- 1、[LG] Combinatorial optimization and reasoning with graph neural networks
- 2、[CV] Unbiased Teacher for Semi-Supervised Object Detection
- 3、[CV] Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts
- 4、[CV] Clockwork Variational Autoencoders for Video Prediction
- 5、[CL] Going Full-TILT Boogie on Document Understanding with Text-Image-Layout Transformer
- [LG] Quantum field-theoretic machine learning
- [LG] State Entropy Maximization with Random Encoders for Efficient Exploration
- [CL] Quiz-Style Question Generation for News Stories
- [LG] Bridging the Gap Between Adversarial Robustness and Optimization Bias
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
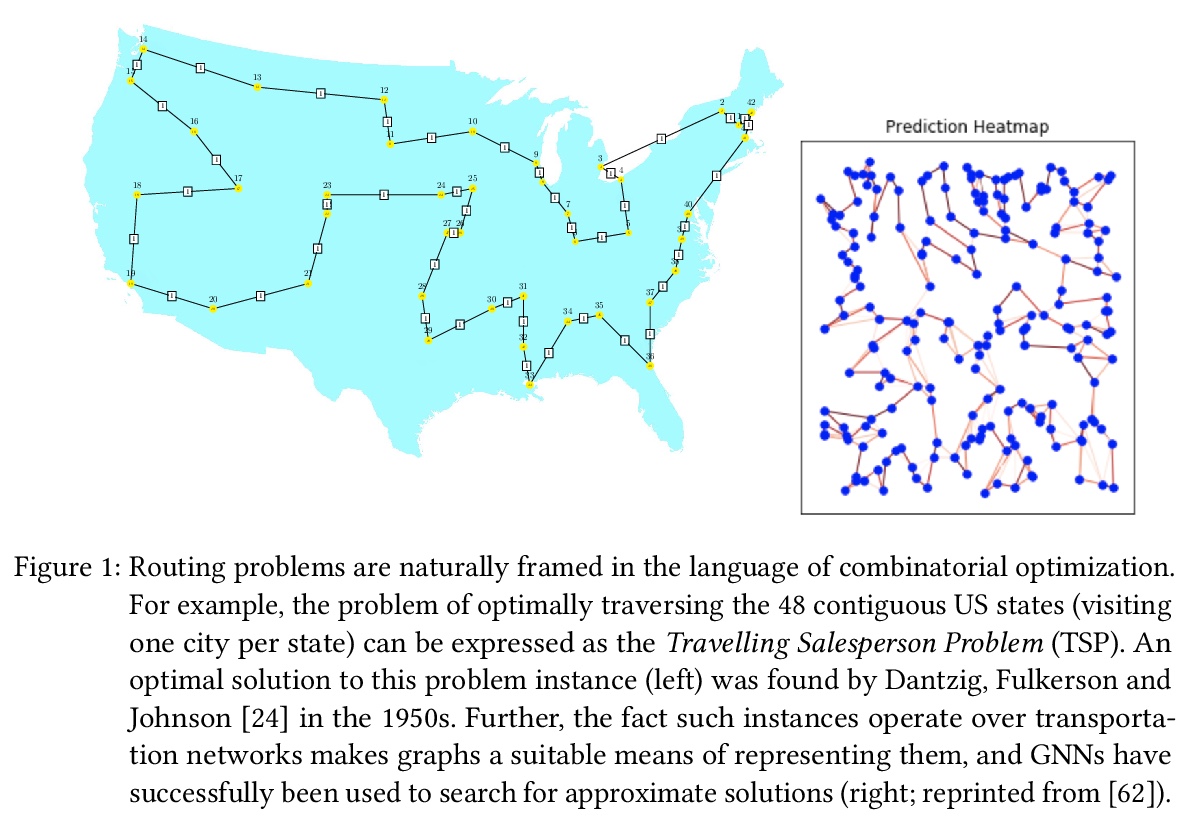
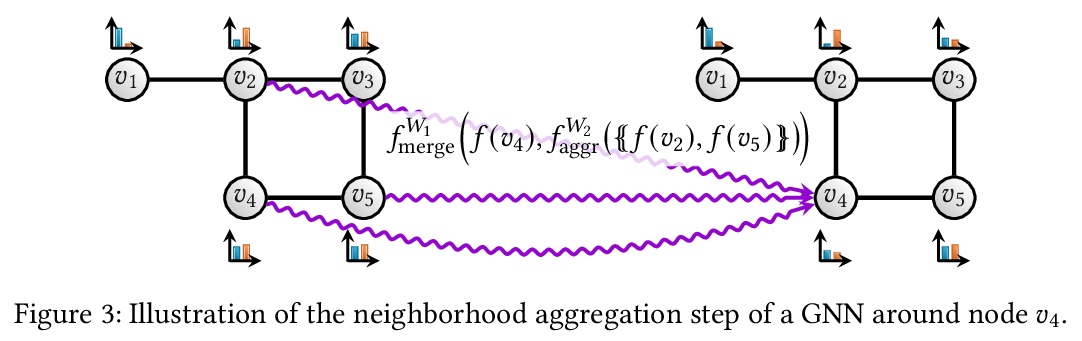
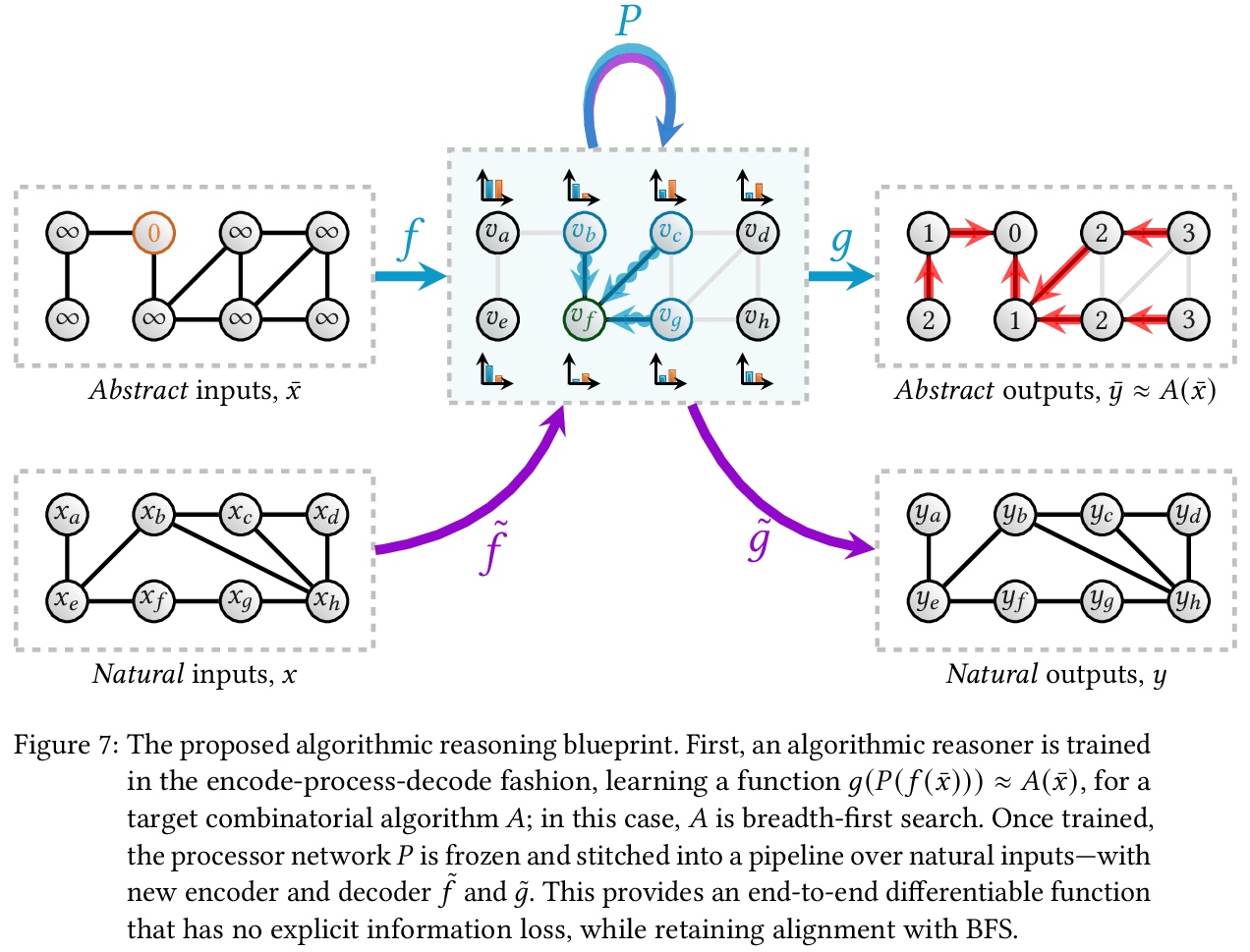
1、[LG] Combinatorial optimization and reasoning with graph neural networks
Q Cappart, D Chételat, E Khalil, A Lodi, C Morris, P Veličković
[Polytechnique Montréal & University of Toronto & DeepMind]
图神经网络组合优化与推理综述。对图神经网络最近在组合优化方面的应用进行综述。对组合优化、各种机器学习方法和图神经网络做了简要介绍,调研了旨在借助图神经网络寻找启发式或最优解的基本方法,探讨了最近的双重方法,即那些试图证明给定解是最优解的方法。还对算法推理进行了综述,即旨在克服经典算法局限性的数据驱动方法。讨论了有关图神经网络应用于组合优化的缺点和研究方向,指出了一系列关键挑战,以进一步刺激未来的研究,并推动新兴领域的发展。
Combinatorial optimization is a well-established area in operations research and computer science. Until recently, its methods have focused on solving problem instances in isolation, ignoring the fact that they often stem from related data distributions in practice. However, recent years have seen a surge of interest in using machine learning, especially graph neural networks (GNNs), as a key building block for combinatorial tasks, either as solvers or as helper functions. GNNs are an inductive bias that effectively encodes combinatorial and relational input due to their permutation-invariance and sparsity awareness. This paper presents a conceptual review of recent key advancements in this emerging field, aiming at both the optimization and machine learning researcher.
https://weibo.com/1402400261/K2KB95sbQ

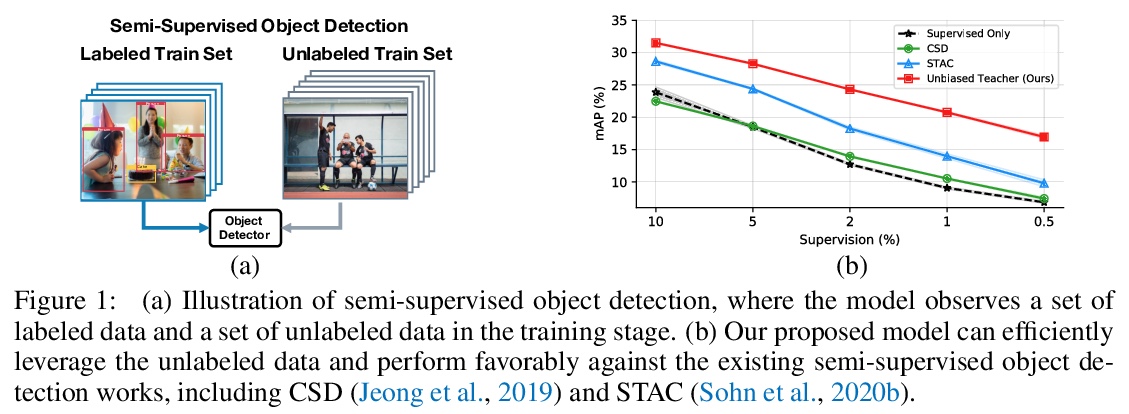
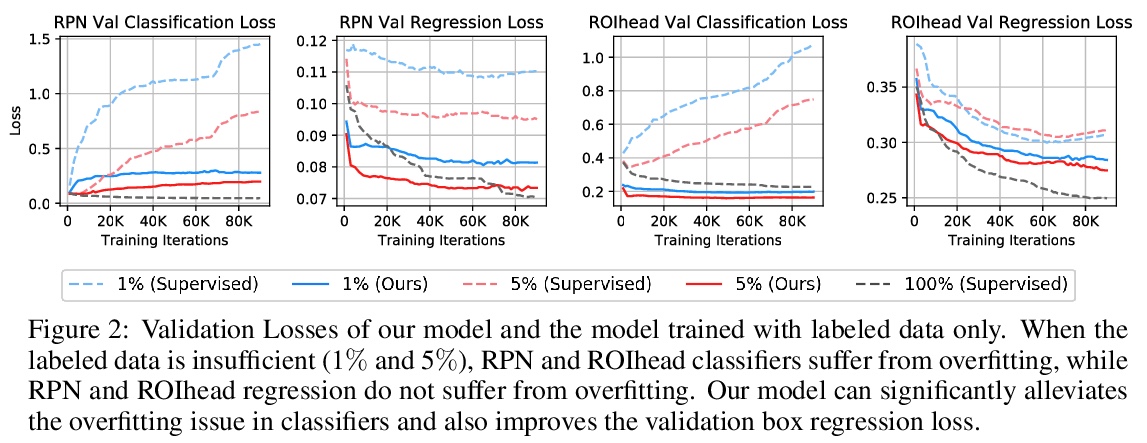
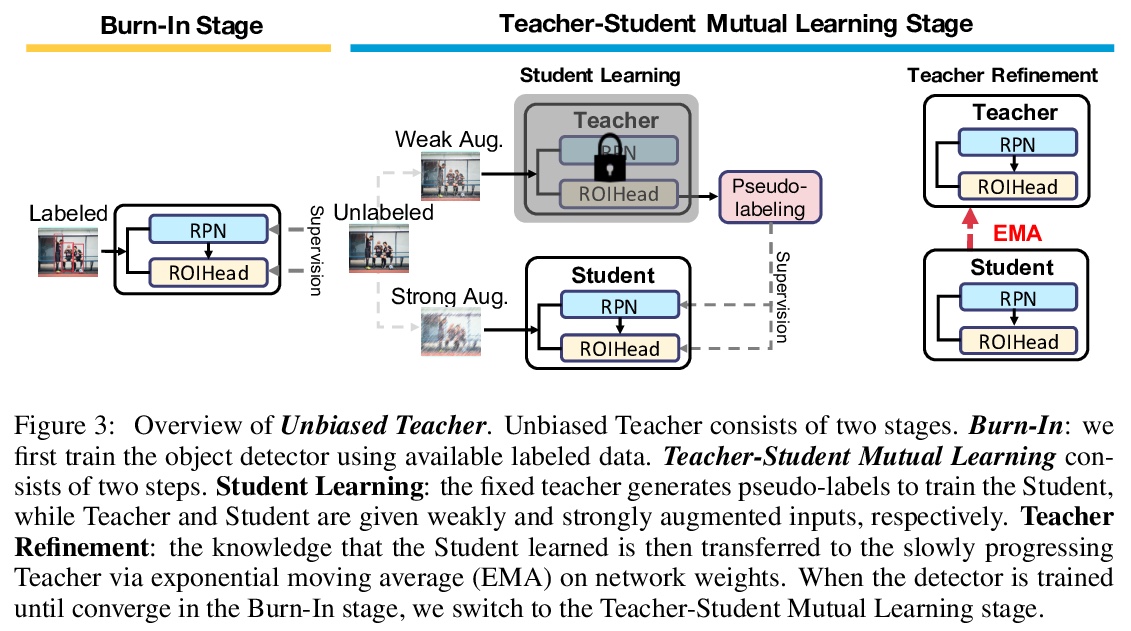
2、[CV] Unbiased Teacher for Semi-Supervised Object Detection
Y Liu, C Ma, Z He, C Kuo, K Chen, P Zhang, B Wu, Z Kira, P Vajda
[Georgia Tech & Facebook]
基于无偏教师的半监督目标检测。重新审视了半监督目标检测任务,通过分析低标签场景下的目标检测器,发现并解决了两个主要问题:过拟合和类间不平衡,提出了无偏教师(Unbiased Teacher),一个由教师和学生组成的统一框架,共同学习,互相提高,以解决由于真值标记存在的类间不平衡所导致的伪标签偏差问题,以及由于标记数据的稀缺性所导致的过拟合问题。在COCO-standard、COCO-additional和VOC数据集的半监督目标检测实现了最先进的性能。
Semi-supervised learning, i.e., training networks with both labeled and unlabeled data, has made significant progress recently. However, existing works have primarily focused on image classification tasks and neglected object detection which requires more annotation effort. In this work, we revisit the Semi-Supervised Object Detection (SS-OD) and identify the pseudo-labeling bias issue in SS-OD. To address this, we introduce Unbiased Teacher, a simple yet effective approach that jointly trains a student and a gradually progressing teacher in a mutually-beneficial manner. Together with a class-balance loss to downweight overly confident pseudo-labels, Unbiased Teacher consistently improved state-of-the-art methods by significant margins on COCO-standard, COCO-additional, and VOC datasets. Specifically, Unbiased Teacher achieves 6.8 absolute mAP improvements against state-of-the-art method when using 1% of labeled data on MS-COCO, achieves around 10 mAP improvements against the supervised baseline when using only 0.5, 1, 2% of labeled data on MS-COCO.
https://weibo.com/1402400261/K2KGfvmF0
3、[CV] Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts
S Changpinyo, P Sharma, N Ding, R Soricut
[Google Research]
Conceptual 12M:推动网络规模图像-文本预训练以识别长尾视觉概念。通过放宽Conceptual Captions 3M (CC3M)的数据收集管道,在突破视觉和语言预训练数据的极限方面更进一步,引入Conceptual 12M (CC12M),一个包含1200万图像-文本对的数据集,比现有数据集涵盖了更广泛的概念,专门用于视觉-语言预训练。对该数据集进行了分析,并在多个下游任务上与CC3M进行了效果基准测试,重点是长尾视觉识别。定量和定性的结果清楚地说明了扩大视觉和语言任务的预训练数据的好处,以及在nocaps(新型目标描述)和Conceptual Captions(概念描述)基准上的最新结果。
The availability of large-scale image captioning and visual question answering datasets has contributed significantly to recent successes in vision-and-language pre-training. However, these datasets are often collected with overrestrictive requirements, inherited from their original target tasks (e.g., image caption generation), which limit the resulting dataset scale and diversity. We take a step further in pushing the limits of vision-and-language pre-training data by relaxing the data collection pipeline used in Conceptual Captions 3M (CC3M) [Sharma et al. 2018] and introduce the Conceptual 12M (CC12M), a dataset with 12 million image-text pairs specifically meant to be used for vision-and-language pre-training. We perform an analysis of this dataset, as well as benchmark its effectiveness against CC3M on multiple downstream tasks with an emphasis on long-tail visual recognition. The quantitative and qualitative results clearly illustrate the benefit of scaling up pre-training data for vision-and-language tasks, as indicated by the new state-of-the-art results on both the nocaps and Conceptual Captions benchmarks.
https://weibo.com/1402400261/K2KM13bBH


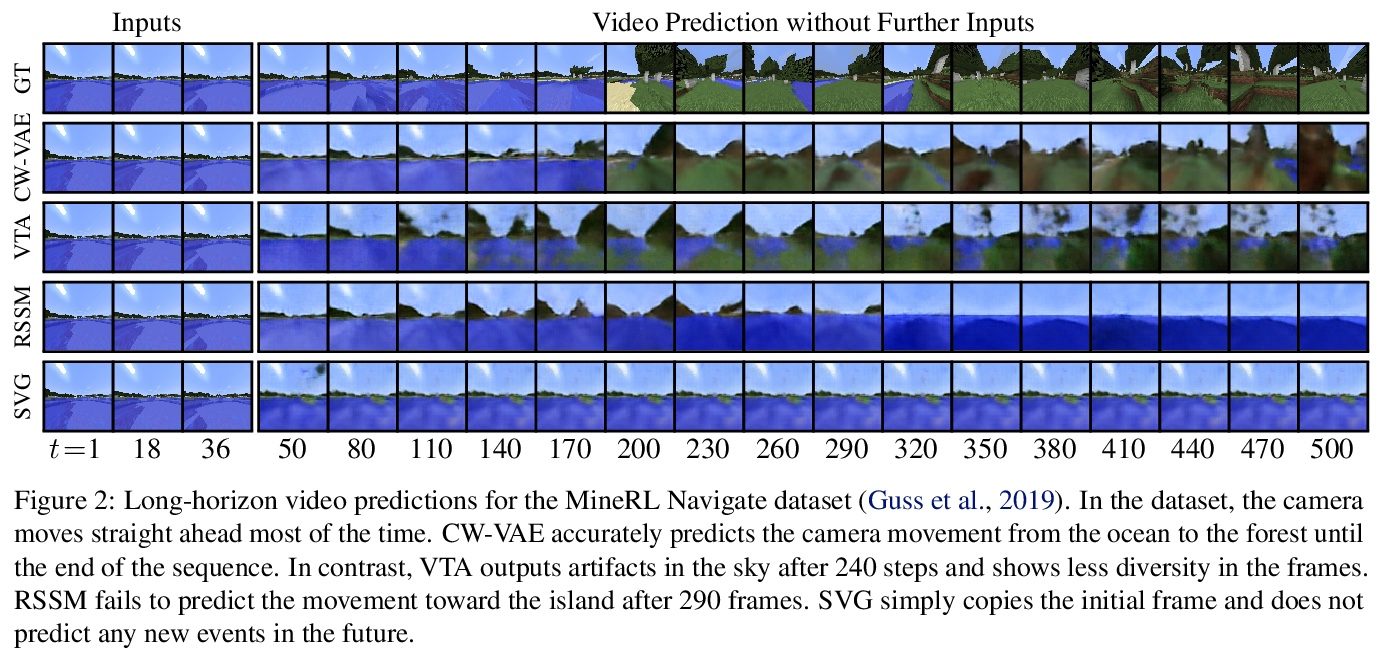
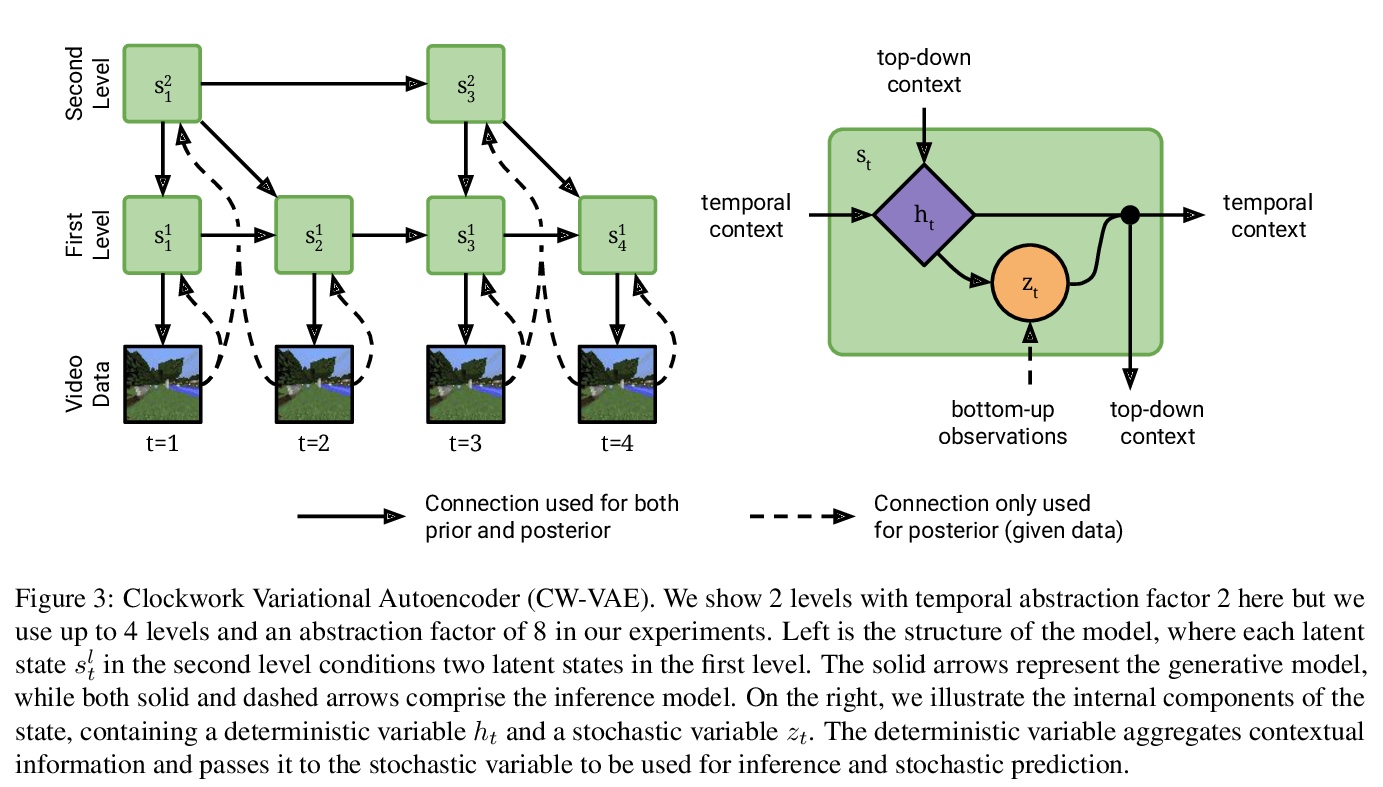
4、[CV] Clockwork Variational Autoencoders for Video Prediction
V Saxena, J Ba, D Hafner
[University of Toronto]
面向视频预测的Clockwork变分自编码器。引入了视频预测模型Clockwork VAE (CW-VAE),一个简单的分层视频预测模型,利用每层不同的时钟速度来学习视频中的长程依赖性。在4个不同的视频预测数据集上展示了分层潜抽象和时序抽象的优势,序列多达1000帧,其中CW-VAE的表现在多个指标上都优于SVG-LP、VTA和RSSM等强基线。还提出了一个用于长程视频预测的Minecraft Navigate数据集500帧视频预测挑战基准。证明了CW-VAE会自适应数据集帧率,较慢的级别可学习表示视频中变化较慢的对象,而较快的级别可学习表示更快的对象。
Deep learning has enabled algorithms to generate realistic images. However, accurately predicting long video sequences requires understanding long-term dependencies and remains an open challenge. While existing video prediction models succeed at generating sharp images, they tend to fail at accurately predicting far into the future. We introduce the Clockwork VAE (CW-VAE), a video prediction model that leverages a hierarchy of latent sequences, where higher levels tick at slower intervals. We demonstrate the benefits of both hierarchical latents and temporal abstraction on 4 diverse video prediction datasets with sequences of up to 1000 frames, where CW-VAE outperforms top video prediction models. Additionally, we propose a Minecraft benchmark for long-term video prediction. We conduct several experiments to gain insights into CW-VAE and confirm that slower levels learn to represent objects that change more slowly in the video, and faster levels learn to represent faster objects.
https://weibo.com/1402400261/K2KQq49qi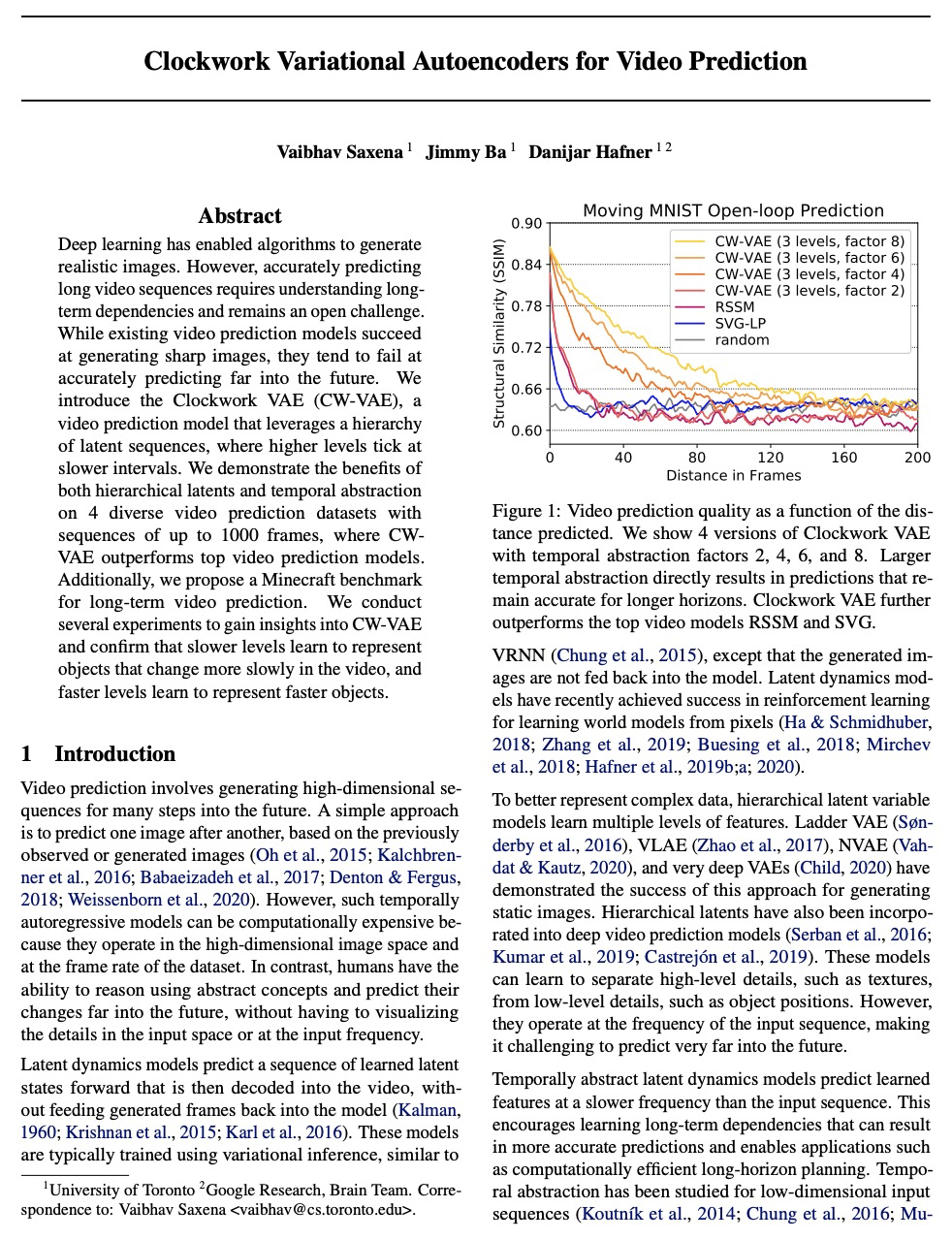

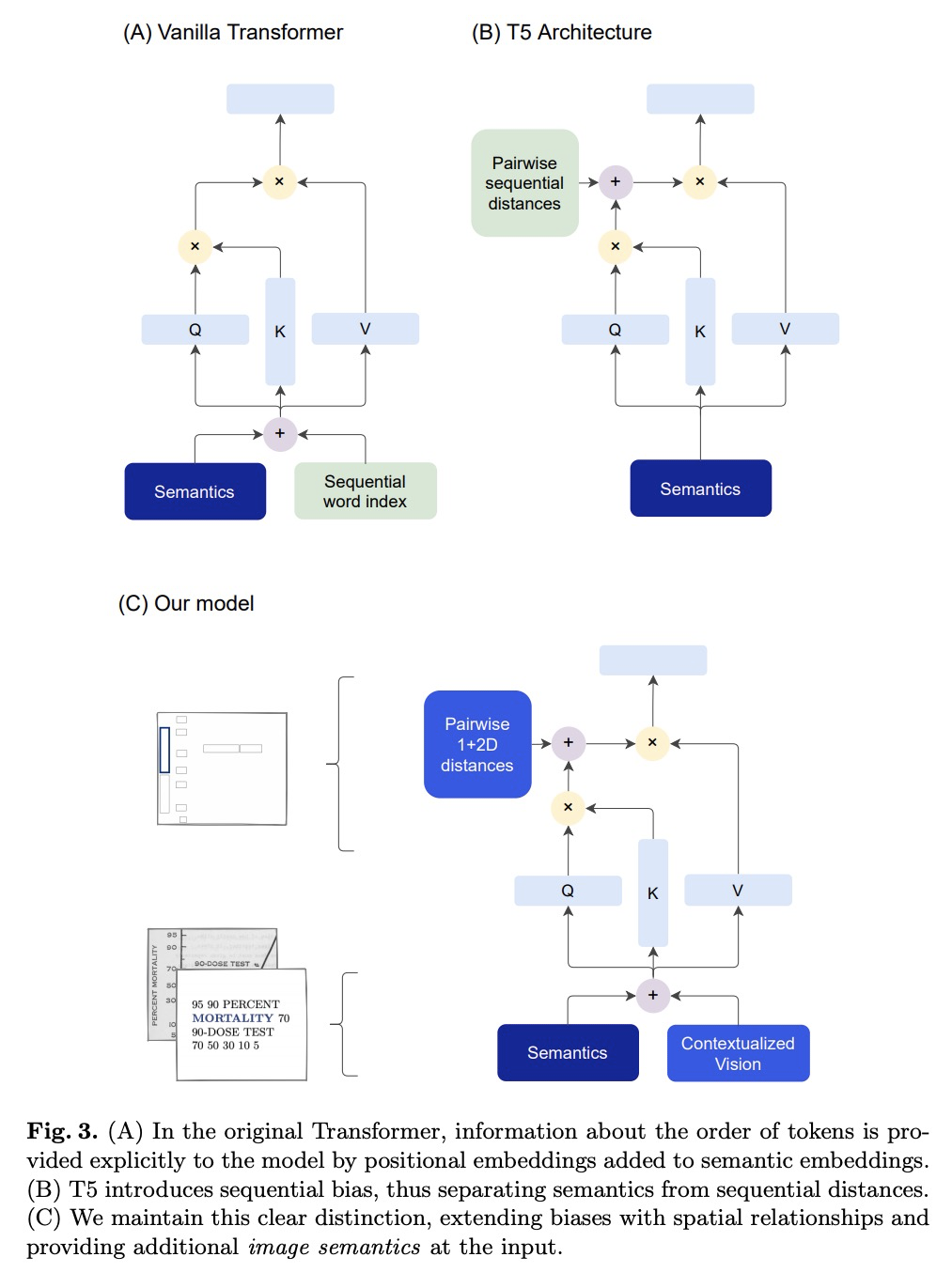
5、[CL] Going Full-TILT Boogie on Document Understanding with Text-Image-Layout Transformer
R Powalski, Ł Borchmann, D Jurkiewicz, T Dwojak, M Pietruszka, G Pałka
[Applica.ai]
基于文本-图像-布局Transformer的文档理解。通过引入同时学习布局信息、视觉特征和文本语义的TILT神经网络架构,来解决超越纯文本文档的自然语言理解这一挑战性问题。与以往的方法不同,依靠一个能够解决所有涉及自然语言问题的解码器。布局被表示为一个注意力偏差,并辅以上下文视觉信息,模型核心是一个预训练的编码器-解码器Transformer。在具有不同布局的真实文档上训练了网络,如表格、插图和表单,在从文档提取信息和回答问题方面达到了最先进的水平,在三个数据集(docVQA、CORD、WikiOps)上达到了最高性能,并在SROIE和RVL-CDIP上表现与之前的最佳成绩相当,不过工作流程要简单得多。Transformer模型空间和图像上的丰富性,使得TILT能结合来自文本、布局和图像模式的信息。所提出的正则化方法对于实现最先进的结果至关重要。
We address the challenging problem of Natural Language Comprehension beyond plain-text documents by introducing the TILT neural network architecture which simultaneously learns layout information, visual features, and textual semantics. Contrary to previous approaches, we rely on a decoder capable of solving all problems involving natural language. The layout is represented as an attention bias and complemented with contextualized visual information, while the core of our model is a pretrained encoder-decoder Transformer. We trained our network on real-world documents with different layouts, such as tables, figures, and forms. Our novel approach achieves state-of-the-art in extracting information from documents and answering questions, demanding layout understanding (DocVQA, CORD, WikiOps, SROIE). At the same time, we simplify the process by employing an end-to-end model.
https://weibo.com/1402400261/K2KXCw9L7

另外几篇值得关注的论文:
[LG] Quantum field-theoretic machine learning
量子场论机器学习
D Bachtis, G Aarts, B Lucini
[Swansea University]
https://weibo.com/1402400261/K2KVG4fg5
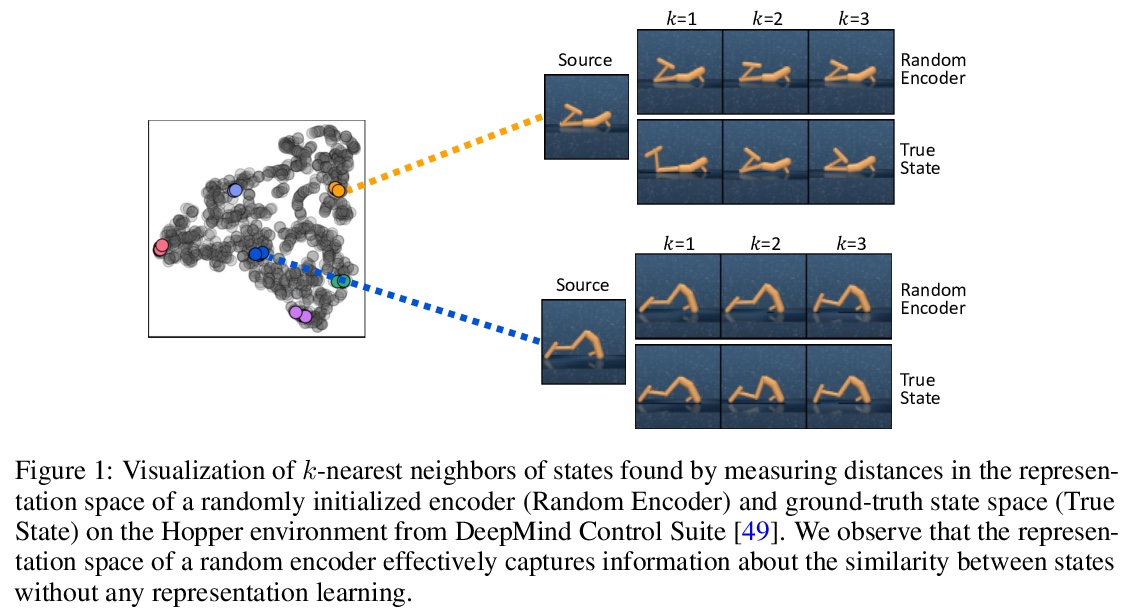
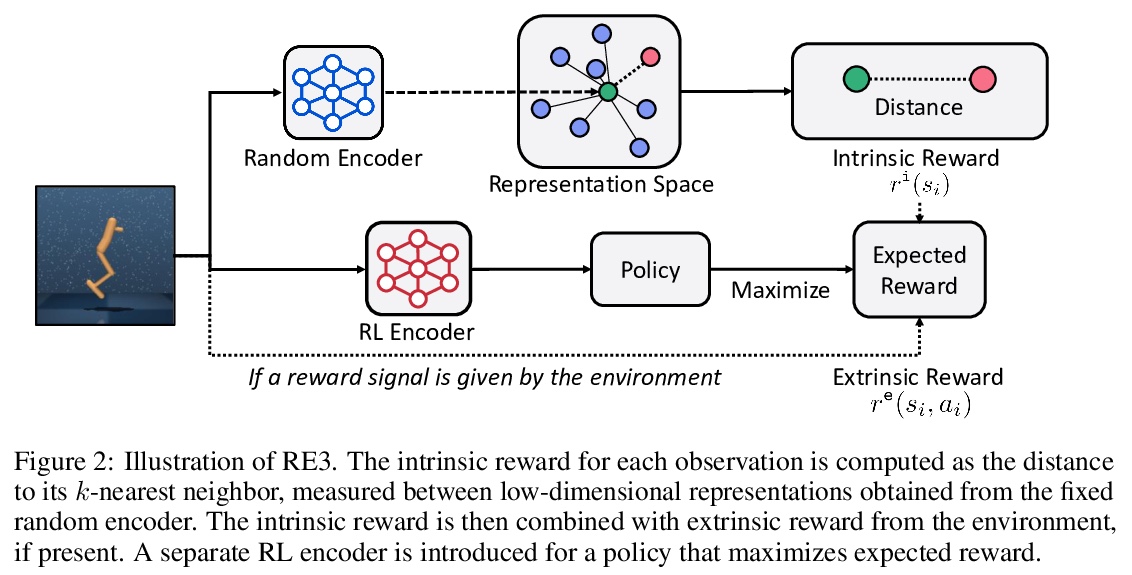
[LG] State Entropy Maximization with Random Encoders for Efficient Exploration
随机编码器状态熵最大化高效探索
Y Seo, L Chen, J Shin, H Lee, P Abbeel, K Lee
[Korea Advanced Institute of Science and Technology & UC Berkeley & University of Michigan]
https://weibo.com/1402400261/K2L4Fy6An
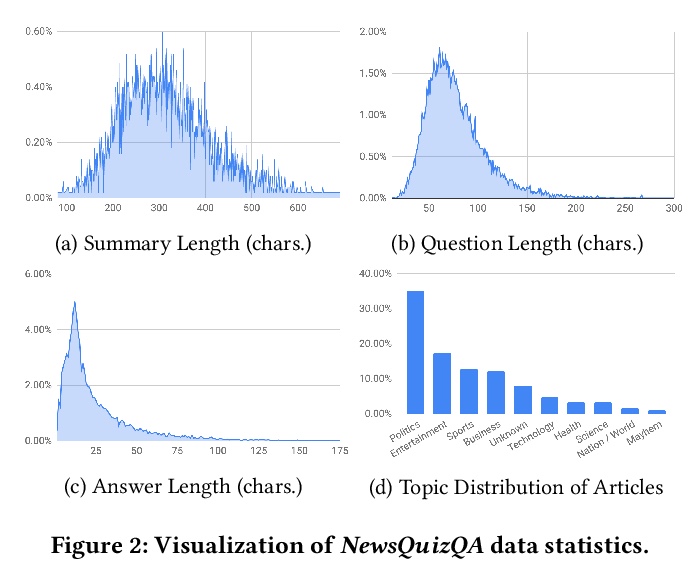
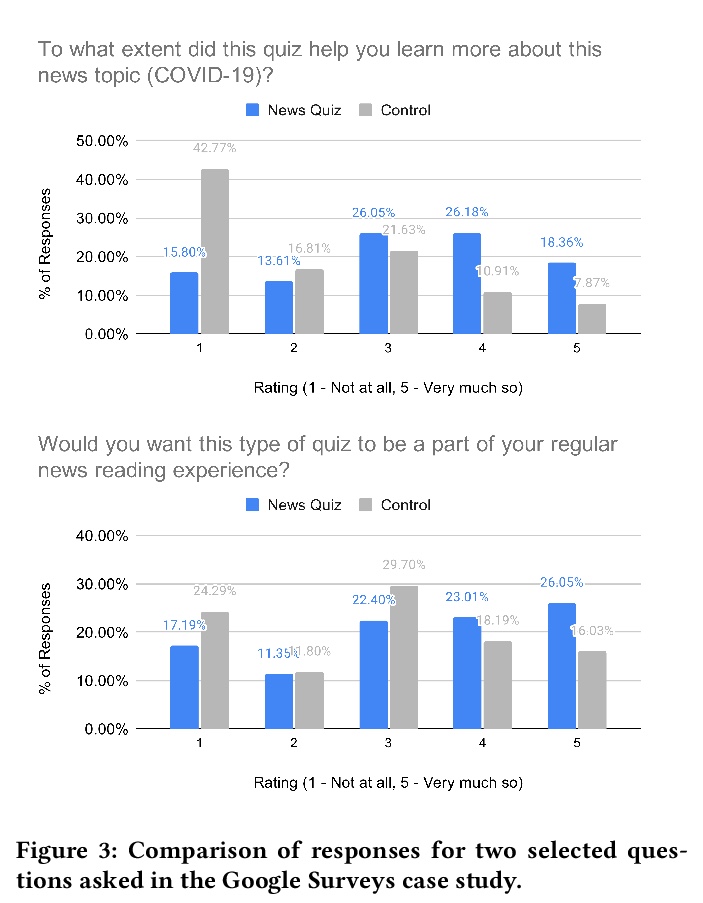
[CL] Quiz-Style Question Generation for News Stories
新闻故事的问答测验式问题生成
A D. Lelkes, V Q. Tran, C Yu
[Google Research]
https://weibo.com/1402400261/K2Lb7921c

[LG] Bridging the Gap Between Adversarial Robustness and Optimization Bias
对抗性鲁棒性与标准泛化优化偏差
F Faghri, C Vasconcelos, D J. Fleet, F Pedregosa, N L Roux
[University of Toronto & Google Research]
https://weibo.com/1402400261/K2LgRbYk0



若有收获,就点个赞吧
0 人点赞
