- 1、[LG] Self-Supervised Learning of Graph Neural Networks: A Unified Review
- 2、[LG] Learning Neural Network Subspaces
- 3、[CV] Do Generative Models Know Disentanglement? Contrastive Learning is All You Need
- 4、[LG] MolCLR: Molecular Contrastive Learning of Representations via Graph Neural Networks
- 5、[CV] Do We Really Need Explicit Position Encodings for Vision Transformers?
- [LG] A Theory of Label Propagation for Subpopulation Shift
- [CV] Towards Accurate and Compact Architectures via Neural Architecture Transformer
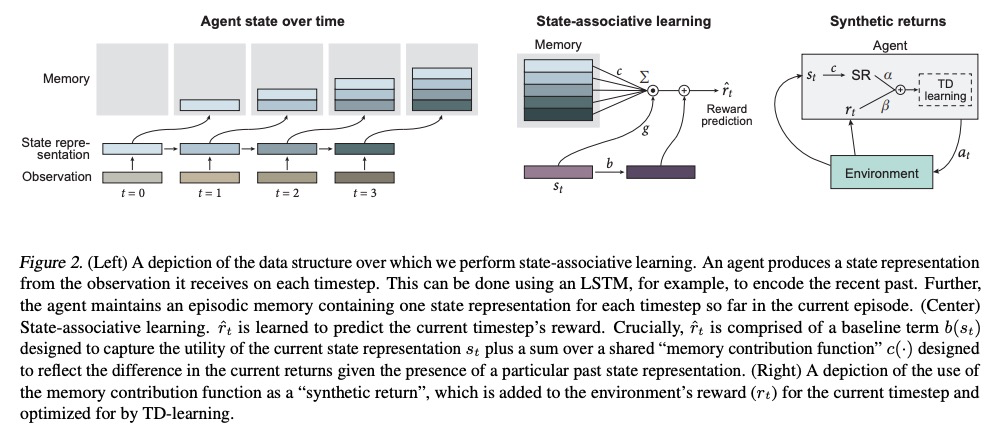
- [LG] Synthetic Returns for Long-Term Credit Assignment
- [CV] Point-set Distances for Learning Representations of 3D Point Clouds
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Self-Supervised Learning of Graph Neural Networks: A Unified Review
Y Xie, Z Xu, Z Wang, S Ji
[Texas A&M University & Amazon]
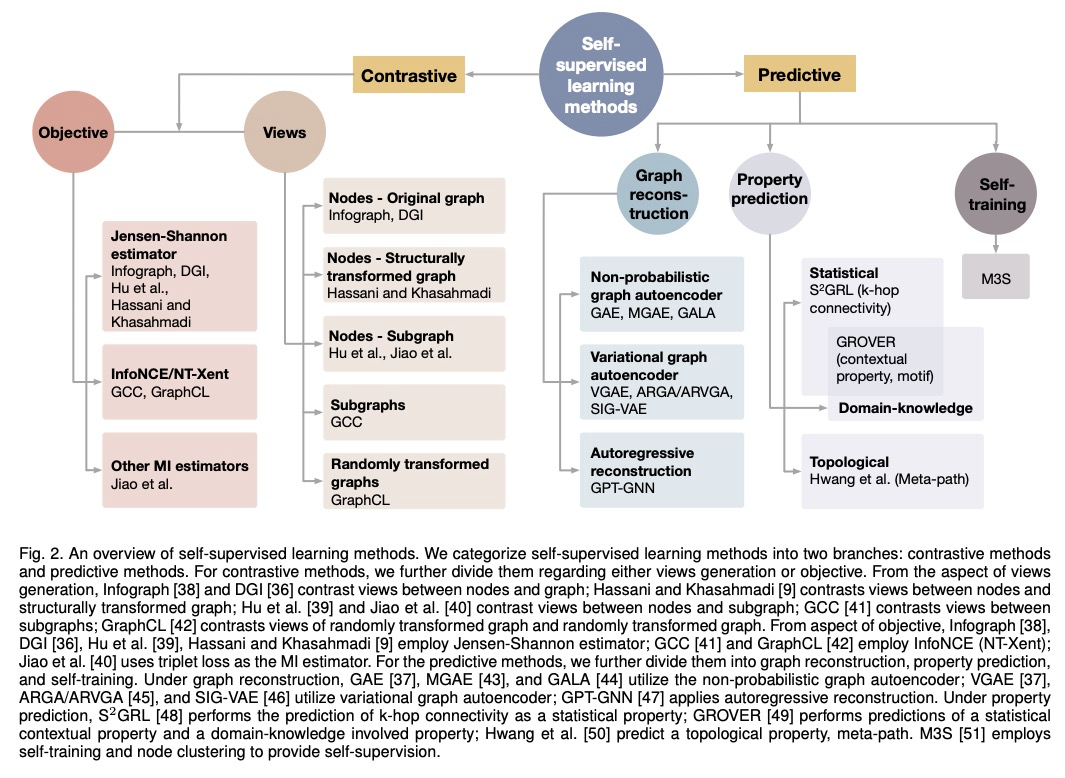
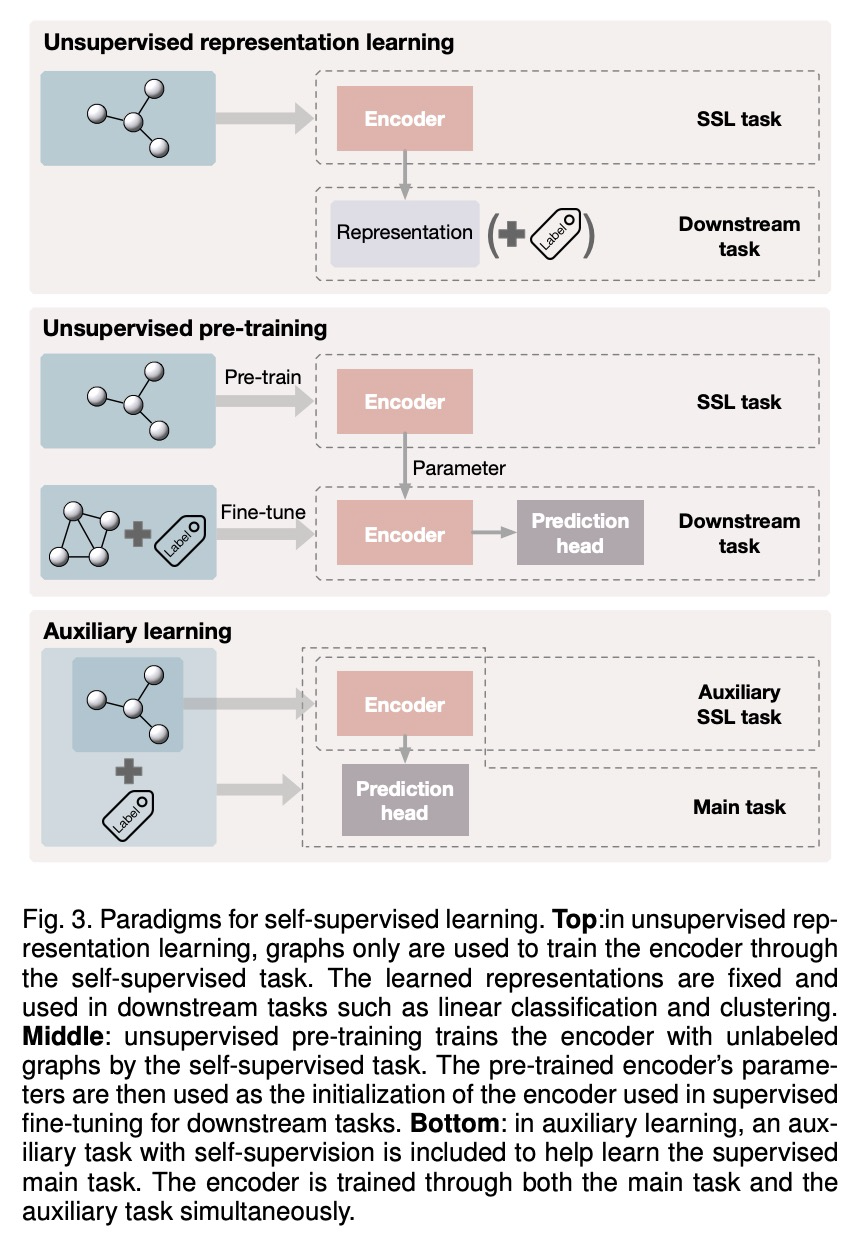
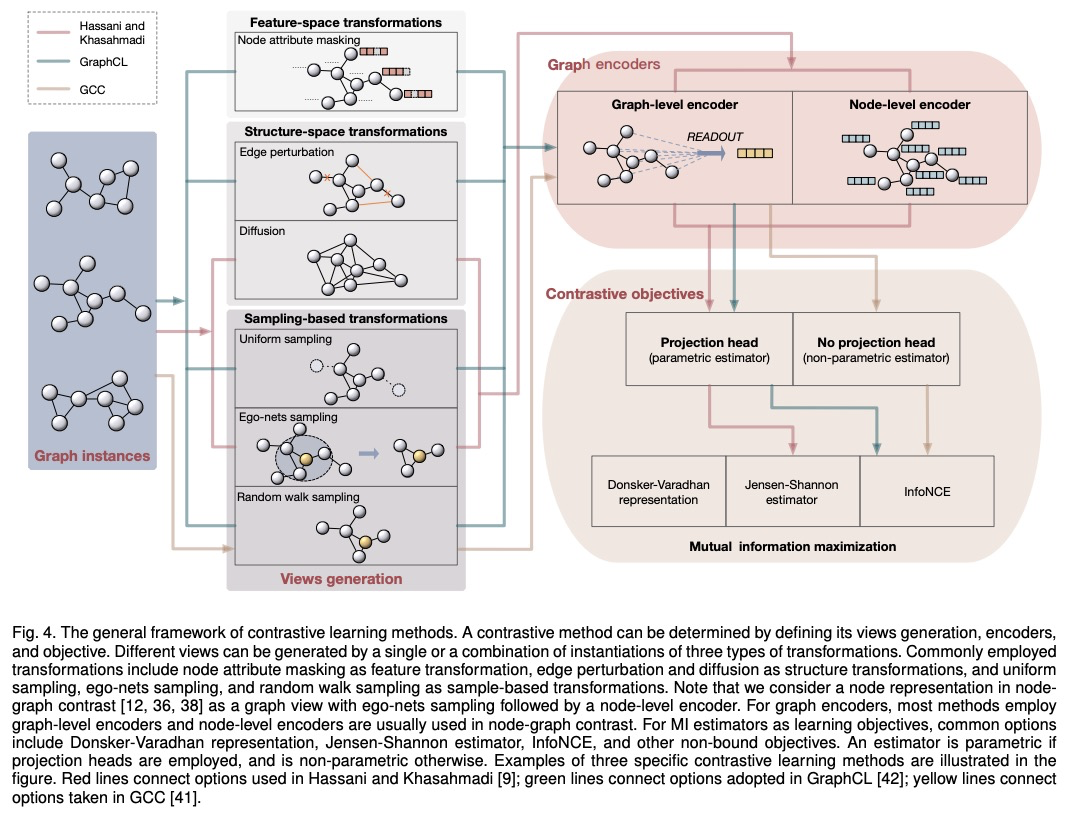
图神经网络自监督学习的统一综述。对使用自监督学习训练图神经网络的不同方法进行了统一回顾,将自监督学习方法分为对比性模型和预测性模型,提供了统一的方法框架,从互信息角度统一了对比性目标,将带有自生标签的自监督学习方法归类并统一为预测性学习方法,通过不同的标签获取方式阐明它们的联系和区别,揭示了这些方法在框架下各组成部分的不同之处,为开发新方法和算法奠定了基础。总结了不同的自监督学习设置以及各设置使用的数据集。为GNN中的自监督学习开发了一个标准化测试平台,包括常见的基线方法、数据集和评价指标的实现。
Deep models trained in supervised mode have achieved remarkable success on a variety of tasks. When labeled samples are limited, self-supervised learning (SSL) is emerging as a new paradigm for making use of large amounts of unlabeled samples. SSL has achieved promising performance on natural language and image learning tasks. Recently, there is a trend to extend such success to graph data using graph neural networks (GNNs). In this survey, we provide a unified review of different ways of training GNNs using SSL. Specifically, we categorize SSL methods into contrastive and predictive models. In either category, we provide a unified framework for methods as well as how these methods differ in each component under the framework. Our unified treatment of SSL methods for GNNs sheds light on the similarities and differences of various methods, setting the stage for developing new methods and algorithms. We also summarize different SSL settings and the corresponding datasets used in each setting. To facilitate methodological development and empirical comparison, we develop a standardized testbed for SSL in GNNs, including implementations of common baseline methods, datasets, and evaluation metrics.
https://weibo.com/1402400261/K479vc7HD
2、[LG] Learning Neural Network Subspaces
M Wortsman, M Horton, C Guestrin, A Farhadi, M Rastegari
[University of Washington & Apple]
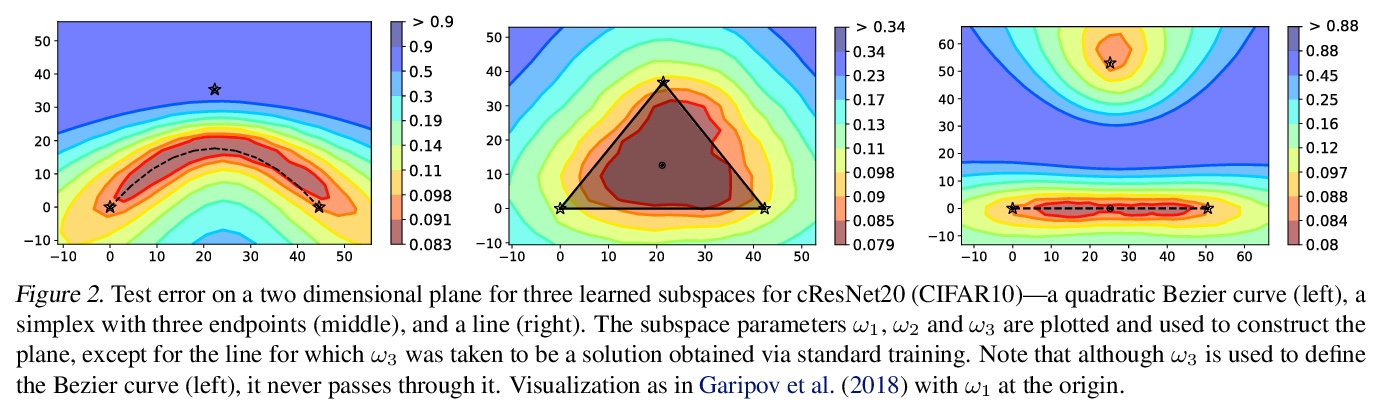
神经网络子空间学习。提出了在与训练单个模型相似的计算成本下,学习多样化、高精确度神经网络的线、曲线和单形的方法,这些神经网络子空间包含了多样化的解决方案,可进行集成,在不增加训练成本的情况下,接近独立训练网络的集成性能,用子空间中点可提升精度、校准和对标签噪声的鲁棒性,优于随机加权平均法。
Recent observations have advanced our understanding of the neural network optimization landscape, revealing the existence of (1) paths of high accuracy containing diverse solutions and (2) wider minima offering improved performance. Previous methods observing diverse paths require multiple training runs. In contrast we aim to leverage both property (1) and (2) with a single method and in a single training run. With a similar computational cost as training one model, we learn lines, curves, and simplexes of high-accuracy neural networks. These neural network subspaces contain diverse solutions that can be ensembled, approaching the ensemble performance of independently trained networks without the training cost. Moreover, using the subspace midpoint boosts accuracy, calibration, and robustness to label noise, outperforming Stochastic Weight Averaging.
https://weibo.com/1402400261/K47eqv0Qr
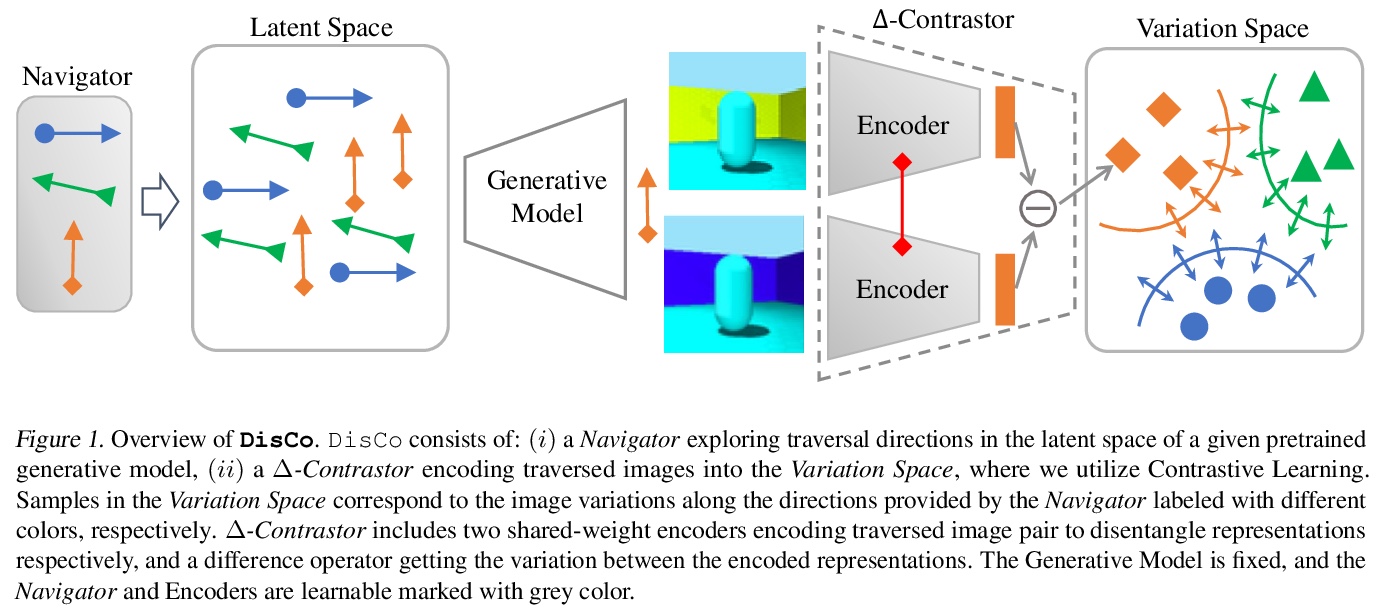
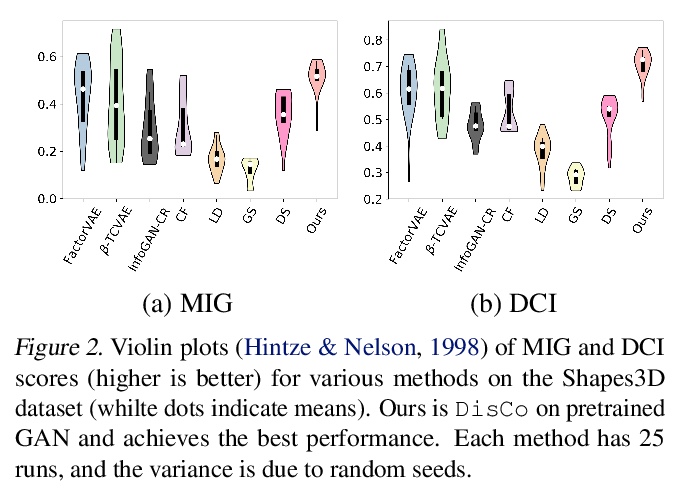
3、[CV] Do Generative Models Know Disentanglement? Contrastive Learning is All You Need
X Ren, T Yang, Y Wang, W Zeng
[HKUST & Xi’an Jiaotong University & Microsoft Research Asia]
用对比学习从预训练生成模型中提取解缠表示。提出一种无监督和模型无关的方法,通过对比进行解缠(DisCo),可发现预训练生成模型的潜空间中的解缠方向,并提取图像的解缠表示。提出了一种基于熵的支配损失和硬负翻转策略,以实现更好的解缠。DisCo优于典型的无监督解缠方法,同时也保持了较高的图像质量。
Disentangled generative models are typically trained with an extra regularization term, which encourages the traversal of each latent factor to make a distinct and independent change at the cost of generation quality. When traversing the latent space of generative models trained without the disentanglement term, the generated samples show semantically meaningful change, raising the question: do generative models know disentanglement? We propose an unsupervised and model-agnostic method: Disentanglement via Contrast (DisCo) in the Variation Space. DisCo consists of: (i) a Navigator providing traversal directions in the latent space, and (ii) a > Δ-Contrastor composed of two shared-weight Encoders, which encode image pairs along these directions to disentangled representations respectively, and a difference operator to map the encoded representations to the Variation Space. We propose two more key techniques for DisCo: entropy-based domination loss to make the encoded representations more disentangled and the strategy of flipping hard negatives to address directions with the same semantic meaning. By optimizing the Navigator to discover disentangled directions in the latent space and Encoders to extract disentangled representations from images with Contrastive Learning, DisCo achieves the state-of-the-art disentanglement given pretrained non-disentangled generative models, including GAN, VAE, and Flow. Project page at > this https URL.
https://weibo.com/1402400261/K47k4481p

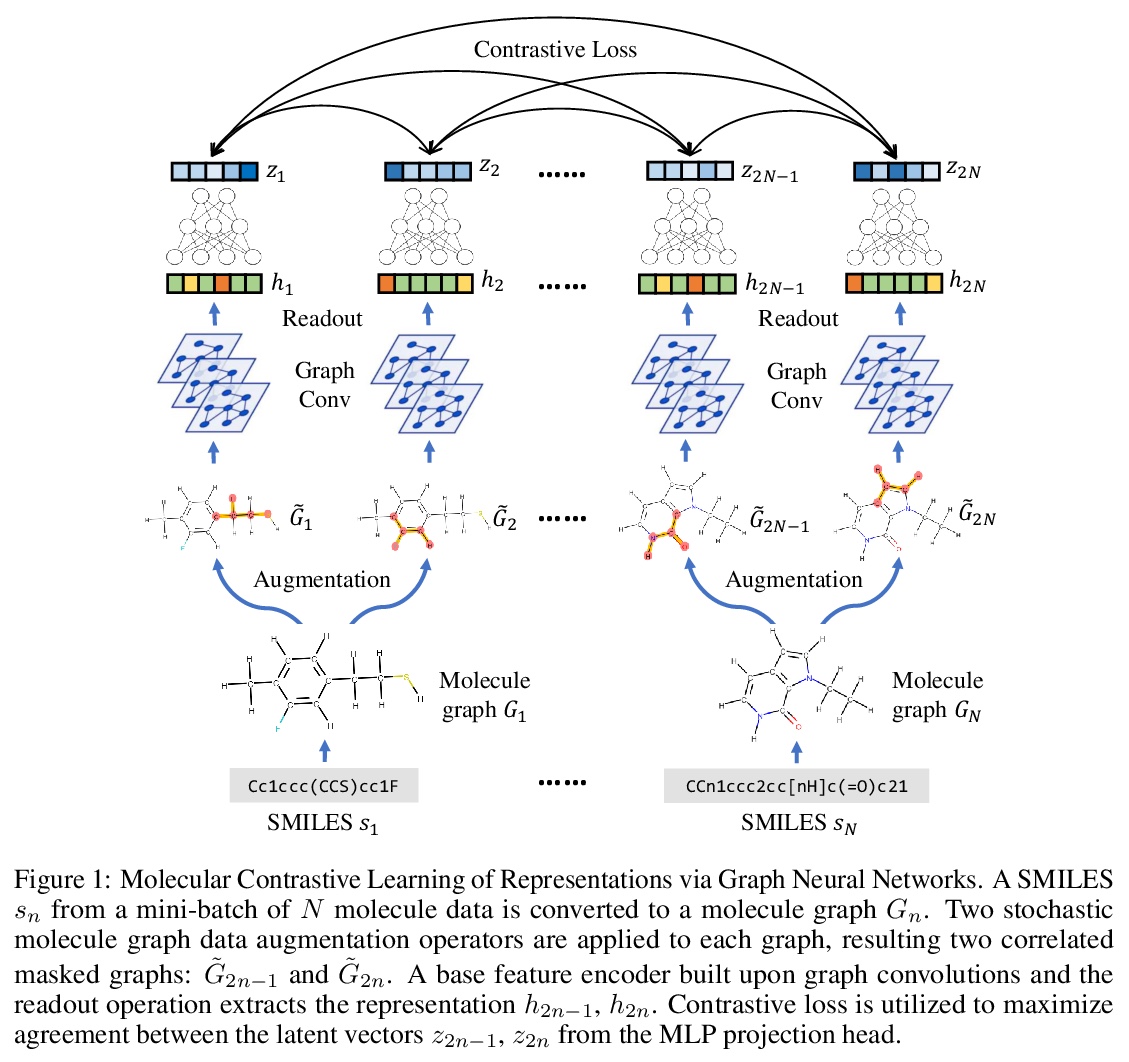
4、[LG] MolCLR: Molecular Contrastive Learning of Representations via Graph Neural Networks
Y Wang, J Wang, Z Cao, A B Farimani
[CMU]
MolCLR:图神经网络分子对比表示学习。提出了针对大型非标注分子数据集的自监督学习框架MolCLR,建立分子图,其中每个节点代表一个原子,每条边代表一个化学键,用图神经网络对分子图进行编码。提出了三种新的分子图增强方法:原子遮蔽、键删除和子图删除。用对比估计器来最大限度提高来自同一分子的不同图增强的一致性。通过微调在几个下游分子分类任务上实现了最先进性能,表明MolCLR能在没有领域知识的情况下学习信息丰富的分子表示。
Molecular machine learning bears promise for efficient molecule property prediction and drug discovery. However, due to the limited labeled data and the giant chemical space, machine learning models trained via supervised learning perform poorly in generalization. This greatly limits the applications of machine learning methods for molecular design and discovery. In this work, we present MolCLR: Molecular Contrastive Learning of Representations via Graph Neural Networks (GNNs), a self-supervised learning framework for large unlabeled molecule datasets. Specifically, we first build a molecular graph, where each node represents an atom and each edge represents a chemical bond. A GNN is then used to encode the molecule graph. We propose three novel molecule graph augmentations: atom masking, bond deletion, and subgraph removal. A contrastive estimator is utilized to maximize the agreement of different graph augmentations from the same molecule. Experiments show that molecule representations learned by MolCLR can be transferred to multiple downstream molecular property prediction tasks. Our method thus achieves state-of-the-art performance on many challenging datasets. We also prove the efficiency of our proposed molecule graph augmentations on supervised molecular classification tasks.
https://weibo.com/1402400261/K47nQ1v59


5、[CV] Do We Really Need Explicit Position Encodings for Vision Transformers?
X Chu, B Zhang, Z Tian, X Wei, H Xia
[Meituan Inc & The University of Adelaide]
视觉Transformer真的需要显式位置编码吗?提出一种隐条件位置编码方案,以输入token的局部邻域为条件,很容易就能实现,称为位置编码生成器(PEG),可无缝融入到变换器框架中。新模型与PEG合称为条件位置编码视觉Transformer(CPVT),可自然地处理任意长度的输入序列。证明了CPVT可产生视觉上相似的注意力图,获得甚至比预定义位置编码更好的性能。
Almost all visual transformers such as ViT or DeiT rely on predefined positional encodings to incorporate the order of each input token. These encodings are often implemented as learnable fixed-dimension vectors or sinusoidal functions of different frequencies, which are not possible to accommodate variable-length input sequences. This inevitably limits a wider application of transformers in vision, where many tasks require changing the input size on-the-fly.In this paper, we propose to employ a conditional position encoding scheme, which is conditioned on the local neighborhood of the input token. It is effortlessly implemented as what we call Position Encoding Generator (PEG), which can be seamlessly incorporated into the current transformer framework. Our new model with PEG is named Conditional Position encoding Visual Transformer (CPVT) and can naturally process the input sequences of arbitrary length. We demonstrate that CPVT can result in visually similar attention maps and even better performance than those with predefined positional encodings. We obtain state-of-the-art results on the ImageNet classification task compared with visual Transformers to date. Our code will be made available at > this https URL .
https://weibo.com/1402400261/K47rXpaM8

另外几篇值得关注的论文:
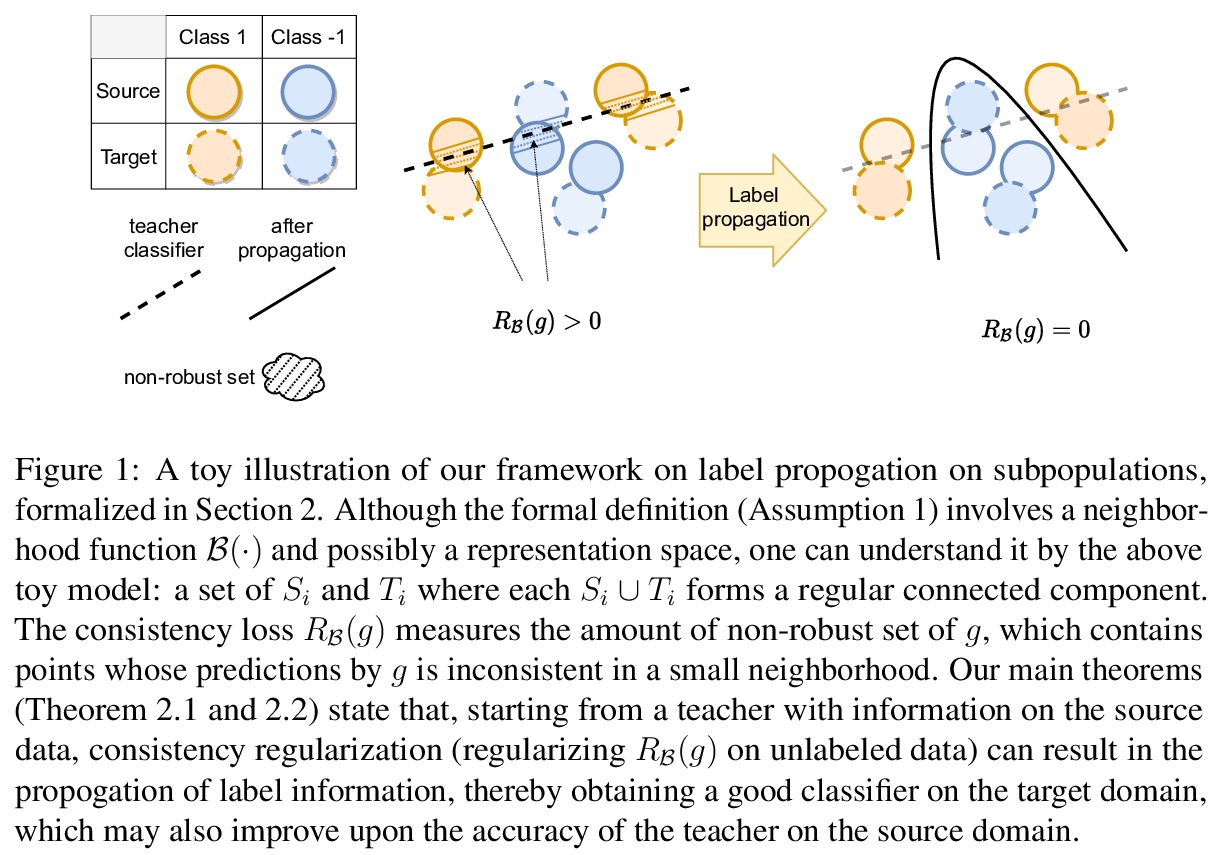
[LG] A Theory of Label Propagation for Subpopulation Shift
亚族群转移标签传播理论
T Cai, R Gao, J D. Lee, Q Lei
[Princeton University]
https://weibo.com/1402400261/K47xI4RiH
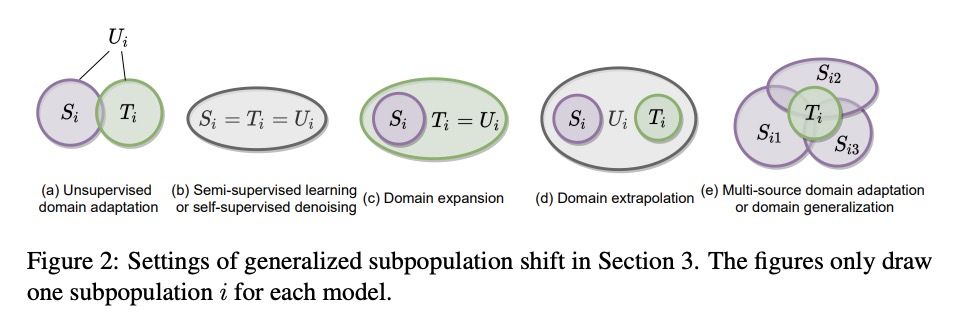
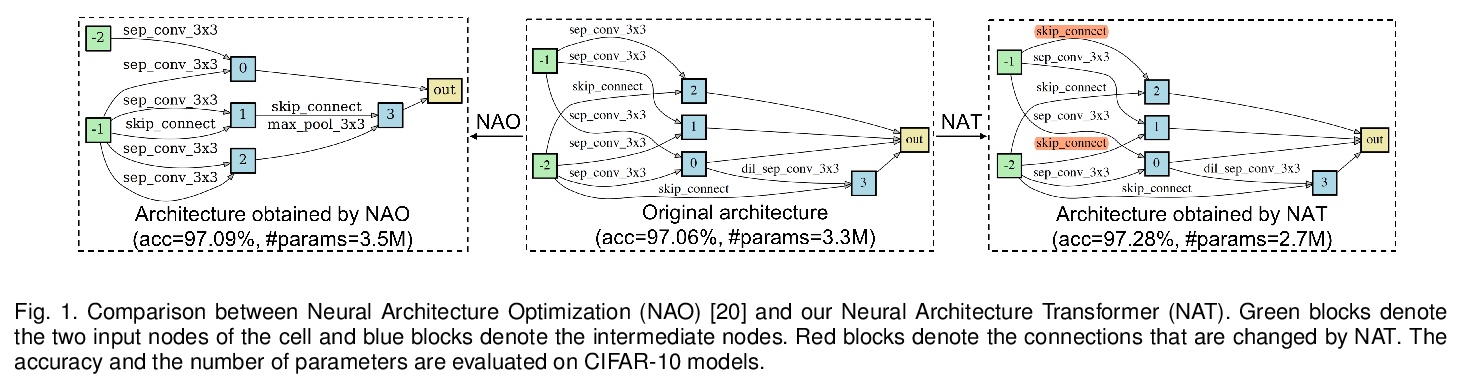
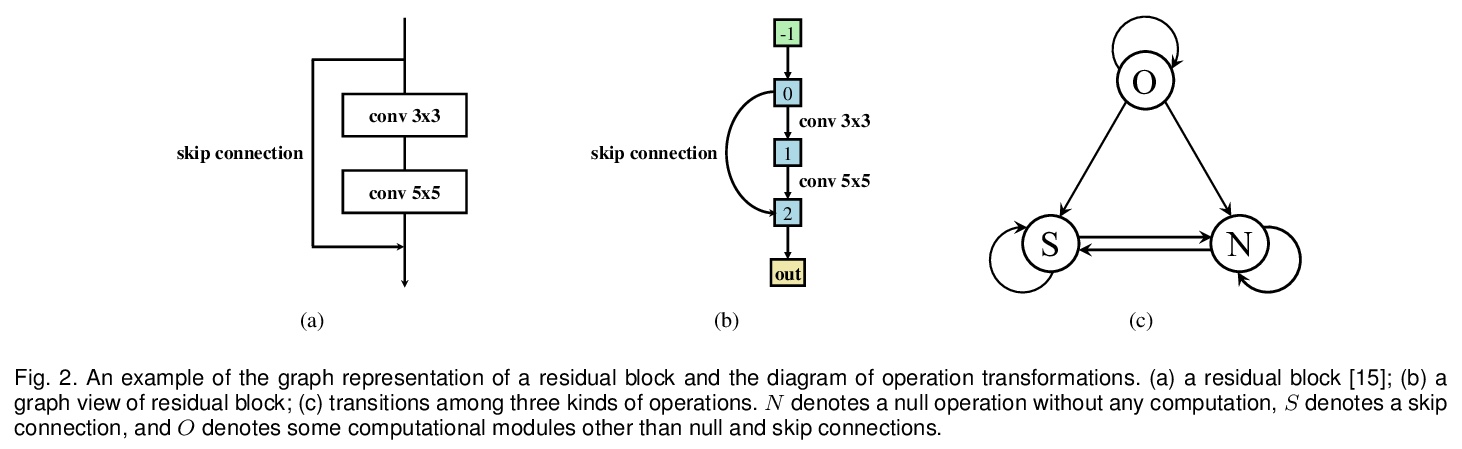
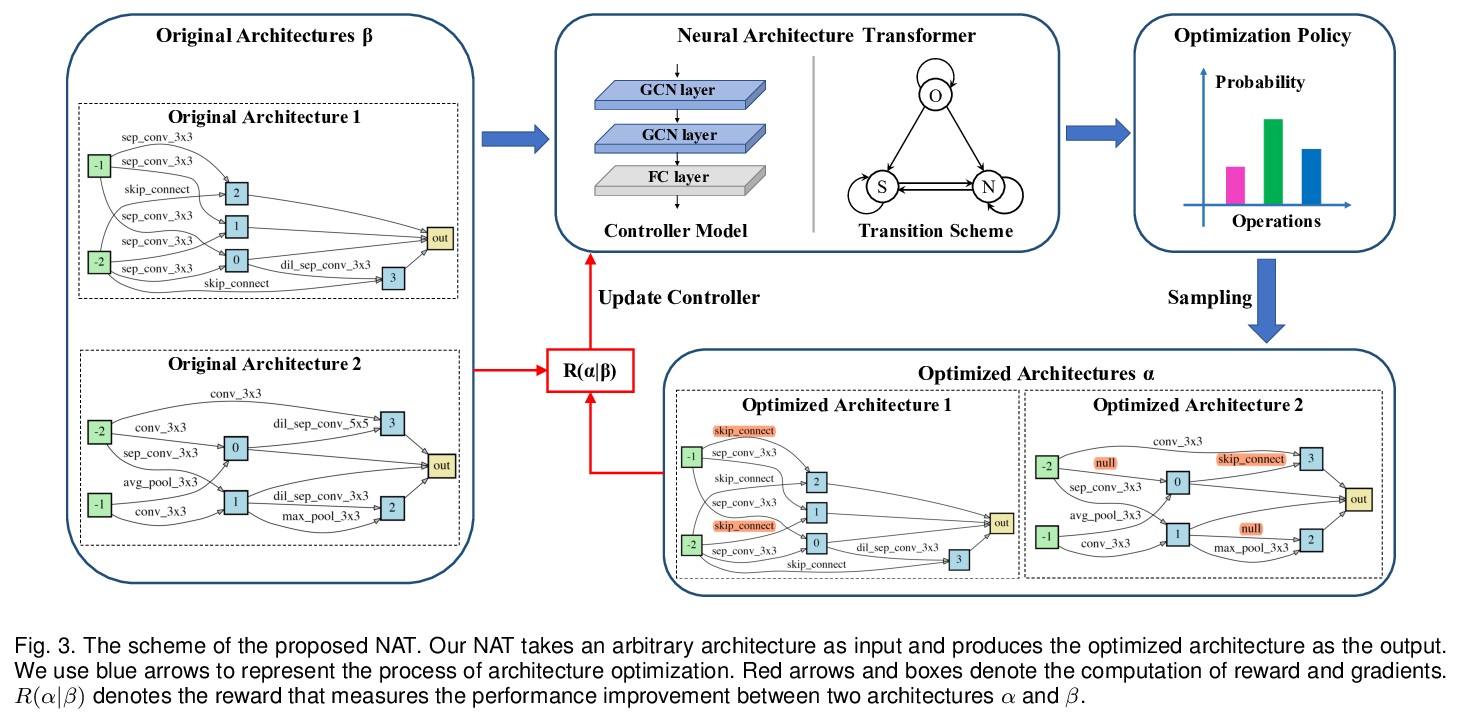
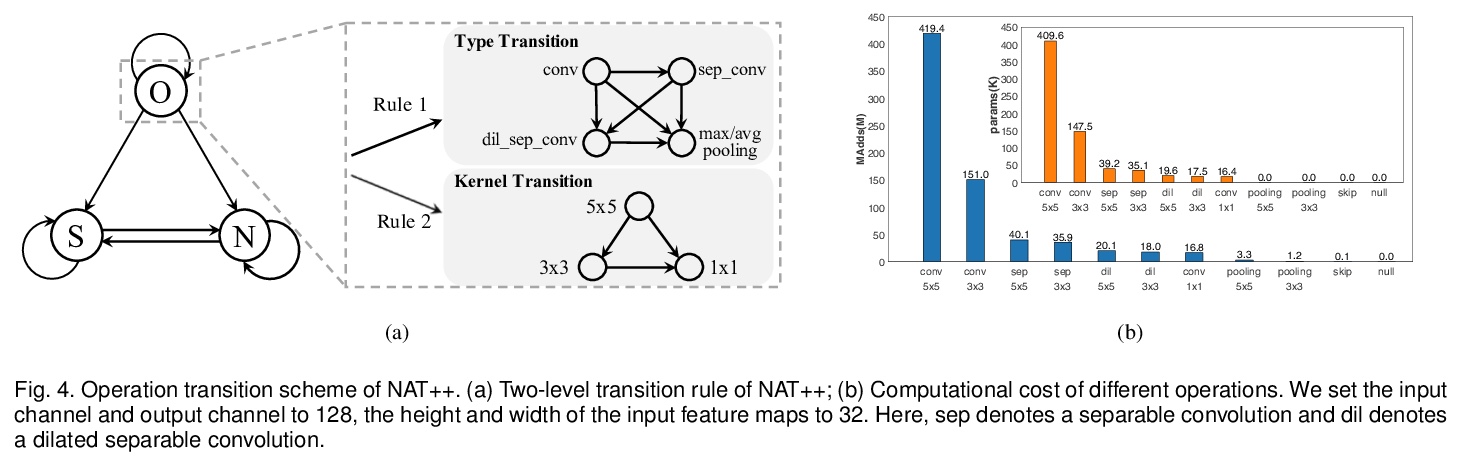
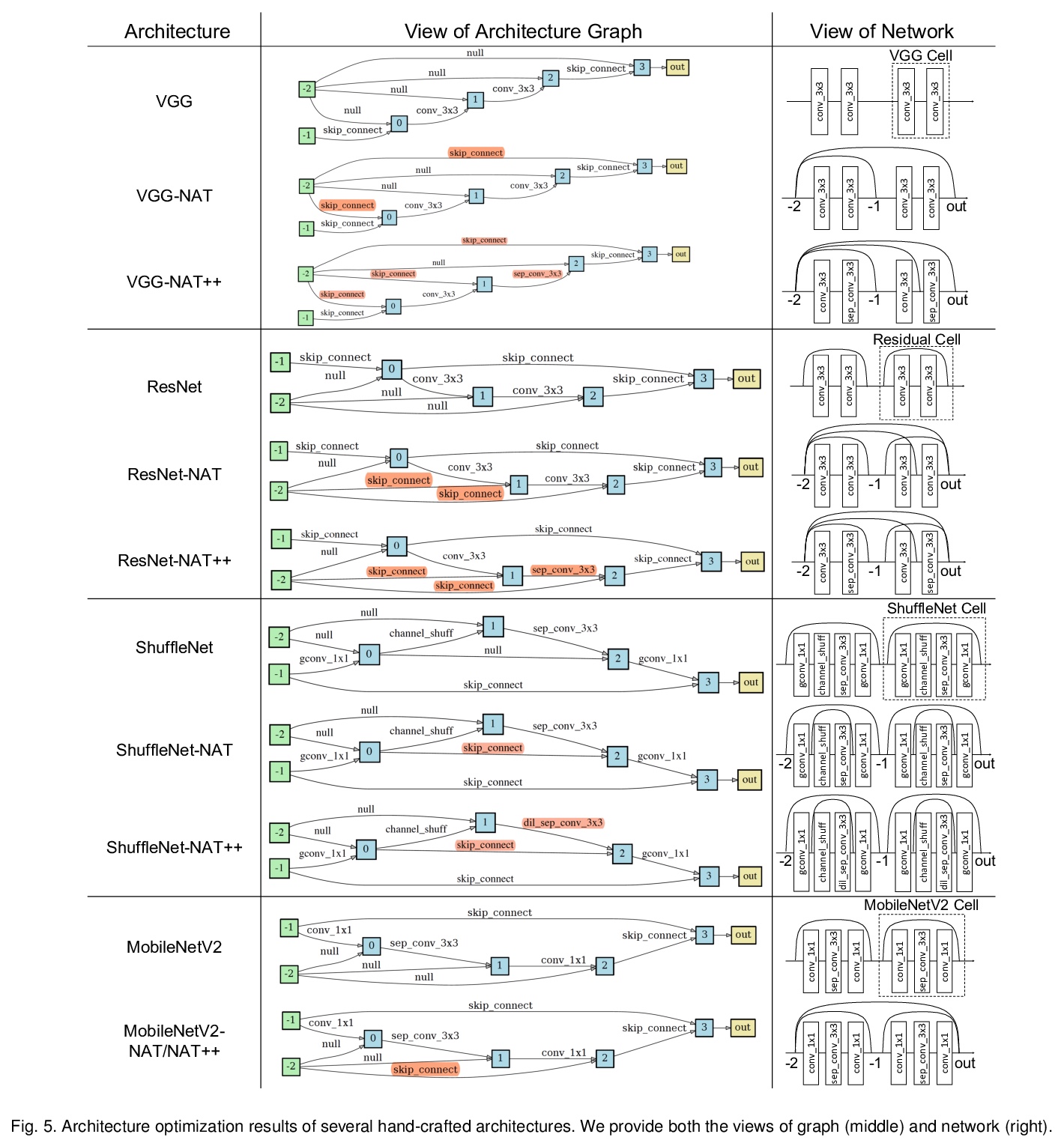
[CV] Towards Accurate and Compact Architectures via Neural Architecture Transformer
用神经架构Transformer实现更精确更紧凑架构
Y Guo, Y Zheng, M Tan, Q Chen, Z Li, J Chen, P Zhao, J Huang
[South China University of Technology & Tencent]
https://weibo.com/1402400261/K47AvehXT
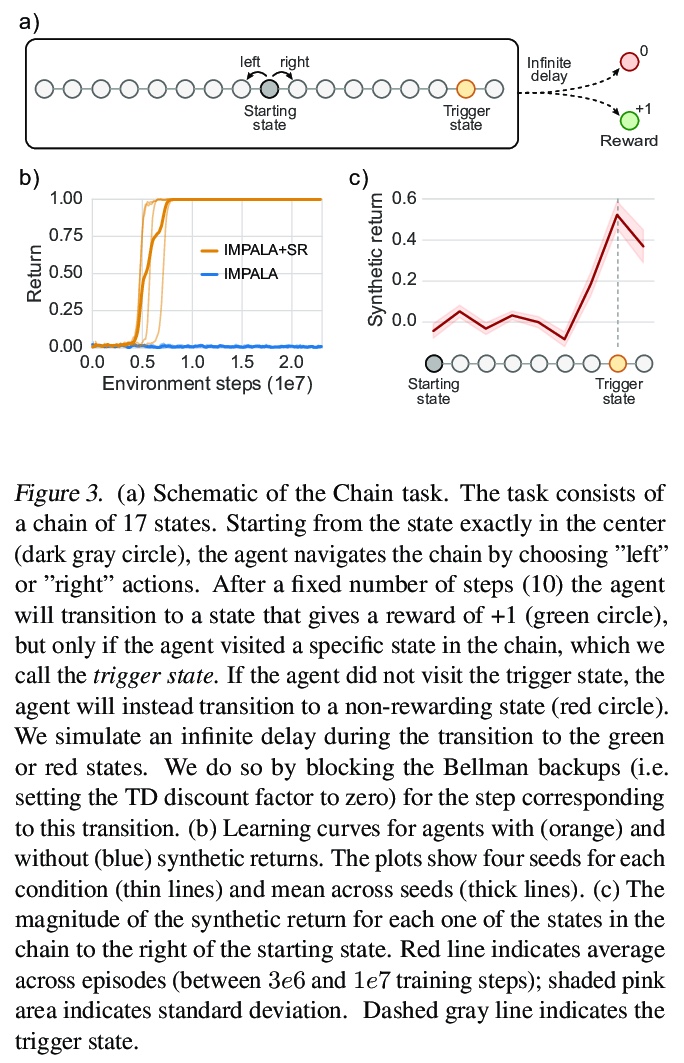
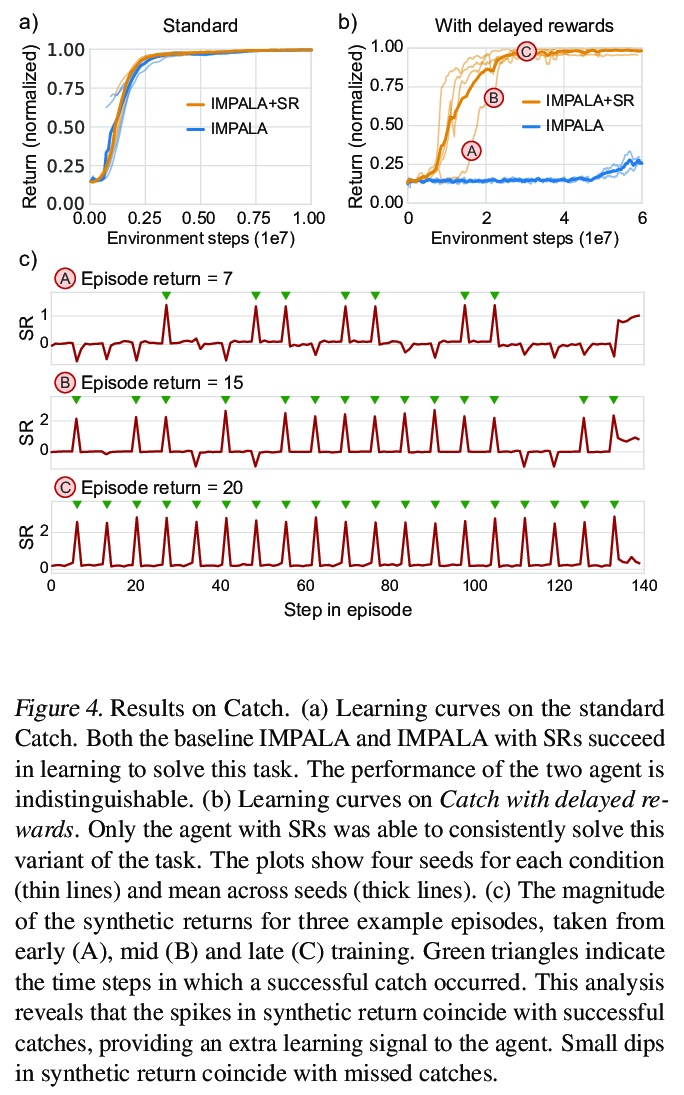
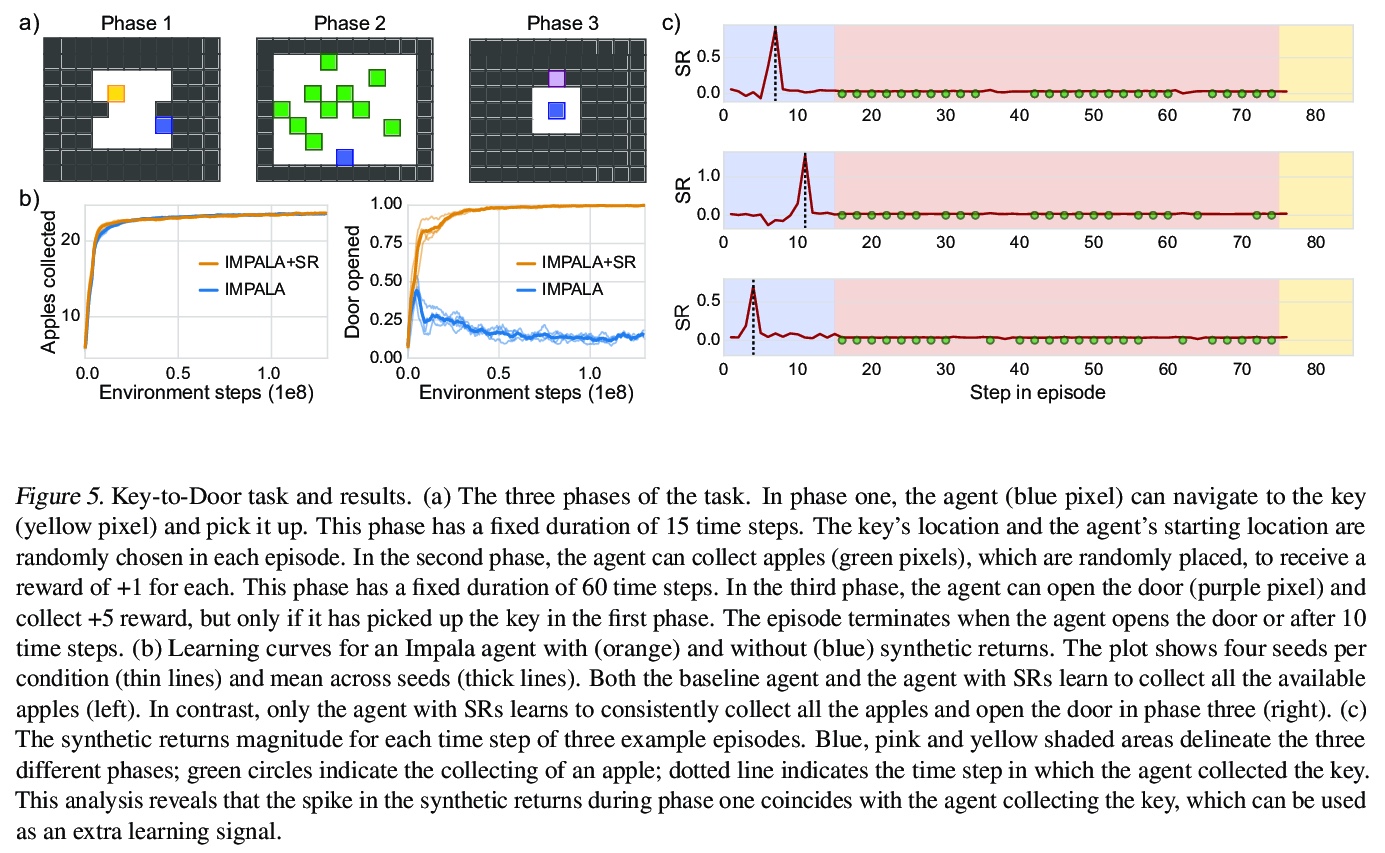
[LG] Synthetic Returns for Long-Term Credit Assignment
长期信用分配的综合回报
D Raposo, S Ritter, A Santoro, G Wayne, T Weber, M Botvinick, H v Hasselt, F Song
[Google]
https://weibo.com/1402400261/K47F3pTAa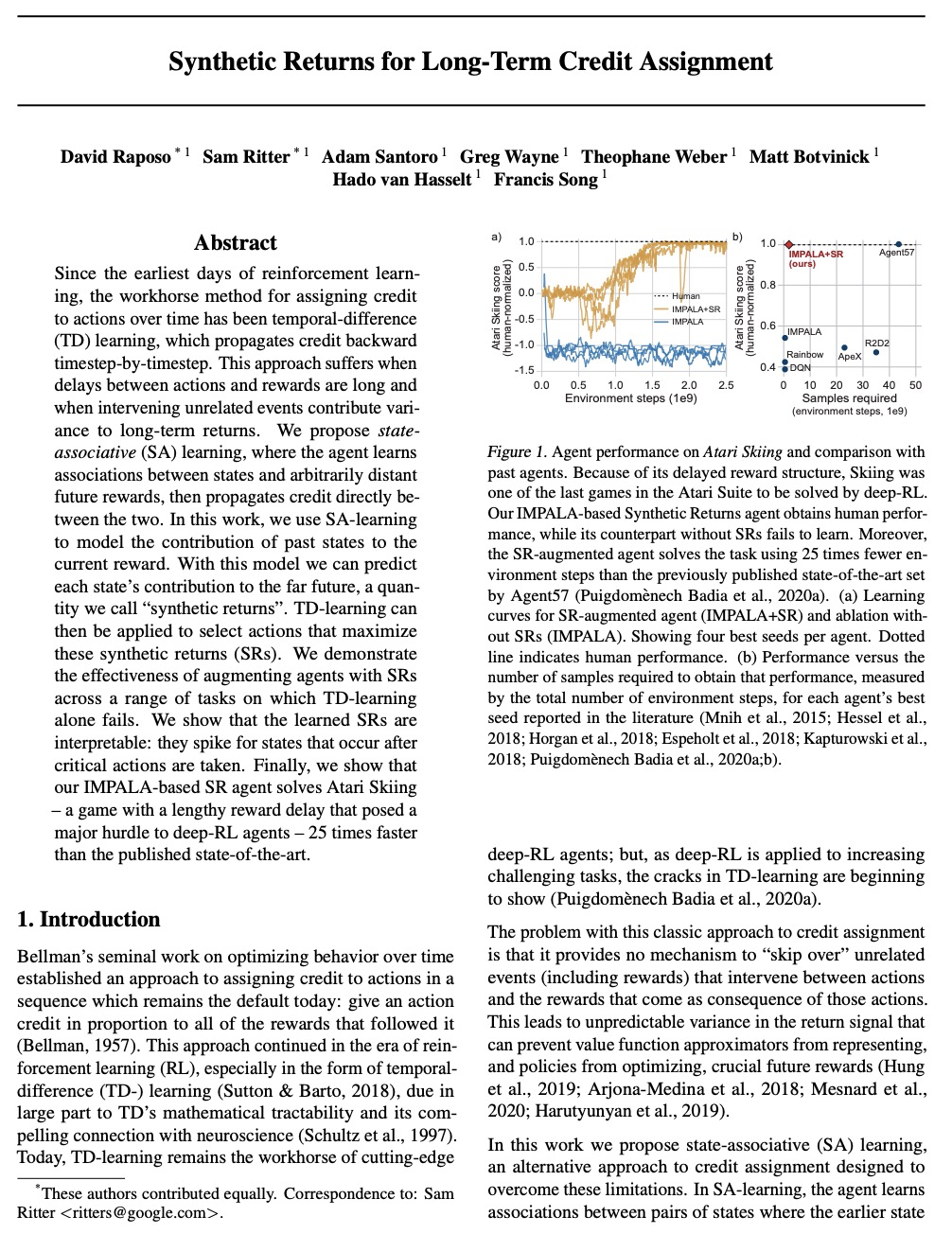
[CV] Point-set Distances for Learning Representations of 3D Point Clouds
基于点集距离的3D点云表示学习
T Nguyen, Q Pham, T Le, T Pham, N Ho, B Hua
[VinAI Research & Singapore University of Technology and Design & RIKEN AIP & University of Texas]
https://weibo.com/1402400261/K47H5y7Hk




若有收获,就点个赞吧
0 人点赞
