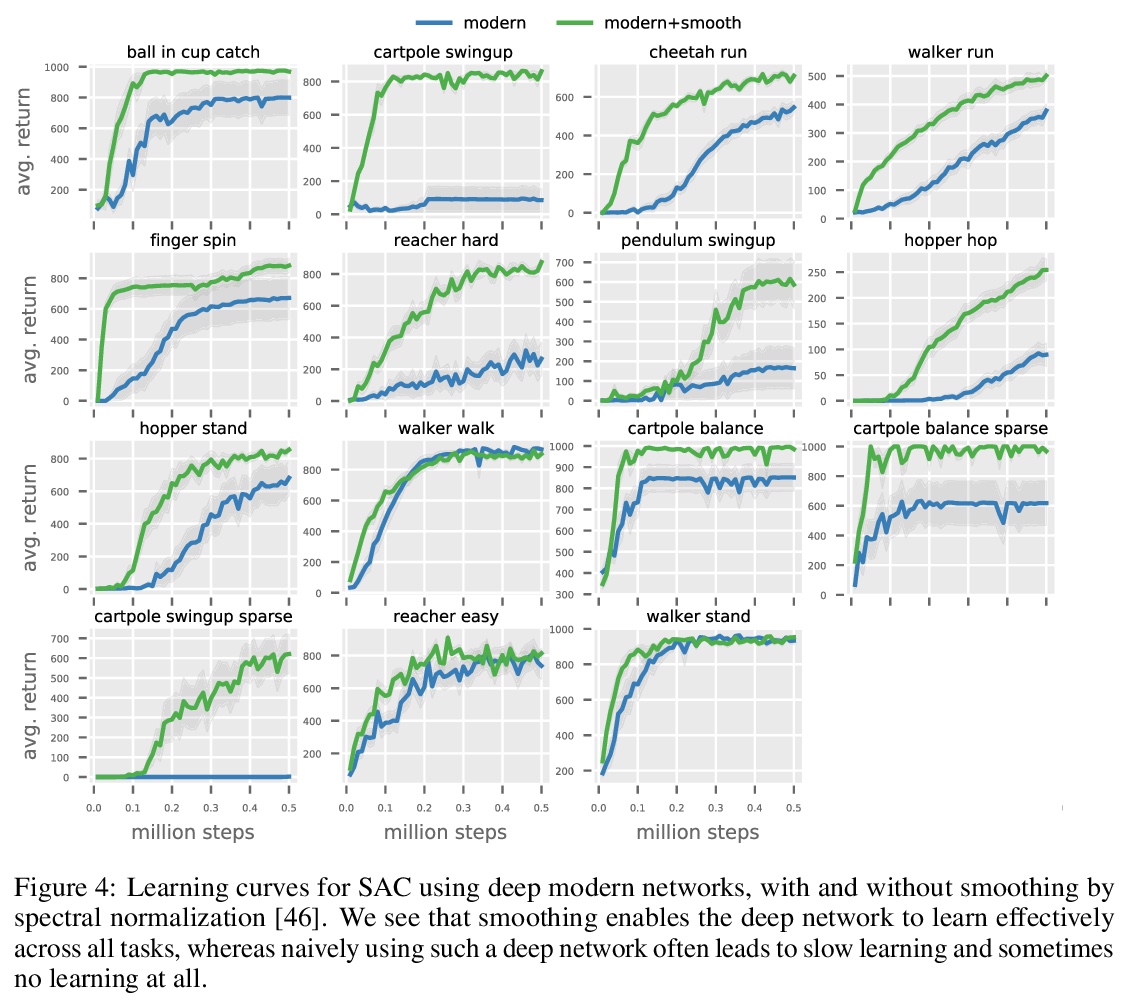
3、[LG] Towards Deeper Deep Reinforcement Learning
J Bjorck, C P. Gomes, K Q. Weinberger
[Cornell University]
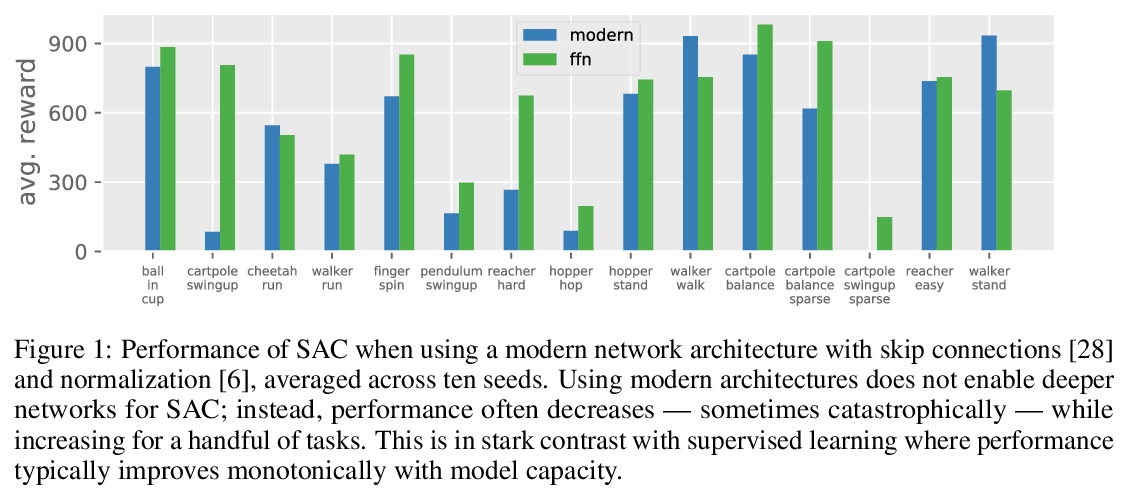
更深的深度强化学习。在计算机视觉和自然语言处理中,模型结构的创新导致了模型容量的增加,并可靠地转化为性能的提高。与这一趋势形成鲜明对比的是,最先进的强化学习(RL)算法通常只用小型MLP,性能的提高通常来自于算法创新。可以很自然地假设,强化学习中的小数据集需要简单的模型来避免过拟合;而该假设还未得到验证。本文研究了用带有跳接和规范化的大型现代网络替换小型MLP与对RL代理的影响,特别关注soft actor-critic(SAC)算法。通过实验验证,简单采用这样的架构,会导致不稳定和糟糕的性能,这可能有助于简单模型在实践中的普及。然而,数据集大小并不是限制因素,SAC中actor通过critic获取梯度的内在不稳定性,才是真正的问题所在。提出一种简单的平滑方法,以缓解该问题,使得大型现代架构的稳定训练成为可能。平滑后,更大模型对最先进的智能体产生了巨大的性能改进——这表明除了算法创新之外,关注模型架构也可以获得更”容易”的收益。
In computer vision and natural language processing, innovations in model architecture that lead to increases in model capacity have reliably translated into gains in performance. In stark contrast with this trend, state-of-the-art reinforcement learning (RL) algorithms often use only small MLPs, and gains in performance typically originate from algorithmic innovations. It is natural to hypothesize that small datasets in RL necessitate simple models to avoid overfitting; however, this hypothesis is untested. In this paper we investigate how RL agents are affected by exchanging the small MLPs with larger modern networks with skip connections and normalization, focusing specifically on soft actor-critic (SAC) algorithms. We verify, empirically, that naïvely adopting such architectures leads to instabilities and poor performance, likely contributing to the popularity of simple models in practice. However, we show that dataset size is not the limiting factor, and instead argue that intrinsic instability from the actor in SAC taking gradients through the critic is the culprit. We demonstrate that a simple smoothing method can mitigate this issue, which enables stable training with large modern architectures. After smoothing, larger models yield dramatic performance improvements for state-ofthe-art agents — suggesting that more “easy” gains may be had by focusing on model architectures in addition to algorithmic innovations.
https://weibo.com/1402400261/KiyMIwW2J

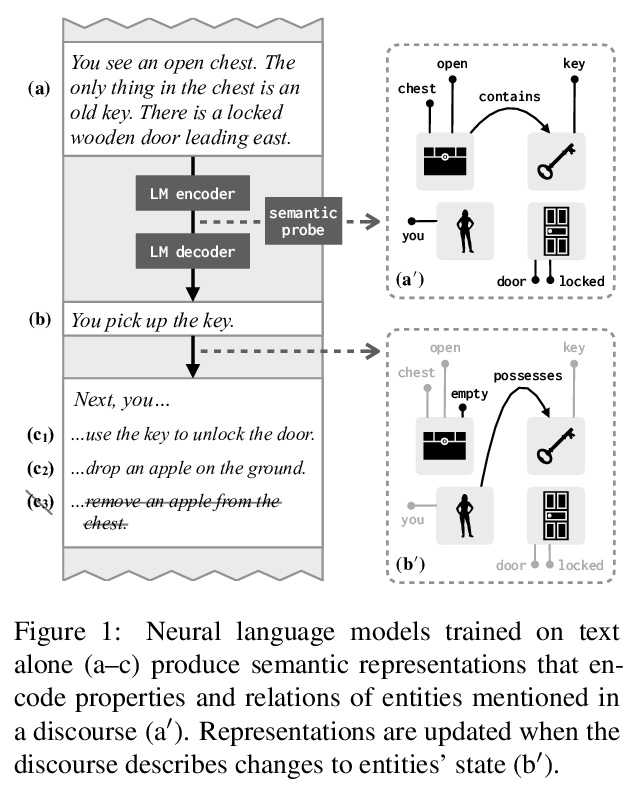
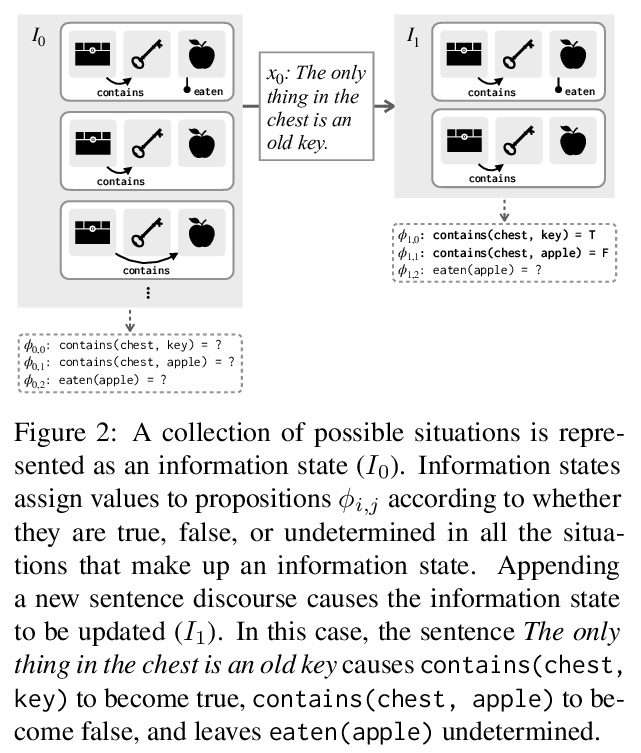
4、[CL] Implicit Representations of Meaning in Neural Language Models
B Z. Li, M Nye, J Andreas
[MIT]
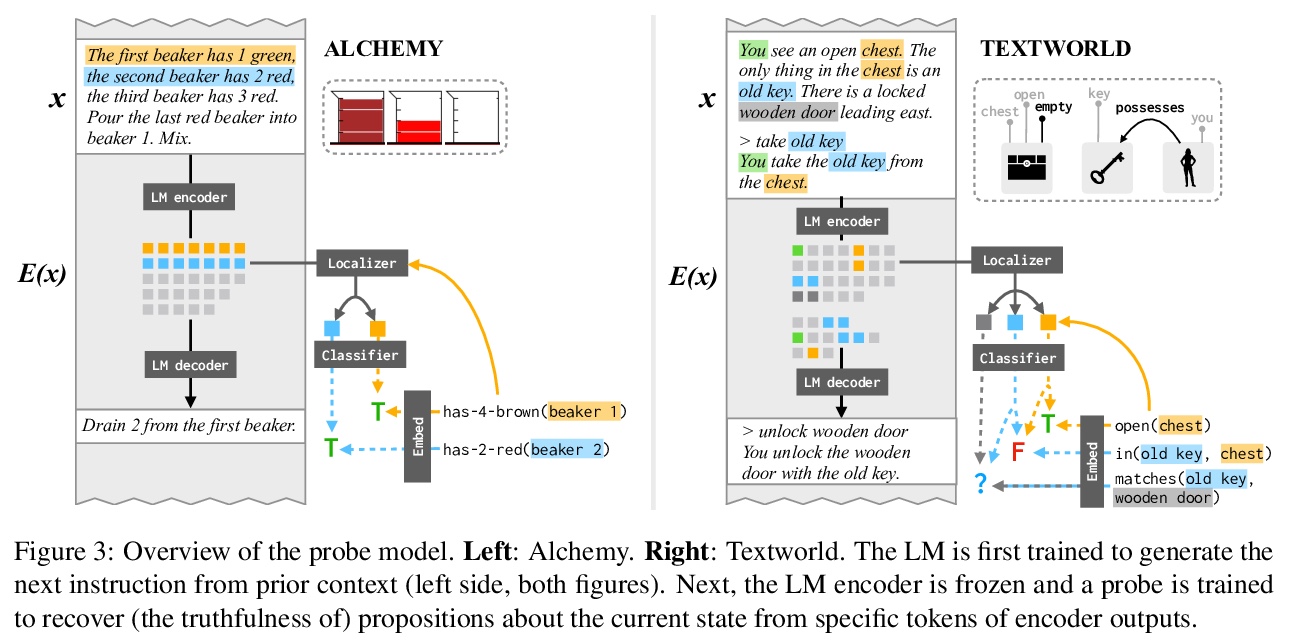
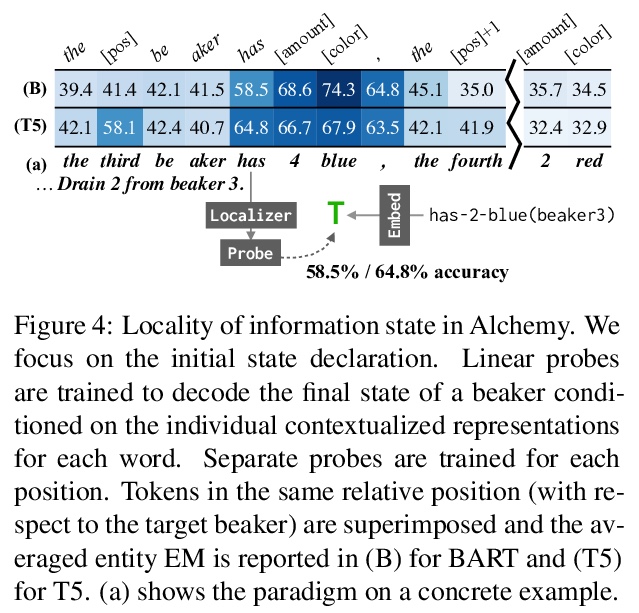
神经网络语言模型中意义的隐性表征。神经网络语言模型的有效性,是否完全来自于对表面词共现统计的准确建模,这些模型是否表示和推理它们所描述的世界?在BART和T5 transformer语言模型中,识别了上下文词表示,及其作为实体和情境的模型在整个话语中的演变。这些神经网络表征,与动态语义的语言模型在功能上有相似之处:支持对每个实体的当前属性和关系的线性读出,可通过对语言生成的可预测影响进行操作。实验结果表明,在预训练神经网络语言模型中,预测至少有一部分是由意义的动态表征和实体状态的隐性仿真支持的,这种行为可以只用文本作为训练数据来学习。
Does the effectiveness of neural language models derive entirely from accurate modeling of surface word co-occurrence statistics, or do these models represent and reason about the world they describe? In BART and T5 transformer language models, we identify contextual word representations that function as models of entities and situations as they evolve throughout a discourse. These neural representations have functional similarities to linguistic models of dynamic semantics: they support a linear readout of each entity’s current properties and relations, and can be manipulated with predictable effects on language generation. Our results indicate that prediction in pretrained neural language models is supported, at least in part, by dynamic representations of meaning and implicit simulation of entity state, and that this behavior can be learned with only text as training data.
https://weibo.com/1402400261/KiyQ81XXc
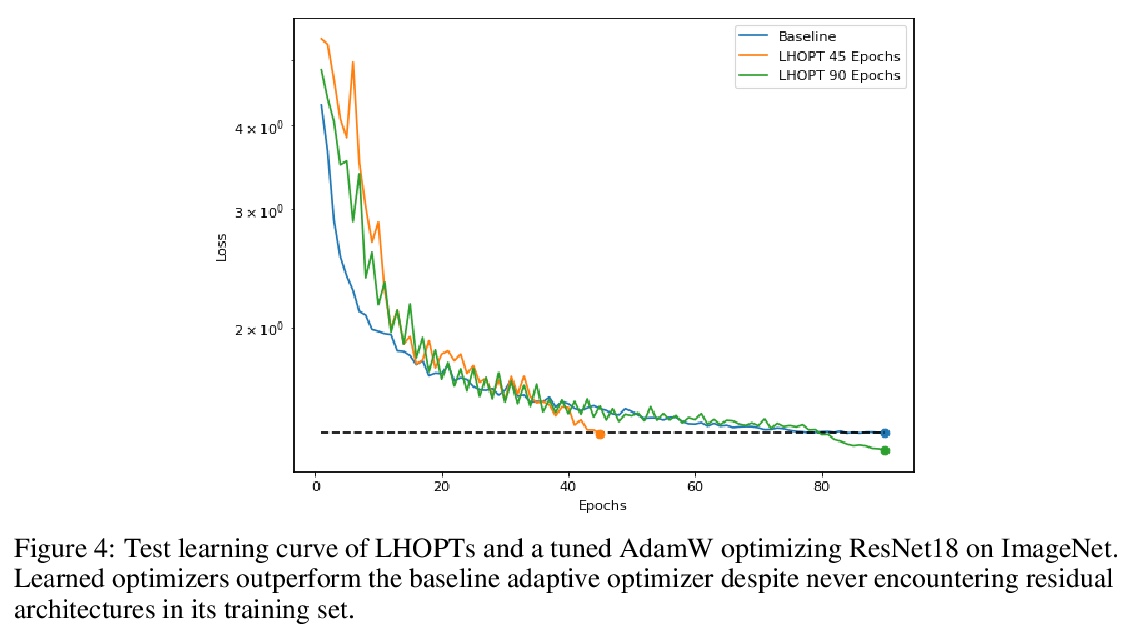
5、[LG] A Generalizable Approach to Learning Optimizers
D Almeida, C Winter, J Tang, W Zaremba
[OpenAI]
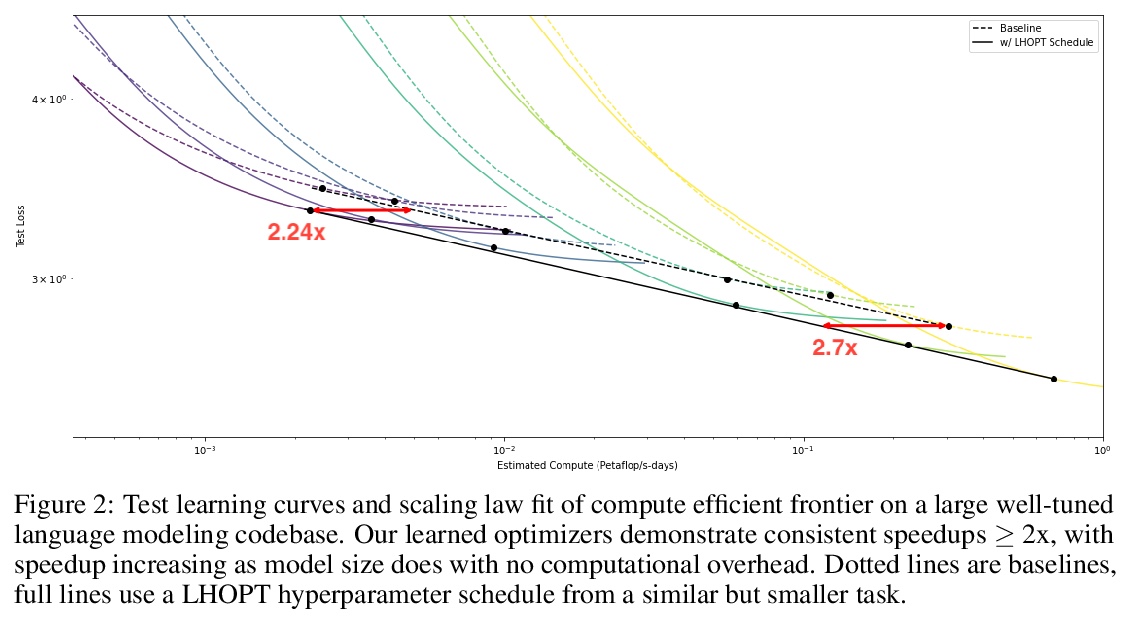
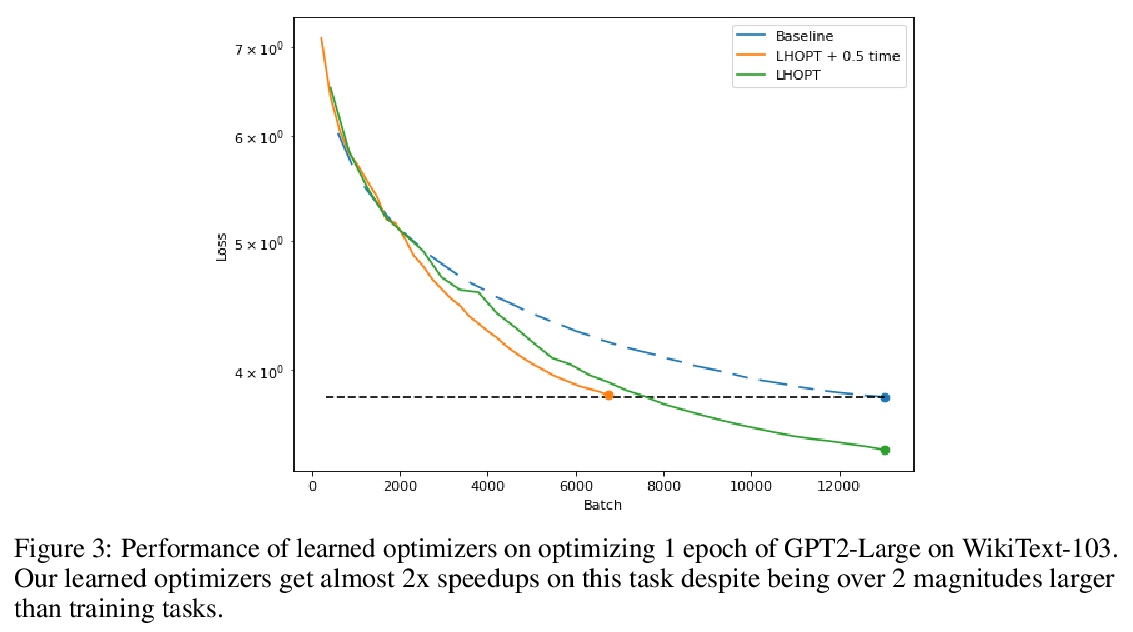
优化器学习的可泛化方法。神经网络优化学习的一个核心问题是缺乏对现实世界问题的泛化。为解决该问题,本文提出了一个从泛化优先角度设计的系统,学习更新优化器超参数,而不是直接用新的特征、行动和奖励函数的模型参数。该系统在所有神经网络任务中都优于Adam,包括训练过程中未出现的模式。在ImageNet上实现了2倍的加速,在语言建模任务上实现了2.5倍的加速。
A core issue with learning to optimize neural networks has been the lack of generalization to real world problems. To address this, we describe a system designed from a generalization-first perspective, learning to update optimizer hyperparameters instead of model parameters directly using novel features, actions, and a reward function. This system outperforms Adam at all neural network tasks including on modalities not seen during training. We achieve 2x speedups on ImageNet, and a 2.5x speedup on a language modeling task using over 5 orders of magnitude more compute than the training tasks.
https://weibo.com/1402400261/KiyUJsuf0
另外几篇值得关注的论文:
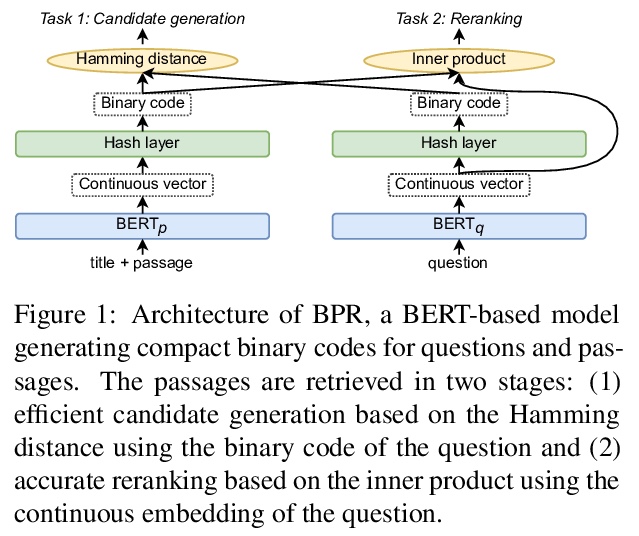
[CL] Efficient Passage Retrieval with Hashing for Open-domain Question Answering
面向开放域问答的高效哈希段落检索
I Yamada, A Asai, H Hajishirzi
[Studio Ousia & University of Washington]
https://weibo.com/1402400261/KiyXdsTci
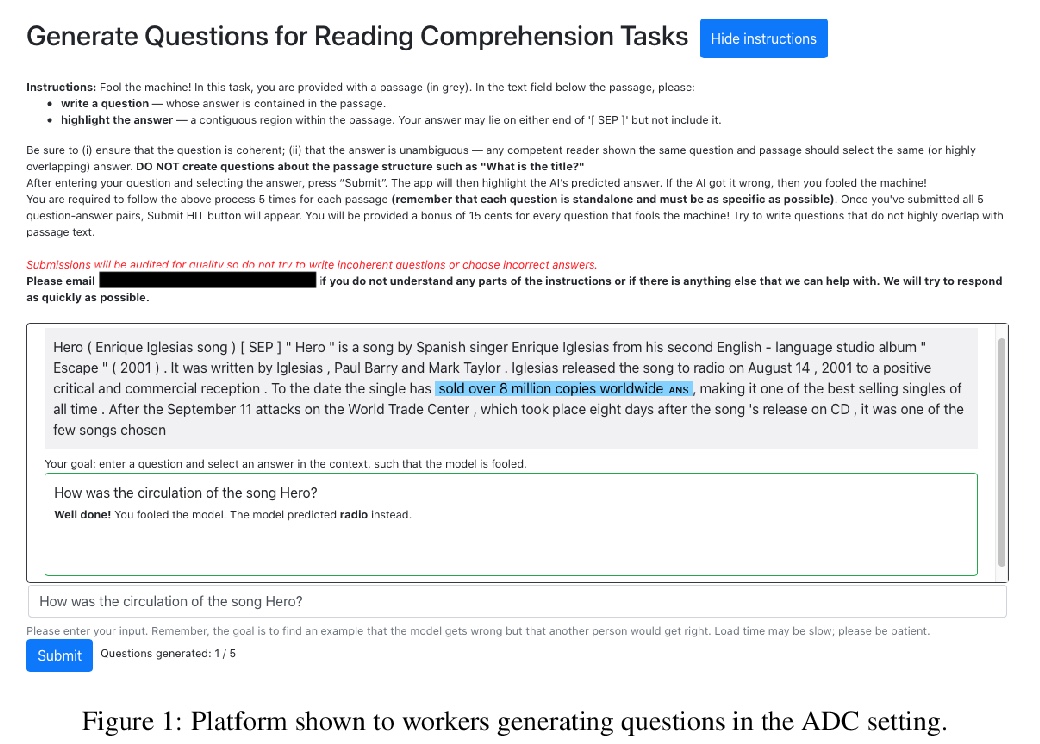
[CL] On the Efficacy of Adversarial Data Collection for Question Answering: Results from a Large-Scale Randomized Study
对抗数据集对问答的有效性:一项大规模随机研究的结果
D Kaushik, D Kiela, Z C. Lipton, W Yih
[CMU & Facebook AI Research]
https://weibo.com/1402400261/KiyYM7HXL

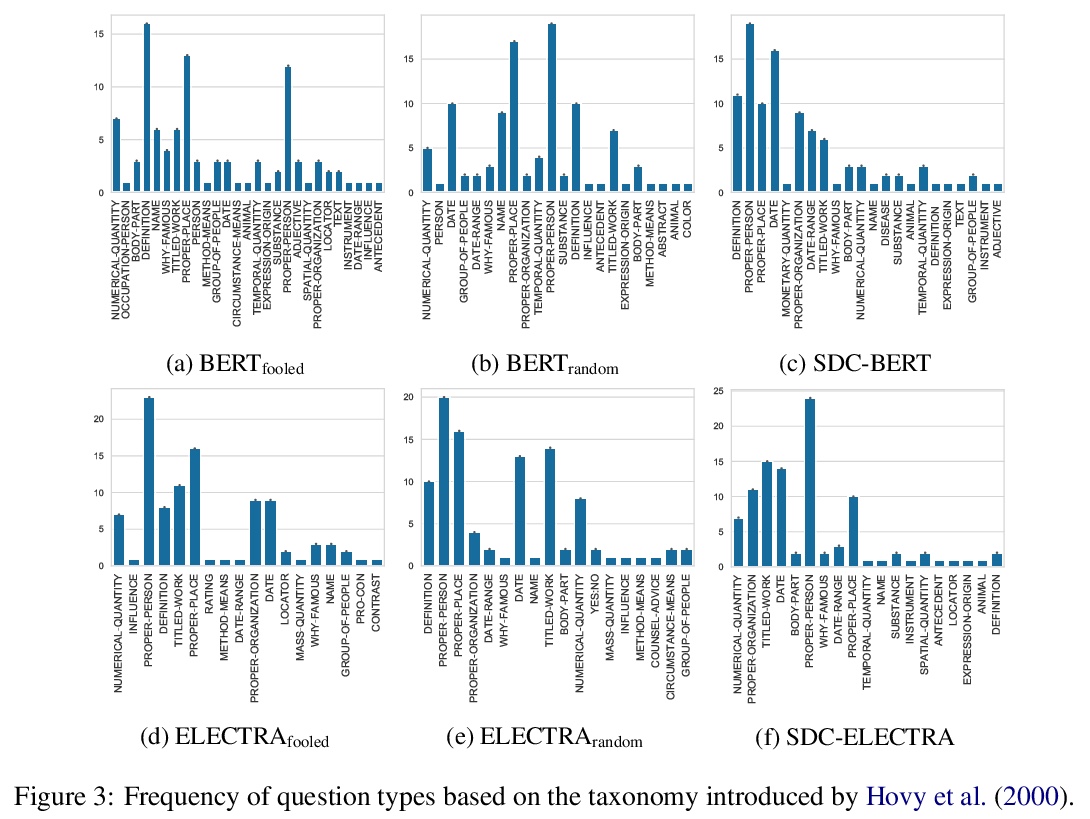
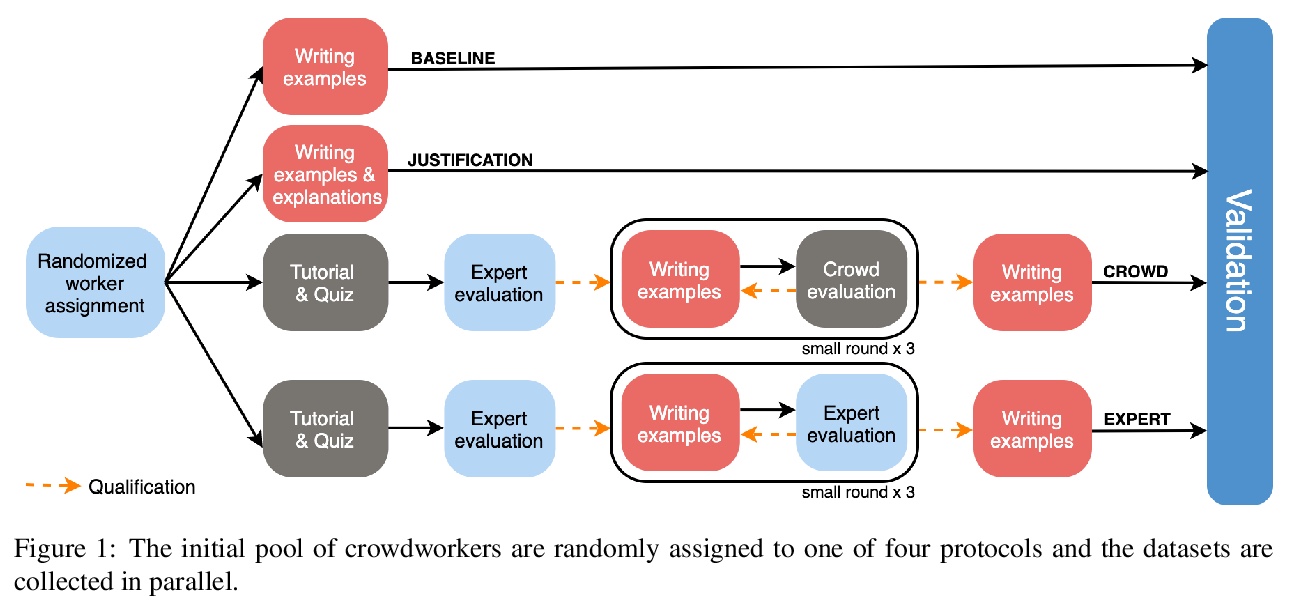
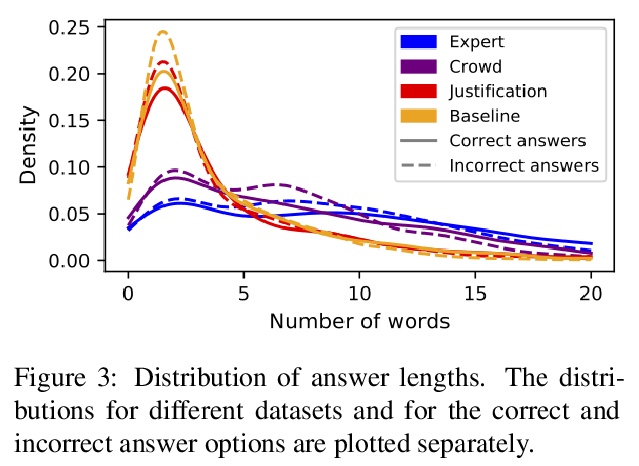
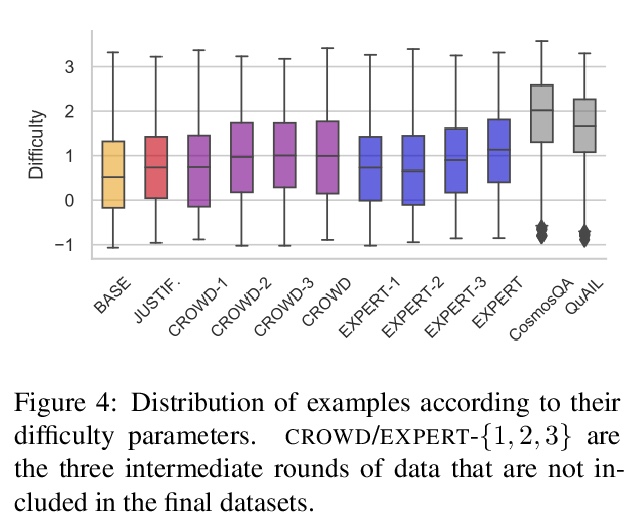
[CL] What Ingredients Make for an Effective Crowdsourcing Protocol for Difficult NLU Data Collection Tasks?
困难NLU数据收集任务有效的众包协议有哪些要素?
N Nangia, S Sugawara, H Trivedi, A Warstadt, C Vania, S R. Bowman
[New York University & National Institute of Informatics & Stony Brook University & Amazon]
https://weibo.com/1402400261/Kiz1OljAG

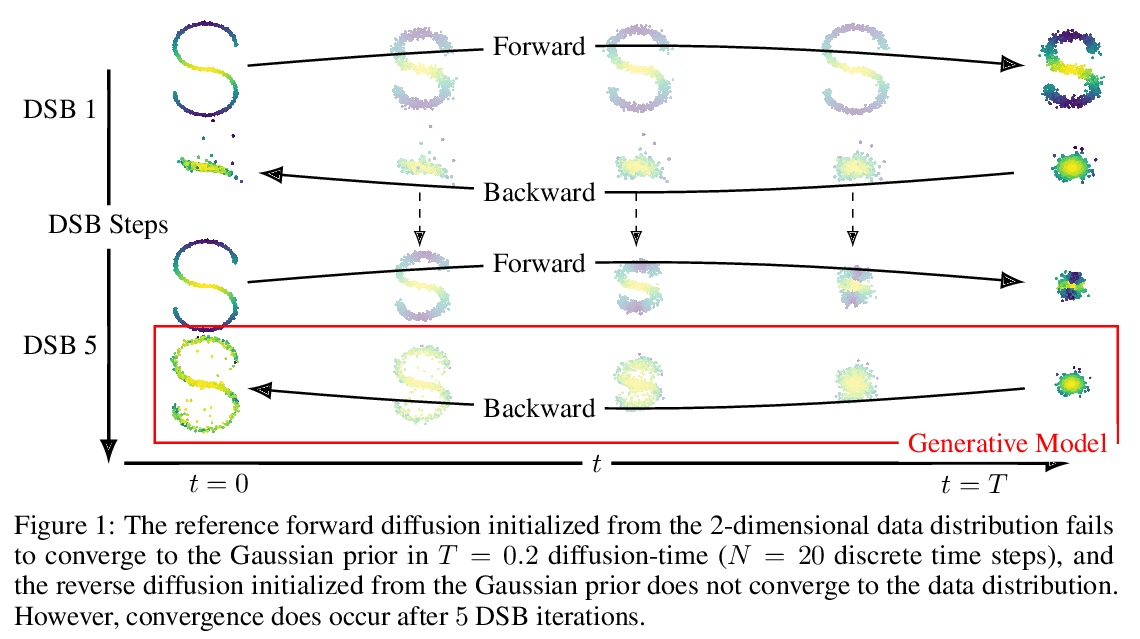
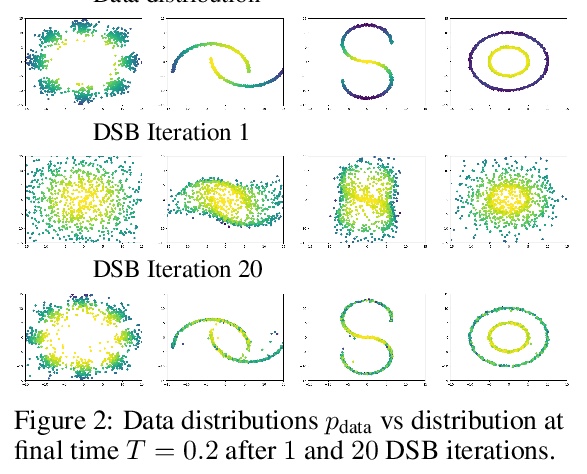
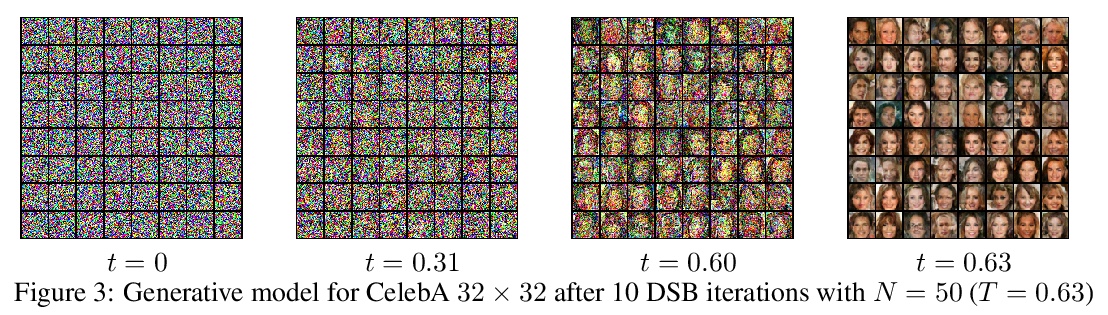
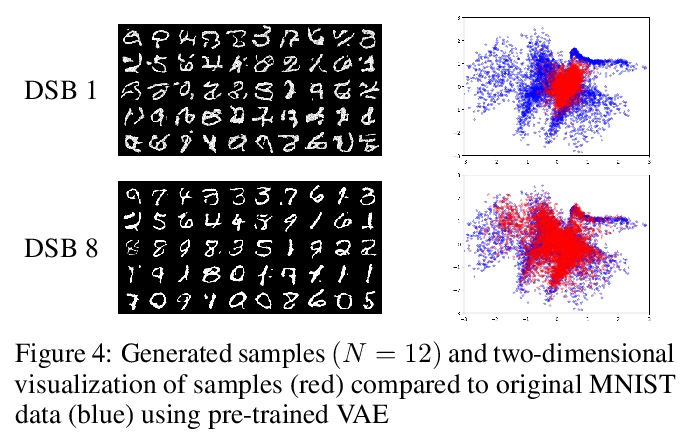
[LG] Diffusion Schrödinger Bridge with Applications to Score-Based Generative Modeling
Diffusion Schrödinger Bridge及其在基于分数的生成式建模中的应用
V D Bortoli, J Thornton, J Heng, A Doucet
[University of Oxford & ESSEC Business School]
https://weibo.com/1402400261/Kiz496FHP

若有收获,就点个赞吧
0 人点赞
