LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[CV] From Show to Tell: A Survey on Image Captioning
M Stefanini, M Cornia, L Baraldi, S Cascianelli, G Fiameni, R Cucchiara
[University of Modena and Reggio Emilia & NVIDIA AI Technology Centre]
从展示到描述:图像描述生成综述。将视觉和语言联系起来,是生成式智能的重要组成部分。过去几年,在图像描述生成上投入了大量的研究工作,即用句法和语义上有意义的句子来描述图像的任务。从2015年开始,这项任务通常由一个视觉编码步骤和一个文本生成的语言模型组成的管道来解决。这些年,通过对物体区域、属性和关系的利用,以及引入多模态连接、全注意力方法和类似BERT的早期融合策略,两个组件都有了很大的发展。然而,尽管取得了令人印象深刻的成果,图像描述生成的研究还没有达到一个结论性的答案。本文的目的是提供一个全面的概述,并对图像字幕的方法进行分类,从视觉编码和文本生成到训练策略、使用的数据集和评估指标。对许多相关的最先进方法进行了定量比较,以确定图像描述生成架构和训练策略中最有影响的技术创新。此外,还分析和讨论了该问题的许多变体及其公开挑战。本文最终目标是作为一个工具,用于了解现有的最先进的技术,并强调计算机视觉和自然语言处理可以找到最佳协同作用的研究领域的未来方向。
Connecting Vision and Language plays an essential role in Generative Intelligence. For this reason, in the last few years, a large research effort has been devoted to image captioning, i.e. the task of describing images with syntactically and semantically meaningful sentences. Starting from 2015 the task has generally been addressed with pipelines composed of a visual encoding step and a language model for text generation. During these years, both components have evolved considerably through the exploitation of object regions, attributes, and relationships and the introduction of multi-modal connections, fully-attentive approaches, and BERT-like early-fusion strategies. However, regardless of the impressive results obtained, research in image captioning has not reached a conclusive answer yet. This work aims at providing a comprehensive overview and categorization of image captioning approaches, from visual encoding and text generation to training strategies, used datasets, and evaluation metrics. In this respect, we quantitatively compare many relevant state-of-the-art approaches to identify the most impactful technical innovations in image captioning architectures and training strategies. Moreover, many variants of the problem and its open challenges are analyzed and discussed. The final goal of this work is to serve as a tool for understanding the existing state-of-the-art and highlighting the future directions for an area of research where Computer Vision and Natural Language Processing can find an optimal synergy.
https://weibo.com/1402400261/Kp6cdigQw

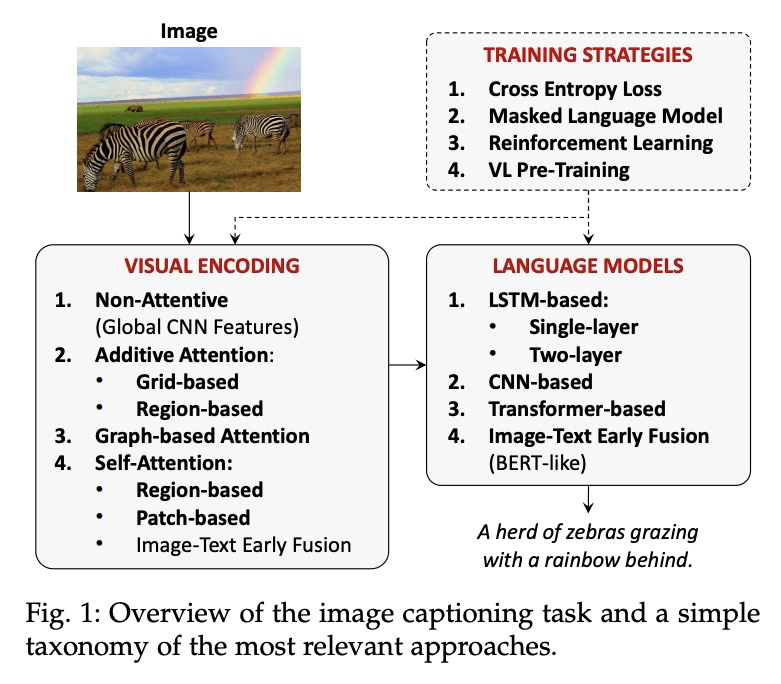
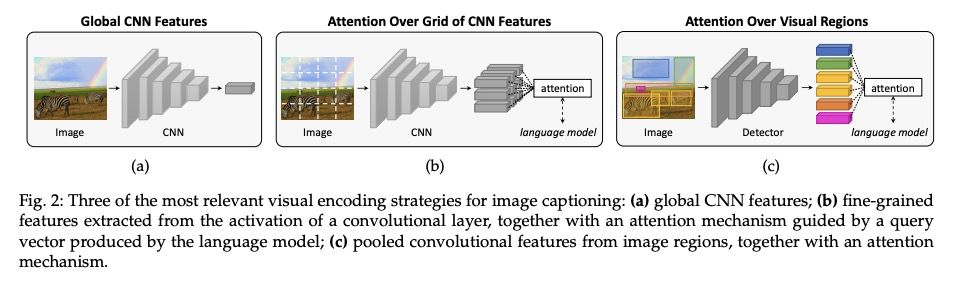
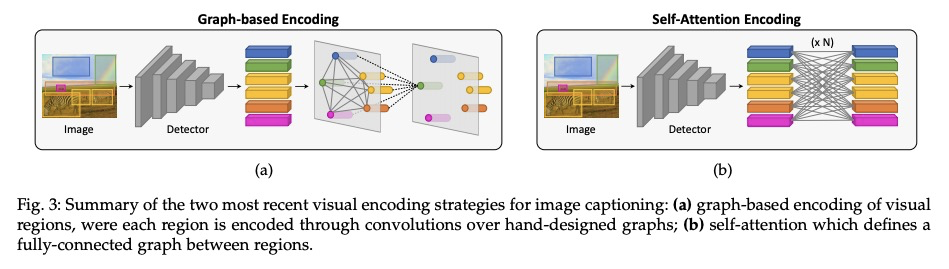
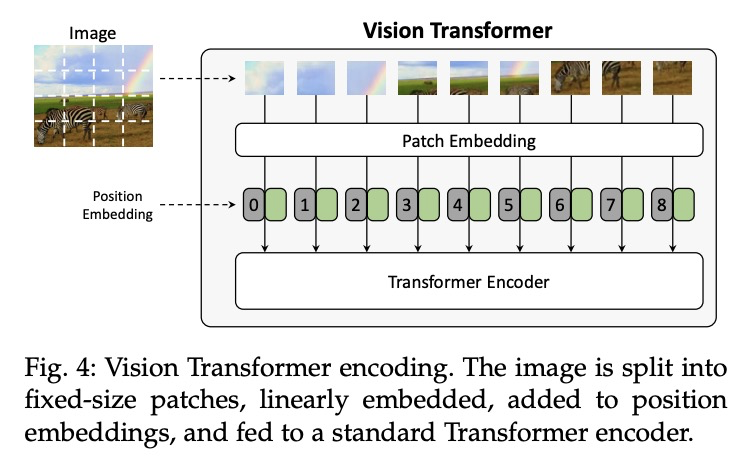
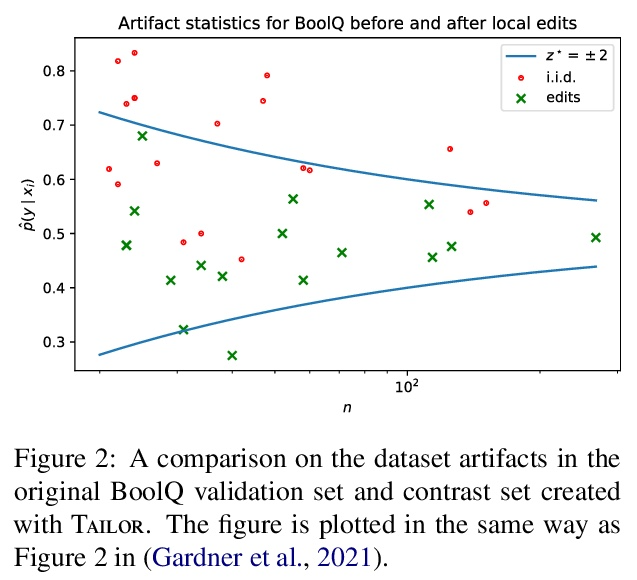
2、[CL] Tailor: Generating and Perturbing Text with Semantic Controls
A Ross, T Wu, H Peng, M E. Peters, M Gardner
[Allen Institute for Artificial Intelligence & University of Washington]
Tailor:基于语义控制的文本生成和扰动。进行受控的扰动,对于各种任务(例如数据增强)来说是必不可少的,但建立特定任务的生成器可能是昂贵的。本文提出Tailor,一种与任务无关的生成系统,以语义控制的方式扰动文本。通过组合扰动操作,Tailor实现了复杂的和上下文感知的变化,支持各种下游应用。通过非似然训练,设计了Tailor的生成器,以遵循一系列从语义角色衍生出来的控制代码。通过对这些控制代码的修改,Tailor可以产生精细的扰动。本文在控制代码上实现了一套操作,可以组成复杂的扰动策略,并在三个不同的应用中证明其有效性。首先,Tailor有助于构建高质量的对比集,这些对比集在词汇上是多样化的,并且比原始任务测试数据的偏差要小。第二,与自动标签启发式方法配对,Tailor有助于通过数据增强来提高模型的泛化性。通过对训练数据≈5%的扰动,在NLI挑战集上获得1.73的平均增益。第三,在没有任何微调开销的情况下,Tailor的扰动有效地提高了细粒度风格迁移的构成性,在6个迁移上超过了微调基线的表现。
Making controlled perturbations is essential for various tasks (e.g., data augmentation), but building task-specific generators can be expensive. We introduce Tailor, a taskagnostic generation system that perturbs text in a semantically-controlled way. With unlikelihood training, we design Tailor’s generator to follow a series of control codes derived from semantic roles. Through modifications of these control codes, Tailor can produce fine-grained perturbations. We implement a set of operations on control codes that can be composed into complex perturbation strategies, and demonstrate their effectiveness in three distinct applications: First, Tailor facilitates the construction of high-quality contrast sets that are lexically diverse, and less biased than original task test data. Second, paired with automated labeling heuristics, Tailor helps improve model generalization through data augmentation: We obtain an average gain of 1.73 on an NLI challenge set by perturbing just ≈5% of training data. Third, without any finetuning overhead, Tailor’s perturbations effectively improve compositionality in fine-grained style transfer, outperforming fine-tuned baselines on 6 transfers.
https://weibo.com/1402400261/Kp6gNiyot


3、[CL] Wordcraft: a Human-AI Collaborative Editor for Story Writing
A Coenen, L Davis, D Ippolito, E Reif, A Yuan
[Google Research]
Wordcraft:面向故事创作的人-AI协同编辑器。随着神经语言模型效率的提高,它们越来越多地被应用于现实世界中。然而,这些应用在其支持的互动模式方面往往是有限的。本文提出Wordcraft,一种用于故事写作的人工智能辅助编辑器,人类作者和对话系统合作写一个故事。其新颖的界面使用少样本学习和对话的自然能供性来支持各种互动。协同编辑器为作家提供了一个沙盒,以探索基于Transformer的语言模型的界限,并为未来的人在环路训练管道和新的评估方法铺平道路。
As neural language models grow in effectiveness, they are increasingly being applied in real-world settings. However these applications tend to be limited in the modes of interaction they support. In this extended abstract, we propose Wordcraft, an AI-assisted editor for story writing in which a writer and a dialog system collaborate to write a story. Our novel interface uses few-shot learning and the natural affordances of conversation to support a variety of interactions. Our editor provides a sandbox for writers to probe the boundaries of transformer-based language models and paves the way for future human-in-the-loop training pipelines and novel evaluation methods.
https://weibo.com/1402400261/Kp6l990jk



4、[CL] HTLM: Hyper-Text Pre-Training and Prompting of Language Models
A Aghajanyan, D Okhonko, M Lewis, M Joshi, H Xu, G Ghosh, L Zettlemoyer
[Facebook AI]
HTLM:语言模型的超文本预训练和提示。本文提出HTLM,一种在大规模网络爬取中训练的超文本语言模型。建立超文本模型有许多优点。(1)很容易大规模收集,(2)提供了丰富的文档级和与终端任务相关的监督(例如,class和id属性经常编码文档类别信息),(3)允许遵循HTML既定语义的新的结构化提示(例如,通过为包含输入文本的网页的标签来进行零样本摘要)。直接在简化的HTML上用BART风格的去噪损失进行预训练,为广泛的终端任务和监督水平提供了高度有效的迁移。HTLM在零样本提示和分类基准的微调方面的表现与规模相当的纯文本语言模型相匹配,甚至超过了后者,同时也为零样本摘要设定了新的最先进性能水平。就数据效率而言,超文本提示为HTLM提供了比纯文本提示对现有语言模型更多的价值,HTLM在自动提示方面非常有效,只需为任何可用的训练数据生成最可能的超文本格式。相对于其他只对自然语言进行建模的预训练模型,对结构化数据的预训练提高了微调的性能。</strong><br />We introduce HTLM, a hyper-text language model trained on a large-scale web crawl. Modeling hyper-text has a number of advantages: (1) it is easily gathered at scale, (2) it provides rich document-level and end-taskadjacent supervision (e.g. class and id attributes often encode document category information), and (3) it allows for new structured prompting that follows the established semantics of HTML (e.g. to do zero-shot summarization by infilling <title> tags for a webpage that contains the input text). We show that pretraining with a BART-style denoising loss directly on simplified HTML provides highly effective transfer for a wide range of end tasks and supervision levels. HTLM matches or exceeds the performance of comparably sized text-only LMs for zero-shot prompting and fine-tuning for classification benchmarks, while also setting new state-of-the-art performance levels for zero-shot summarization. We also find that hyper-text prompts provide more value to HTLM, in terms of data efficiency, than plain text prompts do for existing LMs, and that HTLM is highly effective at autoprompting itself, by simply generating the most likely hyper-text formatting for any available training data. We will release all code and models to support future HTLM research. <br /><a rel="nofollow" href="https://weibo.com/1402400261/Kp6nvB6hq">https://weibo.com/1402400261/Kp6nvB6hq</a> <br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478166231-0477e6fb-9036-4bc9-8722-95f824232641.png#clientId=u31b38185-e038-4&from=paste&id=u53d25ac2&margin=%5Bobject%20Object%5D&name=image.png&originHeight=1415&originWidth=948&originalType=url&ratio=1&size=785352&status=done&style=none&taskId=u1ed7aa4f-dda4-44cf-9943-8869095aef5" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478166209-b4f2b7ca-066b-473c-beee-a196870a6037.png#clientId=u31b38185-e038-4&from=paste&id=u5b90e6c7&margin=%5Bobject%20Object%5D&name=image.png&originHeight=659&originWidth=639&originalType=url&ratio=1&size=155663&status=done&style=none&taskId=u0331f93e-e489-4b41-b721-361a023c0c4" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478166850-f4b5c1f9-43d3-4c1f-8c60-f8252f6cc9b0.png#clientId=u31b38185-e038-4&from=paste&id=u6a6fae88&margin=%5Bobject%20Object%5D&name=image.png&originHeight=511&originWidth=1290&originalType=url&ratio=1&size=212089&status=done&style=none&taskId=u5f92d526-07e6-47c2-9ea9-197fbc45194" alt="image.png">
<a name="lObRx"></a></p>
<h3 id="j8waf"><a name="j8waf" class="reference-link"></a><span class="header-link octicon octicon-link"></span>5、[CV] StyleFusion: A Generative Model for Disentangling Spatial Segments</h3><p>O Kafri, O Patashnik, Y Alaluf, D Cohen-Or <br />[Tel Aviv University] <br /><strong>StyleFusion:面向空间分段解缠的生成模型。提出StyleFusion,一种面向StyleGAN的新的映射架构,将一些潜代码作为输入,并将它们融合成一个单一的风格代码。将得到的风格代码插入预训练好的StyleGAN生成器中,就会产生一个统一的图像,其中每个语义区域都由输入的潜代码之一控制。StyleFusion产生了图像的解缠表示,对生成的图像的每个区域提供了细粒度的控制。此外,为了便于对生成图像进行全局控制,一个特殊的输入潜代码被纳入融合后的表示中。StyleFusion以分层的方式运作,每一层的任务是学习拆分一对图像区域(如车身和车轮)。由此产生的习得解缠允许人们修改局部的、细粒度的语义(如人脸特征)以及更全面的特征(如姿态和背景),在合成过程中提供更好的灵活性。作为一个自然的扩展,StyleFusion能对未对齐区域进行语义感知的跨图像混合。最后,展示了StyleFusion如何与现有的编辑技术对接,以更忠实地将编辑约束在用户感兴趣的区域。</strong><br />We present StyleFusion, a new mapping architecture for StyleGAN, which takes as input a number of latent codes and fuses them into a single style code. Inserting the resulting style code into a pre-trained StyleGAN generator results in a single harmonized image in which each semantic region is controlled by one of the input latent codes. Effectively, StyleFusion yields a disentangled representation of the image, providing fine-grained control over each region of the generated image. Moreover, to help facilitate global control over the generated image, a special input latent code is incorporated into the fused representation. StyleFusion operates in a hierarchical manner, where each level is tasked with learning to disentangle a pair of image regions (e.g., the car body and wheels). The resulting learned disentanglement allows one to modify both local, fine-grained semantics (e.g., facial features) as well as more global features (e.g., pose and background), providing improved flexibility in the synthesis process. As a natural extension, StyleFusion enables one to perform semantically-aware crossimage mixing of regions that are not necessarily aligned. Finally, we demonstrate how StyleFusion can be paired with existing editing techniques to more faithfully constrain the edit to the user’s region of interest. <br /><a rel="nofollow" href="https://weibo.com/1402400261/Kp6s9brju">https://weibo.com/1402400261/Kp6s9brju</a> <br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478168017-9a001966-df56-4018-ab65-f89809ceb5ea.png#clientId=u31b38185-e038-4&from=paste&id=u7911d5bf&margin=%5Bobject%20Object%5D&name=image.png&originHeight=1240&originWidth=980&originalType=url&ratio=1&size=1180076&status=done&style=none&taskId=uc95d8d76-e209-4a09-888f-dac46799c39" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478168554-b881f6e1-e157-463d-bc3b-91d5a885b784.png#clientId=u31b38185-e038-4&from=paste&id=u2e032991&margin=%5Bobject%20Object%5D&name=image.png&originHeight=409&originWidth=984&originalType=url&ratio=1&size=544674&status=done&style=none&taskId=u814c2cd7-b215-46b3-995a-ed836dc7966" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478168953-dcb07ba2-b013-4c2f-b91f-5267d3ab9668.png#clientId=u31b38185-e038-4&from=paste&id=u967209be&margin=%5Bobject%20Object%5D&name=image.png&originHeight=499&originWidth=1404&originalType=url&ratio=1&size=491166&status=done&style=none&taskId=ua185dc3e-89eb-487b-af61-46a9a5d3844" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478168849-d3c3e714-bf7f-45f1-913e-d2e4ca99e4cf.png#clientId=u31b38185-e038-4&from=paste&id=u0d00f188&margin=%5Bobject%20Object%5D&name=image.png&originHeight=487&originWidth=685&originalType=url&ratio=1&size=388104&status=done&style=none&taskId=ue10140e0-d5ec-4782-af09-83258d4cde1" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478171471-d9d62ab5-2711-4f1e-b338-2f3c34911ec1.png#clientId=u31b38185-e038-4&from=paste&id=ua31ff1d6&margin=%5Bobject%20Object%5D&name=image.png&originHeight=636&originWidth=707&originalType=url&ratio=1&size=731118&status=done&style=none&taskId=u5fa002b6-f8ec-44c9-aeb6-6f28d71862f" alt="image.png"><br />另外几篇值得关注的论文:
<a name="gZjxQ"></a></p>
<h3 id="f7crtm"><a name="f7crtm" class="reference-link"></a><span class="header-link octicon octicon-link"></span>[CV] Level generation and style enhancement — deep learning for game development overview</h3><p><strong>关卡生成与画风增强——深度学习游戏开发概览</strong><br />P Migdał, B Olechno, B Podgórski <br />[ECC Games SA] <br /><a rel="nofollow" href="https://weibo.com/1402400261/Kp6CLcRu5">https://weibo.com/1402400261/Kp6CLcRu5</a> <br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478170922-e6a5fe9d-933c-4169-a97f-c9b612d70d04.png#clientId=u31b38185-e038-4&from=paste&id=udbc0dfe0&margin=%5Bobject%20Object%5D&name=image.png&originHeight=1179&originWidth=997&originalType=url&ratio=1&size=463290&status=done&style=none&taskId=udae6739d-ed16-42fd-9a1f-e0ffe508646" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478172194-80e4b60b-b06b-4d2c-be62-f25d6fb11f1c.png#clientId=u31b38185-e038-4&from=paste&id=ua4425d82&margin=%5Bobject%20Object%5D&name=image.png&originHeight=995&originWidth=1001&originalType=url&ratio=1&size=729139&status=done&style=none&taskId=ua62e848f-1dcb-4443-9a5f-86789d7e65e" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478171871-a201817a-968c-4e2f-8f96-49bb8836938b.png#clientId=u31b38185-e038-4&from=paste&id=ub8dbbe4c&margin=%5Bobject%20Object%5D&name=image.png&originHeight=415&originWidth=996&originalType=url&ratio=1&size=514672&status=done&style=none&taskId=ue97f2554-532c-4f63-9526-0efc6286cee" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478172231-4f0d964a-da95-422a-baa5-991443dbbe22.png#clientId=u31b38185-e038-4&from=paste&id=u660adbb6&margin=%5Bobject%20Object%5D&name=image.png&originHeight=379&originWidth=785&originalType=url&ratio=1&size=501658&status=done&style=none&taskId=ua447db42-eb6d-4bbb-80ed-78061d93b60" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478173234-4397164b-2880-4dd1-86a9-a89a4c606718.png#clientId=u31b38185-e038-4&from=paste&id=ud65795a9&margin=%5Bobject%20Object%5D&name=image.png&originHeight=313&originWidth=1002&originalType=url&ratio=1&size=344219&status=done&style=none&taskId=uaf37d15f-08a2-4986-960e-51d529c2137" alt="image.png">
<a name="x1Rba"></a></p>
<h3 id="fdgxuf"><a name="fdgxuf" class="reference-link"></a><span class="header-link octicon octicon-link"></span>[CV] StyleVideoGAN: A Temporal Generative Model using a Pretrained StyleGAN</h3><p><strong>StyleVideoGAN:基于预训练StyleGAN的时间生成模型</strong><br />G Fox, A Tewari, M Elgharib, C Theobalt <br />[Max Planck Institute for Informatics] <br /><a rel="nofollow" href="https://weibo.com/1402400261/Kp6JDnbNI">https://weibo.com/1402400261/Kp6JDnbNI</a> <br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478174354-5b9dc922-2fb9-4550-9f58-e655ec84d687.png#clientId=u31b38185-e038-4&from=paste&id=uf6d971da&margin=%5Bobject%20Object%5D&name=image.png&originHeight=1309&originWidth=926&originalType=url&ratio=1&size=774013&status=done&style=none&taskId=ub5823ce1-58fd-4867-9c6c-77d4350c126" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478174479-565cf030-2733-4ae0-b5af-351621f75642.png#clientId=u31b38185-e038-4&from=paste&id=u01500230&margin=%5Bobject%20Object%5D&name=image.png&originHeight=346&originWidth=1337&originalType=url&ratio=1&size=676938&status=done&style=none&taskId=u2d949735-7ed7-4acd-bb0f-3f2976cd942" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478173738-46cf4bfb-ae1e-412c-b67b-03d1c5314f7b.png#clientId=u31b38185-e038-4&from=paste&id=ub09fe553&margin=%5Bobject%20Object%5D&name=image.png&originHeight=400&originWidth=683&originalType=url&ratio=1&size=155080&status=done&style=none&taskId=ub5fecaf9-289f-4201-b39b-391a8765330" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478174545-50710a2c-f88d-43e6-8558-e261c19024bd.png#clientId=u31b38185-e038-4&from=paste&id=u11c5c2a2&margin=%5Bobject%20Object%5D&name=image.png&originHeight=497&originWidth=684&originalType=url&ratio=1&size=520736&status=done&style=none&taskId=uace77175-9250-47d5-b66e-dea3d2332ba" alt="image.png">
<a name="jnhCs"></a></p>
<h3 id="b2ue4b"><a name="b2ue4b" class="reference-link"></a><span class="header-link octicon octicon-link"></span>[CL] Turning Tables: Generating Examples from Semi-structured Tables for Endowing Language Models with Reasoning Skills</h3><p><strong>Turning Tables:从半结构化表格生成样本赋予语言模型推理技能</strong><br />O Yoran, A Talmor, J Berant <br />[Tel-Aviv University] <br /><a rel="nofollow" href="https://weibo.com/1402400261/Kp6MUAzjO">https://weibo.com/1402400261/Kp6MUAzjO</a> <br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478175419-c8f847bf-3c44-4985-965f-d04785f3b0a4.png#clientId=u31b38185-e038-4&from=paste&id=u2ba85db6&margin=%5Bobject%20Object%5D&name=image.png&originHeight=1519&originWidth=997&originalType=url&ratio=1&size=1209712&status=done&style=none&taskId=ue1de90c2-1f51-425e-80fc-0e61362400d" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478175061-422bb604-423b-47a1-9e96-a6d10cec8e08.png#clientId=u31b38185-e038-4&from=paste&id=ufbf92d03&margin=%5Bobject%20Object%5D&name=image.png&originHeight=709&originWidth=640&originalType=url&ratio=1&size=353921&status=done&style=none&taskId=ud64147d3-a72a-4046-9e49-80db7730448" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478176159-21ab81f5-6bfa-4927-843c-b5a9ccf77e4b.png#clientId=u31b38185-e038-4&from=paste&id=uf2a1a800&margin=%5Bobject%20Object%5D&name=image.png&originHeight=493&originWidth=1291&originalType=url&ratio=1&size=419910&status=done&style=none&taskId=u5e46915a-189c-4fc7-9adf-307d3a9de40" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478175918-39e85538-60f6-4193-b1f8-ec5201996cac.png#clientId=u31b38185-e038-4&from=paste&id=u276bb08d&margin=%5Bobject%20Object%5D&name=image.png&originHeight=523&originWidth=642&originalType=url&ratio=1&size=201894&status=done&style=none&taskId=u0412bb69-bc7d-4d51-8975-27d97be5e33" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478176757-0010e1eb-8d83-4713-a6ea-dc5b8db38d62.png#clientId=u31b38185-e038-4&from=paste&id=u59e2dd20&margin=%5Bobject%20Object%5D&name=image.png&originHeight=400&originWidth=1288&originalType=url&ratio=1&size=311208&status=done&style=none&taskId=u28a76b17-a12b-41ff-be58-21b43a682bb" alt="image.png">
<a name="FmHn7"></a></p>
<h3 id="1dq7n6"><a name="1dq7n6" class="reference-link"></a><span class="header-link octicon octicon-link"></span>[LG] Algorithmic Concept-based Explainable Reasoning</h3><p><strong>基于算法概念的可解释推理</strong><br />D Georgiev, P Barbiero, D Kazhdan, P Veličković, P Liò <br />[University of Cambridge & DeepMind] <br /><a rel="nofollow" href="https://weibo.com/1402400261/Kp6P5llVo">https://weibo.com/1402400261/Kp6P5llVo</a> <br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478178481-f382b4c0-699d-4264-a4d1-ea4483dde0b5.png#clientId=u31b38185-e038-4&from=paste&id=ufec845c2&margin=%5Bobject%20Object%5D&name=image.png&originHeight=1545&originWidth=1002&originalType=url&ratio=1&size=841660&status=done&style=none&taskId=u4d302855-f71d-4b9e-abcf-e1cac0f00cd" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478178036-e1fec800-5313-40b5-8b22-1cebaf5cc7cb.png#clientId=u31b38185-e038-4&from=paste&id=uf7944bcc&margin=%5Bobject%20Object%5D&name=image.png&originHeight=676&originWidth=1133&originalType=url&ratio=1&size=314980&status=done&style=none&taskId=uf2c514a4-0d6e-4e52-b71a-f98f353fa4d" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478178320-fe672a1d-ee7f-4593-8ffa-38fa5938429e.png#clientId=u31b38185-e038-4&from=paste&id=u789115e1&margin=%5Bobject%20Object%5D&name=image.png&originHeight=633&originWidth=1131&originalType=url&ratio=1&size=394198&status=done&style=none&taskId=ucb9b9a4b-ed15-458e-9628-9182a33e6ff" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478178524-51b12ece-e53f-4169-92f4-1e63337b9ebf.png#clientId=u31b38185-e038-4&from=paste&id=u576cd420&margin=%5Bobject%20Object%5D&name=image.png&originHeight=536&originWidth=1133&originalType=url&ratio=1&size=481774&status=done&style=none&taskId=u5b421db3-aef4-4237-b0dc-04c0d564af2" alt="image.png"><br /><img src="https://cdn.nlark.com/yuque/0/2021/png/315747/1626478179356-5c0c3d14-2ea9-4ecb-8246-09a2d439259e.png#clientId=u31b38185-e038-4&from=paste&id=u4a1cbdf8&margin=%5Bobject%20Object%5D&name=image.png&originHeight=474&originWidth=1129&originalType=url&ratio=1&size=166554&status=done&style=none&taskId=u2b295f2e-9633-4c69-b434-cacdd1227f8" alt="image.png"></p>

