- 1、[LG] Training GANs with Stronger Augmentations via Contrastive Discriminator
- 2、[CV] You Only Look One-level Feature
- 3、[LG] Learning Robust State Abstractions for Hidden-Parameter Block MDPs
- 4、[LG] A Practical Guide to Multi-Objective Reinforcement Learning and Planning
- 5、[CV] ALADIN: All Layer Adaptive Instance Normalization for Fine-grained Style Similarity
- [AI] Evaluation of soccer team defense based on prediction models of ball recovery and being attacked
- [LG] DoubleML — An Object-Oriented Implementation of Double Machine Learning in R
- [LG] Physics-Informed Deep-Learning for Scientific Computing
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Training GANs with Stronger Augmentations via Contrastive Discriminator
J Jeong, J Shin
[Korea Advanced Institute of Science and Technology (KAIST)]
基于对比判别器的GAN更强增强训练。提出对比鉴别器(ContraD),一种新的GAN判别器训练方式,结合对比学习原理,不直接针对GAN损失优化判别器网络,而是主要利用网络从给定数据增强和(真实或生成)样本集中提取对比性表示。将GAN损失最小化的实际判别器是根据对比表示独立定义的,结果发现一个简单的二层网络足以作为一个完整的GAN工作。通过设计,ContraD可自然地使用对比学习文献中使用的增强功能进行训练,例如SimCLR提出的增强功能,这些增强功能实际上比GAN训练背景下的典型实践强得多。当用一个共享表示联合训练时,对比学习任务(对独立的真实样本中的每一个进行区分)和GAN辨别器的任务(将假样本从真实样本中区分出来)相互受益。
Recent works in Generative Adversarial Networks (GANs) are actively revisiting various data augmentation techniques as an effective way to prevent discriminator overfitting. It is still unclear, however, that which augmentations could actually improve GANs, and in particular, how to apply a wider range of augmentations in training. In this paper, we propose a novel way to address these questions by incorporating a recent contrastive representation learning scheme into the GAN discriminator, coined ContraD. This “fusion” enables the discriminators to work with much stronger augmentations without increasing their training instability, thereby preventing the discriminator overfitting issue in GANs more effectively. Even better, we observe that the contrastive learning itself also benefits from our GAN training, i.e., by maintaining discriminative features between real and fake samples, suggesting a strong coherence between the two worlds: good contrastive representations are also good for GAN discriminators, and vice versa. Our experimental results show that GANs with ContraD consistently improve FID and IS compared to other recent techniques incorporating data augmentations, still maintaining highly discriminative features in the discriminator in terms of the linear evaluation. Finally, as a byproduct, we also show that our GANs trained in an unsupervised manner (without labels) can induce many conditional generative models via a simple latent sampling, leveraging the learned features of ContraD. Code is available at > this https URL.
https://weibo.com/1402400261/K6QD5nUXX



2、[CV] You Only Look One-level Feature
Q Chen, Y Wang, T Yang, X Zhang, J Cheng, J Sun
[Chinese Academy of Sciences & MEGVII Technology]
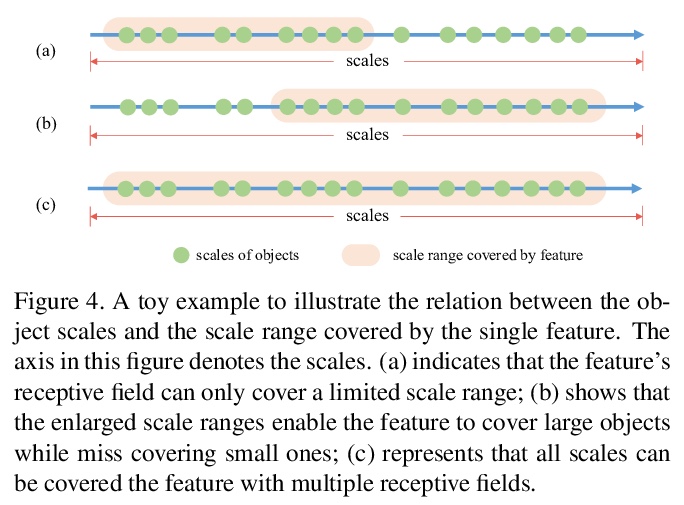
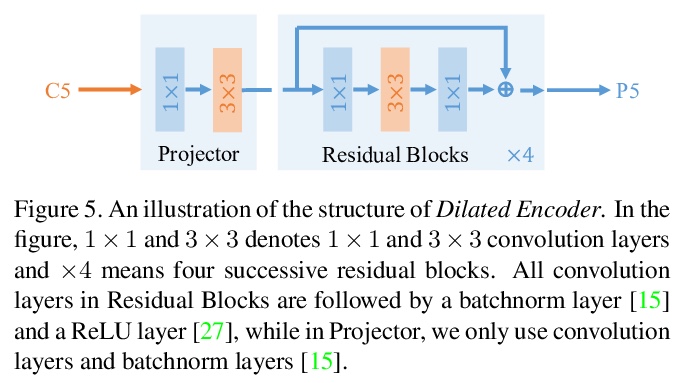
只看一级特征(YOLOF)。指出FPN最显著的优势是它在密集目标检测中对优化问题的分而治之解决方案,而不是多尺度特征融合。从优化角度出发,提出另一种解决方法,不使用FPN的简单高效基线,只利用一级特征进行检测。基于简单高效的解决方案,提出了”只看一级特征”(YOLOF),提出了稀释编码器(Dilated Encoder)和统一匹配(Uniform Matching)两个关键部分,弥补了SiSo编码器和MiMo编码器之间的性能差距。在COCO基准上的大量实验证明了所提出模型的有效性。YOLOF实现了与其特征金字塔对应的RetinaNet相当的结果,同时速度快了2.5倍。在不使用变换层的情况下,YOLOF可以以单层特征的方式与DETR的性能相媲美,同时减少了7倍的训练时间。在图像尺寸为608×608的情况下,YOLOF在2080Ti上以60fps的速度运行时达到44.3mAP,比YOLOv4快13%。
This paper revisits feature pyramids networks (FPN) for one-stage detectors and points out that the success of FPN is due to its divide-and-conquer solution to the optimization problem in object detection rather than multi-scale feature fusion. From the perspective of optimization, we introduce an alternative way to address the problem instead of adopting the complex feature pyramids - {\em utilizing only one-level feature for detection}. Based on the simple and efficient solution, we present You Only Look One-level Feature (YOLOF). In our method, two key components, Dilated Encoder and Uniform Matching, are proposed and bring considerable improvements. Extensive experiments on the COCO benchmark prove the effectiveness of the proposed model. Our YOLOF achieves comparable results with its feature pyramids counterpart RetinaNet while being > 2.5× faster. Without transformer layers, YOLOF can match the performance of DETR in a single-level feature manner with > 7× less training epochs. With an image size of > 608×608, YOLOF achieves 44.3 mAP running at 60 fps on 2080Ti, which is > 13% faster than YOLOv4. Code is available at \url{> this https URL}.
https://weibo.com/1402400261/K6QHyx2c4

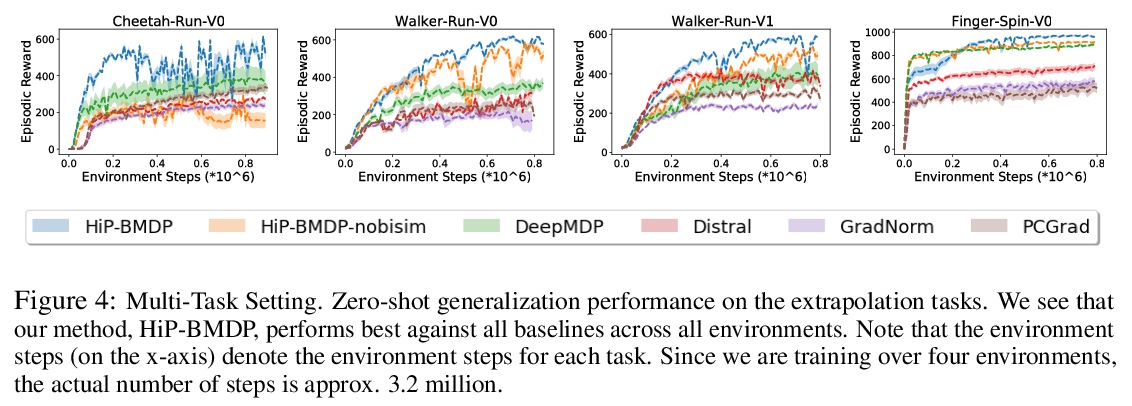
3、[LG] Learning Robust State Abstractions for Hidden-Parameter Block MDPs
A Zhang, S Sodhani, K Khetarpal, J Pineau
[McGill University & Facebook AI Research]
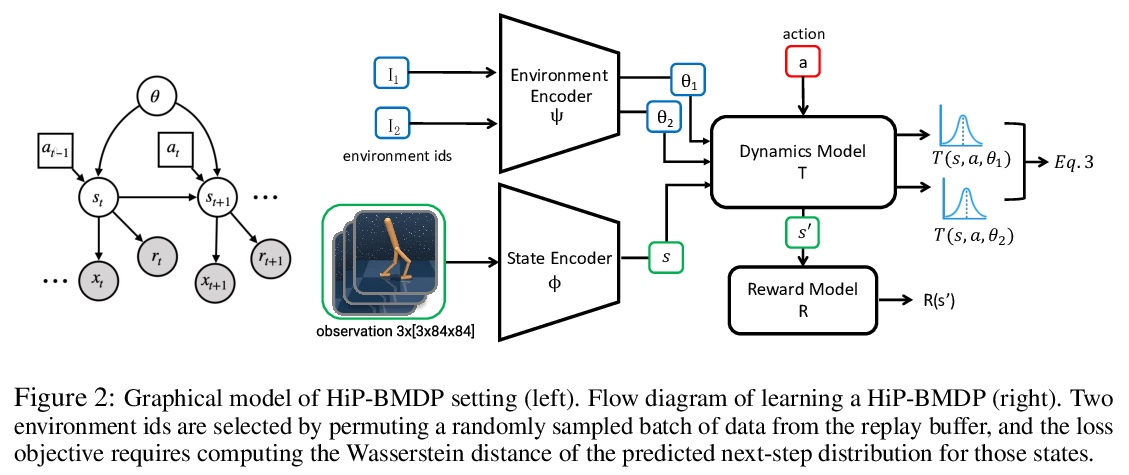
隐藏参数块MDP的鲁棒状态抽象学习。提出一种针对多任务强化学习环境的新框架HiP-BMDP,与之前方法一样,HiP-BMDP假设了跨任务的共享状态和动作空间,另外还假设了动态中的潜结构。通过学习具有潜参数θ的通用动力学模型来利用这种结构,该模型捕获了不同任务的行为相似性。为多任务强化学习(MTRL)和元强化学习(Meta-RL)设置推导出该框架的实例。提供了基于任务和状态相似性的迁移和泛化界,以及依赖于任务间样本总数而非任务数量的样本复杂度界,比之前使用相同环境假设的工作有了显著改进。为进一步证明所提出方法的有效性,对多任务和元强化学习基线进行了实证比较并展示了改进。
Many control tasks exhibit similar dynamics that can be modeled as having common latent structure. Hidden-Parameter Markov Decision Processes (HiP-MDPs) explicitly model this structure to improve sample efficiency in multi-task settings. However, this setting makes strong assumptions on the observability of the state that limit its application in real-world scenarios with rich observation spaces. In this work, we leverage ideas of common structure from the HiP-MDP setting, and extend it to enable robust state abstractions inspired by Block MDPs. We derive instantiations of this new framework for both multi-task reinforcement learning (MTRL) and meta-reinforcement learning (Meta-RL) settings. Further, we provide transfer and generalization bounds based on task and state similarity, along with sample complexity bounds that depend on the aggregate number of samples across tasks, rather than the number of tasks, a significant improvement over prior work that use the same environment assumptions. To further demonstrate the efficacy of the proposed method, we empirically compare and show improvement over multi-task and meta-reinforcement learning baselines.
https://weibo.com/1402400261/K6QMR6fj9
4、[LG] A Practical Guide to Multi-Objective Reinforcement Learning and Planning
C F. Hayes, R Rădulescu, E Bargiacchi, J Källström, M Macfarlane, M Reymond, T Verstraeten, L M. Zintgraf, R Dazeley, F Heintz, E Howley, A A. Irissappane, P Mannion, A Nowé, G Ramos, M Restelli, P Vamplew, D M. Roijers
[National University of Ireland Galway & Vrije Universiteit Brussel & Linköping University]
多目标再强化学习与规划实践指南。现实世界中的决策任务一般都很复杂,需要在多个往往相互冲突的目标之间进行权衡。尽管如此,大多数强化学习和决策理论规划的研究要么只假设一个目标,要么认为多个目标可通过简单的线性组合充分处理。这种方法可能会过度简化基本问题,从而产生次优结果。本文作为多目标方法应用于困难问题的指南,主要针对已经熟悉单目标强化学习和规划方法、希望采用多目标视角进行研究的研究人员,以及在实践中遇到多目标决策问题的从业人员。本文确定了可能影响所需解决方案性质的因素,并通过实例说明这些因素如何影响复杂问题的多目标决策系统的设计,目的是对多目标决策进行介绍,并指导读者开始建立模型解决此类决策问题。
Real-world decision-making tasks are generally complex, requiring trade-offs between multiple, often conflicting, objectives. Despite this, the majority of research in reinforcement learning and decision-theoretic planning either assumes only a single objective, or that multiple objectives can be adequately handled via a simple linear combination. Such approaches may oversimplify the underlying problem and hence produce suboptimal results. This paper serves as a guide to the application of multi-objective methods to difficult problems, and is aimed at researchers who are already familiar with single-objective reinforcement learning and planning methods who wish to adopt a multi-objective perspective on their research, as well as practitioners who encounter multi-objective decision problems in practice. It identifies the factors that may influence the nature of the desired solution, and illustrates by example how these influence the design of multi-objective decision-making systems for complex problems.
https://weibo.com/1402400261/K6QSpCD9h
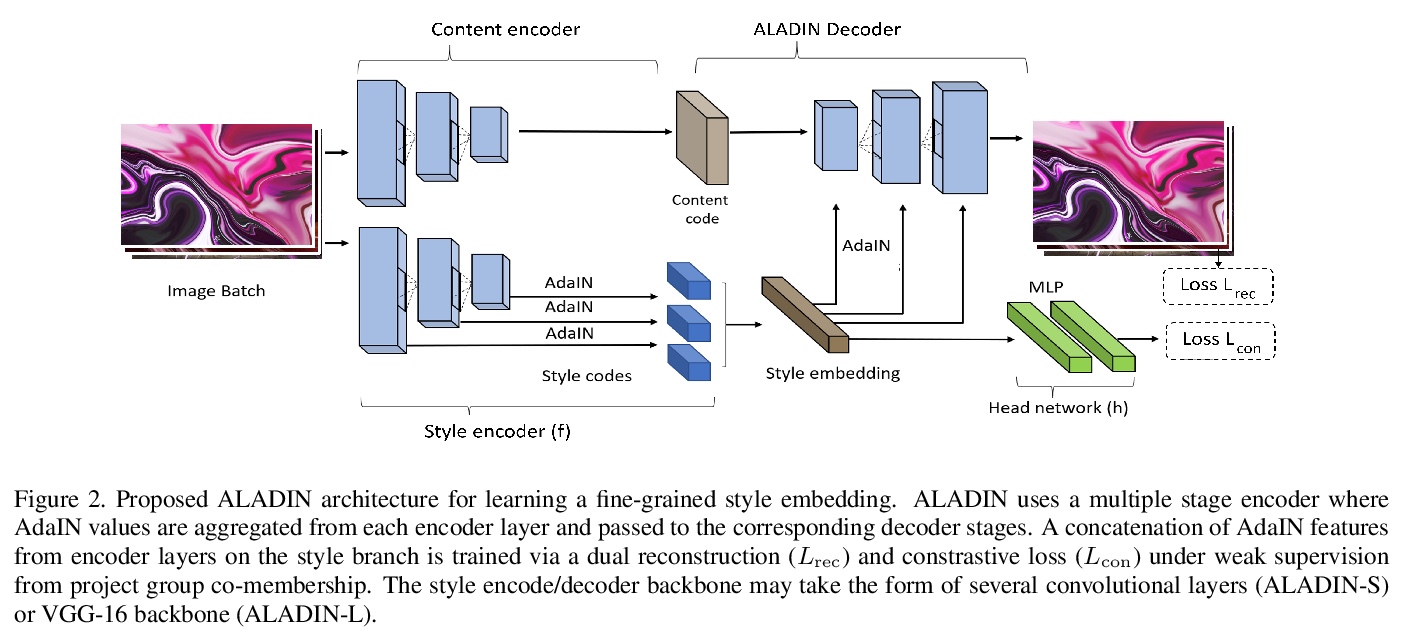
5、[CV] ALADIN: All Layer Adaptive Instance Normalization for Fine-grained Style Similarity
D Ruta, S Motiian, B Faieta, Z Lin, H Jin, A Filipkowski, A Gilbert, J Collomosse
[University of Surrey & Adobe Research]
ALADIN:用于细粒度风格相似性的全层自适应实例归一化。提出一种编码器-解码器(E-D)架构ALADIN(All Layer AdaIN),以学习一种细粒度表示,用于度量细粒度艺术风格相似性。ALADIN的灵感来自于用于驱动内容风格化的E-D模型,其明确地将内容和风格跨网络分支进行解缠。提出并使用一种弱监督方法来学习这种表示,用对数累积策略的对比训练使之可行。ALADIN达到了细粒度辨别的最先进性能,在使用清理过的分组数据进行训练和融合时进一步提高。贡献了一个包含31万个细粒度风格分组的262万图像数据集。
We present ALADIN (All Layer AdaIN); a novel architecture for searching images based on the similarity of their artistic style. Representation learning is critical to visual search, where distance in the learned search embedding reflects image similarity. Learning an embedding that discriminates fine-grained variations in style is hard, due to the difficulty of defining and labelling style. ALADIN takes a weakly supervised approach to learning a representation for fine-grained style similarity of digital artworks, leveraging BAM-FG, a novel large-scale dataset of user generated content groupings gathered from the web. ALADIN sets a new state of the art accuracy for style-based visual search over both coarse labelled style data (BAM) and BAM-FG; a new 2.62 million image dataset of 310,000 fine-grained style groupings also contributed by this work.
https://weibo.com/1402400261/K6R0zyVrt


另外几篇值得关注的论文:
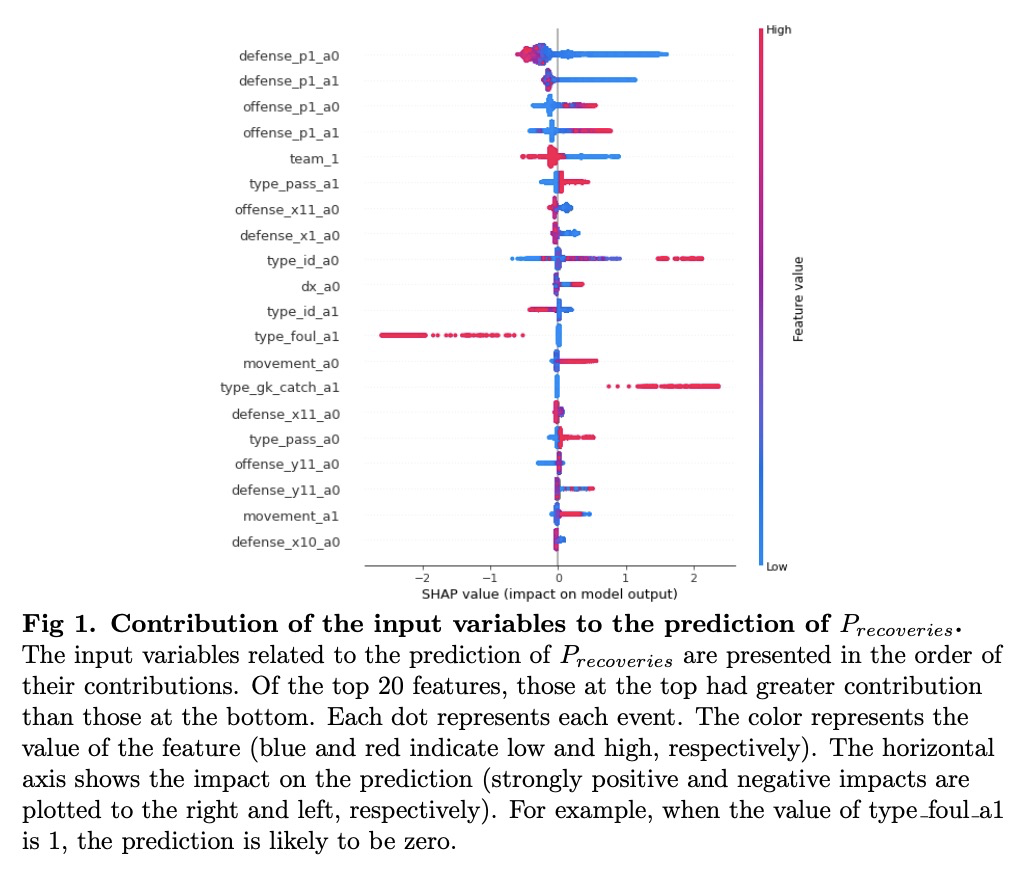
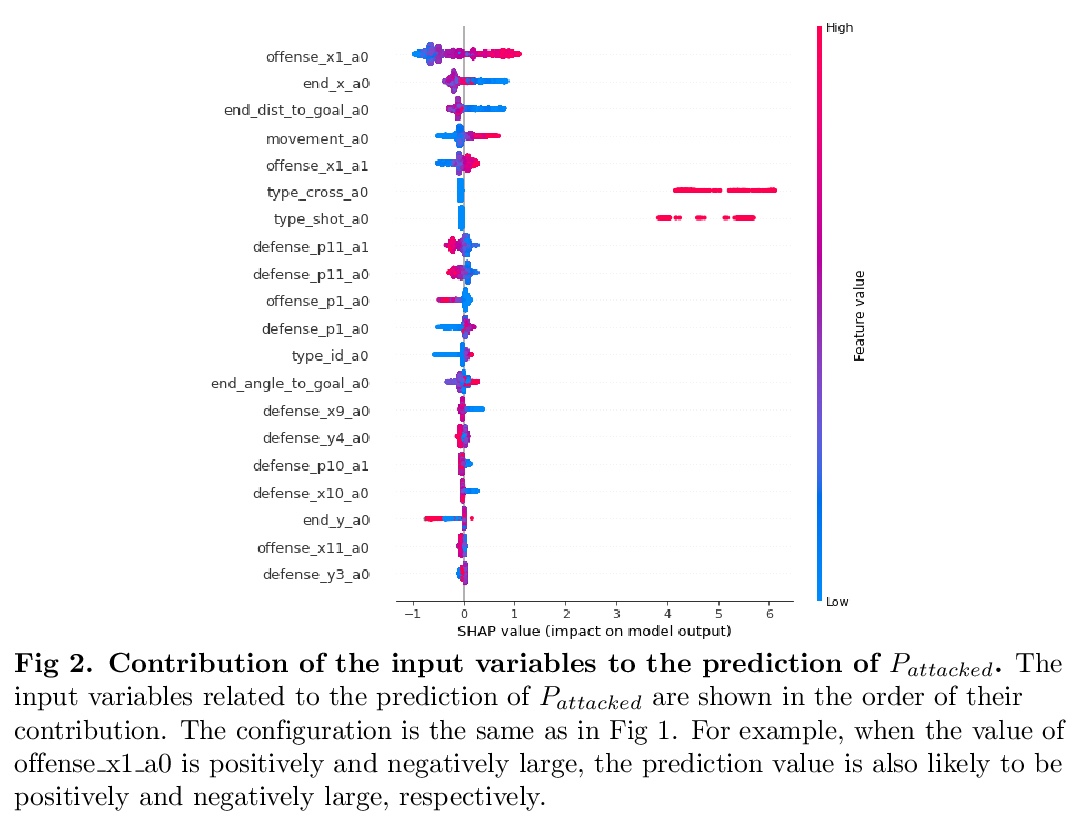
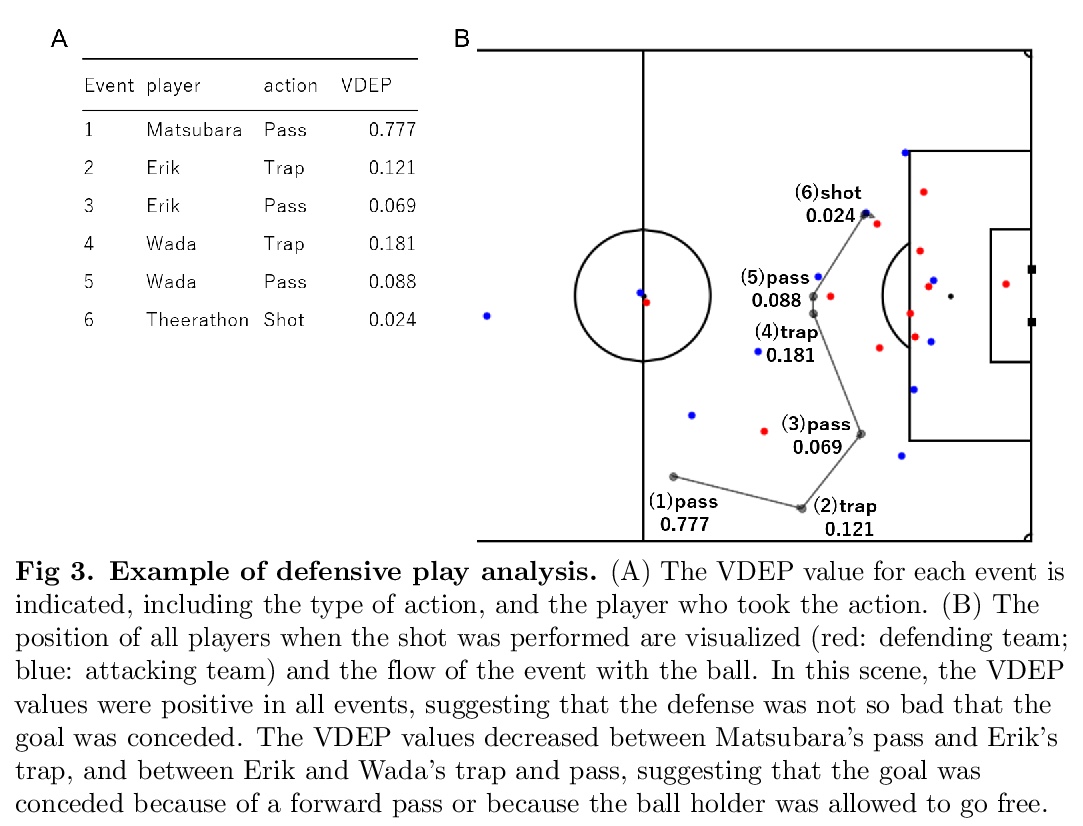
[AI] Evaluation of soccer team defense based on prediction models of ball recovery and being attacked
基于收球和被攻预测模型的足球队防守评价
K Toda, M Teranishi, K Kushiro, K Fujii
[Kyoto University & Nagoya University]
https://weibo.com/1402400261/K6R3Z7fJE
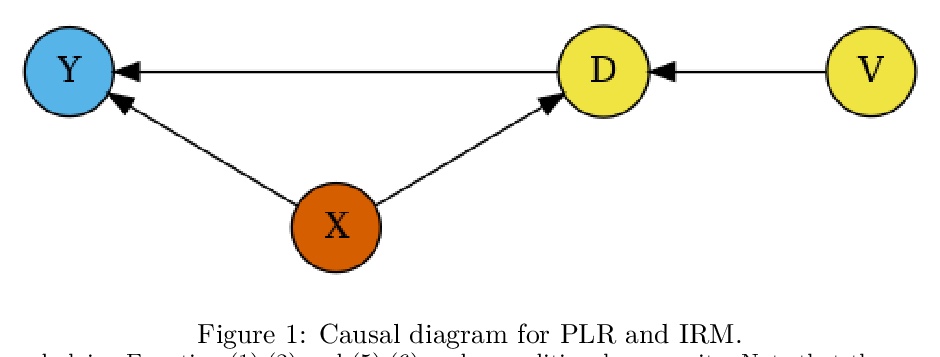
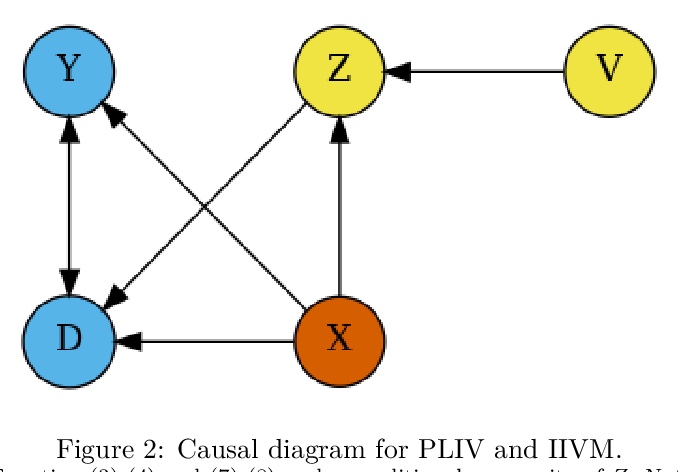
[LG] DoubleML — An Object-Oriented Implementation of Double Machine Learning in R
DoubleML:双机学习框架的面向对象R语言实现
P Bach, V Chernozhukov, M S. Kurz, M Spindler
[University of Hamburg & MIT]
https://weibo.com/1402400261/K6R7nxNLf
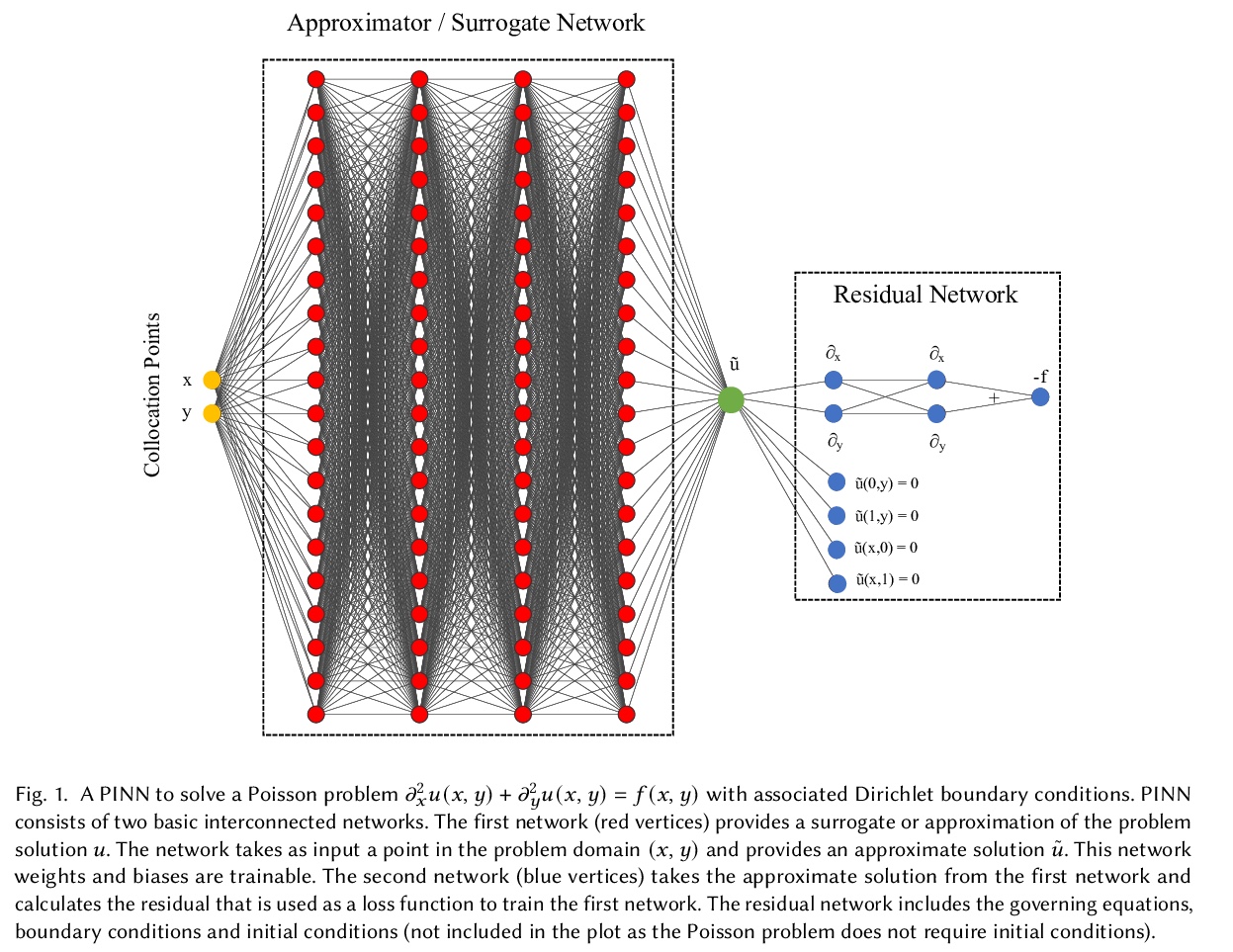
[LG] Physics-Informed Deep-Learning for Scientific Computing
面向科学计算的物理信息深度学习
S Markidis
[KTH Royal Institute of Technology]
https://weibo.com/1402400261/K6R9s1WPQ

若有收获,就点个赞吧
0 人点赞
