- 1、[CV] Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution Merging
- 2、[CL] Changing the World by Changing the Data
- 3、[CV] ResT: An Efficient Transformer for Visual Recognition
- 4、[CV] What Is Considered Complete for Visual Recognition?
- 5、[AS] DiffSVC: A Diffusion Probabilistic Model for Singing Voice Conversion
- [CV] NViSII: A Scriptable Tool for Photorealistic Image Generation
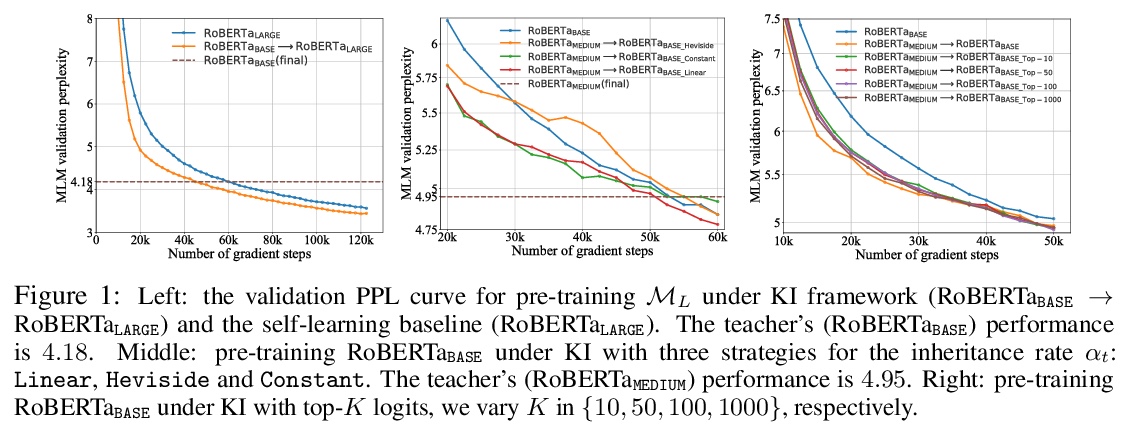
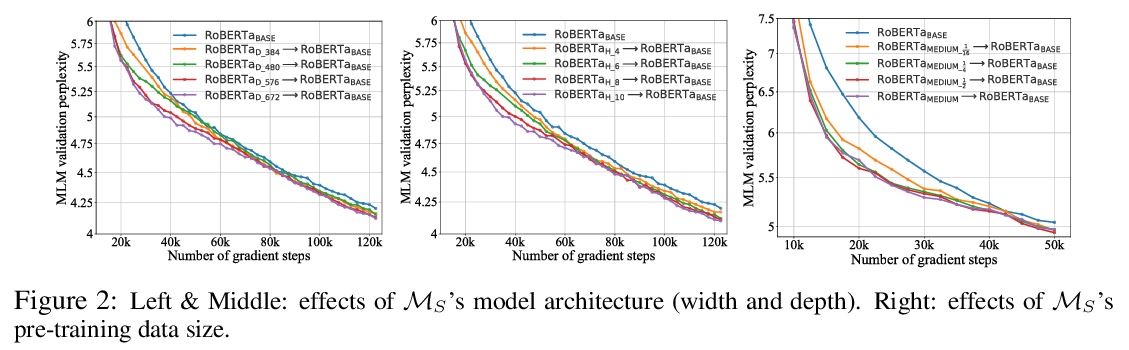
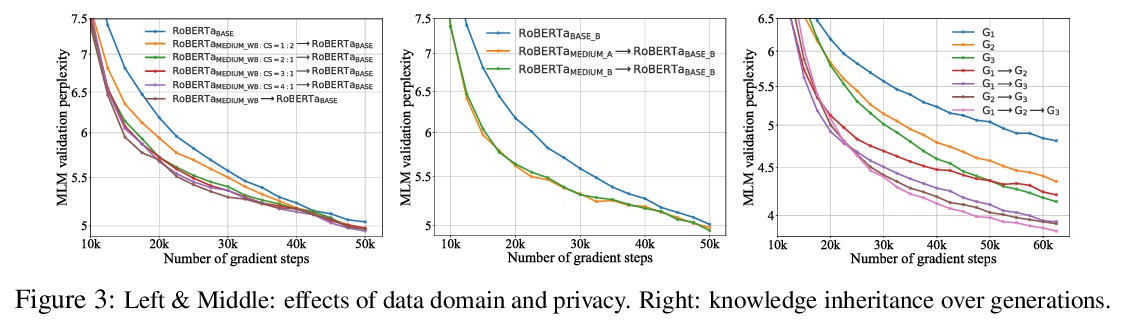
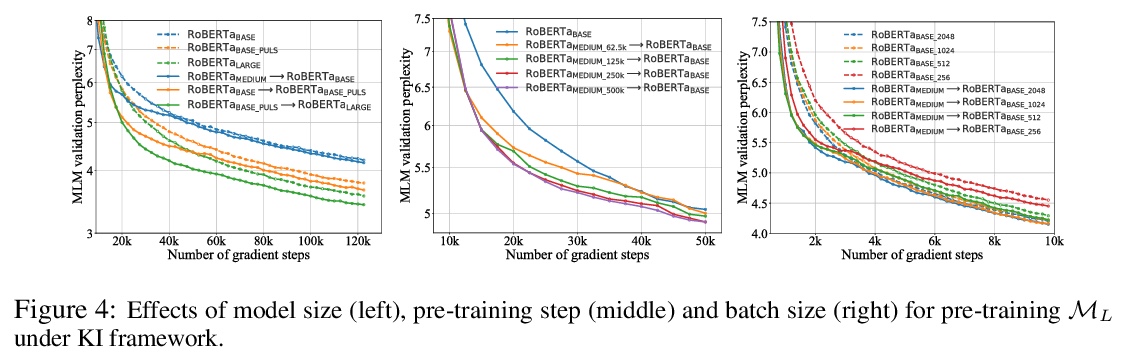
- [CL] Knowledge Inheritance for Pre-trained Language Models
- [CV] Revitalizing Optimization for 3D Human Pose and Shape Estimation: A Sparse Constrained Formulation
- [LG] Discretization Drift in Two-Player Games
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[CV] Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution Merging
S. M H. Miangoleh, S Dille, L Mai, S Paris, Y Aksoy
[Simon Fraser University & Adobe Research]
基于内容自适应多分辨率合并的高分辨率单目深度估计。神经网络在估计单幅图像深度方面显示出巨大能力,但推断出的深度图远低于百万像素分辨率,往往缺乏细粒度细节,限制了其实用性。本文提出的方法,建立在对输入分辨率和场景结构如何影响深度估计性能的分析上,证明了在一致的场景结构和高频细节之间存在着权衡,用一个简单的深度合并网络,合并了低分辨率和高分辨率的估计,以利用这种双重性。提出一种双重估计方法,改善了整图的深度估计,提出一种图块选择方法,为最终结果增加了局部细节。通过合并不同分辨率下的估计,在不断变化的背景下,可以用预训练好的模型,生成具有高水平细节的数百万像素深度图。
Neural networks have shown great abilities in estimating depth from a single image. However, the inferred depth maps are well below one-megapixel resolution and often lack fine-grained details, which limits their practicality. Our method builds on our analysis on how the input resolution and the scene structure affects depth estimation performance. We demonstrate that there is a trade-off between a consistent scene structure and the high-frequency details, and merge lowand high-resolution estimations to take advantage of this duality using a simple depth merging network. We present a double estimation method that improves the whole-image depth estimation and a patch selection method that adds local details to the final result. We demonstrate that by merging estimations at different resolutions with changing context, we can generate multimegapixel depth maps with a high level of detail using a pre-trained model.
https://weibo.com/1402400261/Ki6lAb7HY




2、[CL] Changing the World by Changing the Data
A Rogers
[University of Copenhagen]
通过改变数据改变世界。NLP社区目前在深度学习模型开发上投入了大量的研究和资源,而不是在训练数据上。虽然取得了很大进展,但很明显模型学到了各种虚假模式、社会偏见和人为标记。到目前为止,算法解决方案取得了有限的成功。一个正在被积极讨论的替代方案,是对数据集进行更仔细的设计,以提供特定信号。本意见书从语言学和伦理学的角度,汇集了支持和反对数据策展的论点。其提出的理由是,策展无可避免,并且已经在发生,我们所做的任何数据选择,无论显式的还是隐式,都会影响现实世界。因此,辩论只关于我们该在这个过程中投入多少思考。如果要尝试引导它,必须克服跨学科的紧张关系,重新考虑什么才是”NLP工作”。
NLP community is currently investing a lot more research and resources into development of deep learning models than training data. While we have made a lot of progress, it is now clear that our models learn all kinds of spurious patterns, social biases, and annotation artifacts. Algorithmic solutions have so far had limited success. An alternative that is being actively discussed is more careful design of datasets so as to deliver specific signals. This position paper maps out the arguments for and against data curation, and argues that fundamentally the point is moot: curation already is and will be happening, and it is changing the world. The question is only how much thought we want to invest into that process.
https://weibo.com/1402400261/Ki6qBlllj
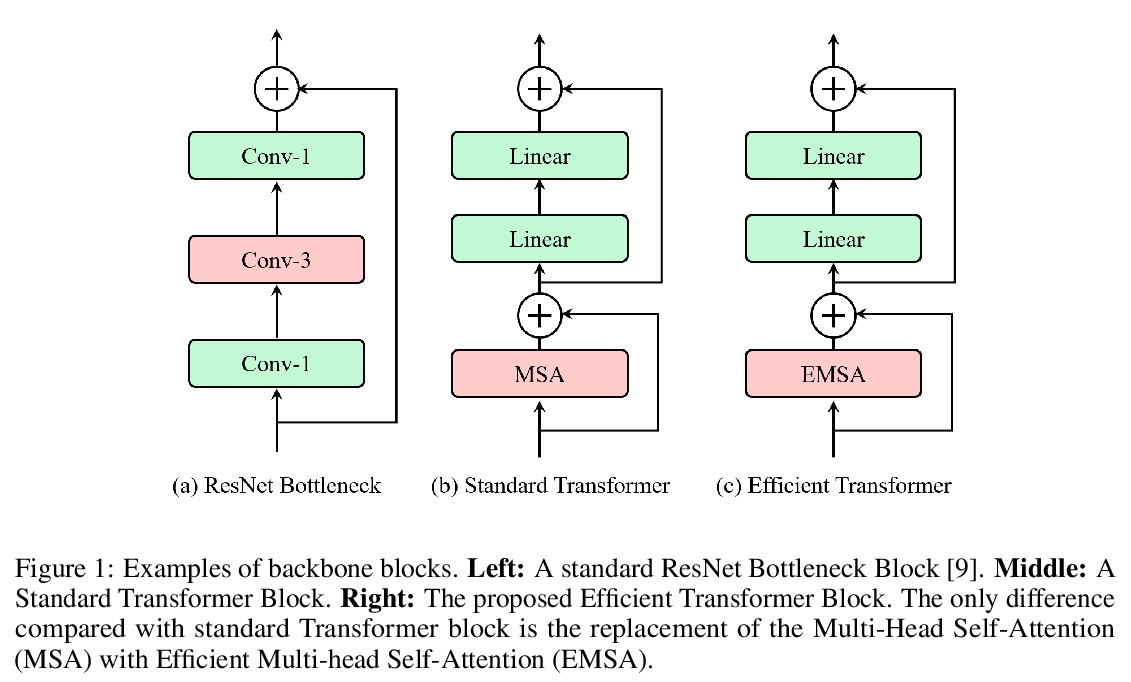
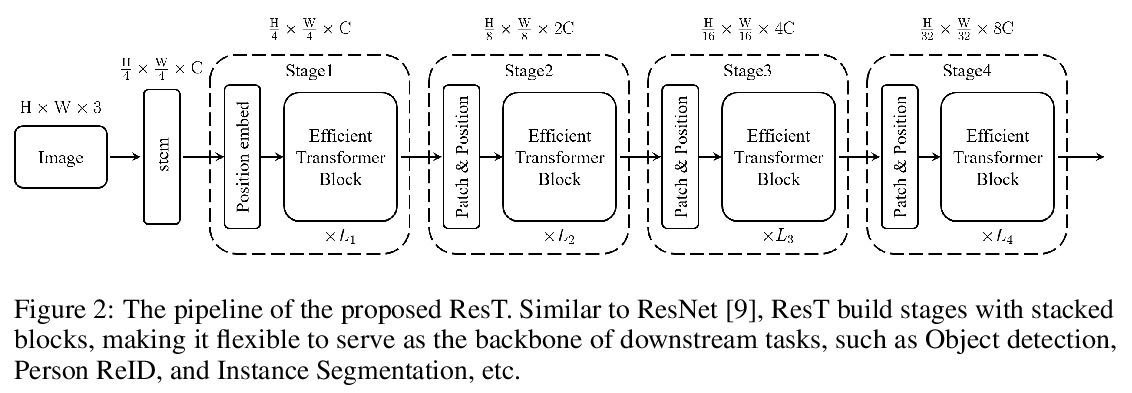
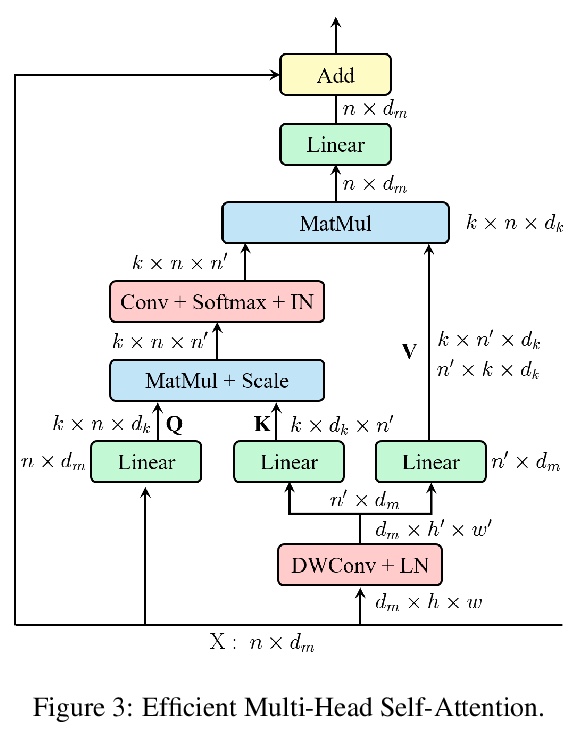
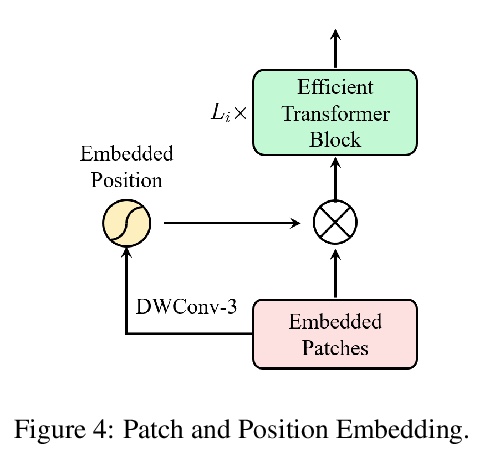
3、[CV] ResT: An Efficient Transformer for Visual Recognition
Q Zhang, Y Yang
[Nanjing University]
ResT:面向视觉识别的高效Transformer。提出一种高效的多尺度视觉Transformer,称为ResT,可作为图像识别的通用骨干。与现有Transformer方法不同,ResT采用标准Transformer块来处理具有固定分辨率的原始图像,该Transformer有几个优点:(1) 构建了一个记忆高效的多头自注意力,通过简单的深度卷积压缩记忆,在保持多头多样性能力的同时,投射跨注意力-头维度的交互;(2) 位置编码被构建为空间注意力,更加灵活,可处理任意大小的输入图像,无需插值或微调;(3) 没有在各阶段开始进行直接的标记化,而是将图块嵌入设计为堆叠的重叠卷积操作,对标记图进行stride处理。在图像分类和下游任务上全面验证了ResT,实验结果表明,ResT能以很大幅度超过目前最先进的骨干网,证明了ResT作为强骨干网的潜力。
This paper presents an efficient multi-scale vision Transformer, called ResT, that capably served as a general-purpose backbone for image recognition. Unlike existing Transformer methods, which employ standard Transformer blocks to tackle raw images with a fixed resolution, our ResT have several advantages: (1) A memory-efficient multi-head self-attention is built, which compresses the memory by a simple depth-wise convolution, and projects the interaction across the attention-heads dimension while keeping the diversity ability of multi-heads; (2) Position encoding is constructed as spatial attention, which is more flexible and can tackle with input images of arbitrary size without interpolation or fine-tune; (3) Instead of the straightforward tokenization at the beginning of each stage, we design the patch embedding as a stack of overlapping convolution operation with stride on the token map. We comprehensively validate ResT on image classification and downstream tasks. Experimental results show that the proposed ResT can outperform the recently state-of-the-art backbones by a large margin, demonstrating the potential of ResT as strong backbones.
https://weibo.com/1402400261/Ki6vlzpuU
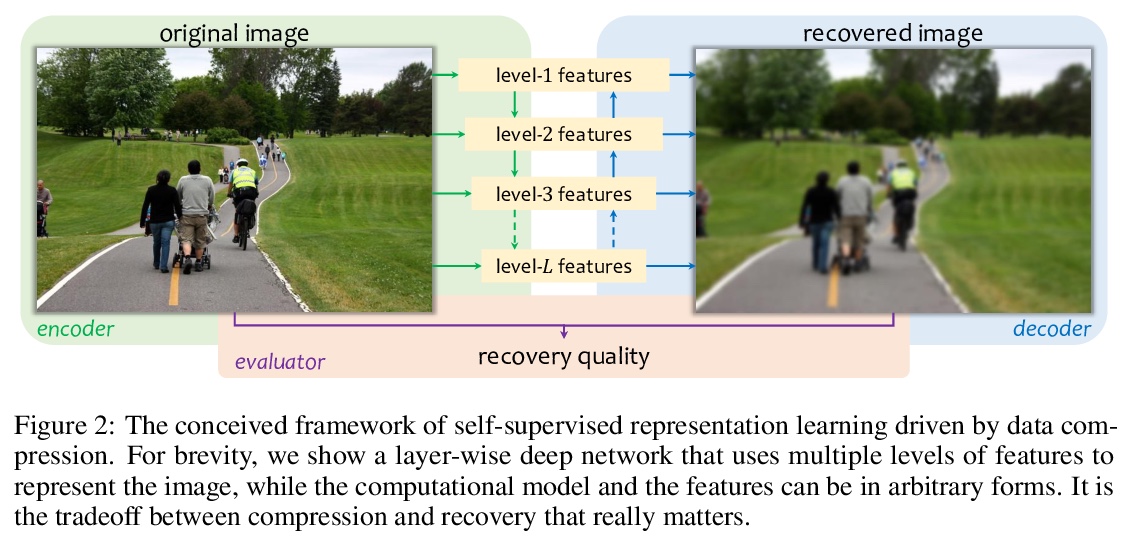
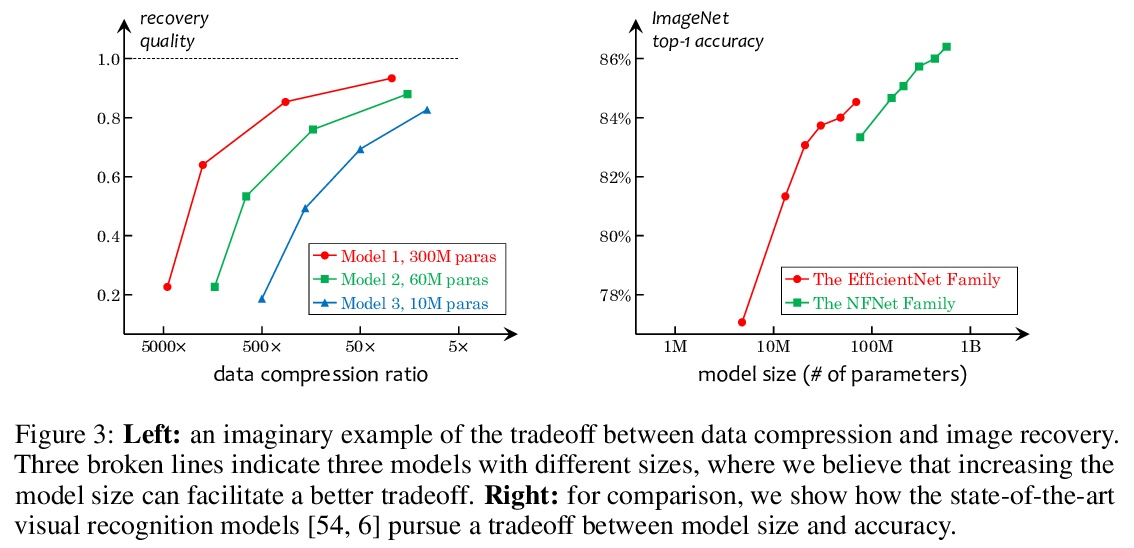
4、[CV] What Is Considered Complete for Visual Recognition?
L Xie, X Zhang, L Wei, J Chang, Q Tian
[Huawei Inc]
怎样才算完成视觉识别?这是一篇观点文章。希望传递一个关键信息:目前的视觉识别系统还远未完成,即识别人类能识别的所有东西,但通过不断增加人工标注来弥补这一差距的可能性很小。基于这一观察,本文主张采用一种新的预训练任务——压缩学习。计算模型(如深度网络)被优化以使用紧凑特征来表示视觉数据,并且这些特征保留了恢复原始数据的能力。语义标注,如果有的话,起到了弱监督的作用。一个重要但具有挑战性的问题是图像恢复的评估,本文提出一些设计原则和未来的研究方向,希望这些建议能激励社区追求压缩-恢复的权衡,而不是精度-复杂度的权衡。
This is an opinion paper. We hope to deliver a key message that current visual recognition systems are far from complete, i.e., recognizing everything that human can recognize, yet it is very unlikely that the gap can be bridged by continuously increasing human annotations. Based on the observation, we advocate for a new type of pre-training task named learning-by-compression. The computational models (e.g., a deep network) are optimized to represent the visual data using compact features, and the features preserve the ability to recover the original data. Semantic annotations, when available, play the role of weak supervision. An important yet challenging issue is the evaluation of image recovery, where we suggest some design principles and future research directions. We hope our proposal can inspire the community to pursue the compression-recovery tradeoff rather than the accuracy-complexity tradeoff.
https://weibo.com/1402400261/Ki6zpDLP3


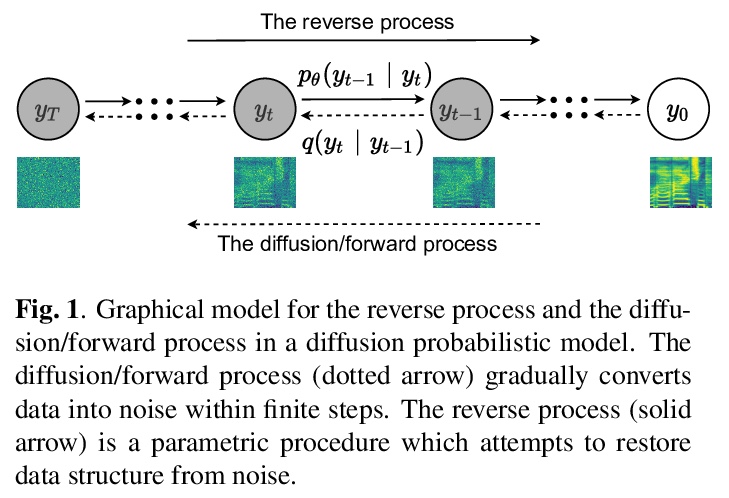
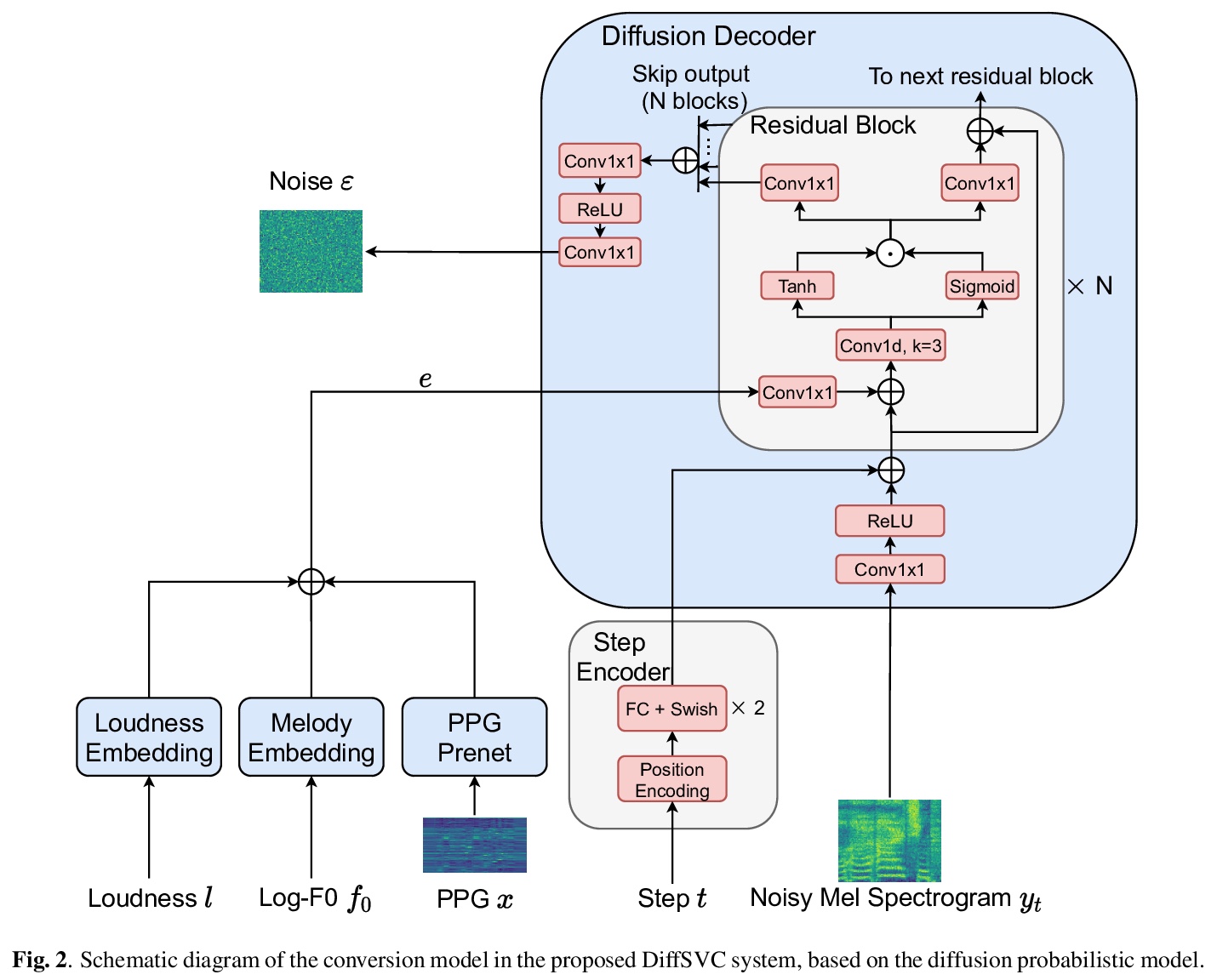
5、[AS] DiffSVC: A Diffusion Probabilistic Model for Singing Voice Conversion
S Liu, Y Cao, D Su, H Meng
[The Chinese University of Hong Kong & Tencent AI Lab]
DiffSVC:面向歌唱声音转换的扩散概率模型。歌声转换(SVC)是一项很有前途的技术,通过赋予计算机生成高保真和富有表现力的歌声的能力,丰富人机交互方式。本文提出DiffSVC,一种基于去噪扩散概率模型的SVC系统,用语音后验图(PPG)作为内容特征。在DiffSVC中训练一个去噪模块,该模块将由扩散/前向过程产生的被破坏的梅尔谱及其相应的步进信息作为输入,以预测添加的高斯噪声。用PPG、基频特征和响度特征作为辅助输入来帮去噪过程。实验表明,与目前最先进的SVC方法相比,DiffSVC在自然度和语音相似度方面可以达到更高的转换性能。
Singing voice conversion (SVC) is one promising technique which can enrich the way of human-computer interaction by endowing a computer the ability to produce high-fidelity and expressive singing voice. In this paper, we propose DiffSVC, an SVC system based on denoising diffusion probabilistic model. DiffSVC uses phonetic posteriorgrams (PPGs) as content features. A denoising module is trained in DiffSVC, which takes destroyed mel spectrogram produced by the diffusion/forward process and its corresponding step information as input to predict the added Gaussian noise. We use PPGs, fundamental frequency features and loudness features as auxiliary input to assist the denoising process. Experiments show that DiffSVC can achieve superior conversion performance in terms of naturalness and voice similarity to current state-of-the-art SVC approaches.
https://weibo.com/1402400261/Ki6DzBERW
另外几篇值得关注的论文:
[CV] NViSII: A Scriptable Tool for Photorealistic Image Generation
NViSII:用于生成逼真图像的脚本化工具
N Morrical, J Tremblay, Y Lin, S Tyree, S Birchfield, V Pascucci, I Wald
[NVIDIA]
https://weibo.com/1402400261/Ki6HUf4w2




[CL] Knowledge Inheritance for Pre-trained Language Models
预训练语言模型的知识继承
Y Qin, Y Lin, J Yi, J Zhang, X Han, Z Zhang, Y Su, Z Liu, P Li, M Sun, J Zhou
[Tsinghua University & WeChat AI]
https://weibo.com/1402400261/Ki6JrnUIk
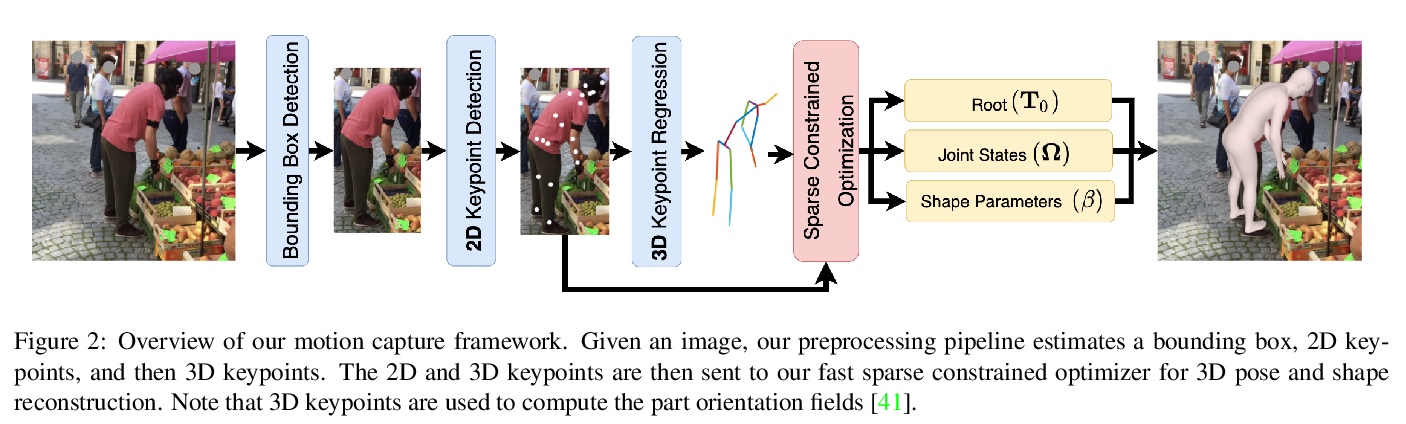
[CV] Revitalizing Optimization for 3D Human Pose and Shape Estimation: A Sparse Constrained Formulation
3D人体姿态和形状估计的再生优化:稀疏约束公式
T Fan, K V Alwala, D Xiang, W Xu, T Murphey, M Mukadam
[Facebook AI Research & Northwestern University & Facebook Reality Labs & CMU]
https://weibo.com/1402400261/Ki6M0ljfR



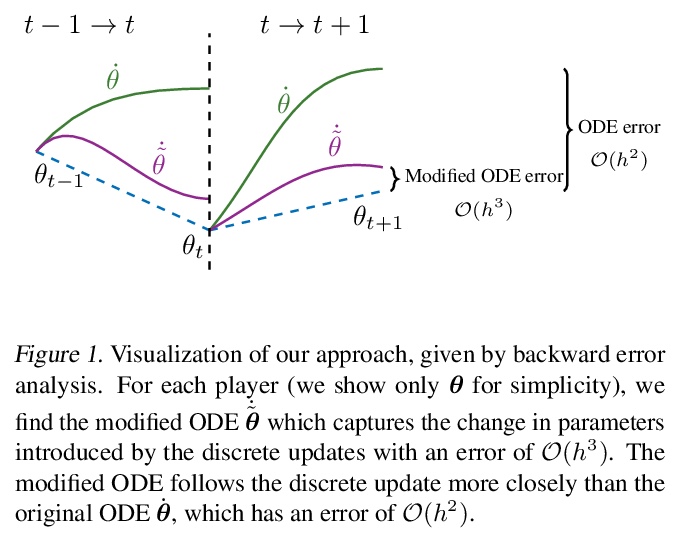
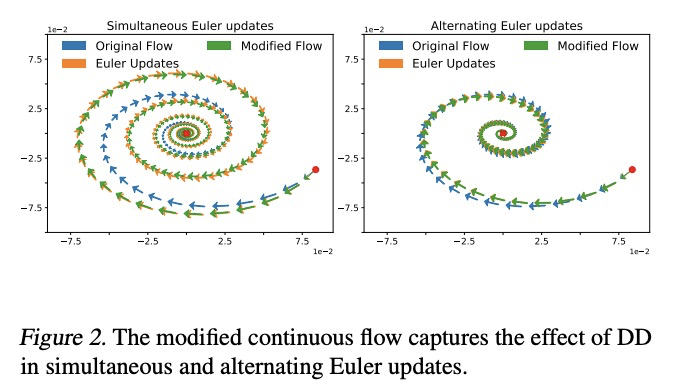
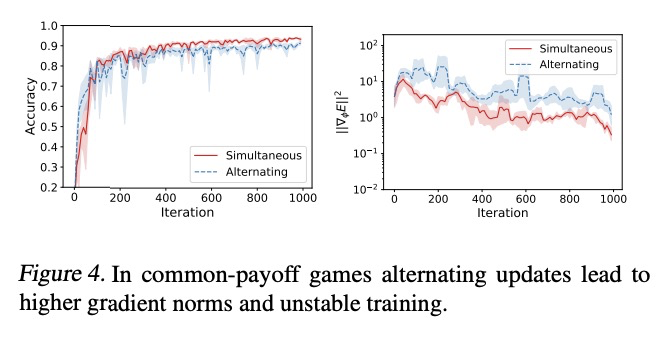
[LG] Discretization Drift in Two-Player Games
双人游戏的离散化漂移
M Rosca, Y Wu, B Dherin, D G. T. Barrett
[DeepMind & Google]
https://weibo.com/1402400261/Ki6PYtWkW


若有收获,就点个赞吧
0 人点赞
