- 1、[CV] Monocular Quasi-Dense 3D Object Tracking
- 2、[CV] FaceBlit: Instant Real-time Example-based Style Transfer to Facial Videos
- 3、[LG] Neural tensor contractions and the expressive power of deep neural quantum states
- 4、[RO] Autonomous Drone Racing with Deep Reinforcement Learning
- 5、[AI] Self-learning Machines based on Hamiltonian Echo Backpropagation
- [CV] On Semantic Similarity in Video Retrieval
- [AS] Contrastive Learning of Musical Representations
- [CV] AutoDO: Robust AutoAugment for Biased Data with Label Noise via Scalable Probabilistic Implicit Differentiation
- [CV] Unsupervised Image Transformation Learning via Generative Adversarial Networks
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Monocular Quasi-Dense 3D Object Tracking
H Hu, Y Yang, T Fischer, T Darrell, F Yu, M Sun
[NTHU & UC Berkeley & ETH Zurich]
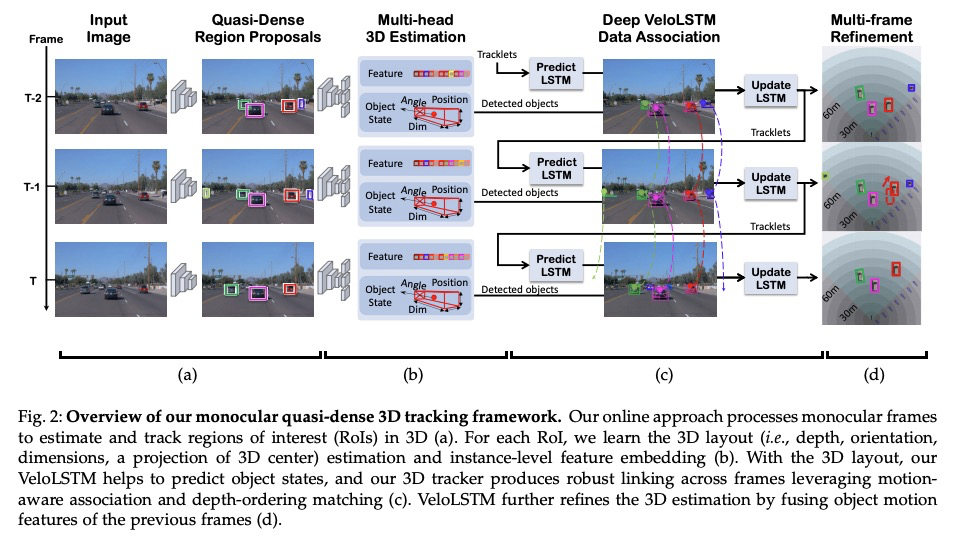
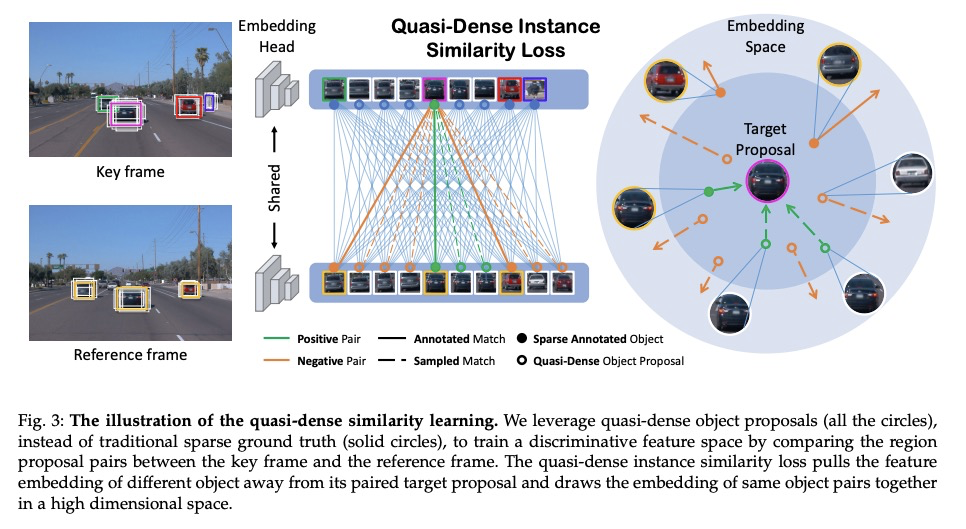
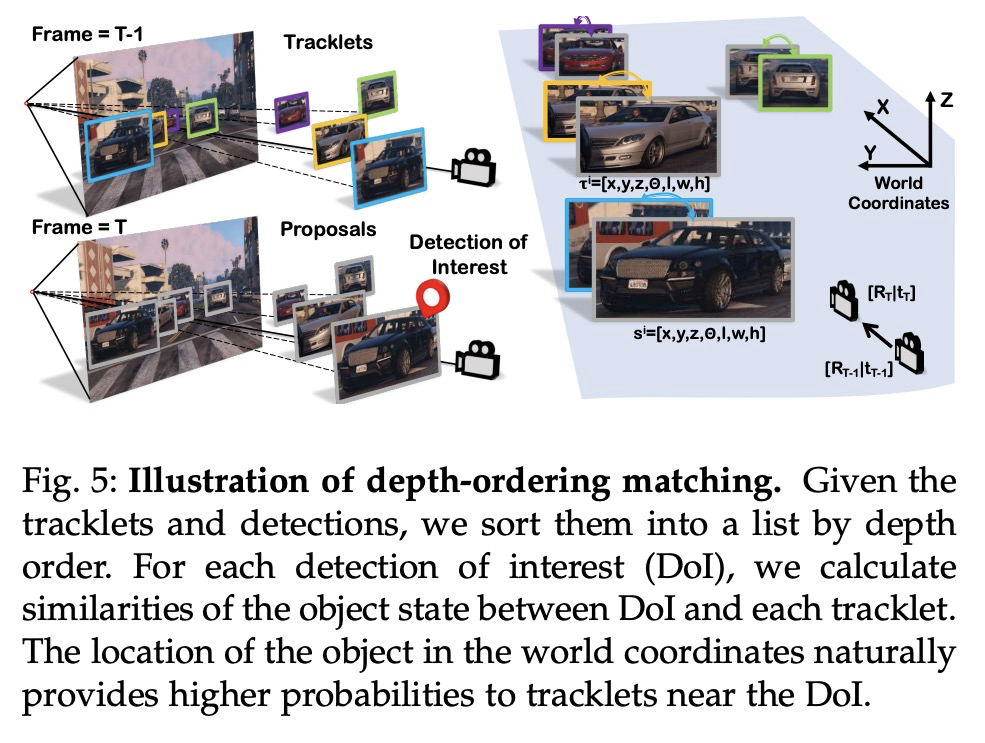
单目准密集3D目标跟踪系统。提出一种在线3D目标检测和跟踪框架,结合准密集相似性学习和3D实例动力学,来跟踪3D世界中的移动目标。更新的流水线由四部分组成:单帧单眼3D目标推理模型、跨帧对比特征学习网络、用于帧间目标关联的多模态亲和力匹配方案,以及基于LSTM的运动模型,用于从位置轨迹中提炼3D外延。此外,还引入了3D检测置信度,以提供单帧深度估计和多帧运动模型完善的平衡线索。提出了三维边框深度排序匹配的鲁棒实例关联,利用基于运动的三维轨迹预测来重新识别被遮挡车辆。设计了一个对象运动学习模块VeloLSTM,独立于摄像机运动更新每个目标的位置。实验表明,准密集3D跟踪管道利用了动态3D轨迹,并在城市驾驶情况下提供了强大的数据关联。准密集3D跟踪管道在nuScenes 3D跟踪基准上的表现比基于摄像头的技术水平高出近500%,同时弥补了与基于LiDAR方法的差距。
A reliable and accurate 3D tracking framework is essential for predicting future locations of surrounding objects and planning the observer’s actions in numerous applications such as autonomous driving. We propose a framework that can effectively associate moving objects over time and estimate their full 3D bounding box information from a sequence of 2D images captured on a moving platform. The object association leverages quasi-dense similarity learning to identify objects in various poses and viewpoints with appearance cues only. After initial 2D association, we further utilize 3D bounding boxes depth-ordering heuristics for robust instance association and motion-based 3D trajectory prediction for re-identification of occluded vehicles. In the end, an LSTM-based object velocity learning module aggregates the long-term trajectory information for more accurate motion extrapolation. Experiments on our proposed simulation data and real-world benchmarks, including KITTI, nuScenes, and Waymo datasets, show that our tracking framework offers robust object association and tracking on urban-driving scenarios. On the Waymo Open benchmark, we establish the first camera-only baseline in the 3D tracking and 3D detection challenges. Our quasi-dense 3D tracking pipeline achieves impressive improvements on the nuScenes 3D tracking benchmark with near five times tracking accuracy of the best vision-only submission among all published methods. Our code, data and trained models are available at > this https URL.
https://weibo.com/1402400261/K7j7QyEIK
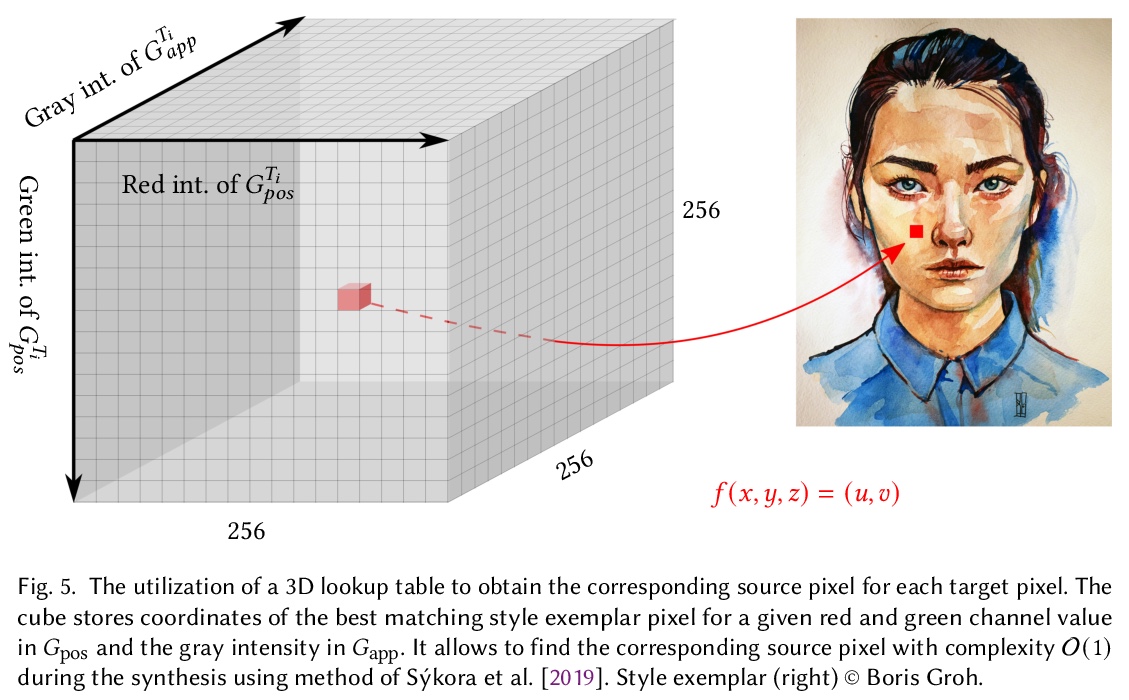
2、[CV] FaceBlit: Instant Real-time Example-based Style Transfer to Facial Videos
A Texler, O Texler, M kučera, M Chai, D sýkora
[Czech Technical University in Prague & Snap Inc]
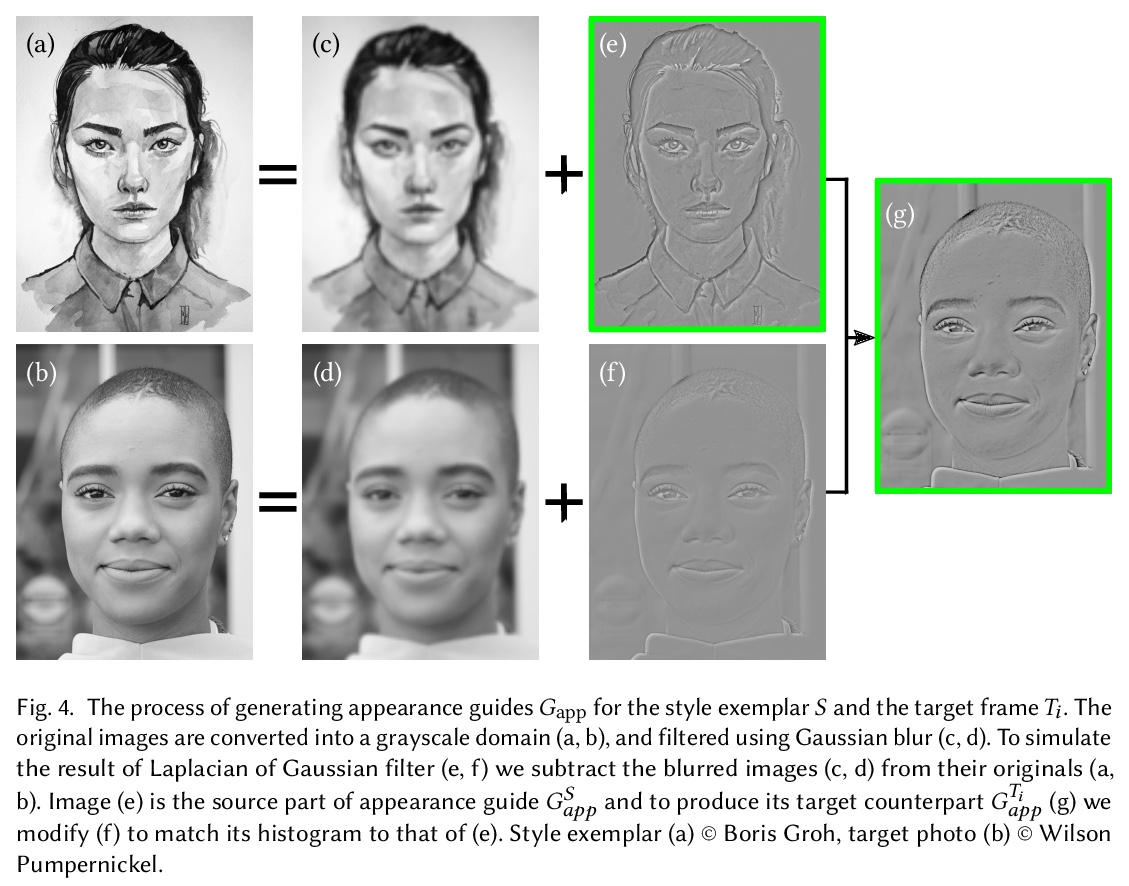
FaceBlit:基于示例的实时人脸视频画风迁移。提出一个基于示例的实时人脸视频风格化系统FaceBlit,可实现人脸视频基于示例的实时风格化,并提供语义上有意义的输出,保留原始艺术媒体概念的同时,保留了目标主体的身份,无需进行冗长的预计算或训练。展示了如何快速计算一组基本的引导通道,并将它们插入到基于补丁的合成算法的快速变体中,即使在移动设备上也能提供交互式画风迁移。该方法与当前最先进的技术相比,大大降低了计算开销,同时仍然提供了相当的风格化质量和身份保持。
We present FaceBlit—a system for real-time example-based face video stylization that retains textural details of the style in a semantically meaningful manner, i.e., strokes used to depict specific features in the style are present at the appropriate locations in the target image. As compared to previous techniques, our system preserves the identity of the target subject and runs in real-time without the need for large datasets nor lengthy training phase. To achieve this, we modify the existing face stylization pipeline of Fišer et al. [2017] so that it can quickly generate a set of guiding channels that handle identity preservation of the target subject while are still compatible with a faster variant of patch-based synthesis algorithm of Sýkora et al. [2019]. Thanks to these improvements we demonstrate a first face stylization pipeline that can instantly transfer artistic style from a single portrait to the target video at interactive rates even on mobile devices.
https://weibo.com/1402400261/K7jeyj6oH


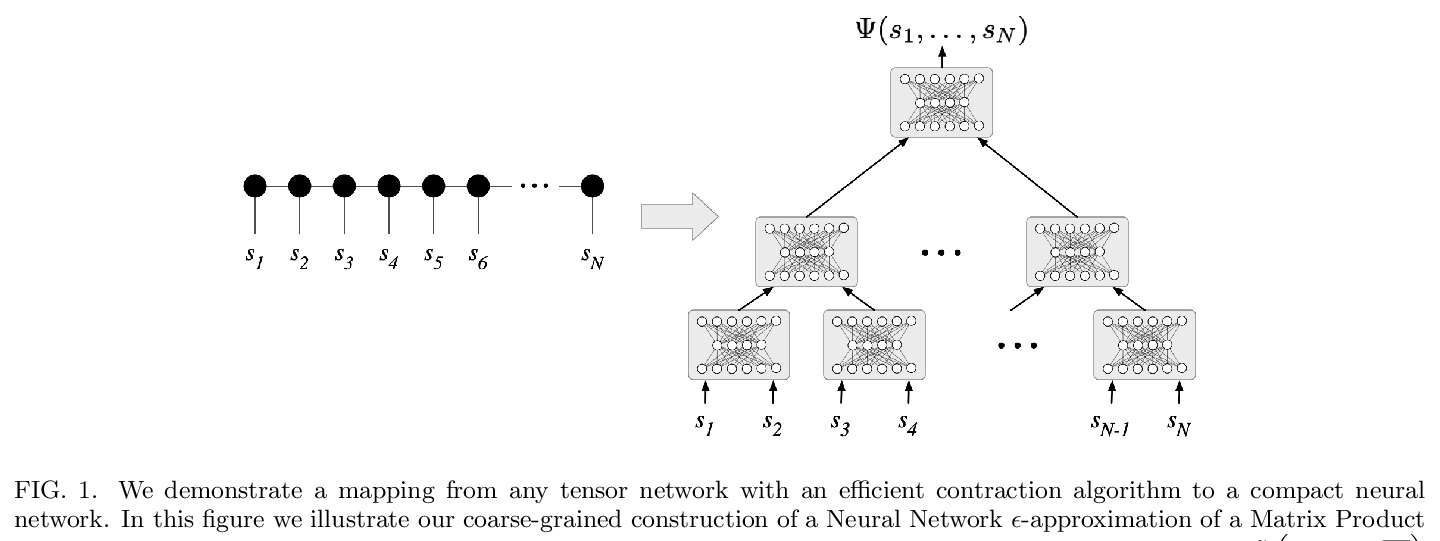
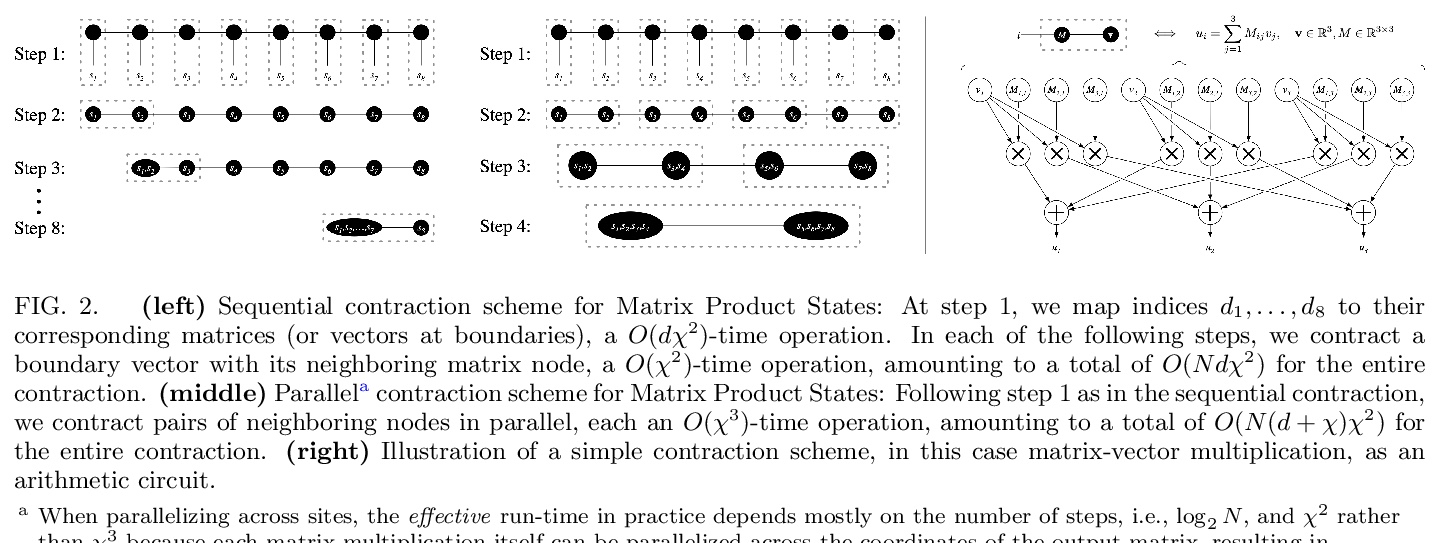
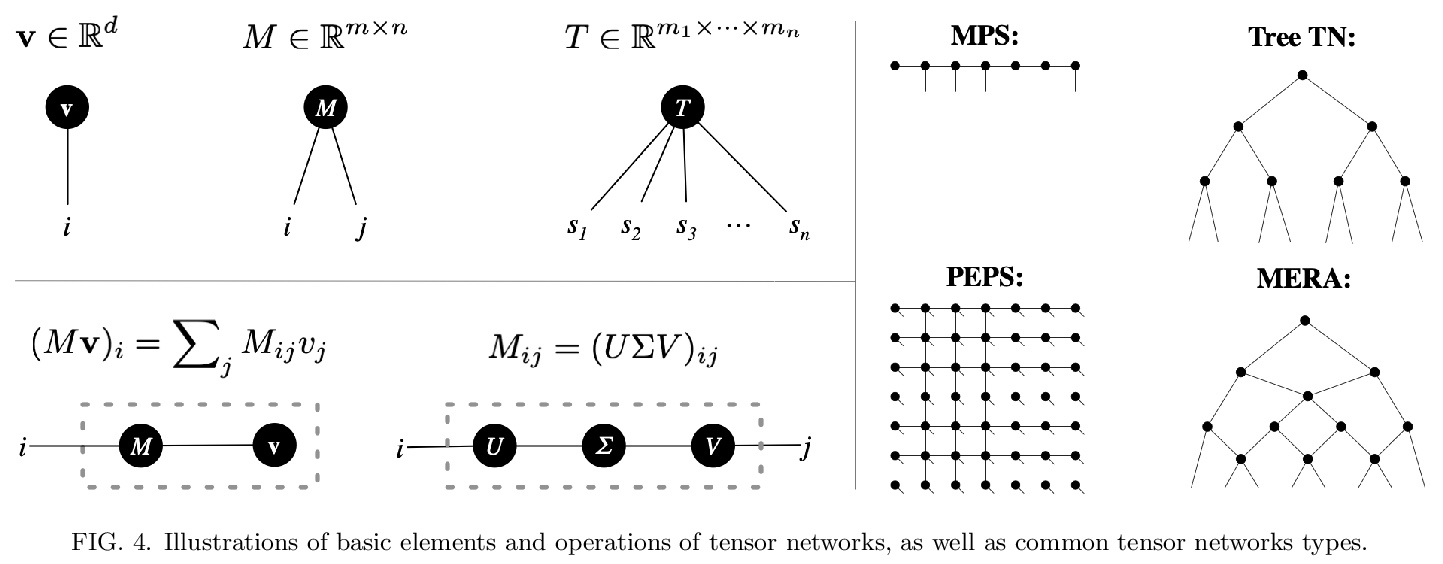
3、[LG] Neural tensor contractions and the expressive power of deep neural quantum states
O Sharir, A Shashua, G Carleo
[The Hebrew University of Jerusalem & EPFL]
神经张量收缩与深度神经量子态的表现力。建立了一般张量网络和深度前馈人工神经网络之间的直接联系。结果的核心是构建神经网络层,有效地执行张量收缩,并使用通常采用的非线性激活函数。所得到的深度网络的特征是边缘数量与要近似的张量网络的收缩复杂度紧密匹配。在多体量子态背景下,这一结果确立了神经网络态具有严格意义上的相同或更高的表达能力,而不是实际可用的变异张量网络。
We establish a direct connection between general tensor networks and deep feed-forward artificial neural networks. The core of our results is the construction of neural-network layers that efficiently perform tensor contractions, and that use commonly adopted non-linear activation functions. The resulting deep networks feature a number of edges that closely matches the contraction complexity of the tensor networks to be approximated. In the context of many-body quantum states, this result establishes that neural-network states have strictly the same or higher expressive power than practically usable variational tensor networks. As an example, we show that all matrix product states can be efficiently written as neural-network states with a number of edges polynomial in the bond dimension and depth logarithmic in the system size. The opposite instead does not hold true, and our results imply that there exist quantum states that are not efficiently expressible in terms of matrix product states or practically usable PEPS, but that are instead efficiently expressible with neural network states.
https://weibo.com/1402400261/K7jiOawl9

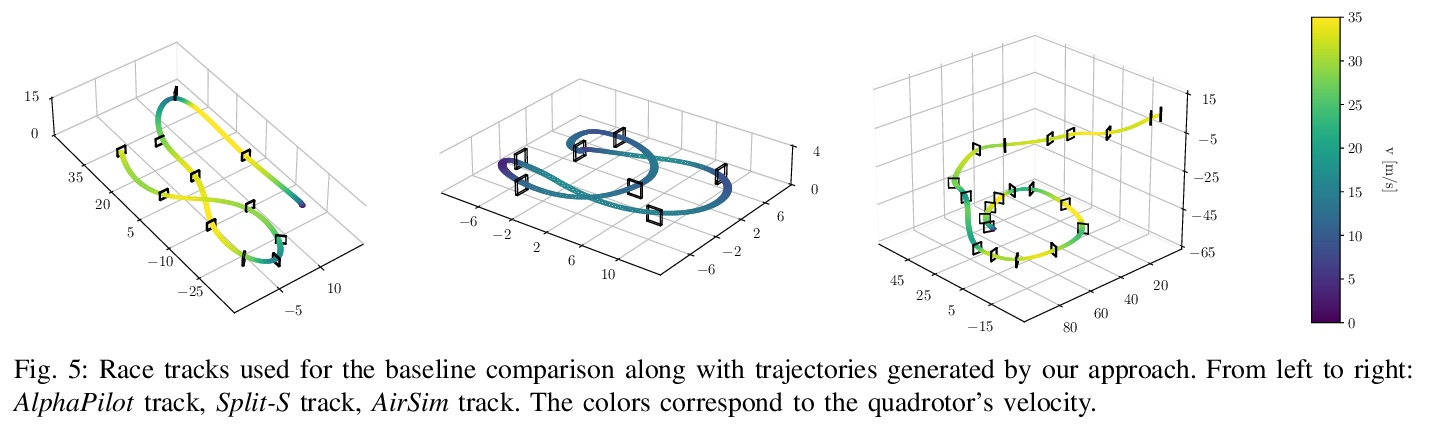
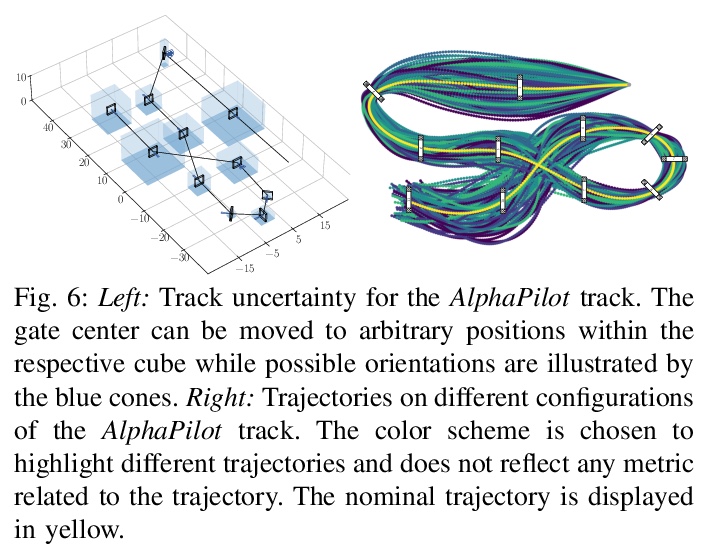
4、[RO] Autonomous Drone Racing with Deep Reinforcement Learning
Y Song, M Steinweg, E Kaufmann, D Scaramuzza
[University of Zurich & ETH Zurich]
基于深度强化学习的自主无人机竞速。提出一种基于学习的方法,用于训练神经网络策略,该策略可通过多个门为四旋翼飞行器生成近乎时间最优的轨迹。展示了该方法的优势,包括近时间最优性能,处理大的轨迹不确定性的能力,以及处理大规模随机轨迹布局的可扩展性和通用性,同时保留计算效率。用物理四旋翼飞机验证了生成的轨迹,并实现了速度高达17米/秒的激进飞行。
In many robotic tasks, such as drone racing, the goal is to travel through a set of waypoints as fast as possible. A key challenge for this task is planning the minimum-time trajectory, which is typically solved by assuming perfect knowledge of the waypoints to pass in advance. The resulting solutions are either highly specialized for a single-track layout, or suboptimal due to simplifying assumptions about the platform dynamics. In this work, a new approach to minimum-time trajectory generation for quadrotors is presented. Leveraging deep reinforcement learning and relative gate observations, this approach can adaptively compute near-time-optimal trajectories for random track layouts. Our method exhibits a significant computational advantage over approaches based on trajectory optimization for non-trivial track configurations. The proposed approach is evaluated on a set of race tracks in simulation and the real world, achieving speeds of up to 17 m/s with a physical quadrotor.
https://weibo.com/1402400261/K7jljjyWX
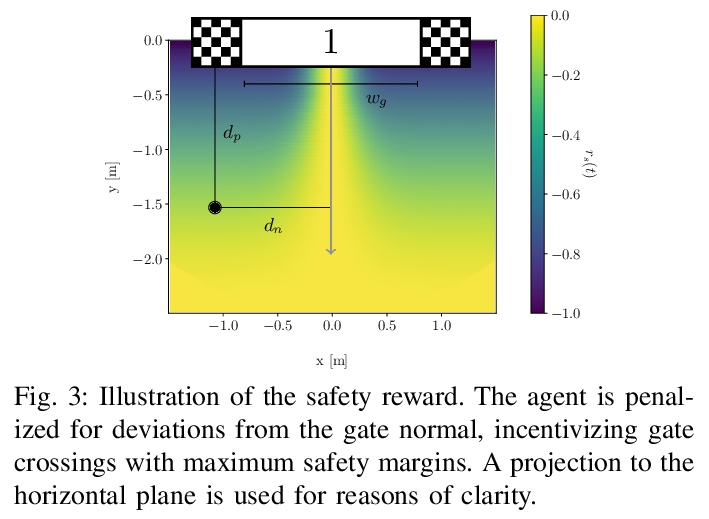

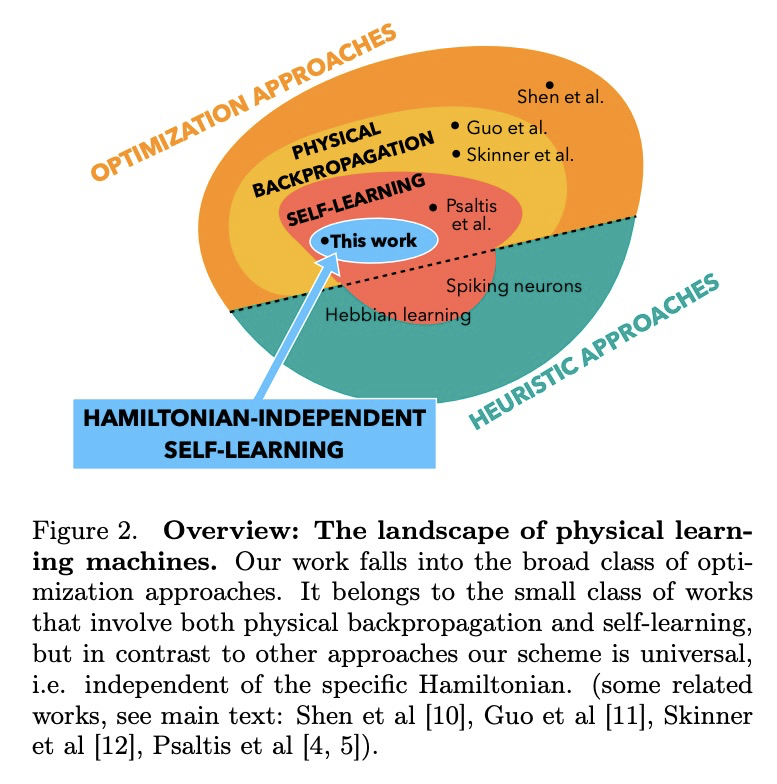
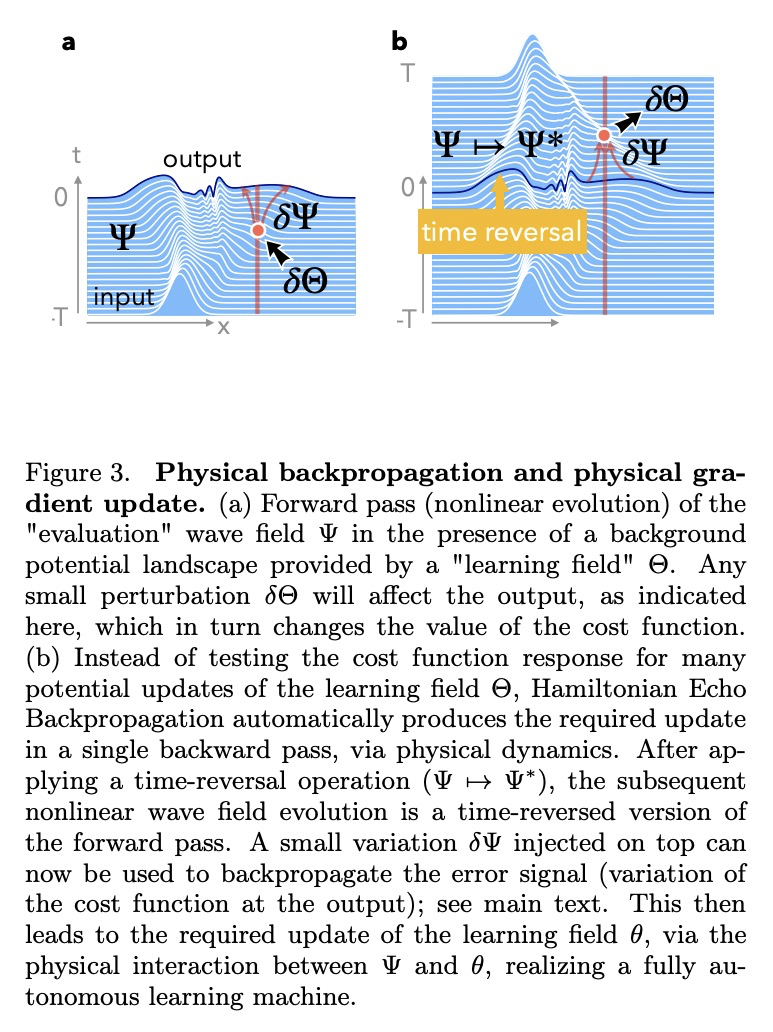
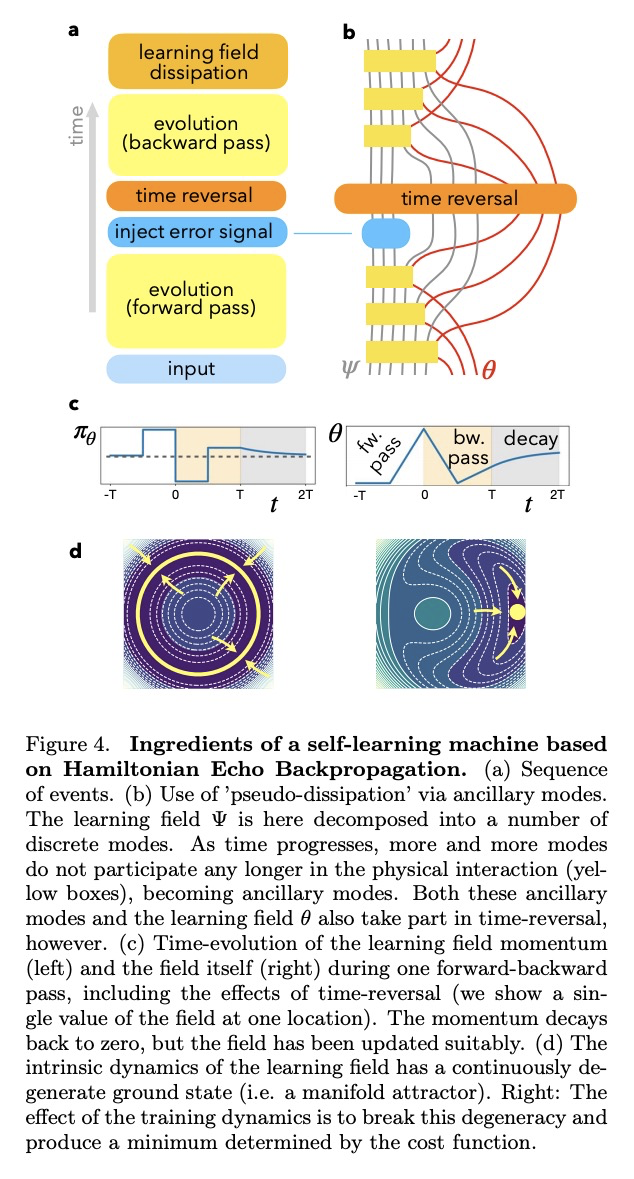
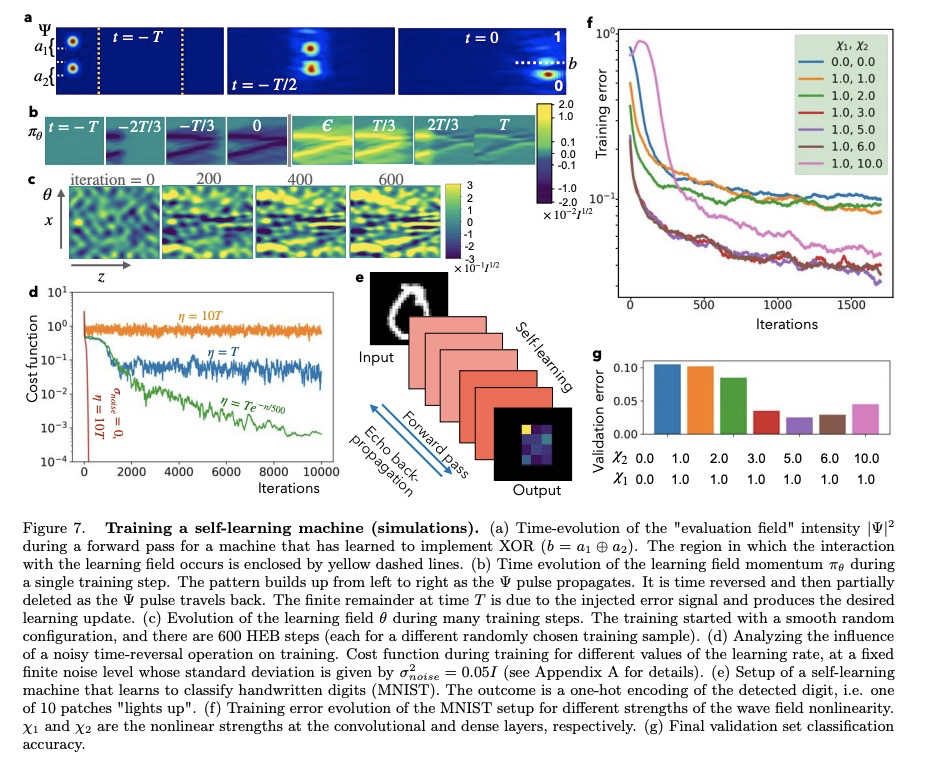
5、[AI] Self-learning Machines based on Hamiltonian Echo Backpropagation
V Lopez-Pastor, F Marquardt
[Max Planck Institute for the Science of Light & Friedrich-Alexander-Universität Erlangen-Nürnberg]
基于汉密尔顿回声反向传播的自学习机。物理自学习机可定义为一个非线性动态系统,可在数据上进行训练(类似于人工神经网络),但作为可学习参数的内部自由度的更新是自主进行的,既不需要外部处理和反馈,也不需要这些内部自由度的知识(和控制)。介绍了一种在任何时间可逆的汉密尔顿系统中进行自学习的一般方案,用数值方法说明了这种自学习机在耦合非线性波场情况下的训练。
A physical self-learning machine can be defined as a nonlinear dynamical system that can be trained on data (similar to artificial neural networks), but where the update of the internal degrees of freedom that serve as learnable parameters happens autonomously. In this way, neither external processing and feedback nor knowledge of (and control of) these internal degrees of freedom is required. We introduce a general scheme for self-learning in any time-reversible Hamiltonian system. We illustrate the training of such a self-learning machine numerically for the case of coupled nonlinear wave fields.
https://weibo.com/1402400261/K7jnBtBwK
另外几篇值得关注的论文:
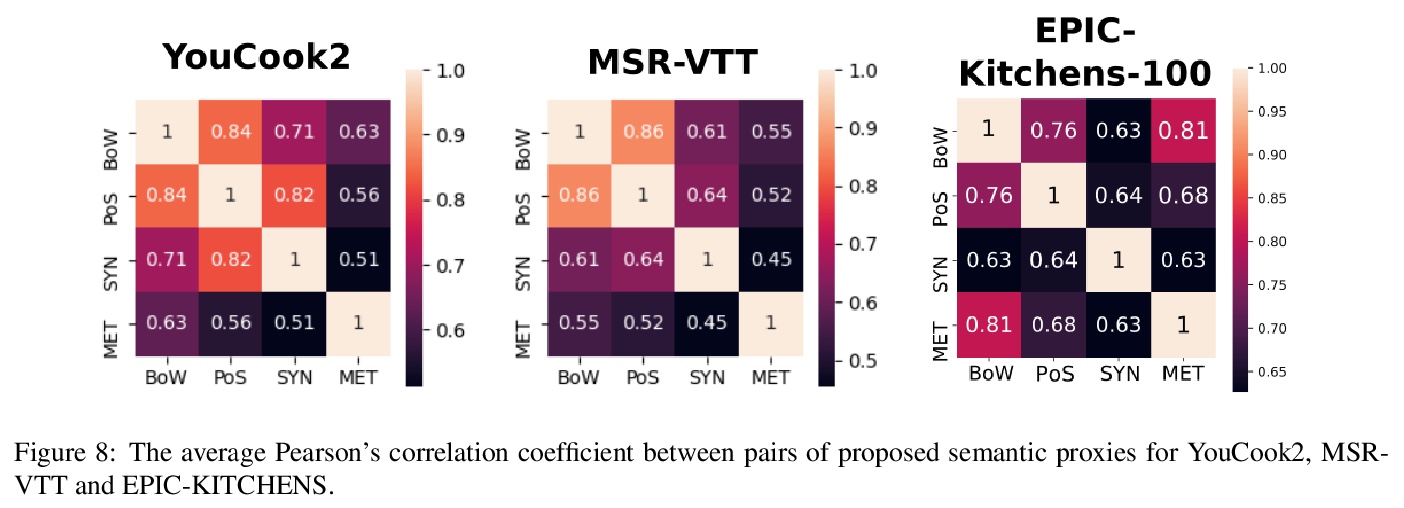
[CV] On Semantic Similarity in Video Retrieval
视频检索中的语义相似性研究
M Wray, H Doughty, D Damen
[University of Bristol]
https://weibo.com/1402400261/K7jql7CxY


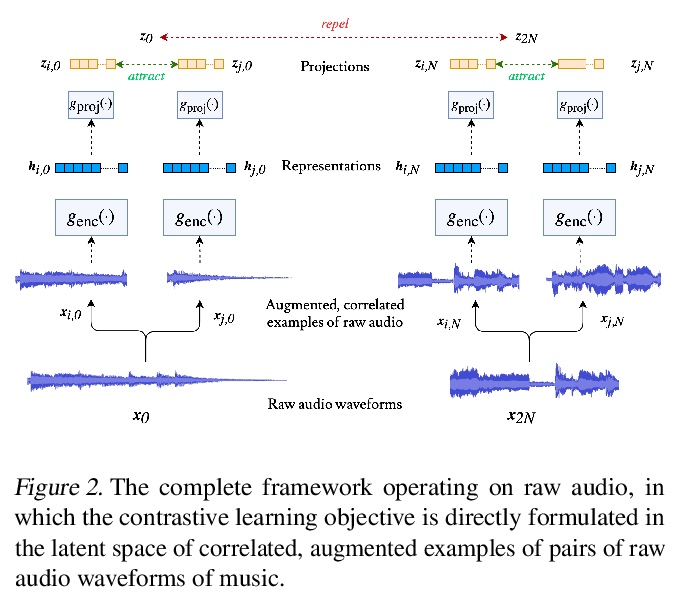
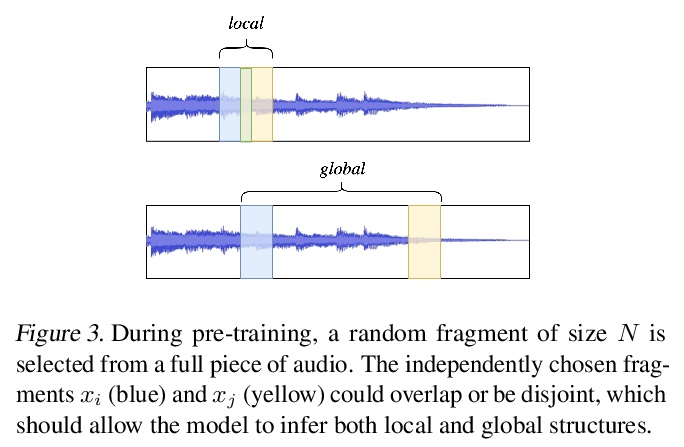
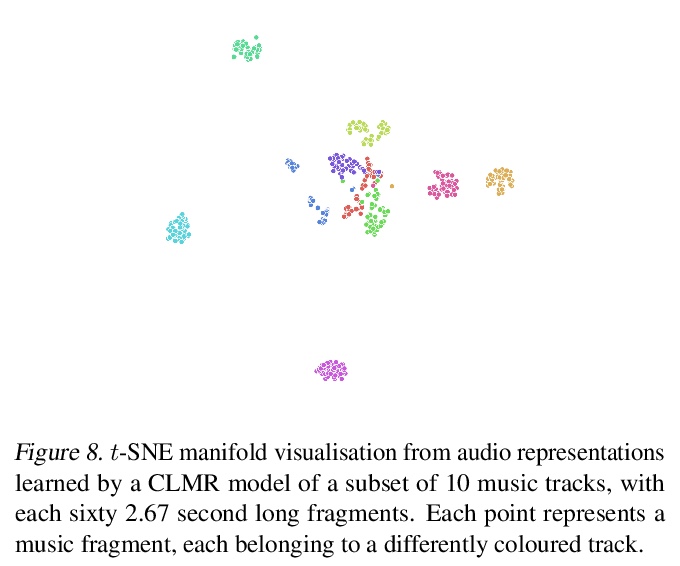
[AS] Contrastive Learning of Musical Representations
音乐表征的对比学习
J Spijkervet, J A Burgoyne
[University of Amsterdam]
https://weibo.com/1402400261/K7jrLaZKm
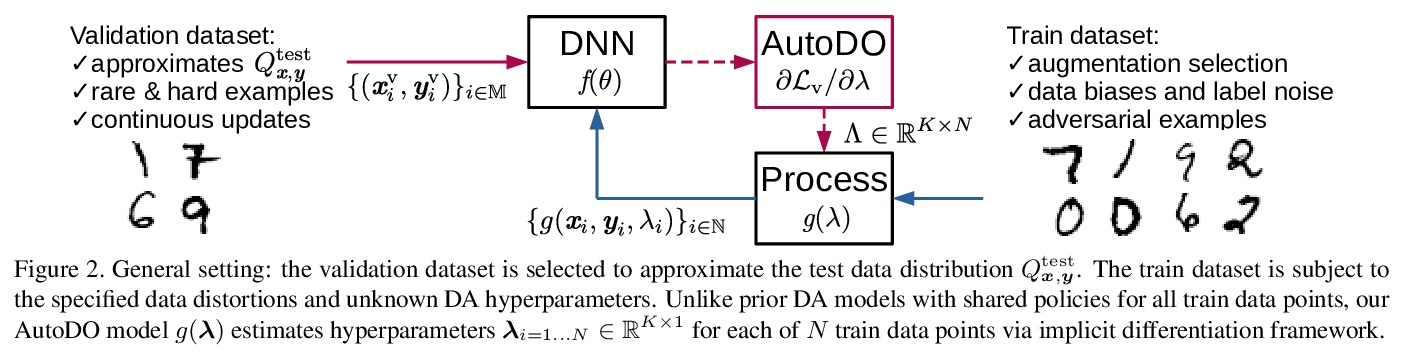
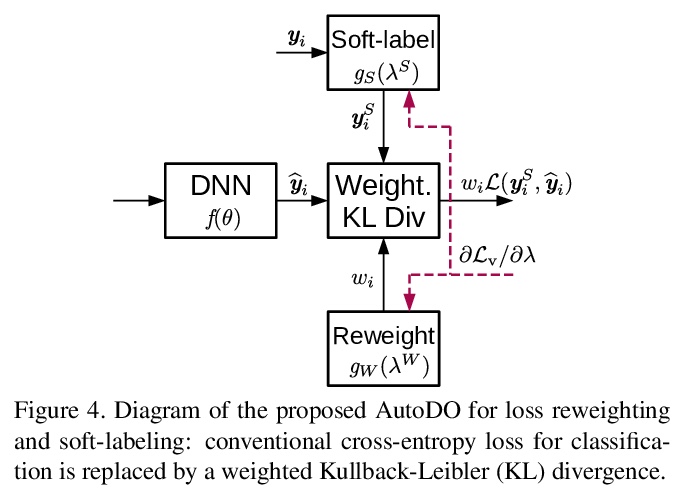
[CV] AutoDO: Robust AutoAugment for Biased Data with Label Noise via Scalable Probabilistic Implicit Differentiation
AutoDO:基于可扩展概率隐式微分的带标签噪声的有偏数据鲁棒自动校正
D Gudovskiy, L Rigazio, S Ishizaka, K Kozuka, S Tsukizawa
[Panasonic AI Lab & AIoli Labs & Panasonic Technology Division]
https://weibo.com/1402400261/K7jsZ4d4j

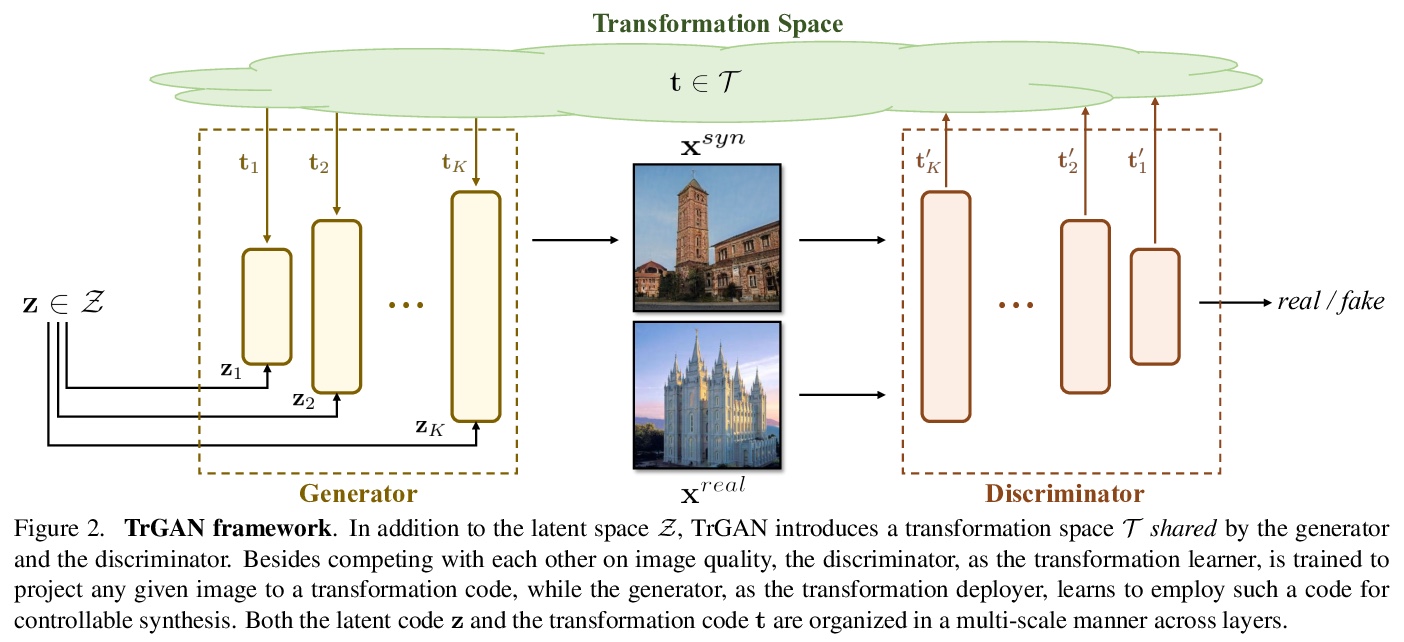
[CV] Unsupervised Image Transformation Learning via Generative Adversarial Networks
基于生成对抗网络的无监督图像变换学习
K Zha, Y Shen, B Zhou
[MIT CSAIL & The Chinese University of Hong Kong]
https://weibo.com/1402400261/K7jux8ugF



若有收获,就点个赞吧
0 人点赞
