- 1、[LG] What Are Bayesian Neural Network Posteriors Really Like?
- 2、[CV] Emerging Properties in Self-Supervised Vision Transformers
- 3、[CV] With a Little Help from My Friends: Nearest-Neighbor Contrastive Learning of Visual Representations
- 4、[CV] MarioNette: Self-Supervised Sprite Learning
- 5、[CV] LightTrack: Finding Lightweight Neural Networks for Object Tracking via One-Shot Architecture Search
- [CL] Dynabench: Rethinking Benchmarking in NLP
- [CV] A Large-Scale Study on Unsupervised Spatiotemporal Representation Learning
- [CV] Ensembling with Deep Generative Views
- [CL] Experts, Errors, and Context: A Large-Scale Study of Human Evaluation for Machine Translation
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] What Are Bayesian Neural Network Posteriors Really Like?
P Izmailov, S Vikram, M D. Hoffman, A G Wilson
[New York University & Google Research]
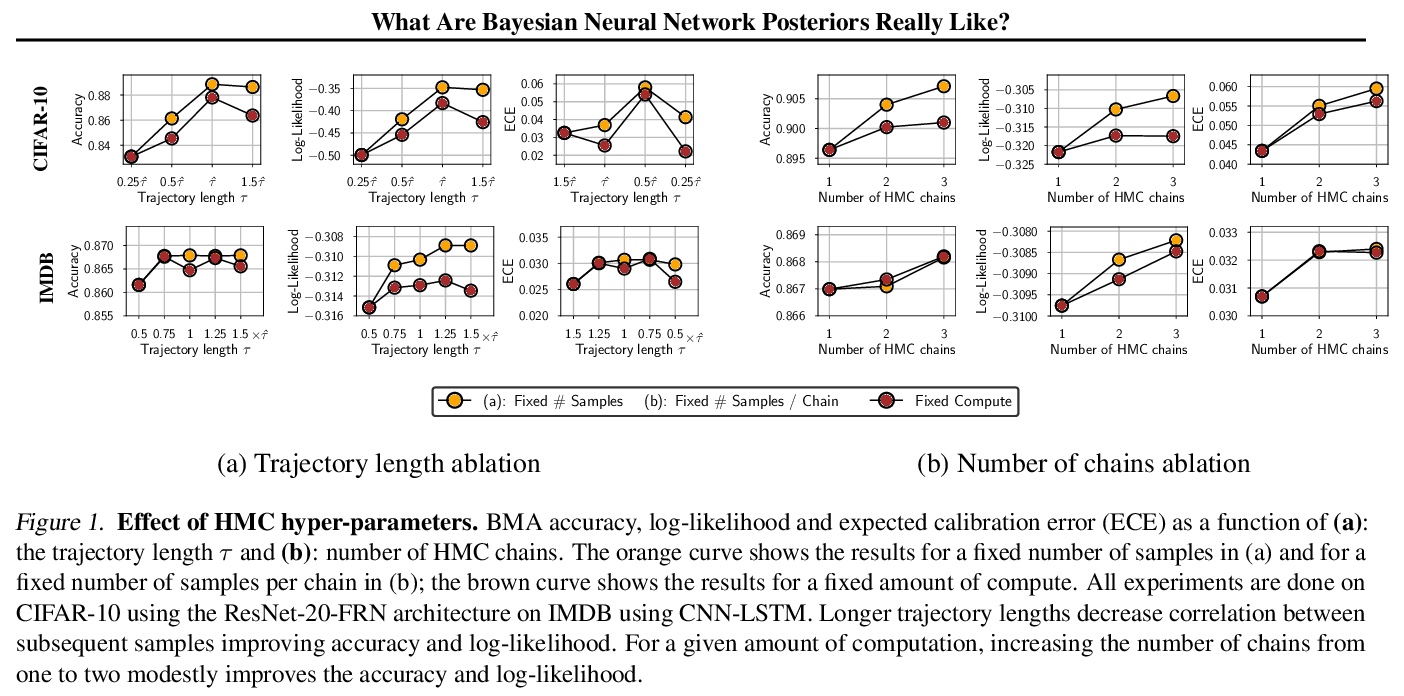
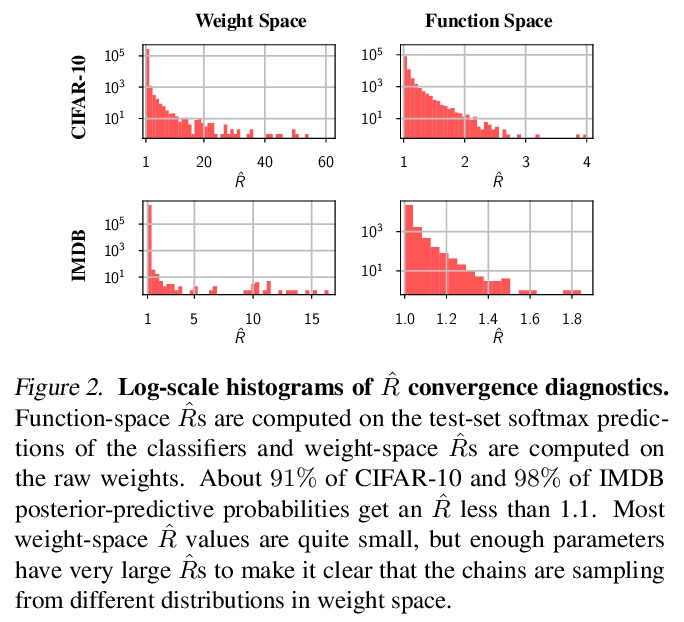
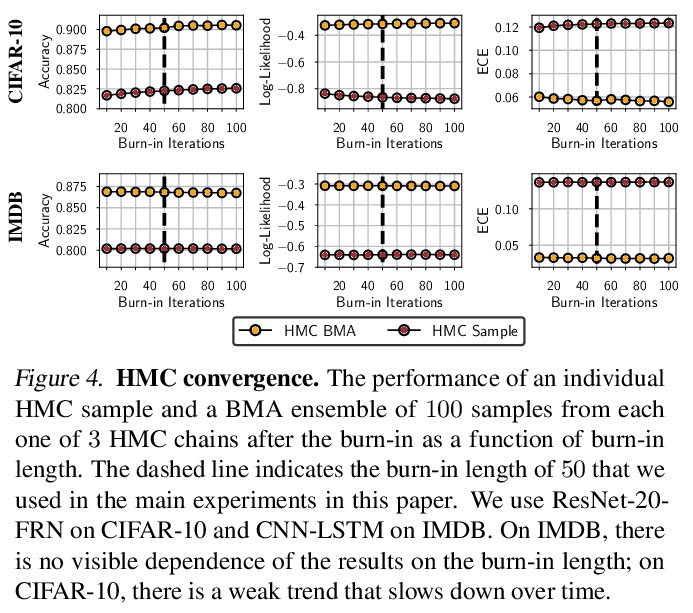
贝叶斯神经网络后验到底什么样?贝叶斯神经网络(BNN)参数后验,是非常高维且非凸的。由于计算上的原因,研究人员用廉价的mini-batch方法,如流形变分推理或随机梯度马尔科夫链蒙特卡洛(SGMCMC)来近似这一后验。为研究贝叶斯深度学习的基础问题,本文在现代架构上用full-batch的汉密尔顿蒙特卡洛(HMC),表明:(1) 相比标准训练和深度集成BNN可取得明显的性能提升;(2)单一长HMC链可提供与多短链相当的后验表示; (3)要达到近最优性能,不需要后验调节,几乎没有证据表明”冷后验”效应,这主要是数据增强的副作用;(4)BMA的性能对先验尺度的选择是鲁棒的,对于对角高斯、高斯混合和逻辑先验来说相对相似;(5)贝叶斯神经网络在领域迁移的情况下显示出令人惊讶的低泛化;(6)虽然更便宜的替代方案,如深度集成和SGMCMC,可以提供良好的泛化,但它们提供的预测分布与HMC不同。值得注意的是,深度集成预测分布与标准SGLD类似,与HMC接近,比标准变分推理更接近。
The posterior over Bayesian neural network (BNN) parameters is extremely high-dimensional and non-convex. For computational reasons, researchers approximate this posterior using inexpensive mini-batch methods such as meanfield variational inference or stochastic-gradient Markov chain Monte Carlo (SGMCMC). To investigate foundational questions in Bayesian deep learning, we instead use full-batch Hamiltonian Monte Carlo (HMC) on modern architectures. We show that (1) BNNs can achieve significant performance gains over standard training and deep ensembles; (2) a single long HMC chain can provide a comparable representation of the posterior to multiple shorter chains; (3) in contrast to recent studies, we find posterior tempering is not needed for near-optimal performance, with little evidence for a “cold posterior” effect, which we show is largely an artifact of data augmentation; (4) BMA performance is robust to the choice of prior scale, and relatively similar for diagonal Gaussian, mixture of Gaussian, and logistic priors; (5) Bayesian neural networks show surprisingly poor generalization under domain shift; (6) while cheaper alternatives such as deep ensembles and SGMCMC can provide good generalization, they provide distinct predictive distributions from HMC. Notably, deep ensemble predictive distributions are similarly close to HMC as standard SGLD, and closer than standard variational inference.
https://weibo.com/1402400261/KdoqJu84d

2、[CV] Emerging Properties in Self-Supervised Vision Transformers
M Caron, H Touvron, I Misra, H Jégou, J Mairal, P Bojanowski, A Joulin
[Facebook AI Research]
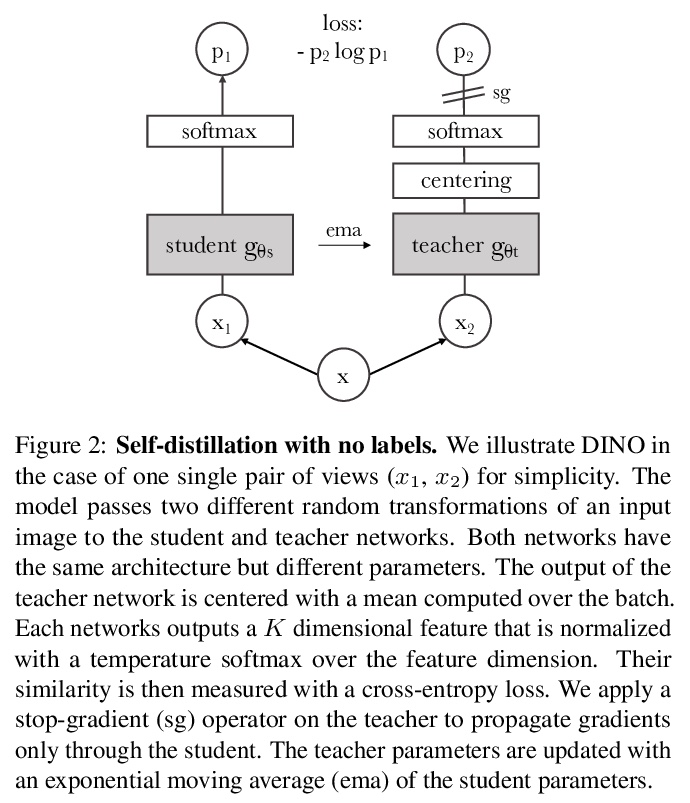
自监督视觉Transformer的新特性。探讨自监督学习是否为视觉Transformer(ViT)提供了与卷积网络相比突出的新特性。将自监督方法很好的用于该架构,展示了自监督预训练标准ViT模型的潜力,并提出以下看法:首先,自监督ViT特征包含关于图像语义分割的明确信息,这在有监督ViT中并没有出现,在卷积网络中也没有。其次,自监督ViT特征在基本的K近邻分类器(k-NN)下表现特别好,没有任何微调、线性分类器也未做数据增强的情况下,在ImageNet上达到78.3%的最高准确率。自监督学习可能是开发基于ViT的类似BERT模型的关键。强调了ViT采用动量编码器、多裁剪训练及小批量的重要性。将以上发现落实到一个简单的自监督方法DINO中,将其解释为一种无标记的自蒸馏形式。DINO和ViT之间的协同作用,在使用ViT-Base的线性评估中,在ImageNet上取得了80.1%的最高分。
In this paper, we question if self-supervised learning provides new properties to Vision Transformer (ViT) [18] that stand out compared to convolutional networks (convnets). Beyond the fact that adapting self-supervised methods to this architecture works particularly well, we make the following observations: first, self-supervised ViT features contain explicit information about the semantic segmentation of an image, which does not emerge as clearly with supervised ViTs, nor with convnets. Second, these features are also excellent k-NN classifiers, reaching 78.3% top-1 on ImageNet with a small ViT. Our study also underlines the importance of momentum encoder [31], multi-crop training [10], and the use of small patches with ViTs. We implement our findings into a simple self-supervised method, called DINO, which we interpret as a form of self-distillation with no labels. We show the synergy between DINO and ViTs by achieving 80.1% top-1 on ImageNet in linear evaluation with ViT-Base.
https://weibo.com/1402400261/Kdoz4xs20



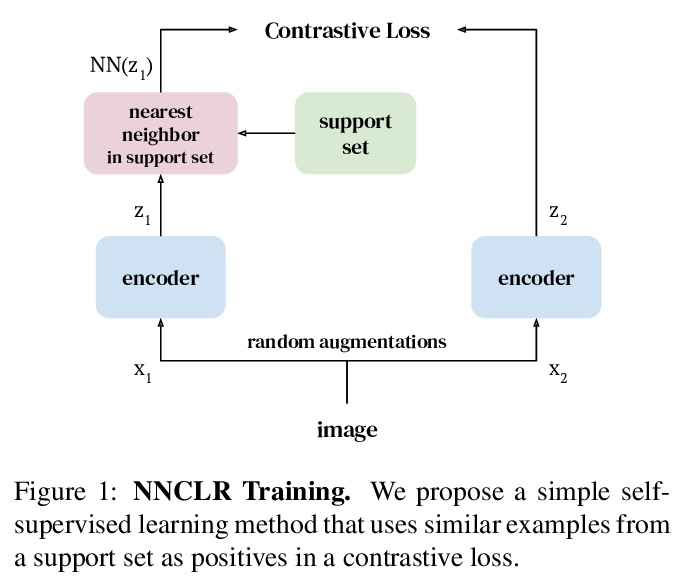
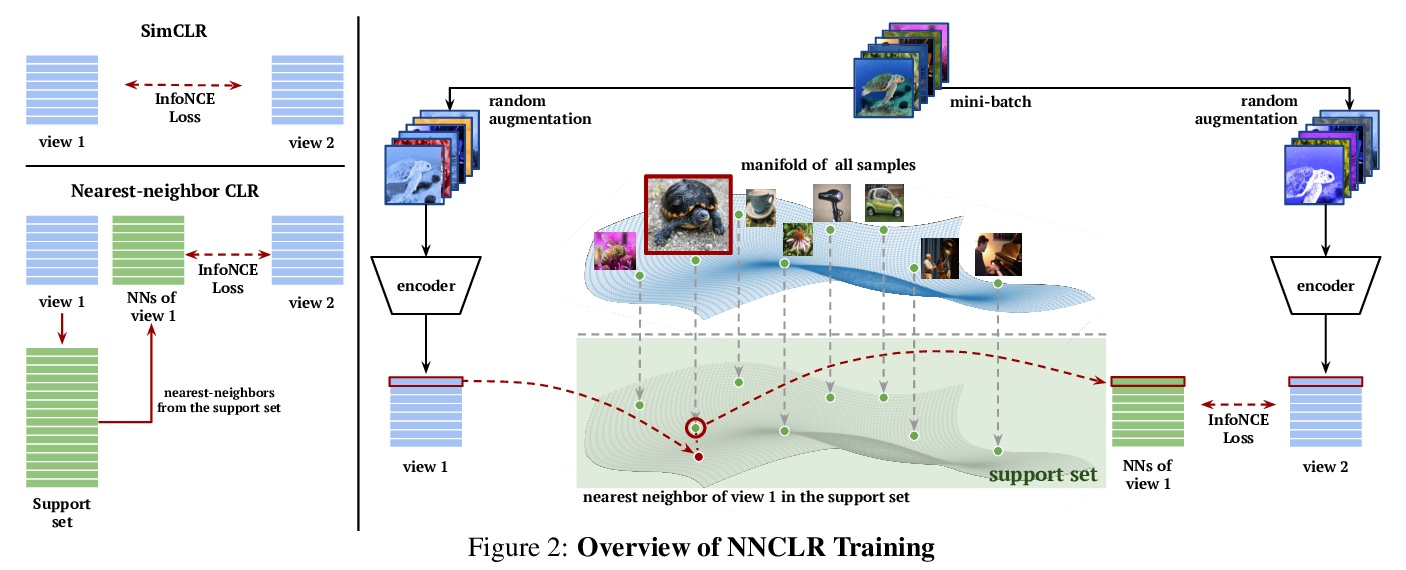
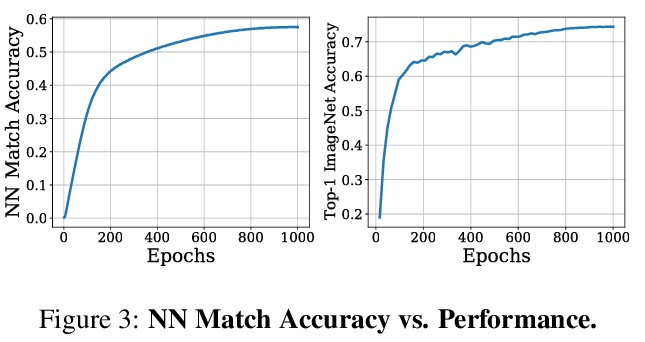
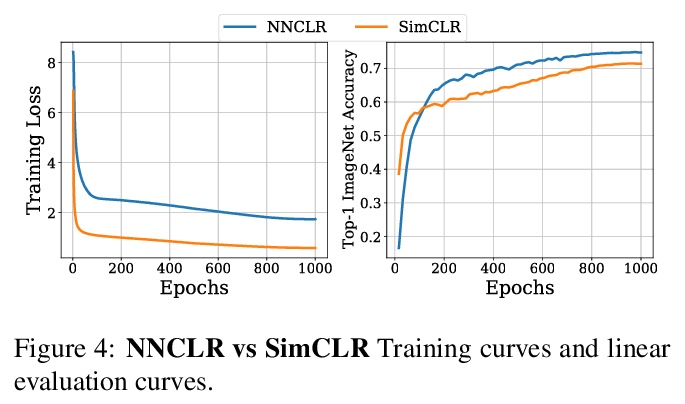
3、[CV] With a Little Help from My Friends: Nearest-Neighbor Contrastive Learning of Visual Representations
D Dwibedi, Y Aytar, J Tompson, P Sermanet, A Zisserman
[Google Research & DeepMind]
视觉表征的最近邻对比学习。基于实例判别的自监督学习算法,主要是训练编码器不受同一实例预定义变换的影响。大多数方法将同一图像的不同视图视为对比损失的正例,本文探索将数据集中的其他实例用作正例。提出视觉表征的最近邻对比学习(NNCLR),从潜空间数据集中抽取近邻,并将其作为正例,比预定义变换提供了更多的语义变化。在对比性损失中使用最近邻作为正例,可显著提高ImageNet分类的性能,从71.7%提高到75.6%,超过了之前最先进的方法。在半监督学习基准上,当只有1%的ImageNet标记可用时,性能明显提高,从53.8%提高到56.5%。在迁移学习基准上,该方法在12个下游数据集中的8个上,超过了最先进的方法(包括用ImageNet进行监督学习)。该方法对复杂数据增强的依赖性较低,当只用随机裁剪进行训练时,ImageNet Top-1的准确率只相对降低了2.1%。
Self-supervised learning algorithms based on instance discrimination train encoders to be invariant to pre-defined transformations of the same instance. While most methods treat different views of the same image as positives for a contrastive loss, we are interested in using positives from other instances in the dataset. Our method, NearestNeighbor Contrastive Learning of visual Representations (NNCLR), samples the nearest neighbors from the dataset in the latent space, and treats them as positives. This provides more semantic variations than pre-defined transformations. We find that using the nearest-neighbor as positive in contrastive losses improves performance significantly on ImageNet classification, from 71.7% to 75.6%, outperforming previous state-of-the-art methods. On semisupervised learning benchmarks we improve performance significantly when only 1% ImageNet labels are available, from 53.8% to 56.5%. On transfer learning benchmarks our method outperforms state-of-the-art methods (including supervised learning with ImageNet) on 8 out of 12 downstream datasets. Furthermore, we demonstrate empirically that our method is less reliant on complex data augmentations. We see a relative reduction of only 2.1% ImageNet Top-1 accuracy when we train using only random crops.
https://weibo.com/1402400261/KdoHi2HsU
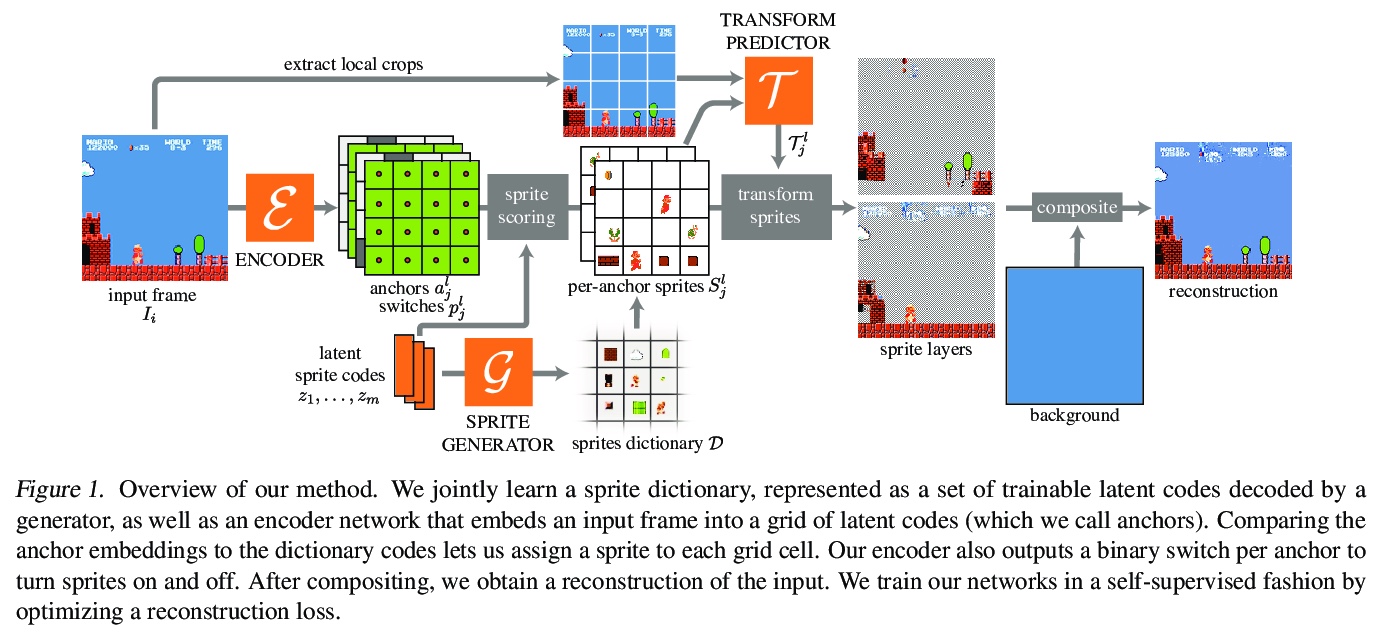
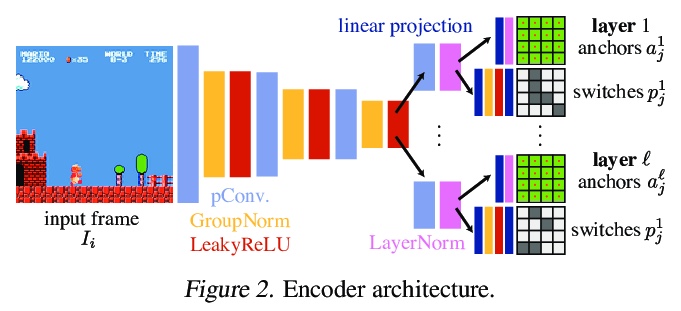
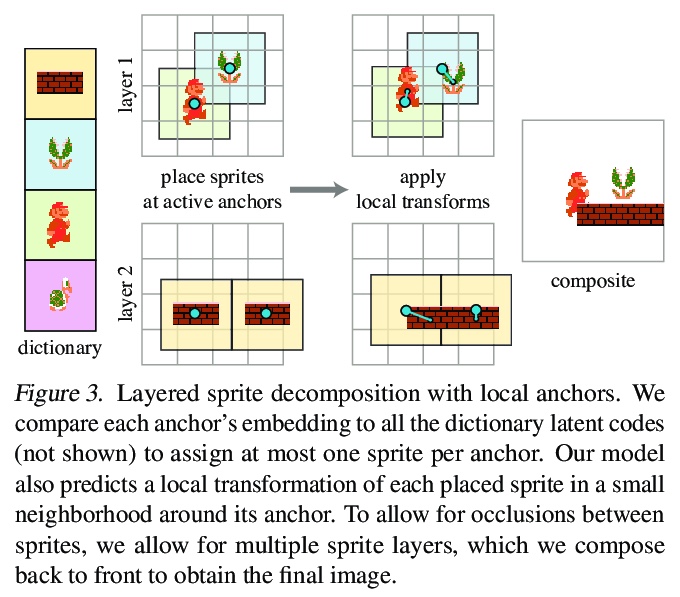
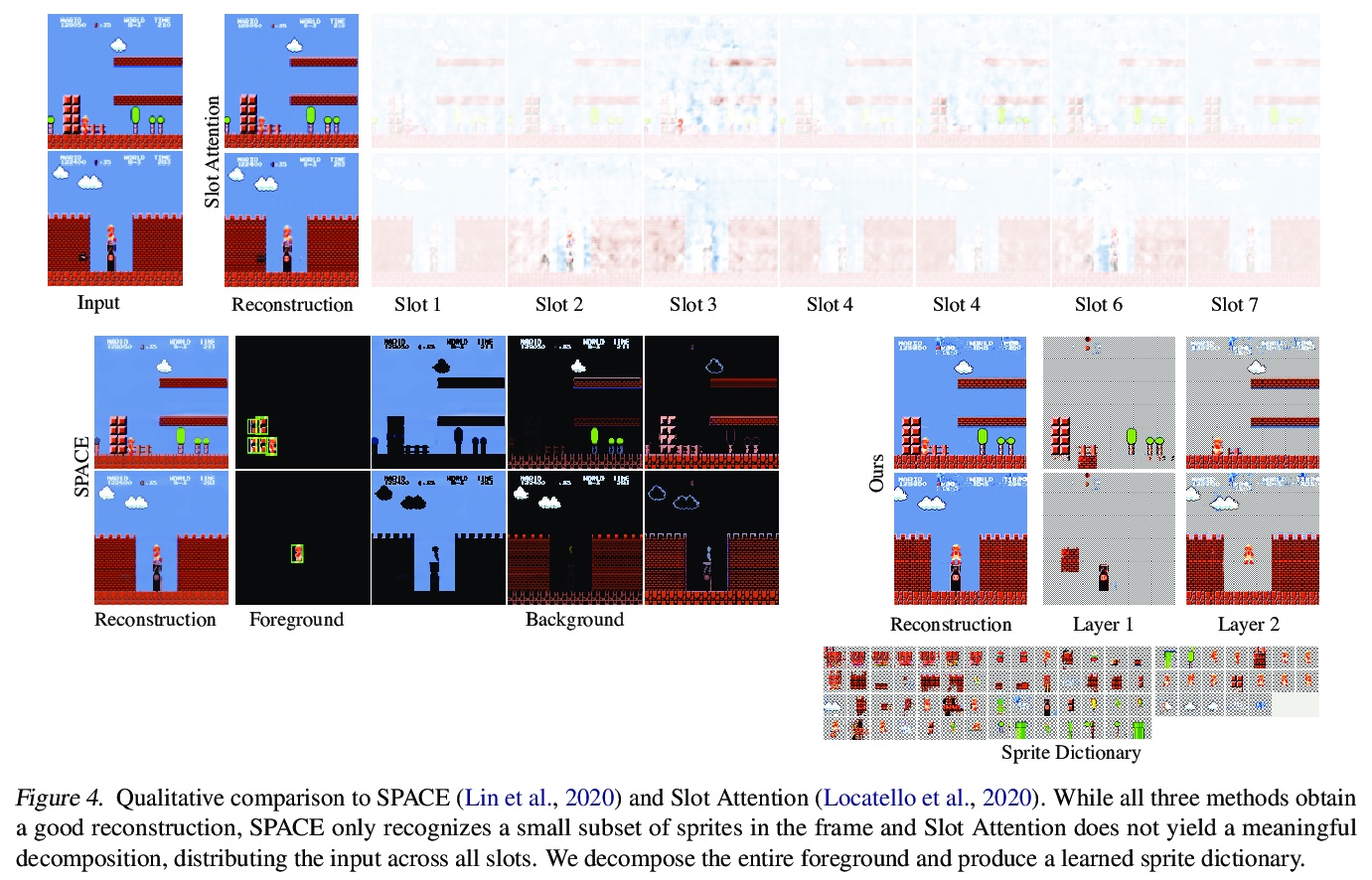
4、[CV] MarioNette: Self-Supervised Sprite Learning
D Smirnov, M Gharbi, M Fisher, V Guizilini, A A. Efros, J Solomon
[MIT & Adobe Research & Toyota Research Institute]
MarioNette:自监督子图形学习。视觉内容往往包含重复出现的元素。文本是由同一字体的字形组成的,动画,如卡通或视频游戏,是由在屏幕上移动的子图形组成的,而自然视频常出现物体的重复视图。本文提出一种深度学习方法,以完全自监督的方式获得重复出现元素的解缠图像表示。通过联合学习纹理图块字典,训练将其放在画布上的网络,有效地将基于子图形的内容解缠为稀疏的、一致的、可解释的表示,编码器将帧解释为字典中元素的组合,将其锚定在规则网格上。通过生成多层带透明度蒙版的子图形,并预测每个子图形的局部变换,可恢复精细运动,实现了高质量重建,并产生带有语义的、良好解缠的子图形,应用于具有显著重复性的内容,如文本或二维视频游戏,可恢复结构上的重要图块,如字形或移动角色。该框架为在无监督情况下发现图像集合中的重复模式提供了一个很有前途的方法,可以很容易地用于下游任务。
Visual content often contains recurring elements. Text is made up of glyphs from the same font, animations, such as cartoons or video games, are composed of sprites moving around the screen, and natural videos frequently have repeated views of objects. In this paper, we propose a deep learning approach for obtaining a graphically disentangled representation of recurring elements in a completely self-supervised manner. By jointly learning a dictionary of texture patches and training a network that places them onto a canvas, we effectively deconstruct sprite-based content into a sparse, consistent, and interpretable representation that can be easily used in downstream tasks. Our framework offers a promising approach for discovering recurring patterns in image collections without supervision.
https://weibo.com/1402400261/KdoLLbOuo
5、[CV] LightTrack: Finding Lightweight Neural Networks for Object Tracking via One-Shot Architecture Search
B Yan, H Peng, K Wu, D Wang, J Fu, H Lu
[Microsoft Research Asia & Dalian University of Technology]
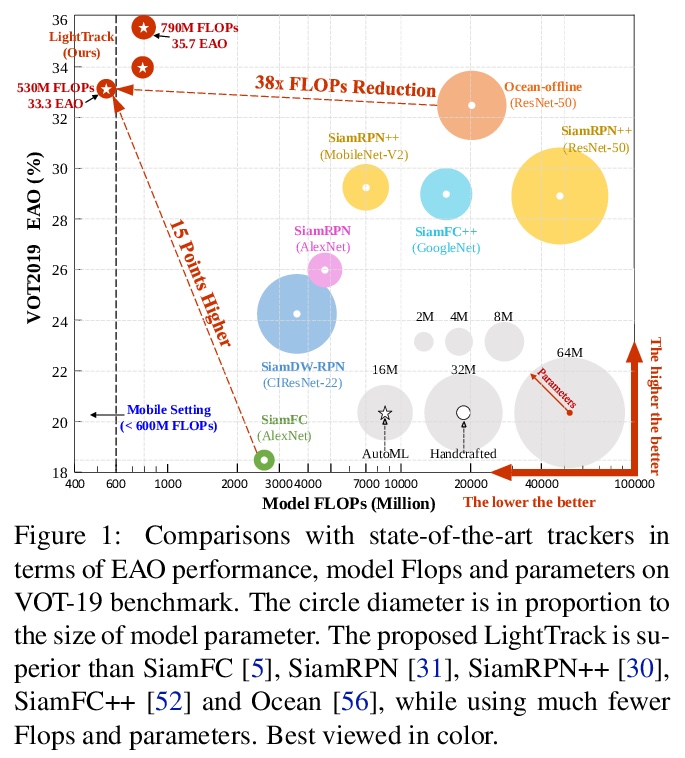
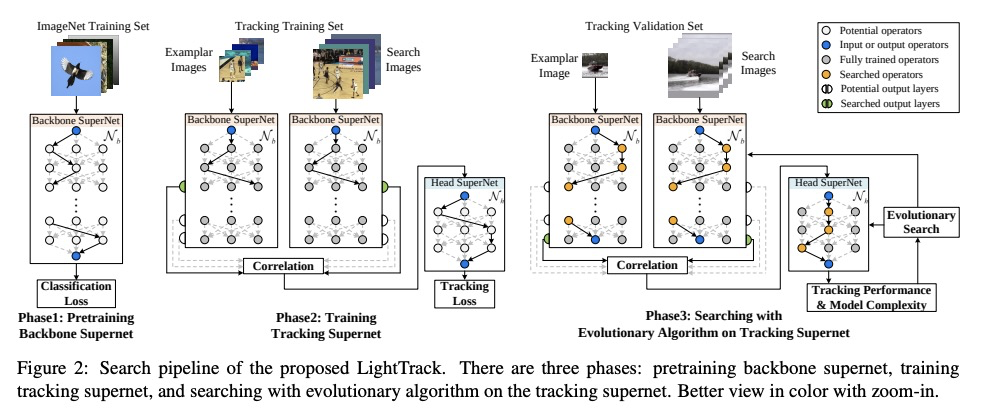
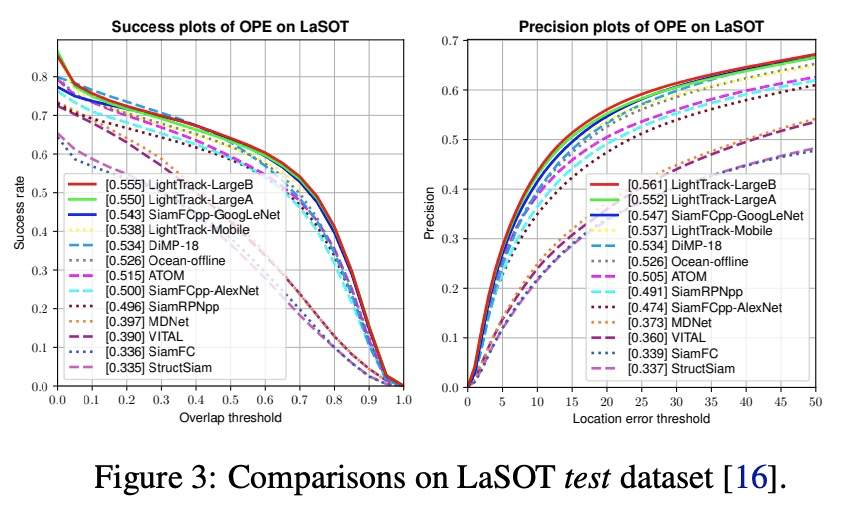
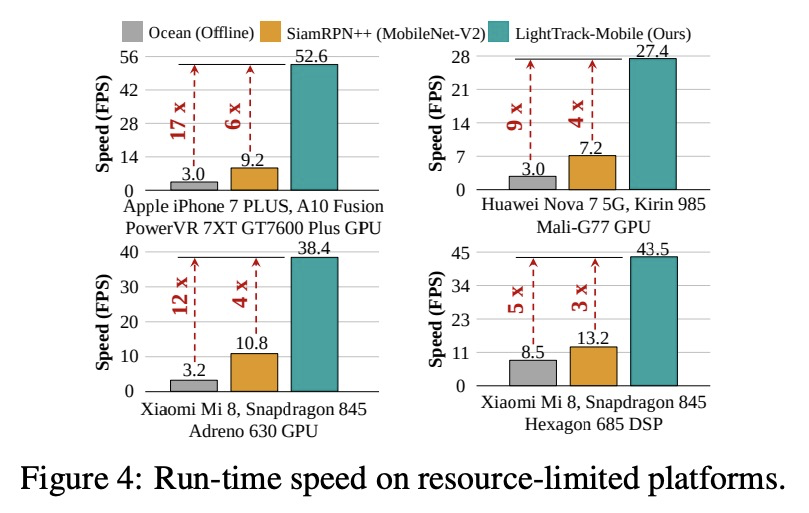
LightTrack: 通过单样本架构搜索寻找面向目标追踪的轻量级神经网络。过去几年,目标追踪取得了重大进展。然而,最先进的追踪器变得越来越沉重和昂贵,限制了它们在资源有限应用中的部署。本文提出LightTrack,用神经架构搜索(NAS),来设计更轻巧和高效的目标追踪器,重新制定了专用于目标跟踪的单样本NAS,引入一个有效的搜索空间。综合实验表明,LightTrack是有效的,与手工打造的SOTA追踪器如SiamRPN++和Ocean相比,能找到性能优越的追踪器,而使用的模型Flops和参数则少得多。此外,当部署在资源受限的移动芯片组上时,所发现的追踪器运行得更快。例如,在Snapdragon 845 Adreno GPU上,LightTrack比Ocean快12倍,而使用的参数少13倍,Flops少38倍。这样的改进可能会缩小学术模型与目标追踪任务的工业部署之间的差距。
Object tracking has achieved significant progress over the past few years. However, state-of-the-art trackers become increasingly heavy and expensive, which limits their deployments in resource-constrained applications. In this work, we present LightTrack, which uses neural architecture search (NAS) to design more lightweight and efficient object trackers. Comprehensive experiments show that our LightTrack is effective. It can find trackers that achieve superior performance compared to handcrafted SOTA trackers, such as SiamRPN++ and Ocean, while using much fewer model Flops and parameters. Moreover, when deployed on resource-constrained mobile chipsets, the discovered trackers run much faster. For example, on Snapdragon 845 Adreno GPU, LightTrack runs12×faster than Ocean, while using13×fewer parameters and38×fewer Flops. Such improvements might narrow the gap between academic models and industrial deployments in object tracking task. LightTrack is released atthis https URL.
https://weibo.com/1402400261/KdoRrpj7v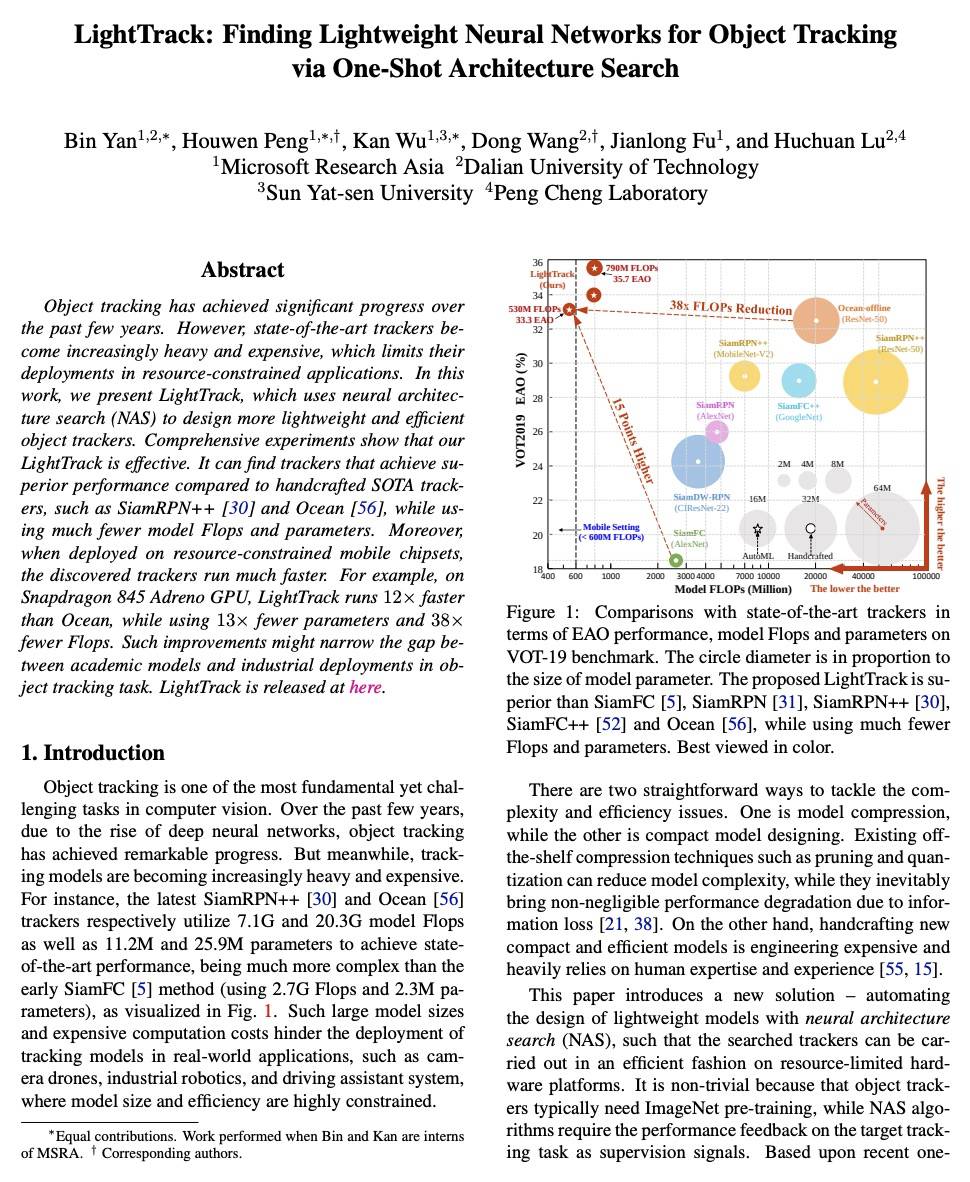
另外几篇值得关注的论文:
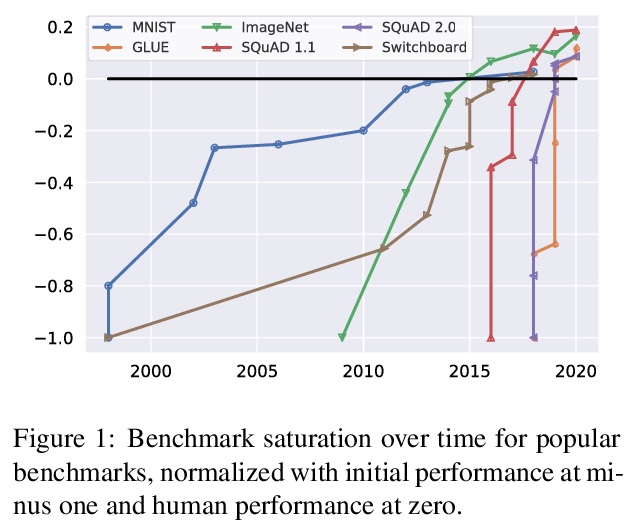
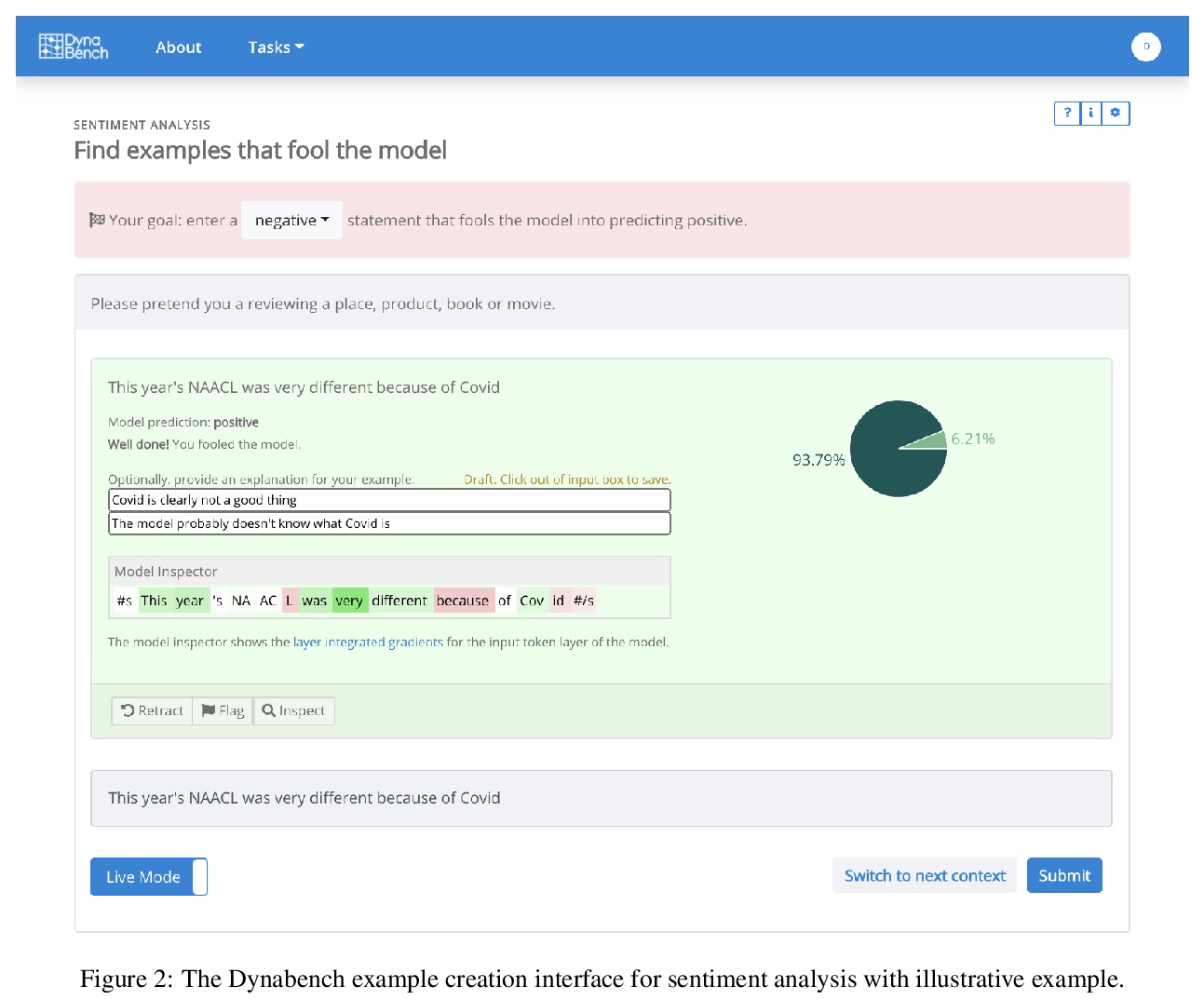
[CL] Dynabench: Rethinking Benchmarking in NLP
Dynabench:自然语言处理基准的反思(动态数据集创建和模型基准测试开源平台)
D Kiela, M Bartolo, Y Nie, D Kaushik, A Geiger, Z Wu, B Vidgen, G Prasad, A Singh, P Ringshia, Z Ma, T Thrush, S Riedel, Z Waseem, P Stenetorp, R Jia, M Bansal, C Potts, A Williams
[Facebook AI Research & UCL & UNC Chapel Hill & CMU & Stanford University & Alan Turing Institute & JHU & Simon Fraser University]
https://weibo.com/1402400261/KdoWxeVbk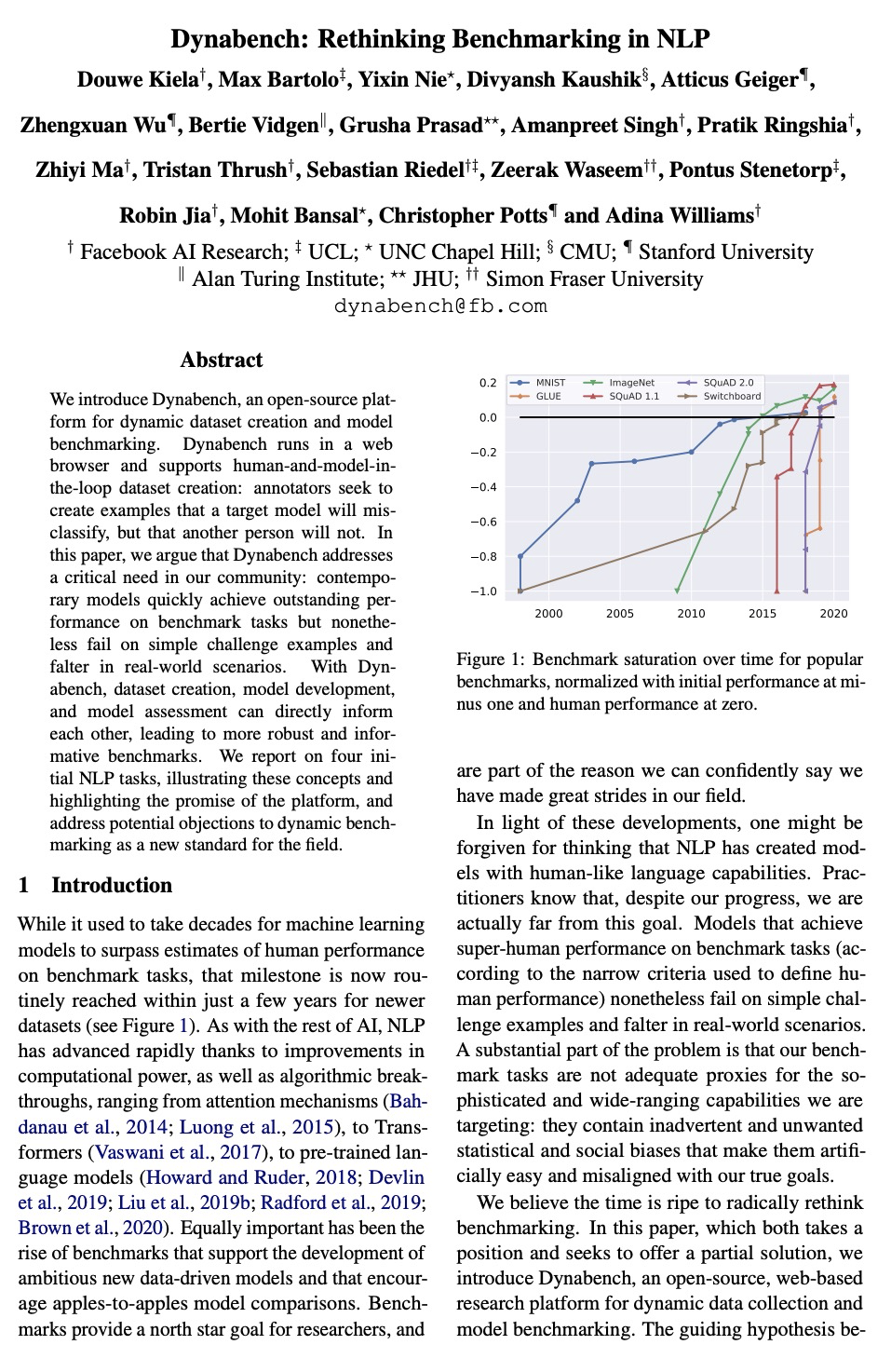
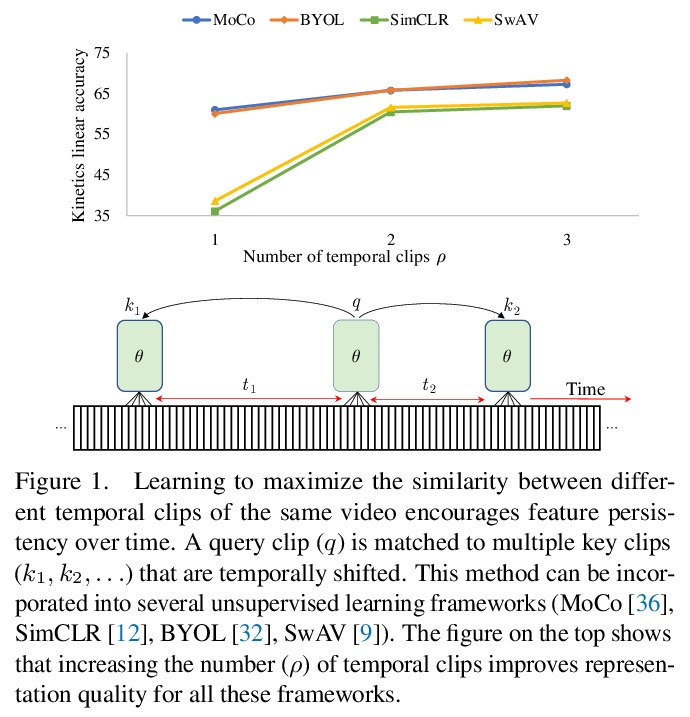
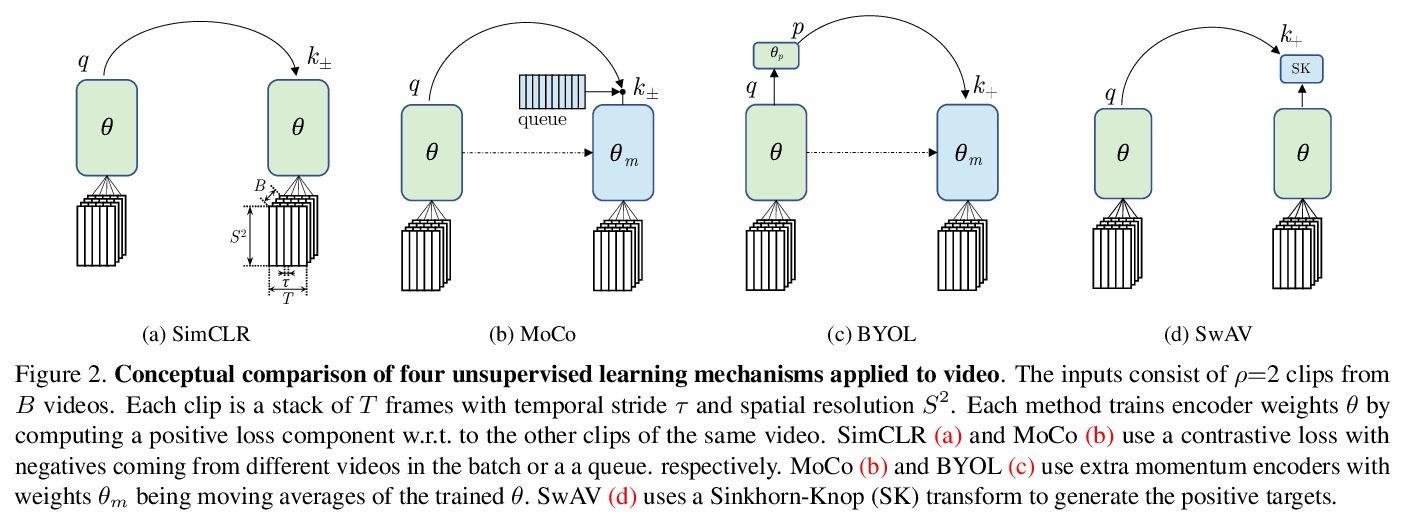
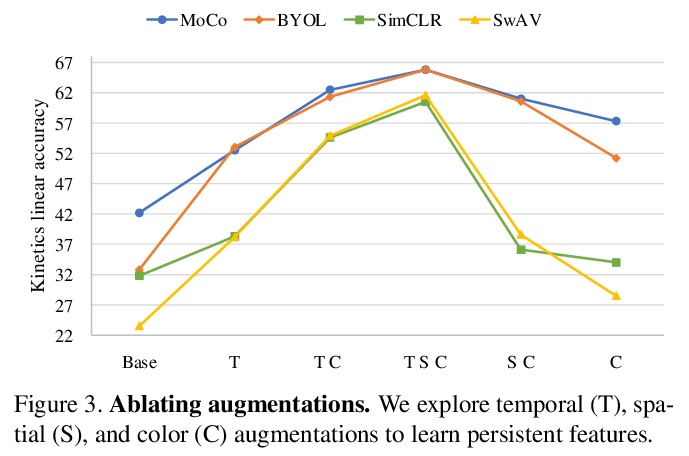
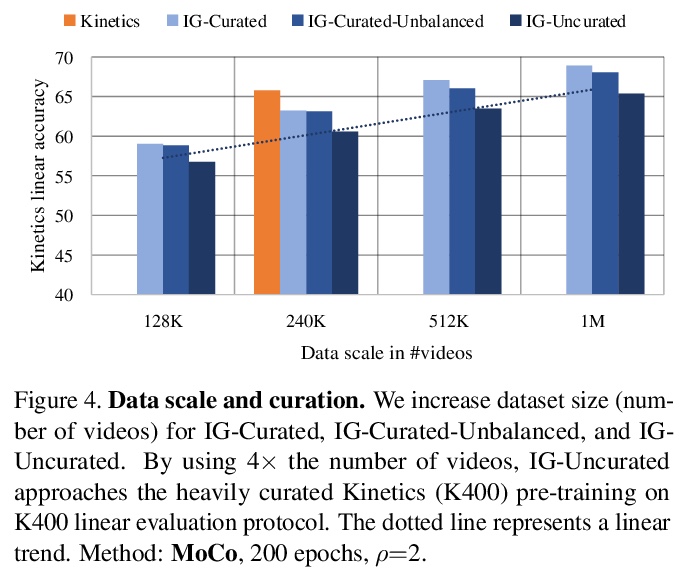
[CV] A Large-Scale Study on Unsupervised Spatiotemporal Representation Learning
无监督时空表征学习的大规模研究
C Feichtenhofer, H Fan, B Xiong, R Girshick, K He
[Facebook AI Research]
https://weibo.com/1402400261/KdoYzqsnd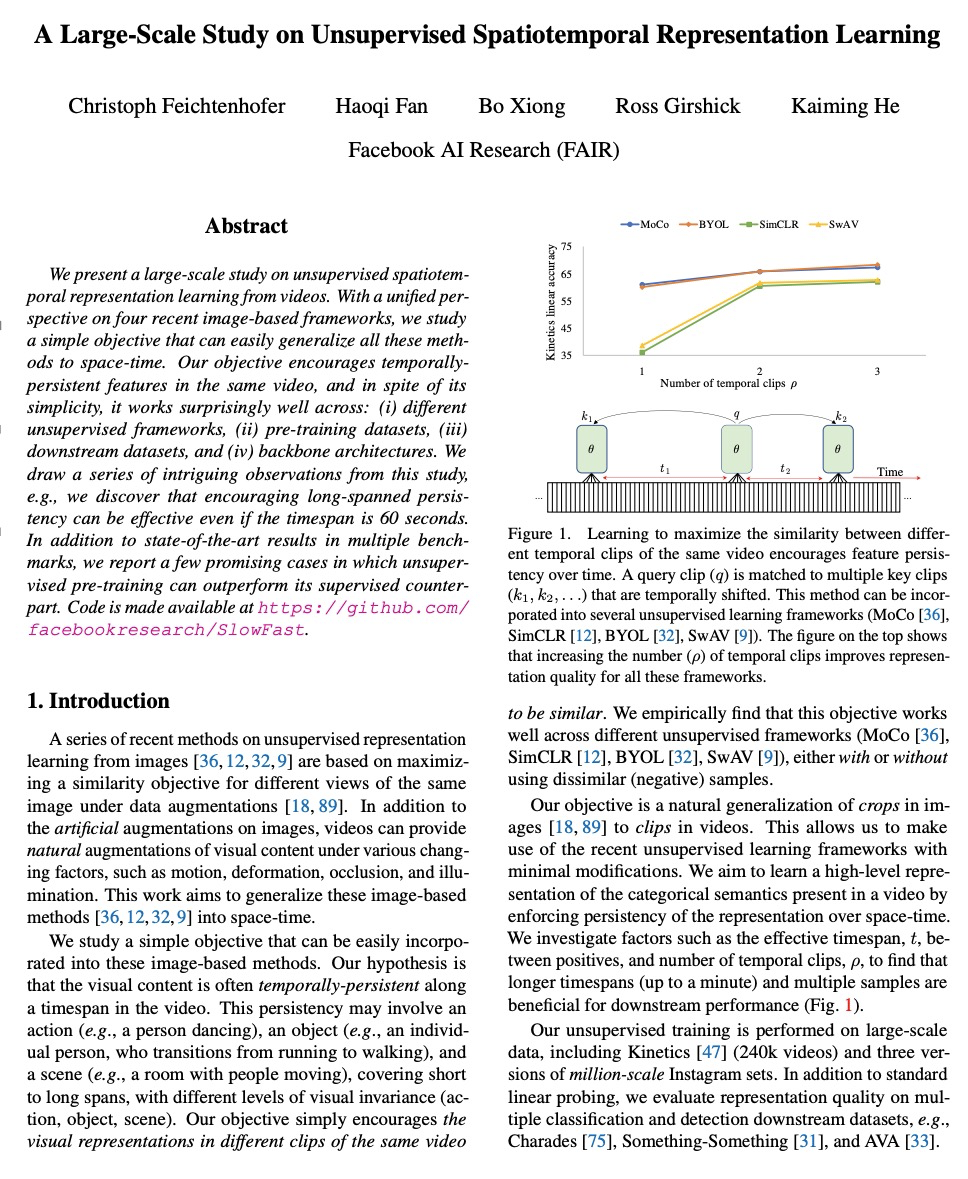
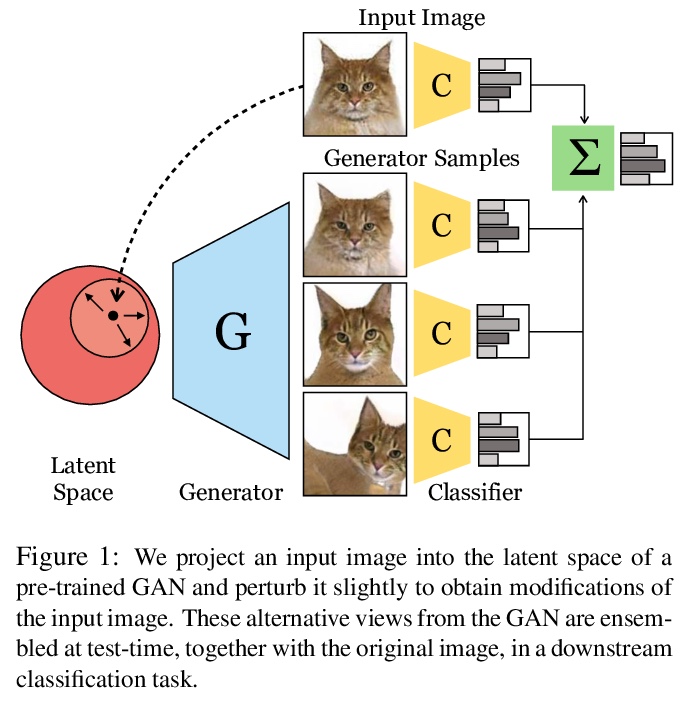
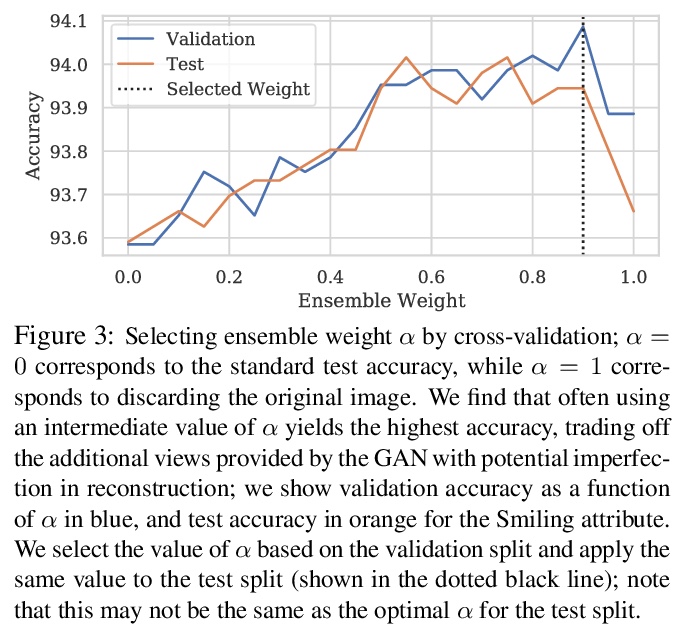
[CV] Ensembling with Deep Generative Views
深度生成视图集成
L Chai, J Zhu, E Shechtman, P Isola, R Zhang
[MIT & Adobe Research]
https://weibo.com/1402400261/Kdp0r001k

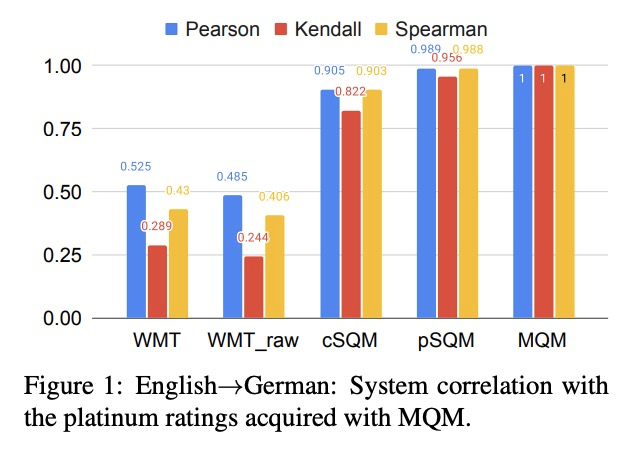
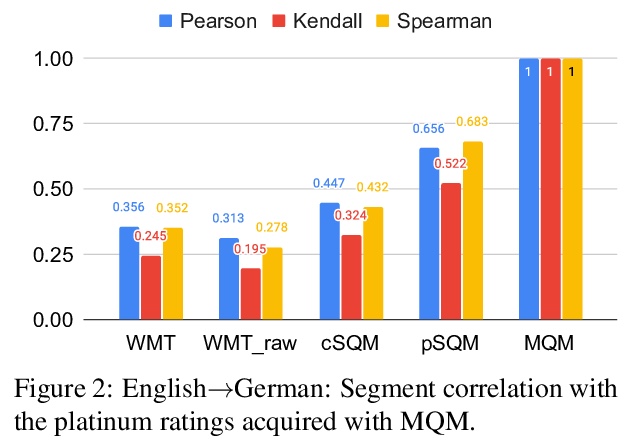
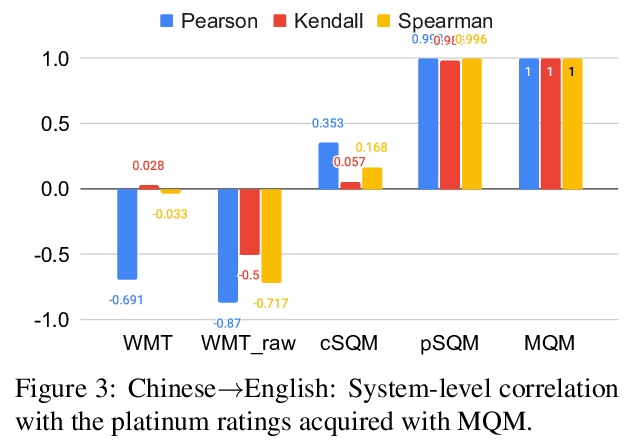
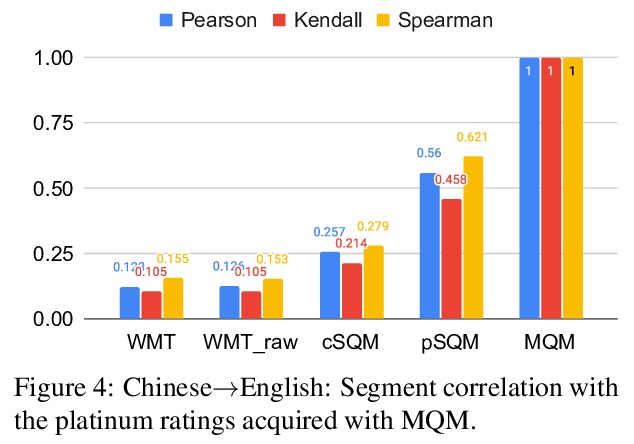
[CL] Experts, Errors, and Context: A Large-Scale Study of Human Evaluation for Machine Translation
专家、错误和上下文:机器翻译人工评价的大规模研究
M Freitag, G Foster, D Grangier, V Ratnakar, Q Tan, W Macherey
[Google Research]
https://weibo.com/1402400261/Kdp4yiaOl

若有收获,就点个赞吧
0 人点赞
