- 1、[CV] Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data
- 2、[AS] Sequence-to-Sequence Piano Transcription with Transformers
- 3、[CV] DOVE: Learning Deformable 3D Objects by Watching Videos
- 4、[CL] Multi-Stream Transformers
- 5、[LG] Solving high-dimensional parabolic PDEs using the tensor train format
- [CV] Query2Label: A Simple Transformer Way to Multi-Label Classification
- [CV] HANT: Hardware-Aware Network Transformation
- [CL] To Ship or Not to Ship: An Extensive Evaluation of Automatic Metrics for Machine Translation
- [LG] Typing assumptions improve identification in causal discovery
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[CV] Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data
X Wang, L Xie, C Dong, Y Shan
[Tencent PCG & Chinese Academy of Sciences]
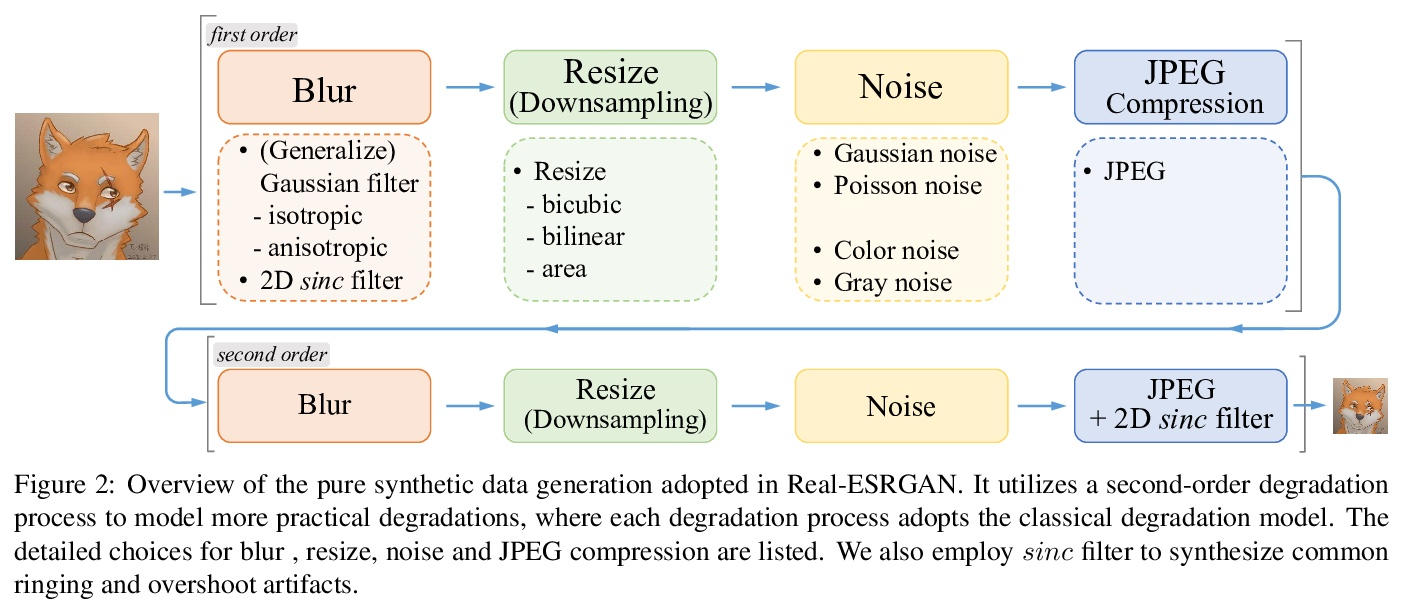
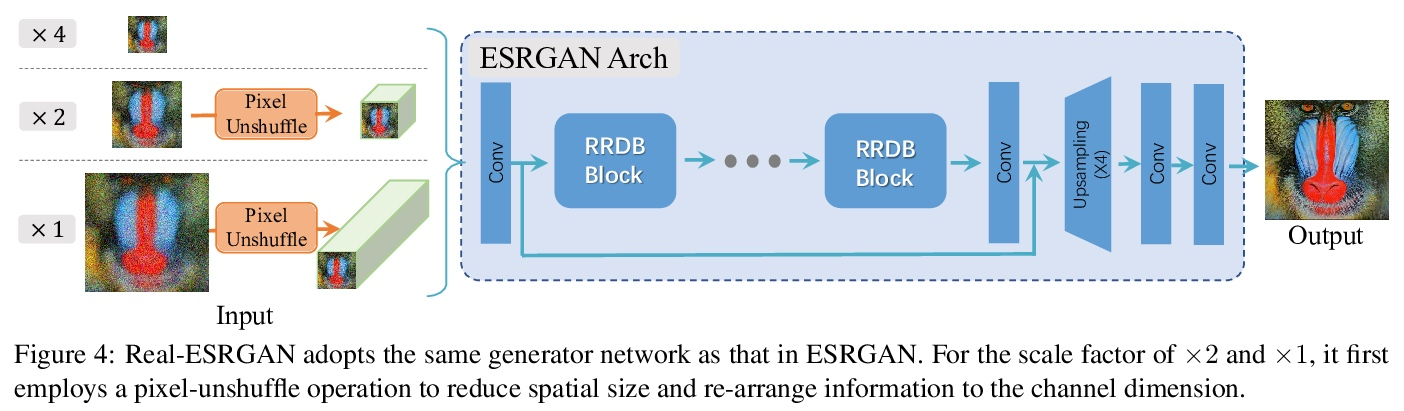
Real-ESRGAN:基于纯合成数据训练的现实世界盲超分辨率。尽管在盲超分辨率方面已经做了许多尝试,以恢复具有未知和复杂退化的低分辨率图像,但仍远远不能解决一般现实世界的退化图像。本文将强大的ESRGAN扩展到一个实际的修复应用中(即Real-ESRGAN),用纯合成数据进行训练。引入高阶退化建模过程,以更好地模拟复杂的真实世界的退化情况,考虑了合成过程中常见的振铃和过冲伪影,采用带有频谱归一化的U-Net鉴别器,以提高鉴别器的能力并稳定训练的动态性。广泛的比较表明,在各种真实数据集上,其视觉性能优于之前的工作。本文还提供了高效的实现方法,以在应用中实时合成训练对。
Though many attempts have been made in blind superresolution to restore low-resolution images with unknown and complex degradations, they are still far from addressing general real-world degraded images. In this work, we extend the powerful ESRGAN to a practical restoration application (namely, Real-ESRGAN), which is trained with pure synthetic data. Specifically, a high-order degradation modeling process is introduced to better simulate complex realworld degradations. We also consider the common ringing and overshoot artifacts in the synthesis process. In addition, we employ a U-Net discriminator with spectral normalization to increase discriminator capability and stabilize the training dynamics. Extensive comparisons have shown its superior visual performance than prior works on various real datasets. We also provide efficient implementations to synthesize training pairs on the fly.
https://weibo.com/1402400261/Kqa6hAslN 


2、[AS] Sequence-to-Sequence Piano Transcription with Transformers
C Hawthorne, I Simon, R Swavely, E Manilow, J Engel
[Google Research]
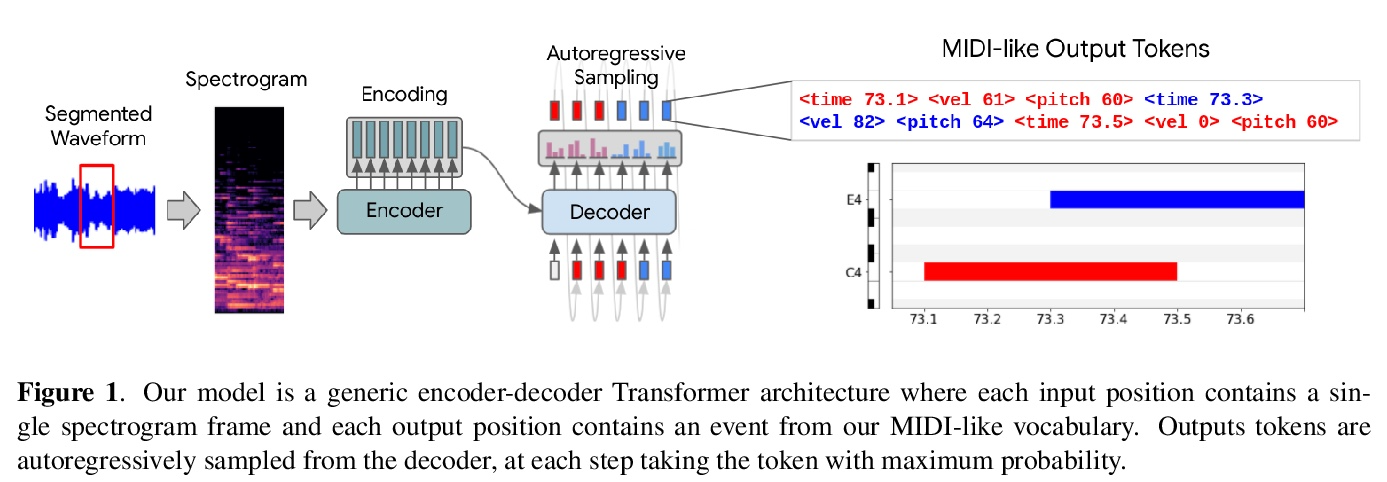
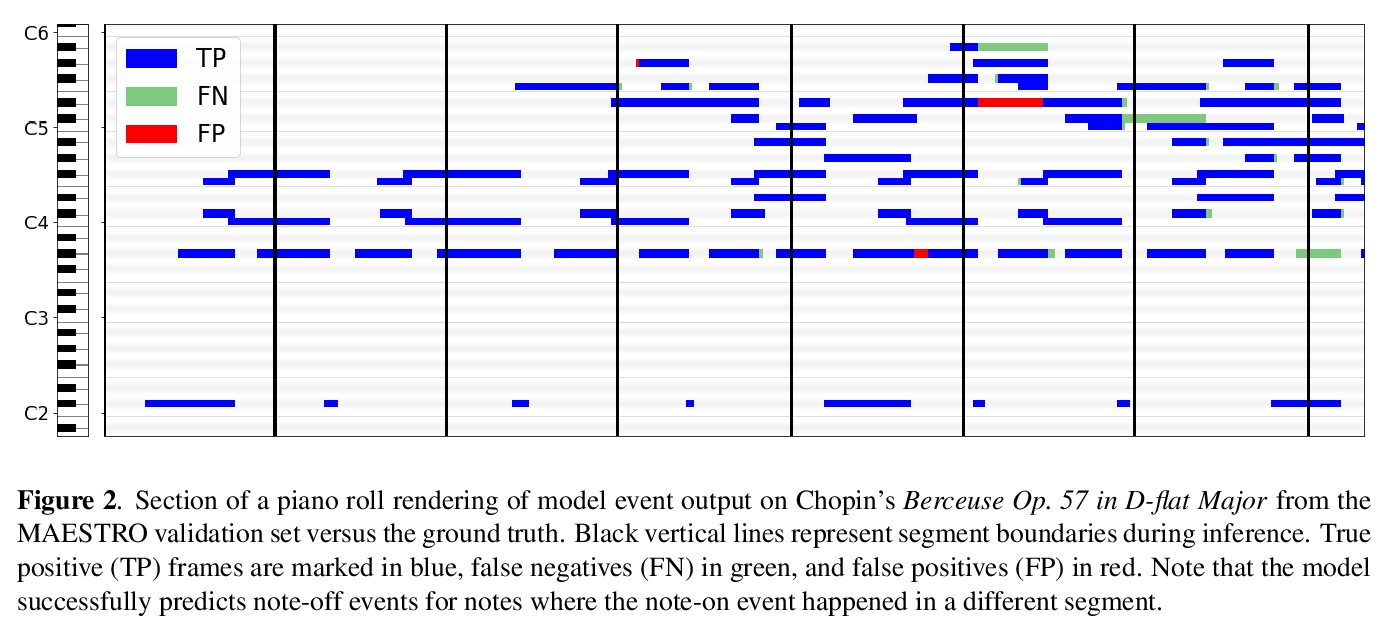
基于Transformer的序列到序列钢琴转录。近年来,通过在大型数据集上训练定制的深度神经网络,自动音乐转录取得了重大进展。然而,这些模型需要对网络架构、输入/输出表示和复杂的解码方案进行广泛的特定领域设计。本文表明,用一个通用的编码器-解码器Transformer和标准的解码方法可以实现同等的性能。该模型可以学习将频谱图输入直接转化为类似MIDI的输出事件,用于几种转录任务。这种序列到序列的方法通过联合建模音频特征和类似语言的输出依赖性简化了转录,消除了对特定任务架构的需要。实验结果表明,通过关注数据集的创建和标记而不是自定义模型设计来创建新的音乐信息检索模型的可能性。带有Transformers的通用序列到序列框架可能也有利于其他MIR任务,如节拍跟踪、基本频率估计、和弦估计等。
Automatic Music Transcription has seen significant progress in recent years by training custom deep neural networks on large datasets. However, these models have required extensive domain-specific design of network architectures, input/output representations, and complex decoding schemes. In this work, we show that equivalent performance can be achieved using a generic encoderdecoder Transformer with standard decoding methods. We demonstrate that the model can learn to translate spectrogram inputs directly to MIDI-like output events for several transcription tasks. This sequence-to-sequence approach simplifies transcription by jointly modeling audio features and language-like output dependencies, thus removing the need for task-specific architectures. These results point toward possibilities for creating new Music Information Retrieval models by focusing on dataset creation and labeling rather than custom model design.
https://weibo.com/1402400261/Kqa9UrA4m 
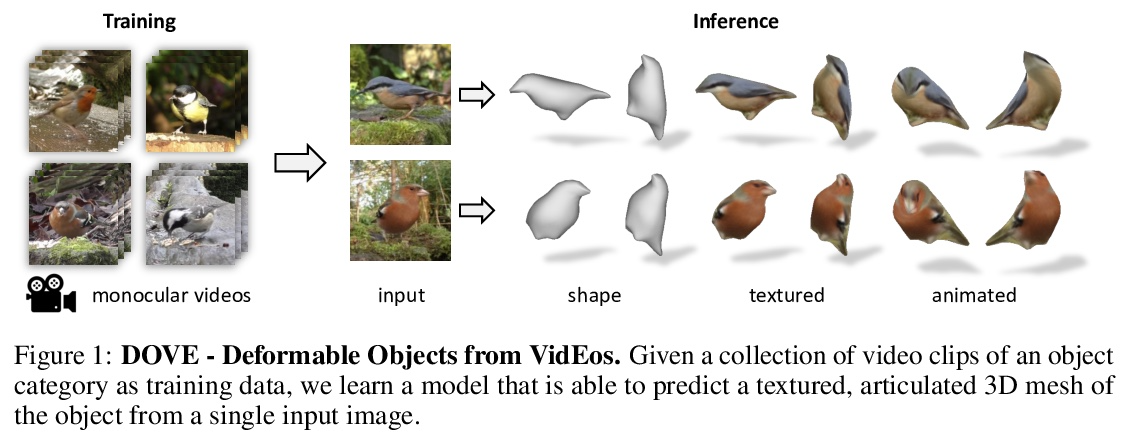
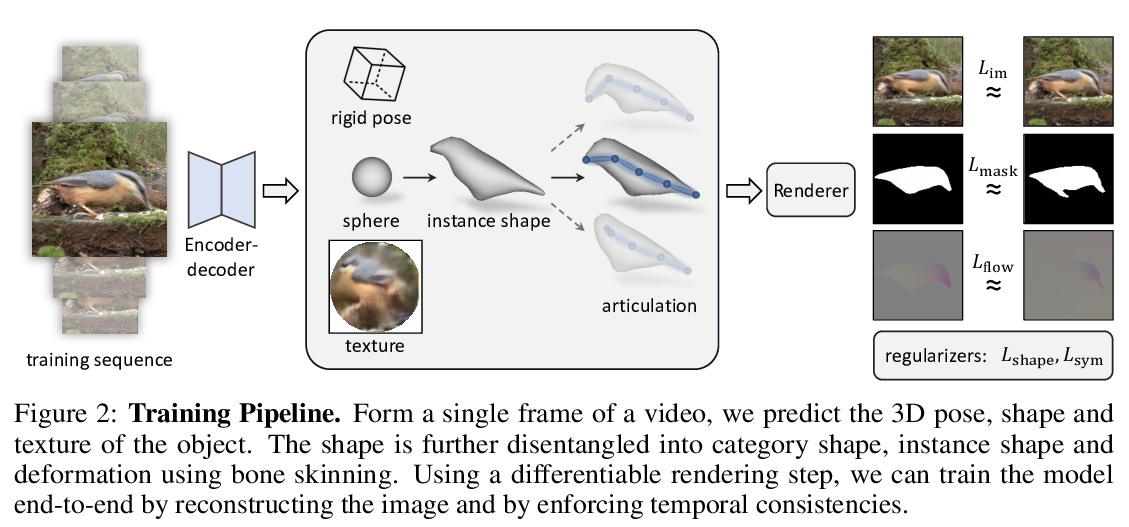
3、[CV] DOVE: Learning Deformable 3D Objects by Watching Videos
S Wu, T Jakab, C Rupprecht, A Vedaldi
[University of Oxford]
DOVE:通过观看视频学习可变形3D物体。从2D图像学习可变形3D物体是一个非常棘手的问题。现有方法依靠显式的监督来建立多视图的对应关系,如模板形状模型和关键点标注,这限制了它们对”真实场景”物体的适用性。本文建议使用单目视频,它自然地提供了跨时间的对应关系,能在没有显式关键点或模板形状的情况下学习可变形物体类别的3D形状。提出DOVE,可从鸟类单一2D图像中学习预测3D典型形状、变形、视角和纹理,给定鸟类视频集以及自动获得的剪影和光流作为训练数据。该方法重建了时间上一致的3D形状和变形,能从单一图像的任意视角对鸟进行动画和重新渲染。
Learning deformable 3D objects from 2D images is an extremely ill-posed problem. Existing methods rely on explicit supervision to establish multi-view correspondences, such as template shape models and keypoint annotations, which restricts their applicability on objects “in the wild”. In this paper, we propose to use monocular videos, which naturally provide correspondences across time, allowing us to learn 3D shapes of deformable object categories without explicit keypoints or template shapes. Specifically, we present DOVE, which learns to predict 3D canonical shape, deformation, viewpoint and texture from a single 2D image of a bird, given a bird video collection as well as automatically obtained silhouettes and optical flows as training data. Our method reconstructs temporally consistent 3D shape and deformation, which allows us to animate and re-render the bird from arbitrary viewpoints from a single image.
https://weibo.com/1402400261/KqadHnGKn 


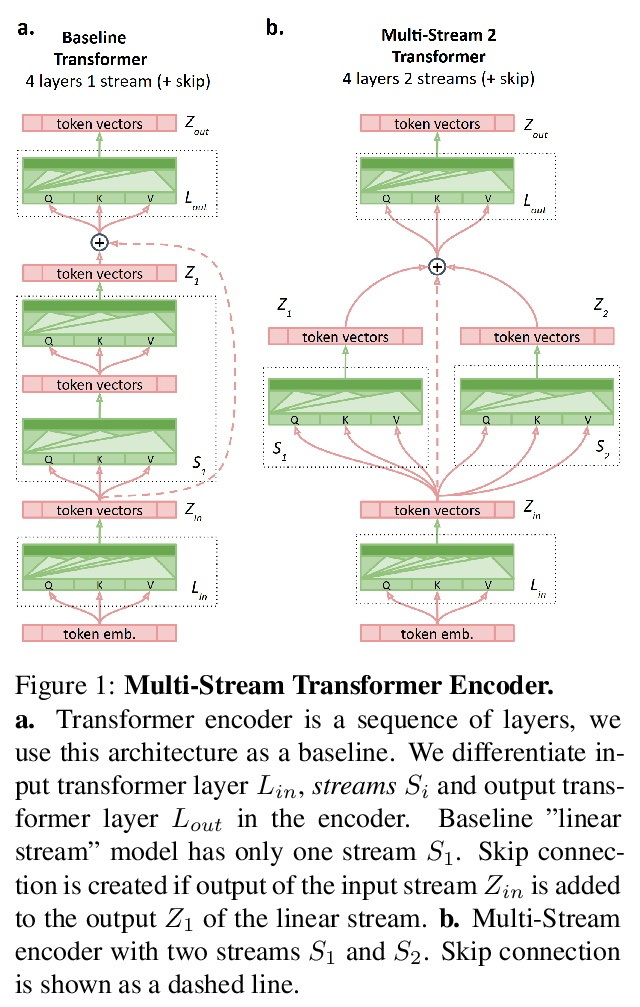
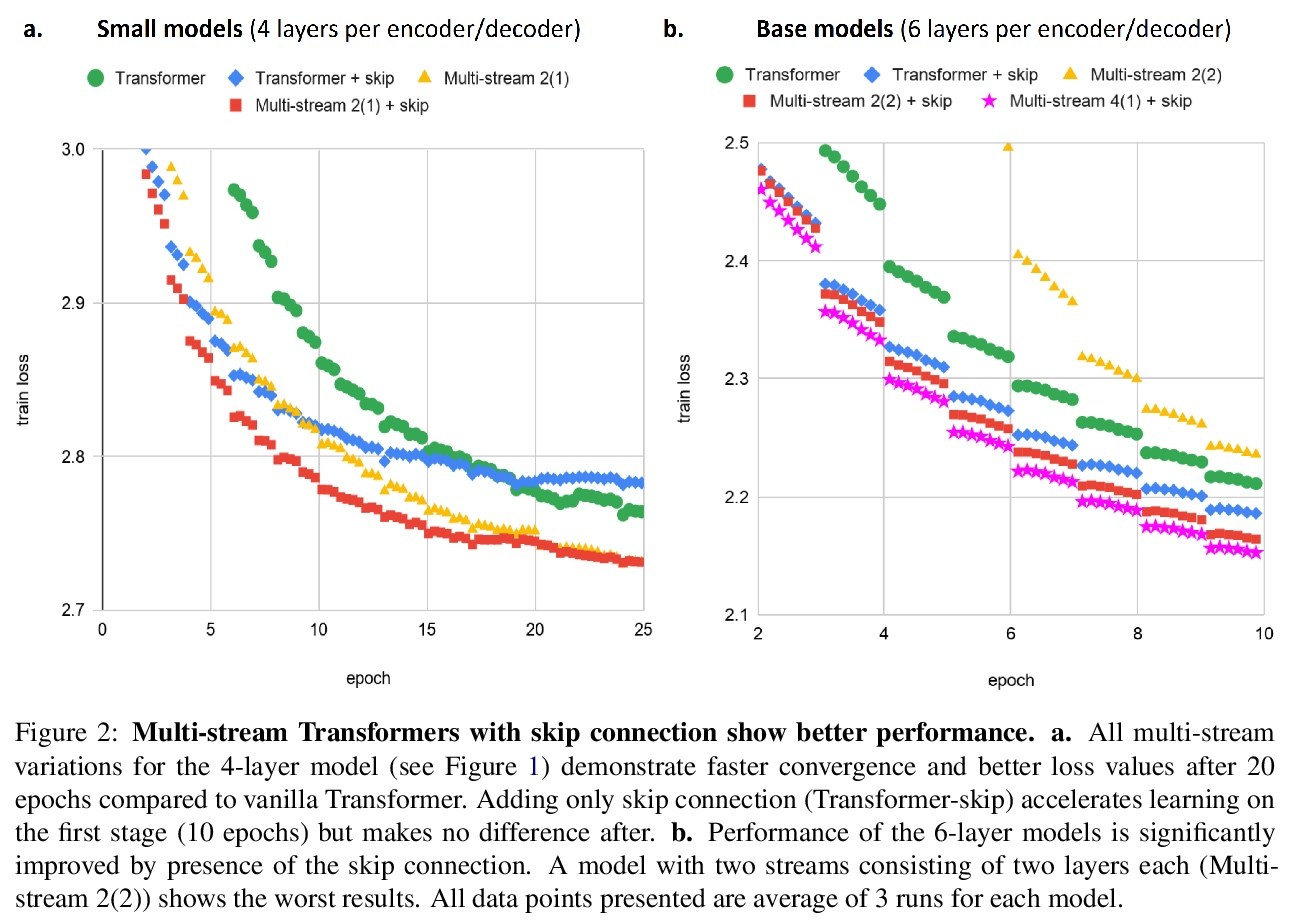
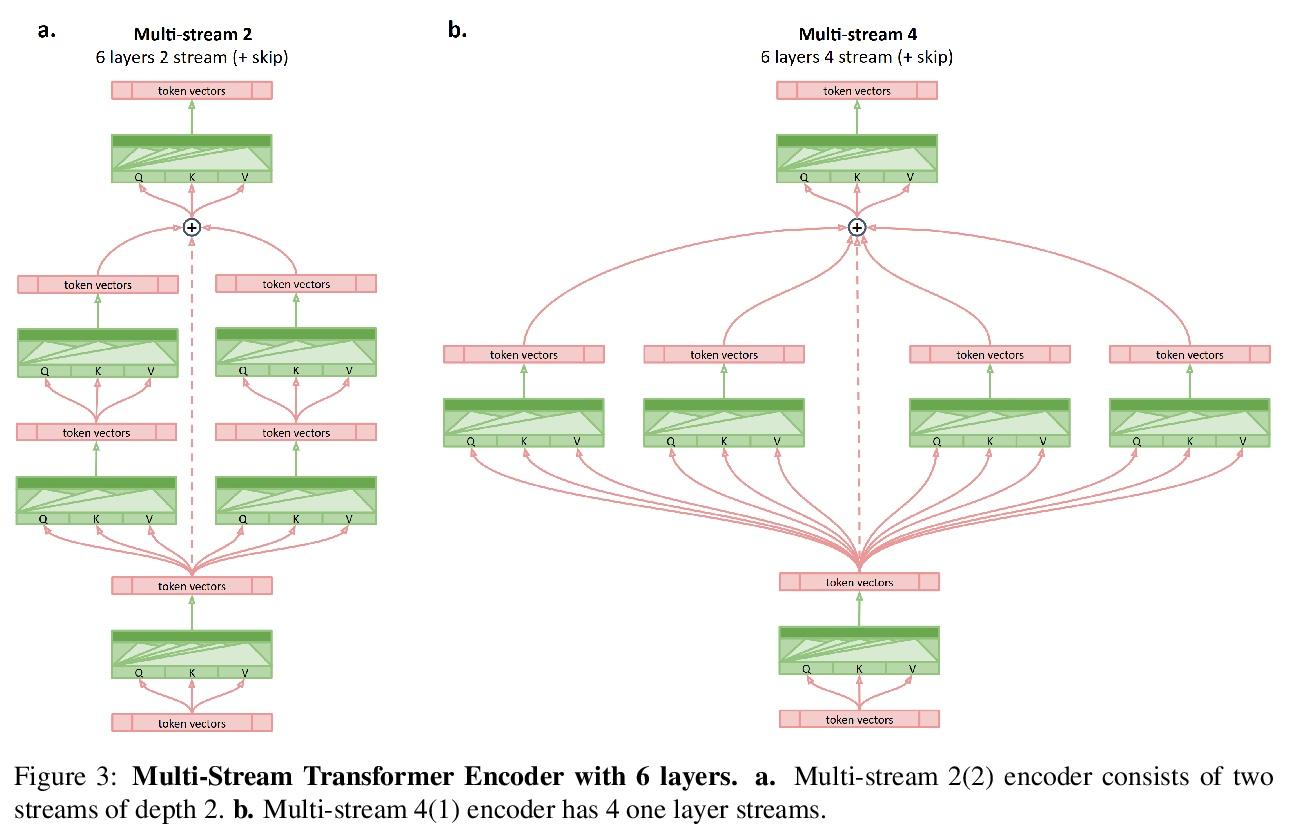
4、[CL] Multi-Stream Transformers
M Burtsev, A Rumshisky
[Artificial Intelligence Research Institute & Univ. of Massachusetts Lowell]
多流Transformer。基于Transformer的编码器-解码器模型在每编码器层之后产生一个融合的逐标记表示。本文研究了允许编码器保留和探索替代假设的效果,并在编码过程结束时进行合并。设计并检验了一个多流Transformer架构,发现将Transformer编码器分成多个编码器流,允许模型合并多个表示假设,可提高性能,通过在第一个和最后一个编码器层之间增加一个跳过连接来获得进一步的改进。
Transformer-based encoder-decoder models produce a fused token-wise representation after every encoder layer. We investigate the effects of allowing the encoder to preserve and explore alternative hypotheses, combined at the end of the encoding process. To that end, we design and examine a Multi-stream Transformer architecture and find that splitting the Transformer encoder into multiple encoder streams and allowing the model to merge multiple representational hypotheses improves performance, with further improvement obtained by adding a skip connection between the first and the final encoder layer.
https://weibo.com/1402400261/KqagAclQ9 

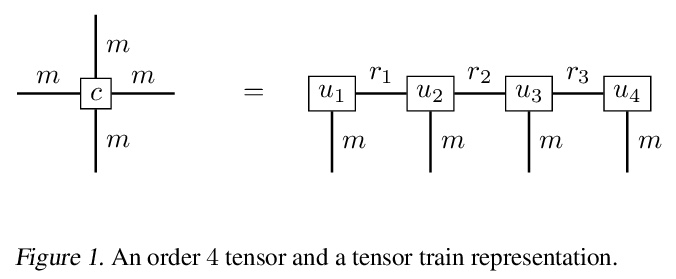
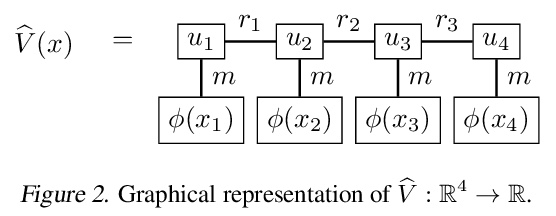
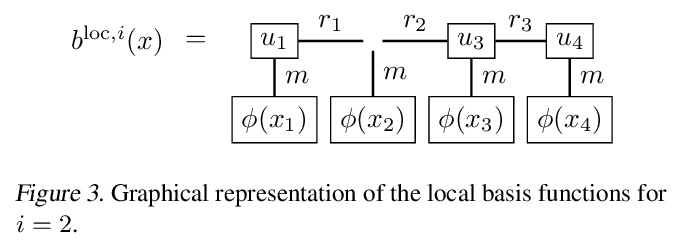
5、[LG] Solving high-dimensional parabolic PDEs using the tensor train format
L Richter, L Sallandt, N Nüsken
[Freie Universitat Berlin & Technische Universitat Berlin & Universitat Potsdam]
基于张量列格式求解高维抛物线PDE。高维偏微分方程(PDE)在经济、科学和工程领域无处不在。然而,由于传统基于网格的方法往往受到维度诅咒的影响,给数值处理带来了巨大挑战。本文认为张量列(TT)为抛物线型PDE提供了一个有吸引力的近似框架:张量格式的后向随机微分方程和回归型方法的重新表述相结合,有望利用潜在的低秩结构实现压缩和高效计算。按照这种模式,本文开发了新的迭代方案,包括显式快速或隐式精确的更新。实际例子证明,与最先进的基于神经网络的方法相比,该方法在准确性和计算效率之间取得了有利的权衡。
High-dimensional partial differential equations (PDEs) are ubiquitous in economics, science and engineering. However, their numerical treatment poses formidable challenges since traditional grid-based methods tend to be frustrated by the curse of dimensionality. In this paper, we argue that tensor trains provide an appealing approximation framework for parabolic PDEs: the combination of reformulations in terms of backward stochastic differential equations and regression-type methods in the tensor format holds the promise of leveraging latent low-rank structures enabling both compression and efficient computation. Following this paradigm, we develop novel iterative schemes, involving either explicit and fast or implicit and accurate updates. We demonstrate in a number of examples that our methods achieve a favorable trade-off between accuracy and computational efficiency in comparison with state-of-the-art neural network based approaches.
https://weibo.com/1402400261/KqajnDnH2 
另外几篇值得关注的论文:
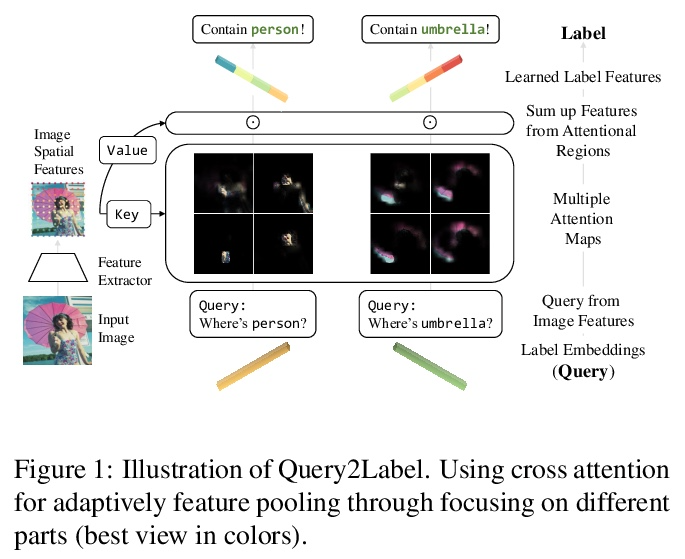
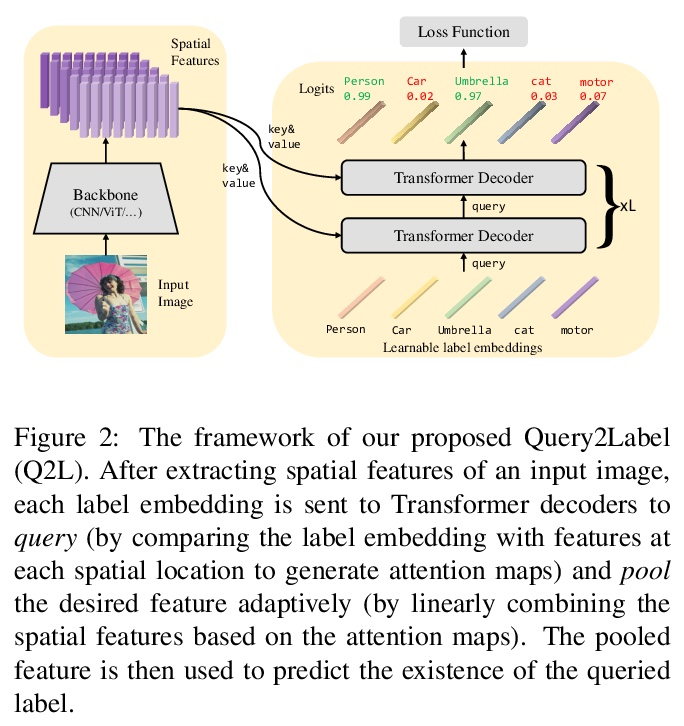
[CV] Query2Label: A Simple Transformer Way to Multi-Label Classification
Query2Label:多标签分类的简单Transformer方法
S Liu, L Zhang, X Yang, H Su, J Zhu
[Tsinghua University]
https://weibo.com/1402400261/KqanSe4LG 


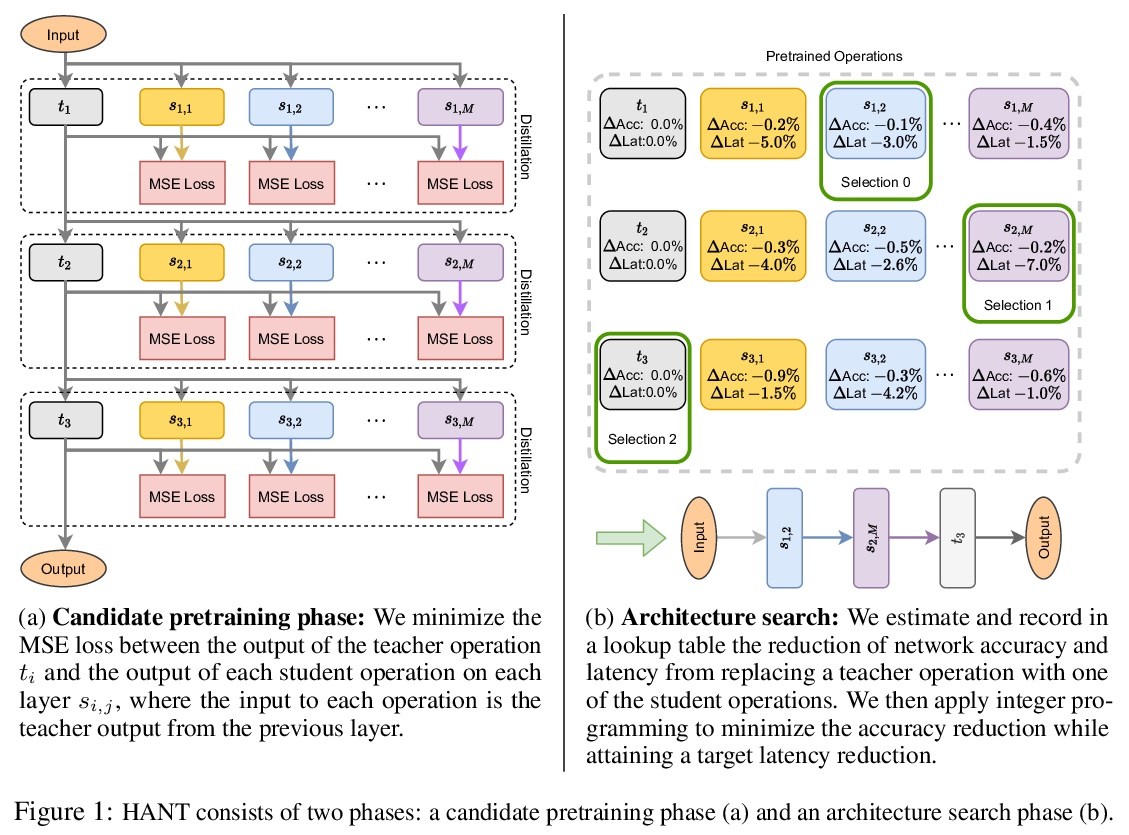
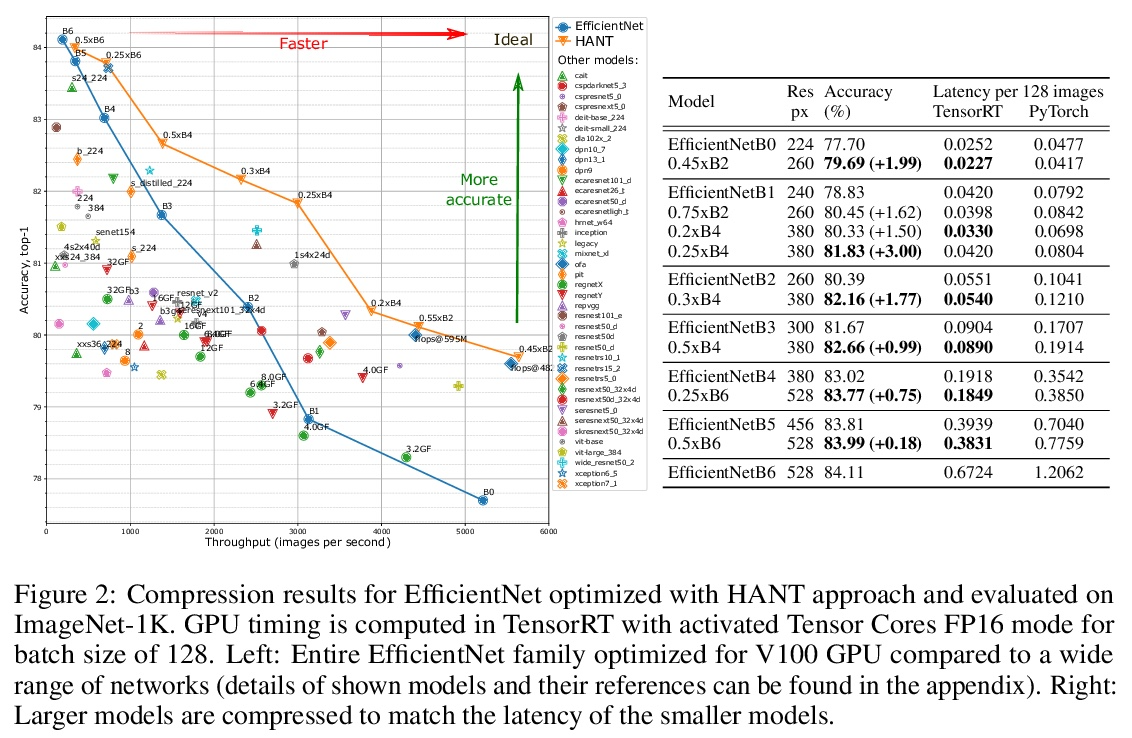
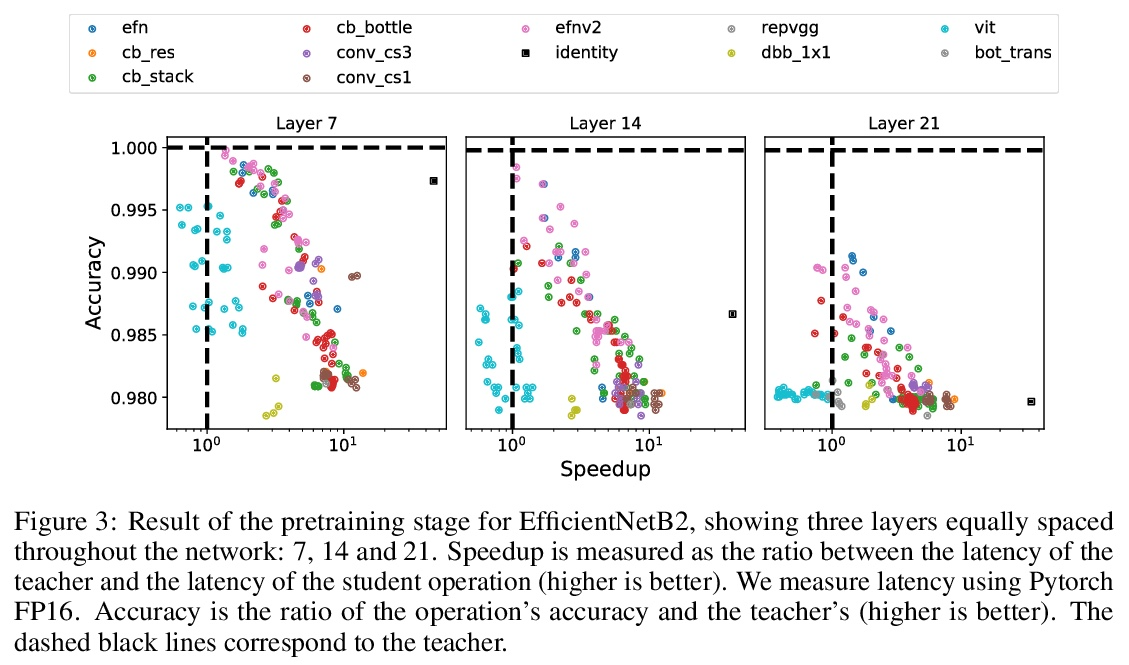
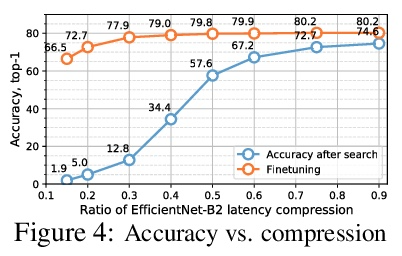
[CV] HANT: Hardware-Aware Network Transformation
HANT:用于加速预训练网络的硬件感知网络变换
P Molchanov, J Hall, H Yin, J Kautz, N Fusi, A Vahdat
[NVIDIA & Microsoft Research]
https://weibo.com/1402400261/KqapHa6Rc 
、
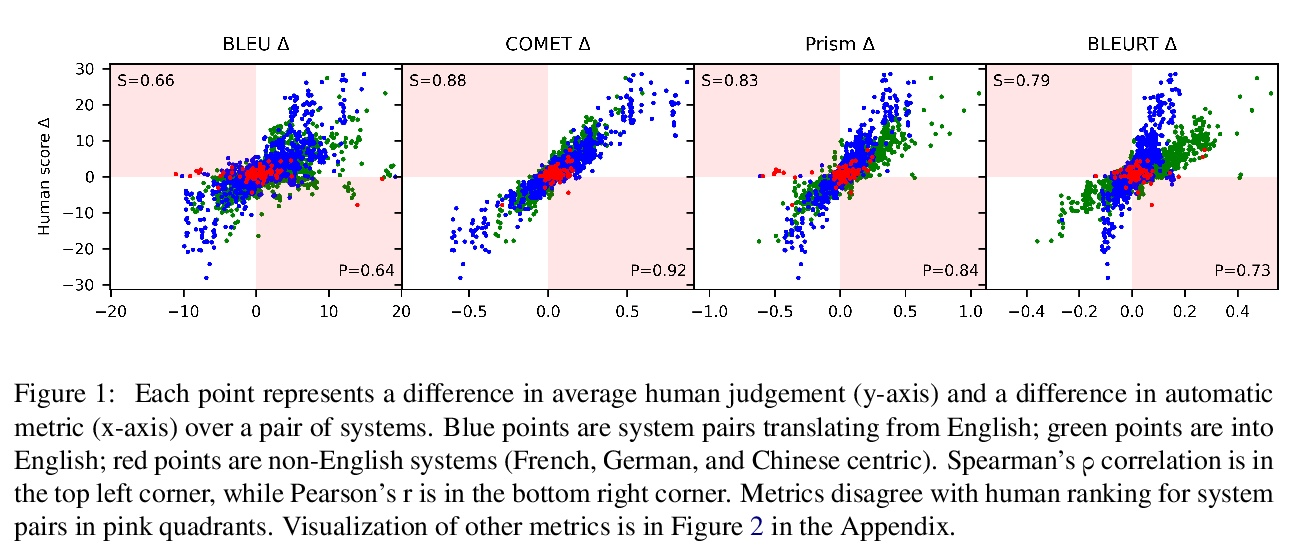
[CL] To Ship or Not to Ship: An Extensive Evaluation of Automatic Metrics for Machine Translation
对机器翻译自动评价指标的扩展评估
T Kocmi, C Federmann, R Grundkiewicz, M Junczys-Dowmunt, H Matsushita, A Menezes
[Microsoft]
https://weibo.com/1402400261/KqarVaTEL 

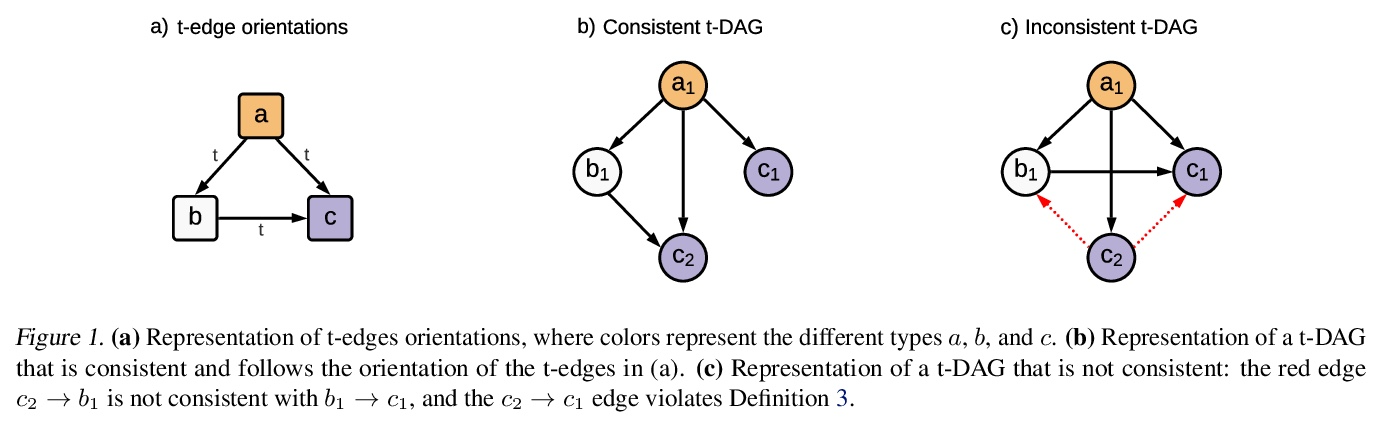
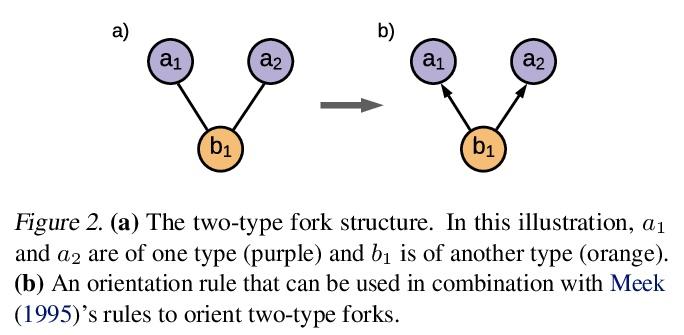
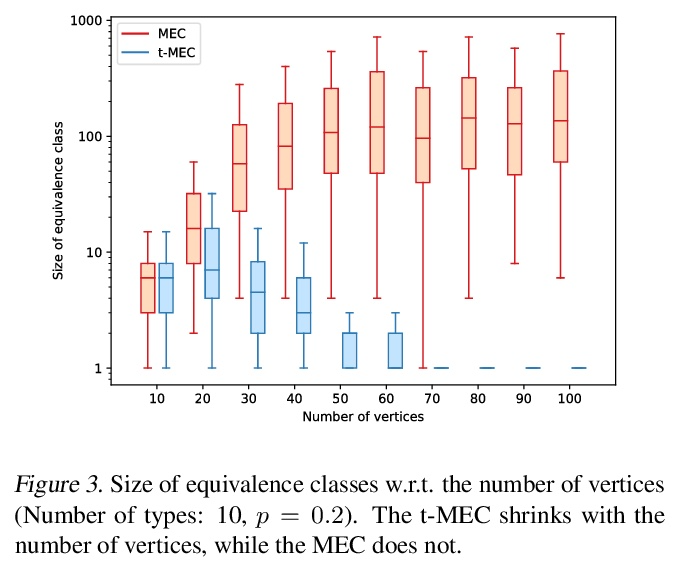
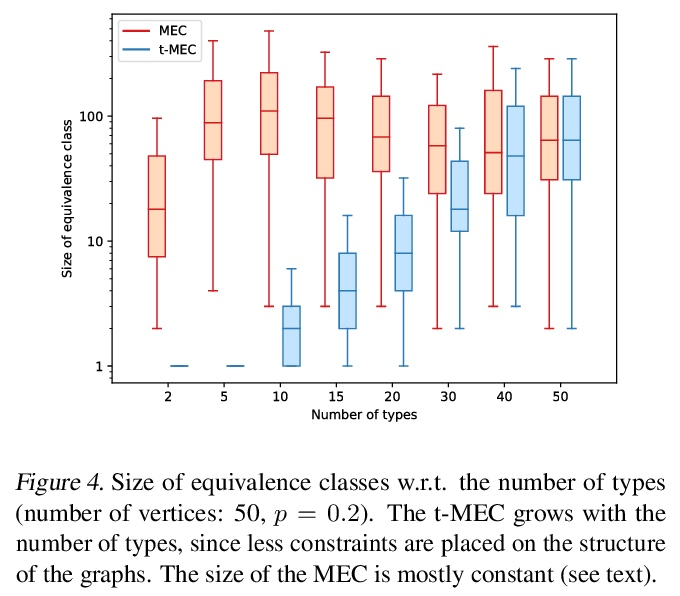
[LG] Typing assumptions improve identification in causal discovery
用类型化假设提高因果发现的识别能力
P Brouillard, P Taslakian, A Lacoste, S Lachapelle, A Drouin
[Element AI & Mila]
https://weibo.com/1402400261/KqatFCxbR 

若有收获,就点个赞吧
0 人点赞
