- 1、[CV] Vision Transformer with Progressive Sampling
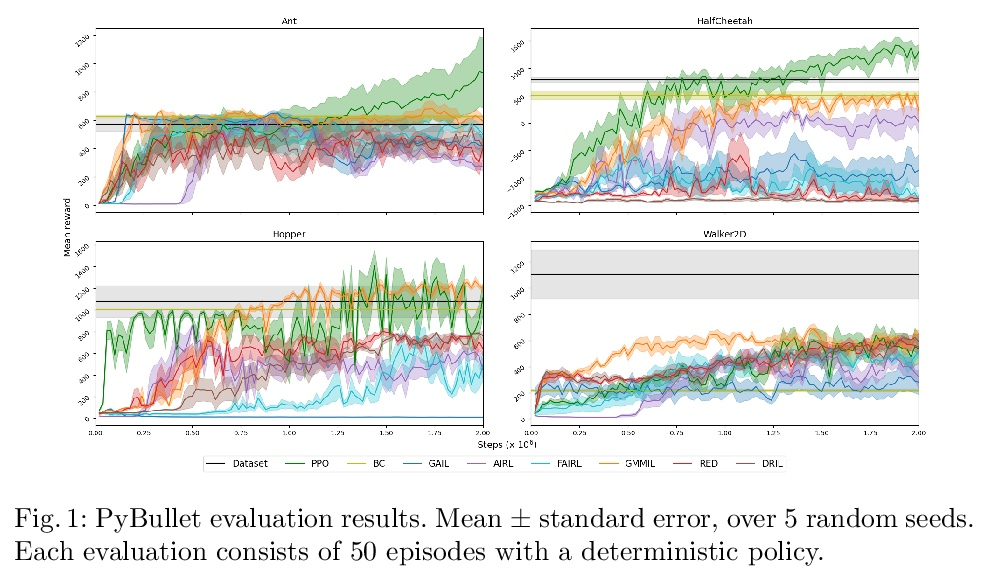
- 2、[LG] A Pragmatic Look at Deep Imitation Learning
- 3、[CV] Internal Video Inpainting by Implicit Long-range Propagation
- 4、[LG] Large-Scale Differentially Private BERT
- 5、[CL] PARADISE: Exploiting Parallel Data for Multilingual Sequence-to-Sequence Pretraining
- [CL] Controlled Text Generation as Continuous Optimization with Multiple Constraints
- [LG] FedJAX: Federated learning simulation with JAX
- [LG] Policy Gradients Incorporating the Future
- [CV] Deep Portrait Lighting Enhancement with 3D Guidance
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[CV] Vision Transformer with Progressive Sampling
X Yue, S Sun, Z Kuang, M Wei, P Torr, W Zhang, D Lin
[Centre for Perceptual and Interactive Intelligence & University of Oxford & SenseTime Research & Tsinghua University]
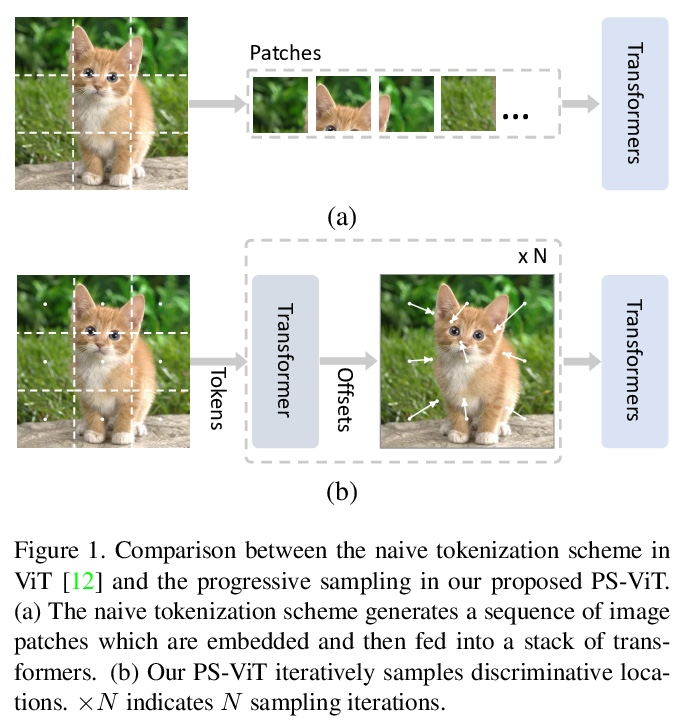
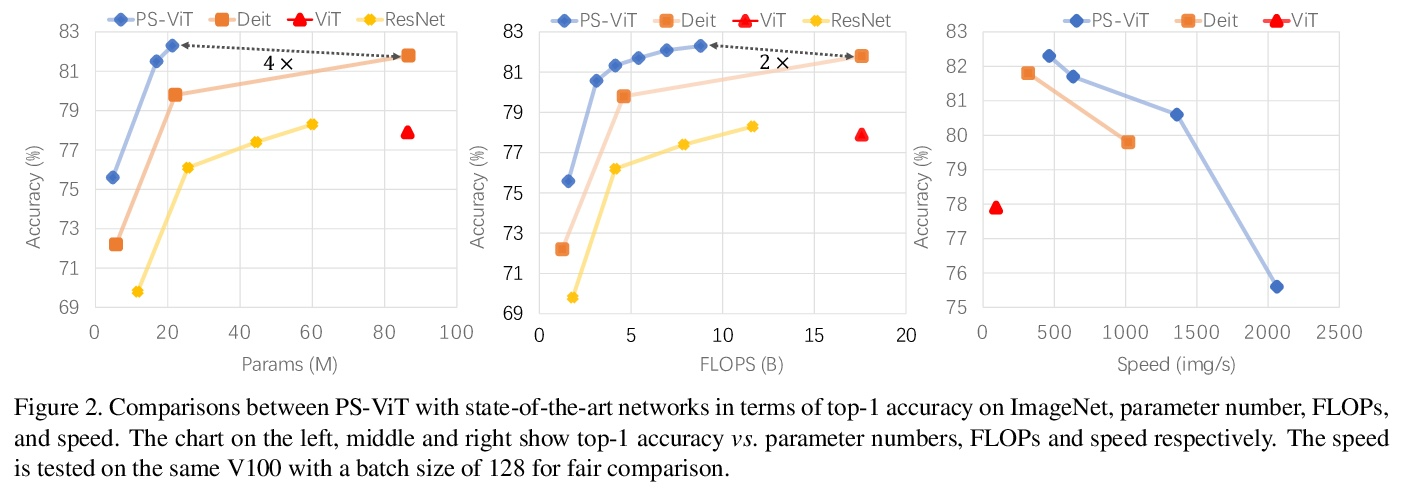
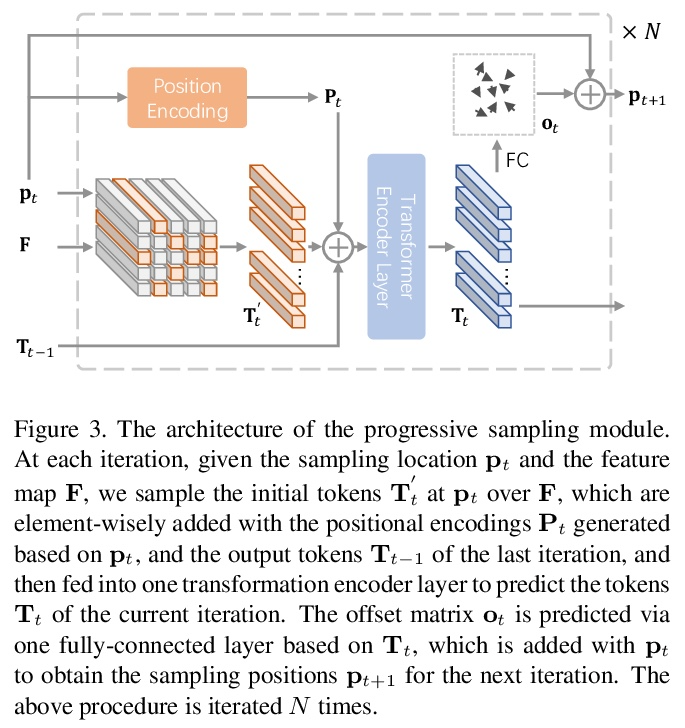
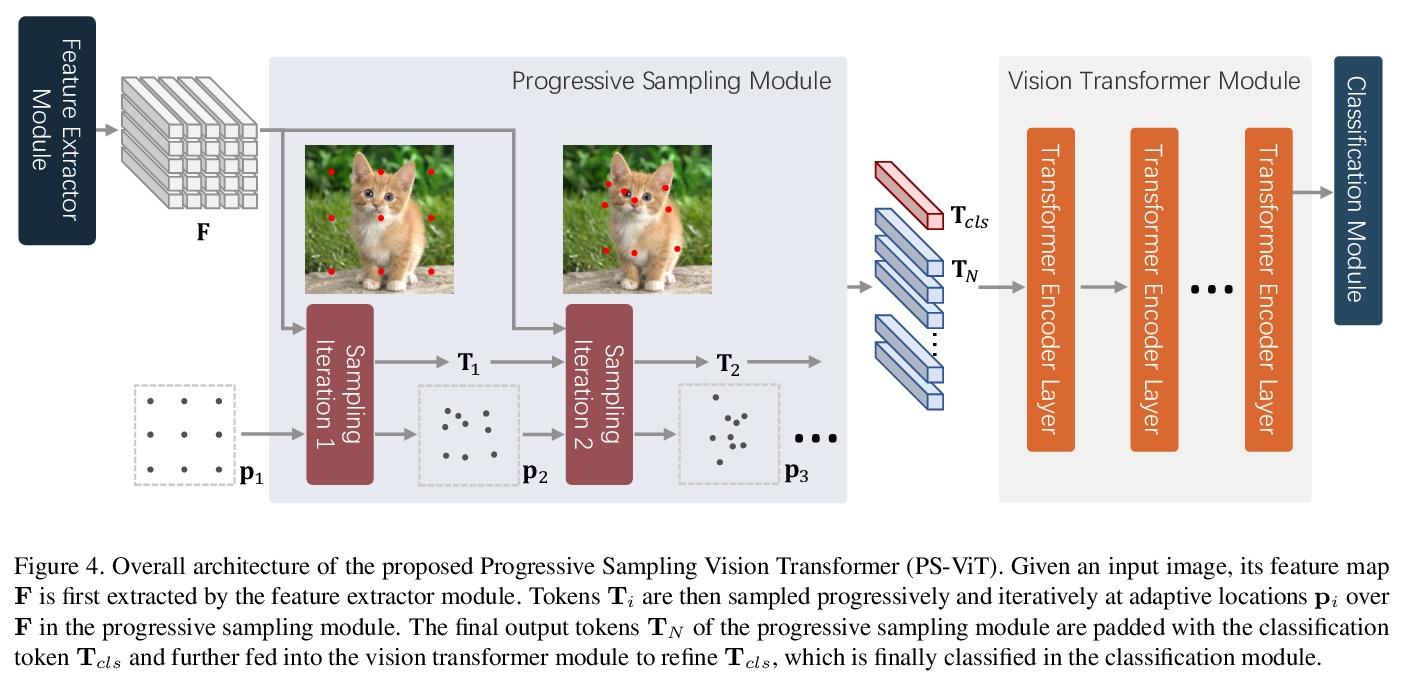
渐进采样视觉Transformer。最近,具有强大全局关系建模能力的Transformer,已经被引入到基本计算机视觉任务中。作为一个典型例子,视觉Transformer(ViT)直接将纯Transformer架构应用于图像分类,通过简单将图像分割成具有固定长度的token,用Transformer学习token之间的关系。然而,这种简单的token化可能会破坏物体结构,将网格分配给不感兴趣的区域,如背景,引入干扰信号。为缓解该问题,本文提出一种迭代和渐进采样策略,以定位鉴别性区域。每次迭代中,当前采样步骤的嵌入被送入一个Transformer编码器层,预测一组采样偏移量,以更新下一步采样位置。渐进式采样是可微的。当与视觉Transformer结合时,得到的PS-ViT网络可以自适应地学习寻找的位置。PS-ViT既有效又高效,在ImageNet上从头开始训练时,PS-ViT比vanilla ViT的top-1准确率高3.8%,参数少4倍,FLOPs少10倍。
Transformers with powerful global relation modeling abilities have been introduced to fundamental computer vision tasks recently. As a typical example, the Vision Transformer (ViT) directly applies a pure transformer architecture on image classification, by simply splitting images into tokens with a fixed length, and employing transformers to learn relations between these tokens. However, such naive tokenization could destruct object structures, assign grids to uninterested regions such as background, and introduce interference signals. To mitigate the above issues, in this paper, we propose an iterative and progressive sampling strategy to locate discriminative regions. At each iteration, embeddings of the current sampling step are fed into a transformer encoder layer, and a group of sampling offsets is predicted to update the sampling locations for the next step. The progressive sampling is differentiable. When combined with the Vision Transformer, the obtained PS-ViT network can adaptively learn where to look. The proposed PS-ViT is both effective and efficient. When trained from scratch on ImageNet, PS-ViT performs 3.8% higher than the vanilla ViT in terms of top-1 accuracy with about 4× fewer parameters and 10× fewer FLOPs.
https://weibo.com/1402400261/Ks8HBjkI2 
2、[LG] A Pragmatic Look at Deep Imitation Learning
K Arulkumaran, D O Lillrank
[ARAYA Inc & AIST]
从务实角度看深度模仿学习。生成式对抗模仿学习(GAIL)算法的引入,推动了基于深度神经网络的可扩展模仿学习方法的发展。GAIL的目标可概括为:1)匹配专家策略的状态分布;2)惩罚所学策略的状态分布;以及3)熵最大化。虽然理论上有动机,但在实践中GAIL可能难以应用,特别是由于对抗性训练的不稳定性。本文中对GAIL和相关的模仿学习算法进行了务实性的研究,找到了它们之间的共同原则。在一个统一的实验设置中实现并自动微调了一系列算法,在相互竞争的方法之间提出了一个公平的评价。唯一持续工作良好的算法是GMMIL,不清楚其他算法是否会成为合理的第二选择。另一方面,GMMIL可能需要相对较多的内存,这使得它对硬件不够友好。从结果来看,主要建议是考虑非对抗性的方法。讨论了模仿学习目标的共同组成部分,并提出了未来研究的有希望的途径。
The introduction of the generative adversarial imitation learning (GAIL) algorithm has spurred the development of scalable imitation learning approaches using deep neural networks. The GAIL objective can be thought of as 1) matching the expert policy’s state distribution; 2) penalising the learned policy’s state distribution; and 3) maximising entropy. While theoretically motivated, in practice GAIL can be difficult to apply, not least due to the instabilities of adversarial training. In this paper, we take a pragmatic look at GAIL and related imitation learning algorithms. We implement and automatically tune a range of algorithms in a unified experimental setup, presenting a fair evaluation between the competing methods. From our results, our primary recommendation is to consider non-adversarial methods. Furthermore, we discuss the common components of imitation learning objectives, and present promising avenues for future research.
https://weibo.com/1402400261/Ks8L57vSB 
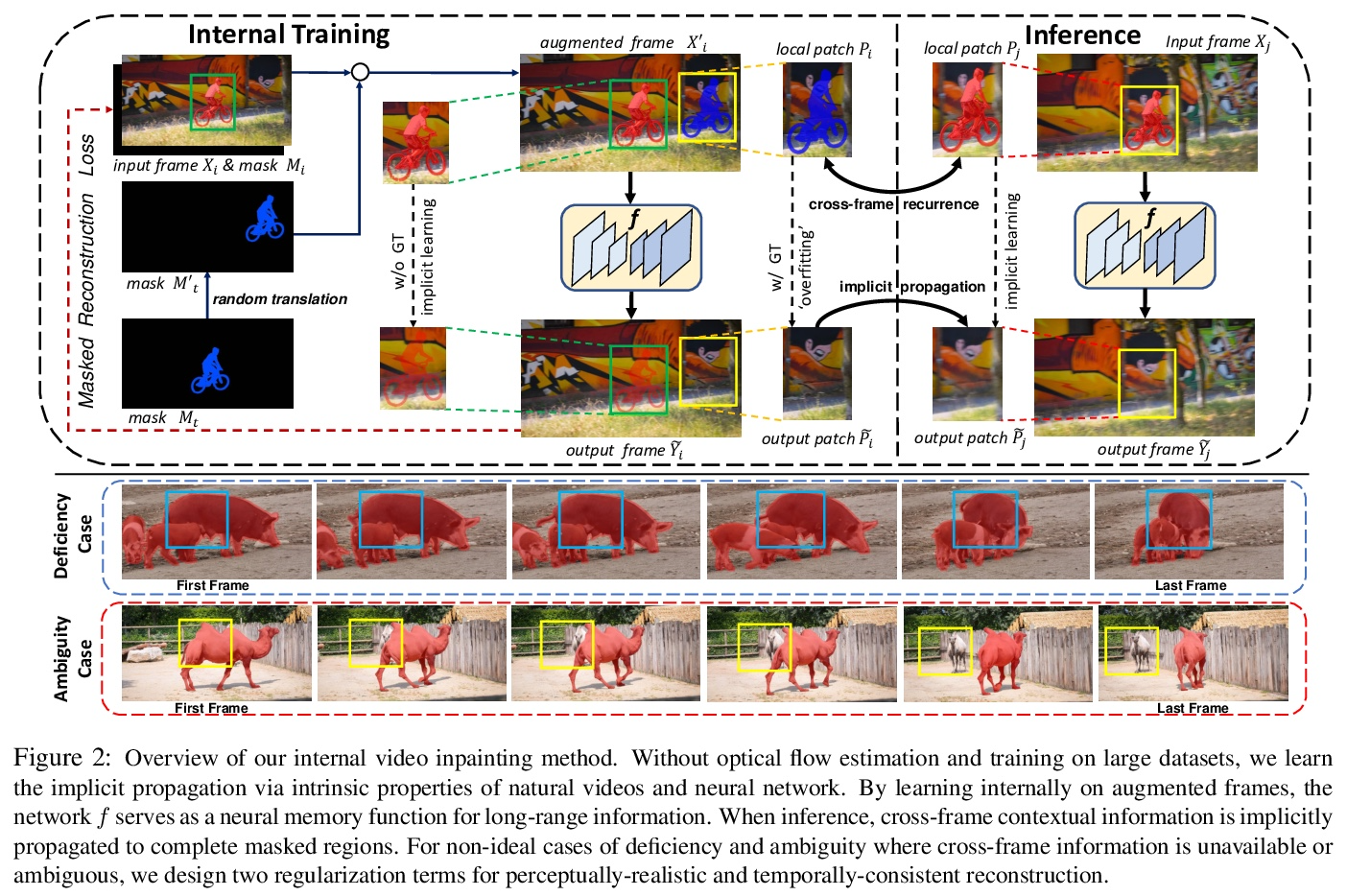
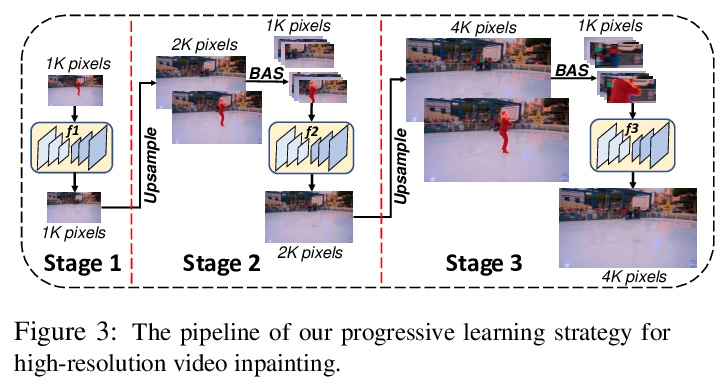
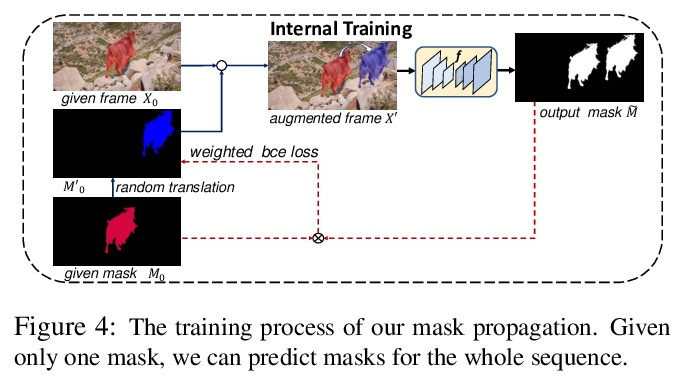
3、[CV] Internal Video Inpainting by Implicit Long-range Propagation
H Ouyang, T Wang, Q Chen
[The Hong Kong University of Science and Technology]
基于隐式长程传播的内部视频补全。本文提出一种新框架,采用内部学习策略来进行视频补全。与之前用光流进行跨帧上下文传播来涂抹未知区域的方法不同,本文通过对已知区域拟合卷积神经网络来隐式实现,用过拟合CNN隐式传播长程信息。为处理具有模糊背景或长期遮挡的挑战性序列,设计了两个正则化项,以保留高频细节和长程时间一致性。在DAVIS数据集上的广泛实验表明,所提出的方法在数量和质量上都达到了最先进的补全质量。进一步将所提出的方法扩展到另一项具有挑战性的任务:在4K视频中只给一个物体蒙版的一帧,学习从视频中移除一个物体。
We propose a novel framework for video inpainting by adopting an internal learning strategy. Unlike previous methods that use optical flow for cross-frame context propagation to inpaint unknown regions, we show that this can be achieved implicitly by fitting a convolutional neural network to the known region. Moreover, to handle challenging sequences with ambiguous backgrounds or long-term occlusion, we design two regularization terms to preserve highfrequency details and long-term temporal consistency. Extensive experiments on the DAVIS dataset demonstrate that the proposed method achieves state-of-the-art inpainting *Equal contribution quality quantitatively and qualitatively. We further extend the proposed method to another challenging task: learning to remove an object from a video giving a single object mask in only one frame in a 4K video.
https://weibo.com/1402400261/Ks8Rq6G1p 

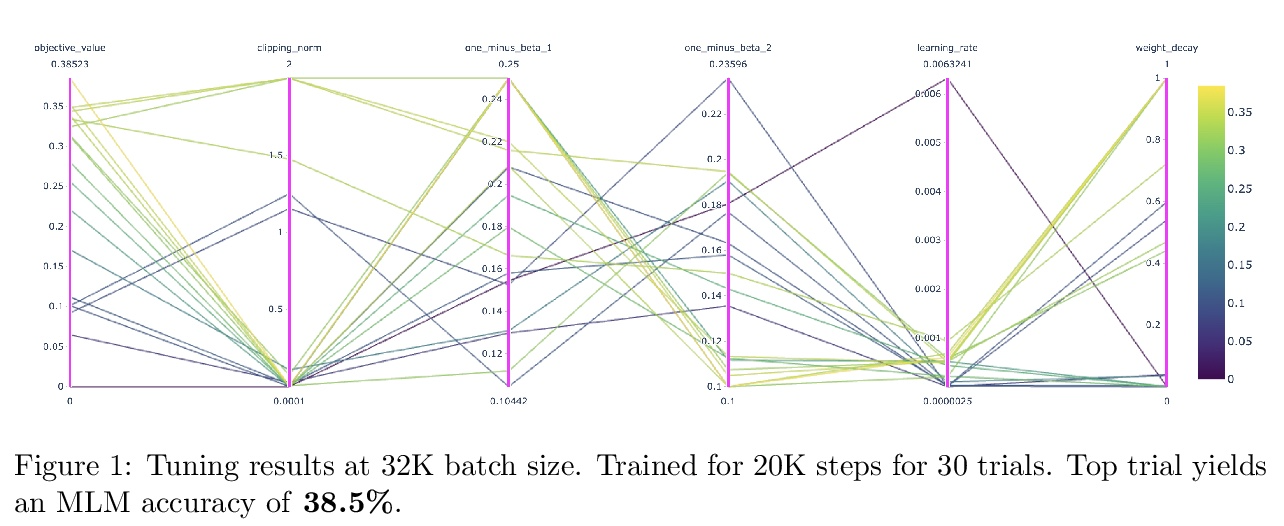
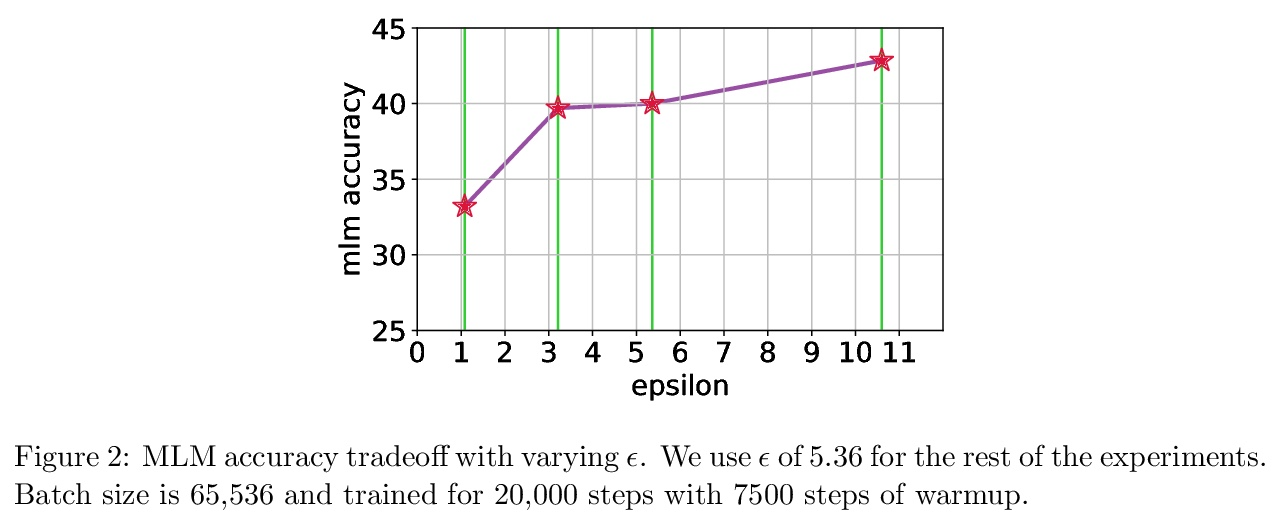
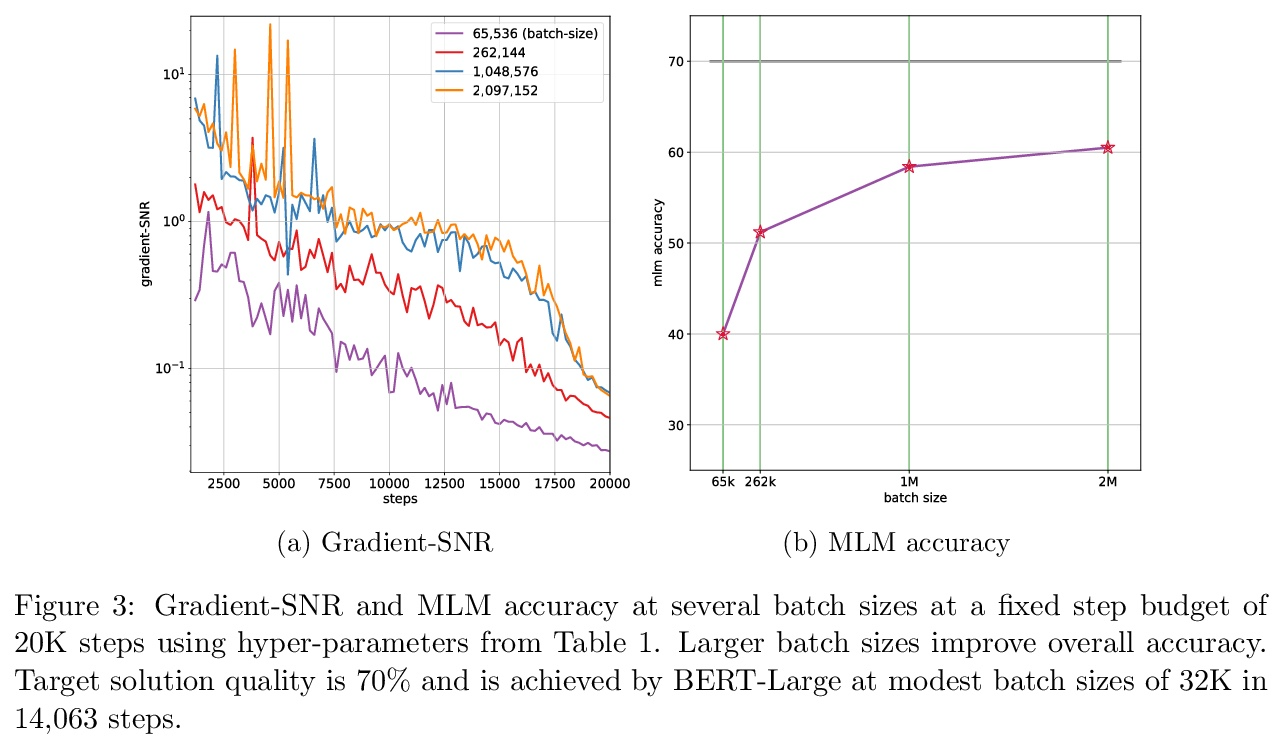
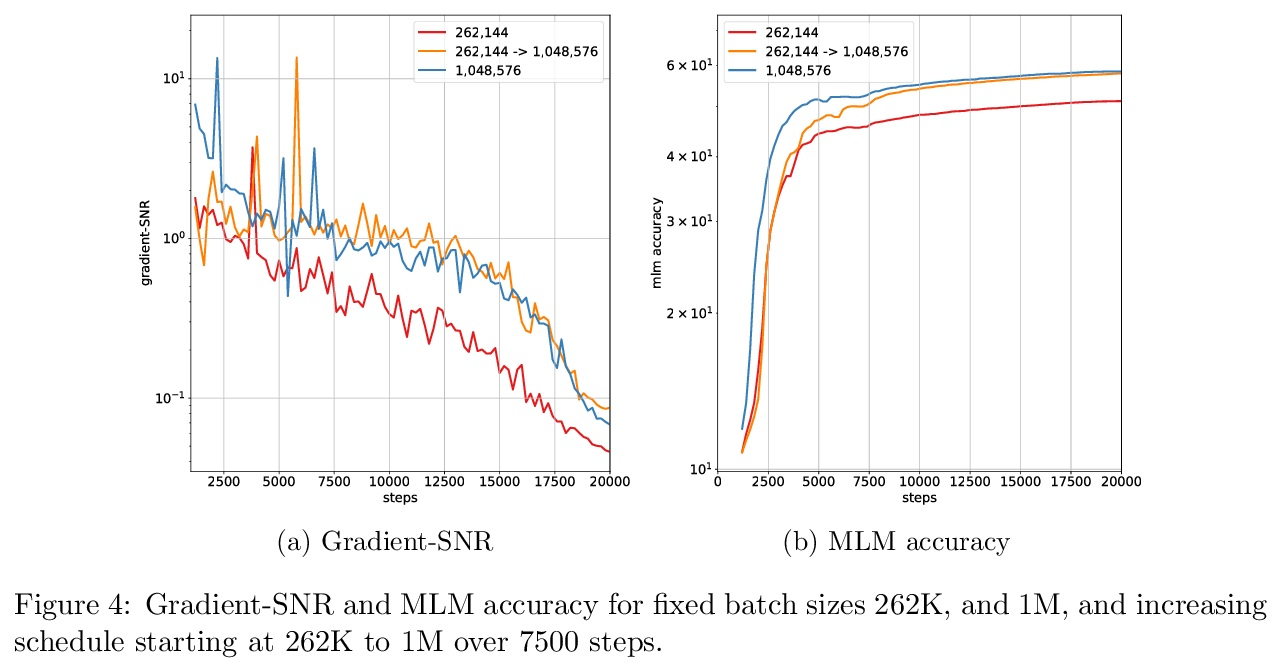
4、[LG] Large-Scale Differentially Private BERT
R Anil, B Ghazi, V Gupta, R Kumar, P Manurangsi
[Google Research]
大规模差分隐私BERT。本文研究了基于差分隐私SGD(DP-SGD)的BERT-Large大规模预训练。结合谨慎的实施,将批处理规模扩展到数百万(巨量批处理),可提高BERT的DP-SGD步骤的效用;通过增加批处理大小时间表提高效率。该实现建立在[SVK20]最近的工作基础上,其证明了通过有效使用JAX基元与XLA编译器相结合,DP-SGD步骤的开销最小。在批处理规模为2M时,实现了60.5%的掩码语言模型的准确性,为=5.36。从这个数字来看,非隐私的BERT模型实现了70%的准确率。
In this work, we study the large-scale pretraining of BERT-Large [DCLT19] with differentially private SGD (DP-SGD). We show that combined with a careful implementation, scaling up the batch size to millions (i.e., mega-batches) improves the utility of the DP-SGD step for BERT; we also enhance its efficiency by using an increasing batch size schedule. Our implementation builds on the recent work of [SVK20], who demonstrated that the overhead of a DP-SGD step is minimized with effective use of JAX [BFH18, FJL18] primitives in conjunction with the XLA compiler [XLA17]. Our implementation achieves a masked language model accuracy of 60.5% at a batch size of 2M, for = 5.36. To put this number in perspective, non-private BERT models achieve an accuracy of ∼70%.
https://weibo.com/1402400261/Ks8UIuTxK 
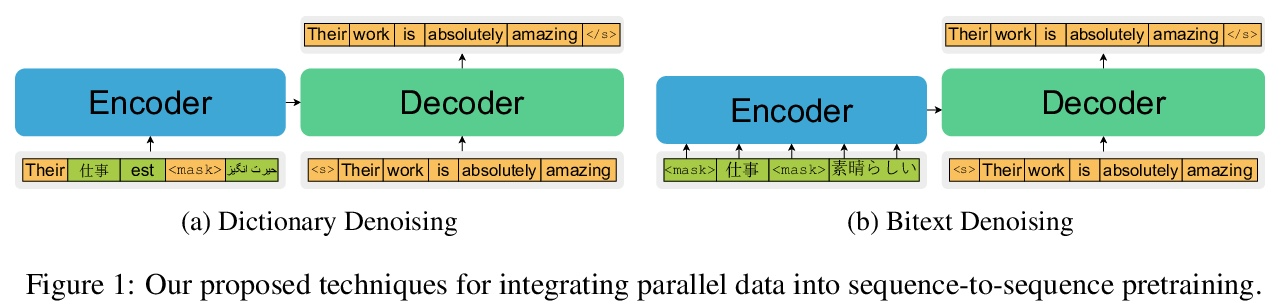
5、[CL] PARADISE: Exploiting Parallel Data for Multilingual Sequence-to-Sequence Pretraining
M Reid, M Artetxe
[The University of Tokyo & Facebook AI Research]
PARADISE:用平行数据进行多语言序列到序列预训练。尽管多语言序列到序列预训练取得了成功,但现有的大多数方法都依赖于单语语料,而没有利用平行数据中包含的强大的跨语言信号。本文提出PARADISE(PARAllel & Denoising Integration in SEquence-tose-quence models),扩展了用于训练这些模型的传统去噪目标,(i)根据多语言词典替换噪声序列中的单词,以及(ii)根据平行语料库预测参考译文,而不是恢复原始序列。在机器翻译和跨语言自然语言推理方面的实验表明,将平行数据整合到预训练中,分别平均提高了2.0个BLEU点和6.7个精度点,获得的结果与几个流行的模型有竞争力,而计算成本却很低。
Despite the success of multilingual sequenceto-sequence pretraining, most existing approaches rely on monolingual corpora, and do not make use of the strong cross-lingual signal contained in parallel data. In this paper, we present PARADISE (PARAllel & Denoising Integration in SEquence-tosequence models), which extends the conventional denoising objective used to train these models by (i) replacing words in the noised sequence according to a multilingual dictionary, and (ii) predicting the reference translation according to a parallel corpus instead of recovering the original sequence. Our experiments on machine translation and crosslingual natural language inference show an average improvement of 2.0 BLEU points and 6.7 accuracy points from integrating parallel data into pretraining, respectively, obtaining results that are competitive with several popular models at a fraction of their computational cost.
https://weibo.com/1402400261/Ks8YGo7ID 
另外几篇值得关注的论文:
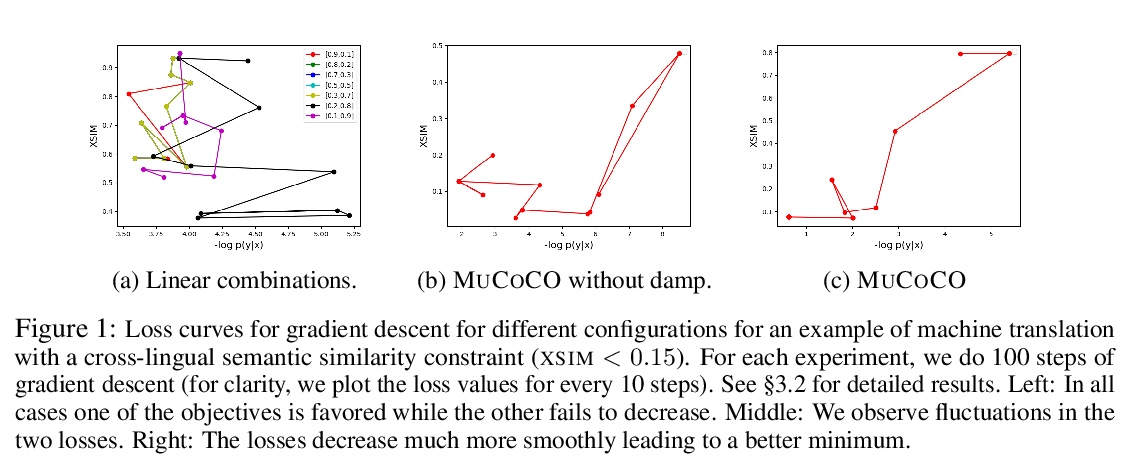
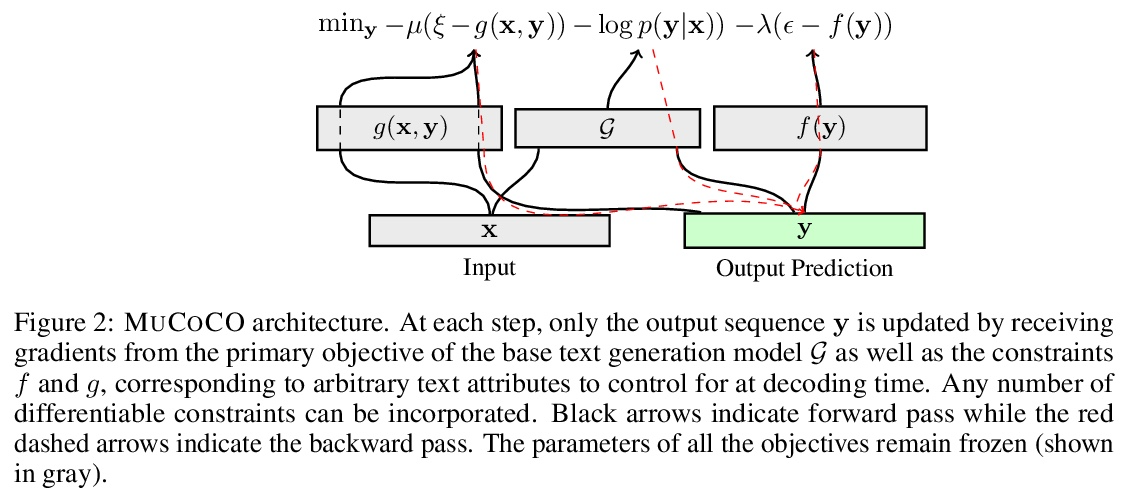
[CL] Controlled Text Generation as Continuous Optimization with Multiple Constraints
多约束连续优化受控文本生成
S Kumar, E Malmi, A Severyn, Y Tsvetkov
[CMU & Google Research & University of Washington]
https://weibo.com/1402400261/Ks90QiXE8 
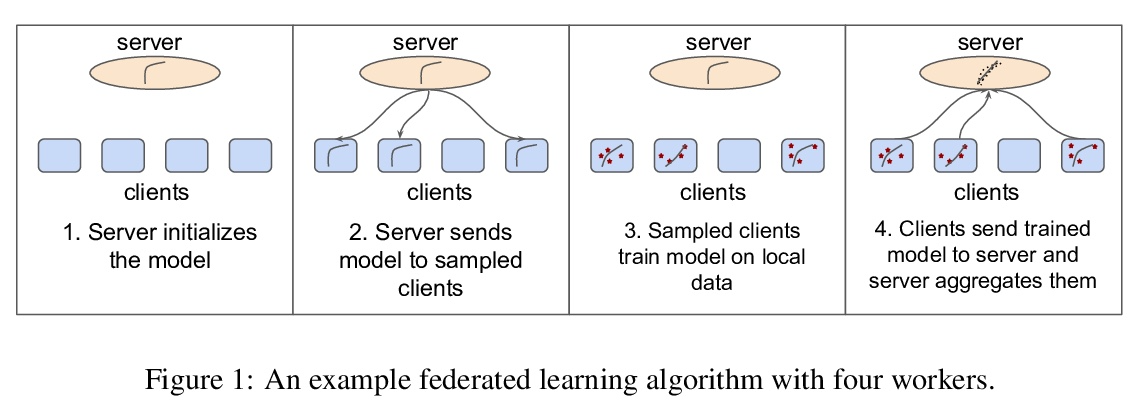
[LG] FedJAX: Federated learning simulation with JAX
FedJAX:基于JAX的联邦学习仿真
J H Ro, A T Suresh, K Wu
[Google Research]
https://weibo.com/1402400261/Ks92foHbO 



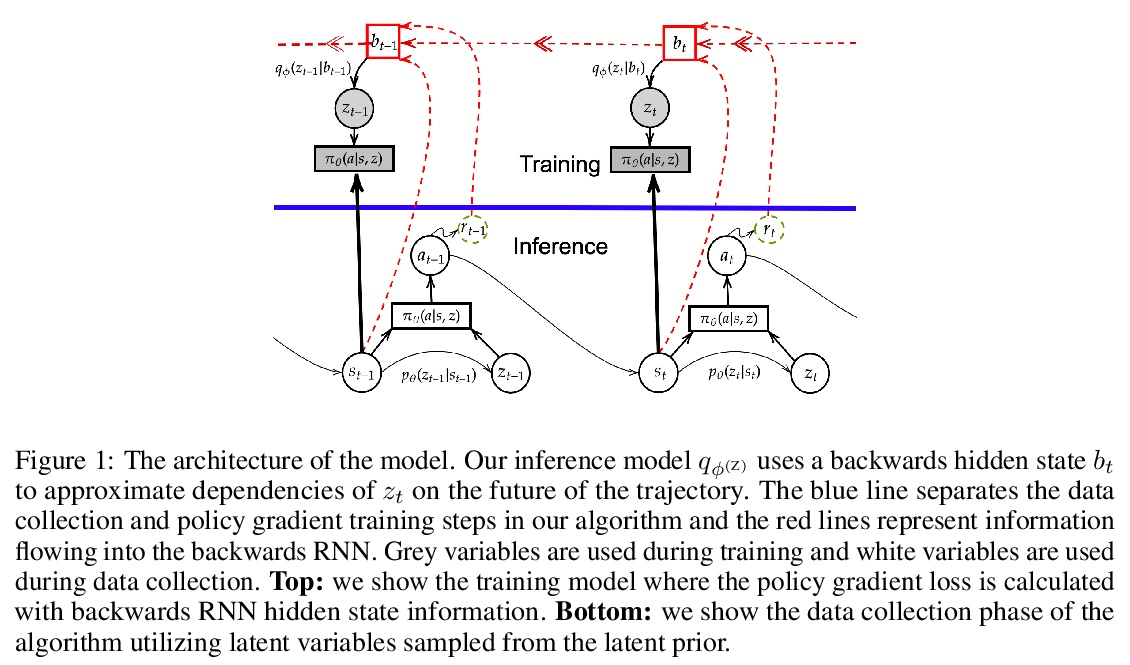
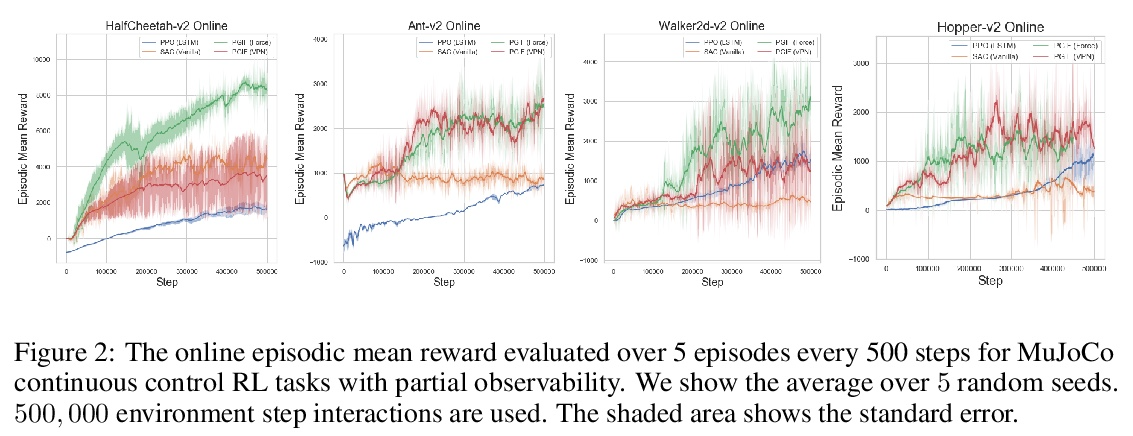
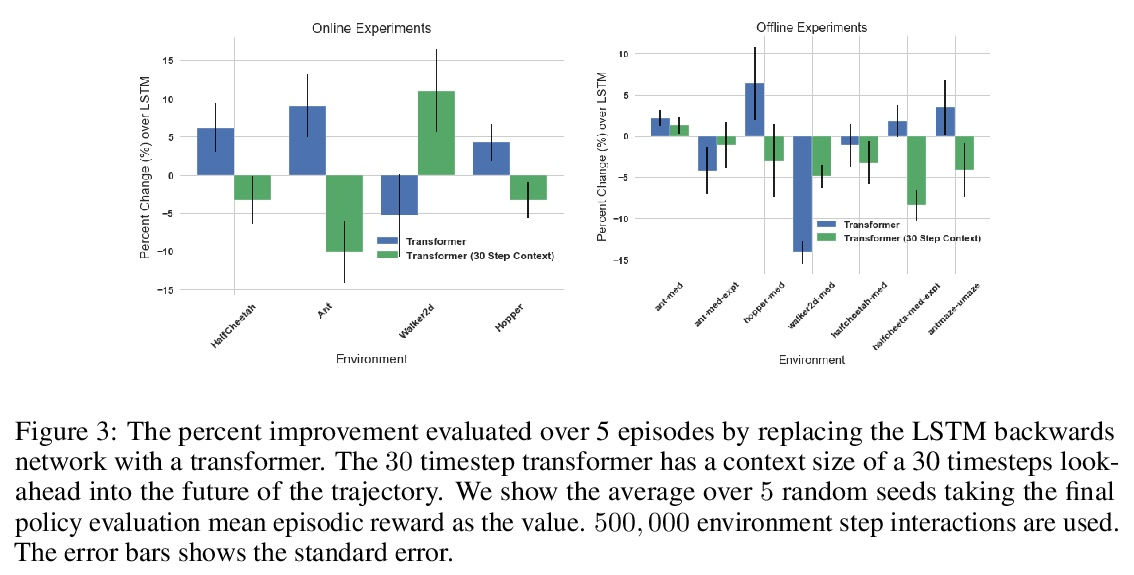
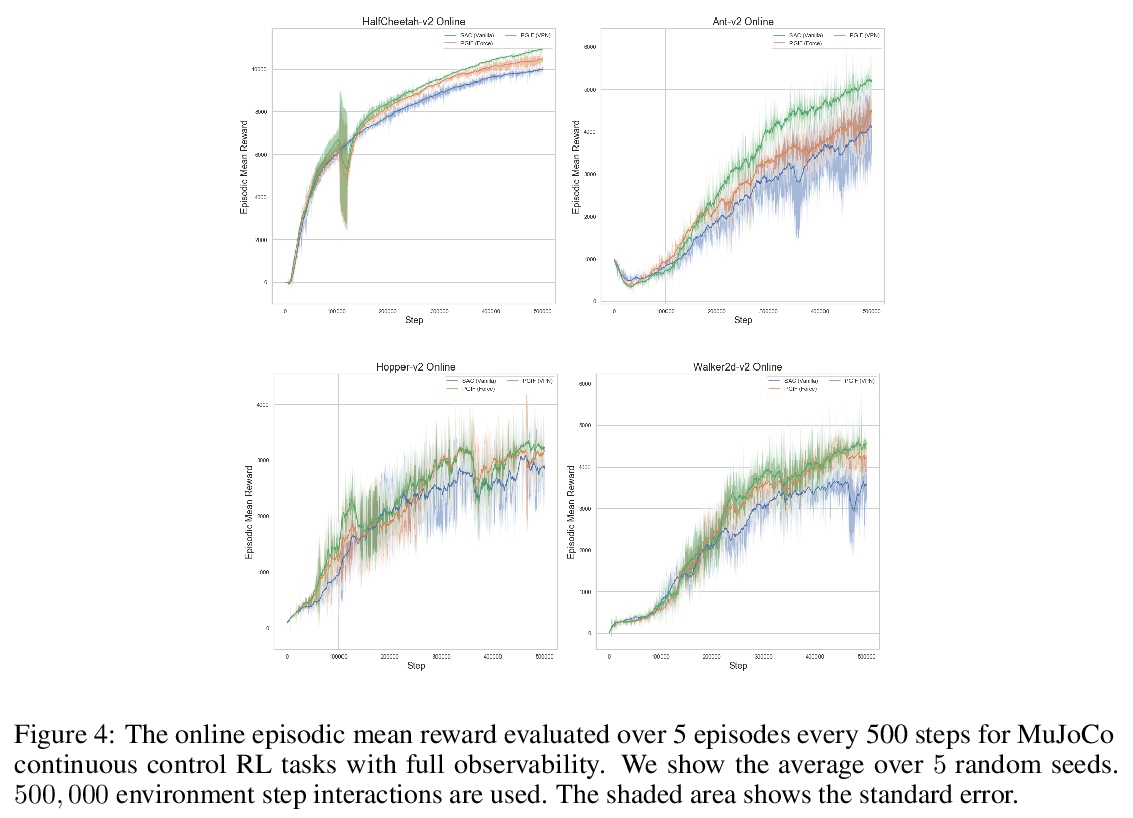
[LG] Policy Gradients Incorporating the Future
融入未来的策略梯度
D Venuto, E Lau, D Precup, O Nachum
[Mila & McGill University & Google Brain]
https://weibo.com/1402400261/Ks93CuKQi 
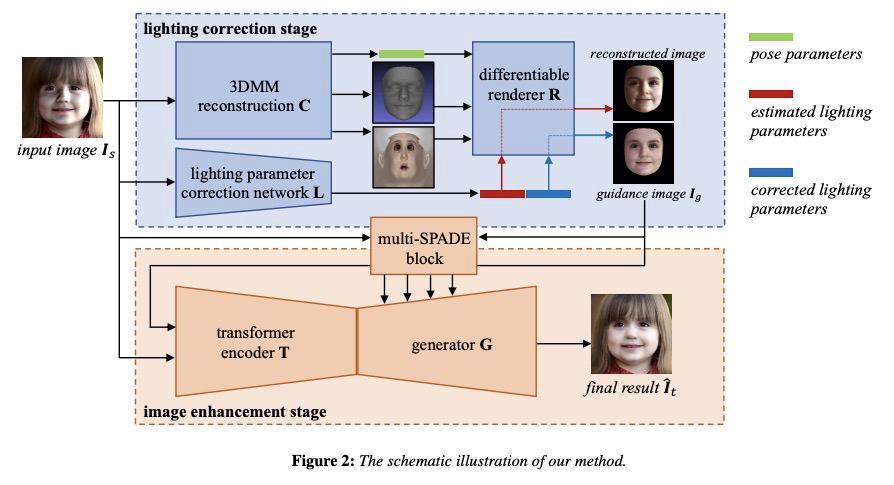
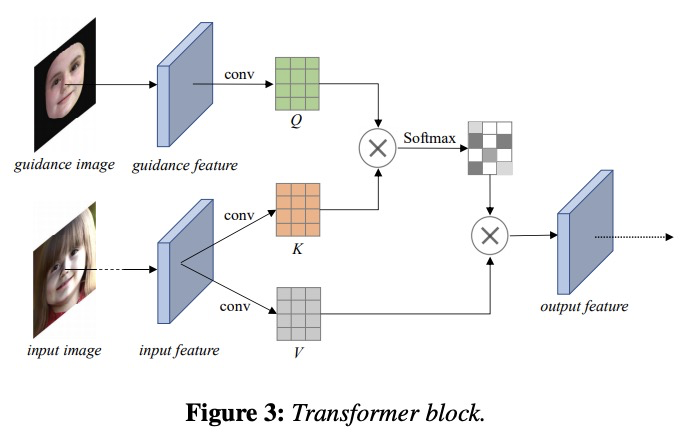
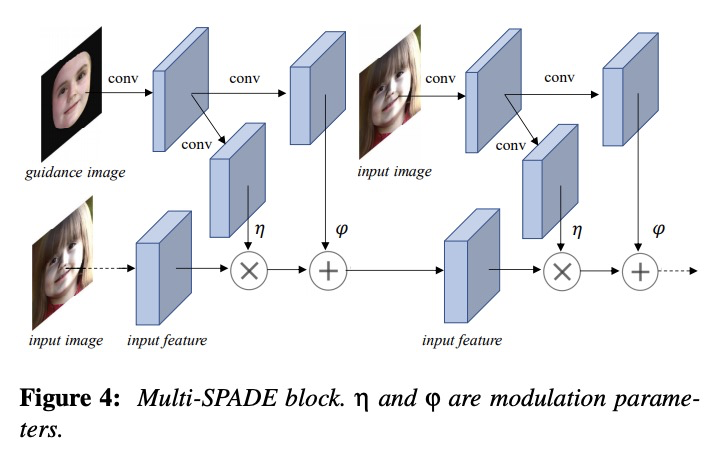
[CV] Deep Portrait Lighting Enhancement with 3D Guidance
3D引导深度人像照明增强
F Han, C Wang, H Du, J Liao
[City University of Hong Kong]
https://weibo.com/1402400261/Ks95R8hGM 


若有收获,就点个赞吧
0 人点赞
