- 1、[CV] Neural 3D Video Synthesis
- 2、[CV] Self-supervised Pretraining of Visual Features in the Wild
- 3、[LG] Computing the Information Content of Trained Neural Networks
- 4、[CV] House-GAN++: Generative Adversarial Layout Refinement Networks
- 5、[CV] Towards Open World Object Detection
- [CV] Style-based Point Generator with Adversarial Rendering for Point Cloud Completion
- [CV] Task Aligned Generative Meta-learning for Zero-shot Learning
- [CV] Adaptive Consistency Regularization for Semi-Supervised Transfer Learning
- [LG] Domain Generalization: A Survey
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Neural 3D Video Synthesis
T Li, M Slavcheva, M Zollhoefer, S Green, C Lassner, C Kim, T Schmidt, S Lovegrove, M Goesele, Z Lv
[University of Southern California & Facebook Reality Labs Research]
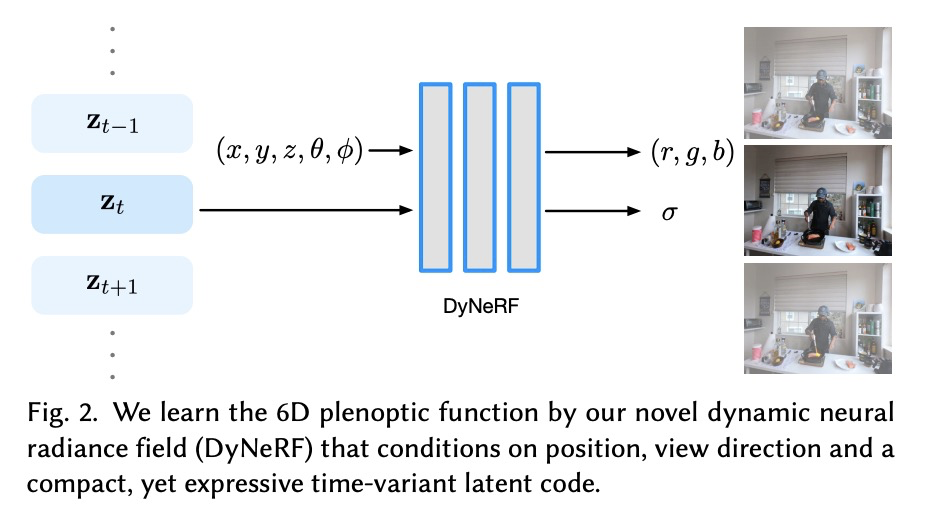
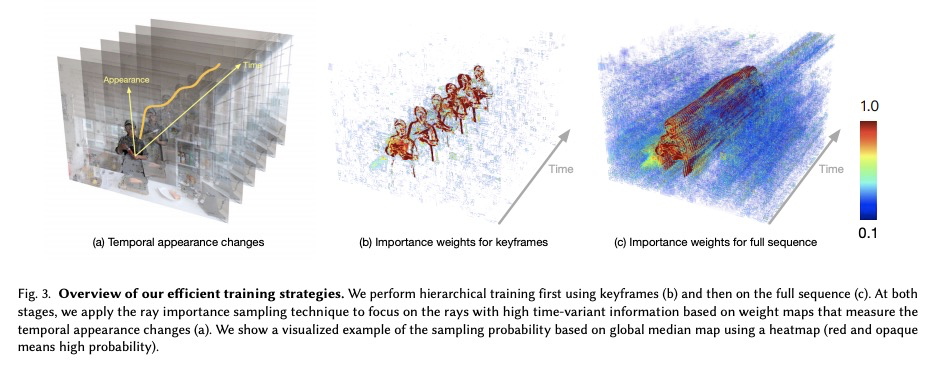
神经网络3D视频合成。提出一种新的3D视频合成方法,能以紧凑而富有表现力的表示方式,来表示动态现实世界场景的多视角视频记录,实现高质量的视图合成和运动插值。该方法将静态神经辐射场的高质量和紧凑性,带入一个新的方向:无模型的动态环境。方法的核心是一种新型的时间条件神经辐射场,使用一组紧凑的潜码来表示场景动态。为了利用视频相邻帧之间变化通常很小且局部一致这一事实,提出两种新策略来高效训练网络:高效的分层训练方案,以及重要性采样策略,根据输入视频的时间变化选择下一条射线进行训练。两种策略相结合,显著提升了训练速度,使训练过程快速收敛,并实现了高质量的结果。学习到的表示方法是高度紧凑的,表示18个摄像机录制的10秒30FPS多视角视频,模型大小仅为28MB。该方法可以在超过1K分辨率下呈现高保真广角新视图,即使是高度复杂和动态场景。
We propose a novel approach for 3D video synthesis that is able to represent multi-view video recordings of a dynamic real-world scene in a compact, yet expressive representation that enables high-quality view synthesis and motion interpolation. Our approach takes the high quality and compactness of static neural radiance fields in a new direction: to a model-free, dynamic setting. At the core of our approach is a novel time-conditioned neural radiance fields that represents scene dynamics using a set of compact latent codes. To exploit the fact that changes between adjacent frames of a video are typically small and locally consistent, we propose two novel strategies for efficient training of our neural network: 1) An efficient hierarchical training scheme, and 2) an importance sampling strategy that selects the next rays for training based on the temporal variation of the input videos. In combination, these two strategies significantly boost the training speed, lead to fast convergence of the training process, and enable high quality results. Our learned representation is highly compact and able to represent a 10 second 30 FPS multi-view video recording by 18 cameras with a model size of just 28MB. We demonstrate that our method can render high-fidelity wide-angle novel views at over 1K resolution, even for highly complex and dynamic scenes. We perform an extensive qualitative and quantitative evaluation that shows that our approach outperforms the current state of the art. We include additional video and information at: > this https URL
https://weibo.com/1402400261/K4IQicCDS

2、[CV] Self-supervised Pretraining of Visual Features in the Wild
P Goyal, M Caron, B Lefaudeux, M Xu, P Wang, V Pai, M Singh, V Liptchinsky, I Misra, A Joulin, P Bojanowski
[Facebook AI Research]
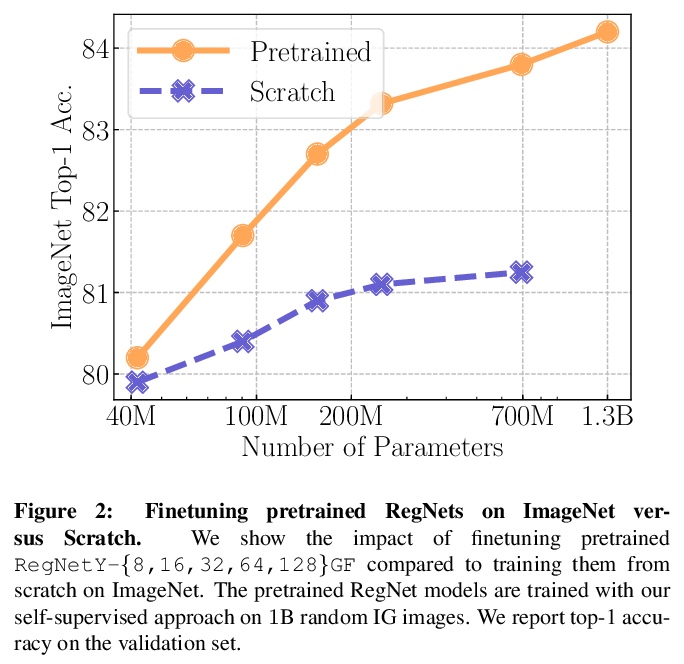
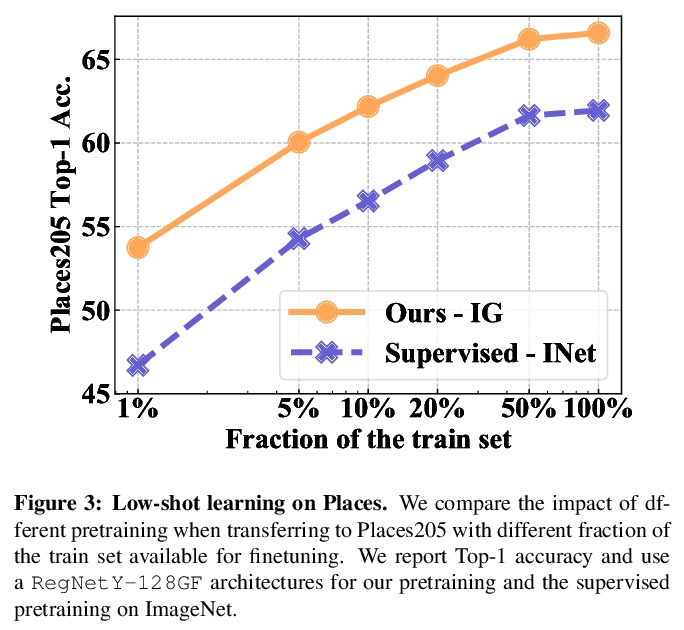
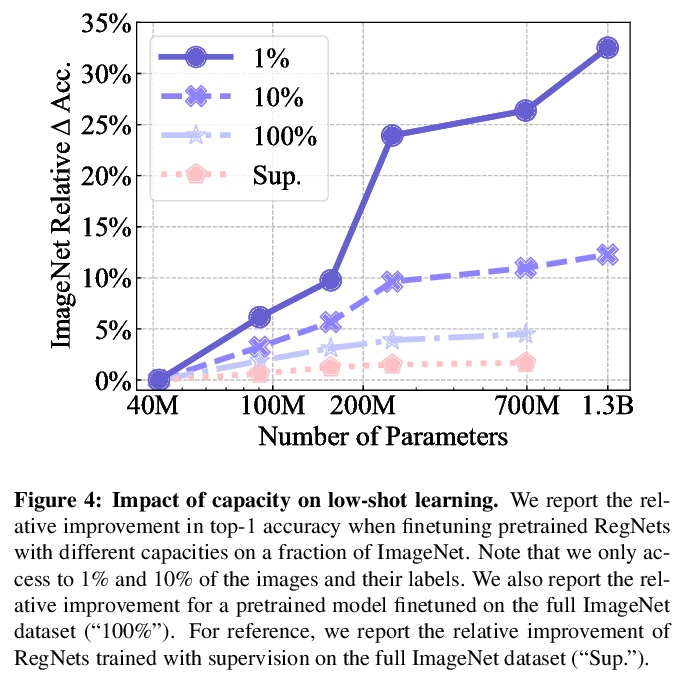
真实场景视觉特征的自监督预训练。自监督学习的前提是它可以从任何随机图像和无约束的数据集中学习,通过在随机的、非策划图像上训练大型模型,在没有监督的情况下,探索自监督是否能达到预期。最终的SElf-supERvised(SEER)模型,即在1B随机图像上用512个GPU训练的具有1.3B参数的RegNetY,达到了84.2%的top-1准确率,超出最好的自监督预训练模型1%,证实了自监督学习在真实世界环境中是有效的。在无标注的随机图像上预训练特征,在所有下游任务上都能达到有竞争力的性能。同时还观察到,自监督模型是良好的少样本学习器,在只访问10%的ImageNet的情况下,实现了77.9%的top-1准确率。现代自监督学习方法在数据方面的可扩展性,以及现代高效的大容量架构,特别是RegNets的可扩展性在推动自监督预训练的极限方面发挥了关键作用。
Recently, self-supervised learning methods like MoCo, SimCLR, BYOL and SwAV have reduced the gap with supervised methods. These results have been achieved in a control environment, that is the highly curated ImageNet dataset. However, the premise of self-supervised learning is that it can learn from any random image and from any unbounded dataset. In this work, we explore if self-supervision lives to its expectation by training large models on random, uncurated images with no supervision. Our final SElf-supERvised (SEER) model, a RegNetY with 1.3B parameters trained on 1B random images with 512 GPUs achieves 84.2% top-1 accuracy, surpassing the best self-supervised pretrained model by 1% and confirming that self-supervised learning works in a real world setting. Interestingly, we also observe that self-supervised models are good few-shot learners achieving 77.9% top-1 with access to only 10% of ImageNet. Code: > this https URL
https://weibo.com/1402400261/K4IV7bAis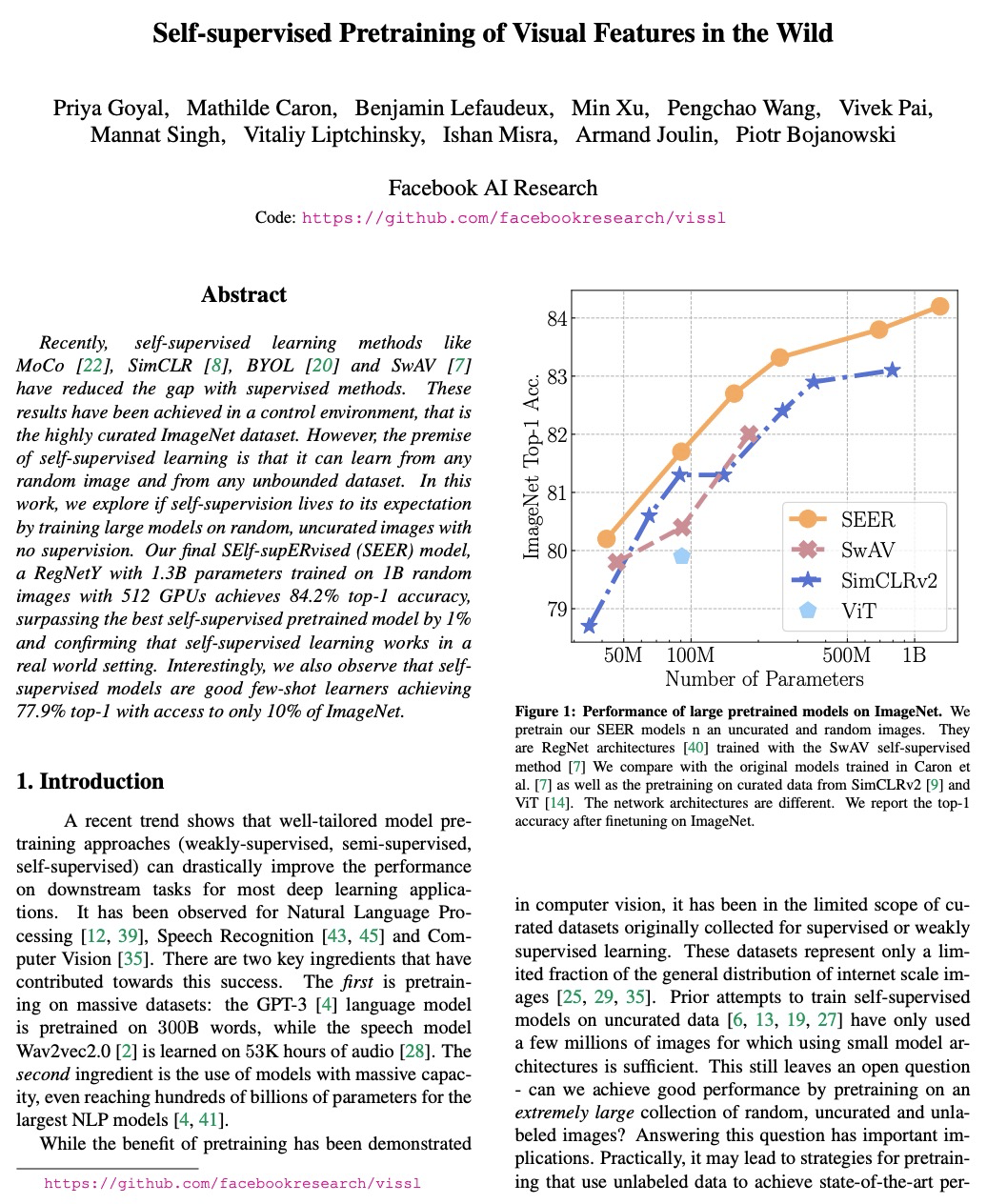
3、[LG] Computing the Information Content of Trained Neural Networks
J Bernstein, Y Yue
[Caltech University]
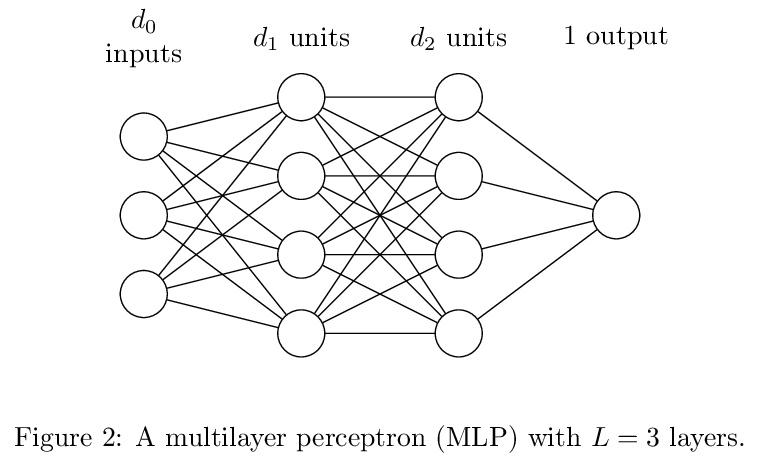
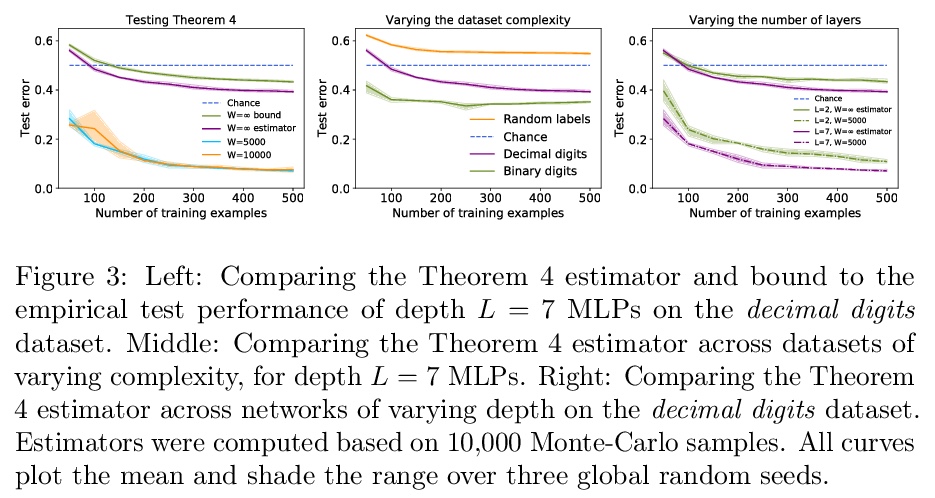
经训练神经网络信息量的计算。学习算法从训练数据中提取了多少信息,存储在神经网络的权重中?如果太多,网络会对训练数据过拟合;太少,网络会一直无法拟合。网络存储的信息量应该与可训练权重数量成正比。这就提出了一个问题:权重大大超过训练数据的神经网络如何还能泛化?这个难题的一个简单解决方案是,权重数量往往是存储的实际信息量的一个糟糕的代表。例如,典型的权重向量可能是高度可压缩的。那么另一个问题就出现了:是否有可能计算出实际存储的信息量?本文推导了一个一致的估计器,和一个关于无限宽神经网络信息量的闭式上界。推导基于神经信息量和高斯正弦负对数概率的识别。这种识别得到的界值可以分析控制无限宽网络整个解空间的泛化行为。该界对网络架构和训练数据都有简单的依赖性。
How much information does a learning algorithm extract from the training data and store in a neural network’s weights? Too much, and the network would overfit to the training data. Too little, and the network would not fit to anything at all. Naïvely, the amount of information the network stores should scale in proportion to the number of trainable weights. This raises the question: how can neural networks with vastly more weights than training data still generalise? A simple resolution to this conundrum is that the number of weights is usually a bad proxy for the actual amount of information stored. For instance, typical weight vectors may be highly compressible. Then another question occurs: is it possible to compute the actual amount of information stored? This paper derives both a consistent estimator and a closed-form upper bound on the information content of infinitely wide neural networks. The derivation is based on an identification between neural information content and the negative log probability of a Gaussian orthant. This identification yields bounds that analytically control the generalisation behaviour of the entire solution space of infinitely wide networks. The bounds have a simple dependence on both the network architecture and the training data. Corroborating the findings of Valle-Pérez et al. (2019), who conducted a similar analysis using approximate Gaussian integration techniques, the bounds are found to be both non-vacuous and correlated with the empirical generalisation behaviour at finite width.
https://weibo.com/1402400261/K4J0Rv1Kw

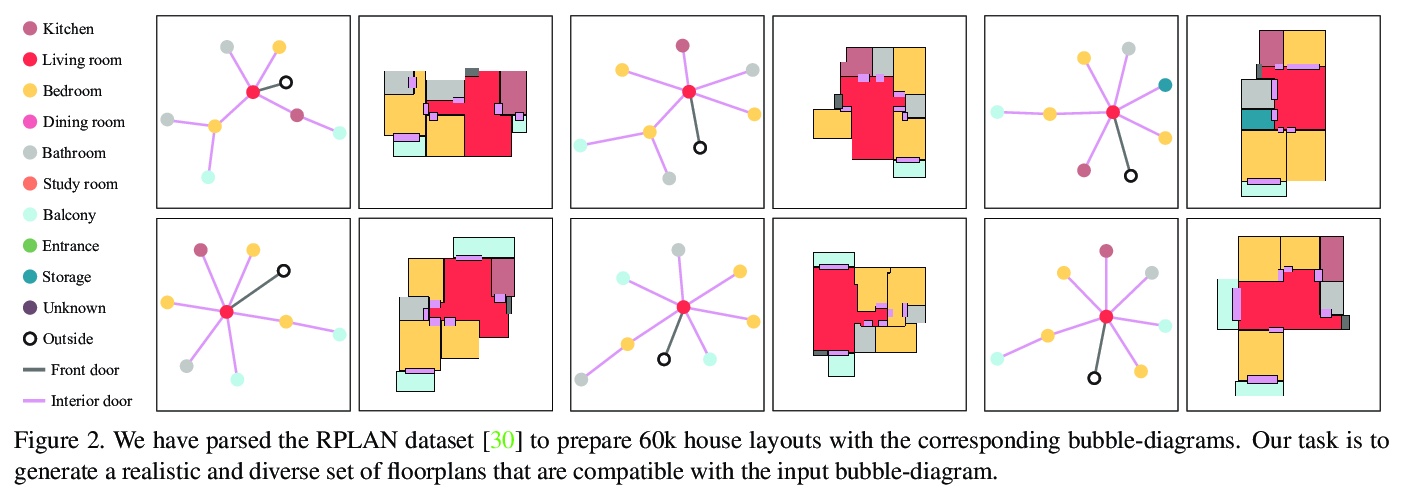
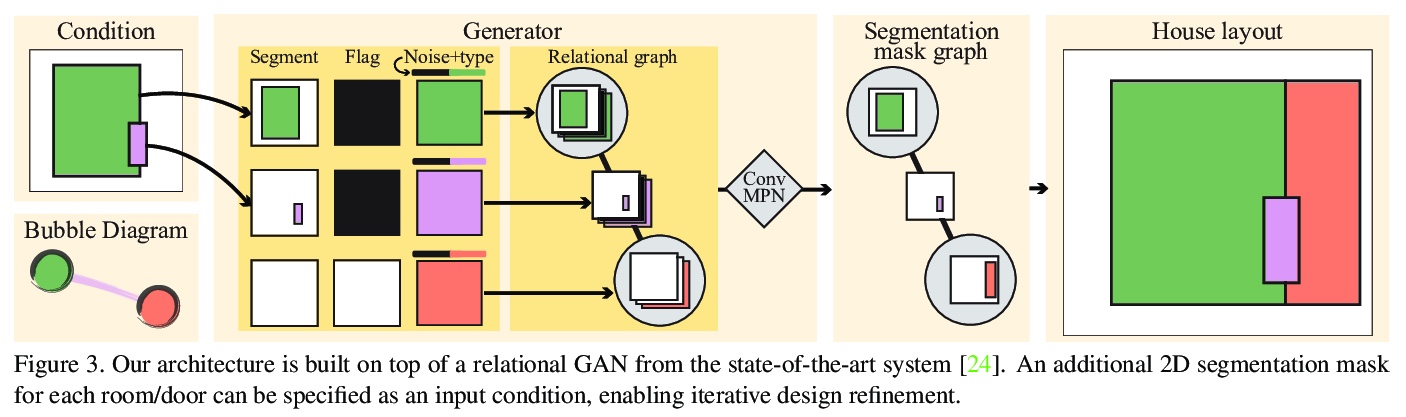
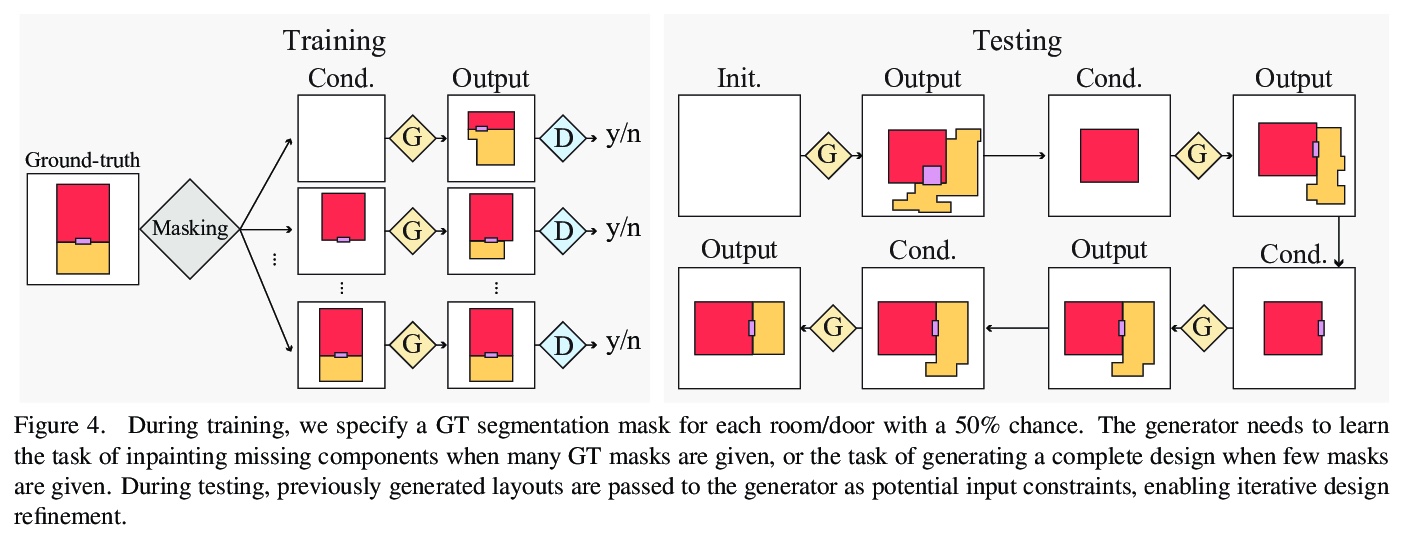
4、[CV] House-GAN++: Generative Adversarial Layout Refinement Networks
N Nauata, S Hosseini, K Chang, H Chu, C Cheng, Y Furukawa
[Simon Fraser University & Autodesk Research]
House-GAN++:生成式对抗性布局细化网络。提出一种新的生成式对抗性布局细化网络,用于自动生成平面图,在自动生成房屋布局的任务中取得了突破性的进展,生成的矢量平面图通常与地面真相无法区分。该架构是图约束关系型GAN和条件型GAN的集成,之前生成的布局成为下一输入约束,从而实现迭代细化。简单的非迭代训练过程,即所谓的组件化GT-conditioning,对于学习这样的生成器是有效的。迭代生成器还创造了一个新的机会,通过在迭代布局细化过程中控制何时传递哪些输入约束,通过元优化技术进一步改善选择的度量。基于三个标准指标的定性和定量评估表明,所提出的系统比目前最先进的系统有显著改进,甚至可以与专业建筑师设计的真实平面图竞争。
This paper proposes a novel generative adversarial layout refinement network for automated floorplan generation. Our architecture is an integration of a graph-constrained relational GAN and a conditional GAN, where a previously generated layout becomes the next input constraint, enabling iterative refinement. A surprising discovery of our research is that a simple non-iterative training process, dubbed component-wise GT-conditioning, is effective in learning such a generator. The iterative generator also creates a new opportunity in further improving a metric of choice via meta-optimization techniques by controlling when to pass which input constraints during iterative layout refinement. Our qualitative and quantitative evaluation based on the three standard metrics demonstrate that the proposed system makes significant improvements over the current state-of-the-art, even competitive against the ground-truth floorplans, designed by professional architects.
https://weibo.com/1402400261/K4J5curfu
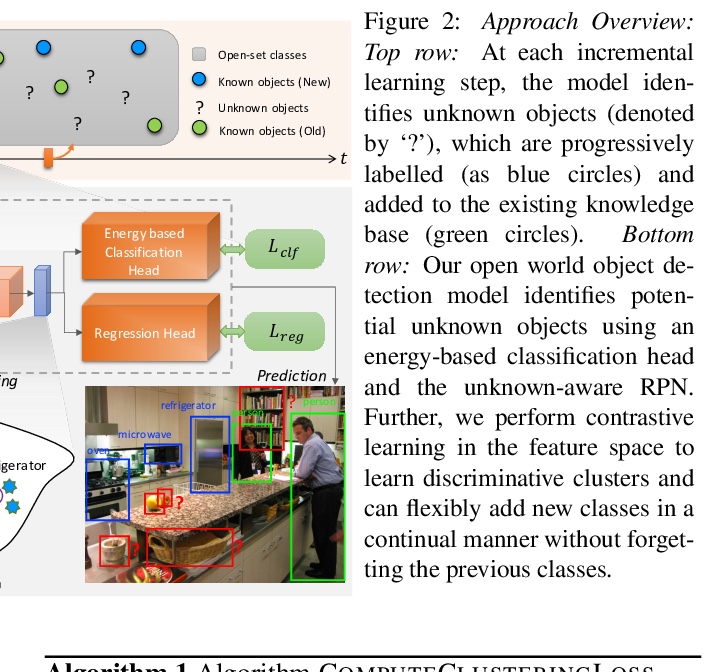
5、[CV] Towards Open World Object Detection
K J Joseph, S Khan, F S Khan, V N Balasubramanian
[Indian Institute of Technology Hyderabad & Mohamed bin Zayed University of AI]
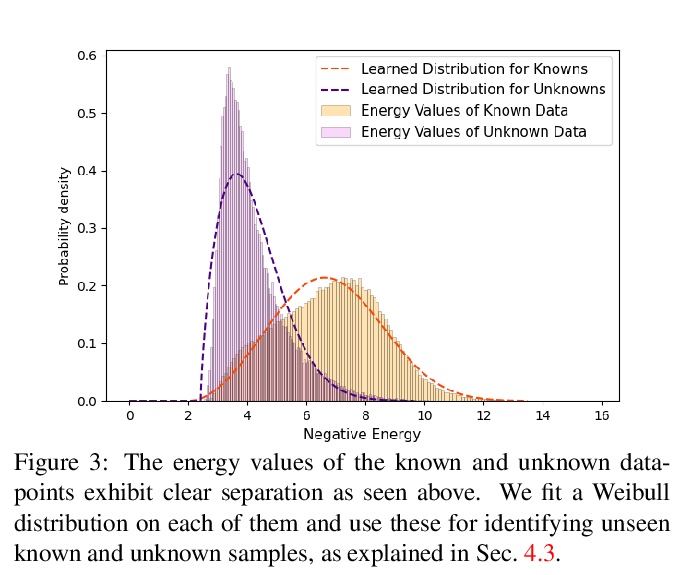
开放世界目标检测。提出了一个新的计算机视觉问题,称为”开放世界目标检测”,模型的任务是:1)在没有明确监督的情况下,将没有被引入的对象识别为 “未知”;2)当逐步接收到相应标签时,逐步学习这些被识别的未知类别,而不忘记之前学习的类别。开发了一种新的方法ORE,基于对比聚类、未知感知提案网络和基于能量的未知识别来解决开放世界目标检测的挑战。引入了一个全面的实验环境,有助于测量目标检测器的开放世界特性,并在其上与竞争性的基线方法进行ORE的基准测试。
Humans have a natural instinct to identify unknown object instances in their environments. The intrinsic curiosity about these unknown instances aids in learning about them, when the corresponding knowledge is eventually available. This motivates us to propose a novel computer vision problem called: Open World Object Detection', where a model is tasked to: 1) identify objects that have not been introduced to it asunknown’, without explicit supervision to do so, and 2) incrementally learn these identified unknown categories without forgetting previously learned classes, when the corresponding labels are progressively received. We formulate the problem, introduce a strong evaluation protocol and provide a novel solution, which we call ORE: Open World Object Detector, based on contrastive clustering and energy based unknown identification. Our experimental evaluation and ablation studies analyze the efficacy of ORE in achieving Open World objectives. As an interesting by-product, we find that identifying and characterizing unknown instances helps to reduce confusion in an incremental object detection setting, where we achieve state-of-the-art performance, with no extra methodological effort. We hope that our work will attract further research into this newly identified, yet crucial research direction.
https://weibo.com/1402400261/K4J8rm8ZS

另外几篇值得关注的论文:
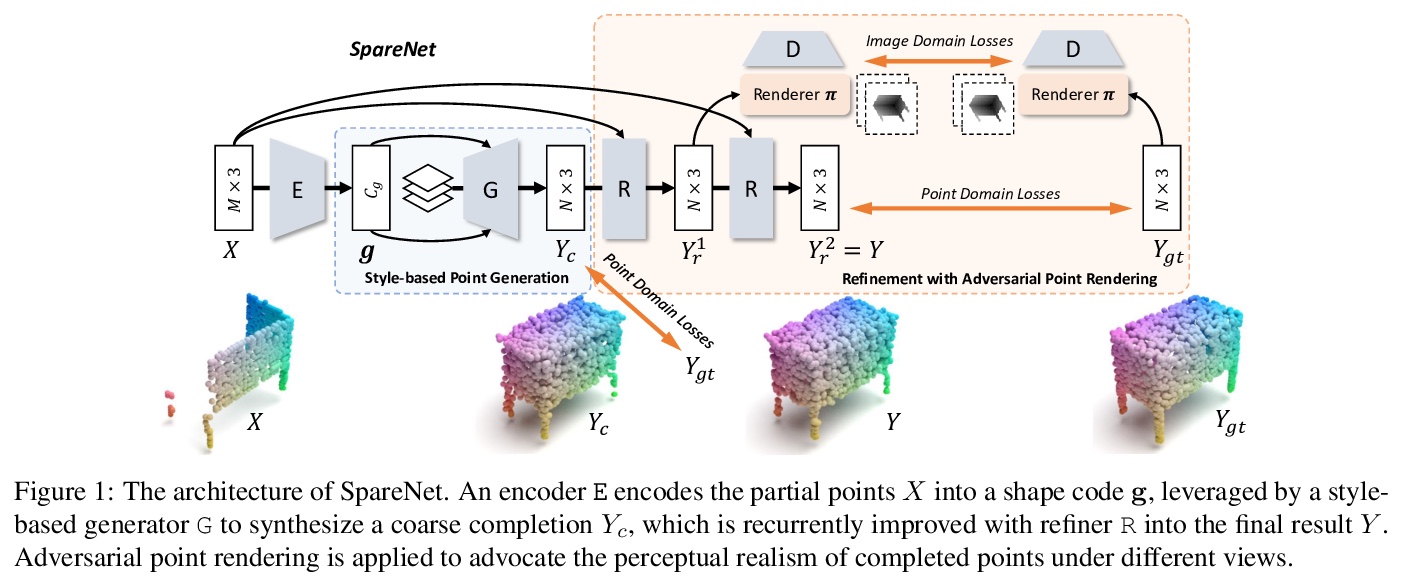
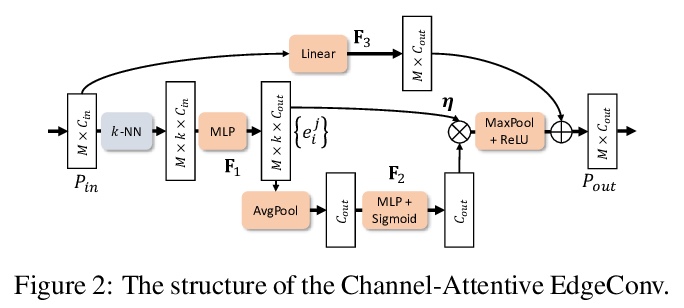
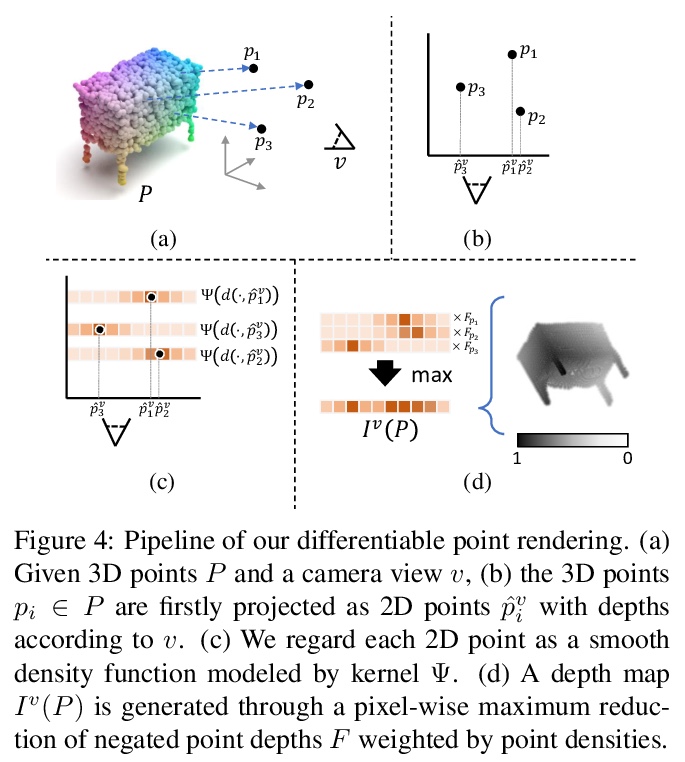
[CV] Style-based Point Generator with Adversarial Rendering for Point Cloud Completion
基于对抗渲染样式点生成器的点云补全
C Xie, C Wang, B Zhang, H Yang, D Chen, F Wen
[University of Illinois at Urbana-Champaign & University of Science and Technology of China & Microsoft Research Asia]
https://weibo.com/1402400261/K4JcfcACR

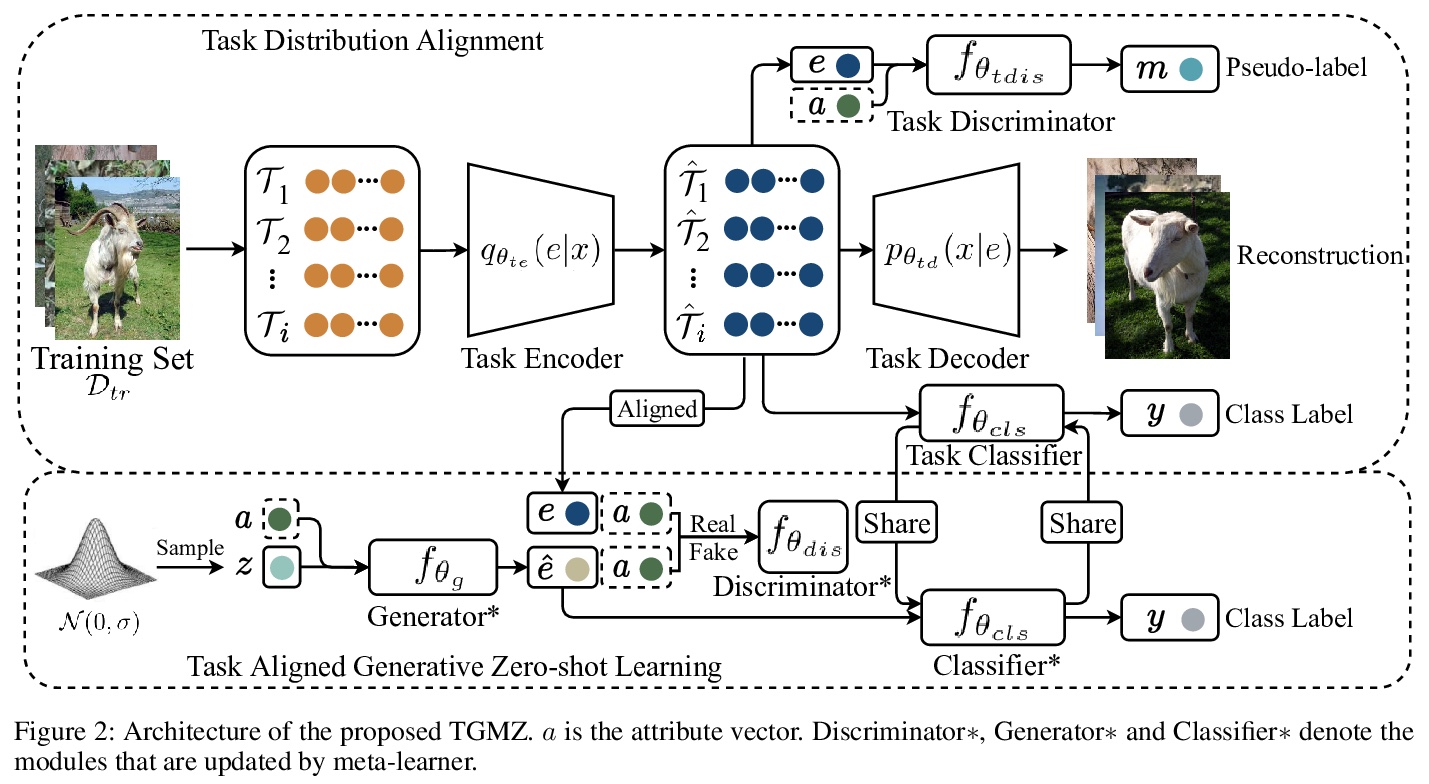
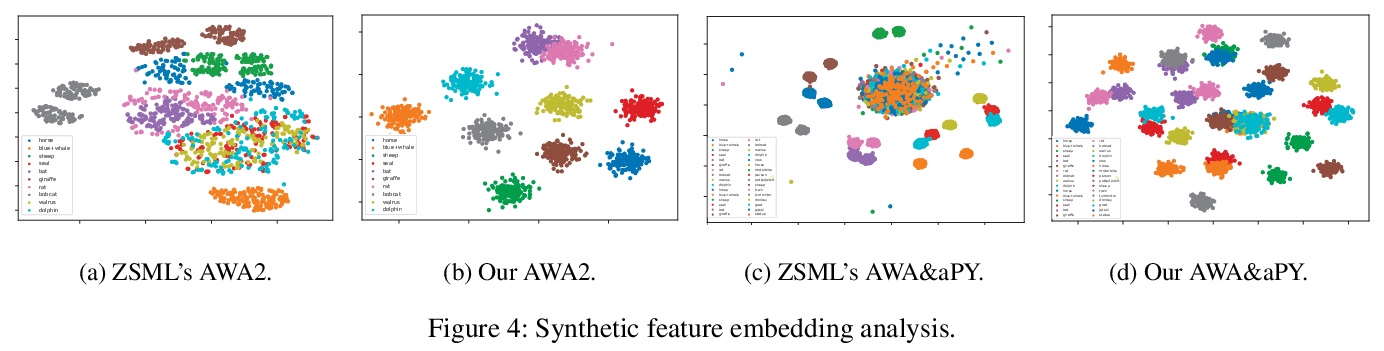
[CV] Task Aligned Generative Meta-learning for Zero-shot Learning
面向零样本学习的任务对齐生成式元学习
Z Liu, Y Li, L Yao, X Wang, G Long
[University of New South Wales & University of Technology Sydney]
https://weibo.com/1402400261/K4Je0uaqG
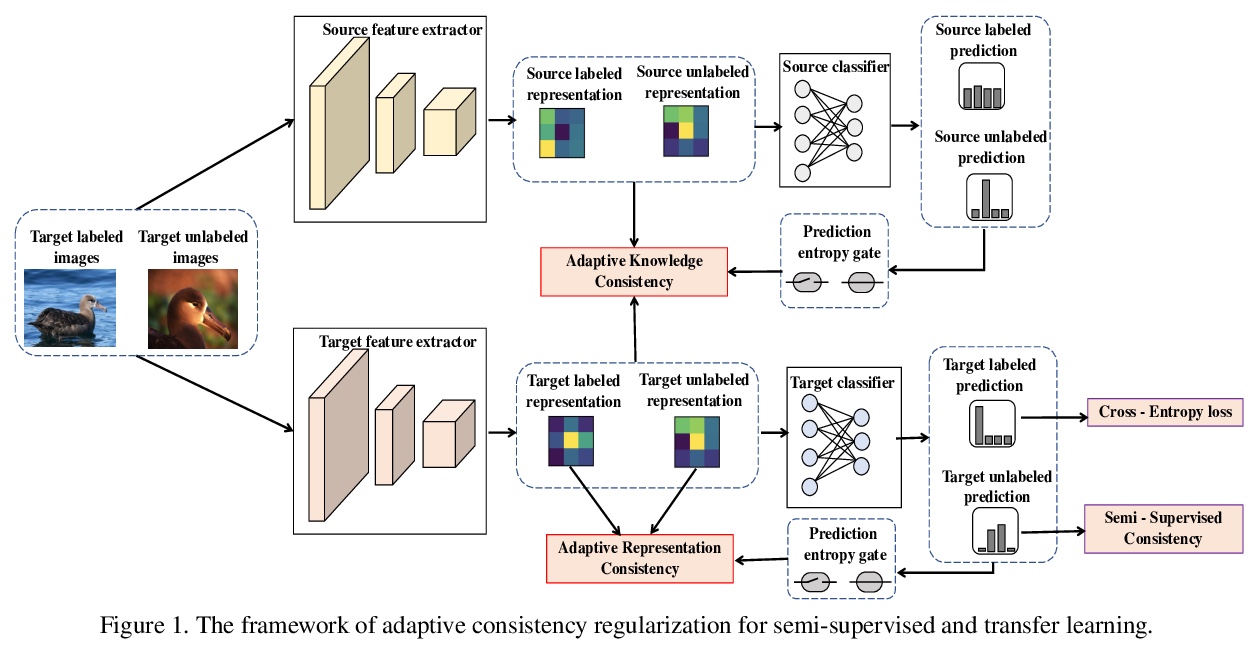
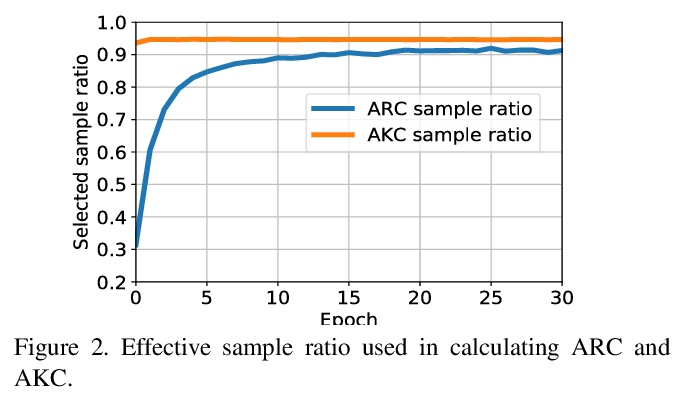
[CV] Adaptive Consistency Regularization for Semi-Supervised Transfer Learning
半监督迁移学习自适应一致正则化
A Abuduweili, X Li, H Shi, C Xu, D Dou
[Baidu Research & University of Oregon & University of Macau]
https://weibo.com/1402400261/K4Jfp40gU
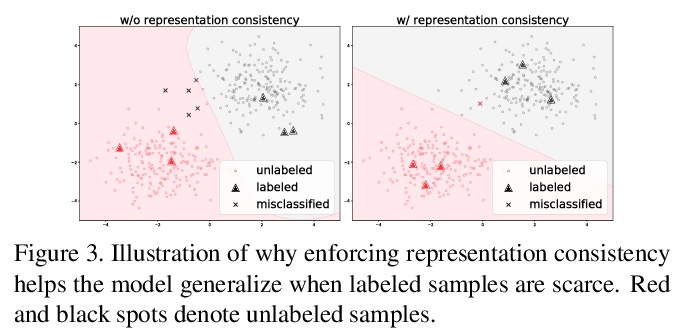
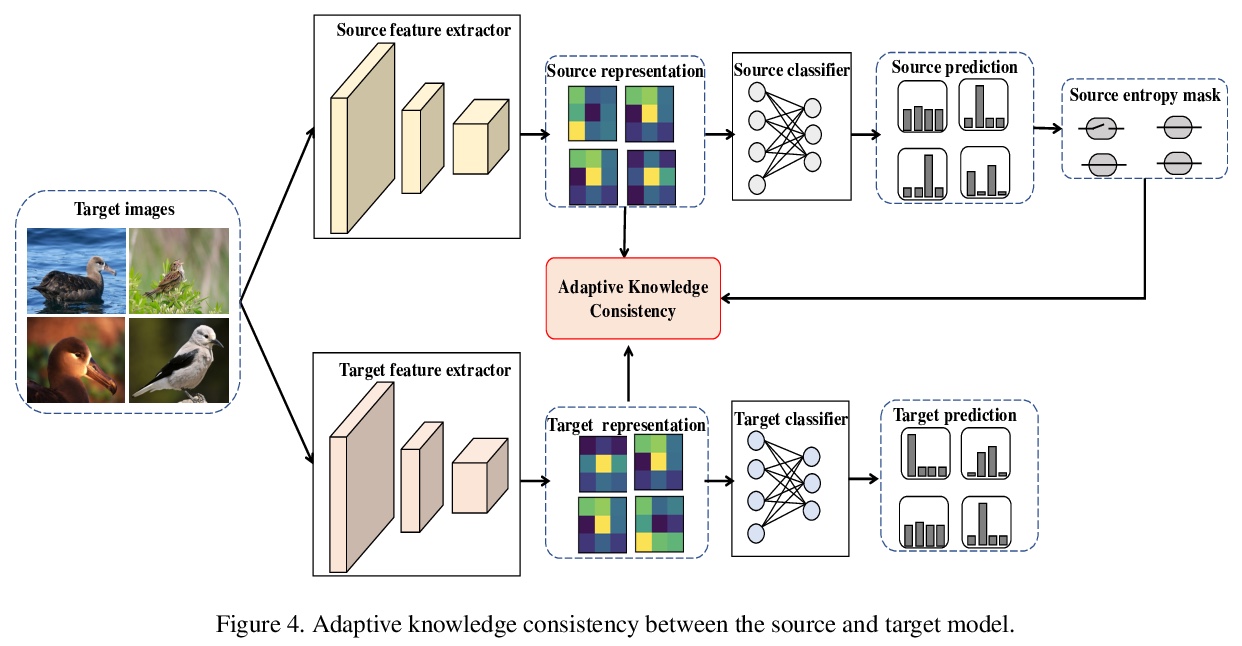
[LG] Domain Generalization: A Survey
领域泛化综述
K Zhou, Z Liu, Y Qiao, T Xiang, C C Loy
[Nanyang Technological University & Chinese Academy of Sciences & University of Surrey]
https://weibo.com/1402400261/K4Jjj9Z2J


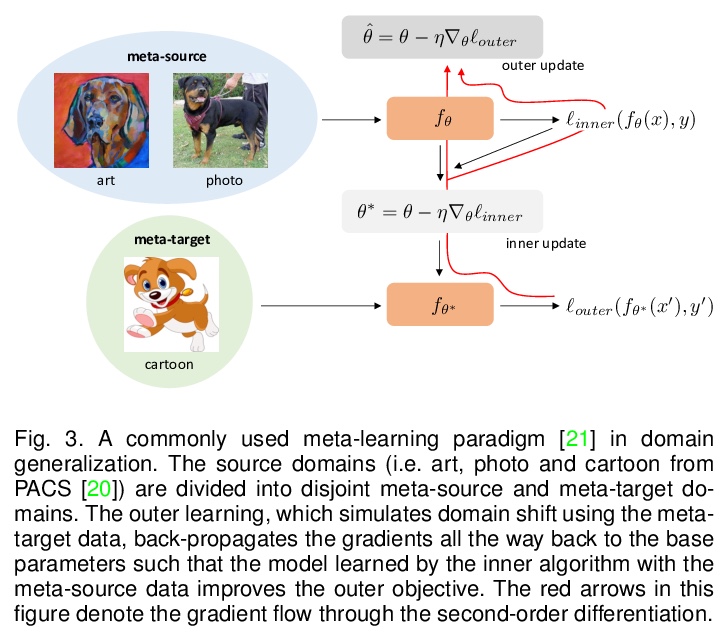
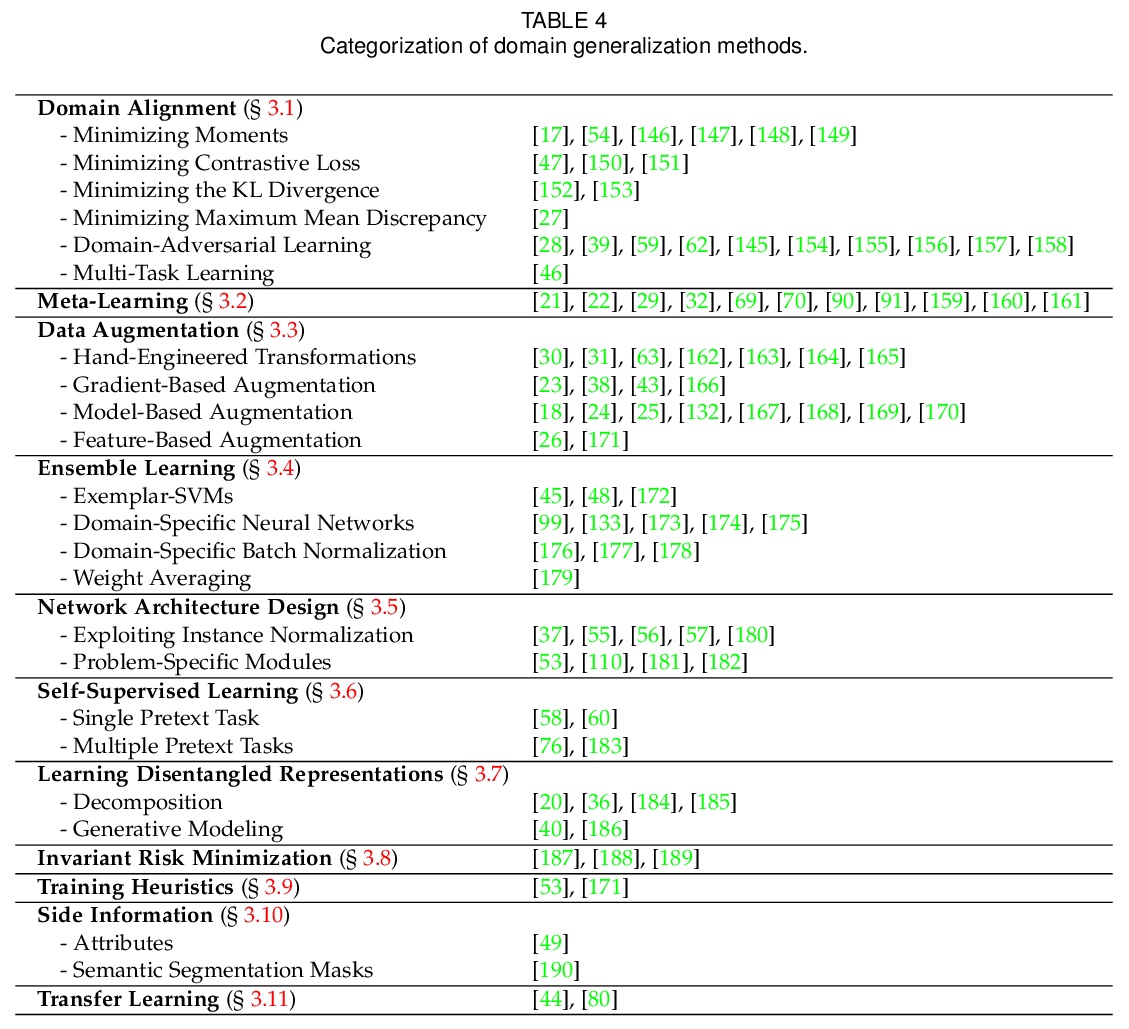

若有收获,就点个赞吧
0 人点赞
