- 1、[SI] The Atlas for the Aspiring Network Scientist
- 2、[CV] Damaged Fingerprint Recognition by Convolutional Long Short-Term Memory Networks for Forensic Purposes
- 3、[CL] Cross-Document Language Modeling
- 4、[CL] KM-BART: Knowledge Enhanced Multimodal BART for Visual Commonsense Generation
- 5、[CL] EarlyBERT: Efficient BERT Training via Early-bird Lottery Tickets
- [CV] VinVL: Making Visual Representations Matter in Vision-Language Models
- [LG] Provable Generalization of SGD-trained Neural Networks of Any Width in the Presence of Adversarial Label Noise
- [CL] End-to-End Training of Neural Retrievers for Open-Domain Question Answering
- [CV] Transformers in Vision: A Survey
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 SI - 社交网络分析 (*表示值得重点关注)
1、[SI] The Atlas for the Aspiring Network Scientist
M Coscia
[Michele Coscia]
(电子书)网络科学家手册。网络科学是用网络研究和分析复杂系统的领域,要理解复杂网络,需要掌握庞大的分析工具箱:图论和概率论、线性代数、统计物理学、机器学习、组合学等等。本书旨在提有这些工具的第一手资料,其目的是作为一张”地图”,其目的不在于让读者成为这些技术的专家,而是对所有这些方法的存在和机制有一个大致的了解,并以此作为网络科学领域事业的起点。这是一项跨学科的工作,其创始人来自许多不同背景:数学、社会学、计算机科学、物理学、历史、数字人文等。本书将指引读者成为不同于所有这些的人:一个纯粹的网络科学家。
Network science is the field dedicated to the investigation and analysis of complex systems via their representations as networks. We normally model such networks as graphs: sets of nodes connected by sets of edges and a number of node and edge attributes. This deceptively simple object is the starting point of never-ending complexity, due to its ability to represent almost every facet of reality: chemical interactions, protein pathways inside cells, neural connections inside the brain, scientific collaborations, financial relations, citations in art history, just to name a few examples. If we hope to make sense of complex networks, we need to master a large analytic toolbox: graph and probability theory, linear algebra, statistical physics, machine learning, combinatorics, and more.This book aims at providing the first access to all these tools. It is intended as an “Atlas”, because its interest is not in making you a specialist in using any of these techniques. Rather, after reading this book, you will have a general understanding about the existence and the mechanics of all these approaches. You can use such an understanding as the starting point of your own career in the field of network science. This has been, so far, an interdisciplinary endeavor. The founding fathers of this field come from many different backgrounds: mathematics, sociology, computer science, physics, history, digital humanities, and more. This Atlas is charting your path to be something different from all of that: a pure network scientist.
https://weibo.com/1402400261/JBRt26RxI
2、[CV] Damaged Fingerprint Recognition by Convolutional Long Short-Term Memory Networks for Forensic Purposes
J Fattahi, M Mejri
[Laval University]
面向取证的卷积LSTM网络受损指纹识别。主要研究卷积长短时记忆网络对受损指纹的识别,提出了模型架构,并展示了其性能,可达到99%精度,接近95%召回和99%的AUC。
Fingerprint recognition is often a game-changing step in establishing evidence against criminals. However, we are increasingly finding that criminals deliberately alter their fingerprints in a variety of ways to make it difficult for technicians and automatic sensors to recognize their fingerprints, making it tedious for investigators to establish strong evidence against them in a forensic procedure. In this sense, deep learning comes out as a prime candidate to assist in the recognition of damaged fingerprints. In particular, convolution algorithms. In this paper, we focus on the recognition of damaged fingerprints by Convolutional Long Short-Term Memory networks. We present the architecture of our model and demonstrate its performance which exceeds 95% accuracy, 99% precision, and approaches 95% recall and 99% AUC.
https://weibo.com/1402400261/JBRyXqIJW

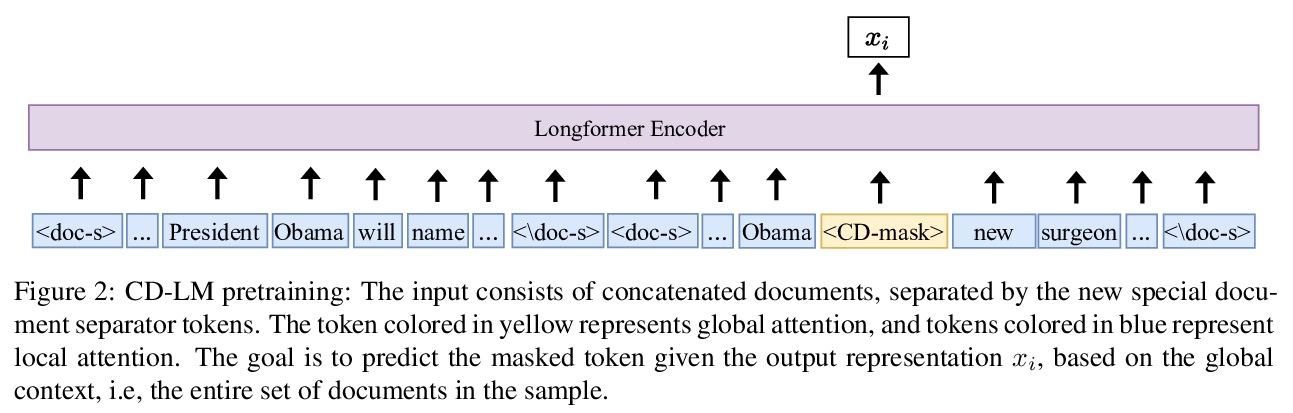
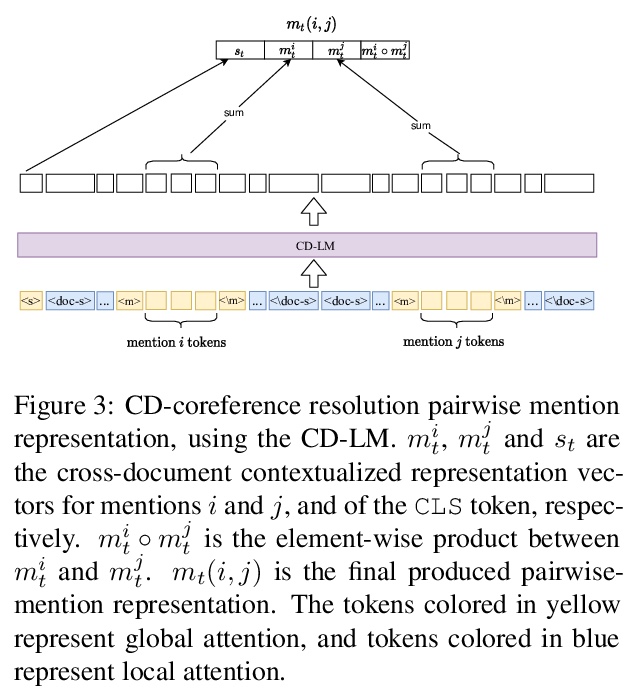
3、[CL] Cross-Document Language Modeling
A Caciularu, A Cohan, I Beltagy, M E. Peters, A Cattan, I Dagan
[Bar-Ilan University & Allen Institute for Artificial Intelligence]
跨文档语言建模。提出一种新型的跨文档语言建模(CD-LM)预训练策略和技术,为跨文档下游任务提供更好的编码。通过跨文档掩蔽,在单个输入中用多个相关文档进行预训练,鼓励模型学习跨文档和远程关系;扩展了Longformer模型,用数千个标记的长上下文进行预训练,引入一种新的注意力模式,用序列级全局注意力来预测掩蔽标记,同时在其他地方保留熟悉的局部注意力。CD-LM在几个多文本任务上取得了最先进的结果,包括跨文档事件和实体参考分析,论文引用推荐,以及文档剽窃检测,相对于之前工作大量减少了训练参数。
We introduce a new pretraining approach for language models that are geared to support multi-document NLP tasks. Our cross-document language model (CD-LM) improves masked language modeling for these tasks with two key ideas. First, we pretrain with multiple related documents in a single input, via cross-document masking, which encourages the model to learn cross-document and long-range relationships. Second, extending the recent Longformer model, we pretrain with long contexts of several thousand tokens and introduce a new attention pattern that uses sequence-level global attention to predict masked tokens, while retaining the familiar local attention elsewhere. We show that our CD-LM sets new state-of-the-art results for several multi-text tasks, including cross-document event and entity coreference resolution, paper citation recommendation, and documents plagiarism detection, while using a significantly reduced number of training parameters relative to prior works.
https://weibo.com/1402400261/JBRDqh8Rg

4、[CL] KM-BART: Knowledge Enhanced Multimodal BART for Visual Commonsense Generation
Y Xing, Z Shi, Z Meng, Y Ma, R Wattenhofer
[RWTH Aachen & LMU Munich & ETH Zurich]
面向视觉常识生成的知识增强多模态BART。提出知识增强型多模态BART(KM-BART),一种基于Transformer的模型,能从图像和文本的跨模态输入中,推理和生成常识描述。提出了”基于知识的常识生成”预训练任务,利用外部常识知识图谱上的大规模预训练语言模型,来提高KM-BART的推理能力,并用自训练技术对自动生成的常识描述进行清洗。在下游的视觉常识生成任务上的实验结果表明,KM-BART达到了最先进的性能。
We present Knowledge Enhanced Multimodal BART (KM-BART), which is a Transformer-based sequence-to-sequence model capable of reasoning about commonsense knowledge from multimodal inputs of images and texts. We extend the popular BART architecture to a multi-modal model. We design a new pretraining task to improve the model performance on Visual Commonsense Generation task. Our pretraining task improves the Visual Commonsense Generation performance by leveraging knowledge from a large language model pretrained on an external knowledge graph. To the best of our knowledge, we are the first to propose a dedicated task for improving model performance on Visual Commonsense Generation. Experimental results show that by pretraining, our model reaches state-of-the-art performance on the Visual Commonsense Generation task.
https://weibo.com/1402400261/JBRHr6AAw

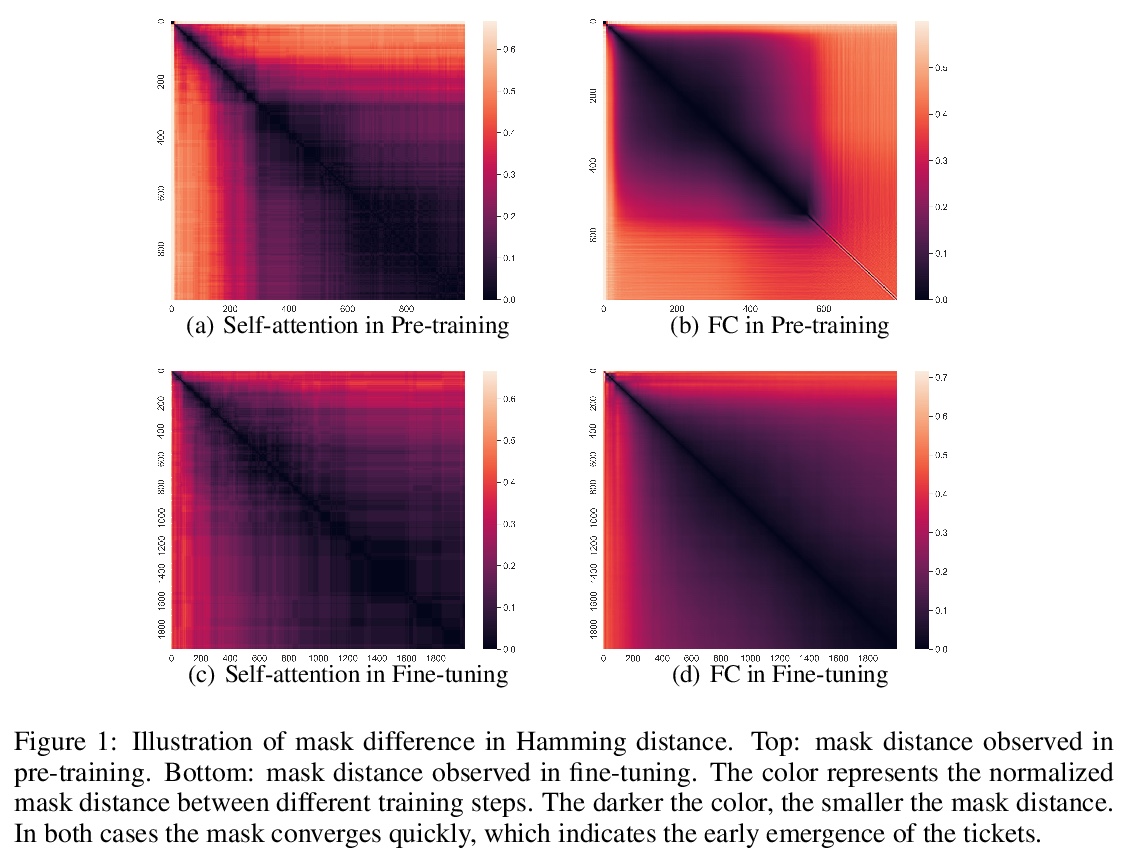
5、[CL] EarlyBERT: Efficient BERT Training via Early-bird Lottery Tickets
X Chen, Y Cheng, S Wang, Z Gan, Z Wang, J Liu
[University of Texas at Austin]
基于早搏彩票的高效BERT训练。受计算机视觉任务所研究的早博彩票启发,提出了EarlyBERT,一种通用的高效训练算法,适用于大规模语言模型的预训练和微调。我们率先在BERT训练的早期阶段识别结构化的中奖彩票,并将其用于高效训练。基于彩票假说,EarlyBERT在早期识别结构化中奖彩票,用修剪后的网络进行高效训练。在GLUE和SQuAD上的实验结果表明,所提出的方法能够以更少的训练时间实现与标准BERT相当的性能。
Deep, heavily overparameterized language models such as BERT, XLNet and T5 have achieved impressive success in many NLP tasks. However, their high model complexity requires enormous computation resources and extremely long training time for both pre-training and fine-tuning. Many works have studied model compression on large NLP models, but only focus on reducing inference cost/time, while still requiring expensive training process. Other works use extremely large batch sizes to shorten the pre-training time at the expense of high demand for computation resources. In this paper, inspired by the Early-Bird Lottery Tickets studied for computer vision tasks, we propose EarlyBERT, a general computationally-efficient training algorithm applicable to both pre-training and fine-tuning of large-scale language models. We are the first to identify structured winning tickets in the early stage of BERT training, and use them for efficient training. Comprehensive pre-training and fine-tuning experiments on GLUE and SQuAD downstream tasks show that EarlyBERT easily achieves comparable performance to standard BERT with 35~45% less training time.
https://weibo.com/1402400261/JBRKlEbti
另外几篇值得关注的论文:
[CV] VinVL: Making Visual Representations Matter in Vision-Language Models
VinVL:视觉-语言模型中视觉表示的改进
P Zhang, X Li, X Hu, J Yang, L Zhang, L Wang, Y Choi, J Gao
[Microsoft & University of Washington]
https://weibo.com/1402400261/JBRP2reDS



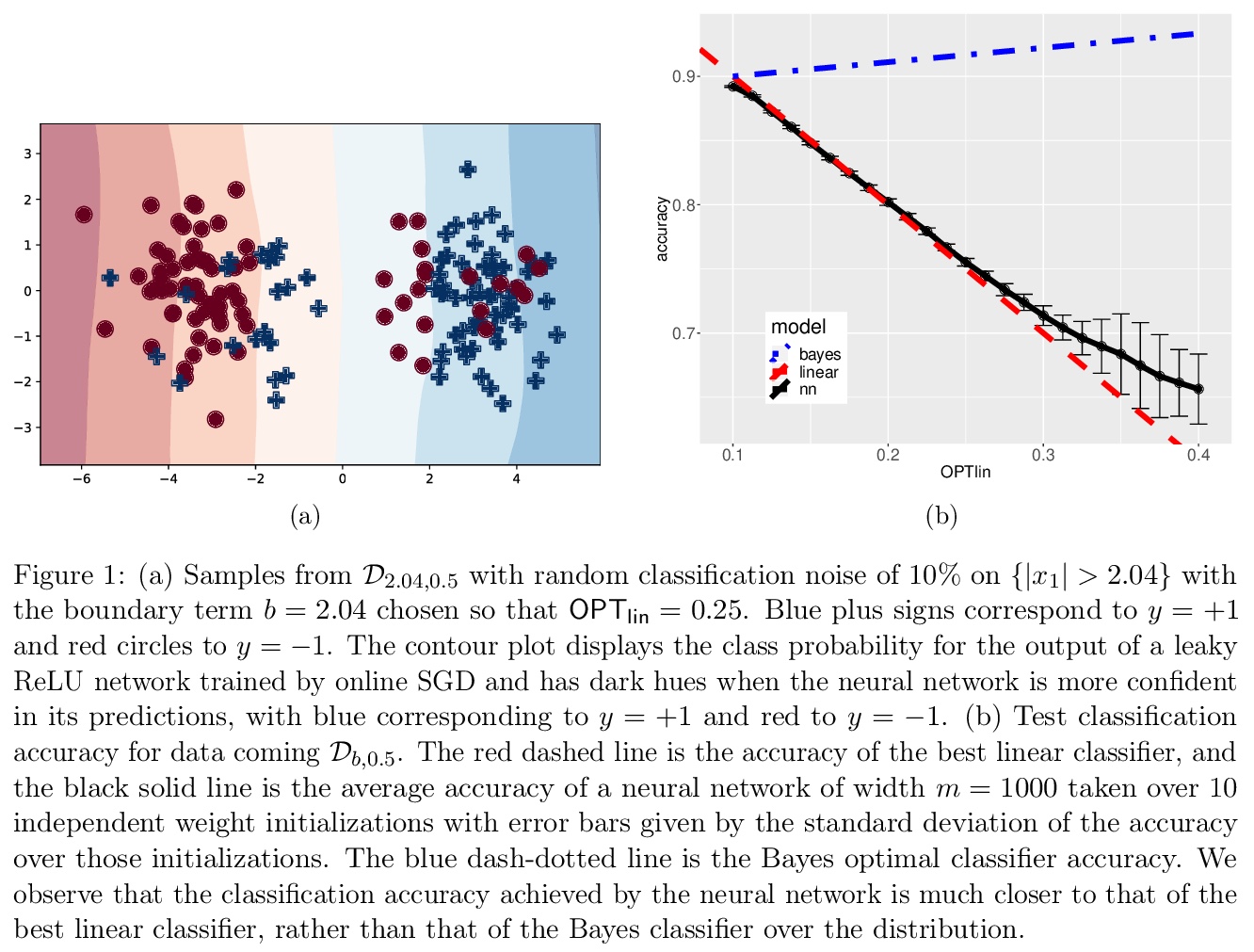
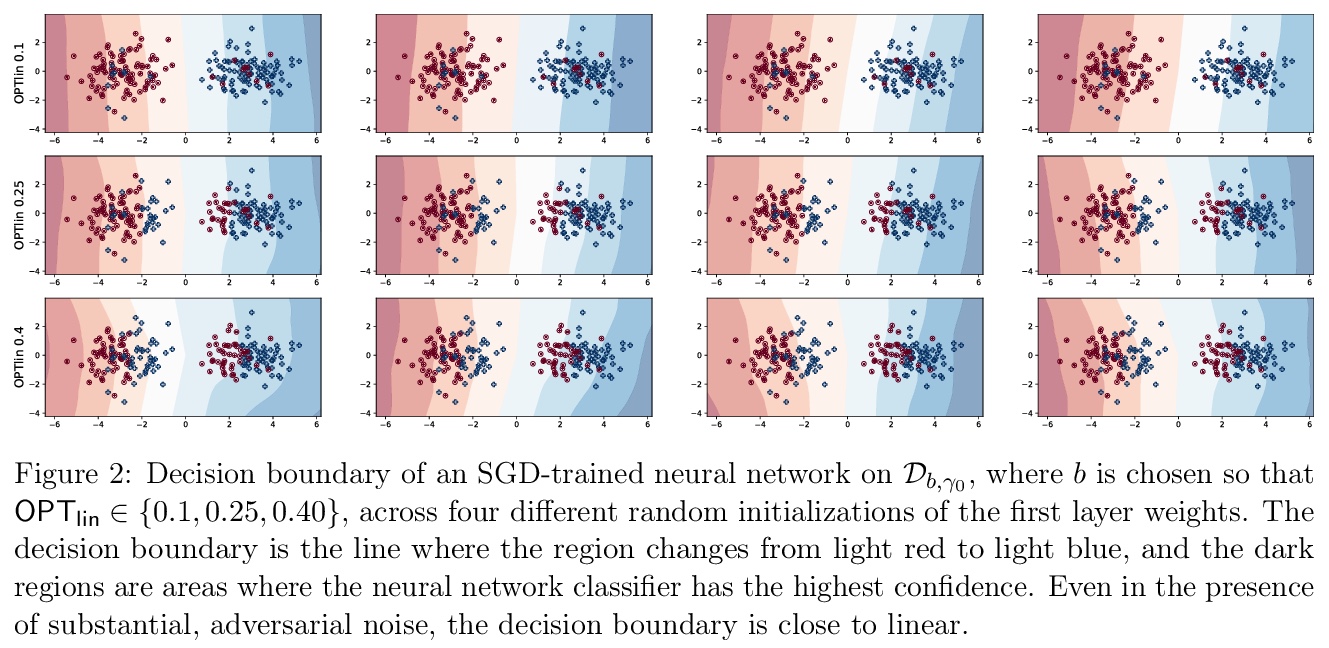
[LG] Provable Generalization of SGD-trained Neural Networks of Any Width in the Presence of Adversarial Label Noise
对抗标签噪声下SGD训练的任意宽度神经网络的可证泛化
S Frei, Y Cao, Q Gu
[UCLA]
https://weibo.com/1402400261/JBRRQrIdR
[CL] End-to-End Training of Neural Retrievers for Open-Domain Question Answering
面向开放域问答的神经检索器端到端训练
D S Sachan, M Patwary, M Shoeybi, N Kant, W Ping, W L Hamilton, B Catanzaro
[Mila & NVIDIA]
https://weibo.com/1402400261/JBRTKqem1

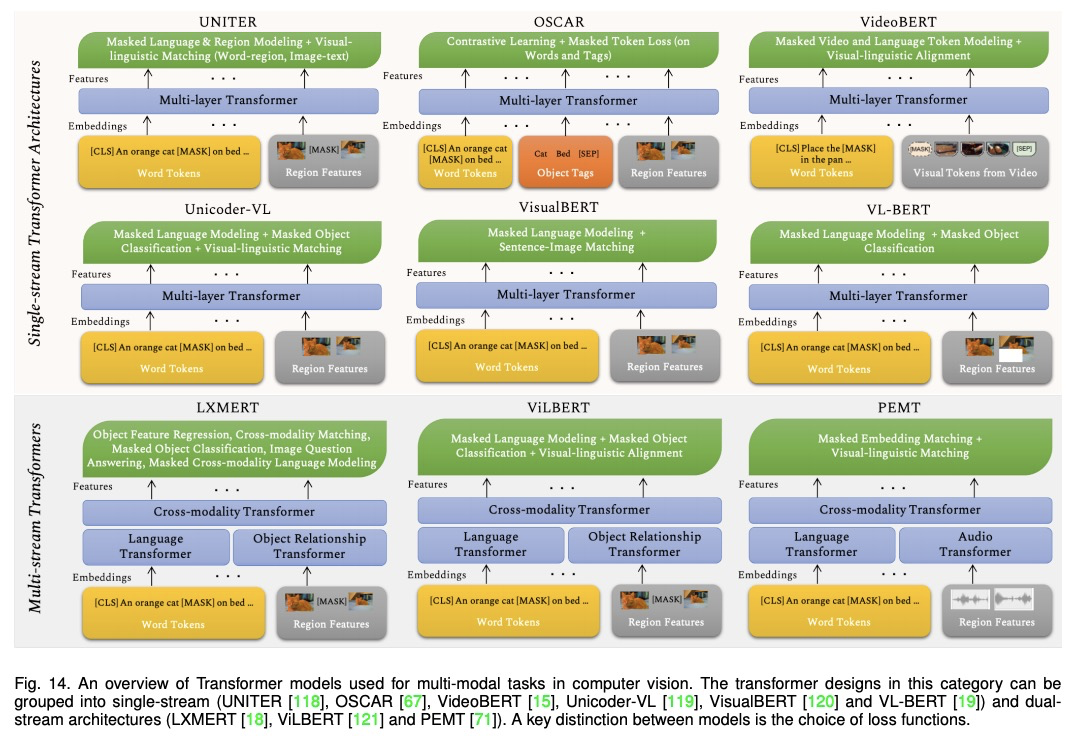
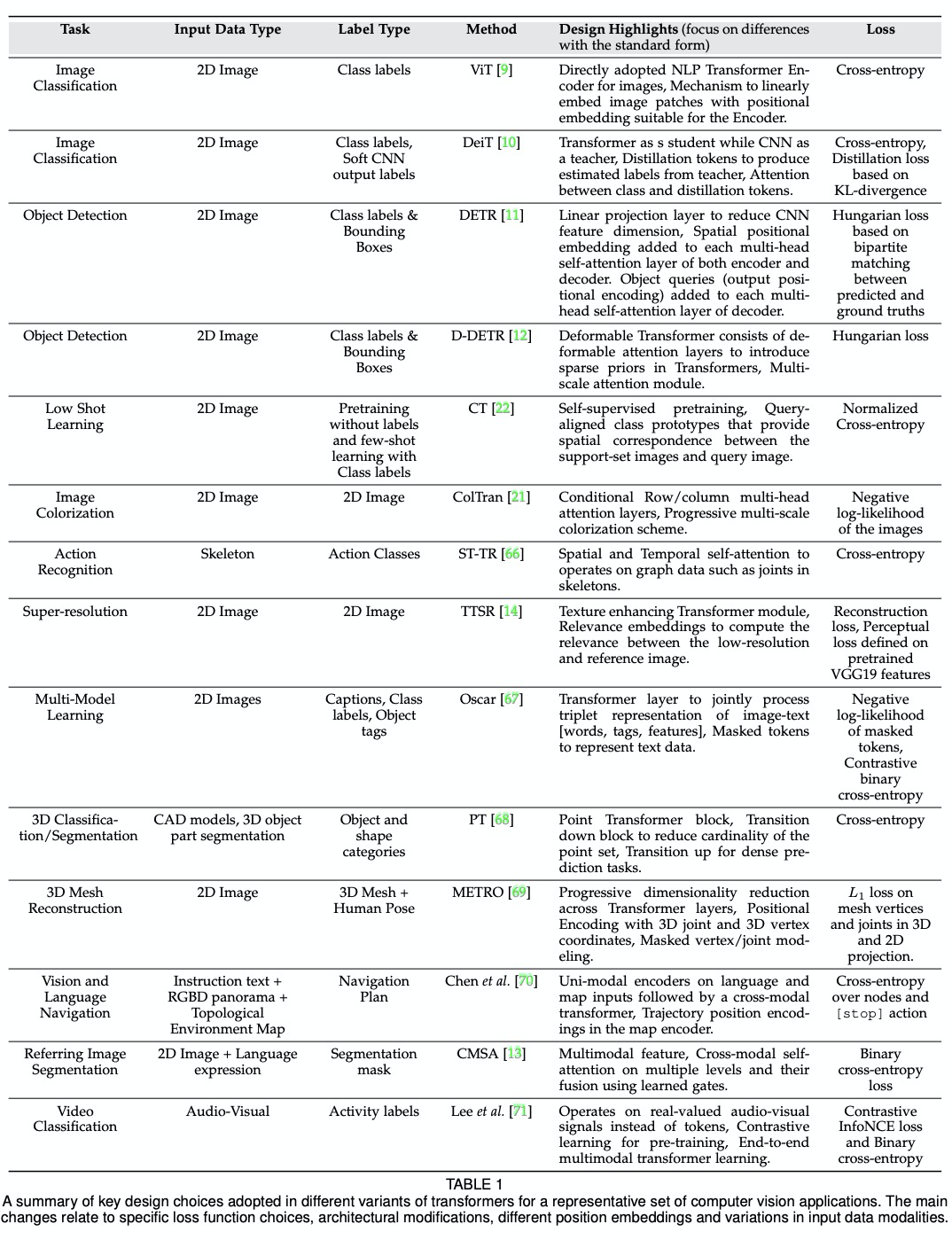
[CV] Transformers in Vision: A Survey
Transformer视觉应用综述
S Khan, M Naseer, M Hayat, S W Zamir, F S Khan, M Shah
[MBZ University of Artificial Intelligence & Monash University]

若有收获,就点个赞吧
0 人点赞
