LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、**[LG] Feature Learning in Infinite-Width Neural Networks
G Yang, E J. Hu
[Microsoft Research AI]
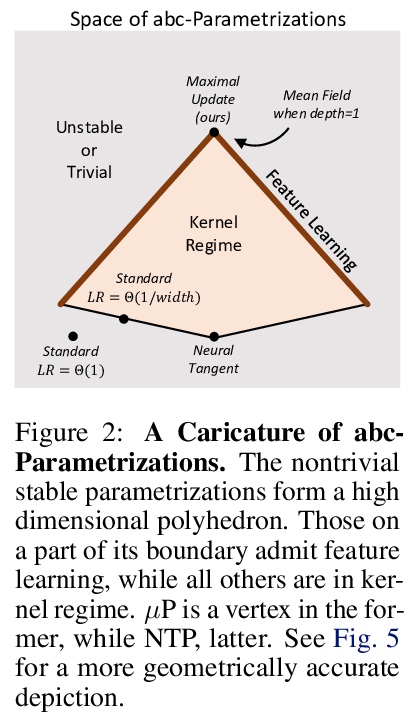
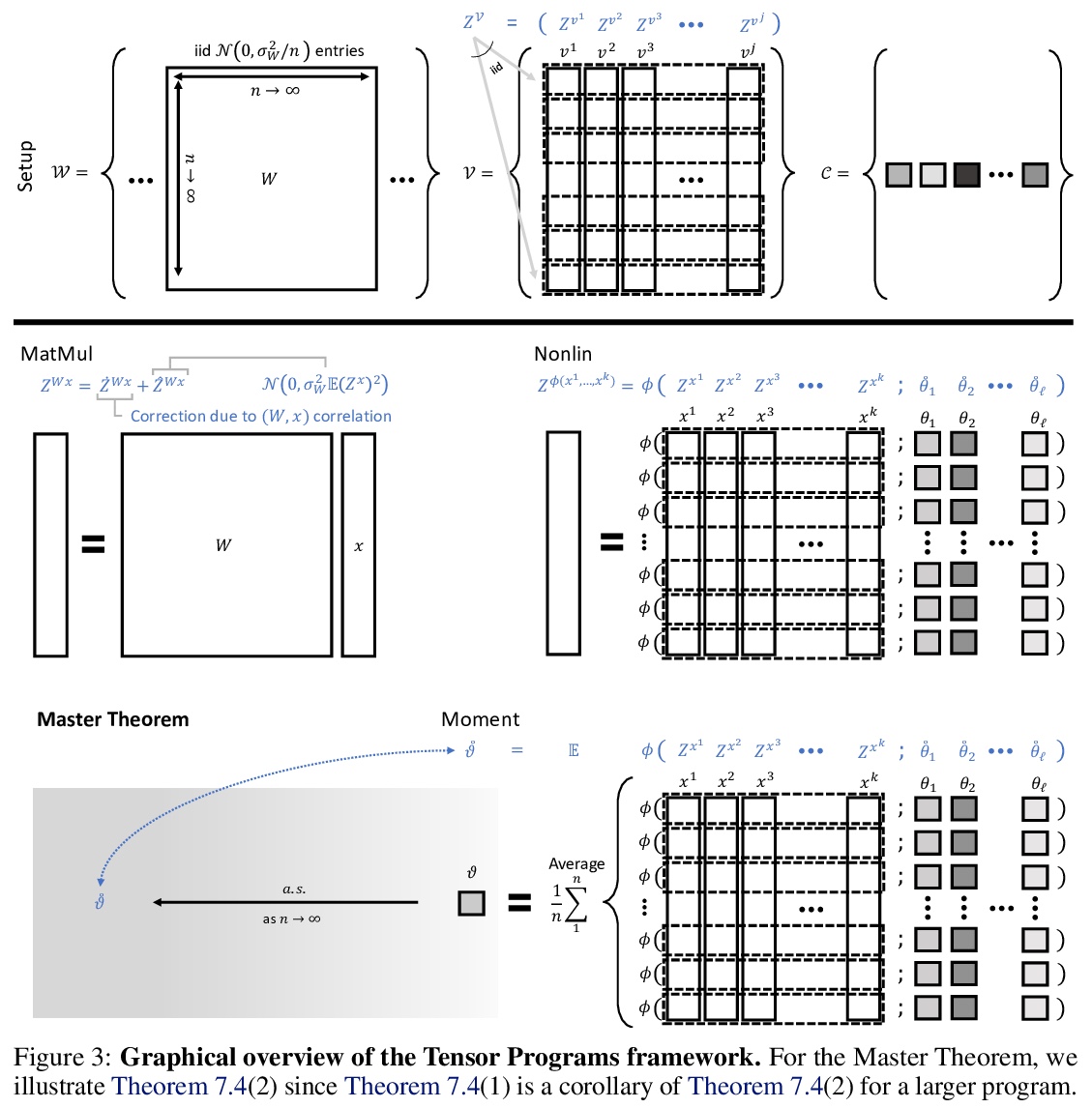
无限宽神经网络特征学习。基于abc参数化和张量规划技术的概念,提出统一大规模宽网络神经正切核(NTK)和平均场极限的框架,在动态二分定理中,将abc参数化分为特征学习和核参数化两类,提出了最大更新参数化(µP),推导出可实现特征学习的无限宽度极限。在Word2Vec和通过MAML在Omniglot上进行的少样本学习实验中,证明了在神经网络中,该模型是一个很好的特征学习行为模型,其性能优于NTK基线和有限宽度网络,后者随着宽度增加而接近无限宽特征学习性能。*
As its width tends to infinity, a deep neural network’s behavior under gradient descent can become simplified and predictable (e.g. given by the Neural Tangent Kernel (NTK)), if it is parametrized appropriately (e.g. the NTK parametrization). However, we show that the standard and NTK parametrizations of a neural network do not admit infinite-width limits that can learn features, which is crucial for pretraining and transfer learning such as with BERT. We propose simple modifications to the standard parametrization to allow for feature learning in the limit. Using the Tensor Programs* technique, we derive explicit formulas for such limits. On Word2Vec and few-shot learning on Omniglot via MAML, two canonical tasks that rely crucially on feature learning, we compute these limits exactly. We find that they outperform both NTK baselines and finite-width networks, with the latter approaching the infinite-width feature learning performance as width increases.More generally, we classify a natural space of neural network parametrizations that generalizes standard, NTK, and Mean Field parametrizations. We show 1) any parametrization in this space either admits feature learning or has an infinite-width training dynamics given by kernel gradient descent, but not both; 2) any such infinite-width limit can be computed using the Tensor Programs technique.
https://weibo.com/1402400261/JxiCc7Yvi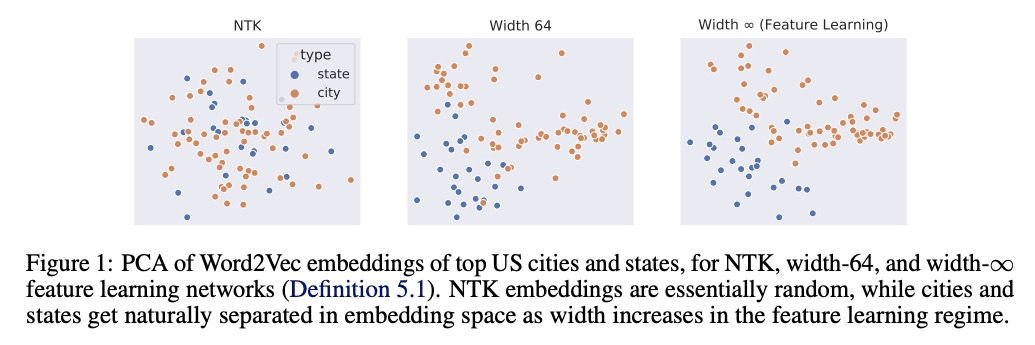
2、** **[LG] Integrable Nonparametric Flows
D Pfau, D Rezende
[DeepMind]
可积非参数化流。提出了在给定概率分布(可能非归一化的)极微小变化时重构极微小标准化流的方法。与常规标准化流任务不同,不是给定未知目标分布的样本,学习近似该分布的流,而是给定初始分布的扰动,重建流以产生已知扰动分布的样本,流可用完全非参数化的方式表示。
We introduce a method for reconstructing an infinitesimal normalizing flow given only an infinitesimal change to a (possibly unnormalized) probability distribution. This reverses the conventional task of normalizing flows — rather than being given samples from a unknown target distribution and learning a flow that approximates the distribution, we are given a perturbation to an initial distribution and aim to reconstruct a flow that would generate samples from the known perturbed distribution. While this is an underdetermined problem, we find that choosing the flow to be an integrable vector field yields a solution closely related to electrostatics, and a solution can be computed by the method of Green’s functions. Unlike conventional normalizing flows, this flow can be represented in an entirely nonparametric manner. We validate this derivation on low-dimensional problems, and discuss potential applications to problems in quantum Monte Carlo and machine learning.
https://weibo.com/1402400261/JxiLv1ASV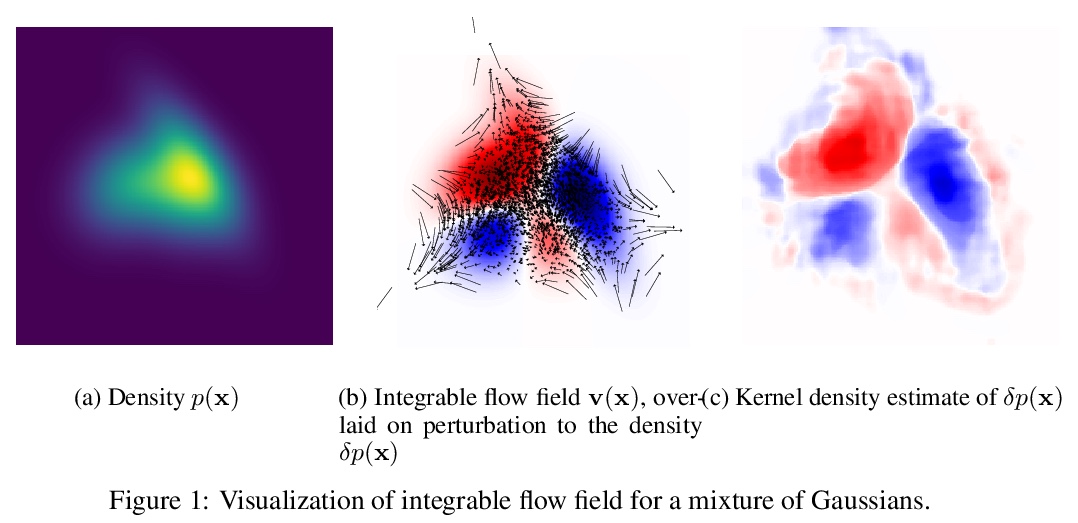
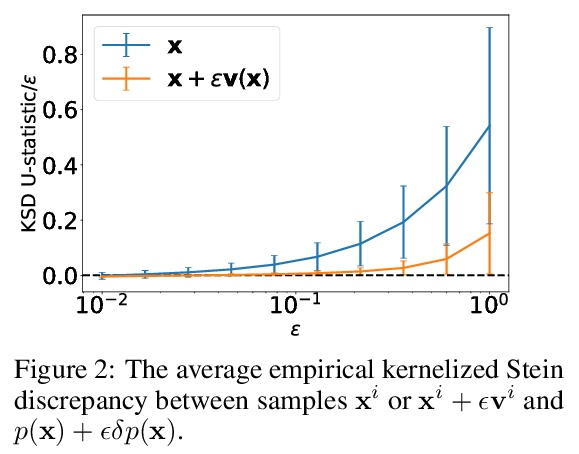
3、** **[CV] Single-Shot Freestyle Dance Reenactment
O Gafni, O Ashual, L Wolf
[Facebook AI Research]
单样本自由式舞蹈重演。提出一种新方法,结合分割映射网络、真实帧渲染网络、人脸细化网络三种网络,让图片里目标人根据视频中舞者动作改变位姿生成舞蹈重演动画。与之前方法相比,获得了明显更好的视觉质量,能捕捉到各种姿态下不同的体型和外观。
The task of motion transfer between a source dancer and a target person is a special case of the pose transfer problem, in which the target person changes their pose in accordance with the motions of the dancer.In this work, we propose a novel method that can reanimate a single image by arbitrary video sequences, unseen during training. The method combines three networks: (i) a segmentation-mapping network, (ii) a realistic frame-rendering network, and (iii) a face refinement network. By separating this task into three stages, we are able to attain a novel sequence of realistic frames, capturing natural motion and appearance. Our method obtains significantly better visual quality than previous methods and is able to animate diverse body types and appearances, which are captured in challenging poses, as shown in the experiments and supplementary video.
https://weibo.com/1402400261/JxiRgvSvY

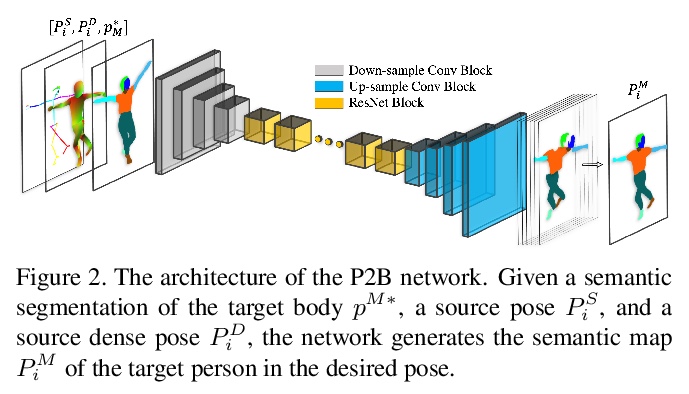
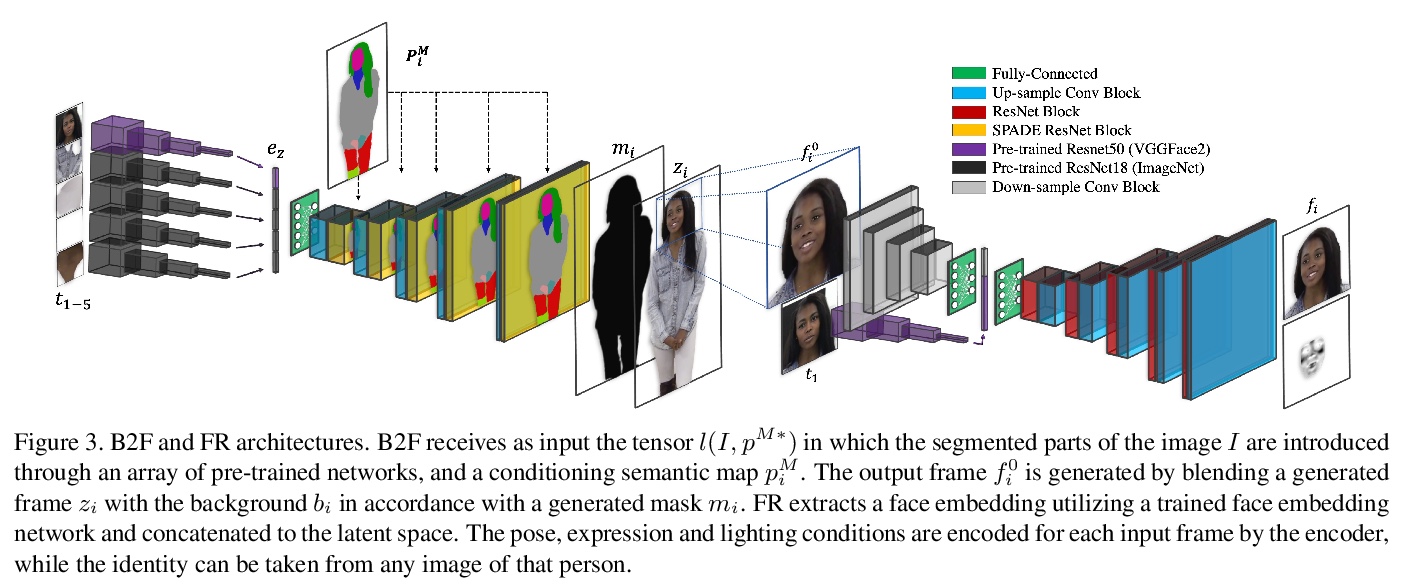
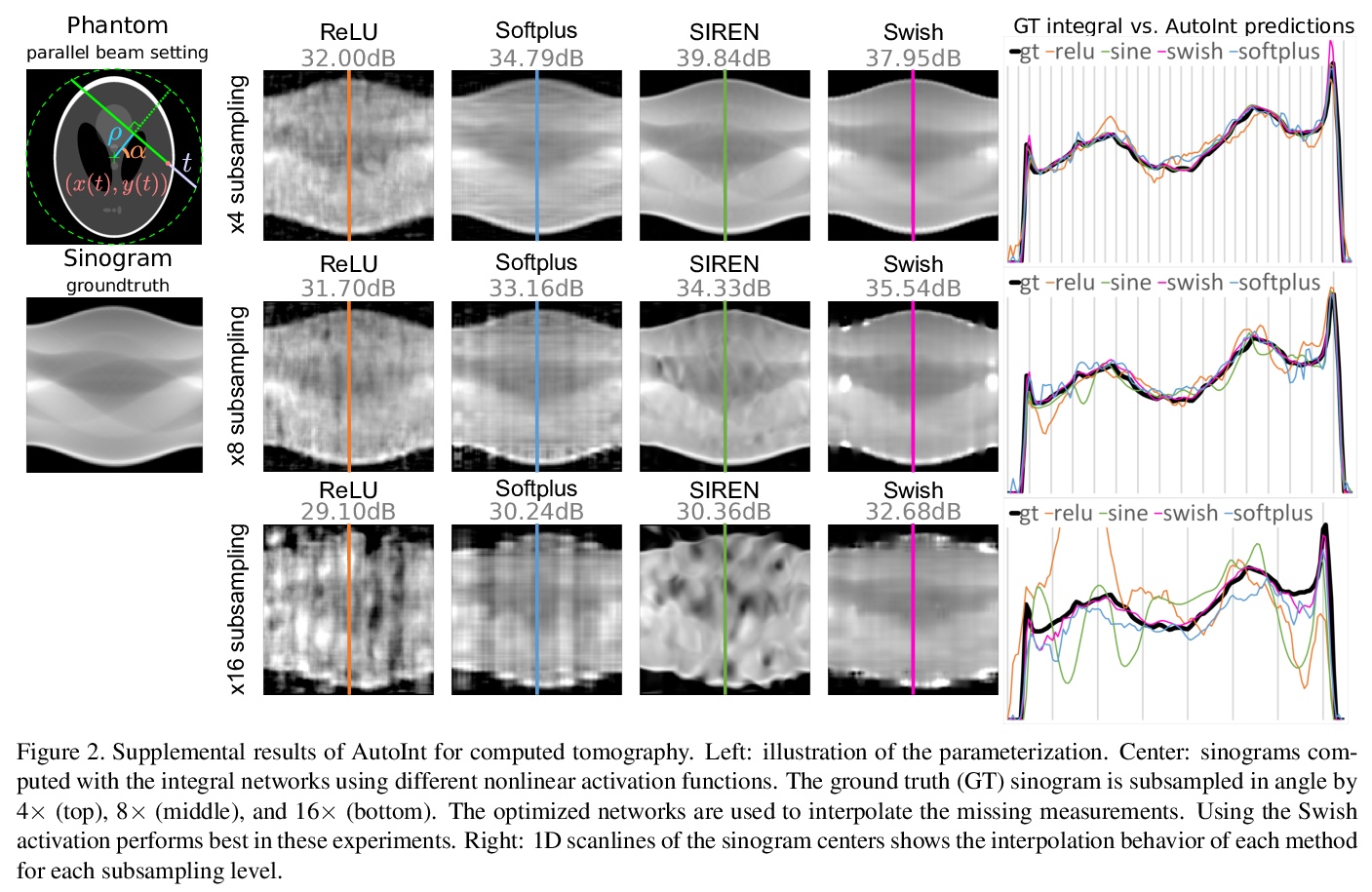
4、** **[CV] AutoInt: Automatic Integration for Fast Neural Volume Rendering
D B. Lindell, J N. P. Martel, G Wetzstein
[Stanford University]
面向快速神经体渲染的自动积分。提出了自动积分框架AutoInt,用隐式神经表示网络得到积分的封闭解,通过学习积分封闭解显著提高计算效率。在训练中,实例化与隐式神经表示的导数相对应的计算图,用图拟合信号来实现积分,优化后,对图进行重组,得到表示不定积分的网络。用这种方法,实现了在计算需求上超过10倍的改进,实现了快速神经体渲染。
Numerical integration is a foundational technique in scientific computing and is at the core of many computer vision applications. Among these applications, implicit neural volume rendering has recently been proposed as a new paradigm for view synthesis, achieving photorealistic image quality. However, a fundamental obstacle to making these methods practical is the extreme computational and memory requirements caused by the required volume integrations along the rendered rays during training and inference. Millions of rays, each requiring hundreds of forward passes through a neural network are needed to approximate those integrations with Monte Carlo sampling. Here, we propose automatic integration, a new framework for learning efficient, closed-form solutions to integrals using implicit neural representation networks. For training, we instantiate the computational graph corresponding to the derivative of the implicit neural representation. The graph is fitted to the signal to integrate. After optimization, we reassemble the graph to obtain a network that represents the antiderivative. By the fundamental theorem of calculus, this enables the calculation of any definite integral in two evaluations of the network. Using this approach, we demonstrate a greater than 10x improvement in computation requirements, enabling fast neural volume rendering.
https://weibo.com/1402400261/JxiWpFTX1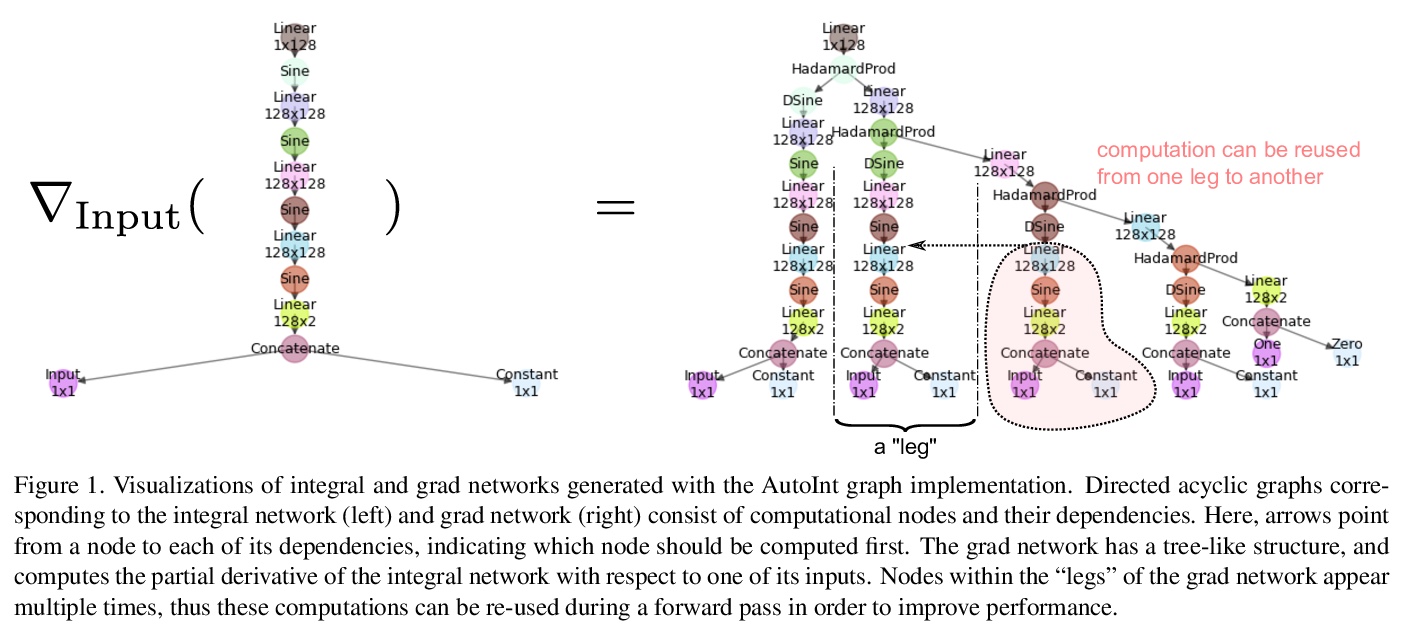

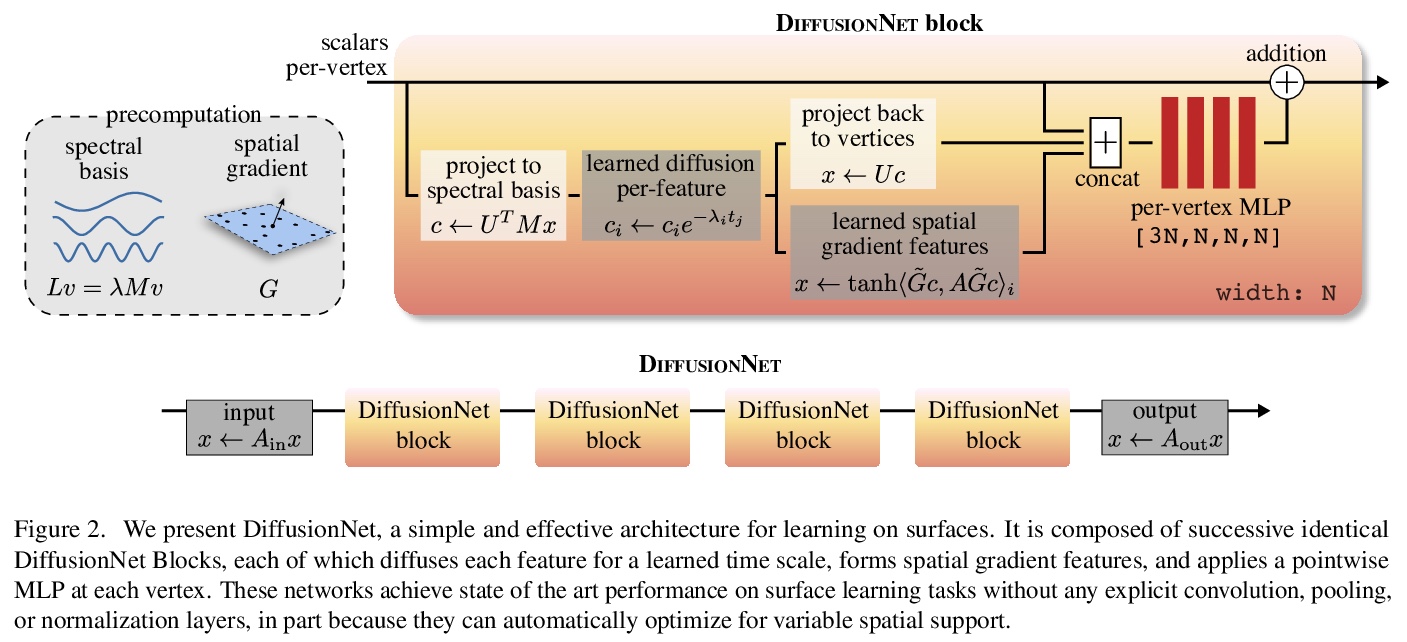
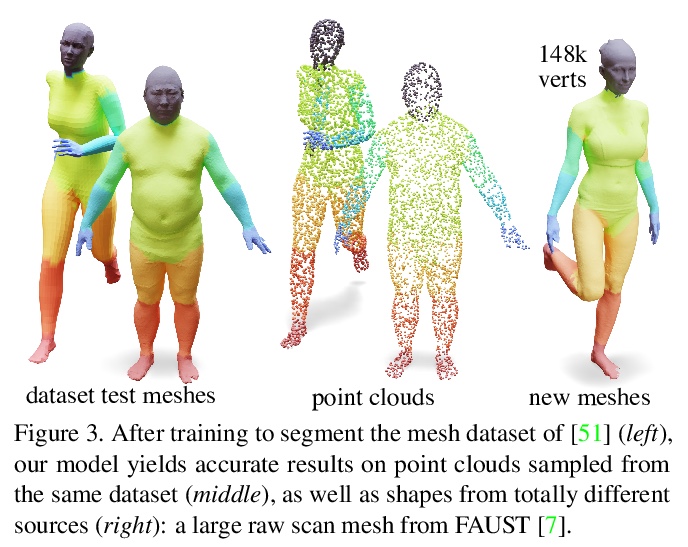
5、** **[CV] Diffusion is All You Need for Learning on Surfaces
N Sharp, S Attaiki, K Crane, M Ovsjanikov
[CMU & Ecole Polytechnique]
基于扩散和空间梯度的3D表面深度学习。提出一种3D表面学习的新方法,只用习得扩散和空间梯度,实现了最先进结果。简单的习得扩散层就可在空间上有原则地共享数据,取代像卷积和池这样表面上复杂且昂贵的操作;网络中的空间梯度操作,用导数的点积来编码切线不变滤波器;以及在每个点独立应用的多层感知器。由此产生的架构DiffusionNet,非常简单、高效、可扩展。
We introduce a new approach to deep learning on 3D surfaces such as meshes or point clouds. Our key insight is that a simple learned diffusion layer can spatially share data in a principled manner, replacing operations like convolution and pooling which are complicated and expensive on surfaces. The only other ingredients in our network are a spatial gradient operation, which uses dot-products of derivatives to encode tangent-invariant filters, and a multi-layer perceptron applied independently at each point. The resulting architecture, which we call DiffusionNet, is remarkably simple, efficient, and scalable. Continuously optimizing for spatial support avoids the need to pick neighborhood sizes or filter widths a priori, or worry about their impact on network size/training time. Furthermore, the principled, geometric nature of these networks makes them agnostic to the underlying representation and insensitive to discretization. In practice, this means significant robustness to mesh sampling, and even the ability to train on a mesh and evaluate on a point cloud. Our experiments demonstrate that these networks achieve state-of-the-art results for a variety of tasks on both meshes and point clouds, including surface classification, segmentation, and non-rigid correspondence.
https://weibo.com/1402400261/Jxj2BvwAg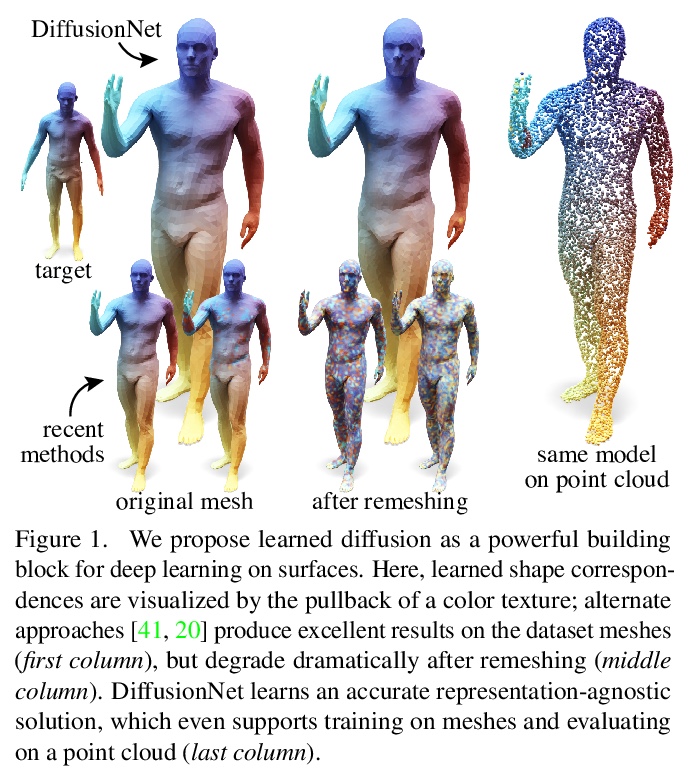
另外几篇值得关注的额论文:
[CV] A Photogrammetry-based Framework to Facilitate Image-based Modeling and Automatic Camera Tracking
面向基于图像的建模和自动摄像机跟踪的基于摄影测量的框架
S Bullinger, C Bodensteiner, M Arens
[Fraunhofer IOSB]
https://weibo.com/1402400261/Jxj72BFlB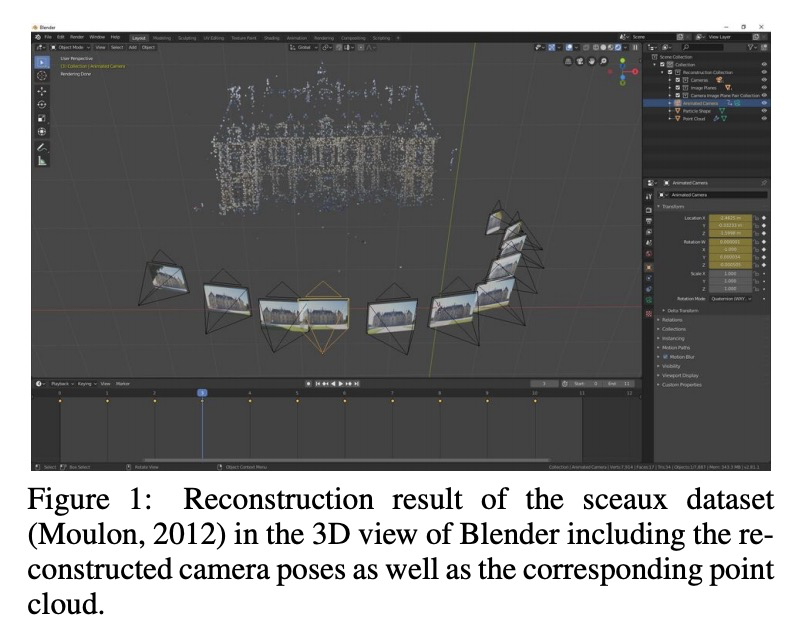
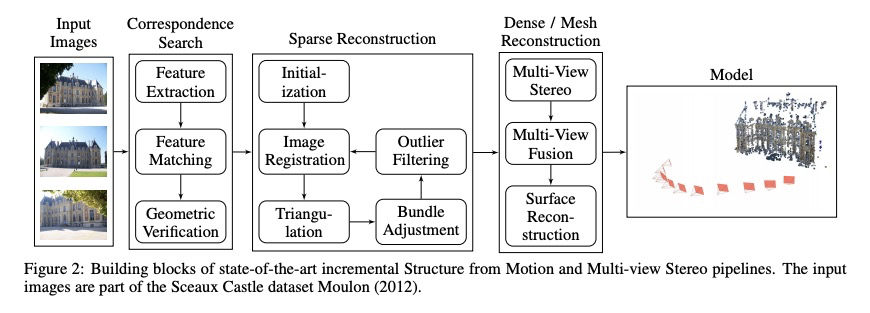

[LG] Every Model Learned by Gradient Descent Is Approximately a Kernel Machine
所有梯度下降习得模型都是近似的核机器
P Domingos
[University of Washington]
https://weibo.com/1402400261/Jxj8kBVYz
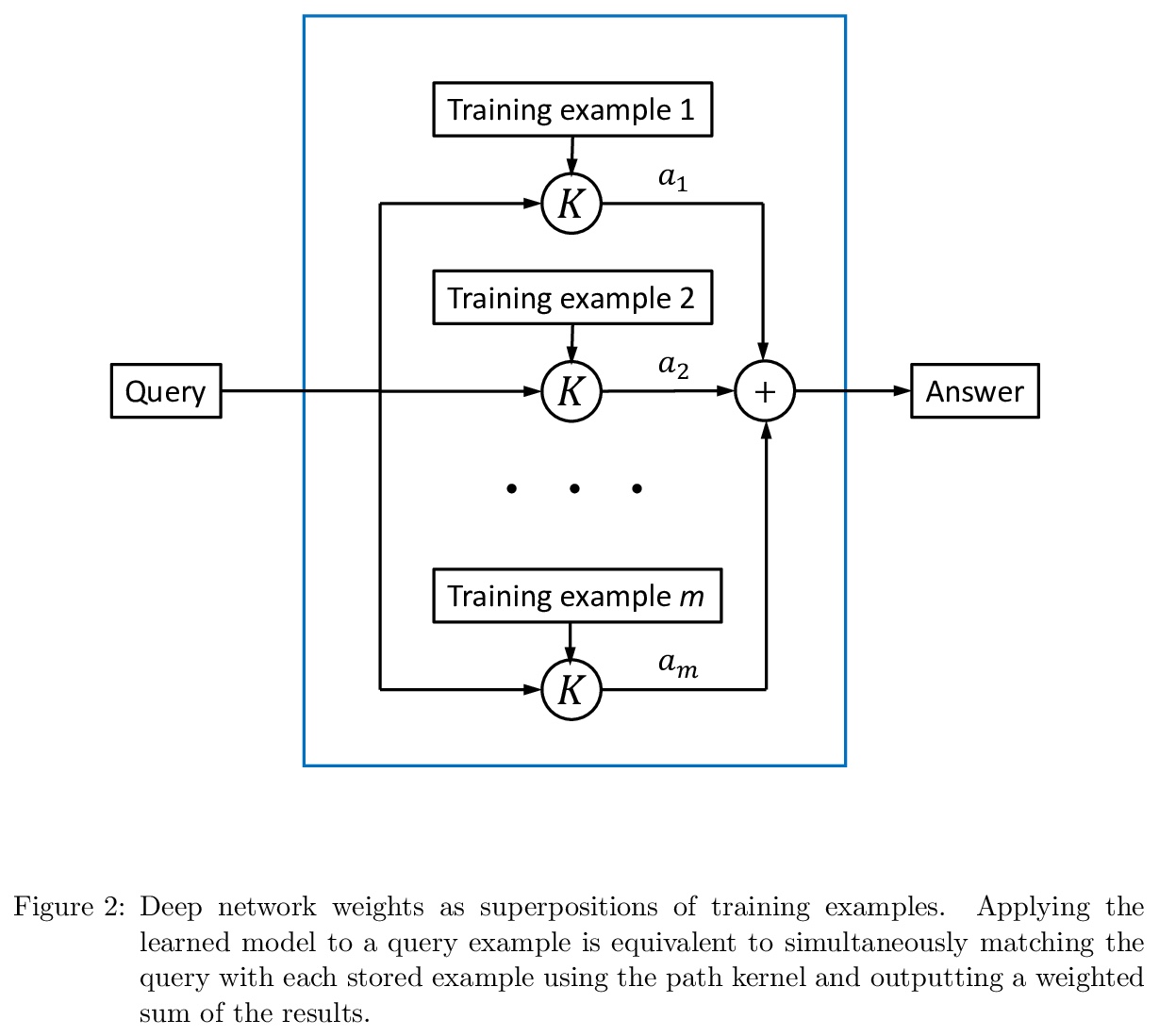
[CV] DeepVideoMVS: Multi-View Stereo on Video with Recurrent Spatio-Temporal Fusion
DeepVideoMVS:循环时空融合多视立体视频
A Düzçeker, S Galliani, C Vogel, P Speciale, M Dusmanu, M Pollefeys
[ETH Zurich & Microsoft Mixed Reality]
https://weibo.com/1402400261/JxjaDqUIc

[AI] Meta-learning in natural and artificial intelligence
自然和人工智能中的元学习
J X. Wang
https://weibo.com/1402400261/JxjbMAksa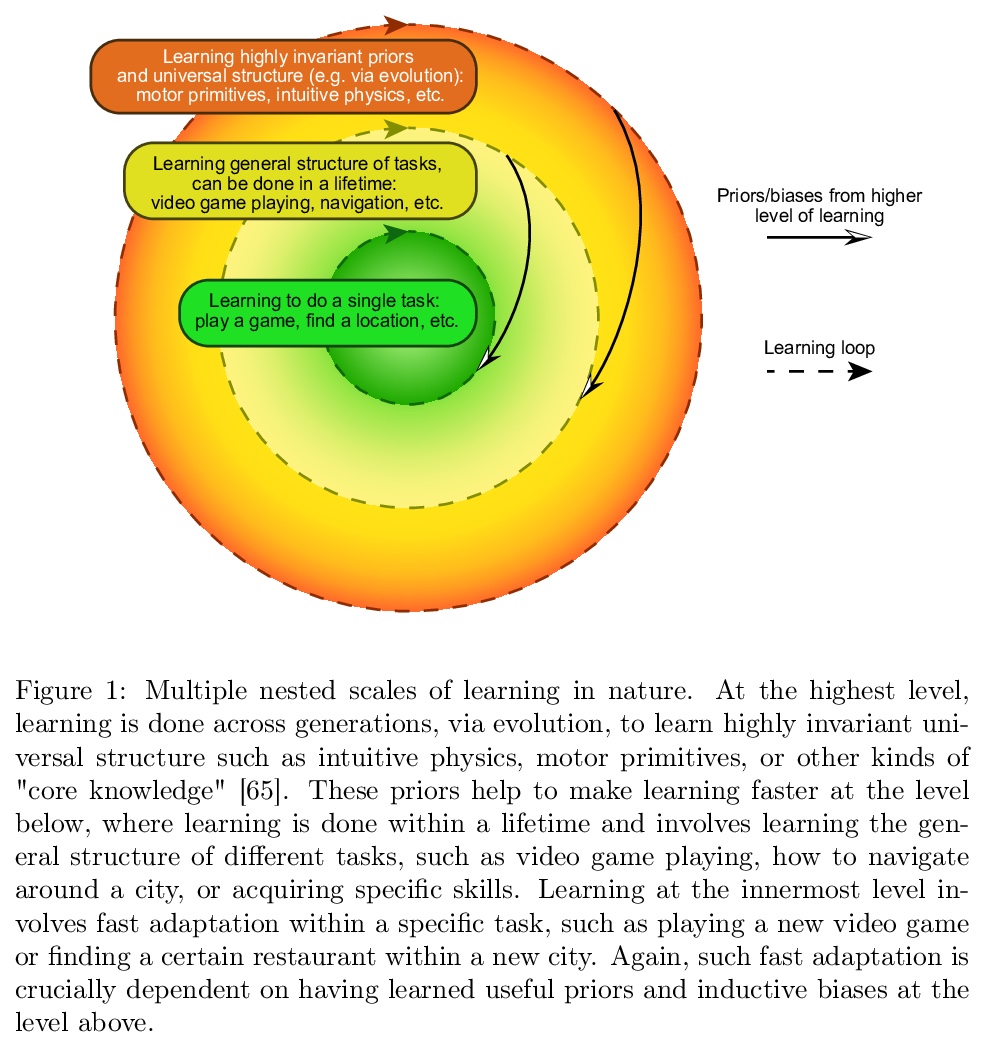
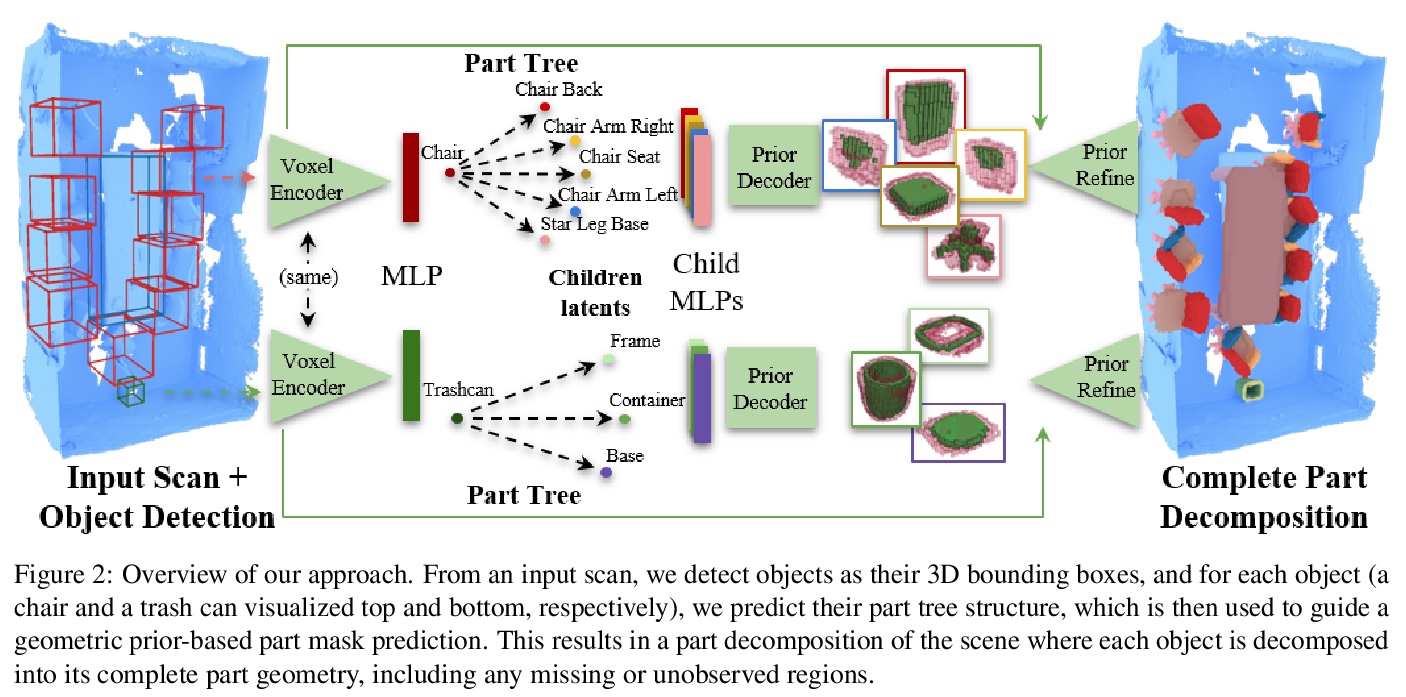
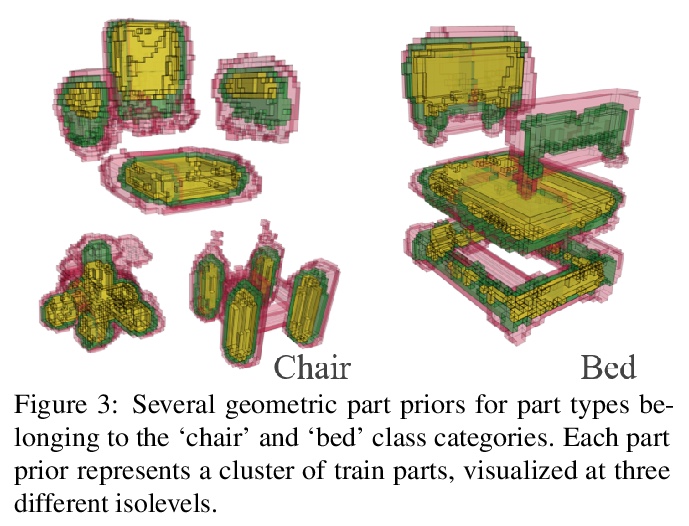
[CV] Towards Part-Based Understanding of RGB-D Scans
基于部分的RGB-D扫描理解
A Bokhovkin, V Ishimtsev, E Bogomolov, D Zorin, A Artemov, E Burnaev, A Dai
[Technical University of Munich & Skolkovo Institute of Science and Technology & New York University]
https://weibo.com/1402400261/JxjdvADlE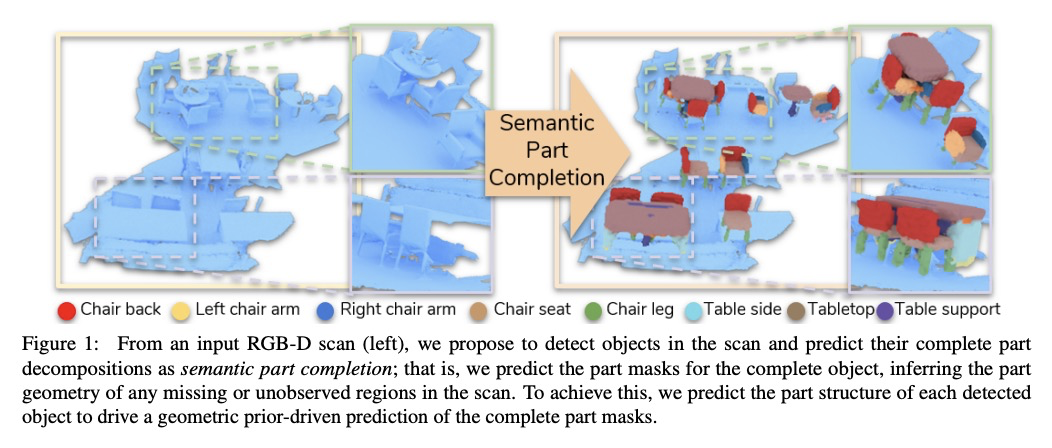
[CV] Generalized Pose-and-Scale Estimation using 4-Point Congruence Constraints
四点一致性约束广义位姿-比例估计
V Fragoso, S Sinha
[Microsoft]
https://weibo.com/1402400261/Jxjfhw3bL

若有收获,就点个赞吧
0 人点赞
