- 1、[LG] Coordination Among Neural Modules Through a Shared Global Workspace
- 2、[LG] Kernel Interpolation for Scalable Online Gaussian Processes
- 3、[LG] Loss Surface Simplexes for Mode Connecting Volumes and Fast Ensembling
- 4、[CV] TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
- 5、[CV] Deep Perceptual Image Quality Assessment for Compression
- [CV] NeuTex: Neural Texture Mapping for Volumetric Neural Rendering
- [CV] Medical Transformer: Gated Axial-Attention for Medical Image Segmentation
- [CV] COIN: COmpression with Implicit Neural representations
- [LG] Continuous Coordination As a Realistic Scenario for Lifelong Learning
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Coordination Among Neural Modules Through a Shared Global Workspace
A Goyal, A Didolkar, A Lamb, K Badola, N R Ke, N Rahaman, J Binas, C Blundell, M Mozer, Y Bengio
[Mila & Deepmind & Google Brain]
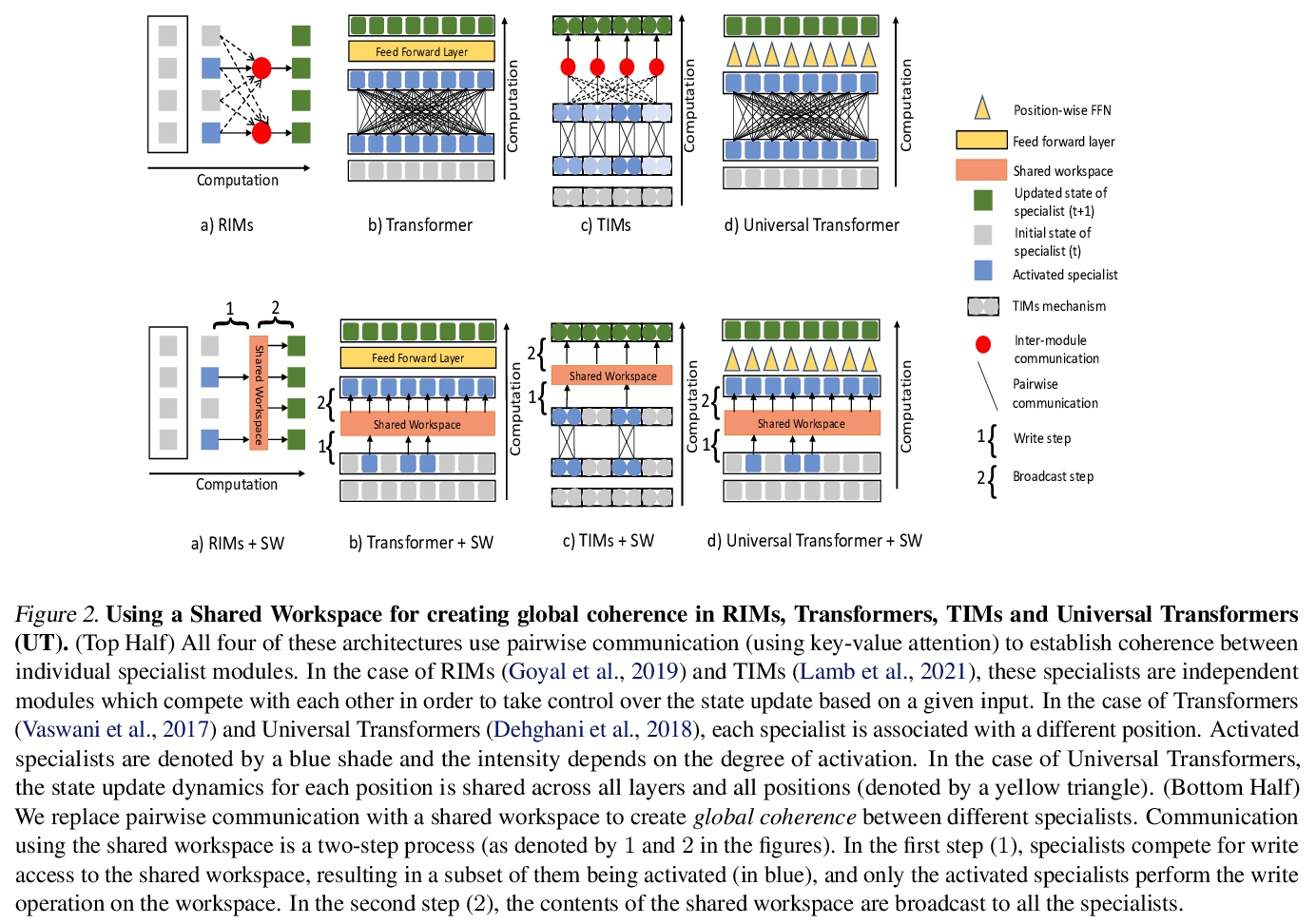
基于共享全局工作空间的神经模块协调。受认知神经科学全局工作空间理论启发,提出一种共享工作空间模型,用于实现神经模块间一致性,同时交换信息。用一个有限容量的共享工作空间作为瓶颈来调解模块之间的交流,与通常在自注意力方案中使用的对偶交互相比,在广泛的视觉推理基准上会有更好表现。在预测和视觉推理任务上的实验,突出了模块化和共享工作空间的结合带来的优势。所提出的模型结合了几个关键特性:知识和专业技术在模块之间进行划分,竞争式向工作空间发布新内容,更新后,共享工作空间可以被所有模块访问,以便其自我更新。
Deep learning has seen a movement away from representing examples with a monolithic hidden state towards a richly structured state. For example, Transformers segment by position, and object-centric architectures decompose images into entities. In all these architectures, interactions between different elements are modeled via pairwise interactions: Transformers make use of self-attention to incorporate information from other positions; object-centric architectures make use of graph neural networks to model interactions among entities. However, pairwise interactions may not achieve global coordination or a coherent, integrated representation that can be used for downstream tasks. In cognitive science, a global workspace architecture has been proposed in which functionally specialized components share information through a common, bandwidth-limited communication channel. We explore the use of such a communication channel in the context of deep learning for modeling the structure of complex environments. The proposed method includes a shared workspace through which communication among different specialist modules takes place but due to limits on the communication bandwidth, specialist modules must compete for access. We show that capacity limitations have a rational basis in that (1) they encourage specialization and compositionality and (2) they facilitate the synchronization of otherwise independent specialists.
https://weibo.com/1402400261/K5b0OoXk9

2、[LG] Kernel Interpolation for Scalable Online Gaussian Processes
S Stanton, W J. Maddox, I Delbridge, A G Wilson
[New York University & Cornell University]
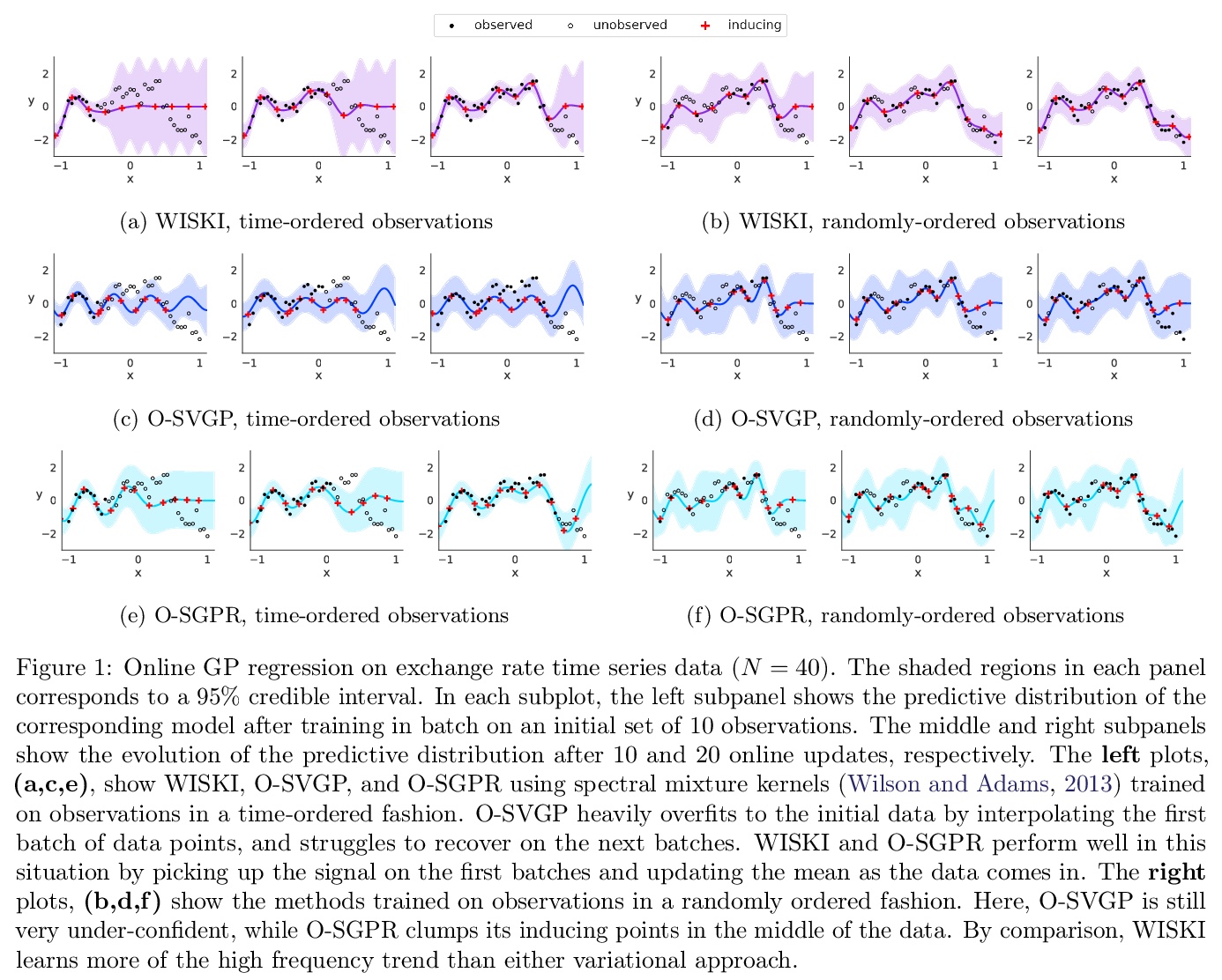
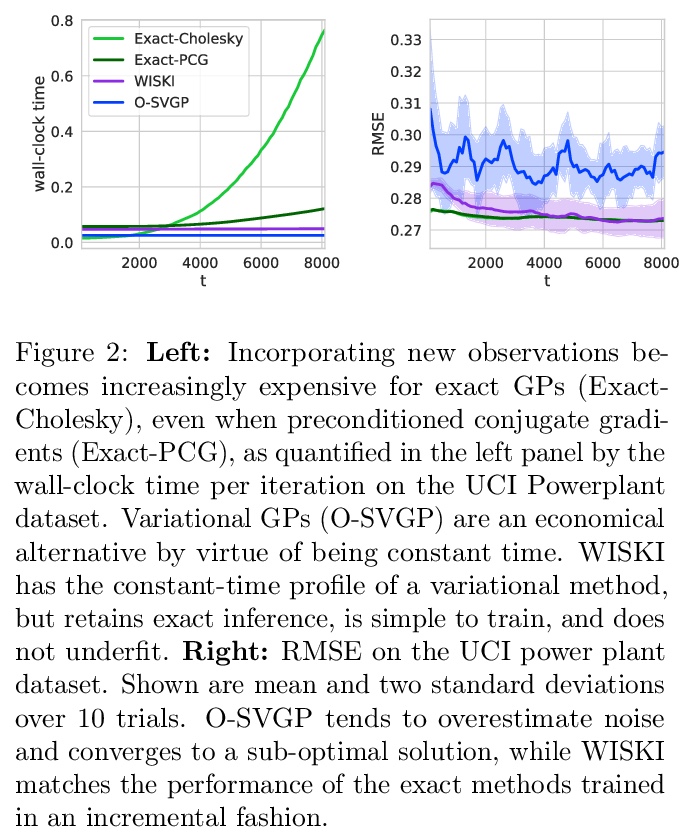
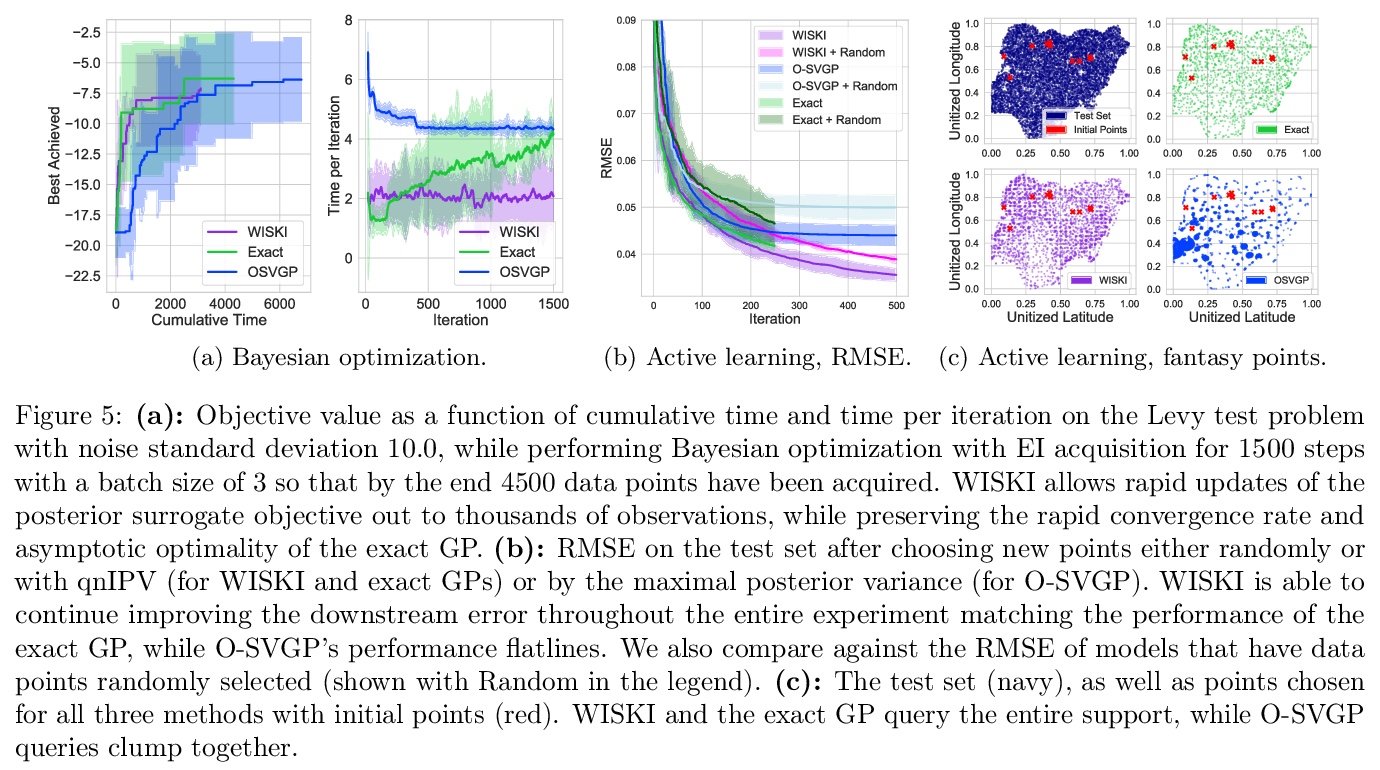
核插值可扩展在线高斯过程。高斯过程(GP)为在线环境下的性能提供了黄金标准,如样本高效控制和黑盒优化,在这种情况下,需要在连续获取数据时更新后验分布。然而,在精确的环境中,观察n个点后,更新GP后验以拟合哪怕一个新的观察结果,都会引起至少O(n)次计算。论文展示了如何使用结构化核插值来高效回收计算,以实现相对于点数n的恒定时间O(1)在线更新,同时保留精确推理。通过所提出的WISKI方法,实现了与精确核高斯过程相当的性能,以及与最先进的基于变分的流式高斯过程相当的速度。
Gaussian processes (GPs) provide a gold standard for performance in online settings, such as sample-efficient control and black box optimization, where we need to update a posterior distribution as we acquire data in a sequential fashion. However, updating a GP posterior to accommodate even a single new observation after having observed > n points incurs at least > O(n) computations in the exact setting. We show how to use structured kernel interpolation to efficiently recycle computations for constant-time > O(1) online updates with respect to the number of points > n, while retaining exact inference. We demonstrate the promise of our approach in a range of online regression and classification settings, Bayesian optimization, and active sampling to reduce error in malaria incidence forecasting. Code is available at > this https URL.
https://weibo.com/1402400261/K5b5puA39
3、[LG] Loss Surface Simplexes for Mode Connecting Volumes and Fast Ensembling
G W. Benton, W J. Maddox, S Lotfi, A G Wilson
[New York University]
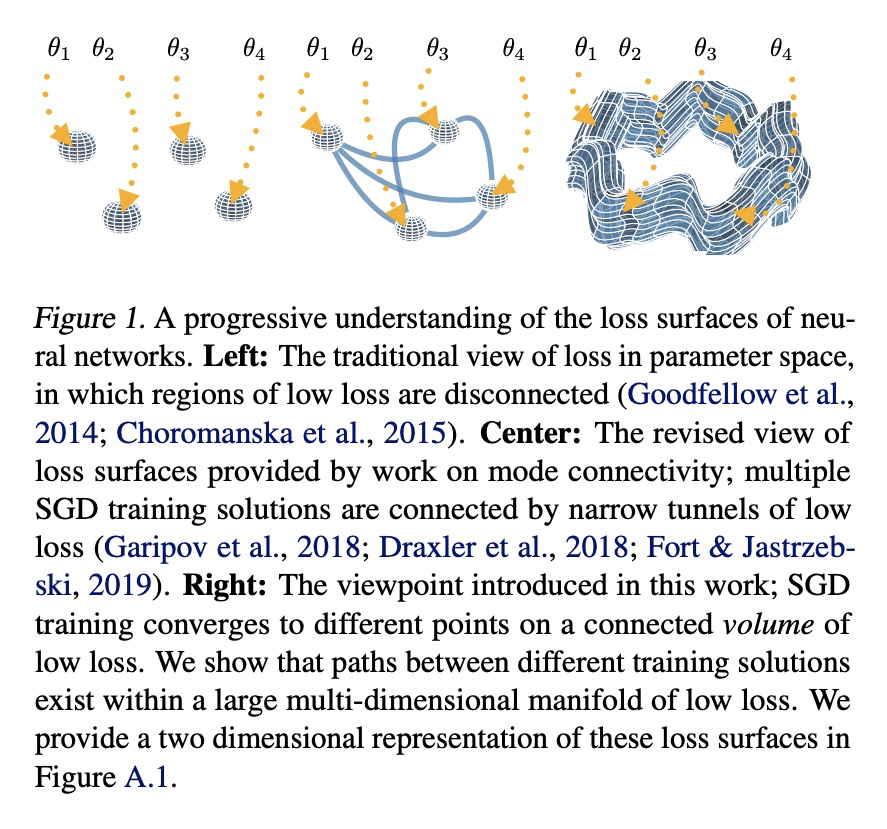
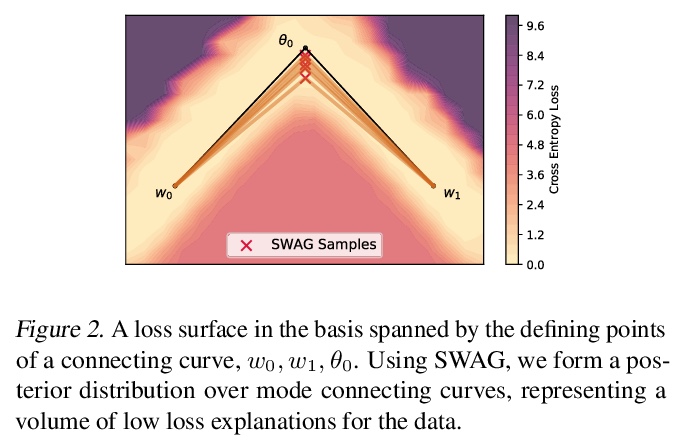
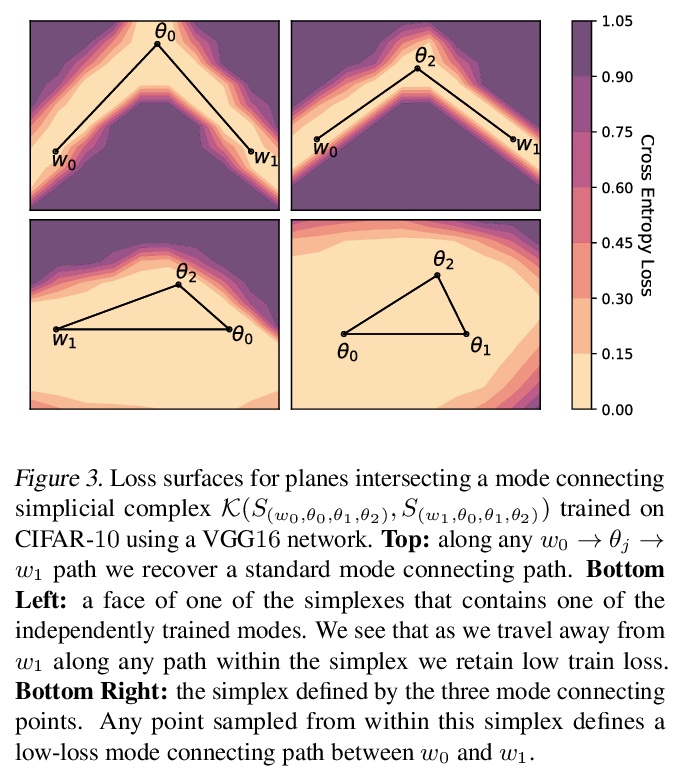
面向模式连接体和快速集成的损失面复合。深度神经网络的损失景观,包含了大量的低损失解的多维复合,提出一种简单方法SPRO,来发现这些复合。展示了如何利用这种几何发现来开发高度实用的集成方法,这种方法通过从复合中抽取不同的低损失解来工作。该方法改进了最先进的方法,包括深度集成和MultiSWAG,在精度和鲁棒性方面都有提高。该方法对深度学习损失景观如何结构化提供了一种新的理解:不是孤立的模式,或是由薄隧道连接的引力盆地,而是存在连接方案的大量多维流形。
With a better understanding of the loss surfaces for multilayer networks, we can build more robust and accurate training procedures. Recently it was discovered that independently trained SGD solutions can be connected along one-dimensional paths of near-constant training loss. In this paper, we show that there are mode-connecting simplicial complexes that form multi-dimensional manifolds of low loss, connecting many independently trained models. Inspired by this discovery, we show how to efficiently build simplicial complexes for fast ensembling, outperforming independently trained deep ensembles in accuracy, calibration, and robustness to dataset shift. Notably, our approach only requires a few training epochs to discover a low-loss simplex, starting from a pre-trained solution. Code is available at > this https URL.
https://weibo.com/1402400261/K5bbsg9AE

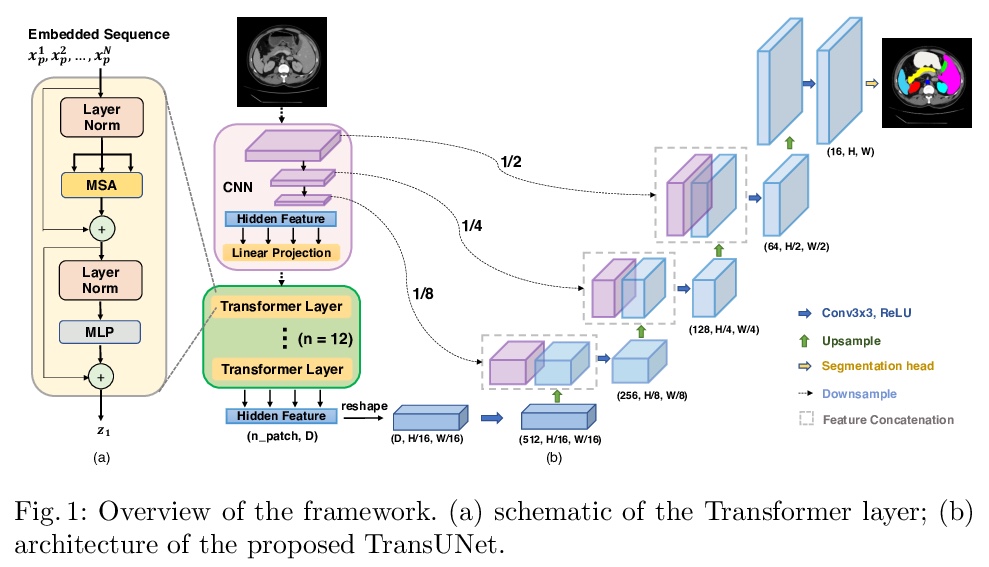
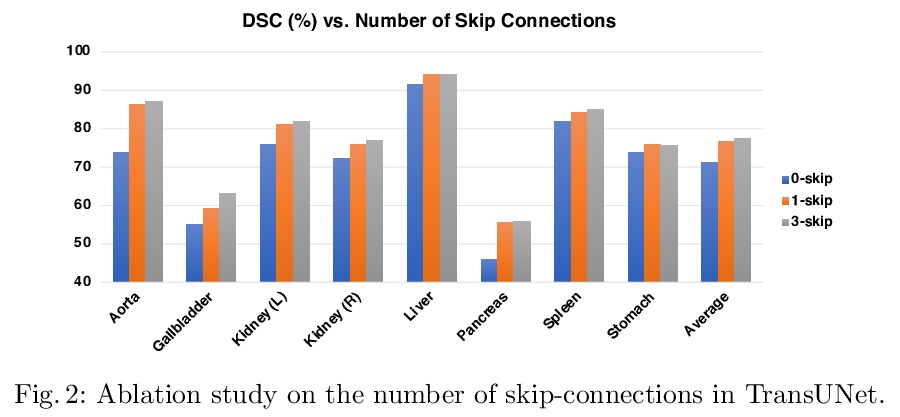
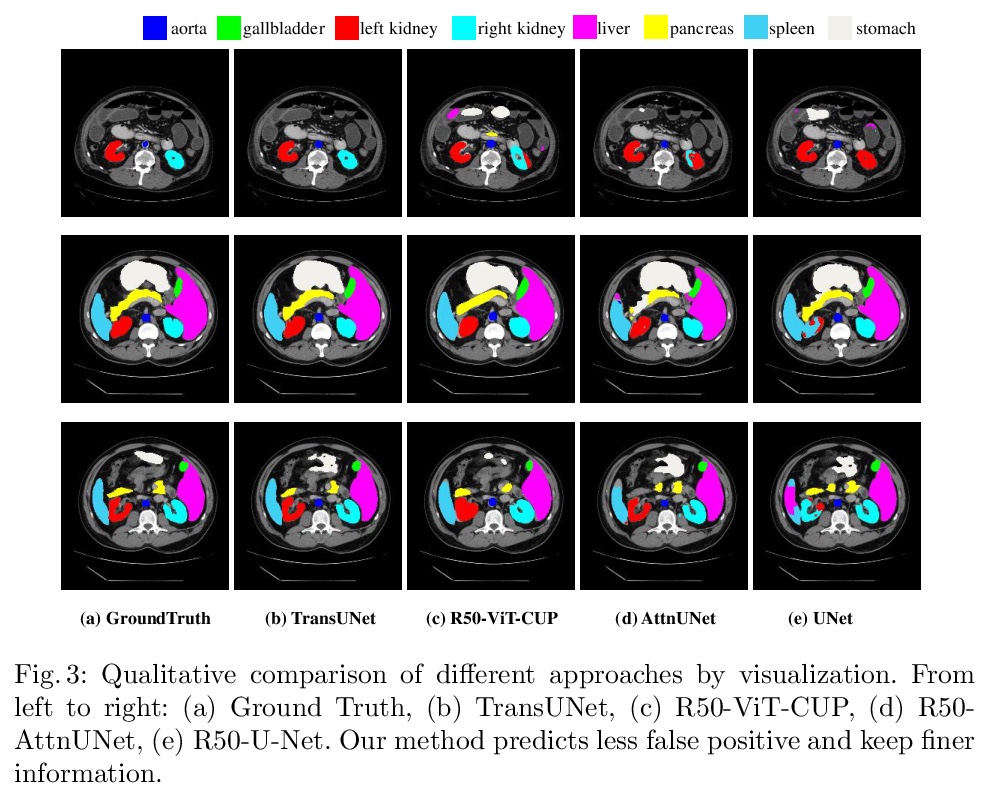
4、[CV] TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
J Chen, Y Lu, Q Yu, X Luo, E Adeli, Y Wang, L Lu, A L. Yuille, Y Zhou
[Johns Hopkins University & University of Electronic Science and Technology of China & Stanford University & East China Normal University & PAII Inc]
TransUNet: 基于Transformer的医学图像分割编码器。提出TransUNet,兼有Transformer和U-Net的优点,是医学图像分割的有力替代方案。一方面,Transformer将卷积神经网络(CNN)特征图中的标记化图像块进行编码,作为提取全局上下文的输入序列。另一方面,解码器对编码后的特征进行上采样,与高分辨率的CNN特征图相结合,以实现精确定位。TransUNet不仅通过将图像特征作为序列来编码强全局上下文,还通过u型混合架构设计很好地利用了低级CNN特征。作为主流的基于FCN的医学图像分割方法的替代框架,TransUNet实现了优于各种竞争方法的性能,包括基于CNN的自关注方法,在不同的医疗应用上实现了优于各种竞争方法的性能,包括多器官分割和心脏分割。
Medical image segmentation is an essential prerequisite for developing healthcare systems, especially for disease diagnosis and treatment planning. On various medical image segmentation tasks, the u-shaped architecture, also known as U-Net, has become the de-facto standard and achieved tremendous success. However, due to the intrinsic locality of convolution operations, U-Net generally demonstrates limitations in explicitly modeling long-range dependency. Transformers, designed for sequence-to-sequence prediction, have emerged as alternative architectures with innate global self-attention mechanisms, but can result in limited localization abilities due to insufficient low-level details. In this paper, we propose TransUNet, which merits both Transformers and U-Net, as a strong alternative for medical image segmentation. On one hand, the Transformer encodes tokenized image patches from a convolution neural network (CNN) feature map as the input sequence for extracting global contexts. On the other hand, the decoder upsamples the encoded features which are then combined with the high-resolution CNN feature maps to enable precise localization.We argue that Transformers can serve as strong encoders for medical image segmentation tasks, with the combination of U-Net to enhance finer details by recovering localized spatial information. TransUNet achieves superior performances to various competing methods on different medical applications including multi-organ segmentation and cardiac segmentation. Code and models are available at > this https URL.
https://weibo.com/1402400261/K5bj23Yc8
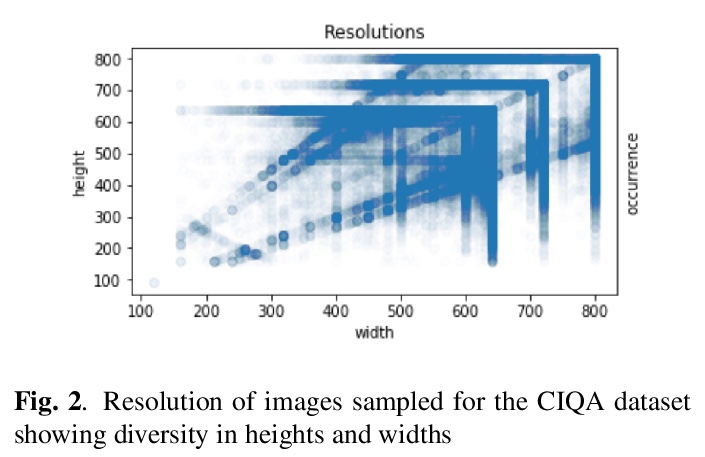
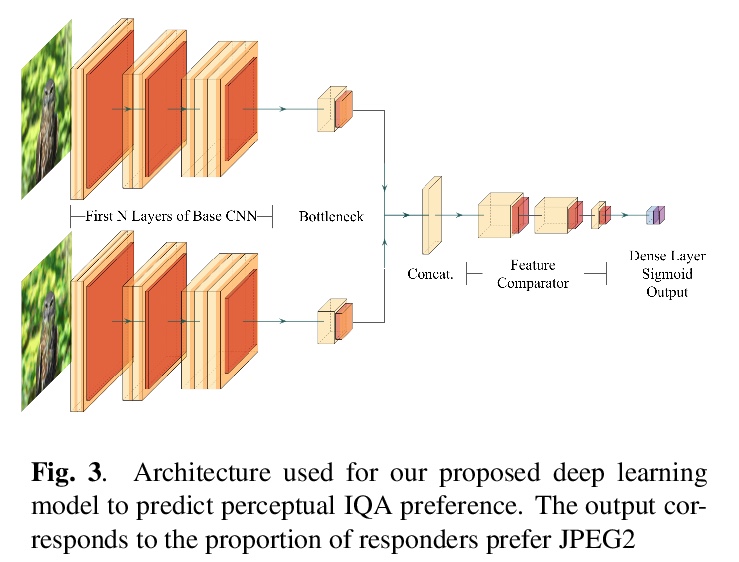
5、[CV] Deep Perceptual Image Quality Assessment for Compression
J C Mier, E Huang, H Talebi, F Yang, P Milanfar
[Google Research]
深度感知压缩图像质量评价。提出了迄今为止最大的、具有人类感知偏好的图像压缩质量数据集,使得深度学习的使用成为可能,开发了一种用于有损图像压缩的全参考感知质量评价指标,其性能优于现有最先进方法。所提出的模型可有效地从新数据集数千个样本中学习,可以更好地泛化到其他未见的人类感知偏好数据集。
Lossy Image compression is necessary for efficient storage and transfer of data. Typically the trade-off between bit-rate and quality determines the optimal compression level. This makes the image quality metric an integral part of any imaging system. While the existing full-reference metrics such as PSNR and SSIM may be less sensitive to perceptual quality, the recently introduced learning methods may fail to generalize to unseen data. In this paper we propose the largest image compression quality dataset to date with human perceptual preferences, enabling the use of deep learning, and we develop a full reference perceptual quality assessment metric for lossy image compression that outperforms the existing state-of-the-art methods. We show that the proposed model can effectively learn from thousands of examples available in the new dataset, and consequently it generalizes better to other unseen datasets of human perceptual preference.
https://weibo.com/1402400261/K5bnAAtzR

另外几篇值得关注的论文:
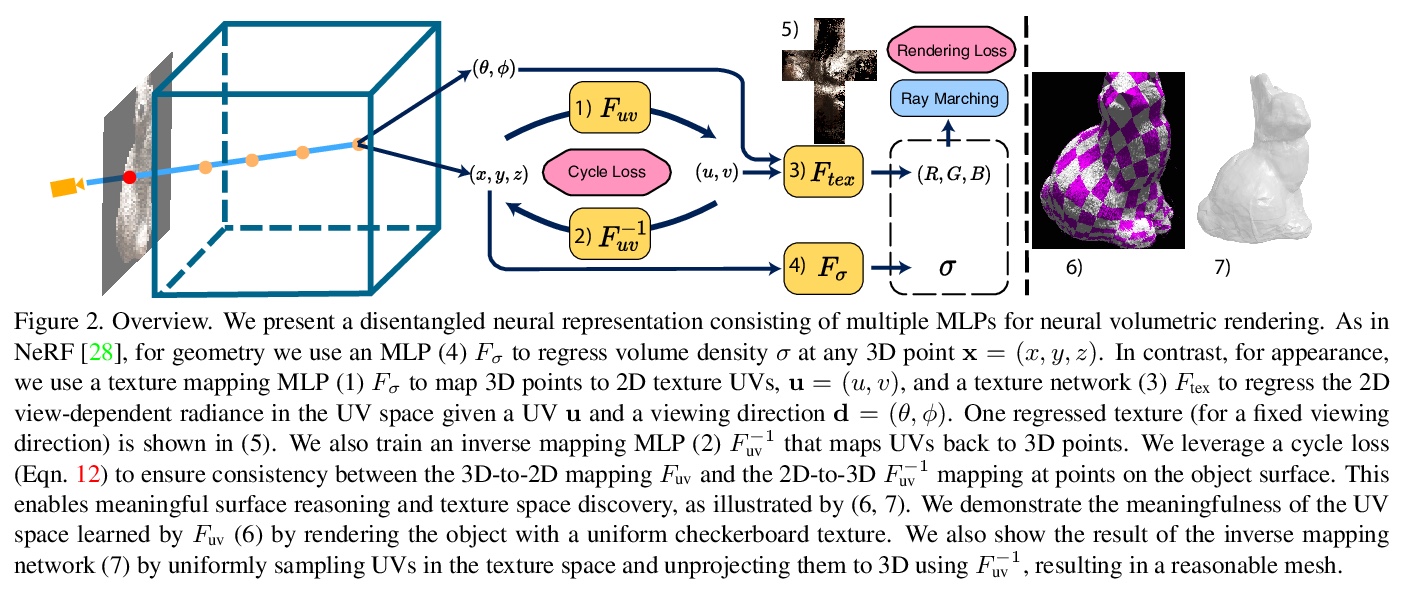
[CV] NeuTex: Neural Texture Mapping for Volumetric Neural Rendering
NeuTex:体神经渲染神经纹理映射
F Xiang, Z Xu, M Hašan, Y Hold-Geoffroy, K Sunkavalli, H Su
[University of California, San Diego & Adobe Research]
https://weibo.com/1402400261/K5bpIkDCX


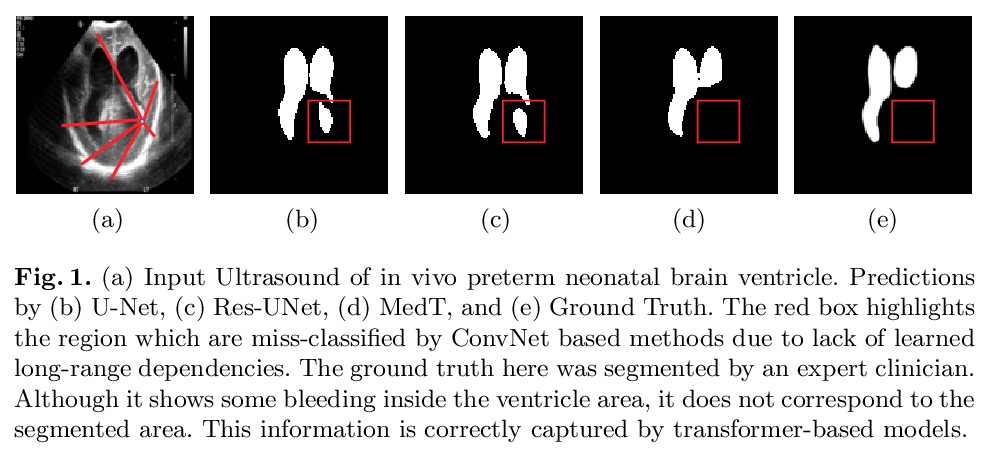
[CV] Medical Transformer: Gated Axial-Attention for Medical Image Segmentation
医用Transformer:用于医学图像分割的门控轴向注意力
J M J Valanarasu, P Oza, I Hacihaliloglu, V M. Patel
[Johns Hopkins University & The State University of New Jersey]
https://weibo.com/1402400261/K5bqTzeBc


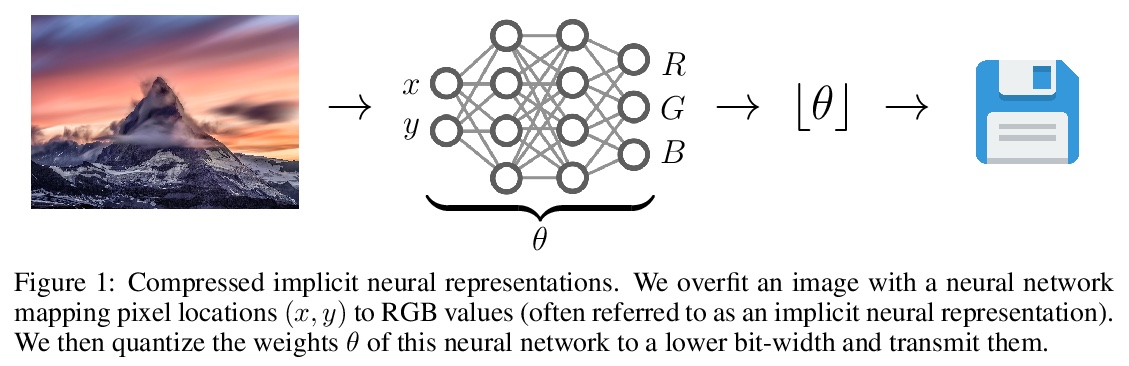
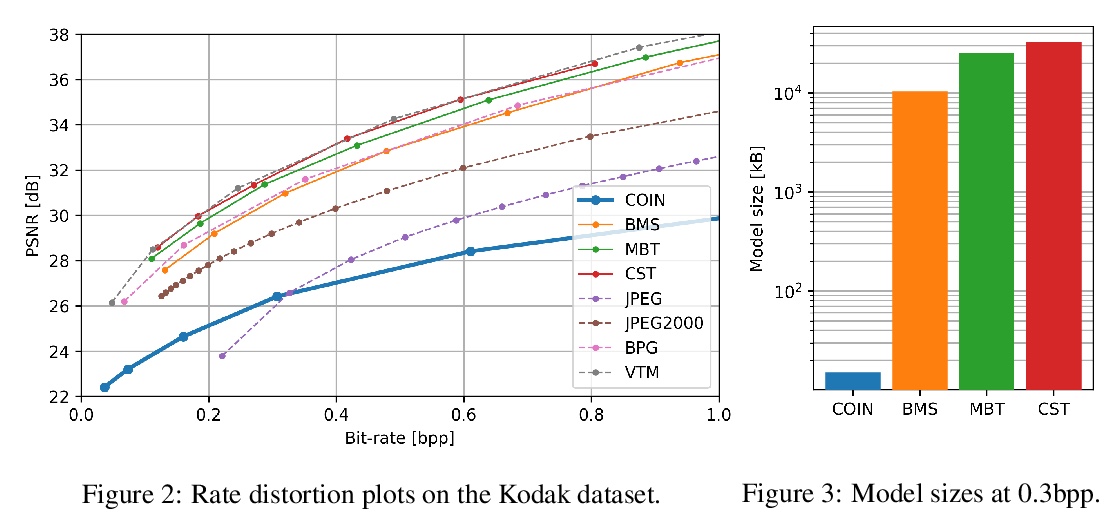
[CV] COIN: COmpression with Implicit Neural representations
COIN:隐神经表示压缩
E Dupont, A Goliński, M Alizadeh, Y W Teh, A Doucet
[University of Oxford]
https://weibo.com/1402400261/K5bsrpdlQ
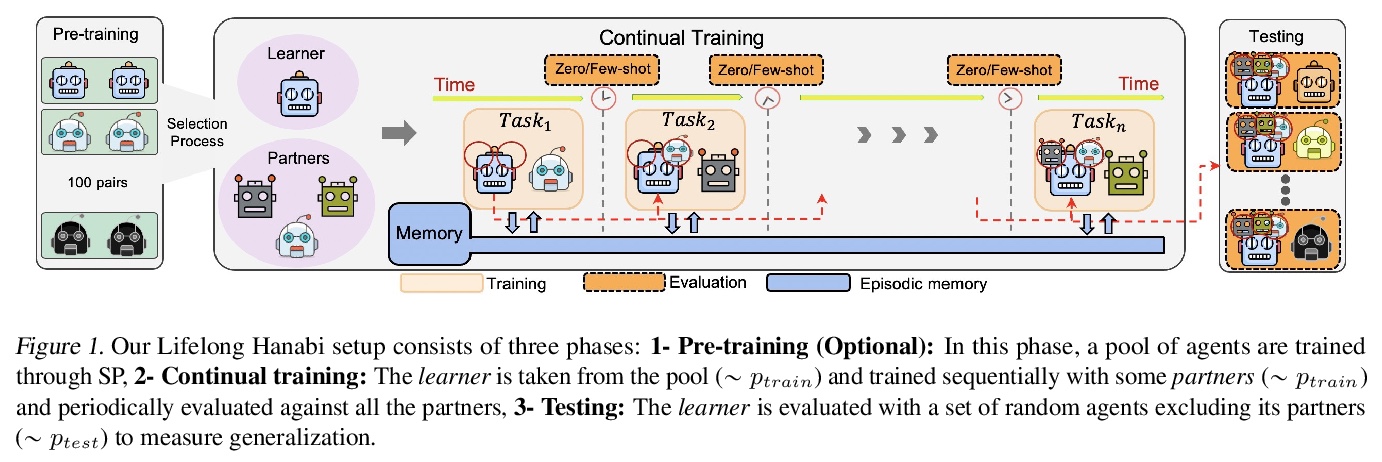
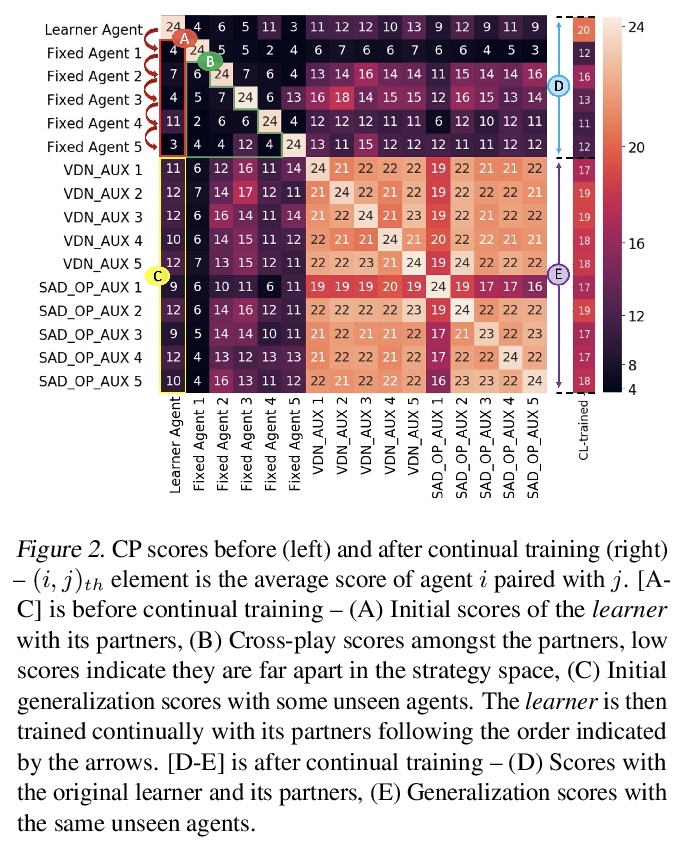
[LG] Continuous Coordination As a Realistic Scenario for Lifelong Learning
作为终身学习现实场景的持续协调
H Nekoei, A Badrinaaraayanan, A Courville, S Chandar
[Mila]
https://weibo.com/1402400261/K5btUFiJB

若有收获,就点个赞吧
0 人点赞
