- 1、[LG] Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better
- 2、[CL] Compacter: Efficient Low-Rank Hypercomplex Adapter Layers
- 3、[LG] Sleeper Agent: Scalable Hidden Trigger Backdoors for Neural Networks Trained from Scratch
- 4、[CV] Invertible Attention
- 5、[CL] Targeted Data Acquisition for Evolving Negotiation Agents
- [CV] Smoothing the Disentangled Latent Style Space for Unsupervised Image-to-Image Translation
- [LG] KALE Flow: A Relaxed KL Gradient Flow for Probabilities with Disjoint Support
- [CV] Differentiable Diffusion for Dense Depth Estimation from Multi-view Images
- [CV] The Oxford Road Boundaries Dataset
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[LG] Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better
G Menghani
[Google Research]
高效深度学习综述:更小、更快、更好的深度学习模型。深度学习彻底改变了计算机视觉、自然语言理解、语音识别、信息检索等领域。然而,随着深度学习模型的逐步完善,其参数数量、延迟、训练所需资源等都有了明显增加。因此,关注一个模型的这些足迹指标也变得很重要,而不仅仅是它的质量。本文聚焦深度学习中的效率问题,并加以提炼,对模型效率的五个核心领域(包括建模技术、基础设施和硬件)以及相关开创性工作进行了彻底的调研。提出了一个基于实验的指南及其代码,供从业者优化模型训练和部署。
Deep Learning has revolutionized the fields of computer vision, natural language understanding, speech recognition, information retrieval and more. However, with the progressive improvements in deep learning models, their number of parameters, latency, resources required to train, etc. have all have increased significantly. Consequently, it has become important to pay attention to these footprint metrics of a model as well, not just its quality. We present and motivate the problem of efficiency in deep learning, followed by a thorough survey of the five core areas of model efficiency (spanning modeling techniques, infrastructure, and hardware) and the seminal work there. We also present an experiment-based guide along with code, for practitioners to optimize their model training and deployment. We believe this is the first comprehensive survey in the efficient deep learning space that covers the landscape of model efficiency from modeling techniques to hardware support. Our hope is that this survey would provide the reader with the mental model and the necessary understanding of the field to apply generic efficiency techniques to immediately get significant improvements, and also equip them with ideas for further research and experimentation to achieve additional gains.
https://weibo.com/1402400261/KkGEdldXG
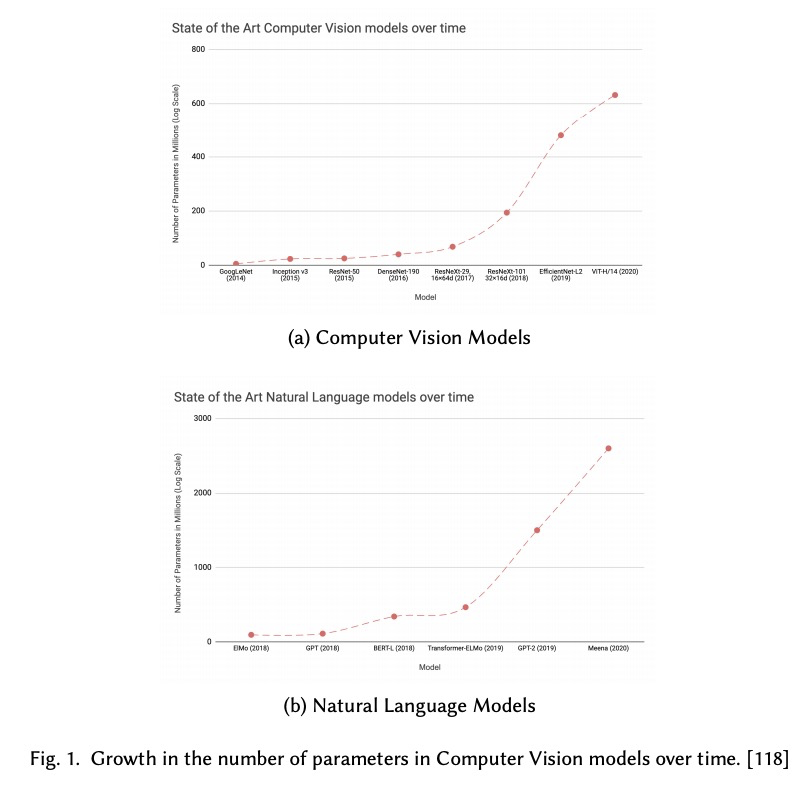
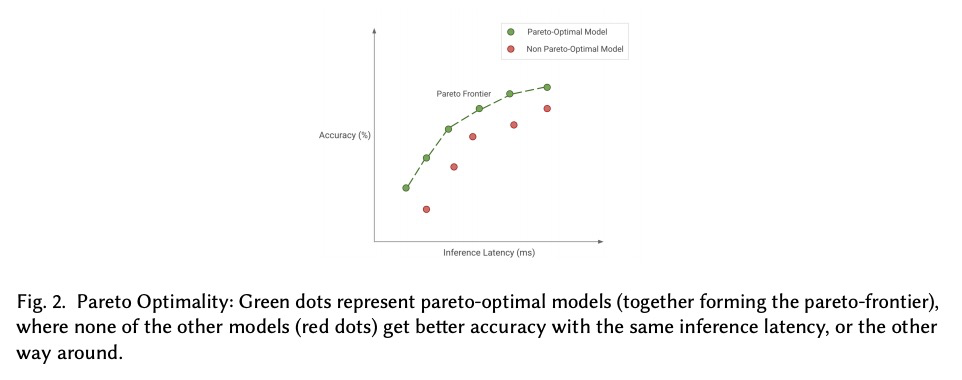

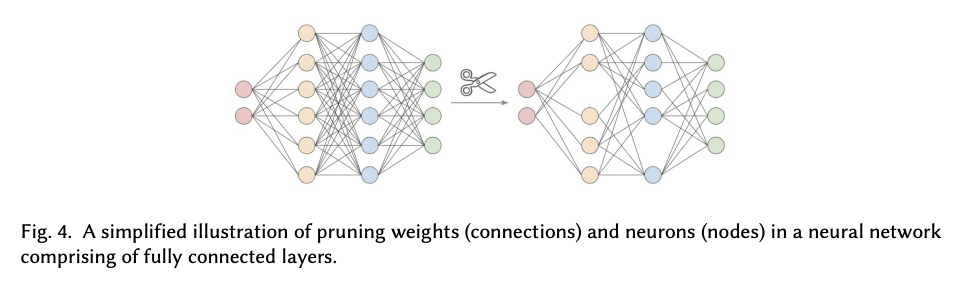
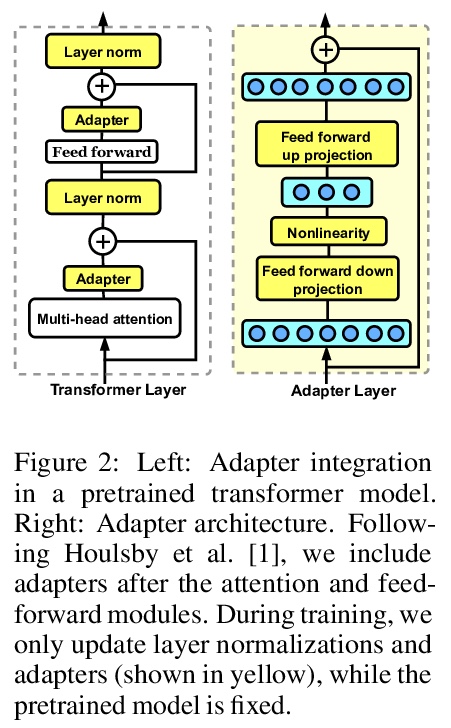
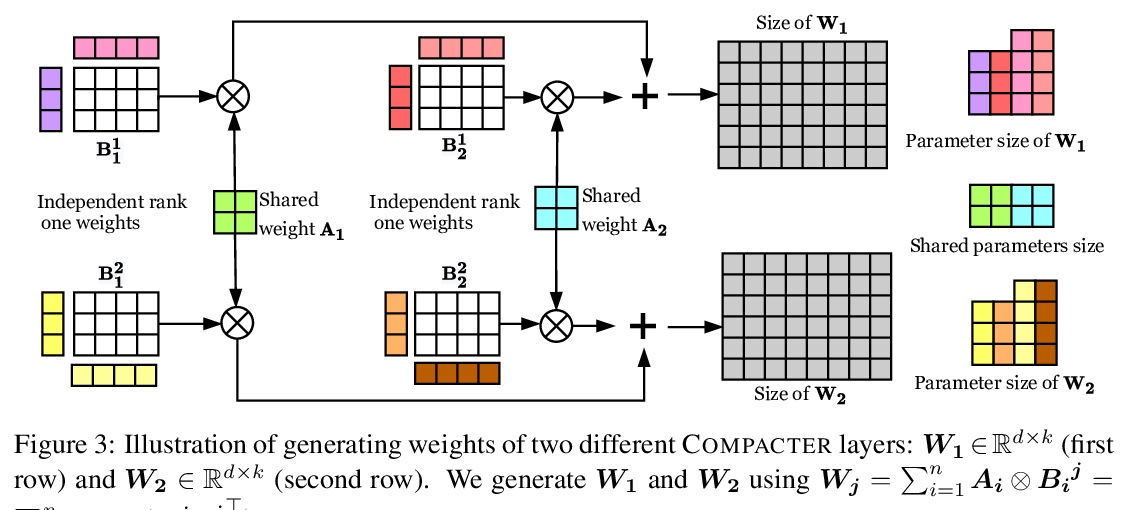
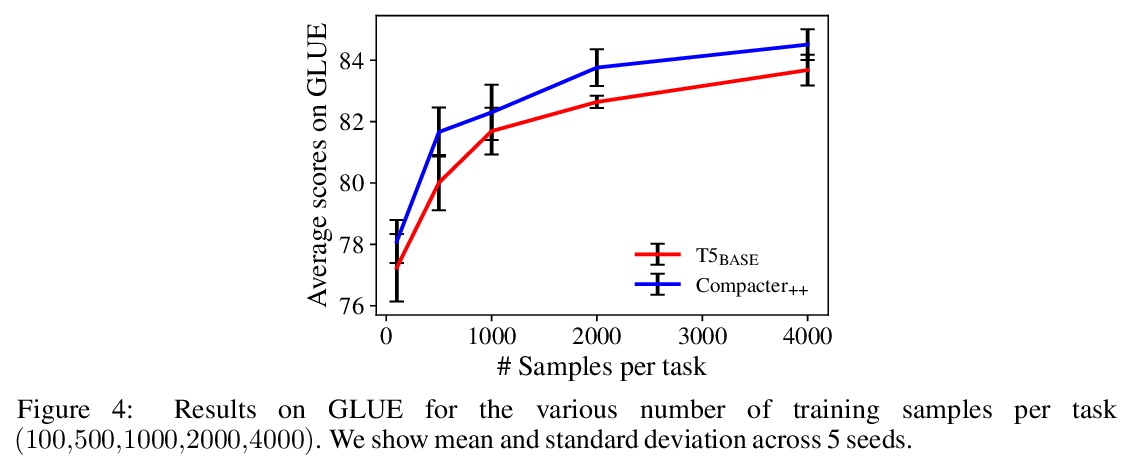
2、[CL] Compacter: Efficient Low-Rank Hypercomplex Adapter Layers
R K Mahabadi, J Henderson, S Ruder
[EPFL University & Idiap Research Institute & DeepMind]
COMPACTER:高效低秩超复数适配层。通过微调使大规模预训练语言模型适应下游任务,是在NLP基准上实现最先进性能的标准方法。然而,对具有数百万或数十亿参数的模型的所有权重进行微调是低效的,在低资源环境下是不稳定的,并且是浪费的,因为它需要为每个任务存储一个单独的模型副本。最近的工作开发了参数高效的微调方法,但这些方法要么仍然需要相对大量的参数,要么性能低于标准微调。本文提出COMPACTER,一种用于微调大规模语言模型的方法,在任务性能和可训练参数数量之间的权衡,比之前的工作更好。COMPACTER通过建立在适配器、低秩优化和参数化超复数乘法层的想法之上来实现这一目标,将特定任务权重矩阵插入预训练模型的权重中,将这些权重有效地计算为共享的”慢”权重和”快”秩1矩阵间的克朗克乘积之和,并在每个COMPACTER层定义。只需训练0.047%的预训练模型的参数,COMPACTER的表现就与GLUE上的标准微调相当,并在低资源环境下胜过微调。
Adapting large-scale pretrained language models to downstream tasks via fine-tuning is the standard method for achieving state-of-the-art performance on NLP benchmarks. However, fine-tuning all weights of models with millions or billions of parameters is sample-inefficient, unstable in low-resource settings, and wasteful as it requires storing a separate copy of the model for each task. Recent work has developed parameter-efficient fine-tuning methods, but these approaches either still require a relatively large number of parameters or underperform standard fine-tuning. In this work, we propose COMPACTER, a method for fine-tuning large-scale language models with a better trade-off between task performance and the number of trainable parameters than prior work. COMPACTER accomplishes this by building on top of ideas from adapters, low-rank optimization, and parameterized hypercomplex multiplication layers. Specifically, COMPACTER inserts task-specific weight matrices into a pretrained model’s weights, which are computed efficiently as a sum of Kronecker products between shared “slow” weights and “fast” rank-one matrices defined per COMPACTER layer. By only training 0.047% of a pretrained model’s parameters, COMPACTER performs on par with standard fine-tuning on GLUE and outperforms fine-tuning in low-resource settings.
https://weibo.com/1402400261/KkGIxFHbN
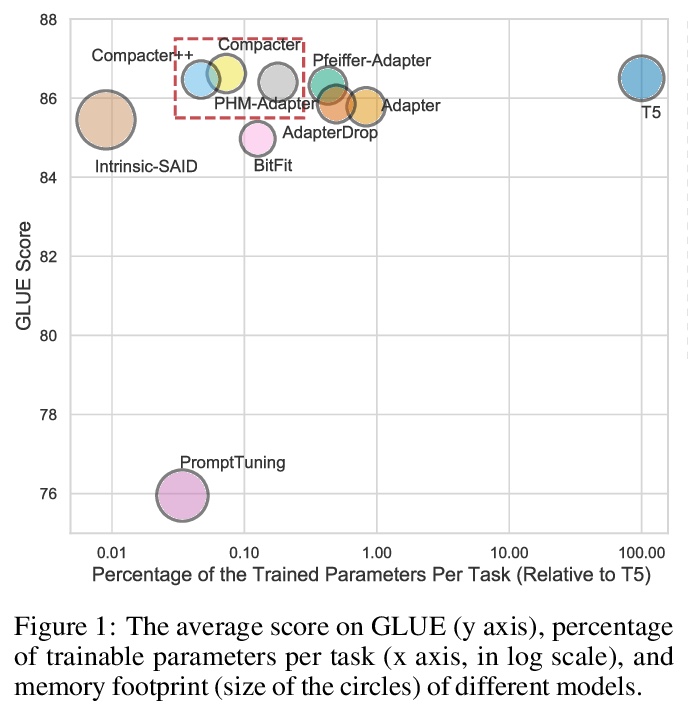
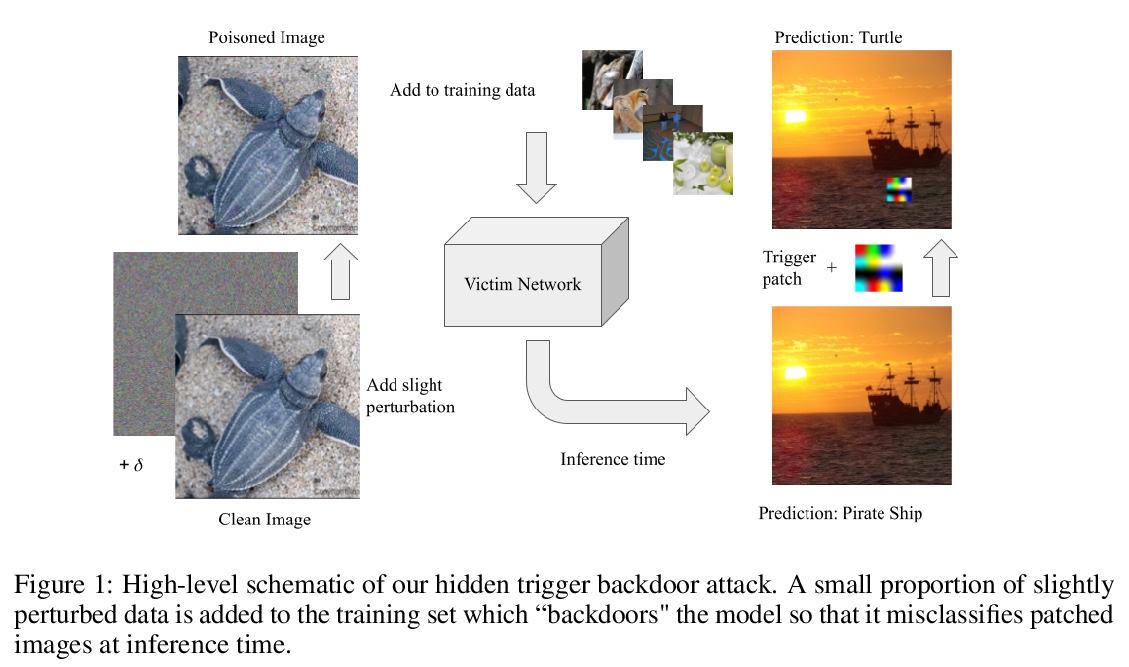
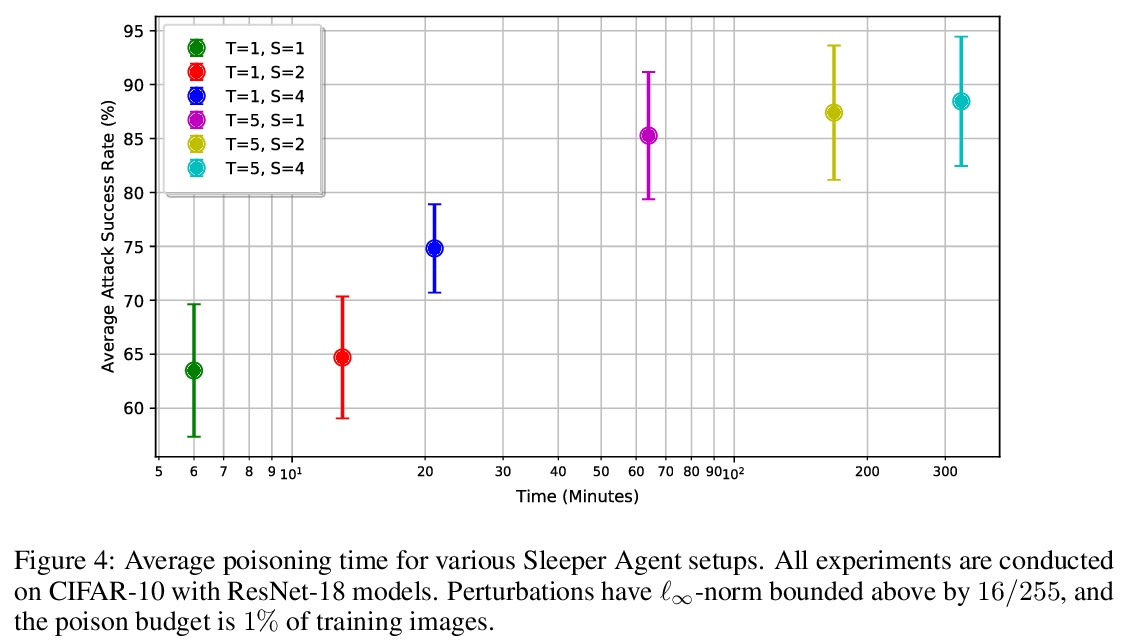
3、[LG] Sleeper Agent: Scalable Hidden Trigger Backdoors for Neural Networks Trained from Scratch
H Souri, M Goldblum, L Fowl, R Chellappa, T Goldstein
[Johns Hopkins University & University of Maryland]
Sleeper Agent:从头训练神经网络的可扩展隐式触发器后门。随着机器学习的数据整理变得越来越自动化,数据集篡改的威胁也越来越大。后门攻击者篡改训练数据,将漏洞植入在该数据上训练的模型中,通过在模型的输入中放置”触发器”,使漏洞在推理时被激活。典型的后门攻击将触发器直接插入训练数据中,尽管这种攻击的存在在检查时可能是可见的。相比之下,隐藏触发器后门攻击根本不需要将触发器放入训练数据中,即可让模型中毒。然而,这种隐藏的触发器攻击,无法让从头开始训练的神经网络中毒。本文提出一种新的隐式触发器攻击,即Sleeper Agent,在制作过程中采用了梯度匹配、数据选择和目标模型再训练。Sleeper Agent是第一个对从头开始训练神经网络有效的隐式触发器后门攻击,在ImageNet和黑盒环境中证明了它的有效性。
As the curation of data for machine learning becomes increasingly automated, dataset tampering is a mounting threat. Backdoor attackers tamper with training data to embed a vulnerability in models that are trained on that data. This vulnerability is then activated at inference time by placing a “trigger” into the model’s input. Typical backdoor attacks insert the trigger directly into the training data, although the presence of such an attack may be visible upon inspection. In contrast, the Hidden Trigger Backdoor Attack achieves poisoning without placing a trigger into the training data at all. However, this hidden trigger attack is ineffective at poisoning neural networks trained from scratch. We develop a new hidden trigger attack, Sleeper Agent, which employs gradient matching, data selection, and target model re-training during the crafting process. Sleeper Agent is the first hidden trigger backdoor attack to be effective against neural networks trained from scratch. We demonstrate its effectiveness on ImageNet and in black-box settings.
https://weibo.com/1402400261/KkGLXtqcE


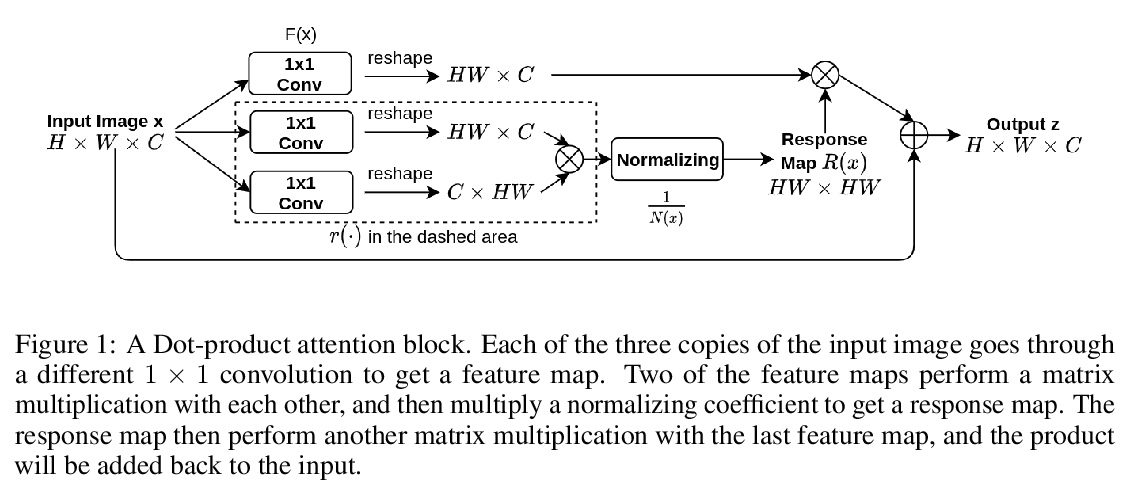
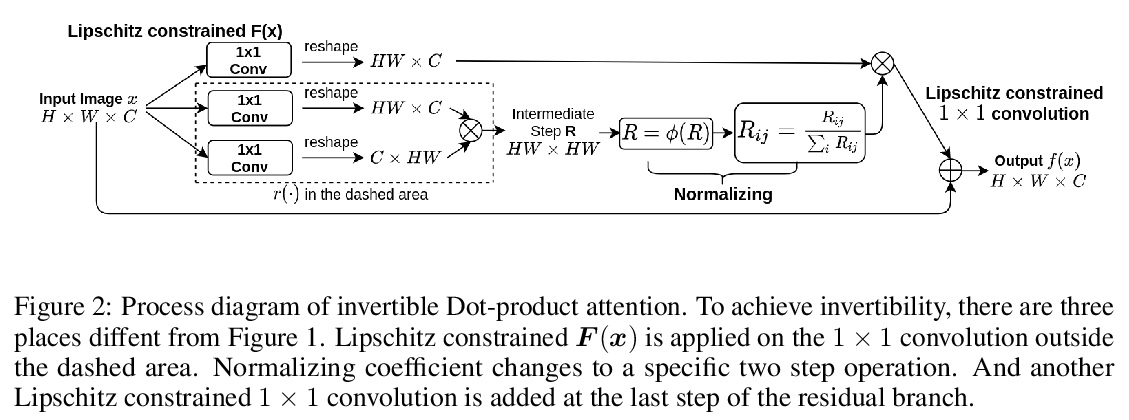
4、[CV] Invertible Attention
J Zha, Y Zhong, J Zhang, L Zheng, R Hartley
[Australian National University]
可逆注意力。注意力已经证明是捕捉长程依赖关系的一种有效机制。然而,到目前为止,它还没有被部署在可逆网络中。这是由于为了使网络可逆,网络中的每个组件都需要是双射变换,但正常的注意力块不是。本文提出了可逆注意力,可插入到现有的可逆模型中。从数学和实验上证明,注意力模型的可逆性可通过仔细约束其Lipschitz常数来实现。用3个流行的数据集(CIFAR-10、SVHN和CelebA)验证了可逆注意力在图像重建任务中的可逆性。在密集预测任务上,可逆注意力与普通的不可逆注意力相比,取得了相似的性能。
Attention has been proved to be an efficient mechanism to capture long-range dependencies. However, so far it has not been deployed in invertible networks. This is due to the fact that in order to make a network invertible, every component within the network needs to be a bijective transformation, but a normal attention block is not. In this paper, we propose invertible attention that can be plugged into existing invertible models. We mathematically and experimentally prove that the invertibility of an attention model can be achieved by carefully constraining its Lipschitz constant. We validate the invertibility of our invertible attention on image reconstruction task with 3 popular datasets: CIFAR-10, SVHN, and CelebA. We also show that our invertible attention achieves similar performance in comparison with normal non-invertible attention on dense prediction tasks.
https://weibo.com/1402400261/KkGPxa2g8


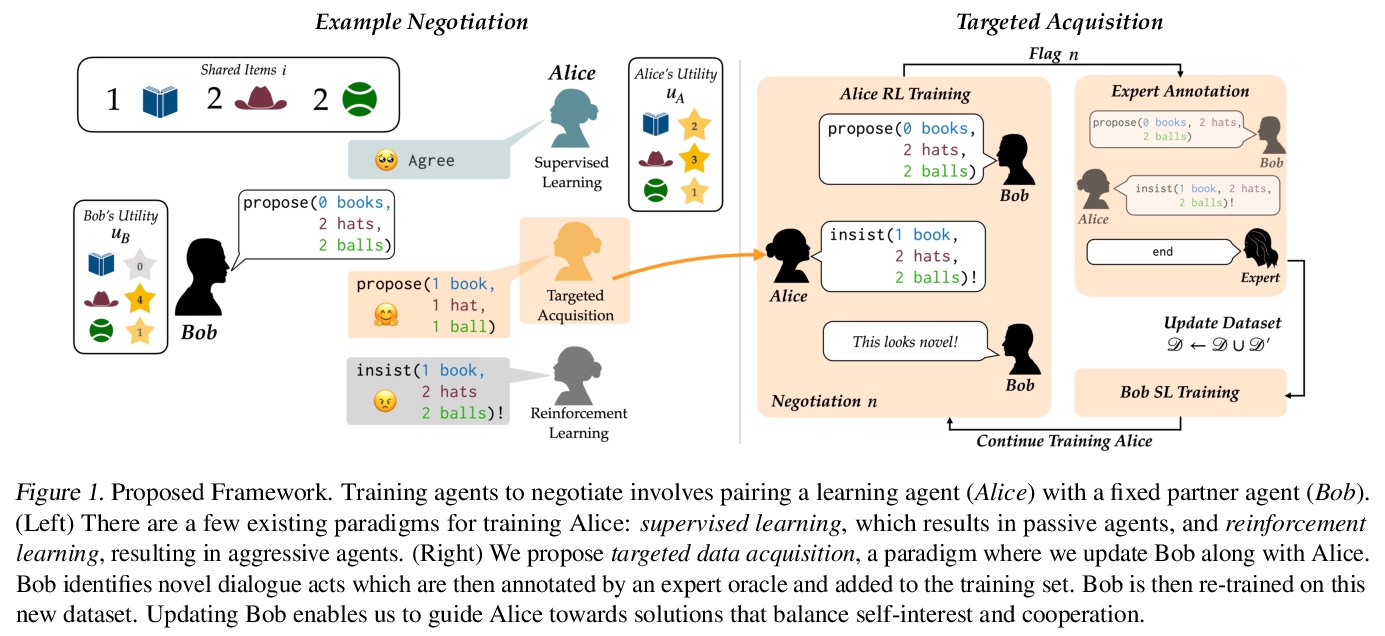
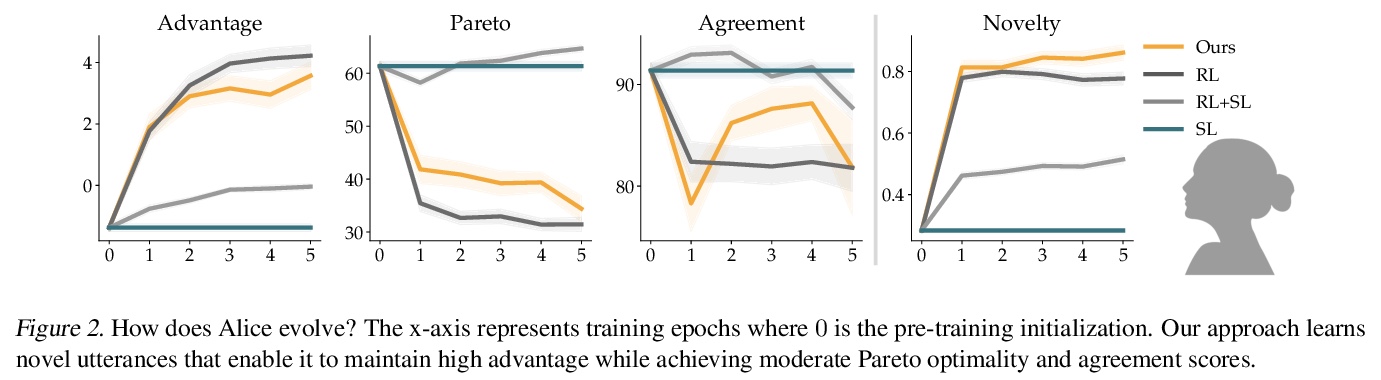
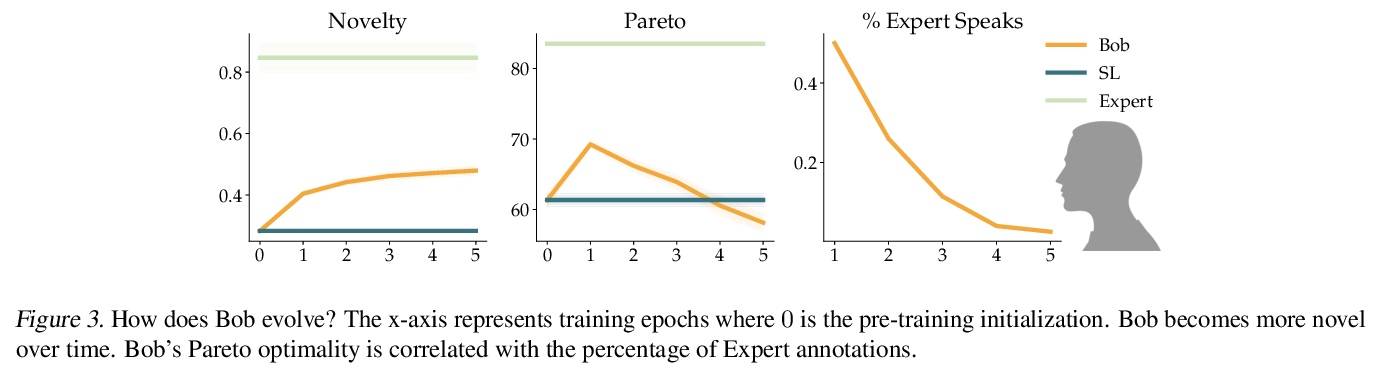
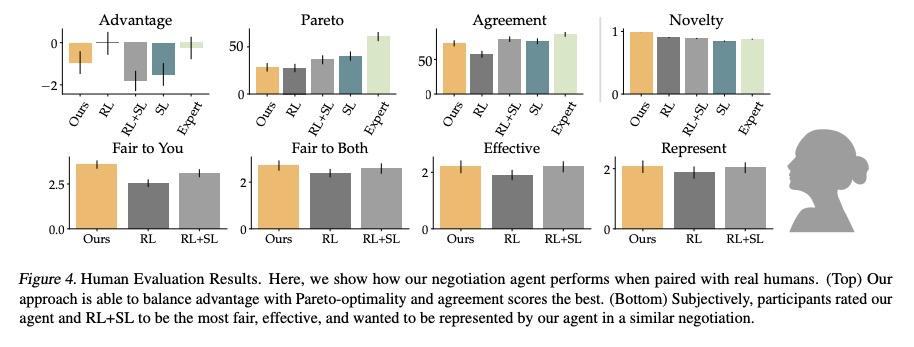
5、[CL] Targeted Data Acquisition for Evolving Negotiation Agents
M Kwon, S Karamcheti, M Cuellar, D Sadigh
[Stanford University]
为演进谈判智能体提供有针对性的数据采集。成功的谈判者,必须学会如何平衡自我利益和合作间的优化。然而,目前的人工谈判智能体,往往严重依赖用来训练的静态数据集的质量,限制了其形成平衡自我利益和合作的适应性反应的能力。本文发现这些智能体可实现高效用或合作,但不能同时实现。为解决这个问题,提出一种有针对性的数据采集框架,利用专家解读的标记,来指导强化学习智能体的探索。有指导的探索激励学习代理超越其静态数据集,并开发新的谈判策略。与标准的有监督学习和强化学习方法相比,智能体在与模拟和人类伙伴谈判时,能获得更高回报和更多的帕累托最优解决方案。当把使用该目标数据采集框架的智能体,与使用有监督学习和强化学习混合训练的智能体变体,或使用明确优化效用和帕累托最优的定制奖励函数的智能体进行比较时,这一趋势也是成立的。
Successful negotiators must learn how to balance optimizing for self-interest and cooperation. Yet current artificial negotiation agents often heavily depend on the quality of the static datasets they were trained on, limiting their capacity to fashion an adaptive response balancing self-interest and cooperation. For this reason, we find that these agents can achieve either high utility or cooperation, but not both. To address this, we introduce a targeted data acquisition framework where we guide the exploration of a reinforcement learning agent using annotations from an expert oracle. The guided exploration incentivizes the learning agent to go beyond its static dataset and develop new negotiation strategies. We show that this enables our agents to obtain higher-reward and more Pareto-optimal solutions when negotiating with both simulated and human partners compared to standard supervised learning and reinforcement learning methods. This trend additionally holds when comparing agents using our targeted data acquisition framework to variants of agents trained with a mix of supervised learning and reinforcement learning, or to agents using tailored reward functions that explicitly optimize for utility and Pareto-optimality.
https://weibo.com/1402400261/KkGSnfGbX
另外几篇值得关注的论文:
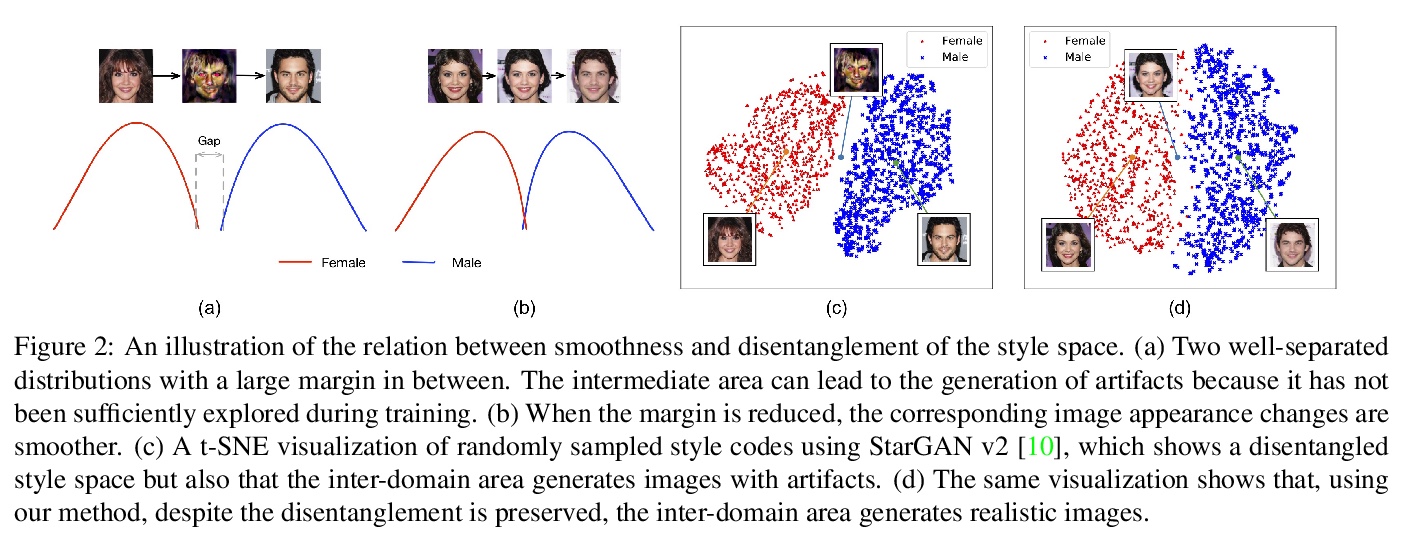
[CV] Smoothing the Disentangled Latent Style Space for Unsupervised Image-to-Image Translation
面向无监督图像-图像变换的解缠潜风格空间平滑
Y Liu, E Sangineto, Y Chen, L Bao, H Zhang, N Sebe, B Lepri, W Wang, M D Nadai
[University of Trento & Tencent AI Lab & Fondazione Bruno Kessler]
https://weibo.com/1402400261/KkGWj5VOa



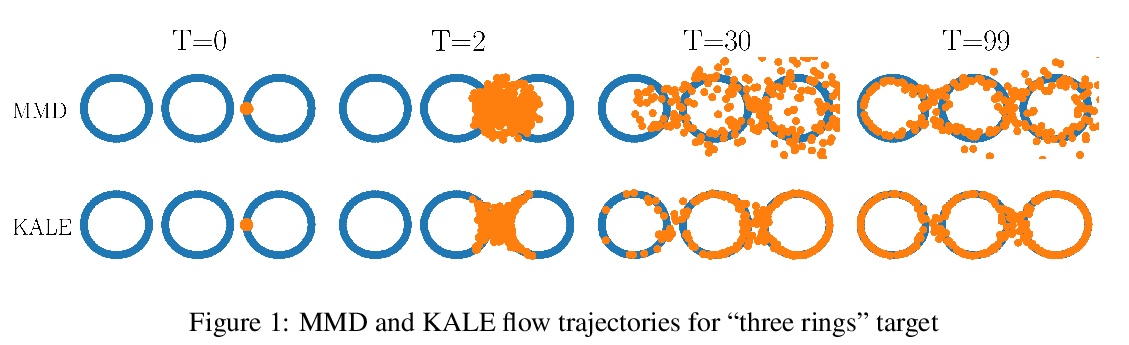
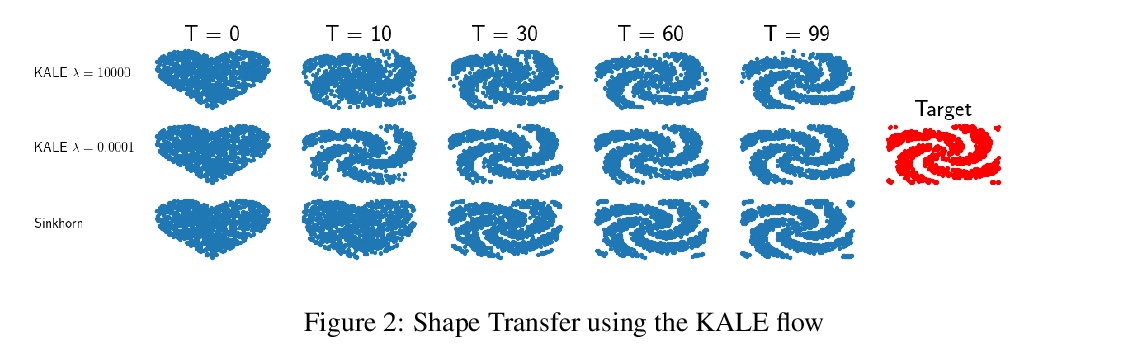
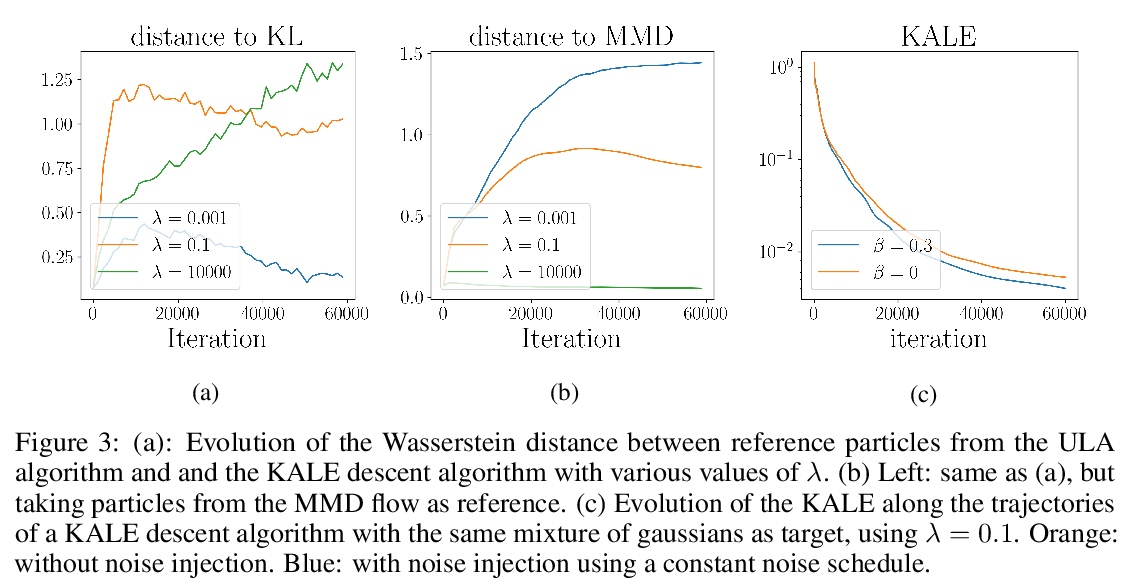
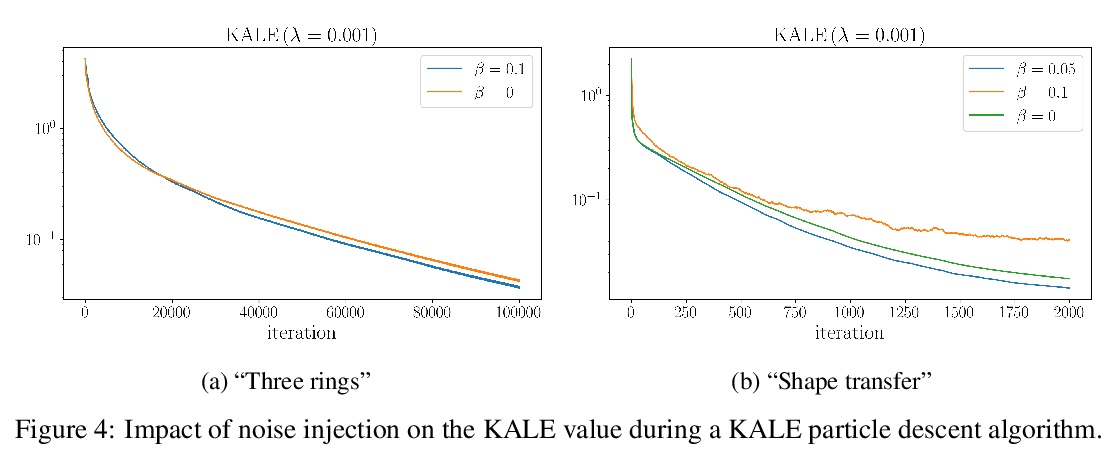
[LG] KALE Flow: A Relaxed KL Gradient Flow for Probabilities with Disjoint Support
KALE Flow:不相交支持概率松弛KL梯度流
P Glaser, M Arbel, A Gretton
[University College London & INRIA]
https://weibo.com/1402400261/KkGYe6uNt
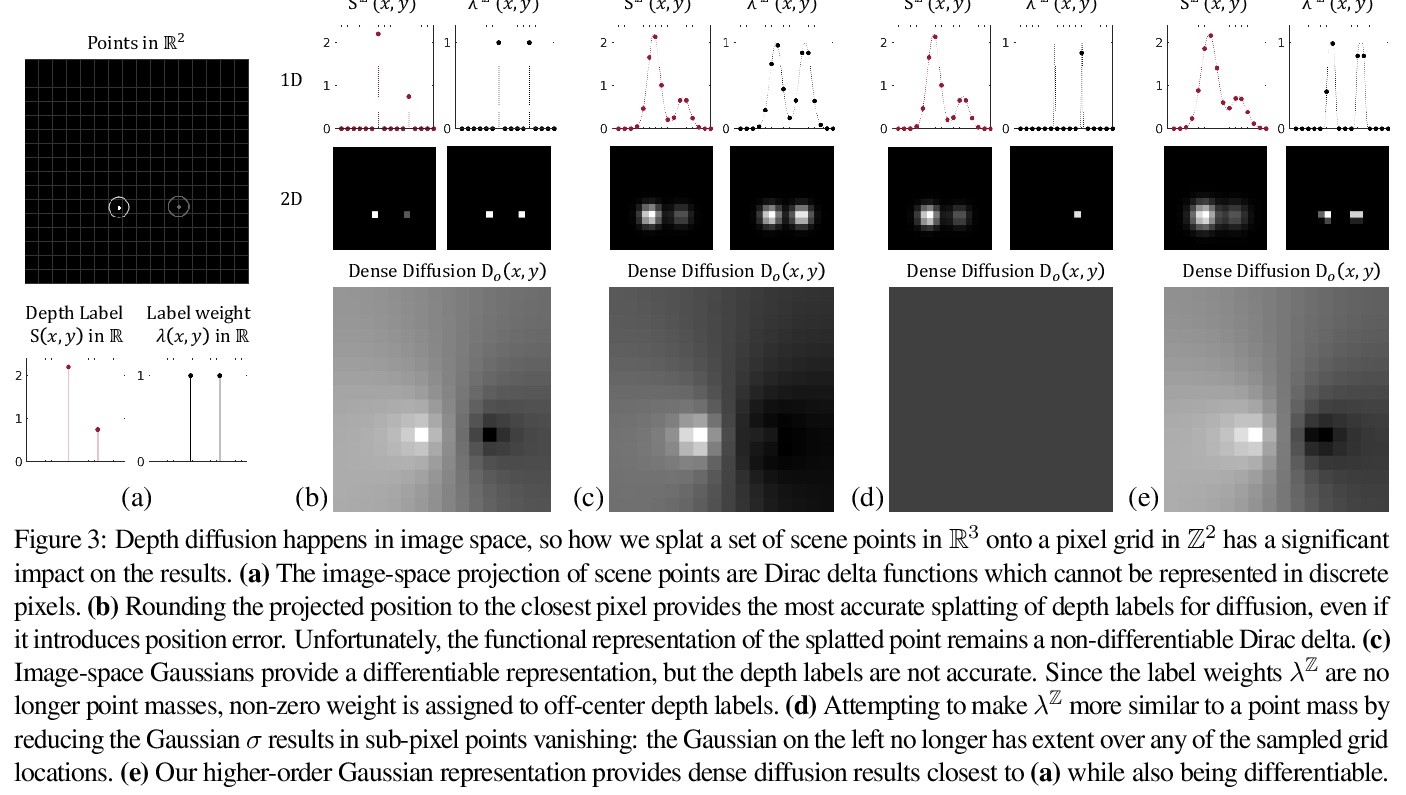
[CV] Differentiable Diffusion for Dense Depth Estimation from Multi-view Images
基于可微扩散的多视角图像密集深度估计
N Khan, M H. Kim, J Tompkin
[Brown University & KAIST]
https://weibo.com/1402400261/KkH0I5NuJ



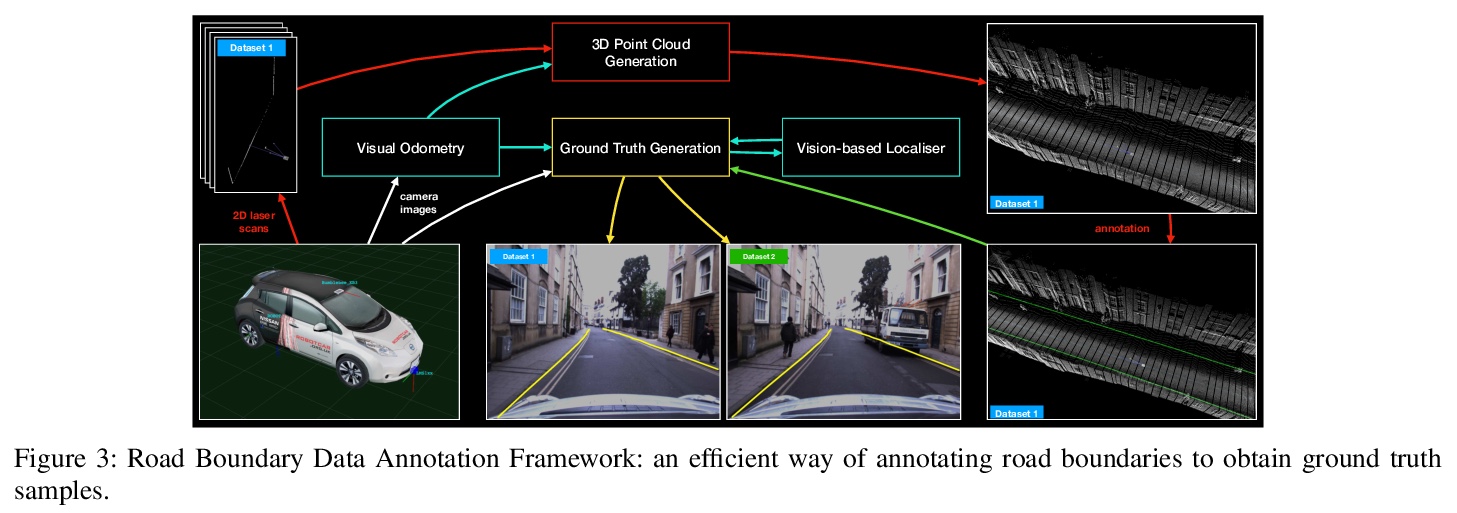
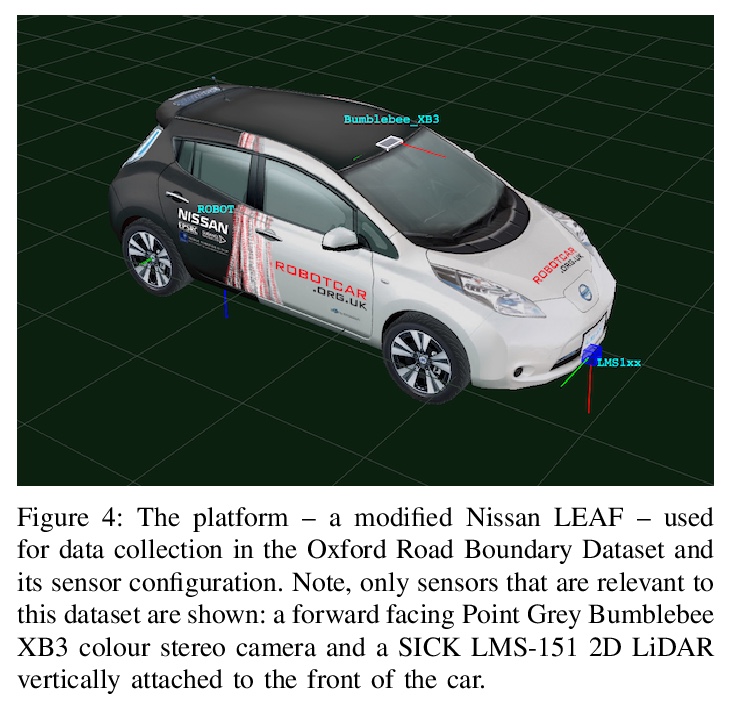
[CV] The Oxford Road Boundaries Dataset
牛津道路边界数据集
T Suleymanov, M Gadd, D D Martini, P Newman
[University of Oxford]
https://weibo.com/1402400261/KkH2d8mv0



若有收获,就点个赞吧
0 人点赞
