LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
(*表示值得重点关注)
1、[LG] *Algorithms for Causal Reasoning in Probability Trees
T Genewein, T McGrath, G Déletang, V Mikulik, M Martic, S Legg, P A. Ortega
[DeepMind]
概率树因果推理算法。提出了离散概率树中因果推理的具体算法,覆盖全部因果层次(关联、干预和反事实),并对任意命题和因果事件进行操作。该工作将因果推理的领域,扩展到非常通用的的离散随机过程。**
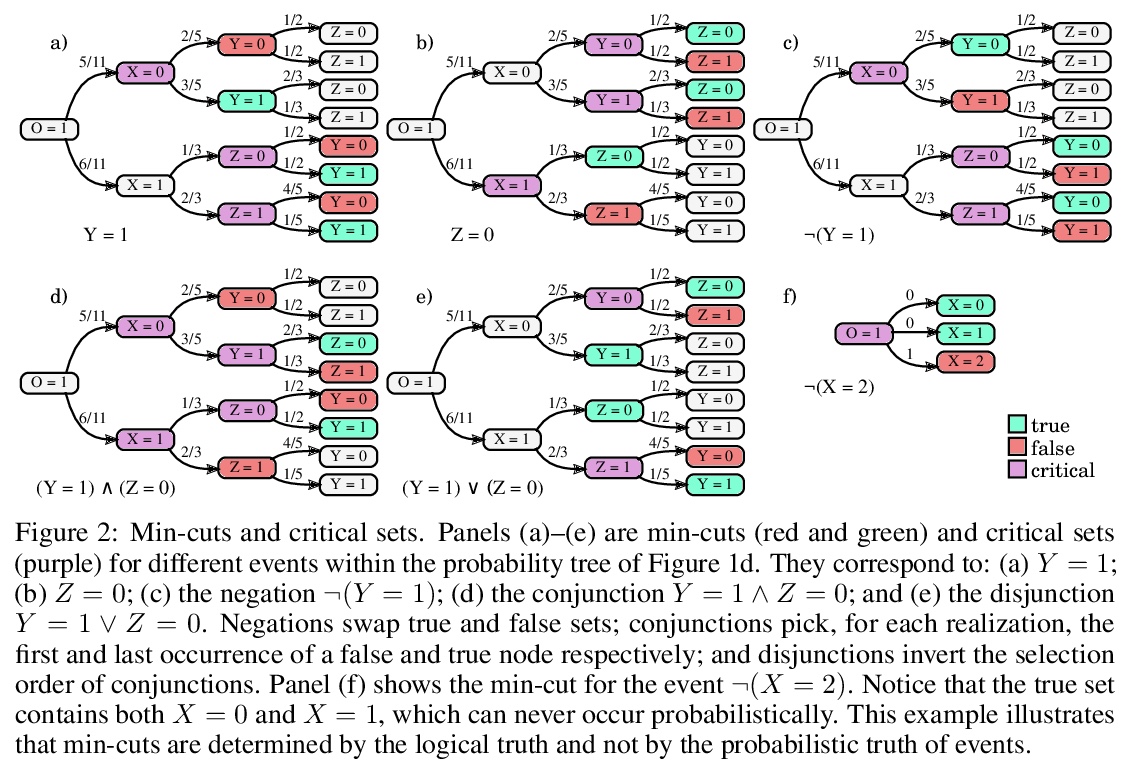
Probability trees are one of the simplest models of causal generative processes. They possess clean semantics and — unlike causal Bayesian networks — they can represent context-specific causal dependencies, which are necessary for e.g. causal induction. Yet, they have received little attention from the AI and ML community. Here we present concrete algorithms for causal reasoning in discrete probability trees that cover the entire causal hierarchy (association, intervention, and counterfactuals), and operate on arbitrary propositional and causal events. Our work expands the domain of causal reasoning to a very general class of discrete stochastic processes.
https://weibo.com/1402400261/JrwuViYrR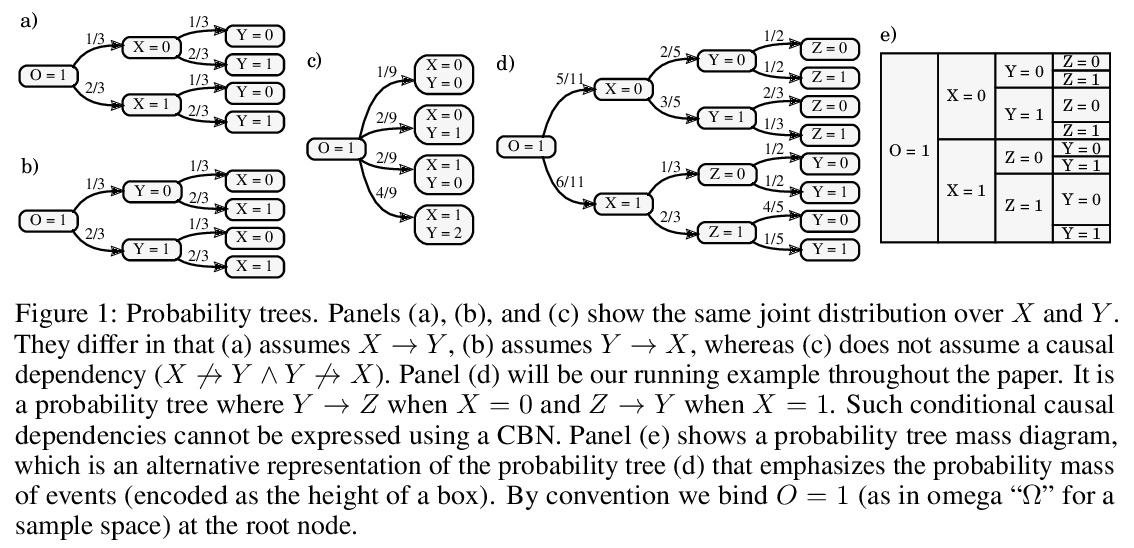

2、[AS] *Attention is All You Need in Speech Separation
C Subakan, M Ravanelli, S Cornell, M Bronzi, J Zhong
[Mila-Quebec AI Institute & Universita Politecnica delle Marche & University of Rochester]
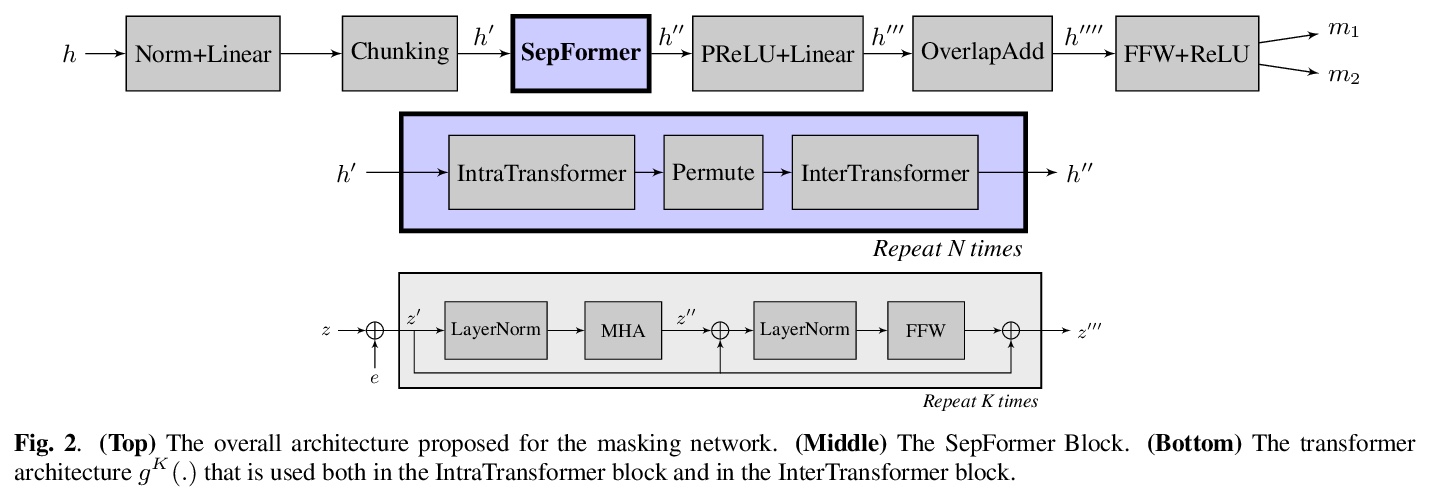
基于Transformer的语音分离架构SepFormer。提出一种新的语音分离神经网络模型SepFormer(Separation Transformer),一个非RNN的网络架构,采用由Transformer组成的屏蔽网络,掩蔽网络通过多尺度方法学习短期和长期依赖关系。与最新的基于RNN的系统相比,SepFormer的速度快得多,对内存的要求也少得多。
Recurrent Neural Networks (RNNs) have long been the dominant architecture in sequence-to-sequence learning. RNNs, however, are inherently sequential models that do not allow parallelization of their computations. Transformers are emerging as a natural alternative to standard RNNs, replacing recurrent computations with a multi-head attention mechanism. In this paper, we propose the `SepFormer’, a novel RNN-free Transformer-based neural network for speech separation. The SepFormer learns short and long-term dependencies with a multi-scale approach that employs transformers. The proposed model matches or overtakes the state-of-the-art (SOTA) performance on the standard WSJ0-2/3mix datasets. It indeed achieves an SI-SNRi of 20.2 dB on WSJ0-2mix matching the SOTA, and an SI-SNRi of 17.6 dB on WSJ0-3mix, a SOTA result. The SepFormer inherits the parallelization advantages of Transformers and achieves a competitive performance even when downsampling the encoded representation by a factor of 8. It is thus significantly faster and it is less memory-demanding than the latest RNN-based systems.
https://weibo.com/1402400261/JrwygqcX8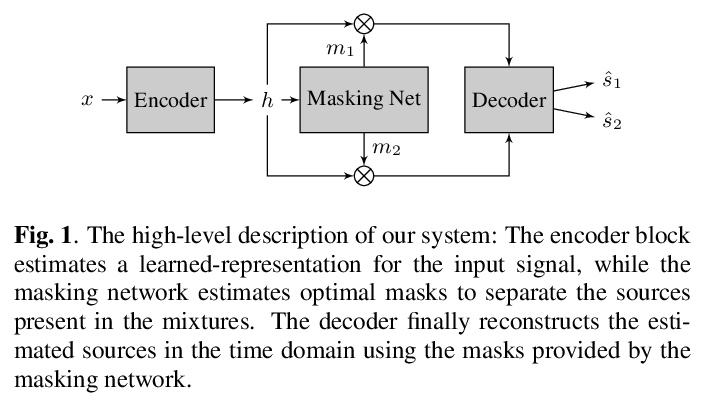
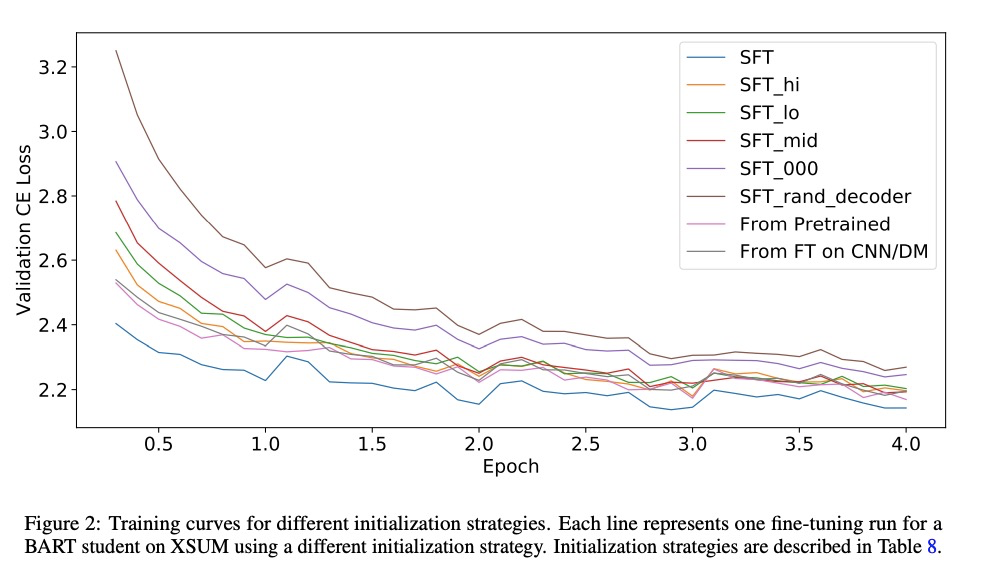
3、[CL] *Pre-trained Summarization Distillation
S Shleifer, A M. Rush
[Hugging Face]
面向摘要任务的预训练Transformer模型蒸馏方法。从Seq2Seq转换器中去除精心选取的解码器层,继续微调,可快速生成高质量的学生模型,在某些情况下,使用相同初始化策略的更复杂的训练技术可以产生额外的质量改进。**
Recent state-of-the-art approaches to summarization utilize large pre-trained Transformer models. Distilling these models to smaller student models has become critically important for practical use; however there are many different distillation methods proposed by the NLP literature. Recent work on distilling BERT for classification and regression tasks shows strong performance using direct knowledge distillation. Alternatively, machine translation practitioners distill using pseudo-labeling, where a small model is trained on the translations of a larger model. A third, simpler approach is to ‘shrink and fine-tune’ (SFT), which avoids any explicit distillation by copying parameters to a smaller student model and then fine-tuning. We compare these three approaches for distillation of Pegasus and BART, the current and former state of the art, pre-trained summarization models, and find that SFT outperforms knowledge distillation and pseudo-labeling on the CNN/DailyMail dataset, but under-performs pseudo-labeling on the more abstractive XSUM dataset. PyTorch Code and checkpoints of different sizes are available through Hugging Face transformers here > this http URL.
https://weibo.com/1402400261/JrwCpsESr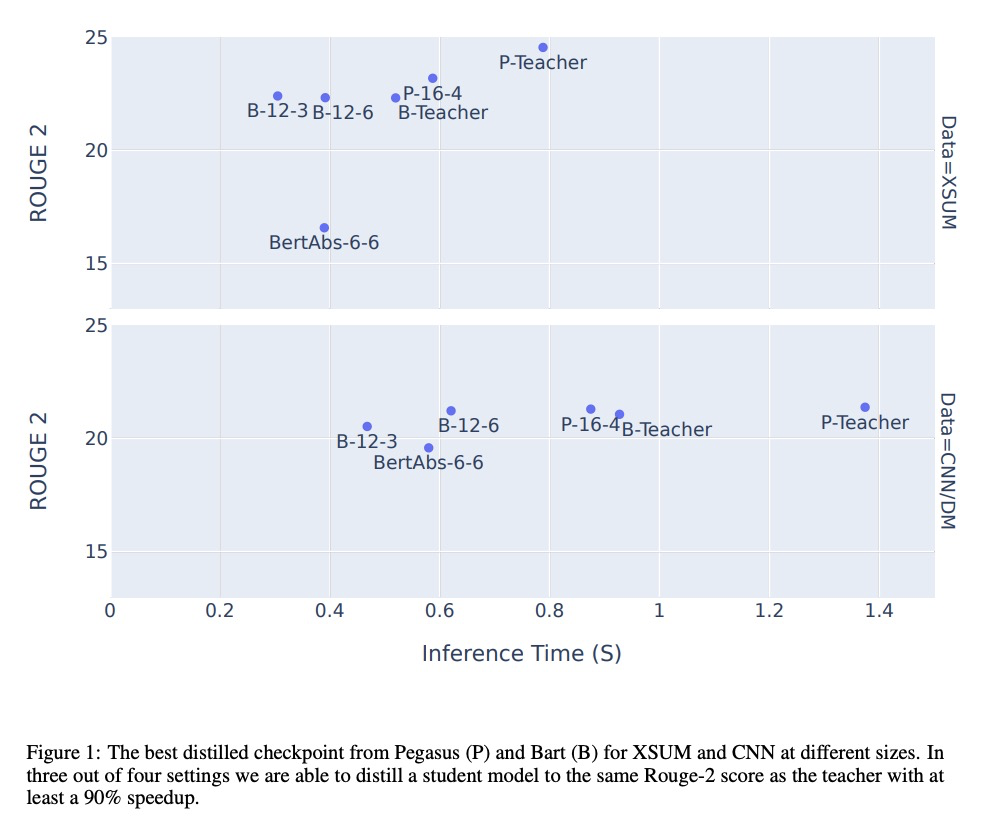
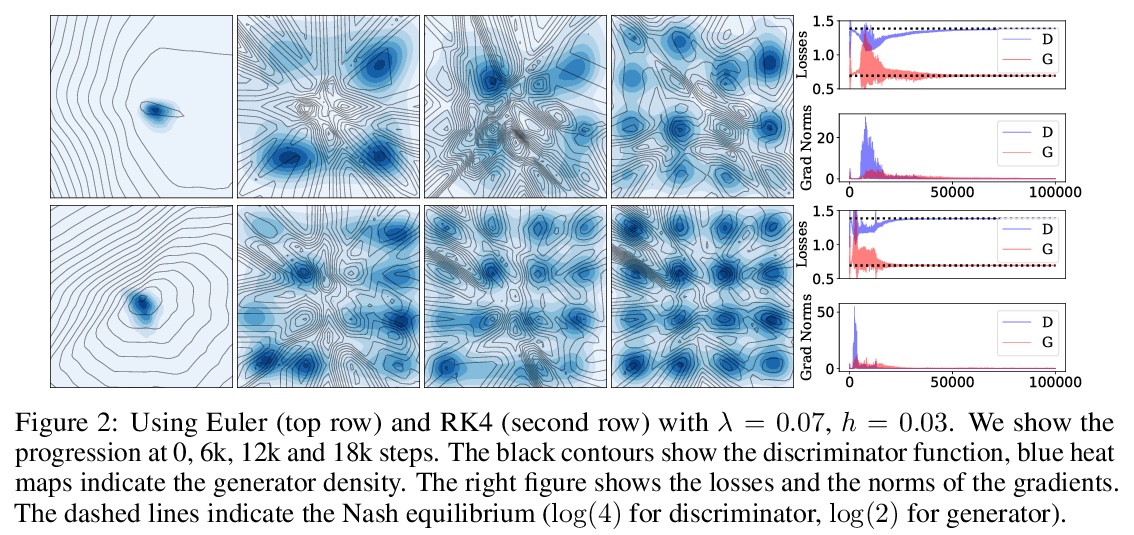
4、[LG] **Training Generative Adversarial Networks by Solving Ordinary Differential Equations
C Qin, Y Wu, J T Springenberg, A Brock, J Donahue, T P. Lillicrap, P Kohli
[DeepMind]
通过求解常微分方程训练GAN。该工作将当前机器学习研究的一个重要部分(生成模型)与一个古老的研究领域(动态系统集成)联系起来。假设GAN训练的不稳定性,是由连续动力学离散化的积分误差引起的,通过实验验证,当与控制积分误差的调节器结合时,著名的ODE求解器(如Runge-Kutta)能使GAN模型的训练更加稳定。**
The instability of Generative Adversarial Network (GAN) training has frequently been attributed to gradient descent. Consequently, recent methods have aimed to tailor the models and training procedures to stabilise the discrete updates. In contrast, we study the continuous-time dynamics induced by GAN training. Both theory and toy experiments suggest that these dynamics are in fact surprisingly stable. From this perspective, we hypothesise that instabilities in training GANs arise from the integration error in discretising the continuous dynamics. We experimentally verify that well-known ODE solvers (such as Runge-Kutta) can stabilise training - when combined with a regulariser that controls the integration error. Our approach represents a radical departure from previous methods which typically use adaptive optimisation and stabilisation techniques that constrain the functional space (e.g. Spectral Normalisation). Evaluation on CIFAR-10 and ImageNet shows that our method outperforms several strong baselines, demonstrating its efficacy.
https://weibo.com/1402400261/JrwOFcuKc
5、[LG] **Label-Aware Neural Tangent Kernel: Toward Better Generalization and Local Elasticity
S Chen, H He, W J. Su
[University of Pennsylvania]
标签感知神经切核。提出标签感知的概念,来解释和减少由NTK训练的模型与真实网络神经网络之间的性能差距。受通用标签感知核Hoeffding分解的启发,提出了两个标签感知版本的NTK,通过理论研究和综合实验表明,用所提出核训练的模型,在泛化能力和局部弹性方面能更好地模拟神经网络的行为。**
As a popular approach to modeling the dynamics of training overparametrized neural networks (NNs), the neural tangent kernels (NTK) are known to fall behind real-world NNs in generalization ability. This performance gap is in part due to the \textit{label agnostic} nature of the NTK, which renders the resulting kernel not as \textit{locally elastic} as NNs~\citep{he2019local}. In this paper, we introduce a novel approach from the perspective of \emph{label-awareness} to reduce this gap for the NTK. Specifically, we propose two label-aware kernels that are each a superimposition of a label-agnostic part and a hierarchy of label-aware parts with increasing complexity of label dependence, using the Hoeffding decomposition. Through both theoretical and empirical evidence, we show that the models trained with the proposed kernels better simulate NNs in terms of generalization ability and local elasticity.
https://weibo.com/1402400261/JrwSkocoX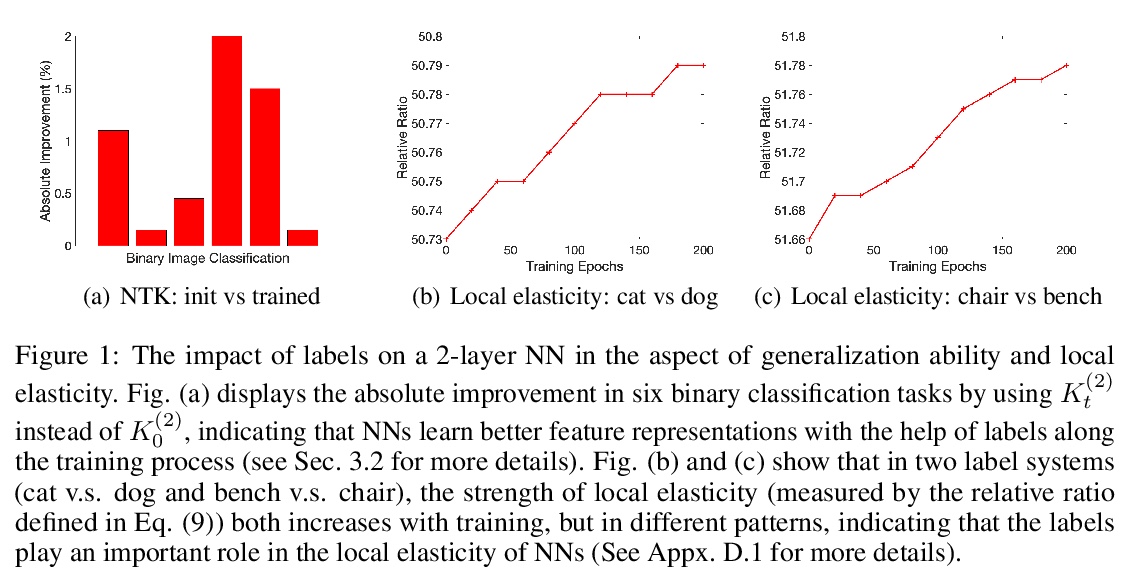

[LG] Enforcing Interpretability and its Statistical Impacts: Trade-offs between Accuracy and Interpretability
增强可解释性及其统计影响:用简化的学习模型研究准确性(风险)和可解释性之间的权衡
G K Dziugaite, S Ben-David, D M. Roy
[Element AI & University of Waterloo & University of Toronto]
https://weibo.com/1402400261/JrwGVDuwv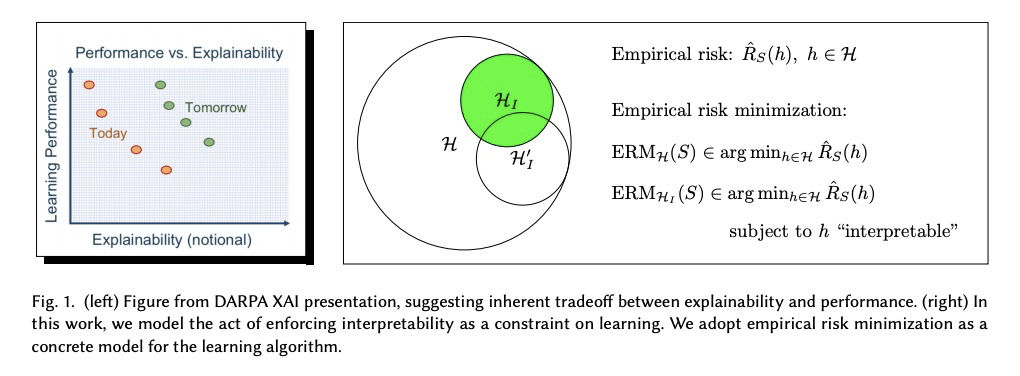
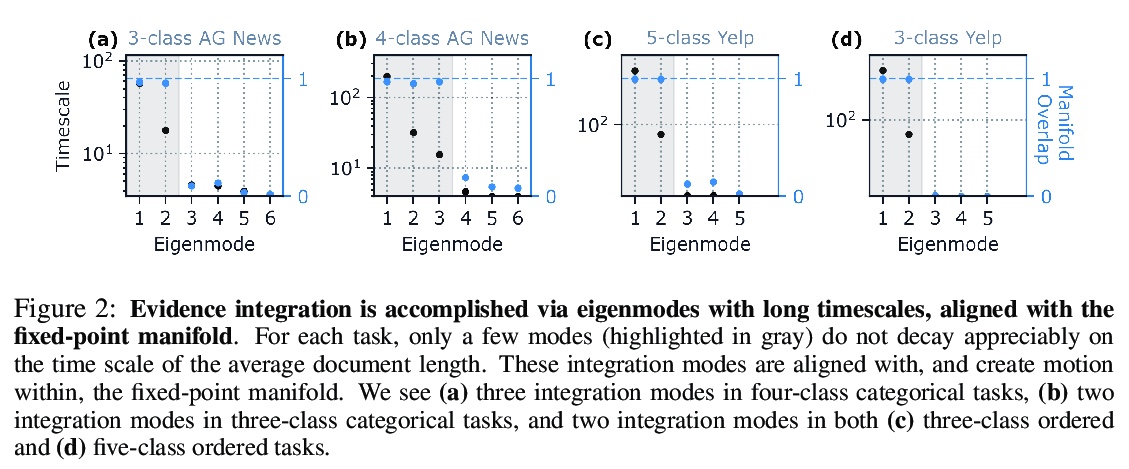
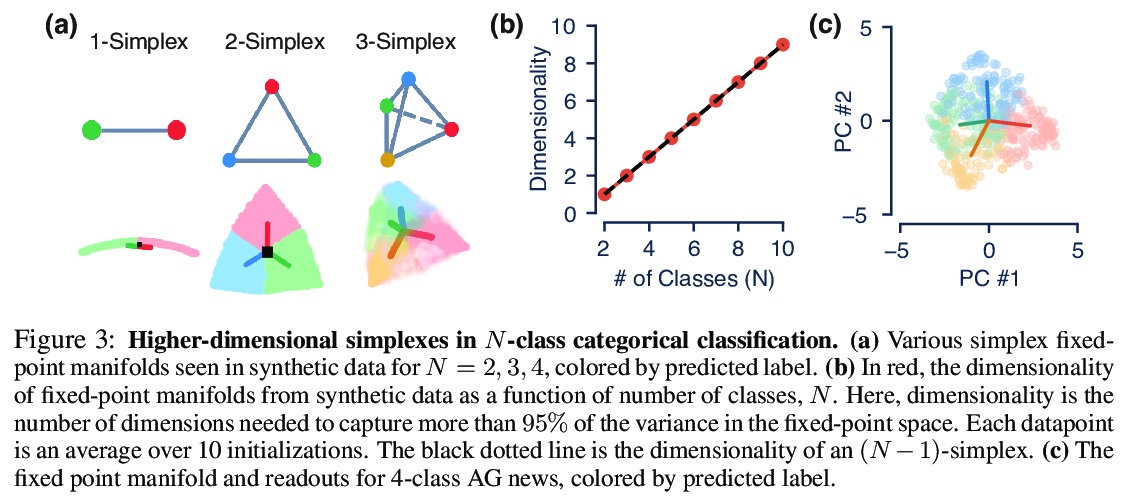
[LG] The geometry of integration in text classification RNNs
文本分类RNN的整合几何
K Aitken, V V. Ramasesh, A Garg, Y Cao, D Sussillo, N Maheswaranathan
[University of Washington & Google]
https://weibo.com/1402400261/JrwY6vdA0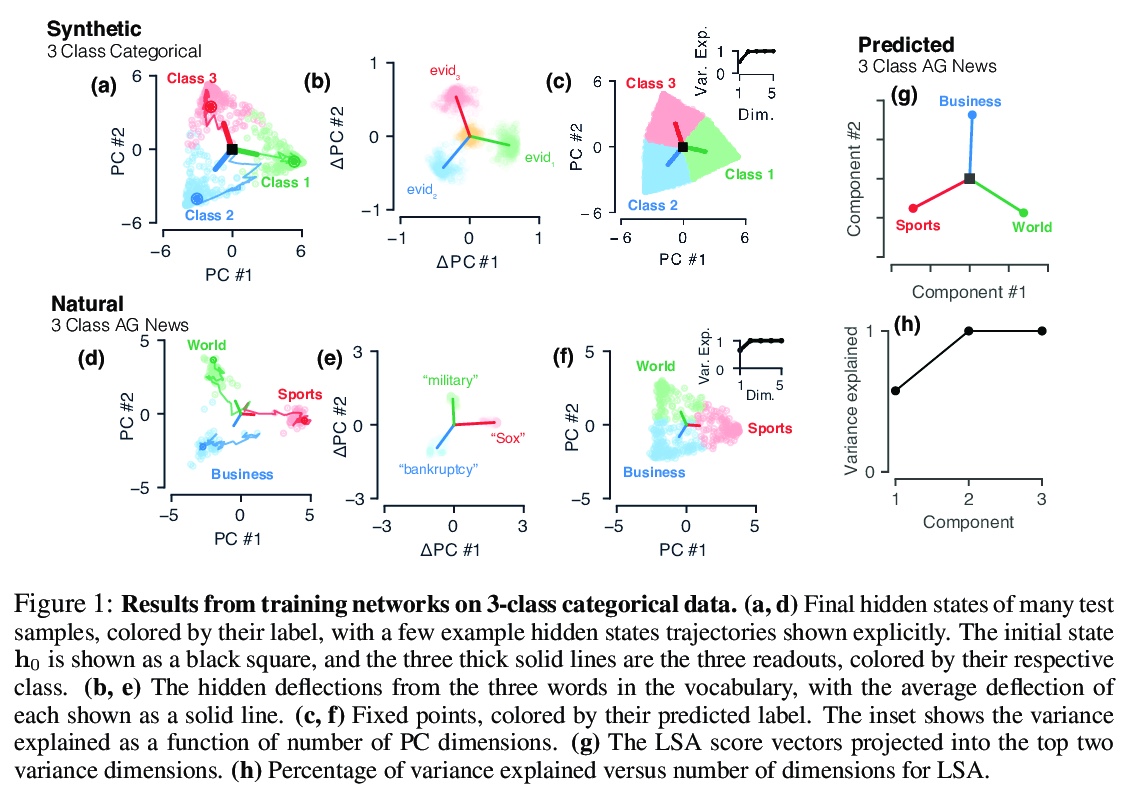
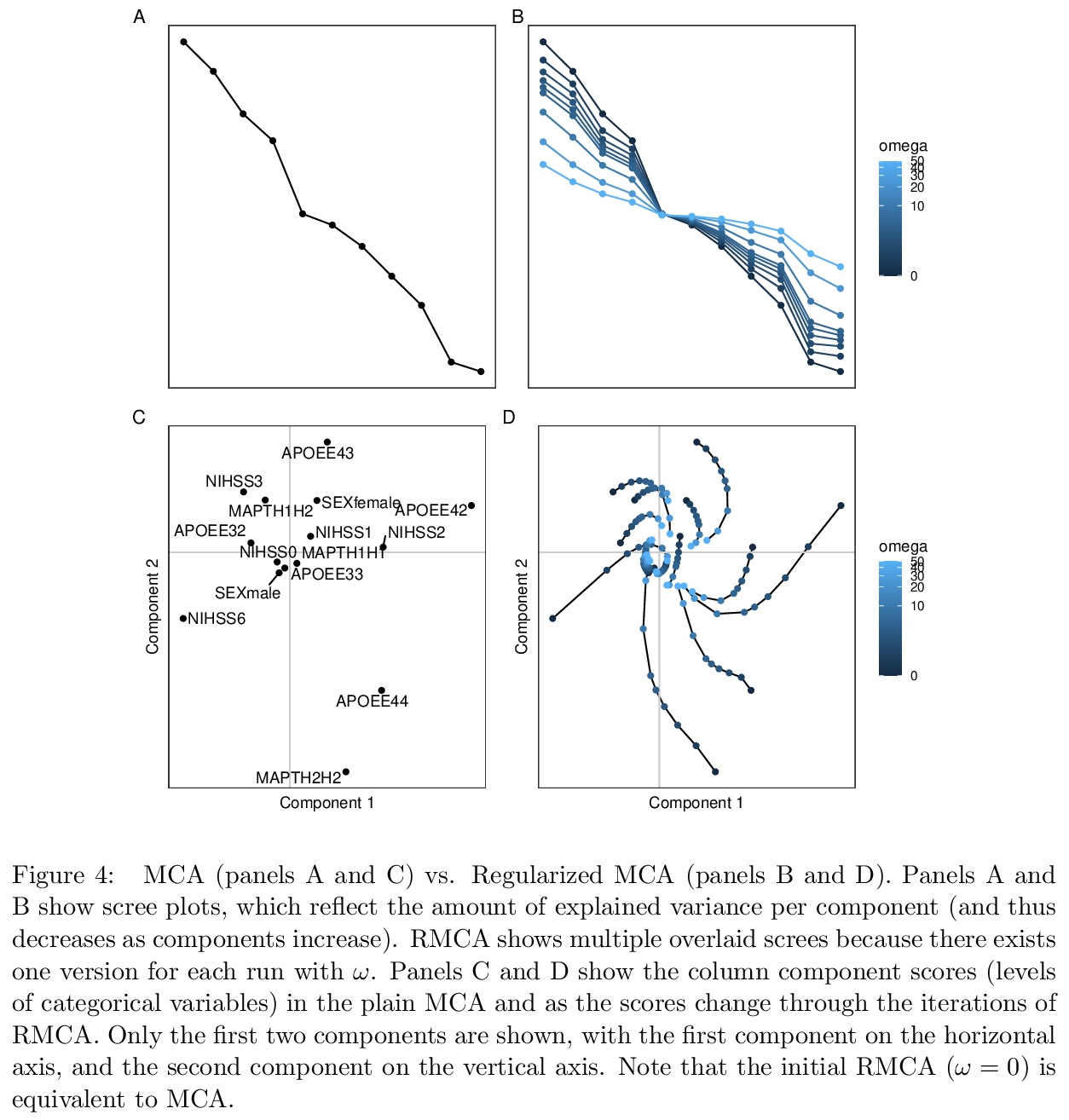
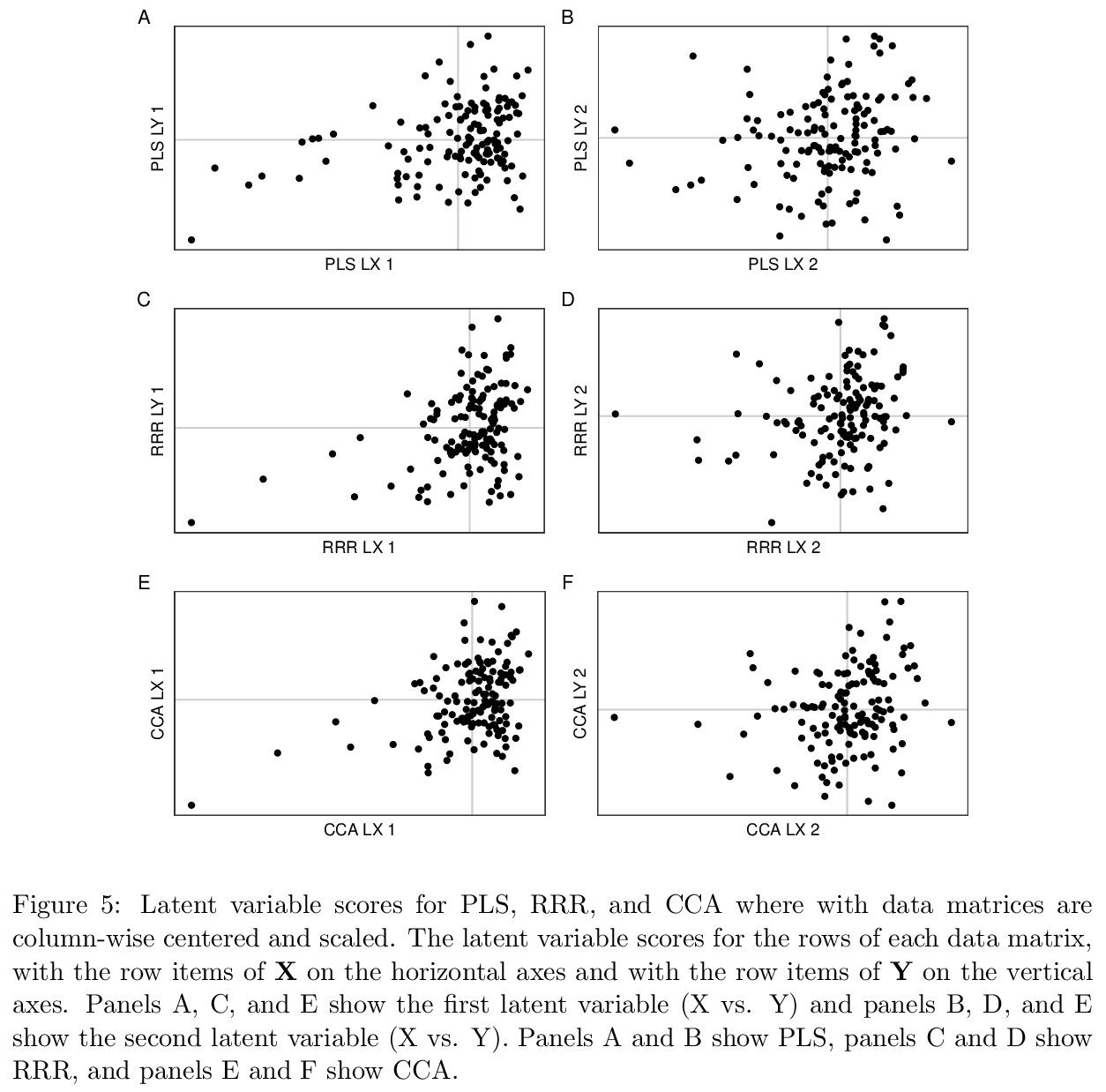
[LG] Generalized eigen, singular value, and partial least squares decompositions: The GSVD package
广义特征值、奇异值和偏最小二乘分解:GSVD包
D Beaton
[Baycrest Health Sciences]
https://weibo.com/1402400261/Jrx0xxcB7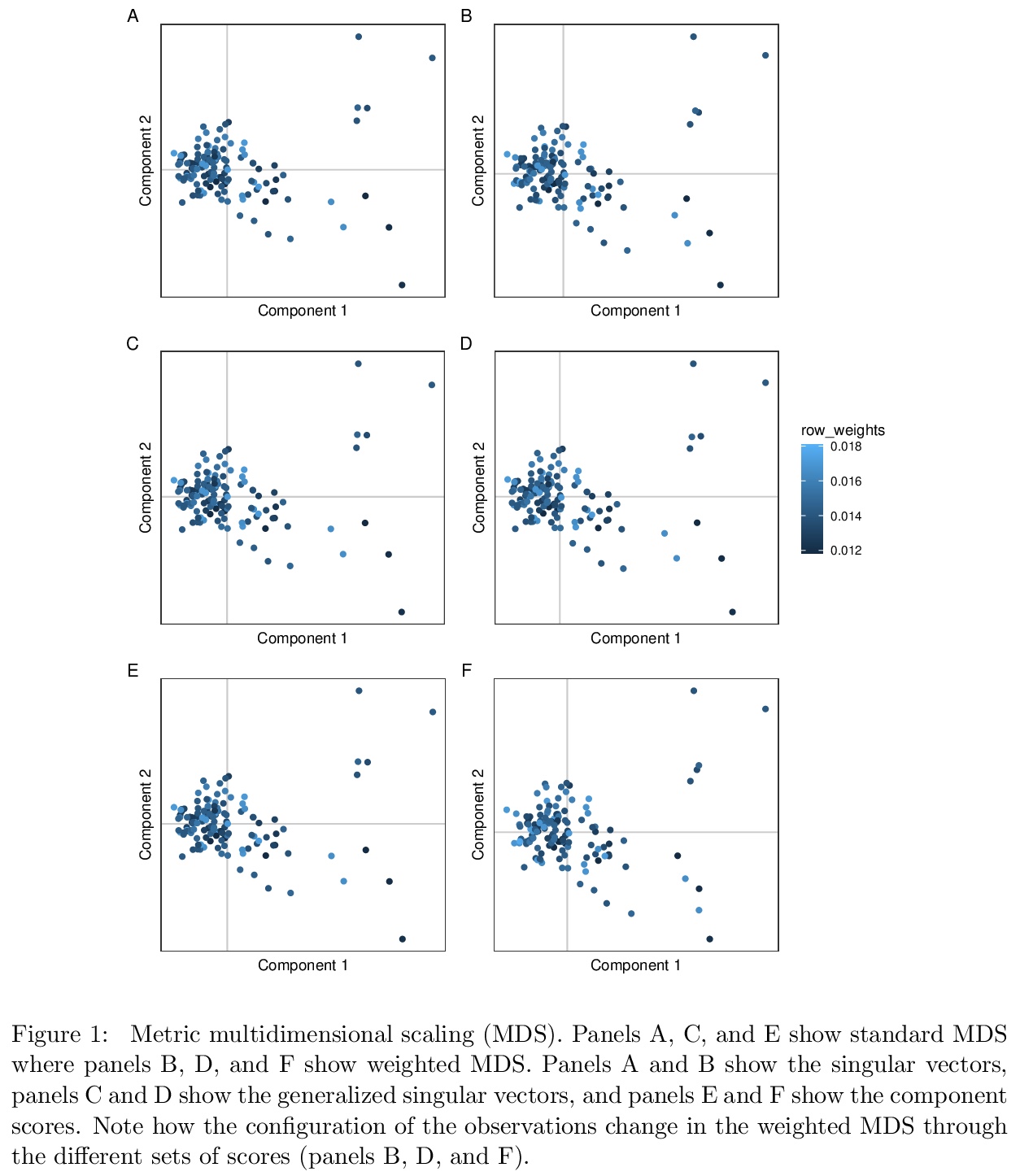

若有收获,就点个赞吧
0 人点赞
